
Video Captioning Based on Channel Soft Attention and Semantic Reconstructor


Abstract
1. Introduction
- A deep learning framework for video captioning is proposed, which optimizes the Sequential VLAD encoding by channel soft attention and leverages the semantic information by a semantic reconstructor.
- An effective attention module is implemented, which exploits the temporal structure for each channel, where the c-th channel of input feature maps at t-th time step is the weighted sum of c-th channel of all feature maps.
- A semantic reconstructor network is proposed which is composed of LSTM to assist the decoder to fully use the semantic information.
2. Related Work
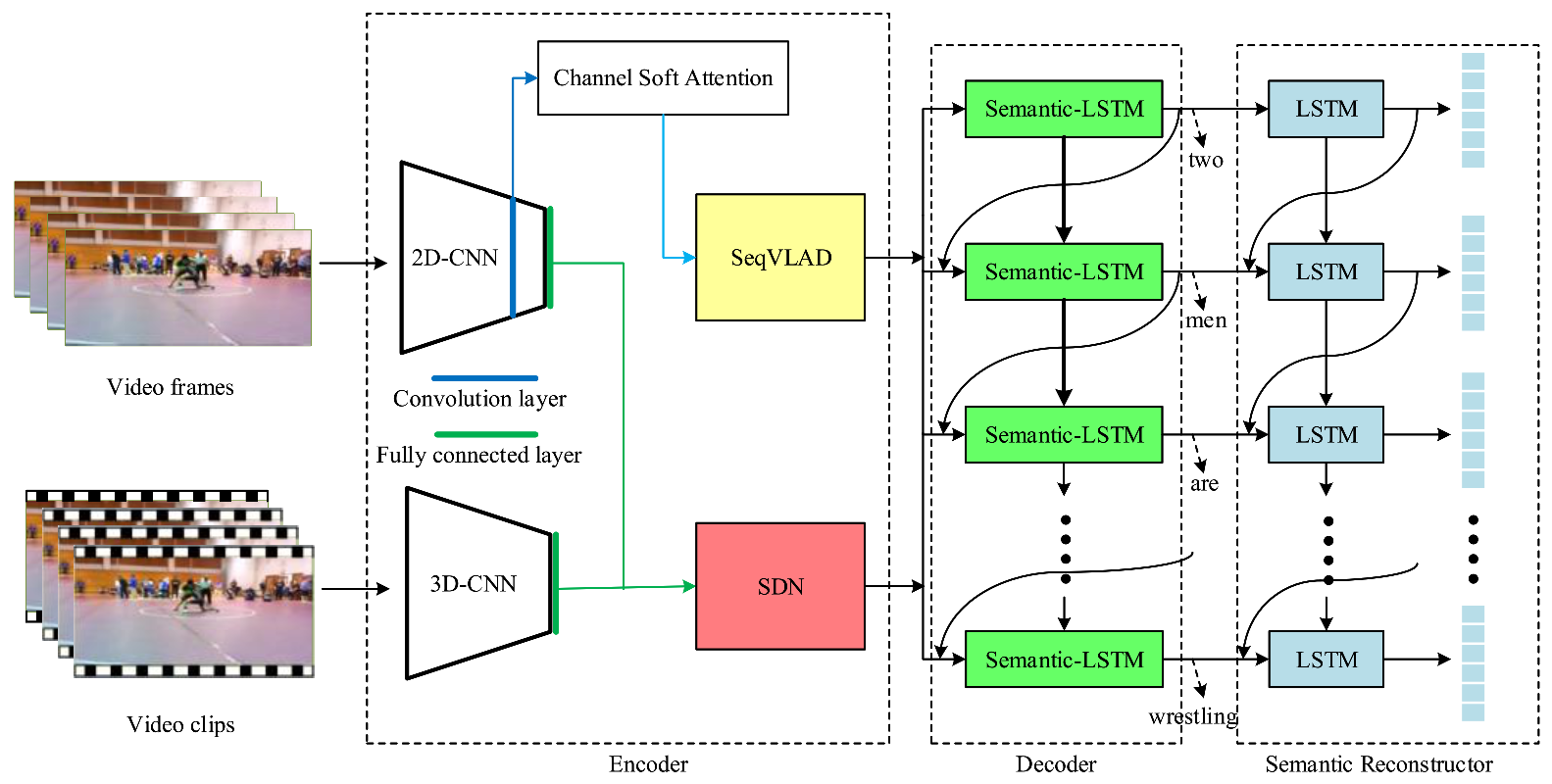
3. Method
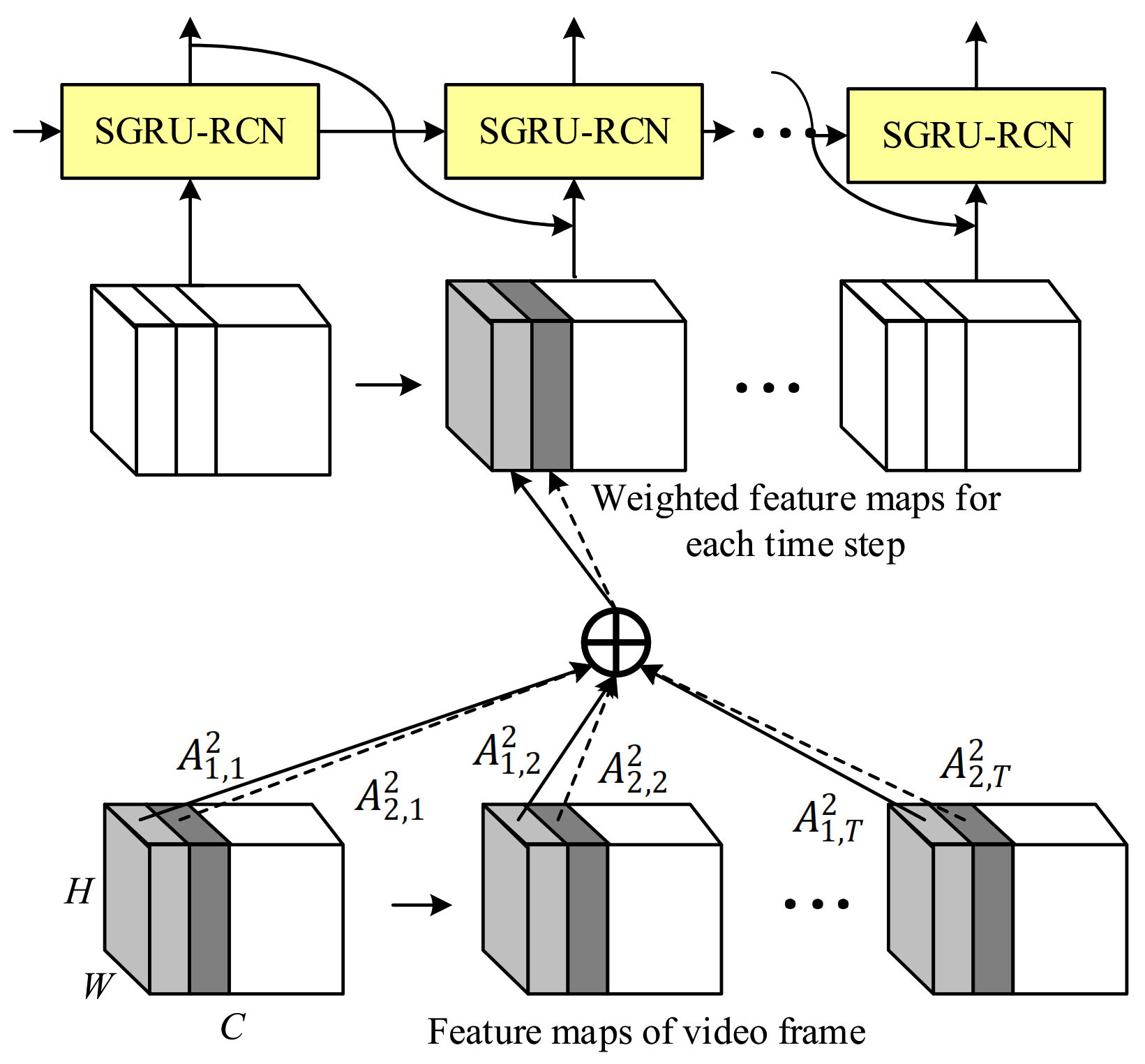
3.1. VLAD and SeqVLAD
3.2. Channel Soft Attention
3.3. Semantic Reconstruction Network
3.4. Training
4. Experimental Evaluation
4.1. Datasets
4.2. Evaluation Metrics
4.3. Implementation Details
4.4. Results and Analysis
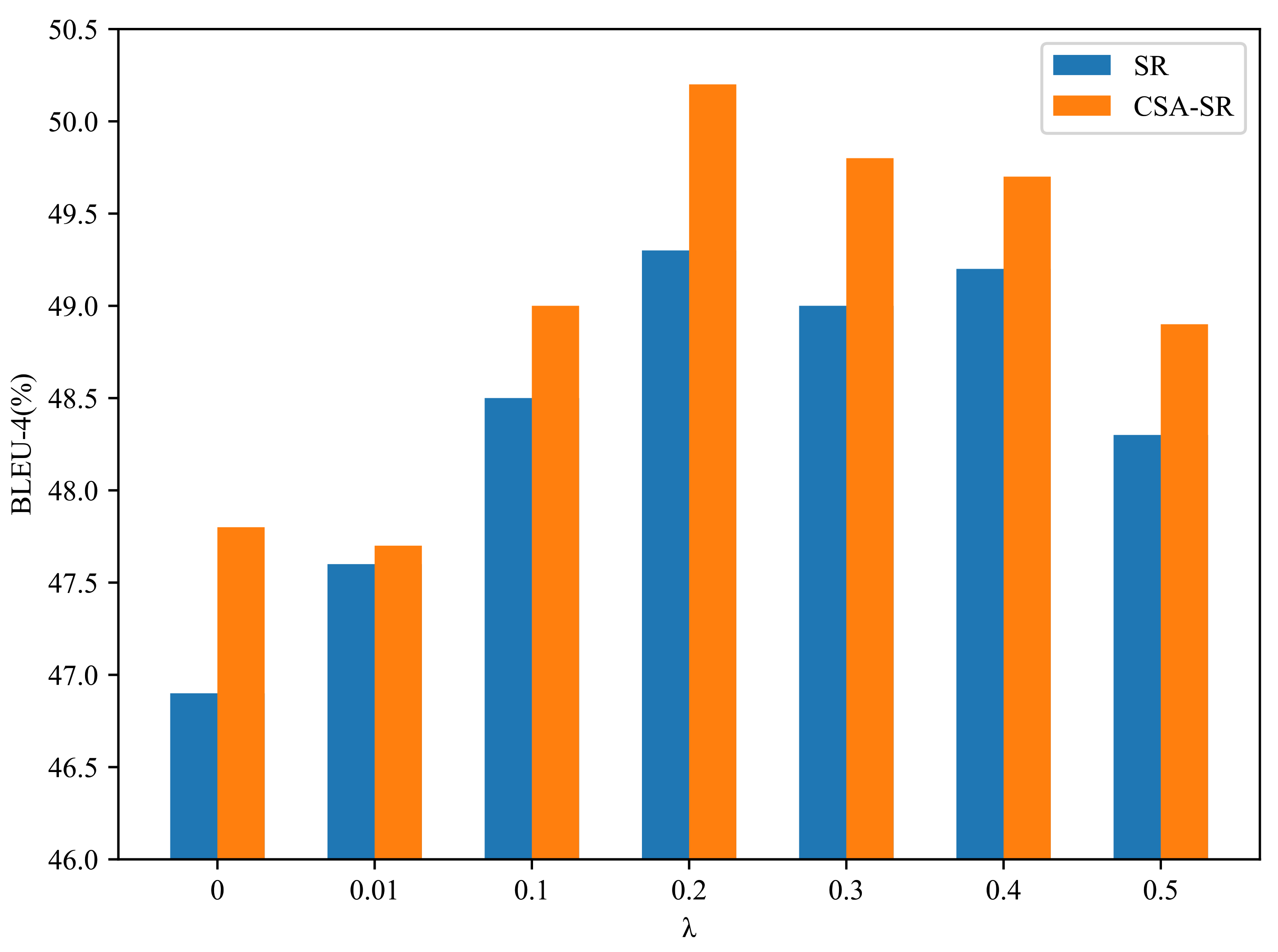
4.4.1. Study on Modules
4.4.2. Results on MSVD Dataset
- S2VT [20] is an encoder–decoder framework with two layers of LSTM, where the first layer encodes the video representation and the second generates video descriptions.
- SA [21] which is based on temporal attention focuses on both the local and global temporal structure of the video, and select the most relevant temporal segments automatically.
- h-RNN [44] introduces a hierarchical structure for sentence generator and paragraph generator. Both sentence generator and paragraph generator are made up of the recurrent neural network.
- HRNE [45] is a hierarchical recurrent neural encoder with a soft attention mechanism and explores the temporal transitions between frame chunks with different granularities.
- SCN-LSTM [11] detects semantic tags before training caption models, and uses semantic compositional networks to embed semantic information for caption generating.
- PickNet [46] selects the useful part of video frames for the encoder–decoder framework. It aims to reduce the computation and the noise caused by redundant frames.
- TDDF [47] uses a task-driven dynamic fusion mechanism to reduce the ambiguity in the video description and refines the degree of the description of the video content.
- RecNet [24] is a dual learning model that has forward flow and backward flow while training a model. The video representation will be reconstructed using the output of the decoder.
- TDConvED [48] introduces a TDConvED that constructs encoder and decoder by fully use convolutions.
- GRU-EVE [49] mainly applied Short Fourier Transform into CNN features which could enrich the visual features with temporal dynamics.
4.4.3. Results on MSR-VTT Dataset
4.4.4. User Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, H.; Klaser, A.; Schmid, C.; Liu, C.L. Action Recognition by Dense Trajectories. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Springs, CO, USA, 20–25 June 2011; IEEE Computer Society: Los Alamitos, CA, USA, 2011; pp. 3169–3176. [Google Scholar] [CrossRef]
- Wang, H.; Schmid, C. Action Recognition with Improved Trajectories. In Proceedings of the 2013 IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2013; IEEE Computer Society: Los Alamitos, CA, USA, 2013; pp. 3551–3558. [Google Scholar] [CrossRef]
- Jegou, H.; Schmid, C.; Douze, M.; Perez, P. Aggregating local descriptors into a compact image representation. In Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; IEEE Computer Society: Los Alamitos, CA, USA, 2010; pp. 3304–3311. [Google Scholar] [CrossRef]
- Sánchez, J.; Perronnin, F.; Mensink, T.; Verbeek, J. Image Classification with the Fisher Vector: Theory and Practice. Int. J. Comput. Vision 2013, 105, 222–245. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 12–17 June 2015; pp. 1–9. [Google Scholar]
- Xu, Y.; Han, Y.; Hong, R.; Tian, Q. Sequential Video VLAD: Training the Aggregation Locally and Temporally. IEEE Trans. Image Process. 2018, 27, 4933–4944. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the 2018 European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Cham, Germany, 2018; pp. 3–19. [Google Scholar]
- Luong, T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-based Neural Machine Translation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; Association for Computational Linguistics: Lisbon, Portugal, 2015; pp. 1412–1421. [Google Scholar] [CrossRef]
- You, Q.; Jin, H.; Wang, Z.; Fang, C.; Luo, J. Image Captioning with Semantic Attention. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4651–4659. [Google Scholar]
- Wu, Q.; Shen, C.; Liu, L.; Dick, A.; Van Den Hengel, A. What Value Do Explicit High Level Concepts Have in Vision to Language Problems? In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 203–212. [Google Scholar]
- Gan, Z.; Gan, C.; He, X.; Pu, Y.; Tran, K.; Gao, J.; Carin, L.; Deng, L. Semantic Compositional Networks for Visual Captioning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1141–1150. [Google Scholar]
- Chen, D.L.; Dolan, W.B. Collecting Highly Parallel Data for Paraphrase Evaluation. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2021; Association for Computational Linguistics: St. Stroudsburg, PA, USA, 2011; Volume 1, pp. 190–200. [Google Scholar]
- Xu, J.; Mei, T.; Yao, T.; Rui, Y. MSR-VTT: A Large Video Description Dataset for Bridging Video and Language. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 5288–5296. [Google Scholar]
- Lebret, R.; Pinheiro, P.O.; Collobert, R. Phrase-Based Image Captioning. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, Lille, France, 6–11 July 2015; Volume 37, pp. 2085–2094. [Google Scholar]
- Rohrbach, M.; Qiu, W.; Titov, I.; Thater, S.; Pinkal, M.; Schiele, B. Translating Video Content to Natural Language Descriptions. In Proceedings of the 2013 IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2013; IEEE Computer Society: Los Alamitos, CA, USA, 2013; pp. 433–440. [Google Scholar] [CrossRef]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 12–17 June 2015; pp. 3156–3164. [Google Scholar]
- Donahue, J.; Hendricks, L.A.; Rohrbach, M.; Venugopalan, S.; Guadarrama, S.; Saenko, K.; Darrell, T. Long-Term Recurrent Convolutional Networks for Visual Recognition and Description. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 677–691. [Google Scholar] [CrossRef]
- Venugopalan, S.; Xu, H.; Donahue, J.; Rohrbach, M.; Mooney, R.; Saenko, K. Translating Videos to Natural Language Using Deep Recurrent Neural Networks. arXiv 2014, arXiv:1412.4729. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vision 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Venugopalan, S.; Rohrbach, M.; Donahue, J.; Mooney, R.; Darrell, T.; Saenko, K. Sequence to Sequence—Video to Text. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 11–18 December 2015; IEEE Computer Society: Los Alamitos, CA, USA, 2015; pp. 4534–4542. [Google Scholar] [CrossRef]
- Yao, L.; Torabi, A.; Cho, K.; Ballas, N.; Pal, C.; Larochelle, H.; Courville, A. Describing Videos by Exploiting Temporal Structure. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 11–18 December 2015; IEEE Computer Society: Los Alamitos, CA, USA, 2015; pp. 4507–4515. [Google Scholar] [CrossRef]
- Pan, Y.; Mei, T.; Yao, T.; Li, H.; Rui, Y. Jointly Modeling Embedding and Translation to Bridge Video and Language. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4594–4602. [Google Scholar]
- Pan, Y.; Yao, T.; Li, H.; Mei, T. Video Captioning with Transferred Semantic Attributes. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 984–992. [Google Scholar]
- Wang, B.; Ma, L.; Zhang, W.; Liu, W. Reconstruction Network for Video Captioning. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7622–7631. [Google Scholar]
- Stollenga, M.F.; Masci, J.; Gomez, F.; Schmidhuber, J. Deep Networks with Internal Selective Attention through Feedback Connections. In Proceedings of the 27th International Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–11 December 2014; MIT Press: Cambridge, MA, USA, 2014; pp. 3545–3553. [Google Scholar]
- Chorowski, J.; Bahdanau, D.; Serdyuk, D.; Cho, K.; Bengio, Y. Attention-Based Models for Speech Recognition. In Proceedings of the 28th International Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 7–10 December 2015; MIT Press: Cambridge, MA, USA, 2015; pp. 577–585. [Google Scholar]
- Pan, Y.; Yao, T.; Li, Y.; Mei, T. X-Linear Attention Networks for Image Captioning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 14–15 June 2020; pp. 10968–10977. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef]
- Ray, S.; Chandra, N. Domain Based Ontology and Automated Text Categorization Based on Improved Term Frequency—Inverse Document Frequency. Int. J. Mod. Educ. Comput. Sci. 2012, 4. [Google Scholar] [CrossRef]
- Kastrati, Z.; Imran, A.S.; Yayilgan, S.Y. The impact of deep learning on document classification using semantically rich representations. Inf. Process. Manag. 2019, 56, 1618–1632. [Google Scholar] [CrossRef]
- Guadarrama, S.; Krishnamoorthy, N.; Malkarnenkar, G.; Venugopalan, S.; Mooney, R.; Darrell, T.; Saenko, K. YouTube2Text: Recognizing and Describing Arbitrary Activities Using Semantic Hierarchies and Zero-Shot Recognition. In Proceedings of the 2013 IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, 1–3 December 2013; IEEE Computer Society: Los Alamitos, CA, USA, 2013; pp. 2712–2719. [Google Scholar] [CrossRef]
- Lavie, A.; Agarwal, A. Meteor: An Automatic Metric for MT Evaluation with High Levels of Correlation with Human Judgments. In Proceedings of the Second Workshop on Statistical Machine Translation, Stroudsburg, PA, USA, 23 June 2007; pp. 228–231. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2020; Association for Computational Linguistics: St. Stroudsburg, PA, USA, 2002; pp. 311–318. [Google Scholar] [CrossRef]
- Lin, C.Y. ROUGE: A Package for Automatic Evaluation of Summaries. In Text Summarization Branches Out; Association for Computational Linguistics: Barcelona, Spain, 2004; pp. 74–81. [Google Scholar]
- Vedantam, R.; Zitnick, C.L.; Parikh, D. CIDEr: Consensus-based image description evaluation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4566–4575. [Google Scholar]
- Chen, X.; Fang, H.; Lin, T.Y.; Vedantam, R.; Gupta, S.; Dollar, P.; Zitnick, C.L. Microsoft COCO Captions: Data Collection and Evaluation Server. arXiv 2015, arXiv:1504.00325. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4278–4284. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; IEEE Computer Society: St. Stroudsburg, PA, USA, 2015; pp. 4489–4497. [Google Scholar] [CrossRef]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-Scale Video Classification with Convolutional Neural Networks. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014; IEEE Computer Society: Los Alamitos, CA, USA, 2014; pp. 1725–1732. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global Vectors for Word Representation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Douze, M.; Jégou, H.; Mikolov, T. FastText.zip: Compressing text classification models. arXiv 2016, arXiv:1612.03651. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed Representations of Words and Phrases and Their Compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Sydney, Australia, 12–15 December 2019; Curran Associates Inc.: Red Hook, NY, USA, 2019; Volume 2, pp. 3111–3119. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Yu, H.; Wang, J.; Huang, Z.; Yang, Y.; Xu, W. Video Paragraph Captioning Using Hierarchical Recurrent Neural Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4584–4593. [Google Scholar]
- Pan, P.; Xu, Z.; Yang, Y.; Wu, F.; Zhuang, Y. Hierarchical Recurrent Neural Encoder for Video Representation with Application to Captioning. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1029–1038. [Google Scholar]
- Chen, Y.; Wang, S.; Zhang, W.; Huang, Q. Less Is More: Picking Informative Frames for Video Captioning. In Proceedings of the 2018 European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Cham, Germany, 2018; pp. 367–384. [Google Scholar]
- Zhang, X.; Gao, K.; Zhang, Y.; Zhang, D.; Li, J.; Tian, Q. Task-Driven Dynamic Fusion: Reducing Ambiguity in Video Description. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6250–6258. [Google Scholar]
- Chen, J.; Pan, Y.; Li, Y.; Yao, T.; Chao, H.; Mei, T. Temporal deformable convolutional encoder-decoder networks for video captioning. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8167–8174. [Google Scholar]
- Aafaq, N.; Akhtar, N.; Liu, W.; Gilani, S.Z.; Mian, A. Spatio-Temporal Dynamics and Semantic Attribute Enriched Visual Encoding for Video Captioning. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seoul, Korea, 27 October–2 November 2019; pp. 12479–12488. [Google Scholar]
- Dong, J.; Li, X.; Lan, W.; Huo, Y.; Snoek, C.G. Early Embedding and Late Reranking for Video Captioning. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 1082–1086. [Google Scholar] [CrossRef]
- Shetty, R.; Laaksonen, J. Frame- and Segment-Level Features and Candidate Pool Evaluation for Video Caption Generation. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 1073–1076. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | METEOR | BLEU-4 | CIDEr | ROUGE-L |
|---|---|---|---|---|
| SVLAD | 33.8 | 45.9 | 77.5 | 68.9 |
| SVLAD | 34.9 | 48.8 | 80.6 | 70.2 |
| SVLAD | 34.8 | 49.8 | 81.9 | 71.1 |
| SVLAD | 34.9 | 50.2 | 81.5 | 71.4 |
| SVLAD | 35.1 | 49.9 | 83.7 | 71.5 |
| Module | Parameters | MACs |
|---|---|---|
| CA | ||
| SeqVLAD | ||
| SDN | ||
| Decoder | ||
| Reconstructor | ||
| CSA-SR |
| Model | METEOR | BLEU-4 | CIDEr | ROUGE-L |
|---|---|---|---|---|
| SVLAD | 33.8 | 45.9 | 77.5 | 68.9 |
| SVLAD | 35.1 | 49.9 | 83.7 | 71.5 |
| SVLAD | 34.6 | 48.9 | 79.7 | 69.8 |
| SVLAD | 34.8 | 51.3 | 80.4 | 70.5 |
| SVLAD | 35.2 | 49.8 | 80.1 | 71.8 |
| SVLAD | 35.6 | 52.2 | 83.4 | 72.7 |
| Model | METEOR | BLEU-4 | CIDEr | ROUGE-L |
|---|---|---|---|---|
| S2VT [20] | 29.2 | - | - | - |
| SA [21] | 29.6 | 41.9 | 51.6 | - |
| h-RNN [44] | 32.6 | 49.9 | 65.8 | - |
| HRNE [45] | 33.1 | 43.8 | - | - |
| SCN-LSTM [11] | 33.5 | 51.1 | 77.7 | - |
| PickNet [46] | 33.1 | 46.1 | 76.0 | 69.2 |
| TDDF [47] | 33.3 | 45.8 | 73.0 | 69.7 |
| RecNet [24] | 34.1 | 52.3 | 80.3 | 69.8 |
| TDConvED [48] | 33.8 | 53.3 | 76.4 | - |
| GRU-EVE [49] | 35.0 | 47.9 | 78.1 | 71.5 |
| SeqVLAD [6] | 33.8 | 45.9 | 77.5 | 68.9 |
| SR | 34.8 | 51.3 | 80.4 | 70.5 |
| CSA | 35.1 | 49.9 | 83.7 | 71.5 |
| CSA-SR | 35.6 | 52.2 | 83.4 | 72.7 |
| Model | METEOR | BLEU-4 | CIDEr | ROUGE-L |
|---|---|---|---|---|
| Alto [51] | 26.9 | 39.8 | 45.7 | 59.8 |
| RUC-UVA [50] | 26.9 | 38.7 | 45.9 | 58.7 |
| TDDF [47] | 27.8 | 37.3 | 43.8 | 59.2 |
| PickNet [46] | 27.2 | 38.9 | 42.1 | 59.5 |
| RecNet [24] | 26.6 | 39.1 | 42.7 | 59.3 |
| TDConvED [48] | 27.5 | 39.5 | 42.8 | - |
| GRU-EVE [49] | 28.4 | 38.3 | 48.1 | 60.7 |
| CSA-SR(ours) | 28.2 | 41.3 | 48.6 | 61.9 |
| User | ||||||
|---|---|---|---|---|---|---|
| No.1 | 9 | 11 | 45% | 7 | 13 | 35% |
| No.2 | 9 | 11 | 45% | 6 | 14 | 30% |
| No.3 | 7 | 13 | 35% | 8 | 12 | 40% |
| No.4 | 10 | 10 | 50% | 7 | 13 | 35% |
| No.5 | 9 | 11 | 45% | 9 | 11 | 45% |
| No.6 | 8 | 12 | 40% | 7 | 13 | 35% |
| No.7 | 11 | 9 | 55% | 9 | 11 | 45% |
| No.8 | 6 | 14 | 55% | 7 | 13 | 35% |
| No.9 | 9 | 11 | 45% | 5 | 15 | 25% |
| No.10 | 8 | 12 | 40% | 7 | 13 | 35% |
| Avg | 8.6 | 11.4 | 43% | 7.2 | 12.8 | 36% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lei, Z.; Huang, Y. Video Captioning Based on Channel Soft Attention and Semantic Reconstructor. Future Internet 2021, 13, 55. https://doi.org/10.3390/fi13020055
Lei Z, Huang Y. Video Captioning Based on Channel Soft Attention and Semantic Reconstructor. Future Internet. 2021; 13(2):55. https://doi.org/10.3390/fi13020055
Chicago/Turabian StyleLei, Zhou, and Yiyong Huang. 2021. "Video Captioning Based on Channel Soft Attention and Semantic Reconstructor" Future Internet 13, no. 2: 55. https://doi.org/10.3390/fi13020055
APA StyleLei, Z., & Huang, Y. (2021). Video Captioning Based on Channel Soft Attention and Semantic Reconstructor. Future Internet, 13(2), 55. https://doi.org/10.3390/fi13020055