
Reconstruction of a 3D Human Foot Shape Model Based on a Video Stream Using Photogrammetry and Deep Neural Networks

 , , and
, , and
Abstract
:1. Introduction
- Orthopedic tailoring of individual shoes. Enterprises can use 3D models for subsequent printing on industrial 3D printers and for the construction of individual shoes based on the original pads;
- Medical diagnostics. Medical staff with orthopedic qualifications will be able to diagnose the initial stages of diseases affecting the human locomotor system via a remote format;
- Online shoe selection. People who actively use online stores often lack necessary information regarding their shoe size or face a discrepancy in the size grid. The methodology allows them to accurately determine their size, according to the dimensional grid, down to the millimeter.
2. Analysis of Existing Technology Solutions
2.1. Developed Products and Applications
2.2. Methods, Tools, and Techniques
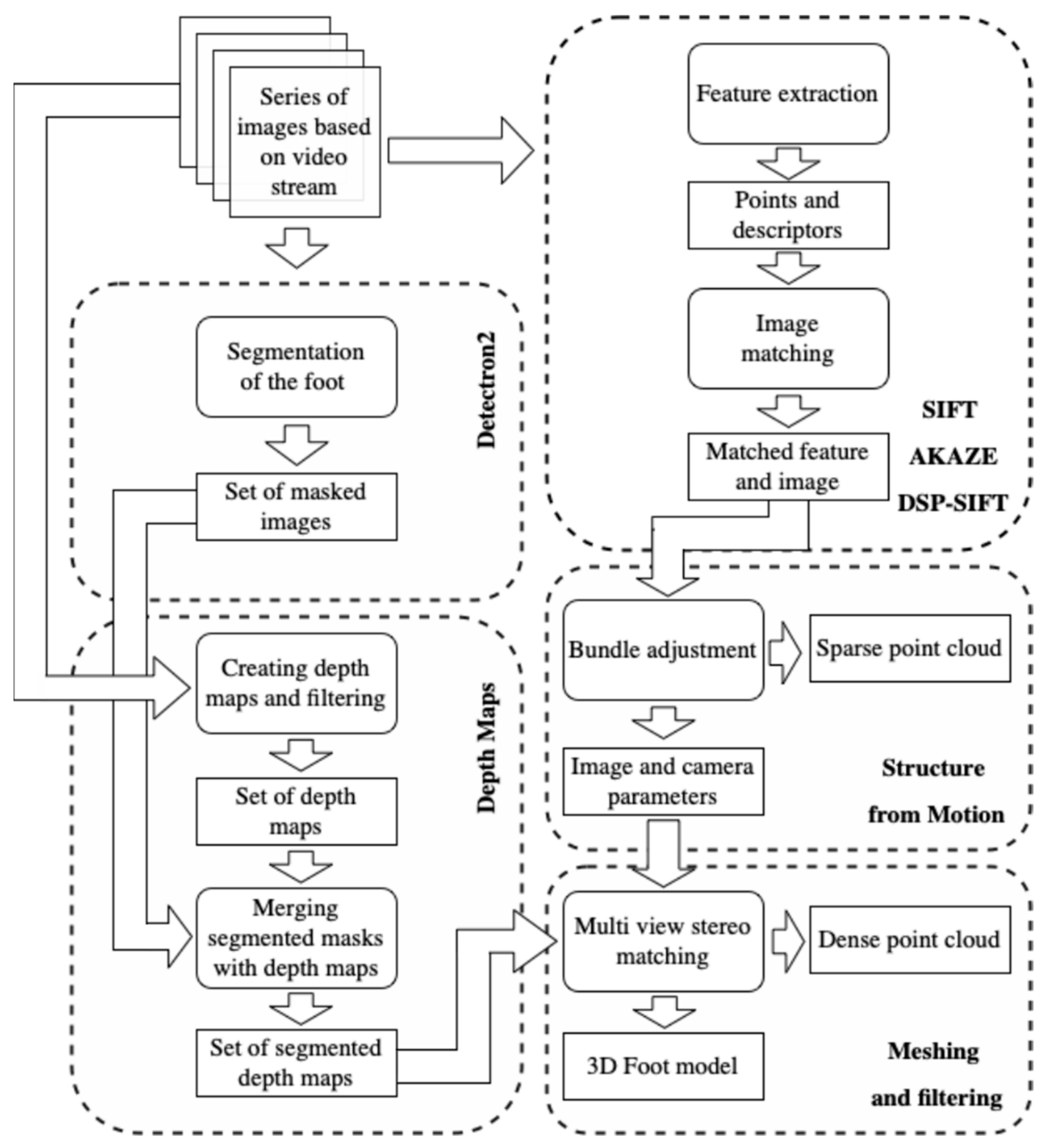
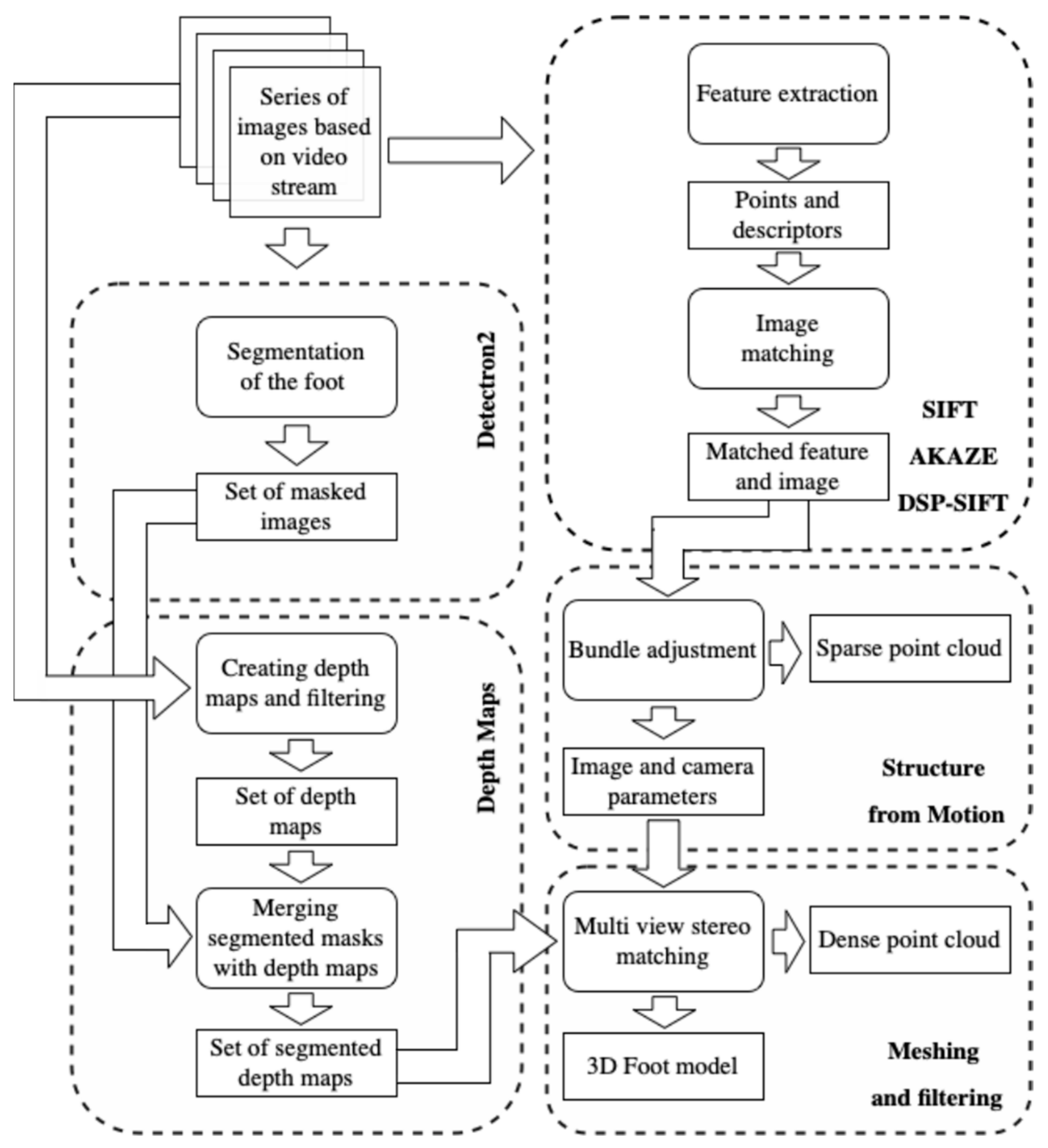
3. Methodology of Reconstructing the 3D Foot Shape
3.1. Dataset Formation (Series of Images Based on Video Stream)
- To obtain a high-quality reconstruction, it is important to involve an assistant (someone who can help in the process of creating the dataset);
- The person whose foot is to be reconstructed must be in a horizontal position. The foot should be fixed in space by hands;
- Using a smartphone that allows for video recording with a resolution of at least 1920 × 1080 (pixels);
- The video format can be both horizontal and vertical;
- The duration of the circular video must be 30 s. The foot must be strictly fixed in the center of the stream during the entire video;
- It is acceptable to vary the distance between the camera lens and the foot from 30 to 70 cm;
- Avoid glare, flare, and other artifacts during shooting. The person that is recording the video should minimize extra actions during the shooting;
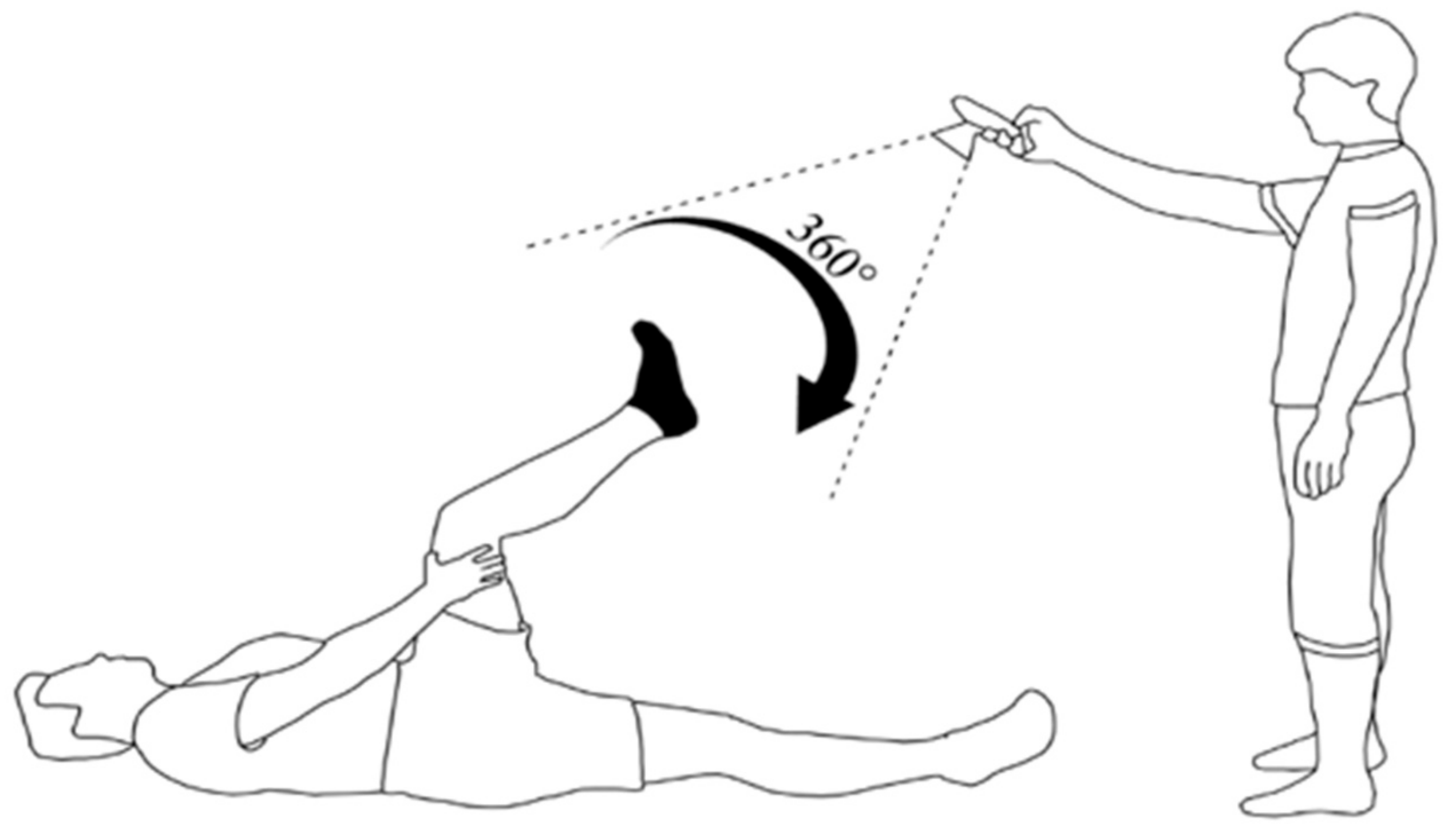
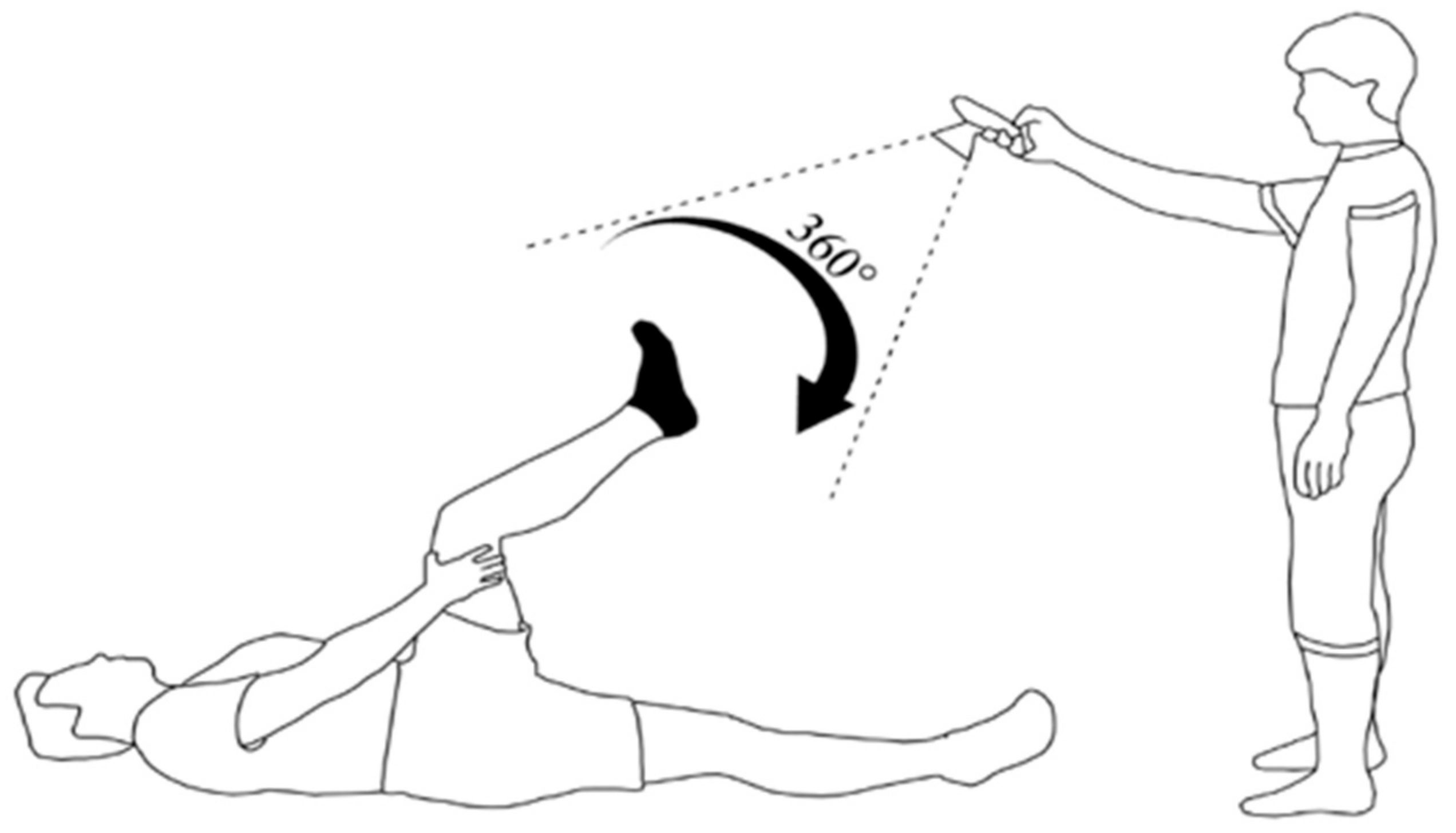
- The angle of shooting is shown in Figure 2. The angle between the foot and the surface should be between 75 and 90 degrees. The bend angle of the knee should be between 135 and 150 degrees;
- The resulting video stream must be split into N frames (from 50 to 150).
3.2. Feature Extraction
- Definition of extremums of the scale space;
- Precise localization of key points;
- Defining the orientation of the camera in space;
- Calculation of the local image descriptor.
3.3. Feature and Image Matching
3.4. Structure-from-Motion
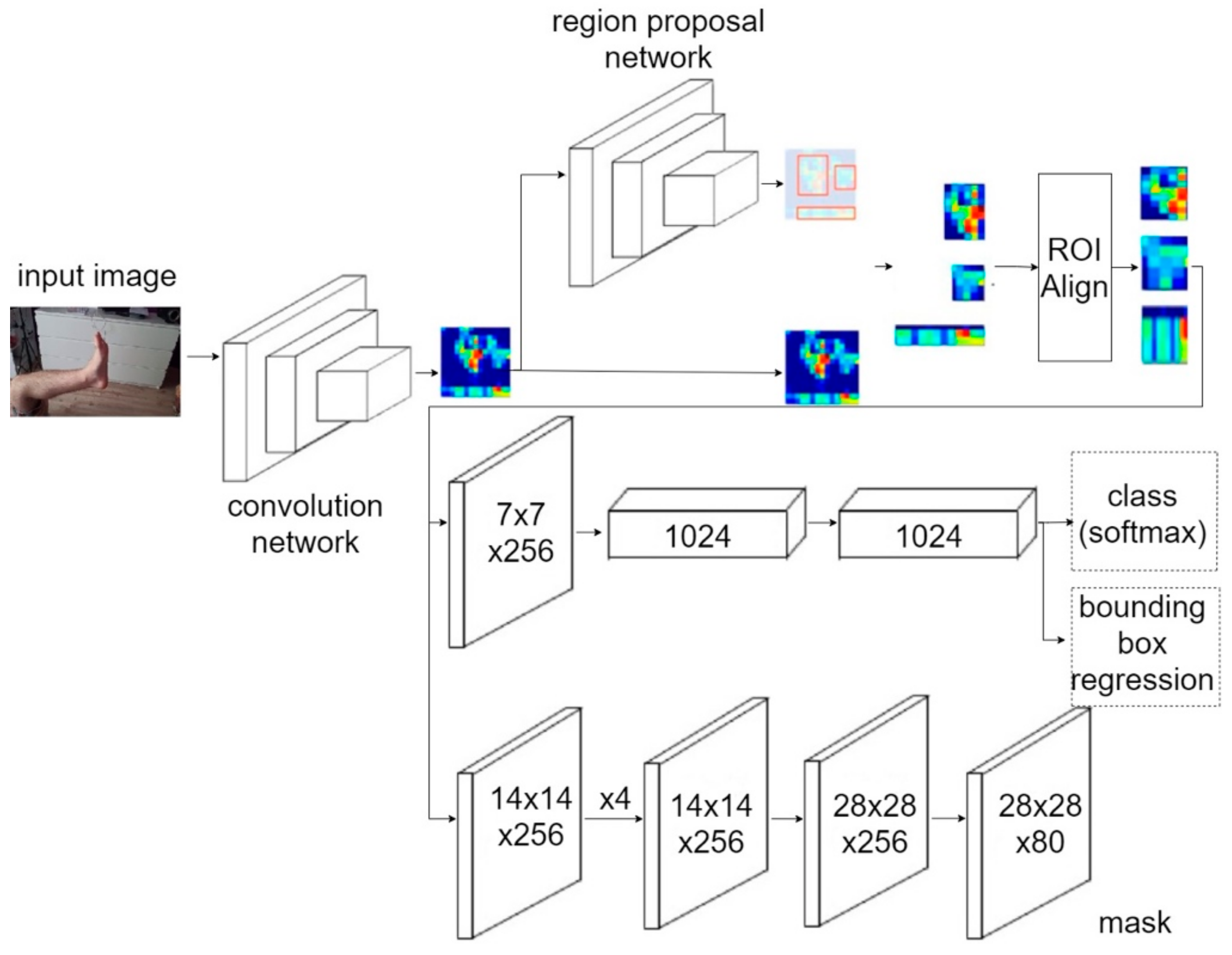
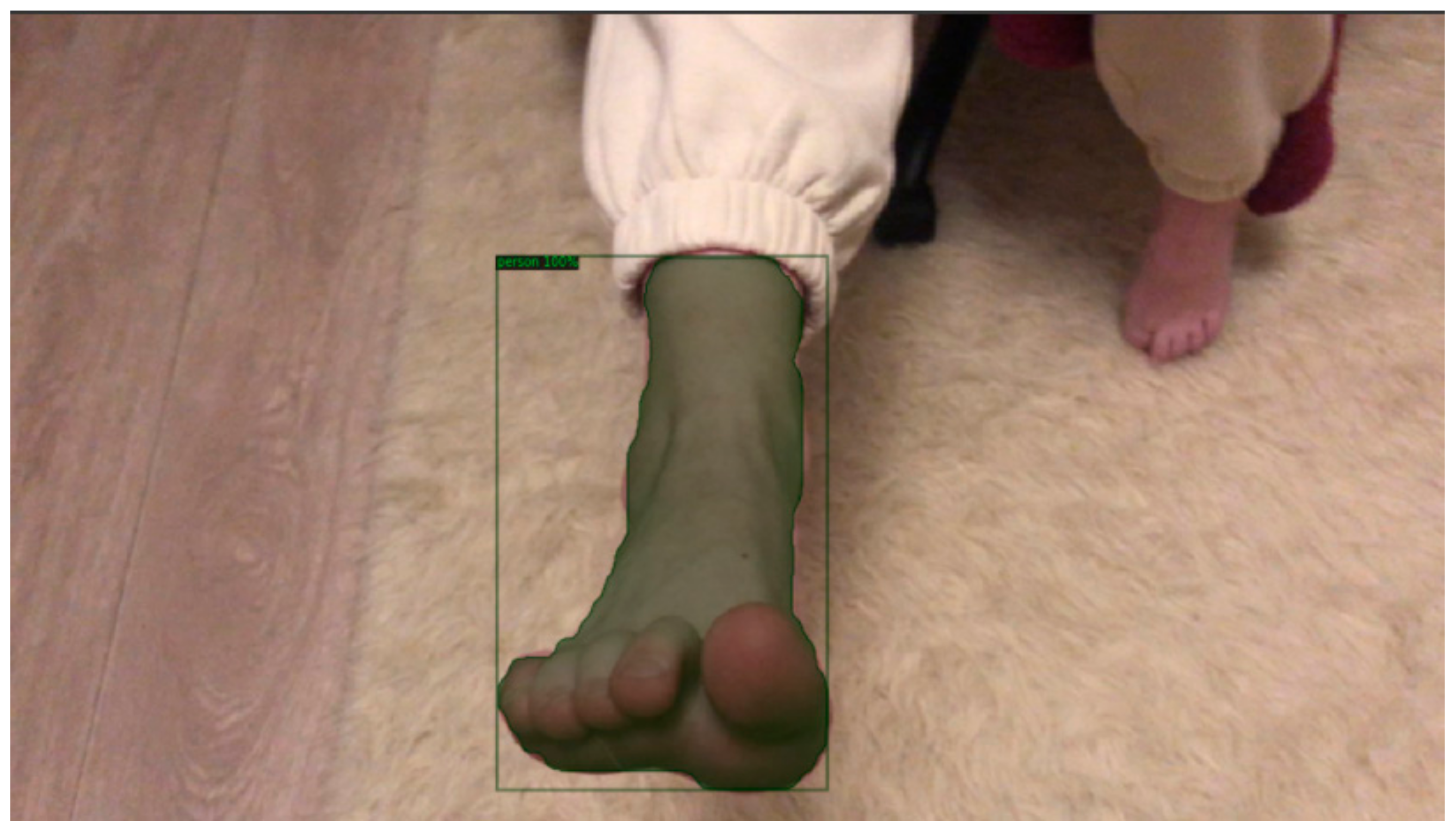
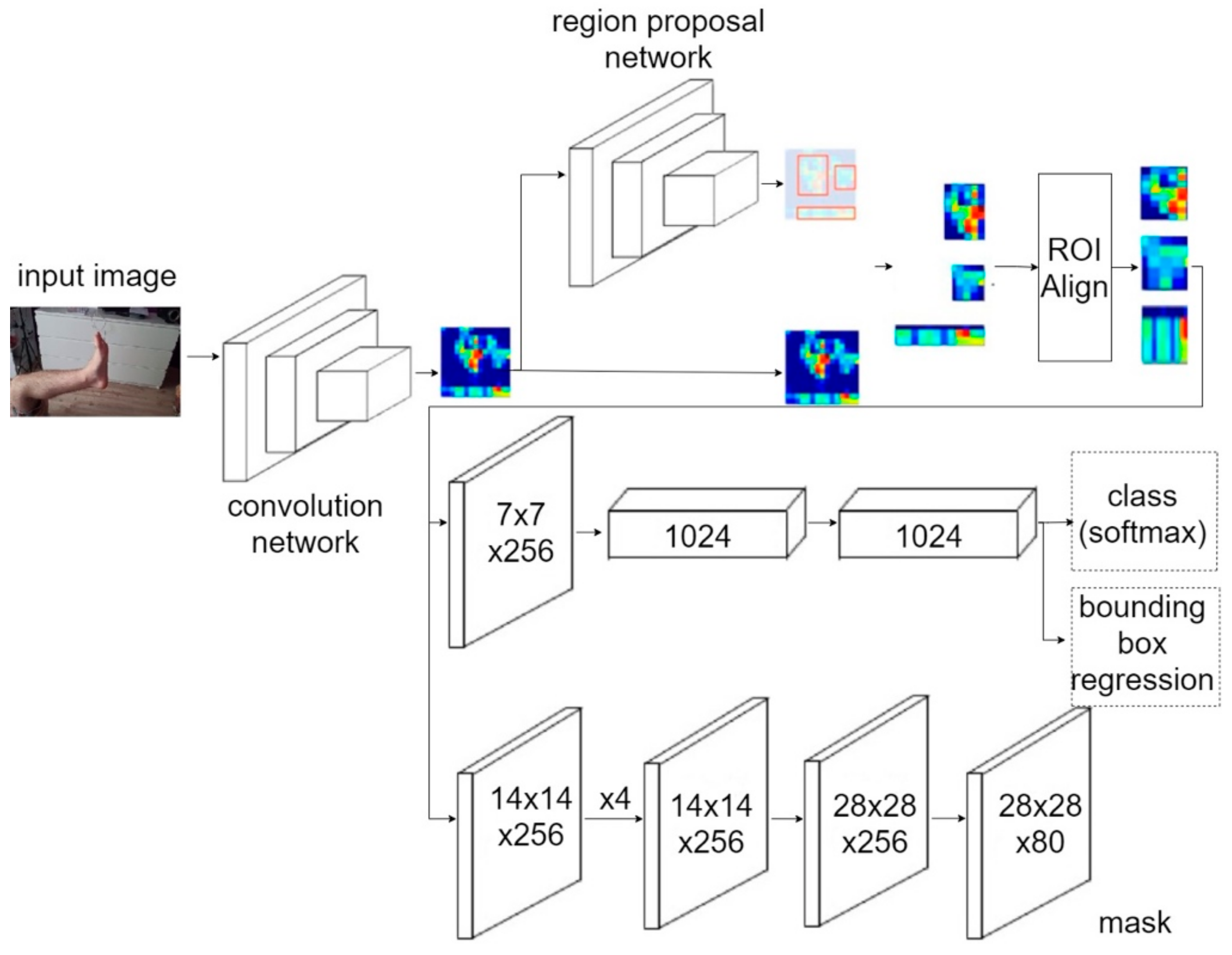
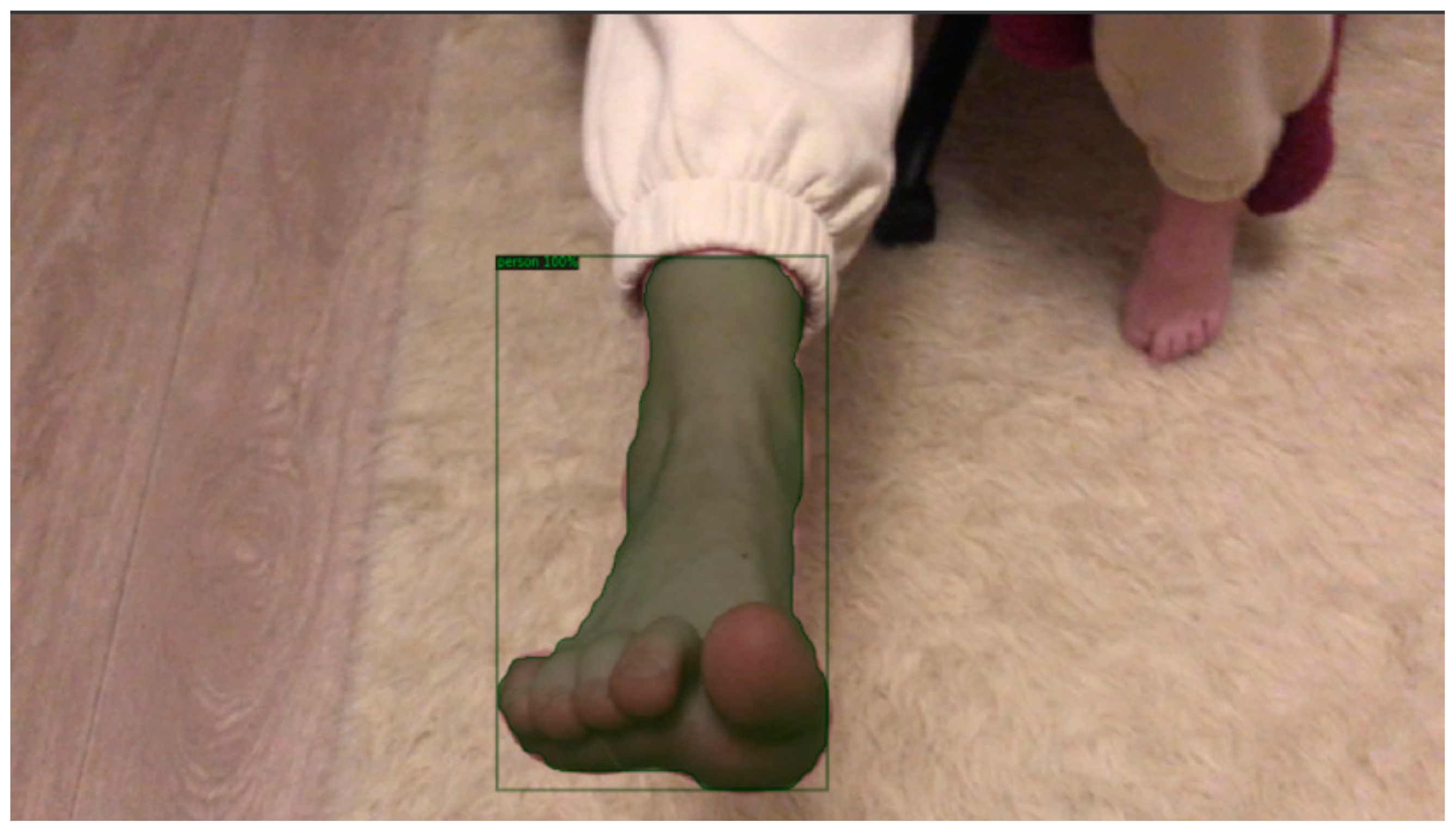
3.5. Segmentation Foot Image
3.5.1. Dataset for Training
3.5.2. Architecture
3.5.3. Loss Function
3.6. Estimate and Filtering Depth Maps
| Algorithm 1 Depth map segmentation | ||
| 1: | procedure segmentation_depth_map(dm_dir, mask_dir) | |
| 2: | dm_matrix <- {∅}{∅} | ► Create empty DM matrix |
| 3: | dm_matrix <- read_dm (dm_dir) | ► Read DM and covert in matrix |
| 4: | mask_matrix <- {∅}{∅}{∅} | ► Create empty mask matrix |
| 5: | mask_matrix <- read_mask(mask_dir) | ► Read mask and convert in RGB matrix |
| 6: | for x < dm_matrix {max} do | |
| 7: | for y < dm_matrix {max}{max} do | |
| 8: | if mask_matrix {x}{y} = {0,0,0} | ► Where {0,0,0} means black color in RGB |
| 9: | dp_matrix {x}{y} <- -1 | ► −1 means that this point |
| 10: | end for | ► Will not use in reconstruction |
| 11: | end for | |
| 12: | return dm_matrix | |
| 13: | end procedure | |
3.7. Meshing and Filtering
| Algorithm 2 Meshing and filtering | ||
| 1: | procedure create_filtering_mesh(dm_dir, sfm_data, cameras_dir, lambda, iter) | |
| 2: | list_depth <- {∅} | |
| 3: | list_depth <- list_of_files_in_dir(dm_dir) | ► Read all depth_maps |
| 4: | hexah <- {8}{∅}{∅}{∅} | ► Init start of hexahedron matrix |
| 5: | nb_cameras <- {∅} | ► Init list of neighbour cameras |
| 6: | for g < count(list_depth) do | |
| 7: | nb_cameras <- find_nb_cameras (list_depth[g], sfm_data) | |
| 8: | octree <- create_octree(list_of_files_in_dir[g], nb_cameras) | |
| 9: | end for | |
| 10: | dense_geometric_representation <- {∅}{∅}{∅} | |
| 11: | dense_geometric_representation <- create_dense(hexah, octree, sfm_data) | |
| 12: | mesh_object <- create_mesh(dense_geometric_representation) | |
| 13: | mesh_filtered <- mesh_filtering(lambda, iter, mesh_object) | |
| 14: | return mesh_filtered | |
| 15: | end procedure | |
4. Experiments
4.1. Training and Evaluate Model Accuracy
- Number of iterations—6000;
- Number of classes—1;
- Learning rate—0.00025.
4.2. Formation of an Experimental Dataset for 3D Modeling
4.3. Extracting Foot Parameters
4.4. Investigation of the Influence of Different Algorithms for Extracting and Comparing Informative Features on the Quality of 3D Models
4.5. Research on the Effect of Different Image Resolutions on the Processing Efficiency and Quality of 3D Models
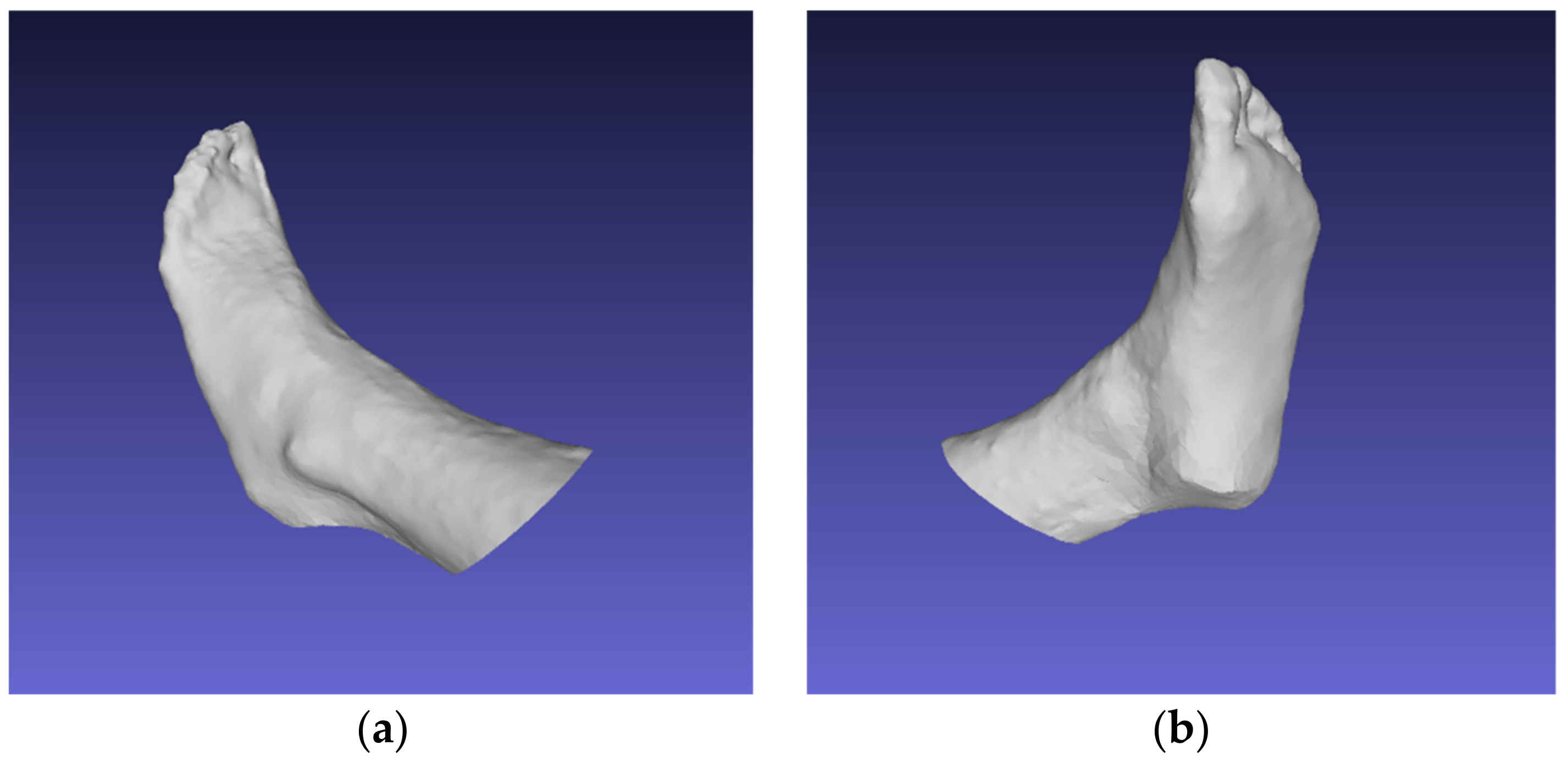
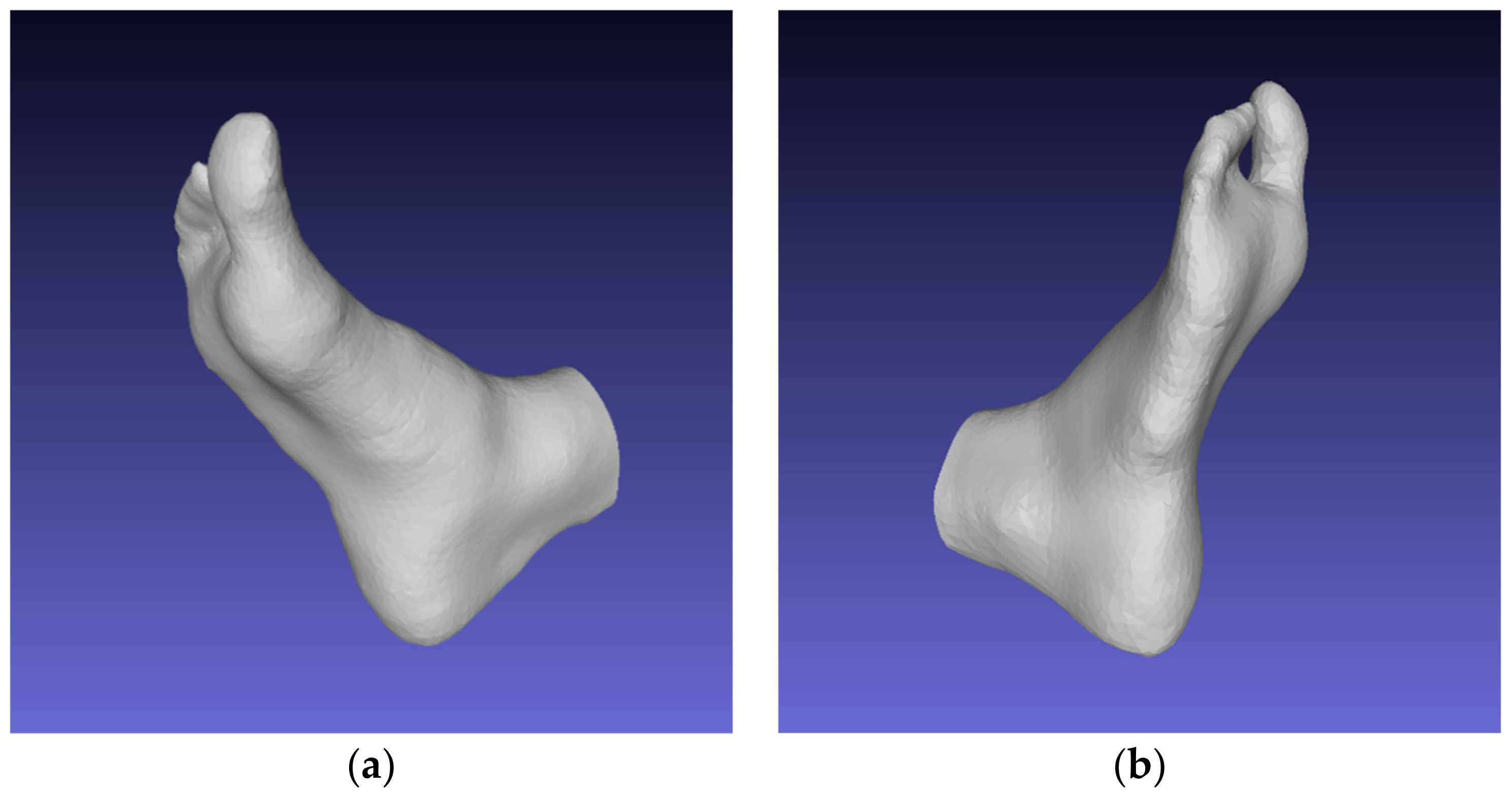
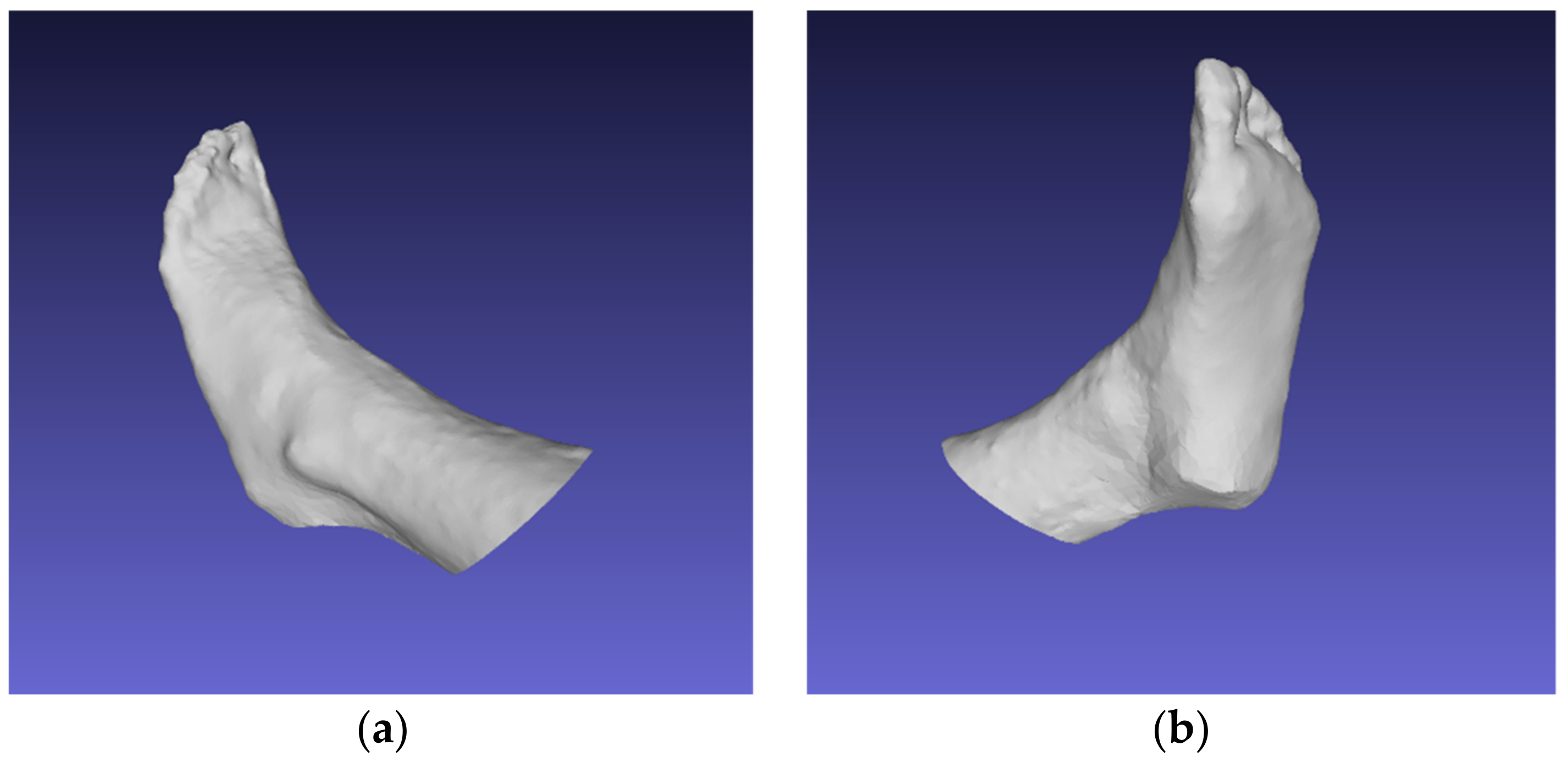
4.6. Evaluation of the Results
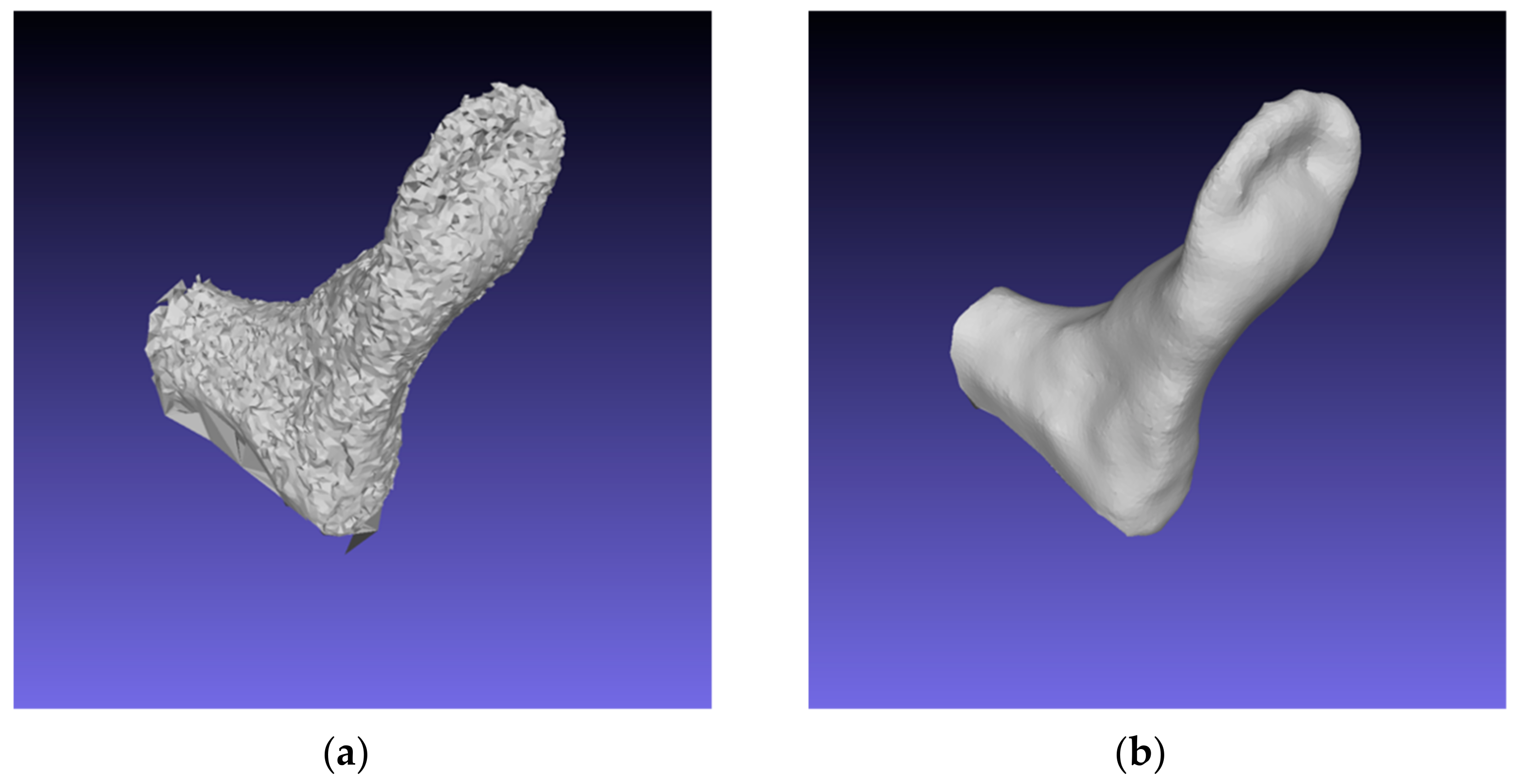
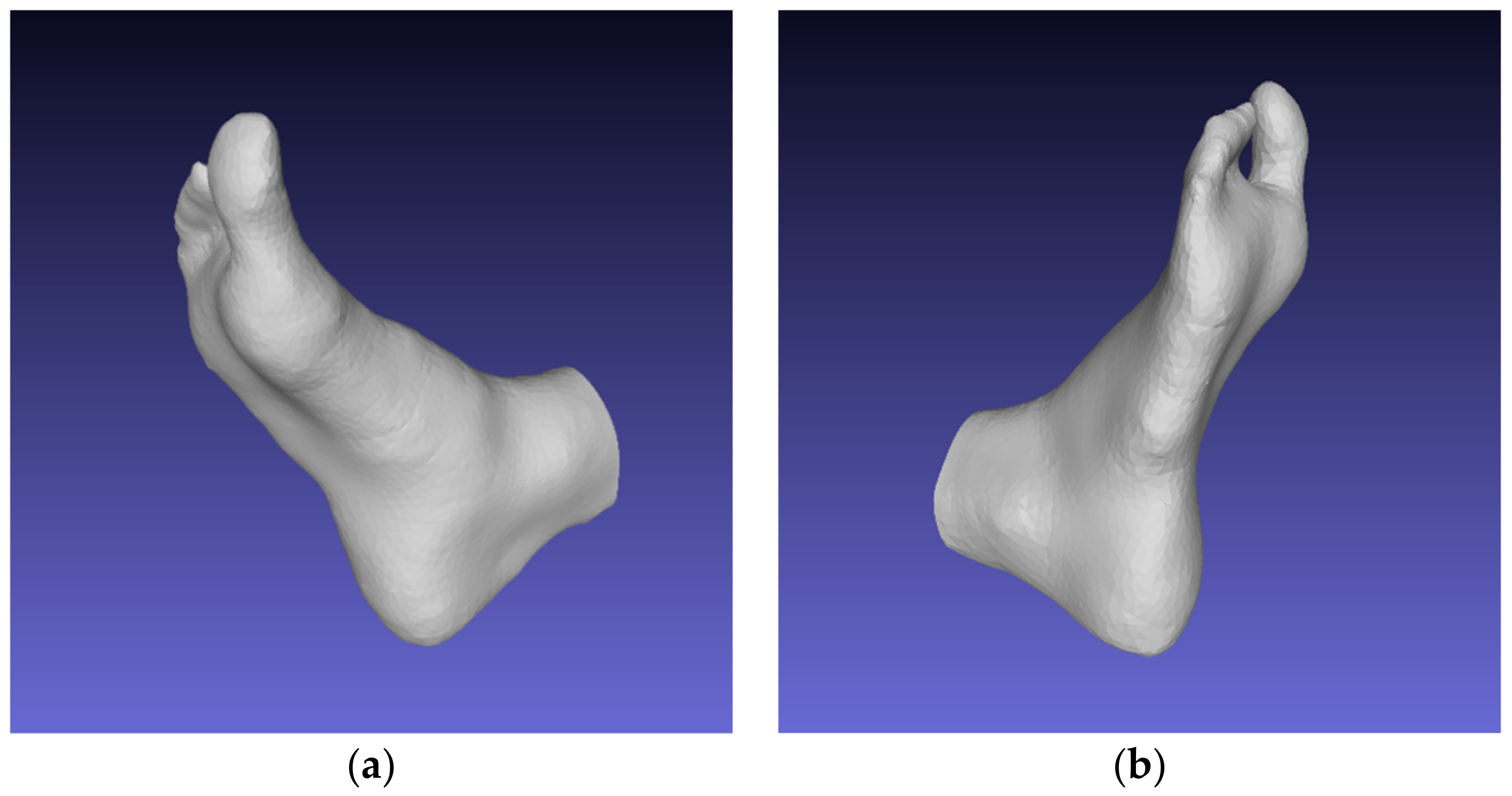
- The small dataset for training the segmentation model—the average length for the male and female sets for both feet was about 266.71 mm and 255.47 mm, respectively. Important foot segments (parts of the toes) were not captured during mask formation; an example for model 4 is shown in Figure 11. Thus, reconstructed models whose values are close to the mean values are recommended, as they have the smallest deviations;
- Influence of lighting—the photogrammetry approach is very sensitive to different types of glare, shadows, and the amount of light flux (lumens) hitting the object in the process of shooting;
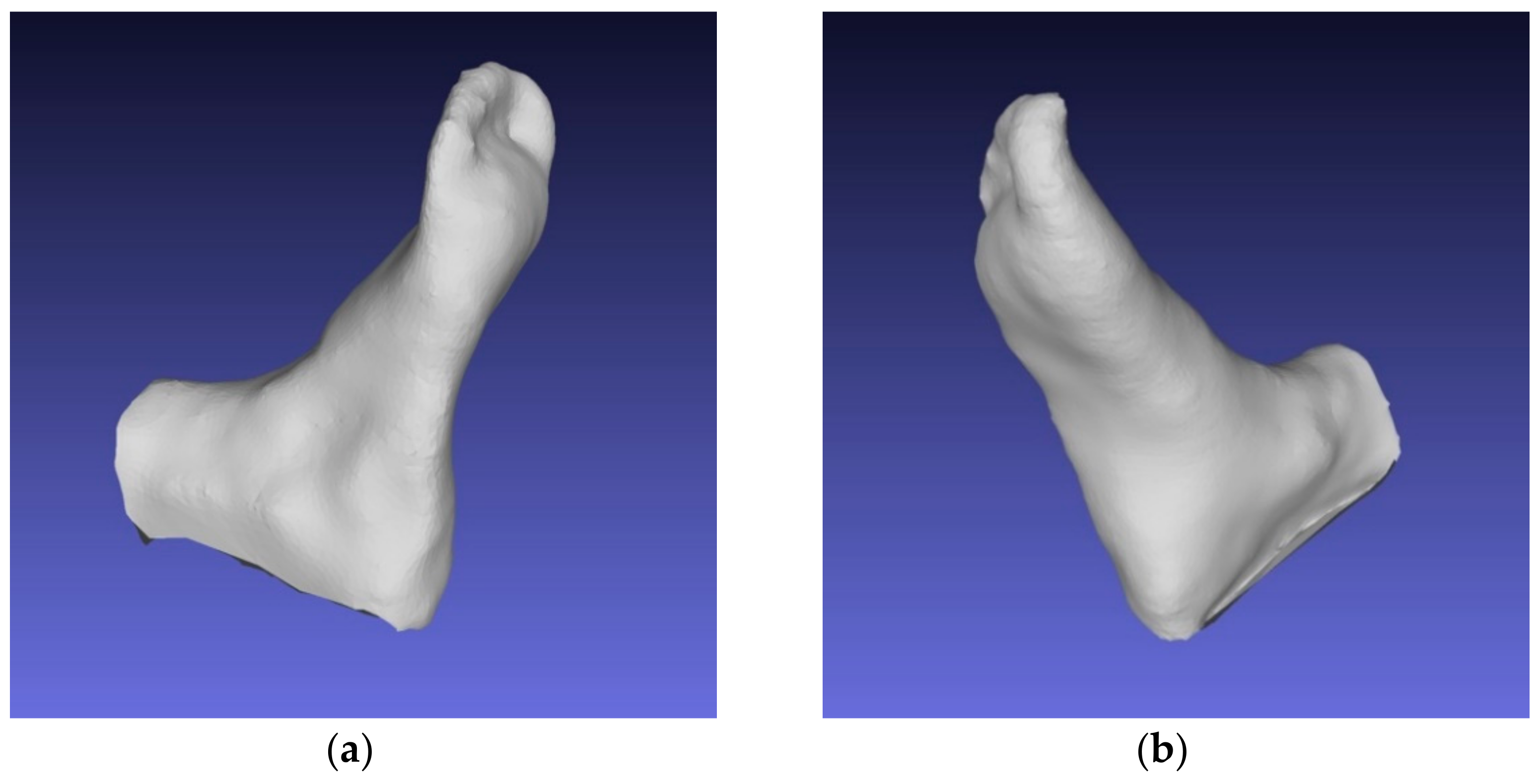
- The peculiarity of circular video lies in the process of obtaining a video stream: users should consider all parts of the foot from all sides. The foot should remain stationary during the video recording process. An example of an unsuccessful reconstruction for model #4, where the volunteer was unable to capture the heel part of the foot, is shown in Figure 12.
5. Discussion
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cieza, A.; Causey, K.; Kamenov, K.; Hanson, S.W.; Chatterji, S.; Vos, T. Global estimates of the need for rehabilitation based on the Global Burden of Disease study 2019: A systematic analysis for the Global Burden of Disease Study 2019. Lancet 2021, 396, 2006–2017. [Google Scholar] [CrossRef]
- Kulikajevas, A.; Maskeliunas, R.; Damasevicius, R.; Scherer, R. HUMANNET—A Two-Tiered Deep Neural Network Architecture for Self-Occluding Humanoid Pose Reconstruction. Sensors 2021, 21, 3945. [Google Scholar] [CrossRef] [PubMed]
- Kulikajevas, A.; Maskeliūnas, R.; Damaševičius, R.; Wlodarczyk-Sielicka, M. Auto-Refining Reconstruction Algorithm for Recreation of Limited Angle Humanoid Depth Data. Sensors 2021, 21, 3702. [Google Scholar] [CrossRef]
- Kulikajevas, A.; Maskeliunas, R.; Damasevicius, R. Adversarial 3D Human Pointcloud Completion from Limited Angle Depth Data. IEEE Sens. J. 2021. [Google Scholar] [CrossRef]
- Parrilla, E.; Ballester, A.; Solves-Camallonga, C.; Nácher, B.; Antonio Puigcerver, S.; Uriel, J.; Piérola, A.; González, J.C.; Alemany, S. Low-cost 3D foot scanner using a mobile app. Footwear Sci. 2015, 7, S26–S28. [Google Scholar] [CrossRef]
- Amstutz, E.; Teshima, T.; Kimura, M.; Mochimaru, M.; Saito, H. Pca-based 3d shape reconstruction of human foot using multiple viewpoint cameras. Int. J. Autom. Comput. 2008, 5, 217–225. [Google Scholar] [CrossRef] [Green Version]
- Revkov, A.; Kanin, D. FITTINTM-Online 3D Shoe Try-on. In Proceedings of the 3DBODY.TECH 2020—11th International Conference and Exhibition on 3D Body Scanning and Processing Technologies, Online/Virtual, 17–18 November 2020; Available online: http://www.3dbodyscanning.org/cap/papers/2020/2058revkov.pdf (accessed on 5 December 2021).
- Chuyko, G.; Shedrin, I.; Revkov, E.; Grishko, N.; Posmetev, V.; Kanin, D.; Buhtojarov, L. Method and Device for Measuring the Shape, Dimensions and Flexibility of Shoes. United States Patent 10782124, 22 September 2020. [Google Scholar]
- DomeScan/IBV. Available online: https://www.ibv.org/en/domescan/ (accessed on 8 November 2021).
- Ballester, A.; Piérola, A.; Parrilla, E.; Izquierdo, M.; Uriel, J.; Nácher, B.; Alemany, S. Fast, portable and low-cost 3D foot digitizers: Validity and reliability of measurements. In Proceedings of the 3DBODY, TECH 2017 8th International Conference and Exhibition on 3D Body Scanning and Processing Technologies, Montreal, QC, Canada, 11–12 October 2017; pp. 218–225. [Google Scholar]
- Volumental. Fit-Tech. Available online: https://volumental.com (accessed on 9 November 2021).
- Wang, M.; Wang, X.; Fan, Z.; Zhang, S.; Peng, C.; Liu, Z. A 3D foot shape feature parameter measurement algorithm based on Kinect. EURASIP J. Image Video Process. 2018, 2018, 119. [Google Scholar] [CrossRef]
- Zhao, K.; Luximon, A.; Chan, C.K. Low cost 3D foot scan with Kinect. Int. J. Digit. Hum. 2018, 2, 97–114. [Google Scholar] [CrossRef]
- Rogati, G.; Leardini, A.; Ortolani, M.; Caravaggi, P. Validation of a novel Kinect-based device for 3D scanning of the foot plantar surface in weight-bearing. J. Foot Ankle Res. 2019, 12, 46. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Besl, P.J.; McKay, N.D. A method for registration of 3-D shapes. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 239–256. [Google Scholar] [CrossRef]
- Yuan, M.; Li, X.; Xu, J.; Jia, C.; Li, X. 3D foot scanning using multiple RealSense cameras. Multimed. Tools Appl. 2021, 80, 22773–22793. [Google Scholar] [CrossRef]
- Novel Use of the IntelRealsense SR300 Camera for Foot 3D Reconstruction. Available online: https://www.proquest.com/openview/24c68afef1be76b5cb04180006933a52/ (accessed on 10 November 2021).
- Pambudi, D.S.; Hidayah, L. Foot 3D Reconstruction and Measurement using Depth Data. J. Inf. Syst. Eng. Bus. Intellegence 2020, 6, 37–45. [Google Scholar] [CrossRef]
- Kobayashi, T.; Ienaga, N.; Sugiura, Y.; Saito, H.; Miyata, N.; Tada, M. A simple 3D scanning system of the human foot using a smartphone with depth camera. J. Jpn. Soc. Precis. Eng. 2018, 84, 996–1002. [Google Scholar] [CrossRef]
- Zhang, H.; Chen, Z.; Guo, S.; Lin, J.; Shi, Y.; Liu, X. Sensock: 3D Foot Reconstruction with Flexible Sensors. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25 April–30 April 2020; pp. 1–13. [Google Scholar]
- Niu, L.; Xiong, G.; Shang, X.; Guo, C.; Chen, X.; Wu, H. 3D Foot Reconstruction Based on Mobile Phone Photographing. Appl. Sci. 2021, 11, 4040. [Google Scholar] [CrossRef]
- Reljić, I.; Dunđer, I.; Seljan, S. Photogrammetric 3D scanning of physical objects: Tools and workflow. TEM J. 2019, 8, 383. [Google Scholar]
- Grazioso, S.; Caporaso, T.; Selvaggio, M.; Panariello, D.; Ruggiero, R.; Di Gironimo, G. Using photogrammetric 3D body reconstruction for the design of patient–tailored assistive devices. In Proceedings of the IEEE 2019 II Workshop on Metrology for Industry 4.0 and IoT (MetroInd4.0 & IoT), Naples, Italy, 4–6 June 2019; pp. 240–242. [Google Scholar]
- Rey-Otero, I.; Morel, J.M.; Delbracio, M. An analysis of the factors affecting keypoint stability in scale-space. arXiv 2015, arXiv:1511.08478. [Google Scholar] [CrossRef] [Green Version]
- Shan, Q.; Adams, R.; Curless, B.; Furukawa, Y.; Seitz, S.M. The Visual Turing Test for Scene Reconstruction. In Proceedings of the IEEE International Conference on 3D Vision-3DV, Seattle, WA, USA, 29 June–1 July 2013; pp. 25–32. [Google Scholar]
- Zhu, H.; Liu, Y.; Fan, J.; Dai, Q.; Cao, X. Video-Based Outdoor Human Reconstruction. IEEE Trans. Circ. Syst. Vid. Tech. 2016, 27, 760–770. [Google Scholar] [CrossRef]
- Moulon, P.; Monasse, P.; Perrot, R.; Marlet, R. OpenMVG: Open Multiple View Geometry. In Proceedings of the Workshop on Reproducible Research in Pattern Recognition, Cancún, Mexico, 4 December 2016; pp. 60–74. [Google Scholar]
- Ravi, T.; Ranganathan, R.; Ramesh, S.P.; Dandotiya, D.S. 3D Printed Personalized Orthotic Inserts Using Photogrammetry and FDM Technology. In Fused Deposition Modeling Based 3D Printing; Springer: Cham, Switzerland, 2021; pp. 349–361. [Google Scholar]
- Real Time Segmentation of Feet on Smartphone. Available online: http://urn.kb.se/resolve?urn=urn:nbn:se:kth:diva-231779 (accessed on 11 November 2021).
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. ENet: Deep Neural Network Architecture for Real-Time Semantic Segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- Chaurasia, A.; Culurciello, E. LinkNet: Exploiting Encoder Representations for Efficient Semantic Segmentation. arXiv 2017, arXiv:1707.03718. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Kok, F.; Charles, J.; Cipolla, R. FootNet: An Efficient Convolutional Network for Multiview 3D Foot Reconstruction. In Proceedings of the Asian Conference on Computer Vision; Springer: New York, NY, USA, 26 February 2021; Available online: https://link.springer.com/chapter/10.1007%2F978-3-030-69544-6_3 (accessed on 5 December 2021).
- Çiçek, Ö.; Abdulkadir, A.; Lienkamp, S.S.; Brox, T.; Ronneberger, O. 3D U-net: Learning dense volumetric segmentation from sparse annotation. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Quebec City, QC, Canada, 2016; Volume 9901, pp. 424–432. [Google Scholar]
- Zelek, J.; Lunscher, N. Point cloud completion of foot shape from a single depth map for fit matching using deep learning view synthesis. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshop (ICCVW), Venice, Italy, 22–29 October 2017; pp. 2300–2305. [Google Scholar]
- Robinette, K.M.; Daanen, H.; Paquet, E. The CAESAR project: A 3-D surface anthropometry survey. In Proceedings of the Second International Conference on 3-D Digital Imaging and Modeling, Ottawa, ON, Canada, 4–8 October 1999; pp. 380–386. [Google Scholar]
- Alcantarilla, P.F.; Solutions, T. Fast explicit diffusion for accelerated features in nonlinear scale spaces. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 1281–1298. [Google Scholar]
- Nister, D.; Stewenius, H. Scalable recognition with a vocabulary tree. In Proceedings of the IEEE CVPR 2006, New York, NY, USA, 17–22 June 2006; pp. 2161–2168. [Google Scholar]
- Detectron2. Available online: https://github.com/facebookresearch/detectron2 (accessed on 12 November 2021).
- Girshick, R. Fast R-CNN. In Proceedings of the International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Gúler, R.A.; Neverova, N.; Kokkinos, I. DensePose: Dense Human Pose Estimation in the Wild. arXiv 2018, arXiv:1802.00434. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving Into High Quality Object Detection. In Proceedings of the Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Di Stefano, L.; Mattoccia, S.; Tombari, F. ZNCC-based template matching using bounded partial correlation. Pattern Recognit. Lett. 2005, 26, 2129–2134. [Google Scholar] [CrossRef]
- AliceVision. Photogrammetric Computer Vision Framework. Available online: https://alicevision.org/ (accessed on 15 November 2021).
- Dice, L.R. Measures of the amount of ecologic association between species. Ecology 1945, 26, 297–302. [Google Scholar] [CrossRef]
- Rezatofighi, S.H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.D.; Savarese, S. Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression. arXiv 2019, arXiv:1902.09630. [Google Scholar]
- Arteaga-Marrero, N.; Hernández, A.; Villa, E.; González-Pérez, S.; Luque, C.; Ruiz-Alzola, J. Segmentation Approaches for Diabetic Foot Disorders. Sensors 2021, 21, 934. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Measurements | Men | Women | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Left Foot | Right Foot | Left Foot | Right Foot | |||||||||||||
| Min | Max | Avg | Std | Min | Max | Avg | Std | Min | Max | Avg | Std | Min | Max | Avg | Std | |
| Length foot (mm) | 253 | 307 | 266.15 | 13.91 | 252 | 307 | 267.07 | 14.05 | 228 | 319 | 255.93 | 23.02 | 232 | 321 | 255 | 23.07 |
| Width foot (mm) | 95 | 128 | 116 | 12.56 | 95 | 129 | 13.29 | 44.53 | 80 | 111 | 94.93 | 9.85 | 80 | 111 | 96.07 | 10.46 |
| Instep girth (mm) | 200 | 265 | 247.43 | 19.91 | 204 | 270 | 248.93 | 17.14 | 210 | 270 | 228.79 | 15.33 | 208 | 277 | 229.43 | 17.27 |
| Ball girth (mm) | 232 | 270 | 250 | 9.27 | 231 | 270 | 249.71 | 9.65 | 199 | 282 | 228.14 | 21.63 | 210 | 279 | 229.36 | 19.30 |
| Heel girth (mm) | 245 | 360 | 322.64 | 31.13 | 243 | 360 | 323.43 | 31.41 | 280 | 360 | 311.57 | 26.51 | 282 | 360 | 309.93 | 25.90 |
| Shin girth (mm) | 203 | 260 | 226.86 | 16.76 | 201 | 261 | 226.86 | 18.22 | 182 | 280 | 218.86 | 27.50 | 181 | 260 | 217.64 | 22.35 |
| Model | DICE (%) | IoU (%) | Inference Time (ms) |
|---|---|---|---|
| Mask R-CNN | 97.88 | 98.27 | 471 |
| UPD [48] | 95.35 | 91.11 | - |
| MobileSeg [29] | 97.64 | 95.52 | 552 |
| Number of Models | Manual Measurement | SIFT | SIFT, AKAZE | SIFT, AKAZE, DSP-SIFT | ||||
|---|---|---|---|---|---|---|---|---|
| FL (mm) | FW (mm) | FL (mm) | FW (mm) | FL (mm) | FW (mm) | FL (mm) | FW (mm) | |
| 1 | 265 | 123 | 264.5/(0.5) | 122.9/(0.1) | 264.7/(0.3) | 122.9 (0.1) | 264.9/(0.1) | 122.9/(0.1) |
| 2 | 247 | 98 | 247.3/(0.3) | 98.8/(0.8) | 247.1/(0.1) | 98.5/(0.5) | 247.2/(0.2) | 98.4/(0.4) |
| 3 | 242 | 95 | 243.2/(1.2) | 97.3/(2.3) | 243.1/(1.1) | 96.9/(1.9) | 242.9/(0.9) | 96.3/(1.3) |
| 4 | 285 | 125 | 288.3/(3.3) | 127.1/(2.1) | 287.7/(2.7) | 126.8/(1.8) | 286.9/(1.9) | 126.4/(1.4) |
| 5 | 235 | 93 | 235.2/(0.2) | 93.4/(0.4) | 235.2/(0.2) | 93.3/(0.3) | 235.1/(0.1) | 93.2/(0.2) |
| 6 | 261 | 119 | 262.5/(1.5) | 120.9/(1.9) | 262.1/(1.1) | 120.5/(1.5) | 261.5/(0.5) | 120.3/(1.3) |
| 7 | 238 | 91 | 237.5/(0.5) | 90.7/(0.3) | 237.7/(0.3) | 90.8/(0.2) | 237.8/(0.2) | 90.9/(0.1) |
| 8 | 235 | 92 | 239.5/(4.5) | 92.9/(0.9) | 238.7/(3.7) | 92.7/(0.7) | 238.4/(3.4) | 92.5/(0.5) |
| 9 | 269 | 121 | 268.1/(0.9) | 121.7/(0.7) | 268.5/(0.5) | 121.5/(0.5) | 268.8/(0.2) | 121.5/(0.5) |
| 10 | 272 | 127 | 274.3/(2.3) | 127.9/(0.9) | 274.1/(2.1) | 127.7/(0.7) | 273.8/(1.8) | 127.6/(0.6) |
| Avg. Time (min) | 3.31 | 9.58 | 11.29 | |||||
| Standard deviation (mm) | 1.14 | 0.99 | 0.87 | |||||
| Number of Models | Manual Measurement | 960 × 540 | 640 × 360 | 480 × 270 | ||||
|---|---|---|---|---|---|---|---|---|
| FL (mm) | FW (mm) | FL (mm) | FW (mm) | FL (mm) | FW (mm) | FL (mm) | FW (mm) | |
| 1 | 265 | 123 | 264.5/(0.5) | 122.8/(0.2) | 264.7/(0.3) | 122.8 (0.2) | 264.8/(0.2) | 122.9/(0.1) |
| 2 | 247 | 98 | 247.4/(0.4) | 98.7/(0.7) | 247.2/(0.2) | 98.7/(0.7) | 247.3/(0.3) | 98.4/(0.4) |
| 3 | 242 | 95 | 243.3/(1.3) | 97.4/(2.4) | 243.3/(1.3) | 97/(2.0) | 243.1/(1.1) | 96.7/(1.7) |
| 4 | 285 | 125 | 288.5/(3.5) | 127.3/(2.3) | 288.3/(3.3) | 127.1/(2.1) | 288.2/(3.2) | 127/(2.0) |
| 5 | 235 | 93 | 235.4/(0.4) | 93.3/(0.3) | 235.3/(0.3) | 93.3/(0.3) | 235.3/(0.3) | 93.2/(0.2) |
| 6 | 261 | 119 | 262.7/(1.7) | 121.1/(2.1) | 262.6/(1.6) | 120.9/(1.9) | 262.4/(1.4) | 120.8/(1.8) |
| 7 | 238 | 91 | 237.3/(0.7) | 90.5/(0.5) | 237.4/(0.6) | 90.5/(0.5) | 237.4/(0.6) | 90.4/(0.6) |
| 8 | 235 | 92 | 238.5/(3.5) | 92.7/(0.7) | 238.3/(3.3) | 92.7/(0.7) | 238.4/(3.4) | 92.6/(0.6) |
| 9 | 269 | 121 | 268/(1.0) | 121.8/(0.8) | 268.3/(0.7) | 121.7/(0.7) | 268.4/(0.6) | 121.6/(0.6) |
| 10 | 272 | 127 | 274.1/(2.1) | 127.7/(0.7) | 273.9/(1.9) | 127.5/(0.5) | 273.8/(1.8) | 127.5/(1.5) |
| Avg. Time (min) | 3.22 | 2.12 | 1.35 | |||||
| Standard deviation (mm) | 1.03 | 0.97 | 0.95 | |||||
| Author | Year | Method | Input Data | Standard Deviation (mm) | The Lower Arch of the Foot is Included |
|---|---|---|---|---|---|
| Parrilla E. et al. [5] | 2015 | PCA | Multiple RGB images | 1.7 | - |
| Pambudi D. S., Hidayah L. [18] | 2018 | RGB-D—camera, Intel Realsense | Depth image | 0.355 | + |
| Wang M. et al. [12] | 2018 | RGB-D—camera, Microsoft Kinect | Depth Image | 0.85 | + |
| Kobayashi T. et al. [19] | 2018 | Smartphone depth-camera, PCA | Depth image | 1.13 | + |
| Revkov A., Kanin D. [7] | 2020 | Multi-stage decision tree is based on NNs | Multiple RGB images | 1.3 | − |
| Kok F., Charles J., Cipolla R. [33] | 2020 | CNN, PCA | Multiple RGB images | 4 | − |
| Niu L. et al. [21] | 2021 | Photogrammetry | Multiple RGB images | 1.08 | − |
| Ours | 2021 | Photogrammetry, CNN | Multiple RGB images | 0.95 | + |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shilov, L.; Shanshin, S.; Romanov, A.; Fedotova, A.; Kurtukova, A.; Kostyuchenko, E.; Sidorov, I. Reconstruction of a 3D Human Foot Shape Model Based on a Video Stream Using Photogrammetry and Deep Neural Networks. Future Internet 2021, 13, 315. https://doi.org/10.3390/fi13120315
Shilov L, Shanshin S, Romanov A, Fedotova A, Kurtukova A, Kostyuchenko E, Sidorov I. Reconstruction of a 3D Human Foot Shape Model Based on a Video Stream Using Photogrammetry and Deep Neural Networks. Future Internet. 2021; 13(12):315. https://doi.org/10.3390/fi13120315
Chicago/Turabian StyleShilov, Lev, Semen Shanshin, Aleksandr Romanov, Anastasia Fedotova, Anna Kurtukova, Evgeny Kostyuchenko, and Ivan Sidorov. 2021. "Reconstruction of a 3D Human Foot Shape Model Based on a Video Stream Using Photogrammetry and Deep Neural Networks" Future Internet 13, no. 12: 315. https://doi.org/10.3390/fi13120315
APA StyleShilov, L., Shanshin, S., Romanov, A., Fedotova, A., Kurtukova, A., Kostyuchenko, E., & Sidorov, I. (2021). Reconstruction of a 3D Human Foot Shape Model Based on a Video Stream Using Photogrammetry and Deep Neural Networks. Future Internet, 13(12), 315. https://doi.org/10.3390/fi13120315