Volunteer Down: How COVID-19 Created the Largest Idling Supercomputer on Earth


Abstract
1. Introduction
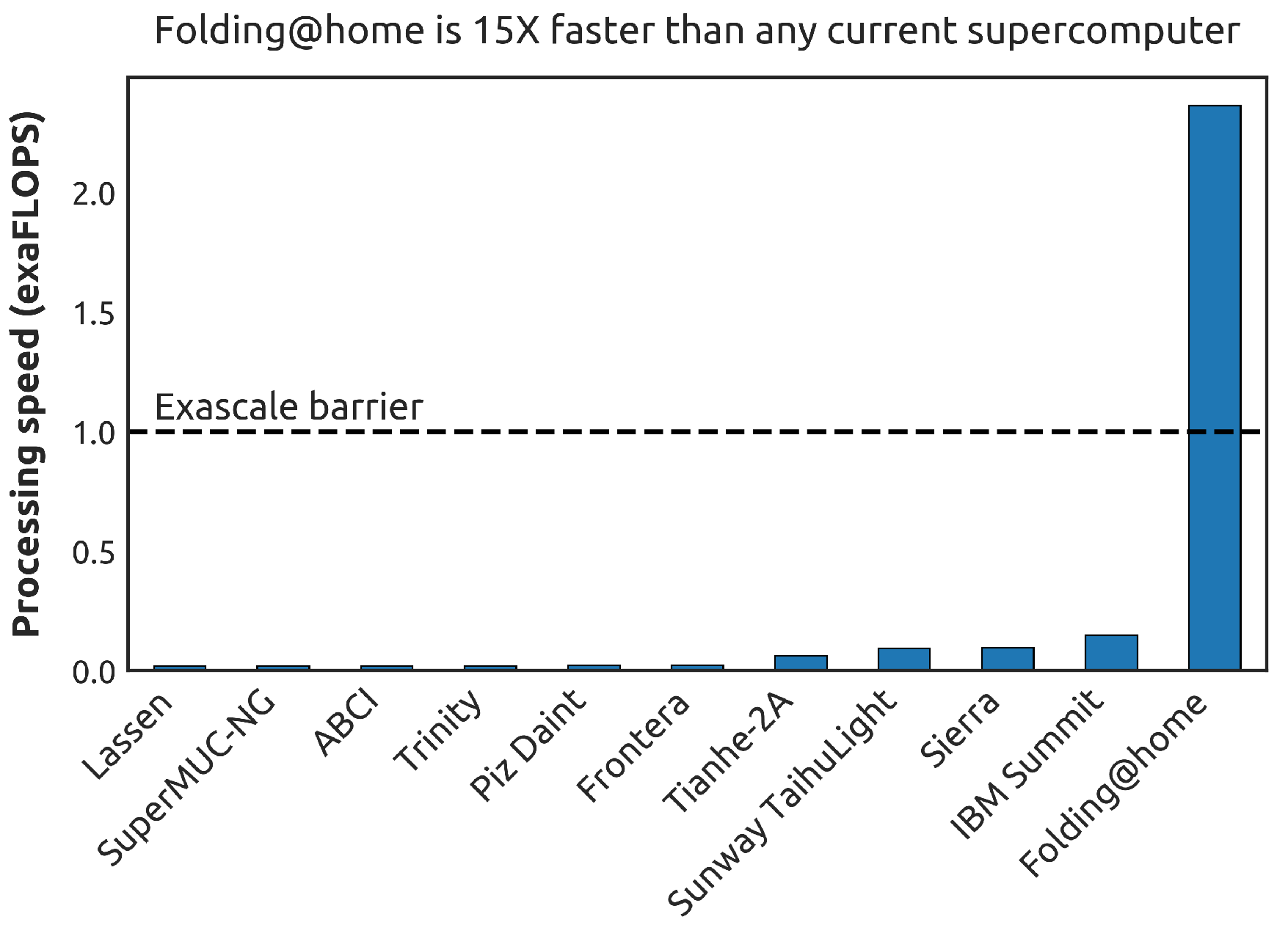
@Folding@home is continuing its growth spurt! There are now 3.5 M devices participating, including 2.8 M CPUs (19 M cores!) and 700 K GPUs.
2. Review on Volunteer Computing
2.1. Categories of Volunteer Computing
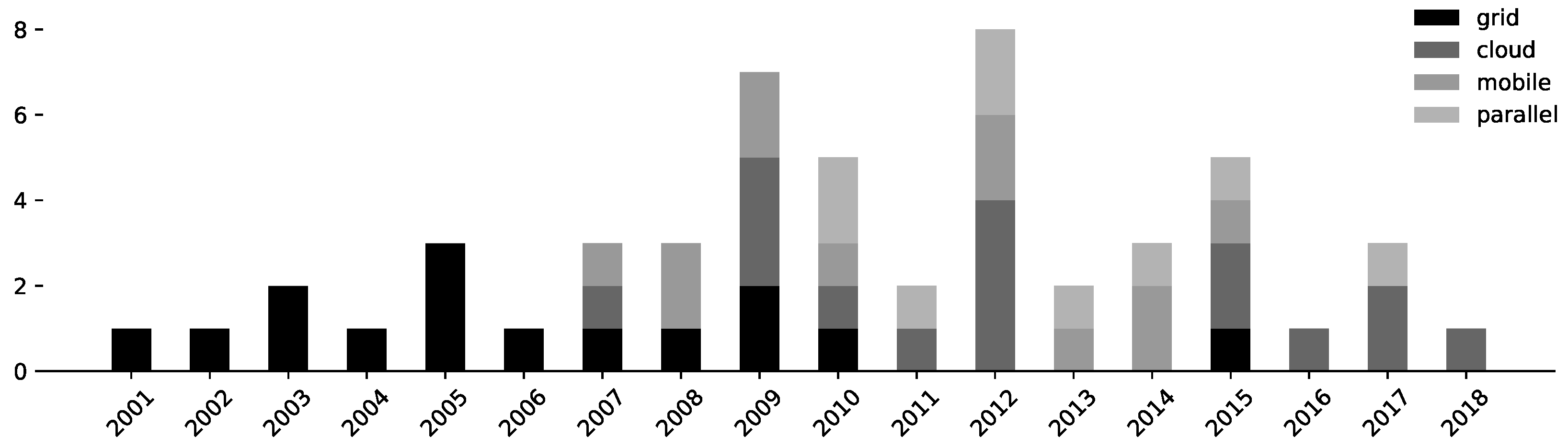
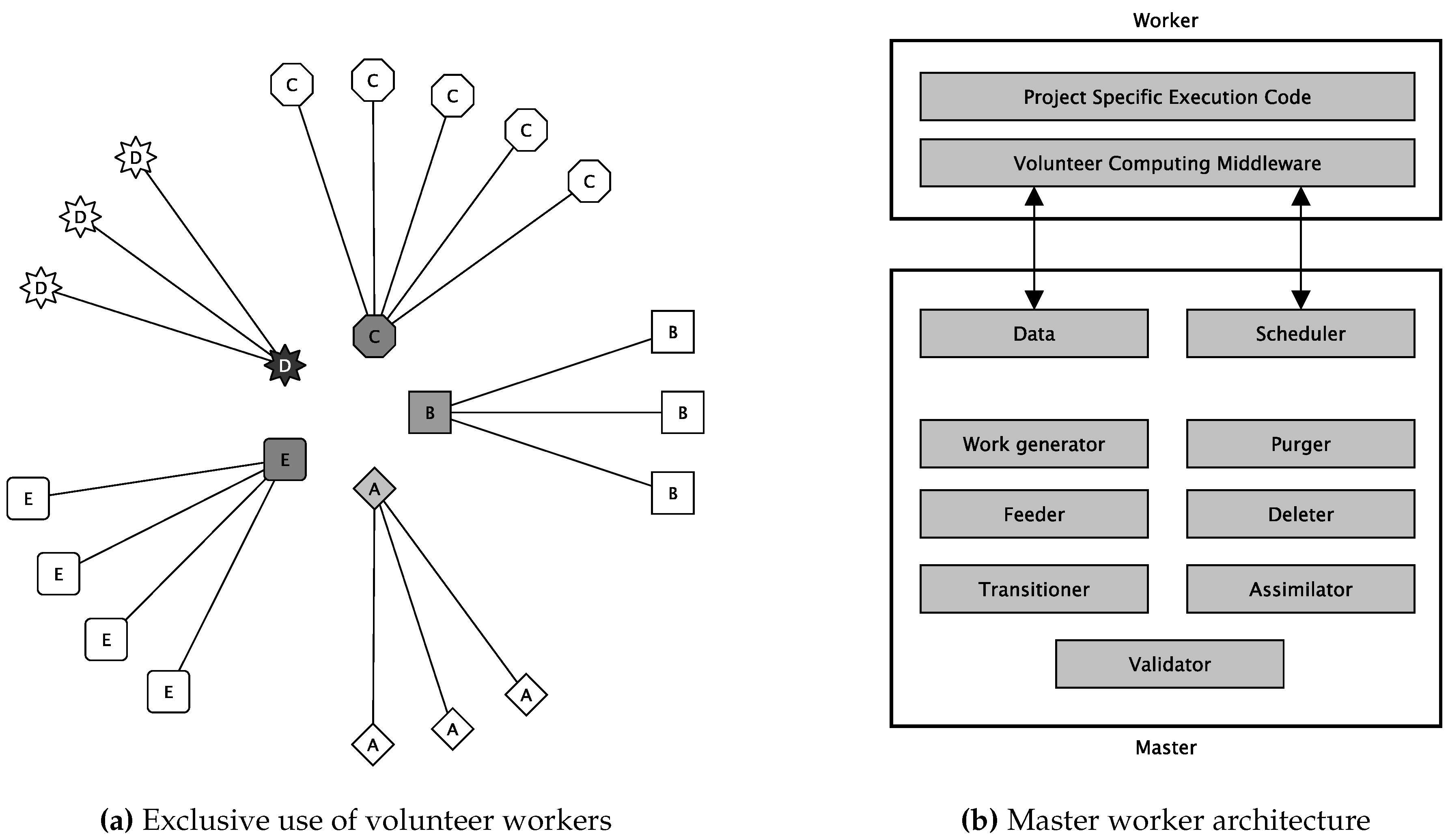
- Volunteer Grid Computing makes use of the aggregated computing resources of volunteer devices. “Volunteer grids are one way of fulfilling the original goal of Grid Computing, where anyone can donate computing resources to the grid so that users can use it for their computational needs. Contrary to the traditional grid infrastructure, which needs a dedicated infrastructure to run on, volunteer grid runs on scavenging computing resources from desktop computers for computationally intensive applications.” [5] These kinds of systems form the majority of all VC approaches (see Figure 4).
- Volunteer Cloud Computing provides volunteer clouds as opportunistic cloud systems that run over donated quotas of resources of volunteer computers. Volunteer cloud systems come in different shapes, such as desktop clouds, peer-to-peer clouds, social clouds, volunteer storage cloud, and more [5]. The approach mimics the Cloud Computing service models (IaaS, PaaS, SaaS) without relying on centralized data centers that are operated by hyperscaling service providers like Amazon Web Services, Google, or Microsoft. These clouds are multipurpose and usually have no specific mission like volunteer grid computing projects that are focused on a specific research discipline or even a specific research question.
- Mobile Volunteer Computing makes use of advances in low-power consuming processors of portable computers such as tablets and smartphones that can handle computationally intensive applications. According to [5], nearly 50% of the worldwide population use smartphones and tablets—more than conventional Laptop and PCs. The increasing computing power, fast-growing number, and their power-efficient design make mobile devices interesting for distributed computing [7]. Consequently, many traditional VC systems are extended to include such devices. For example, BOINC provides an Android-based client (https://boinc.berkeley.edu/wiki/Android_FAQ).
- Most VC systems support embarrassingly parallel tasks that need no or little communication among the tasks [5]. However, parallel VC addresses use cases that need massive communication among the tasks, based on MPI, MapReduce, or other platforms.
2.2. Reference Model of Volunteer Computing
2.3. Open Problems in Volunteer Computing
- Heterogeneity [64]: Different VC devices have different power, memory and processing capabilities, as well as different communication interfaces, making it hard to classify, design, and assign device optimized work units.
- Result verification [64]: Volunteers perform their required computation and send data results back to the master. The master then verifies data results and discards inadequate or erroneous results. In this way, massive computation (several hours or even days are not unlikely) is wasted as result verification is done at the end of processing. Intermediate result verification mechanisms or smaller chunks could minimize this waste.
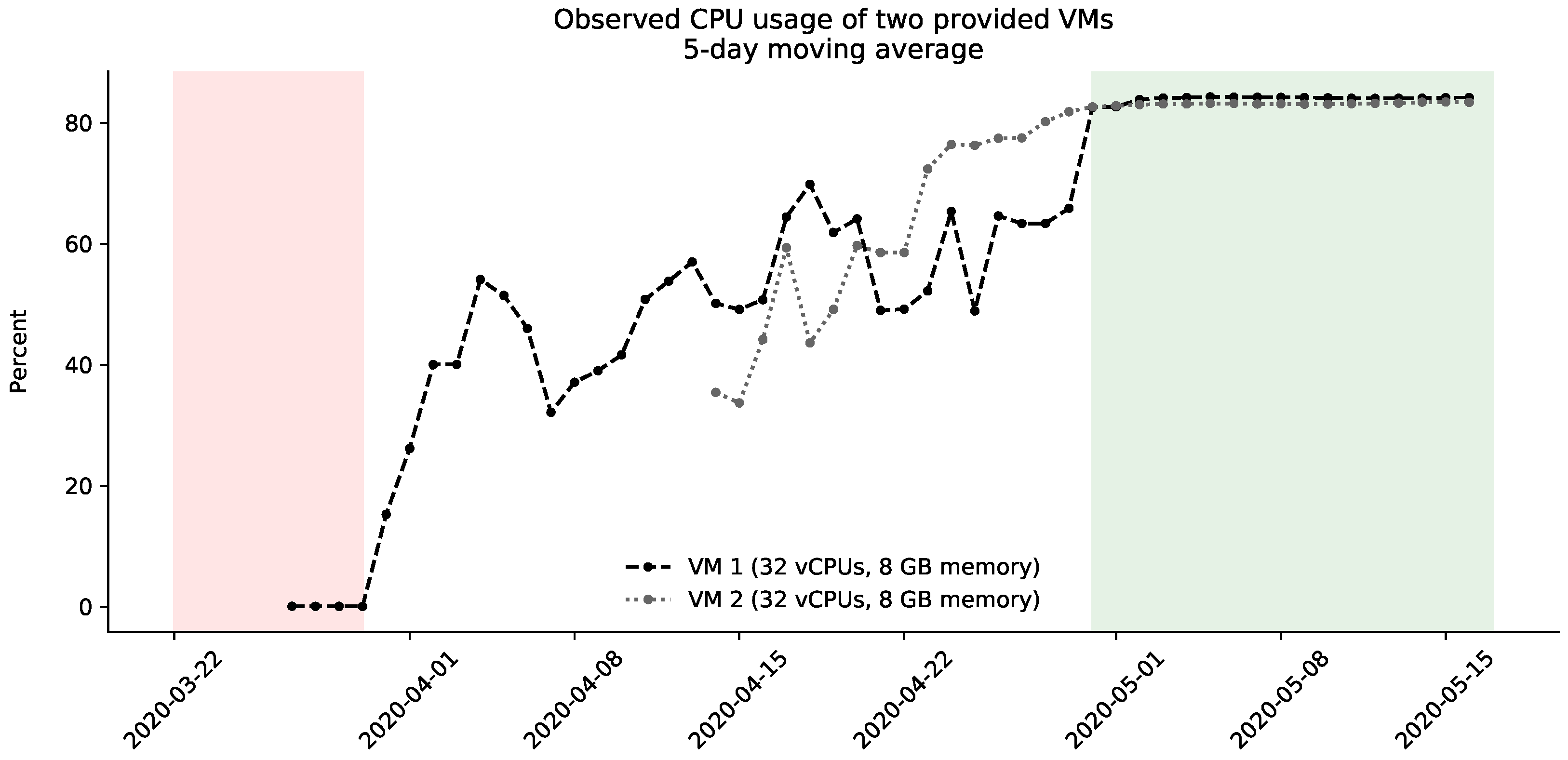
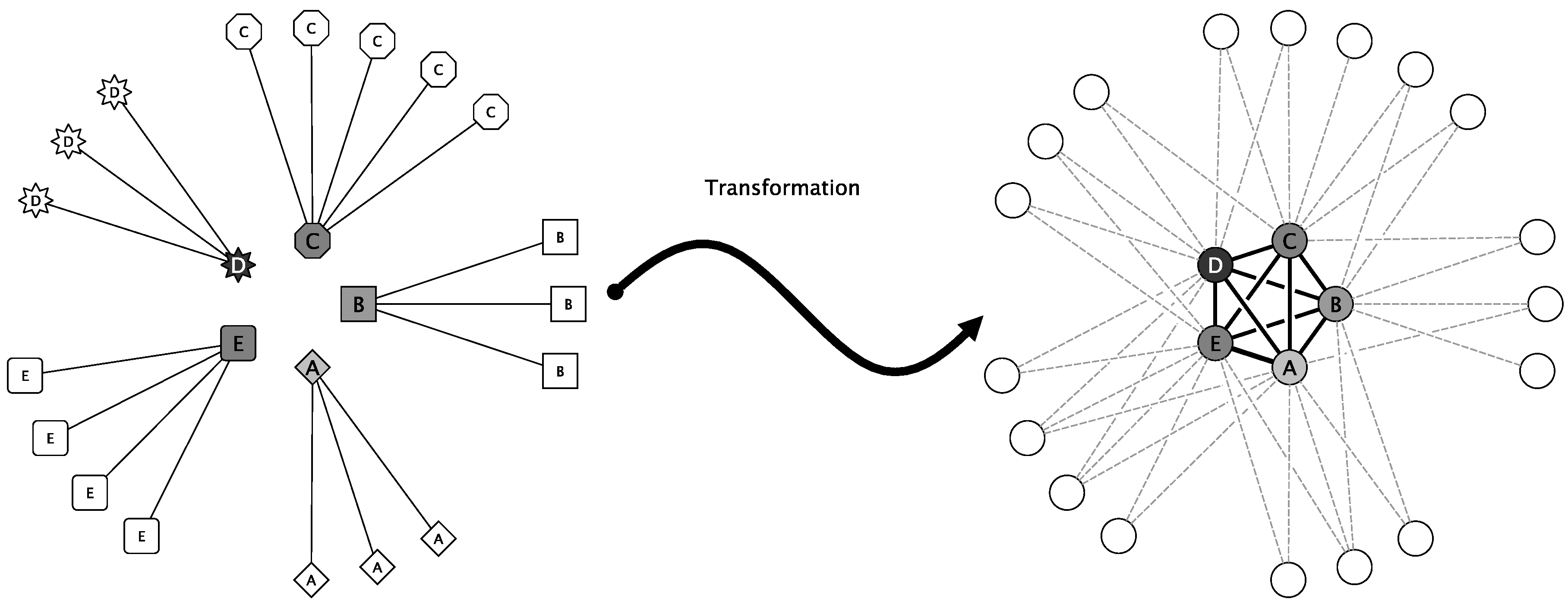
- Project exclusiveness: Currently, for most VC platforms, projects are organizations (usually academic research groups) that need computational power. Each project runs on project-dedicated master servers. On the one hand, this enables trust, but hinders sharing of devices across different projects. This exclusiveness can result in situations that the Folding@home project faced in March and April 2020 due to the massive COVID-19 scale-out. In this situation, all of the unused CPU cycles (see Figure 2) could have been provided with ease to other VC projects dedicated to further respectable motives. Thus, in March and April 2020, plenty of possible computations for cancer, climate change, and further research projects could have been processed without disadvantaging COVID-19 research. The COVID-19 pipelines were almost empty in that phase because there were more devices than tasks. There was nothing to process.
- Security: Good security is multi-layered. For instance, the BOINC system maintains reasonable security practices at several levels (https://boinc.berkeley.edu/trac/wiki/SecurityIssues). Let us investigate them from a best-practice point of view.All VC systems require that donators have to run executables provided by a third party—the company or institution running the project. Thus, these third party executables are highly suspicious from a security point of view. The following counter-measures are combined to mitigate corresponding risks.
- –
- Overall project security measures very often include security audits of project code, enforcing SSL communication with project infrastructure, and virus scanning of project files.
- –
- Code signing can be used to provide valid official builds and to detect code injection attacks on the client-side.
- –
- Result verification is used on the master side to verify that malicious clients have not manipulated results.
- –
- Sandboxing can limit the risk for donators from malicious or insecure project code. However, sandboxing must be very client operation system-specific.
However, most VC projects are operated by domain-matter experts and not by IT-security experts. It would be a benefit for the VC projects (reduced efforts) and the donators (improved security) if both sides could rely on proven security infrastructures. - Scalability and elasticity [5]: VC systems can have millions of volunteer nodes connected to them. Moreover, this amount of nodes can grow exponentially and quickly as COVID-19 taught us. Thus, more scalable and elastic approaches are required to handle this significant number of volunteer nodes coupled with their intermittent availability. Using more decentralized architectures has already been proposed and implemented [13]. However, the Folding@home project still could not scale-out fast enough to handle all of the COVID-19 volunteers (see Figure 2).
3. A Review of the Current State of Cloud Computing
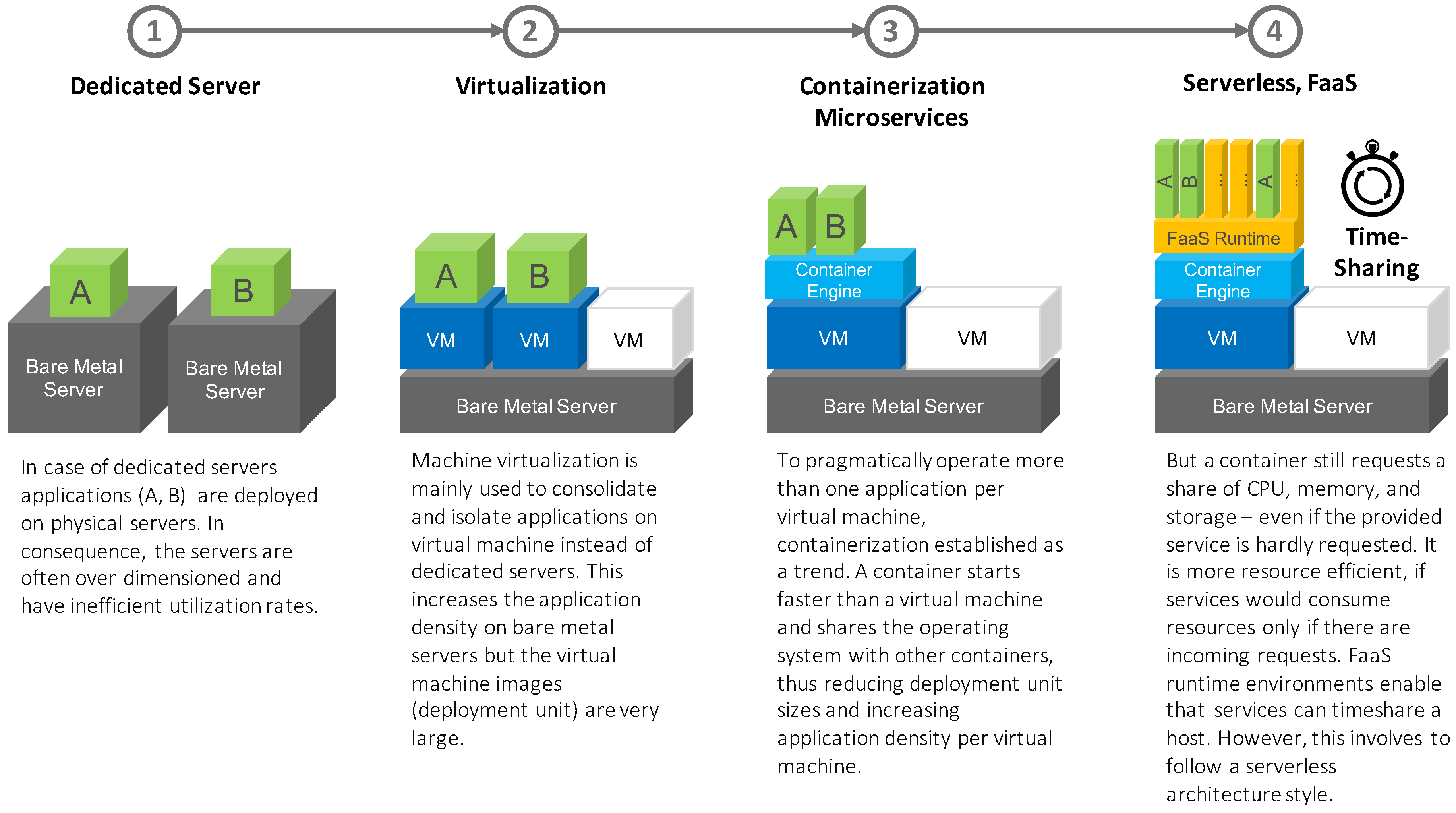
3.1. A Review of the Resource Utilization Evolution
- Service-oriented architectures (SOA) fitted very well with monolithic deployment approaches that can be provided using standardized virtual machines (IaaS).
- Microservice architectures are built on top of loosely coupled and independently deployable services. These services can be provided via much smaller and standardized containers. We could rate Microservices as a kind of standardized PaaS cloud service provision model.
- Finally, serverless architectures are mainly event-driven service-of-service architectures where their functionality is provided as “nano”-services via functions. Serverless and FaaS are the latest trends in cloud computing, so functions are not standardized yet. However, more and more Cloud-native computing foundation (CNCF) hosted serverless approaches like Kubeless (https://kubeless.io), Knative (https://knative.dev), or OpenWhisk (https://openwhisk.apache.org) make use of containers to package and deploy functions. Thus, it seems likely that containers might evolve as the de-facto deployment unit format not only for microservices, but also for functions.
3.2. A Review of the Architectural Evolution
3.2.1. Microservice Architectures
- Service discovery technologies decouple services from each other. Services must not explicitly refer to network locations.
- Container orchestration technologies automate container allocation and management tasks.
- Monitoring technologies enable runtime monitoring and analysis of the runtime behavior of microservices.
- Latency and fault-tolerant communication libraries enable efficient and reliable service communication in permanently changing configurations.
- Service proxy technologies provide service discovery and fault-tolerant communication features that are exposed over HTTP.
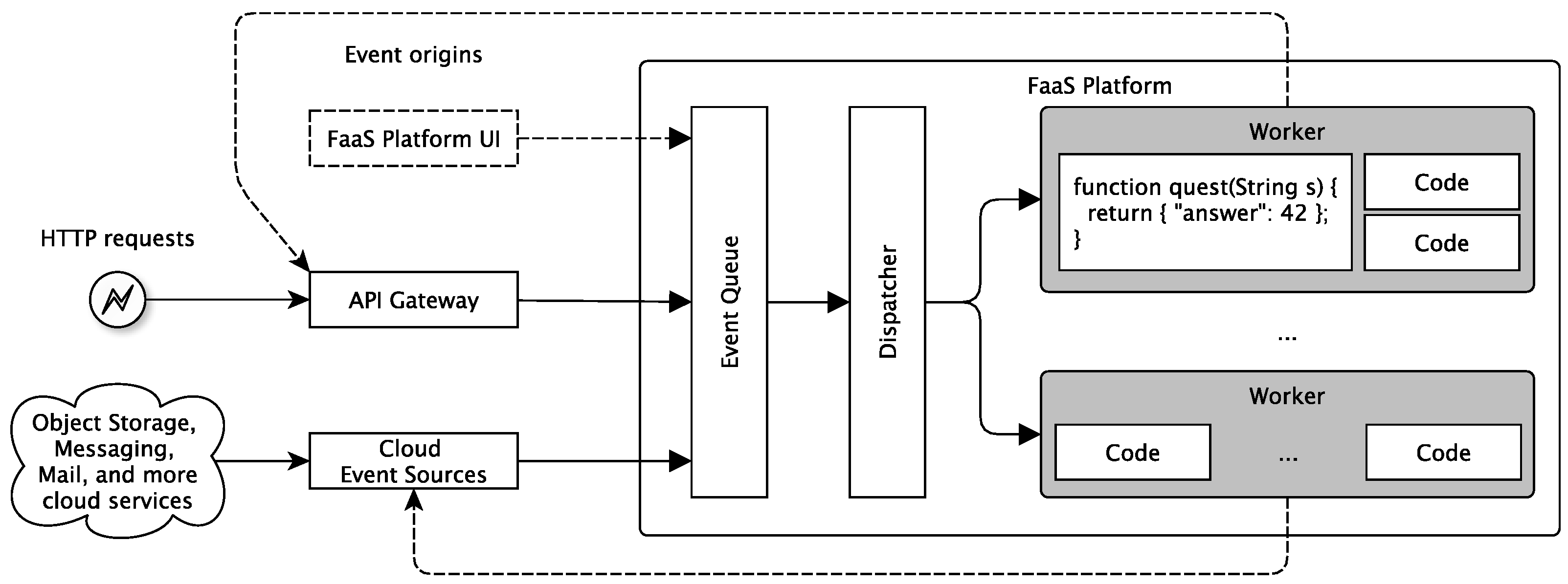
3.2.2. Serverless Architectures
- Cross-sectional logic, like authentication or storage, is sourced to external third party services.
- End-user clients or edge devices do the Service composition. Thus, service orchestration is not done by the service provider but by the service consumer via provided applications.
- Endpoints using HTTP- and REST-based/REST-like communication protocols that can be provided easily via API gateways are generally preferred.
- Only very domain or service-specific functions are provided on FaaS platforms.
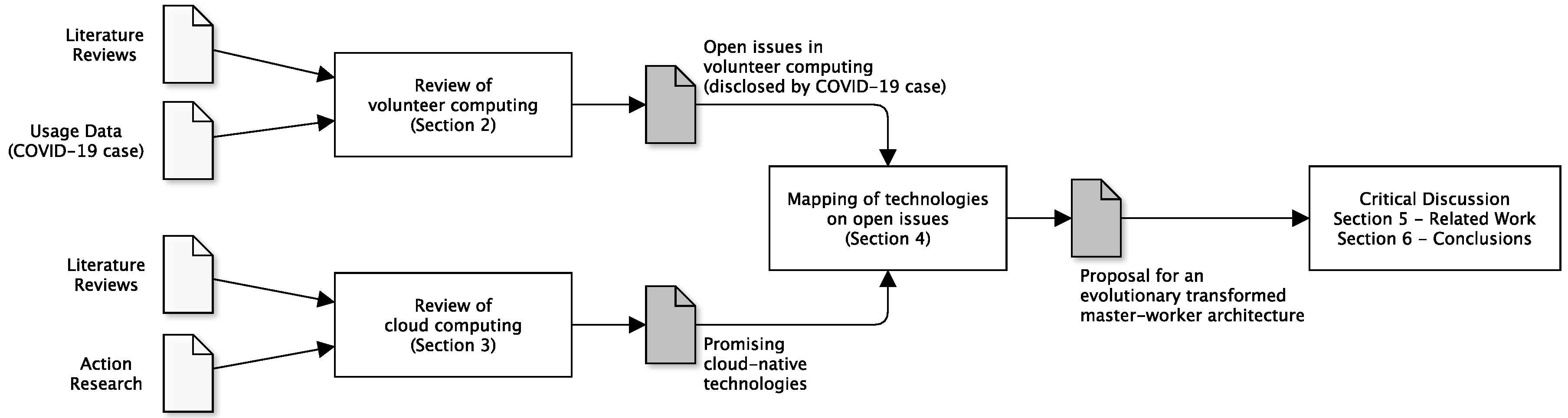
4. Discussion of Technological and Architectural Opportunities for Future Volunteer Computing
4.1. Standardization of Deployment Units
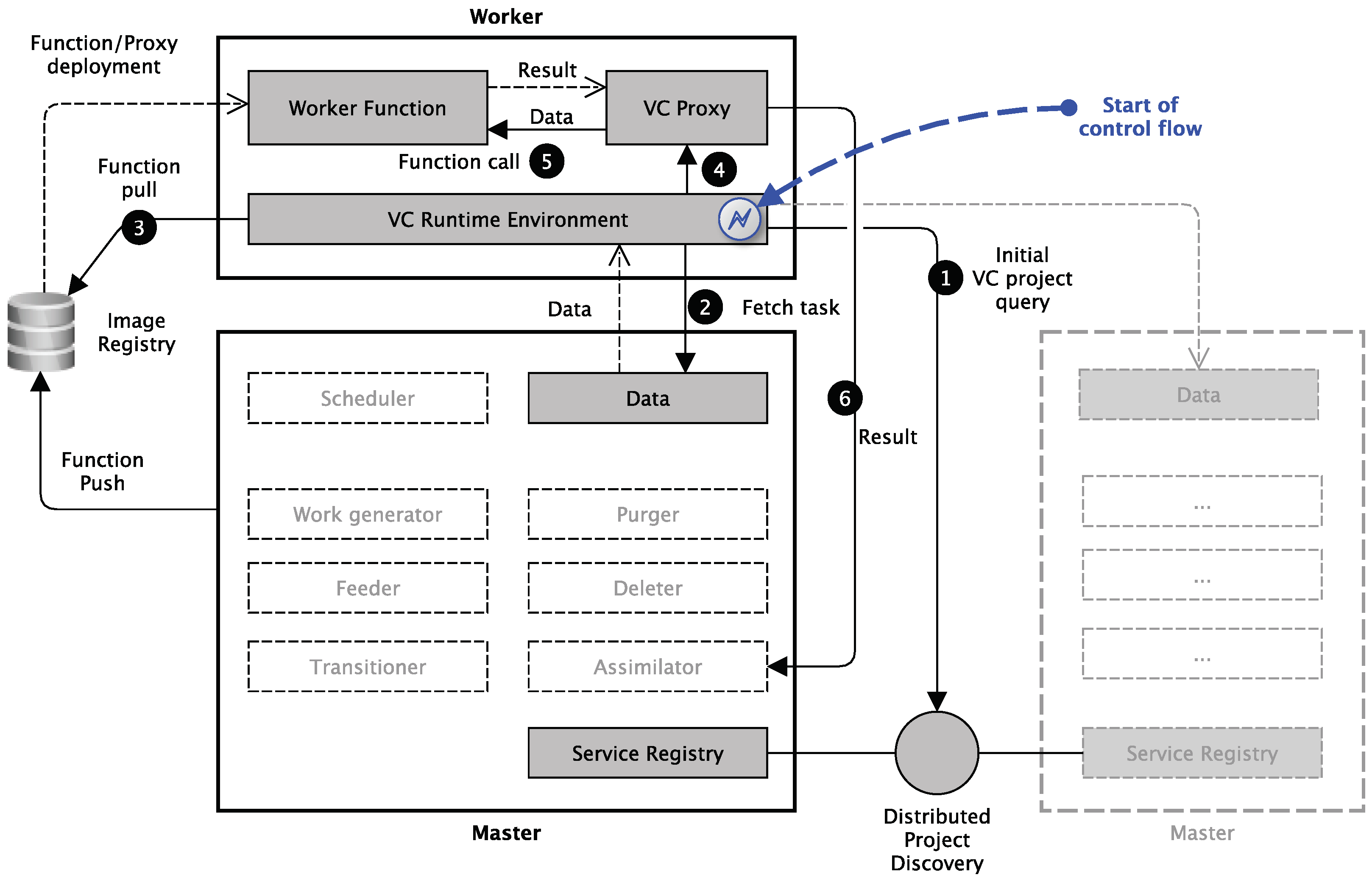
4.2. Client-Side Service Discovery Initiated Workflow
- In Step ➊, the VC Runtime Environment of a worker node queries periodically (for example, each day, every six hours or similar) the distributed VC project discovery service that is formed by master nodes of various VC projects. This updates a worker node’s VC project awareness to decide which master nodes to ask for processing tasks.
- In Step ➋, the VC Runtime Environment of a worker node selects a master node according to its updated project awareness and fetches a task (including the data to be processed). If this fails (for instance, the master node might be not available, has no jobs, etc.), another task from another master node (even from a different project) is fetched according to worker node preferences.
- In Step ➌, the VC Runtime Environment analysis the task and triggers a corresponding Function pull from a public image registry to fetch (if not already present) and start the VC project-specific Worker function container image. Therefore, the address of the image registry, the unique image name of the Worker function, and image version must be part of the task description. Furthermore, the task description must contain the URL of the data to be processed.
- In Step ➍, the VC Runtime Environment handles the control over to a VC proxy. This proxy does communication with the Worker function and decouples the runtime environment from the Worker function.
- In Step ➎, the VC proxy calls the Worker function with the to be processed data and receives the result.
- Finally, in Step ➏, the VC proxy can even do the result verification on the Worker-side (and not on the Master). Like the Worker function, the VC proxy is simply a container that is instantiated from a trusted image and may, therefore, contain signed result verification logic that cannot be tampered unnoticed. As a last step, the VC proxy transmits the result to the assimilation endpoint of the master node (this endpoint must also be part of the task description).
5. Critical Discussion and Related Work
6. Conclusions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| API | Application Programming Interface |
| BOINC | Berkeley Open Infrastructure for Network Computing (https://boinc.berkeley.edu) |
| CNCF | Cloud-Native Computing Foundation (https://cncf.io) |
| HTTP | Hypertext Transfer Protocol |
| HW | Hardware |
| IaaS | Infrastructure as a Service |
| IP | Internet Protocol |
| OCI | Open Container Initiative (https://opencontainers.org) |
| PaaS | Platform as a Service |
| REST | Representational State Transfer |
| SaaS | Software as a Service |
| SOA | Service Oriented Architecture |
| URL | Uniform Resource Locator |
| VC | Volunteer Computing |
| QoS | Quality of Service |
References
- Kratzke, N.; Siegfried, R. Towards cloud-native simulations–lessons learned from the front-line of cloud computing. J. Def. Model. Simul. 2020. [Google Scholar] [CrossRef]
- Kratzke, N.; Quint, P.C. Understanding Cloud-native Applications after 10 Years of Cloud Computing—A Systematic Mapping Study. J. Syst. Softw. 2017, 126, 1–16. [Google Scholar] [CrossRef]
- Kratzke, N. A Brief History of Cloud Application Architectures. Appl. Sci. 2018, 8, 1368. [Google Scholar] [CrossRef]
- Kratzke, N.; Quint, P.C. Technical Report of Project CloudTRANSIT-Transfer Cloud-Native Applications at Runtime; Technical Report; Lübeck University of Applied Sciences: Lübeck, Germany, 2018. [Google Scholar] [CrossRef]
- Mengistu, T.M.; Che, D. Survey and Taxonomy of Volunteer Computing. ACM Comput. Surv. 2019, 52. [Google Scholar] [CrossRef]
- Project, B. Publications by BOINC Projects. 2020. Available online: https://boinc.berkeley.edu/wiki/Project_list (accessed on 5 June 2020).
- Chu, D.C.; Humphrey, M. Mobile OGSI.NET: Grid computing on mobile devices. In Proceedings of the Fifth IEEE/ACM International Workshop on Grid Computing, Pittsburgh, PA, USA, 8 November 2004; pp. 182–191. [Google Scholar]
- Litzkow, M.J.; Livny, M.; Mutka, M.W. Condor-a hunter of idle workstations. In Proceedings of the 8th International Conference on Distributed, San Jose, CA, USA, 13–17 June 1988; pp. 104–111. [Google Scholar]
- Fedak, G.; Germain, C.; Neri, V.; Cappello, F. XtremWeb: A generic global computing system. In Proceedings of the First IEEE/ACM International Symposium on Cluster Computing and the Grid, Brisbane, Australia, 15–18 May 2001; pp. 582–587. [Google Scholar]
- Anderson, D.P.; Cobb, J.; Korpela, E.; Lebofsky, M.; Werthimer, D. SETI@home: An Experiment in Public-Resource Computing. Commun. ACM 2002, 45, 56–61. [Google Scholar] [CrossRef]
- Chien, A.; Calder, B.; Elbert, S.; Bhatia, K. Entropia: Architecture and performance of an enterprise desktop grid system. J. Parallel Distrib. Comput. 2003, 63, 597–610. [Google Scholar] [CrossRef]
- Adya, A.; Bolosky, W.J.; Castro, M.; Cermak, G.; Chaiken, R.; Douceur, J.R.; Howell, J.; Lorch, J.R.; Theimer, M.; Wattenhofer, R.P. Farsite: Federated, Available, and Reliable Storage for an Incompletely Trusted Environment. SIGOPS Oper. Syst. Rev. 2003, 36, 1–14. [Google Scholar] [CrossRef]
- Anderson, D.P. BOINC: A system for public-resource computing and storage. In Proceedings of the Fifth IEEE/ACM International Workshop on Grid Computing, Pittsburgh, PA, USA, 8 November 2004; pp. 4–10. [Google Scholar]
- Zhou, D.; Lo, V. Cluster Computing on the Fly: Resource discovery in a cycle sharing peer-to-peer system. In Proceedings of the IEEE International Symposium on Cluster Computing and the Grid, Chicago, IL, USA, 19–22 April 2004; pp. 66–73. [Google Scholar]
- Butt, A.R.; Johnson, T.A.; Zheng, Y.; Hu, Y.C. Kosha: A Peer-to-Peer Enhancement for the Network File System. In Proceedings of the 2004 ACM/IEEE Conference on Supercomputing, Pittsburgh, PA, USA, 6–12 November 2004; 2004; p. 51. [Google Scholar]
- Andrade, N.; Costa, L.; Germoglio, G.; Cirne, W. Peer-to-peer grid computing with the ourgrid community. In Proceedings of the SBRC 2005-IV Salao de Ferramentas, Agia Napa, Cyprus, 31 October–4 November 2005. [Google Scholar]
- Luther, A.; Buyya, R.; Ranjan, R.; Venugopal, S. Alchemi: A. NET-based Enterprise Grid Computing System. In Proceedings of the 6th International Conference on Internet Computing (ICOMP’05), Las Vegas, NV, USA, 27–30 June 2005. [Google Scholar]
- Vazhkudai, S.S.; Ma, X.; Freeh, V.W.; Strickland, J.W.; Tammineedi, N.; Scott, S.L. FreeLoader: Scavenging Desktop Storage Resources for Scientific Data. In Proceedings of the 2005 ACM/IEEE Conference on Supercomputing, Seattle, WA, USA, 12–18 November 2005; p. 56. [Google Scholar]
- Herr, W.; McIntosh, E.; Schmidt, F.; Kaltchev, D. Large Scale Beam-Beam Simulations for the Cern LHC Using DIstributed Computing. In Proceedings of the 10th European Particle Accelerator Conference, Edinburgh, UK, 26–30 June 2006. [Google Scholar]
- Chu, X.; Nadiminti, K.; Jin, C.; Venugopal, S.; Buyya, R. Aneka: Next-Generation Enterprise Grid Platform for e-Science and e-Business Applications. In Proceedings of the Third IEEE International Conference on e-Science and Grid Computing (e-Science 2007), Washington, DC, USA, 10–13 December 2007; pp. 151–159. [Google Scholar]
- Schulz, S.; Blochinger, W.; Held, M.; Dangelmayr, C. COHESION—A microkernel based Desktop Grid platform for irregular task-parallel applications. Future Gener. Comput. Syst. 2008, 24, 354–370. [Google Scholar] [CrossRef]
- Urbah, E.; Kacsuk, P.; Farkas, Z.; Fedak, G.; Kecskemeti, G.; Lodygensky, O.; Marosi, C.A.; Balaton, Z.; Caillat, G.; Gombás, G.; et al. EDGeS: Bridging EGEE to BOINC and XtremWeb. J. Grid Comput. 2009, 7, 335–354. [Google Scholar] [CrossRef]
- Fedak, G.; He, H.; Cappello, F. BitDew: A Data Management and Distribution Service with Multi-Protocol File Transfer and Metadata Abstraction. J. Netw. Comput. Appl. 2009, 32, 961–975. [Google Scholar] [CrossRef]
- Castro, H.; Rosales, E.; Villamizar, M.; Jiménez, A. UnaGrid: On Demand Opportunistic Desktop Grid. In Proceedings of the 2010 10th IEEE/ACM International Conference on Cluster, Cloud and Grid Computing, Melbourne, Australia, 2–5 November 2010; pp. 661–666. [Google Scholar]
- Adam-Bourdarios, C.; Cameron, D.; Filipčič, A.; Lancon, E.; Wu, W. ATLAS@Home: Harnessing Volunteer Computing for HEP. J. Phys. Conf. Ser. 2015, 664, 022009. [Google Scholar] [CrossRef]
- Beberg, A.L.; Pande, V.S. Storage@home: Petascale Distributed Storage. In Proceedings of the 2007 IEEE International Parallel and Distributed Processing Symposium, Hagenberg, Austria, 5–8 June 2007; pp. 1–6. [Google Scholar]
- Cunsolo, V.D.; Distefano, S.; Puliafito, A.; Scarpa, M. Volunteer Computing and Desktop Cloud: The Cloud@Home Paradigm. In Proceedings of the 2009 Eighth IEEE International Symposium on Network Computing and Applications, Cambridge, MA, USA, 9–11 July 2009; pp. 134–139. [Google Scholar]
- Cappos, J.; Beschastnikh, I.; Krishnamurthy, A.; Anderson, T. Seattle: A Platform for Educational Cloud Computing. SIGCSE Bull. 2009, 41, 111–115. [Google Scholar] [CrossRef]
- Briscoe, G.; Marinos, A. Digital ecosystems in the clouds: Towards community cloud computing. In Proceedings of the 2009 3rd IEEE International Conference on Digital Ecosystems and Technologies, Istanbul, France, 1–3 June 2009; pp. 103–108. [Google Scholar]
- Graffi, K.; Stingl, D.; Gross, C.; Nguyen, H.; Kovacevic, A.; Steinmetz, R. Towards a P2P Cloud: Reliable Resource Reservations in Unreliable P2P Systems. In Proceedings of the 2010 IEEE 16th International Conference on Parallel and Distributed Systems, Shanghai, China, 8–10 December 2010; pp. 27–34. [Google Scholar]
- Neumann, D.; Bodenstein, C.; Rana, O.F.; Krishnaswamy, R. STACEE: Enhancing Storage Clouds Using Edge Devices. In Proceedings of the 1st ACM/IEEE Workshop on Autonomic Computing in Economics, Karlsruhe, Germany, 14–18 June 2011; Association for Computing Machinery: New York, NY, USA, 2011; pp. 19–26. [Google Scholar] [CrossRef]
- Osorio, J.D.; Castro, H.; Brasileiro, F. Perspectives of UnaCloud: An Opportunistic Cloud Computing Solution for Facilitating Research. In Proceedings of the 2012 12th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (ccgrid 2012), Ottawa, ON, Canada, 13–16 May 2012; pp. 717–718. [Google Scholar]
- Hari, A.; Viswanathan, R.; Lakshman, T.V.; Chang, Y.J. The Personal Cloud: Design, Architecture and Matchmaking Algorithms for Resource Management. In Proceedings of the 2nd USENIX Conference on Hot Topics in Management of Internet, Cloud, and Enterprise Networks and Services, San Jose, CA, USA, 24 April 2012; USENIX Association: Berkeley, CA, USA, 2012; p. 3. [Google Scholar]
- Babaoglu, O.; Marzolla, M.; Tamburini, M. Design and Implementation of a P2P Cloud System. In Proceedings of the 27th Annual ACM Symposium on Applied Computing, Riva del Garda (Trento), Italy, 26–30 March 2012; Association for Computing Machinery: New York, NY, USA, 2012; pp. 412–417. [Google Scholar] [CrossRef]
- Chard, R.; Bubendorfer, K.; Chard, K. Experiences in the design and implementation of a Social Cloud for Volunteer Computing. In Proceedings of the 2012 IEEE 8th International Conference on E-Science, Chicago, IL, USA, 8–12 October 2012; pp. 1–8. [Google Scholar]
- Qin, A.; Hu, D.; Liu, J.; Yang, W.; Tan, D. Fatman: Building Reliable Archival Storage Based on Low-Cost Volunteer Resources. J. Comput. Sci. Technol. 2015, 30, 273–282. [Google Scholar] [CrossRef]
- McGilvary, G.A.; Barker, A.; Atkinson, M. Ad Hoc Cloud Computing. In Proceedings of the 2015 IEEE 8th International Conference on Cloud Computing, New York, NY, USA, 27 June–2 July 2015; pp. 1063–1068. [Google Scholar]
- Al Noor, S.; Hossain, M.M.; Hasan, R. SASCloud: Ad Hoc Cloud as Secure Storage. In Proceedings of the 2016 IEEE International Conferences on Big Data and Cloud Computing (BDCloud), Social Computing and Networking (SocialCom), Sustainable Computing and Communications (SustainCom) (BDCloud-SocialCom-SustainCom), Atlanta, GA, USA, 8–10 October 2016; pp. 37–44. [Google Scholar]
- Kim, H.W.; Han, J.; Park, J.H.; Jeong, Y.S. DIaaS: Resource Management System for the Intra-Cloud with On-Premise Desktops. Symmetry 2017, 9, 8. [Google Scholar] [CrossRef]
- Jonathan, A.; Ryden, M.; Oh, K.; Chandra, A.; Weissman, J. Nebula: Distributed Edge Cloud for Data Intensive Computing. IEEE Trans. Parallel Distrib. Syst. 2017, 28, 3229–3242. [Google Scholar] [CrossRef]
- Mengistu, T.; Alahmadi, A.; Alsenani, Y.; Albuali, A.; Che, D. cuCloud: Volunteer Computing as a Service (VCaaS) System. In International Conference on Cloud Computing; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Agapie, E.; Chen, G.; Houston, D.; Howard, E.; Kim, J.H.; Mun, M.Y.; Mondschein, A.; Reddy, S.; Rosario, R.; Ryder, J.; et al. Seeing our signals: Combining location traces and web-based models for personal discovery. In Proceedings of the 9th workshop on Mobile Computing Systems and Applications, Napa Valley, CA, USA, 25–26 February 2008. [Google Scholar]
- Cornelius, C.; Kapadia, A.; Kotz, D.; Peebles, D.; Shin, M.; Triandopoulos, N. Anonysense: Privacy-Aware People-Centric Sensing. In MobiSys ’08, Proceedings of the 6th International Conference on Mobile Systems, Applications, and Services, Breckenridge, CO, USA, 17–20 June 2008; Association for Computing Machinery: New York, NY, USA, 2008; pp. 211–224. [Google Scholar] [CrossRef]
- Gaonkar, S.; Li, J.; Choudhury, R.R.; Cox, L.; Schmidt, A. Micro-Blog: Sharing and Querying Content Through Mobile Phones and Social Participation. In Proceedings of the ACM 6th International Conference on Mobile Systems, Applications, and Services (MOBISYS ’08), Breckenridge, CO, USA, 17–20 June 2008. [Google Scholar]
- Deng, L.; Cox, L.P. LiveCompare: Grocery Bargain Hunting through Participatory Sensing. In HotMobile ’09, Proceedings of the 10th Workshop on Mobile Computing Systems and Applications, Santa Cruz, CA, USA, 23 February 2009; Association for Computing Machinery: New York, NY, USA, 2009. [Google Scholar] [CrossRef]
- Lu, H.; Lane, N.D.; Eisenman, S.B.; Campbell, A.T. Fast Track Article: Bubble-Sensing: Binding Sensing Tasks to the Physical World. Pervasive Mob. Comput. 2010, 6, 58–71. [Google Scholar] [CrossRef]
- Das, T.; Mohan, P.; Padmanabhan, V.N.; Ramjee, R.; Sharma, A. PRISM: Platform for remote sensing using smartphones. In Proceedings of the 8th International Conference on Mobile Systems, Applications, and Services, San Francisco, CA, USA, 15–18 June 2010. [Google Scholar]
- Calderón, A.; García-Carballeira, F.; Bergua, B.; Sánchez, L.M.; Carretero, J. Expanding the Volunteer Computing Scenario: A Novel Approach to Use Parallel Applications on Volunteer Computing. Future Gener. Comput. Syst. 2012, 28, 881–889. [Google Scholar] [CrossRef]
- Arslan, M.Y.; Singh, I.; Singh, S.; Madhyastha, H.V.; Sundaresan, K.; Krishnamurthy, S.V. Computing While Charging: Building a Distributed Computing Infrastructure Using Smartphones. In Proceedings of the 8th International Conference on Emerging Networking Experiments and Technologies, Nice, France, 10–13 December 2012; Association for Computing Machinery: New York, NY, USA, 2012; pp. 193–204. [Google Scholar] [CrossRef]
- Shi, C.; Lakafosis, V.; Ammar, M.H.; Zegura, E.W. Serendipity: Enabling Remote Computing among Intermittently Connected Mobile Devices. In Proceedings of the Thirteenth ACM International Symposium on Mobile Ad Hoc Networking and Computing, Hilton Head, SC, USA, 11–14 June 2012; Association for Computing Machinery: New York, NY, USA, 2012; pp. 145–154. [Google Scholar] [CrossRef]
- Mtibaa, A.; Fahim, A.; Harras, K.A.; Ammar, M.H. Towards Resource Sharing in Mobile Device Clouds: Power Balancing across Mobile Devices. SIGCOMM Comput. Commun. Rev. 2013, 43, 51–56. [Google Scholar] [CrossRef]
- Noor, S.A.; Hasan, R.; Haque, M.M. CellCloud: A Novel Cost Effective Formation of Mobile Cloud Based on Bidding Incentives. In Proceedings of the 2014 IEEE 7th International Conference on Cloud Computing, Anchorage, AK, USA, 27 June–2 July 2014; pp. 200–207. [Google Scholar]
- Funai, C.; Tapparello, C.; Ba, H.; Karaoglu, B.; Heinzelman, W. Extending volunteer computing through mobile ad hoc networking. In Proceedings of the 2014 IEEE Global Communications Conference, Austin, TX, USA, 8–12 December 2014; pp. 32–38. [Google Scholar]
- Habak, K.; Ammar, M.; Harras, K.A.; Zegura, E. Femto Clouds: Leveraging Mobile Devices to Provide Cloud Service at the Edge. In Proceedings of the 2015 IEEE 8th International Conference on Cloud Computing, New York, NY, USA, 27 June–2 July 2015; pp. 9–16. [Google Scholar]
- Gordienko, N.; Lodygensky, O.; Fedak, G.; Gordienko, Y. Synergy of volunteer measurements and volunteer computing for effective data collecting, processing, simulating and analyzing on a worldwide scale. In Proceedings of the 2015 38th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 25–29 May 2015; pp. 193–198. [Google Scholar]
- LeBlanc, T.P.; Subhlok, J.; Gabriel, E. A High-Level Interpreted MPI Library for Parallel Computing in Volunteer Environments. In Proceedings of the 2010 10th IEEE/ACM International Conference on Cluster, Cloud and Grid Computing, Melbourne, VIC, Australia, 17–20 May 2010; pp. 673–678. [Google Scholar]
- Lin, H.; Ma, X.; Archuleta, J.S.; chun Feng, W.; Gardner, M.K.; Zhang, Z. MOON: MapReduce on Opportunistic eNvironments. In Proceedings of the 19th ACM International Symposium on High Performance Distributed Computing, Chicago, IL, USA, 21–25 June 2010. [Google Scholar]
- Costa, F.; Silva, L.; Dahlin, M. Volunteer Cloud Computing: MapReduce over the Internet. In Proceedings of the 2011 IEEE International Symposium on Parallel and Distributed Processing Workshops and Phd Forum, Shanghai, China, 16–20 May 2011; pp. 1855–1862. [Google Scholar]
- Jin, H.; Yang, X.; Sun, X.; Raicu, I. ADAPT: Availability-Aware MapReduce Data Placement for Non-dedicated Distributed Computing. In Proceedings of the 2012 IEEE 32nd International Conference on Distributed Computing Systems, Macau, China, 18–21 June 2012; pp. 516–525. [Google Scholar]
- Costa, F.; Veiga, L.; Ferreira, P. Internet-scale support for map-reduce processing. J. Internet Serv. Appl. 2013, 4, 18. [Google Scholar] [CrossRef]
- Bruno, R.; Ferreira, P. FreeCycles: Efficient Data Distribution for Volunteer Computing. In Proceedings of the Fourth International Workshop on Cloud Data and Platforms, Amsterdam, The Netherlands, 13–16 April 2014; Association for Computing Machinery: New York, NY, USA, 2014. [Google Scholar] [CrossRef]
- Hamdaqa, M.; Sabri, M.M.; Singh, A.; Tahvildari, L. Adoop: MapReduce for Ad-Hoc Cloud Computing. In Proceedings of the 25th Annual International Conference on Computer Science and Software Engineering, Markham, ON, Canada, 2–4 November 2015; IBM Corp.: New York, NY, USA, 2015; pp. 26–34. [Google Scholar]
- Rezgui, A.; Davis, N.; Malik, Z.; Medjahed, B.; Soliman, H. CloudFinder: A System for Processing Big Data Workloads on Volunteered Federated Clouds. IEEE Trans. Big Data 2017, 6, 347–358. [Google Scholar] [CrossRef]
- Nouman Durrani, M.; Shamsi, J.A. Review: Volunteer Computing: Requirements, Challenges, and Solutions. J. Netw. Comput. Appl. 2014, 39, 369–380. [Google Scholar] [CrossRef]
- Weinman, J. Mathematical Proof of the Inevitability of Cloud Computing. Available online: http://www.joeweinman.com/Resources/Joe_Weinman_Inevitability_Of_Cloud.pdf (accessed on 11 May 2020).
- Villamizar, M.; Garcés, O.; Ochoa, L.; Castro, H.; Salamanca, L.; Verano, M.; Casallas, R.; Gil, S.; Valencia, C.; Zambrano, A.; et al. Infrastructure Cost Comparison of Running Web Applications in the Cloud Using AWS Lambda and Monolithic and Microservice Architectures. In Proceedings of the 2016 16th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGrid), Cartagena, Colombia, 16–19 May 2016; pp. 179–182. [Google Scholar]
- Jamshidi, P.; Pahl, C.; Mendonça, N.C.; Lewis, J.; Tilkov, S. Microservices: The Journey So Far and Challenges Ahead. IEEE Softw. 2018, 35, 24–35. [Google Scholar] [CrossRef]
- Taibi, D.; Lenarduzzi, V.; Pahl, C. Architectural Patterns for Microservices: A Systematic Mapping Study; SCITEPRESS: Setúbal, Portugal, 2018. [Google Scholar]
- Roberts, M.; Chapin, J. What Is Serverless? O’Reilly Media, Incorporated: Sebastopol, CA, USA, 2017. [Google Scholar]
- Baldini, I.; Castro, P.; Chang, K.; Cheng, P.; Fink, S.; Ishakian, V.; Mitchell, N.; Muthusamy, V.; Rabbah, R.; Slominski, A.; et al. Serverless computing: Current trends and open problems. In Research Advances in Cloud Computing; Springer: Berlin, Germany, 2017; pp. 1–20. [Google Scholar]
- Baldini, I.; Castro, P.; Cheng, P.; Fink, S.; Ishakian, V.; Mitchell, N.; Muthusamy, V.; Rabbah, R.; Suter, P. Cloud-native, event-based programming for mobile applications. In Proceedings of the International Conference on Mobile Software Engineering and Systems, Seoul, Korea, 25–26 May 2016; pp. 287–288. [Google Scholar]
- Rubab, S.; Hassan, M.F.; Mahmood, A.K.; Shah, S.N.M. A review on resource availability prediction methods in volunteer grid computing. In Proceedings of the 2014 IEEE International Conference on Control System, Computing and Engineering (ICCSCE 2014), Penang, Malaysia, 28–30 November 2014; pp. 478–483. [Google Scholar]
- Anderson, D.P. BOINC: A Platform for Volunteer Computing. J. Grid Comput. 2019, 18, 122–199. [Google Scholar] [CrossRef]
- Nov, O.; Anderson, D.; Arazy, O. Volunteer computing: A model of the factors determining contribution to community-based scientific research. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010. [Google Scholar]
- Kloetzer, L.; Costa, J.D.; Schneider, D. Not so passive: Engagement and learning in Volunteer Computing projects. Hum. Comput. 2016, 3, 25–68. [Google Scholar] [CrossRef][Green Version]
- Edinger, J.; Edinger-Schons, L.M.; Schäfer, D.; Stelmaszczyk, A.; Becker, C. Of Money and Morals—The Contingent Effect of Monetary Incentives in Peer-to-Peer Volunteer Computing. In Proceedings of the 52nd Hawaii International Conference on System Sciences, Maui, HI, USA, 8 January–11 Friday 2019. [Google Scholar]
- Ritu Arora, C.R. Scalable Software Infrastructure for Integrating Supercomputing with Volunteer Computing and Cloud Computing. Commun. Comput. Inf. Sci. 2019, 964, 105–119. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Platforms and References (Ordered by Publication Date) |
|---|---|
| Volunteer grid computing | Condor [8], XtremWeb [9], SETI@home [10], Entropia [11], Farsite [12], BOINC [13], CCOF [14], Kosha [15], OurGrid [16], Alchemi [17],FreeLoader [18], LHC@home [19], Aneka [20], Cohesion [21], EDGeS [22], BitDew [23], unaGrid [24], ATLAS@home [25] |
| Volunteer cloud computing | Storage@home [26], Cloud@home [27], Seattle [28], C3 [29], P3R3.O.KOM [30], STACEE [31], UnaCloud [32], Personal Cloud [33], P2PCS [34], SoCVC [35], Fatman [36], AdHoc Cloud [37], SASCloud [38], DIaaS [39], Nebula [40], cuCloud [41] |
| Volunteer mobile computing | Mobiscope [42], AnonySense [43], Micro-blog [44], LiveCompare [45], Bubblesensing [46], PRISM [47], CrowdLab [48], CWC [49], Serendipity [50], Mobile Device Clouds [51], CellCloud [52], GEMCloud [53], FemtoCloud [54], AirShower@home [55] |
| Volunteer parallel computing | VolpexPyMPI [56], MOON [57], BOINC-MR [58], MPIWS [48], ADAPT [59], GiGi-MR [60], freeCycles [61], Adoop [62], CloudFinder [63] |
| VC Issues | Container | Function | Image Registry | Service Registry | Service Proxy | Remarks |
|---|---|---|---|---|---|---|
| HW heterogenity | x | x | Containers (and functions packaged as containers) are a standardized deployment format that is useable on all primary desktop and server operating platforms (Windows, Linux, Mac OS). | |||
| Verification of (large) results | x | x | Functions are used in cloud-native architectures to process events that must be computed in a limited amount of time. Functions (if packaged as containers) can be accompanied by trusted service proxies that could validate function results before sending them to the master. Because of the time limitations (minutes instead of hours or even days), the result verification would be faster and might be even processed decentrally. | |||
| Code signing and updating | x | Image content trust technologies provide the ability to use digital signatures for image registry operations (push, pull). Publishers can sign their pushed images, and image consumers can ensure that pulled images are signed. If images are updated they can be fetched automatically by the clients in their next event processing cycle. Current image registries like Harbor, DockerHub, quai.io, GitLab registry, and many more provide signed images for automatic deployments out of the box. | ||||
| Sandboxing | x | x | The original intent of operating system virtualization (containers) was sandboxing. Thus, containers (and functions packaged as containers) provide inherent and reliable sandboxing out of the box. This sandboxing is much more fine-grained than virtual machines and available on all major desktop and server platforms (see HW heterogeneity). | |||
| Project exclusiveness | x | A service registry is a database containing the network locations of service instances. It consists typically of components that use a replication protocol. Examples for reliable cloud-native products are etcd (https://etcd.io), consul (https://www.consul.io), or Zookeeper (https://zookeeper.apache.org). Such solutions can share VC project information and network locations of master nodes for clients in a project agnostic format. Thus, clients that are bound to one master component can do client-side service discovery of further VC projects. |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kratzke, N. Volunteer Down: How COVID-19 Created the Largest Idling Supercomputer on Earth. Future Internet 2020, 12, 98. https://doi.org/10.3390/fi12060098
Kratzke N. Volunteer Down: How COVID-19 Created the Largest Idling Supercomputer on Earth. Future Internet. 2020; 12(6):98. https://doi.org/10.3390/fi12060098
Chicago/Turabian StyleKratzke, Nane. 2020. "Volunteer Down: How COVID-19 Created the Largest Idling Supercomputer on Earth" Future Internet 12, no. 6: 98. https://doi.org/10.3390/fi12060098
APA StyleKratzke, N. (2020). Volunteer Down: How COVID-19 Created the Largest Idling Supercomputer on Earth. Future Internet, 12(6), 98. https://doi.org/10.3390/fi12060098