
An Advanced Deep Learning Approach for Multi-Object Counting in Urban Vehicular Environments

 , ,
, ,  ,
,
Abstract
:1. Introduction
2. Background
- Center of a bounding box.
- Width and Height.
- The value (c) which is corresponding to a class of an object.
- The (pc) value, which is the probability that there is an object in the bounding box.
3. Related Work
3.1. Object Detection and Counting Using Traditional Approaches
3.2. Object Detection and Counting Using Deep Learning Techniques
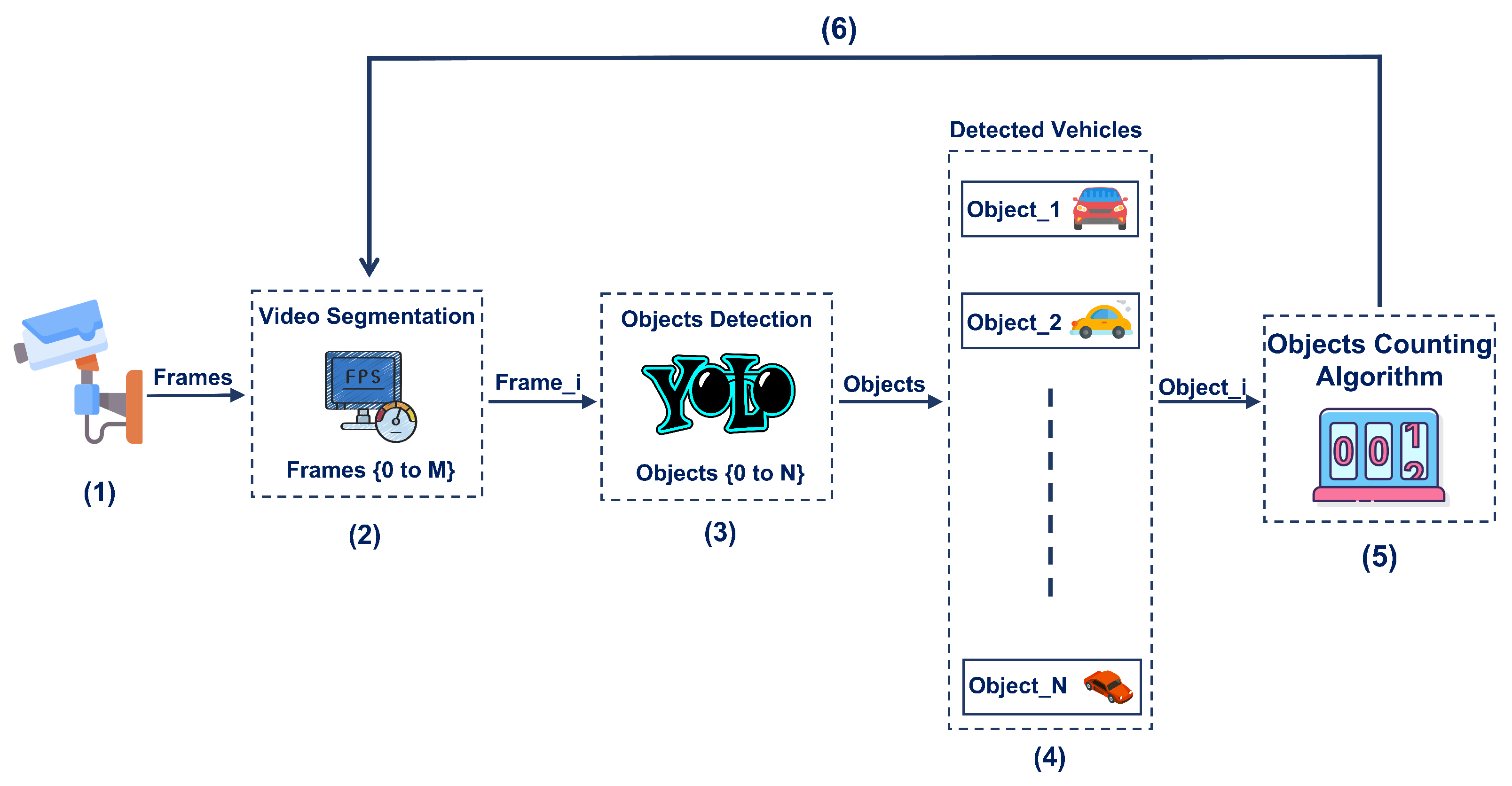
4. System Architecture
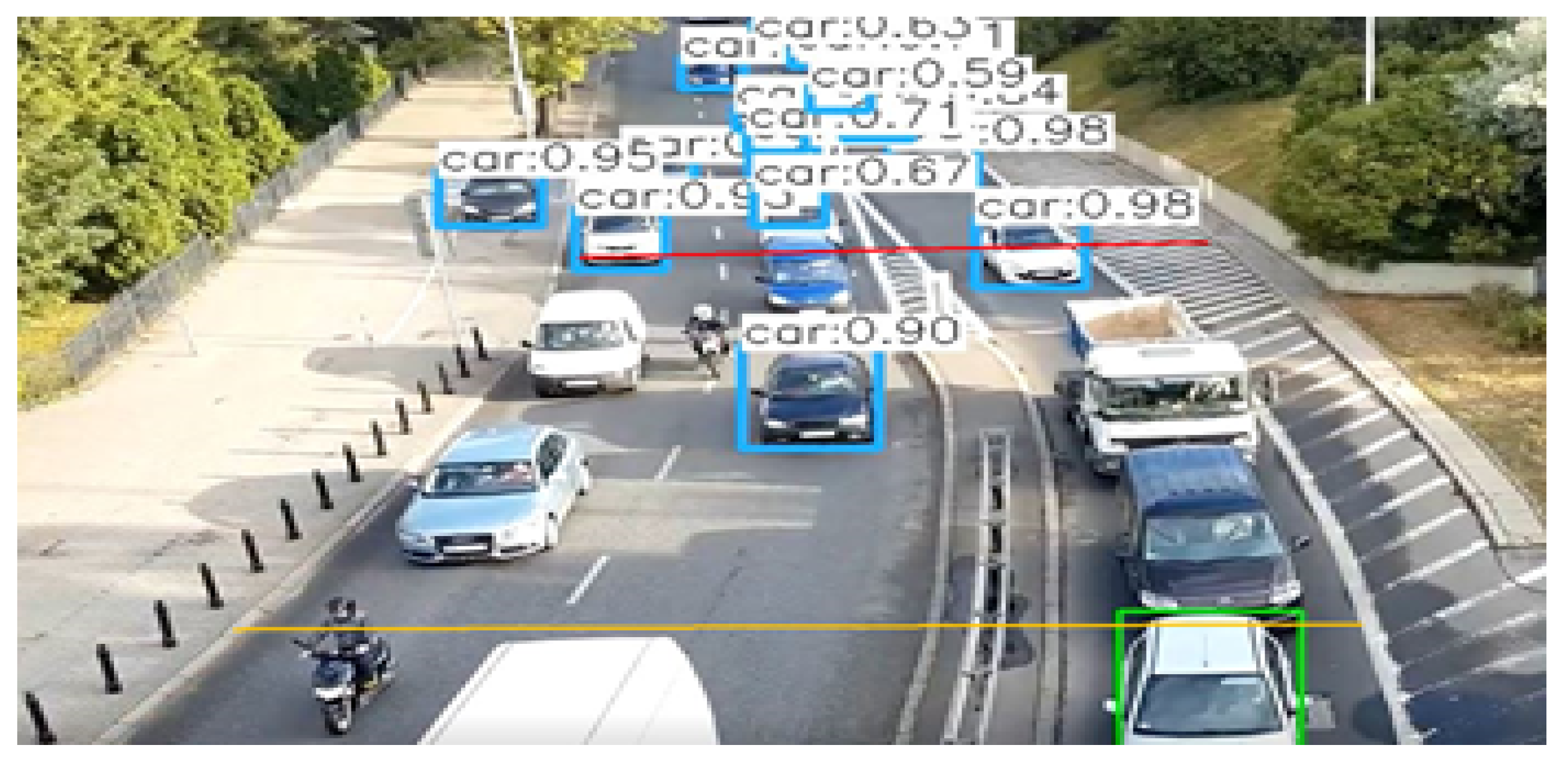
4.1. Object Detection Stage
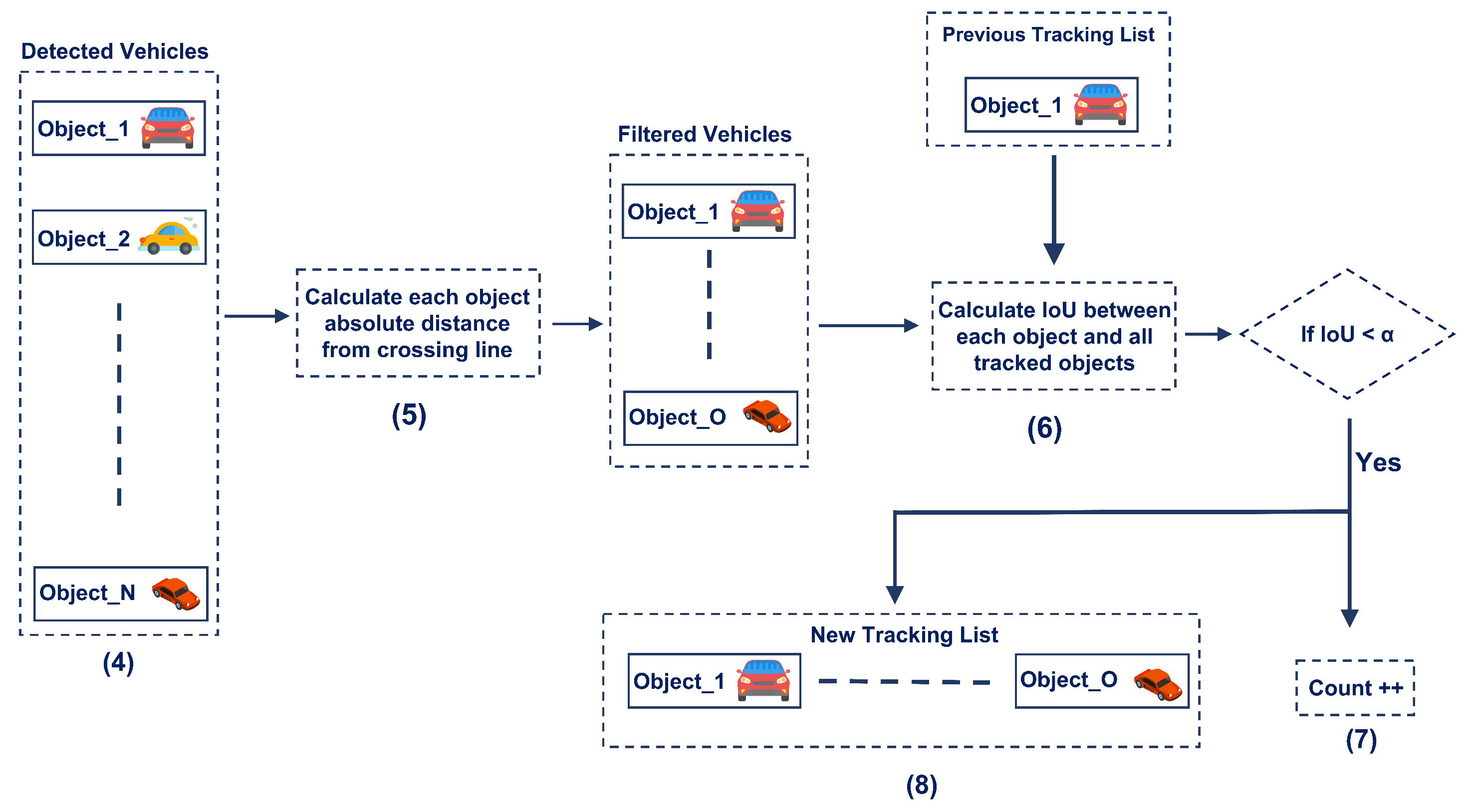
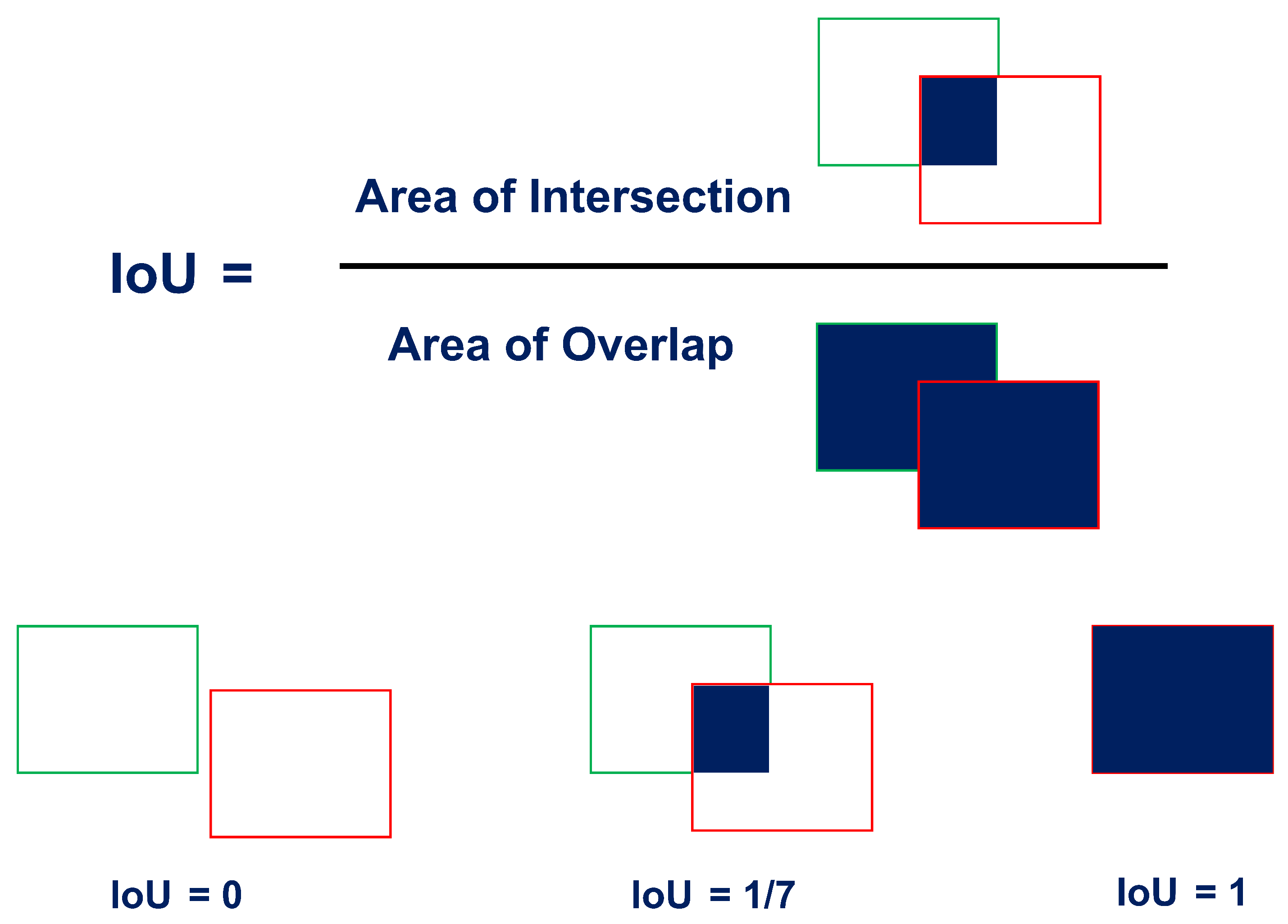
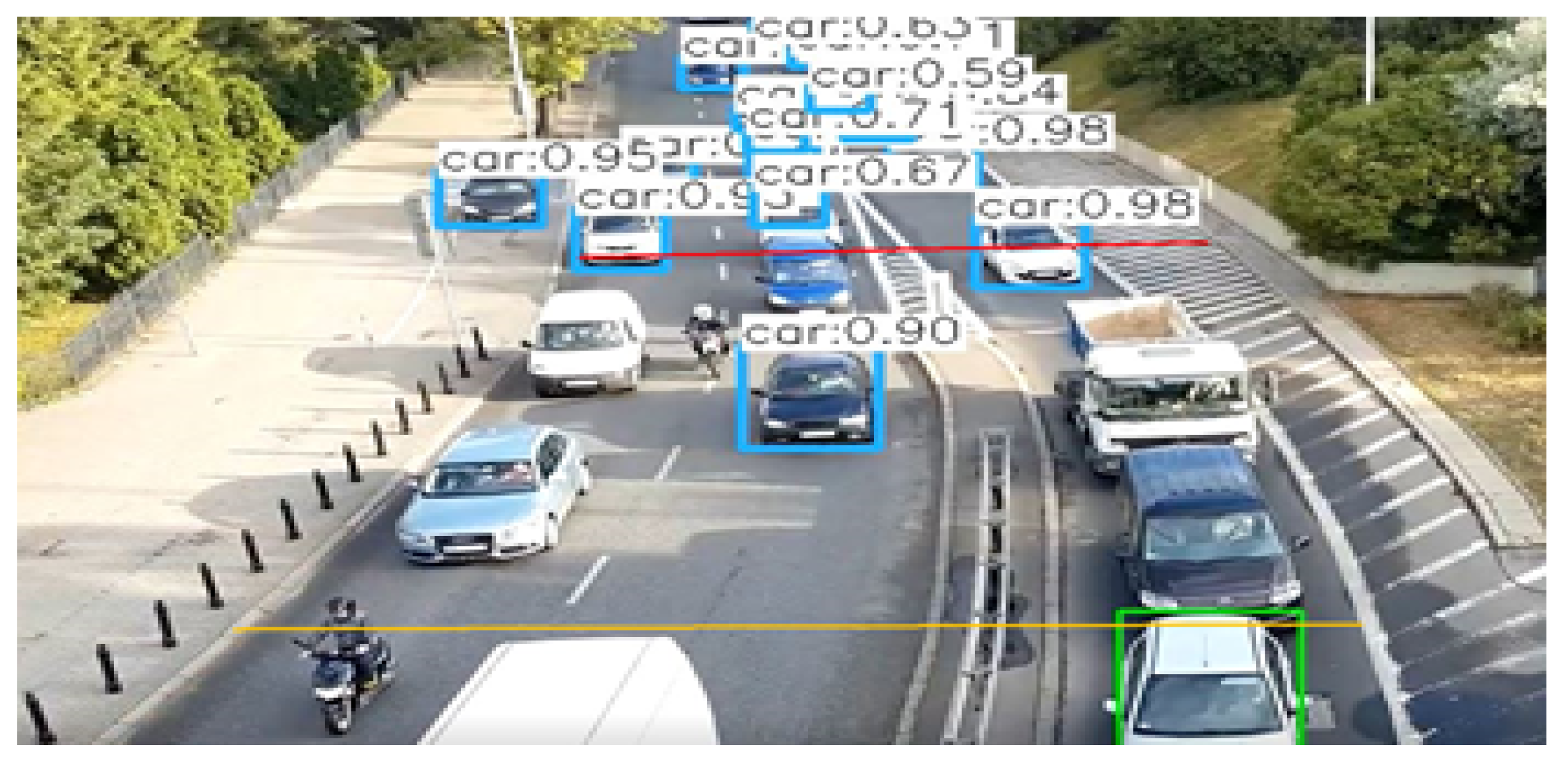
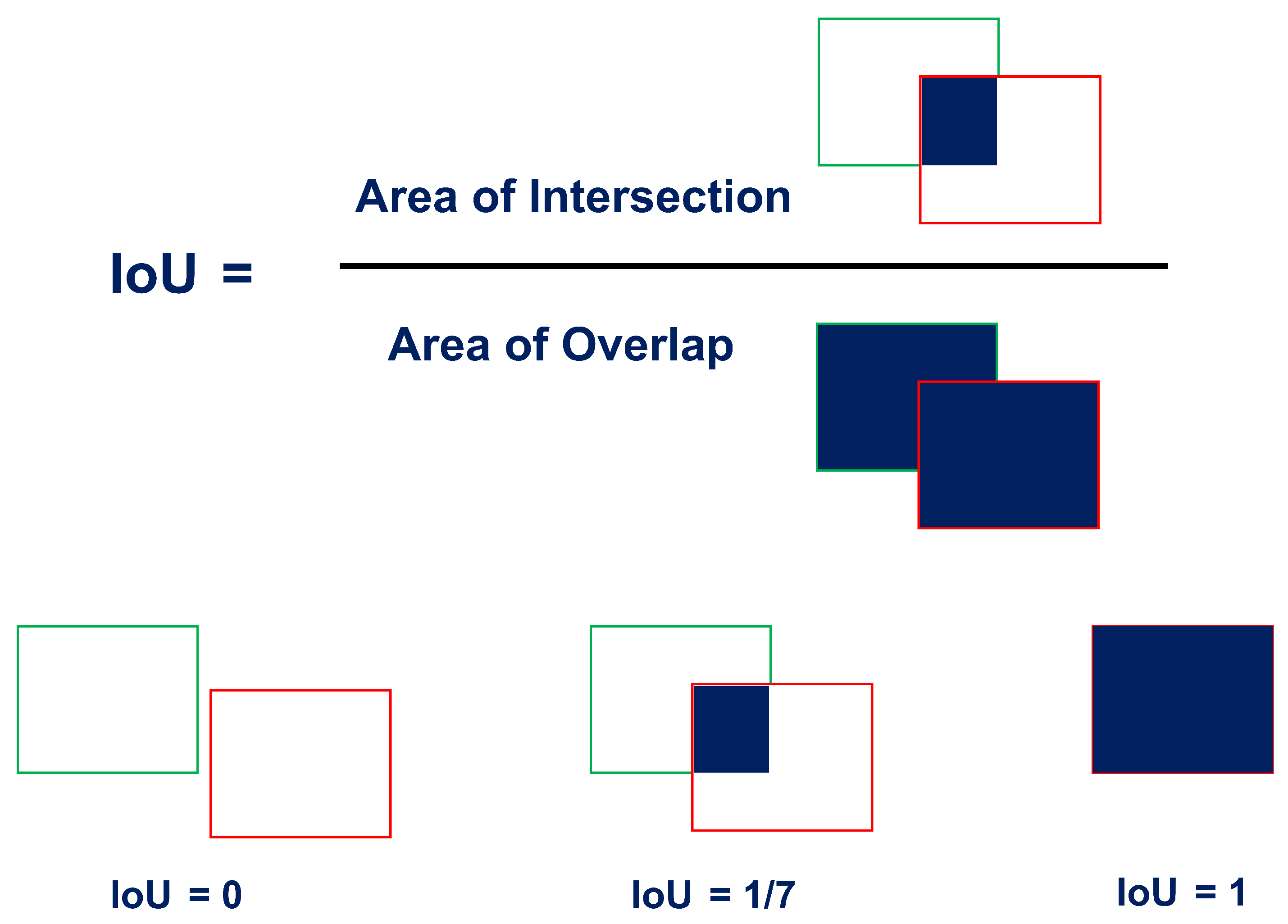
4.2. Object Counting Stage
| Algorithm 1: Object Counting Algorithm V2 |
 |
5. Preparation of Datasets
5.1. Density of Objects
5.2. Quality of Images
5.3. Angle of View
5.4. Speed and Direction of Motion
6. Performance Evaluation
6.1. Density of Objects
6.2. Quality of Images
6.3. Angle of View
6.4. Speed and Direction of Motion
6.5. Performance Comparison with Other Related Works
7. Discussion and Future Work
- Implementing the 3GPP Enhanced Sensors use case scenario by evolving the contribution of this article. One of the major ingredients in this case will involve additional sensors to be deployed on the drone. This activity will allow us to investigate the role of 5G C-V2X capabilities (including side-ling, PC 5), etc. for meeting the ITS service quality requirements.
- Investigating the potential of Federated Learning for achieving the objectives of level 5 autonomous driving. For this, we plan to deploy the learning instances at the three levels i.e., vehicle, smart edges (roadside units), and backends of the OEMs, mobile network providers, and ITS service providers. It should be highlighted that the envisioned ecosystem with the engagement of aforementioned stakeholders, federated learning is expected to be a natural fit.
- We plan to evolve the contributed approach to further classify vehicles based on their types and cluster them along with their counts, which can further be analyzed for the use-cases of level 5 autonomous driving.
- Owing to the fact that contribution aligns well with other verticals and application domains, we also plan to extend the proposed methodology in the field of agriculture, to provide detailed analysis on various factors related to plant health status, productivity, and disease attacks. This analysis will guide the agriculturist to improve crop productivity and take early preventive measures on disease attacks.
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
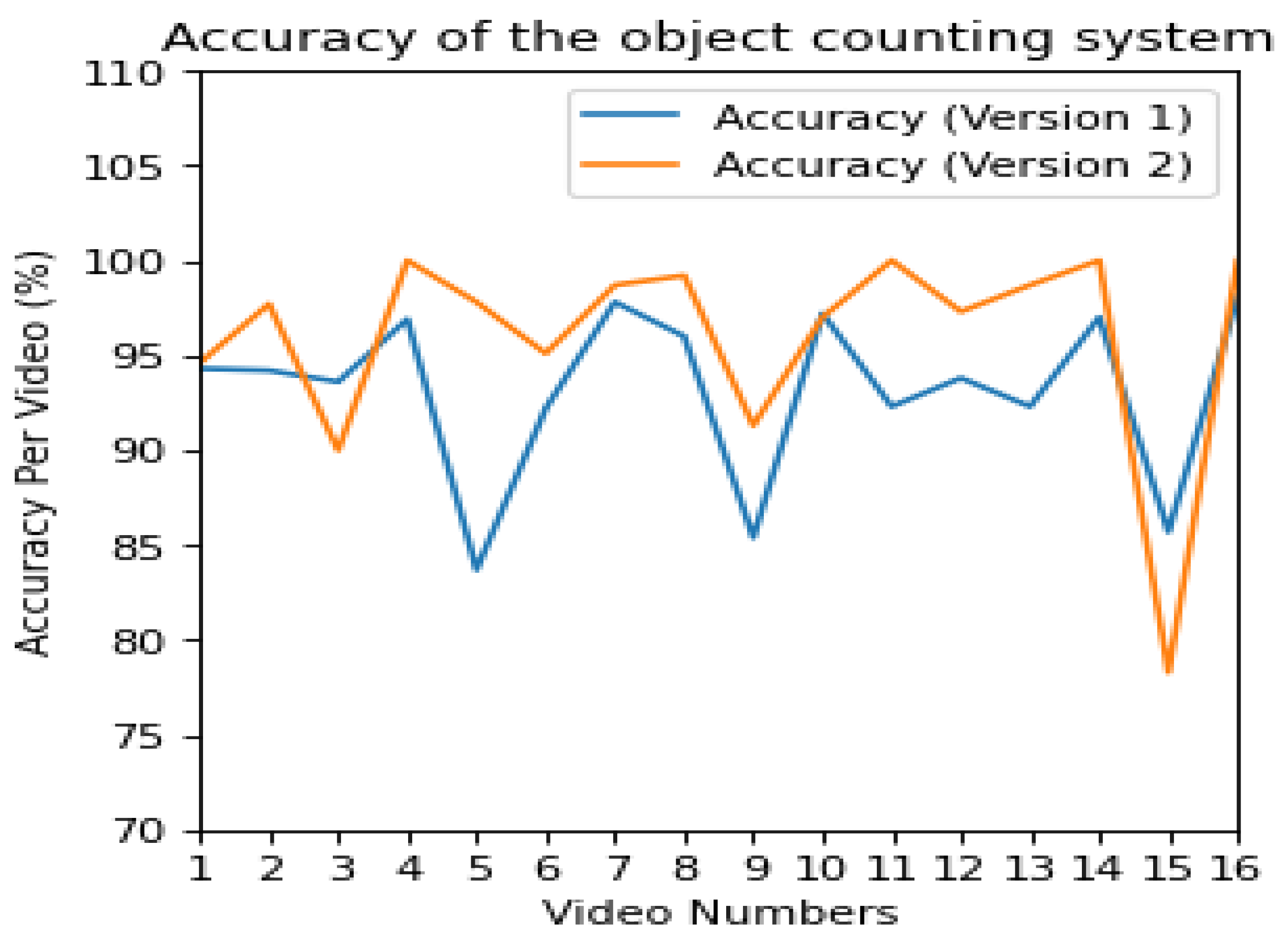
| Normal traffic with trucks and perfect image view | Normal car density with buses and perfect image view | High car density with high speed and curved road | Aerial image view with traffic density and good image resolution |
 |  |  |  |
| version[1.0] = 94.3% version[2.0] = 94.6% | version[1.0] = 94.2% version[2.0] = 97.7% | version[1.0] = 93.6% version[2.0] = 90.0% | version[1.0] = 96.9% version[2.0] = 100% |
| Curved road with normal traffic and blind spot | Normal traffic and perfect image view | Normal traffic with trucks and blind spot | Normal traffic with outgoing cars and perfect image view |
 |  |  |  |
| version[1.0] = 83.7% version[2.0] = 97.8% | version[1.0] = 92.2% version[2.0] = 95.1% | version[1.0] = 97.8% version[2.0] = 98.7% | version[1.0] = 96.0% version[2.0] = 99.2% |
| High traffic density with low speed | Low traffic density and perfect image view | Normal traffic and perfect image view | High traffic density and speed with occlusion and perfect image view |
 |  |  |  |
| version[1.0] = 85.4% version[2.0] = 91.3% | version[1.0] = 97.2% version[2.0] = 97.0% | version[1.0] = 92.3% version[2.0] = 100% | version[1.0] = 93.8% version[2.0] = 97.3% |
| Normal traffic with trucks and blind spot | Normal traffic at night | High traffic with distraction and noise and low speed | Extra Low traffic and perfect image view |
 |  |  |  |
| version[1.0] = 92.3% version[2.0] = 98.7% | version[1.0] = 97.0% version[2.0] = 100% | version[1.0] = 85.7% version[2.0] = 78.2% | version[1.0] = 98.1% version[2.0] = 100% |
References
- Kugler, L. Real-world applications for drones. Commun. ACM 2019, 62, 19–21. [Google Scholar] [CrossRef] [Green Version]
- Rosser, J.C., Jr.; Vignesh, V.; Terwilliger, B.A.; Parker, B.C. Surgical and medical applications of drones: A comprehensive review. J. Soc. Laparoendosc. Surg. 2018, 22. Available online: https://pubmed.ncbi.nlm.nih.gov/30356360/ (accessed on 27 November 2021). [CrossRef] [PubMed] [Green Version]
- Hassanalian, M.; Abdelkefi, A. Classifications, applications, and design challenges of drones: A review. Prog. Aerosp. Sci. 2017, 91, 99–131. [Google Scholar] [CrossRef]
- Hassanalian, M.; Rice, D.; Abdelkefi, A. Evolution of space drones for planetary exploration: A review. Prog. Aerosp. Sci. 2018, 97, 61–105. [Google Scholar] [CrossRef]
- Mirthubashini, J.; Santhi, V. Video Based Vehicle Counting Using Deep Learning Algorithms. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 6–7 March 2020; pp. 142–147. [Google Scholar] [CrossRef]
- Dai, Z.; Song, H.; Wang, X.; Fang, Y.; Yun, X.; Zhang, Z.; Li, H. Video-Based Vehicle Counting Framework. IEEE Access 2019, 7, 64460–64470. [Google Scholar] [CrossRef]
- Yang, Y.; Gao, W. A Method of Pedestrians Counting Based on Deep Learning. In Proceedings of the 2019 3rd International Conference on Electronic Information Technology and Computer Engineering (EITCE), Xiamen, China, 18–20 October 2019; pp. 2010–2013. [Google Scholar] [CrossRef]
- Mamdouh, N.; Khattab, A. YOLO-Based Deep Learning Framework for Olive Fruit Fly Detection and Counting. IEEE Access 2021, 9, 84252–84262. Available online: https://ieeexplore.ieee.org/abstract/document/9450822 (accessed on 27 November 2021). [CrossRef]
- Dirir, A.; Adib, M.; Mahmoud, A.; Al-Gunaid, M.; El-Sayed, H. An Efficient Multi-Object Tracking and Counting Framework Using Video Streaming in Urban Vehicular Environments. In Proceedings of the 2020 International Conference on Communications, Signal Processing, and their Applications (ICCSPA), Sharjah, United Arab Emirates, 16–18 March 2021; pp. 1–7. [Google Scholar] [CrossRef]
- Farkhodov, K.; Lee, S.-H.; Kwon, K.-R. Object Tracking Using CSRT Tracker and RCNN Farkhodov2020object. 2020, pp. 209–212. Available online: https://www.scitepress.org/Papers/2020/91838/91838.pdf (accessed on 27 November 2021).
- Piccardi, M. Background subtraction techniques: A review. IEEE Proc. Int. Conf. Syst. Man Cybern. 2004, 4, 3099–3104. [Google Scholar]
- Del Blanco, C.R.; Jaureguizar, F.; García, N. Visual tracking of multiple interacting objects through raoblackwellized data association particle filtering. In Proceedings of the 2010 IEEE International Conference on Image Processing, Hong Kong, China, 26–29 September 2010; pp. 821–824. Available online: https://ieeexplore.ieee.org/document/5653411 (accessed on 27 November 2021).
- Genovesio, A.; Olivo-Marin, J.C. Split and merge data association filter for dense multi-target tracking. In Proceedings of the 17th International Conference on Pattern Recognition, 2004. ICPR 2004, Cambridge, UK, 26 August 2004; Volume 4, pp. 677–680. [Google Scholar]
- Ma, Y.; Yu, Q.; Cohen, I. Target tracking with incomplete detection. Comp. Vis. Image Underst. 2009, 113, 580–587. [Google Scholar] [CrossRef]
- Yu, Q.; Medioni, G. Multiple-target tracking by spatiotemporal monte carlo markov chain data association. IEEE Trans. Patern Anal. Mach. Intell. 2009, 31, 2196–2210. [Google Scholar]
- Khan, Z.; Balch, T.; Dellaert, F. Multitarget tracking with split and merged measurements. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 605–610. [Google Scholar]
- Del Blanco, C.R.; Jaureguizar, F.; García, N. Bayesian Visual Surveillance: A Model for Detecting and Tracking a variable number of moving objects. In Proceedings of the 2011 18th IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011; pp. 1437–1440. Available online: https://ieeexplore.ieee.org/document/6115712 (accessed on 27 November 2021).
- Yam, K.; Siu, W.; Law, N.; Chan, C. Effective bidirectional people flow counting for real time surveillance system. In Proceedings of the 2011 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 9–12 January 2011; pp. 863–864. [Google Scholar]
- Tuzel, O.; Porikli, F.; Meer, P. Learning on lie groups for invariant detection and tracking. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. Available online: https://ieeexplore.ieee.org/document/4587521 (accessed on 27 November 2021).
- Galvez, R.L.; Bandala, A.A.; Dadios, E.P.; Vicerra, R.R.; Maningo, J.M. Object Detection Using Convolutional Neural Networks. In Proceedings of the TENCON 2018—2018 IEEE Region 10 Conference, Jeju, Korea, 28 October 2018; pp. 2023–2027. Available online: https://ieeexplore.ieee.org/abstract/document/8650517 (accessed on 27 November 2021).
- Huang, Z.; Wang, J.; Fu, X.; Yu, T.; Guo, Y.; Wang, R. DC-SPP-YOLO: Dense connection and spatial pyramid pooling based YOLO for object detection. Inf. Sci. 2020, 522, 241–258. [Google Scholar] [CrossRef] [Green Version]
- Sun, X.; Wu, P.; Hoi, S.C. Face detection using deep learning: An improved faster RCNN approach. Neurocomputing 2018, 299, 42–50. [Google Scholar] [CrossRef] [Green Version]
- Broad, A.; Jones, M.; Lee, T.Y. Recurrent Multi-frame Single Shot Detector for Video Object Detection. In BMVC 2018 Sep. p. 94. Available online: http://bmvc2018.org/contents/papers/0309.pdf (accessed on 27 November 2021).
- Naik, Z.K.; Gandhi, M.R. A Review: Object Detection using Deep Learning. Int. J. Comput. Appl. 2018, 180, 46–48. [Google Scholar]
- Anusha, C.; Avadhani, P.S. Object Detection using Deep Learning. Int. J. Comput. Appl. 2018, 182, 18–22. [Google Scholar] [CrossRef]
- Pathak, A.; Pandey, M.; Rautaray, S. Application of Deep Learning for Object Detection. Procedia Comput. Sci. 2018, 132, 1706–1717. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. Proc. Cvpr 2016, 779–788. Available online: https://www.cv-foundation.org/openaccess/content_cvpr_2016/html/Redmon_You_Only_Look_CVPR_2016_paper.html (accessed on 27 November 2021).
- Redmon, J.; Farhadi, A. Yolo9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. Available online: https://link.springer.com/chapter/10.1007/978-3-319-46448-0_2 (accessed on 27 November 2021).
- Fu, C.-Y.; Liu, W.; Ranga, A.; Tyagi, A. Berg.Dssd: Deconvolutional single shots detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of ICCV; 2017; pp. 2961–2969. Available online: https://openaccess.thecvf.com/content_iccv_2017/html/He_Mask_R-CNN_ICCV_2017_paper.html (accessed on 27 November 2021).
- Sunkara, J.; Santhosh, M.; Cherukuri, S.; Gopi Krishna, L. Object Tracking Techniques and Performance Measures—A Conceptual Survey. In Proceedings of the IEEE International Conference on Power, Control, Signals and Instrumentation Engineering (ICPCSI-2017), Chennai, India, 21–22 September 2017. [Google Scholar]
- Zhang, D.; Maei, H.; Wang, X.; Wang, Y. Deep reinforcement learning for visual object tracking in videos. Comput. Res. Repos. 2017. Available online: https://arxiv.org/pdf/1701.08936.pdf (accessed on 27 November 2021).
- Saxena, G.; Gupta, A.; Verma, D.K.; Rajan, A.; Rawat, A. Robust Algorithms for Counting and Detection of Moving Vehicles using Deep Learning. In Proceedings of the 2019 IEEE 9th International Conference on Advanced Computing (IACC), Tiruchirappalli, India, 13–14 December 2019; pp. 235–239. [Google Scholar] [CrossRef]
- Hardjono, B.; Tjahyadi, H. Vehicle Counting Quantitative Comparison Using Background Subtraction, Viola Jones and Deep Learning Methods. In Proceedings of the 2018 IEEE 9th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON); Available online: https://ieeexplore.ieee.org/abstract/document/8615085 (accessed on 27 November 2021).
- Lin, J.-P.; Sun, M.-T. A YOLO-Based Traffic Counting System. In Proceedings of the 2018 Conference on Technologies and Applications of Artificial Intelligence (TAAI), Taichung, Taiwan, 30 November–2 December 2018. [Google Scholar]
- Asha, C.S.; Narasimhadhan, A.V. Vehicle Counting for Traffic Management System using YOLO and Correlation Filter. In Proceedings of the 2018 IEEE International Conference on Electronics, Computing and Communication Technologies (CONECCT); Available online: https://ieeexplore.ieee.org/abstract/document/8482380 (accessed on 27 November 2021).
- Forero, A.; Calderon, F. Vehicle and pedestrian video-tracking with classification based on deep convolutional neural networks. In Proceedings of the 2019 XXII Symposium on Image, Signal Processing and Artificial Vision (STSIVA), Bucaramanga, Colombia, 24–26 April 2019. [Google Scholar]
- Mohamed, A.A. Accurate Vehicle Counting Approach Based on Deep Neural Networks. In Proceedings of the 2019 International Conference on Innovative Trends in Computer Engineering (ITCE), Aswan, Egypt, 8–9 February 2020. [Google Scholar]
- Amitha, I.C.; Narayanan, N.K. Object Detection Using YOLO Framework for Intelligent Traffic Monitoring. In Machine Vision and Augmented Intelligence—Theory and Applications; Springer: Singapore, 2021; pp. 405–412. [Google Scholar]
- Can, V.X.; Vu, P.X.; Rui-fang, M.; Thuat, V.T.; Van Duy, V.; Noi, N.D. Vehicle Detection and Counting Under Mixed Traffic Conditions in Vietnam Using Yolov4. Available online: https://d1wqtxts1xzle7.cloudfront.net/67640687/IJARET_12_02_072.pdf?1623818829=&response-content-disposition=inline%3B+filename%3DVEHICLE_DETECTION_AND_COUNTING_UNDER_MIX.pdf&Expires=1638195611&Signature=A7yVUQcYKePsOgUZFH4zqVXbmsP0QpVRlDLAYnmHiCIEDdV6uo4VJS-1T945AeWp~IkEcwak8YlVah0TFMs9mw4rNFO3ISDAFnqciqzKZL2uFZqckHtJIdTSwwJrFDpSk1zgPep6yr8wKQw~6-abIhv-2-yWSOi0DAOzYtFuUzlShv~Z4mWUefyI-OZcxqfDj3SUkaTvELtGCZlrNtXHQa2s0RicIT3xw0mGGFf-6~u-xuaviKnFuCz9~dtn2XCmQEuAkOjCSDn3uQjJksZsA7U4HiUf~ziZ1G9ke~4u~Uv5n6YpAO4KpL0y3oOumdc71J~aHvBE0rzaYtk0rQOO1w__&Key-Pair-Id=APKAJLOHF5GGSLRBV4ZA (accessed on 27 November 2021).
- Al-qaness, M.A.; Abbasi, A.A.; Fan, H.; Ibrahim, R.A.; Alsamhi, S.H.; Hawbani, A. An improved YOLO-based road traffic monitoring system. Computing 2021, 103, 211–230. [Google Scholar] [CrossRef]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dirir, A.; Ignatious, H.; Elsayed, H.; Khan, M.; Adib, M.; Mahmoud, A.; Al-Gunaid, M. An Advanced Deep Learning Approach for Multi-Object Counting in Urban Vehicular Environments. Future Internet 2021, 13, 306. https://doi.org/10.3390/fi13120306
Dirir A, Ignatious H, Elsayed H, Khan M, Adib M, Mahmoud A, Al-Gunaid M. An Advanced Deep Learning Approach for Multi-Object Counting in Urban Vehicular Environments. Future Internet. 2021; 13(12):306. https://doi.org/10.3390/fi13120306
Chicago/Turabian StyleDirir, Ahmed, Henry Ignatious, Hesham Elsayed, Manzoor Khan, Mohammed Adib, Anas Mahmoud, and Moatasem Al-Gunaid. 2021. "An Advanced Deep Learning Approach for Multi-Object Counting in Urban Vehicular Environments" Future Internet 13, no. 12: 306. https://doi.org/10.3390/fi13120306
APA StyleDirir, A., Ignatious, H., Elsayed, H., Khan, M., Adib, M., Mahmoud, A., & Al-Gunaid, M. (2021). An Advanced Deep Learning Approach for Multi-Object Counting in Urban Vehicular Environments. Future Internet, 13(12), 306. https://doi.org/10.3390/fi13120306