A Scalable and Semantic Data as a Service Marketplace for Enhancing Cloud-Based Applications

 , , ,
, , ,
Abstract
1. Introduction
1.1. General Concepts
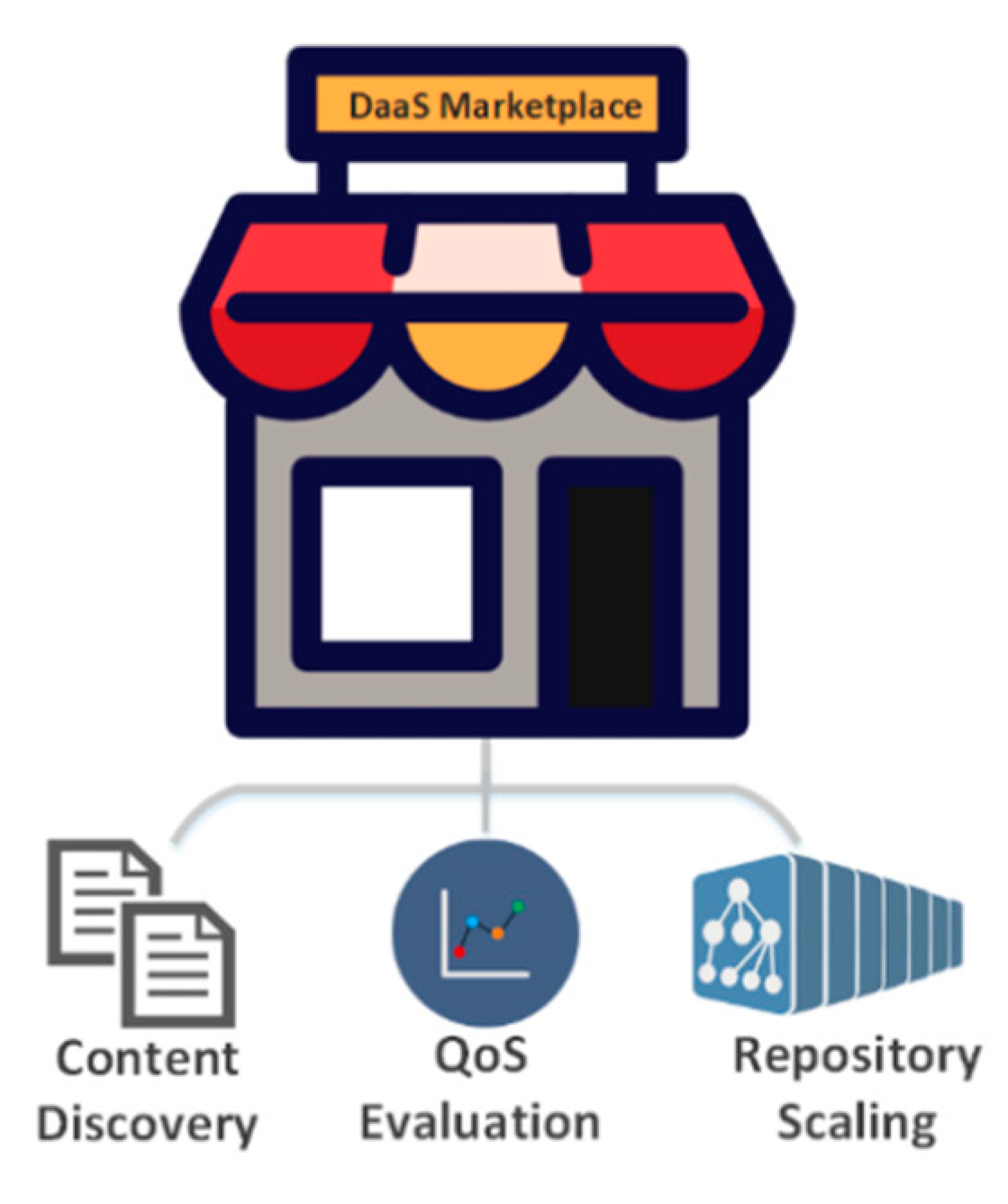
- Content discovery: A semantically enhanced content discovery component that aids the data buyer to find the most suitable data as far as the content is concerned. Also, aids the data provider to better describe their data in order to make them more easily discoverable.
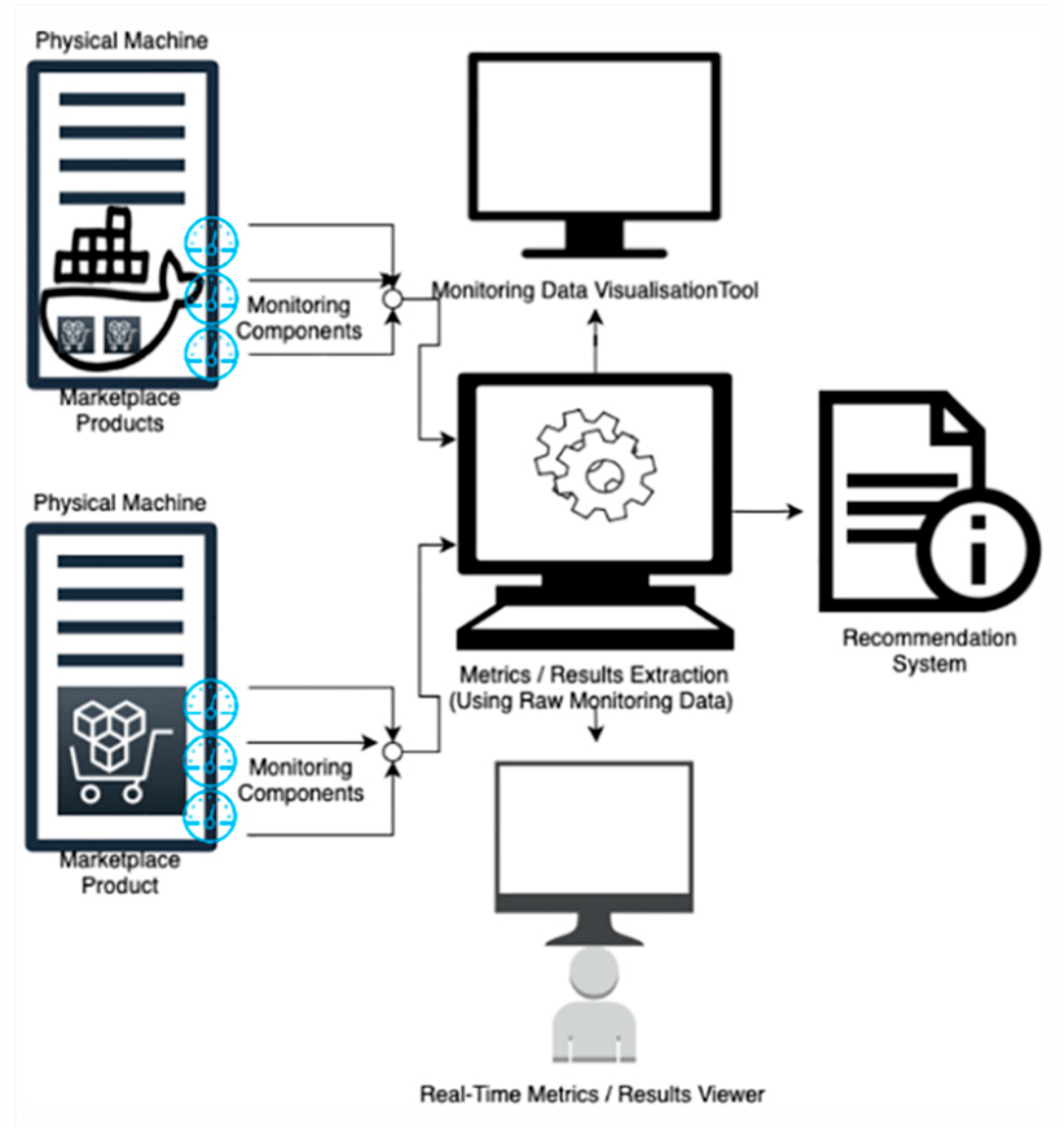
- QoS evaluation: An assessment tool that produces analytics and QoS metrics for the services that provide the data, in order to aid the data buyer not only to assess the QoD but also the QoS in which the data are delivered.
- DaaS repository scalability: A scalability component that enables the dynamic scaling of the DaaS Marketplace repository in order to ensure business continuity and fault tolerance.
1.2. Related Work
2. Materials and Methods
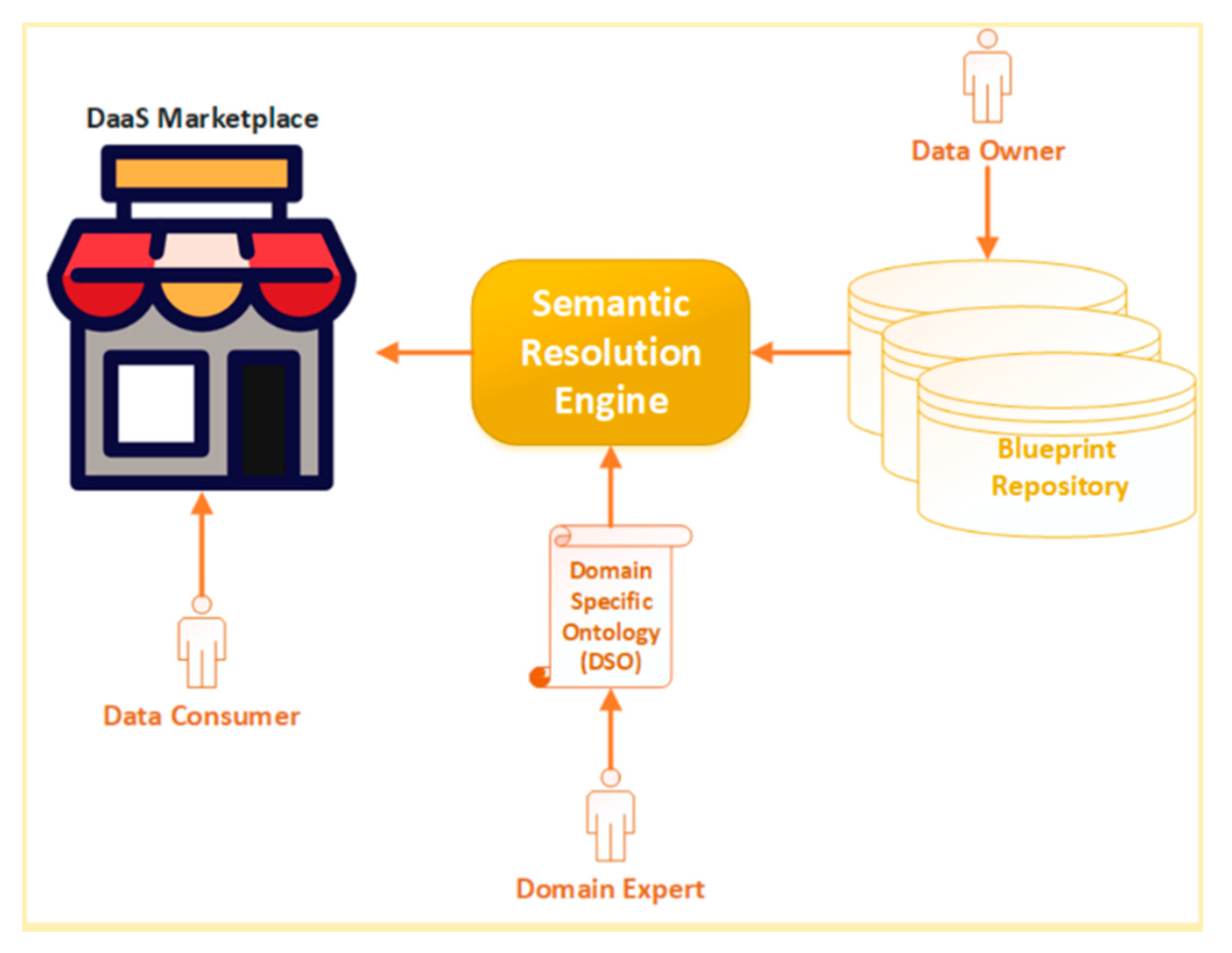
2.1. Architectural Conceptualization
2.2. Components Description
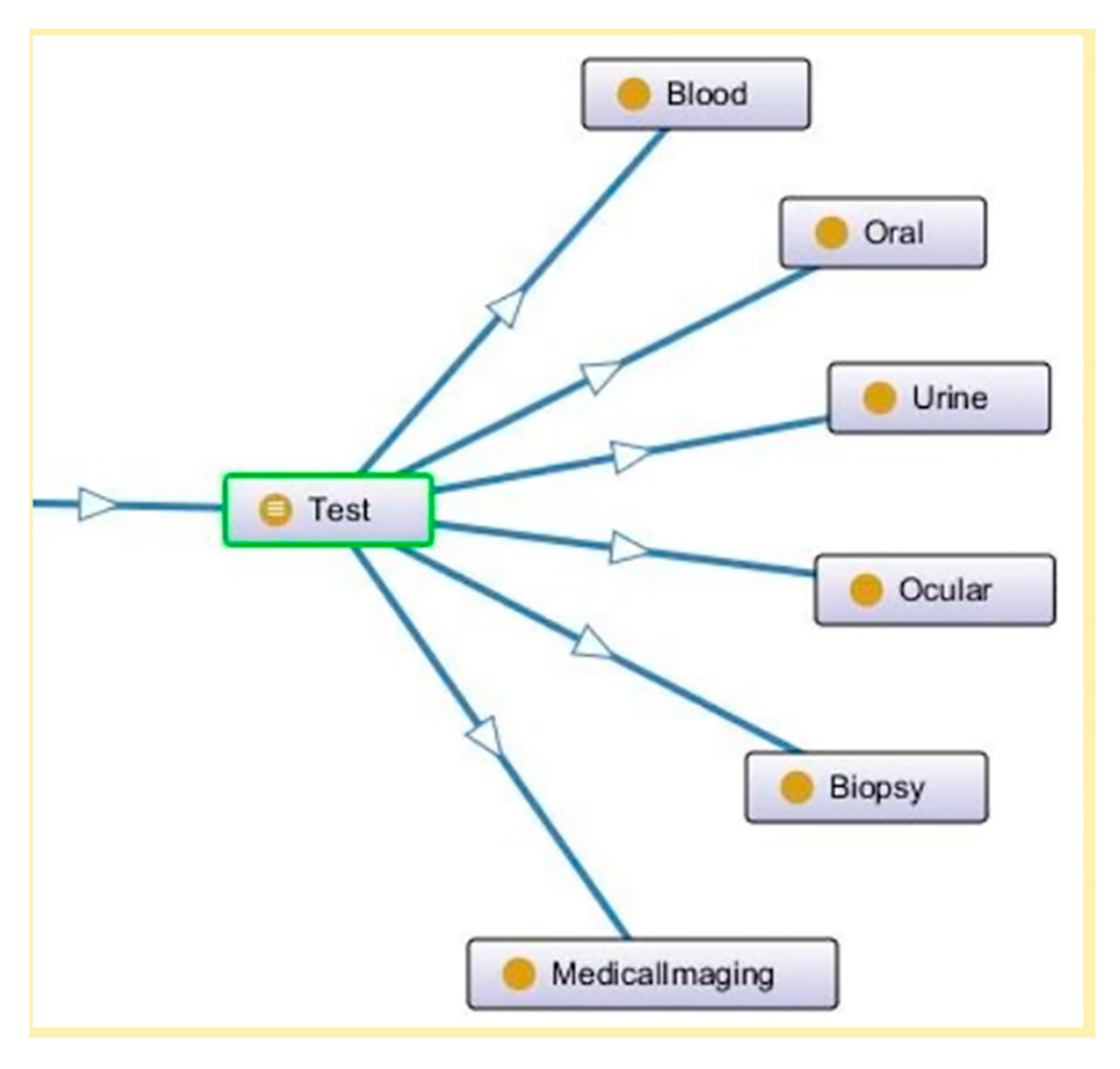
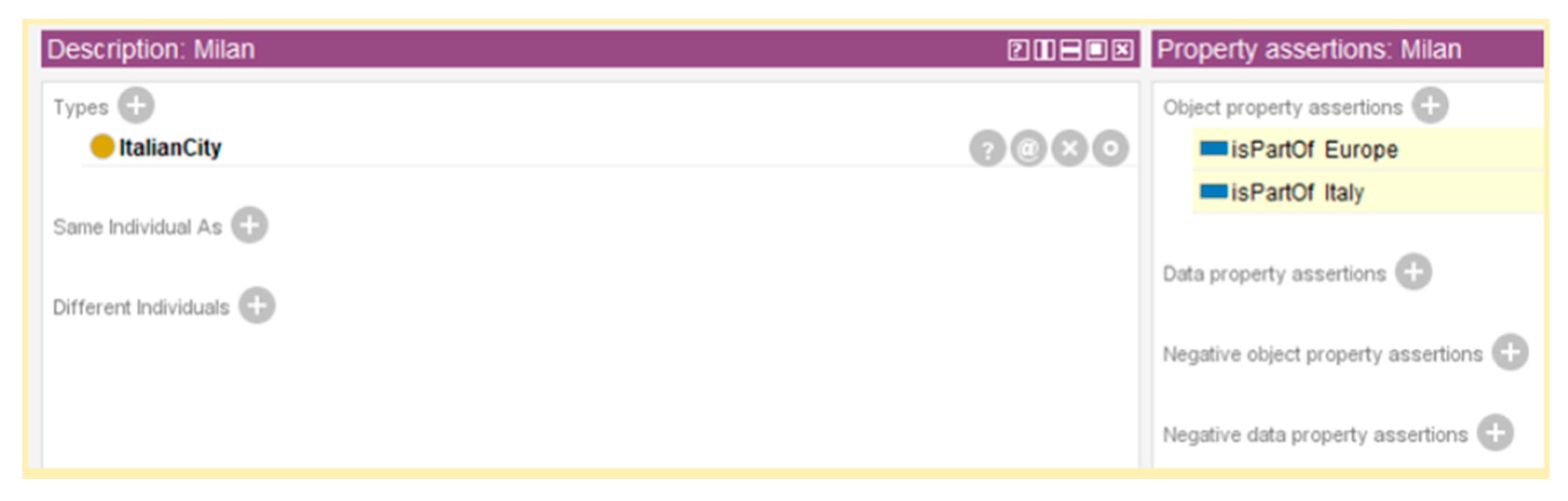
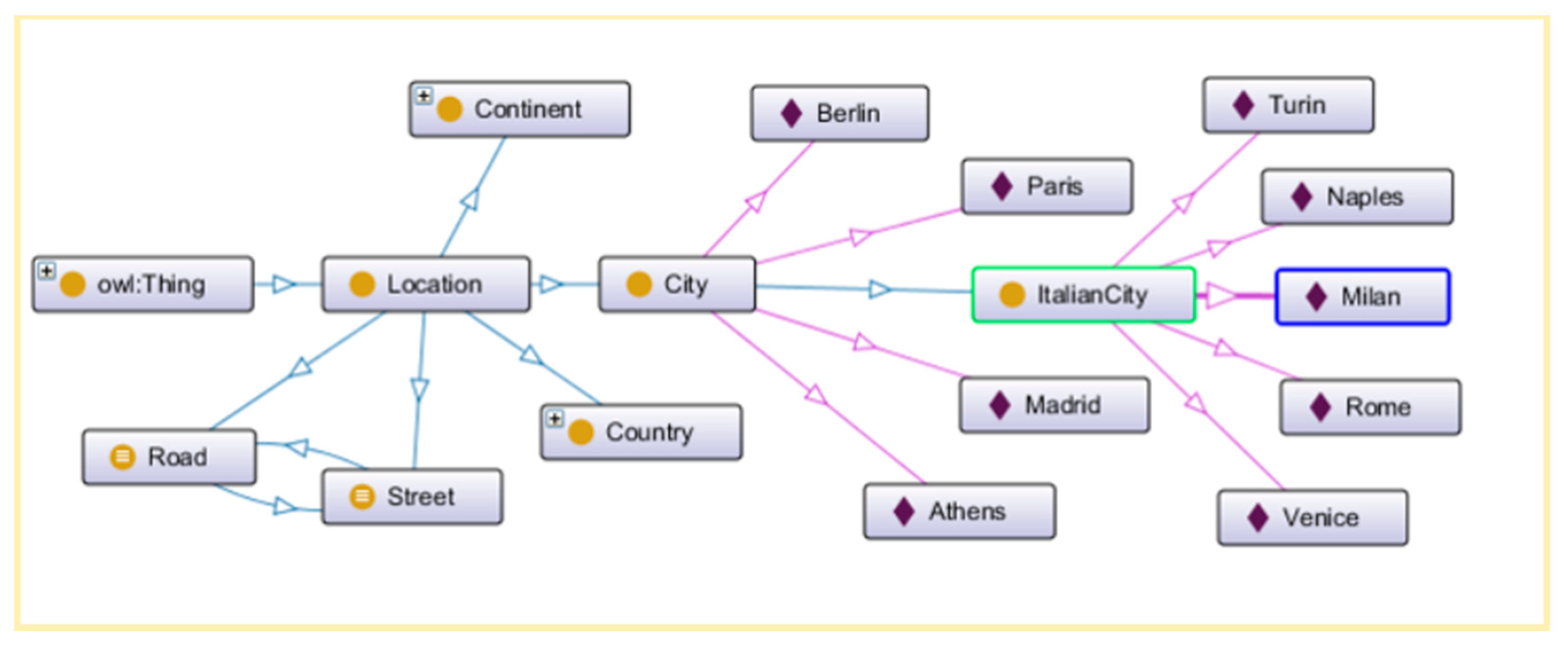
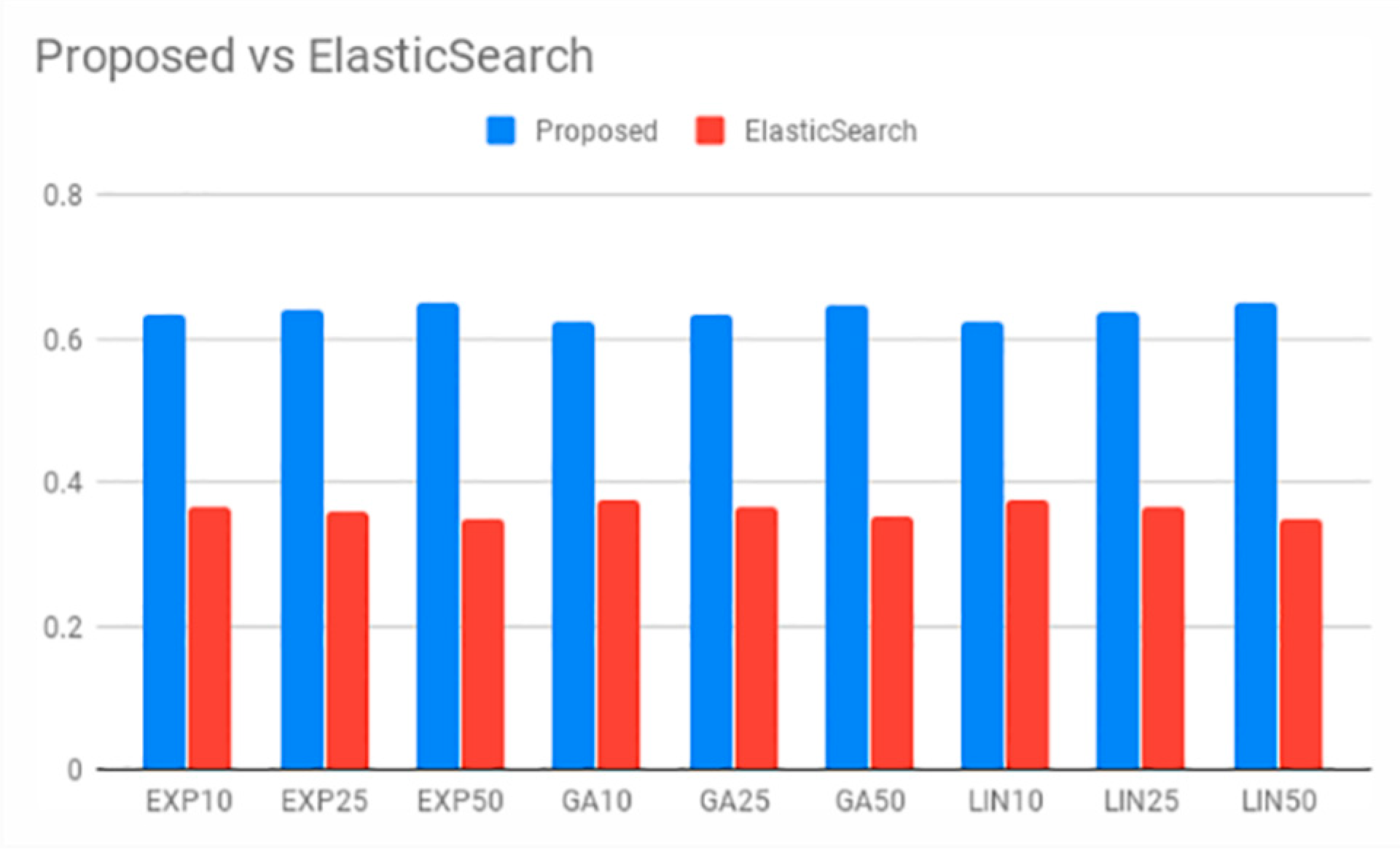
2.2.1. Semantic Resolution Engine
2.2.2. SEMS
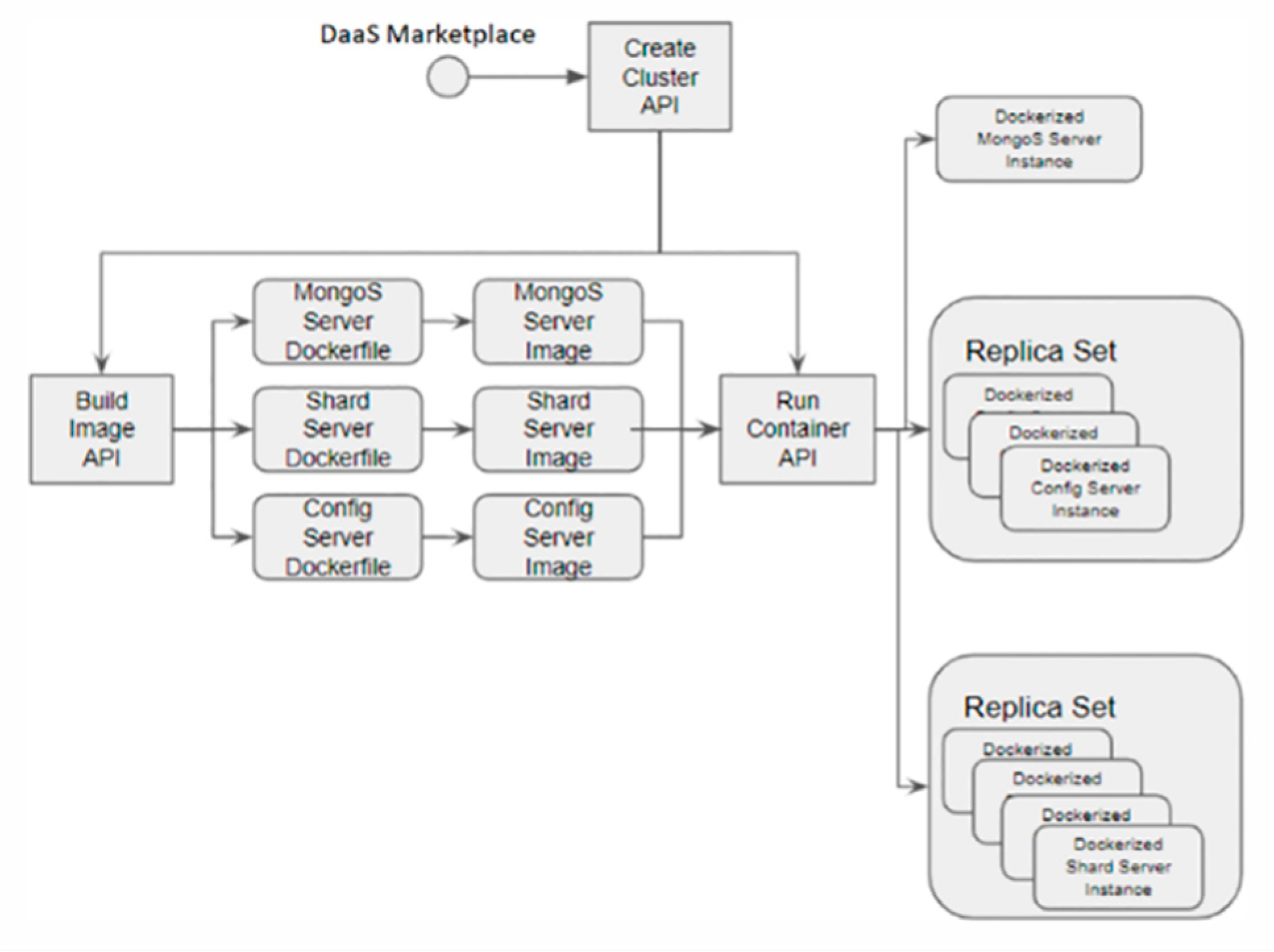
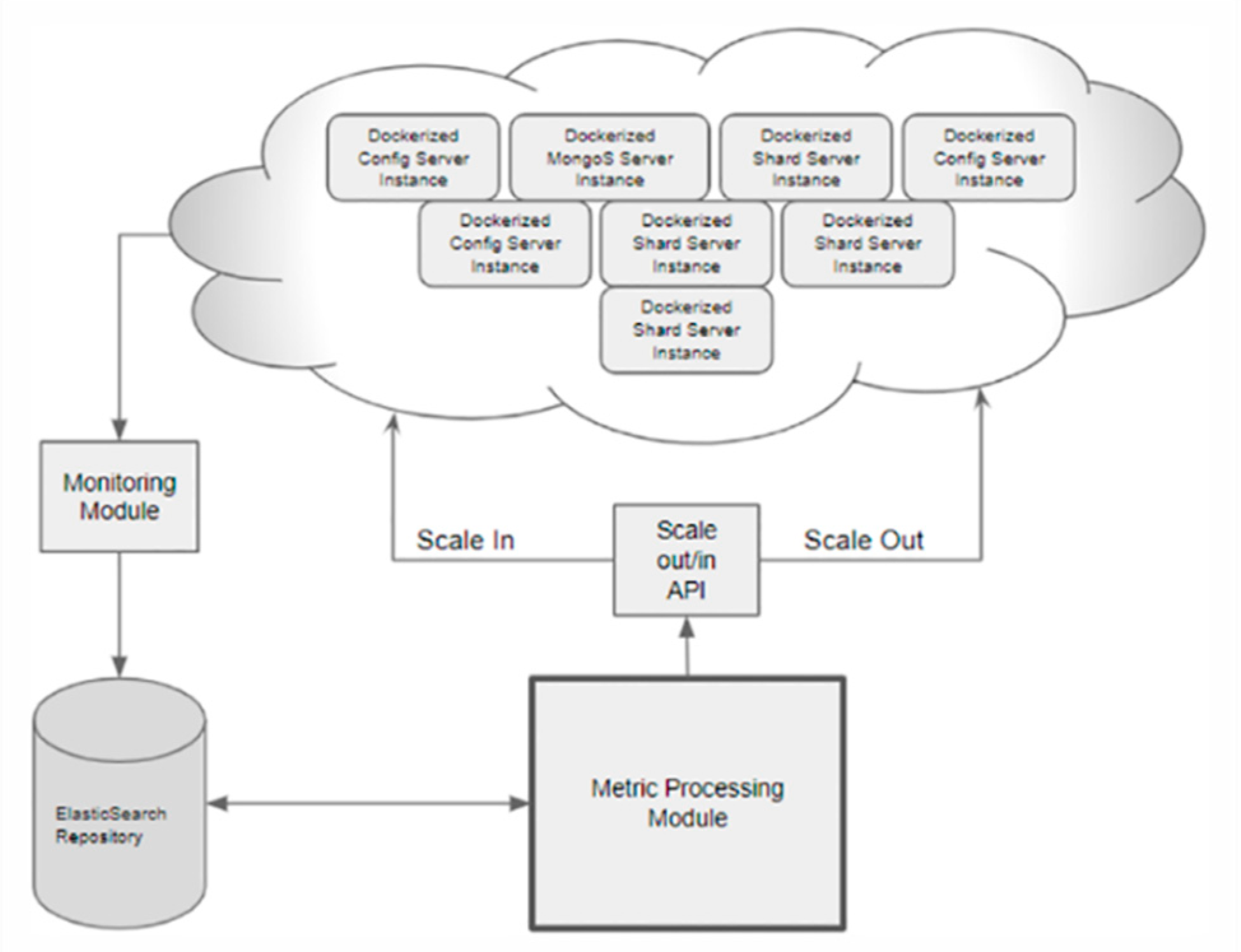
2.2.3. Repository Manager
- The MongoDB APIs, which handle the configuration of the MongoDB cluster, as well as the communication needed to ensure that the configurations are correctly applied and the status of all machines is within acceptable thresholds.
- The Docker APIs, which handle the Docker hosts, the images hosted in them, and the containers that are or will be parts of the MongoDB cluster.
- The Kubernetes APIs, which also handle the Docker hosts, images, and containers, but on a higher level using the Kubernetes orchestration APIs.
- The Scaling APIs, which provide the coordination APIs that combine all others in order to provide the services promised by MaRScaF.
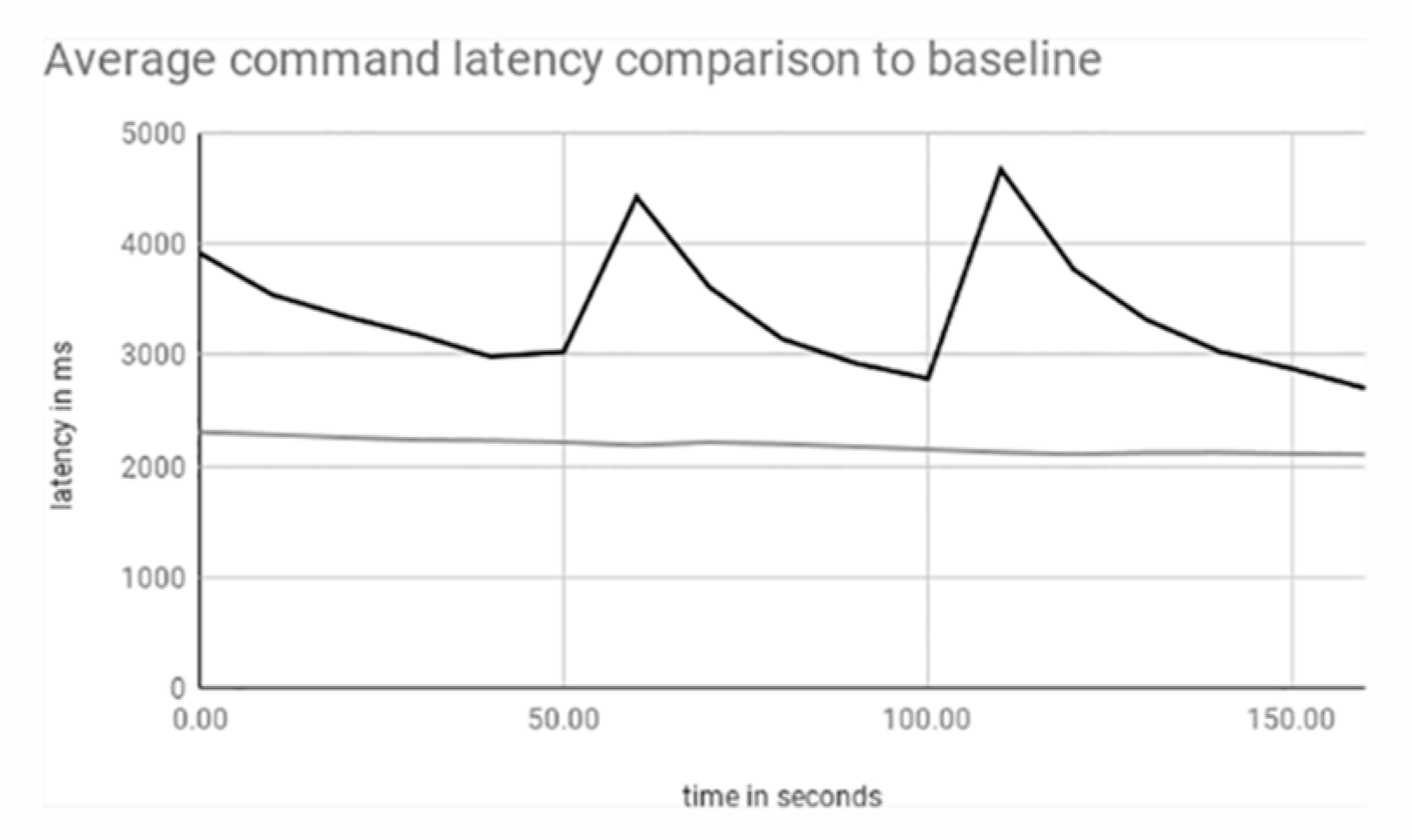
3. Results
- Single shard cluster: 1 Mongos, 1 configuration server and 1 shard server
- Double shard cluster: 1 Mongos, 1 configuration server and 2 shard servers
- Triple shard cluster: 1 Mongos, 1 configuration server and 3 shard servers
- Single to Double: A single shard cluster that was scaled to a double shard cluster
- Single to Double to Triple: A single shard cluster that was scaled to a double shard and then to a triple shard.
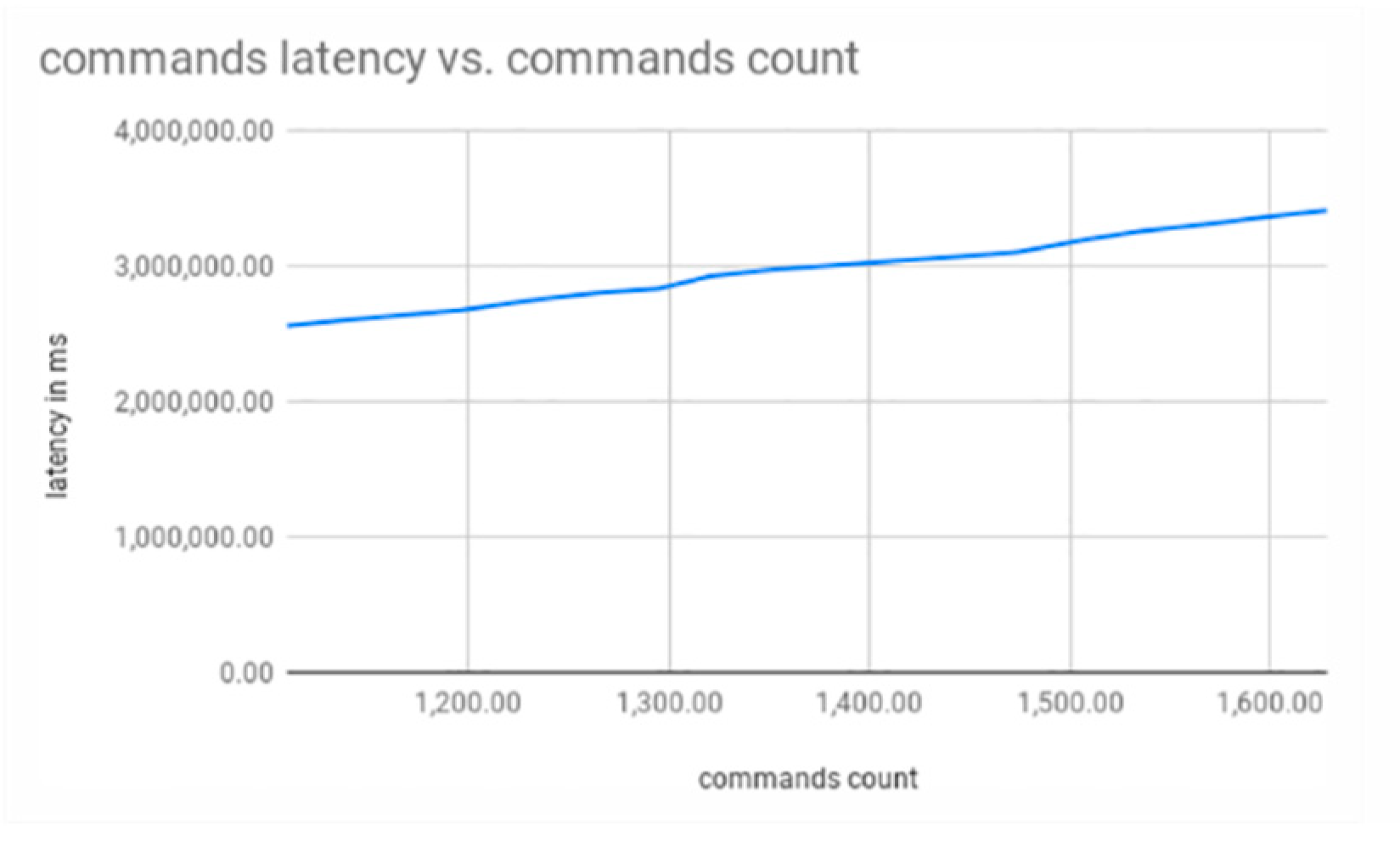
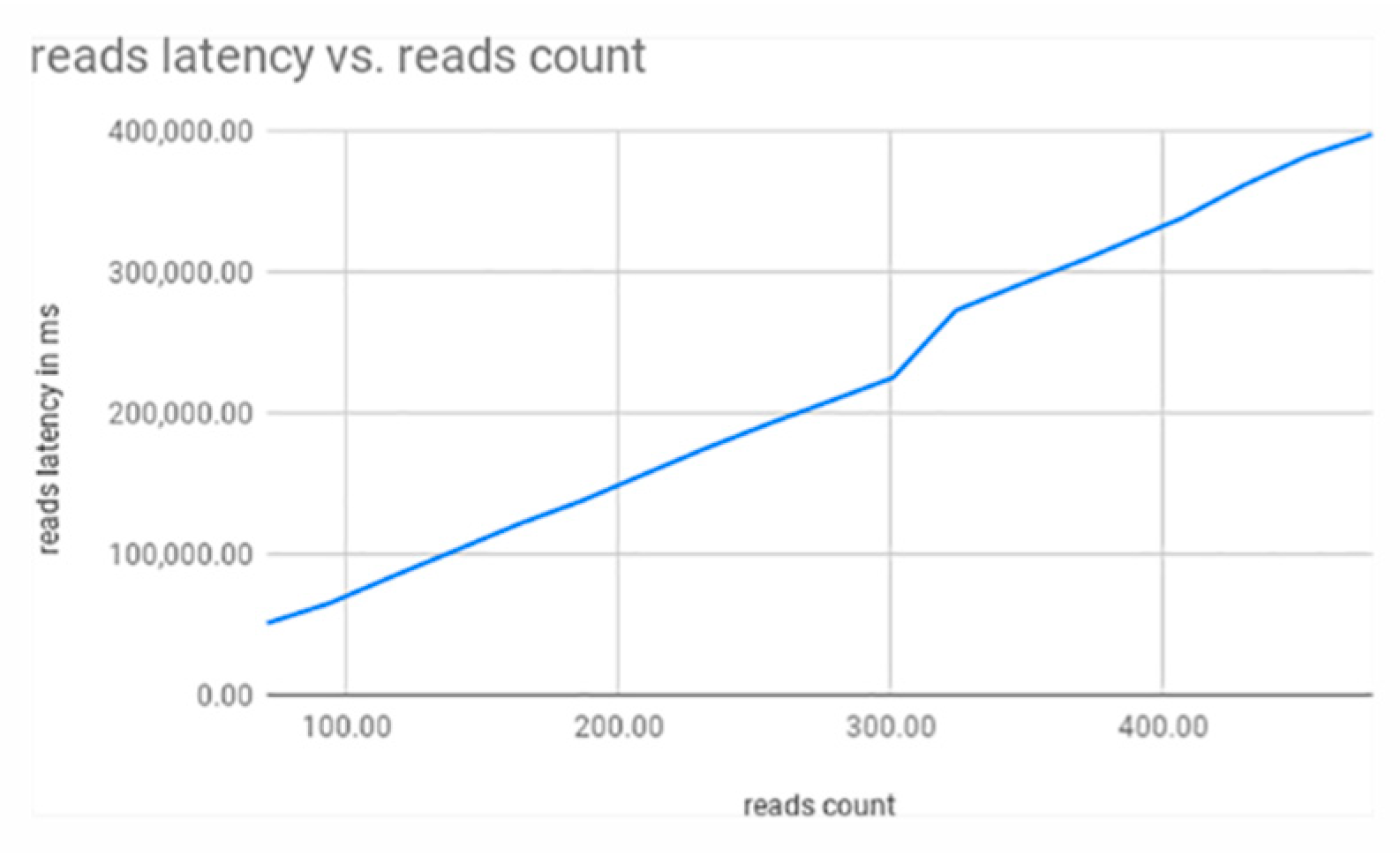
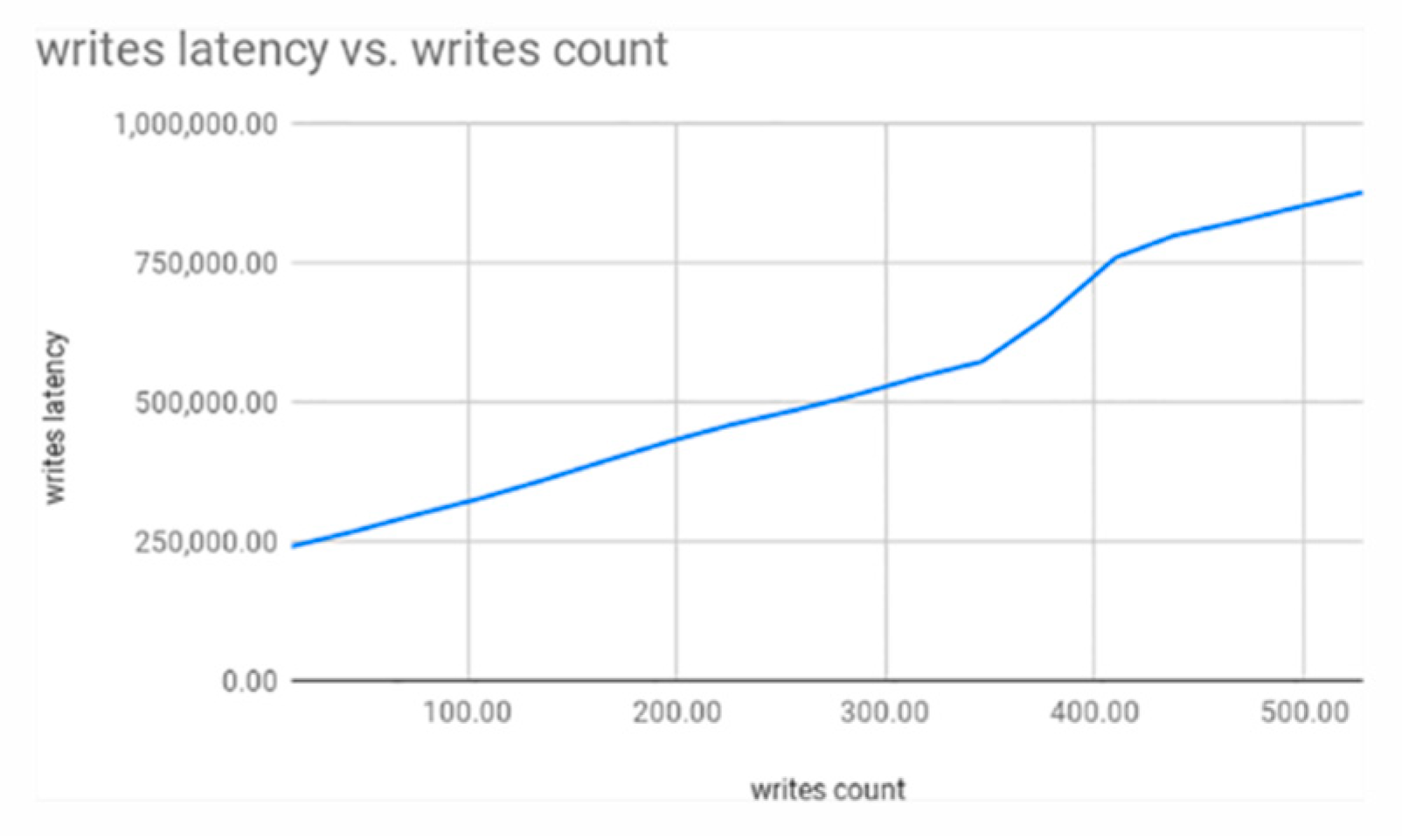
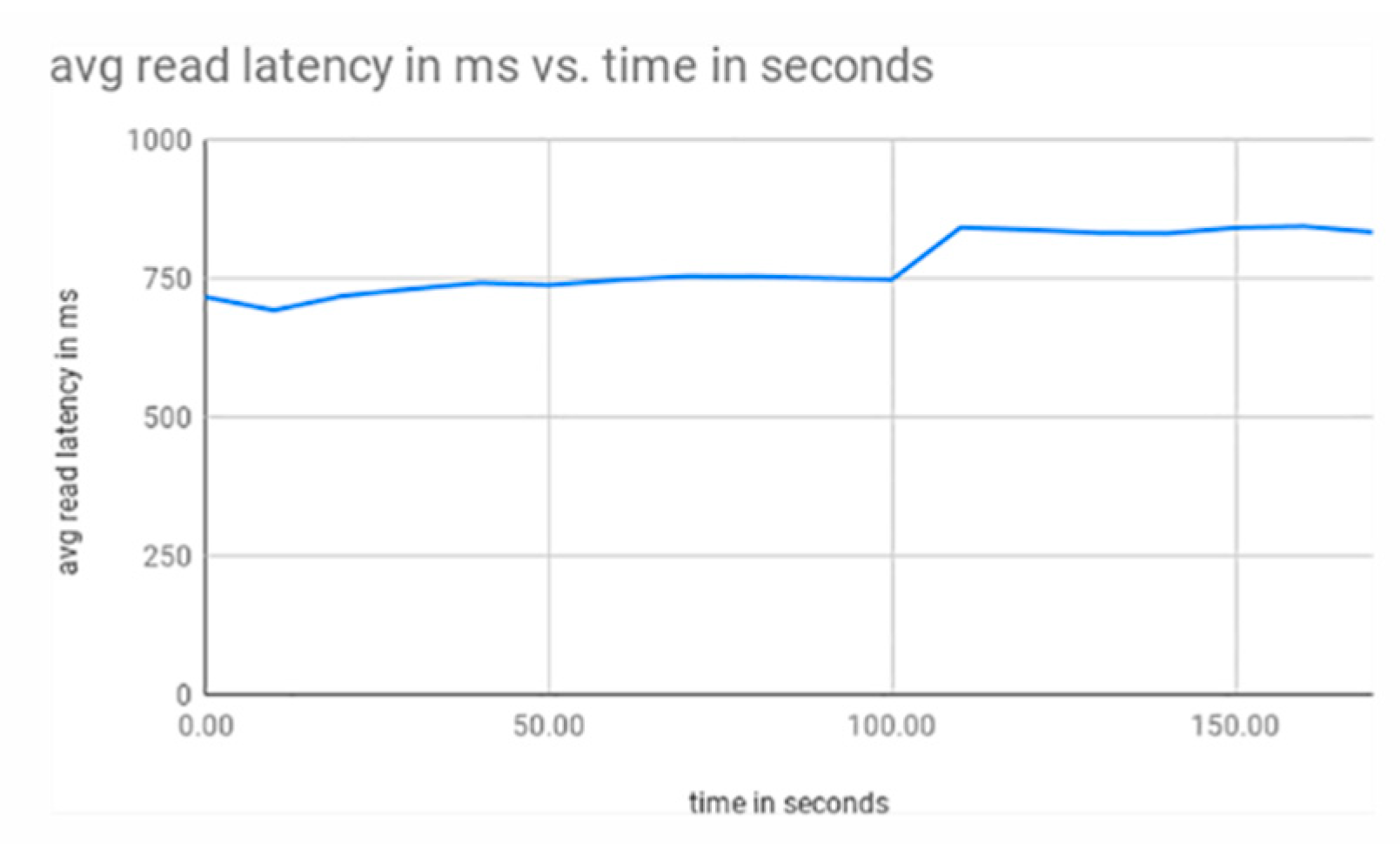
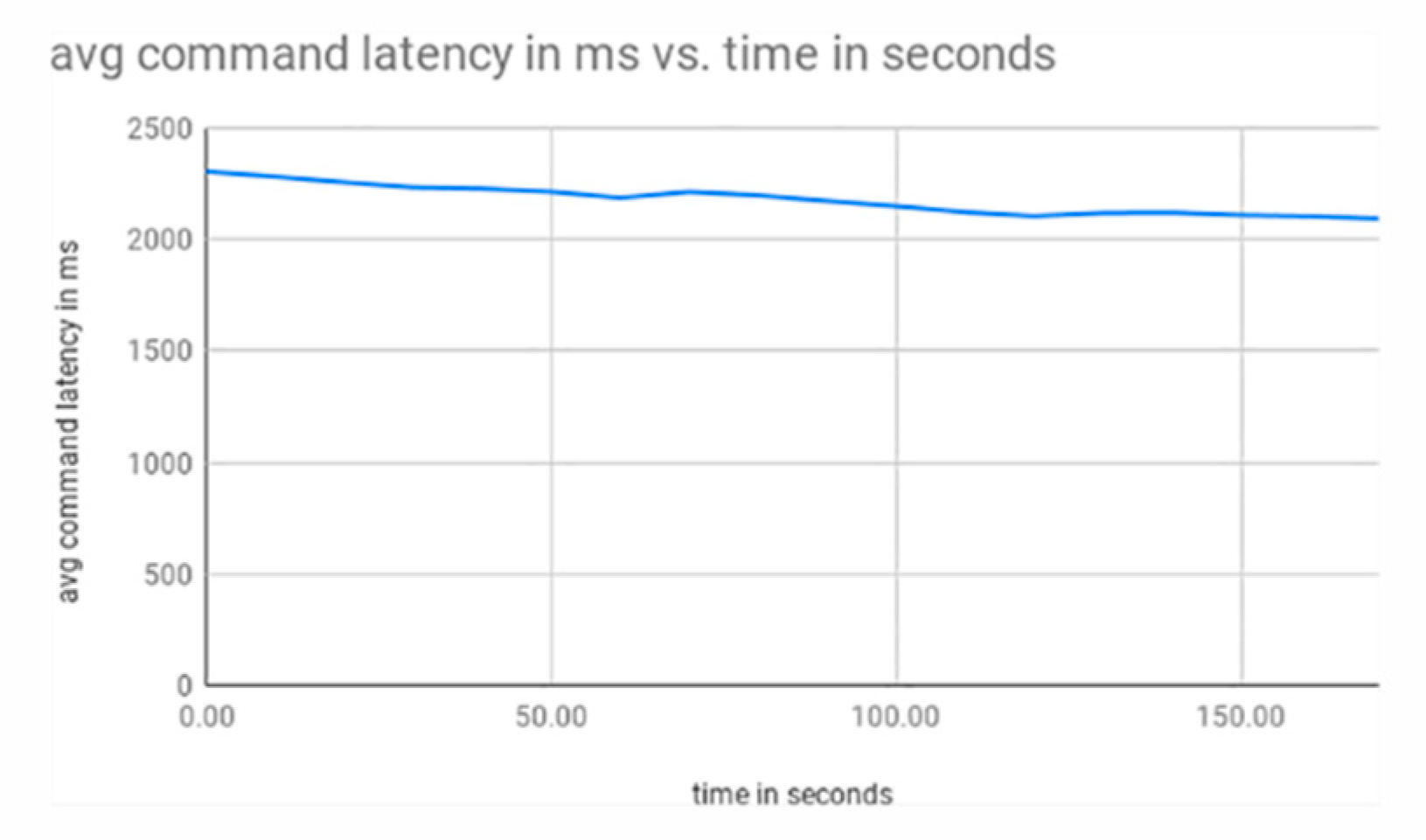
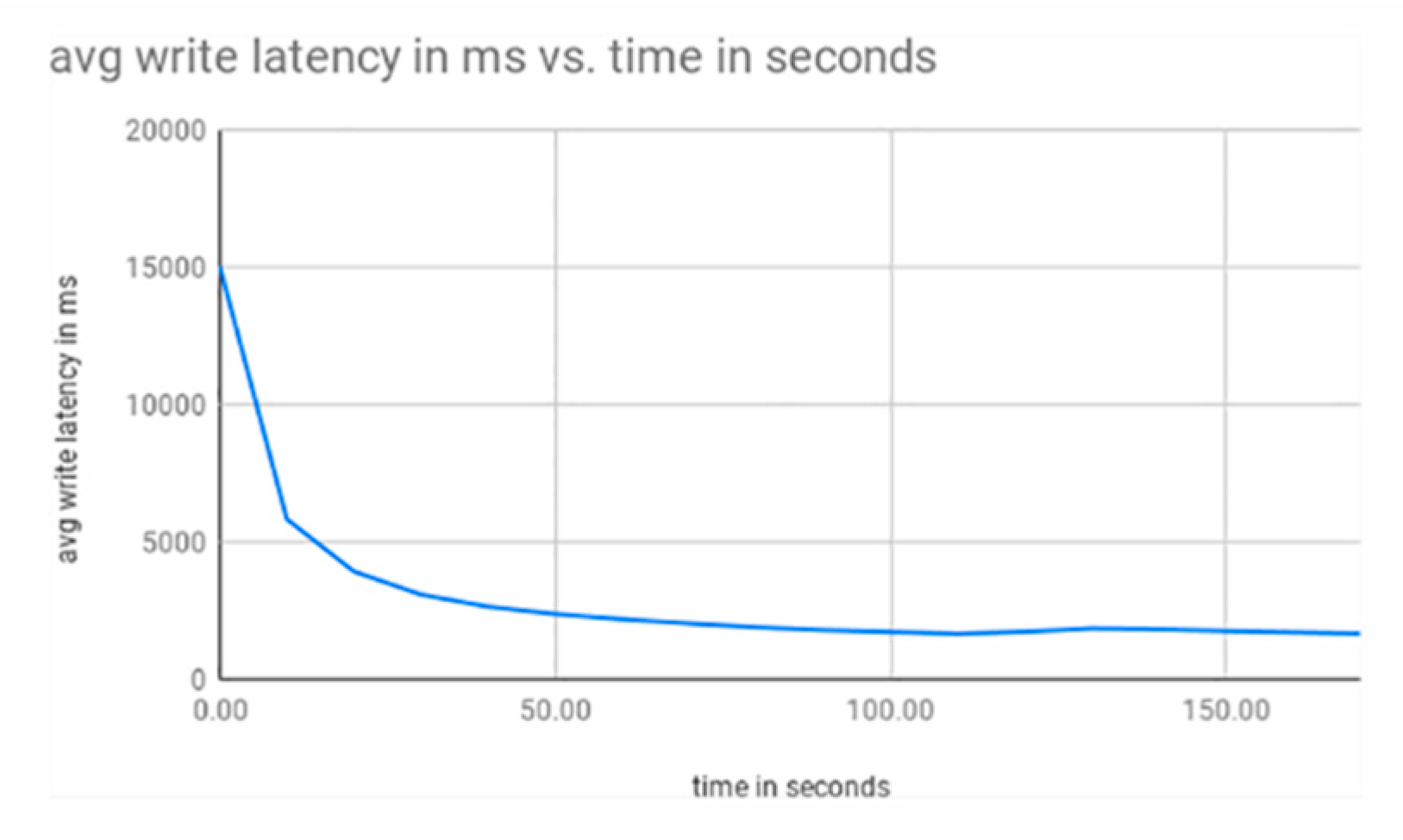
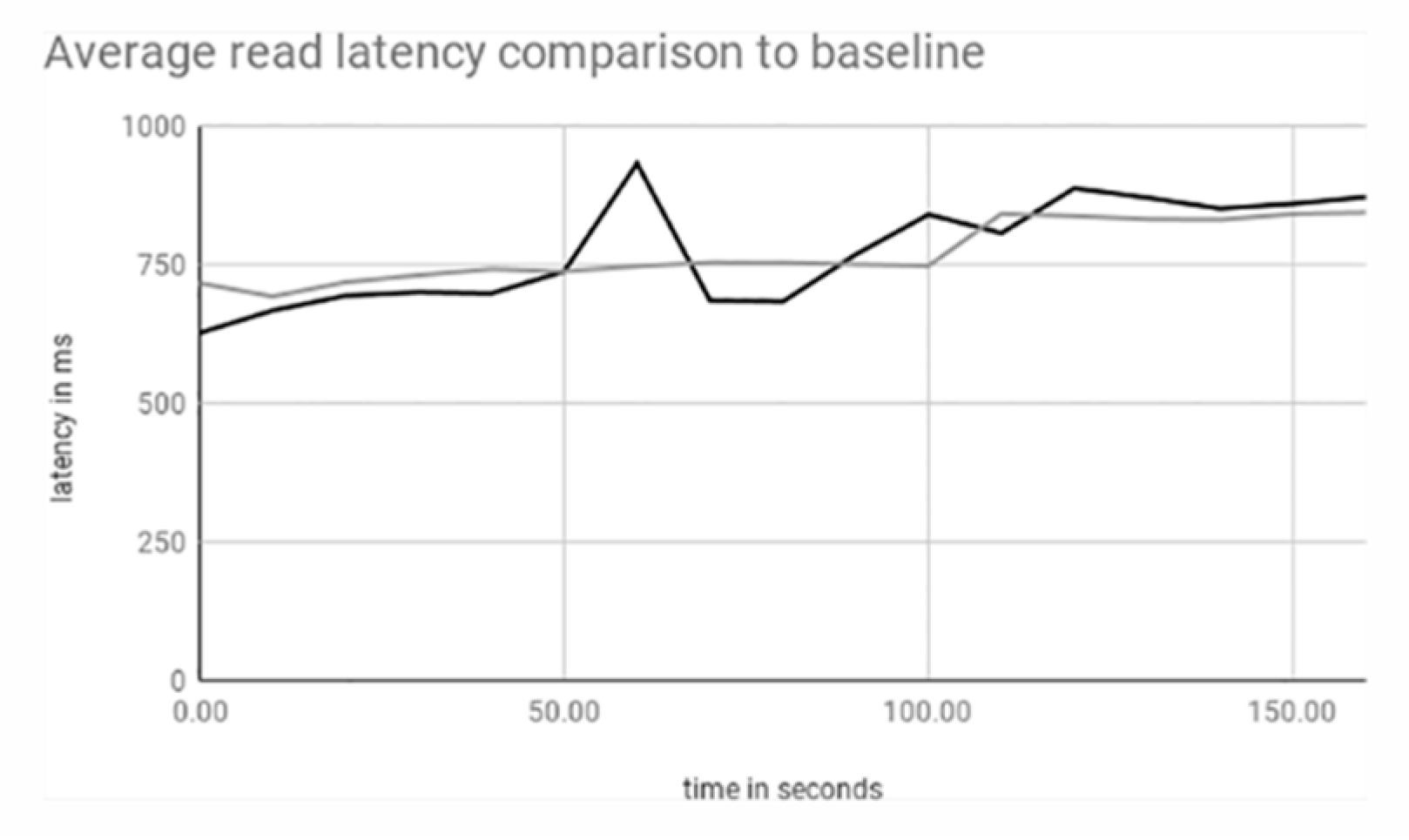
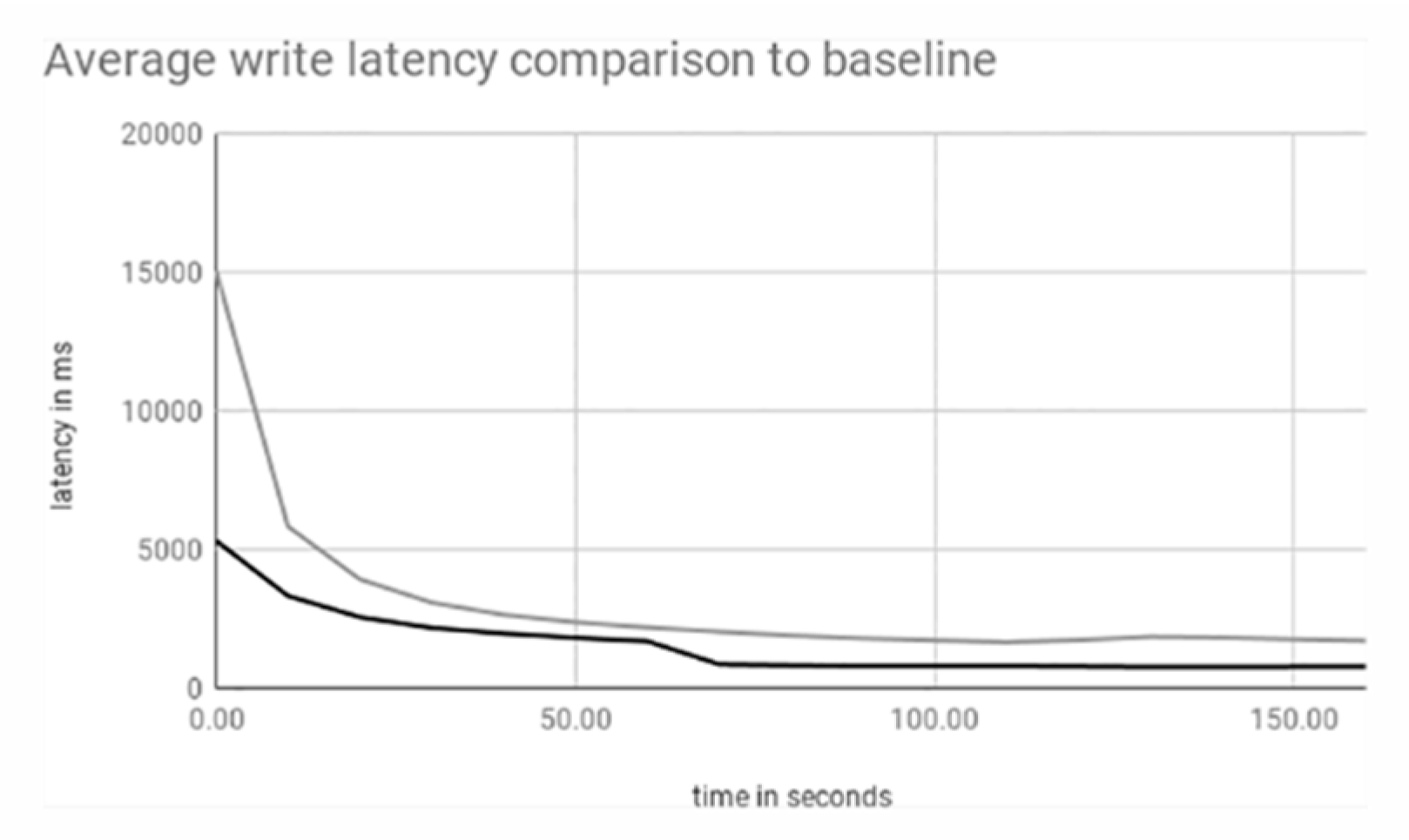
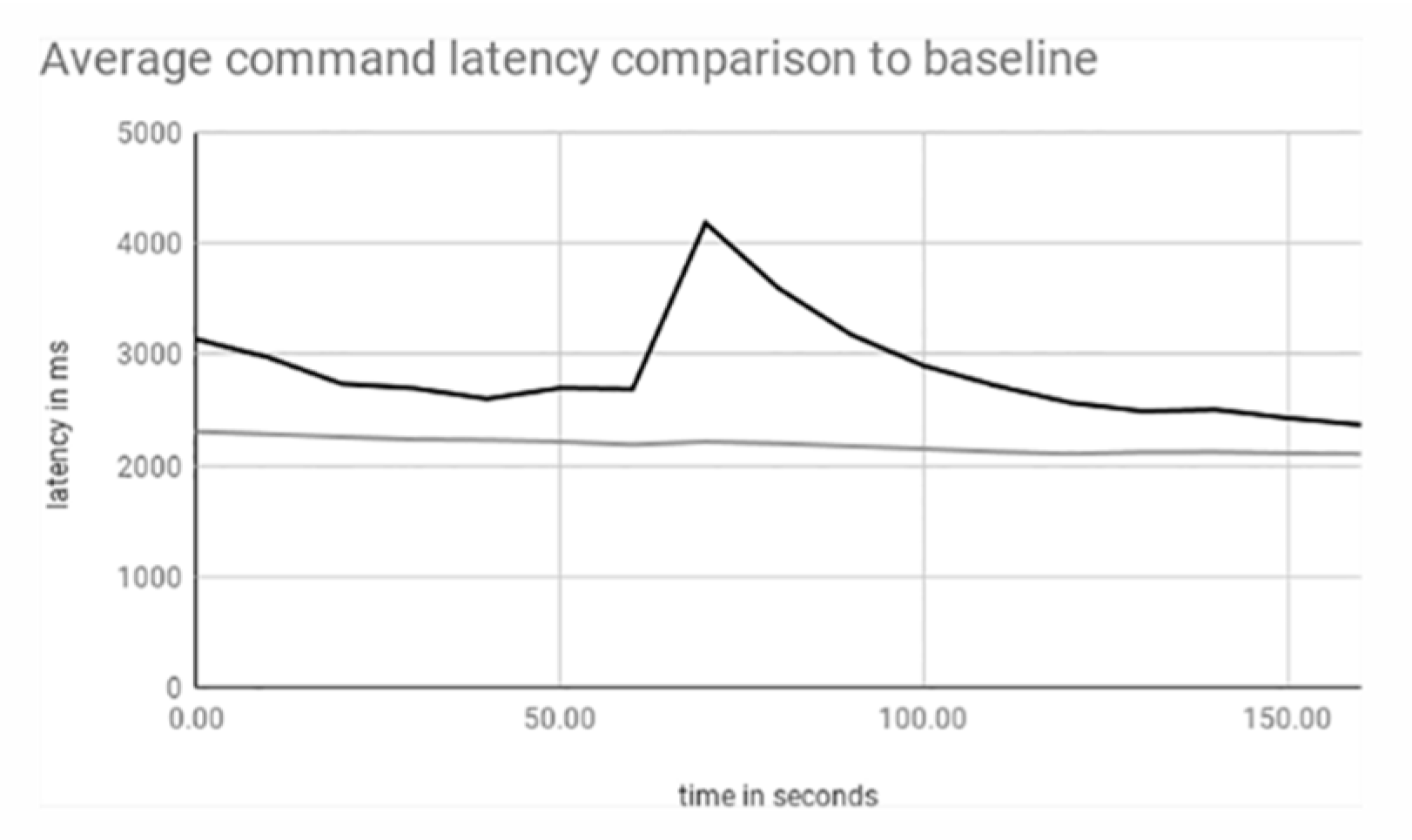
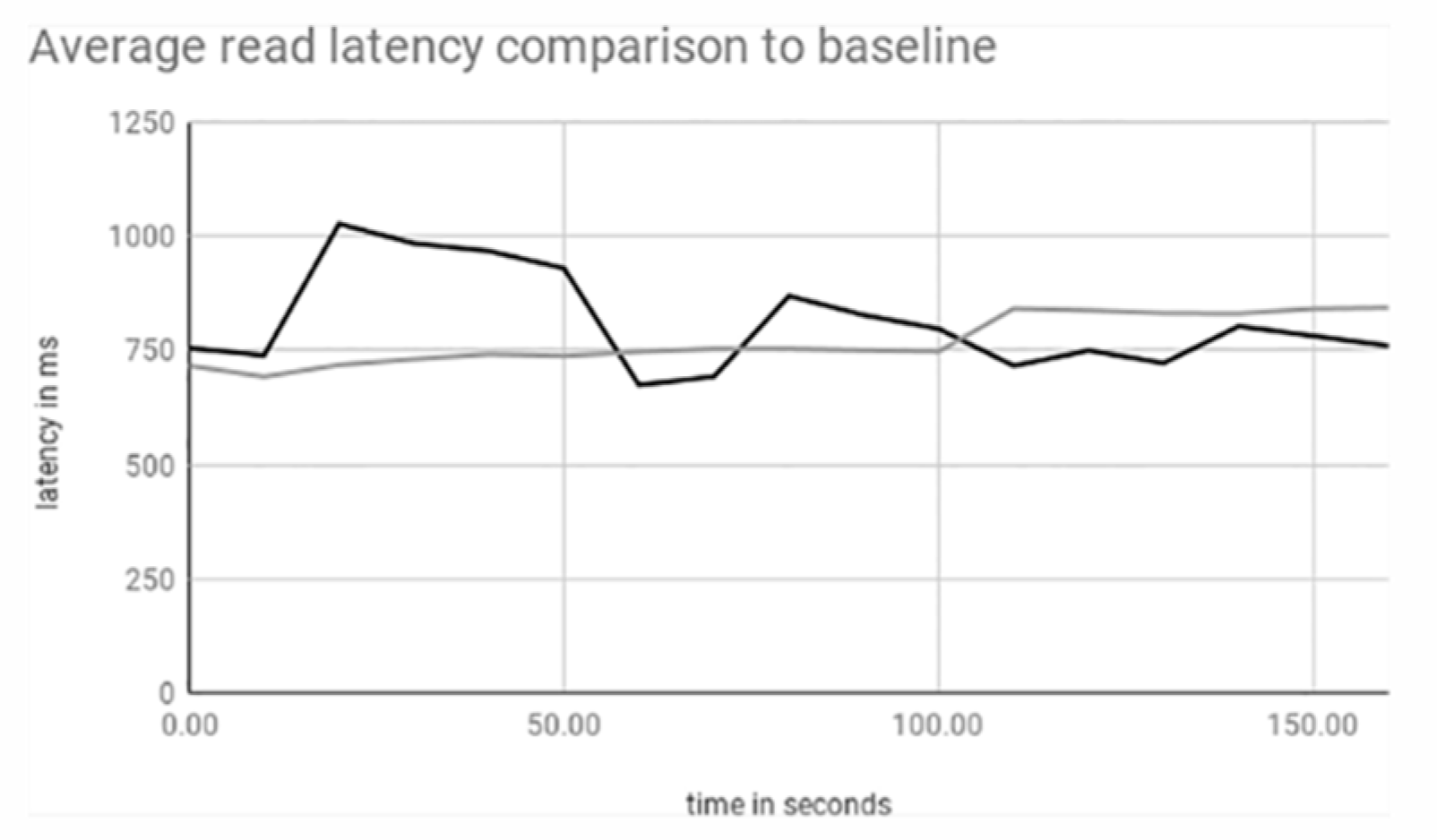
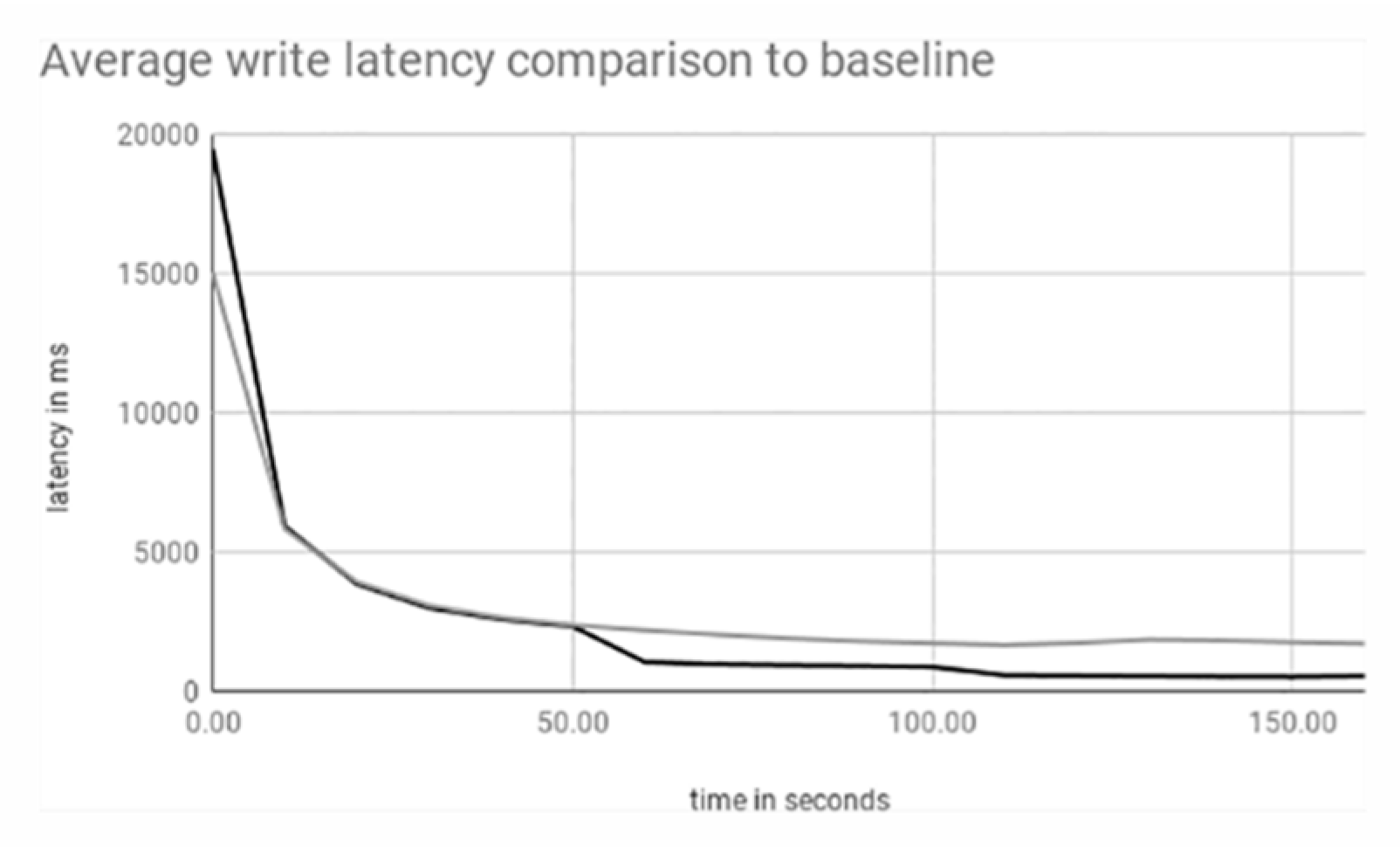
3.1. Single Shard
3.2. Single to Double Shard
3.3. Single to Double to Triple Shard
4. Discussion
Author Contributions
Funding
Conflicts of Interest
References
- The Rise of the Data Marketplace. March 2017. Available online: https://www.datawatch.com/wp-content/uploads/2017/03/The-Rise-of-the-Data-Marketplace.pdf (accessed on 23 March 2020).
- Reinsel, D.; Gantz, J.; Rydning, J. Data age 2025: The evolution of data to life-critical. In Don’t Focus on Big Data; IDC Corporate: Framingham, MA, USA, 2017; pp. 2–24. [Google Scholar]
- Häubl, G.; Murray, K.B. Preference Construction and Persistence in Digital Marketplaces: The Role of Electronic Recommendation Agents. J. Consum. Psychol. 2003, 13, 75–91, Social Science Research Network, Rochester, NY, SSRN Scholarly Paper ID 964192, Aug. 2001. [Google Scholar] [CrossRef]
- Elasticsearch, B.V. Open Source Search: The Creators of Elasticsearch, ELK Stack & Kibana | Elastic. 2020. Available online: https://www.elastic.co/ (accessed on 28 March 2020).
- Dang, T.K.; Vo, A.K.; Küng, J. A NoSQL Data-Based Personalized Recommendation System for C2C e-Commerce. In Database and Expert Systems Applications; Springer: Cham, Switzerland, 2017; pp. 313–324. [Google Scholar] [CrossRef]
- Lai, V.; Shim, K.J.; Oentaryo, R.J.; Prasetyo, P.K.; Vu, C.; Lim, E.P.; Lo, D. CareerMapper: An automated resume evaluation tool. In Proceedings of the 2016 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 5–8 December 2016; pp. 4005–4007. [Google Scholar] [CrossRef]
- Mbah, R.B.; Rege, M.; Misra, B. Discovering Job Market Trends with Text Analytics. In Proceedings of the 2017 International Conference on Information Technology (ICIT), Bhubaneswar, India, 21–23 December 2017; pp. 137–142. [Google Scholar] [CrossRef]
- Chen, D.; Chen, Y.; Brownlow, B.N.; Kanjamala, P.P.; Arredondo, C.A.G.; Radspinner, B.L.; Raveling, M.A. Real-Time or Near Real-Time Persisting Daily Healthcare Data Into HDFS and ElasticSearch Index Inside a Big Data Platform. IEEE Trans. Ind. Inform. 2017, 13, 595–606. [Google Scholar] [CrossRef]
- Klibisz, A. Elastik-Nearest-Neighbors. 2019. Available online: https://github.com/alexklibisz/elastik-nearest-neighbors (accessed on 28 March 2020).
- Amato, G.; Bolettieri, P.; Carrara, F.; Falchi, F.; Gennaro, C. Large-Scale Image Retrieval with Elasticsearch. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 June 2018; pp. 925–928. [Google Scholar] [CrossRef]
- Gupta, P.; Kanhere, S.S.; Jurdak, R. A Decentralized IoT Data Marketplace. In Proceedings of the 3rd Symposium on Distributed Ledger Technology, Gold Coast, Australia, 12 November 2018. [Google Scholar]
- Ghosh, H. Data marketplace as a platform for sharing scientific data. In Data Science Landscape; Springer: Berlin/Heidelberg, Germany, 2018; pp. 99–105. [Google Scholar]
- Wien, T. Data as a Service, Data Marketplace and Data Lake–Models, Data Concerns and Engineering. Available online: https://linhsolar.github.io/ase/pdfs/truong-ase-2018-lecture4-daas_datalake_datamarket_dataconcerns.pdf (accessed on 28 March 2020).
- Smith, G.; Ofe, H.A.; Sandberg, J. Digital service innovation from open data: Exploring the value proposition of an open data marketplace. In Proceedings of the 2016 49th Hawaii International Conference on System Sciences (HICSS), Koloa, HI, USA, 5–8 January 2016; pp. 1277–1286. [Google Scholar]
- Mišura, K.; Žagar, M. Data marketplace for Internet of Things. In Proceedings of the 2016 International Conference on Smart Systems and Technologies (SST), Osijek, Croatia, 12–14 October 2016; pp. 255–260. [Google Scholar]
- Casalicchio, E.; Perciballi, V. Measuring docker performance: What a mess‼! In Proceedings of the 8th ACM/SPEC on International Conference on Performance Engineering Companion, L’Aquila, Italy, 22–26 April 2017; pp. 11–16. [Google Scholar]
- Jiménez, L.L.; Simón, M.G.; Schelén, O.; Kristiansson, J.; Synnes, K.; Åhlund, C. CoMA: Resource Monitoring of Docker Containers. In Proceedings of the 5th International Conference on Cloud Computing and Services Science, Lisbon, Portugal, 20–22 May 2015; pp. 145–154. [Google Scholar] [CrossRef]
- Soam, A.K.; Jha, A.K.; Kumar, A.; Thakur, V.K.; Hore, P. Resource Monitoring of Docker Containers. IJAERD 2016, 3. [Google Scholar] [CrossRef]
- Bagnasco, S.; Berzano, D.; Guarise, A.; Lusso, S.; Masera, M.; Vallero, S. Monitoring of IaaS and scientific applications on the Cloud using the Elasticsearch ecosystem. In Journal of physics: Conference Series; IOP Publishing: Bristol, UK, 2015; Volume 608. [Google Scholar]
- Abraham, S.M. Comparative Analysis of MongoDB Deployments in Diverse Application Areas. Int. J. Eng. Manag. Res. (IJEMR) 2016, 6, 21–24. [Google Scholar]
- Jose, B.; Abraham, S. Exploring the merits of nosql: A study based on mongodb. In Proceedings of the 2017 International Conference on Networks & Advances in Computational Technologies (NetACT), Trivandrum, Kerala, India, 20–22 July 2017; pp. 266–271. [Google Scholar]
- Aboutorabi, S.H.; Rezapour, M.; Moradi, M.; Ghadiri, N. Performance evaluation of SQL and MongoDB databases for big e-commerce data. In Proceedings of the 2015 International Symposium on Computer Science and Software Engineering (CSSE), Tabriz, Iran, 18–19 August 2015; pp. 1–7. [Google Scholar]
- Klein, J.; Gorton, I.; Ernst, N.; Donohoe, P.; Pham, K.; Matser, C. Performance evaluation of NoSQL databases: A case study. In Proceedings of the 1st Workshop on Performance Analysis of Big Data Systems, Austin, TX, USA, 1 February 2015; pp. 5–10. [Google Scholar]
- Docker-Build, Ship, and Run Any App, Anywhere. Available online: https://www.docker.com/ (accessed on 17 November 2017).
- Liu, Q.; Zheng, W.; Zhang, M.; Wang, Y.; Yu, K. Docker-based automatic deployment for nuclear fusion experimental data archive cluster. IEEE Trans. Plasma Sci. 2018, 46, 1281–1284. [Google Scholar] [CrossRef]
- Jovanov, G. Mongo + Docker Swarm (Fully Automated Cluster). In Medium; 2019; Available online: https://medium.com/@gjovanov/mongo-docker-swarm-fully-automated-cluster-9d42cddcaaf5 (accessed on 9 October 2019).
- Alam, M.; Rufino, J.; Ferreira, J.; Ahmed, S.H.; Shah, N.; Chen, Y. Orchestration of microservices for iot using docker and edge computing. IEEE Commun. Mag. 2018, 56, 118–123. [Google Scholar] [CrossRef]
- MacKenzie, C.M.; Laskey, K.; McCabe, F.; Brown, P.F.; Metz, R.; Hamilton, B.A. Reference Model for Service Oriented Architecture v1.0. In Reference Model for Service Oriented Architecture 1.0; OASIS: Burlington, MA, USA, 2006; Available online: https://docs.oasis-open.org/soa-rm/v1.0/soa-rm.html (accessed on 28 March 2020).
- Plebani, P.; Garcia-Perez, D.; Anderson, M.; Bermbach, D.; Cappiello, C.; Kat, R.I.; Marinakis, A.; Moulos, V.; Pallas, F.; Tai, S.; et al. Data and Computation Movement in Fog Environments: The DITAS Approach. In Fog Computing: Concepts, Frameworks and Technologies; Mahmood, Z., Ed.; Springer International Publishing: Cham, Switzerland, 2018; pp. 249–266. [Google Scholar]
- Plebani, P.; Garcia-Perez, D.; Anderson, M.; Bermbach, D.; Cappiello, C.; Kat, R.I.; Marinakis, A.; Moulos, V.; Pallas, F.; Pernici, B.; et al. DITAS: Unleashing the Potential of Fog Computing to Improve Data-Intensive Applications. In Advances in Service-Oriented and Cloud Computing; Springer: Cham, Switzerland, 2018; pp. 154–158. [Google Scholar]

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Format | Examples | Description |
|---|---|---|
| Key-Value | Riak, Redis, Couchbase | These databases use a key-value data format in order to create primary keys, which improve their performance when the single primary key architecture is possible. |
| Document | MongoDB, CouchDB, Terrastore | These databases provide the advantage of storing all information concerning an object in a single document, using nested documents and arrays. This improves the performance, minimizing the queries needed to retrieve all requested data and removing the need to join tables. It also provides the ability to create indexes based on any datafield in a document, not only primary keys. |
| Column family | HBase, Cassandra, Amazon DynamoDB | These systems initially resemble an SQL datastore, having columns and rows, but they provide the ability of inserting unstructured data. This is possible because instead of using regular columns, they use column families that are grouped together in order to form a traditional table. |
| Graph | Neo4J, FlockDB, InfiniteGraph | These datastores are based on the relations between each datapoint, which is called a node. These nodes and the relations between them form clusters of data in the form of graphs. The datastores perform well when the relation between the data points is more important than or at least as important as that of the actual data contained in the nodes. Their intolerance to horizontal partitioning makes them hard to use in data intensive production environments. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Psomakelis, E.; Nikolakopoulos, A.; Marinakis, A.; Psychas, A.; Moulos, V.; Varvarigou, T.; Christou, A. A Scalable and Semantic Data as a Service Marketplace for Enhancing Cloud-Based Applications. Future Internet 2020, 12, 77. https://doi.org/10.3390/fi12050077
Psomakelis E, Nikolakopoulos A, Marinakis A, Psychas A, Moulos V, Varvarigou T, Christou A. A Scalable and Semantic Data as a Service Marketplace for Enhancing Cloud-Based Applications. Future Internet. 2020; 12(5):77. https://doi.org/10.3390/fi12050077
Chicago/Turabian StylePsomakelis, Evangelos, Anastasios Nikolakopoulos, Achilleas Marinakis, Alexandros Psychas, Vrettos Moulos, Theodora Varvarigou, and Andreas Christou. 2020. "A Scalable and Semantic Data as a Service Marketplace for Enhancing Cloud-Based Applications" Future Internet 12, no. 5: 77. https://doi.org/10.3390/fi12050077
APA StylePsomakelis, E., Nikolakopoulos, A., Marinakis, A., Psychas, A., Moulos, V., Varvarigou, T., & Christou, A. (2020). A Scalable and Semantic Data as a Service Marketplace for Enhancing Cloud-Based Applications. Future Internet, 12(5), 77. https://doi.org/10.3390/fi12050077