
Adaptive Multi-Grained Buffer Management for Database Systems


Abstract
:1. Introduction
- We propose AMG-Buffer to use two page buffers and a tuple buffer for organizing the buffer pool. AMG-Buffer can adapt to access patterns and choose either the page buffering scheme or the tuple-based scheme according to the user request.
- We present a detailed architecture and detailed algorithms for the AMG-Buffer, including the algorithms of reading a tuple and writing a tuple. In addition, we propose an efficient algorithm to adjust the size of the tuple buffer, which can improve the space efficiency of the buffer and make the AMG-Buffer adapt to dynamic workloads.
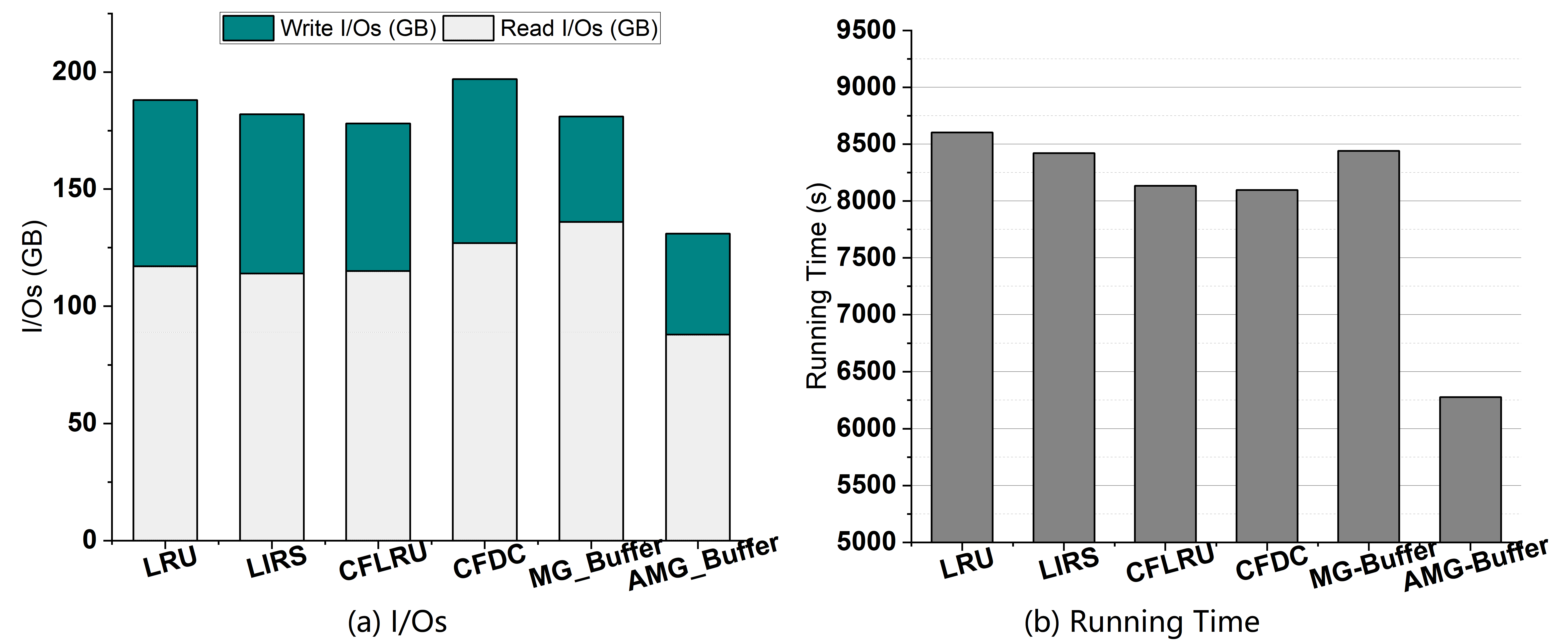
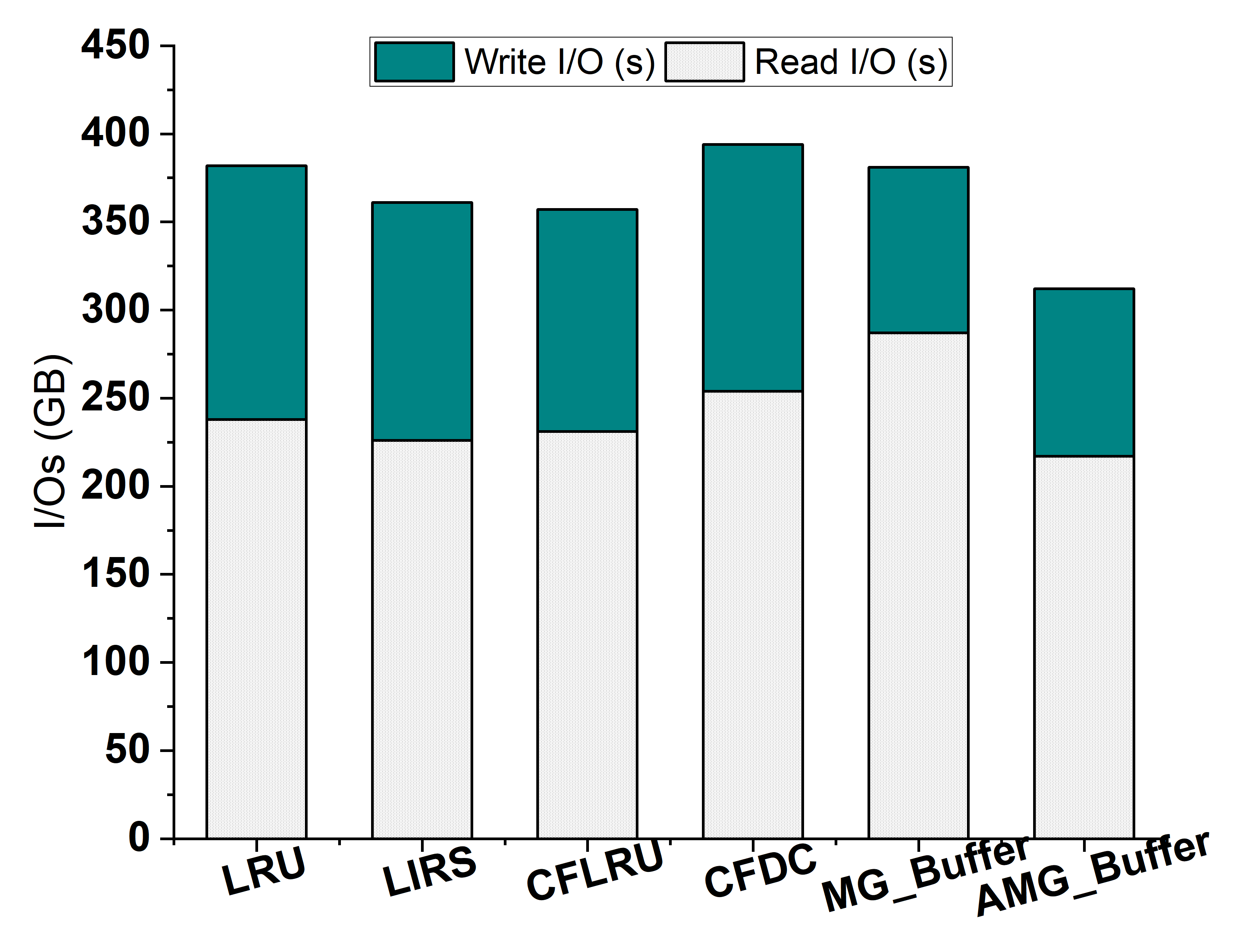
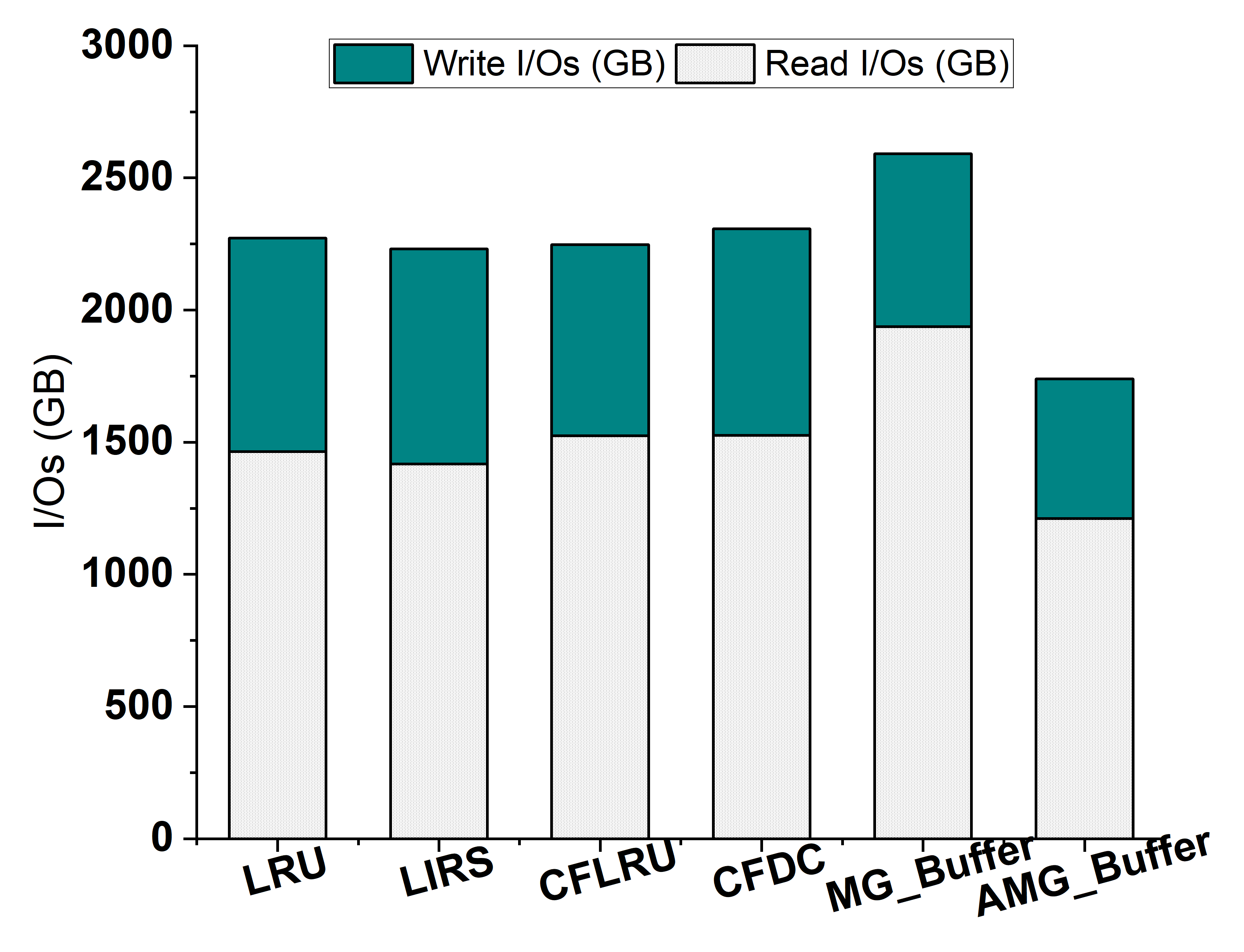
- We conduct experiments over various workloads to evaluate the performance of the AMG-Buffer. We compare our proposal with five existing buffer management schemes. The results show that the AMG-Buffer can significantly improve the hit ratio and reduce the I/Os. Moreover, the experiment on a dynamic workload and a large dataset suggests the adaptivity and scalability of AMG-Buffer.
2. Related Work
2.1. Traditional Buffer Management
2.2. Buffer Management for SSD-Based Database Systems
2.3. Key-Value Cache Management
3. Adaptive Multi-Grained Buffer Management
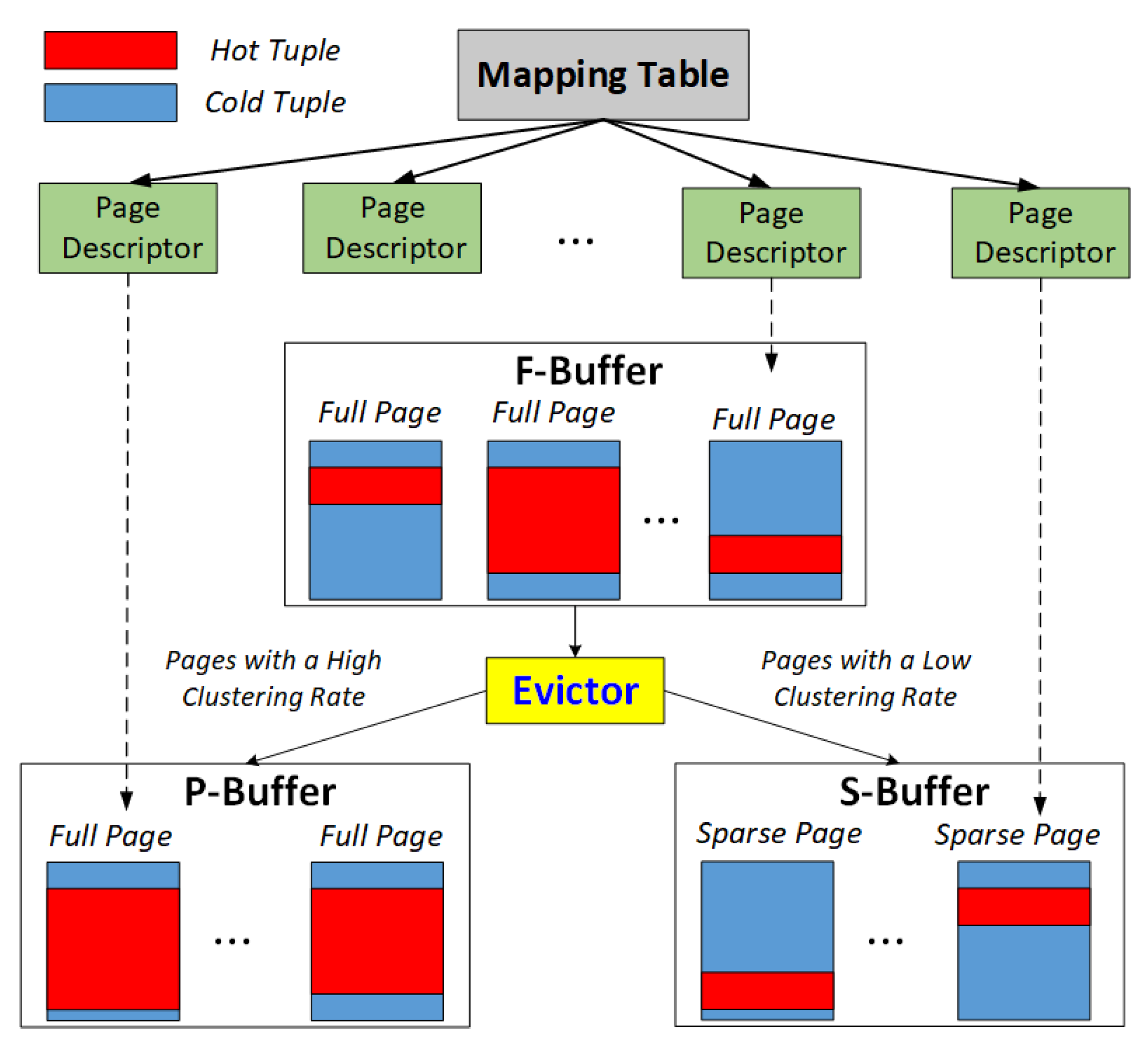
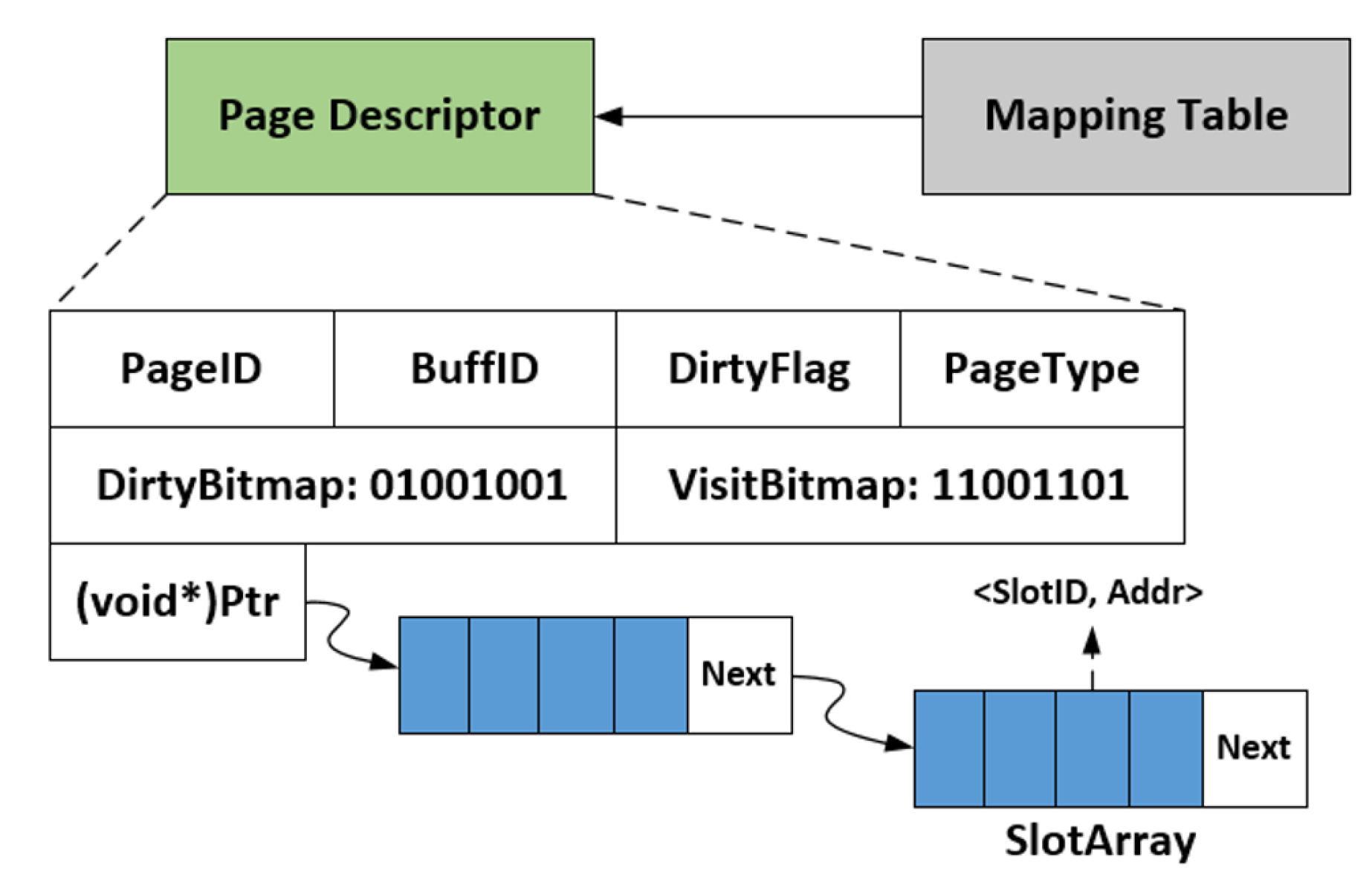
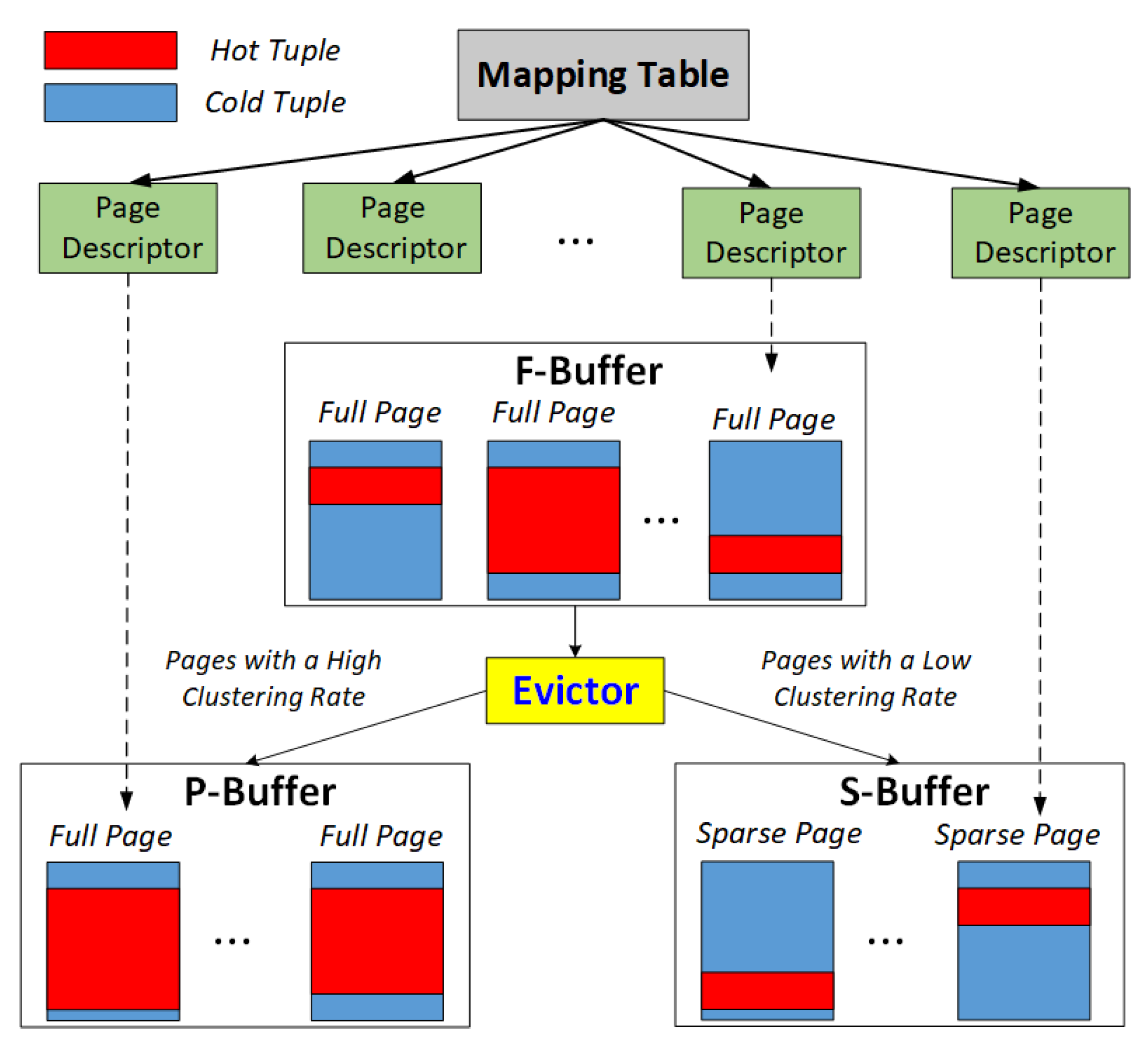
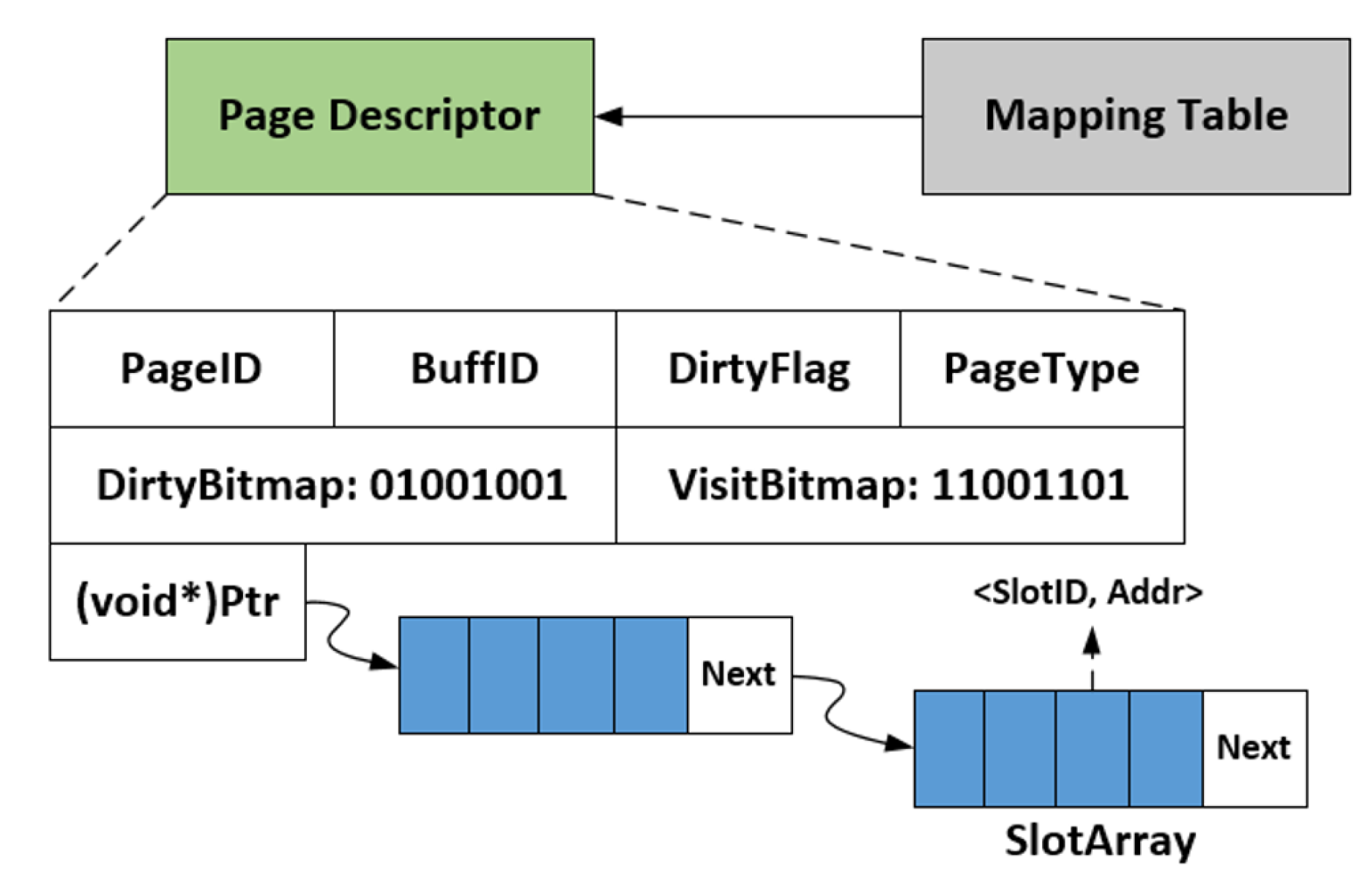
3.1. Architecture of AMG-Buffer
- (1)
- AMG-Buffer proposes to use both a page buffer and a tuple buffer to organize the whole buffer space. The hot or dirty tuples in the page buffer will be moved to the tuple buffer if the page in the page buffer is evicted out. Thus, the buffered page can be released to offer more buffer space for subsequent requests. With such a mechanism, AMG-Buffer can hold more hot tuples than the conventional page-based buffer, yielding the increasing of hit ratio and overall performance. Note that the requests to hot tuples will still hit in the tuple buffer.
- (2)
- We notice that when the tuple buffer manages hot tuples that come from different pages, it loses the benefit of spatial locality, which worses the efficiency of the memory. Furthermore, writing dirty tuples may incur additional read I/Os. In other words, either the page buffer or the tuple buffer is not efficient for all access patterns. Thus, AMG-Buffer introduces clustering rate to quantify the hot-tuple rate on a page.Definition 1.Clustering Rate. The clustering rate of a page refers to the ratio of the hot tuples within the page. A higher clustering rate means the page contains more hot tuples, and the page is more suitable to be managed by a page-grained buffer manager. On the other hand, a lower clustering rate means that a tuple buffer should be more efficient.
- (3)
- We develop algorithms to automatically perform tuple migration in AMG-Buffer according to the clustering rate of buffered pages. We experimentally demonstrate that the proposed AMG-Buffer can outperform both conventional buffering schemes, such as like LRU and LIRS, and SSD-aware buffering policies like CFDC and CFLRU. We also show that AMG-Buffer performs better than the non-adaptive multi-grained buffer manager.
3.2. Operations of AMG-Buffer
3.2.1. Read-Tuple Operation
| Algorithm 1: Read Tuple |
 |
3.2.2. Tuple Migration
3.2.3. Merging
3.2.4. Write-Tuple Operation
| Algorithm 2: Write Tuple |
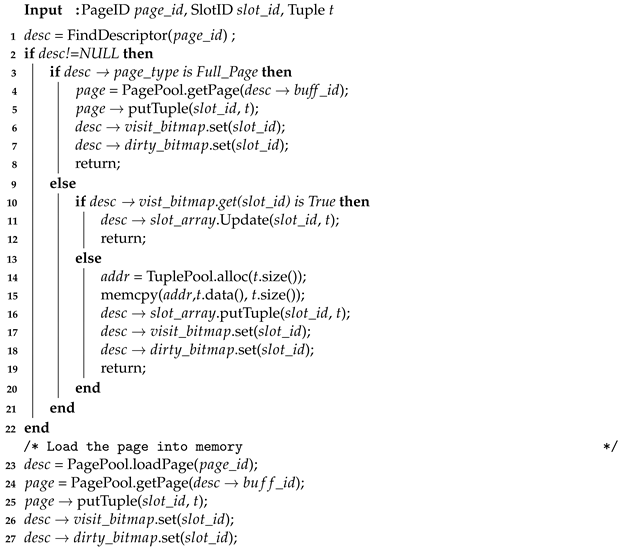 |
3.3. Adjustment of the P-Buffer
| Algorithm 3: Adjust the P-Buffer |
 |
3.4. Theoretical Analysis
4. Performance Evaluation
4.1. Settings
4.2. Workloads
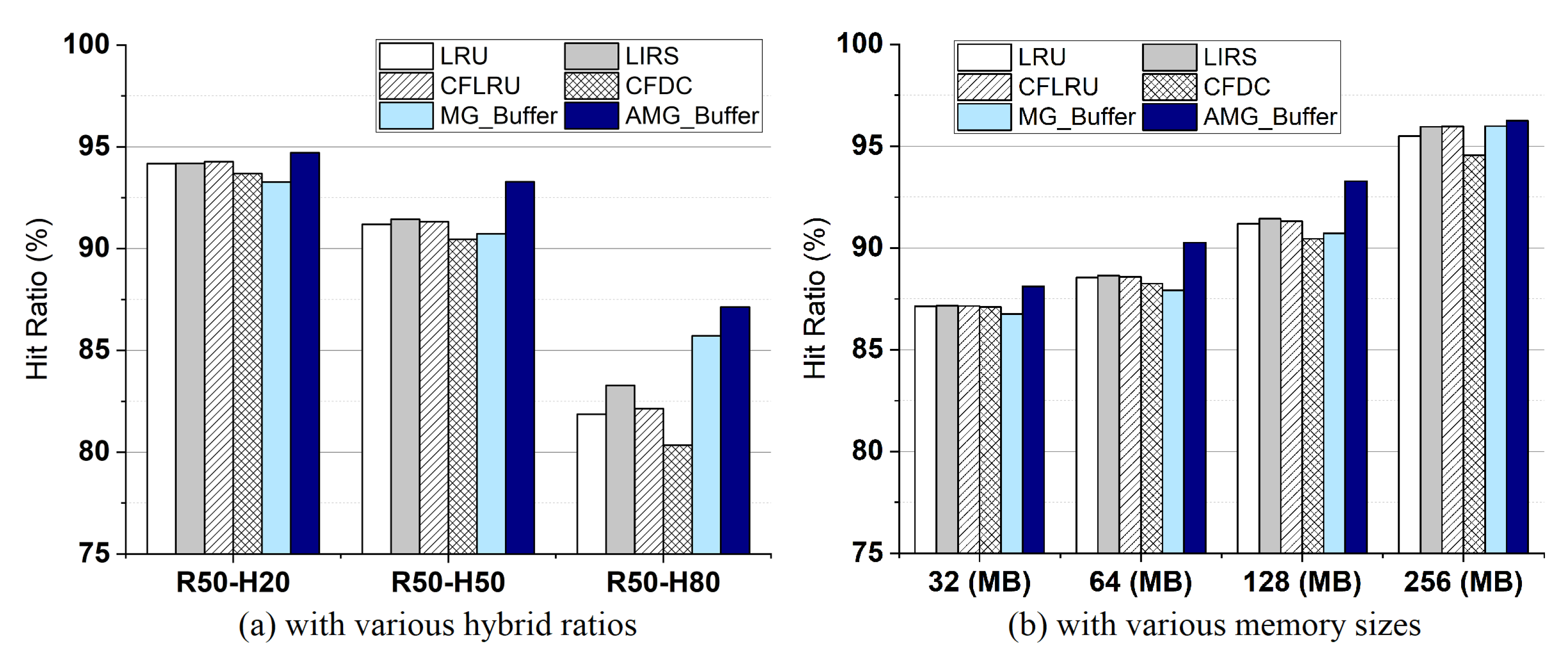
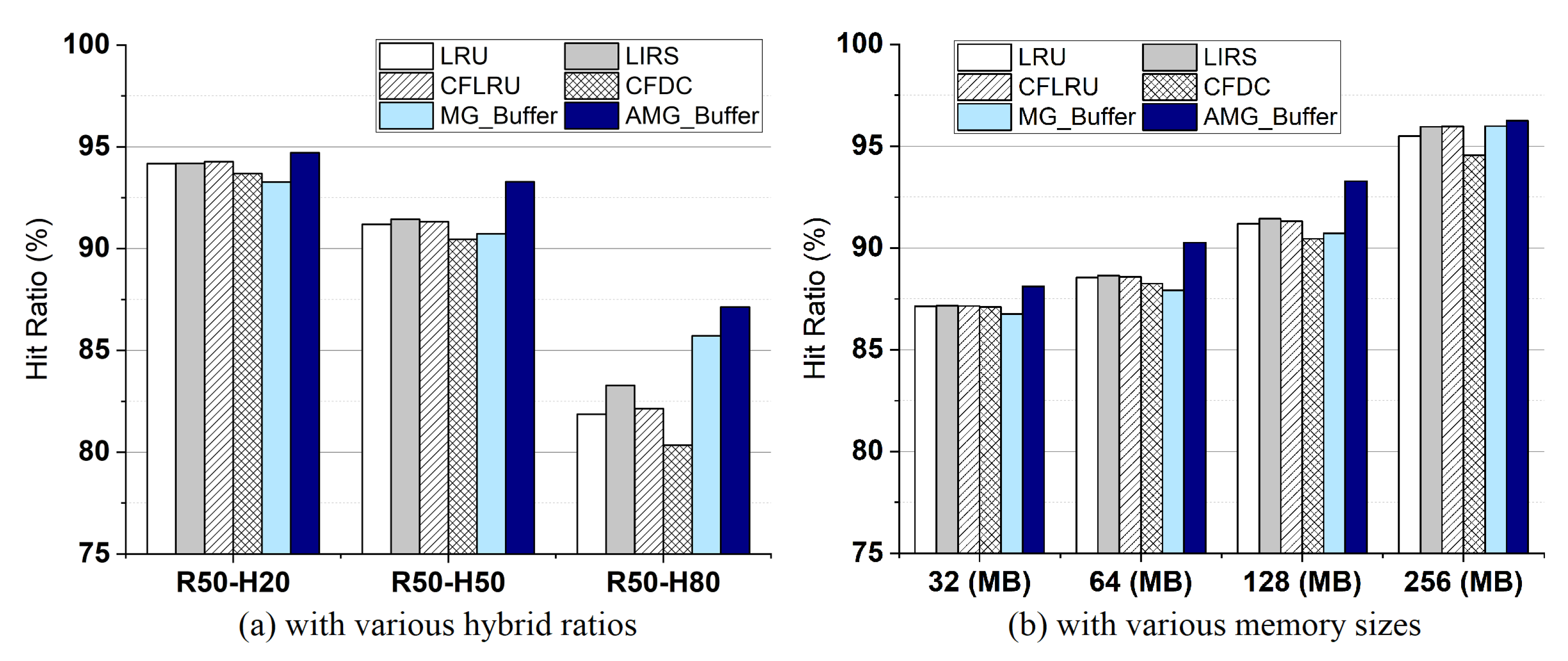
4.3. Hit Ratio
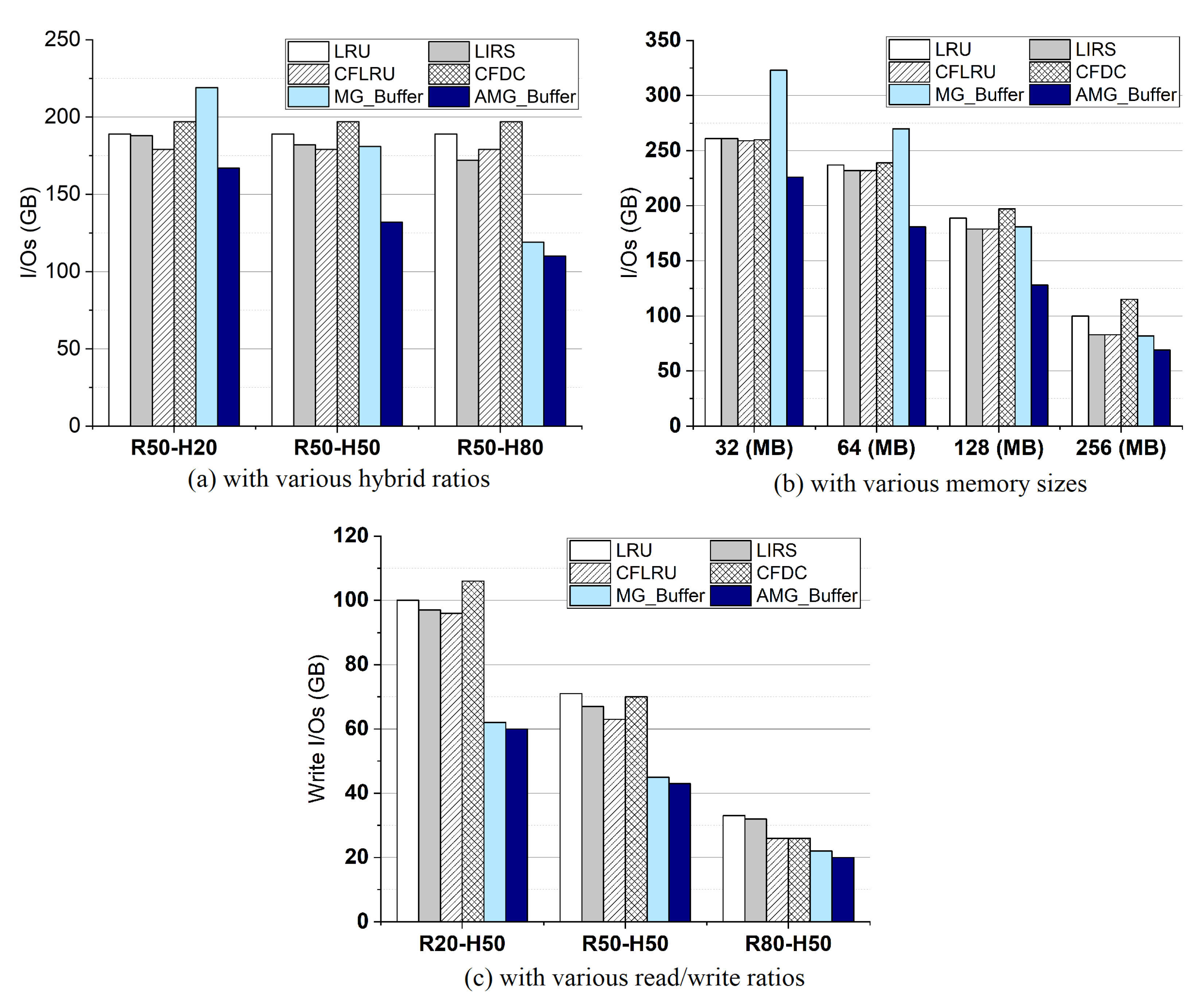
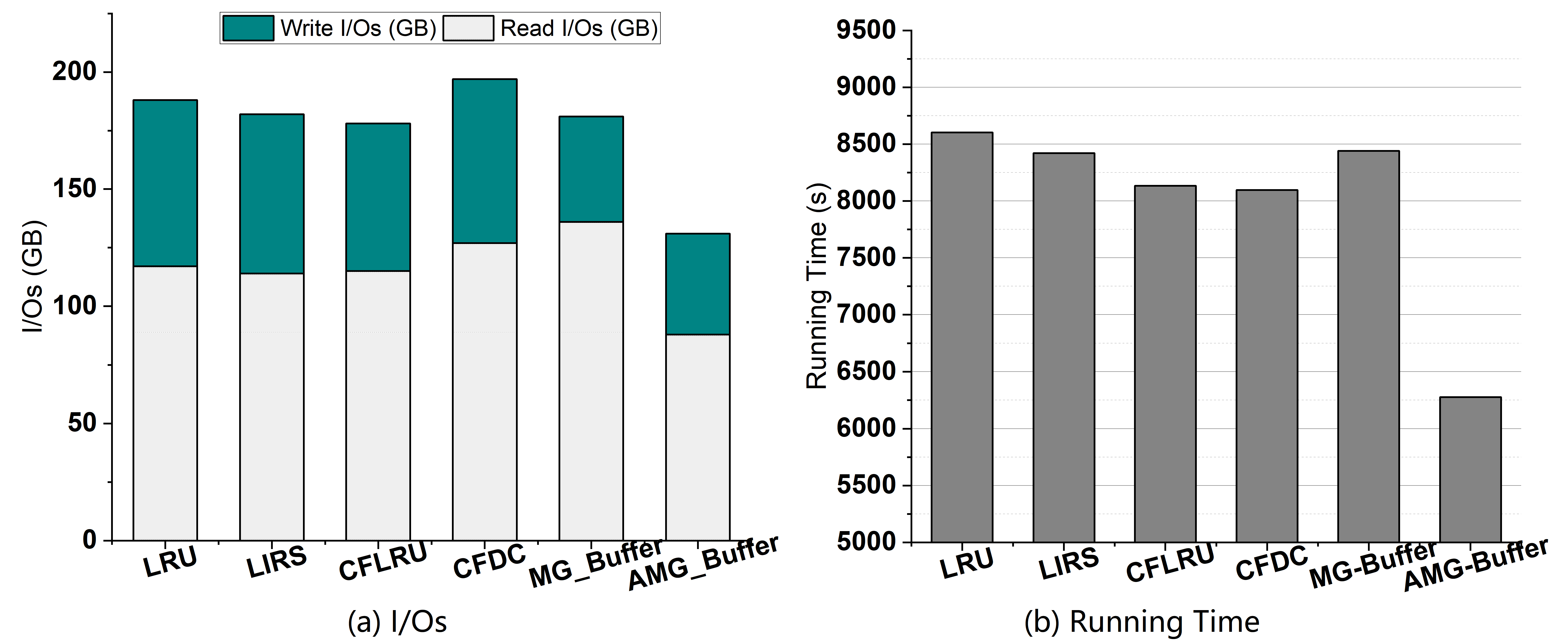
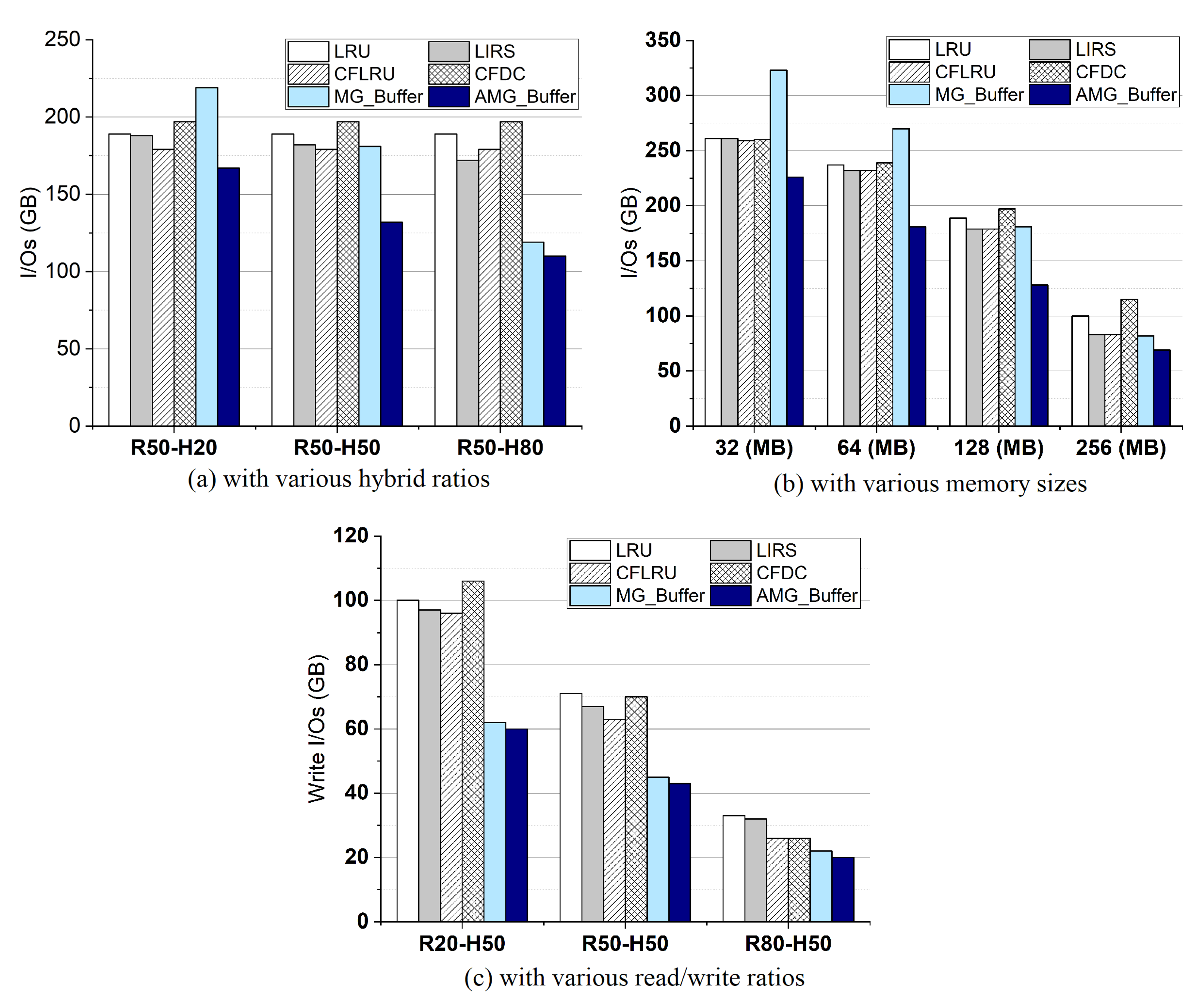
4.4. I/Os
4.5. Workload Adaptivity
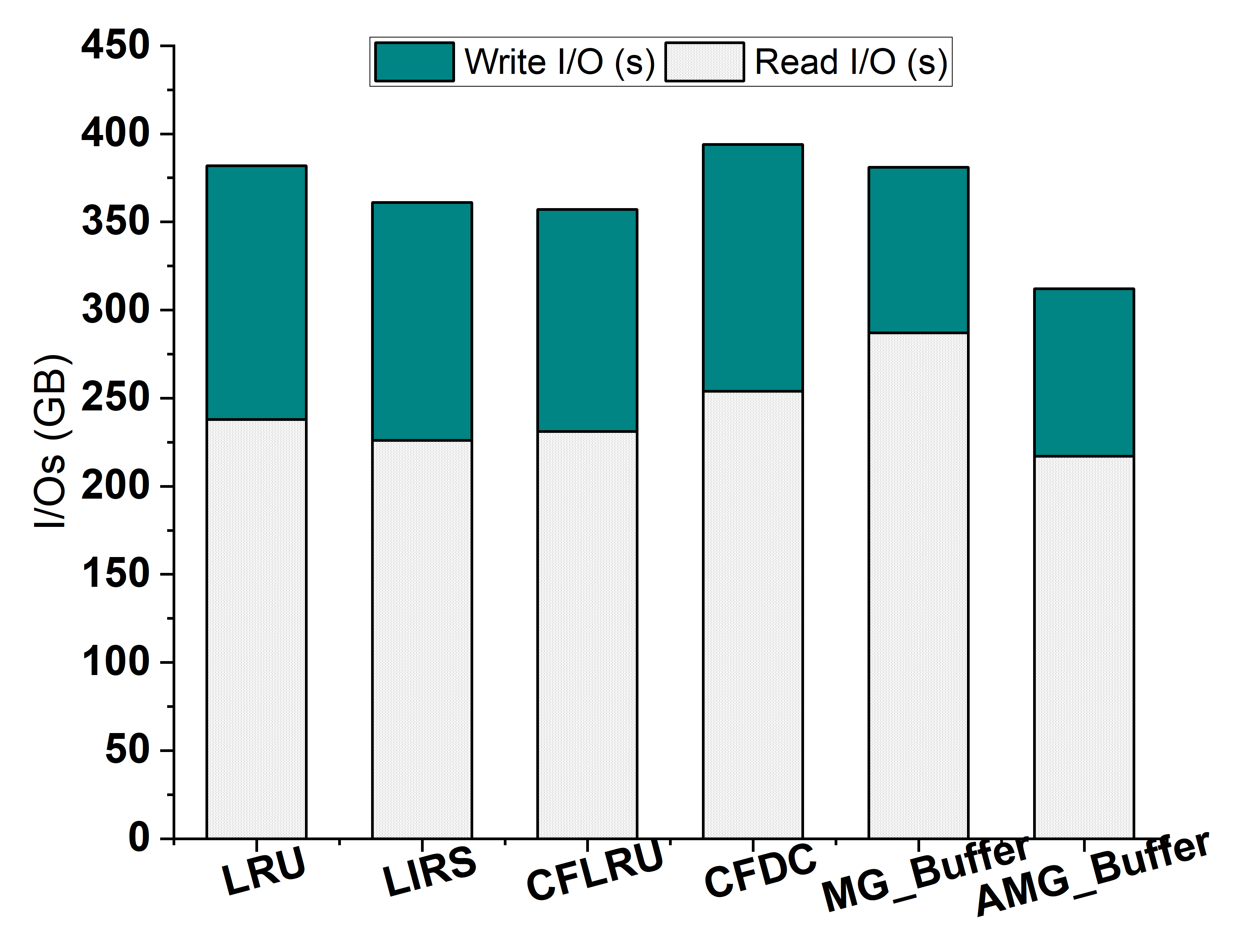
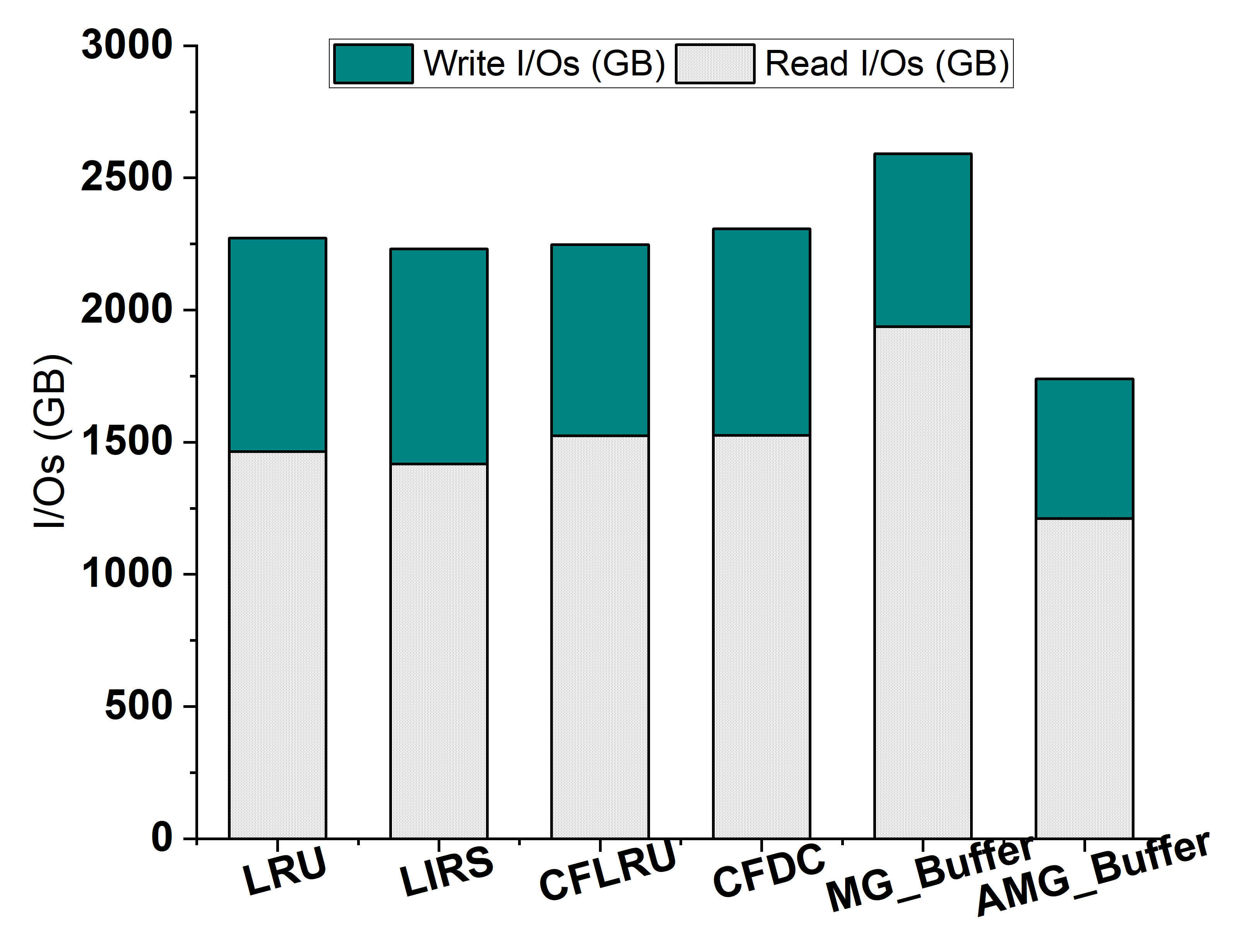
4.6. Performance on a Large Data Set
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Effelsberg, W.; Härder, T. Principles of Database Buffer Management. ACM Trans. Database Syst. 1984, 9, 560–595. [Google Scholar] [CrossRef]
- Jiang, S.; Zhang, X. LIRS: An efficient low inter-reference recency set replacement policy to improve buffer cache performance. ACM SIGMETRICS Perform. Eval. Rev. 2002, 30, 31–42. [Google Scholar] [CrossRef]
- Johnson, T.; Shasha, D.E. 2Q: A Low Overhead High Performance Buffer Management Replacement Algorithm. In Proceedings of the Twentieth International Conference on Very Large Databases, Santiago, Chile, 12–15 September 1994; pp. 439–450. [Google Scholar]
- Park, S.; Jung, D.; Kang, J.; Kim, J.; Lee, J. CFLRU: A replacement algorithm for flash memory. In Proceedings of the 2006 International Conference on Compilers, Architecture and Synthesis for Embedded Systems, Seoul, Korea, 22–25 October 2006; pp. 234–241. [Google Scholar]
- Ou, Y.; Härder, T.; Jin, P. CFDC: A Flash-Aware Buffer Management Algorithm for Database Systems. In East European Conference on Advances in Databases and Information Systems; Springer: Berlin/Heidelberg, Germany, 2010; pp. 435–449. [Google Scholar]
- Meng, Q.; Zhou, X.; Wang, S.; Huang, H.; Liu, X. A Twin-Buffer Scheme for High-Throughput Logging. In International Conference on Database Systems for Advanced Applications; Springer: Cham, Switzerland, 2018; pp. 725–737. [Google Scholar]
- Wang, X.; Jin, P.; Liu, R.; Zhang, Z.; Wan, S.; Hua, B. MG-Buffer: A Read/Write-Optimized Multi-Grained Buffer Management Scheme for Database Systems. In Proceedings of the 2019 IEEE 21st International Conference on High Performance Computing and Communications; IEEE 17th International Conference on Smart City; IEEE 5th International Conference on Data Science and Systems (HPCC/SmartCity/DSS), Zhangjiajie, China, 10–12 August 2019; pp. 1212–1219. [Google Scholar]
- Tan, Y.; Wang, B.; Yan, Z.; Srisa-an, W.; Chen, X.; Liu, D. APMigration: Improving Performance of Hybrid Memory Performance via An Adaptive Page Migration Method. IEEE Trans. Parallel Distrib. Syst. 2020, 31, 266–278. [Google Scholar] [CrossRef]
- Ding, X.; Shan, J.; Jiang, S. A General Approach to Scalable Buffer Pool Management. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 2182–2195. [Google Scholar] [CrossRef]
- Tan, J.; Zhang, T.; Li, F.; Chen, J.; Zheng, Q.; Zhang, P.; Qiao, H.; Shi, Y.; Cao, W.; Zhang, R. iBTune: Individualized Buffer Tuning for Large-scale Cloud Databases. Proc. VLDB Endow. 2019, 12, 1221–1234. [Google Scholar] [CrossRef] [Green Version]
- Jiang, Z.; Zhang, Y.; Wang, J.; Xing, C. A Cost-aware Buffer Management Policy for Flash-based Storage Devices. In International Conference on Database Systems for Advanced Applications; Springer: Cham, Switzerland, 2015; pp. 175–190. [Google Scholar]
- Kallman, R.; Kimura, H.; Natkins, J.; Pavlo, A.; Rasin, A.; Zdonik, S.B.; Jones, E.P.C.; Madden, S.; Stonebraker, M.; Zhang, Y.; et al. H-store: A high-performance, distributed main memory transaction processing system. Proc. VLDB Endow. 2008, 1, 1496–1499. [Google Scholar] [CrossRef]
- Leis, V.; Haubenschild, M.; Kemper, A.; Neumann, T. LeanStore: In-Memory Data Management beyond Main Memory. In Proceedings of the 2018 IEEE 34th International Conference on Data Engineering (ICDE), Paris, France, 16–19 April 2018; pp. 185–196. [Google Scholar]
- Neumann, T.; Freitag, M.J. Umbra: A Disk-Based System with In-Memory Performance. In Proceedings of the CIDR, 2020; Available online: http://cidrdb.org/cidr2020/papers/p29-neumann-cidr20.pdf (accessed on 24 November 2021).
- Diaconu, C.; Freedman, C.; Ismert, E.; Larson, P.; Mittal, P.; Stonecipher, R.; Verma, N.; Zwilling, M. Hekaton: SQL server’s memory-optimized OLTP engine. In Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data, New York, NY, USA, 22–27 June 2013; pp. 1243–1254. [Google Scholar]
- Färber, F.; Cha, S.K.; Primsch, J.; Bornhövd, C.; Sigg, S.; Lehner, W. SAP HANA database: Data management for modern business applications. SIGMOD Rec. 2011, 40, 45–51. [Google Scholar] [CrossRef]
- Jin, P.; Yang, C.; Wang, X.; Yue, L.; Zhang, D. SAL-Hashing: A Self-Adaptive Linear Hashing Index for SSDs. IEEE Trans. Knowl. Data Eng. 2020, 32, 519–532. [Google Scholar] [CrossRef]
- Yang, C.; Jin, P.; Yue, L.; Yang, P. Efficient Buffer Management for Tree Indexes on Solid State Drives. Int. J. Parallel Program. 2016, 44, 5–25. [Google Scholar] [CrossRef]
- Jin, P.; Yang, C.; Jensen, C.S.; Yang, P.; Yue, L. Read/write-optimized tree indexing for solid-state drives. VLDB J. 2016, 25, 695–717. [Google Scholar] [CrossRef]
- Zhao, H.; Jin, P.; Yang, P.; Yue, L. BPCLC: An Efficient Write Buffer Management Scheme for Flash-Based Solid State Disks. Int. J. Digit. Content Technol. Its Appl. 2010, 4, 123–133. [Google Scholar]
- Wang, S.; Lu, Z.; Cao, Q.; Jiang, H.; Yao, J.; Dong, Y.; Yang, P. BCW: Buffer-Controlled Writes to HDDs for SSD-HDD Hybrid Storage Server. In Proceedings of the 18th USENIX Conference on File and Storage Technologies (FAST 20), Santa Clara, CA, USA, 24–27 February 2020; pp. 253–266. [Google Scholar]
- Choi, J.; Kim, K.M.; Kwak, J.W. WPA: Write Pattern Aware Hybrid Disk Buffer Management for Improving Lifespan of NAND Flash Memory. IEEE Trans. Consum. Electron. 2020, 66, 193–202. [Google Scholar] [CrossRef]
- Li, Z.; Jin, P.; Su, X.; Cui, K.; Yue, L. CCF-LRU: A new buffer replacement algorithm for flash memory. IEEE Trans. Consum. Electron. 2009, 55, 1351–1359. [Google Scholar] [CrossRef]
- On, S.T.; Gao, S.; He, B.; Wu, M.; Luo, Q.; Xu, J. FD-Buffer: A Cost-Based Adaptive Buffer Replacement Algorithm for FlashMemory Devices. IEEE Trans. Comput. 2014, 63, 2288–2301. [Google Scholar] [CrossRef]
- Jin, P.; Ou, Y.; Härder, T.; Li, Z. AD-LRU: An efficient buffer replacement algorithm for flash-based databases. Data Knowl. Eng. 2012, 72, 83–102. [Google Scholar] [CrossRef]
- DeBrabant, J.; Pavlo, A.; Tu, S.; Stonebraker, M.; Zdonik, S.B. Anti-Caching: A New Approach to Database Management System Architecture. Proc. VLDB Endow. 2013, 6, 1942–1953. [Google Scholar] [CrossRef] [Green Version]
- Zheng, S.; Shen, Y.; Zhu, Y.; Huang, L. An Adaptive Eviction Framework for Anti-caching Based In-Memory Databases. In International Conference on Database Systems for Advanced Applications; Springer: Cham, Switzerland, 2018; pp. 247–263. [Google Scholar]
- Zhang, H.; Chen, G.; Ooi, B.C.; Wong, W.; Wu, S.; Xia, Y. “Anti-Caching”-based elastic memory management for Big Data. In Proceedings of the 2015 IEEE 31st International Conference on Data Engineering, Seoul, Korea, 13–17 April 2015; pp. 1268–1279. [Google Scholar]
- Ma, L.; Ding, B.; Das, S.; Swaminathan, A. Active Learning for ML Enhanced Database Systems. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, Portland, OR, USA, 14–19 June 2020; pp. 175–191. [Google Scholar]
- Hashemi, M.; Swersky, K.; Smith, J.A.; Ayers, G.; Litz, H.; Chang, J.; Kozyrakis, C.; Ranganathan, P. Learning Memory Access Patterns. In Proceedings of the International Conference on Machine Learning, 28–30 September 2018; pp. 1919–1928. Available online: http://proceedings.mlr.press/v80/hashemi18a/hashemi18a.pdf (accessed on 24 November 2021).
- Jin, P.; Yang, P.; Yue, L. Optimizing B+-tree for hybrid storage systems. Distrib. Parallel Databases 2015, 33, 449–475. [Google Scholar] [CrossRef]
- van Renen, A.; Leis, V.; Kemper, A.; Neumann, T.; Hashida, T.; Oe, K.; Doi, Y.; Harada, L.; Sato, M. Managing Non-Volatile Memory in Database Systems. In Proceedings of the 2018 International Conference on Management of Data, Houston, TX, USA, 10–15 June 2018; pp. 1541–1555. [Google Scholar]
- Shi, Z.; Huang, X.; Jain, A.; Lin, C. Applying Deep Learning to the Cache Replacement Problem. In Proceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture, 2018; pp. 413–425. Available online: https://dl.acm.org/doi/10.1145/3352460.3358319 (accessed on 24 November 2021).
- Vila, P.; Ganty, P.; Guarnieri, M.; Köpf, B. CacheQuery: Learning replacement policies from hardware caches. In Proceedings of the 41st ACM SIGPLAN Conference on Programming Language Design and Implementation, London, UK, 15–20 June 2020; pp. 519–532. [Google Scholar]
- Yuan, Y.; Jin, P. Learned buffer management: A new frontier: Work-in-progress. In Proceedings of the 2021 International Conference on Hardware/Software Codesign and System Synthesis, Virtual Event, 10–13 October 2021; pp. 25–26. [Google Scholar]
- Jasny, M.; Ziegler, T.; Kraska, T.; Röhm, U.; Binnig, C. DB4ML—An In-Memory Database Kernel with Machine Learning Support. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, Portland, OR, USA, 14–19 June 2020; pp. 159–173. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| D | The database size (e.g., 10 GB) |
| P | The page size (e.g, 4 KB) |
| T | The tuple size (e.g., 128 B) |
| M | The whole buffer size (e.g., 128 MB) |
| Method | Hot Tuples in the Buffer | Hit Ratio |
|---|---|---|
| LRU | ||
| AMG-Buffer |
| Type | Number of Queries | R/W Ratio | Hybrid Ratio |
|---|---|---|---|
| R50-H20 | 50,000,000 | 50/50 | 20/80 |
| R50-H50 | 50,000,000 | 50/50 | 50/50 |
| R50-H80 | 50,000,000 | 50/50 | 80/20 |
| R20-H50 | 50,000,000 | 20/80 | 50/50 |
| R80-H50 | 50,000,000 | 80/20 | 50/50 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Jin, P. Adaptive Multi-Grained Buffer Management for Database Systems. Future Internet 2021, 13, 303. https://doi.org/10.3390/fi13120303
Wang X, Jin P. Adaptive Multi-Grained Buffer Management for Database Systems. Future Internet. 2021; 13(12):303. https://doi.org/10.3390/fi13120303
Chicago/Turabian StyleWang, Xiaoliang, and Peiquan Jin. 2021. "Adaptive Multi-Grained Buffer Management for Database Systems" Future Internet 13, no. 12: 303. https://doi.org/10.3390/fi13120303
APA StyleWang, X., & Jin, P. (2021). Adaptive Multi-Grained Buffer Management for Database Systems. Future Internet, 13(12), 303. https://doi.org/10.3390/fi13120303