1. Introduction
Digital technologies provide many opportunities, including overcoming a disability and simplifying access to knowledge and services [
1,
2,
3]. Several initiatives and laws, e.g., the Americans with Disabilities Act (
https://adata.org/topic/technology-accessible, accessed on 1 September 2021), promote full participation of individuals to all areas of the society and reduction of discriminations, including the digital sector [
4]. For fostering software accessibility on personal computers and mobile devices, computer accessibility guidelines and standards have been proposed by organizations [
5], including the International Organization for Standardization, the International Electronical Commission [
6], the European Commission, the US Congress [
4], and the W3C [
7,
8,
9,
10].
In this paper, we focus on visual accessibility in operating systems (OS). Vision is the focal point of the recent studies in software accessibility [
5]. Unfortunately, there is no unique reference for software accessibility [
5,
11] and OS manufacturers make various interpretations of the existing international recommendations [
4]. As a consequence, each OS proposes its own set of visual accessibility options, with specific terms, organization and implementation. This variability has a number of practical consequences. We hereafter mention just a few. During requirement analysis, it may be challenging for a manufacturer to both integrate international recommendations and analyze competing OS, in order to identify core solutions, or to propose advanced ones. For end users, finding the OS that best matches their needs may be tricky. In addition, when users need to move to a new system, it is difficult to assist them to select the OS preserving a significant part of their current settings. This is very sensitive for users who have specific needs, especially those who are visually impaired. For a single option, this may be relatively easy, e.g., a user wishing option “invert colors” will find it in Android, iOS, MacOS and Ubuntu, but not in Windows. However, if the user has complex settings, composed of many specific options, it might be difficult to find which system will provide the same or the closest configuration from OS descriptions with different vocabulary and presentations.
Solutions to these issues involve comprehending OS variability. This can be based on comparative studies, metrics, classifications and mappings between needs and OS. Comparative studies, classification and mappings are addressed in studies on OS accessibility that have been conducted in the past on a limited set of OS and options [
12,
13,
14,
15]. They mainly present and discuss tables that show which option appears in which OS, and they remain at a coarse-grained level of description. These results are evidently useful, but we think that it is possible to go beyond texts and tables and propose another approach for analyzing and rendering variability at a fine-grained level. In particular, we would like to provide a variability model supporting more assistance tools. e.g., finding the OS providing a configuration best-matching the user needs or previous settings is not easy with a table, especially if there are no details on options implementing a high-level feature, or if there are many columns. Variability metrics are surveyed in [
16]. Some of them are directly connected to our work and some correspond to code variability that we do not approach. Here, we aim to propose a variability model which can be navigated, and metrics.
The approach we propose is based on Formal Concept Analysis (FCA, [
17]). This framework builds classifications (also called
conceptual structures) in which
concepts group similar objects. The hierarchical structure (
concept lattice) highlights commonalities and differences. In addition, it provides an easy support for navigation in the classifications [
18,
19,
20]. We also leverage an extension of FCA, namely Relational Concept Analysis (RCA, [
21]), to analyze variability along
separate concerns, such as contrast and color theme, text style, brightness or zoom. With RCA, we analyze variability within each concern, and considering all of them as well. As FCA applies to standardized descriptions, which do not exist for all visual accessibility options in OS, we build an ontology. We develop an exploratory case study, where we observe different types of variability relationships on eight operating systems.
To summarize our contributions, we propose:
A methodology to build a variability model in the form of conceptual structures. This model can be navigated to comprehend variability. It can also be observed through various metrics. The novelty is that it allows us to analyze variability along separate concerns, or as a whole. The variability model is a classification built with a fine-grained knowledge on options. It thus opens the possibilities, for example, to help manufacturers to position their offer with respect to competing ones, to help users to choose an OS from scratch, given their preferences or needs, or to find an OS providing settings close to their current settings in another OS by introducing their settings in the classification (i.e., classifying the settings).
An ontology for visual accessibility options stemming from representative OS and the mappings between the OS terms and the ontology concepts. The existence of the ontology is useful in this work to standardize the vocabulary and build an OS classification. Outside this work, it may serve as the basis for other tasks. During OS development, it may sensitize developers, help to standardize the documentation, structure the work along a package hierarchy and test cases, and have a harmonized description over different versions. If a documentary base is built on visual accessibility, the ontology may be used to improve efficiency and reduce ambiguity in document indexing and query expression. For teaching and communicating on visual accessibility, it may be used to organize the presentation of visual accessibility features, and the mappings help in understanding how and where the features are implemented. In addition, the ontology may help in sketching questionnaires to capture the user’s needs.
A proof-of-concept with an exploratory case study. This case study includes several OS from the mainstream OS families. This case study is guided by the research question “How do accessibility options vary in practice?”. We answer by observing feature relationships (omnipresence, co-occurrences, binary implications, mutual exclusions) and operating system relationships (similarity, superiority, incomparability).
In
Section 2, we draw the outline of the approach, which follows the knowledge discovery process proposed in [
22]. Data preparation is detailed in
Section 3.
Section 4 presents the selected data mining method (FCA and RCA) and how it applies in our context.
Section 5 shows how results are interpreted.
Section 6 develops the exploratory case study.
Section 7 discusses related work. We conclude and draw future research directions in
Section 8.
2. Outline of the Variability Model Building
To build the variability model, we follow the general view of the Knowledge Discovery process presented in [
22] and largely adopted in the literature. This process is outlined as a linear flow, although steps may be repeated to consolidate results. During the first major step,
data preparation, data is selected, pre-processed and transformed to conform to the chosen data mining method and tool input.
Data mining algorithms are applied during the second step. They output knowledge patterns, that are subject to
interpretation in the third step: they are analyzed, post-processed and delivered to domain experts.
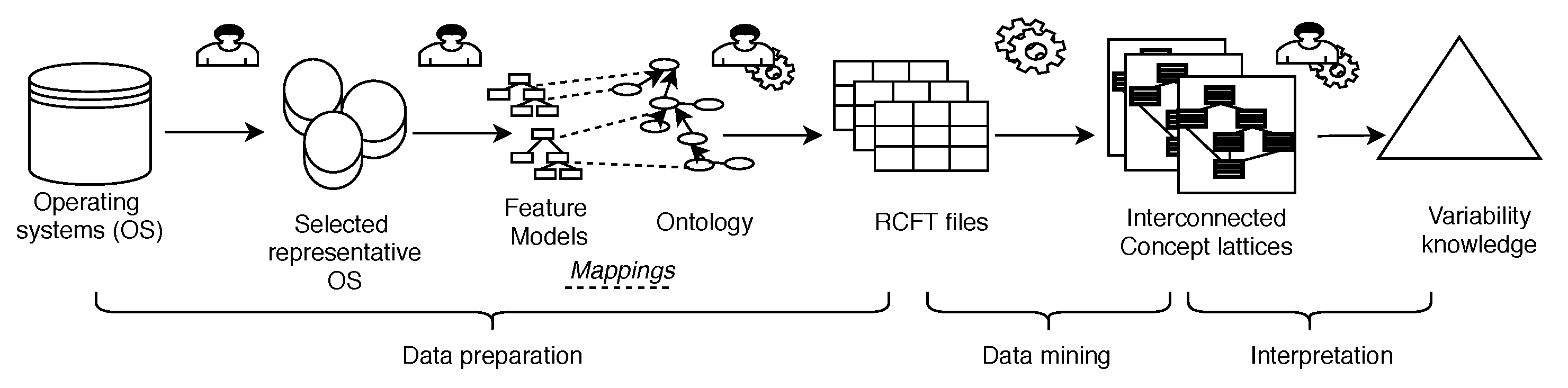
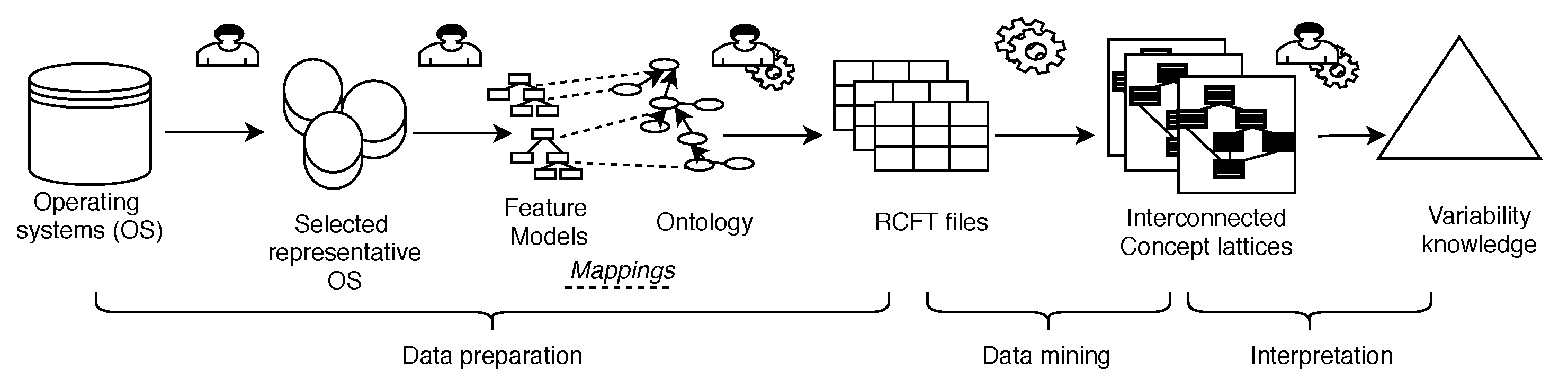
Figure 1 draws the main steps of our implemented KD process.
Data preparation step (see
Section 3) is composed of several sub-steps. The first one consists in selecting representative operating systems (
Section 3.1). Then, in
Section 3.2, we formalize the domain knowledge of each single operating system in a Feature Model (FM). This corresponds to a) a list of features (also called options in our paper) and b) hierarchical relationships between these features. FMs are variability models used in Software Product Line Engineering [
23,
24]. We manually build these FMs during an exhaustive navigation of the accessibility option set. To this aim, we explore the user interface provided by the operating system. Vocabulary and organization of these FMs are very different. Thus, we also manually build a domain ontology, capturing concepts of the studied visual accessibility mechanisms (
Section 3.3). This ontology is used to have a standard description. In addition, we establish a mapping between each option of each single operating system and one ontology concept (
Section 3.4). This mapping ensures that a correspondence exists between: the interpretation and vocabulary used in each operating system version, on one side, and the common domain knowledge, on the other side. The last part of data preparation consists in translating and enriching the descriptions of the different accessibility option sets. This is made using the ontology concepts to obtain a consistent and standardized description.
Section 3.5 explains how we encode these descriptions in a simple data model composed of objects, boolean attributes and binary relations between objects (RCFT). This data model conforms to the input of Relational Concept Analysis (RCA).
Data mining step (
Section 4) uses RCA to build a set of interconnected conceptual structures. The final variability model is composed with these structures. They exhaustively contain logical variability information.
During
Interpretation step (
Section 5), we post-process the conceptual structures with a tool for extracting variability relationships. We also navigate them to produce knowledge that can be delivered to non-experts. In the future, this analysis could be guided by appropriate tools. This would enable non-experts to interpret the output.
In what follows, the data preparation step is illustrated using the real description of the brightness mechanism in representative operating systems (those that are used in the case study). This mechanism is indeed sufficiently small in these systems. Brightness is also chosen because of its primary importance to assist people with low vision. Then the following steps are illustrated with a small fictitious yet realistic example. It includes five operating systems, and options inspired by four mechanisms (contrast, text style, brightness and zoom). It has been chosen to illustrate all the possible situations.
3. Data Preparation
This step builds data conform to the input of the data-mining method (Relational Concept Analysis). It comprises five sub-steps: selection of representative operating systems (
Section 3.1); building of Feature Models (
Section 3.2); building of an ontology (
Section 3.3); mapping between the FMs and the ontology (
Section 3.4); building of a set of binary tables for RCA (
Section 3.5).
3.1. Operating System Selection
To have a variety of systems, we consider a few versions of widely used operating systems, that we expect representative: , /, and . They are used to explain the first steps of data preparation and in the case study. We analyze 8 different operating systems, two from each family: , , , , , , and . In these systems, we consider separately four mechanisms: brightness, contrast and color, text style and zoom. This division has been proposed by one co-author who is an expert in visual accessibility for persons with low vision.
3.2. Modeling Accessibility Mechanisms through Features Models
The formalism for modeling options in a single operating system is borrowed from the product line engineering paradigm [
25]. In this paradigm, the high-level features are gathered in feature sets and then organized into Feature Models (FMs). FMs are kinds of logical trees [
23,
24]. The nodes represent the features and the child-parent edges represent various types of refinement. Decorations on edges give information about optionality versus obligation, and about feature groups (Or, Xor). The FMs also include textual logical constraints. At the data-mining step, we will consider only the features and child-parent relationships. Textual constraints will not be considered in this paper. Nevertheless, we thought useful to formalize them for exhaustive description and further research.
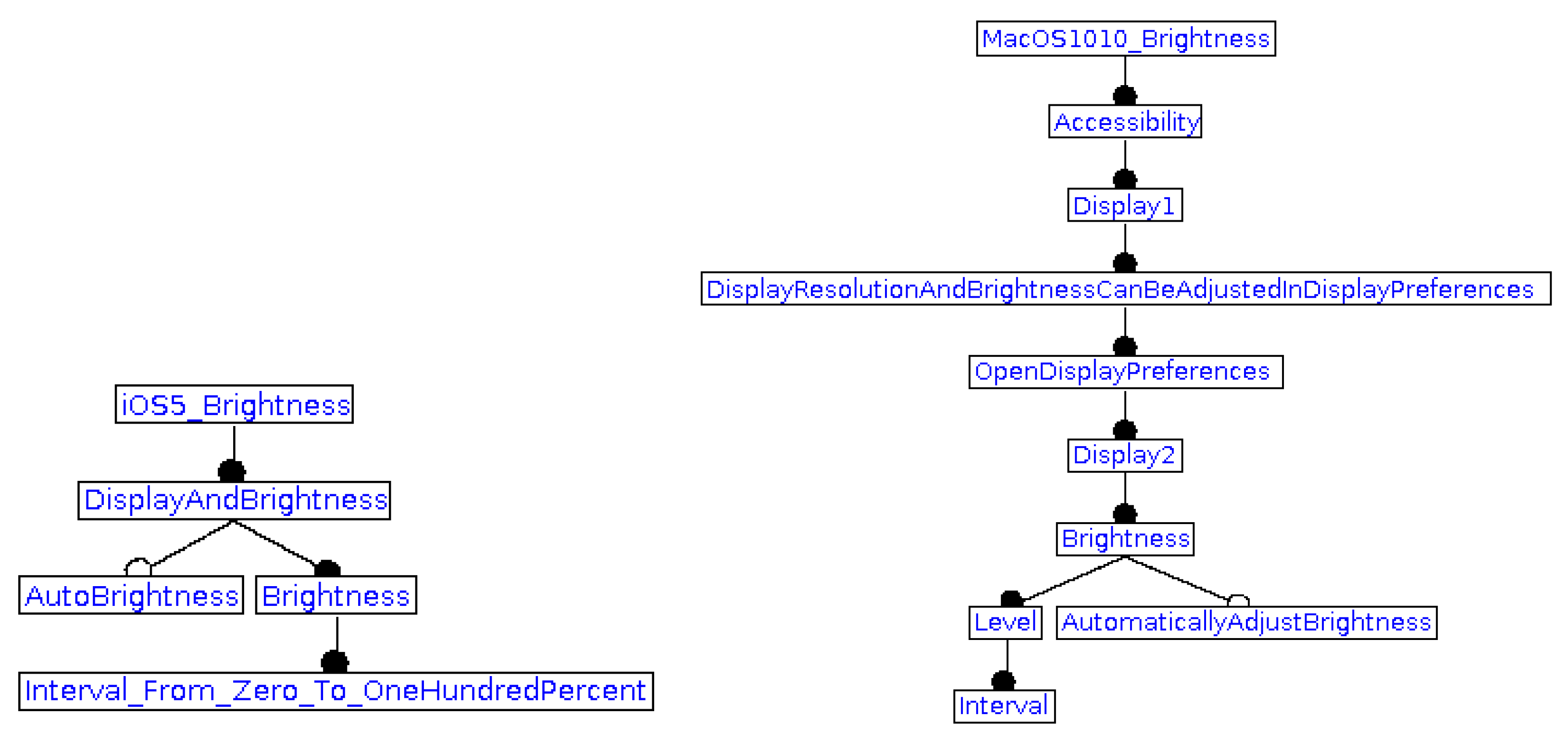
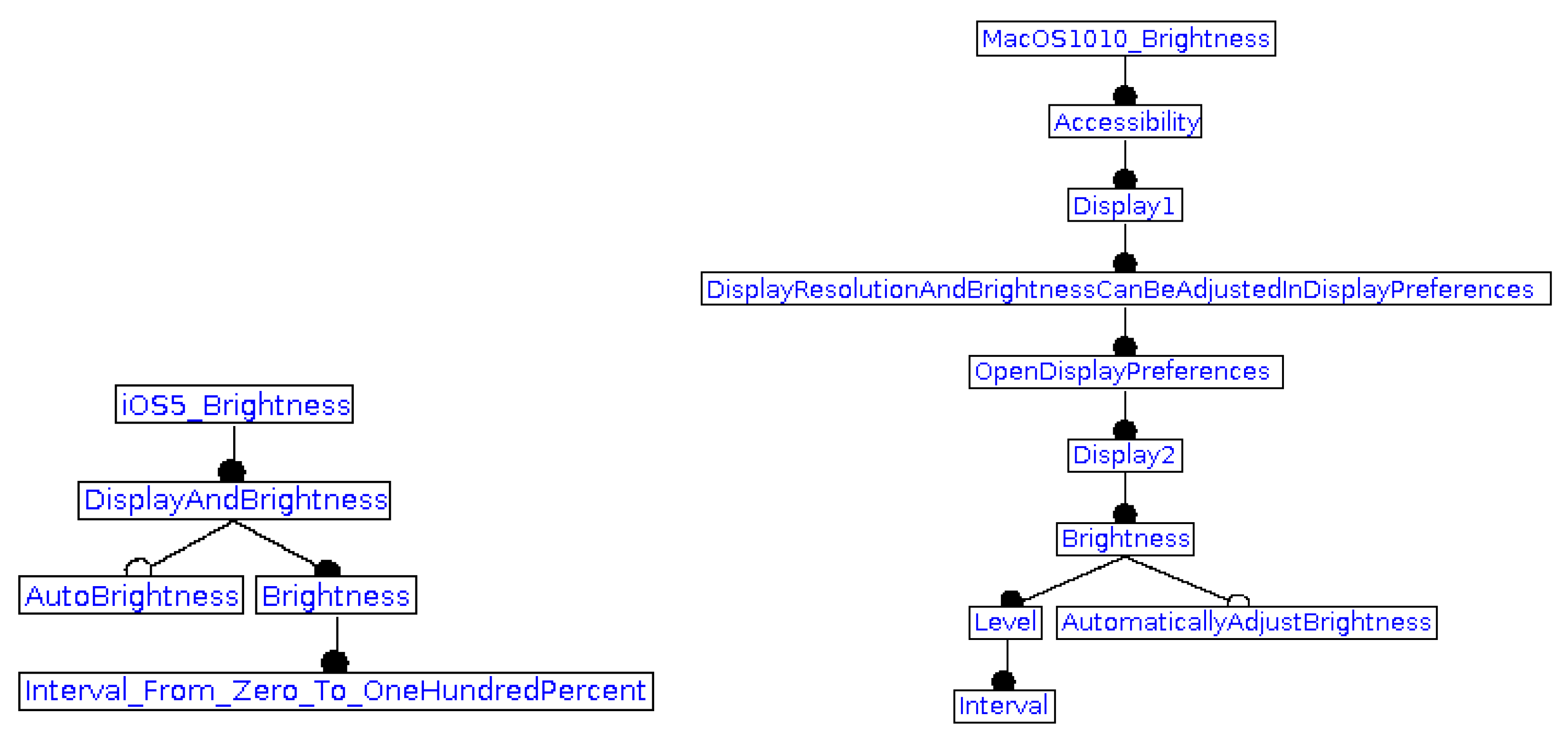
Figure 2 (left-hand side) shows the FM for brightness in operating system
. In this system, an end user configuration contains or may contain:
the root feature (mandatorily);
feature (mandatorily);
feature (optionally);
features and (mandatorily).
Let us note that alternative modeling could be done during this phase. For example, all possible values of brightness (if in finite number) could be shown as different features in an Xor group, rather than making explicit an interval and its bounds. FM building is summarized as follows (
Box 1).
Box 1. Feature Model building.
FM building. Let us denote the set of operating systems by and the set of mechanisms by . At FM building step, , we build the Feature Set and the Feature Model . The whole feature set is denoted by . The relation associating the systems with the features they own is denoted by .
We do it concretely by exhaustively and manually exploring the accessibility options as users who would be creating their accessibility profile. We use the path which allows us to find the options of the mechanisms through the user interface to incrementally add the options and organize them in the FM. The FM is built with
FAMILIAR (
https://familiar-project.github.io/, accessed on 1 September 2021)
(FeAture Model scrIpt Language for manIpulation and Automatic Reasoning) [
27].
Figure 2 shows two FMs for brightness. The other FMs can be seen in the online repository (
https://gite.lirmm.fr/AccessibiliteNumerique/osvisualaccessibilityoptions, accessed on 1 September 2021).
3.3. Ontology Construction
Some high-level domain options with the same name share the same meaning in several systems, e.g.,
and
provide options called
(increase brightness). However, for other terms, there is a need of clarification and standardization. We here use ontologies as
a specification of a conceptualization designed for the purpose of enabling knowledge sharing and reuse [
28]. We illustrate this with the brightness mechanism.
Some options have the same meaning (e.g., “adjust automatically brightness”), but different names (e.g., in and in ); in and in seem to be synonyms as well.
Some options can be considered as specializations of others (and the corresponding names can be considered as hyponyms), e.g., term of , where this term means “manually set brightness”, can be considered a specialization of term and in .
Some options gathered during the manual exploration of systems do not describe brightness concepts, they correspond to paths in user interface, such as OpenDisplayPreferences in . We consider that they are accidentally present for our analysis.
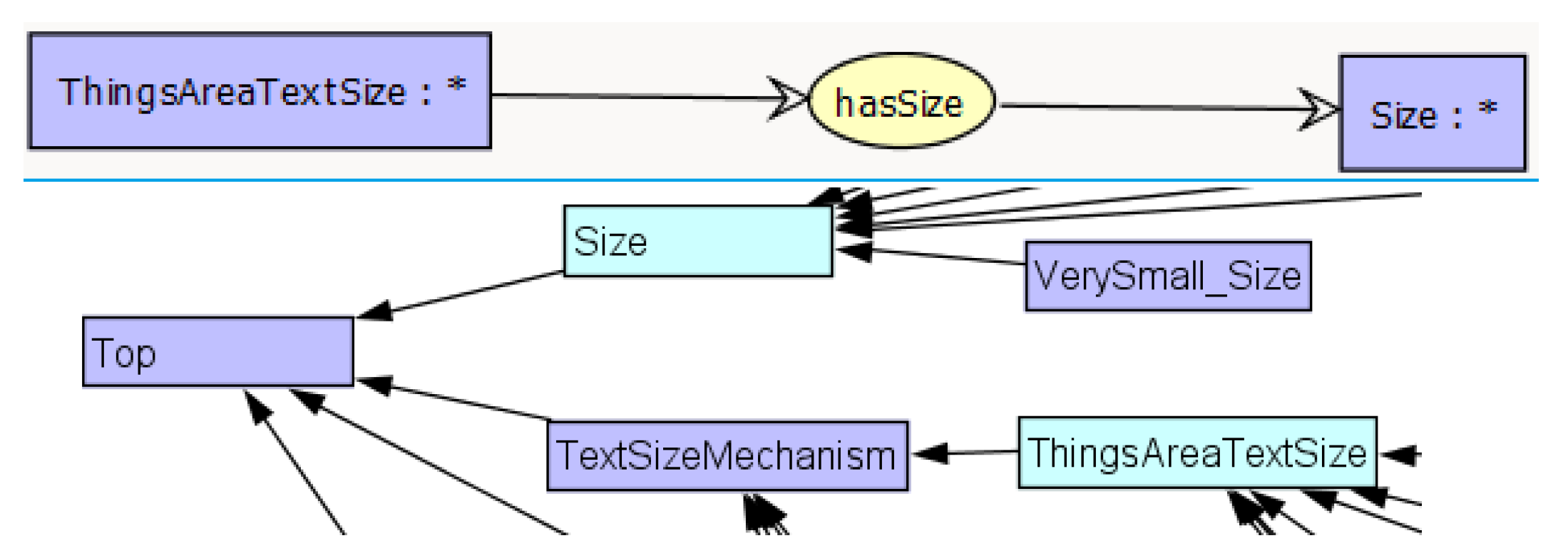
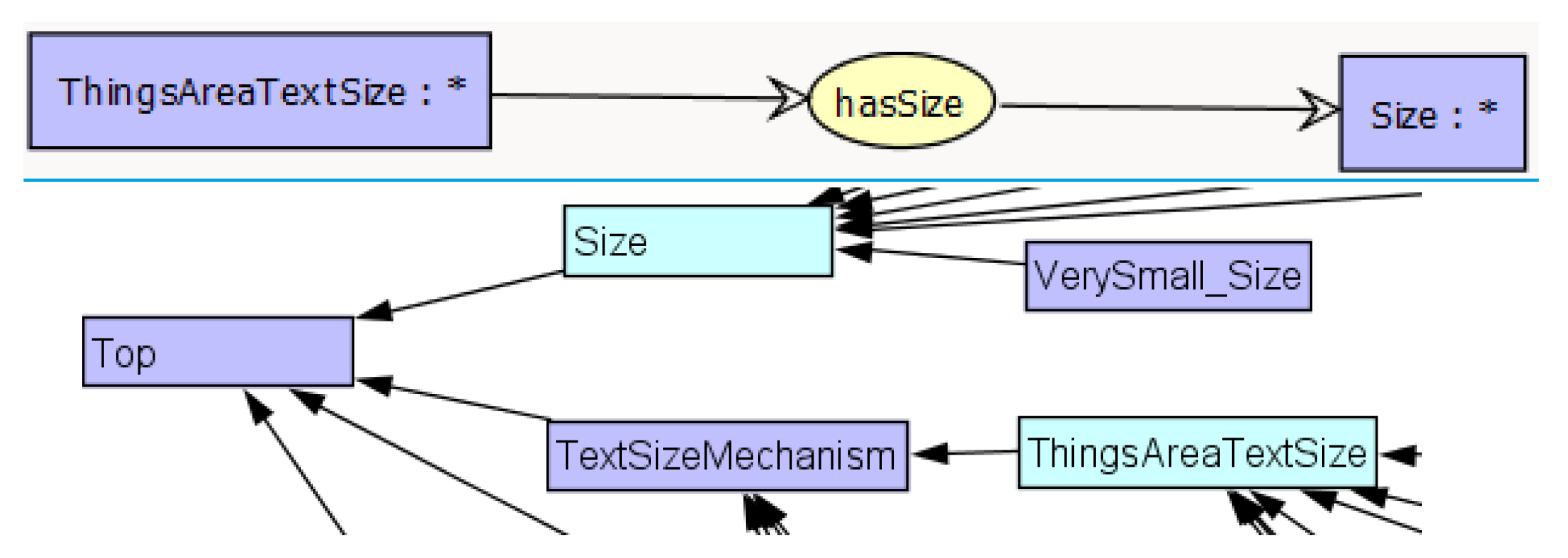
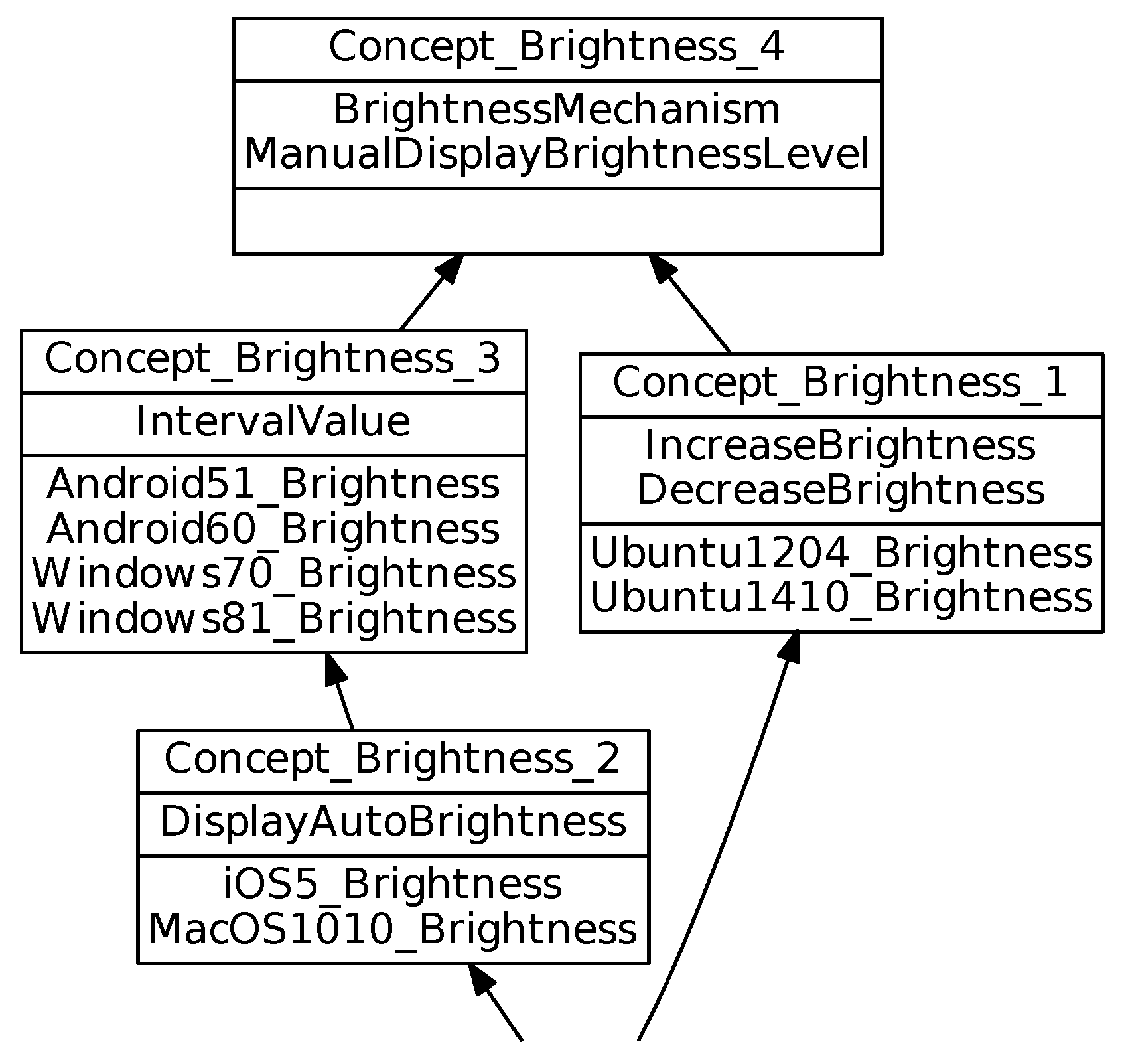
To standardize these descriptions, we designed an ontology composed of 4 parts, one per mechanism (they also can be considered as 4 ontologies). The ontology plays the role of a formal and common vocabulary composed of concepts and relations. Each option of a particular system can be mapped onto one ontology concept. In practice, to build the brightness ontology, we analyzed the features in all the systems and we modeled and organized the underlying concepts. The brightness ontology is shown in
Figure 3. It highlights the concept
which can be specialized into two types of setting functionalities:
and
, represented by two sub-concepts. The first consists of enabling or disabling: if the user enables it, the system automatically sets the value. For the second one, the user chooses one value among a set of values. As a result, we define the concept
as a specialization of
. Alternatively the setting consists to increase (resp. decrease) the brightness level. That is why we define the concepts
and
as specializations of
.
In addition to specialization, other relations can be included in the ontology, and numerical values need to be represented. For example, in the text style ontology, we establish
between concepts
and
(see
Figure 4).
3.4. Feature-to-Ontology Concept Mapping
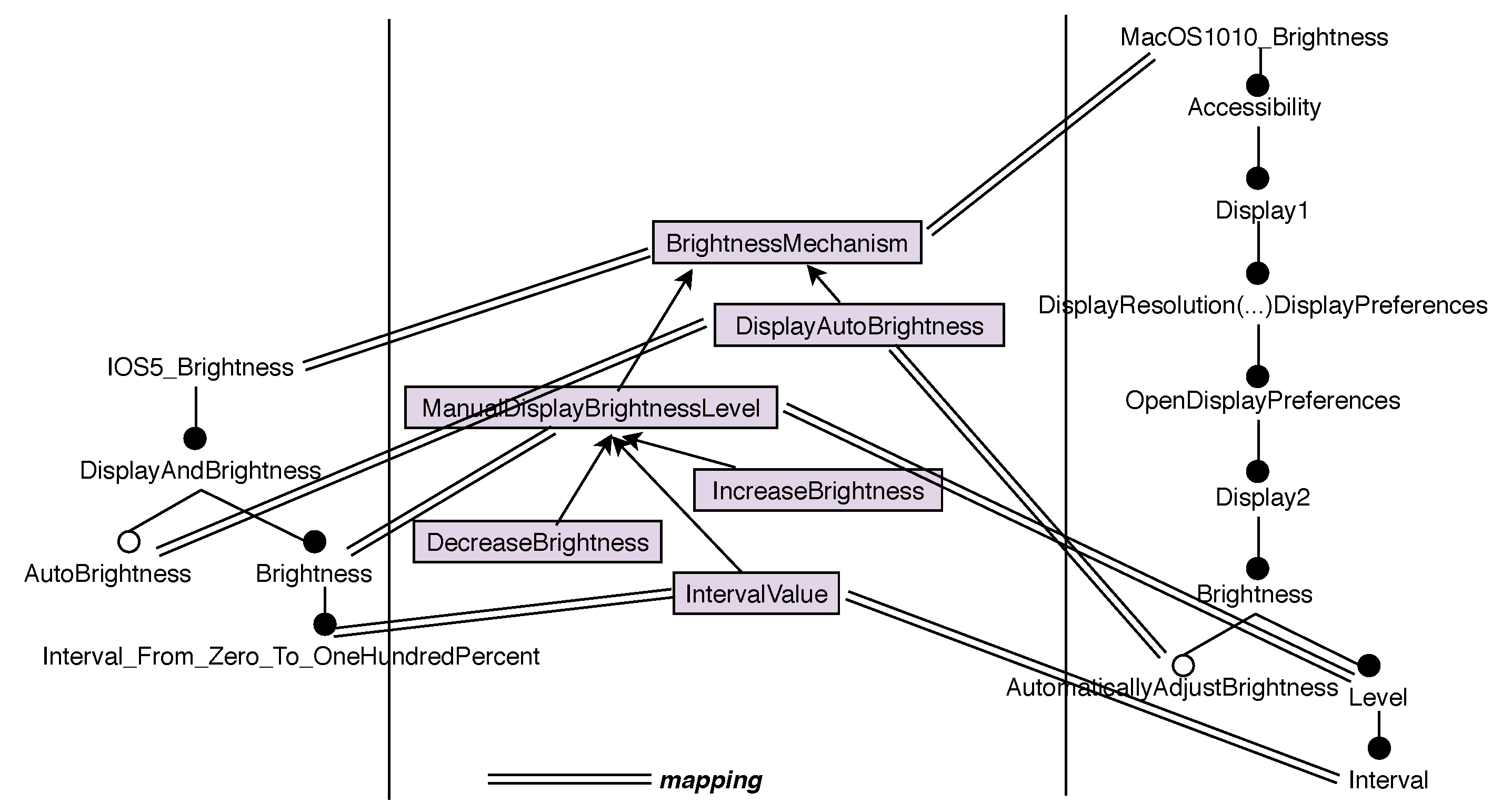
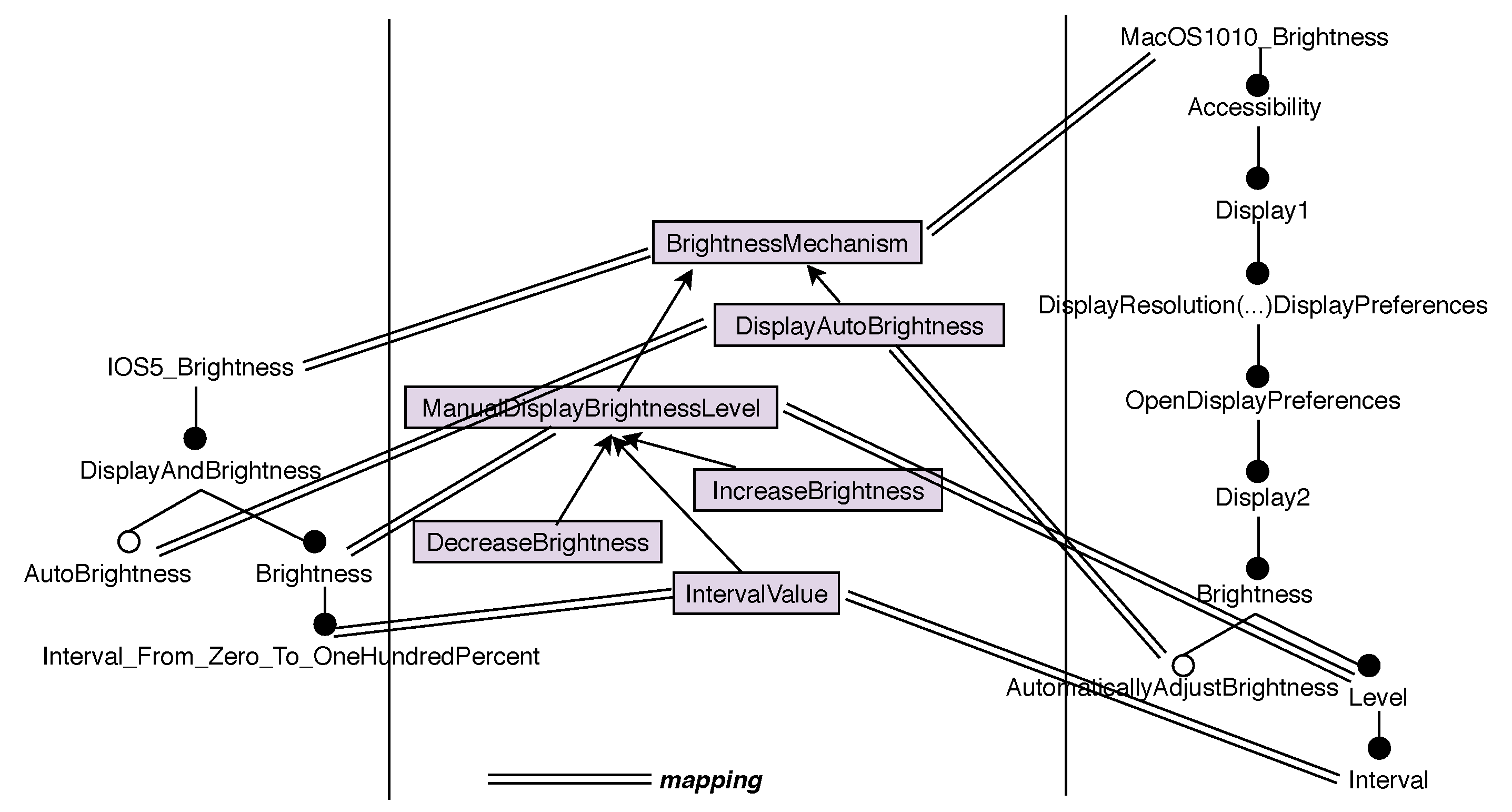
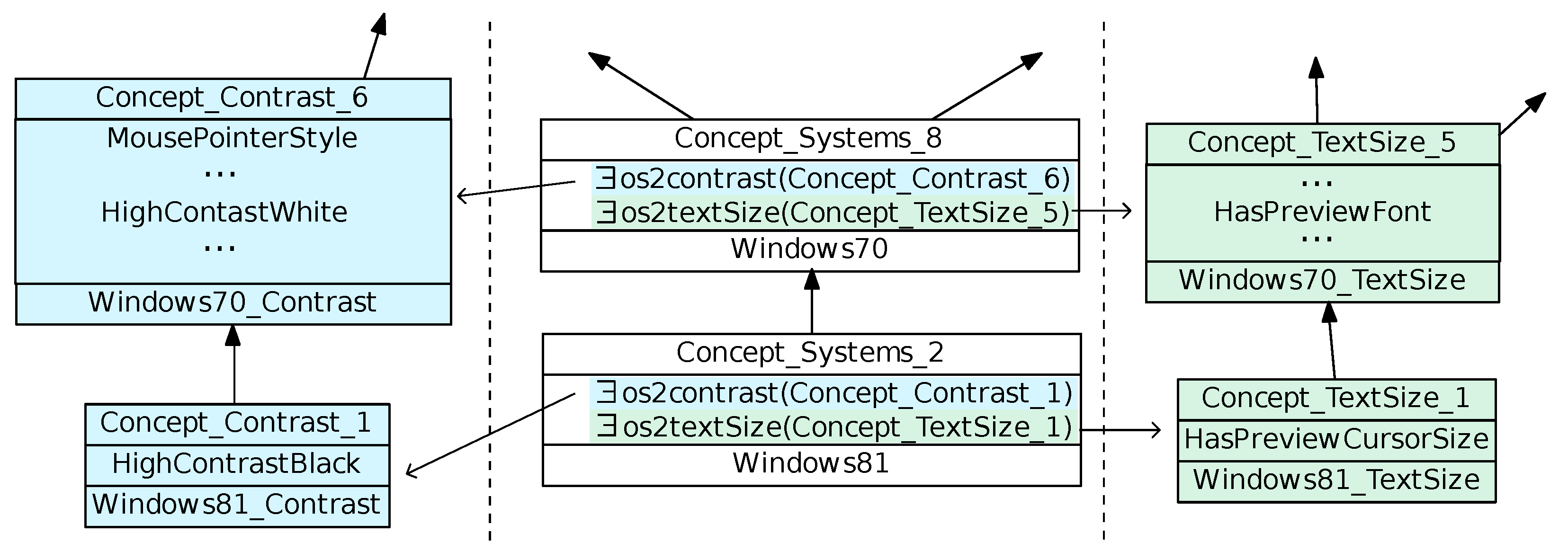
In parallel, a mapping between the specific features and the ontology concepts is established.
Table 1 shows the 8 OS brightness features mapped onto the ontology. This is schematized for
and
in
Figure 5. This mapping is very important because it traces the identified correspondences. It is also used to build standardized input data for the data-mining step. It shows, for example, that
of
and
of
are mapped to
.
of
is mapped onto
concept, making it a specialization of
on which
of
is mapped. Accidental options, such as
or
are discarded from the ontology and the mapping. The two steps (ontology building and mapping) are summarized as follows (
Box 2).
Box 2. Ontology and mapping building.
Ontology and mapping building. We build the ontology feature concepts and relations, as well as the mapping between the specific operating system features and the ontology elements. The ontology element set is denoted by , and the mapping is denoted by .
3.5. Construction of the Data Mining Method Input
The selected data mining method, i.e., FCA and its RCA extension expect as input simple binary tables. The input table for FCA, called a formal context (FC), describes objects and their attributes. RCA considers several object categories. The objects are described by attributes, and by links to other objects of the same category, or of a different category. RCA expects a set of binary tables, called a Relational Context Family (RCF). These tables are of two kinds: formal contexts (FC), as FCA, and relational contexts (RC). RCA is used to study the mechanisms both independently and combined in systems. Each mechanism (e.g., brightness) is described by a formal context associating the implementations of this mechanism in systems to the corresponding options. Another central formal context globally describes the systems. It is left empty here, but could introduce some intrinsic attributes. Relational contexts associate each system to its mechanism implementations. We detail this description in the remainder of this section.
3.5.1. FCA Input: Formal Context (FC)
For each mechanism
m, we build a formal context
designed to describe the operating systems by their accessibility options, after terminology standardization. For example,
Table 2 shows the formal context for brightness mechanism. It is built as follows.
The objects of are the operating system implementations of m. The attributes of are the ontology elements, i.e., concepts or roles other than specialization (e.g., ). Roles and concepts both represent provided options using the standardized terminology.
The incidence relation associates operating systems with ontology elements:
A first rule encodes feature owning. For example, according to
Table 1, we have
and
, that is why, we have
(see
Table 2). Formally, system
o is associated with an ontology element
a when it owns a feature which is mapped to that element: if
and
, then we have
.
A second rule encodes the ontology specialization. For example,
has a feature mapped to
, and
is a subconcept of
. Thus
is associated in the formal context to both
and
(see
in
Table 2). Notice that initially,
has no feature which is mapped to
. This is an information which is added for the purpose of generalization and to better identify commonalities in the systems. Formally, for two ontology elements
such that
is a specialization of
, if
, then we also have
.
3.5.2. RCA Input: Relational Context Family (RCF)
We switch to a fictitious smallest example, inspired by the real systems. This example allows us to illustrate all possible situations a conceptual structure may contain. We consider 5 fictitious operating systems:
,
,
,
, and
.
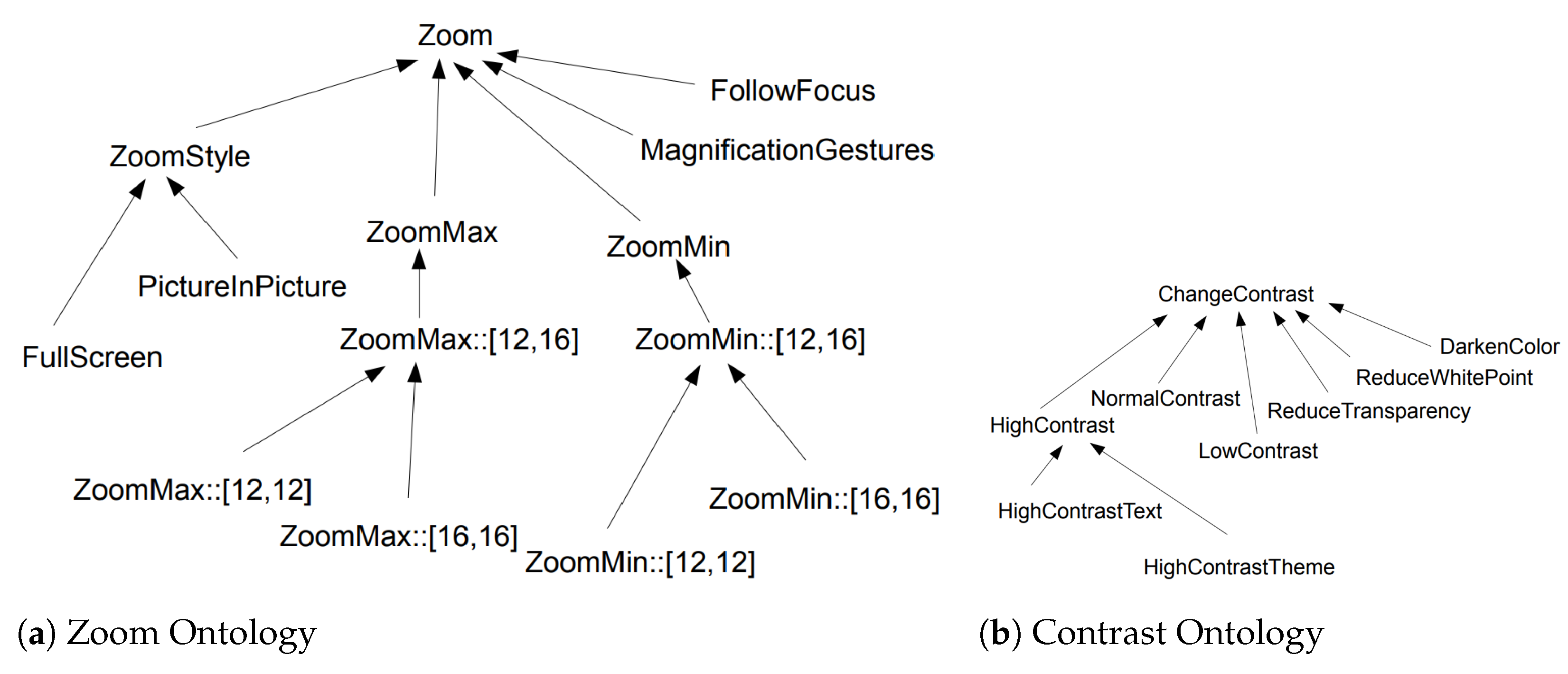
Figure 6 shows the parts of the ontology for 2 mechanisms (zoom, contrast) out of 4 (additionally including brightness and text style mechanisms). The whole example is available online (
https://gite.lirmm.fr/AccessibiliteNumerique/osvisualaccessibilityoptions, accessed on 1 September 2021).
Table 3 shows the contrast formal context. It can be used separately to analyze each system with respect to contrast, as the formal context shown in
Table 2 can be used to separately analyze brightness. For example, each row (i.e., each object) of
Table 3 (
Contrast Formal Context) represents the contrast implementation of a particular operating system. Each attribute is an ontology element that appears in
Figure 6b. A formal context is built for each mechanism.
The systems are described in an empty formal context
System Formal Context representing the systems. It is shown in
Table 4. This formal context is empty because there is no intrinsic attribute used in this analysis. However, we could imagine introducing attributes, like the system families (system for personal computer, system for mobile phone, Unix, Linux, MacOS, Windows, etc.).
Relational contexts, also called
object-object contexts, express relations between objects of several formal contexts. Here they are introduced to connect the systems and their four mechanism implementations.
Table 5 (
Relational Context os2Contrast) shows the relational context which connects systems (rows) to their contrast mechanism implementations (columns). They are all built using the same scheme, with a diagonal of crosses.
RCF building is summarized as follows (Box
3).
Box 3. Relational Context Family Building.
RCF building. We build a Relational Context Family composed of:
One
system formal context: objects are the operating systems, attributes are empty (or intrinsic attributes), e.g.,
Table 4.
Several
mechanism formal contexts, one for each mechanism: objects are operating system implementations for this mechanism, e.g.,
Table 3 for Contrast.
Several
Systems-to-mechanisms relational contexts, one for each mechanism: source context objects are the operating systems, target context objects are the operating system implementations for this mechanism, e.g.,
Table 5 for Systems-to-Contrast.
4. Data Mining Method
Knowledge Discovery (KD) methods are many, ranging from decision trees to deep learning, covering various needs including classification, categorization, regression, clustering, pattern recognition, rule mining, recommendation or data summarizing. They also differ in their capacity to deal more or less easily with different kinds of data, such as data structured along data model, numerical data, images, sound, text, etc. As introduced before, the selected data mining method for this paper relies on Formal Concept Analysis (FCA), a KD method grounded on lattice theory [
17]. FCA aims to extract knowledge, mainly in the form of classifications, and associations or implications rule bases [
30]. FCA is well adapted to symbolic data mining. It provides solutions for complex data, and belongs to the KD methods that enable output result explanation, visualization and exploration. It has many extensions from the original binary formalism, to deal with numbers, intervals, sequences, trees, graphs and multi-relational datasets [
21,
31,
32,
33]. FCA methods fit our problem area since operating system description is mainly symbolic, with a few numerical descriptions, for example for text size. There is an implicit underlying data model, revealed during feature model and ontology extraction. Separating the analysis of the different mechanisms is made possible by Relational Concept Analysis (RCA). In this section, we detail FCA and RCA for our purpose.
4.1. FCA Basics
FCA primary purpose is the extraction of a set of formal concepts. For a formal context
, each concept
is a maximal group of objects
E associated with a maximal group of attributes
I these objects share.
is the concept extent (objects sharing the attributes of
I) and
is the concept intent (attributes owned by the objects of
E). For example, in the concept
, objects
share attributes
(see in
Table 3 and
in
Figure 7).
A specialization relation is established between the extracted concepts. Let us consider two concepts
, and
, the specialization relation states that
if and only if
(and equivalently
). For example, if we consider the concept
with
and
}, we have
. The concept lattice is the set of all concepts
of the formal context
K, provided with the specialization relation
. We denote by
the set of concepts introducing attributes (
attribute introducer). A concept is an introducer concept for attribute
a, whenever it is the highest concept containing this attribute. For example
introduces
, because it is the highest concept containing this attribute (see
Figure 7).
We used the tool
RCAexplore (
http://dataqual.engees.unistra.fr/logiciels/rcaExplore, accessed on 1 September 2021) to generate these lattices. Based on the specialization order definition, a sub-concept inherits the attributes of its super-concepts. The inherited attributes can thus be omitted in the graphical representation of the sub-concept, as it is shown in the figures. Symmetrically, a super-concept inherits the objects of its sub-concepts (and the inherited objects can be omitted in the graphical representation in the super-concept, as it is shown in the figures).
The concept lattices for the formal contexts
zoom and
contrast are shown in
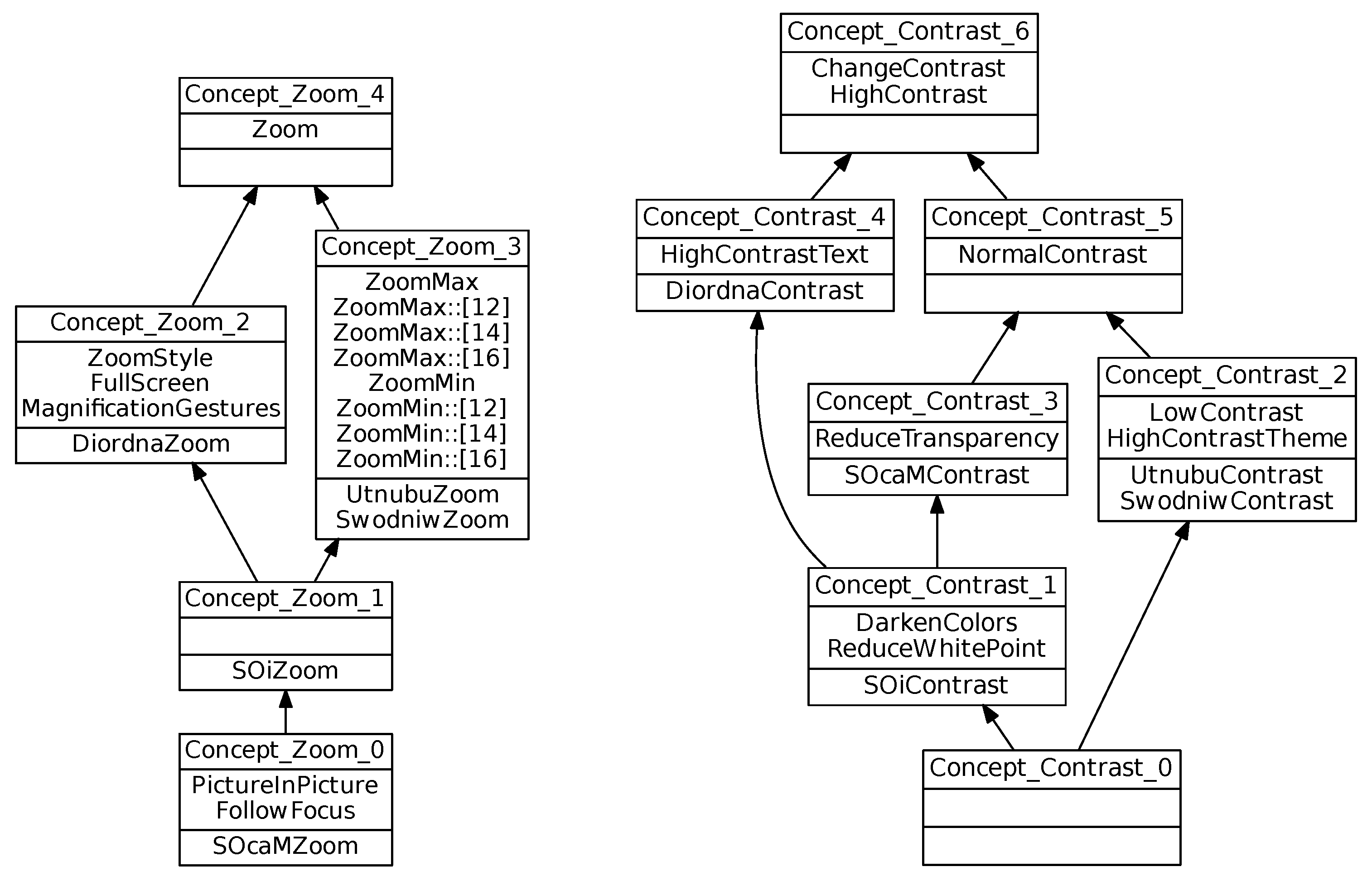
Figure 7.
4.2. RCA Basics
Relational Concept Analysis (RCA) has been designed to deal with multi-relational datasets [
21]. In the present study, the different relations represent either the systems, or the different implementations of the mechanisms in the systems, or they connect the systems to their mechanism implementation. RCA input, i.e., a relational context family (RCF), is formally a pair (K,R) with: K =
a set of formal contexts
and a set of relational contexts R =
.
for
. RCA groups objects (e.g., operating systems), not only by their intrinsic attributes, but also by the relations they share to other objects or object groups (concepts). This is highlighted through relational attributes. From a relation
, relational attributes for
are built using relations between objects of
and concepts built upon objects of
. A relational attribute is similar to a formula in Description Logics. It is composed of a quantifier (e.g., ∃,
), a relation (e.g.,
), and a concept (e.g.,
) [
34]. For example, using
Relational Context os2Contrast from
Table 5 and
contrast concept lattice from
Figure 7 (right): The relational attribute
is associated with
and
because they have at least one link for
with an object of the
extent.
As previously shown, in our framework, the RCF is composed of a central formal context, describing operating systems, together with four formal contexts describing the different mechanisms and relations connecting the operating systems to the mechanism implementations. This is reproduced at the level of lattices. The central concept lattice, shown in
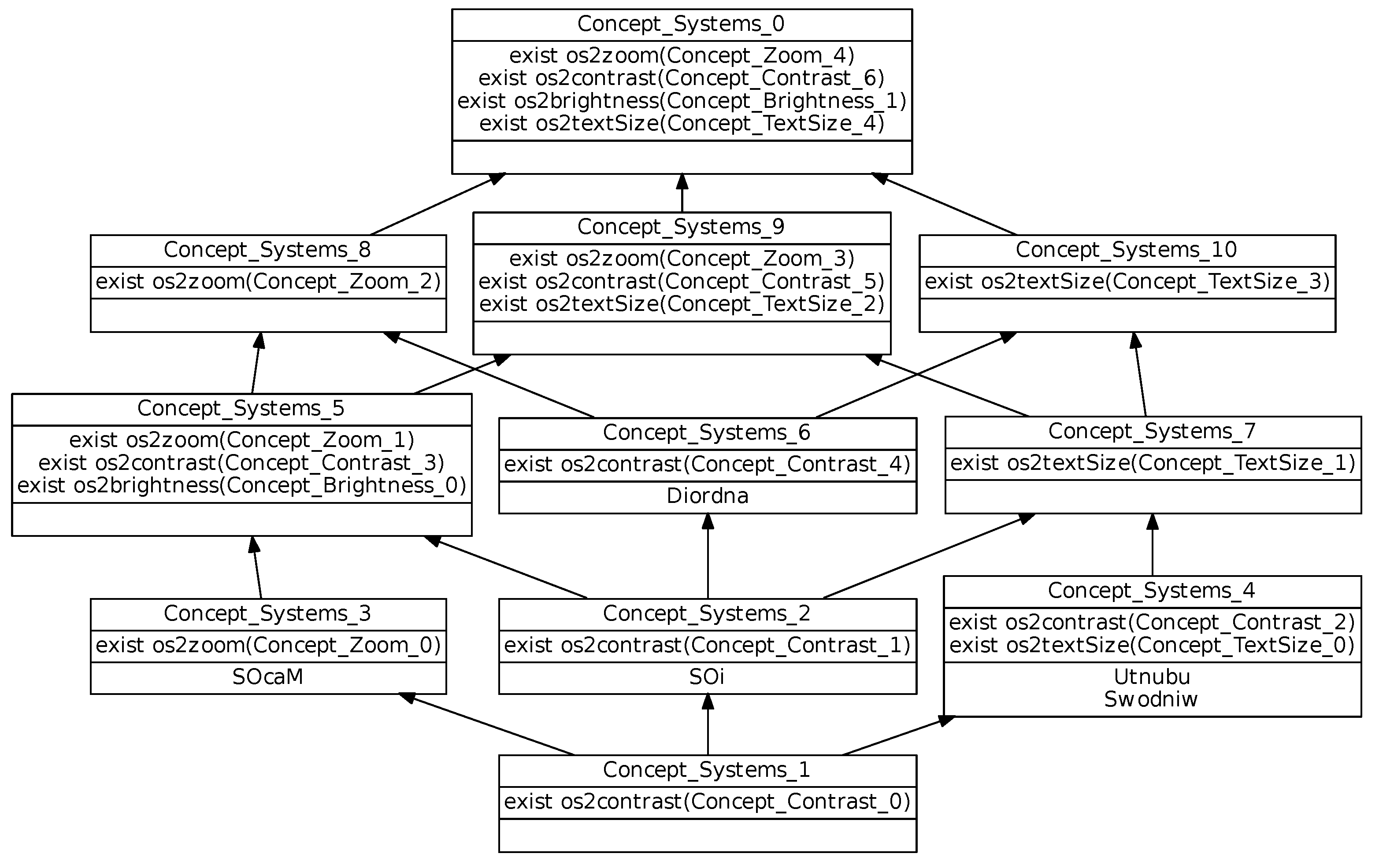
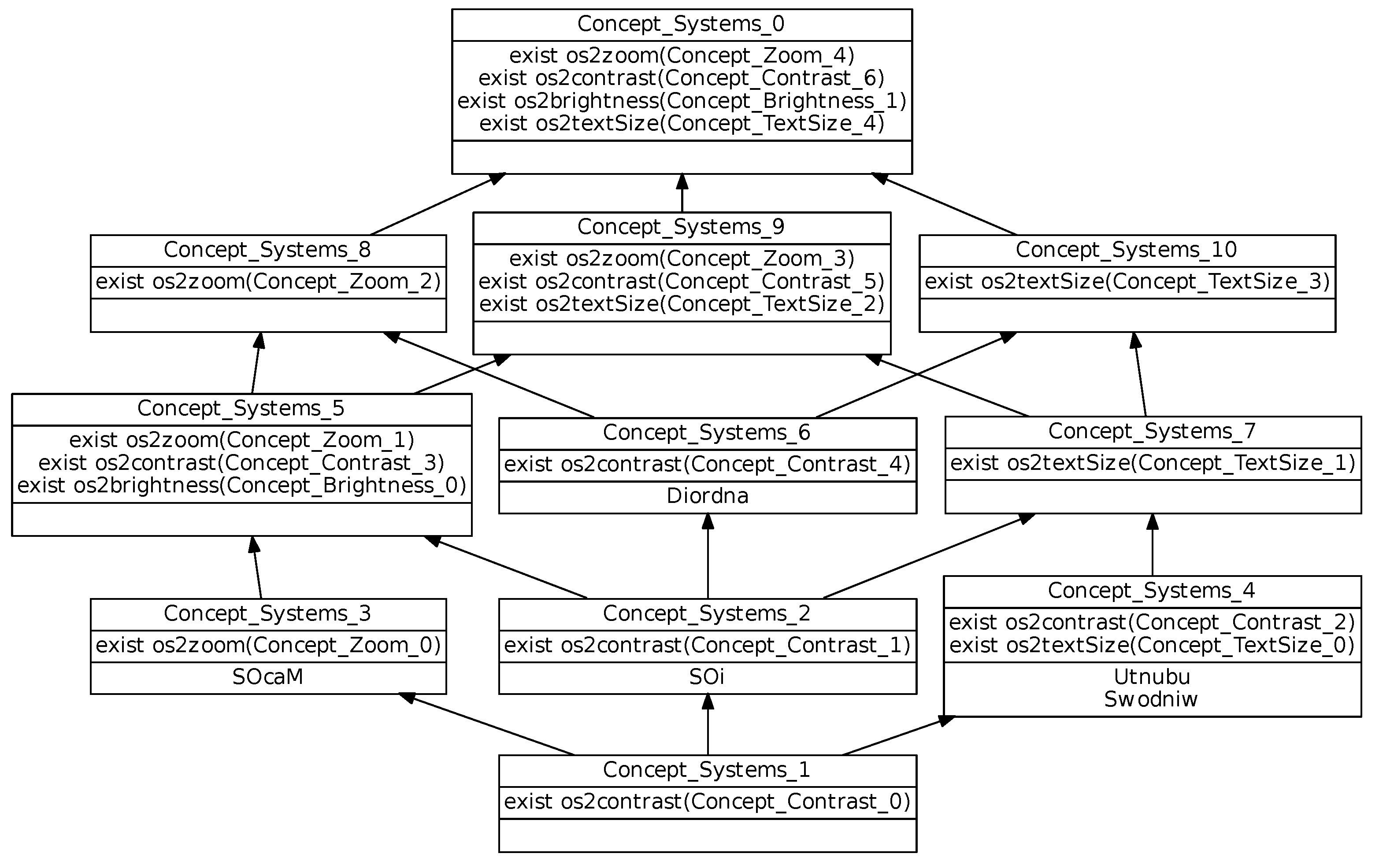
Figure 8, combines information given in the different concept lattices defined for the different mechanisms. Its top concept (
) shows the relational attributes that are common to all studied systems. One example is relational attribute
which indicates that all operating systems have at least one
link towards an object in
. This means that all operating systems have accessibility options that concern the contrast mechanism. More informative relational attributes will be presented hereafter.
The data mining output method is summarized below (Box
4). Its results are interpreted in the next section for the target domain in the software product line paradigm.
Box 4. Output of Relational Concept Analysis.
RCA output. From the formal and relational contexts, we generate, through the RCAexplore tool, one concept lattice for each formal context:
One central
system lattice, which structures information about all systems on all mechanisms, e.g.,
Figure 8.
Several
mechanism lattices, each focusing on a mechanism, e.g.,
Figure 7a,b for zoom and contrast.
6. Case Study
In this section, we conduct an exploratory case study based on our proposed method applied to concrete operating systems. The case study is guided by four research questions which are presented in
Section 6.1. These questions are refinements of the general question “How do accessibility options vary in practice?”.
Section 6.2 presents the experimental setup. Observations are presented and discussed in
Section 6.3, and threats to validity are discussed in
Section 6.4.
6.1. Research Questions
We focus on four main research questions (RQ1, RQ2, RQ3, and RQ4). The first three questions are related to the variability relationships between features. They correspond to typical feature relationships that are studied in variability analyses [
25]. The last one is related to the possible relationships between operating systems regarding their offered accessibility options (similarity, superiority, incomparability).
RQ1: Omnipresence of options. Which (and how many) accessibility options are present in all operating systems?
RQ2: Binary implications and co-occurrences. What kind of (and how many) binary implications and co-occurrences between features can we find?
RQ3: Mutual exclusions. What kind of (and how many) mutual exclusion relationships between features can we find?
RQ4: System relationships. What kind of relationships between the different operating systems can we find?
6.2. Experimental Setup and Process
As presented before, we analyze 8 operating systems: , , , , , , and . We study zoom, contrast/colors, text style (font size and style) and brightness. When we apply the KD process on these systems, data preparation step produces:
32 feature models corresponding to the 4 mechanisms for the 8 systems;
then we reduced the dataset to: 3 ontology parts and 3 mapping tables, for brightness, contrast and colors, and text styles mechanisms; this reduction has been decided for time and human effort reduction purpose; it is worth to note that we included the largest mechanism (contrast and colors).
using the ontology, mapping tables and feature models, we derive the formal contexts: one central formal context lists the 8 OS; 3 formal contexts are derived for the 3 mechanisms. Each of them describes the implementation of the mechanism by the 8 OS on this mechanism. Finally, 3 relational contexts link the OS of the central context to their implementation on one mechanism.
The data mining step produces 4 concept lattices: one for each mechanism (contrast and colors, text styles, brightness), and one for the OS (the central one).
Table 8 presents the number of objects, attributes and concepts. Then the 4 resulting lattices are analyzed at the interpretation step.
Table 9 shows metrics about OS feature models, that is about variability inside each OS, taken individually. To compute these metrics, we used the
FAMILIAR tool which provides the values of these metrics for any given feature model [
27]. The feature models in
FAMILIAR format are available in the repository associated to this paper (See Data Availability Statement and Footnote 2).
FAMILIAR is a feature model editor that we used in the data preparation step. It also provides many other operations for reasoning about feature models. These feature models are built in the data preparation step and are the input of the data mining step, where OS are classified. From
Table 9, we know that the description of OS by feature models has a reasonable size, having a small or medium number of features. The number of configurations is the number of possible user settings. It is an indicator of how difficult it will be to choose an OS in this search space, or to move from one OS to another. We might expect it will be easy for brightness, but tricky for contrast and color. The four columns contain respectively: the FM name, the feature number, the valid configuration number, and the depth (edge number of a longest path). We can make the following observations. FMs
and
(resp.
and
) have the highest (resp. the lowest) number of features. FM
(resp.
) has the maximum (resp. the minimum) number of contrast features. FM
(resp.
) has the maximum (resp. the minimum) number of size and font type features. FM
(resp.
and
) has (resp. have) the maximum (resp. the minimum) number of Zoom features.
During this evaluation, the concept lattice building has been achieved with the tool
RCAexplore. RQ1 did not need extra tools for the analysis, as the results are easy to get visually. RQ2 and RQ3 required the use of an additional tool for extracting implications and mutex. We used the Java library CLEF [
35]. We visually analyzed the object introducer concepts of the central lattice for answering RQ4.
6.3. Results
6.3.1. Omnipresent Features (RQ1)
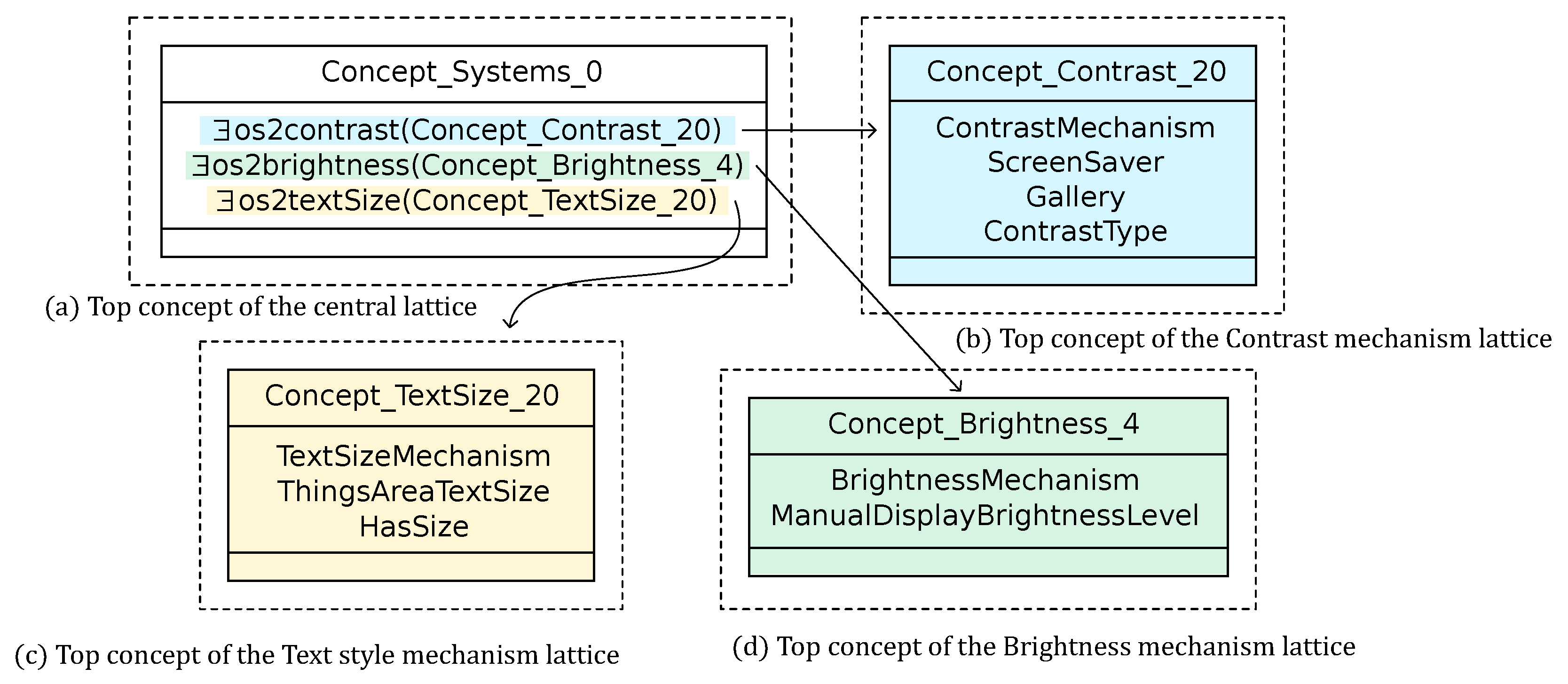
To find omnipresent features, we observe the top concept intents in the different lattices (
Figure 9), which indicate the features that are present in all systems. We consider meaningful an attribute which is different from the root of an hypothetical feature model. For example, the Brightness lattice top concept intent (
in
Figure 9d) introduces
and
.
would be the root feature in a feature model for the Brightness mechanism. As the root, it is trivially omnipresent, thus it is not considered as meaningful here.
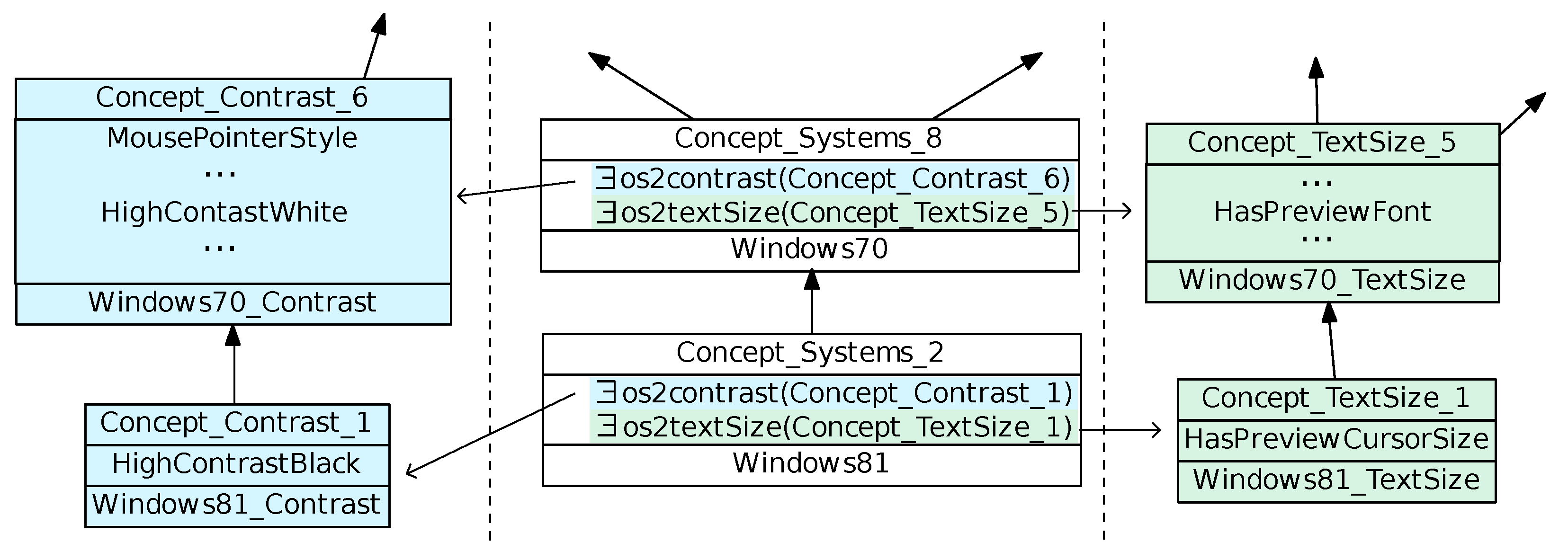
The Central lattice top concept intent (
Figure 9a) introduces relational attributes that point to the top concepts of Contrast, Brightness and Text style lattices respectively. This means that all operating systems provide options in the three mechanisms.
The extraction shows that omnipresent features are very few. We learn that all systems propose manual setting for brightness, the possibility to set text size in various elements, a gallery, a screen saver option and the possibility to define a contrast type. This low number of shared features reveals a diversity in approaching the visual accessibility option design.
6.3.2. Binary Implications and Co-Occurrences (RQ2)
We apply here the method explained in
Section 5.3 to extract binary implications and co-occurrences.
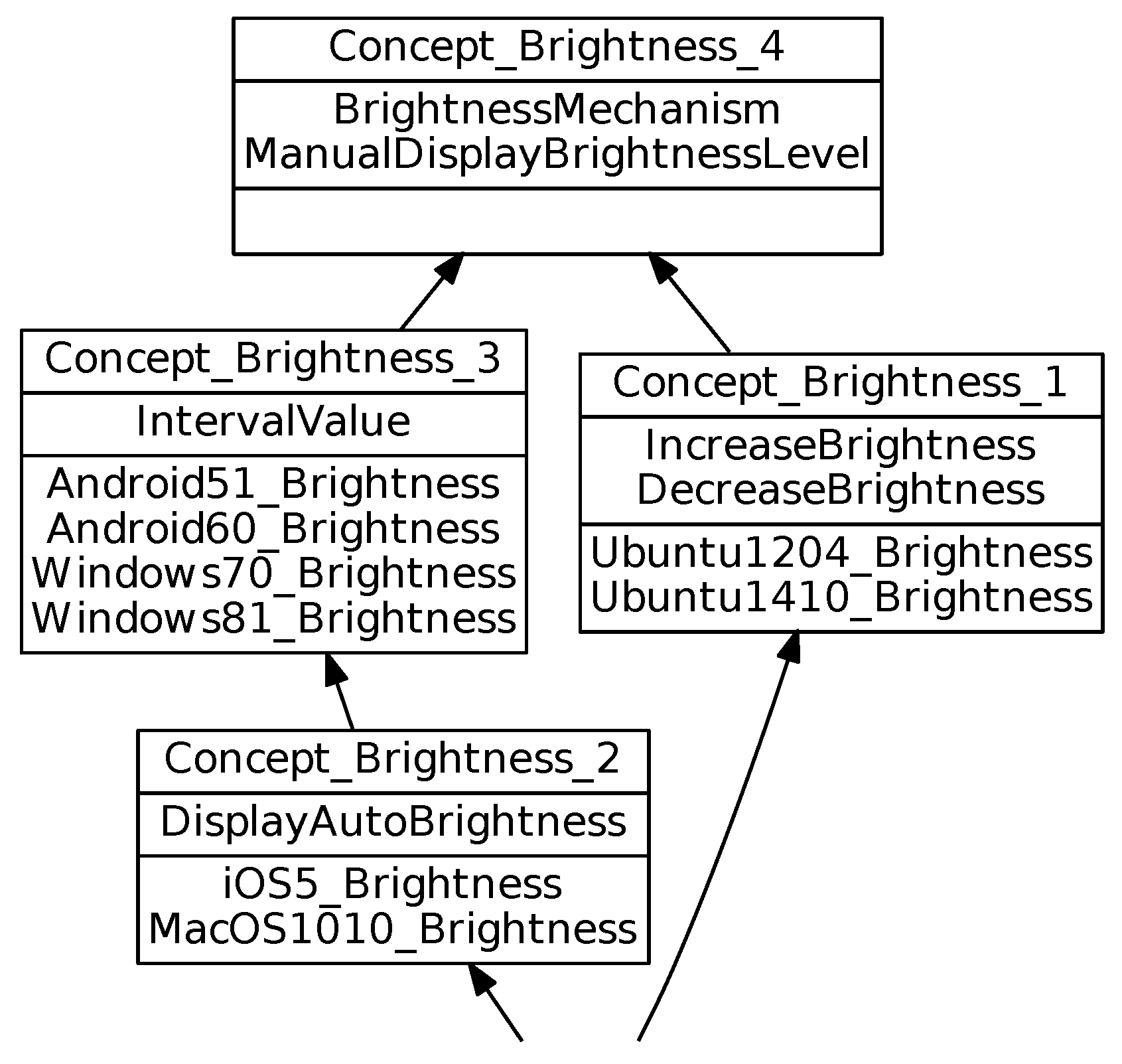
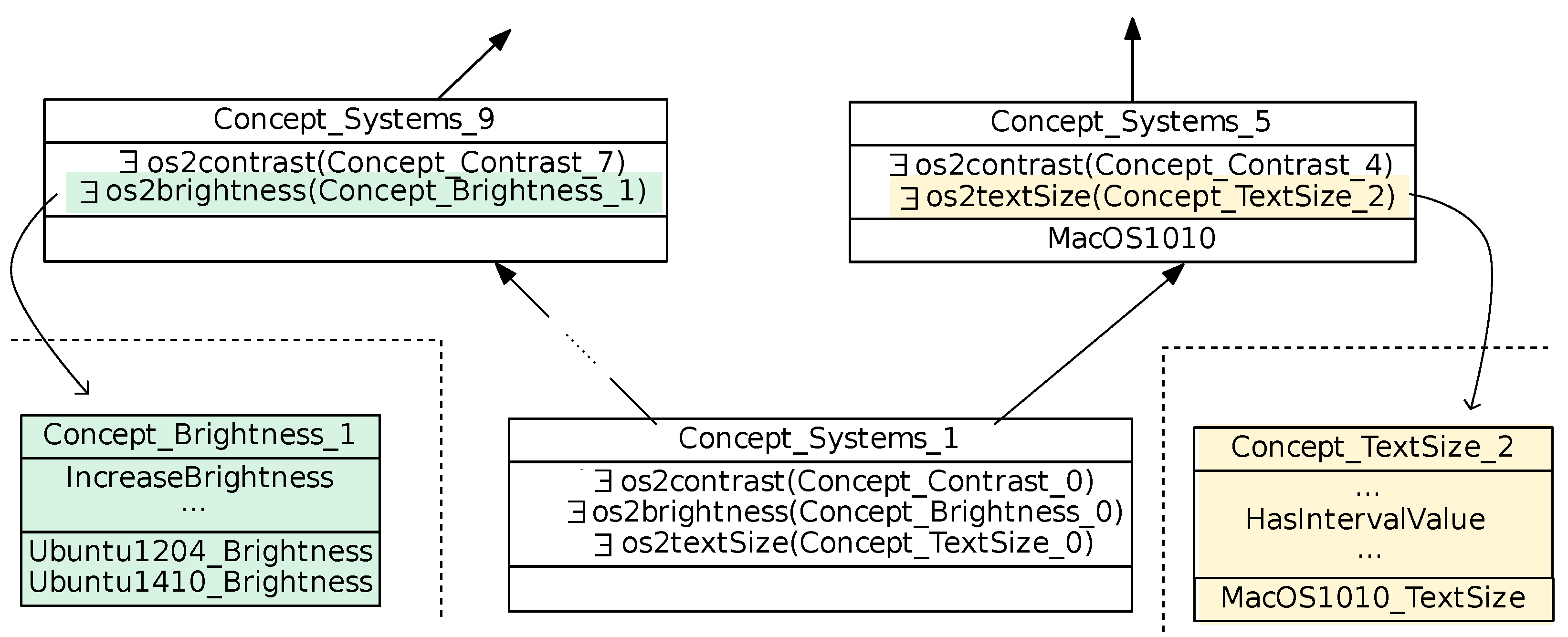
Table 10 presents the number of features, the number of binary implications and co-occurrences and their respective upper bounds in the different lattices. We notice that the Brightness mechanism has the smallest values. The Text style mechanism and central lattice have the average values. The Contrast and Color mechanism has the largest values. We observe in the central concept lattice a number of features, corresponding to the relational attributes, which is not so high, compared to the number of features in the different mechanisms. This is explained by the fact that the features for systems are groups of features from the different mechanisms. This reduction is a quality of RCA. The features are separated along the different concerns and the central lattice gives a global and summarized overview. Thanks to FCA, the variability of operating systems is analyzed with regard to co-occurring feature groups. RCA helps analyzing the different concerns (mechanisms) separately or as a whole. The number of logical relationships increases when the feature number increases. Besides, in Text style and Contrast contexts, the number of relationships is higher than the number of features. A high number of co-occurrences (i.e., of pairs of co-occurring features) may hide a few number of large groups of co-occurring features, as in the contrast mechanism case. In this case, their analysis and use as a requirement guideline is not too heavy. For example, in the Brightness concept lattice (see
Figure 10):
Binary implication
comes from the fact that .
Co-occurrence
comes from the fact they are both introduced in .
From the central concept lattice (see
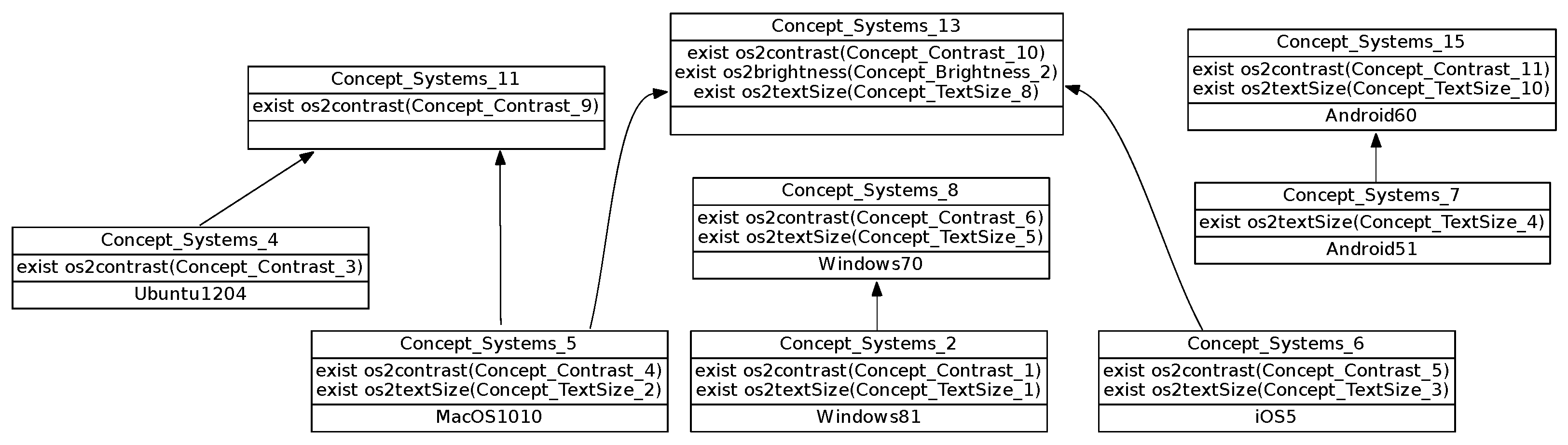
Figure 11), the relationships refer to the other lattices and may involve several mechanisms, for example:
Binary implication
,
because .
All system mechanisms in have . All systems in have . Thus we can deduce a cross-mechanism information between contrast and text style: Systems that provide , also provide .
Co-occurrence
because both attributes are introduced in .
All systems in have . We can deduce a cross-mechanism information between contrast and text style: Systems that provide , also provide and reciprocally.
Co-occurrences at the system level reveal groups of features having a common purpose, as increase versus decrease brightness in Ubuntu, which may correspond to a feature group in a feature model at the user level. They also highlight groups of features having different purposes, as contrast type and screen saver. From this information, the OS manufacturers can decide if these co-occurrences are accidental or part of a relevant requirement specification.
6.3.3. Mutex (RQ3)
We use the method explained in
Section 5.3 to extract mutex. The fifth and the last columns of
Table 10 respectively represent the exact number and the maximal number of mutex. There is a high and very high number of mutex respectively for Text style and for Contrast and Color mechanisms. Again we can notice the reduction effect of RCA in the number of mutex concerning the relational attributes (central lattice).
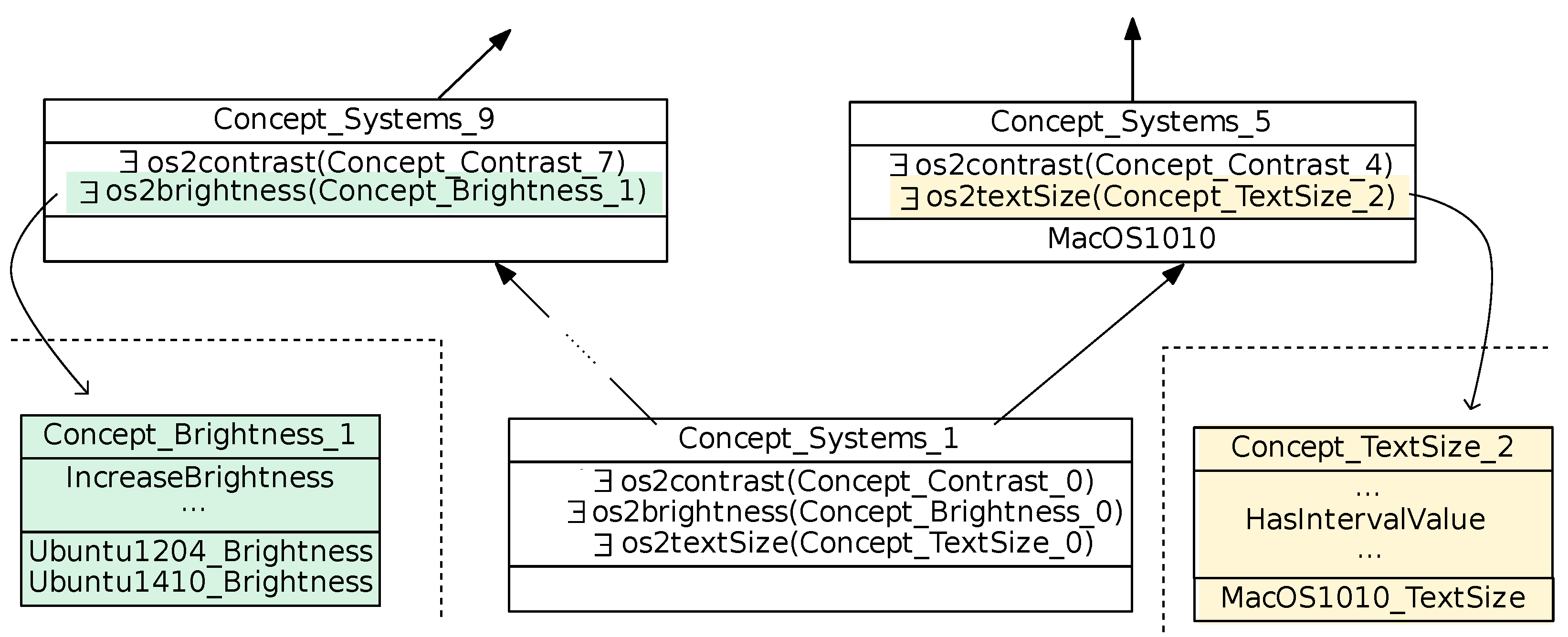
The Brightness concept lattice (see
Figure 10) supports the mutex
, since:
(introducing
) and
(introducing
) have an empty intersection.
The following mutex can be extracted from the central concept lattice (see
Figure 12):
.
They come from the empty intersection of the extents of the feature introducers (introducing ) and (introducing ). All Systems in have ; All Systems in have . Hence we can deduce this information involving brightness and text style: Systems that provide , do not provide . The central lattice again highlights cross-mechanism information, here about mutex. Mutex can be accidental, but some correspond to orthogonal design choices, as the one presented for Brightness mechanism between and on one side, versus on the other side, and are relevant to know.
6.3.4. Relationships between Operating Systems (RQ4)
For RQ4, we analyze the extents of the object introducer concepts. The concept lattice excerpts highlight a few examples. We analyze into details the Brightness lattice. Then we show how relationships are combined in the central lattice.
The Brightness lattice (shown
Figure 10) is small, but it contains the main possible situations. We can observe for example:
System option set equivalence:
- –
and are in the same simplified extent (). This means that and provide exactly the same Brightness features.
System option set specialization:
- –
highlights the fact that and have more Brightness features than , , and .
Incomparable option sets with shared intersection:
- –
As is incomparable for with , this indicates that , , , , and only share the top concept features with and .
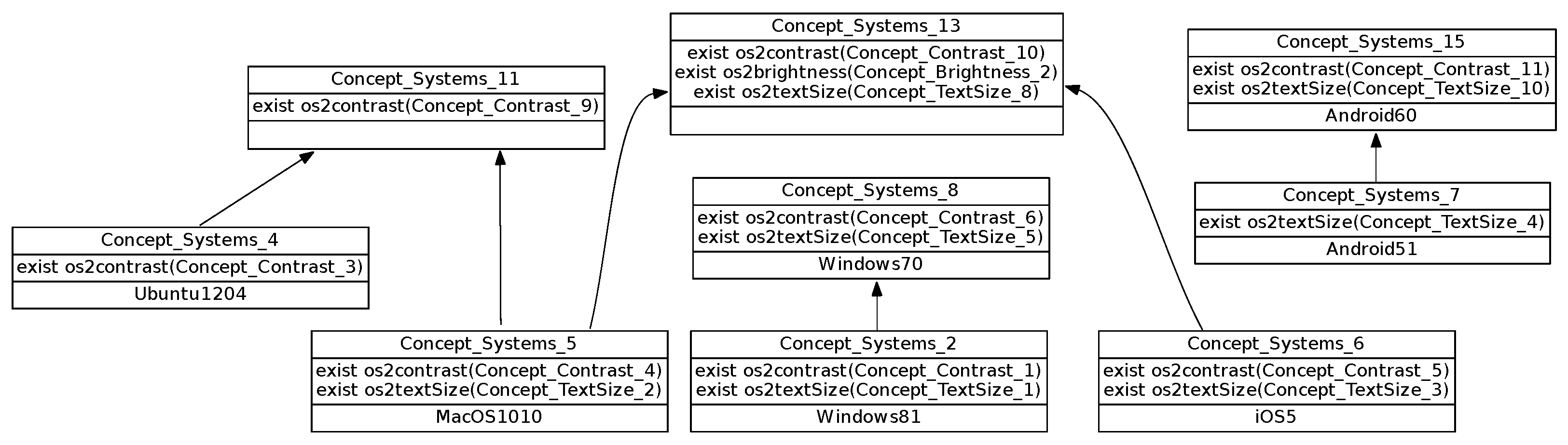
The central concept lattice (excerpt in
Figure 13) allows us to analyze the different systems taking into account all mechanisms together. Systems are respectively introduced in separate concepts, e.g.,
is introduced in
. This means that there are no identical systems.
For example, from the concept specialization, we obtain the following information:
meaning that provides more features than , which means that the option set has been reduced during system upgrade;
meaning that provides more options than ;
is the least upper bound (and the direct cover) of and , highlighting some proximity of and ;
is the least upper bound (and the direct cover) of and , revealing and closeness.
The results of this analysis illustrate the system diversity and the needs to propose guidance to OS manufacturers. From the analysis of the various systems, and by navigating the concept lattices, they can overview common options (that they should implement) and more rare ones (that they can decide to add or not). It also informs end users about the existing configurations in the different systems, that can guide them in the choice of a system, or guide the migration.
The concept lattices are the search space for solving tasks, such as comparing OS, classifying user settings, either independently in each mechanism, or considering all mechanisms together.
Table 7 and
Table 8 show the size of this search space for the fictitious example and our case study, respectively. The number of concepts in a concept lattice varies between 1 (i.e., when all OS have an identical description) and
(i.e., when the concept lattice is isomorphic to the powerset of the OS set). This number of concepts thus indicates a variability level between the OS, and also the size of the search space. The figures presented in
Table 7 and
Table 8 show that this search space is of reasonable size (between 5 and 34 concepts for the case study) and practical for navigation purposes. For example, for contrast and color, the concept lattice groups attributes into a structure with 21 concepts which is far more easy to comprehend and exploit, compared to a table with 88 columns.
6.4. Threats to Validity
In this section, we discuss the threats to validity of this approach. We first analyze internal validity through data collection and used tools reliability, in order to explore the possible biases. Construct validity is then assessed: We examine the relevance of the used metrics. Then we study conclusion validity to ascertain the conclusions we draw from our results are reasonable. Finally, we approach external validity, to evaluate to what extent our results can be generalized.
6.4.1. Internal Validity
Two persons, co-authors of this paper, were strongly involved in the data collection. One of them is visually impaired and has a very good knowledge of operating systems and their accessibility options. During the data collection, both had to exchange their understanding of accessibility options and to reconcile their points of view, that were sometimes diverging, in order to build the ontology and the mappings. One person spent about 1 month to manually cross all access paths of accessibility options related to low vision in the 8 systems, and report them in the feature models. Both manually checked the feature models during about 10 days. About 10 other days were spent by the same two persons to build the ontology and the mappings. This was time consuming, but this was needed as a bootstrap to obtain meaningful results. We plan to use the built ontology and mappings to feed supervised learning-based automated analyses to avoid or at least reduce the manual work in next system analyses. Two days were spent to build the formal and relational contexts with partially automated procedures. From these contexts, the lattices were built with
RCAexplore in a few minutes. One day was needed to analyze the lattices by a non expert person. Manually collecting the accessibility options can be source of error, thus having the check by two persons has been important for reliability. Another co-author was familiar with the usage of the tools and the lattice analysis. CLEF has been used in previous evaluations [
37]. RCAexplore is used for several years in a significant number of experiments [
38].
6.4.2. Construct Validity
We did not evaluated the ontology, and it has a subjective aspect. Its organization in four parts can be compared to the W3C accessibility requirements for people with low vision (
https://www.w3.org/TR/low-vision-needs/#overview-of-low-vision, accessed on 1 September 2021). Our
Brightness and
Contrast and color mechanisms correspond to several subsections of
Brightness and color.
Text styles and
Zoom mechanisms correspond to different subsections of
Perceiving. The W3C wiki (
https://www.w3.org/WAI/GL/low-vision-a11y-tf/wiki/Main_Page, accessed on 1 September 2021) present settings of a few platforms, but there is no standardized description e.g., in Firefox (Mac) we find
Colors..>Text and Background>Background: (Default white) Choose a color from popup color picker, and in Windows 10, we find
Personalization>background color. We are confident in the proposed ontology, because it has been made with a person expert in the domain. Ontology building methodologies have been proposed to guide humans in this task [
39]. They can be assisted by automatic extraction from texts, but the human knowledge remains the main component to ensure the quality of the result [
40].
We evaluated our results through metrics that show the number of existing relationships between features or between systems. The counted relationships are those that are typically searched during variability analysis, and among the main logical relationships that are considered during the building of variability models, such as feature models in their most common form. It would be interesting to look for feature groups, as in [
41]. We did not perform this kind of analysis at that time, as this is time-consuming and not always relevant: It may be unfeasible to reach a result; many accidental groups may be built.
6.4.3. Conclusion Validity
The lattices show a reasonable classification of systems, e.g., systems of the same family provide close or similar features. The variability relationships number is not surprising, with regard to previous evaluations we did [
36]. There are likely many accidental relationships.
6.4.4. External Validity
The analysis is limited to 8 operating systems, when many exist. Besides, our study only focuses on visual impairment, when operating systems also address other impairments, such as hearing or motor disabilities. These threats are mitigated by the fact that: low vision is a very common impairment, with many different forms; it is relevant to study separately one deficiency; the chosen systems are representative of the mainstream operating systems. It would be interesting to investigate the application of the methodology to other fields. This would help to assess whether visual accessibility features are specific and to which extent the method can be generalized. Firstly, other disabilities could be addressed. Let us take the example of mobility. In this case, the accessibility features provided by the OS are divisible into separate concerns, e.g., accessibility keyboard, control with adaptive switch hardware, or voice to navigate, as reported in [
15]. By reading OS documentations, the need for writing (or not) an ontology and mappings for these features would appear. After this preparation step, formal and relational contexts would be built and the remainder of the methodology would be applied. Applying the methodology and analyzing the results would enable discussing the generalization at this level. If this is positive, i.e., if the method has been fruitfully applied in this similar situation, we can envision a larger application context, to any field where: variability has to be studied in a family of products; studying this variability through different concerns or as a whole is relevant. It can be the case for cars, where managing variation in car families is useful for mass production and personalization. Different concerns are visible in the car configurators of the car brands: motorization, seats, driving assistance and so on.
8. Conclusions
In this paper, we propose a methodology to build a variability model on operating systems (OS) regarding visual accessibility. We divide the visual accessibility options into different mechanisms, such as contrast and color, brightness, text style, or zoom. We standardize the vocabulary and organization via the building of an ontology. Using the division into mechanisms, we build interconnected classifications. OS are classified according each mechanism: we build one classification for contrast and color, one classification for brightness, and so on. In addition, OS are classified according all mechanisms, in a structure that contains links to the mechanism classifications. These classifications are built with Relational Concept Analysis (RCA). They can be analyzed visually. They also exhaustively embed logical variability relationships, that can be derived in a textual form. We extract some variability relationships, i.e., co-occurrences, binary implications, and mutex. An exploratory case study is conducted on 8 representative operating systems. This allows us to observe the way accessibility options vary in practice.
As future work, we plan to analyze
more platforms, namely more OS and software distributed on the web, such as web browsers. We also plan to
automate more the analysis process. One track will be to benefit from the manually built ontology, from external lexical and semantical resources, and from natural processing tools, to analyze new systems, at least semi-automatically. For this analysis, we will have to establish a mapping from new system features to ontology concepts. We probably will have to evolve the ontology and the mappings by integrating new concepts in the right place in the ontology. We also will work on the ontology dissemination. We have not found other ontologies at the moment on this precise topic. In other domains, there are initiatives to gather ontologies (e.g., Bioportal (
https://bioportal.bioontology.org/, accessed on 1 September 2021) or Agroportal (
http://agroportal.lirmm.fr/, accessed on 1 September 2021) [
52,
53]). As far as we know, there is no such initiative about technical visual accessibility. Existing ontologies deal with handicap description from the health and skills point of view, e.g., ICF (
http://bioportal.lirmm.fr/ontologies/ICF, accessed on 1 September 2021) or [
54]. Open repositories can be used for sharing (
https://ontologforum.org/index.php/WikiHomePage, accessed on 1 September 2021). Our ontology can be exported in Protege (
https://protege.stanford.edu/, accessed on 1 September 2021), making it portable, easy to distribute and reusable. We will follow guidelines gathered in [
55,
56] for the delivery. A
user assistance would be useful for guiding OS manufacturers, or software developers in general, as well as end users. Proposing such assistance requires to develop complete solutions for comprehension, system requirement analysis, or user setting recommendation and migration. Concept lattices are built in the same spirit as Feature models in the domain of software product lines. They can serve to derive product (here OS) configurators in the form of structured checkboxes. We also plan to exploit this analysis in our project EWPA (
http://ewpa.lirmm.fr/en/, accessed on 1 September 2021) to improve the proposed options in the context of web page adaptation. Variability analysis can be
refined as well. A first track could be to distinguish mandatory features versus optional features in the OS description. A second track could be to consider different variability levels, namely (1) intra-OS families (e.g., Ubuntu family) versus inter-OS families and (2) variability among end user settings.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}