
An SDR-Based Experimental Study of Reliable and Low-Latency Ethernet-Based Fronthaul with MAC-PHY Split


Abstract
:1. Introduction
- Proof of concept of the proposed solution in an industry-grade hardware testbed;
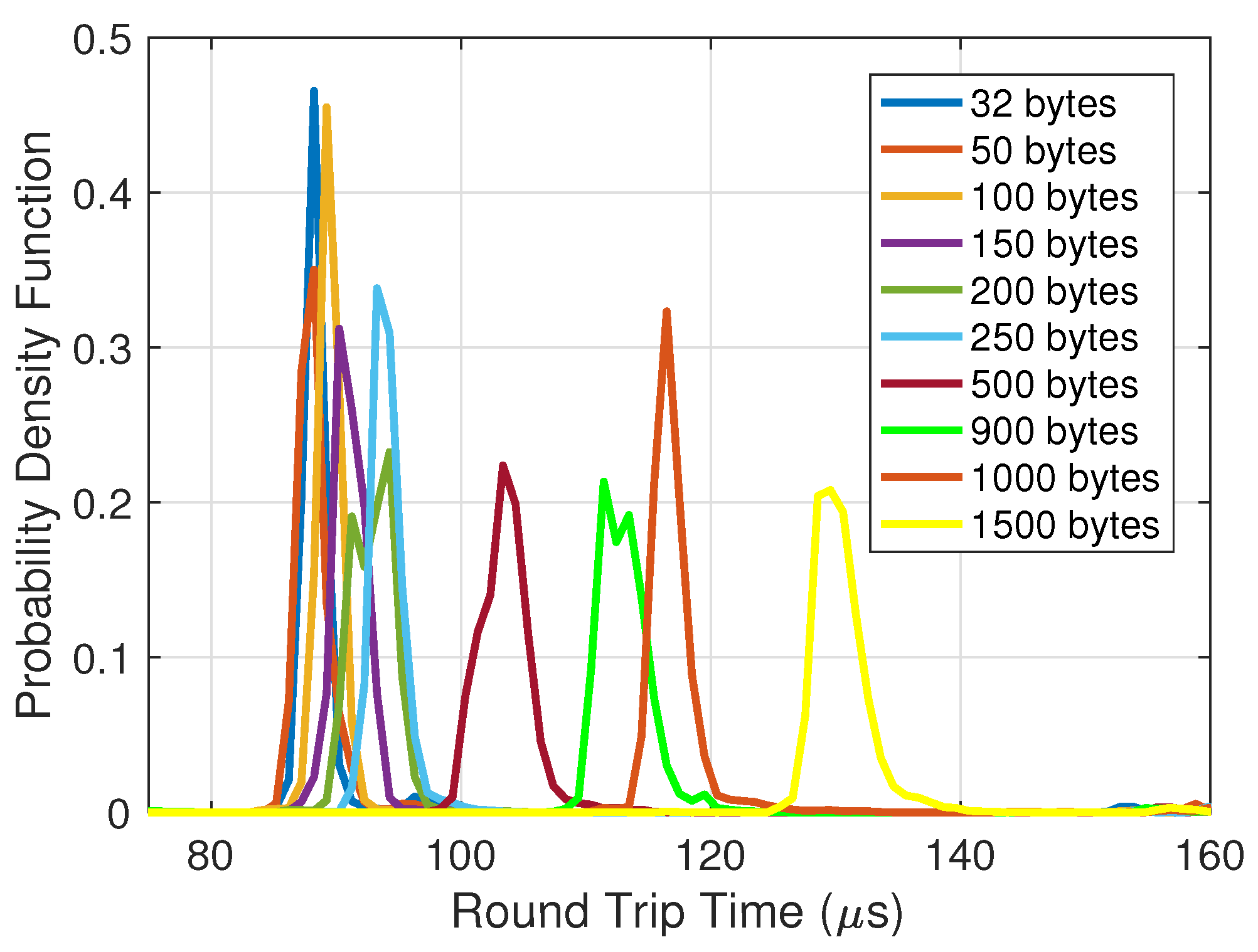
- Consideration of a realistic scenario by taking into account varied packet sizes (32–1500 bytes) and background traffic in the fronthaul network;
- Reporting and discussing the results of hardware experiments in order to evaluate the solution’s performance.
2. Reliable, Low-Latency Fronthaul Model
- Purging scenario, that is, after k out of n encoded blocks are received, the other remaining encoded blocks are removed from the queues;
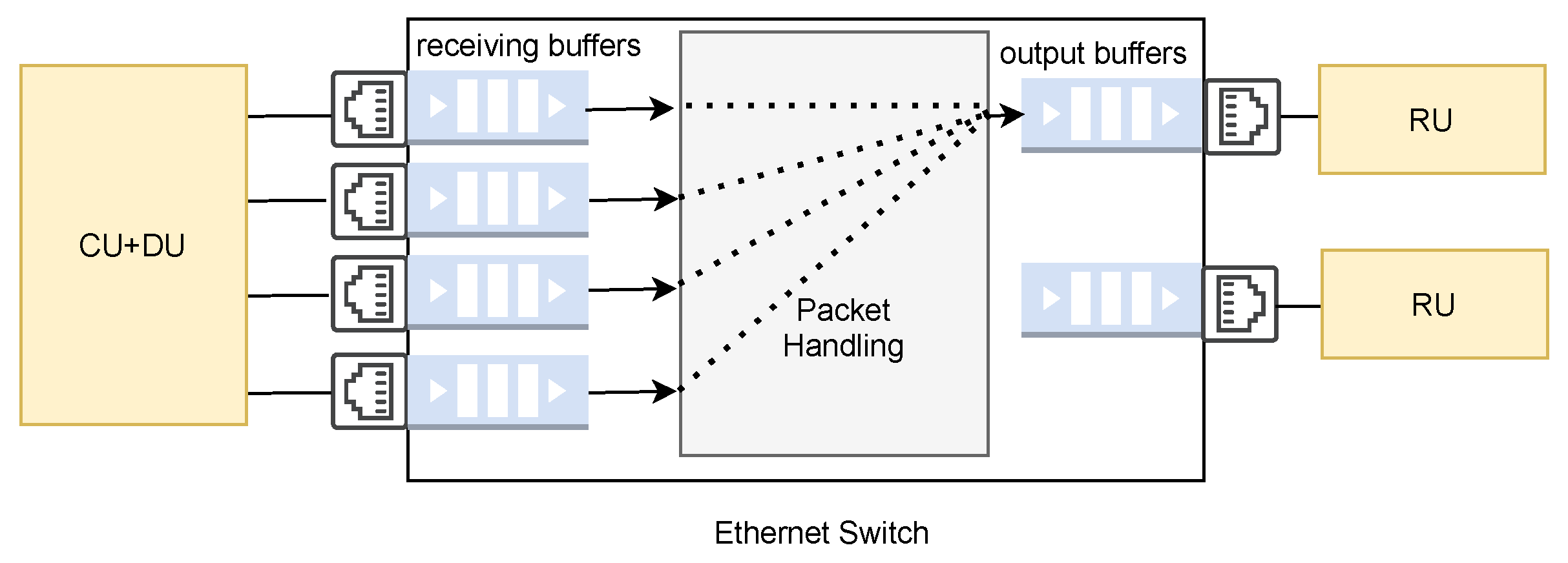
- The switch on the fronthaul has a negligible delay and hence the switch delay is not included in the fronthul latency budget.
- Assess the impact of the proposed solution on end-to-end system performance: by executing the solution on a hardware testbed, we can ensure that the system is functioning properly by ensuring that user equipment remains synchronized with the network and maintains network connection, as well as that network resources, such as memory, storage space and queue buffers, are sufficiently available for executing the proposed solution;
- Packets are not removed from the fronthaul network; that is, after receiving k out of n encoded blocks, the remaining n − k encoded blocks are not removed from the fronthaul network and they will continue to be processed, which is more realistic;
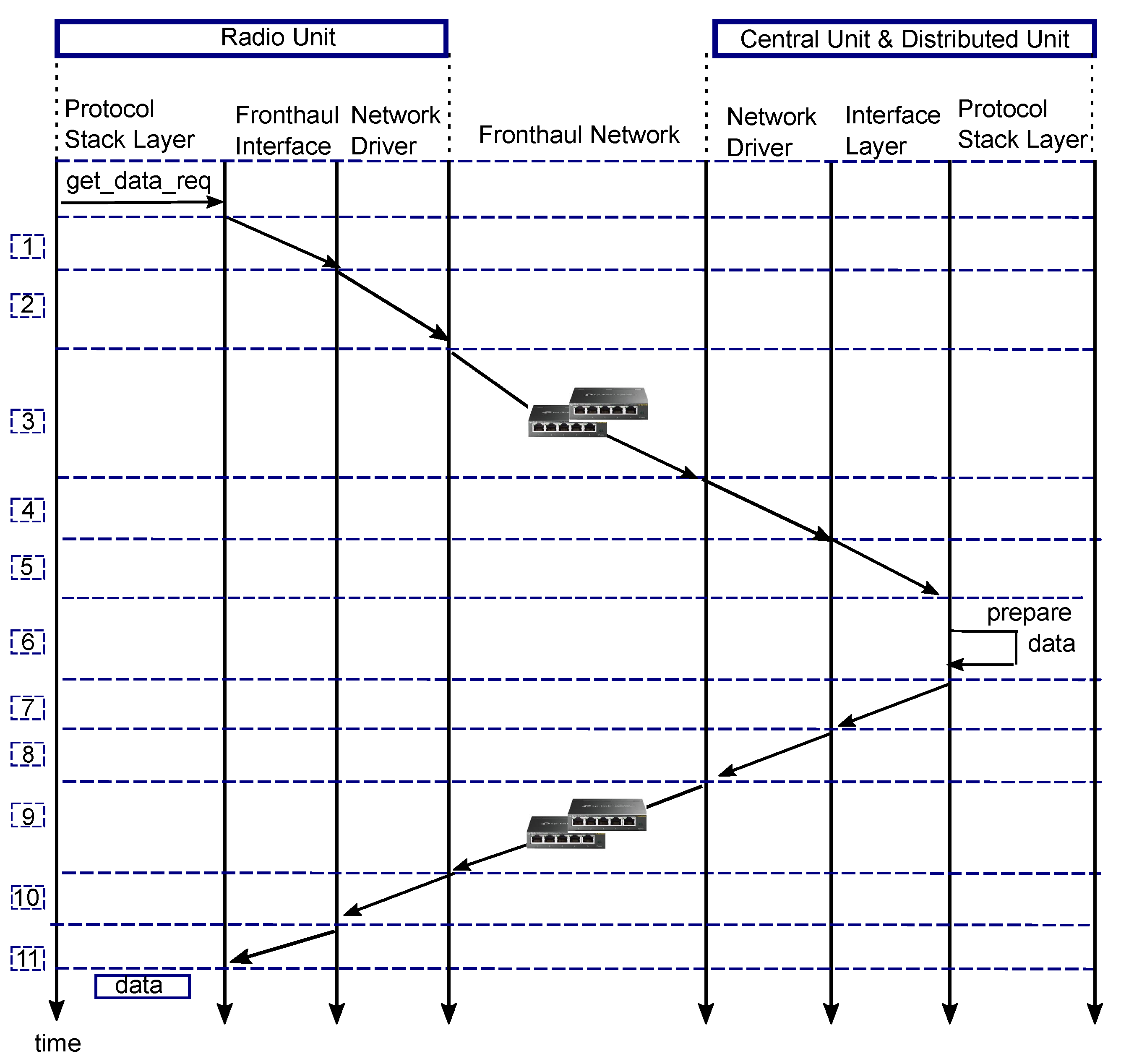
- Consider internal process delay in the (CU + DU) entity: processing time including scheduling, queueing, encoding and packetizing data which might affect the performance of the system. The time taken depends, essentially, on capabilities of the hardware used and how functions are processed. In this experimental, function blocks are sequentially processed on a general purpose processor;
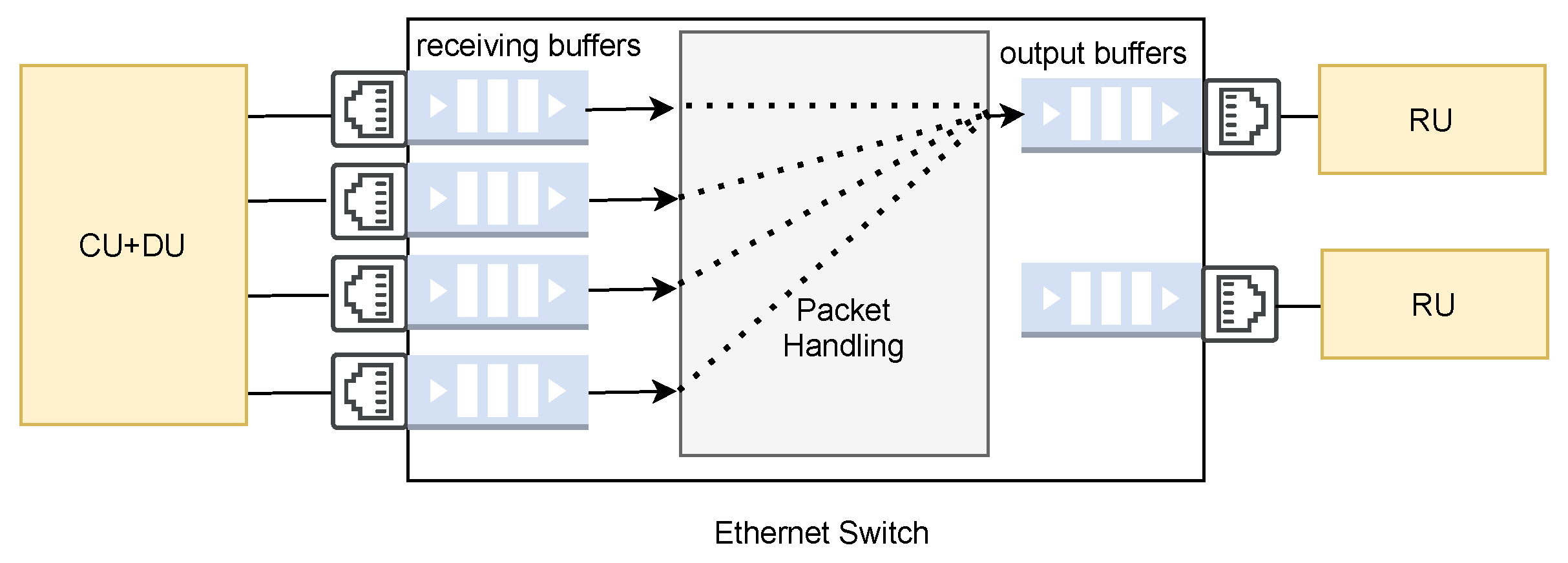
- Include switch queueing delay: the amount of time spent queuing at the switch aggregator to demonstrate the feasibility of aggregating traffic in the fronthaul network, resulting in more realistic latency measurements. The worst case scenario happens when all the n encoded blocks arrive at the switch aggregator at the same time. Such a scenario is very likely to occur when the n encoded blocks are serialised at the same time on n separate fronthaul paths with the same capacity;
- Include network driver delay: the amount of time it takes to send a packet onto a fronthaul network, which is subject to a queueing delay;
- Emulate traffic congestion on the fronthaul to account for scenarios with background traffic.
3. Experimental Testbed & Evaluation Methodology
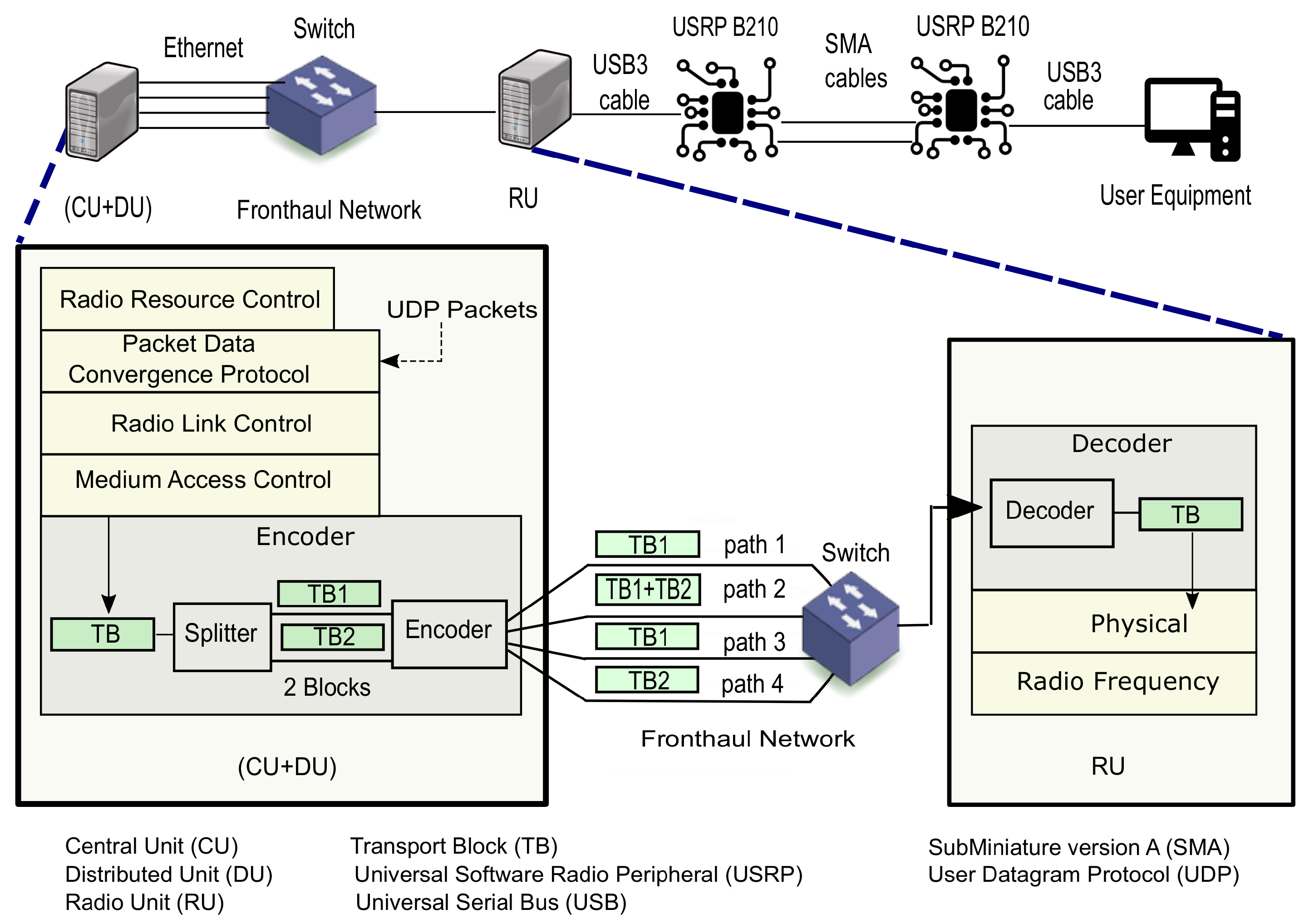
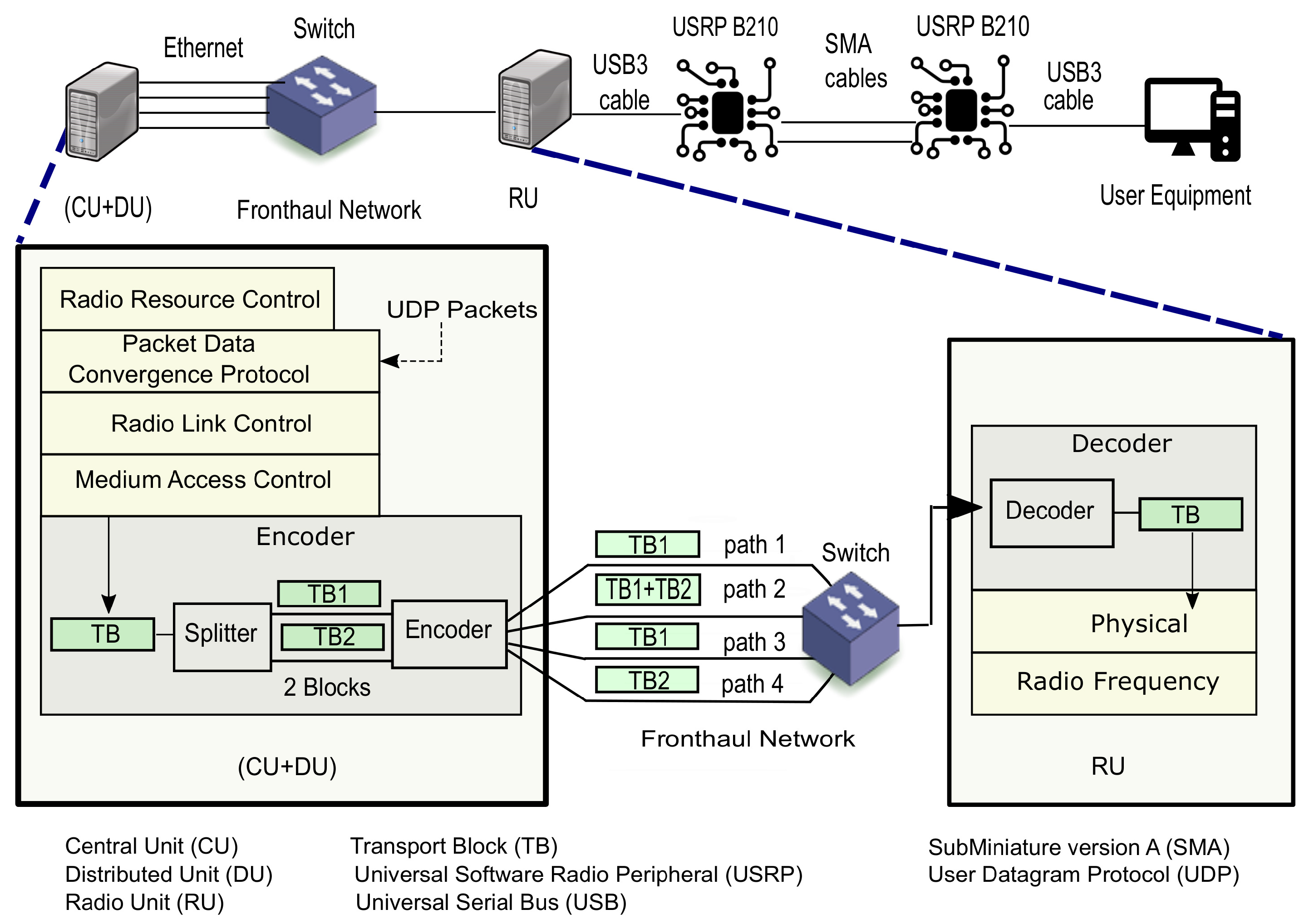
3.1. Implementation of Experimental Testbed
- Decouple RAN functions between (CU + DU) entity and RU entity;
- Support channel coding in order to encode/decode data streams;
- Packetize/depacketize packets to transmit/receive them over the Ethernet-based fronthaul interface;
- Support the multiple Ethernet-based fronthaul by transmitting over multiple Ethernet ports, each connected to a separate Ethernet link.
3.2. Evaluation Methodology
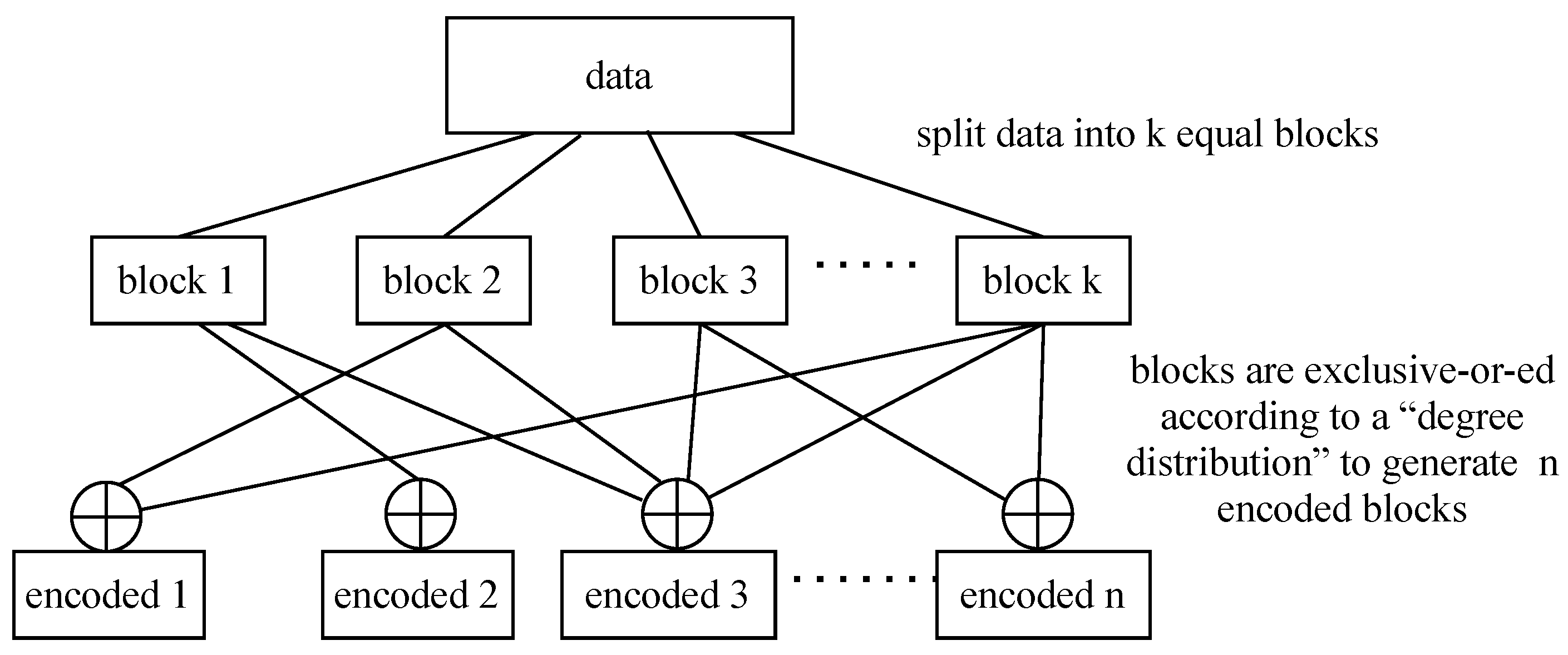
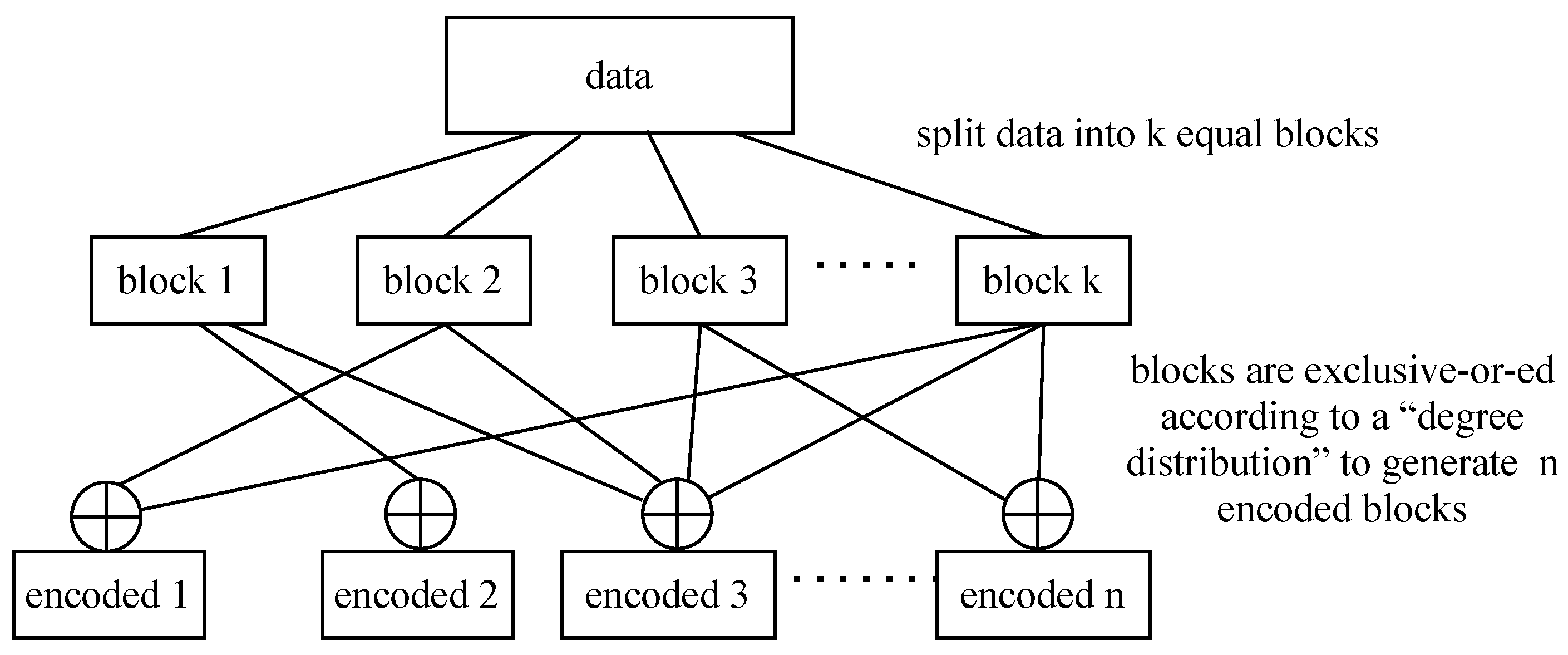
- Splitter which splits each TB into k = 2 equal blocks;
- Encoder that encodes the k blocks into n = 4 encoded blocks of the same size using fountain code and sends each encoded block into one of the n fronthaul paths.
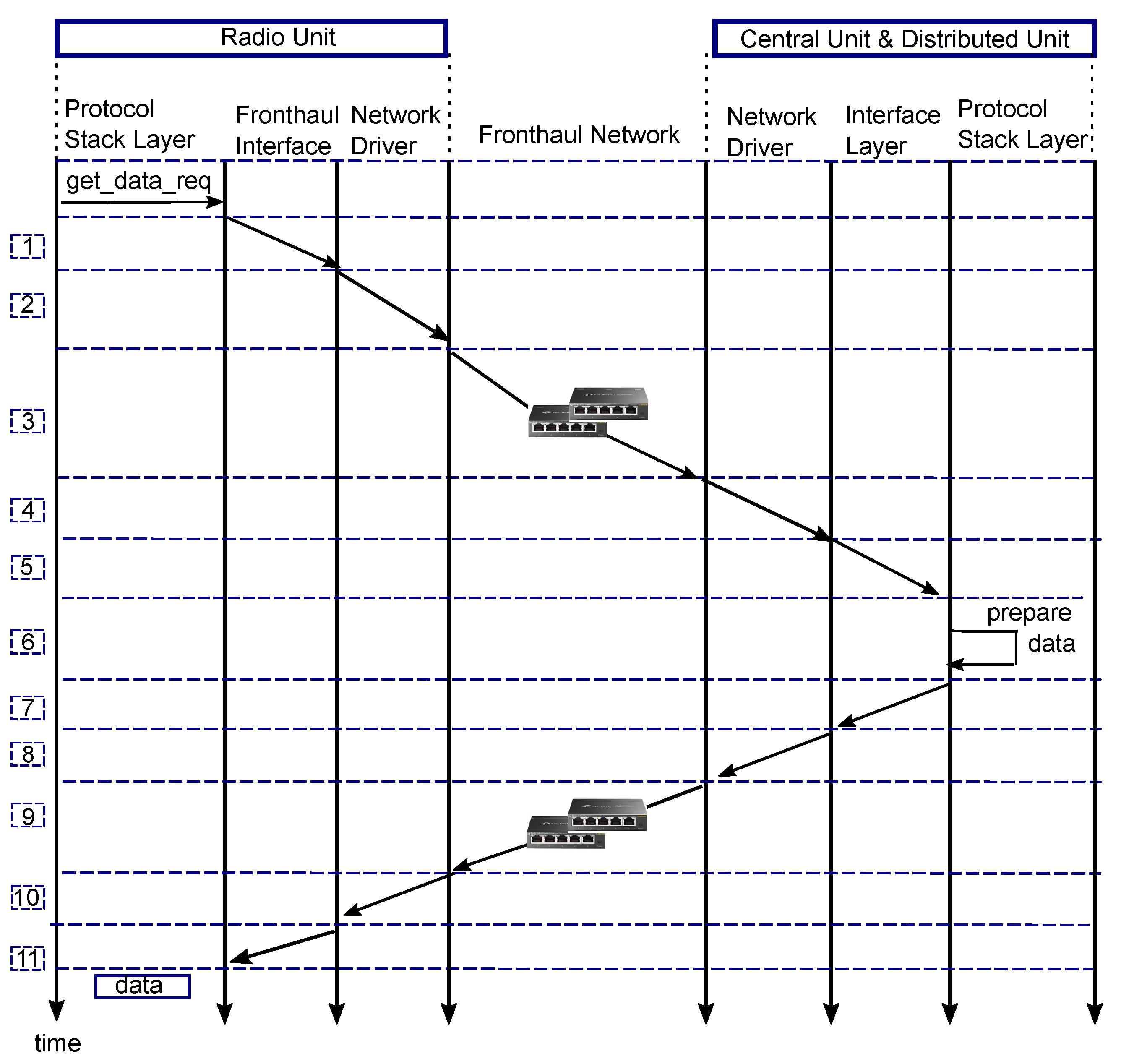
| Algorithm 1 Round trip time (RTT) measurement |
|
4. Analysis of the Experimental Results
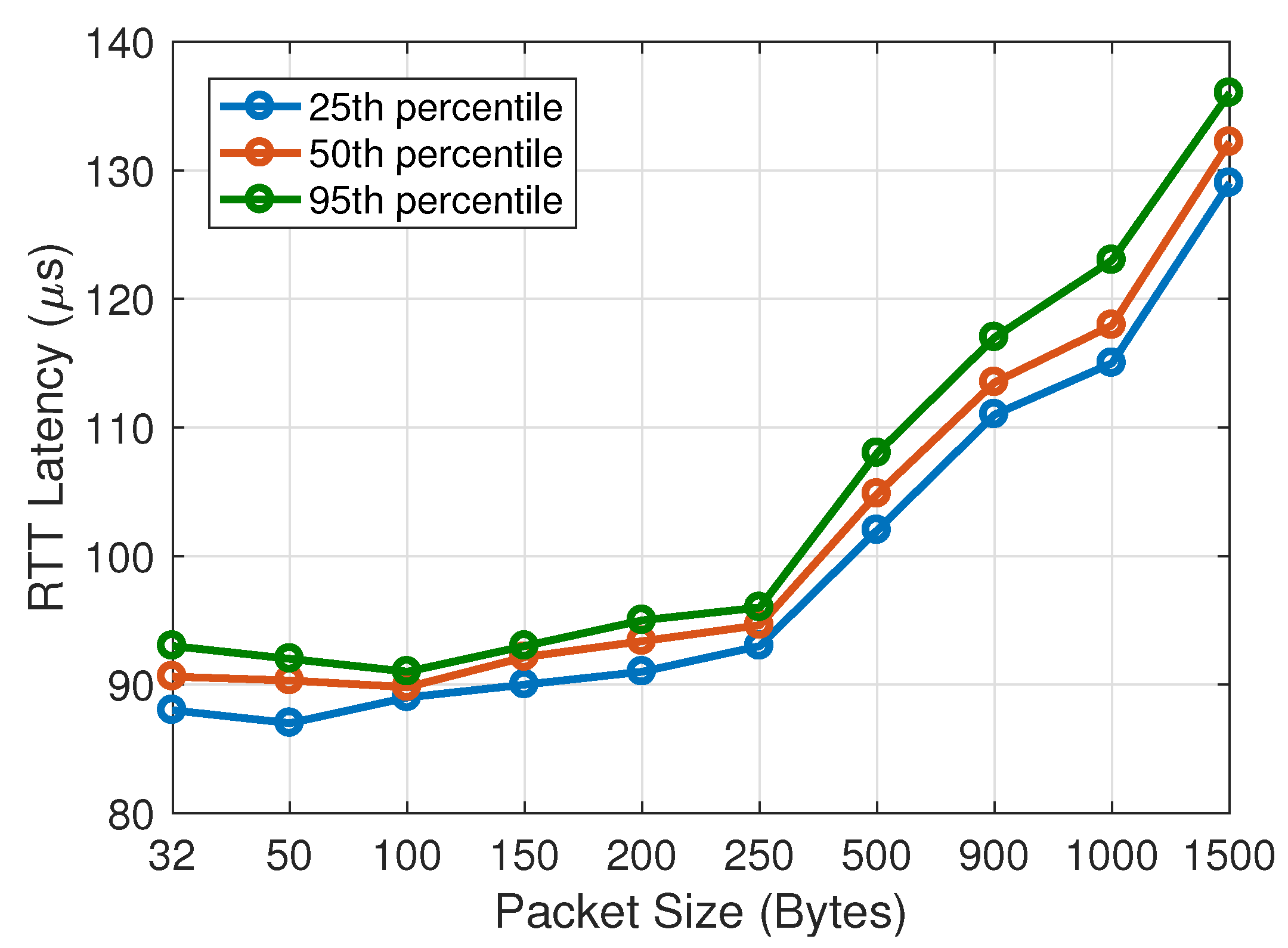
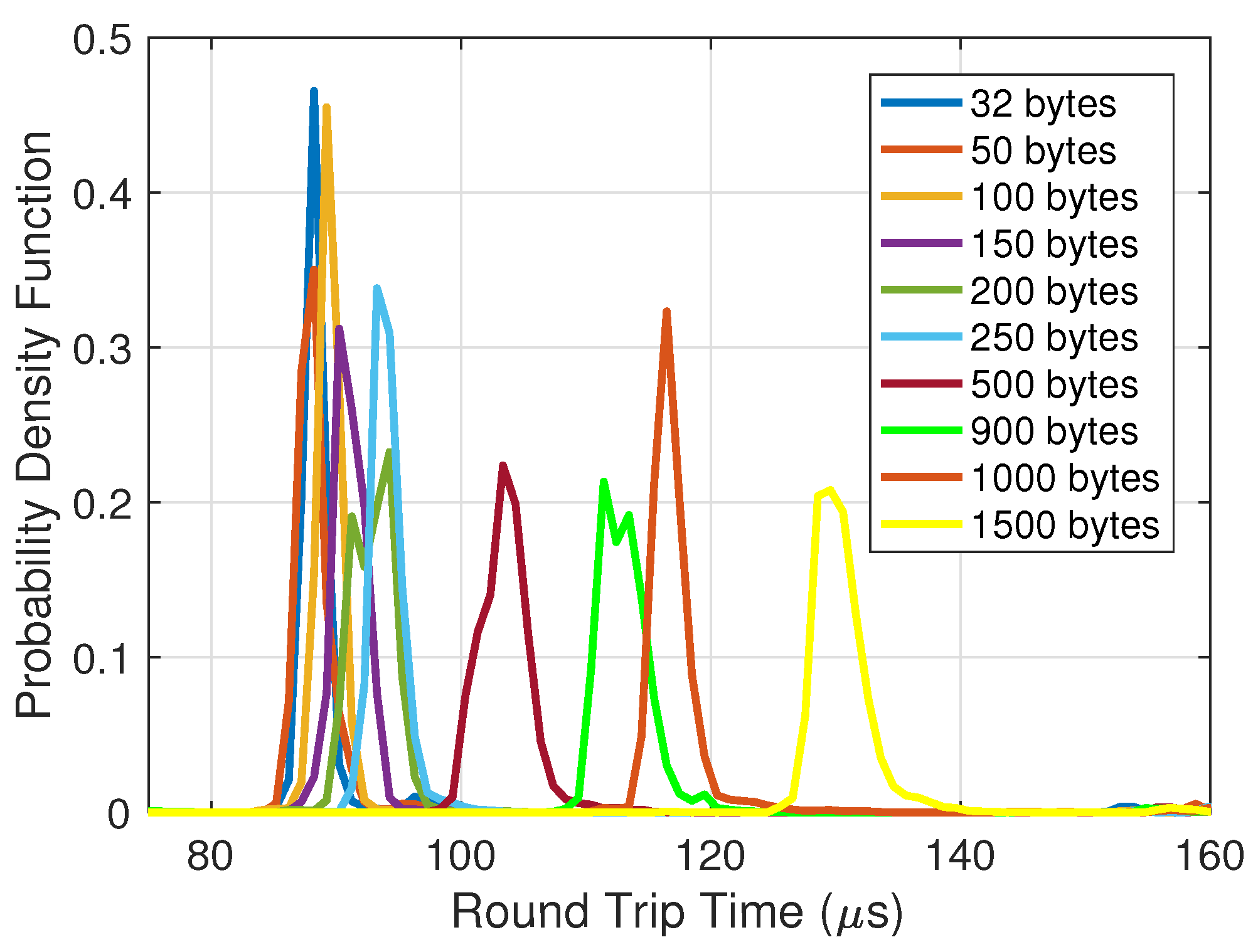
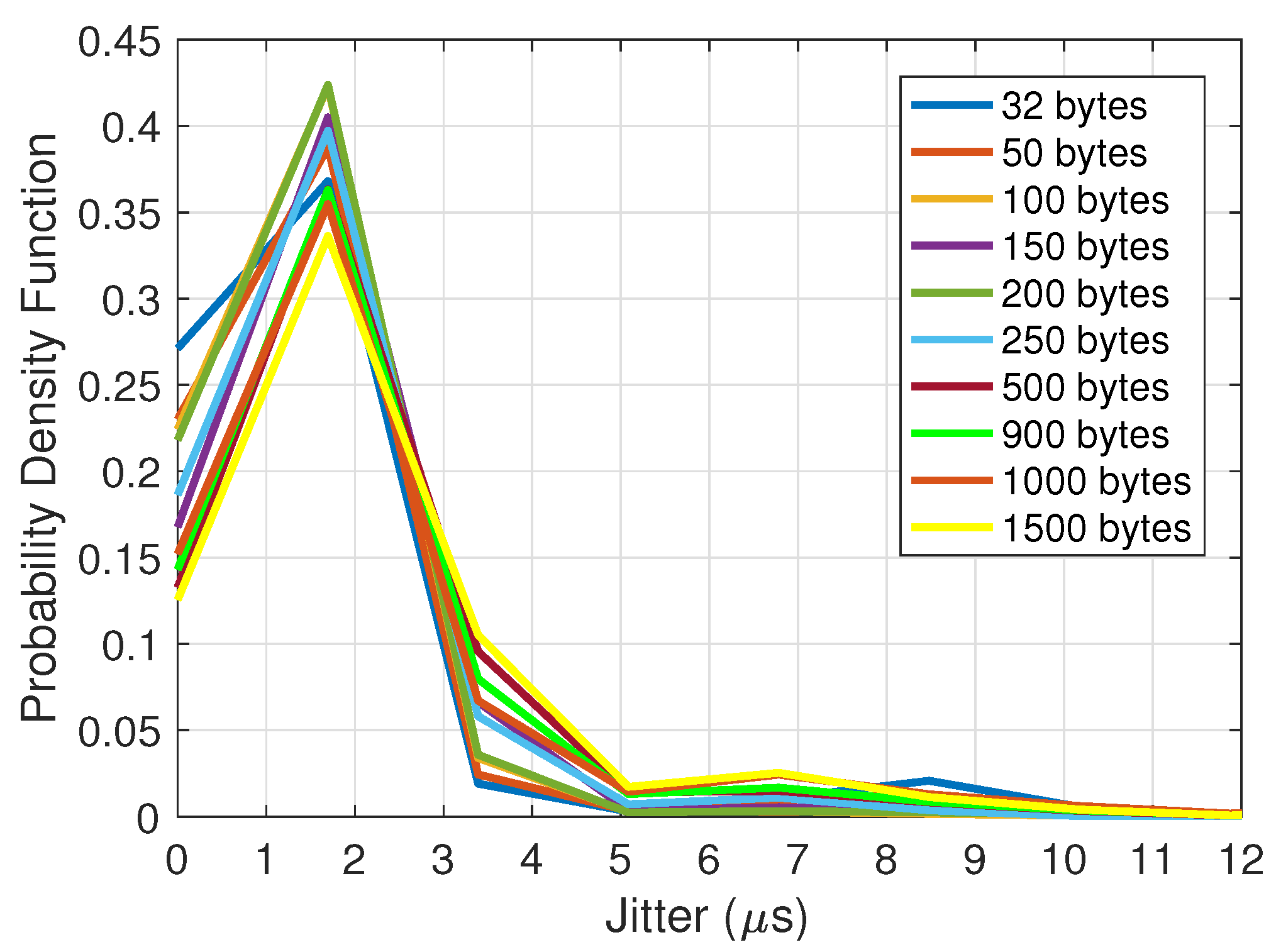
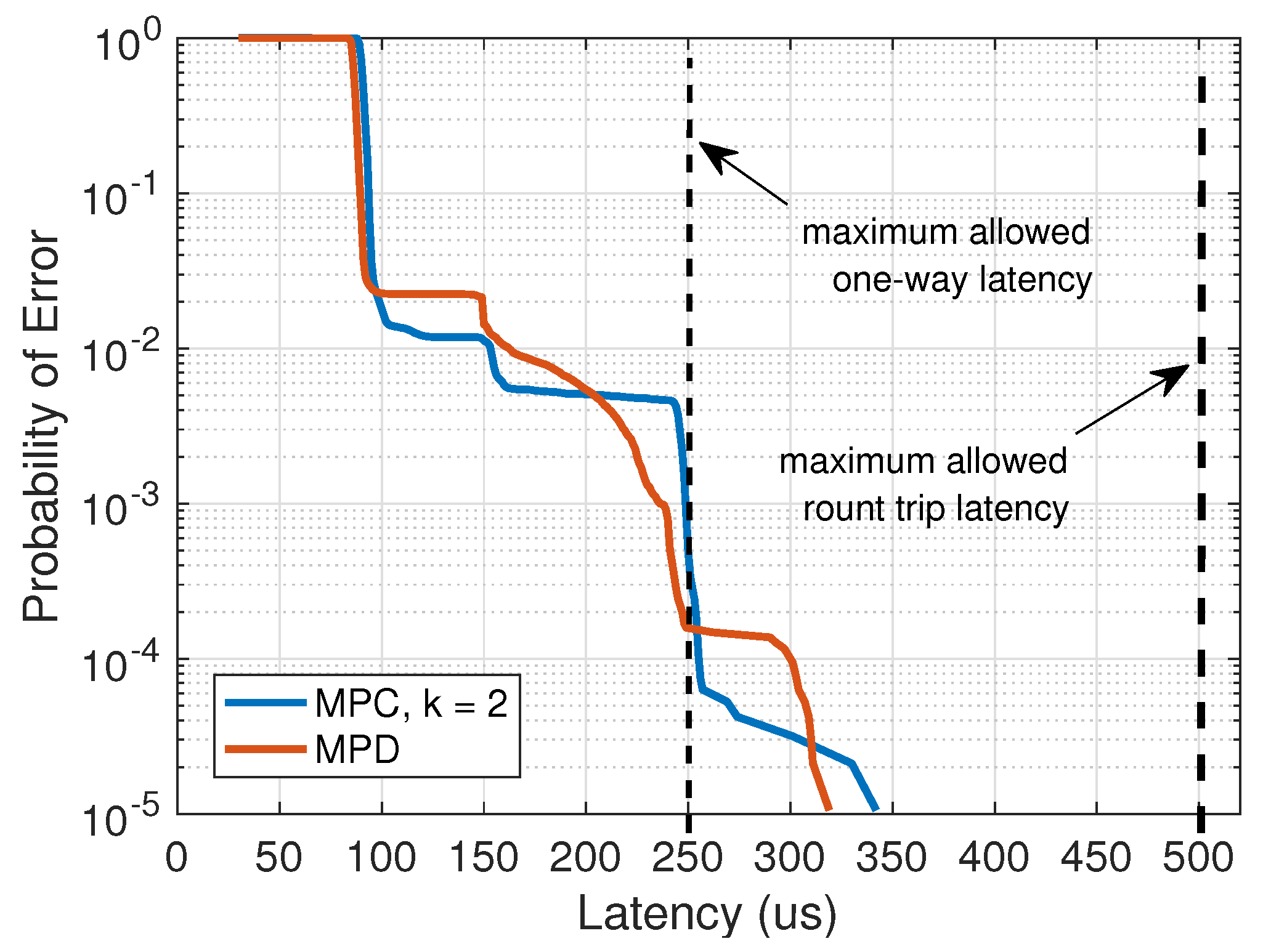
4.1. Analysis of Latency and Jitter for MPC
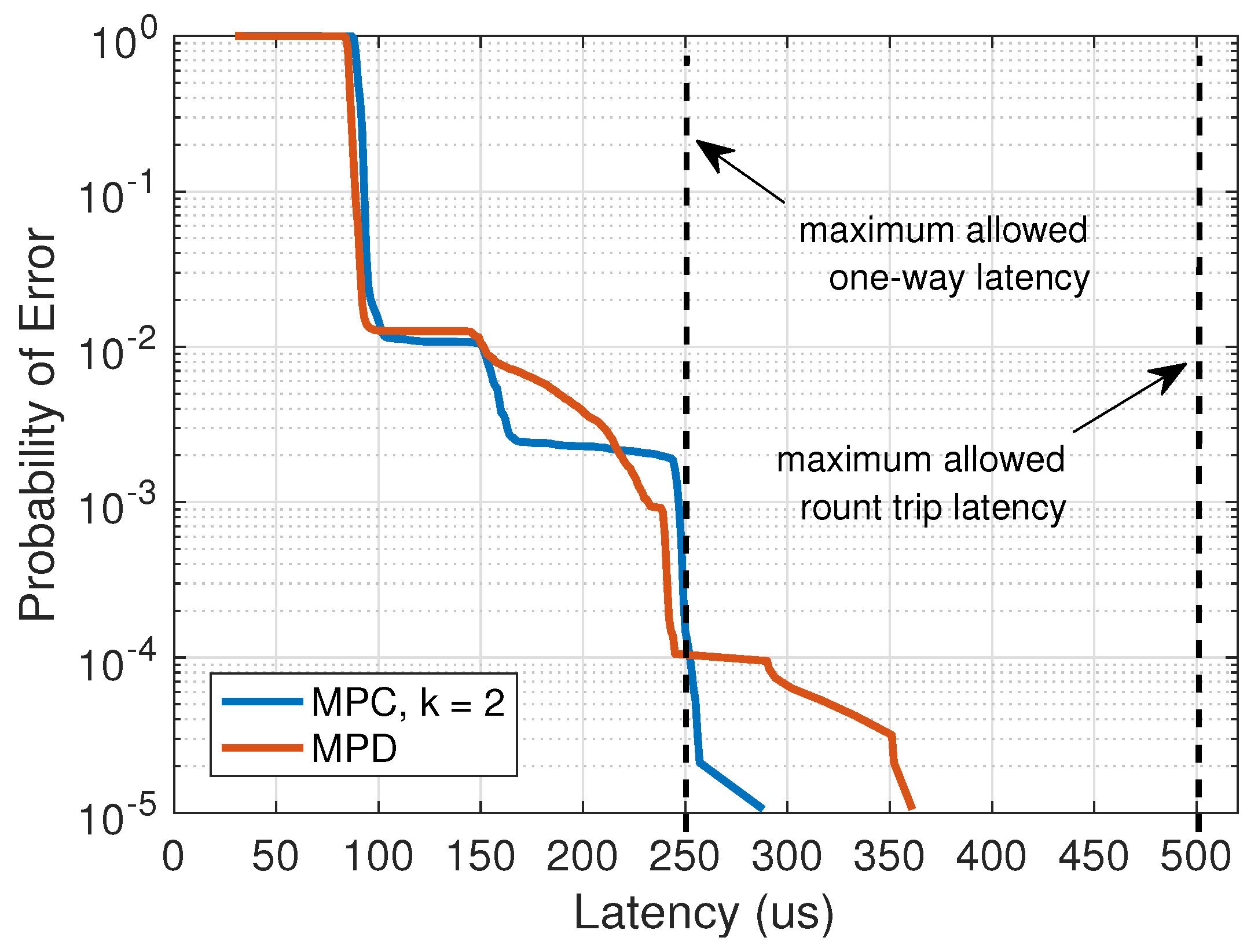
4.2. Comparison of MPC and Multi-Path Fronthaul with Duplication (MPD)
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- NGMN. 5G RAN CU—DU Network Architecture, Transport Options and Dimensioning; White Paper; Version 1.0; NGMN: Frankfurt am Main, Germany, 2019. [Google Scholar]
- Condoluci, M.; Mahmoodi, T. Softwarization and virtualization in 5G mobile networks: Benefits, trends and challenges. Comput. Netw. 2018, 146, 65–84. [Google Scholar] [CrossRef] [Green Version]
- Miroslaw, K. Latency-Aware DU/CU Placement in Convergent Packet-Based 5G Fronthaul Transport Networks. Appl. Sci. 2020, 10, 7429. [Google Scholar]
- Yusupov, J.; Ksentini, A.; Marchetto, G.; Sisto, R. Multi-Objective Function Splitting and Placement of Network Slices in 5G Mobile Networks. In Proceedings of the 2018 IEEE Conference on Standards for Communications and Networking (CSCN), Paris, France, 29–31 October 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Mountaser, G.; Condoluci, M.; Mahmoodi, T.; Dohler, M.; Mings, I. Cloud-RAN in Support of URLLC. In Proceedings of the 2017 IEEE Globecom Workshops, Singapore, 4–8 December 2017. [Google Scholar] [CrossRef]
- Hadi, M.U.; Awais, M.; Raza, M. Multiband 5G NR-over-Fiber System Using Analog Front Haul. In Proceedings of the 2020 International Topical Meeting on Microwave Photonics (MWP), Virtual Conference, Online. 24–26 November 2020; pp. 136–139. [Google Scholar]
- Hadjer, T.; Hind, C.-T.; Badii, J.; Sara, A. Split analysis and fronthaul dimensioning in 5G C-RAN to guarantee ultra low latency. In Proceedings of the 2020 IEEE 17th Annual Consumer Communications & Networking Conference, Las Vegas, NV, USA, 10–13 January 2020; pp. 1–4. [Google Scholar]
- ORAN-WG4. Control, User and Synchronization Plane Specification. Available online: https://www.o-ran.org/blog/2020/6/29/23-new-o-ran-specifications-have-been-released-in-the-first-half-of-2020 (accessed on 29 June 2021).
- CPRI. eCPRI Interface Specification. Interface Specification, Common Public Radio Interface, 2019. V2.0. Available online: http://www.cpri.info/downloads/eCPRI_v_2.0_2019_05_10c.pdf (accessed on 29 June 2021).
- Khosravirad, S.R.; Viswanathan, H.; Yu, W. Exploiting Diversity for Ultra-Reliable and Low-Latency Wireless Control. IEEE Trans. Wirel. Commun. 2021, 20, 316–331. [Google Scholar] [CrossRef]
- Belschner, J.; Michalopoulos, D.S. A Hybrid Approach for Data Duplication and Network Coding. In Proceedings of the 2019 European Conference on Networks and Communications (EuCNC), Valencia, Spain, 18–21 June 2019; pp. 369–373. [Google Scholar] [CrossRef] [Green Version]
- Park, S.H.; Simeone, O.; Shamai, S. Robust Baseband Compression Against Congestion in Packet-Based Fronthaul Networks Using Multiple Description Coding. Entropy 2019, 21, 433. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mountaser, G.; Mahmoodi, T.; Simeone, O. Reliable and Low-Latency Fronthaul for Tactile Internet Applications. IEEE JSAC 2018, 36, 2455–2463. [Google Scholar] [CrossRef] [Green Version]
- 3GPP. Radio Access Architecture and Interface (Release 14); Technical Report 38.801. Available online: https://portal.3gpp.org/desktopmodules/Specifications/SpecificationDetails.aspx?specificationId=3056 (accessed on 29 June 2021).
- Brown, G. New Transport Network Architectures for 5G RAN. White Paper. Available online: https://www.fujitsu.com/us/Images/New-Transport-Network-Architectures-for-5G-RAN.pdf (accessed on 29 June 2021).
- Cui, M.; Zhang, H.; Huang, Y.; Xu, Z.; Zhao, Q. A Fountain-Coding Based Cooperative Jamming Strategy for Secure Service Migration in Edge Computing. Wirel. Netw. 2021. [Google Scholar] [CrossRef]
- Nikaien, N. OpenAirInterface Simulator Emulator. White Paper. 2015. Available online: https://openairinterface.org/docs/oai_oaisim_desc.pdf (accessed on 29 June 2021).
- 3GPP. Technical Specification Group Services and System Aspects; Service Requirements for the 5G System; Stage 1 (Release 16). Technical Report 22.261. 2018. Available online: https://portal.3gpp.org/desktopmodules/Specifications/SpecificationDetails.aspx?specificationId=3107 (accessed on 29 June 2021).
- Prytz, G. A performance analysis of EtherCAT and PROFINET IRT. In Proceedings of the 2008 IEEE International Conference on Emerging Technologies and Factory Automation, Hamburg, Germany, 15–18 September 2008; pp. 408–415. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Values |
|---|---|
| Carrier Frequency | 2.68 GHz |
| System Bandwidth | 5 MHz |
| Frame Type | Frequency Division Duplex |
| Radio Frequency frontend | 1 transmit antenna/1 receive radio frequency |
| Modulation | Adaptive Quadrature Amplitude Modulation (QAM): QAM, 16 QAM and 64 QAM) |
| Packet Size | 32–1500 bytes |
| Fronthaul Capacity | 1 Gigabit per second |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mountaser, G.; Mahmoodi, T. An SDR-Based Experimental Study of Reliable and Low-Latency Ethernet-Based Fronthaul with MAC-PHY Split. Future Internet 2021, 13, 170. https://doi.org/10.3390/fi13070170
Mountaser G, Mahmoodi T. An SDR-Based Experimental Study of Reliable and Low-Latency Ethernet-Based Fronthaul with MAC-PHY Split. Future Internet. 2021; 13(7):170. https://doi.org/10.3390/fi13070170
Chicago/Turabian StyleMountaser, Ghizlane, and Toktam Mahmoodi. 2021. "An SDR-Based Experimental Study of Reliable and Low-Latency Ethernet-Based Fronthaul with MAC-PHY Split" Future Internet 13, no. 7: 170. https://doi.org/10.3390/fi13070170
APA StyleMountaser, G., & Mahmoodi, T. (2021). An SDR-Based Experimental Study of Reliable and Low-Latency Ethernet-Based Fronthaul with MAC-PHY Split. Future Internet, 13(7), 170. https://doi.org/10.3390/fi13070170