
Decorrelation-Based Deep Learning for Bias Mitigation


Abstract
:1. Introduction
- The introduction of a new loss function to ANN, CNN, and DNN to decorrelate bias from the learned features, which helps in mitigating bias;
- Generalizing the idea of decorrelation across different domains and biases;
- Comparing our proposed DcDNN and DcANN methods to existing methods.
2. Related Studies
3. Materials and Methods
3.1. Distance Correlation
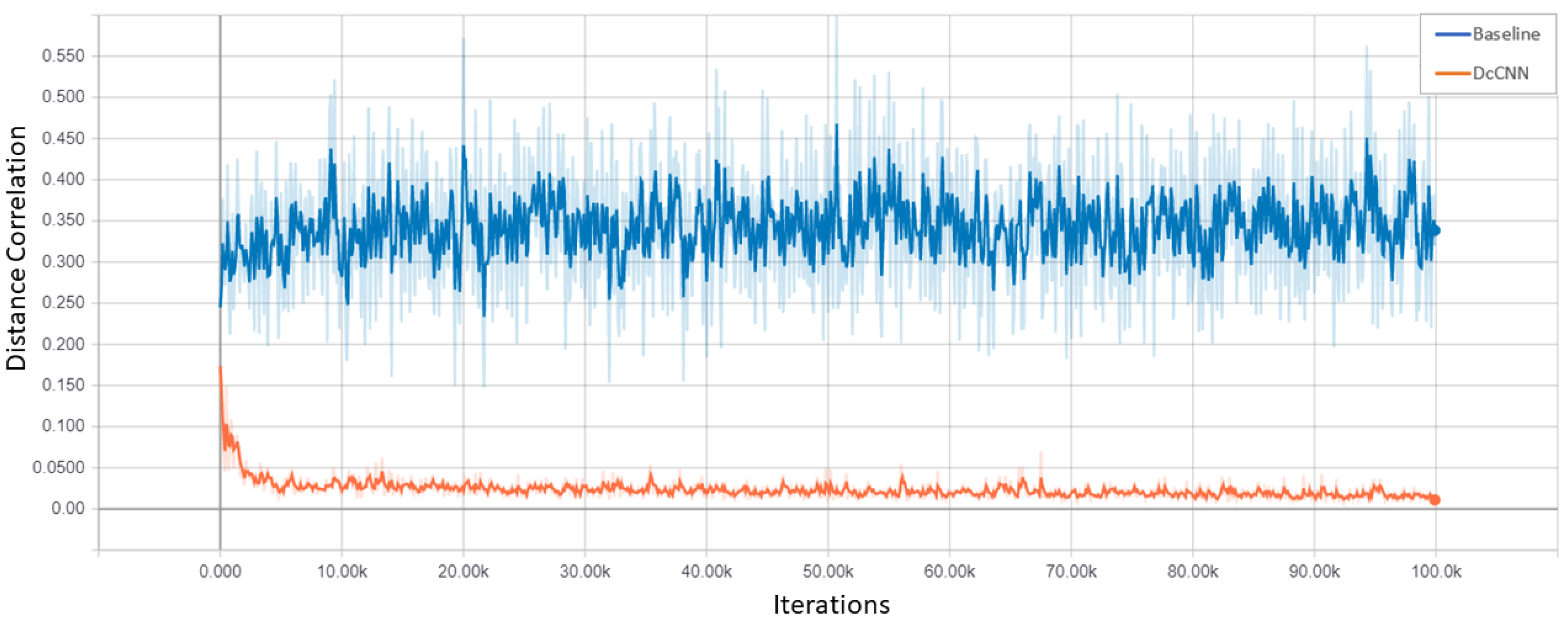
3.2. Decorrelation in Objective Function
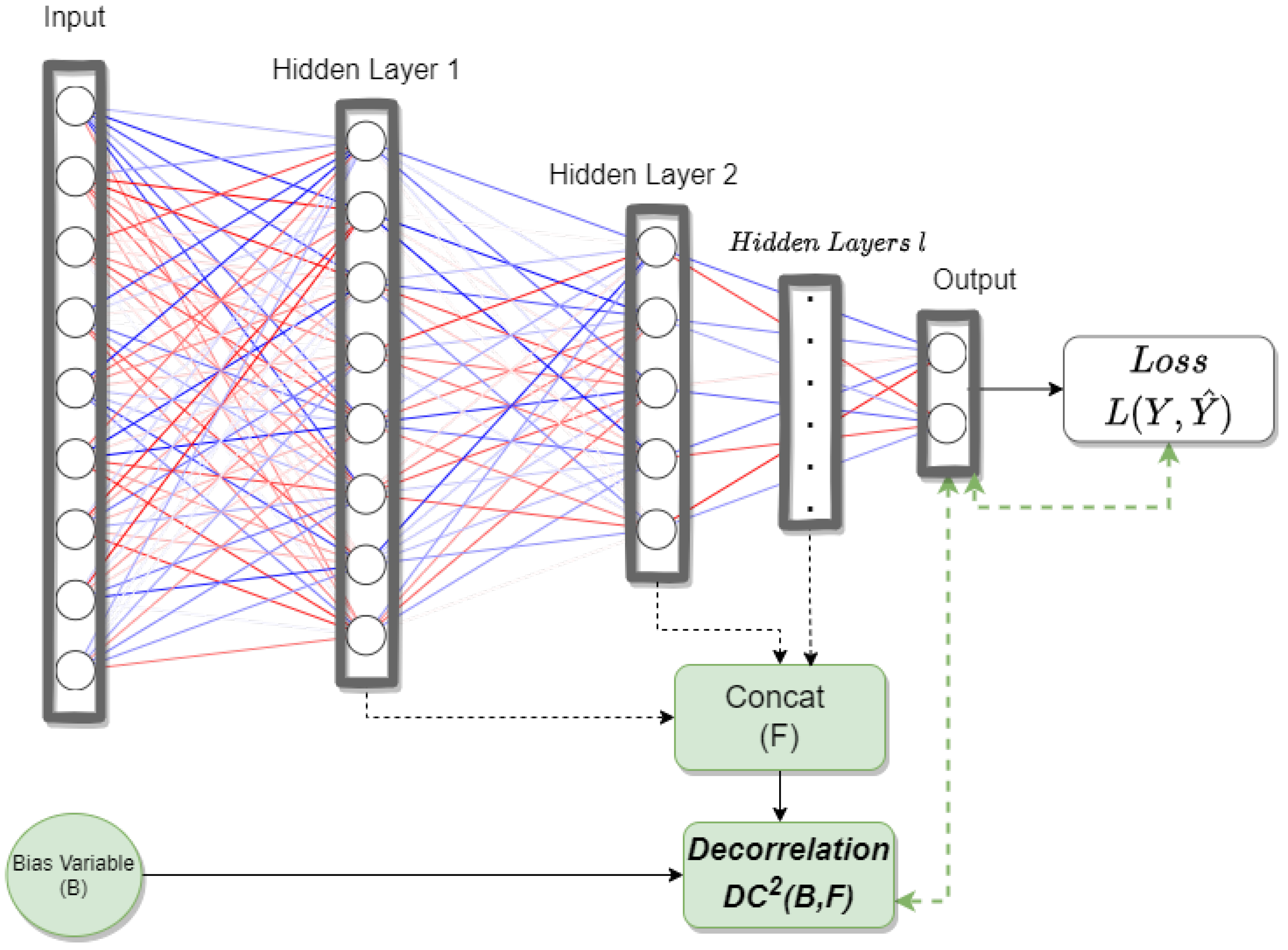
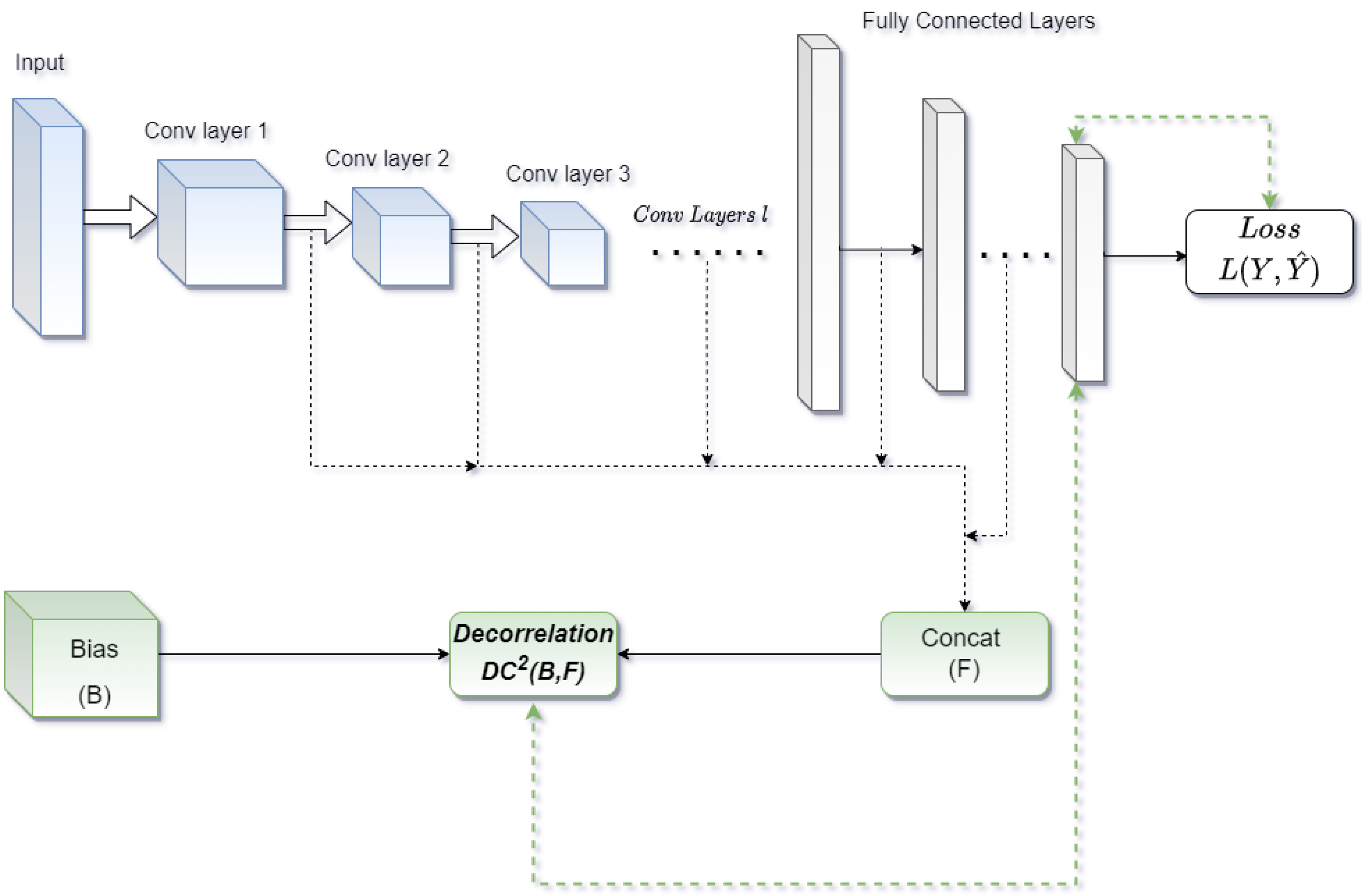
3.3. DcANN and DcCNN
3.4. Experimental Setup
4. Results
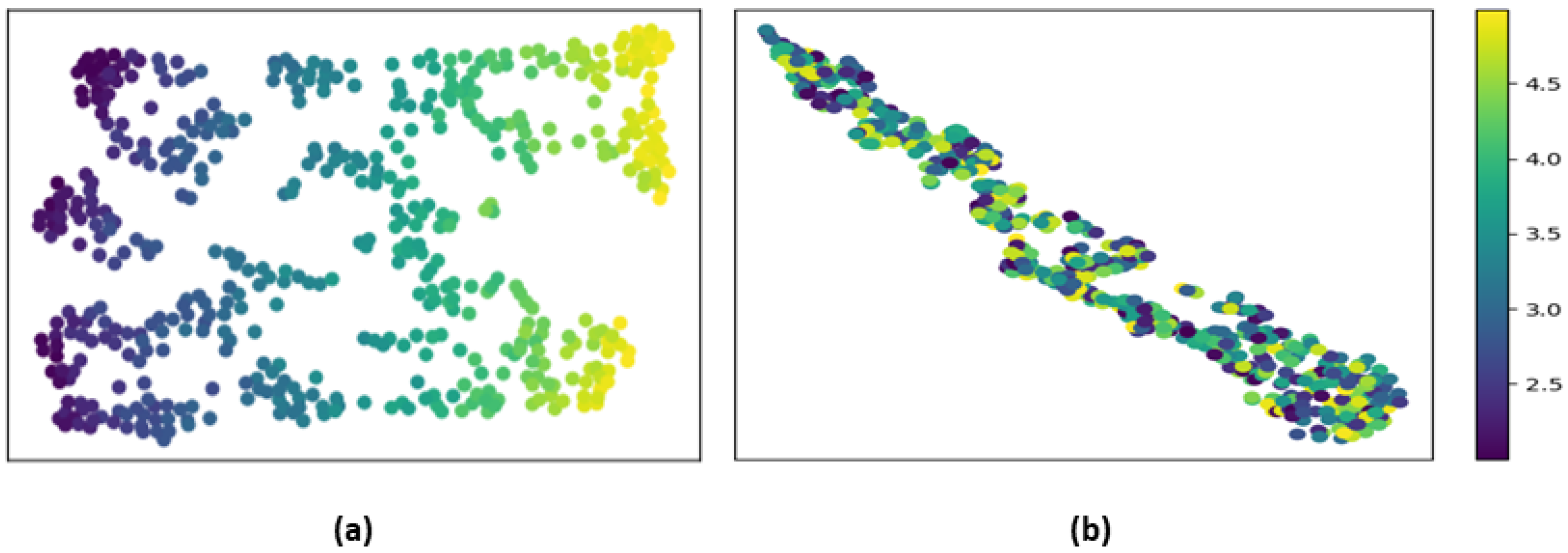
4.1. Simulated Dataset
4.2. Age Biased German Dataset
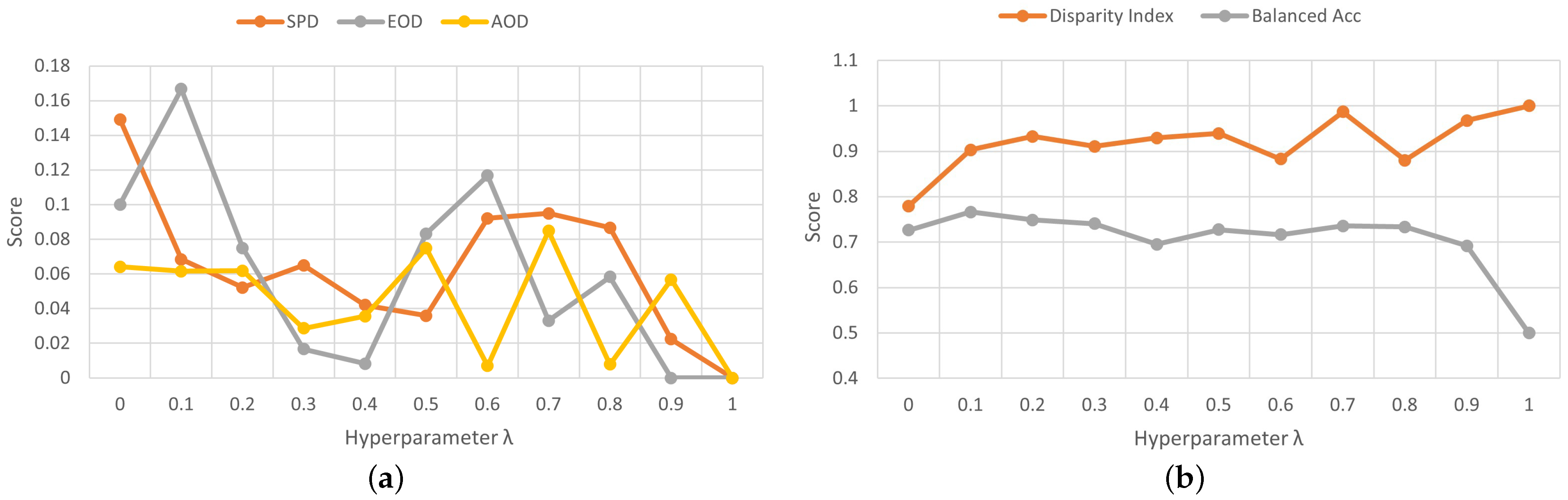
4.2.1. Hyperparamter Analysis
4.2.2. Evaluation Fairness Metrics
4.2.3. Comparative Evaluations
4.3. Gender-Biased Adult Dataset
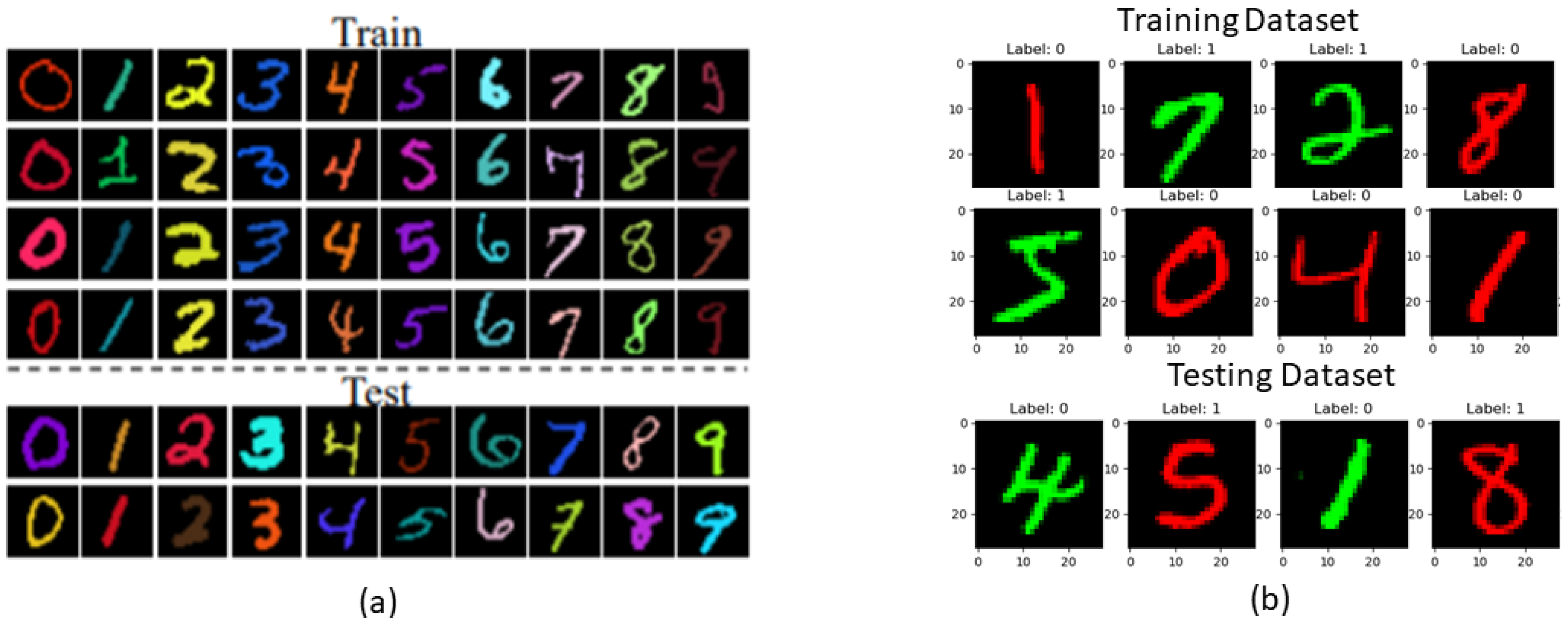
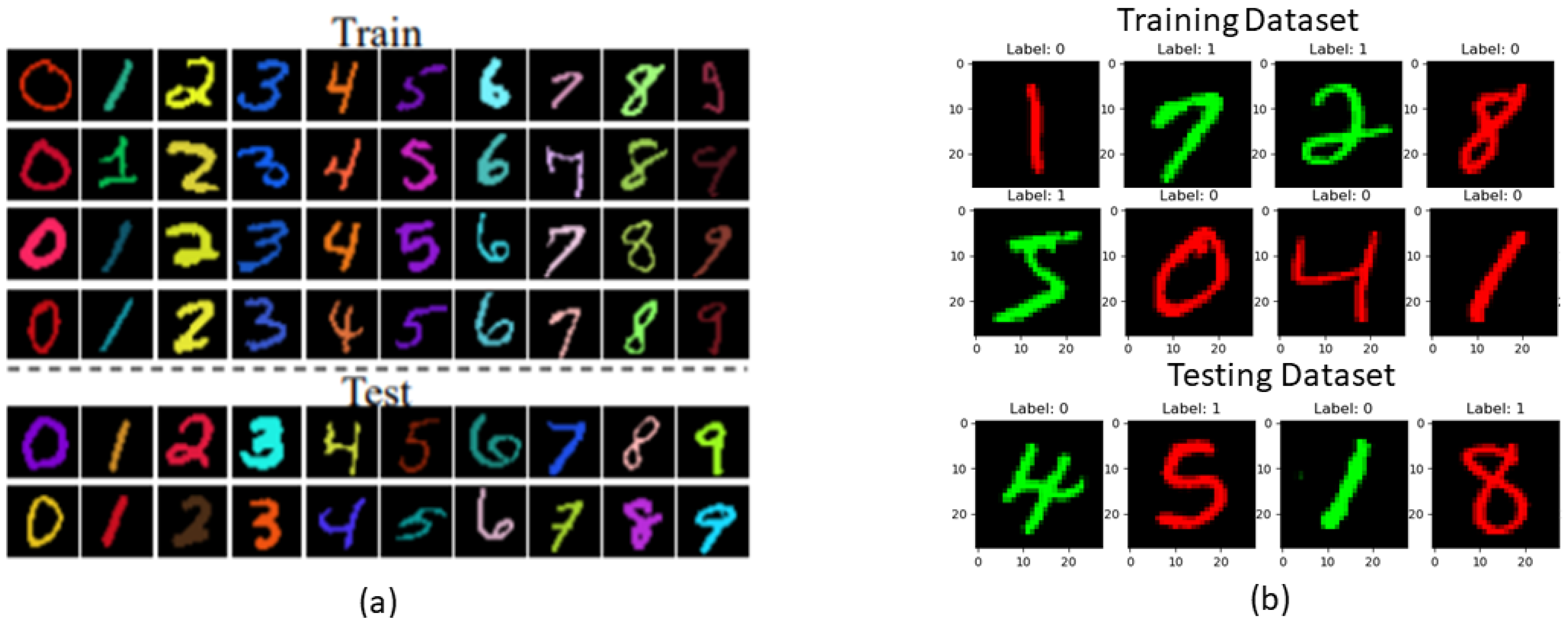
4.4. Color-Biased MNIST Dataset
4.5. Reversed Color-Biased MNIST Dataset
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mehrabi, N.; Morstatter, F.; Saxena, N.; Lerman, K.; Galstyan, A. A survey on bias and fairness in machine learning. ACM Comput. Surv. (CSUR) 2021, 54, 1–35. [Google Scholar] [CrossRef]
- Kärkkäinen, K.; Joo, J. Fairface: Face attribute dataset for balanced race, gender, and age. arXiv 2019, arXiv:1908.04913. [Google Scholar]
- Tommasi, T.; Patricia, N.; Caputo, B.; Tuytelaars, T. A deeper look at dataset bias. In Domain Adaptation in Computer Vision Applications; Springer: Berlin/Heidelberg, Germany, 2017; pp. 37–55. [Google Scholar]
- LeCun, Y.; Boser, B.; Denker, J.; Henderson, D.; Howard, R.; Hubbard, W.; Jackel, L. Handwritten digit recognition with a back-propagation network. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 27–30 November 1989; Volume 2. [Google Scholar]
- Kamiran, F.; Calders, T. Data preprocessing techniques for classification without discrimination. Knowl. Inf. Syst. 2012, 33, 1–33. [Google Scholar] [CrossRef] [Green Version]
- Kim, B.; Kim, H.; Kim, K.; Kim, S.; Kim, J. Learning not to learn: Training deep neural networks with biased data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9012–9020. [Google Scholar]
- Adeli, E.; Zhao, Q.; Pfefferbaum, A.; Sullivan, E.V.; Fei-Fei, L.; Niebles, J.C.; Pohl, K.M. Representation learning with statistical independence to mitigate bias. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 2513–2523. [Google Scholar]
- Hagan, M.T.; Demuth, H.B.; Beale, M. Neural Network Design; PWS Publishing Co.: Stillwater, OK, USA, 1997. [Google Scholar]
- Kasieczka, G.; Shih, D. DisCo Fever: Robust Networks through Distance Correlation. arXiv 2020, arXiv:2001.05310. [Google Scholar]
- Calmon, F.; Wei, D.; Vinzamuri, B.; Natesan Ramamurthy, K.; Varshney, K.R. Optimized pre-processing for discrimination prevention. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Li, Y.; Vasconcelos, N. Repair: Removing representation bias by dataset resampling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9572–9581. [Google Scholar]
- Dinsdale, N.K.; Jenkinson, M.; Namburete, A.I. Deep learning-based unlearning of dataset bias for MRI harmonisation and confound removal. NeuroImage 2021, 228, 117689. [Google Scholar] [CrossRef] [PubMed]
- Zhang, B.H.; Lemoine, B.; Mitchell, M. Mitigating unwanted biases with adversarial learning. In Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society, New Orleans, LA, USA, 2–3 February 2018; pp. 335–340. [Google Scholar]
- Mandis, I.S. Reducing Racial and Gender Bias in Machine Learning and Natural Language Processing Tasks Using a GAN Approach. Available online: https://terra-docs.s3.us-east-2.amazonaws.com/IJHSR/Articles/volume3-issue6/2021_36_p17_Mandis.pdf (accessed on 15 November 2021).
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Sadeghi, B.; Yu, R.; Boddeti, V. On the global optima of kernelized adversarial representation learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 7971–7979. [Google Scholar]
- Zhao, T.; Dai, E.; Shu, K.; Wang, S. Towards Fair Classifiers without Sensitive Attributes: Exploring Biases in Related Features. 2022. Available online: http://www.cs.iit.edu/~kshu/files/fair-wsdm22.pdf (accessed on 20 January 2022).
- Wang, T.; Zhao, J.; Yatskar, M.; Chang, K.W.; Ordonez, V. Balanced datasets are not enough: Estimating and mitigating gender bias in deep image representations. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 5310–5319. [Google Scholar]
- Alvi, M.; Zisserman, A.; Nellåker, C. Turning a blind eye: Explicit removal of biases and variation from deep neural network embeddings. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Wang, R.; Karimi, A.H.; Ghodsi, A. Distance correlation autoencoder. In Proceedings of the IEEE 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar]
- Lee Rodgers, J.; Nicewander, W.A. Thirteen ways to look at the correlation coefficient. Am. Stat. 1988, 42, 59–66. [Google Scholar] [CrossRef]
- Székely, G.J.; Rizzo, M.L.; Bakirov, N.K. Measuring and testing dependence by correlation of distances. Ann. Stat. 2007, 35, 2769–2794. [Google Scholar] [CrossRef]
- Patil, P. Flexible Image Recognition Software Toolbox (First); Oklahoma State University: Stillwater, OK, USA, 2013. [Google Scholar]
- Dua, D.; Graff, C. UCI Machine Learning Repository. (University of California, Irvine, School of Information, 2017). Available online: http://archive.ics.uci.edu/ml (accessed on 1 August 2020).
- LeCun, Y.; Cortes, C. MNIST Handwritten Digit Database. 2010. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 25 July 2020).
- Arjovsky, M.; Bottou, L.; Gulrajani, I.; Lopez-Paz, D. Invariant risk minimization. arXiv 2019, arXiv:1907.02893. [Google Scholar]
- Deep Learning Ami—Developer Guide. AWS Deep Learning AMIs Documentation. Available online: https://docs.aws.amazon.com/dlami/latest/devguide/dlami-dg.pdf (accessed on 12 February 2019).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: https://www.tensorflow.org/ (accessed on 6 January 2019).
- Chetlur, S.; Woolley, C.; Vandermersch, P.; Cohen, J.; Tran, J.; Catanzaro, B.; Shelhamer, E. Cudnn: Efficient primitives for deep learning. arXiv 2014, arXiv:1410.0759. [Google Scholar]
- Kusner, M.J.; Loftus, J.; Russell, C.; Silva, R. Counterfactual fairness. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Feldman, M.; Friedler, S.A.; Moeller, J.; Scheidegger, C.; Venkatasubramanian, S. Certifying and removing disparate impact. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 259–268. [Google Scholar]
- Li, X.; Cui, Z.; Wu, Y.; Gu, L.; Harada, T. Estimating and improving fairness with adversarial learning. arXiv 2021, arXiv:2103.04243. [Google Scholar]
- Bellamy, R.K.; Dey, K.; Hind, M.; Hoffman, S.C.; Houde, S.; Kannan, K.; Lohia, P.; Martino, J.; Mehta, S.; Mojsilovic, A.; et al. AI Fairness 360: An extensible toolkit for detecting, understanding, and mitigating unwanted algorithmic bias. arXiv 2018, arXiv:1810.01943. [Google Scholar]
- Feldman, T.; Peake, A. End-To-End Bias Mitigation: Removing Gender Bias in Deep Learning. arXiv 2021, arXiv:2104.02532. [Google Scholar]
- Pleiss, G.; Raghavan, M.; Wu, F.; Kleinberg, J.; Weinberger, K.Q. On fairness and calibration. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 2096–2030. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Bias Variable | Class Labels |
|---|---|---|
| German Credit | Age | Good and Bad Credit |
| UCI Adult | Gender | Income: >50 K and ≤50 K |
| Methods | SPD | EOD | AOD | DI | BA |
|---|---|---|---|---|---|
| Baseline | −0.3162 | −0.318 | −0.2876 | 0.3112 | 0.6534 |
| Reweighing | −0.2049 | −0.2318 | −0.2016 | 0.6229 | 0.6687 |
| Optimized pre | −0.0351 | 0.0254 | −0.0639 | 0.9421 | 0.6872 |
| Advers-Debias | 0.0713 | 0.0393 | 0.0931 | 1.0834 | 0.6633 |
| B-DcANN ( = 0) | −0.1491 | −0.1 | −0.0642 | 0.7798 | 0.7262 |
| DcANN | −0.03144 | −0.03918 | 0.06223 | 0.95927 | 0.7093 |
| Methods | SPD | EOD | AOD | DI | BA |
|---|---|---|---|---|---|
| Baseline | −0.3752 | −0.3716 | −0.3258 | 0.2876 | 0.7472 |
| Reweighing | −0.2924 | −0.3815 | −0.3234 | 0.3831 | 0.7110 |
| Optimized pre | −0.2144 | −0.1991 | −0.1945 | 0.568 | 0.7231 |
| Advers-Debias | −0.0876 | −0.0592 | −0.0373 | 0.5775 | 0.6656 |
| DIR + Advers-Debias + CEO | −0.0301 | 0.0785 | 0.051 | - | 0.8113 |
| B-DcANN ( = 0) | −0.3394 | −0.1545 | −0.1965 | 0.3025 | 0.8226 |
| DcANN | −0.0964 | 0.0657 | 0.0325 | 0.8063 | 0.7747 |
| Methods | Var = 0.02 | Var = 0.03 | Var = 0.035 | Var = 0.045 | Var = 0.05 |
|---|---|---|---|---|---|
| Baseline | 0.4055 | 0.5996 | 0.6626 | 0.7973 | 0.845 |
| BlindEye | 0.6741 | 0.7883 | 0.8203 | 0.8927 | 0.9159 |
| Advers Training | 0.8185 | 0.9137 | 0.9306 | 0.9555 | 0.9618 |
| Advers Training-no Pretrain | 0.7336 | 0.8516 | 0.8781 | 0.9277 | 0.9429 |
| DcCNN | 0.8100 | 0.8910 | 0.9250 | 0.9500 | 0.9604 |
| Methods | Accuracy |
|---|---|
| Baseline: ERM | 0.1115 |
| IRM | 0.6208 |
| DcCNN | 0.6630 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Patil, P.; Purcell, K. Decorrelation-Based Deep Learning for Bias Mitigation. Future Internet 2022, 14, 110. https://doi.org/10.3390/fi14040110
Patil P, Purcell K. Decorrelation-Based Deep Learning for Bias Mitigation. Future Internet. 2022; 14(4):110. https://doi.org/10.3390/fi14040110
Chicago/Turabian StylePatil, Pranita, and Kevin Purcell. 2022. "Decorrelation-Based Deep Learning for Bias Mitigation" Future Internet 14, no. 4: 110. https://doi.org/10.3390/fi14040110
APA StylePatil, P., & Purcell, K. (2022). Decorrelation-Based Deep Learning for Bias Mitigation. Future Internet, 14(4), 110. https://doi.org/10.3390/fi14040110