1. Introduction
The increase in a bit rate of multimedia traffic makes the TCP/IP architecture inefficient in delivering time-sensitive multimedia traffic. We need the content-based network instead of a host-based network [
1]. Named Data Network (NDN) is a content-centric network that utilizes network resources to store data on routers [
2]. The whole network resources need to support communication maximally. NDN allows consumers to find the data requested at the nearest router. This mechanism reduces the overall network load and potential delay. Furthermore, the placement of content at a certain node that is closer to the consumer causes communication to be more efficient, while router nodes independently place content in its content store without coordinating with others on the network. This mechanism also makes NDN strongly support consumer mobility with content requests based on the name, and not on a specific host address [
2,
3]. The network responds to a consumer request in the aggregate, and it makes communication more efficient.
Nowadays, communication occurs with some unique characteristics [
4], such as consumers repeatedly asking for the same content from the server, the character is similar to the local environment, and dynamic changes in demand over time. The IP network has become inefficient because the consumer is only served by the server, despite the distance. This system is called host-based communication. In the IP network, the consumers request content to a specific address. Therefore, a shift to the host-based paradigm into the content-based, namely Named Data Network (NDN), is needed because what is needed by the consumer is content, not the server. NDN makes the process of sending data more efficient than IP networks because, it allows consumers to transfer interest packets to the system, and not to a specific IP address [
5,
6]. NDN routers can store data/content in its content store, and when an interest packet containing the consumer’s request enters an NDN router, it checks whether the requested content exists on its content store. When the router has the requested data, it immediately sends a copy to the consumer, and when it does not, it checks the Pending Interest Table (PIT). When the PIT has no information on the requested data, the router adds this request information and the information of the sending side. The request is therefore forwarded to the next router using the information in the Forwarding Information Base (FIB) until it identifies the desired content.
One of the essential components of the NDN router with a limited resource is the content store. Therefore, a caching mechanism capable of optimizing the content stores is needed by considering the difference in traffic character on the network. The size of the content store [
7] and the cache policy [
8] affect the system performance. Several studies have been conducted on energy consumption [
9,
10].
Yovita et al. explained that research on the caching mechanism in NDN that distinguishes content treatment for different services is vital [
11]. Kim et al. researched the differentiation of service classes on NDN. These studies discussed differentiating service classes on IP, such as DiffServ, which is adjusted and used in NDN [
12]. In this scheme, content groups have been distinguished with differing interest packet’s marking rate depending on the class, without special treatment on the cache. Furthermore, differentiation of package treatment is carried out on its forwarding activities. Wu et al. [
13] stated that the difference in the treatment of data is carried out by statically and manually distinguishing its lifetime for each class.
Zhang et al. carried out a research that formulated caching placement into optimizing problem in accordance with the imbalance of caching gain caused by different content popularity [
14]. Zhang et al. further proposed a scheme regarding interdomain traffic saving and weighted hop saving. Carofiglio et al. [
15] conducted research on the content store settings for different applications. The data is saved based on Time to Live (TTL) for each application type, with several methods analyzed by setting a static memory allocation, determining the priority application, and calculating the amount of allocated memory based on the application’s weight. In addition, the other class can utilize a proportion, when the capacity is not full.
The other research related to the traffic characteristics were explained by Cho et al. [
16,
17]. They stated that there are variations in requirements and traffic patterns on the network. The 2020 Mobile Internet Phenomena Report shows that approximately 65% of the worldwide mobile downstream traffic is video related-content, and 12.7% is social networking traffic [
18]. Therefore, the process of selecting traffic that needs to be cached is still an open issue. The development of caching algorithms until 2019 focused on popularity and probabilistic-based caching [
19].
Presently, there are no caching techniques that pay attention to the popularity and exploit the characteristics of content class to maximize network cache hit ratio. NDN routers require the caching method to autonomously and independently determine where the content is to be cached and also the portion. The role is potent in influencing cache hits and hop lengths, which affect network delay and load. Therefore a technique capable of differentiating and optimizing the treatment based on the content classes is needed. This technique is expected to consider the popularity of the content in determining the cache proportion at the router’s content store, in order to provide better performance in NDN.
This research aims to develop a new caching algorithm, named Cache Based on Popularity and Class (CAPIC), that is capable of providing answers to the problems previously described and improve the overall NDN network performance. The detailed mechanism of the CAPIC algorithm is explained in the next section. Two different mechanisms were applied to the CAPIC algorithm, namely Static and Dynamic. The purpose of Static-CAPIC is to enhance the total network cache hit ratio using the simple technique [
20]. We explain Static-CAPIC mathematically and analyze its performance. Then we define the improvement to Dynamic-CAPIC to accommodate the demand more flexibly. The Static-CAPIC and Dynamic-CAPIC are similar at the global mechanism, but they are different in cache proportion determination. Static-CAPIC has the static proportion for cache, while Dynamic-CAPIC specifies the cache proportions dynamically and in accordance with the Dynamic-CAPIC proportion formula. The proportion can change every time according to the actual consumer request rate.
This research is written in the following order.
Section 2 discusses the general scheme of Cache Based on Popularity and Class (CAPIC).
Section 3 explains the Static-CAPIC, including mathematical analysis for the partitioned content store.
Section 4 describes Dynamic-CAPIC, a modification of Static-CAPIC with a dynamic cache proportion computation mechanism for each content service class.
Section 5 simulates the model and test results, while
Section 6 concludes the research.
Section 7 is future research.
2. Basic of Cache Based on Popularity and Class
There are two types of packages in NDN, namely interest packet and data packet. The interest packet contains a request for content (data) and consumers send it to the network. The data packet includes contents that are requested by consumers. The interest packet is sent by the consumer, while the producer or the router sends the data packet. The terms ‘interest packet’ and ‘data packet’ are used often in this paper. The name ‘data’ means ‘content’ and can be interchangeable. In NDN, the router or producer node sends the data packet to consumers only when consumers first send the interest packet to inform what content they need. This process is efficient and fast when the data location is close to them because it only involves less node or router in the network. There are lots of content in the network, therefore, the caching mechanism is needed to decide where the node is to cache the copy of data and in the amount saved on the router’s content store. It is important to keep the data close as much to the consumer and provide the optimal network performance.
2.1. Background and Related Research
Caching strategies can be grouped into cache placement, content selection, and policy [
4]. Cache placement is a mechanism used to decide the cache location of the data. Cache content selection determines the content to be cached or deleted from the content store. Cache policy regulates the cooperation mechanism between router nodes, coordination between nodes, etc.
One of the cache placement techniques is Leave Copy Down (LCD). This technique give an additional bit, called ‘flag’, on the data. When an interest packet enters the router, it changes the flag bit in the packet to ‘1’. The downstream router that receives the data stores a copy in the content store [
21]. LCD technique places data closer to consumers for any popular content. Every time there is a consumer request, the data are being copied to the one-hop router closer to the consumer.
A caching scheme similar to LCD is used on WAVE algorithm [
16], which is a data file that is divided into several smaller packages called chunks. Interest packages come from users and contain requests for content. When a consumer sends an interest packet, the content chunk ‘A’ is sent from the producer to the one-hop downstream router to be stored, before it is sent to the consumer. Furthermore, when the next consumer sends an interest packet to request the same content, the next downstream router saves the chunk ‘A’ before sending it to the consumer. Every new request for the same content shifts the chunk ‘A’ that needs to be kept at the router one hop closer to the consumer.
The idea of the LCD and WAVE mechanism is modified and applied to our new cache algorithm, which is Cache Based on the Popularity and Class (CAPIC) algorithm as the cache placement method. In the CAPIC algorithm, data are cached one hop closer to the consumer for each interest packet sent by the consumer. On the router, the cache policy is enforced to run on differentiated cache proportion of each content class. When the content store is full, the cache replacement technique is used to select the content to be removed. This mechanism draws the content closer to the consumer every time it is requested.
2.2. Caching Strategy of CAPIC
There are several routers involved in communication network, with its members optimally utilized to improve network performance. To accommodate this strategy, a Cache Based on Popularity and Class (CAPIC) scheme for Named Data Network (NDN) is proposed. This scheme is accommodated in two things, namely the popularity of the content and the class of content services. This means, there are two steps in the CAPIC mechanism. The first step aims to guarantee the content placement based on priority, while the second step guarantees the consideration of content class in this system. The popularity of the content determines the router the content will be cached in, while the content class determines the proportion of its cache storage. The detailed mechanism of the CAPIC algorithm is carried out in the following two steps:
In the first step, the content popularity determines the cache location (cache placement). Every time consumers request content, these data are sent, and a copy is stored in the one-hop downstream router that is closer to the consumer. The more popular content, the closer it is cached to the consumer. The mechanism implemented in CAPIC continues to the second step.
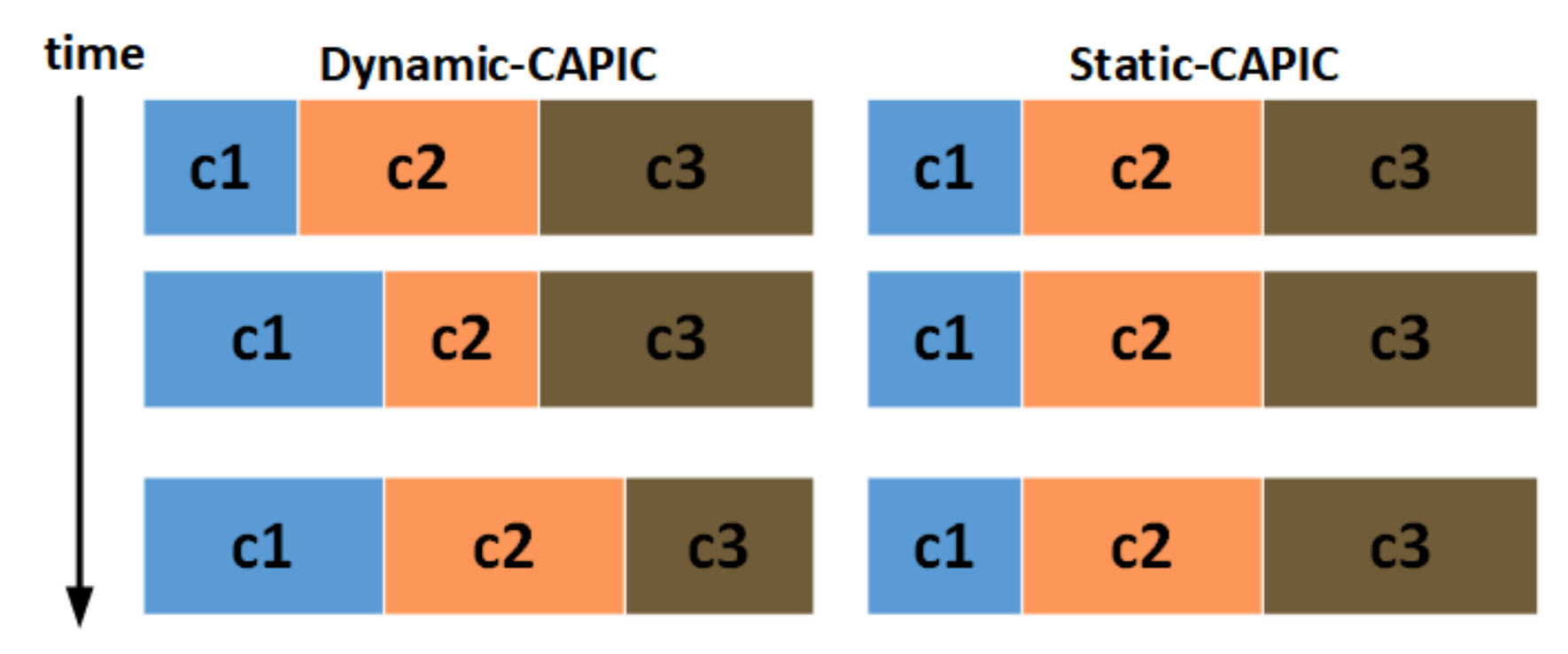
In the second step, the proportion of cache storage (cache policy) is determined on the router based on its content class. However, only a certain proportion of the router’s content store is used for store certain content class data. When the section’s capacity is full, data are deleted using the cache replacement technique. For the Static-CAPIC, the content store’s size of each class is pre-determined, based on request pattern observation over a certain period. The changing proportion of Static-CAPIC is still carried out manually. Meanwhile, in the Dynamic-CAPIC, the cache proportion is determined dynamically following the new proposed formula of Dynamic-CAPIC, and it can change in real-time based on the consumer request pattern.
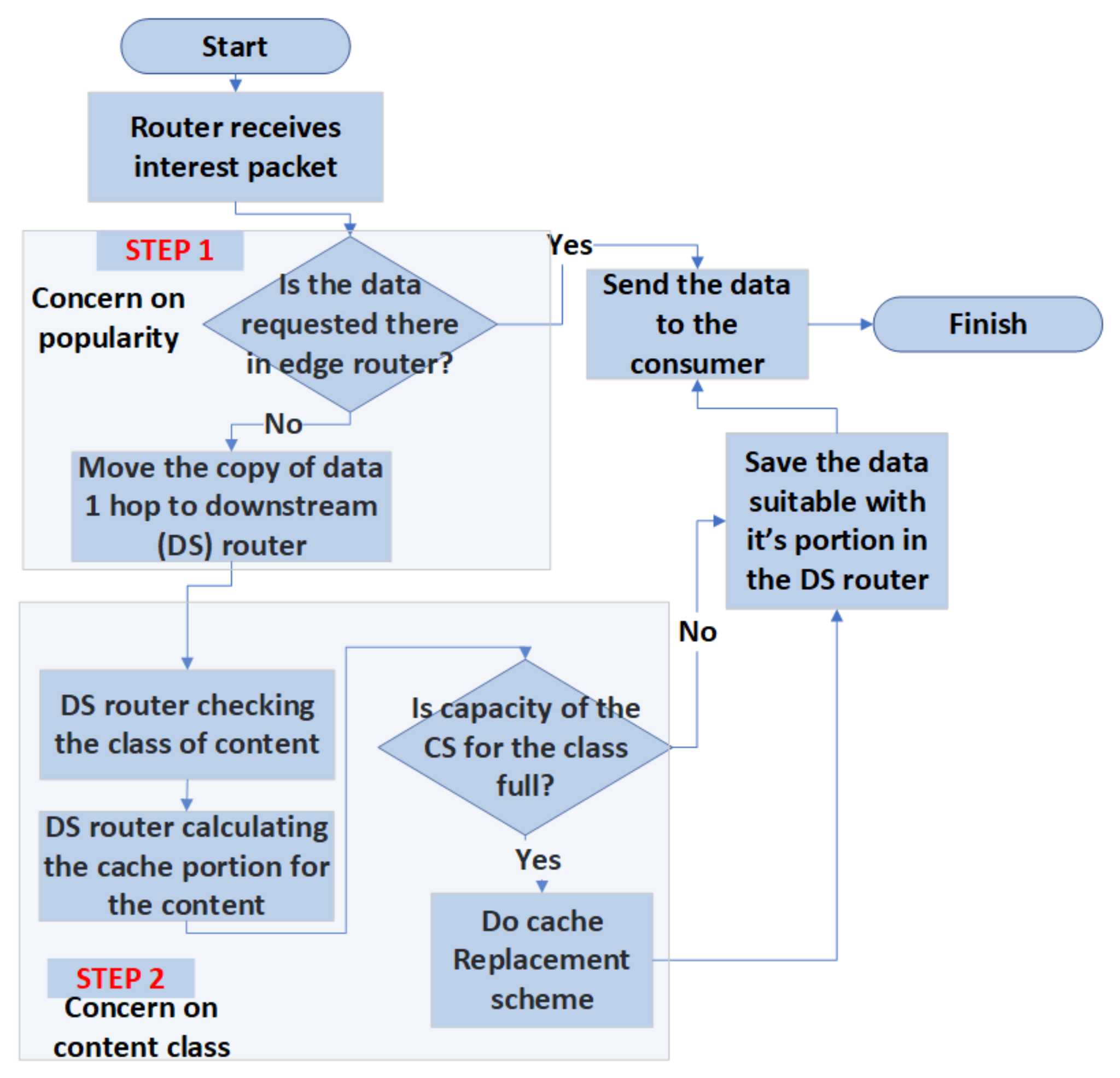
The CAPIC mechanism flowchart is shown in
Figure 1. After the NDN routing protocol is established, consumers send the interest packet to request a data to the network. When the interest packet enters the NDN router, its content is checked to determine possible initial existence. Assuming the router already has the data requested by the consumer, a copy is sent to the closest router with a copy sent to the consumer. This procedure is the first step of the CAPIC algorithm that is conducted based on the content popularity and its ability to move the data one hop closer for every request until it reaches the edge router. The second step is based on the class of content. Therefore, when the router decides to save the copy of data, it needs first to calculate the amount of data a specific content class can save in its content store. This is because content that belongs to a particular class is not being stored in the storage that is intended for other classes. This second step is conducted with dependency on the type of CAPIC, that is Static or Dynamic. For the Static-CAPIC and Dynamic-CAPIC, the proportions are followed by the pre-determined size and Dynamic-CAPIC formula, respectively. This step is carried out every time the router needs to save the data. When the content store is full, the content replacement scheme is performed. In this research, the LFU mechanism is used to carry out this activity [
21] because of its strength and effectiveness with request pattern following the Zipf–Mandelbrot distribution [
3].
2.3. System Model
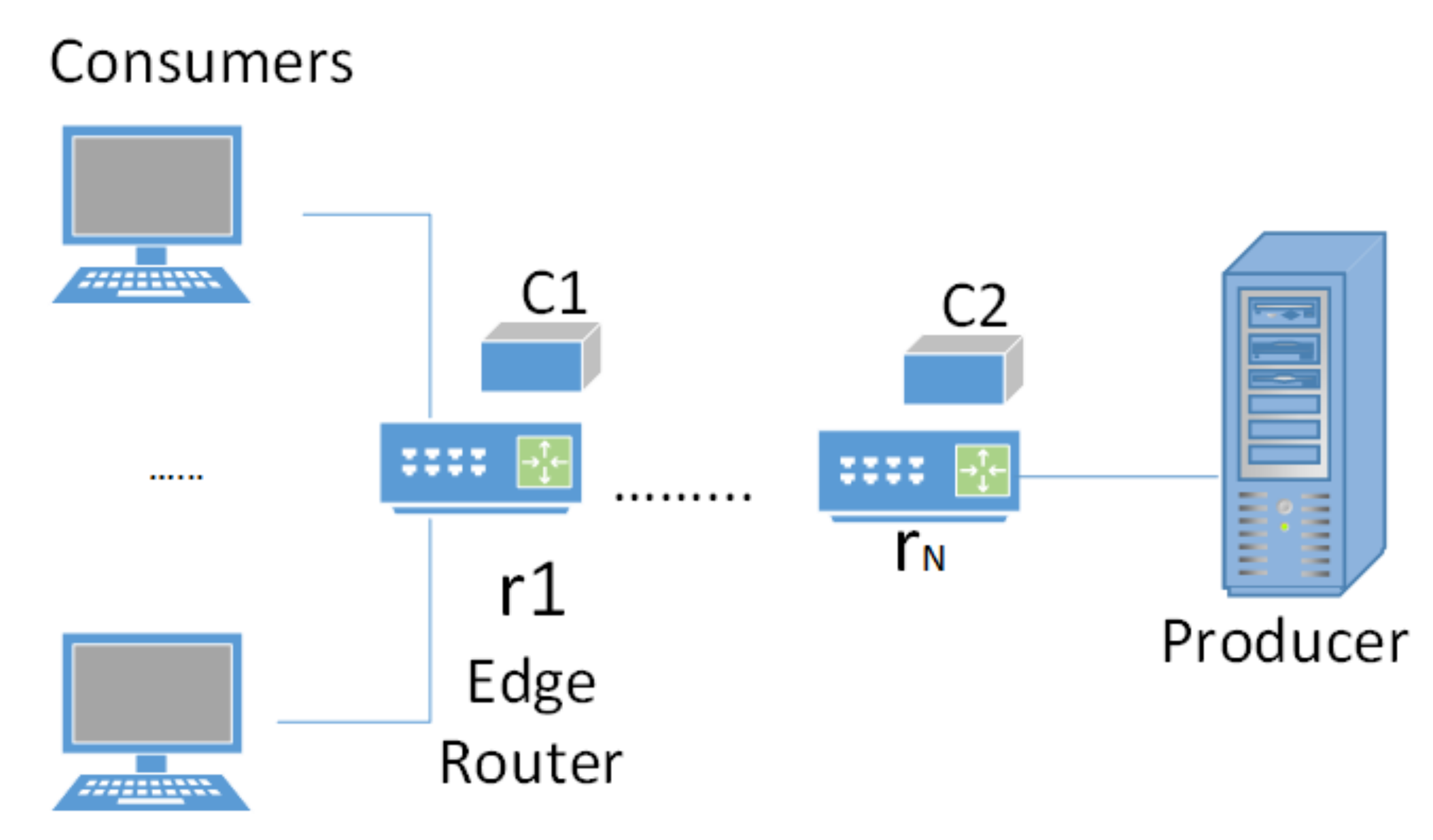
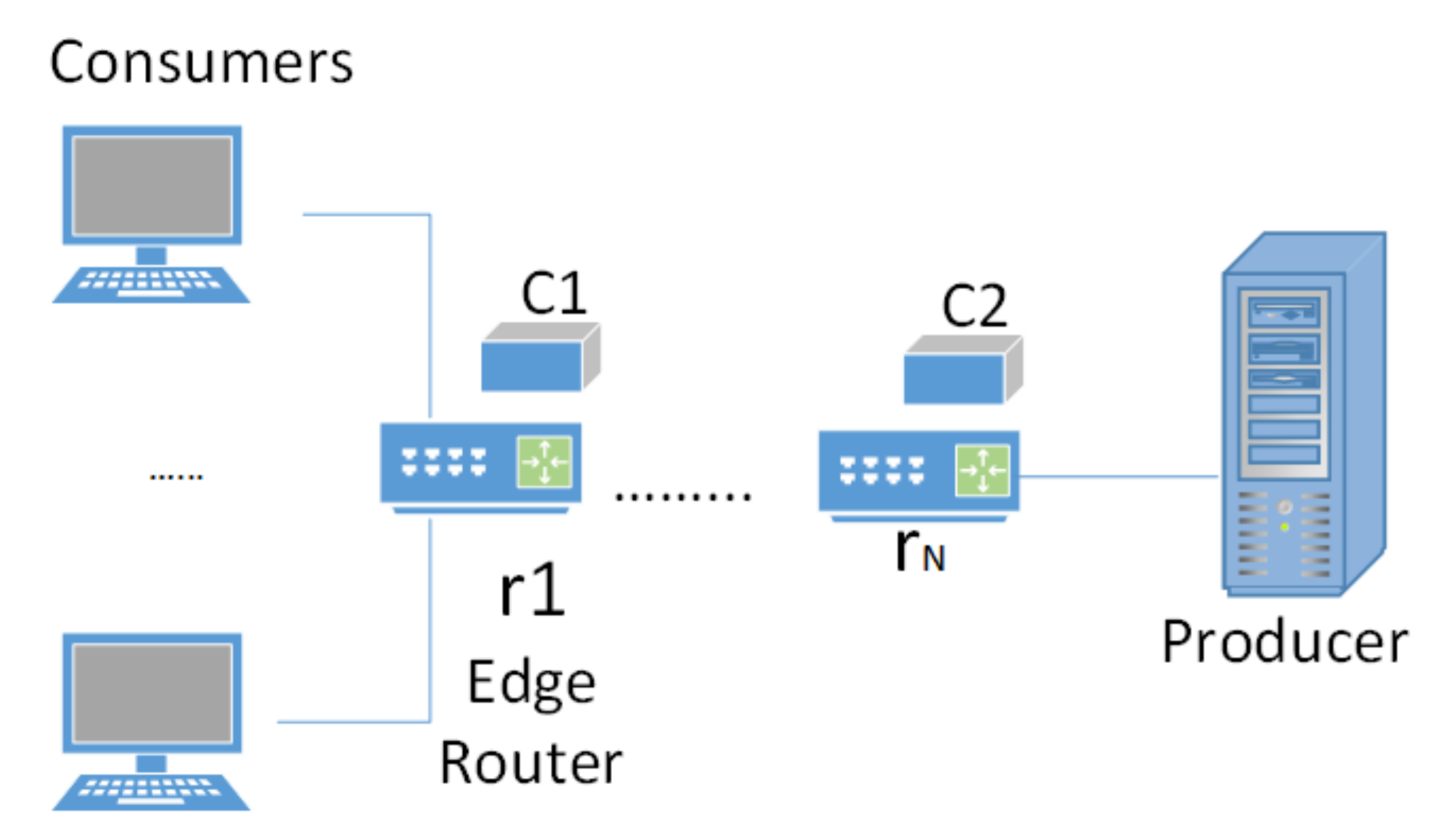
In accordance with
Figure 2, the network model is made with N router members. The set member is routers
, where
, …,
N. Router
, also known as an edge router, is the closest router to the consumer, while router
is the closest router to the producer. Parameter
is specified as the cache size for class
c, on the router
.
The consumer demand is modeled according to the results of several previous studies. Fricker et al. provide measurement results of consumer’s request to the web traffic services, User Generated Content (UGC), and video content [
22]. All requests can be modeled following the Zipf-like distribution with a similar exponent factor value, which is approximately 0.8. RFC7945 used to determine the variation of the Zipf–Mandelbrots distribution. Zipf–Mandelbrot provides a better model for the environment where the node can store the requested content locally [
23]. Studies on the characteristics of traffic also explain that the web content population is the largest, followed by User Generated Content (UGC) and video on demand (VoD) content [
22]. One other study of the demand model was carried out by Che et al. [
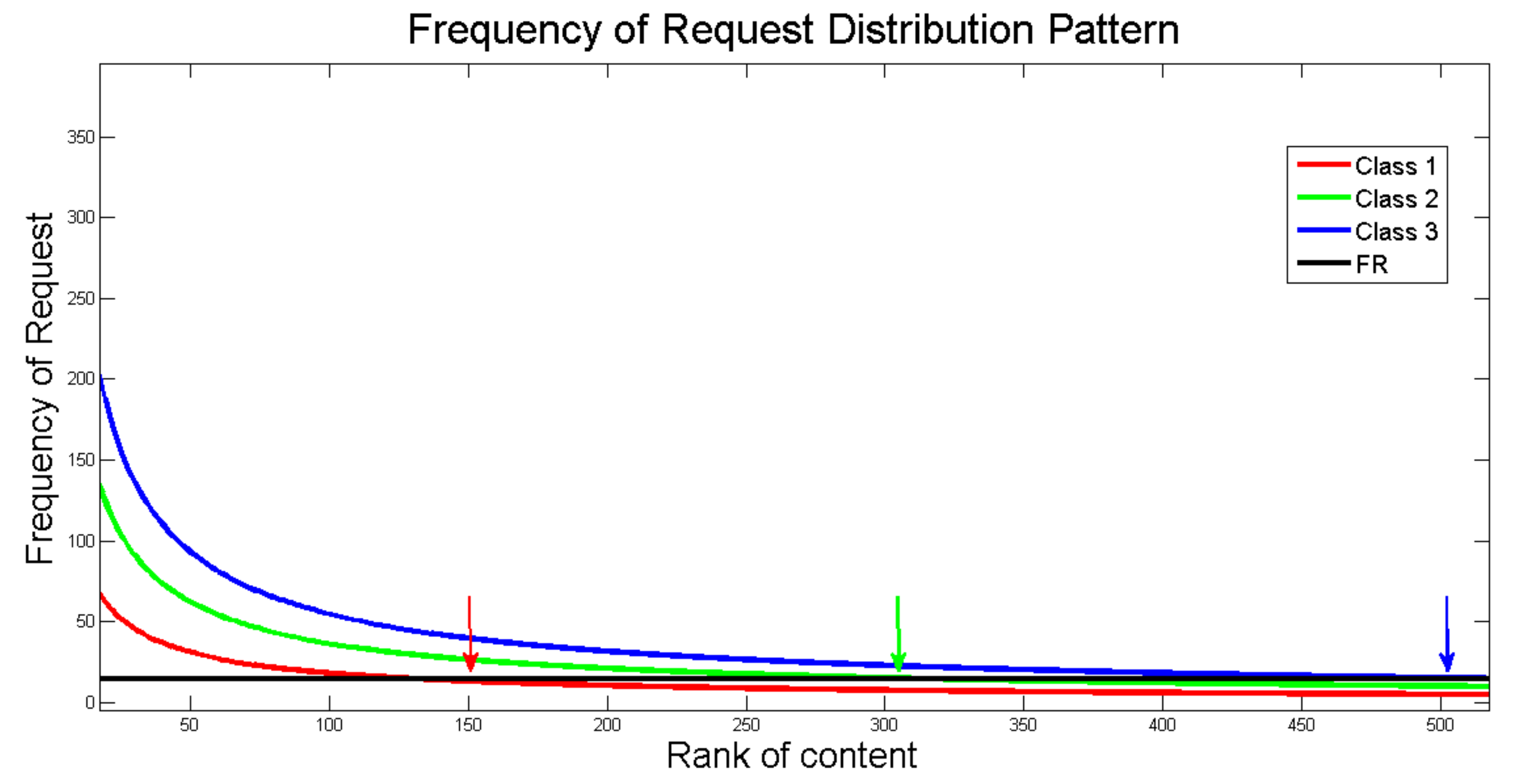
24] on modeling a document request based on the Poisson distribution with an average value of the request at a certain time. The demand model is as shown in
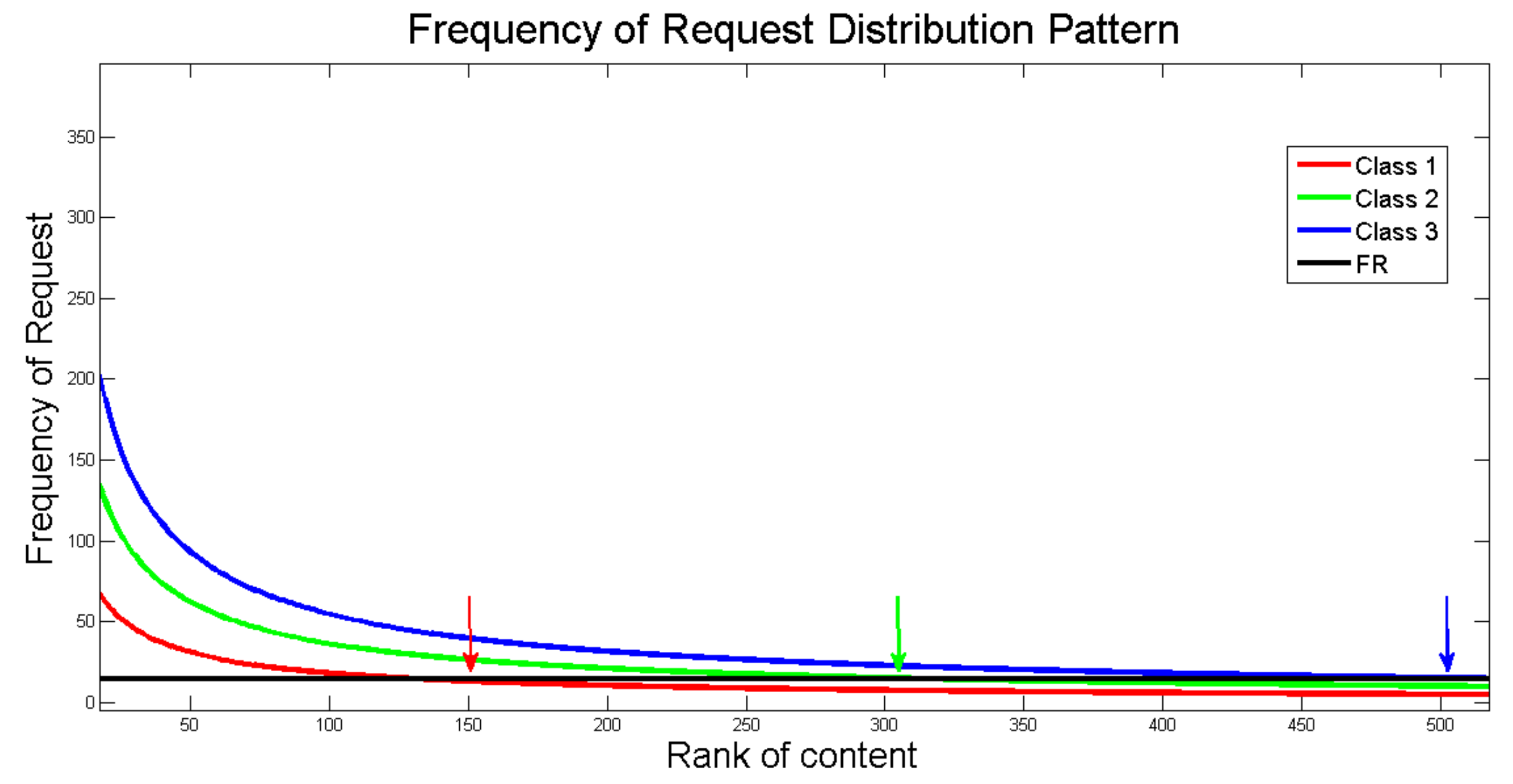
Figure 3, where the average number of requests for a content service class follows the Poisson distribution with the request rate
for class
k, which is follows the Zipf–Mandelbrot distribution with exponent factor
for class
k.
Contents on the network are divided into several classes according to their characteristics [
17]. The content class classification is based on delay and jitter requirements, content usage duration, and the request rate pattern at a certain interval for each class. The first class requires low delay and low jitter with the contents repeatedly requested by many users in years, and the request rate is medium relative to other classes. The second class is User Generated Content (UGC), with a the medium requirement delay and less jitter. UGC comprises of any content that has been created and published by unpaid contributors, such as blogs, social media content, etc. It has a medium content use duration, and in most situations, it is repeatedly request for a few weeks. Furthermore, it has a high request rate relative to other content classes. The third content class is a web application, which has the same requirement of delay and jitter as the second class, and a higher usage period than the first and second class. The first class has the highest priority in terms of the delay and jitter requirements, followed by the second and third classes.
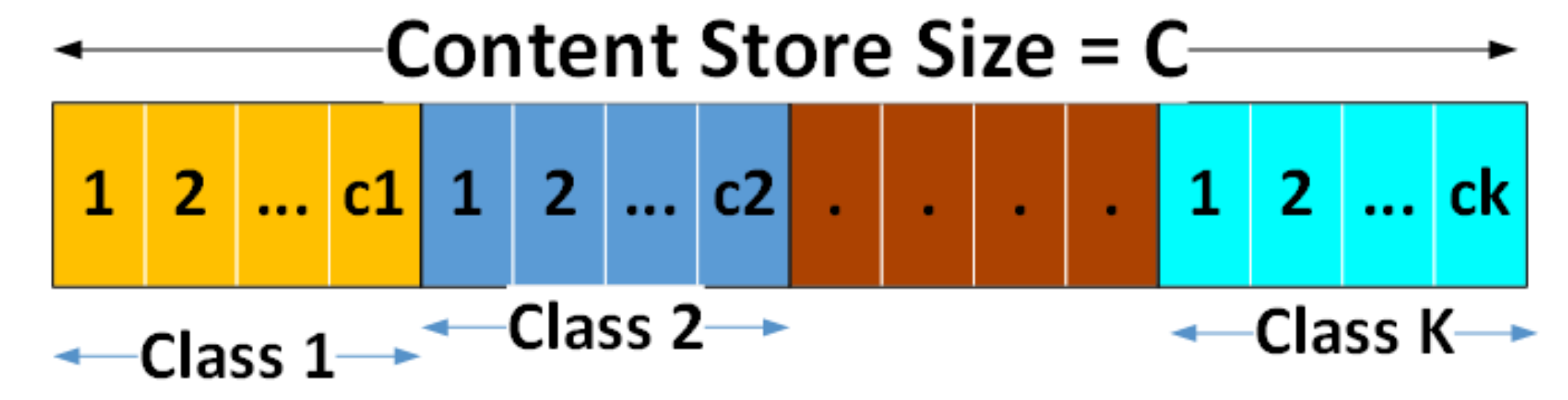
Table 1 shows that there are four content service classes with three service classes that need to be cached, while one does not require cache system. The Cache Based on Popularity and Class (CAPIC) algorithm pays attention to content classification procedure to determines the amount of content thatcan be stored on the content store.
In this research, the number of requests for a content service class follows the Poisson distribution. The Zipf–Mandelbrot distribution, which contains a flattened factor, is used to model requests for data due to content popularity [
24,
25,
26]. Content on the top rankings has a greater probability of being requested by consumers compared to lower rankings. The probability of consumers accessing content
i is expressed by (
1):
where:
= probability request of content i,
N = number of files or content,
q = flattened factor,
= exponential factor.
5. Simulation Models and Results
This research built a comprehensive simulation environment using Matlab to analyze the performance of Static-CAPIC and Dynamic-CAPIC. Furthermore, it also compares both techniques with the combination of two existing techniques, LCD+sharing scheme. The network uses best path routing as a common routing algorithm in NDN. The LCD+sharing scheme carried out the LCD scheme as a first step. Whenever consumers request the content, the router sends data to the consumer and store its copy in the one-hop downstream router. There is no partition in the content store. Every content class is cached as long as it does not exist in the content store when requested, and the content store is not full yet. However, when the content store is full, a cache replacement mechanism is obtained.
The network containing the consumer nodes, producers, and router nodes was modeled in this study to evaluate Static-CAPIC and Dynamic-CAPIC schemes performance. Each router node has a content store with the same total capacity. Contents on the network are grouped into different classes, as in
Table 1. For Static-CAPIC, each class has a statically pre-determined proportion in each router. In contrast, for Dynamic-CAPIC, it is changing dynamically using the Dynamic CAPIC formula as in Equation (
12).
The study assumed that the data have the same size. Every request with an interest package is responded with a data/content package, either by routers or producer nodes. These assumptions simplify the model and make it easier to analyze. One slot in the content store is used to save one packet of content. Therefore, the content store’s capacity is equal to the number of packets that can be saved.
5.1. Simulation Models
To evaluate the performance of Static-CAPIC and Dynamic-CAPIC compared to the LCD+sharing scheme, a test with three content classes that need to be cached was carried out, according to
Table 1. The detail of simulation parameters as shown in
Table 2. For the Static-CAPIC, a pre-determined cache proportion for the first, second, and third class are 15, 42, and 92 packets, respectively. These values are based on the percentage of content population number for each class, which are 5%, 10%, and 15% of the first, second, and third class content population, normalized to the total content store size, which is 150. The parameters analyzed for these tests are cache hit ratio and average path stretch. The cache hit ratio illustrates the ratio between the number of hit requests and the total of consumer requests. The average path stretch indicates the number of hops from the consumer to the node with the requested data. The bigger cache hit ratio is better, while the more significant path stretch is worse.
Consumer’s requests are modeled as described in
Section 2.3. For Static-CAPIC and Dynamic-CAPIC, each content class gets a different treatment and different cache portion in the content store. This differs from the LCD+sharing scheme, where there is no separation in the content store, and every content class is treated in the same manner.
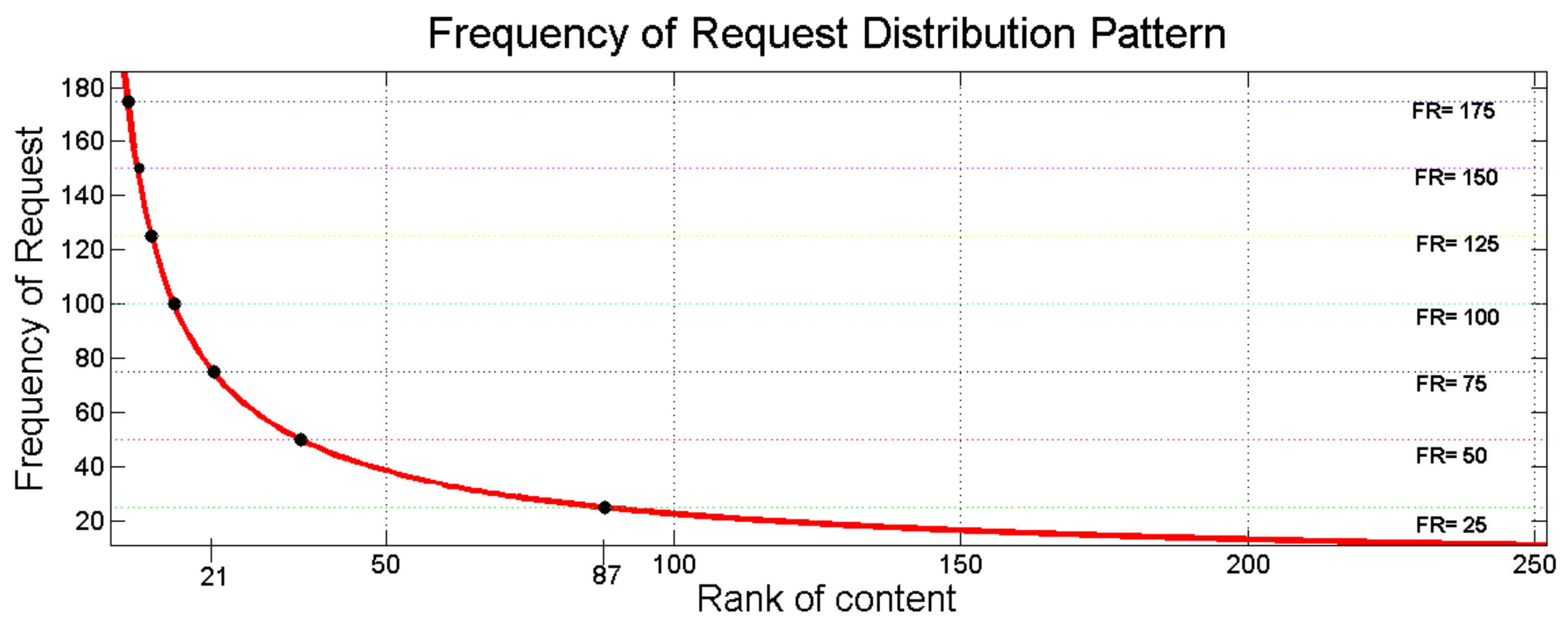
The greater the Frequency Limit Factor, the more limited the amount of top content considered in determining the proportion of cache in the content store. Setting a too small value of Frequency Limit Factor causes all content in the class to be evaluated to determine the proportion of cache.
5.2. Test Results
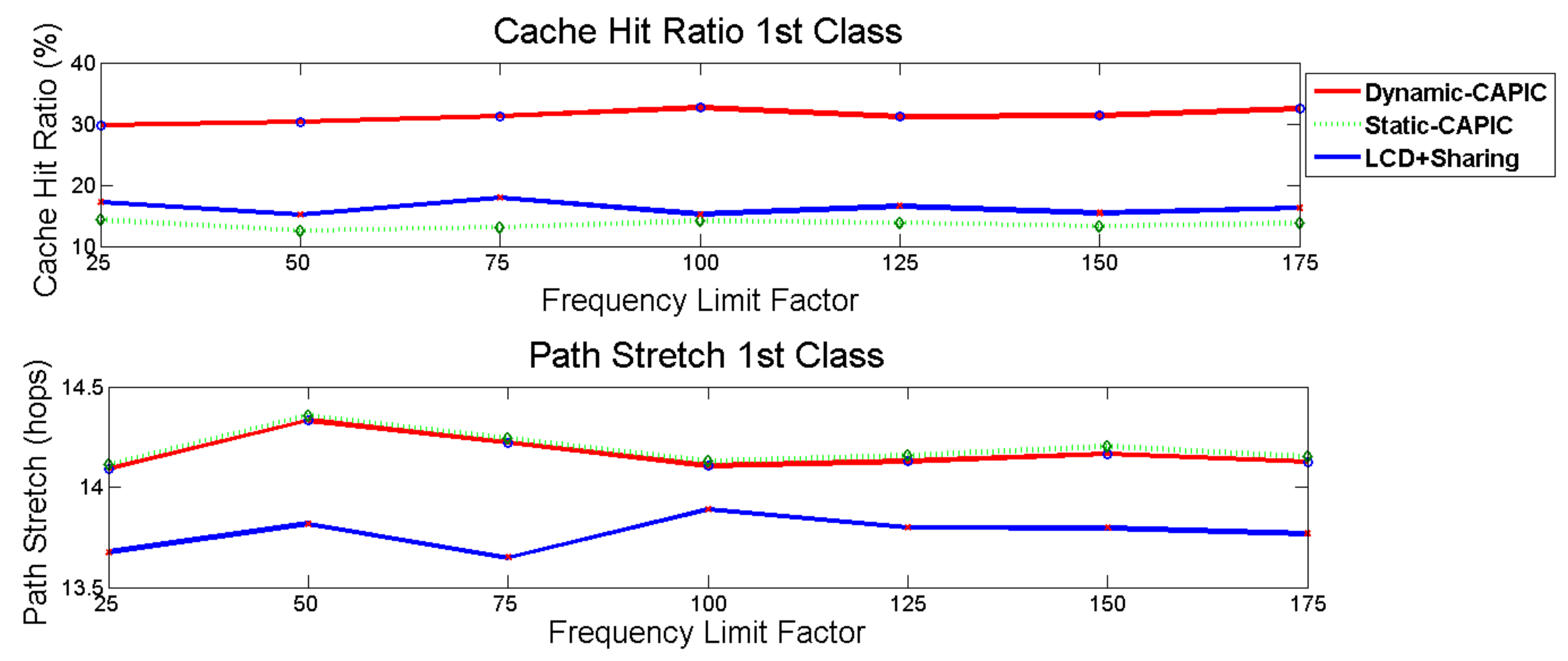
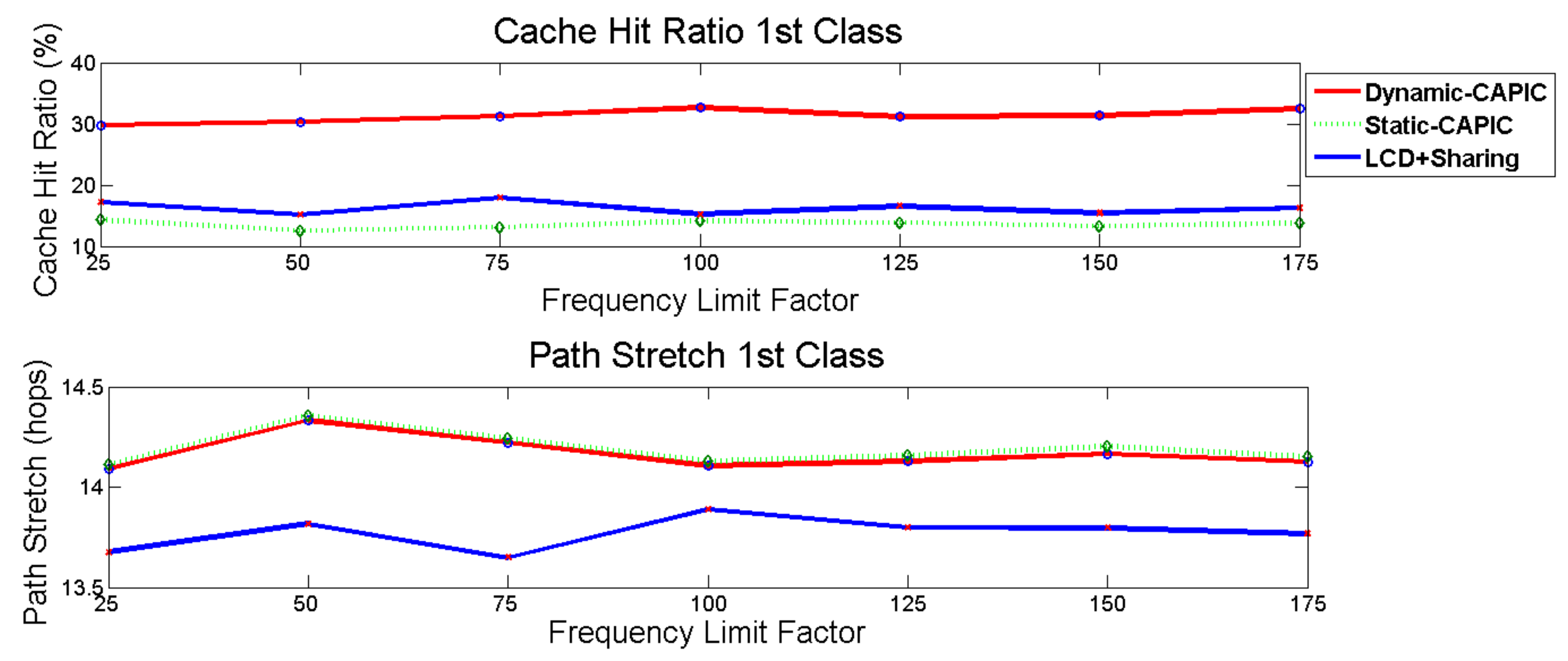
The simulation result in
Figure 8 (above) shows the first class cache hit ratio, while
Figure 8 (below) indicates path stretch of Dynamic-CAPIC, Static-CAPIC, and LCD+sharing scheme.
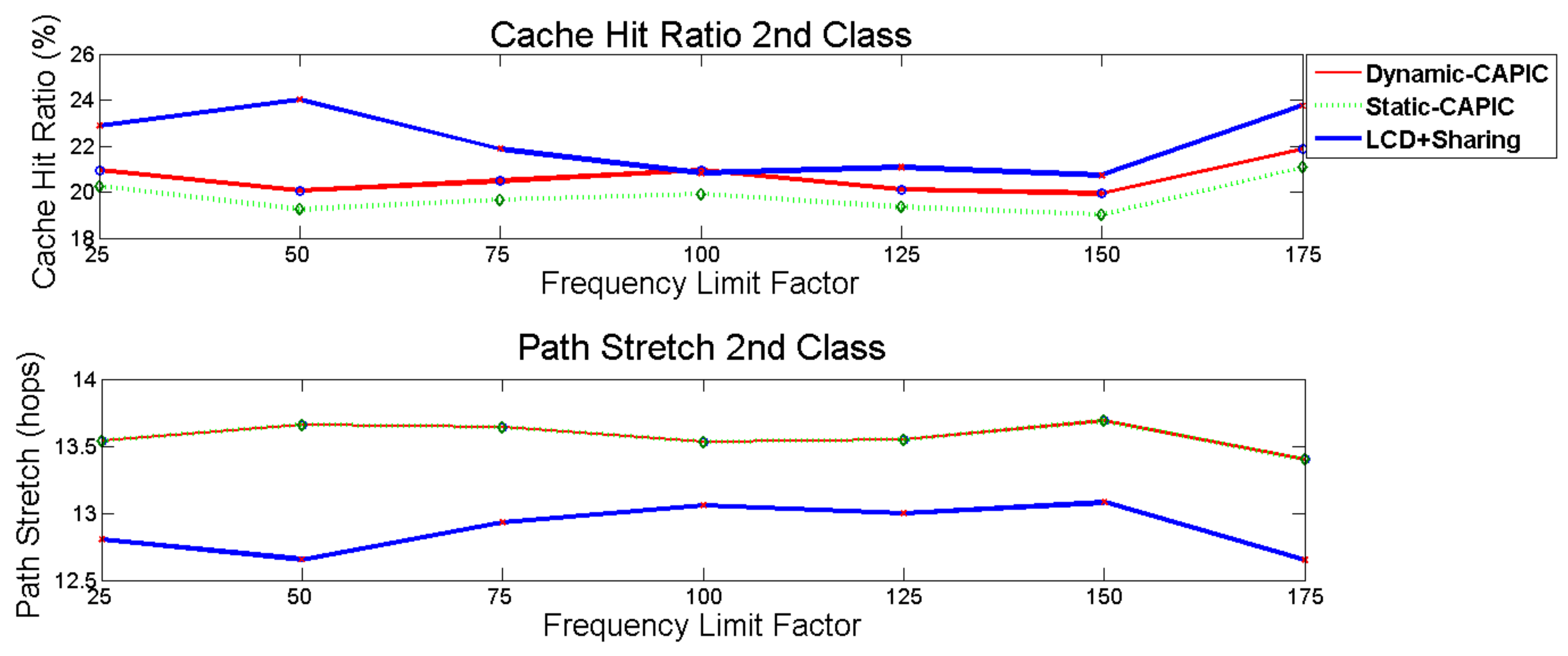
Figure 9 (above) and
Figure 10 (above) shows the cache hit ratio while
Figure 9 (below) and
Figure 10 (below) illustrates the path stretch for second class and third class Dynamic-CAPIC, Static-CAPIC, and LCD+sharing scheme. The network cache hit ratio of Dynamic-CAPIC, Static-CAPIC, and LCD+Sharing scheme are presented in
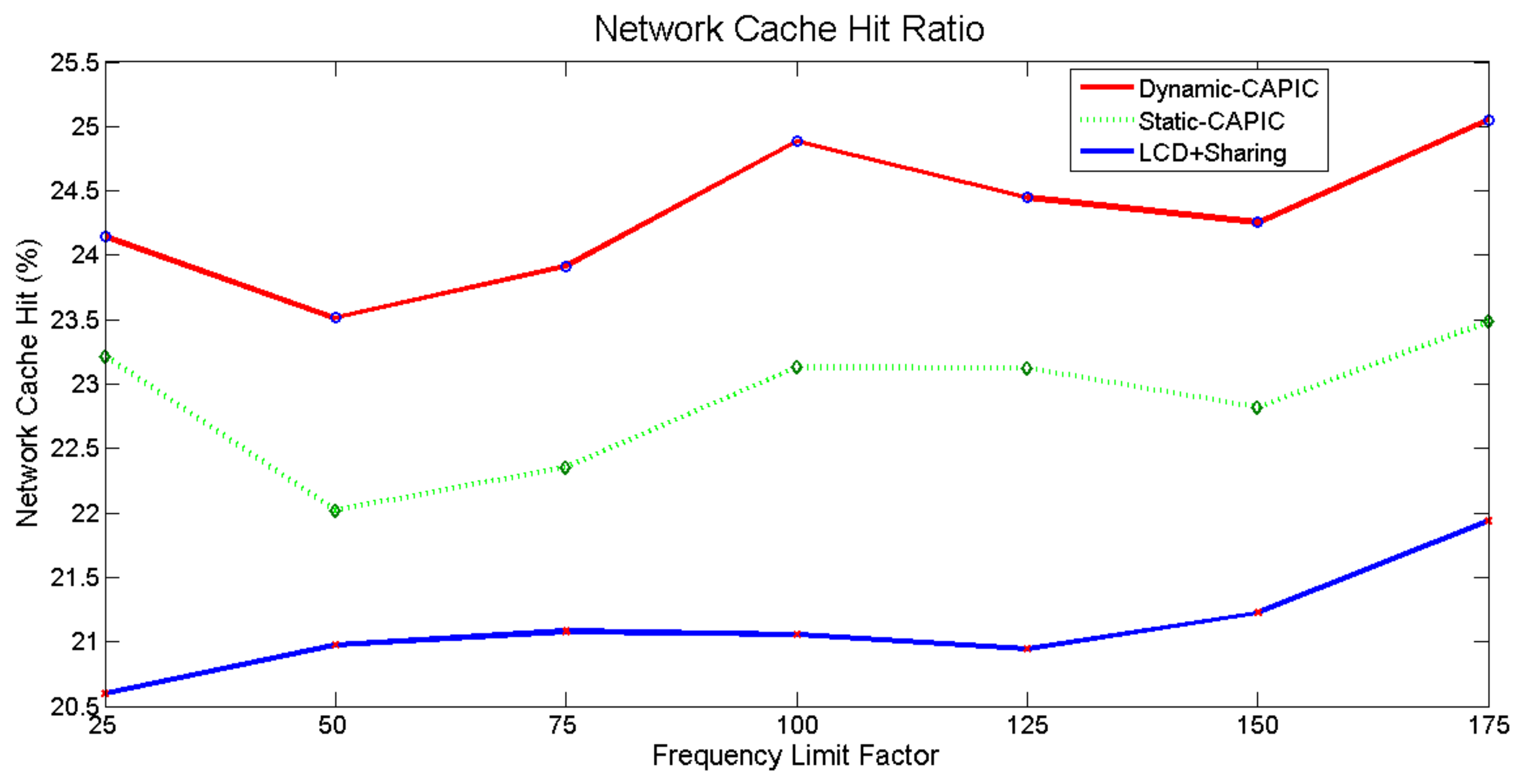
Figure 11. Furthermore, graphs comparing the cache hit ratio, and each content class’s path stretch in an internal Dynamic-CAPIC, Static-CAPIC, and LCD+sharing scheme, respectively, are shown in
Figure 12,
Figure 13 and
Figure 14.
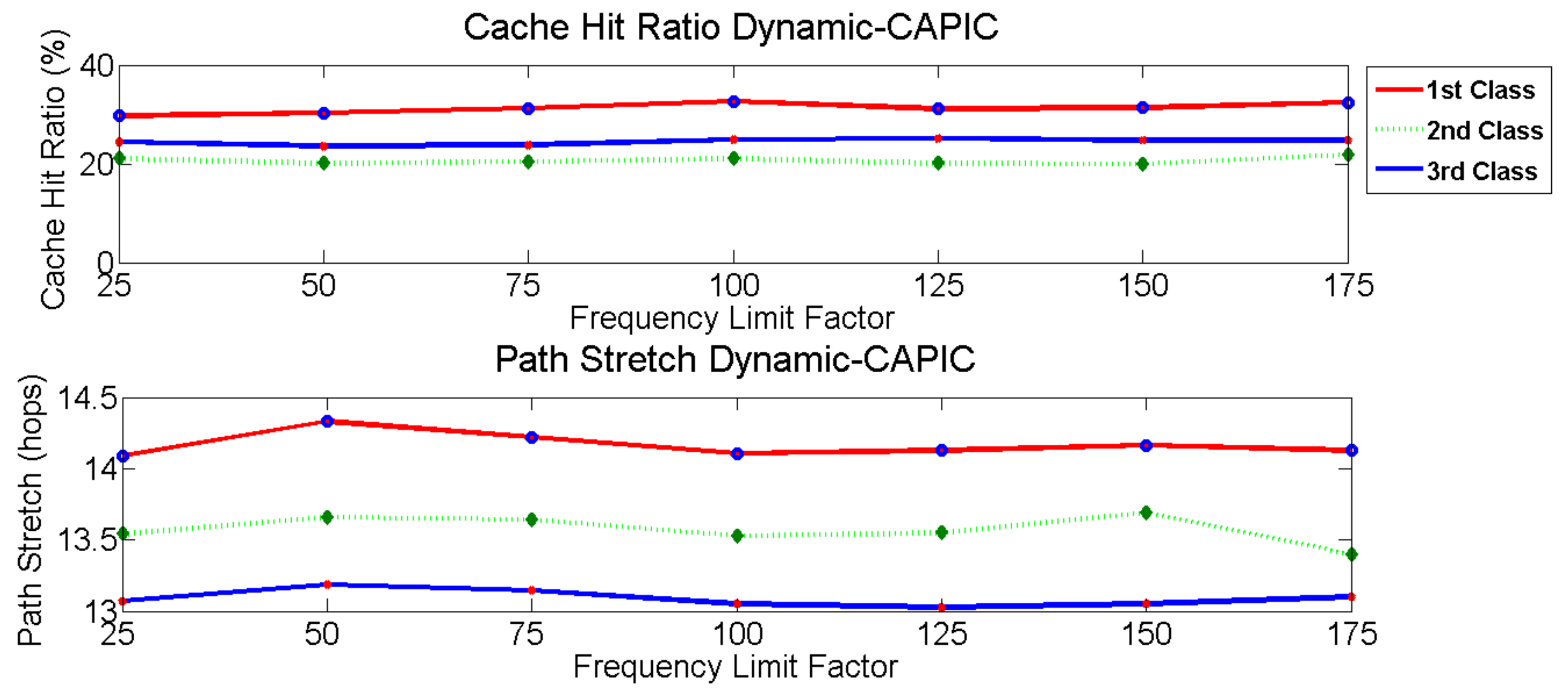
Dynamic-CAPIC gave the highest cache hit ratio for the first class compared to Static-CAPIC and LCD+sharing scheme. Dynamic-CAPIC gave a 130.7% in an average increase in the cache hit ratio compared to Static-CAPIC, and a 92.4% in an average increase compared to the LCD+sharing scheme. The Dynamic-CAPIC produces the highest cache hit ratio for the first class compared to the second and third classes, are shown in
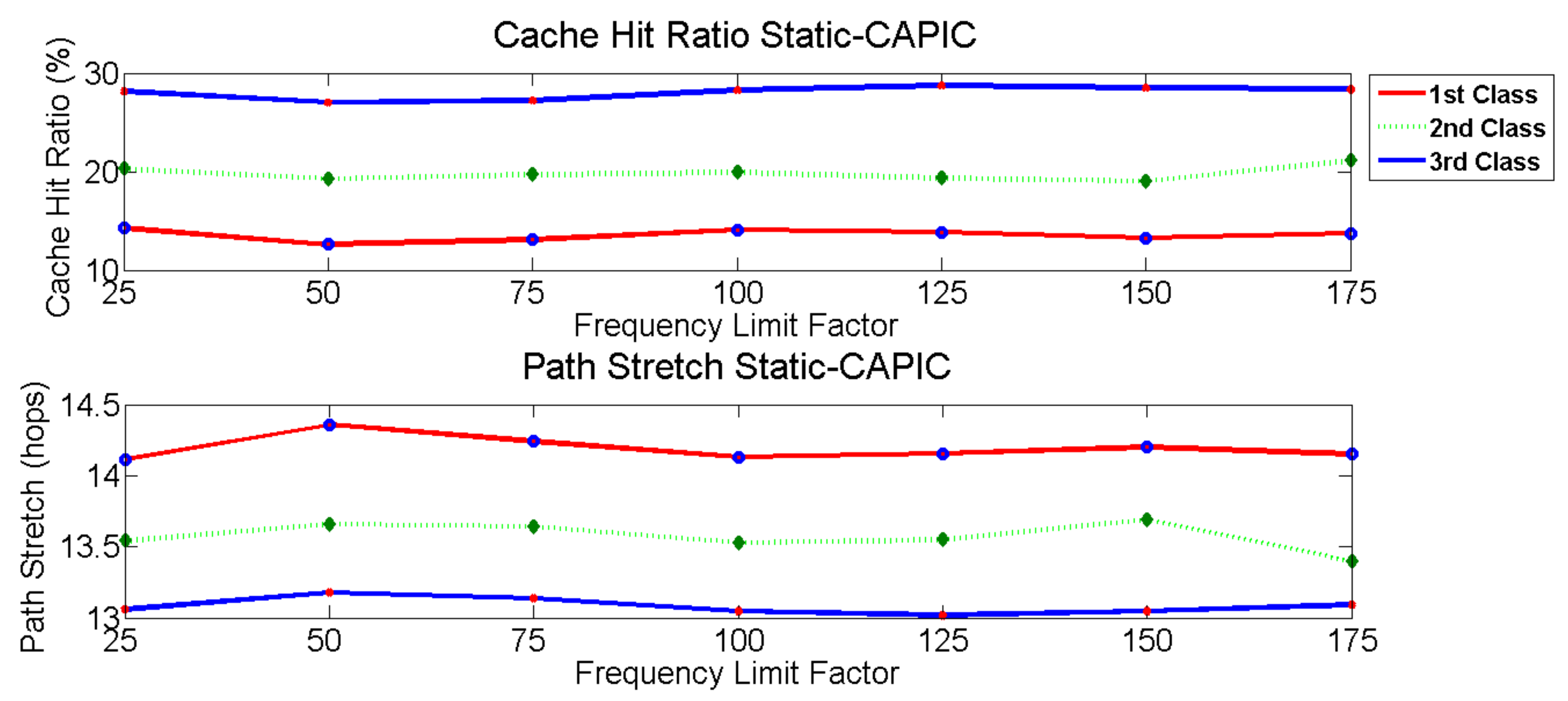
Figure 12. This result is as expected where the first class is concerned with jitter and delay, so content is expected to be available at the nodes in the network without asking the producer, which has the longest distance from the consumer. The condition is different for the Static-CAPIC algorithm. Static-CAPIC gives the largest cache hit ratio to the third class, instead of the first class, as shown in
Figure 13. Dynamic-CAPIC corrects this condition. For the path stretch parameter, as in
Figure 8 (below), the path stretch of Dynamic-CAPIC is similar to Static-CAPIC.
For the second class, LCD+sharing schemes provide a higher cache hit ratio than Dynamic-CAPIC and Static-CAPIC algorithm, as in
Figure 9 (above). The cache hit ratio of LCD+sharing scheme is 6.95% in an average higher compared to Dynamic-CAPIC. Dynamic-CAPIC has a cache hit ratio that is higher than Static-CAPIC by 4.21%. Dynamic-CAPIC cache hit ratio lies between LCD+sharing scheme’s and Static-CAPIC’s cache hit ratio. Dynamic-CAPIC compromises the cache hit ratio in this second content class to provide a larger cache hit ratio for the first class. For the path stretch parameter, it is similar between Dynamic-CAPIC and Static-CAPIC as in
Figure 9 (below).
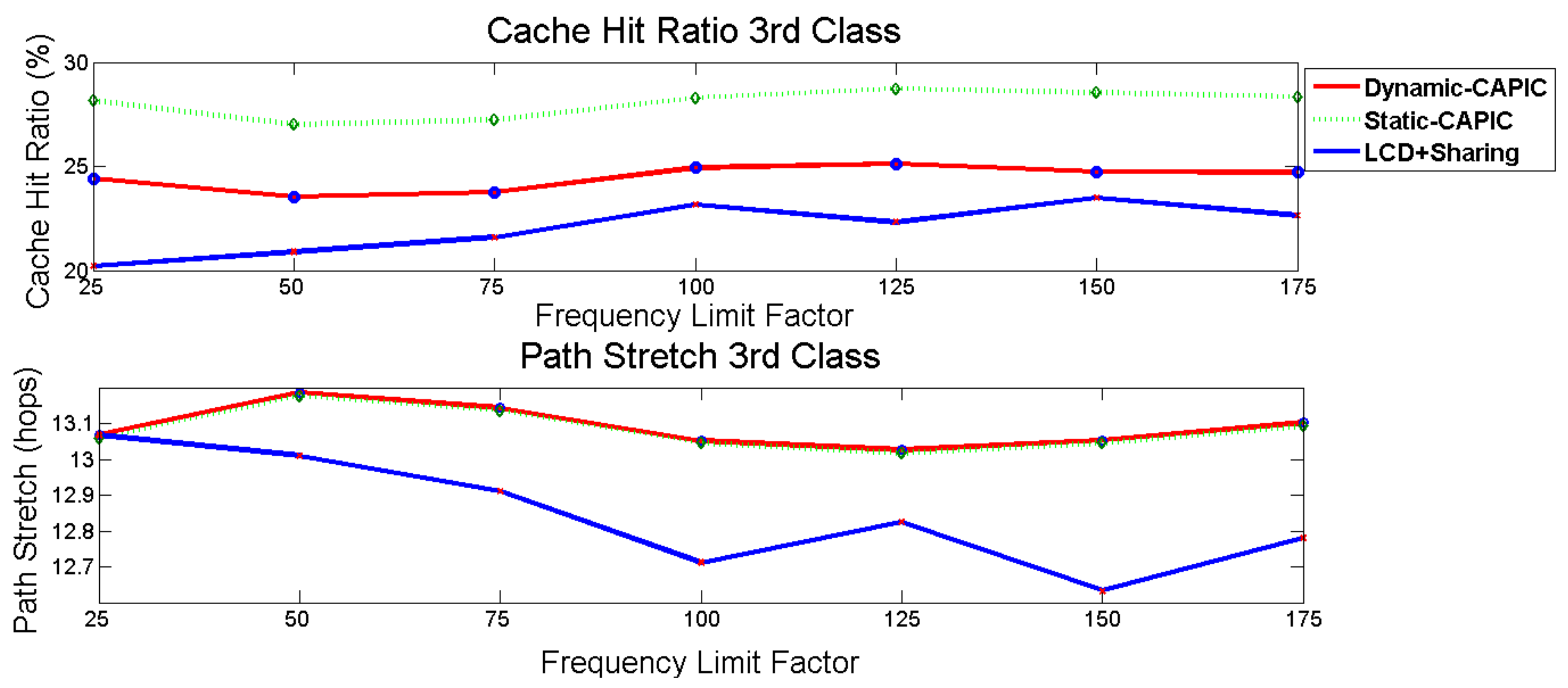
For the third class, Dynamic-CAPIC gives the cache hit ratio between Static-CAPIC and the LCD+sharing scheme ratio, as shown in
Figure 10 (above). Dynamic-CAPIC has a greater cache hit ratio than LCD+sharing scheme of 10.98% on an average and has a smaller cache hit ratio than Static-CAPIC of 12.77%. For the path stretch, as in
Figure 10 (below), the path stretch of Dynamic-CAPIC is similar to Static-CAPIC.
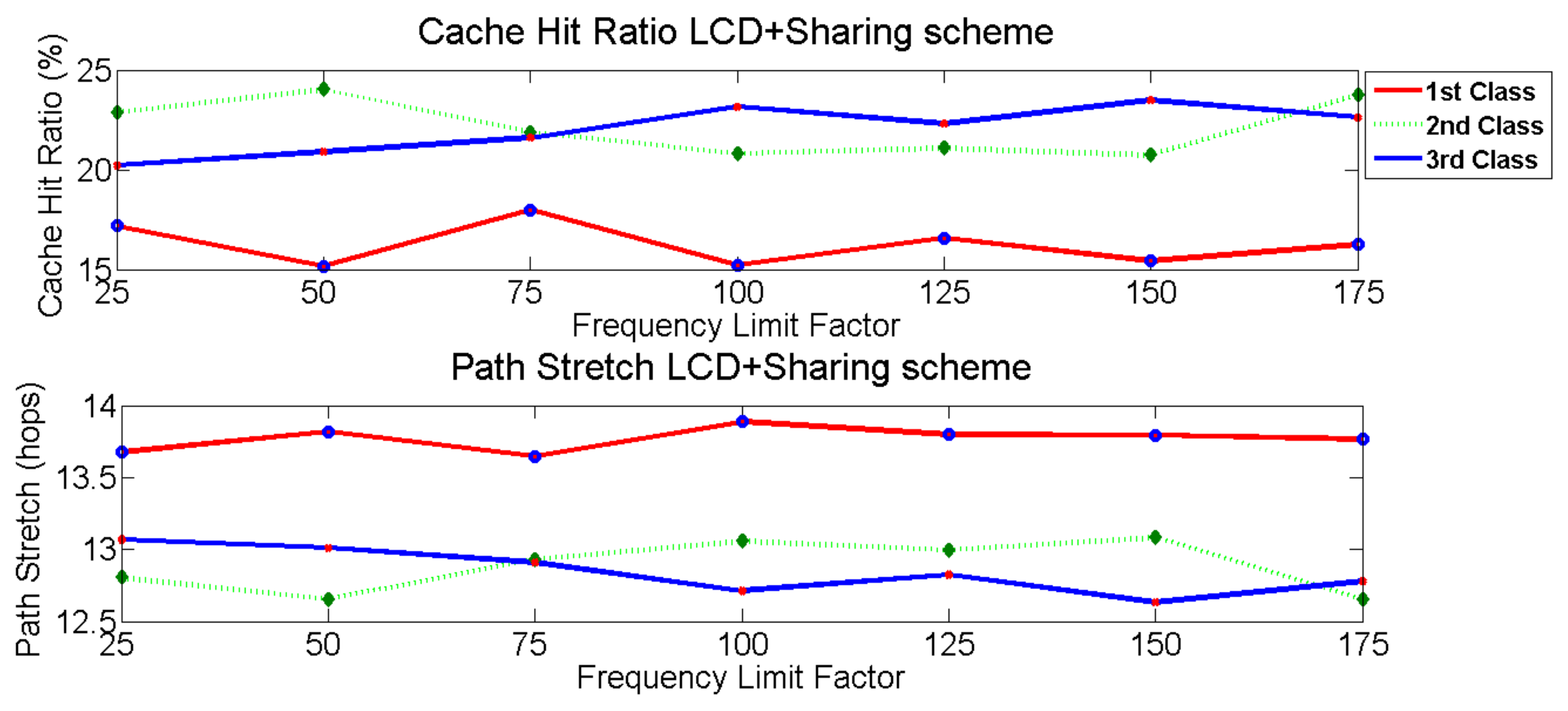
Figure 14 shows that by using LCD+sharing scheme, it is challenging to create a priority mechanism for each content class. The first class of LCD+sharing scheme has the lowest cache hit ratio, and it is unstable for the second and third classes. Content that is popular for one class can be deleted due to a lack of resources to store others. This condition will make the network cache hit ratio not optimal for LCD+sharing scheme. Dynamic-CAPIC provides a highest cache hit ratio for the first class, followed by the third and second classes. These results have fit the requirement of each content class of Dynamic-CAPIC. Dynamic-CAPIC also provides the highest network cache hit ratio compared to Static-CAPIC and LCD+sharing scheme. Meanwhile, Static-CAPIC gives a higher network cache hit ratio than the LCD+sharing scheme, but it cannot provide an appropriate cache hit ratio, especially for the first content class.
The consumers’ demand traffic distribution is complex. In each internal content class, every content popularity follows the Zipf–Mandelbrot distribution, and the average request rate of each class is modeled by Poisson distribution. At any single time, the number of requests for every content in every content classes can change. The Dynamic-CAPIC mechanism provides the cache proportion’s calculation process according to each content class’s real-time needs. The cache proportion is changing every time with a content class possessing the biggest cache proportion, sometimes. In another time, this class tends to have the smallest cache proportion. The condition depends on the request from consumers. As a result of this flexibility, looking from the network side as in
Figure 11, the Dynamic-CAPIC method outperforms the Static-CAPIC and LCD+sharing scheme because Dynamic-CAPIC can keep up with changes in demand patterns every time. Simultaneously, the number of requests for every content in all content classes changes, while the average number of requests has been defined using the Poisson distribution. Dynamic-CAPIC provides calculation of cache portions according to the real-time needs of each content class. Dynamic-CAPIC’s cache hit ratio is the biggest, followed by Static-CAPIC’s and LCD+sharing scheme’s cache hit ratio for all Frequency Limit Factor uses. Dynamic-CAPIC gives an average cache hit ratio of 6.29% compared to Static-CAPIC and an average of 15.15% compared to LCD+sharing scheme.
This research measure the complexity of the algorithm using the Time Complexity parameter. Time complexity is used to measure the time required to run an algorithm with specific inputs. However, the processing time will depend on the type of device, the parallel process being worked on, network load, etc. The value can be biased. For this reason, time complexity can be demonstrated through Big-O notation. Big-O notation converts all steps of an algorithm into a more objective form of algebra. The pseudocode of Dynamic-CAPIC and LCD+sharing scheme is presented in Algorithm 1.
The Dynamic-CAPIC algorithm is written mathematically as an input correlation as, 4K + 2, and the Big-O notation is O(K). The Big-O notation for the LCD+sharing scheme is O(1) because the complexity is always the same for any input value. Ultimately, the complexity of Dynamic-CAPIC is growing as K increase. In addition to the growth of complexity, Dynamic-CAPIC gives the worth compensation. It provides the highest network’s cache hit ratio compared to LCD+sharing scheme for about 8%. The most important thing is Dynamic-CAPIC can control each content class performance following the class requirement in real-time. It gives a maximal 130 % cache hit ratio compared to the LCD+sharing scheme for the first content class.
| Algorithm 1: Function Dynamic-CAPIC and Function LCD+Sharing. |
![Futureinternet 12 00227 i001]() |

 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}