
Cross-Project Defect Prediction Method Based on Manifold Feature Transformation


Abstract
:1. Introduction
2. Related Work
3. Cross-Project Defect Prediction Method Based on Manifold Feature Transformation
3.1. Definition of Related Symbols
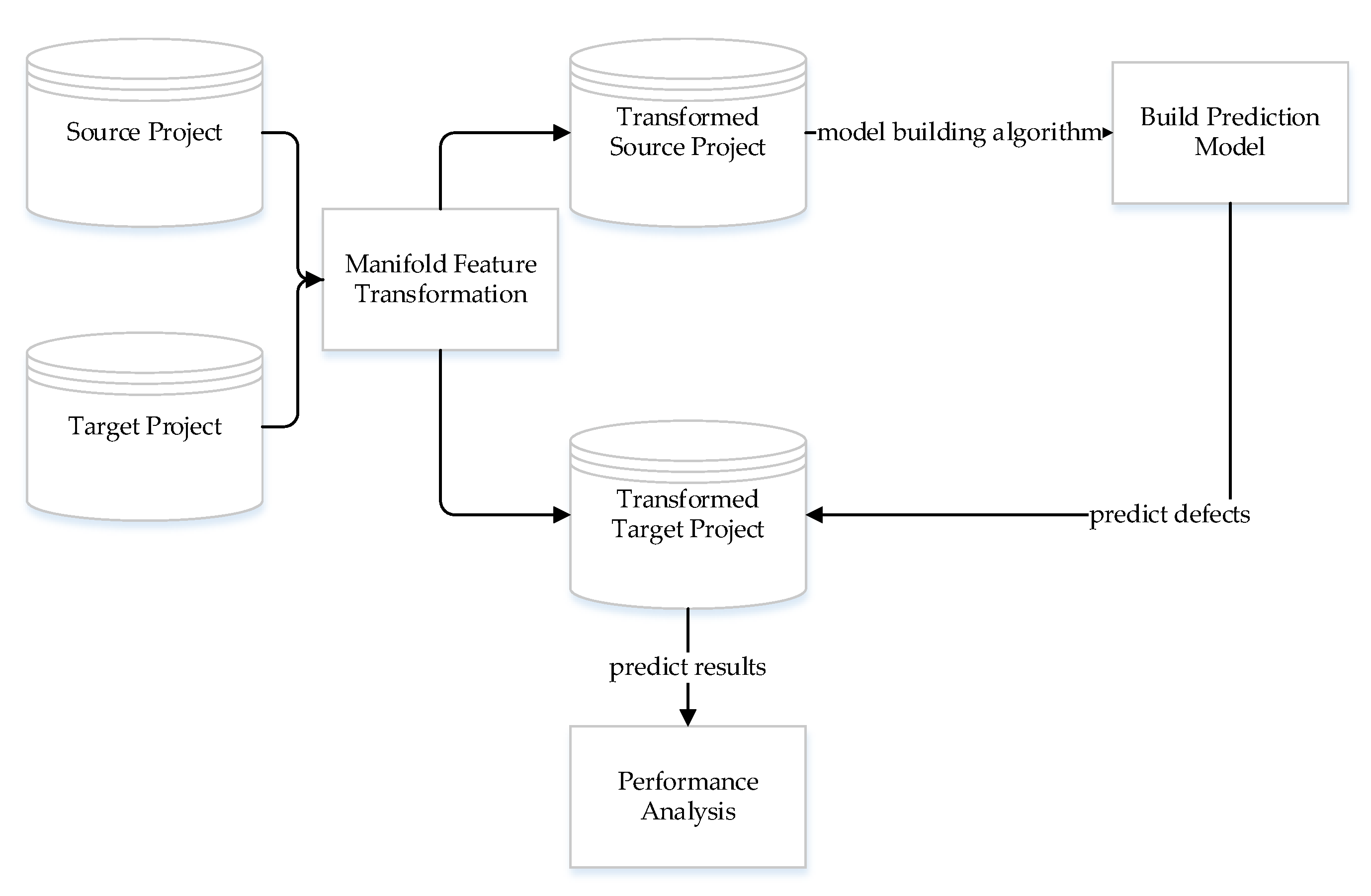
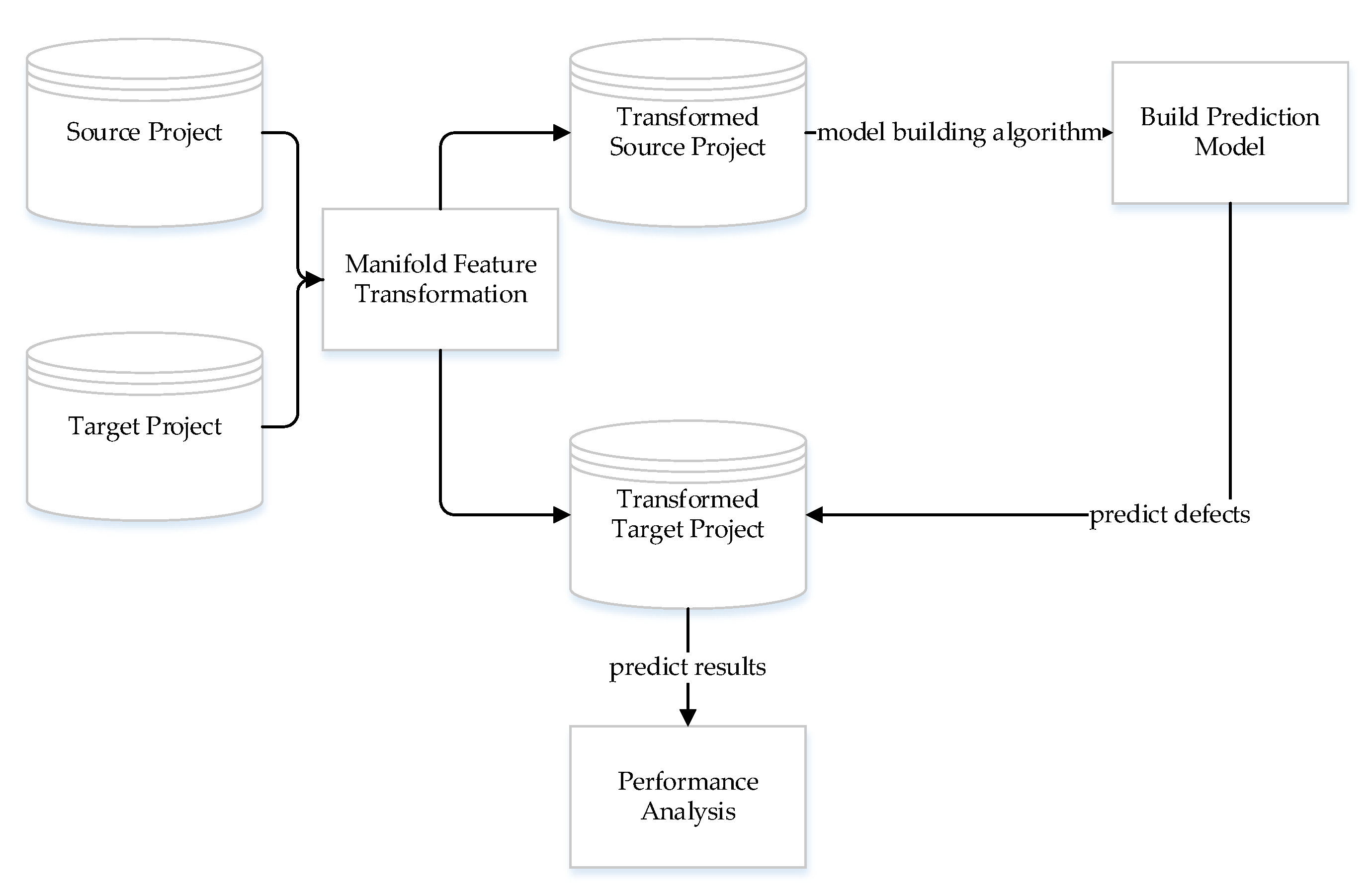
3.2. Method Framework
3.3. Manifold Feature Transformation
3.4. Model Building Algorithm
| Algorithm 1 MFTCPDP |
| Input: Labeled Source Project S, Unlabeled Target Project T Output: Predicted labels L |
| 1: Preprocess the project data to get SP and TP; |
| 2: Construct the manifold space according to Equations (1)–(3); |
| 3: Calculate G according to Equations (5)–(7); |
| 4: Use G to perform a manifold transformation on SP and TP and get SG, TG; |
| 5: Use SG to train naive Bayes classifier and predict the labels of TG; |
| 6: loop all projects. |
4. Experimental Research
4.1. Experimental Datasets
4.2. Evaluation Indicator
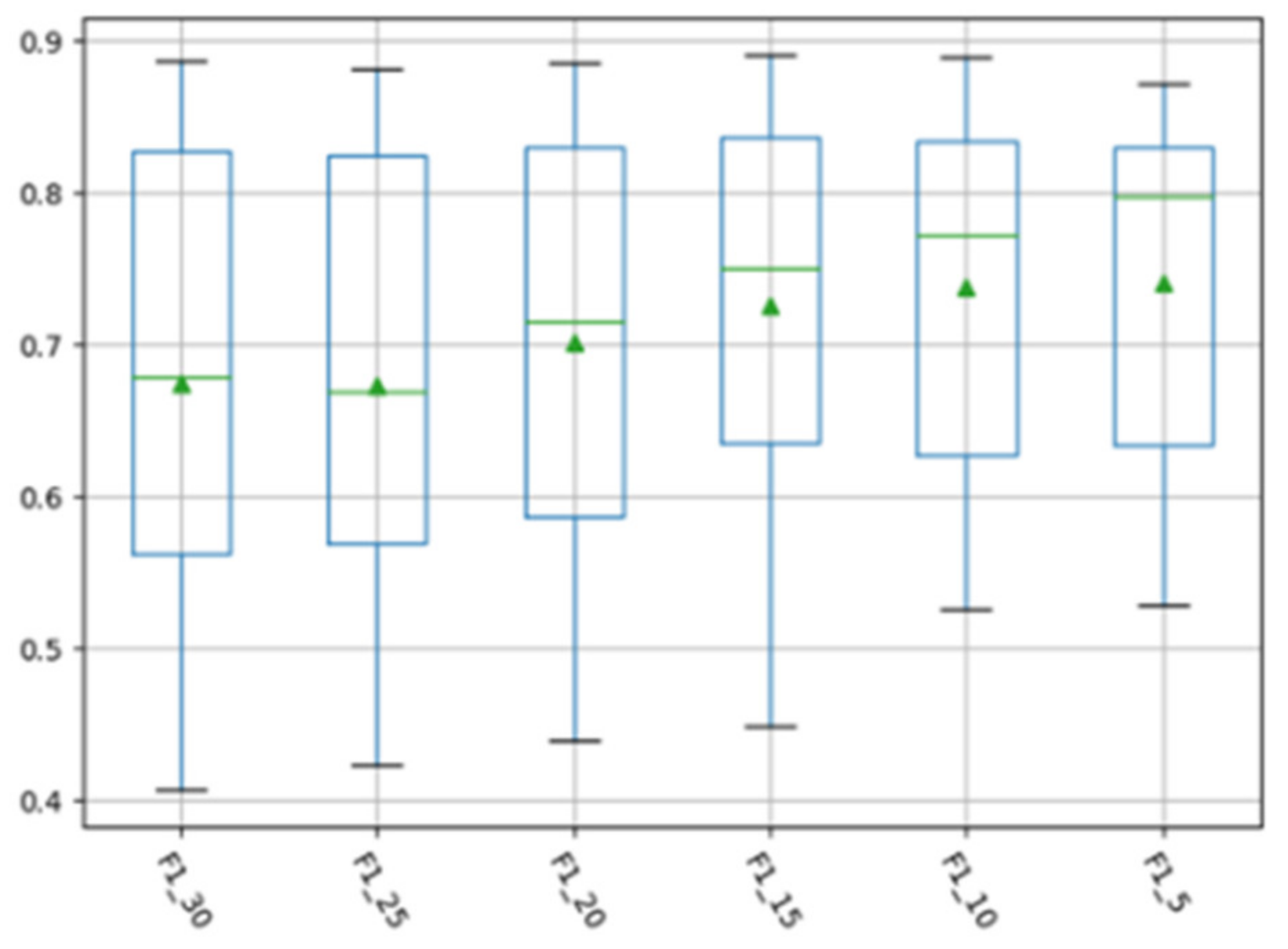
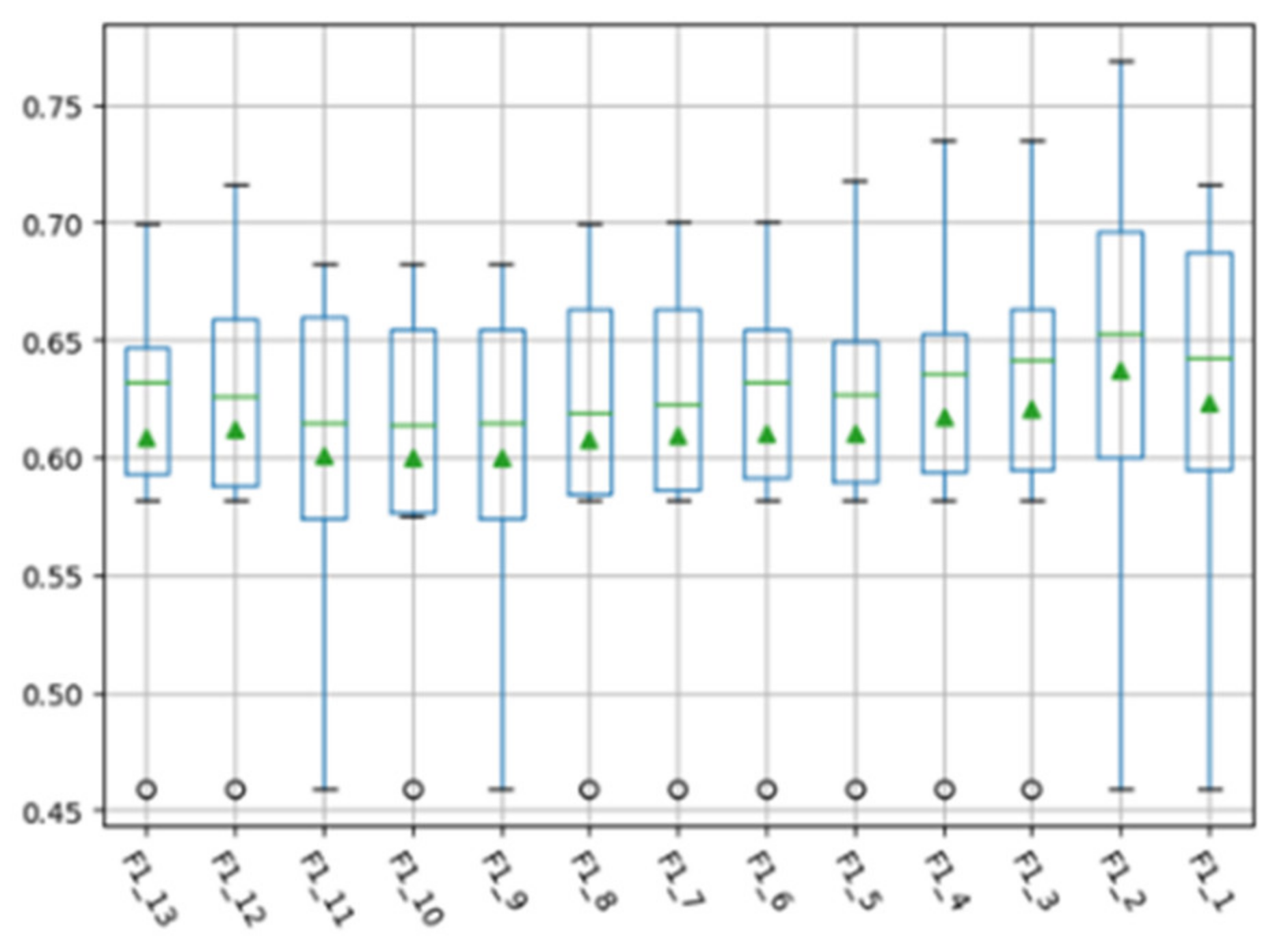
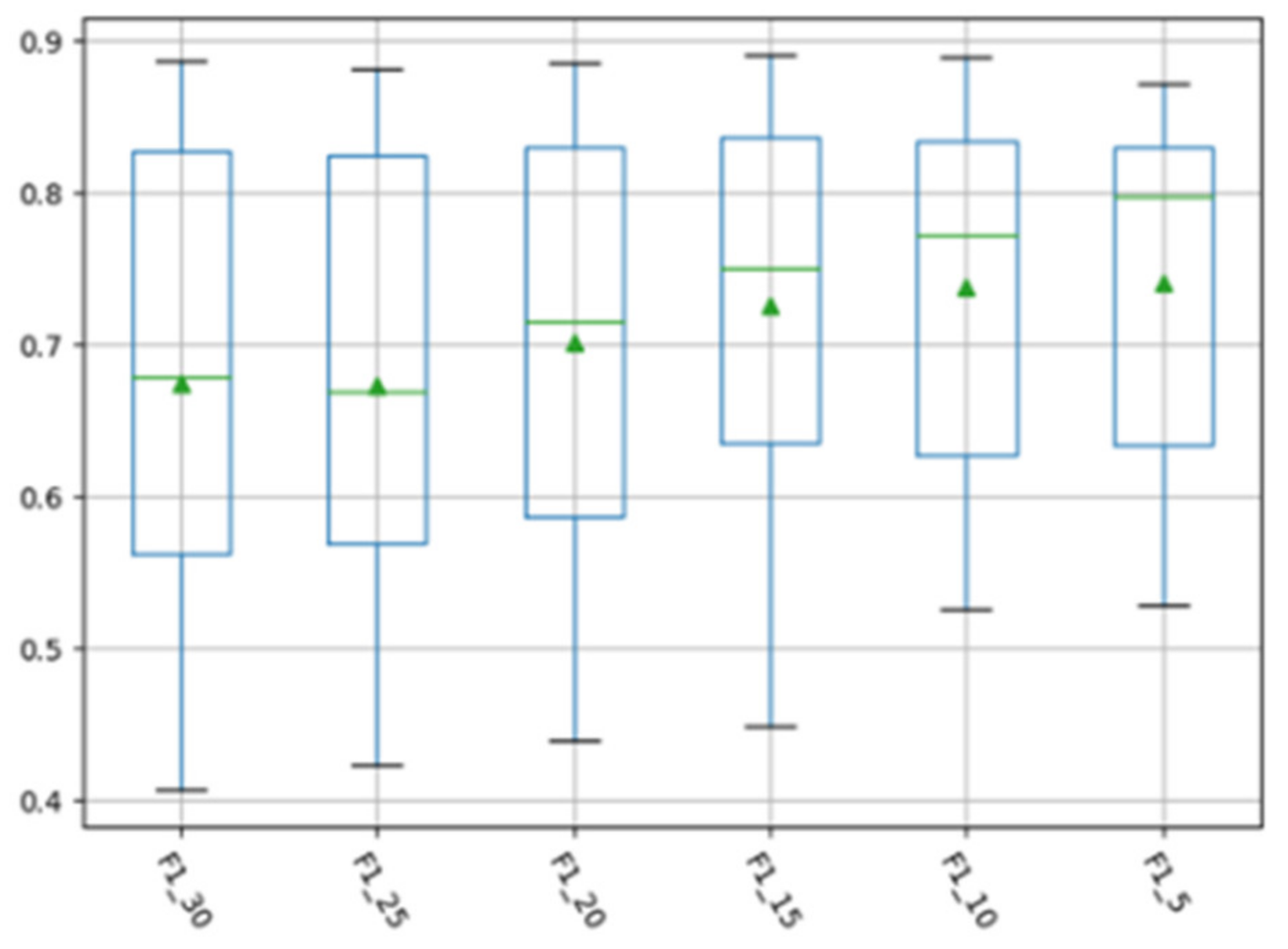
4.3. Experimental Parameter Setting
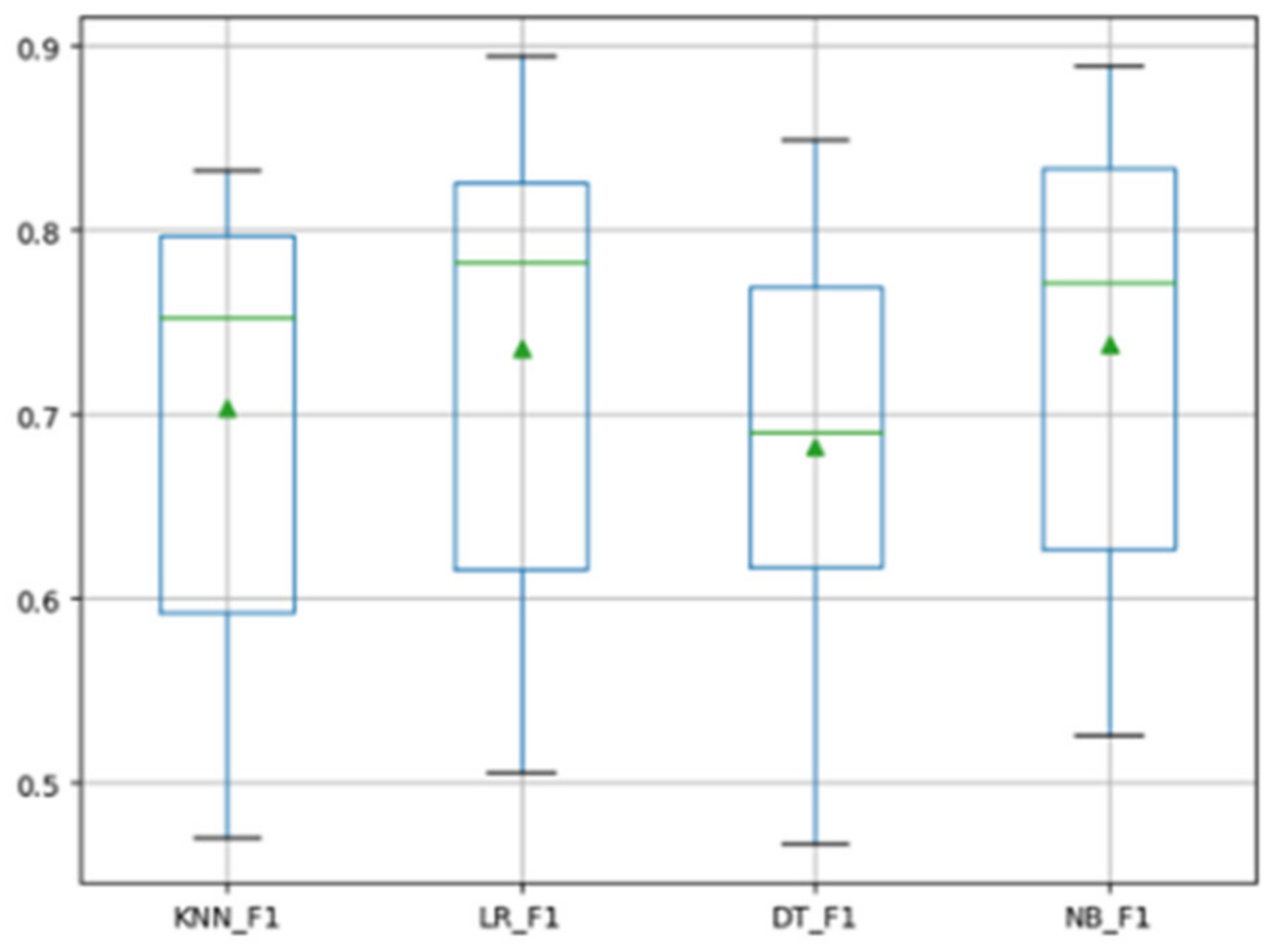
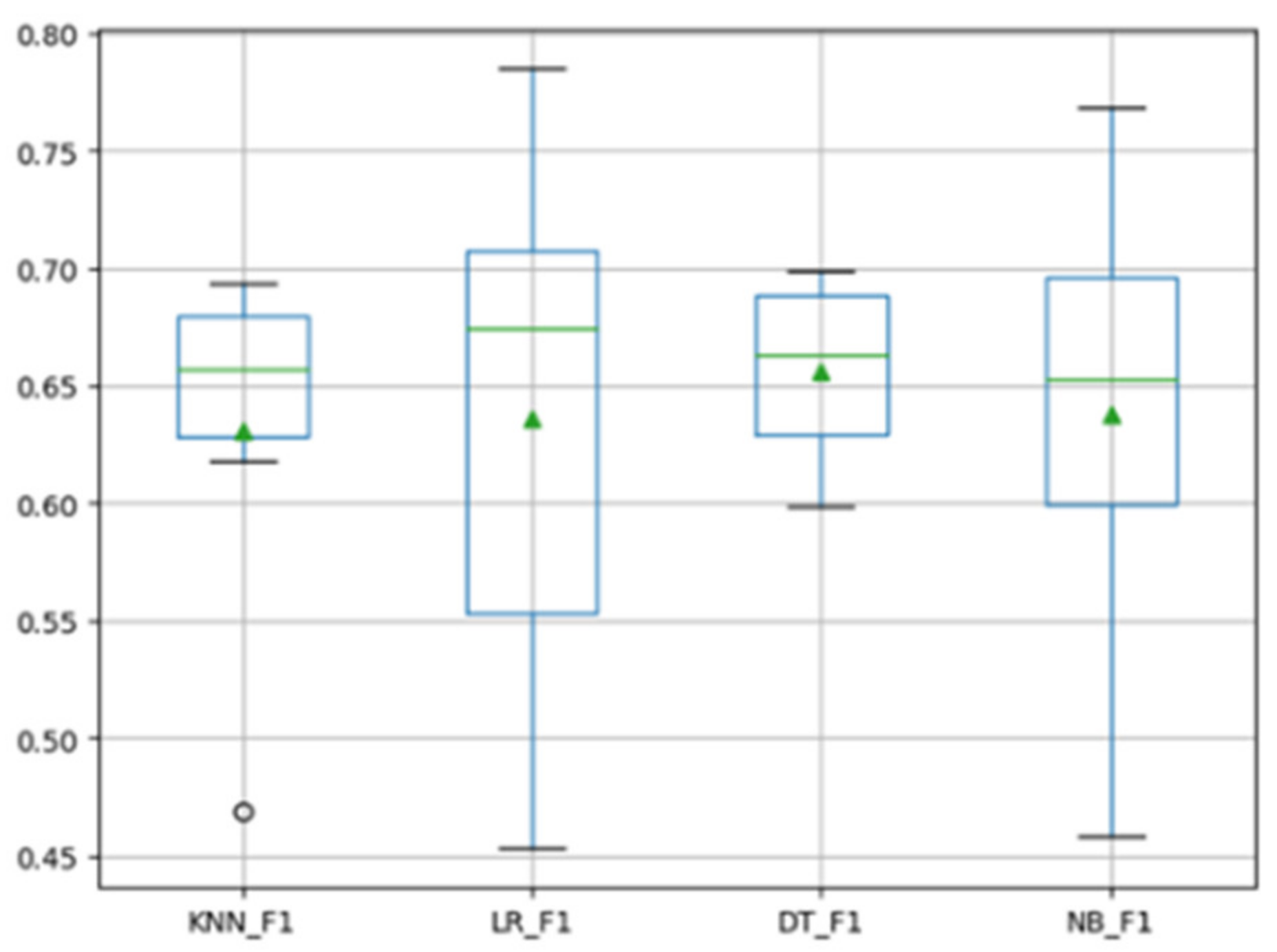
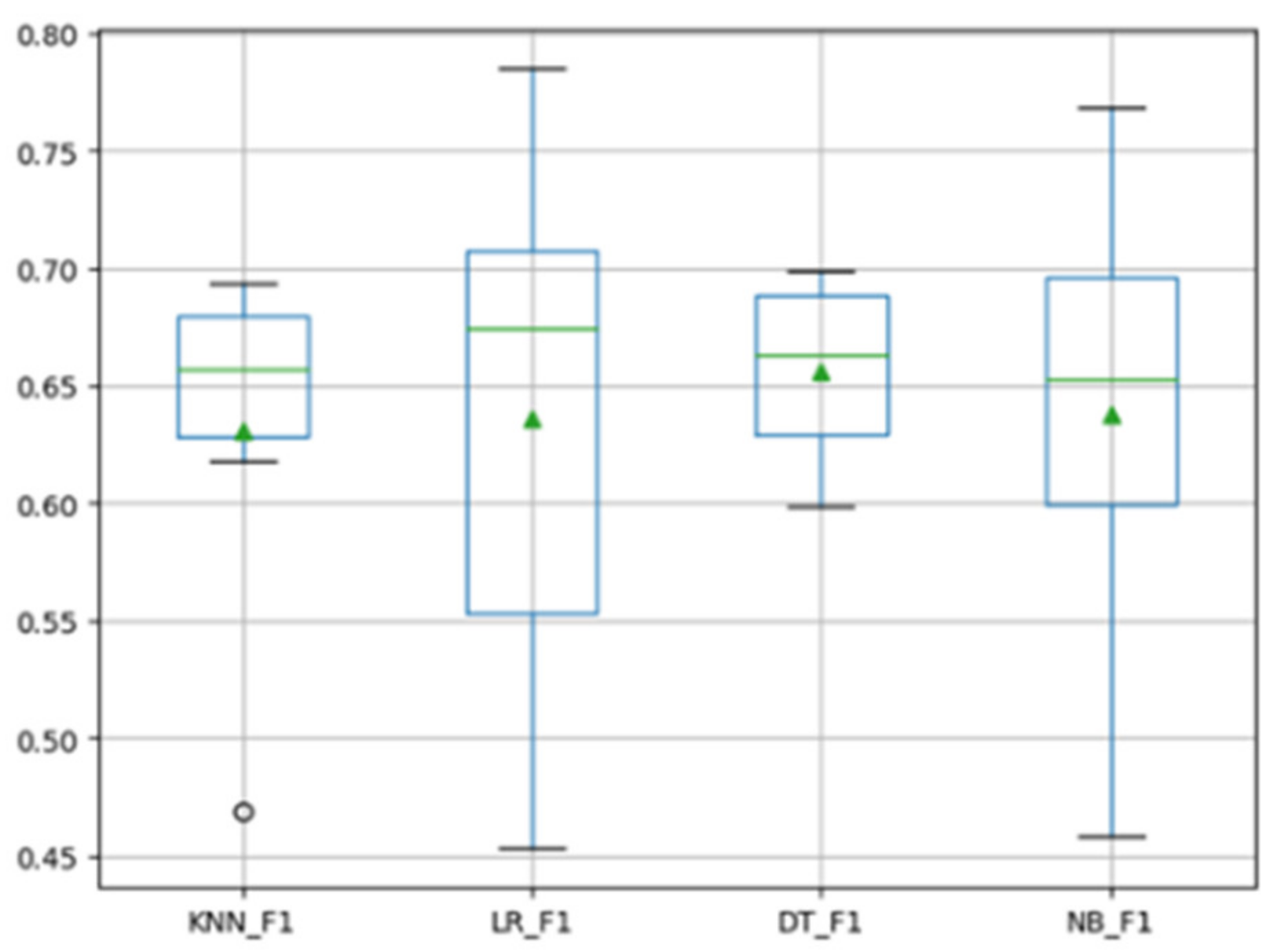
4.4. Experimental Results and Analysis
5. Conclusions and Prospects
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gong, L.N.; Jiang, S.J.; Jiang, L. Research progress of software defect prediction. J. Softw. 2019, 30, 3090–3114. [Google Scholar]
- Chen, X.; Gu, Q.; Liu, W.S.; Liu, S.; Ni, C. Survey of static software defect prediction. J. Softw. 2016, 27, 1–25. [Google Scholar]
- Tracy, H.; Sarah, B.; David, B.; Gray, D.; Counsell, S. A systematic literature review on fault prediction performance. IEEE Trans. Softw. Eng. 2012, 38, 1276–1304. [Google Scholar]
- Li, Z.; Jing, X.Y.; Zhu, X. Progress on approaches to software defect prediction. IET Softw. 2018, 12, 161–175. [Google Scholar] [CrossRef]
- Li, Y.; Huang, Z.Q.; Wang, Y.; Fang, B.W. Survey on data driven software defects prediction. Acta Electron. Sin. 2017, 45, 982–988. [Google Scholar]
- Chidamber, S.R.; Kemerer, C.F. A metrics suite for object-oriented design. IEEE Trans. Softw. Eng. 1994, 20, 476–493. [Google Scholar] [CrossRef] [Green Version]
- Jin, C. Software defect prediction model based on distance metric learning. Soft Comput. 2021, 25, 447–461. [Google Scholar] [CrossRef]
- Hosseini, S.; Turhan, B.; Gunarathna, D. A systematic literature review and meta-analysis on cross project defect prediction. IEEE Trans. Softw. Eng. 2019, 45, 111–147. [Google Scholar] [CrossRef] [Green Version]
- Bowes, D.; Hall, T.; Petric, J. Software defect prediction: Do different classifiers find the same defects. Softw. Qual. J. 2018, 26, 525–552. [Google Scholar] [CrossRef] [Green Version]
- Manjula, C.; Florence, L. Deep neural network-based hybrid approach for software defect prediction using software metrics. Clust. Comput. 2019, 22, 9847–9863. [Google Scholar] [CrossRef]
- Chen, S.; Ye, J.M.; Liu, T. Domain adaptation approach for cross-project software defect prediction. J. Softw. 2020, 31, 266–281. [Google Scholar]
- Chen, X.; Wang, L.P.; Gu, Q.; Wang, Z.; Ni, C.; Liu, W.S.; Wang, Q. A survey on cross-project software defect prediction methods. Chin. J. Comput. 2018, 41, 254–274. [Google Scholar]
- Herbold, S.; Trautsch, A.; Grabowski, J. Global vs. local models for cross-project defect prediction. Empir. Softw. Eng. 2017, 22, 1866–1902. [Google Scholar] [CrossRef]
- Turhan, B.; Menzies, T.; Bener, A.; Di Stefano, J. On the relative value of cross-company and within-company data for defect prediction. Empir. Softw. Eng. 2009, 14, 540–578. [Google Scholar] [CrossRef] [Green Version]
- Peters, F.; Menzies, T.; Marcus, A. Better cross company defect prediction. In Proceedings of the 2013 10th Working Conference on Mining Software Repositories, San Francisco, CA, USA, 18–19 May 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 409–418. [Google Scholar]
- Ying, M.; Luo, G.; Xue, Z.; Chen, A. Transfer learning for cross-company software defect prediction. Inf. Softw. Technol. 2012, 54, 248–256. [Google Scholar]
- Xia, X.; Lo, D.; Pan, S.J.; Nagappan, N.; Wang, X. Hydra: Massively compositional model for cross-project defect prediction. IEEE Trans. Softw. Eng. 2016, 42, 977–998. [Google Scholar] [CrossRef]
- Sun, Z.; Li, J.; Sun, H.; He, L. CFPS: Collaborative filtering based source projects selection for cross-project defect prediction. Appl. Soft Comput. 2020, 99, 106940. [Google Scholar]
- Nam, J.; Pan, S.J.; Kim, S. Transfer defect learning. In Proceedings of the 2013 35th International Conference on Software Engineering, San Francisco, CA, USA, 18–26 May 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 382–391. [Google Scholar]
- Yu, Q.; Jiang, S.; Zhang, Y. A feature matching and transfer approach for cross-company defect prediction. J. Syst. Softw. 2017, 132, 366–378. [Google Scholar] [CrossRef]
- Ni, C.; Chen, X.; Liu, W.S. Cross-project defect prediction method based on feature transfer and instance transfer. J. Softw. 2019, 30, 1308–1329. [Google Scholar]
- Wang, J.; Chen, Y.; Hao, S.; Feng, W.; Shen, Z. Balanced distribution adaptation for transfer learning. In Proceedings of the 2017 IEEE International Conference on Data Mining, New Orleans, LA, USA, 18–21 November 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1129–1134. [Google Scholar]
- Wang, J.; Feng, W.; Chen, Y.; Yu, H.; Huang, M.; Yu, P.S. Visual domain adaptation with manifold embedded distribution alignment. In Proceedings of the 26th ACM International Conference on Multimedia, New York, NY, USA, 22–26 October 2018; ACM: New York, NY, USA, 2018; pp. 402–410. [Google Scholar]
- Baktashmotlagh, M.; Harandi, M.T.; Lovell, B.C.; Salzmann, M. Unsupervised domain adaptation by domain invariant projection. In Proceedings of the IEEE International Conference on Computer Vision. Sydney Convention and Exhibition Centre, Sydney, Australia, 1–8 December 2013; ACM: New York, NY, USA, 2013; pp. 769–776. [Google Scholar]
- Briand, L.C.; Melo, W.L.; Wust, J. Assessing the applicability of fault-proneness models across object-oriented software projects. IEEE Trans. Softw. Eng. 2002, 28, 706–720. [Google Scholar] [CrossRef] [Green Version]
- Zimmermann, T.; Nagappan, N.; Gall, H.; Giger, E.; Murphy, B. Cross-project defect prediction: A large scale experiment on data vs. domain vs. process. In Proceedings of the 7th Joint Meeting of the European Software Engineering Conference and the ACM Sigsoft Symposium on the Foundations of Software Engineering, New York, NY, USA, 24–28 August 2009; pp. 91–100. [Google Scholar]
- He, Z.; Shu, F.; Yang, Y.; Li, M.; Wang, Q. An investigation on the feasibility of cross-project defect prediction. Autom. Softw. Eng. 2012, 19, 167–199. [Google Scholar] [CrossRef]
- Herbold, S. Training data selection for cross-project defect prediction. In Proceedings of the 9th International Conference on Predictive Models in Software Engineering, New York, NY, USA, 9 October 2013; pp. 61–69. [Google Scholar]
- Yu, Q.; Jiang, S.; Qian, J. Which is more important for cross-project defect prediction: Instance or feature. In Proceedings of the 2016 International Conference on Software Analysis, Testing and Evolution, Kunming, China, 3–4 November 2016; Volume 11, pp. 90–95. [Google Scholar]
- Yu, Q.; Qian, J.; Jiang, S.; Wu, Z.; Zhang, G. An empirical study on the effectiveness of feature selection for cross-project defect prediction. IEEE Access 2019, 7, 35710–35718. [Google Scholar] [CrossRef]
- Wu, F.; Jing, X.Y.; Sun, Y.; Sun, J.; Huang, L.; Cui, F. Cross-project and within-project semi supervised software defect prediction: A unified approach. IEEE Trans. Reliab. 2018, 67, 581–597. [Google Scholar] [CrossRef]
- Li, Z.; Jing, X.Y.; Wu, F.; Zhu, X.; Xu, B.; Ying, S. Cost-sensitive transfer kernel canonical correlation analysis for heterogeneous defect prediction. Autom. Softw. Eng. 2018, 25, 201–245. [Google Scholar] [CrossRef]
- Fan, G.; Diao, X.; Yu, H.; Chen, L. Cross-project defect prediction method based on instance filtering and transfer. Comput. Eng. 2020, 46, 197–202+209. [Google Scholar]
- Zhang, Y.; Lo, D.; Xia, X.; Sun, J. An empirical study of classifier combination for cross-project defect prediction. In Proceedings of the IEEE Computer Software & Applications Conference, Taichung, Taiwan, 1–5 July 2015; Volume 7, pp. 264–269. [Google Scholar]
- Chen, J.; Hu, K.; Yang, Y.; Liu, Y.; Xuan, Q. Collective transfer learning for defect prediction. Neurocomputing 2020, 416, 103–116. [Google Scholar] [CrossRef]
- Balasubramanian, M.; Schwartz, E.L.; Tenenbaum, J.B.; de Silva, V.; Langford, J.C. The isomap algorithm and topological stability. Science 2002, 295, 7. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hamm, J.; Lee, D.D. Grassmann discriminant analysis: A unifying view on subspace-based learning. In Proceedings of the 25th International Conference on Machine Learning, New York, NY, USA, 5–9 July 2008; pp. 376–383. [Google Scholar]
- Gopalan, R.; Li, R.; Chellappa, R. Domain adaptation for object recognition: An unsupervised approach. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 999–1006. [Google Scholar]
- Baktashmotlagh, M.; Harandi, M.T.; Lovell, B.C.; Salzmann, M. Domain adaptation on the statistical manifold. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 2481–2488. [Google Scholar]
- Gong, B.; Shi, Y.; Sha, F.; Grauman, K. Geodesic flow kernel for unsupervised domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 2066–2073. [Google Scholar]
- Wang, J.; Chen, Y.; Feng, W.; Yu, H.; Huang, M.; Yang, Q. Transfer learning with dynamic distribution adaptation. ACM Trans. Intell. Syst. Technol. 2020, 11, 1–25. [Google Scholar] [CrossRef] [Green Version]
- Wu, R.; Zhang, H.; Kim, S.; Cheung, S.C. ReLink: Recovering links between bugs and changes. In Proceedings of the 19th ACM SIGSOFT Symposium and the 13th European Conference on Foundations of Software Engineering, Szeged, Hungary, 5–9 September 2011; ACM: New York, NY, USA, 2011; pp. 15–25. [Google Scholar]
- Dambros, M.; Lanza, M.; Robbes, R. Evaluating defect prediction approaches: A benchmark and an extensive comparison. Empir. Softw. Eng. 2012, 17, 531–577. [Google Scholar] [CrossRef]
- Yang, Y.; Yang, J.; Qian, H. Defect prediction by using cluster ensembles. In Proceedings of the 2018 Tenth International Conference on Advanced Computational Intelligence, Xiamen, China, 29–31 March 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 631–636. [Google Scholar]
- Steffen, H.; Alexander, T.; Jens, G. A comparative study to benchmark cross-project defect prediction approaches. IEEE Trans. Softw. Eng. 2017, 44, 811–833. [Google Scholar]
- Zhou, Y.; Yang, Y.; Lu, H.; Chen, L.; Li, Y.; Zhao, Y.; Qian, J.; Xu, B. How far we have progressed in the journey? an examination of cross-project defect prediction. ACM Trans. Softw. Eng. Methodol. 2018, 27, 1–51. [Google Scholar] [CrossRef]
- Watanabe, S.; Kaiya, H.; Kaijiri, K. Adapting a fault prediction model to allow inter language reuse. In Proceedings of the 4th International Workshop on Predictor Models in Software Engineering, Leipzig, Germany, 12–13 May 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 19–24. [Google Scholar]
- Zhao, H.; Zhang, C. An online-learning-based evolutionary many-objective algorithm. Inf. Sci. 2020, 509, 1–21. [Google Scholar] [CrossRef]
- Liu, Z.Z.; Wang, Y.; Huang, P.Q. A many-objective evolutionary algorithm with angle-based selection and shift-based density estimation. Inf. Sci. 2020, 509, 400–419. [Google Scholar] [CrossRef] [Green Version]
- Dulebenets, M.A. A novel memetic algorithm with a deterministic parameter control for efficient berth scheduling at marine container terminals. Marit. Bus. Rev. 2017, 2, 302–330. [Google Scholar] [CrossRef] [Green Version]
- Pasha, J.; Dulebenets, M.A.; Kavoosi, M.; Abioye, O.F.; Wang, H.; Guo, W. An optimization model and solution algorithms for the vehicle routing problem with a “factory-in-a-box”. IEEE Access 2020, 8, 134743–134763. [Google Scholar] [CrossRef]
- D’angelo, G.; Pilla, R.; Tascini, C.; Rampone, S. A proposal for distinguishing between bacterial and viral meningitis using genetic programming and decision trees. Soft Comput. 2019, 23, 11775–11791. [Google Scholar] [CrossRef]
- Panda, N.; Majhi, S.K. How effective is the salp swarm algorithm in data classification. In Computational Intelligence in Pattern Recognition; Springer: Singapore, 2020; pp. 579–588. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Project | Modules | Features | Defects | Defect Ratio |
|---|---|---|---|---|
| Apache | 194 | 26 | 98 | 50% |
| Safe | 56 | 26 | 22 | 39% |
| ZXing | 399 | 26 | 118 | 30% |
| EQ | 325 | 61 | 129 | 40% |
| JDT | 997 | 61 | 206 | 21% |
| LC | 399 | 61 | 64 | 9% |
| ML | 1862 | 61 | 245 | 13% |
| PDE | 1492 | 61 | 209 | 14% |
| Source→Target | DCPDP-Norm | DCPDP |
|---|---|---|
| Apache→Safe | 0.787 | 0.459 |
| Apache→ZXing | 0.606 | 0.582 |
| Safe→Apache | 0.583 | 0.714 |
| Safe→ZXing | 0.651 | 0.654 |
| ZXing→Apache | 0.437 | 0.645 |
| ZXing→Safe | 0.645 | 0.699 |
| EQ→JDT | 0.596 | 0.422 |
| EQ→LC | 0.843 | 0.813 |
| EQ→ML | 0.367 | 0.344 |
| EQ→PDE | 0.775 | 0.687 |
| JDT→EQ | 0.716 | 0.633 |
| JDT→LC | 0.755 | 0.884 |
| JDT→ML | 0.788 | 0.769 |
| JDT→PDE | 0.702 | 0.826 |
| LC→EQ | 0.709 | 0.663 |
| LC→JDT | 0.804 | 0.545 |
| LC→ML | 0.770 | 0.462 |
| LC→PDE | 0.771 | 0.789 |
| ML→EQ | 0.711 | 0.688 |
| ML→JDT | 0.732 | 0.578 |
| ML→LC | 0.837 | 0.875 |
| EQ→JDT | 0.804 | 0.809 |
| EQ→LC | 0.722 | 0.674 |
| EQ→ML | 0.519 | 0.571 |
| EQ→PDE | 0.523 | 0.871 |
| JDT→EQ | 0.384 | 0.437 |
| Source→Target | MFTCPDP | TCA+ | Watanabe | Burak | DCPDP | WPDP |
|---|---|---|---|---|---|---|
| Safe→Apache | 0.711 | 0.670 | 0.716 | 0.565 | 0.714 | 0.625 |
| ZXing→Apache | 0.653 | 0.671 | 0.705 | 0.358 | 0.645 | |
| ZXing→Safe | 0.769 | 0.512 | 0.717 | 0.735 | 0.699 | 0.703 |
| Apache→Safe | 0.460 | 0.569 | 0.717 | 0.234 | 0.459 | |
| Apache→ZXing | 0.587 | 0.595 | 0.653 | 0.155 | 0.582 | 0.666 |
| Safe→ZXing | 0.652 | 0.628 | 0.636 | 0.596 | 0.654 | |
| MEAN | 0.638 | 0.607 | 0.691 | 0.441 | 0.625 | 0.665 |
| JDT→EQ | 0.556 | 0.606 | 0.688 | 0.452 | 0.633 | 0.723 |
| LC→EQ | 0.667 | 0.549 | 0.683 | 0.473 | 0.663 | |
| ML→EQ | 0.623 | 0.637 | 0.679 | 0.452 | 0.688 | |
| PDE→EQ | 0.628 | 0.608 | 0.687 | 0.453 | 0.674 | |
| LC→JDT | 0.572 | 0.731 | 0.818 | 0.700 | 0.545 | 0.829 |
| PDE→JDT | 0.724 | 0.743 | 0.827 | 0.702 | 0.571 | |
| ML→JDT | 0.608 | 0.726 | 0.828 | 0.701 | 0.578 | |
| EQ→JDT | 0.527 | 0.455 | 0.736 | 0.432 | 0.422 | |
| JDT→LC | 0.889 | 0.798 | 0.825 | 0.861 | 0.884 | 0.865 |
| ML→LC | 0.882 | 0.861 | 0.860 | 0.863 | 0.875 | |
| PDE→LC | 0.876 | 0.786 | 0.811 | 0.860 | 0.871 | |
| EQ→LC | 0.842 | 0.479 | 0.015 | 0.808 | 0.813 | |
| JDT→ML | 0.836 | 0.772 | 0.777 | 0.805 | 0.769 | 0.837 |
| LC→ML | 0.781 | 0.470 | 0.806 | 0.807 | 0.462 | |
| PDE→ML | 0.833 | 0.788 | 0.807 | 0.807 | 0.437 | |
| EQ→ML | 0.762 | 0.385 | 0.349 | 0.590 | 0.344 | |
| EQ→PDE | 0.718 | 0.619 | 0.760 | 0.525 | 0.687 | 0.831 |
| JDT→PDE | 0.828 | 0.797 | 0.781 | 0.790 | 0.826 | |
| LC→PDE | 0.780 | 0.804 | 0.812 | 0.796 | 0.789 | |
| ML→PDE | 0.822 | 0.819 | 0.822 | 0.794 | 0.809 | |
| MEAN | 0.738 | 0.671 | 0.718 | 0.684 | 0.667 | 0.817 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Y.; Zhu, Y.; Yu, Q.; Chen, X. Cross-Project Defect Prediction Method Based on Manifold Feature Transformation. Future Internet 2021, 13, 216. https://doi.org/10.3390/fi13080216
Zhao Y, Zhu Y, Yu Q, Chen X. Cross-Project Defect Prediction Method Based on Manifold Feature Transformation. Future Internet. 2021; 13(8):216. https://doi.org/10.3390/fi13080216
Chicago/Turabian StyleZhao, Yu, Yi Zhu, Qiao Yu, and Xiaoying Chen. 2021. "Cross-Project Defect Prediction Method Based on Manifold Feature Transformation" Future Internet 13, no. 8: 216. https://doi.org/10.3390/fi13080216
APA StyleZhao, Y., Zhu, Y., Yu, Q., & Chen, X. (2021). Cross-Project Defect Prediction Method Based on Manifold Feature Transformation. Future Internet, 13(8), 216. https://doi.org/10.3390/fi13080216