1. Introduction
The “curse of dimensionality” is one of well-known machine learning problems, as described in [
1]. Basically, it states that, when the dimensionality increases, the volume of the search space increases so fast that the data become sparse. Nowadays, with the growth of data volumes and increasing effectiveness of neural networks, this problem has faded away from various fields, but it still stands in several high-dimensional data domains, namely medical care, social analysis, and bioinformatics [
2,
3,
4,
5]. For such domains, the number of objects is relatively small while the number of features can be up to several hundreds of thousands, thus resulting in object space sparsity and model overfitting.
This problem was solved with mathematical statistics [
6], but nowadays it is one of the main fields of machine learning, called dimensionality reduction. The problem of selecting features from existing ones is called feature selection while feature extraction builds a projection to new feature space from the old one [
7]. Unfortunately, in bioinformatics and medicine, only feature selection is applicable, as for these domains it is important to retain original features semantics for better understanding of undergoing processes [
8]. Nevertheless, both approaches can reduce the feature set and increase the quality of the resulting models.
With the growth of the computational power, the neural networks approach became really powerful in many machine learning applications. As most of the libraries designed to work with neural networks were programmed in the Python language, it became de facto the international standard for neural network research [
9,
10]. As the popularity of machine learning grew, more researchers were attracted to this field; since neural networks were a huge attraction point in the last years, most of the modern machine learning researchers are using Python as their main programming language. These factors resulted in a huge gap between Python machine learning libraries and libraries on other languages. Nearly all machine learning fields that are not closely tied with neural networks are not properly covered with programming libraries in Python. In this paper, we cover the main existing open-source Python feature selection libraries, show their advantages and disadvantages, and propose our own ITMO FS [
11]. In addition, a comparison with Arizona State University feature selection library [
12] and scikit-learn feature selection module [
13] is presented. This paper has two main purposes: first, to perform an overview of existing open-source Python feature selection libraries and compare them and, second, to present the open-source ITMO FS library and some comparisons of its performance.
The rest of this paper is organized as follows,
Section 2 reviews existing ways for feature selection algorithms categorization.
Section 3 offers a survey of existing feature selection Python libraries and their analysis.
Section 4 describes existing feature selection libraries that are available in other languages, but still can be easily adapted to Python with provided code interfaces.
Section 5 contains a description of the proposed ITMO FS library and its comparison with libraries surveyed in the previous section.
Section 6 has some code samples for better understanding of ITMO FS library architecture and compares its performance with some other libraries.
Section 7 contains the conclusion.
2. Background
To better understand how the modern feature selection library should be designed and what should be included in it, we have to present available types of feature selection algorithms. In this section all main categories of existing feature selection algorithms are presented.
Generally speaking, the feature selection problem can be formalized as follows [
14]: For a given dataset
D with
M objects described with feature set
F,
we need to find some optimal subset of features
in terms of some optimization of
C criteria.
2.1. Traditional Feature Selection Algorithms Categorization
Traditionally, feature selection methods were divided into three main groups: wrapper, filter, and embedded methods [
15]. Wrappers try to build optimal feature subset by the evaluation of the quality measure
for the predefined machine learning algorithm:
where
C is a machine learning model and
Q is the quality measure for the model. For this, a wrapper algorithm works iteratively; on each step, it takes some feature subset and passes it to the model and then, depending on the model quality, it decides to pick another subset or stop the process. The picking procedure and the optimization stopping criteria basically define the wrapper algorithm. The main problem of this approach is that it is too slow for high-dimensional datasets as the number of possible subsets is equal to
and on each step we need to build a model to evaluate the subset quality.
Embedded methods usually use some intrinsic properties of the classifier to get features subset. Feature selection with random forest [
16] is an illustrative example of such approach, where the out of bag error for each feature on each tree is aggregated into resulting feature scores and features that most often result in the elimination of bad classification results. Some of these methods can work even with really high-dimensional data, but their main restriction is the model itself. Basically, features that were selected with one model can result in bad performance if they are used for another model.
Filters are the third traditional group of feature selection algorithms. Instead of evaluating the feature sets with some models, they take into consideration only intrinsic properties of the features themselves. If a filter does not consider any dependencies between features themselves, thus assuming that they are independent, it is called univariate, otherwise it is multivariate. For multivariate filters, the problem is stated as follows:
where
is the feature subset quality measure. On the other hand, for the univariate filters, the feature selection problem is stated without optimization. Instead, every feature is evaluated with feature quality measure
(which for this case should be defined only on
, but not for the whole set of features subsets) and then some cutting rule
is applied.
2.2. Hybrid and Ensembling Feature Selection Algorithms
Nowadays, most scientists distinguish separate groups of feature selection algorithms: hybrids and ensembles. Basically, these types of algorithms implement consecutive and parallel approaches to combine feature selection algorithms.
Hybrid feature selection algorithms try to combine traditional approaches consecutively. This is a powerful compromise between different traditional approaches. For example, to select features from high-dimensional dataset, a filter as a first step can be applied to drastically reduce feature set and after that a wrapper can be applied to the output feature set to get maximum quality from the extracted features.
Alternatively, ensemble feature selection algorithms combine several feature selection algorithms in parallel to improve their quality or even get better stability of selected feature subsets. Ensemble feature selection algorithms work either with separately selected features subsets or with the models, built on them [
17].
2.3. Feature Selection Algorithms Categorization by Input Data
Some researchers categorize feature selection algorithms depending on the input data types. Basically, all data can be divided into streaming and static data. Streaming data can be divided into two big groups: data stream, when new objects are added consecutively, and feature stream, when new features are added to the dataset.
For static data, which are more conventional for traditional feature selection algorithms, some researchers [
18] categorize them into: similarity based, information theory based, sparse learning based, statistical based methods, and others. Similarity based methods build an affinity matrix to get feature scores. As they are kind of univariate filters in traditional classification, they do not take into consideration any model and do not handle feature redundancy. Information theoretical algorithms work the same way as similarity based ones but also utilize the concept of “feature redundancy”. Sparse learning based feature selection algorithms embed feature selection into a machine learning algorithms, working with weights of features. Statistical based feature selection models use statistical measures for features filtering, thus working exactly as most filtering methods in traditional interpretation. This categorization does not include wrappers, thus they are usually categorized as “other”.
5. ITMO FS library Architecture and Comparison
The main issues observed in the libraries presented in
Section 3 and
Section 4 libraries are as follows:
does not support customizable cutting rules for filters (nearly all of them);
does not support ensemble or hybrid feature selection algorithms (which are actually the most commonly used in recent years, nearly all of them);
has high requirements and long delays for new algorithms to be added (scikit-learn);
uses input data paradigm as basis for architecture, as described in
Section 2.3, which is not usually considered (ASU); and
programmed in other languages so has to be either adopted or wrapped with additional computational costs.
Thus, the ITMO FS library was decided to be developed.
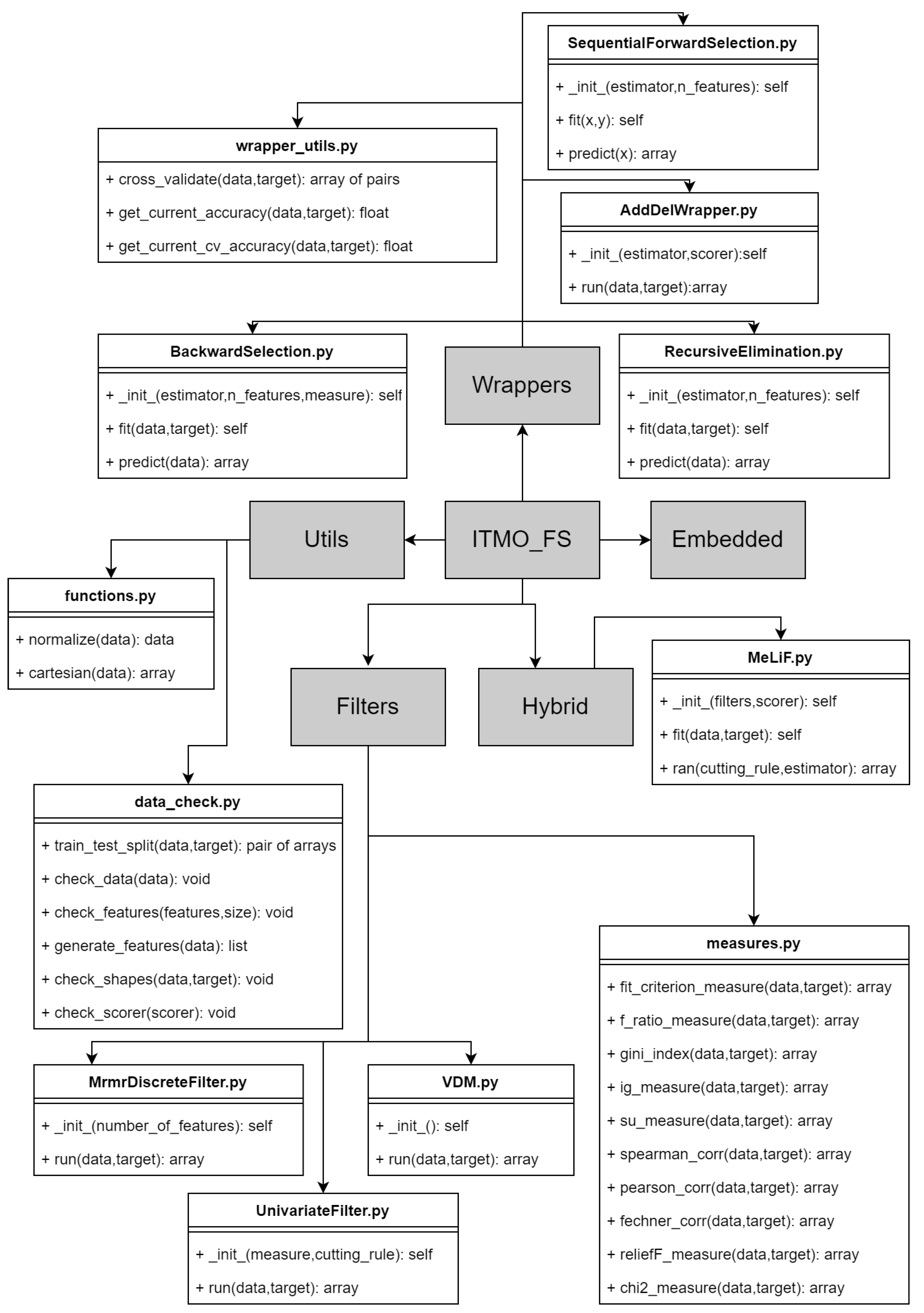
In
Figure 1, the ITMO FS library architecture is shown. It contains filters, wrappers, hybrid, and embedded parts, each of which represents a set of methods from traditional classification. Unfortunately, ensembles are not currently presented in the library scheme as they are still under development. This categorization was inspired by traditional feature selection categorization. All filters are generally described as shown in
Section 2.1, thus they need to have some feature quality measure and a cutting rule. The wrapper module contains several wrapper algorithms. Each of them takes an estimator as input parameter and improves the feature set regarding model performance. The embedded part contains MOSS, MOSNS, and RFE algorithms, each of which selects the feature set according to its importance to the model. The hybrid module for now contains only MeLiF algorithm that was developed by ITMO University [
14].
The only prerequisite for library is numpy package; the library is developed with Python 3 language. The current version of the library contents is shown below and also it could be found on the architecture scheme in
Figure 1:
Filters
- -
UnivariateFilter—class for constructing custom filter (UnivariateFilter.py);
- -
MRMR—class for specific filter (MRMRFilter.py);
- -
VDM—class for specific filter (VDM.py);
Hybrid
- -
MeLiF—class for basic MeLiF (MeLiF.py);
Wrappers
- -
AddDel—class for ADD-DEL wrapper (AddDelWrapper.py);
- -
Backward elimination—class for backward elimination wrapper (BackwardSelection.py);
- -
Sequential forward selection—class for sequential forward selection (SequentialForwardSelection.py);
Embedded
- -
MOSNS—Minimizing Overlapping Selection under No-Sampling (MOSNS.py);
- -
MOSS—Minimizing Overlapping Selection under SMOTE (MOSS.py);
- -
Reccursive Feature Elemenation—class for RFE method (RecursiveElimination.py).
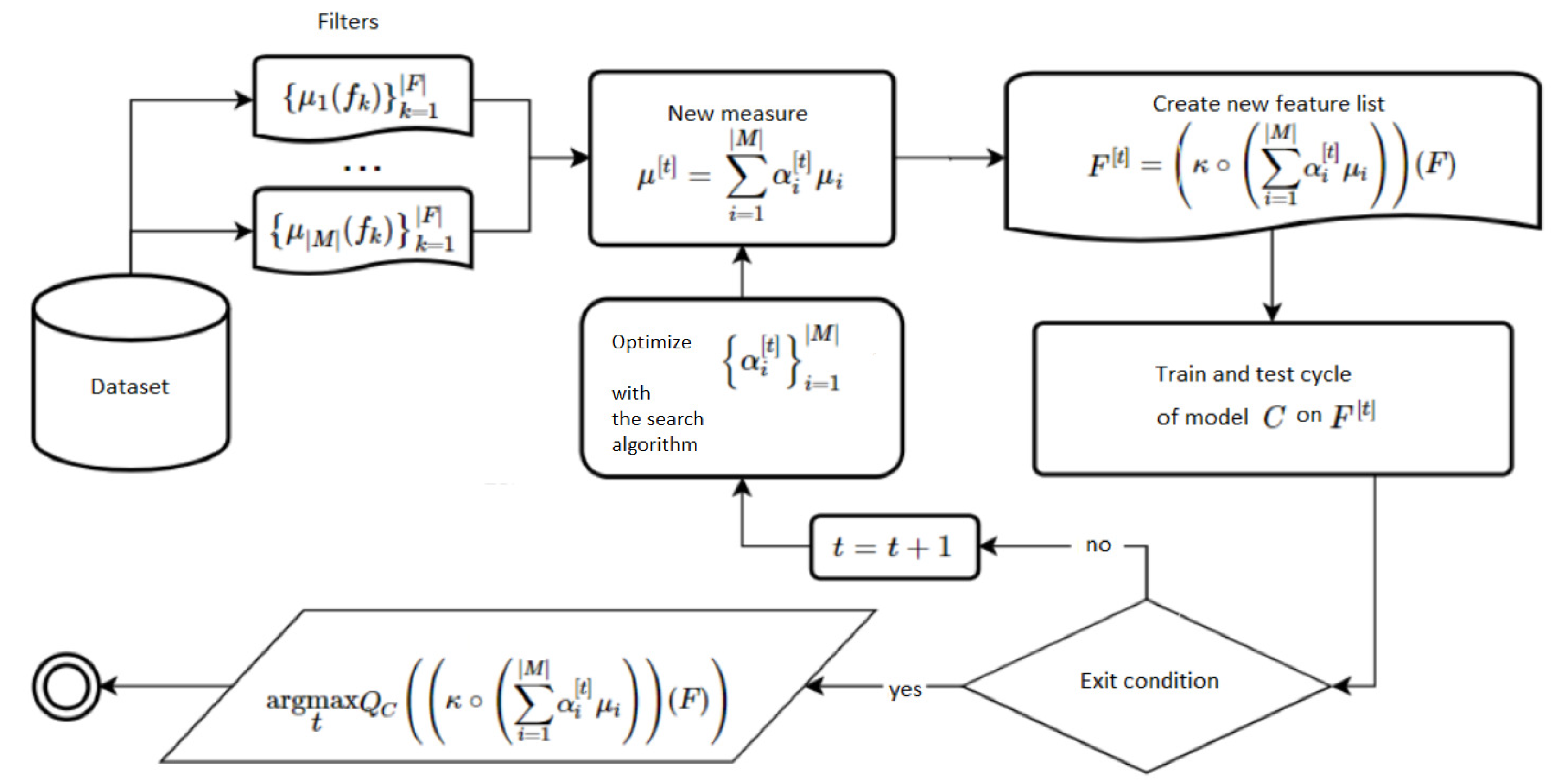
Spearman correlation, Pearson correlation, information gain, Gini index, F-ratio, fit criterion, and symmetric uncertainty are custom measures that are stored with cutting rules in the Filter file. In the future, when we add more basic measures to the library and some more exotic cutting rules, they could be easily added to the library through this file. MeLiF is one of the hybrid methods and it aggregates the result of filter measures and wraps an estimator, greedy optimizing their ensemble weights. The pipeline is displayed in
Figure 2. This algorithm builds a linear combination of the input filters quality measures with some
coefficients and then tunes them in the optimization cycle of the model
C with some quality measure
(for example,
score). In this case, a single cutting rule
is applied for the whole combination.
As shown in
Table 1, the Arizona State University feature selection library has the most implemented algorithms in comparison with others, but this library was updated last time about two years ago. Moreover, it does not have some basic feature selection algorithms such as information gain filter, AddDel, RFE, ROC filter, forward and backward selection, and some others. Scikit-learn feature selection module seems to have some rarely used methods and the general volume of presented algorithms is rather small: it has only six of them. Feature extraction and selection book contains some examples of exotic methods; nevertheless, there are many different feature extraction methods there. Thus, although it is quite useful for dimensionality reduction in general, it is not usable in practice for feature selection. On the right of the double line in
Table 1, Python-compatible feature selection libraries from other languages are shown. None of them has good enough coverage of existing feature selection algorithms. Moreover, as they were not developed in Python from the beginning, their usage requires some additional actions and their computational time is somewhat slower. Development of ITMO Feature Selection library started in the spring of 2019, and at this stage the library has already implemented almost all basic architectural elements; it is scikit-learn compatible and user-friendly. It contains some basic algorithms used in practice as well as some less common methods.
6. ITMO FS Library Usage Examples and Performance Tests
For all code samples, imports from the Listing 2 are required.
| Listing 2. Imports for this section experimental setup. |
 |
During testing, we used the following software versions: sklearn 0.21.3, MLFeatureSelection 0.0.9.5.1, skrebate 0.6, python 3.6.9, numpy 1.17.3, scipy 1.3.1, Boruta 0.3, and ReliefF 0.1.2. In the test_filter function, an example of the filter class with Spearman correlation and “Best by value” cutting rule that equals 0.99 is shown. This notation means that all features which have score higher than 0.99 will be selected. A possibility to customize the cutting rule such as in this example is only supported by the ITMO FS library and is shown in Listing 3 For this example, iris [
30] dataset was chosen.
| Listing 3. Filter usage on the iris dataset with the custom cutting rule. |
 |
In Listing 4, an example of UnivariateFilter class with Pearson correlation and “Best by value” cutting rule that equals 0.0 is shown. A possibility to use lambda functions for cutting rules is only supported by the ITMO FS library. This example uses orlraws10P dataset [
31].
| Listing 4. Filter usage on the ORL10 dataset with the custom lambda cutting rule. |
 |
In Listing 5, the UnivariateFilter class with Pearson correlation and “K best” cutting rule with six best features selected is shown on Line 5. It is compared with scikit-learn SelectKBest usage on Line 9. The test dataset here is Basehock. As can be seen from this example, ITMO FS template is more user friendly and gives an opportunity to use some other cutting rules than “K best”. The testing setup for the Gini index is the same but with the usage of gini_index function instead of pearson_corr.
| Listing 5. Comparison of the K-best cutting rule and Pearson correlation usage at ITMO FS and scikit libraries. |
 |
In Listing 6, the AddDel (Line 4) wrapper method with basic logistic regression (Line 3) as estimator is shown. For quality measure function, score was chosen. Test dataset here is Basehock.
| Listing 6. Example of Add-del wrapper usage. |
 |
In Listing 7, the backward selection wrapper (Line 4) method with logistic regression (Line 3) as estimator is shown. Test dataset here is Basehock. Although the BackwardSelection function is also a wrapper, it has an additional parameter “100” that defines maximum number of features to be removed. In this case, it is a “stopping criteria” in the standard wrapper notation.
| Listing 7. Example of Backward selection wrapper usage. |
 |
Listing 8 shows an example of the MeLiF class with Support vector classifier (Line 7) as estimator. Chosen filters are Gini index (Line 4), fratio (Line 5), and information gain (Line 6). score was chosen as quality measure for MeLiF (Line 7). All input parameters of the ensemble including the cutting rules can be tuned.
| Listing 8. Example of ensemble algorithm MeLiF usage. |
 |
Table 2 shows time comparison between ITMO Feature Selection library and scikit-learn feature selection module at selecting k best features by Gini index and Pearson correlation. Basehock dataset [
32] has 1993 samples and 4862 features, COIL20 dataset [
33] has 1440 samples and 1024 features, and orlraws10P has 100 samples and 10,304 features. The comparison was performed on Intel i7-6700HQ, 4 cores, 2.6 GHz,16 GB DDR4-2400, HDD Toshiba MQ01ABD100, 5400 rpm.
As shown in
Table 2, the ITMO FS library has approximately the same computational time for Pearson correlation coefficient and Gini index filters as in the scikit-learn feature selection module. As these filters are not implemented in scikit-learn, we have put our customized measures in it for this reason.
Listing 9 shows code usage comparison between ASU (Arizona State University) Feature Selection library and ITMO University library. This example was used to estimate execution time of Gini index and F-score index for both libraries. The result of this comparison can be found in
Table 3.
| Listing 9. Time comparison between ASU feature selection and ITMO FS. |
 |
As shown in
Table 3, the ITMO FS library has a slightly bigger computational time for F-score index and far better time for Gini index than the Arizona State University feature selection library. As ASU library does not provide support for cutting rules in the traditional way, we ran intrinsic measures of ITMO FS algorithms separately from cutting rules for proper comparison.
7. Conclusions
In the last few years, Python programming language has become extremely popular in most machine learning applications. Unfortunately, most of the existing Python machine learning tools are neural networks oriented, which results in an increasing gap between existing and implemented methods for most classical machine learning fields.
This paper contains an overview of existing Python feature selection libraries and libraries on other languages that are easily compatible with Python.
This paper pProvides a description of newly created feature selection library ITMO FS. We provided a complete description of the library including program architecture design.
This paper shows that ITMO FS library provides better view to the traditional feature selection algorithms, supports hybrids and ensembles, and in most cases is more user-friendly than other libraries. Moreover, some of the provided test showed that ITMO FS library works more quickly than the biggest Python feature selection ASU library on some algorithms.
This paper provides code samples for better understanding of library usage.
In the future, we plan to implement all algorithms mentioned in
Table 1, more modern algorithms of feature selection as well as more classical ones, and then move to implementation of different ensembling and hybrid algorithms. In this perspective, we will also add meta-learning approaches for easier selection of feature selection algorithms and their tuning.














{kind=link}
{kind=link}