
A Sentiment-Aware Contextual Model for Real-Time Disaster Prediction Using Twitter Data


Abstract
:1. Introduction
2. Related Work
2.1. Social Media Learning Tasks
2.2. RNN/CNN-Based Models in Text Mining
2.3. Transformer-Based Models for Social Text Learning
2.4. Learning-Based Disaster Tweets Detection
3. Material and Methods
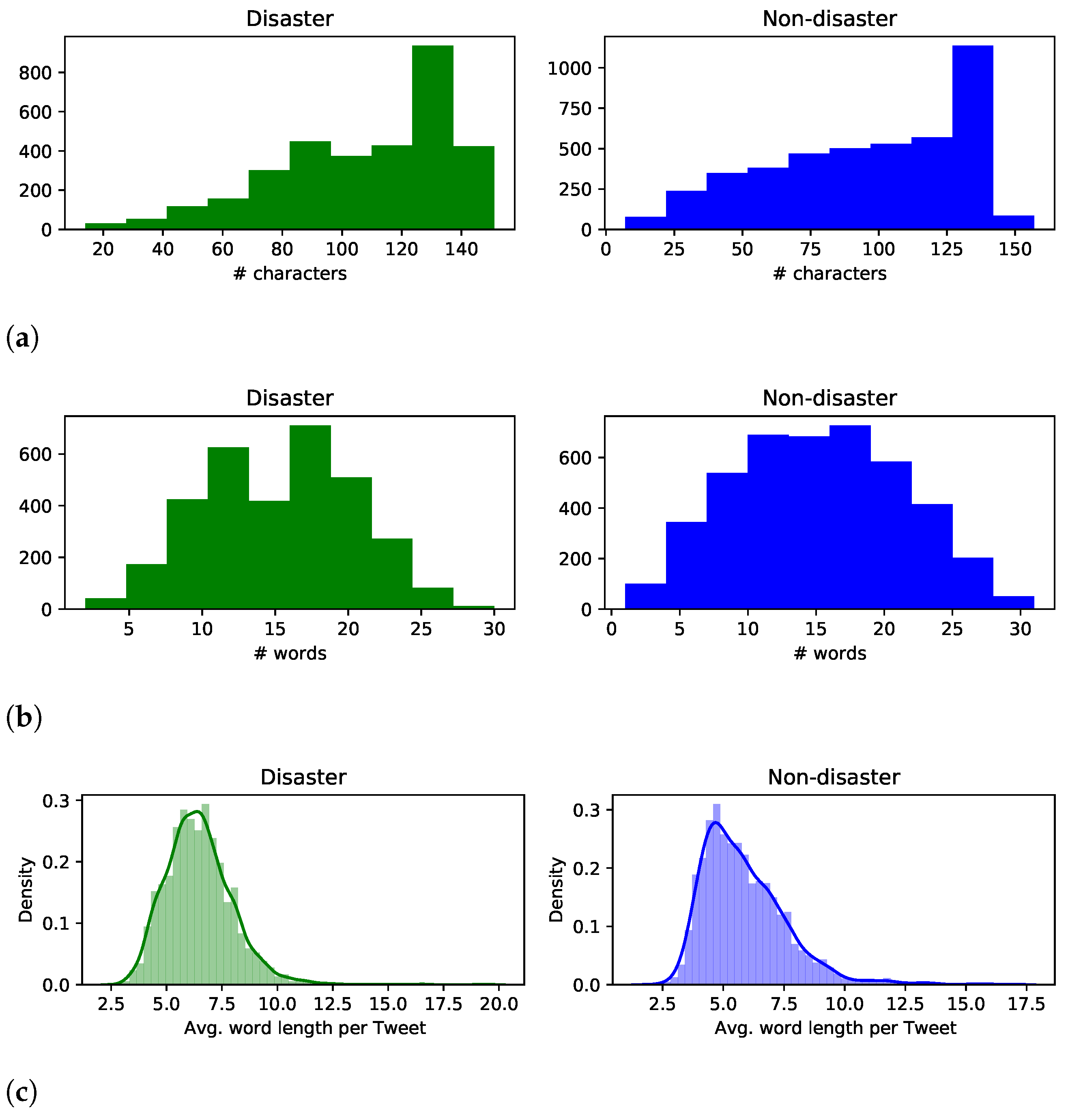
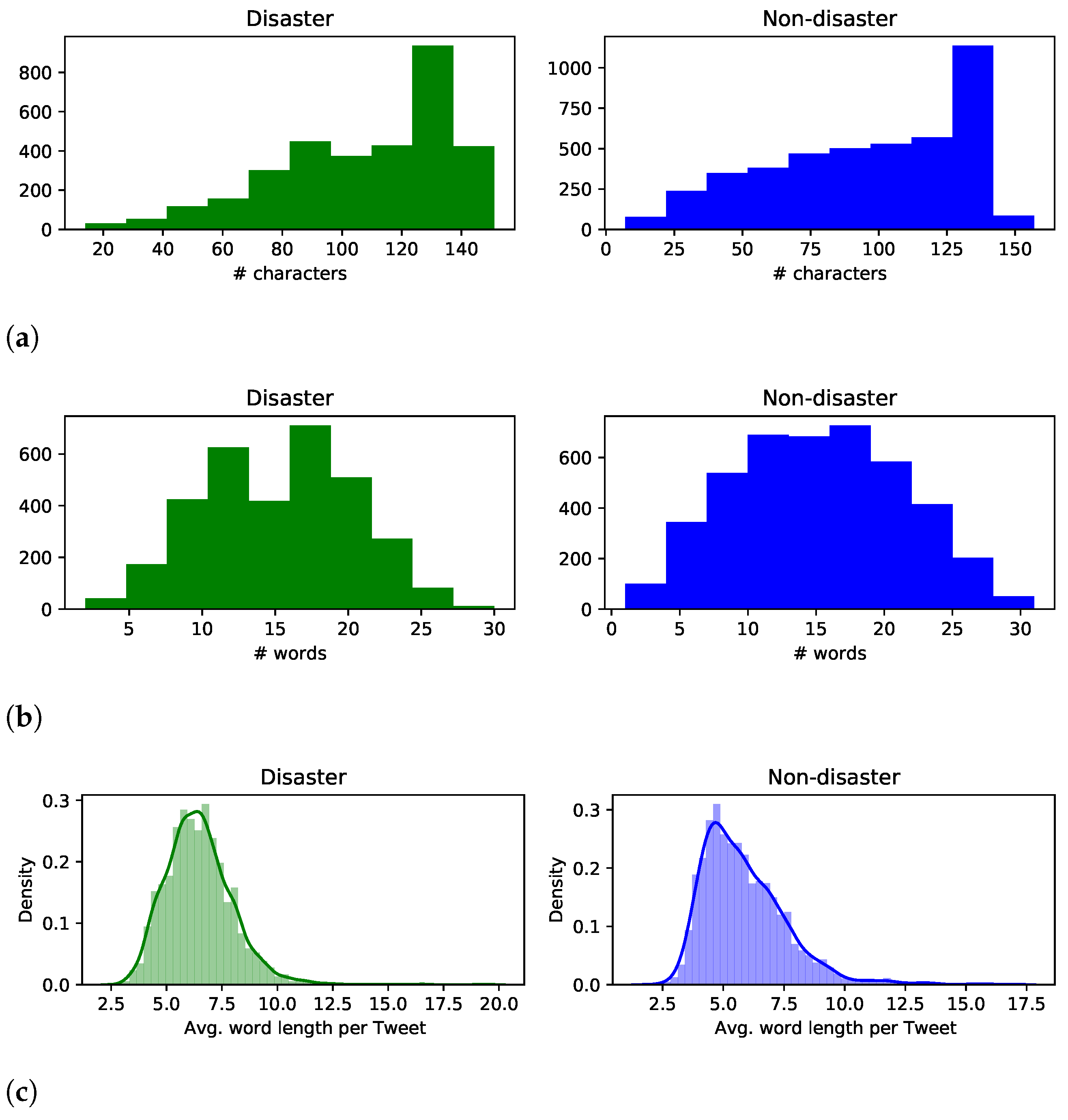
3.1. Dataset
3.2. Data Pre-Processing
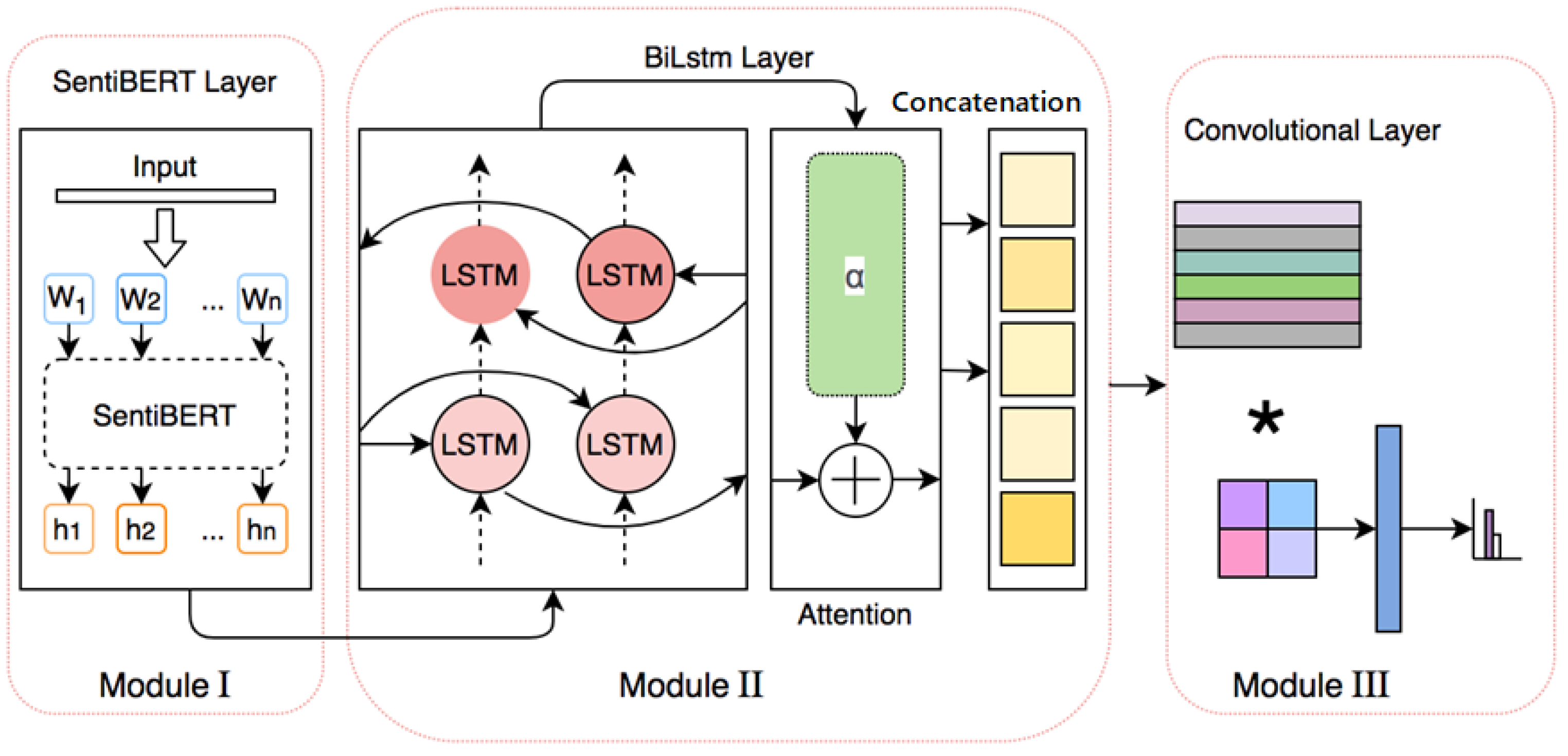
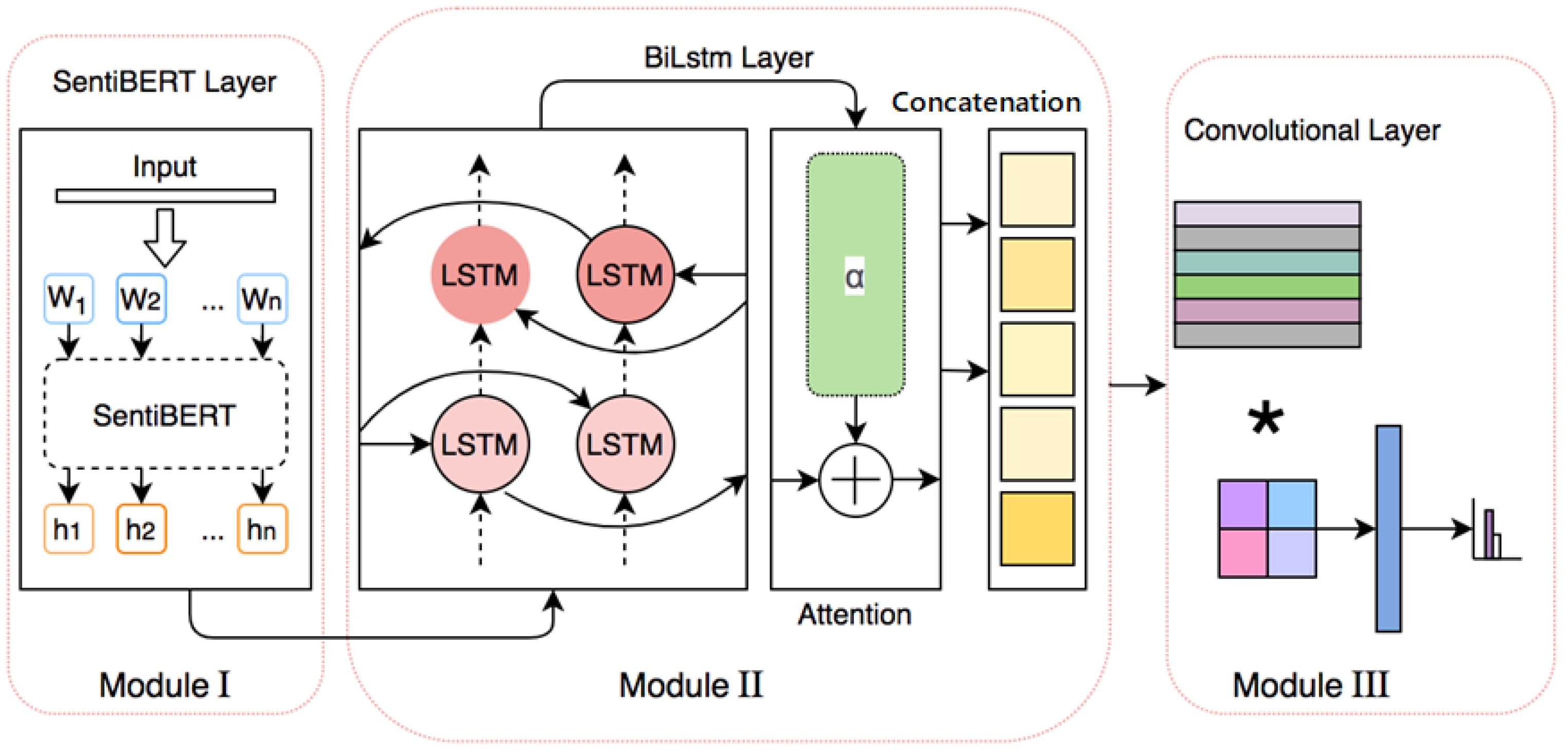
3.3. Overview of the Proposed Learning Pipeline
- SentiBERT is utilized to transform word tokens from the raw Tweet messages to contextual word embeddings. Compared to BERT, SentiBERT is better at understanding and encoding sentiment information.
- BiLSTM is adopted to capture the order information as well as the long-dependency relation in a word sequence.
- CNN acts as a feature extractor that strives to mine textual patterns from the embeddings generated by the BiLSTM module.
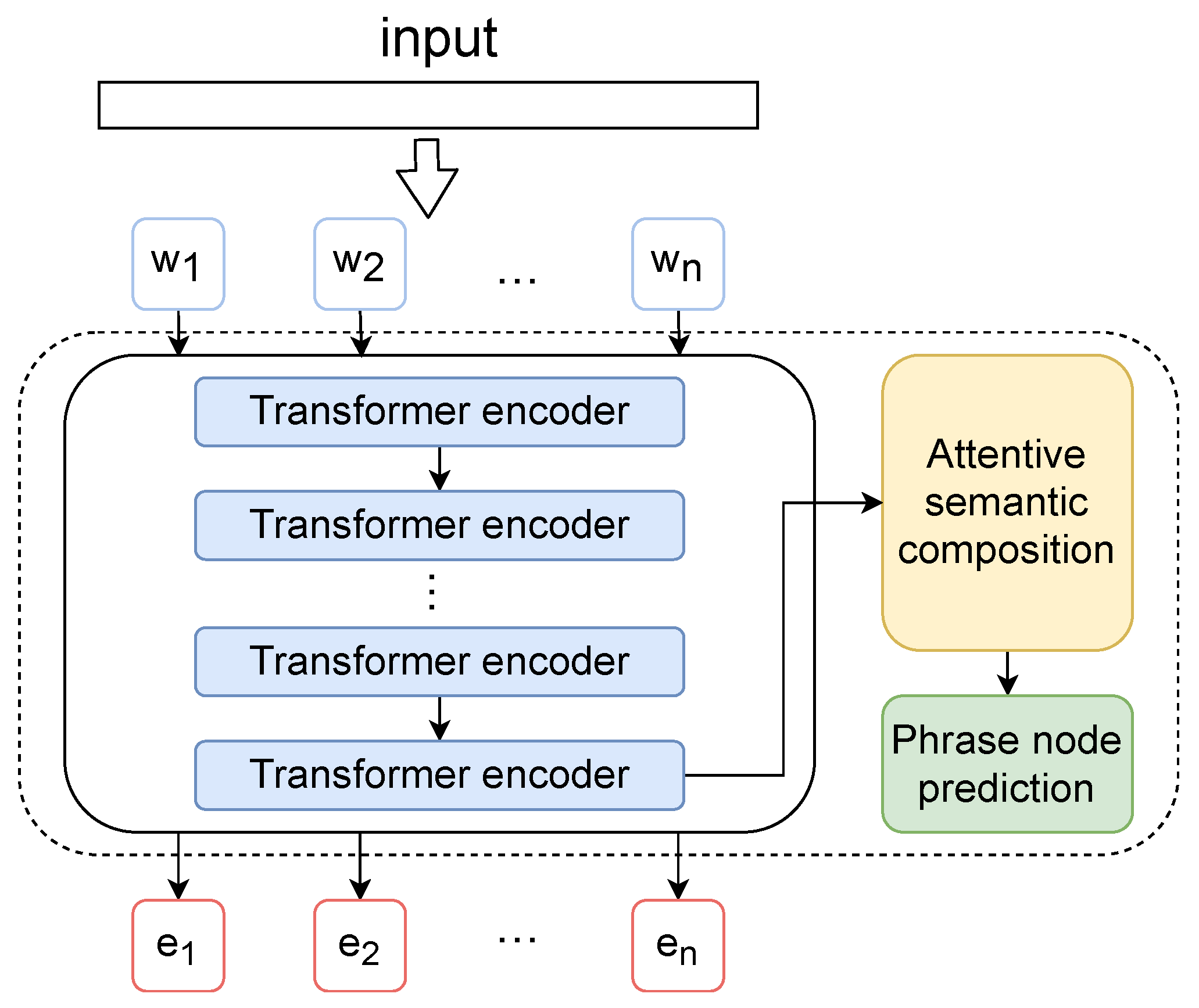
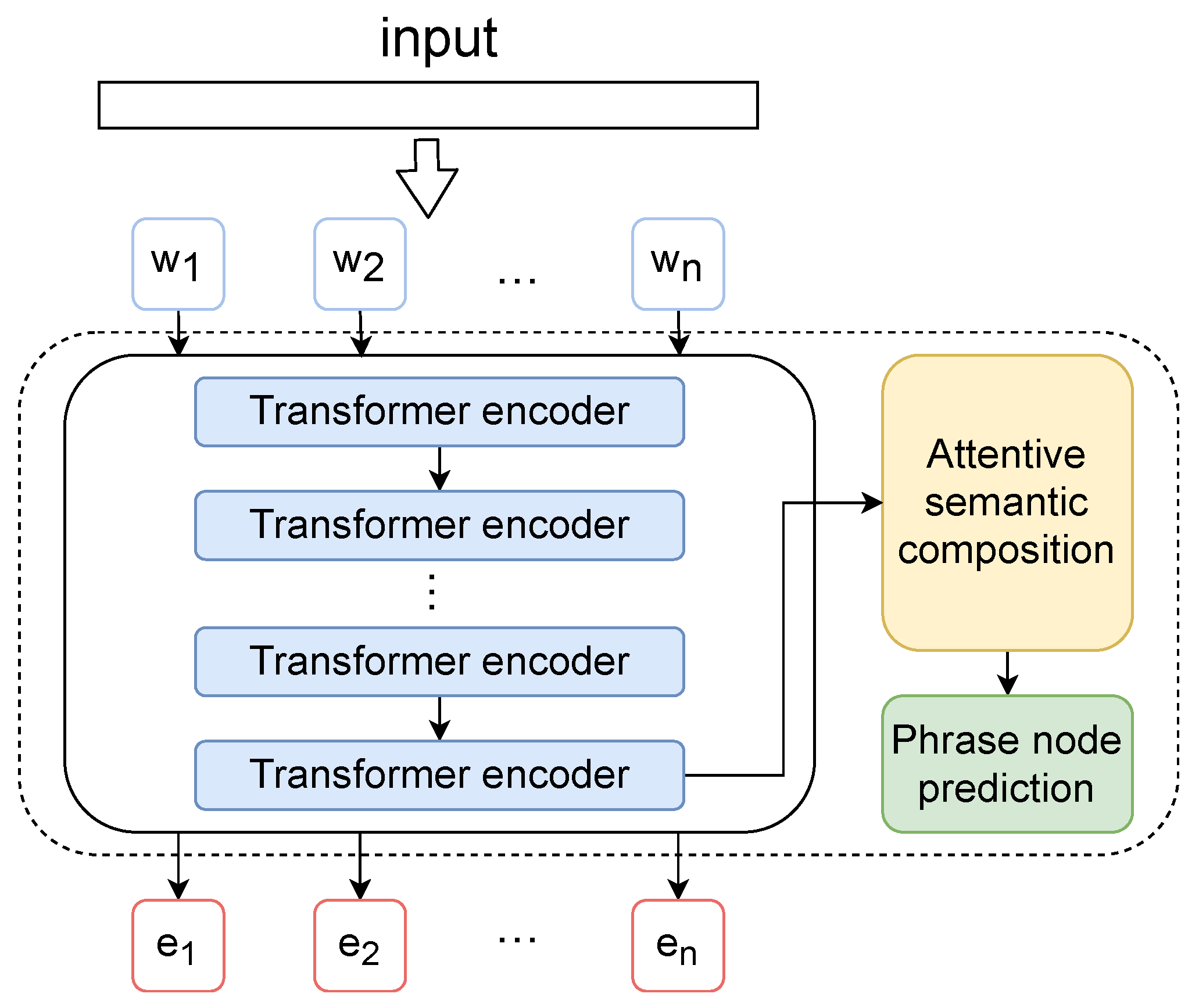
3.4. Sentibert
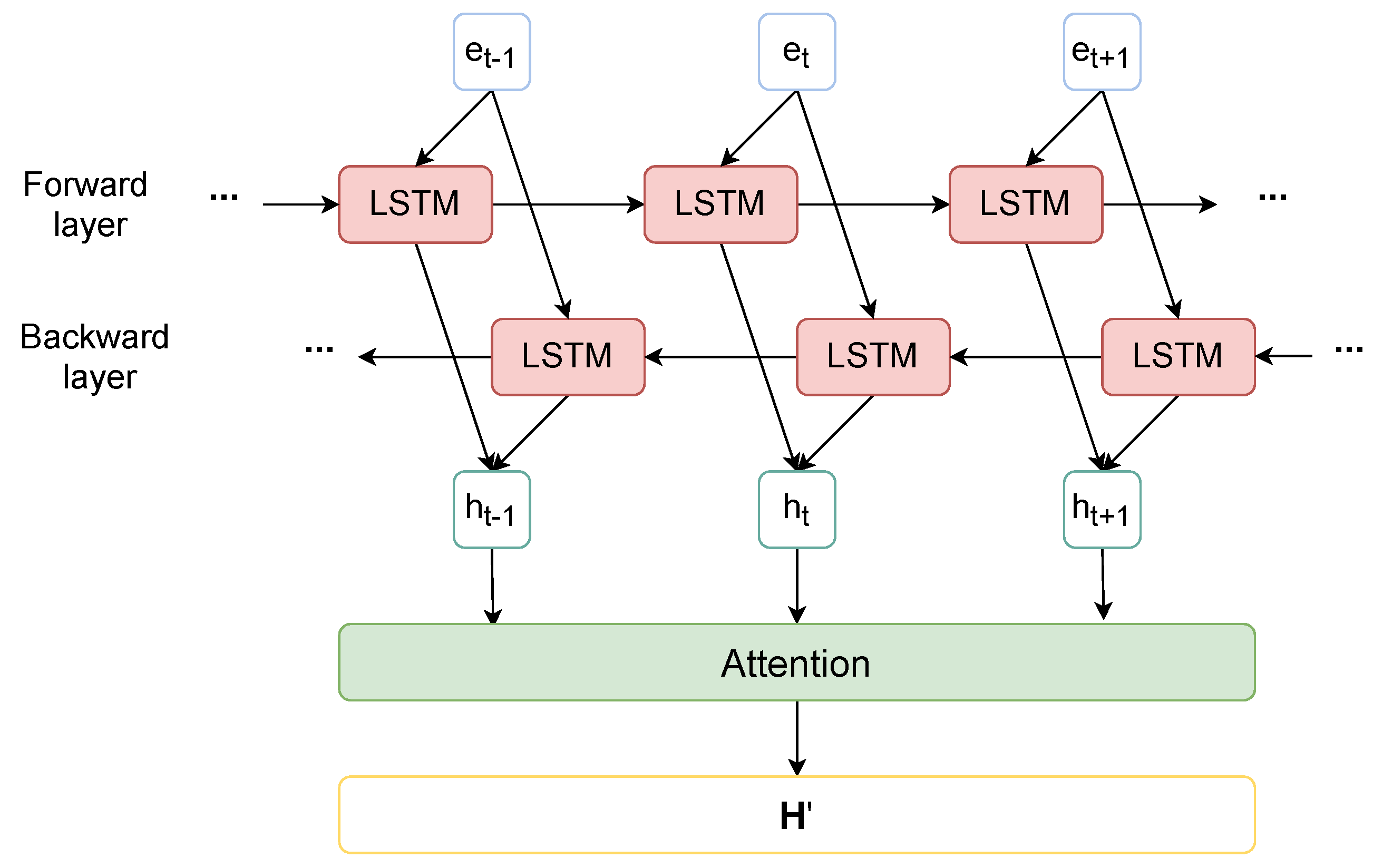
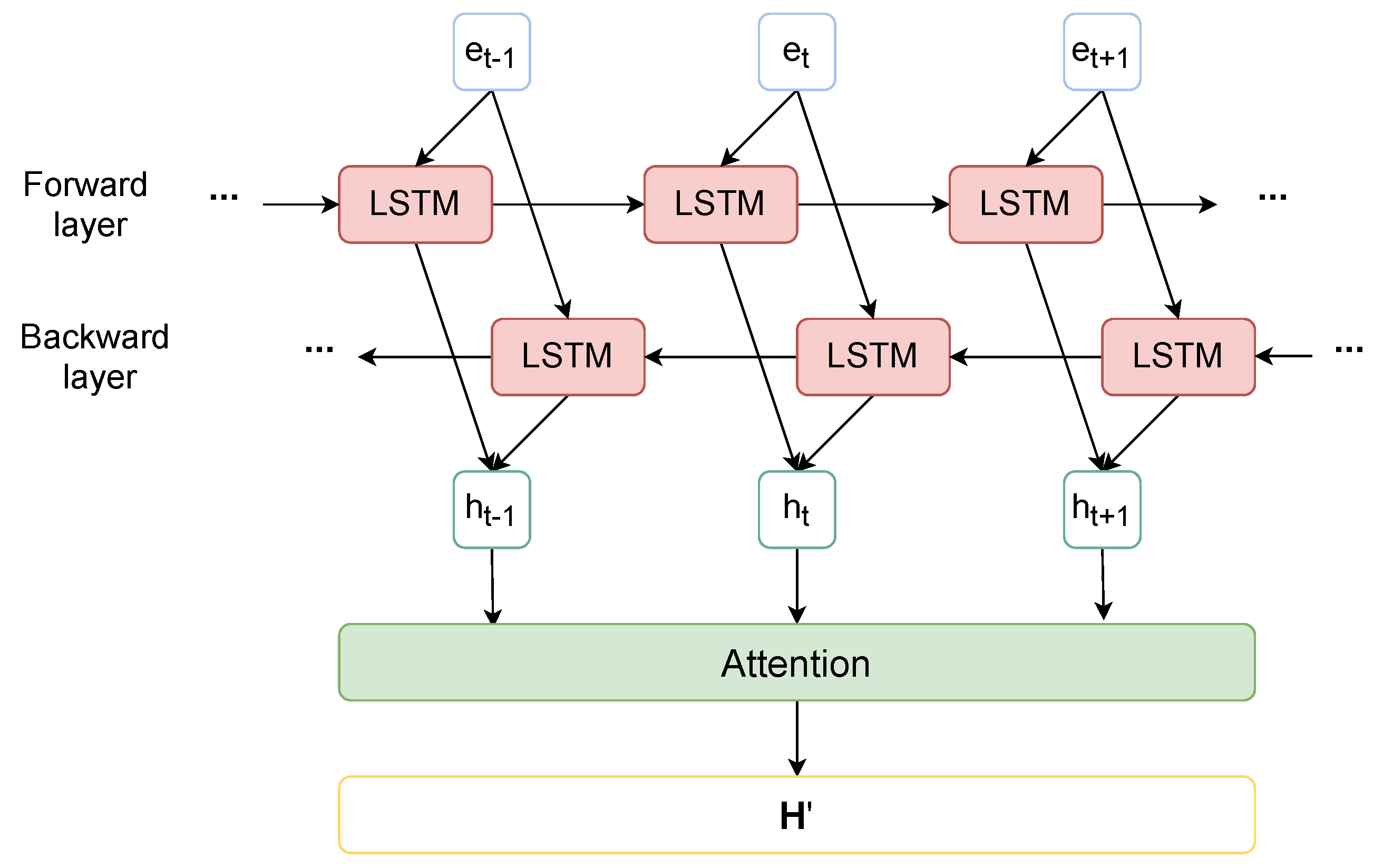
3.5. Bilstm with Attention
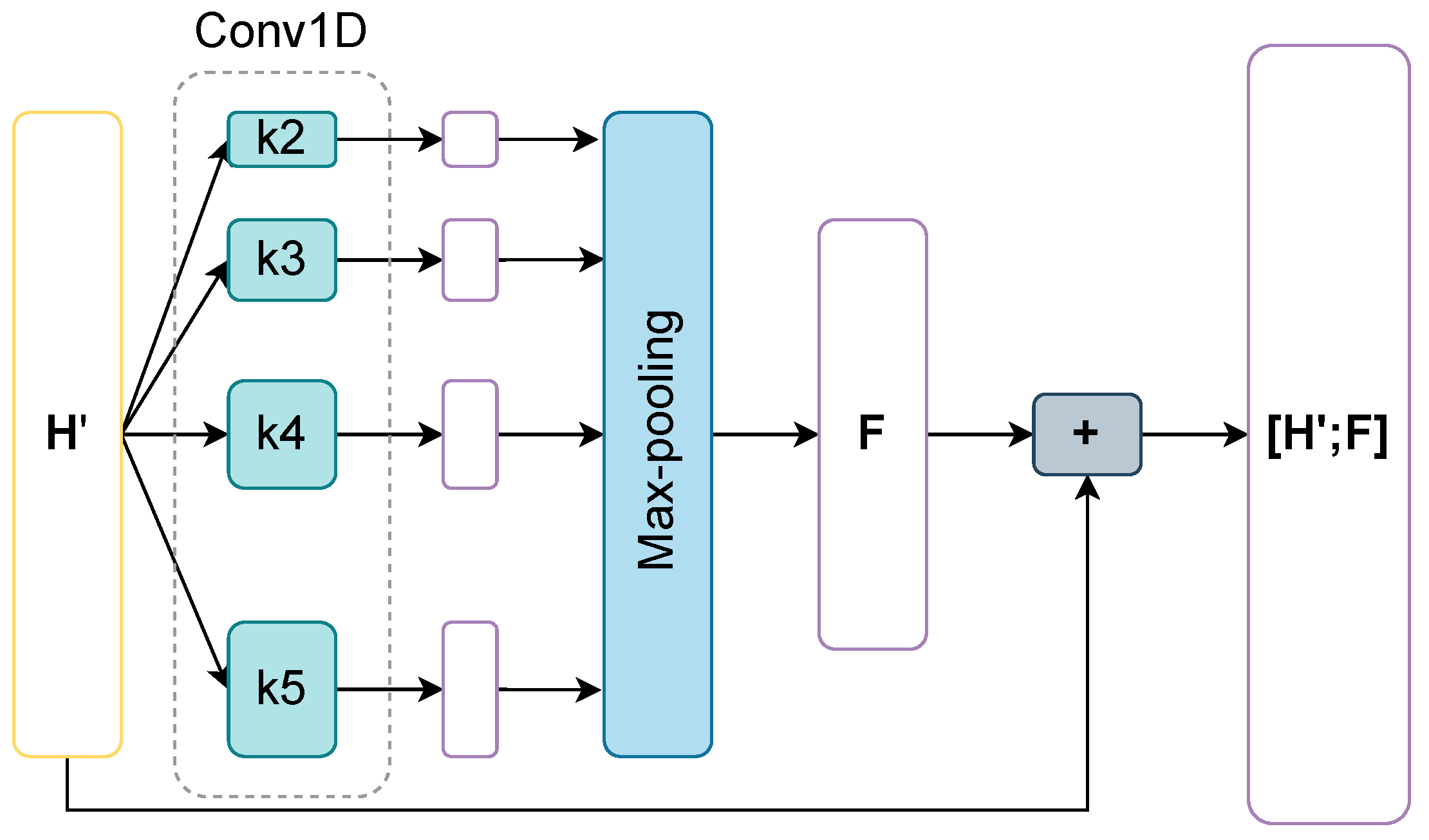
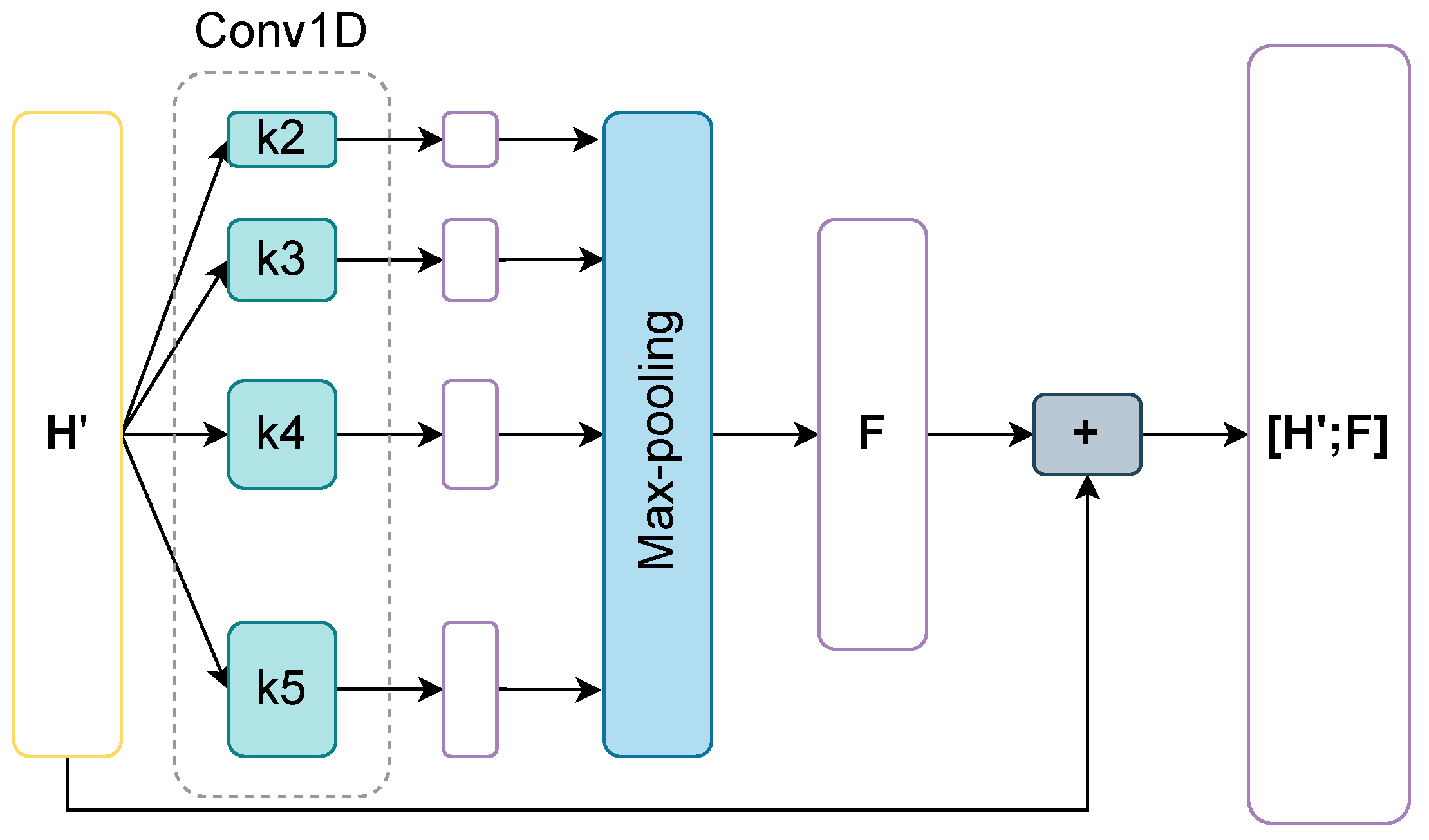
3.6. CNN
3.7. A Fusion of Loss Functions
4. Experiments
4.1. Evaluation Metrics
4.2. Training Setting
4.3. Baseline Model
4.4. Effect of Hyper-Parameter Choices
4.5. The Effect of a Hybrid Loss Function
4.6. Performance Evaluation
- The set of models CNN, BiLSTM, SentiBERT, BiLSTM-CNN, and SentiBERT-BiLSTM-CNN forms an ablation study, from which we can evaluate the performance of each individual module and the combined versions. It can be seen that the pure CNN model performs the worst since a single-layer CNN cannot learn any contextual information. Both BiLSTM (with attention) and SentiBERT present an obvious improvement. SentiBERT is on a par with BiLSTM-CNN in precision, but outperforms it in recall. Our final model, SentiBERT-BiLSTM-CNN tops every other model, showing its power to combine the strength of each individual building block.
- The set of models fastText-BiLSTM-CNN, word2vec-BiLSTM-CNN, BERT-BiLSTM-CNN, and SentiBERT-BiLSTM-CNN are evaluated to compare the effect of word embeddings. FastText [52], word2vec [53], BERT, and SentiBERT are used for the same purpose, i.e., to generate word embeddings. A model’s ability to preserve contextual information determines its performance. From the results, we observe that by adding contextual embeddings, the models gain improvements to varying degrees. SentiBERT-BiLSTM-CNN, as the best-performing model, demonstrates superior capability in encoding contextual information.
- Another observation is that SentiBERT-BiLSTM-CNN outperforms BERT-BiLSTM-CNN by 1.23% in F1, meaning that sentiment in Tweets is a crucial factor that can help detect disaster Tweets, and a sentiment-enhanced BERT validates this hypothesis.
- Lastly, SentiBERT-BiLSTM-CNN outperforms BERThyb, i.e., the SOTA, by 0.77% in F1. Although BERThyb presented the highest precision 0.9413, its precision–recall gap (4.21%) is large, compared to that of SentiBERT-BiLSTM-CNN (0.34%), meaning that BERThyb focuses more on optimizing precision. On the other hand, SentiBERT-BiLSTM-CNN demonstrated a more balanced result in precision and recall.
4.7. Error Analysis
- For the five samples that are marked as disaster Tweets (i.e., samples one through five), none of them are describing a common sense disaster: sample 1 seems to state a personal accident; sample 2 talks about US dollar crisis which may indicate inflation given its context; in sample 3, the phrase “batting collapse” refers to a significant failure of the batting team in a sports game; sample 4 is the closest to a real disaster, but the word “simulate” simply reverses the semantic meaning; sample 5 does mention a disaster “Catastrophic Man-Made Global Warming”, but the user simply expresses his/her opinion against it. Our observation is that the process of manual annotation could introduce some noises that would affect the modeling training. From another perspective, the noises help build more robust classifiers and potentially reduce overfitting.
- For the five negative samples (6–10), we also observe possible cases of mislabeled samples: sample 6 clearly reports a fire accident with the phrase “burning buildings” but was not labeled as a disaster Tweet; sample 7 states a serious traffic accident; sample 8 mentions bio-disaster with the phrase “infectious diseases and bioterrorism”; sample 9 has only three words, and it is hard to tell its class without more context, although the word “bombed” is in the Tweet; sample 10 reflects a person’s suicide intent, which could have been marked as a positive case.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, C.; Weng, J.; He, Q.; Yao, Y.; Datta, A.; Sun, A.; Lee, B.S. Twiner: Named entity recognition in targeted twitter stream. In Proceedings of the 35th international ACM SIGIR Conference on Research and Development in Information Retrieval, Portland, OR, USA, 12–16 August 2012; pp. 721–730. [Google Scholar]
- Ritter, A.; Wright, E.; Casey, W.; Mitchell, T. Weakly supervised extraction of computer security events from twitter. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 896–905. [Google Scholar]
- Soulier, L.; Tamine, L.; Nguyen, G.H. Answering twitter questions: A model for recommending answerers through social collaboration. In Proceedings of the 25th ACM International on Conference on Information and Knowledge Management, Indianapolis, IN, USA, 24–28 October 2016; pp. 267–276. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP); Association for Computational Linguistics: Doha, Qatar, 2014; pp. 1746–1751. [Google Scholar]
- Steinskog, A.; Therkelsen, J.; Gambäck, B. Twitter topic modeling by tweet aggregation. In Proceedings of the 21st Nordic Conference on Computational Linguistics, Gothenburg, Sweden, 22–24 May 2017; pp. 77–86. [Google Scholar]
- Stowe, K.; Paul, M.; Palmer, M.; Palen, L.; Anderson, K.M. Identifying and categorizing disaster-related tweets. In Proceedings of the Fourth International Workshop on Natural Language Processing for Social Media, Austin, TX, USA, 1 November 2016; pp. 1–6. [Google Scholar]
- Bakshi, R.K.; Kaur, N.; Kaur, R.; Kaur, G. Opinion mining and sentiment analysis. In Proceedings of the 2016 3rd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 16–18 March 2016; pp. 452–455. [Google Scholar]
- Go, A.; Bhayani, R.; Huang, L. Twitter sentiment classification using distant supervision. CS224N project report. Stanford 2009, 1, 2009. [Google Scholar]
- Kouloumpis, E.; Wilson, T.; Moore, J. Twitter sentiment analysis: The good the bad and the omg! In Proceedings of the International AAAI Conference on Web and Social Media, Catalonia, Spain, 17–21 July 2011; Volume 5. [Google Scholar]
- Hao, Y.; Mu, T.; Hong, R.; Wang, M.; Liu, X.; Goulermas, J.Y. Cross-domain sentiment encoding through stochastic word embedding. IEEE Trans. Knowl. Data Eng. 2019, 32, 1909–1922. [Google Scholar] [CrossRef] [Green Version]
- Sankaranarayanan, J.; Samet, H.; Teitler, B.E.; Lieberman, M.D.; Sperling, J. Twitterstand: News in tweets. In Proceedings of the 17th ACM Sigspatial International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 4–6 November 2009; pp. 42–51. [Google Scholar]
- Sriram, B.; Fuhry, D.; Demir, E.; Ferhatosmanoglu, H.; Demirbas, M. Short text classification in twitter to improve information filtering. In Proceedings of the 33rd international ACM SIGIR Conference on Research and Development in Information Retrieval, Geneva, Switzerland, 19–23 July 2010; pp. 841–842. [Google Scholar]
- Yin, J.; Lampert, A.; Cameron, M.; Robinson, B.; Power, R. Using social media to enhance emergency situation awareness. IEEE Ann. Hist. Comput. 2012, 27, 52–59. [Google Scholar] [CrossRef]
- Kogan, M.; Palen, L.; Anderson, K.M. Think local, retweet global: Retweeting by the geographically-vulnerable during Hurricane Sandy. In Proceedings of the 18th ACM Conference on Computer Supported Cooperative Work and Social Computing, Vancouver, BC, Canada, 14–18 March 2015; pp. 981–993. [Google Scholar]
- Lamb, A.; Paul, M.; Dredze, M. Separating fact from fear: Tracking flu infections on twitter. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Atlanta, GA, USA, 9–14 June 2013; pp. 789–795. [Google Scholar]
- Verma, S.; Vieweg, S.; Corvey, W.; Palen, L.; Martin, J.; Palmer, M.; Schram, A.; Anderson, K. Natural language processing to the rescue? extracting “situational awareness” tweets during mass emergency. In Proceedings of the International AAAI Conference on Web and Social Media, Catalonia, Spain, 17–21 July 2011; Volume 5. [Google Scholar]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF models for sequence tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Chen, T.; Xu, R.; He, Y.; Wang, X. Improving sentiment analysis via sentence type classification using BiLSTM-CRF and CNN. Expert Syst. Appl. 2017, 72, 221–230. [Google Scholar] [CrossRef] [Green Version]
- Kalchbrenner, N.; Grefenstette, E.; Blunsom, P. A convolutional neural network for modelling sentences. arXiv 2014, arXiv:1404.2188. [Google Scholar]
- Liu, J.; Chang, W.C.; Wu, Y.; Yang, Y. Deep learning for extreme multi-label text classification. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 115–124. [Google Scholar]
- Mou, L.; Men, R.; Li, G.; Xu, Y.; Zhang, L.; Yan, R.; Jin, Z. Natural language inference by tree-based convolution and heuristic matching. arXiv 2015, arXiv:1512.08422. [Google Scholar]
- Pang, L.; Lan, Y.; Guo, J.; Xu, J.; Wan, S.; Cheng, X. Text matching as image recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Wang, J.; Wang, Z.; Zhang, D.; Yan, J. Combining Knowledge with Deep Convolutional Neural Networks for Short Text Classification. In Proceedings of the IJCAI, Melbourne, Australia, 19–25 August 2017; Volume 350. [Google Scholar]
- Karimi, S.; Dai, X.; Hassanzadeh, H.; Nguyen, A. Automatic diagnosis coding of radiology reports: A comparison of deep learning and conventional classification methods. In Proceedings of the BioNLP 2017, Vancouver, BC, Canada, 4 August 2017; pp. 328–332. [Google Scholar]
- Peng, S.; You, R.; Wang, H.; Zhai, C.; Mamitsuka, H.; Zhu, S. DeepMeSH: Deep semantic representation for improving large-scale MeSH indexing. Bioinformatics 2016, 32, i70–i79. [Google Scholar] [CrossRef] [Green Version]
- Rios, A.; Kavuluru, R. Convolutional neural networks for biomedical text classification: Application in indexing biomedical articles. In Proceedings of the 6th ACM Conference on Bioinformatics, Computational Biology and Health Informatics, Atlanta, GA, USA, 9–12 September 2015; pp. 258–267. [Google Scholar]
- Hughes, M.; Li, I.; Kotoulas, S.; Suzumura, T. Medical text classification using convolutional neural networks. Stud. Health Technol. Inform. 2017, 235, 246–250. [Google Scholar]
- Kowsari, K.; Brown, D.E.; Heidarysafa, M.; Meim, K.J.; Gerber, M.S.; Barnes, L.E. Hdltex: Hierarchical deep learning for text classification. In Proceedings of the 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017; pp. 364–371. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A lite bert for self-supervised learning of language representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Joshi, M.; Chen, D.; Liu, Y.; Weld, D.S.; Zettlemoyer, L.; Levy, O. Spanbert: Improving pre-training by representing and predicting spans. Trans. Assoc. Comput. Linguist. 2020, 8, 64–77. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Sun, Y.; Wang, S.; Li, Y.; Feng, S.; Tian, H.; Wu, H.; Wang, H. Ernie 2.0: A continual pre-training framework for language understanding. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8968–8975. [Google Scholar]
- Liu, X.; Cheng, H.; He, P.; Chen, W.; Wang, Y.; Poon, H.; Gao, J. Adversarial training for large neural language models. arXiv 2020, arXiv:2004.08994. [Google Scholar]
- Graves, A.; Jaitly, N.; Mohamed, A.R. Hybrid speech recognition with deep bidirectional LSTM. In Proceedings of the 2013 IEEE Workshop on Automatic Speech Recognition and Understanding, Olomouc, Czech Republic, 8–12 December 2013; pp. 273–278. [Google Scholar]
- Kaliyar, R.K.; Goswami, A.; Narang, P. FakeBERT: Fake news detection in social media with a BERT-based deep learning approach. Multimed. Tools Appl. 2021, 80, 11765–11788. [Google Scholar] [CrossRef]
- Harrag, F.; Debbah, M.; Darwish, K.; Abdelali, A. Bert transformer model for detecting Arabic GPT2 auto-generated tweets. arXiv 2021, arXiv:2101.09345. [Google Scholar]
- Mozafari, M.; Farahbakhsh, R.; Crespi, N. A BERT-based transfer learning approach for hate speech detection in online social media. In International Conference on Complex Networks and Their Applications; Springer: Cham, Switzerland, 2019; pp. 928–940. [Google Scholar]
- Eke, C.I.; Norman, A.A.; Shuib, L. Context-Based Feature Technique for Sarcasm Identification in Benchmark Datasets Using Deep Learning and BERT Model. IEEE Access 2021, 9, 48501–48518. [Google Scholar] [CrossRef]
- Palshikar, G.K.; Apte, M.; Pandita, D. Weakly supervised and online learning of word models for classification to detect disaster reporting tweets. Inf. Syst. Front. 2018, 20, 949–959. [Google Scholar] [CrossRef]
- Algur, S.P.; Venugopal, S. Classification of Disaster Specific Tweets-A Hybrid Approach. In Proceedings of the 2021 8th International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 17–19 March 2021; pp. 774–777. [Google Scholar]
- Singh, J.P.; Dwivedi, Y.K.; Rana, N.P.; Kumar, A.; Kapoor, K.K. Event classification and location prediction from tweets during disasters. Ann. Oper. Res. 2019, 283, 737–757. [Google Scholar] [CrossRef] [Green Version]
- Madichetty, S.; Sridevi, M. Detecting informative tweets during disaster using deep neural networks. In Proceedings of the 2019 11th International Conference on Communication Systems & Networks (COMSNETS), Bengaluru, India, 7–11 January 2019; pp. 709–713. [Google Scholar]
- Joao, R.S. On Informative Tweet Identification For Tracking Mass Events. arXiv 2021, arXiv:2101.05656. [Google Scholar]
- Li, H.; Caragea, D.; Caragea, C.; Herndon, N. Disaster response aided by tweet classification with a domain adaptation approach. J. Contingencies Crisis Manag. 2018, 26, 16–27. [Google Scholar] [CrossRef] [Green Version]
- Ansah, J.; Liu, L.; Kang, W.; Liu, J.; Li, J. Leveraging burst in twitter network communities for event detection. World Wide Web 2020, 23, 2851–2876. [Google Scholar] [CrossRef]
- Saeed, Z.; Abbasi, R.A.; Razzak, I. Evesense: What can you sense from twitter? In European Conference on Information Retrieval; Springer: Cham, Switzerland, 2020; pp. 491–495. [Google Scholar]
- Sani, A.M.; Moeini, A. Real-time Event Detection in Twitter: A Case Study. In Proceedings of the 2020 6th International Conference on Web Research (ICWR), Tehran, Iran, 22–23 April 2020; pp. 48–51. [Google Scholar]
- Yin, D.; Meng, T.; Chang, K.W. Sentibert: A transferable transformer-based architecture for compositional sentiment semantics. arXiv 2020, arXiv:2005.04114. [Google Scholar]
- Song, G.; Huang, D.; Xiao, Z. A Study of Multilingual Toxic Text Detection Approaches under Imbalanced Sample Distribution. Information 2021, 12, 205. [Google Scholar] [CrossRef]
- Bojanowski, P.; Edouard, G.; Arm, J.; Tomas, M. Enriching word vectors with subword information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef] [Green Version]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Alam, F.; Qazi, U.; Imran, M.; Ofli, F. HumAID: Human-Annotated Disaster Incidents Data from Twitter with Deep Learning Benchmarks. arXiv 2021, arXiv:2104.03090. [Google Scholar]
- Alam, F.; Ofli, F.; Imran, M. Crisismmd: Multimodal twitter datasets from natural disasters. In Proceedings of the International AAAI Conference on Web and Social Media, Stanford, CA, USA, 25–28 June 2018; Volume 12. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Sample Tweet | Class |
|---|---|---|
| 1 | Grego saw that pileup on TV keep racing even bleeding. | + |
| 2 | Family members who killed in an airplane’s accident. | + |
| 3 | Pendleton media office said only fire on base right now is the Horno blaze. | + |
| 4 | I know it’s a question of interpretation but this is a sign of the apocalypse. | + |
| 5 | bleeding on the brain don’t know the cause. | − |
| 6 | alrighty Hit me up and we’ll blaze!! | − |
| 7 | waiting for an ambulance. | − |
| 8 | Apocalypse please. | − |
| Epochs | Batch Size | Precision | Recall | F1 Score |
|---|---|---|---|---|
| 6 | 32 | 0.8525 | 0.8478 | 0.8501 |
| 16 | 0.8495 | 0.8364 | 0.8429 | |
| 8 | 32 | 0.8654 | 0.8701 | 0.8677 |
| 16 | 0.8643 | 0.8618 | 0.8630 | |
| 10 | 32 | 0.8987 | 0.8932 | 0.8959 |
| 16 | 0.8903 | 0.8827 | 0.8865 | |
| 12 | 32 | 0.8848 | 0.8956 | 0.8902 |
| 16 | 0.8817 | 0.8893 | 0.8855 | |
| 14 | 32 | 0.8902 | 0.9012 | 0.8957 |
| 16 | 0.8949 | 0.8878 | 0.8913 |
| Loss Function | Epochs | Batch Size | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| 10 | 32 | 0.8987 | 0.8932 | 0.8959 | |
| 10 | 32 | 0.9029 | 0.9135 | 0.9082 | |
| 10 | 32 | 0.9305 | 0.9271 | 0.9275 |
| Model | Precision | Recall | F1 Score |
|---|---|---|---|
| CNN | 0.8064 | 0.8086 | 0.8025 |
| BiLSTM | 0.8571 | 0.8405 | 0.8487 |
| SentiBERT | 0.8668 | 0.8712 | 0.8690 |
| BiLSTM-CNN | 0.8674 | 0.8523 | 0.8598 |
| word2vec-BiLSTM-CNN | 0.8831 | 0.8767 | 0.8799 |
| fastText-BiLSTM-CNN | 0.8935 | 0.8736 | 0.8834 |
| BERT-BiLSTM-CNN | 0.9118 | 0.9187 | 0.9152 |
| BERThyb | 0.9413 | 0.8992 | 0.9198 |
| SentiBERT-BiLSTM-CNN | 0.9305 | 0.9271 | 0.9275 |
| ID | Sample Tweet | Label | Prediction |
|---|---|---|---|
| 1 | I was wrong to call it trusty actually. considering it spontaneously collapsed on me that’s not very trusty. | + | − |
| 2 | Prices here are insane. Our dollar has collapsed against the US and it’s punishing us. Thanks for the info. | + | − |
| 3 | Now that’s what you call a batting collapse. | + | − |
| 4 | Emergency units simulate a chemical explosion at NU. | + | − |
| 5 | 99% of Scientists don’t believe in Catastrophic Man-Made Global Warming only the deluded do. | + | − |
| 6 | all illuminated by the brightly burning buildings all around the town! | − | + |
| 7 | That or they might be killed in an airplane accident in the night a car wreck! Politics at it’s best. | − | + |
| 8 | automation in the fight against infectious diseases and bioterrorism | − | + |
| 9 | misfit got bombed. | − | + |
| 10 | Because I need to know if I’m supposed to throw myself off a bridge for a #Collapse or plan the parade. There is no both. | − | + |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, G.; Huang, D. A Sentiment-Aware Contextual Model for Real-Time Disaster Prediction Using Twitter Data. Future Internet 2021, 13, 163. https://doi.org/10.3390/fi13070163
Song G, Huang D. A Sentiment-Aware Contextual Model for Real-Time Disaster Prediction Using Twitter Data. Future Internet. 2021; 13(7):163. https://doi.org/10.3390/fi13070163
Chicago/Turabian StyleSong, Guizhe, and Degen Huang. 2021. "A Sentiment-Aware Contextual Model for Real-Time Disaster Prediction Using Twitter Data" Future Internet 13, no. 7: 163. https://doi.org/10.3390/fi13070163
APA StyleSong, G., & Huang, D. (2021). A Sentiment-Aware Contextual Model for Real-Time Disaster Prediction Using Twitter Data. Future Internet, 13(7), 163. https://doi.org/10.3390/fi13070163