
Global Contextual Dependency Network for Object Detection


Abstract
:1. Introduction
- We present a novel Global Contextual Dependency Network (GCDN), as a plug-and-play component, to boost the classification ability of two-stage detectors;
- A Context Representation Module (CRM) is proposed to construct multi-scale context representations, and a Context Dependency Module (CDM) is designed to capture global contextual dependencies;
- Our proposed GCDN significantly improves detection performance and is easy to implement. Furthermore, we propose a lite version for little calculation.
2. Related Work
2.1. Object Detection
2.2. Context Dependency for Object Detection
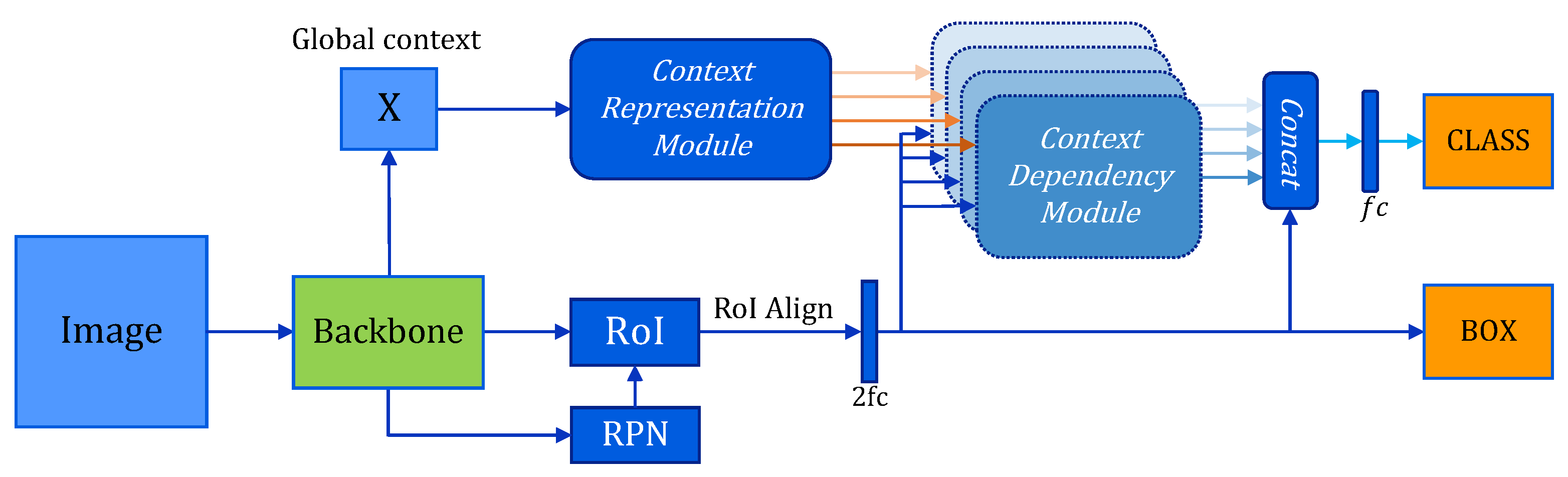
3. Global Contextual Dependency Network
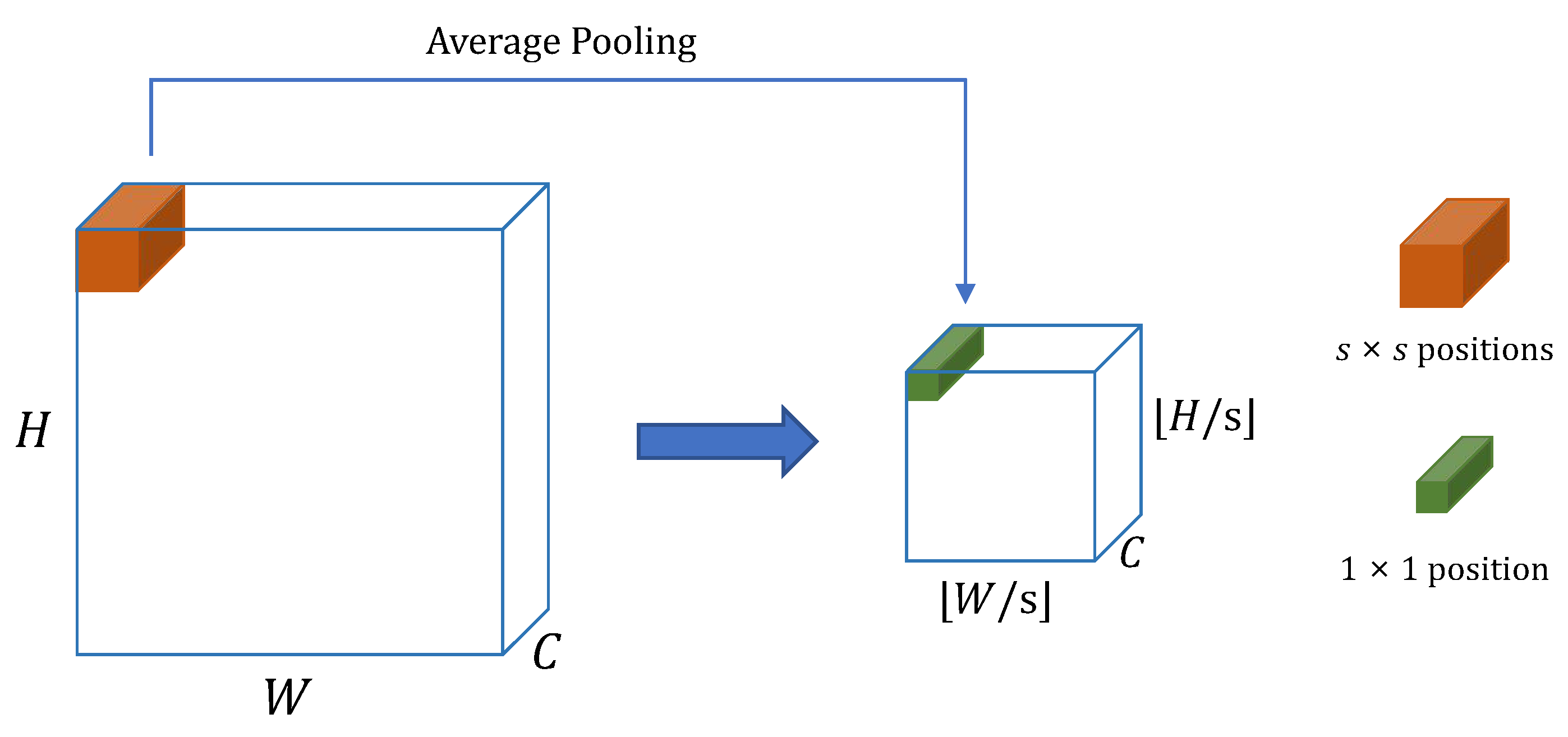
3.1. Context Representation Module
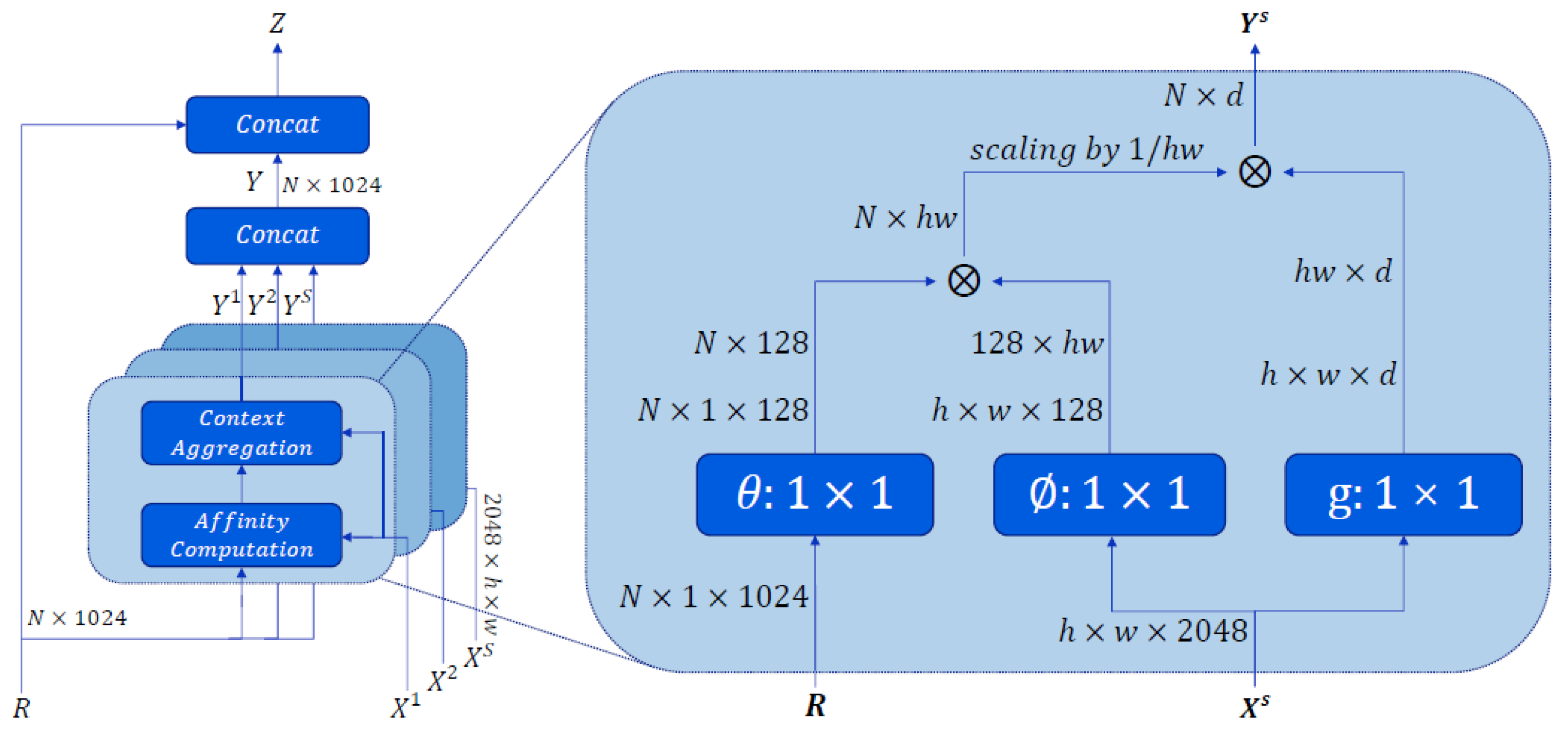
3.2. Context Dependency Module
3.2.1. Affinity Computation
3.2.2. Context Aggregation
3.2.3. Feature Fusion
4. Experiments
4.1. Implementation Details
4.2. Comparisons with Baselines
4.3. Ablation Studies
4.3.1. Context Operations
4.3.2. Pyramid Scales
4.4. Lite Version
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.W.; Chen, J.; Liu, X.; Pietikäinen, M. Deep Learning for Generic Object Detection: A Survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R.S. Understanding the Effective Receptive Field in Deep Convolutional Neural Networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 4898–4906. [Google Scholar]
- Zhang, W.; Fu, C.; Xie, H.; Zhu, M.; Tie, M.; Chen, J. Global context aware RCNN for object detection. Neural Comput. Appl. 2021, 33, 11627–11639. [Google Scholar] [CrossRef]
- Chen, Z.; Jin, X.; Zhao, B.; Wei, X.; Guo, Y. Hierarchical Context Embedding for Region-Based Object Detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 633–648. [Google Scholar]
- Hu, H.; Gu, J.; Zhang, Z.; Dai, J.; Wei, Y. Relation Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3588–3597. [Google Scholar]
- Xu, H.; Jiang, C.; Liang, X.; Li, Z. Spatial-Aware Graph Relation Network for Large-Scale Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9298–9307. [Google Scholar]
- He, J.; Deng, Z.; Zhou, L.; Wang, Y.; Qiao, Y. Adaptive Pyramid Context Network for Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7519–7528. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Lin, T.; Maire, M.; Belongie, S.J.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context; Lecture Notes in Computer Science. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Fleet, D.J., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2014; Volume 8693, pp. 740–755. [Google Scholar]
- Girshick, R.B.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Lecture Notes in Computer Science, Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. [Google Scholar]
- Gupta, D.K.; Arya, D.; Gavves, E. Rotation Equivariant Siamese Networks for Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 12362–12371. [Google Scholar]
- Vesdapunt, N.; Wang, B. CRFace: Confidence Ranker for Model-Agnostic Face Detection Refinement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 1674–1684. [Google Scholar]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Girshick, R.B. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, J.; Rathod, V.; Sun, C.; Zhu, M.; Korattikara, A.; Fathi, A.; Fischer, I.; Wojna, Z.; Song, Y.; Guadarrama, S.; et al. Speed/Accuracy Trade-Offs for Modern Convolutional Object Detectors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3296–3297. [Google Scholar]
- Lin, T.; Dollár, P.; Girshick, R.B.; He, K.; Hariharan, B.; Belongie, S.J. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving Into High Quality Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R.B. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Galleguillos, C.; Belongie, S.J. Context based object categorization: A critical survey. Comput. Vis. Image Underst. 2010, 114, 712–722. [Google Scholar] [CrossRef] [Green Version]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Li, J.; Wei, Y.; Liang, X.; Dong, J.; Xu, T.; Feng, J.; Yan, S. Attentive Contexts for Object Detection. IEEE Trans. Multimed. 2017, 19, 944–954. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Girshick, R.B.; Gupta, A.; He, K. Non-Local Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Liu, Y.; Wang, R.; Shan, S.; Chen, X. Structure Inference Net: Object Detection Using Scene-Level Context and Instance-Level Relationships. In Proceedings of the IEEE Conference on Computer vision And Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6985–6994. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Bell, S.; Zitnick, C.L.; Bala, K.; Girshick, R.B. Inside-Outside Net: Detecting Objects in Context with Skip Pooling and Recurrent Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2874–2883. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Li, F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Backbone | Method | GCDN | AP | AP | AP | AP | AP | AP |
|---|---|---|---|---|---|---|---|---|
| ResNet-50-FPN | FPN | 37.4 | 58.1 | 40.8 | 21.4 | 40.8 | 48.5 | |
| ResNet-50-FPN | FPN | ✓ | 38.9 | 60.3 | 41.9 | 22.7 | 42.6 | 49.8 |
| ResNet-50-FPN | Mask R-CNN | 38.2 | 58.9 | 41.5 | 22.4 | 41.6 | 49.7 | |
| ResNet-50-FPN | Mask R-CNN | ✓ | 39.4 | 60.5 | 42.8 | 23.0 | 43.5 | 50.6 |
| ResNet-101-FPN | FPN | 39.6 | 60.6 | 43.3 | 22.7 | 43.6 | 52.2 | |
| ResNet-101-FPN | FPN | ✓ | 40.3 | 61.5 | 43.8 | 23.8 | 44.5 | 53.0 |
| ResNet-101-FPN | Mask R-CNN | 40.2 | 60.4 | 44.1 | 22.9 | 44.1 | 53.3 | |
| ResNet-101-FPN | Mask R-CNN | ✓ | 41.0 | 62.1 | 44.6 | 24.0 | 45.1 | 53.7 |
| Method | CRM | GAP | CDM | AP | AP | AP | AP | AP | AP |
|---|---|---|---|---|---|---|---|---|---|
| FPN | 37.4 | 58.1 | 40.8 | 21.4 | 40.8 | 48.5 | |||
| FPN | ✓ | 37.8 | 59.1 | 41.0 | 21.9 | 41.4 | 48.3 | ||
| FPN | ✓ | 38.5 | 59.9 | 42.0 | 22.6 | 42.6 | 49.4 | ||
| FPN | ✓ | ✓ | 38.9 | 60.3 | 41.9 | 22.7 | 42.6 | 49.8 |
| Method | Pyramid Scales | AP | AP | AP | AP | AP | AP |
|---|---|---|---|---|---|---|---|
| FPN | {1} | 38.5 | 59.9 | 42.0 | 22.6 | 42.6 | 49.4 |
| FPN | {1,2} | 38.8 | 60.0 | 42.1 | 23.1 | 42.6 | 49.6 |
| FPN | {1,2,3} | 38.8 | 60.1 | 42.2 | 22.8 | 42.6 | 49.7 |
| FPN | {1,2,3,6} | 38.9 | 60.3 | 41.9 | 22.7 | 42.6 | 49.8 |
| Method | Lite | Full | AP | AP | AP | AP | AP | AP | Runtime FPS |
|---|---|---|---|---|---|---|---|---|---|
| FPN | 37.4 | 58.1 | 40.8 | 21.4 | 40.8 | 48.5 | 15.3 | ||
| FPN | ✓ | 38.5 | 59.8 | 41.7 | 22.4 | 42.5 | 49.3 | 14.8 | |
| FPN | ✓ | 38.9 | 60.3 | 41.9 | 22.7 | 42.6 | 49.8 | 14.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Zhang, C.; Yang, B. Global Contextual Dependency Network for Object Detection. Future Internet 2022, 14, 27. https://doi.org/10.3390/fi14010027
Li J, Zhang C, Yang B. Global Contextual Dependency Network for Object Detection. Future Internet. 2022; 14(1):27. https://doi.org/10.3390/fi14010027
Chicago/Turabian StyleLi, Junda, Chunxu Zhang, and Bo Yang. 2022. "Global Contextual Dependency Network for Object Detection" Future Internet 14, no. 1: 27. https://doi.org/10.3390/fi14010027
APA StyleLi, J., Zhang, C., & Yang, B. (2022). Global Contextual Dependency Network for Object Detection. Future Internet, 14(1), 27. https://doi.org/10.3390/fi14010027