
DA-GAN: Dual Attention Generative Adversarial Network for Cross-Modal Retrieval


Abstract
:1. Introduction
- We propose a novel Dual Attention Generative Adversarial Network (DA-GAN) for cross-modal retrieval, which is an integration of the adversarial learning method with a dual attention mechanism.
- To narrow semantic gap and learn high-level semantic features, a dual attention mechanism is designed to capture important semantic features from cross-modal instances in both intra-modal view and inter-modal view, which enhances abstract concepts learning across different modalities.
- To reduce heterogeneity gap, a cross-modal adversarial learning model is employed to learn consistent feature distribution via intra-modal and inter-modal adversarial loss.
2. Related Work
2.1. Cross-Modal Retrieval
2.2. Attention Models
2.3. Generative Adversarial Network
3. Preliminaries
3.1. Problem Definition
3.2. Review of Generative Adversarial Netw
4. Methodology
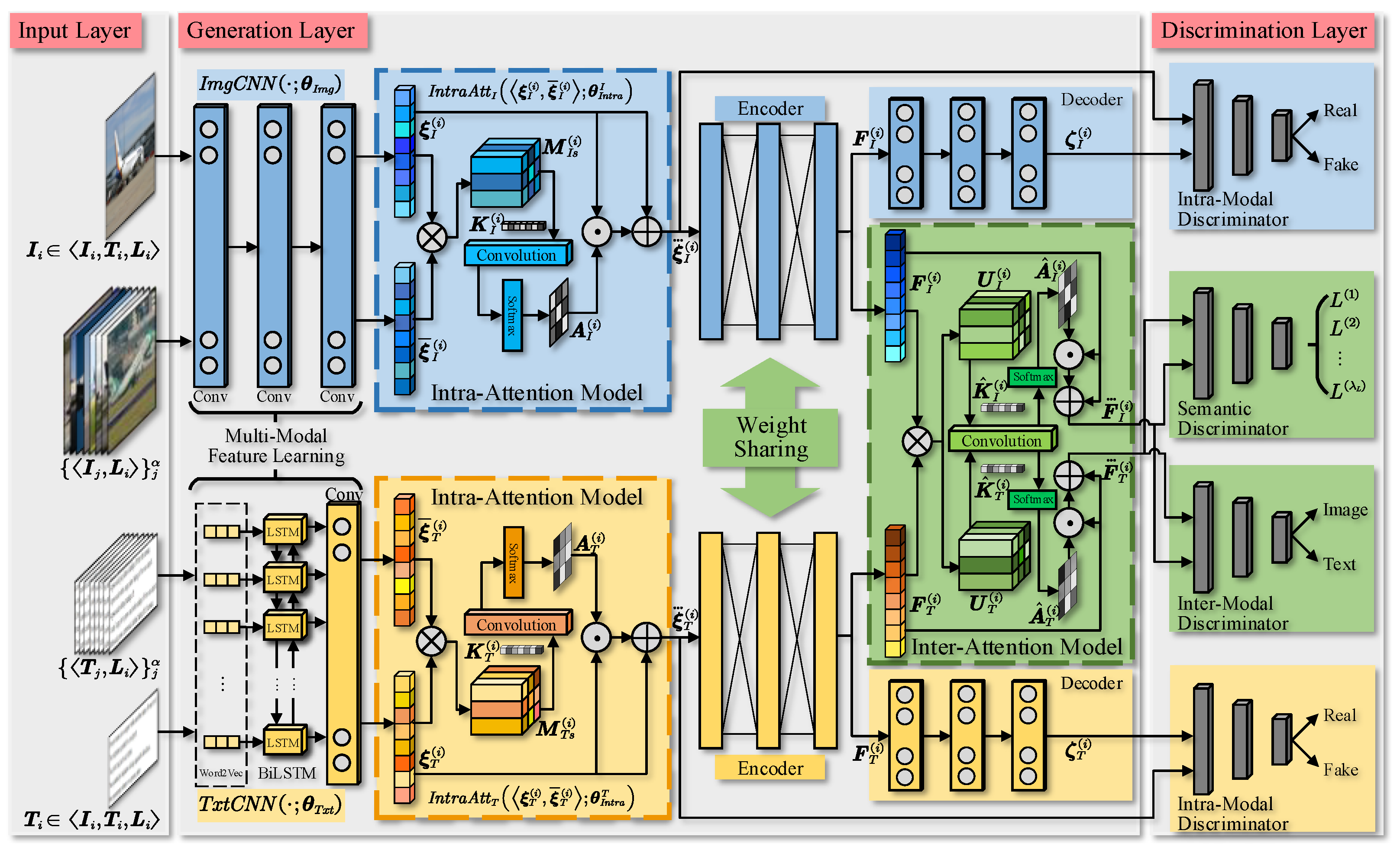
4.1. Overview of DA-GAN
4.2. Multi-Modal Feature Learning
4.2.1. Visual Feature Learning
4.2.2. Textual Feature Learning
4.2.3. Semantic Grouping of Samples
4.3. Adversarial Learning with Dual Attention
4.3.1. Intra-Attention
4.3.2. Inter-Attention
4.3.3. Discriminative Model
4.3.4. Optimization
| Algorithm 1:Pseudocode of optimizing DA-GAN |
|
4.4. Implementation Details
5. Experiments
5.1. Datasets
5.2. Competitors
- CCA [69] is a statistical method that is to learn linear correlations between samples of different modalities.
- KCCA [11] is a non-linear extension of CCA, which employs kernel function to improve the performance of common subspace learning.
- MCCA [70] is a generalization of CCA to more than two views, which is used to recognize similar patterns across multiple domains.
- MvDA [71] jointly learns multiple view-specific linear transforms so as to construct a common subspace for multiple views.
- MvDA-VC [72] is an extension of MvDA with with view consistency, which utilize the structure similarity of views corresponding to the same object.
- JRL [73] uses sparse projection matrix and semi-supervised regularization to explore correlations of labeled and unlabeled cross-modal samples.
- DCCA [42] is implemented by deep neural networks to learn non-linear correlation. It has two separated DNNs, one branch per modality.
- DCCAE [24] is a DCCA extension that integrates CCA model and autoencoder-based model to realize multi-view representation learning.
- CCL [74] realizes a hierarchical network to combine multi-grained fusion and cross-modal correlation exploiting. It includes two learning stages to realize representation learning and intrinsic relevance exploiting.
- CMDN [75] contains two learning stages to model the complementary separate representation of different modalities, and combines cross-modal representations to generate rich cross-media correlation.
- ACMR [57] is a adversarial learning-based method to construct a common subspace for different modalities by generating modality-invariant representations.
- DSCMR [44] exploits semantic discriminative features from both label space and common representation space by supervised learning, and minimizes modality invariance loss via weight-sharing to generate modality-invariant representation.
- CM-GANs [76] models cross-modal joint distributions by two parallel GANs to generate modality-invariance representations.
5.3. Performance Metrics
5.4. Experimental Results
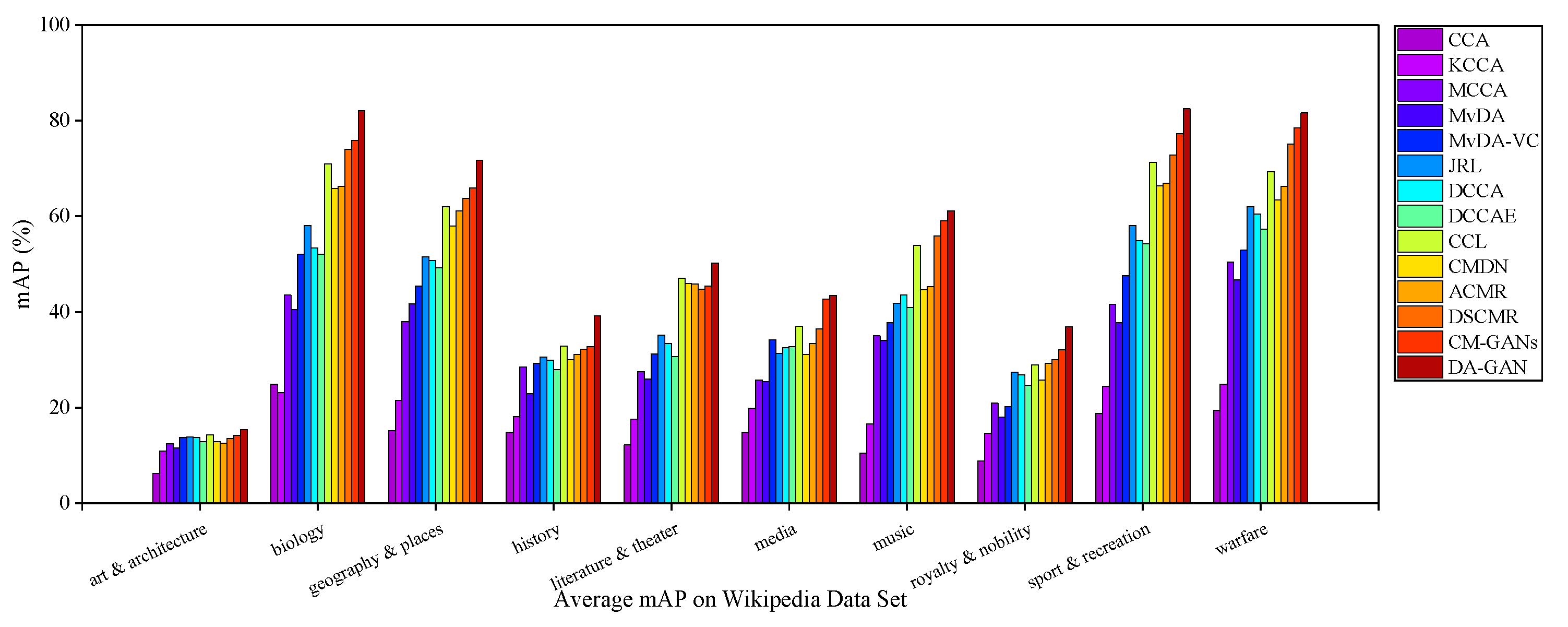
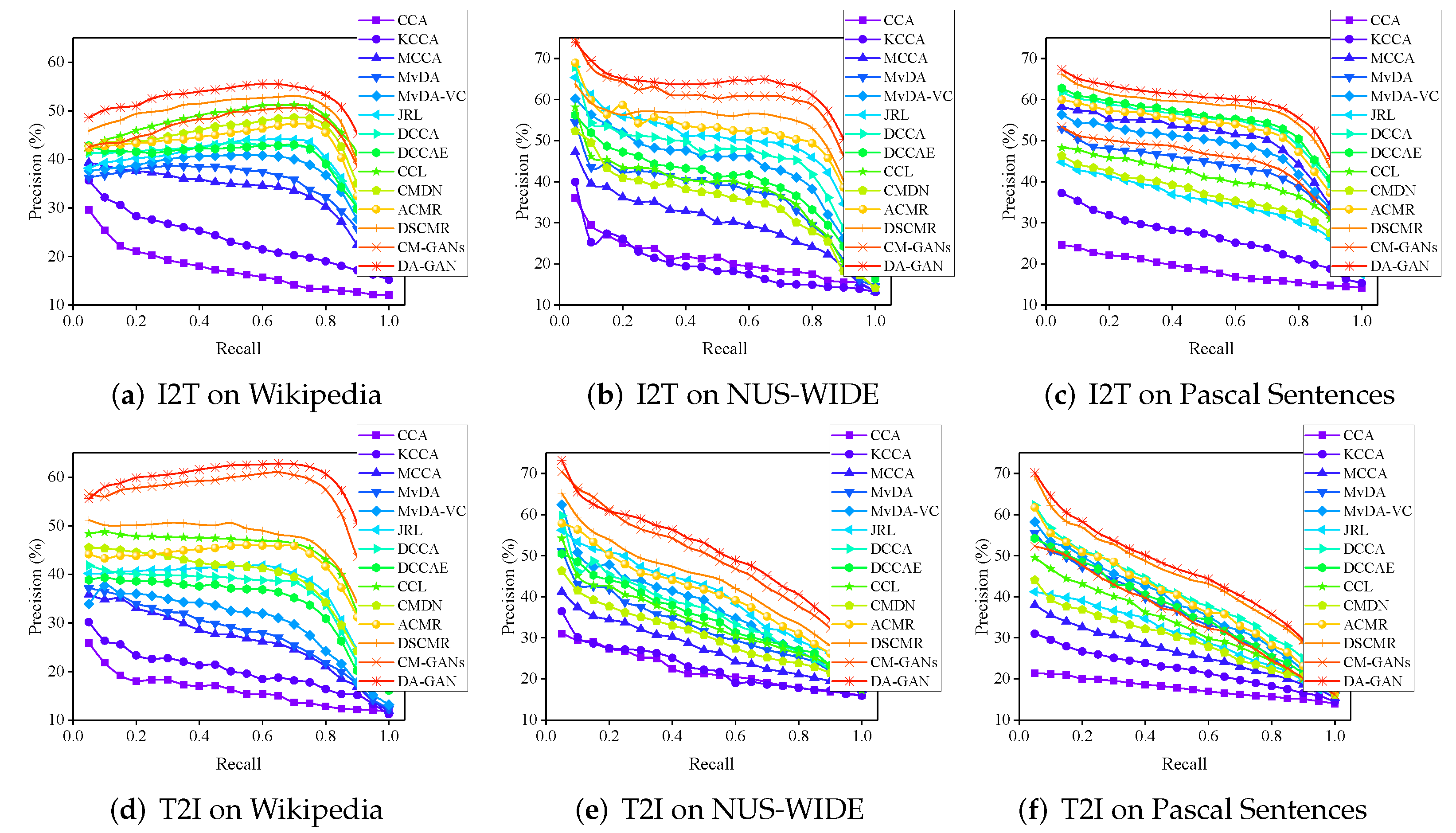
5.4.1. Results on Wikipedia Dataset
5.4.2. Results on Nus-Wide Dataset
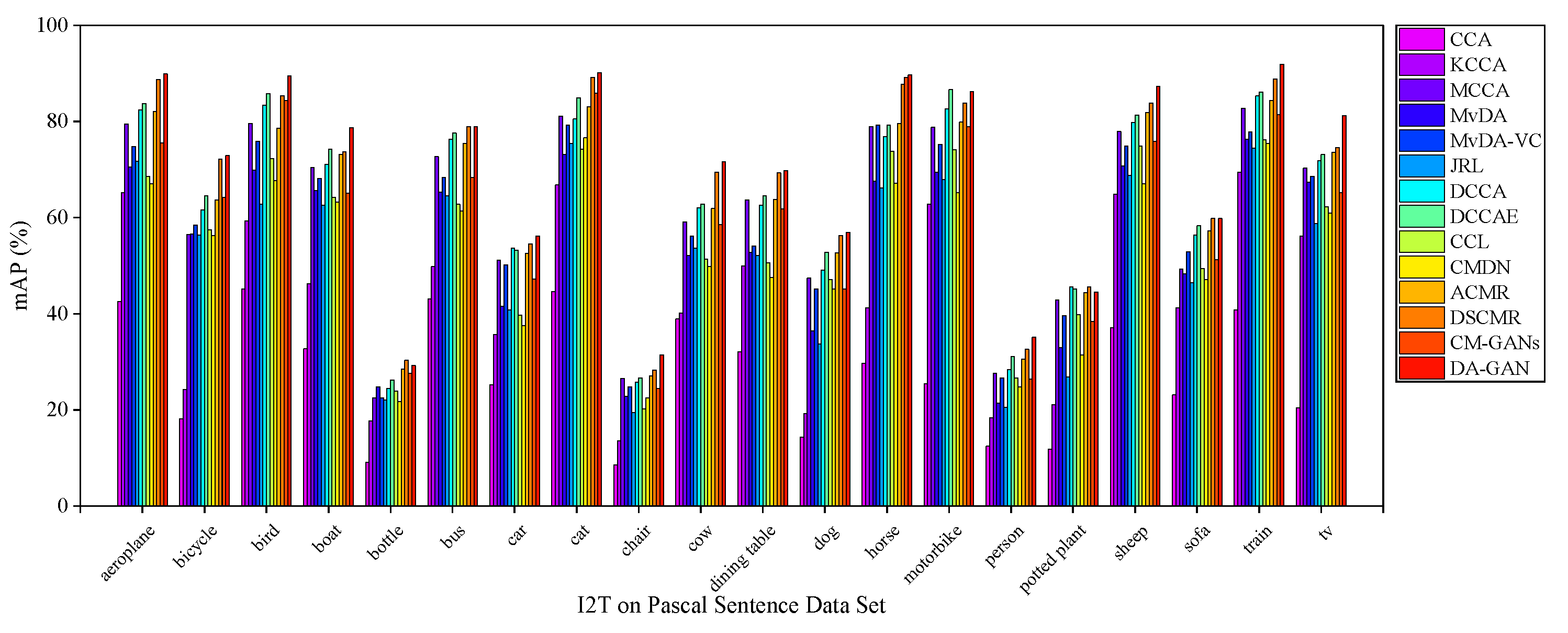
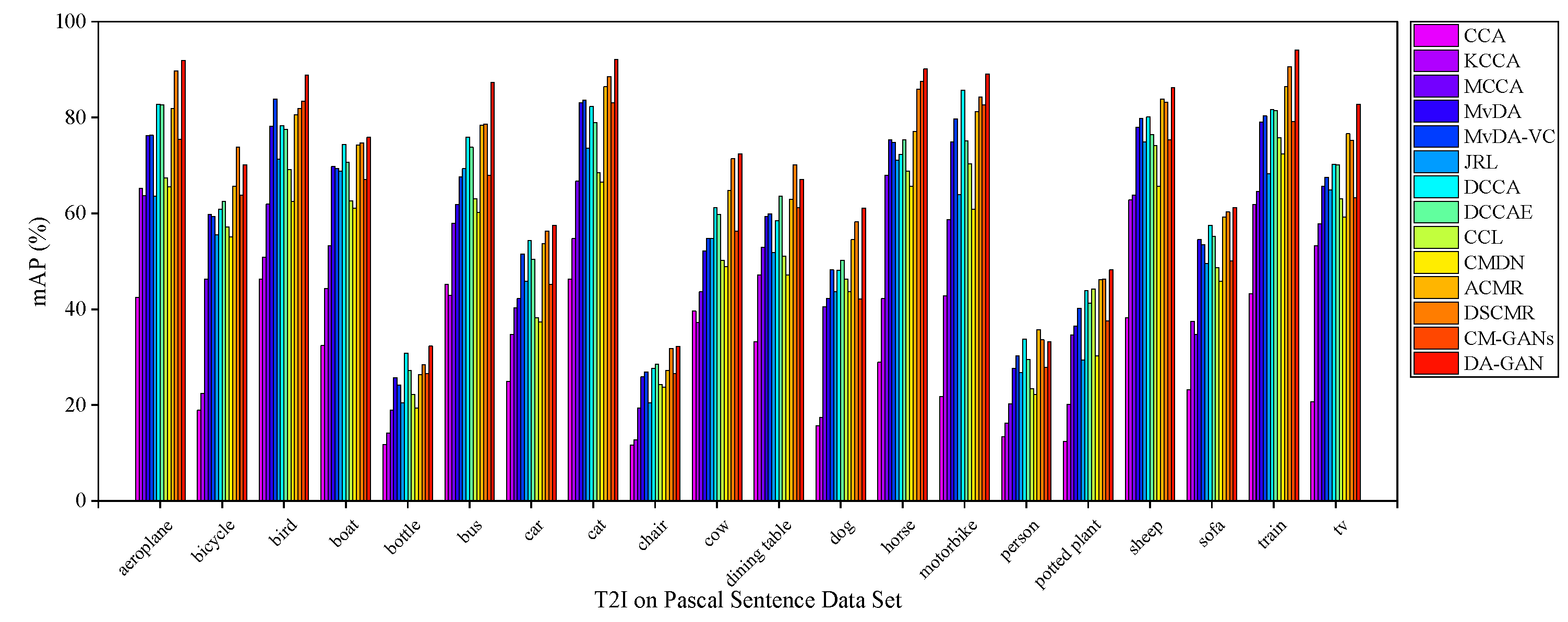
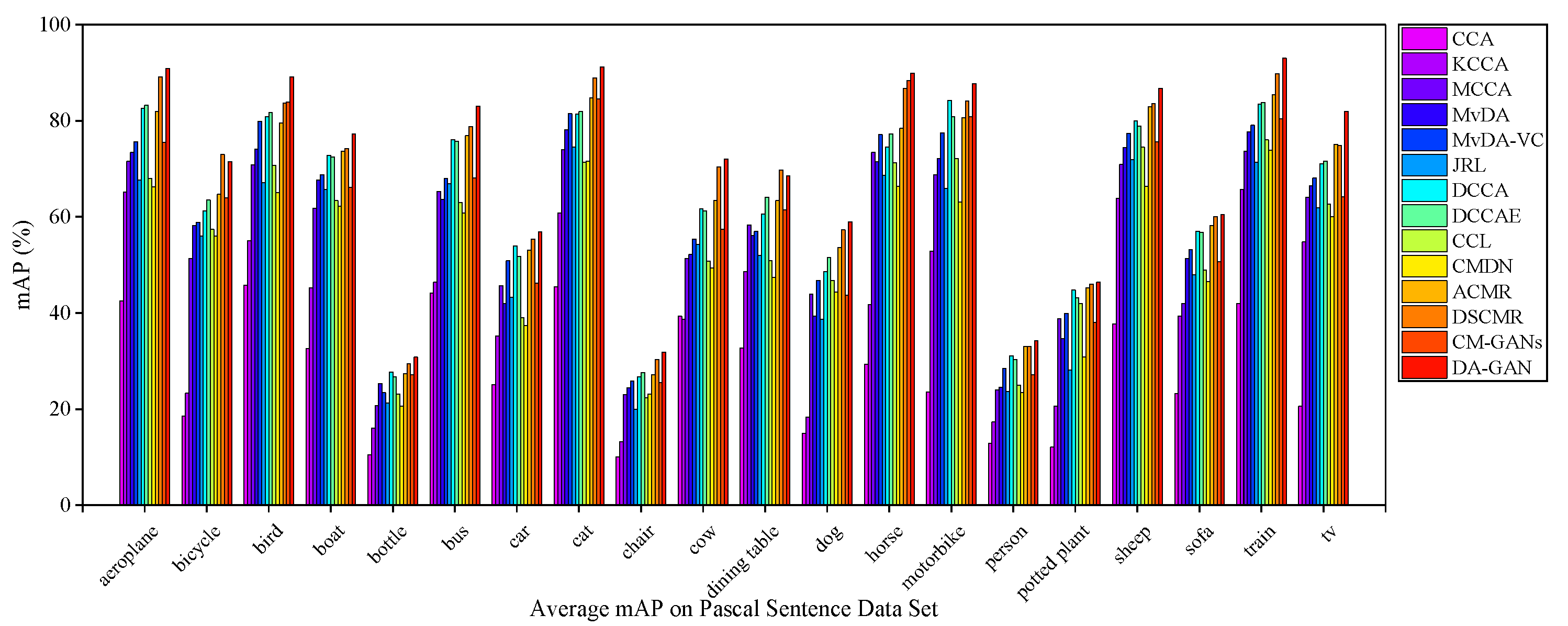
5.4.3. Results on Pascal Sentences Dataset
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Wang, Y. Survey on deep multi-modal data analytics: Collaboration, rivalry, and fusion. ACM Trans. Multimed. Comput. Commun. Appl. 2021, 17, 1–25. [Google Scholar] [CrossRef]
- Ranjan, V.; Rasiwasia, N.; Jawahar, C.V. Multi-label cross-modal retrieval. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4094–4102. [Google Scholar]
- Chen, Y.; Ren, P.; Wang, Y.; de Rijke, M. Bayesian personalized feature interaction selection for factorization machines. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 665–674. [Google Scholar]
- Wu, Y.; Yang, Y. Exploring Heterogeneous Clues for Weakly-Supervised Audio-Visual Video Parsing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1326–1335. [Google Scholar]
- Chen, Y.; Wang, Y.; Ren, P.; Wang, M.; de Rijke, M. Bayesian feature interaction selection for factorization machines. Artif. Intell. 2022, 302, 103589. [Google Scholar] [CrossRef]
- Zhang, C.; Wang, Y.; Zhu, L.; Song, J.; Yin, H. Multi-graph heterogeneous interaction fusion for social recommendation. ACM Trans. Inf. Syst. 2021, 40, 1–26. [Google Scholar] [CrossRef]
- Gu, C.; Bu, J.; Zhou, X.; Yao, C.; Ma, D.; Yu, Z.; Yan, X. Cross-modal Image Retrieval with Deep Mutual Information Maximization. arXiv 2021, arXiv:2103.06032. [Google Scholar]
- Zhang, C.; Song, J.; Zhu, X.; Zhu, L.; Zhang, S. Hcmsl: Hybrid cross-modal similarity learning for cross-modal retrieval. ACM Trans. Multimed. Comput. Commun. Appl. 2021, 17, 1–22. [Google Scholar] [CrossRef]
- Zhang, C.; Zhong, Z.; Zhu, L.; Zhang, S.; Cao, D.; Zhang, J. M2guda: Multi-metrics graph-based unsupervised domain adaptation for cross-modal Hashing. In Proceedings of the 2021 International Conference on Multimedia Retrieval, Taipei, Taiwan, 21–24 August 2021; pp. 674–681. [Google Scholar]
- Thomas, C.; Kovashka, A. Preserving semantic neighborhoods for robust cross-modal retrieval. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 317–335. [Google Scholar]
- Hardoon, D.R.; Szedmák, S.; Shawe-Taylor, J. Canonical correlation analysis: An overview with application to learning methods. Neural Comput. 2004, 16, 2639–2664. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pereira, J.C.; Coviello, E.; Doyle, G.; Rasiwasia, N.; Lanckriet, G.R.G.; Levy, R.; Vasconcelos, N. On the role of correlation and abstraction in cross-modal multimedia retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 521–535. [Google Scholar] [CrossRef] [Green Version]
- Gong, Y.; Ke, Q.; Isard, M.; Lazebnik, S. A multi-view embedding space for modeling internet images, tags, and their semantics. Int. Comput. Vis. 2014, 106, 210–233. [Google Scholar] [CrossRef] [Green Version]
- Sharma, A.; Kumar, A.; Daume, H.; Jacobs, D.W. Generalized multiview analysis: A discriminative latent space. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2160–2167. [Google Scholar]
- Rasiwasia, N.; Mahajan, D.; Mahadevan, V.; Aggarwal, G. Cluster canonical correlation analysis. In Proceedings of the Seventeenth International Conference on Artificial Intelligence and Statistics, AISTATS 2014, Reykjavik, Iceland, 22–25 April 2014. [Google Scholar]
- Lopez-Paz, D.; Sra, S.; Smola, A.; Ghahramani, Z.; Schölkopf, B. Randomized nonlinear component analysis. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 1359–1367. [Google Scholar]
- Sun, T.; Chen, S. Locality preserving cca with applications to data visualization and pose estimation. Image Vis. Comput. 2007, 25, 531–543. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Lin, X.; Wu, L.; Zhang, W. Effective multi-query expansions: Collaborative deep networks for robust landmark retrieval. IEEE Trans. Image Process. 2017, 26, 1393–1404. [Google Scholar] [CrossRef]
- Qian, B.; Wang, Y.; Hong, R.; Wang, M.; Shao, L. Diversifying inference path selection: Moving-mobile-network for landmark recognition. IEEE Trans. Image Process. 2021, 30, 4894–4904. [Google Scholar] [CrossRef]
- Benton, A.; Khayrallah, H.; Gujral, B.; Reisinger, D.; Zhang, S.; Arora, R. Deep generalized canonical correlation analysis. arXiv 2017, arXiv:1702.02519. [Google Scholar]
- Elmadany, N.E.D.; He, Y.; Guan, L. Multiview learning via deep discriminative canonical correlation analysis. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 2409–2413. [Google Scholar]
- Wang, W.; Arora, R.; Livescu, K.; Bilmes, J.A. On deep multi-view representation learning. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; Volume 37, pp. 1083–1092. [Google Scholar]
- Peng, Y.; Qi, J.; Yuan, Y. Modality-specific cross-modal similarity measurement with recurrent attention network. IEEE Trans. Image Process. 2018, 27, 5585–5599. [Google Scholar] [CrossRef] [Green Version]
- Xu, X.; Wang, T.; Yang, Y.; Zuo, L.; Shen, H.T. Cross-modal attention with semantic consistence for image-text matching. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 5412–5425. [Google Scholar] [CrossRef]
- Fang, A.; Zhao, X.; Zhang, Y. Cross-modal image fusion theory guided by subjective visual attention. arXiv 2019, arXiv:1912.10718. [Google Scholar]
- Zhu, L.; Zhang, C.; Song, J.; Liu, L.; Zhang, S.; Li, Y. Multi-graph based hierarchical semantic fusion for cross-modal representation. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Wu, L.; Wang, Y.; Gao, J.; Wang, M.; Zha, Z.-J.; Tao, D. Deep coattention-based comparator for relative representation learning in person re-identification. IEEE Trans. Neural Netw. Learn. 2020, 32, 722–735. [Google Scholar] [CrossRef]
- Wang, K.; He, R.; Wang, L.; Wang, W.; Tan, T. Joint feature selection and subspace learning for cross-modal retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 2010–2023. [Google Scholar] [CrossRef]
- Zhu, L.; Long, J.; Zhang, C.; Yu, W.; Yuan, X.; Sun, L. An efficient approach for geo-multimedia cross-modal retrieval. IEEE Access 2019, 7, 180571–180589. [Google Scholar] [CrossRef]
- Zhu, L.; Song, J.; Zhu, X.; Zhang, C.; Zhang, S.; Yuan, X. Adversarial learning-based semantic correlation representation for cross-modal retrieval. IEEE Multimed. 2020, 27, 79–90. [Google Scholar] [CrossRef]
- Wang, C.; Yang, H.; Meinel, C. Deep semantic mapping for cross-modal retrieval. In Proceedings of the 2015 IEEE 27th International Conference on Tools with Artificial Intelligence (ICTAI), Vietri sul Mare, Italy, 9–11 November 2015; pp. 234–241. [Google Scholar]
- Rasiwasia, N.; Pereira, J.C.; Coviello, E.; Doyle, G.; Lanckriet, G.R.; Levy, R.; Vasconcelos, N. A new approach to cross-modal multimedia Retrieval. In Proceedings of the 18th ACM International Conference on Multimedia, Firenze, Italy, 25–29 October 2010; pp. 251–260. [Google Scholar]
- Ngiam, J.; Khosla, A.; Kim, M.; Nam, J.; Lee, H.; Ng, A.Y. Multimodal deep learning. In Proceedings of the 28th International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2011. [Google Scholar]
- Wu, L.; Wang, Y.; Shao, L. Cycle-consistent deep generative hashing for cross-modal retrieval. IEEE Trans. Image Process. 2018, 28, 1602–1612. [Google Scholar] [CrossRef] [Green Version]
- Zhao, L.; Chen, Z.; Yang, L.T.; Deen, M.J.; Wang, Z.J. Deep semantic mapping for heterogeneous multimedia transfer learning using co-occurrence data. Acm Trans. Multimed. Comput. Commun. Appl. 2019, 15, 1–21. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, W.; Wu, L.; Lin, X.; Fang, M.; Pan, S. Iterative views agreement: An iterative low-rank based structured optimization method to multi-view spectral clustering. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 2153–2159. [Google Scholar]
- Zhang, W.; Yao, T.; Zhu, S.; Saddik, A.E. Deep learning–based multimedia analytics: A review. ACM Trans. Multimed. Comput. Appl. 2019, 15, 1–26. [Google Scholar] [CrossRef]
- Wei, Y.; Zhao, Y.; Lu, C.; Wei, S.; Liu, L.; Zhu, Z.; Yan, S. Cross-modal retrieval with cnn visual features: A new baseline. IEEE Trans. Cybern. 2016, 47, 449–460. [Google Scholar] [CrossRef]
- Zhu, L.; Song, J.; Wei, X.; Yu, H.; Long, J. Caesar: Concept augmentation based semantic representation for cross-modal retrieval. Multimed. Tools Appl. 2020, 1, 1–31. [Google Scholar] [CrossRef]
- Andrew, G.; Arora, R.; Bilmes, J.A.; Livescu, K. Deep canonical correlation Analysis. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; Volume 28, pp. 1247–1255. [Google Scholar]
- Gu, J.; Cai, J.; Joty, S.R.; Niu, L.; Wang, G. Look, imagine and match: Improving textual-visual cross-modal retrieval with generative models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7181–7189. [Google Scholar]
- Zhen, L.; Hu, P.; Wang, X.; Peng, D. Deep supervised cross-modal Retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 10394–10403. [Google Scholar]
- Gao, P.; Jiang, Z.; You, H.; Lu, P.; Hoi, S.C.H.; Wang, X.; Li, H. Dynamic fusion with intra- and inter-modality attention flow for visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 6639–6648. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Liu, J.; Wang, G.; Hu, P.; Duan, L.-Y.; Kot, A.C. Global context-aware attention lstm networks for 3d action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1647–1656. [Google Scholar]
- Xiao, T.; Xu, Y.; Yang, K.; Zhang, J.; Peng, Y.; Zhang, Z. The application of two-level attention models in deep convolutional neural network for fine-grained image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 842–850. [Google Scholar]
- Lu, J.; Yang, J.; Batra, D.; Parikh, D. Hierarchical question-image co-attention for visual question answering. In Advances in Neural Information Processing Systems; 2016; pp. 289–297.
- Wu, L.; Wang, Y.; Li, X.; Gao, J. Deep attention-based spatially recursive networks for fine-grained visual recognition. IEEE Trans. Cybern. 2019, 49, 1791–1802. [Google Scholar] [CrossRef]
- Sudhakaran, S.; Escalera, S.; Lanz, O. Lsta: Long short-term attention for egocentric action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9954–9963. [Google Scholar]
- Wang, X.; Wang, Y.-F.; Wang, W.Y. Watch, listen, and describe: Globally and locally aligned cross-modal attentions for video captioning. In Proceedings of the NAACL-HLT, New Orleans, LA, USA, 1–6 June 2018; pp. 795–801. [Google Scholar]
- Liu, X.; Wang, Z.; Shao, J.; Wang, X.; Li, H. Improving referring expression grounding with cross-modal attention-guided erasing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1950–1959. [Google Scholar]
- Huang, P.-Y.; Chang, X.; Hauptmann, A.G. Improving what cross-modal retrieval models learn through object-oriented inter-and intra-modal attention networks. In Proceedings of the 2019 on International Conference on Multimedia Retrieval, Ottawa, ON, Canada, 10–13 June 2019; pp. 244–252. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Advances in Neural Information Processing Systems; 2014; pp. 2672–2680. Available online: https://proceedings.neurips.cc/paper/2014/file/5ca3e9b122f61f8f06494c97b1afccf3-Paper.pdf (accessed on 3 January 2022).
- Xu, X.; He, L.; Lu, H.; Gao, L.; Ji, Y. Deep adversarial metric learning for cross-modal retrieval. World Wide Web 2019, 22, 657–672. [Google Scholar] [CrossRef]
- Wang, B.; Yang, Y.; Xu, X.; Hanjalic, A.; Shen, H.T. Adversarial cross-modal Retrieval. In Proceedings of the 2017 ACM on Multimedia Conference, Mountain View, CA, USA, 23–27 October 2017; Liu, Q., Lienhart, R., Wang, H., Chen, S.K., Boll, S., Chen, Y.P., Friedland, G., Li, J., Yan, S., Eds.; ACM: New York, NY, USA, 2017; pp. 154–162. [Google Scholar]
- Liu, R.; Zhao, Y.; Wei, S.; Zheng, L.; Yang, Y. Modality-invariant image-text embedding for image-sentence matching. ACM Trans. Multimed. Comput. Commun. Appl. 2019, 15, 1–19. [Google Scholar] [CrossRef]
- Huang, X.; Peng, Y.; Yuan, M. MHTN: Modal-adversarial hybrid transfer network for cross-modal retrieval. IEEE Trans. Cybern. 2020, 50, 1047–1059. [Google Scholar] [CrossRef] [Green Version]
- Zheng, F.; Tang, Y.; Shao, L. Hetero-manifold regularisation for cross-modal hashing. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1059–1071. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Y.; Lin, X.; Wu, L.; Zhang, W.; Zhang, Q. LBMCH: Learning bridging mapping for cross-modal hashing. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; Baeza-Yates, R., Lalmas, M., Moffat, A., Ribeiro-Neto, B.A., Eds.; ACM: New York, NY, USA, 2015; pp. 999–1002. [Google Scholar]
- Zhang, J.; Peng, Y.; Yuan, M. SCH-GAN: Semi-supervised cross-modal hashing by generative adversarial network. IEEE Trans. Cybern. 2020, 50, 489–502. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Graves, A.; Mohamed, A.; Hinton, G.E. Speech recognition with deep recurrent neural networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems 25: 26th Annual Conference on Neural Information Processing Systems 2012, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1106–1114. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P.P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Chua, T.-S.; Tang, J.; Hong, R.; Li, H.; Luo, Z.; Zheng, Y. Nus-wide: A real-world web image database from national university of Singapore. In Proceedings of the ACM International Conference on Image and Video Retrieval, Fira, Greece, 8–10 July 2009; ACM: New York, NY, USA, 2009; p. 48. [Google Scholar]
- Rashtchian, C.; Young, P.; Hodosh, M.; Hockenmaier, J. Collecting image annotations using amazon’s mechanical turk. In Proceedings of the NAACL HLT 2010 Workshop on Creating Speech and Language Data with Amazon’s Mechanical Turk, Los Angeles, CA, USA, 6 June 2010; Association for Computational Linguistics: Stroudsburg, PA, USA, 2010; pp. 139–147. [Google Scholar]
- Hotelling, H. Relations between two sets of variates. Biometrika 1936, 28, 321–377. [Google Scholar] [CrossRef]
- Rupnik, J.; Shawe-Taylor, J. Multi-view canonical correlation analysis. In Proceedings of the Conference on Data Mining and Data Warehouses (SiKDD 2010), Ljubljana, Slovenia, 12 October 2010; pp. 1–4. [Google Scholar]
- Kan, M.; Shan, S.; Zhang, H.; Lao, S.; Chen, X. Multi-view discriminant Analysis. In Proceedings of the Computer Vision—ECCV 2012—12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Fitzgibbon, A.W., Lazebnik, S., Perona, P., Sato, Y., Schmid, C., Eds.; Proceedings, Part I, ser. Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7572, pp. 808–821. [Google Scholar]
- Kan, M.; Shan, S.; Zhang, H.; Lao, S.; Chen, X. Multi-view discriminant analysis. IEEE Trans. Pattern Anal. Machine Intell. 2016, 38, 188–194. [Google Scholar] [CrossRef]
- Zhai, X.; Peng, Y.; Xiao, J. Learning cross-media joint representation with sparse and semisupervised regularization. IEEE Trans. Circuits Syst. Video Techn. 2014, 24, 965–978. [Google Scholar] [CrossRef]
- Peng, Y.; Qi, J.; Huang, X.; Yuan, Y. CCL: Cross-modal correlation learning with multigrained fusion by hierarchical network. IEEE Trans. Multimed. 2018, 20, 405–420. [Google Scholar] [CrossRef] [Green Version]
- Peng, Y.; Huang, X.; Qi, J. Cross-media shared representation by hierarchical learning with multiple deep networks. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 3846–3853. [Google Scholar]
- Peng, Y.; Qi, J. Cm-gans: Cross-modal generative adversarial networks for common representation learning. ACM Trans. Multimed. Comput. Commun. Appl. 2019, 15, 1–24. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Definition |
|---|---|
| a multimedia dataset | |
| the i-th image sample | |
| the i-th text sample | |
| a label vector | |
| Q | a cross-modal query |
| the set of results | |
| a non-linear mapping | |
| the set of semantic concepts | |
| the parameter vector of model | |
| the i-th visual convolutional representation | |
| the i-th textual convolutional representation | |
| the attention-aware representation of image | |
| the attention-aware representation of text | |
| the cross-modal common semantic representation of image | |
| the cross-modal common semantic representation of text | |
| the attention-aware cross-modal common semantic representation of image | |
| the attention-aware cross-modal common semantic representation of text | |
| a hidden vector | |
| a convolutional kernel | |
| a semantic correlation matrix | |
| an attention map | |
| a cross-modal semantic correlation matrix | |
| a reconstructed representation of i-th image | |
| a reconstructed representation of i-th text |
| Traditional Method | I2T | T2I | Aver. |
|---|---|---|---|
| CCA [69] | 13.4 | 13.3 | 13.4 |
| KCCA [11] | 19.8 | 18.6 | 19.2 |
| MCCA [70] | 34.1 | 30.7 | 32.4 |
| MvDA [71] | 33.7 | 30.8 | 32.3 |
| MvDA-VC [72] | 38.8 | 35.8 | 37.3 |
| JRL [73] | 44.9 | 41.8 | 43.4 |
| Deep Learning-Based Method | I2T | T2I | Aver. |
| DCCA [42] | 44.4 | 39.6 | 42.0 |
| DCCAE [24] | 43.5 | 38.5 | 41.0 |
| CCL [74] | 50.4 | 45.7 | 48.1 |
| CMDN [75] | 48.7 | 42.7 | 45.7 |
| ACMR [57] | 47.7 | 43.4 | 45.6 |
| DSCMR [44] | 52.1 | 47.8 | 49.9 |
| CM-GANs [76] | 50.0 | 62.1 | 56.1 |
| The Proposed Method | I2T | T2I | Aver. |
| DA-GAN | 54.3 | 63.9 | 59.1 |
| Traditional Method | I2T | T2I | Aver. |
|---|---|---|---|
| CCA [69] | 37.8 | 39.4 | 38.6 |
| KCCA [11] | 36.2 | 39.4 | 37.8 |
| MCCA [70] | 44.8 | 46.2 | 45.5 |
| MvDA [71] | 50.1 | 52.6 | 51.3 |
| MvDA-VC [72] | 52.6 | 55.7 | 54.2 |
| JRL [73] | 58.6 | 59.8 | 59.2 |
| Deep Learning-Based Method | I2T | T2I | Aver. |
| DCCA [42] | 53.2 | 54.9 | 54.0 |
| DCCAE [24] | 51.1 | 54.0 | 52.5 |
| CCL [74] | 50.6 | 53.5 | 52.1 |
| CMDN [75] | 49.2 | 51.5 | 50.4 |
| ACMR [57] | 58.8 | 59.9 | 59.3 |
| DSCMR [44] | 61.1 | 61.5 | 61.3 |
| CM-GANs [76] | 78.1 | 72.4 | 75.3 |
| The Proposed Method | I2T | T2I | Aver. |
| DA-GAN | 79.7 | 75.2 | 77.5 |
| Traditional Method | I2T | T2I | Aver. |
|---|---|---|---|
| CCA [69] | 22.5 | 22.7 | 22.6 |
| KCCA [11] | 43.3 | 39.8 | 41.6 |
| MCCA [70] | 66.4 | 48.9 | 55.45 |
| MvDA [71] | 59.4 | 62.6 | 61.0 |
| MvDA-VC [72] | 64.8 | 67.3 | 66.1 |
| JRL [73] | 52.7 | 53.4 | 53.1 |
| Deep Learning-Based Method | I2T | T2I | Aver. |
| DCCA [42] | 67.8 | 67.7 | 67.8 |
| DCCAE [24] | 68.0 | 67.1 | 67.5 |
| CCL [74] | 57.6 | 56.1 | 56.9 |
| CMDN [75] | 54.4 | 52.6 | 53.5 |
| ACMR [57] | 67.1 | 67.6 | 67.3 |
| DSCMR [44] | 71.0 | 72.2 | 71.6 |
| CM-GANs [76] | 61.2 | 61.0 | 61.1 |
| The Proposed Method | I2T | T2I | Aver. |
| DA-GAN | 72.9 | 73.5 | 73.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cai, L.; Zhu, L.; Zhang, H.; Zhu, X. DA-GAN: Dual Attention Generative Adversarial Network for Cross-Modal Retrieval. Future Internet 2022, 14, 43. https://doi.org/10.3390/fi14020043
Cai L, Zhu L, Zhang H, Zhu X. DA-GAN: Dual Attention Generative Adversarial Network for Cross-Modal Retrieval. Future Internet. 2022; 14(2):43. https://doi.org/10.3390/fi14020043
Chicago/Turabian StyleCai, Liewu, Lei Zhu, Hongyan Zhang, and Xinghui Zhu. 2022. "DA-GAN: Dual Attention Generative Adversarial Network for Cross-Modal Retrieval" Future Internet 14, no. 2: 43. https://doi.org/10.3390/fi14020043
APA StyleCai, L., Zhu, L., Zhang, H., & Zhu, X. (2022). DA-GAN: Dual Attention Generative Adversarial Network for Cross-Modal Retrieval. Future Internet, 14(2), 43. https://doi.org/10.3390/fi14020043