
Intelligent Traffic Management in Next-Generation Networks



Abstract
:1. Introduction
1.1. Related Work
1.2. Contributions
- We provide a comprehensive view of the state-of-the-art machine/deep learning algorithms used in the SDN;
- We present the benefits of feature selection/extraction with conventional ML algorithms;
- We review the approaches and technologies for deploying DL/ML on SDN ranging from traffic classification to traffic prediction and intrusion detection systems;
- We highlight the problems and challenges encountered when using DL/ML.
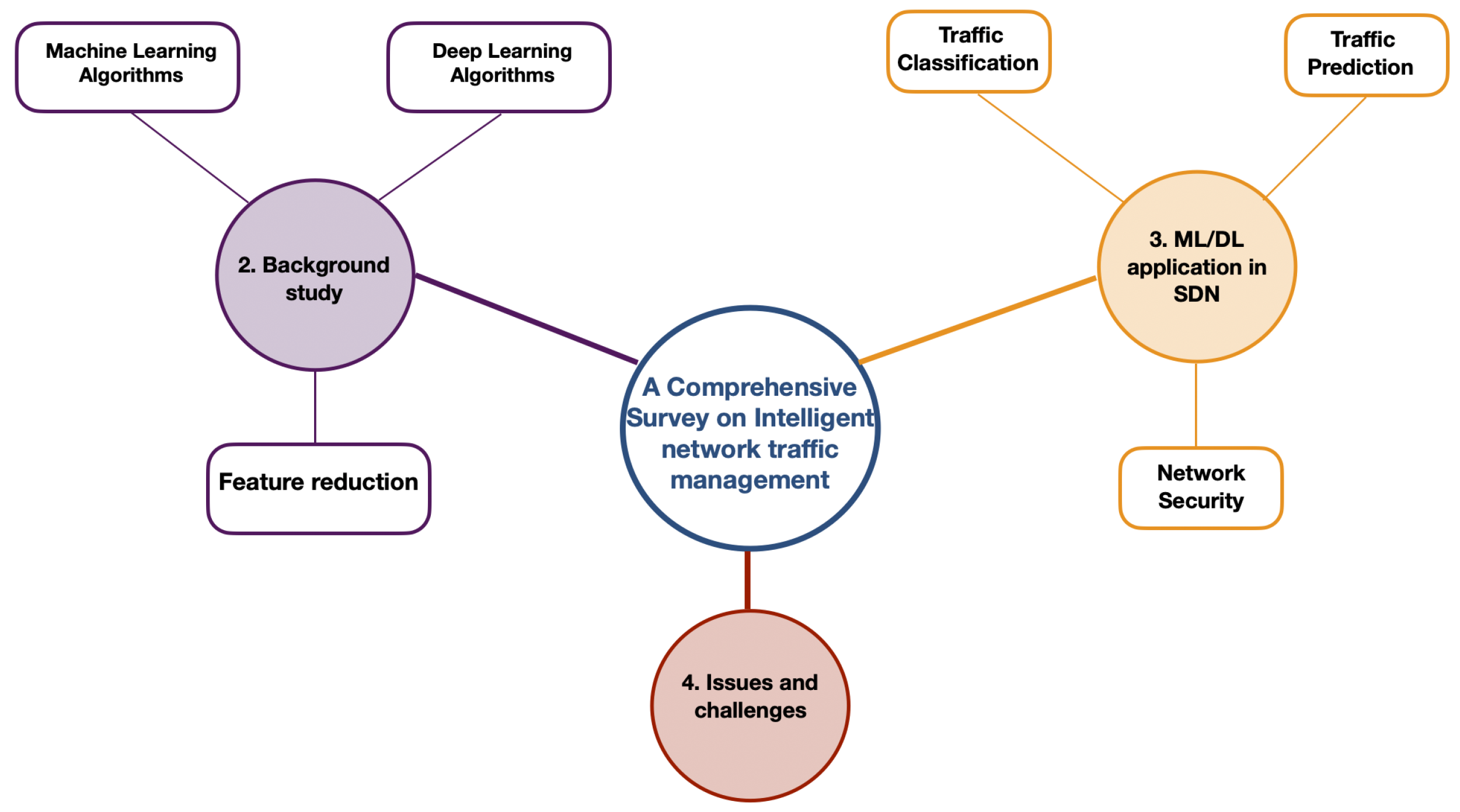
1.3. Paper Organization
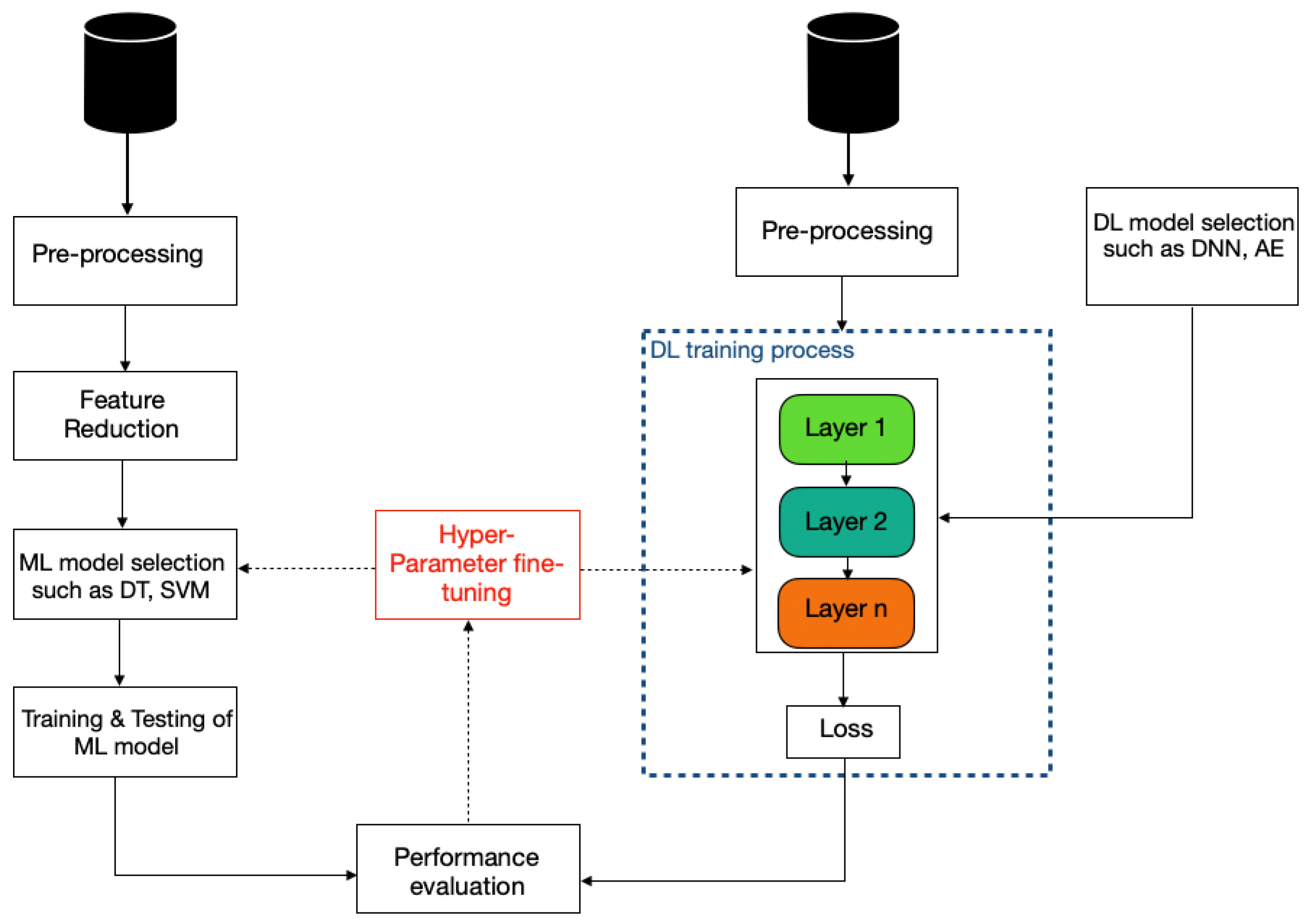
2. Machine Learning
- Supervised learning
- Unsupervised learning
- Semi-supervised learning
- Reinforcement learning (RL)
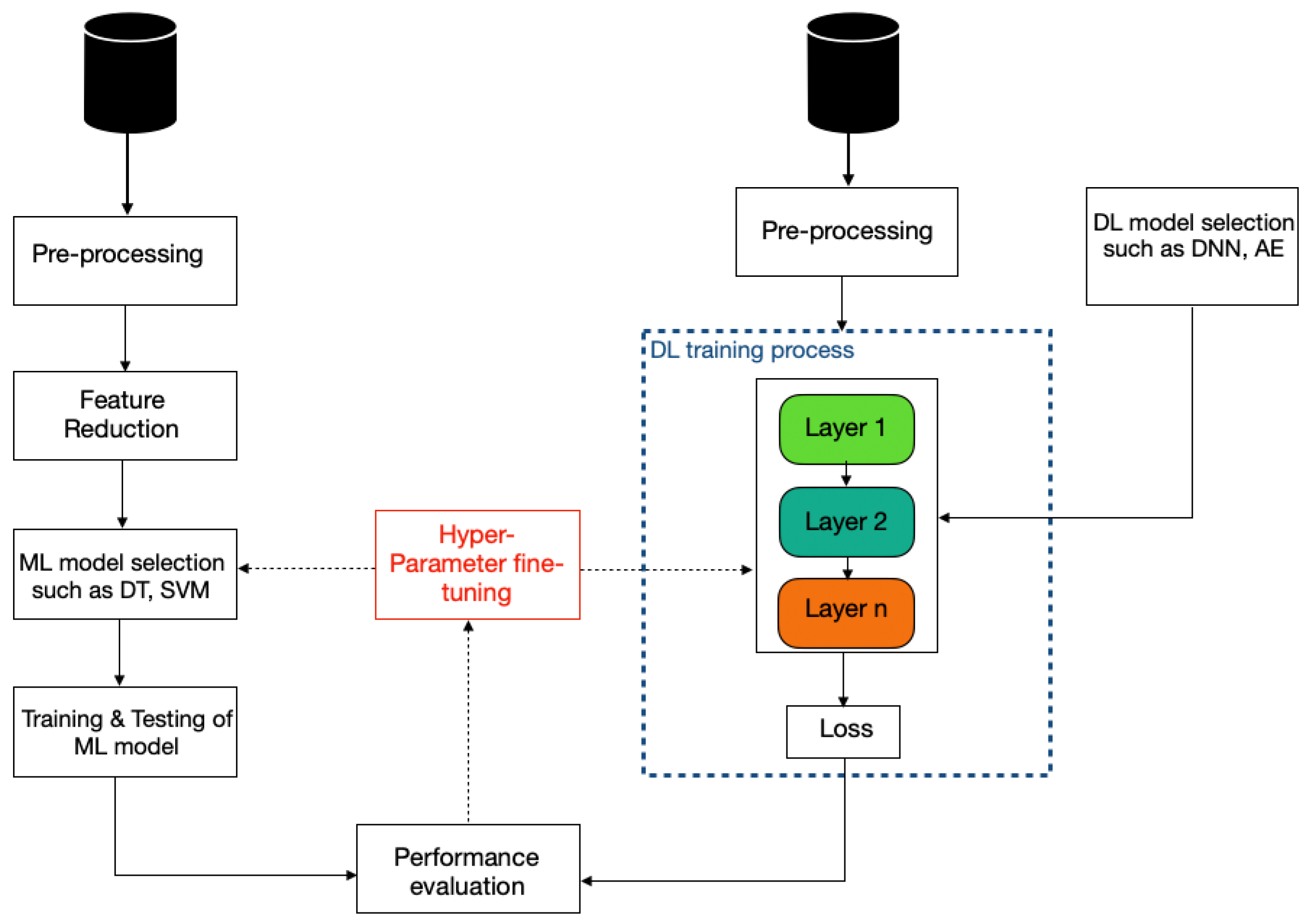
2.1. Deep Learning
2.2. Conventional Machine Learning Models

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Description | Strengths | Weaknesses |
|---|---|---|---|
| Decision tree (DT) | Decision tree is a tree-like structure, where every leaf (terminal) corresponds to a class label and each internal node corresponds to an attribute. The node at the top of the tree is called the root node. Tree splitting uses Gini Index or Information Gain methods [46]. | Simple to understand and interpret, requires little data preparation, handles many types of data (numeric, categorical), easily processesdata with high dimension | Generates a complex tree with numeric data, requires large storage |
| Random forest (RF) | Random forest was developed nearly 20 years ago [47] and is one of the most popular supervised machine learning algorithms that is capable to be used for regression and classification. As their name would suggest, random forests are constructed from decision trees. It uses the bagging method, which enhances the performance. | Efficient against over-fitting | Requires a large training dataset, impractical for real-time applications |
| Support vector machine (SVM) | SVM is a powerful classification algorithm which can be used for both regression and classification problems. However, it is mostly used as classification technique. It was initially developed for binary classification, but it could be efficiently extended to multiclass problems. It can be a linear and non-linear classifier by creating a splitting hyperplane in original input space to separate the data points. | Scalable, handles complex data | Computationally expensive, there is no theorem to select the right kernel function |
| K-nearest neighbour (KNN) | KNN is a supervised model reason with the underlying principal “Tell me who are your friends, I will tell you who are you” [48]. It classifies new instances using the information provided by the K nearest neighbors, so that the assigned class will be the most common among them (majority vote). Additionally, as it does not build a model and no work is done until an unlabeled data pattern arrives, it is thus considered as a lazy approach. | Easy to implement, has good performance with simple problems, non-expert users can use it efficiently | Requires large storage space, determining the optimal value of K is time consuming, K values varies depending on the dataset, testing is slow, and when the training dataset is large, it is not suitable for real-time classification |
| K-means | K-means is a well-known unsupervised model. It can partition the data into K clusters based on a similarity measure, and the observations belonging to the same cluster have high similarity as compared to those of other clusters. | Fast, simple and less complex | Requires a number of cluster in advance, cannot handle the outliers |
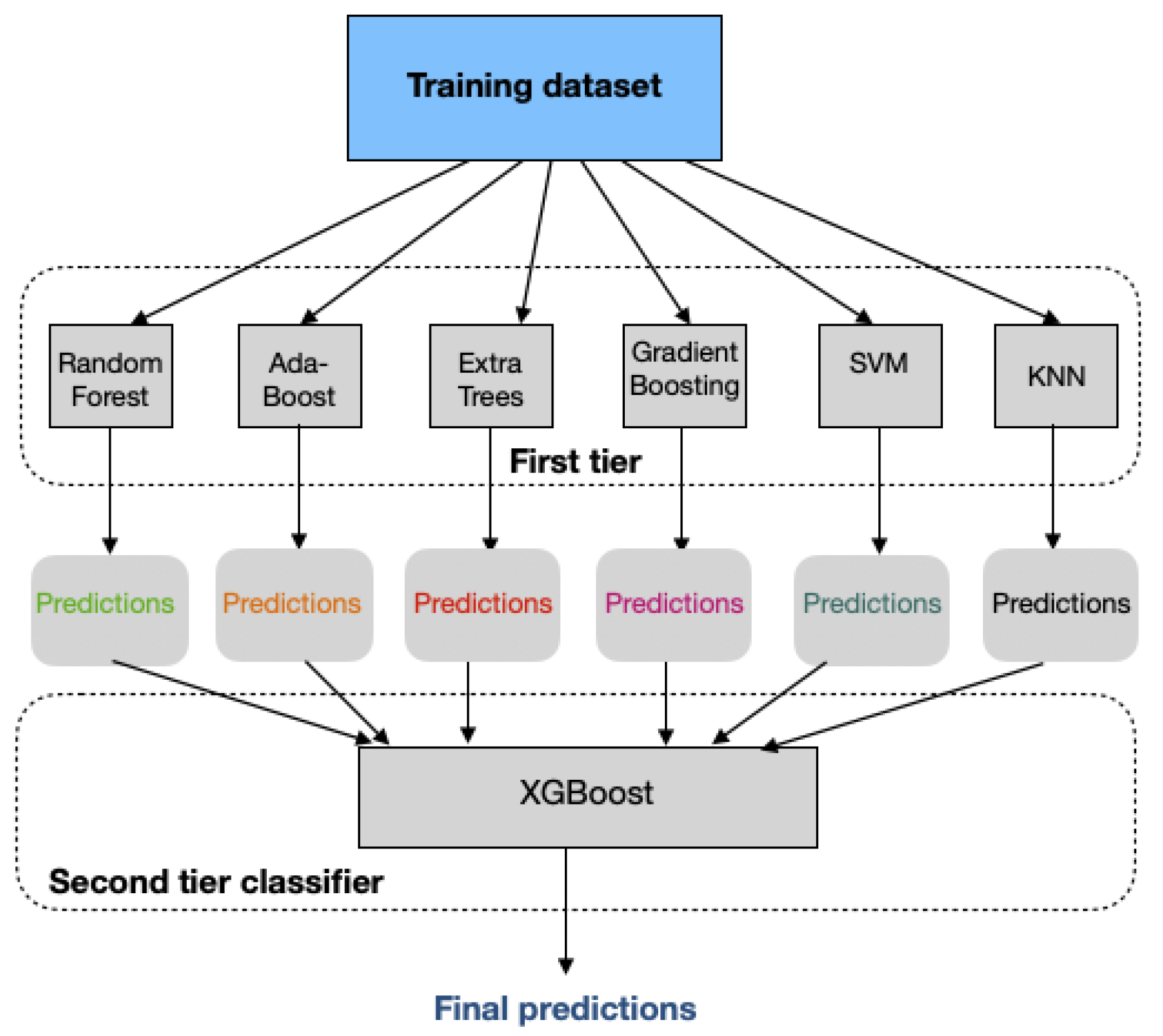
| Boosting algorithms | The main idea of boosting is to improve the performance of any model, even weak learners (i.e., XGBoost, AdaBoost, etc). The base model generates a weak prediction rule, and after several rounds, the boosting algorithms improve the prediction performance by combining the weak rules into a single prediction rule [49]. | High accuracy, efficient against under-fitting | Computationally expensive, hard to find the optimal parameters |
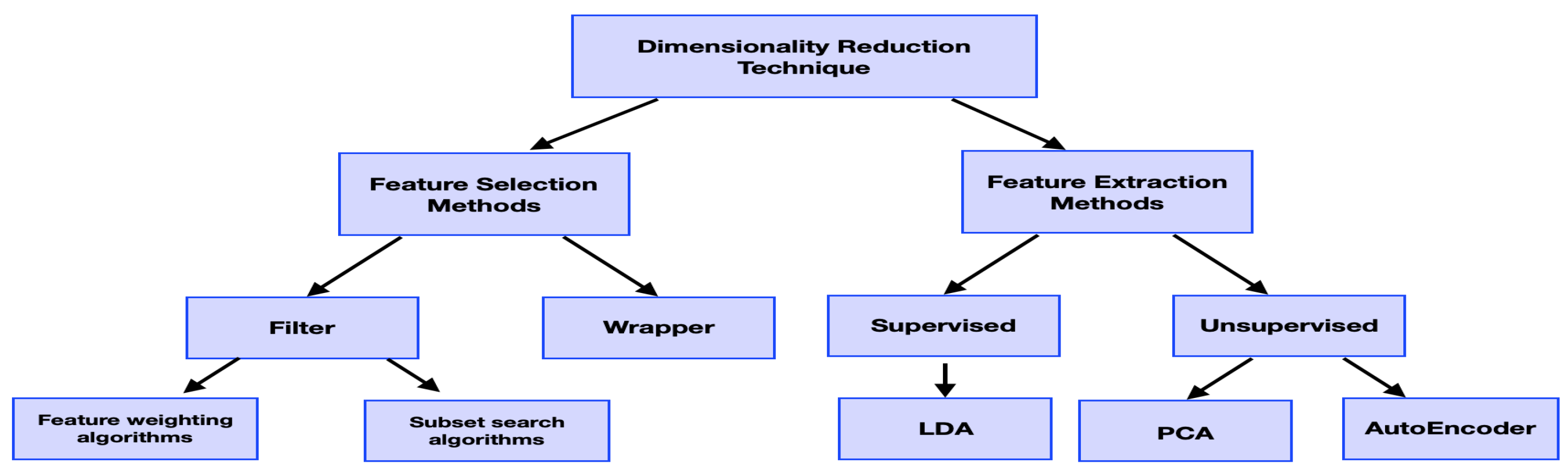
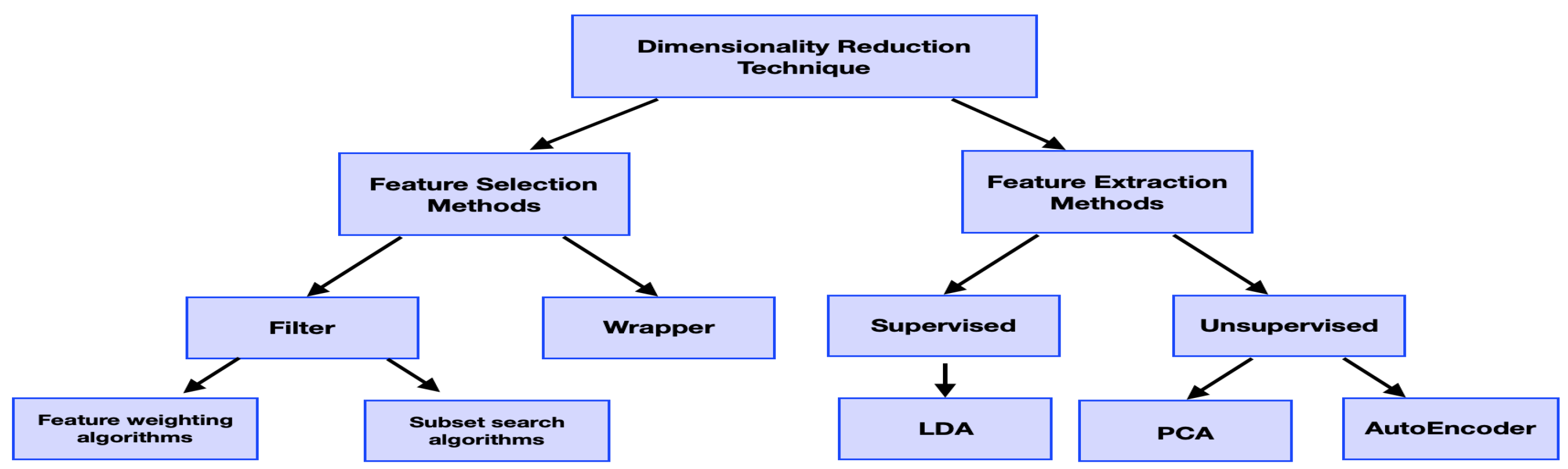
2.3. Feature Reduction
| Method | Advantages | Disadvantages | Methods | Potential Application in SDN |
|---|---|---|---|---|
| Filter | Low computational cost, fast, scalable | Ignores the interaction with the classifier | CFS, IG, FCBF | QoS prediction [58], traffic classification [59,60]. |
| Wrapper | Competitive classification accuracy, interaction with the classifier | Slow, expensive for large feature space, risk of over-fitting | Forward/backward direction | Traffic classification [61], QoS prediction [58]. |
| Feature extraction | Reduces dimension without loss of information | No information about the original features | PCA, LDA, AE | Traffic classification [59,62,63]. |
2.3.1. Feature Selection
- Subset generation is a search procedure that generates candidate feature subsets for evaluation based on a search strategy (i.e., start with no feature or with all features);
- Evaluation of subset tries to measure the discriminating ability of a feature or a subset to distinguish the target variables;
- Stopping criteria determines when the feature selection process should stop (i.e., addition or deletion of any feature does not produce a better subset);
- Result validation tries to test the validity of the selected features.
2.3.2. Feature Extraction
- It assumes that the relations between variables are linear;
- It depends on the scaling of the data (i.e., each variable is normalized to zero mean);
- We do not know how many PCs should be retained (the optimal number of principal components (PCs));
- It does not consider the correlation between target outputs and input features [23];
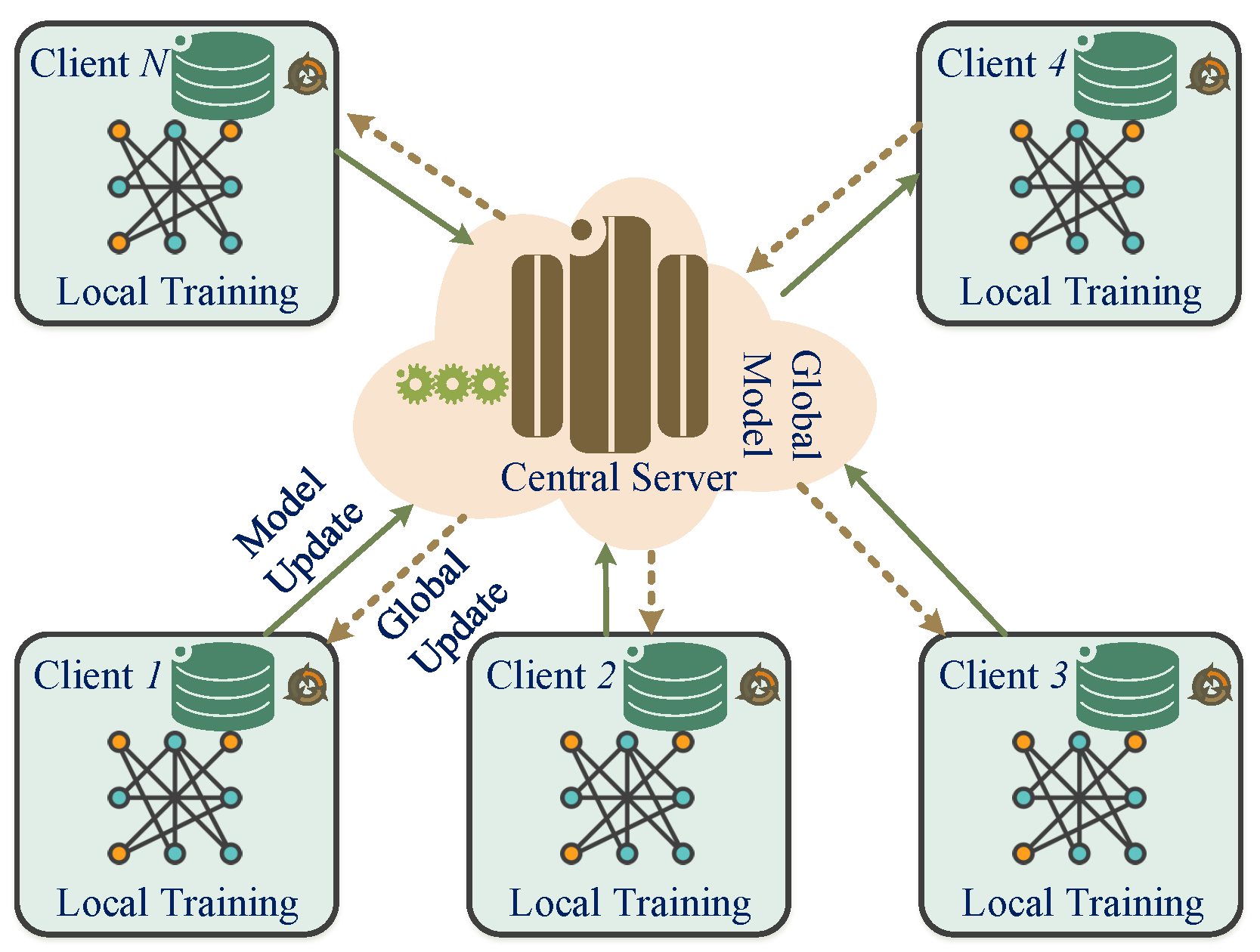
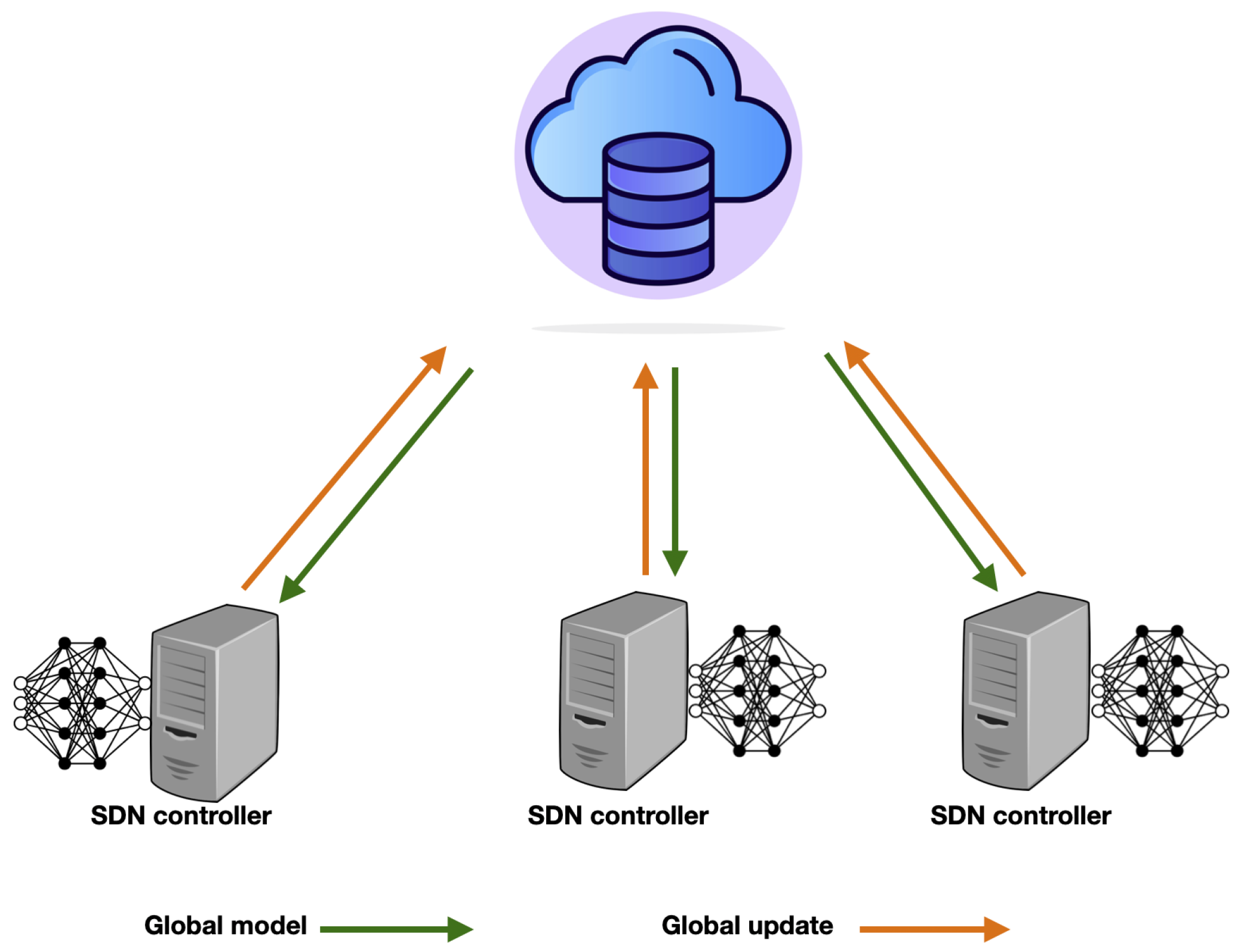
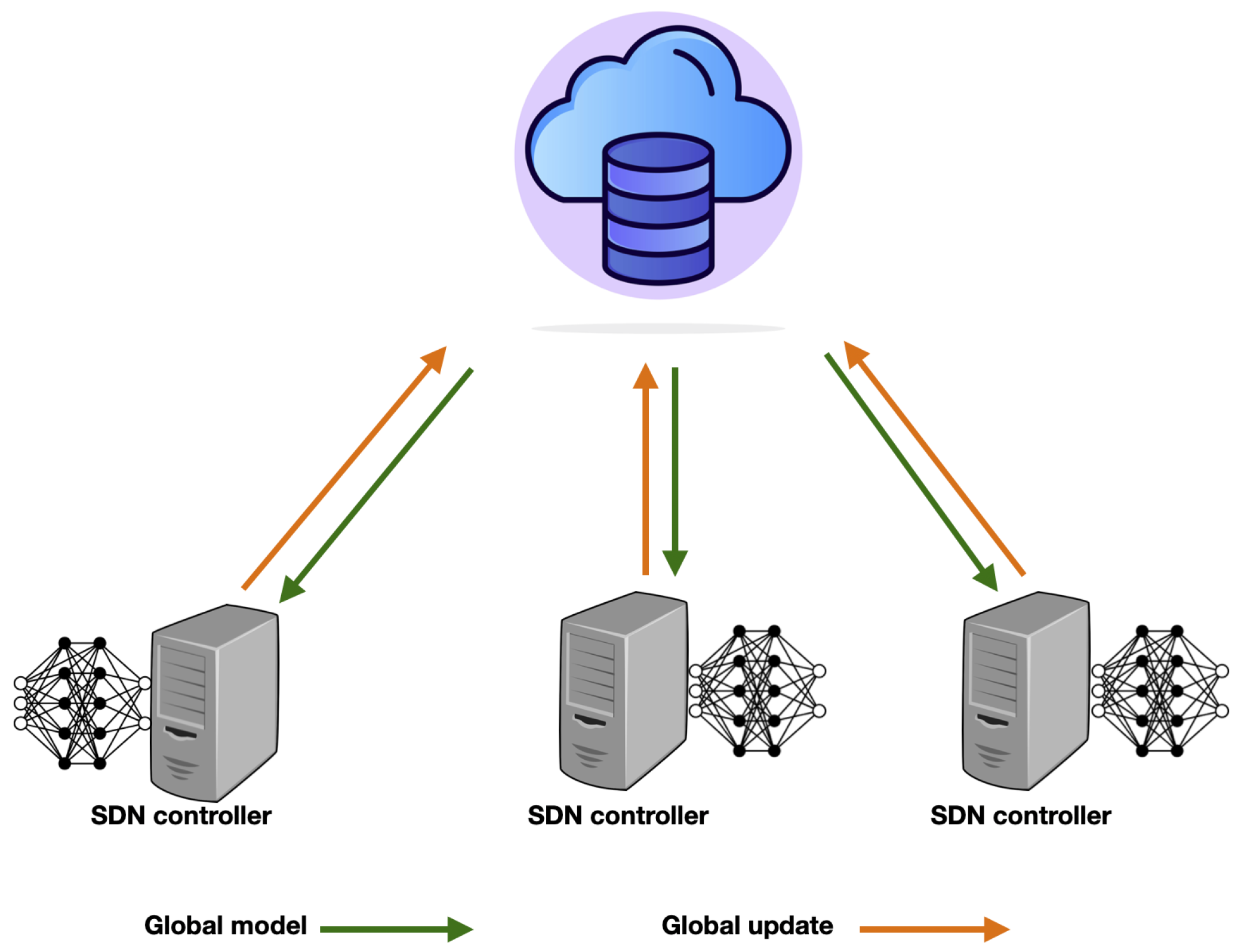
2.4. Federated Learning
3. DL/ML Applications in Software-Defined Networking
3.1. Traffic Classification
3.1.1. Existing Solutions
- Coarse-grained traffic classification
- Fine-grained traffic classification
- Other Approaches for Traffic Classification
3.1.2. Public Datasets
- VPN-nonVPN dataset [96] is a popular encrypted traffic classification dataset. It contains only time-related features and regular traffic, as well as traffic captured over a virtual private network (VPN). Specifically, it consists of four scenarios. Scenario A is used for binary classification in order to indicate whether the traffic flow is VPN or not. Both scenario B and scenario C are classification tasks. Scenario B contains only seven non-VPN traffic services like audio, browsing, etc. Scenario C is similar to Scenario B, but it contains seven traffic services of the VPN version. Scenario D contains all fourteen classes of scenario B and scenario C to perform the 14-classification task;
- Tor-nonTor dataset [102] contains only time-related features. This dataset has eight different labels, corresponding to the eight different types of traffic captured, which are browsing, audio streaming, chat, video streaming, mail, VoIP, P2P, and file transfers;
- QUIC [103] is released by the University of California at Davis. It contains five Google services: Google Drive, Youtube, Google Docs, Google Search, and Google Music.
- Dataset-Unicauca [88] is released by the Universidad Del Cauca, Popayán, Colombia. It was collected through packet captures at different hours during the morning and afternoon over 6 days in 2017. This dataset consists of 87 features, 3,577,296 observations, and 78 classes (Twitter, Google, Amazon, Dropbox, etc.)
3.1.3. Discussion
3.2. Traffic Prediction
3.2.1. Existing Solutions
3.2.2. Public Datasets
- Abilene dataset [117] contains the real trace data from the backbone network located in North America consisting of 12 nodes and 30 unidirectional links. The volume of traffic is aggregated over slots of 5 min starting from 1 March 2004 to 10 September 2004;
- GEANT [118] has 23 nodes and 36 links. A traffic matrix (TM) is summarized every 15 min starting from 8 January 2005 for 16 weeks (10,772 TMs in total);
- Telecom Italia [119] is part of the “Big Data challenge”. The traffic was collected from 1 November 2013 to 1 January 2014 using 10 min as a temporal interval over Milan. The area of Milan is divided into a grid of 100 × 100 squares, and the size of each square is about 235 × 235 m. This dataset contains three types of cellular traffic: SMS, call, and Internet traffic. Additionally, it has 300 million records, which comes to about 19 GB.
3.2.3. Discussion
3.3. Network Security
3.3.1. Existing Solutions
- DDoS attack detection/classification
3.3.2. Public Datasets
- KDD’99 [140] is one of the most well-known datasets for validating IDS. It consists of 41 traffic features and 4 attack categories besides benign traffic. The attack traffic is categorized into denial of service (DoS), remote to local (R2L), user to root (U2R), or probe attacks. This dataset contains redundant observations, and therefore, the trained model can be biased towards the more frequent observations;
- The NSL-KDD dataset [141] is the updated version of the KDD’99 dataset. It solves the issues of the duplicate observations. It contains two subsets, a training set and testing set, where the distribution of attack in the testing set is higher than the training set;
- The ISCX dataset [121] was released by the Canadian Institute for Cybersecurity, University of New Brunswick. It consists of benign traffic and four types of attack, which are brute force attack, DDoS, HttpDoS, and infiltrating attack;
- Gas pipeline and water storage tank [142] is a dataset released by a lab at Mississippi State University in 2014. They proposed two datasets: the first is with a gas pipeline, and the second is for a water storage tank. These datasets consist of 26 features and 1 label. The label contains eight possible values, benign and seven different types of attacks, which are naive malicious response injection, complex malicious response injection, malicious state command injection, malicious parameter command injection, malicious function command injection, reconnaissance, and DoS attacks;
- The UNSW-NB15 dataset [143] is one of the recent datasets; it includes a simulated period of data which was 16 h on 22 January 2015 and 15 h on 17 February 2015. This dataset has nine types of attacks: fuzzers, analysis, backdoors, DoS, exploits, generic, reconnaissance, shellcode, and worms. It contains two subsets, a training set with 175,341 observations and a testing set with 82,332 observations and 49 features;
- The CICDS2017 dataset [144] is one of the recent intrusion detection datasets released by the Canadian Institute for Cybersecurity, University of New Brunswick. It contains 80 features and 7 types of attack network flows: brute force attack, heartbleed attack, botnet, DoS Attack, DDoS Attack, web attack, infiltration attack;
- The DS2OS dataset [145] was generated through the distributed smart space orchestration system (DS2OS) in a virtual IoT environment. This dataset contains benign traffic and seven types of attacks, including DoS, data type probing, malicious control, malicious operation, scan, spying, and wrong setup. It consists of 357,952 observations and 13 features;
- The ToN-IoT dataset [146] was put forward by the IoT Lab of the UNSW Canberra Cyber, the School of Engineering and Information Technology (SEIT), and UNSW Canberra at the Australian Defence Force Academy (ADFA). It contains traffic collected from the Internet of Things (IoT) and industrial IoT devices. It contains benign traffic and 9 different types of attacks (backdoor, DDoS, DoS, injection, MITM, password, ransomware, scanning, and XSS) with 49 features;
- The IoT Botnet dataset [147] uses the MQTT protocol as a communication protocol. It contains 83 features and 4 different types of attacks, including DDoS, DoS, reconnaissance, and theft, along with benign traffic;
- The InSDN dataset [130] is a recent dataset and the first one generated directly from SDN networks. It consists of 80 features and 361,317 observations for both normal and attack traffic. It covers different types of attack types, including DoS, DDoS, probe, botnet, exploitation, password guessing, web attacks, and benign traffic (HTTPS, HTTP, DNS, Email, FTP, SSH) that can occur in the SDN environment.
| Ref. | Category | ML/DL Model | Dimensionality Reduction | Controller | Contribution |
|---|---|---|---|---|---|
| [45] | Intrusion detection | DNN | - | N/A | The first application of the DL approach for intrusion detection in the SDN environment. |
| [127] [128] | Intrusion detection | GRU-RNN | - | POX | The authors achieve a good performance using the GRU-RNN model with only six features. |
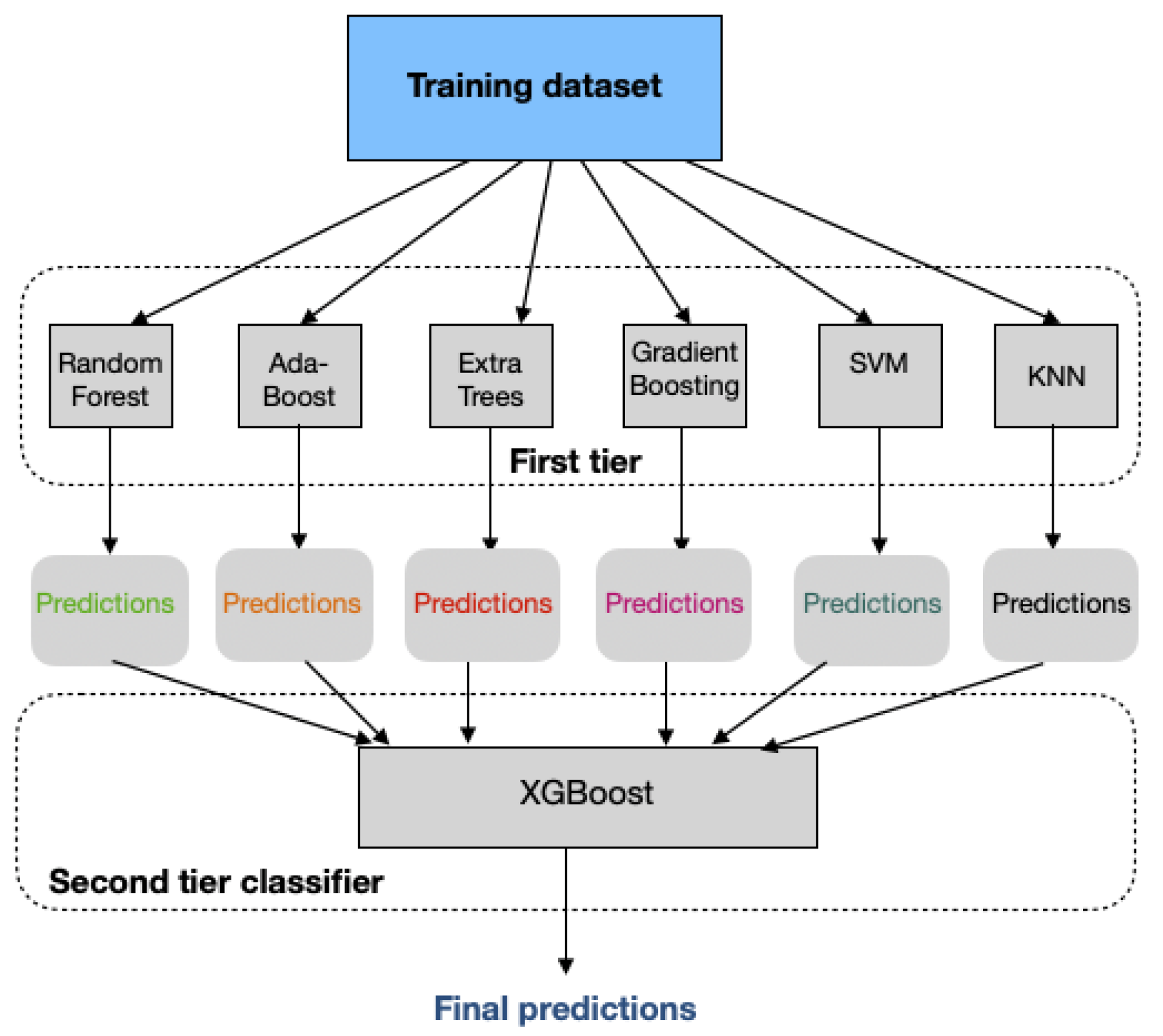
| [135] | DDoS detection | XGBoost | Filter method | POX | The XGBoost algorithm has strong scalability and higher accuracy and a lower false positive rate than random forest and SVM. |
| [136] | DDoS classification | SAE | AE | POX | Before the DDoS attack detection task, the authors used SAE for feature reduction in an unsupervised manner. |
| [120] | DDoS classification | GAN | - | Floodlight | The authors used GAN to make their system more efficient against adversarial attacks. |
| [125] | Attack classification | RF | Filter method | N/A | The authors used an upgrade metaheuristic algorithm for feature selection and RF as a classifier. |
| [124] | Attack classification | AdaBoost | Wrapper method | N/A | The authors demonstrate that using the feature selection method improves the attack classification task as well as produces a low overhead system. |
| [137] | DDoS detection | LSTM, CNN, RNN | - | N/A | The authors have compared different DL-based models. |
| [138] | DDoS detection | CNN | - | N/A | The authors proposed an ensemble CNN model for the DDoS attack detection and compared its performance with other known DL-based models using a benchmark dataset. |
| [139] | DDoS classification | AE+RF | AE | Ryu | The authors proposed a hybrid ML approach by combining deep learning and conventional ML models. The AE is used to extract a reduced version of the initial features, and the RF acts as the main classifier of the system. |
| [129] | Attack classification | CNN+SVM, CNN+RF, CNN+DT | CNN | N/A | The authors demonstrate the potential of CNN for anomaly detection even with a few amount of features (9 features). Additionally, the combination of CNN and SVM, KNN, and especially the RF algorithm enhances the detection rate and provides a higher performance compared to the single CNN. |
| [134] | DDoS detection | SVM, Naive-Bayes, DT, and Logistic Regression | N/A | POX | The authors compare the performance of different well-known ML-based models, including SVM, Naive-Bayes, DT, and logistic regression. |
| [123] | Intrusion detection | DT, RF, AdaBoost, KNN, SVM | PCA | N/A | The authors focused on a comparative analysis between different conventional ML-based models for the intrusion detection task using a benchmark dataset (NSL-KDD dataset). |
| [107] | DDoS classification | SVM | PCA | Floodlight | The authors proposed a framework for detection and classification called ATLANTIC. The attack detection is performed by calculating the deviations in the entropy of flow tables, whereas the attack classification was done by the SVM model. |
| [131] | Attack classification | GAN | - | N/A | The authors proposed an IDS based on distributed SDN in VANETs in order to enable all the distributed SDN controllers to collaboratively train a stronger detection model based on the whole network flow. |
| [74] | Ransomware attacks | Logistic Regression+FL, FNN+FL | - | N/A | The authors proposed a federated learning model in an SDN environment to enable collaborative learning for detection and mitigation of ransomware attacks in healthcare without data exchange. |
| [132] | Intrusion detection | BNN+FL | - | N/A | The authors combined FL and binarized neural networks for intrusion detection using programmable network switches (e.g., P4 language). |
3.3.3. Discussion
4. Research Challenges and Future Directions
5. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cisco Visual Networking Index: Global Mobile Data Traffic Forecast Update, 2017–2022 White Paper; Cisco: San Jose, CA, USA, 2019.
- Ayoubi, S.; Limam, N.; Salahuddin, M.A.; Shahriar, N.; Boutaba, R.; Estrada-Solano, F.; Caicedo, O.M. Machine learning for cognitive network management. IEEE Commun. Mag. 2018, 56, 158–165. [Google Scholar] [CrossRef]
- Mestres, A.; Rodriguez-Natal, A.; Carner, J.; Barlet-Ros, P.; Alarcón, E.; Solé, M.; Muntés-Mulero, V.; Meyer, D.; Barkai, S.; Hibbett, M.J.; et al. Knowledge-defined networking. ACM SIGCOMM Comput. Commun. Rev. 2017, 47, 2–10. [Google Scholar] [CrossRef] [Green Version]
- Xie, J.; Yu, F.R.; Huang, T.; Xie, R.; Liu, J.; Wang, C.; Liu, Y. A survey of machine learning techniques applied to software defined networking (SDN): Research issues and challenges. IEEE Commun. Surv. Tutor. 2018, 21, 393–430. [Google Scholar] [CrossRef]
- Latah, M.; Toker, L. Application of Artificial Intelligence to Software Defined Networking: A survey. Indian J. Sci. Technol. 2016, 9, 1–7. [Google Scholar] [CrossRef]
- Latah, M.; Toker, L. Artificial Intelligence enabled Software-Defined Networking: A comprehensive overview. IET Netw. 2018, 8, 79–99. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Y.; Li, Y.; Zhang, X.; Geng, G.; Zhang, W.; Sun, Y. A survey of networking applications applying the Software Defined Networking concept based on machine learning. IEEE Access 2019, 7, 95397–95417. [Google Scholar] [CrossRef]
- Thupae, R.; Isong, B.; Gasela, N.; Abu-Mahfouz, A.M. Machine learning techniques for traffic identification and classification in SDWSN: A survey. In Proceedings of the 44th Annual Conference of the IEEE Industrial Electronics Society, Washington, DC, USA, 21–23 October 2018; pp. 4645–4650. [Google Scholar]
- Mohammed, A.R.; Mohammed, S.A.; Shirmohammadi, S. Machine Learning and Deep Learning based traffic classification and prediction in Software Defined Networking. In Proceedings of the IEEE International Symposium on Measurements & Networking (M&N), Catania, Italy, 8–10 July 2019; pp. 1–6. [Google Scholar]
- Boutaba, R.; Salahuddin, M.A.; Limam, N.; Ayoubi, S.; Shahriar, N.; Estrada-Solano, F.; Caicedo, O.M. A comprehensive survey on machine learning for networking: Evolution, applications and research opportunities. J. Internet Serv. Appl. 2018, 9, 1–99. [Google Scholar] [CrossRef] [Green Version]
- Sultana, N.; Chilamkurti, N.; Peng, W.; Alhadad, R. Survey on SDN based network intrusion detection system using machine learning approaches. Peer- Netw. Appl. 2019, 12, 493–501. [Google Scholar] [CrossRef]
- Nguyen, T.N. The challenges in SDN/ML based network security: A survey. arXiv 2018, arXiv:1804.03539. [Google Scholar]
- Pouyanfar, S.; Sadiq, S.; Yan, Y.; Tian, H.; Tao, Y.; Reyes, M.P.; Shyu, M.L.; Chen, S.C.; Iyengar, S. A survey on deep learning: Algorithms, techniques, and applications. ACM Comput. Surv. (CSUR) 2018, 51, 1–36. [Google Scholar] [CrossRef]
- Deng, L. A tutorial survey of architectures, algorithms, and applications for deep learning. APSIPA Trans. Signal Inf. Process. 2014, 3, e2. [Google Scholar] [CrossRef] [Green Version]
- Khalid, S.; Khalil, T.; Nasreen, S. A survey of feature selection and feature extraction techniques in machine learning. In Proceedings of the Science and Information Conference, London, UK, 27–29 August 2014; pp. 372–378. [Google Scholar]
- Liu, H.; Yu, L. Toward Integrating Feature Selection Algorithms for Classification and Clustering. IEEE Trans. Knowl. Data Eng. 2005, 17, 491–502. [Google Scholar]
- Kobo, H.I.; Abu-Mahfouz, A.M.; Hancke, G.P. A survey on Software-Defined Wireless Sensor Networks: Challenges and design requirements. IEEE Access 2017, 5, 1872–1899. [Google Scholar] [CrossRef]
- Domingos, P. A few useful things to know about machine learning. Commun. ACM 2012, 55, 78–87. [Google Scholar] [CrossRef] [Green Version]
- Jordan, M.I.; Mitchell, T.M. Machine learning: Trends, perspectives, and prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef]
- Mitchell, T.M. Machine Learning; McGraw-Hill: New York, NY, USA, 1997. [Google Scholar]
- Bengio, Y.; Lee, H. Editorial introduction to the neural networks special issue on deep learning of representations. Neural Netw. 2015, 64, 1–3. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Zhang, G.P. Neural networks for classification: A survey. IEEE Trans. Syst. Man, Cybern. 2000, 30, 451–462. [Google Scholar] [CrossRef] [Green Version]
- Pacheco, F.; Exposito, E.; Gineste, M.; Baudoin, C.; Aguilar, J. Towards the deployment of machine learning solutions in network traffic classification: A systematic survey. IEEE Commun. Surv. Tutor. 2019, 21, 1988–2014. [Google Scholar] [CrossRef] [Green Version]
- Aouedi, O.; Piamrat, K.; Parrein, B. Performance evaluation of feature selection and tree-based algorithms for traffic classification. In Proceedings of the 2021 IEEE International Conference on Communications Workshops (ICC Workshops), Montreal, QC, Canada, 14–23 June 2021. [Google Scholar]
- Tomar, D.; Agarwal, S. A survey on Data Mining approaches for Healthcare. Int. J. Bio-Sci. Bio-Technol. 2013, 5, 241–266. [Google Scholar] [CrossRef]
- Zhu, X.J. Semi-Supervised Learning Literature Survey; Technical Report; University of Wisconsin-Madison Department of Computer Sciences: Madison, WI, USA, 2005. [Google Scholar]
- Aouedi, O.; Piamrat, K.; Bagadthey, D. A semi-supervised stacked autoencoder approach for network traffic classification. In Proceedings of the 2020 IEEE 28th International Conference on Network Protocols (ICNP); Madrid, Spain, 13–16 October 2020. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Introduction to Reinforcement Learning; MIT Press: Cambridge, UK, 1998; Volume 135. [Google Scholar]
- Watkins, C.J.; Dayan, P. Q-learning. Machine Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Boyan, J.A.; Littman, M.L. Packet routing in dynamically changing networks: A reinforcement learning approach. In Advances in Neural Information Processing Systems; Available online: https://proceedings.neurips.cc/paper/1993/hash/4ea06fbc83cdd0a06020c35d50e1e89a-Abstract.html (accessed on 30 December 2021).
- Bitaillou, A.; Parrein, B.; Andrieux, G. Q-routing: From the algorithm to the routing protocol. In Proceedings of the International Conference on Machine Learning for Networking, Paris, France, 3–5 December 2019; pp. 58–69. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Li, Y. Deep reinforcement learning: An overview. arXiv 2017, arXiv:1701.07274. [Google Scholar]
- Ketkar, N.; Santana, E. Deep Learning with Python; Springer: Berlin/Heidelberg, Germany, 2017; Volume 1. [Google Scholar]
- Zhang, Q.; Yang, L.T.; Chen, Z.; Li, P. A survey on deep learning for big data. Inf. Fusion 2018, 42, 146–157. [Google Scholar] [CrossRef]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed]
- Mayer, R.; Jacobsen, H.A. Scalable deep learning on distributed infrastructures: Challenges, techniques, and tools. ACM Comput. Surv. (CSUR) 2020, 53, 1–37. [Google Scholar] [CrossRef] [Green Version]
- Shrestha, A.; Mahmood, A. Review of deep learning algorithms and architectures. IEEE Access 2019, 7, 53040–53065. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Haykin, S. Neural Networks: A Comprehensive Foundation; Prentice-Hall: Hoboken, NJ, USA, 2007. [Google Scholar]
- Woźniak, M.; Grana, M.; Corchado, E. A survey of multiple classifier systems as hybrid systems. Inf. Fusion 2014, 16, 3–17. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Pan, Y. A novel ensemble deep learning model for stock prediction based on stock prices and news. Int. J. Data Sci. Anal. 2021, 1–11. [Google Scholar] [CrossRef]
- Polikar, R. Ensemble based systems in decision making. IEEE Circuits Syst. Mag. 2006, 6, 21–45. [Google Scholar] [CrossRef]
- Tang, T.A.; Mhamdi, L.; McLernon, D.; Zaidi, S.A.R.; Ghogho, M. Deep learning approach for network intrusion detection in Software Defined Networking. In Proceedings of the 2016 International Conference on Wireless Networks and Mobile Communications (WINCOM), Fez, Morocco, 26–29 October 2016; pp. 258–263. [Google Scholar]
- Freund, Y.; Mason, L. The alternating decision tree learning algorithm. In Proceedings of the 16th International Conference on Machine Learning (ICML), Bled, Slovenia, 27–30 June 1999; Volume 99, pp. 124–133. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Abar, T.; Letaifa, A.B.; El Asmi, S. Machine learning based QoE prediction in SDN networks. In Proceedings of the 13th International Wireless Communications and Mobile Computing Conference (IWCMC), Valencia, Spain, 26–30 June 2017; pp. 1395–1400. [Google Scholar]
- Schapire, R.E. The boosting approach to machine learning: An overview. In Nonlinear Estimation and Classification; Springer: New York, NY, USA, 2003; pp. 149–171. [Google Scholar]
- Dainotti, A.; Pescape, A.; Claffy, K.C. Issues and future directions in traffic classification. IEEE Netw. 2012, 26, 35–40. [Google Scholar] [CrossRef] [Green Version]
- L’heureux, A.; Grolinger, K.; Elyamany, H.F.; Capretz, M.A. Machine learning with big data: Challenges and approaches. IEEE Access 2017, 5, 7776–7797. [Google Scholar] [CrossRef]
- Janecek, A.; Gansterer, W.; Demel, M.; Ecker, G. On the relationship between feature selection and classification accuracy. In Proceedings of the New Challenges for Feature Selection in Data Mining and Knowledge Discovery, Antwerp, Belgium, 15 September 2008; Volume 4, pp. 90–105. [Google Scholar]
- Chu, C.T.; Kim, S.K.; Lin, Y.A.; Yu, Y.; Bradski, G.; Olukotun, K.; Ng, A.Y. Map-reduce for machine learning on multicore. Adv. Neural Inf. Process. Syst. 2007, 19, 281–288. [Google Scholar]
- Guyon, I.; Weston, J.; Barnhill, S.; Vapnik, V. Gene selection for cancer classification using support vector machines. Mach. Learn. 2002, 46, 389–422. [Google Scholar] [CrossRef]
- Motoda, H.; Liu, H. Feature selection, extraction and construction. Commun. IICM (Institute Inf. Comput. Mach. Taiwan) 2002, 5, 2. [Google Scholar]
- Rangarajan, L. Bi-level dimensionality reduction methods using feature selection and feature extraction. Int. J. Comput. Appl. 2010, 4, 33–38. [Google Scholar]
- Pal, M.; Foody, G.M. Feature selection for classification of hyperspectral data by SVM. IEEE Trans. Geosci. Remote Sens. 2010, 48, 2297–2307. [Google Scholar] [CrossRef] [Green Version]
- Stadler, R.; Pasquini, R.; Fodor, V. Learning from network device statistics. J. Netw. Syst. Manag. 2017, 25, 672–698. [Google Scholar] [CrossRef] [Green Version]
- Da Silva, A.S.; Machado, C.C.; Bisol, R.V.; Granville, L.Z.; Schaeffer-Filho, A. Identification and selection of flow features for accurate traffic classification in SDN. In Proceedings of the 14th International Symposium on Network Computing and Applications, Cambridge, MA, USA, 28–30 September 2015; pp. 134–141. [Google Scholar]
- Xiao, P.; Qu, W.; Qi, H.; Xu, Y.; Li, Z. An efficient elephant flow detection with cost-sensitive in SDN. In Proceedings of the 1st International Conference on Industrial Networks and Intelligent Systems (INISCom), Tokyo, Japan, 2–4 March 2015; pp. 24–28. [Google Scholar]
- Wang, P.; Lin, S.C.; Luo, M. A framework for QoS-aware traffic classification using semi-supervised machine learning in SDNs. In Proceedings of the IEEE International Conference on Services Computing (SCC), San Francisco, CA, USA, 27 June–2 July 2016; pp. 760–765. [Google Scholar]
- Amaral, P.; Dinis, J.; Pinto, P.; Bernardo, L.; Tavares, J.; Mamede, H.S. Machine learning in software defined networks: Data collection and traffic classification. In Proceedings of the 24th International Conference on Network Protocols (ICNP), Singapore, 8–11 November 2016; pp. 1–5. [Google Scholar]
- Zhang, C.; Wang, X.; Li, F.; He, Q.; Huang, M. Deep learning-based network application classification for SDN. Trans. Emerg. Telecommun. Technol. 2018, 29, e3302. [Google Scholar] [CrossRef]
- Kalousis, A.; Prados, J.; Hilario, M. Stability of Feature Selection Algorithms: A Study on High-Dimensional Spaces. Knowl. Inf. Syst. 2007, 12, 95–116. [Google Scholar] [CrossRef] [Green Version]
- Dash, M.; Liu, H. Feature selection for classification. Intell. Data Anal. 1997, 1, 131–156. [Google Scholar] [CrossRef]
- Dash, M.; Liu, H. Feature selection for clustering. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Kyoto, Japan, 18–20 April 2000; pp. 110–121. [Google Scholar]
- Yu, L.; Liu, H. Feature selection for high-dimensional data: A fast correlation-based filter solution. In Proceedings of the 20th International Conference on Machine Learning (ICML-03), Washington, DC, USA, 21–24 August 2003; pp. 856–863. [Google Scholar]
- Guo, Y.; Liu, Y.; Oerlemans, A.; Lao, S.; Wu, S.; Lew, M.S. Deep learning for visual understanding: A review. Neurocomputing 2016, 187, 27–48. [Google Scholar] [CrossRef]
- Aouedi, O.; Tobji, M.A.B.; Abraham, A. An Ensemble of Deep Auto-Encoders for Healthcare Monitoring. In Proceedings of the International Conference on Hybrid Intelligent Systems, Porto, Portugal, 13–15 December 2018; pp. 96–105. [Google Scholar]
- Fisher, R.A. The use of multiple measurements in taxonomic problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Tharwat, A.; Gaber, T.; Ibrahim, A.; Hassanien, A.E. Linear discriminant analysis: A detailed tutorial. AI Commun. 2017, 30, 169–190. [Google Scholar] [CrossRef] [Green Version]
- Niknam, S.; Dhillon, H.S.; Reed, J.H. Federated Learning for Wireless Communications: Motivation, Opportunities, and Challenges. IEEE Commun. Mag. 2020, 58, 46–51. [Google Scholar] [CrossRef]
- Agrawal, S.; Sarkar, S.; Aouedi, O.; Yenduri, G.; Piamrat, K.; Bhattacharya, S.; Maddikunta, P.K.R.; Gadekallu, T.R. Federated Learning for Intrusion Detection System: Concepts, Challenges and Future Directions. arXiv 2021, arXiv:2106.09527. [Google Scholar]
- Thapa, C.; Karmakar, K.K.; Celdran, A.H.; Camtepe, S.; Varadharajan, V.; Nepal, S. FedDICE: A ransomware spread detection in a distributed integrated clinical environment using federated learning and SDN based mitigation. arXiv 2021, arXiv:2106.05434. [Google Scholar]
- Sacco, A.; Esposito, F.; Marchetto, G. A Federated Learning Approach to Routing in Challenged SDN-Enabled Edge Networks. In Proceedings of the 6th IEEE Conference on Network Softwarization (NetSoft), Ghent, Belgium, 29 June–3 July 2020; pp. 150–154. [Google Scholar]
- Zhang, M.; John, W.; Claffy, K.C.; Brownlee, N. State of the Art in Traffic Classification: A Research Review. In Proceedings of the PAM Student Workshop, Seoul, Korea, 1–3 April 2009; pp. 3–4. [Google Scholar]
- Nguyen, T.T.; Armitage, G. A survey of techniques for internet traffic classification using machine learning. IEEE Commun. Surv. Tutor. 2008, 10, 56–76. [Google Scholar] [CrossRef]
- Parsaei, M.R.; Sobouti, M.J.; Khayami, S.R.; Javidan, R. Network traffic classification using machine learning techniques over software defined networks. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 220–225. [Google Scholar]
- Xiao, P.; Liu, N.; Li, Y.; Lu, Y.; Tang, X.j.; Wang, H.W.; Li, M.X. A traffic classification method with spectral clustering in SDN. In Proceedings of the 17th International Conference on Parallel and Distributed Computing, Applications and Technologies (PDCAT), Guangzhou, China, 16–18 December 2016; pp. 391–394. [Google Scholar]
- Zaki, F.A.M.; Chin, T.S. FWFS: Selecting robust features towards reliable and stable traffic classifier in SDN. IEEE Access 2019, 7, 166011–166020. [Google Scholar] [CrossRef]
- Eom, W.J.; Song, Y.J.; Park, C.H.; Kim, J.K.; Kim, G.H.; Cho, Y.Z. Network Traffic Classification Using Ensemble Learning in Software-Defined Networks. In Proceedings of the 2021 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Jeju Island, Korea, 20–23 April 2021; pp. 89–92. [Google Scholar]
- Yang, T.; Vural, S.; Qian, P.; Rahulan, Y.; Wang, N.; Tafazolli, R. Achieving Robust Performance for Traffic Classification Using Ensemble Learning in SDN Networks. In Proceedings of the IEEE International Conference on Communications, virtual, 14–23 June 2021. [Google Scholar]
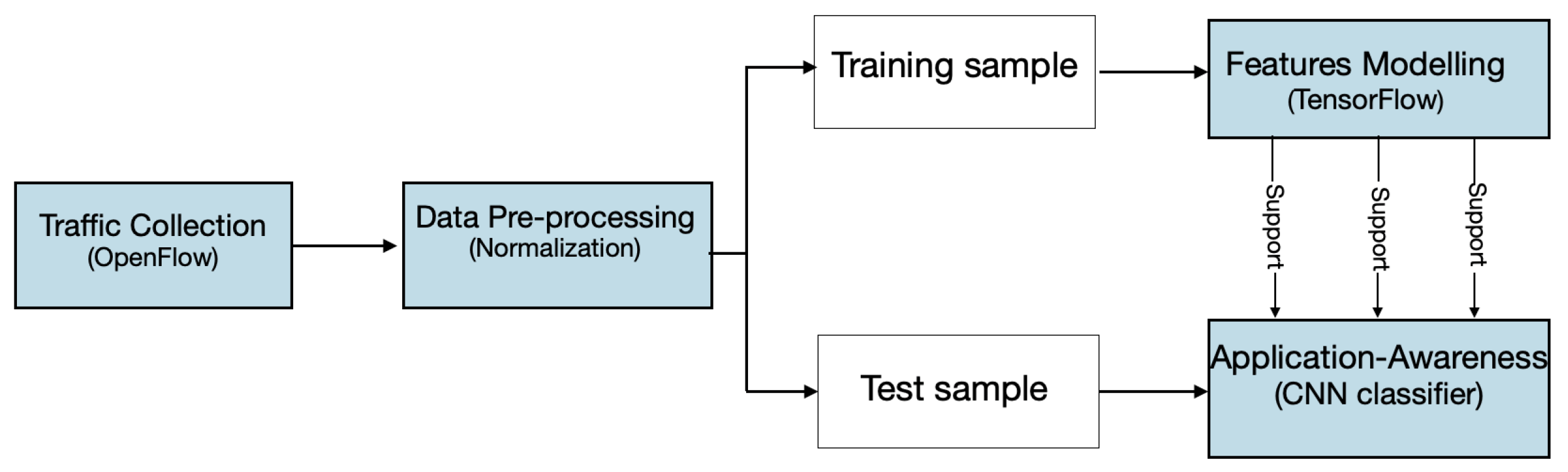
- Hu, N.; Luan, F.; Tian, X.; Wu, C. A Novel SDN-Based Application-Awareness Mechanism by Using Deep Learning. IEEE Access 2020, 8, 160921–160930. [Google Scholar] [CrossRef]
- Moore, A.; Zuev, D.; Crogan, M. Discriminators for Use in Flow-Based Classification. Available online: https://www.cl.cam.ac.uk/~awm22/publication/moore2005discriminators.pdf (accessed on 30 December 2021).
- Malik, A.; de Fréin, R.; Al-Zeyadi, M.; Andreu-Perez, J. Intelligent SDN traffic classification using deep learning: Deep-SDN. In Proceedings of the 2020 2nd International Conference on Computer Communication and the Internet (ICCCI), Nagoya, Japan, 26–29 June 2020; pp. 184–189. [Google Scholar]
- Yu, C.; Lan, J.; Xie, J.; Hu, Y. QoS-aware traffic classification architecture using machine learning and deep packet inspection in SDNs. Procedia Comput. Sci. 2018, 131, 1209–1216. [Google Scholar] [CrossRef]
- Kuranage, M.P.J.; Piamrat, K.; Hamma, S. Network Traffic Classification Using Machine Learning for Software Defined Networks. In Proceedings of the International Conference on Machine Learning for Networking, Paris, France, 3–5 December 2019; pp. 28–39. [Google Scholar]
- Rojas, J.S.; Gallón, Á.R.; Corrales, J.C. Personalized service degradation policies on OTT applications based on the consumption behavior of users. In Proceedings of the International Conference on Computational Science and Its Applications, Melbourne, Australia, 2–5 July 2018; pp. 543–557. [Google Scholar]
- Qazi, Z.A.; Lee, J.; Jin, T.; Bellala, G.; Arndt, M.; Noubir, G. Application-awareness in SDN. In Proceedings of the ACM SIGCOMM conference on SIGCOMM, Hong Kong, China, 12–16 August 2013; pp. 487–488. [Google Scholar]
- Li, Y.; Li, J. MultiClassifier: A combination of DPI and ML for application-layer classification in SDN. In Proceedings of the 2nd International Conference on Systems and Informatics (ICSAI), Shanghai, China, 15–17 November 2014; pp. 682–686. [Google Scholar]
- Raikar, M.M.; Meena, S.; Mulla, M.M.; Shetti, N.S.; Karanandi, M. Data traffic classification in Software Defined Networks (SDN) using supervised-learning. Procedia Comput. Sci. 2020, 171, 2750–2759. [Google Scholar] [CrossRef]
- Uddin, M.; Nadeem, T. TrafficVision: A case for pushing software defined networks to wireless edges. In Proceedings of the 13th International Conference on Mobile Ad Hoc and Sensor Systems (MASS), Brasilia, Brazil, 10–13 October 2016; pp. 37–46. [Google Scholar]
- Amaral, P.; Pinto, P.F.; Bernardo, L.; Mazandarani, A. Application aware SDN architecture using semi-supervised traffic classification. In Proceedings of the 2018 IEEE Conference on Network Function Virtualization and Software Defined Networks (NFV-SDN), Verona, Italy, 27–29 November 2018; pp. 1–6. [Google Scholar]
- Nakao, A.; Du, P. Toward in-network deep machine learning for identifying mobile applications and enabling application specific network slicing. IEICE Trans. Commun. 2018, E101.B, 1536–1543. [Google Scholar] [CrossRef] [Green Version]
- Wang, P.; Ye, F.; Chen, X.; Qian, Y. Datanet: Deep learning based encrypted network traffic classification in sdn home gateway. IEEE Access 2018, 6, 55380–55391. [Google Scholar] [CrossRef]
- Draper-Gil, G.; Lashkari, A.H.; Mamun, M.S.I.; Ghorbani, A.A. Characterization of encrypted and vpn traffic using time-related. In Proceedings of the 2nd International Conference on Information Systems Security and Privacy (ICISSP), Rome, Italy, 19–21 February 2016; pp. 407–414. [Google Scholar]
- Chang, L.H.; Lee, T.H.; Chu, H.C.; Su, C. Application-based online traffic classification with deep learning models on SDN networks. Adv. Technol. Innov. 2020, 5, 216–229. [Google Scholar] [CrossRef]
- Cisco Visual Networking Index: Forecast and Methodology, 2016–2021. Available online: https://www.reinvention.be/webhdfs/v1/docs/complete-white-paper-c11-481360.pdf (accessed on 30 December 2021).
- Rego, A.; Canovas, A.; Jiménez, J.M.; Lloret, J. An intelligent system for video surveillance in IoT environments. IEEE Access 2018, 6, 31580–31598. [Google Scholar] [CrossRef]
- Indira, B.; Valarmathi, K.; Devaraj, D. An approach to enhance packet classification performance of software-defined network using deep learning. Soft Comput. 2019, 23, 8609–8619. [Google Scholar] [CrossRef]
- Abidi, M.H.; Alkhalefah, H.; Moiduddin, K.; Alazab, M.; Mohammed, M.K.; Ameen, W.; Gadekallu, T.R. Optimal 5G network slicing using machine learning and deep learning concepts. Comput. Stand. Interfaces 2021, 76, 103518. [Google Scholar] [CrossRef]
- Lashkari, A.H.; Draper-Gil, G.; Mamun, M.S.I.; Ghorbani, A.A. Characterization of tor traffic using time based features. In Proceedings of the 3rd International Conference on Information System Security and Privacy (ICISSP), Porto, Portugal, 19–21 February 2017; pp. 253–262. [Google Scholar]
- Tong, V.; Tran, H.A.; Souihi, S.; Mellouk, A. A novel QUIC traffic classifier based on convolutional neural networks. In Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, UAE, 9–13 December 2018; pp. 1–6. [Google Scholar]
- Bentéjac, C.; Csørgӧ, A.; Martínez-Muñoz, G. A comparative analysis of gradient boosting algorithms. Artif. Intell. Rev. 2021, 54, 1937–1967. [Google Scholar] [CrossRef]
- López-Raventós, Á.; Wilhelmi, F.; Barrachina-Muñoz, S.; Bellalta, B. Machine learning and software defined networks for high-density wlans. arXiv 2018, arXiv:1804.05534. [Google Scholar]
- Alvizu, R.; Troia, S.; Maier, G.; Pattavina, A. Machine-learning-based prediction and optimization of mobile metro-core networks. In Proceedings of the 2018 IEEE Photonics Society Summer Topical Meeting Series (SUM), Waikoloa, HI, USA, 9–11 July 2018; pp. 155–156. [Google Scholar]
- Silva, A.; Wickboldt, J.; Granville, L.; Schaeffer-Filho, A. ATLANTIC: A framework for anomaly traffic detection, classification, and mitigation in SDN. In Proceedings of the IEEE/IFIP Network Operations and Management Symposium (NOMS), Istanbul, Turkey, 25–29 April 2016; pp. 27–35. [Google Scholar]
- Kumari, A.; Chandra, J.; Sairam, A.S. Predictive Flow Modeling in Software Defined Network. In Proceedings of the TENCON 2019—2019 IEEE Region 10 Conference (TENCON), Kochi, India, 17–20 October 2019; pp. 1494–1498. [Google Scholar]
- Azzouni, A.; Pujolle, G. NeuTM: A neural network-based framework for traffic matrix prediction in SDN. In Proceedings of the IEEE/IFIP Network Operations and Management Symposium (NOMS), Taipei, Taiwan, 23–27 April 2018; pp. 1–5. [Google Scholar]
- Alvizu, R.; Troia, S.; Maier, G.; Pattavina, A. Matheuristic with machine-learning-based prediction for software-defined mobile metro-core networks. J. Opt. Commun. Netw. 2017, 9, 19–30. [Google Scholar] [CrossRef]
- Chen-Xiao, C.; Ya-Bin, X. Research on load balance method in SDN. Int. J. Grid Distrib. Comput. 2016, 9, 25–36. [Google Scholar] [CrossRef]
- Tang, F.; Fadlullah, Z.M.; Mao, B.; Kato, N. An intelligent traffic load prediction-based adaptive channel assignment algorithm in SDN-IoT: A deep learning approach. IEEE Internet Things J. 2018, 5, 5141–5154. [Google Scholar] [CrossRef]
- Lazaris, A.; Prasanna, V.K. Deep learning models for aggregated network traffic prediction. In Proceedings of the 2019 15th International Conference on Network and Service Management (CNSM), Halifax, NS, Canada, 21–25 October 2019; pp. 1–5. [Google Scholar]
- CAIDA Anonymized Internet Traces 2016. 2016. Available online: https://www.youtube.com/watch?v=u8OKjyKqcV8&list=RDqyvwOSHOpT8&index=4 (accessed on 30 December 2021).
- Le, D.H.; Tran, H.A.; Souihi, S.; Mellouk, A. An AI-based Traffic Matrix Prediction Solution for Software-Defined Network. In Proceedings of the ICC 2021-IEEE International Conference on Communications, Montreal, QC, Canada, 14–23 June 2021; pp. 1–6. [Google Scholar]
- Ferreira, D.; Reis, A.B.; Senna, C.; Sargento, S. A Forecasting Approach to Improve Control and Management for 5G Networks. IEEE Trans. Netw. Serv. Manag. 2021, 18, 1817–1831. [Google Scholar] [CrossRef]
- Available online: http://www.cs.utexas.edu/~yzhang/research/AbileneTM/ (accessed on 15 January 2021).
- Uhlig, S.; Quoitin, B.; Lepropre, J.; Balon, S. Providing public intradomain traffic matrices to the research community. ACM SIGCOMM Comput. Commun. Rev. 2006, 36, 83–86. [Google Scholar] [CrossRef]
- Barlacchi, G.; De Nadai, M.; Larcher, R.; Casella, A.; Chitic, C.; Torrisi, G.; Antonelli, F.; Vespignani, A.; Pentland, A.; Lepri, B. A multi-source dataset of urban life in the city of Milan and the Province of Trentino. Sci. Data 2015, 2, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Novaes, M.P.; Carvalho, L.F.; Lloret, J.; Proença, M.L., Jr. Adversarial Deep Learning approach detection and defense against DDoS attacks in SDN environments. Future Gener. Comput. Syst. 2021, 125, 156–167. [Google Scholar] [CrossRef]
- Shiravi, A.; Shiravi, H.; Tavallaee, M.; Ghorbani, A.A. Toward developing a systematic approach to generate benchmark datasets for intrusion detection. Comput. Secur. 2012, 31, 357–374. [Google Scholar] [CrossRef]
- Base, R.; Mell, P. Special Publication on Intrusion Detection Systems; NIST Infidel, Inc., National Institute of Standards and Technology: Scotts Valley, CA, USA, 2001. [Google Scholar]
- Latah, M.; Toker, L. Towards an efficient anomaly-based intrusion detection for software-defined networks. IET Netw. 2018, 7, 453–459. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Zhao, Z.; Li, R. Machine learning-based IDS for Software-Defined 5G network. IET Netw. 2018, 7, 53–60. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Zhao, Z.; Li, R.; Zhang, H. AI-based two-stage intrusion detection for Software Defined IoT networks. IEEE Internet Things J. 2018, 6, 2093–2102. [Google Scholar] [CrossRef] [Green Version]
- Elsayed, M.S.; Le-Khac, N.A.; Dev, S.; Jurcut, A.D. Machine-learning techniques for detecting attacks in SDN. arXiv 2019, arXiv:1910.00817. [Google Scholar]
- Tang, T.A.; Mhamdi, L.; McLernon, D.; Zaidi, S.A.R.; Ghogho, M. Deep recurrent neural network for intrusion detection in sdn-based networks. In Proceedings of the 2018 4th IEEE Conference on Network Softwarization and Workshops (NetSoft), Montreal, QC, Canada, 25–29 June 2018; pp. 202–206. [Google Scholar]
- Tang, T.A.; Mhamdi, L.; McLernon, D.; Zaidi, S.A.R.; Ghogho, M.; El Moussa, F. DeepIDS: Deep learning approach for intrusion detection in Software Defined Networking. Electronics 2020, 9, 1533. [Google Scholar] [CrossRef]
- ElSayed, M.S.; Le-Khac, N.A.; Albahar, M.A.; Jurcut, A. A novel hybrid model for intrusion detection systems in SDNs based on CNN and a new regularization technique. J. Netw. Comput. Appl. 2021, 191, 103160. [Google Scholar] [CrossRef]
- Elsayed, M.S.; Le-Khac, N.A.; Jurcut, A.D. InSDN: A novel SDN intrusion dataset. IEEE Access 2020, 8, 165263–165284. [Google Scholar] [CrossRef]
- Shu, J.; Zhou, L.; Zhang, W.; Du, X.; Guizani, M. Collaborative intrusion detection for VANETs: A deep learning-based distributed SDN approach. IEEE Trans. Intell. Transp. Syst. 2020, 22, 4519–4530. [Google Scholar] [CrossRef]
- Qin, Q.; Poularakis, K.; Leung, K.K.; Tassiulas, L. Line-speed and scalable intrusion detection at the network edge via federated learning. In Proceedings of the 2020 IFIP Networking Conference (Networking), Paris, France, 22–26 June 2020; pp. 352–360. [Google Scholar]
- Singh, J.; Behal, S. Detection and mitigation of DDoS attacks in SDN: A comprehensive review, research challenges and future directions. Comput. Sci. Rev. 2020, 37, 100279. [Google Scholar] [CrossRef]
- Ahmad, A.; Harjula, E.; Ylianttila, M.; Ahmad, I. Evaluation of machine learning techniques for security in SDN. In Proceedings of the 2020 IEEE Globecom Workshops (GC Wkshps), Taipei, Taiwan, 7–11 December 2020; pp. 1–6. [Google Scholar]
- Chen, Z.; Jiang, F.; Cheng, Y.; Gu, X.; Liu, W.; Peng, J. XGBoost classifier for DDoS attack detection and analysis in SDN-based cloud. In Proceedings of the 2018 IEEE International Conference on Big Data and Smart Computing (BIGCOMP), Shanghai, China, 15–17 January 2018; pp. 251–256. [Google Scholar]
- Niyaz, Q.; Sun, W.; Javaid, A.Y. A deep learning based DDoS detection system in software-defined networking (SDN). arXiv 2016, arXiv:1611.07400. [Google Scholar] [CrossRef] [Green Version]
- Li, C.; Wu, Y.; Yuan, X.; Sun, Z.; Wang, W.; Li, X.; Gong, L. Detection and defense of DDoS attack–based on deep learning in OpenFlow-based SDN. Int. J. Commun. Syst. 2018, 31, e3497. [Google Scholar] [CrossRef]
- Haider, S.; Akhunzada, A.; Mustafa, I.; Patel, T.B.; Fernandez, A.; Choo, K.K.R.; Iqbal, J. A deep CNN ensemble framework for efficient DDoS attack detection in software defined networks. IEEE Access 2020, 8, 53972–53983. [Google Scholar] [CrossRef]
- Krishnan, P.; Duttagupta, S.; Achuthan, K. VARMAN: Multi-plane security framework for software defined networks. Comput. Commun. 2019, 148, 215–239. [Google Scholar] [CrossRef]
- KDD Cup 1999. Available online: http://kdd.ics.uci.edu/databases/kddcup99/kddcup99 (accessed on 7 November 2021).
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009; pp. 1–6. [Google Scholar]
- Morris, T.; Gao, W. Industrial control system traffic data sets for intrusion detection research. In International Conference on Critical Infrastructure Protection; Springer: Berlin/Heidelberg, Germany, 2014; pp. 65–78. [Google Scholar]
- Moustafa, N.; Slay, J. UNSW-NB15: A comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set). In Proceedings of the 2015 Military Communications and Information Systems Conference (MilCIS), Canberra, ACT, Australia, 10–12 November 2015; pp. 1–6. [Google Scholar]
- Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. Toward generating a new intrusion detection dataset and intrusion traffic characterization. Int. Confer-Ence Inf. Syst. Secur. Priv. (ICISSP) 2018, 1, 108–116. [Google Scholar]
- Pahl, M.O.; Aubet, F.X. All eyes on you: Distributed Multi-Dimensional IoT microservice anomaly detection. In Proceedings of the 2018 14th International Conference on Network and Service Management (CNSM), Rome, Italy, 5–9 November 2018; pp. 72–80. [Google Scholar]
- Moustafa, N. New Generations of Internet of Things Datasets for Cybersecurity Applications based Machine Learning: TON_IoT Datasets. In Proceedings of the eResearch Australasia Conference, Brisbane, Australia, 21–25 October 2019; pp. 21–25. [Google Scholar]
- Ullah, I.; Mahmoud, Q.H. A two-level flow-based anomalous activity detection system for IoT networks. Electronics 2020, 9, 530. [Google Scholar] [CrossRef] [Green Version]
- Casas, P. Two Decades of AI4NETS-AI/ML for Data Networks: Challenges & Research Directions. In Proceedings of the IEEE/IFIP Network Operations and Management Symposium (NOMS), Budapest, Hungary, 20–24 April 2020; pp. 1–6. [Google Scholar]
- García, V.; Sánchez, J.; Mollineda, R. On the effectiveness of preprocessing methods when dealing with different levels of class imbalance. Knowl.-Based Syst. 2012, 25, 13–21. [Google Scholar] [CrossRef]
- Abd Elrahman, S.M.; Abraham, A. A review of class imbalance problem. J. Netw. Innov. Comput. 2013, 1, 332–340. [Google Scholar]
- Apache Spark. Available online: http://spark.apache.org/ (accessed on 30 December 2021).
- Tan, C.; Sun, F.; Kong, T.; Zhang, W.; Yang, C.; Liu, C. A survey on deep transfer learning. In International Conference on Artificial Neural Networks; Springer: Cham, Switzerland, 2018; pp. 270–279. [Google Scholar]


| Ref. | Topic | Scope | |||
|---|---|---|---|---|---|
| DL | Other ML Models | DR | SDN | ||
| [13] | A survey of deep learning and its applications. | ✓ | |||
| [11] | A brief survey of SDN-based network intrusion detection system using machine and deep learning approaches. | ✓ | ✓ | ✓ | |
| [14] | A tutorial on deep learning. | ✓ | |||
| [6] | An overview of AI techniques in the context of SDN. | ✓ | ✓ | ✓ | |
| [4] | A survey of ML/DL applications in SDN. | ✓ | ✓ | ✓ | |
| [15] | A brief survey of feature selection/extraction methods. | ✓ | |||
| [16] | A survey of the procedure of feature selection and its application. | ✓ | |||
| [17] | A survey of the software-defined wireless sensor networks. | ✓ | |||
| [10] | A survey of the ML-based model applied to fundamental problems in networking | ✓ | |||
| Our paper | A survey of DR, ML and DL in the SDN environment. | ✓ | ✓ | ✓ | ✓ |
| Acronym | Definition | Acronym | Definition |
|---|---|---|---|
| SDN | Software-defined networking | MLP | Multi-layer perceptron |
| SDWSN | Software-defined wireless sensor networks | CNN | Convolutional neural network |
| ML | Machine learning | LSTM | Long short-term memory |
| DL | Deep learning | MVNO | Mobile virtual network operator |
| KDN | Knowledge-defined networking | AE | Autodncoder |
| AI | Artificial intelligence | DR | Dimensionality reduction |
| QoS | Quality of service | QoE | Quality of experience |
| ANN | Artificial neural network | RL | Reinforcement learning |
| ONF | Open network foundation | OF | OpenFlow |
| NFV | Network function virtualisation | FL | Federated learning |
| DBN | Deep belief network | DRL | Deep Reinforcement Learning |
| GRU | Gated recurrent units | NGMN | Next Generation Mobile Networks |
| Method | Strengths | Weaknesses |
|---|---|---|
| Supervised learning | Low computational cost, fast, scalable | Requires data labeling and data training, behaves poorly with highly imbalanced data |
| Unsupervised learning | Requires only the data samples, can detect unknown patterns, generates labeling data | Cannot give precise information |
| Semi-supervised learning | Learns from both labeled and unlabeled data | May lead to worse performance when we choose the wrong rate of unlabeled data |
| Reinforcement learning | Can be used to solve complex problems, efficient when the only way to collect information about the environment is to interact with it | Slow in terms of convergence, needs a lot of data and a lot of computation |
| Method | Learning Model | Description | Strengths | Weaknesses |
|---|---|---|---|---|
| MLP | Supervised, unsupervised | MLP is a simple artificial neural network (ANN) which consists of three layers. The first layer is the input layer. The second layer is used to extract features from the input. The last layer is the output layer. The layers are composed of several neurons. | Easy to implement. | Modest performance, slow convergence, occupies a large amount of memory. |
| AE | Unsupervised | Autoencoder consists of three parts: (i) encoder, (ii) code, and (iii) decoder blocks. The encoder converts the input features into an abstraction, known as a code. Using the code, the decoder tries to reconstruct the input features. It uses some non-linear hidden layers to reduce the input features. | Works with big and unlabeled data, suitable for feature extraction and used in place of manual engineering. | The quality of features depends model architecture and its hyperparameters, hard to find the code layer size. |
| CNN | Supervised, Unsupervised | CNN is a class of DL which consists of a number of convolution and pooling (subsampling) layers followed by a fully connected layers. Pooling and convolution layers are used to reduce the dimensions of features and find useful patterns. Next, fully connected layers are used for classification. It is widely used for image recognition applications. | Weight sharing, extracts relevant features, high competitive performance. | High computational cost, requires large training dataset and high number of hyperparameter tuning to achieve optimal features. |
| LSTM | Supervised | LSTM is an extension of recurrent neural network (RNNs) and was created as the solution to short-term memory. It has internal mechanisms called gates (forget gate, input gate, and output gate) that can learn which data in a sequence is important to keep or throw away. Therefore, it chooses which information is relevant to remember or forget during sequence processing. | Good for sequential information, works well with long sequences. | High model complexity, high computational cost. |
| GRU | Supervised | GRU was proposed in 2014. It is similar to LSTM but has fewer parameters. It works well with sequential data, as does LSTM. However, unlike LSTM, GRU has two gates, which are the update gate and reset gate; hence, it is less complex. | Computationally more efficient than LSTM. | Less efficient in accuracy than LSTM. |
| DRL | Reinforcement | DRL takes advantage of both DL and RL to be applied to larger problems. In others word, DL enables RL to scale to decision-making problems that were previously intractable. | Scalable (i.e., can learn a more complex environment). | Slow in terms of training. |
| DBN | Unsupervised, supervised | DBN is stacked by several restricted Boltzmann machines. It takes advantage of the greedy learning process to initialize the model parameters and then fine-tunes the whole model using the label. | Training is unsupervised, which removes the necessity of labelling data for training or properly initializing the network, which can avoid the local optima, extracting robust features. | High computational cost. |
| DL Frameworks | Creator | Available Interface | Popularity | Released |
|---|---|---|---|---|
| Tensorflow | Google Brain Team | C++, Go, Java, JavaScript, Python, Swift | High | 2015 |
| Caffe2 | Facebook AI research | C++, Python | Low | 2017 |
| Deeplearning4j | Skymind | Java, Scala | Low | 2014 |
| MXNet | Apache Software Foundation | C++, Python, Julia, Matlab, JavaScript, Go, R, Scala, Perl | Medium | 2015 |
| Theano | University of Montreal | Python | Medium | 2017 |
| CNTK | Microsoft Research | C++, C#, Python | Low | 2016 |
| PyTorch | Facebook AI research | C++, Python | High | 2016 |
| Keras (higher level library for TensorFlow, CNTK, Theano, etc.) | François Chollet | Python | High | 2015 |
| Classification Level | Ref. | ML/DL Algorithm | Dimensionality Reduction | Dataset Output | Controller |
|---|---|---|---|---|---|
| Coarse-grained classification | [61] | DPI and Laplacian SVM | Wrapper method | Voice/video conference, interactive data, streaming, bulk data transfer | N/A |
| [78] | Feedforward, MLP | - | Instant message, stream, P2P, HTTP, FTP | Floodlight | |
| [79] | Spectral clustering | N/A | HTTP, SMTP, SSH, P2P, DNS, SSL2 | Floodlight | |
| [59] | SVM | PCA | DDoS attacks, FTP, video streaming | Floodlight | |
| [63] | Stacked Autoencoder | AE | Bulk, database, interactive, mail, services, WWW, P2P, attack, games, multimedia | N/A | |
| [86] | Heteroid tri-training (SVM, KNN, and Bayes classifier) | N/A | Voice, video, bulk data, interactive data | N/A | |
| [87] | SVM, decision tree, random forest, KNN | - | N/A | RYU | |
| [80] | C4.5, KNN, NB, SVM | Filter and wrapper method | WWW, mail, bulk, services, P2P, database, multimedia, attack | N/A | |
| [83] | CNN | - | WWW, mail, FTP-control, FTP-data, P2P, database, multimedia, services, interactive, games | N/A | |
| [81] | DT, RF, GBM, LightGBM | N/A | Web browsing, email, chat, streaming, file transfer, VoIP, P2P | RYU | |
| [82] | Ensemble classifier (KNN, SVM, RF, AdaBoost, Boosting, XGBoost) | - | Video, voice, bulk data transfer, music, interactive | N/A | |
| Fine-grained classification | [85] | Deep learning | - | WWW, mail, FTP-control, FTP-pasv, FTP-data, attack, P2P, database, multimedia, services | POX |
| [90] | DPI and classification algorithm | N/A | N/A | Floodlight | |
| [89] | Decision tree (C5.0) | N/A | Top 40 Android applications | N/A | |
| [62] | Random forest, stochastic gradient boosting, XGBoost | PCA | Bittorent, Dropbox, Facebook, HTTP, Linkedin, Skype, Vimeo, Youtube | HP VAN | |
| [92] | Decision tree (C5.0), KNN | - | The top 40 most popular mobile applications | Floodlight | |
| [95] | MLP, SAE, CNN | AE | AIM, email client, Facebook, Gmail, Hangout, ICQ, Netflix, SCP, SFTP, Skype, Spotify, Twitter, Vimeo, Voipbuster, Youtube | N/A | |
| [94] | Deep Learning | Filter method | 200 mobile applications | N/A | |
| [93] | Random forest | - | Bittorrent, Dropbox, Facebook, HTTP, Linkedin, Skype, Vimeo, Youtube | HPE VAN | |
| [97] | MLP, CNN, SAE | - | Facebook, Gmail, Hangouts, Netflix, Skype, Youtube | Ryu | |
| [91] | SVM, KNN, Naive Bayes | N/A | SMTP, HTTP, VLC | POX | |
| Others | [99] | SVM | Video surveillance traffic in IoT environment (critical or non-critical traffic) | N/A | |
| [60] | Decision tree (C4.5) | Filter method | Elephant flow, mice flow | Floodlight | |
| [100] | DNN | - | Action (accept/reject) | N/A | |
| [101] | Deep belief network, neural network | - | Enhanced mobile broadband slice, massive machine-type communications slice, ultra-reliable low-latency communication slice | N/A |
| Ref. | ML/DL Model | Controller | Contribution |
|---|---|---|---|
| [109] | LSTM | POX | The authors proposed a traffic prediction framework and deployed it on SDN using a real-world dataset under different model configurations. |
| [110] | ANN | N/A | The authors used the prediction results to make online routing decisions. |
| [111] | ANN | Floodlight | The proposed system tries to benefit from the global view of SDN controller in order to collect the bandwidth utilization ratio, packet loss rate, transmission latency, and transmission hop of each path. Then, using the ANN model, it predicts the load condition of each path. |
| [112] | Deep CNN | N/A | The authors presented the performance of their systems with three different systems, which are a centralized SDN system, a semi-centralized SDN system, and a distributed conventional control system without centralized SDN. |
| [106] | GRU-RNN | N/A | The authors used (GRU-RNN) in order to predict the mobile network traffic matrix in the next hour. |
| [108] | SVR | N/A | The authors demonstrate that SVR outperforms the ARIMA method; the average performance improvement is 48% and 26%. |
| [113] | LSTM | N/A | The authors focused on network traffic prediction for short time scales using several variations of the LSTM model. |
| [75] | LSTM+FL | Floodlight | The authors used an LSTM model and federated learning in order to predict the future load to optimize routing decisions and at the same ensure data privacy as well decrease the exchange message between the SDN controller. |
| [115] | LSTM, BiLSTM, GRU | POX | The authors proposed a comparative analysis between three RNN-based models: LSTM, GRU, and BiLSTM. |
| [116] | Shallow ML models, DL models, ensemble learning | N/A | The authors take advantage of the forecasting results in order to manage the network slice resource. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aouedi, O.; Piamrat, K.; Parrein, B. Intelligent Traffic Management in Next-Generation Networks. Future Internet 2022, 14, 44. https://doi.org/10.3390/fi14020044
Aouedi O, Piamrat K, Parrein B. Intelligent Traffic Management in Next-Generation Networks. Future Internet. 2022; 14(2):44. https://doi.org/10.3390/fi14020044
Chicago/Turabian StyleAouedi, Ons, Kandaraj Piamrat, and Benoît Parrein. 2022. "Intelligent Traffic Management in Next-Generation Networks" Future Internet 14, no. 2: 44. https://doi.org/10.3390/fi14020044
APA StyleAouedi, O., Piamrat, K., & Parrein, B. (2022). Intelligent Traffic Management in Next-Generation Networks. Future Internet, 14(2), 44. https://doi.org/10.3390/fi14020044