1. Introduction
The current Service Function Chaining (SFC) architecture suggested by the European Telecommunications Standards Institute (ETSI) [
1] lacks the capability to encrypt and isolate end-user traffic between Service Functions (SFs) in Network Function Virtualisation (NFV). End-to-end encryption of end-user traffic is by design impossible when middleboxes such as SFs require access to the data content of the packets. This constraint in NFV questions how confidentiality can be integrated into an SFC. The scope of our work is to cover this gap, by enabling automated hop-by-hop encryption in an SFC. We aim for contemporary data centre networks to support an architecture of nested SFC tunnels in order to support hop-by-hop encryption within the current NFV [
1] and SFC [
2] standards. As presented in our previous work [
3,
4], the current packet forwarding standards do not support SFC forwarding of encrypted packets because the relevant packet headers for SFC routing are also encrypted. Accordingly, our work explicitly focused on these constraints, aiming initially to provide a Proof-of-Concept for the capacity to deploy a secure architecture as an overlay to the existing NFV infrastructures.
Under this scope, our security-related studies followed five consecutive steps (
Figure 1), following the Design Science Research Methodology (DSRM) defined by Peffers et al. [
5]. Initially (A), the operational constraints and the NFV forwarding standards were surveyed [
6]. Consequently (B), the security requirements have been identified aiming to accommodate the requirements extracted from the aforementioned studies [
4]. Thirdly (C), an automated forwarding architecture has been developed based on a web service architecture, aiming to accommodate the requirements and the constraints [
3]. The fourth step (D) in our studies was to develop a security protocol for exchanging encryption keys between SFs [
7]. This article (E) integrates the previous results into a customised NFV environment and combines it with SFC routing [
8]. In order to overcome the network constraints, we developed a customised virtual switch by the use of P4 [
9] in order to support a new SFC packet header based on Network Service Headers (NSH). Accordingly, we aim to verify that this implementation fulfils the requirements we have developed in our previous work.
Section 2 summarises the related work to this research.
Section 3 presents the operational context under which the developed architecture was designed.
Section 4 and
Section 5 present the architecture and implementation, while
Section 6 gives a verification of the presented scenarios for a closing demonstration. Through defining three episodes in this scenario, we seek to highlight how the elements presented in this paper are supporting a secure SFC implementation in NFV.
2. Related Work
In recent years, NFV based solutions have become a very active research area, due to the benefits promised by cost-effective solutions when virtualising network equipment. Within the research area of NFV, SFC forwarding protocols and their corresponding control plane mechanisms are NFV research areas that have gained attention [
10,
11,
12]. Nevertheless, the security research on these networking standards is limited, where none of the SFC standards are protecting the privacy and the integrity the data plane traffic [
13]. This is a complex problem that consists of data protection problems on multiple levels; the orchestration plane, the control plane and the data plane. Hence, our work aims to cover this research gap, by providing a new packet forwarding standard that is reflected on all these planes.
From a data plane perspective, the Internet Engineering Task Force (IETF) workgroup NVO3 [
14] have considered multiple overlay protocol for use in data centres. Generic UDP Encapsulation [
15], Geneve [
14], VXLAN-GPE [
16], and NSH [
17] are all protocol competing to be the next standard. They all have limitations related to multi-vendor and multi-domain interoperability and they also have a lack of security extensions. MPLS-SR [
18] does support multi-domain topologies, but, in an SFC context, they all rely on the underlying protocol, such as IPSec tunnels, to provide encryption. However, such a tunnel can be perceived as a wire between data centres. Multiples of these tunnels constitute a virtual overlay network that is unprotected from all data threats that reside within the network. Then, there is no protection of the integrity of the headers of the data-flow across multiple domains. In IPv6, Segment Routing (SR) [
8] is supported; however, during encryption, the header is replaced and the segments become invisible for intermediate routers. We aim to solve this by introducing a new overlay packet header that supports encryption inside the overlying network protocols, such as NSH.
With respect to interconnected control planes, we have earlier showed [
6] that there are two orchestration methods across multiple service provider domains. (1) A top-down approach by utilising a hierarchy of orchestration planes [
19] or control planes [
20] or (2) by using an east–west control plane approach such as SDNi [
21] or BGP [
22]. Both interconnection methods try to overcome the problem of multiple forwarding standards and multiple types of network controllers. The industry has responded by providing tenant-based data centres, where each tenant extends their data centre across multiple sites and omits the need for control plane interconnections. Networking by NSX-T [
23] from VMWare is one example of such multi-tenant data centre technologies where a micro-segmented infrastructure can span over multiple sites. However, most of the underlying network protocols, such as Geneve [
14] in NSX-T, are not capable of combining SR with micro-segmentation and flow-based encryption. Hence, we have in our previous work [
3] suggested a new SFC header, based on an NSH extension that adds more granularity to the security aspect of an SFC. Correspondingly, we have in this paper developed a RESTconf based control plane for distributing the forwarding decisions of this new packet header.
Introducing a new packet header has historically been problematic with respect to the adoption into existing hardware. When a new network protocol was suggested, the network operators had to wait for a set of standardisation documents from organisations such as IETF and ONF [
24]. Furthermore, they also had to wait for the switch vendors to develop a new software version. Sometimes, a new network standard also required new hardware. The Programming Protocol-independent Packet Processors (P4) [
25] language aims to solve this issue by defining a framework that directly programs packet parsing and packet forwarding instructions to a switch in runtime. Then, network operators themselves can program their switches and add new protocols and features to them. The ONF group is currently aiming for standardising P4 as a part of SDN through the Stratum project [
24]. In this research, we run P4 inside a Virtual Machine in order to simulate a virtual switch. Due to the lack of OpenFlow implementations in our P4 framework, we used RESTconf for the control plane protocol.
From the encryption perspective, no protocols have been found for providing micro-segmented and flow-based encryption per SFC. However, our previous work [
7] that originated from Software-Defined IPsec Flow Protection in SDN [
26] and IPsec Key Exchange using a Controller [
27], showed how encryption and Software-Defined Security Associations (SD-SA) could be adapted to an NFV domain.
In this paper, we combine this SD-SA encryption architecture [
7] with our new SFC header [
3] and a new flow distribution control plane. The security features of the architecture are verified by demonstrating how the requirements such as isolation and encryption comply with a use case scenario.
3. Operational Context of Proof-of-Concept Scenarios
This section presents a use case scenario of SFC isolation and encryption. Furthermore, we show three episodes of this scenario that are developed based on a set of architectural security requirements.
3.1. Use Case
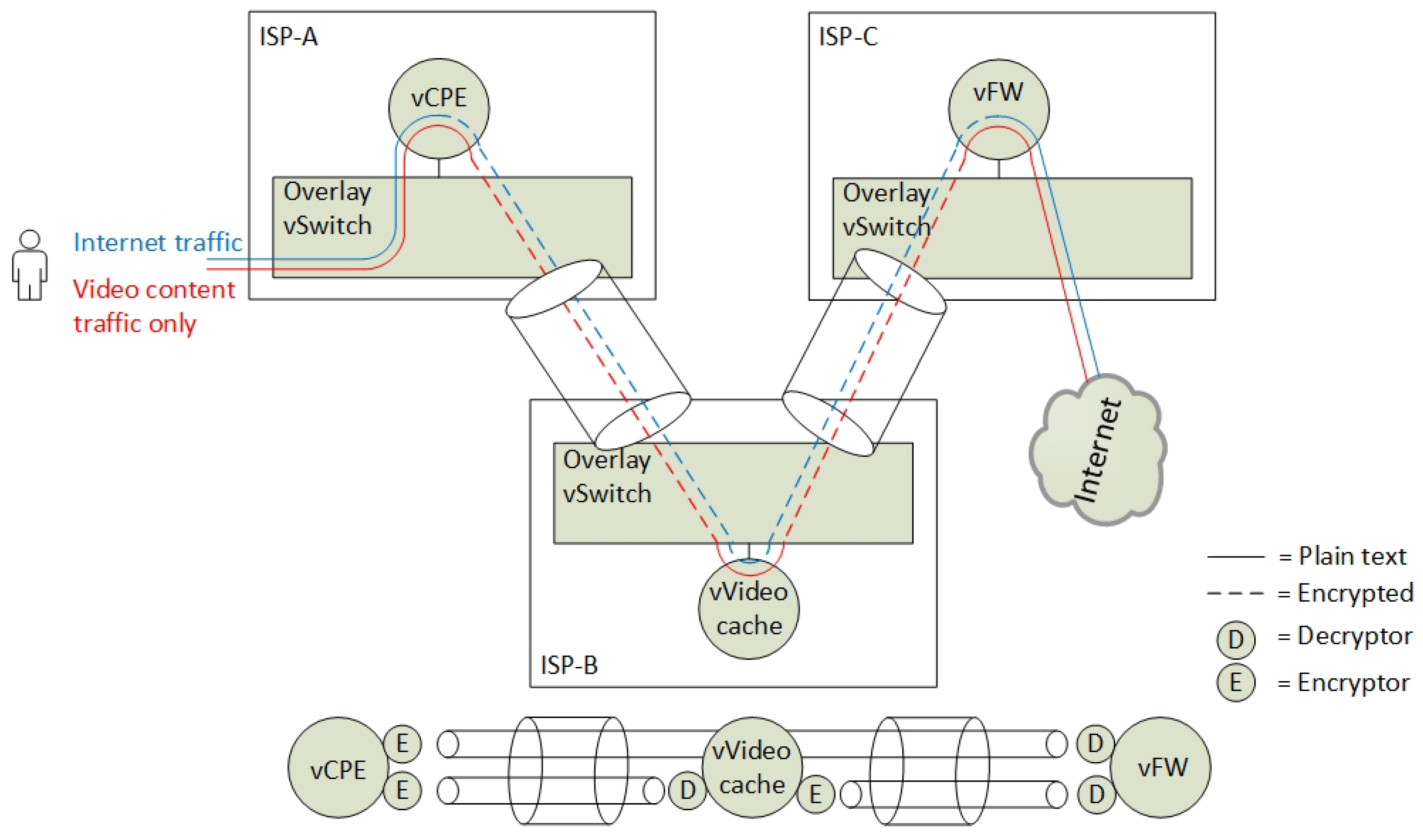
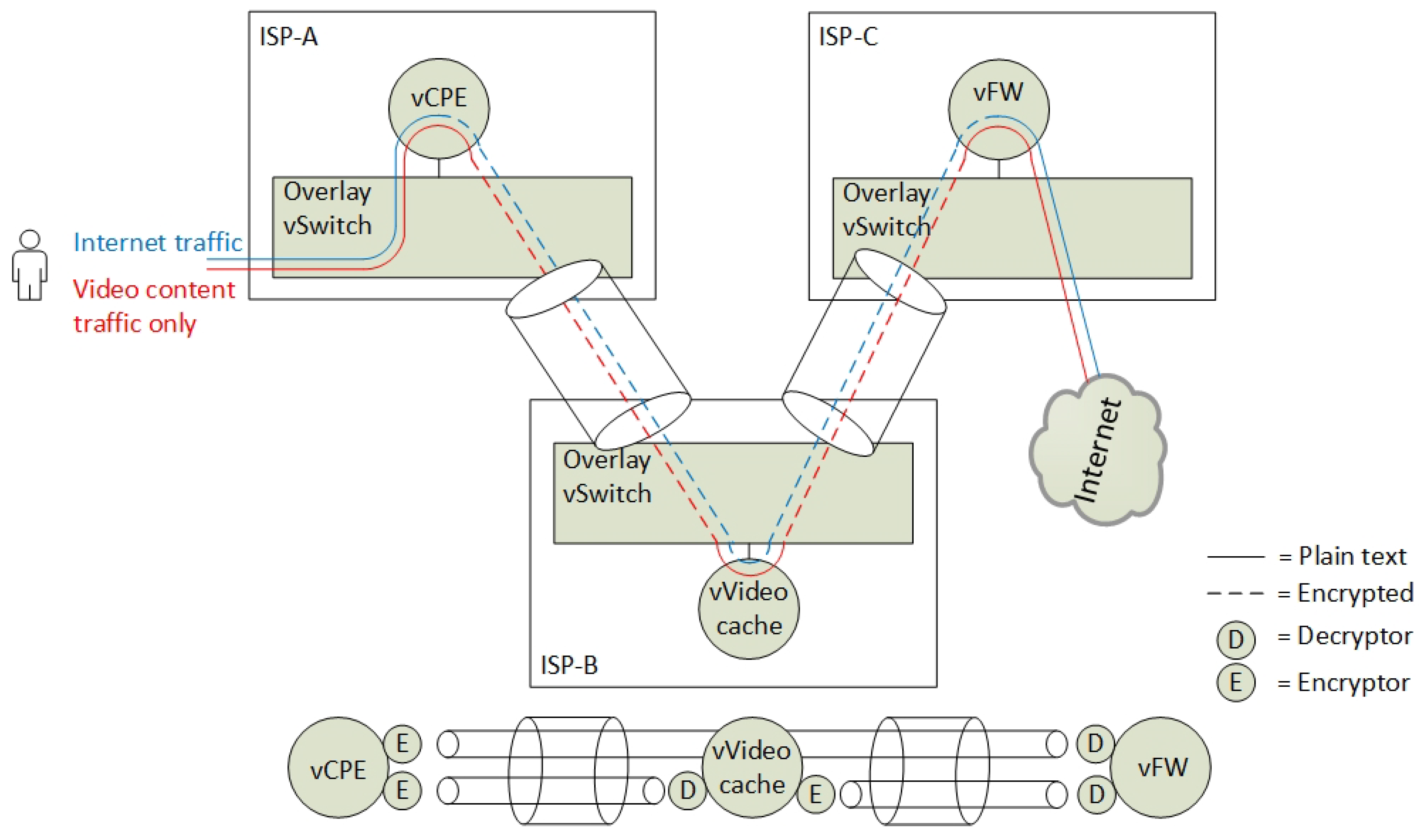
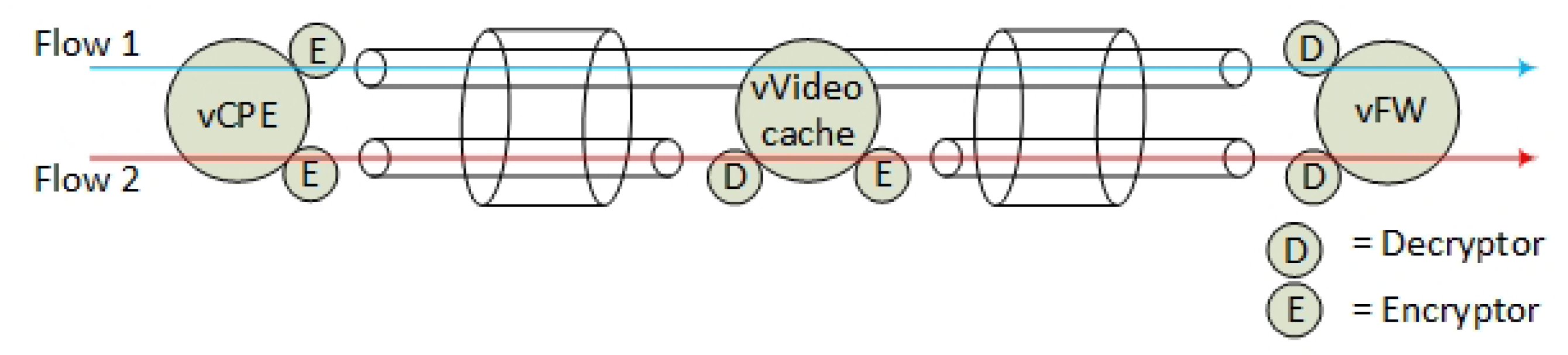
The verification scenario for our Proof-of-Concept demonstration is based on a fictional Internet Service Provider (ISP) that wants to extend their NFV portfolio and their data centre resources. The ISP located in country A, named ISP-A, wants to lower their costs on their Customer Premise Equipment (CPEs) by virtualising them and consequently more efficiently extending their service delivery. They have limited resources in their data centre and want to offload parts of their services to remote data centres. They have found two cooperative partners in country B (ISP-B) and country C (ISP-C) that can provide them with data centre resources. They want all data centres to contribute to delivering and extending their virtual CPE (vCPE) services. They are aiming to provide this by chaining SFs across all data centres by the use of the SFC protocol NSH.
The IETF has defined a variety of SFC use cases [
28], but, for our Proof-of-Concept demonstration, we limit the SFC use case to the following: ISP-A aims to provide three SFs to their customers. Two of the SFs are mandatory, while one additional SF is optional for the end-users to choose. The basic SFs are a vCPE (SF-1) and a firewall (SF-3), while the optional SF is a video caching service (SF-2). Due to the cost of data centre resource consumption and SF security policies, the ISP-A policy is defined to require that the vCPE runs at ISP-A, the video caching service at ISP-B and the firewall at ISP-C. The vCPE is the first element in the SFC. The additional video caching service is placed in the middle of the SFC in order to let the first two services be protected by the last element in the SFC, which is a virtual firewall (SF-3) (
Figure 2). Hence, from a service plane perspective, the firewall is protecting the inner SFs and the end-user from the outside world.
The data centres operate with multi-tenants where ISP-A has interconnected all their tenant instances in an overlay network. In this setup, ISP-A is concerned about the privacy of their customers and they do not know if ISP-B is eavesdropping the end-user traffic traversing them. Neither are they sure whether ISP-B is malicious. ISP-C is, on the other hand, a trusted partner. In order not to let ISP-B being capable of eavesdropping all end-user traffic, all traffic that is traversing ISP-B, except video streaming traffic, must be encrypted. Note: for Proof-of-Concept purposes, the video caching service is categorised as a non-privacy sensitive service.
We simplified the SFC isolation problem by omitting a full mesh topology of the interconnected data centres in the Proof-of-Concept scenario. However, the components in a full mesh topology are also vulnerable to eavesdropping. Corrupt intermediate virtual switches or faulty SFs can modify, intercept and manipulate SFC traffic inside an overlay network. Hence, the protection of the Virtual Link (VL) [
2] is relevant both between the Compute Nodes in one data centre and for the VLs between multiple data centres.
3.2. Requirements
We have in our previous work presented the NFV security requirements [
4] for the encryption and the isolation of the VLs. We summarise these requirements in the context of the aforementioned scenario:
Hop by hop encryption—In order to prevent eavesdropping of the VLs, the VLs must be encrypted per SFC.
Micro-segmented isolation—The SFC specification [
2] does not allow micro-segmentation within one SFC. However, we state that the end-user requires that they must be able to specify what data traffic the SFs are allowed to handle on a flow-based level. Hence, it is required that the associated data plane components are capable of isolating different packet flows with different encryption keys within one single SFC.
Header visibility—When encrypting VLs, the SFC packet header must be non-encrypted in order to enable SFC routing of the encrypted packets. We define that a new SFC header extension must be able to both allow and specify when the inner data-content of an SFC packet header is encrypted.
Control plane flow distribution—Multiple encryption-flows within one SFC require that the control plane is capable of distributing route information about each of these encrypted flows. These flow-rules must be securely distributed. Hence, secure and trusted intra- and inter-domain communication channels from the virtual network devices to the network controllers must be established.
Key distribution—Due to a non-bidirectional data plane between the SFs in an SFC [
2], a new hop-by-hop key distribution mechanism is required. The key distribution mechanism must respond to a dynamic SFC behaviour such as an SFC modification. It must also support future encryption standards or protocol extensions. The key distribution mechanism must ensure confidentiality, integrity and availability of the keys.
Compliance and adoption—A new SFC header and the corresponding provisioning architecture must be compliant with the current NFV standards. In addition, adding encryption to the VLs should not degrade the end-to-end throughput performance more than traditional end-to-end encrypted channels. Another important factor for the architecture to be adopted is that the end-users do not perceive a significant increase in service provisioning times when they apply VL encryption.
Resilience and availability—The architecture must provide resilience towards components failing without reducing the level of security.
Security integrity—An attacker should not be able to manipulate the routing tables or to modify the packet headers in order to enforce access to non-encrypted data packets.
We aggregated these requirements and defined the following episodes from the aforementioned scenario.
Episode 1: Packet forwarding and provisioning (Req: i, iii, iv, vi)
This episode is created from an end-user perspective. An end-user orders a new virtual service according to our scenario. The end-user expects that his broadband service is not affected during service provisioning. A service provisioning demonstration can monitor the provisioning time by measuring network outage. However, demonstrating a full service provisioning also provides evidence of how the architecture provides the setup of the encrypted VLs. In addition, in a fully provisioned SFC, an end-to-end traffic test shows how the encrypted data packets are routed and if the traffic flow is satisfying the security requirement of flow-distribution.
Episode 2: Resilience and availability (Req: v, vii)
In this episode, we simulate hardware failure. From an availability and resilience perspective, the architecture must be resilient to components failing without compromising the network encryption policy. During service recovery, this demonstration also shows the dynamic behaviour of the key distribution during failovers.
Episode 3: Security integrity (Req: ii, viii)
For our third episode, we simulate that one of our data centres (ISP-B) is attacked and that a subset of the components is compromised. When simulating a set of basic network attacks, the architecture must be resistant to this. This also includes a demonstration of how flow-based encryption can protect the end-user data from being compromised by a malicious ISP (ISP-B).
Aiming to highlight a selected subset of the functionalities supported by our developed security architecture, we next present the architecture and the implementation of our Proof-of-Concept demonstration.
Section 6 evaluates how the following architecture fulfils these episodes.
4. Encrypted SFC Architecture
In this section, we describe the architectural components and the network topology for enabling encrypted and isolated VLs. This work follows the design guidelines from our previous work [
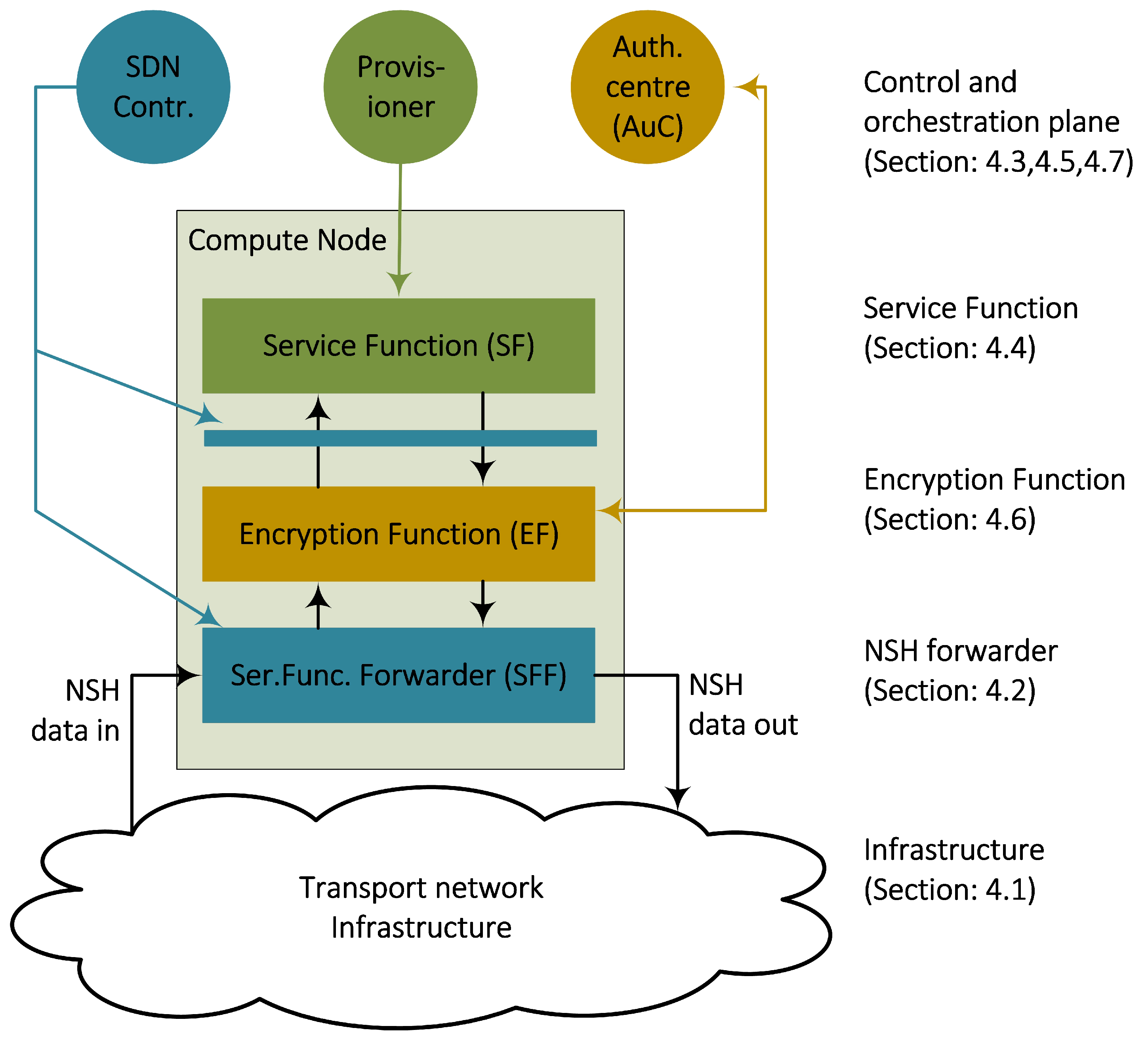
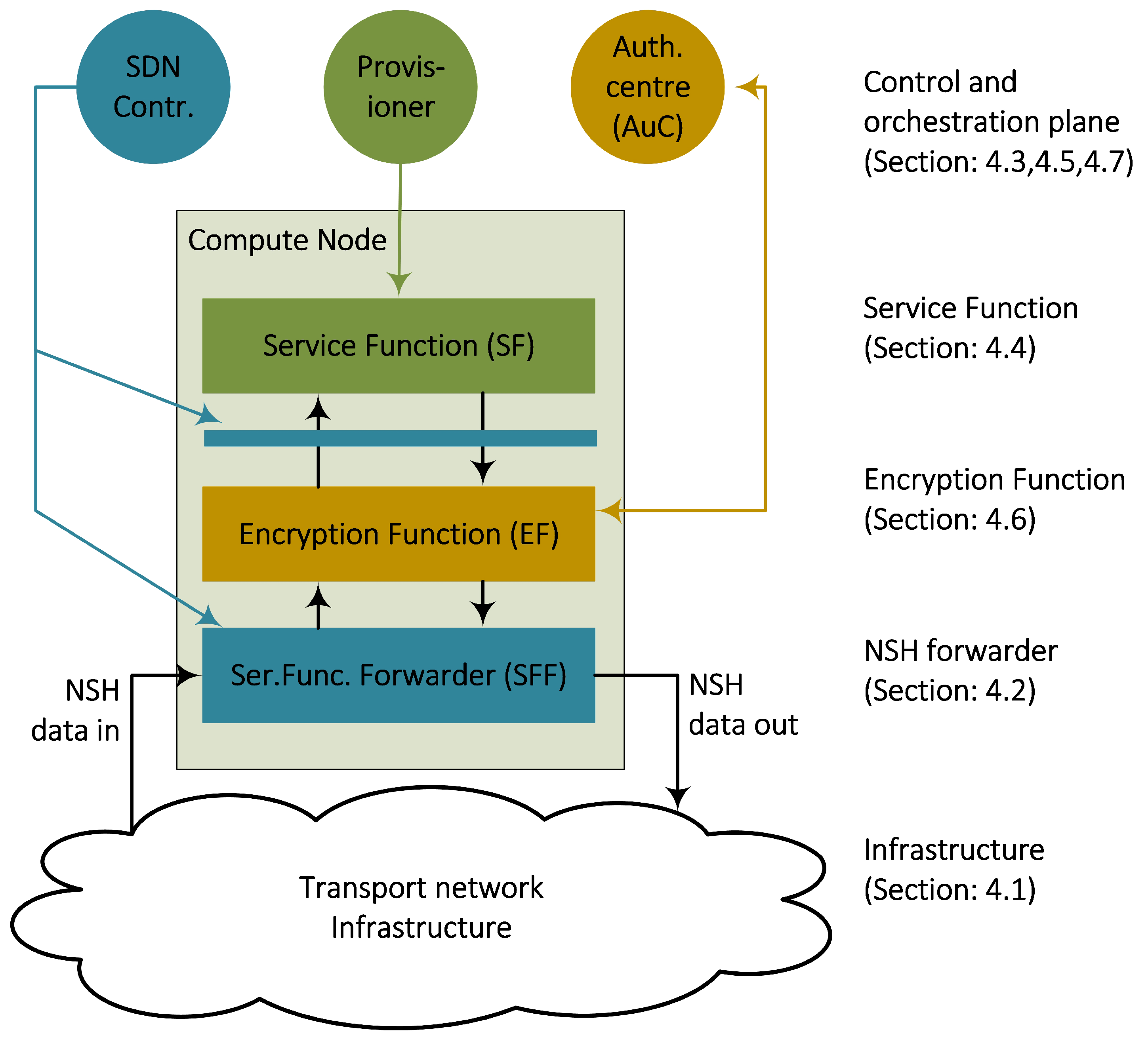
3] where we presented an architecture consisting of a tiered structure of data plane and control plane components. This architectural section summarises this work and focuses on the implementation-specific elements of the design. The main objective of the design is to structure a layered networking architecture into a data centre environment. Specifically, this includes a design of interconnected Compute Node components that are capable of forwarding encrypted SFC packets by the use of two layers of NSH headers. Accordingly, we have provided three data plane components running on the Compute Nodes (
Figure 3); a new Service Function Forwarder (SFF), a new Encryption Function (EF) and a new forwarding framework for the Service Functions (SF). These components are based on the programmable switch language P4 [
9].
Figure 3 shows that these data plane components also have their corresponding control plane units, following the Software-Defined Networking paradigm of centralised control and network programmability. We used a micro-service design principle and implemented each of these components as Virtual Machines (VMs). According to our previous work [
3], we used RESTConf web services to exchange messages between these components.
4.1. The Infrastructure
The nature of an SFC accommodates Segment Routing (SR) [
18,
29,
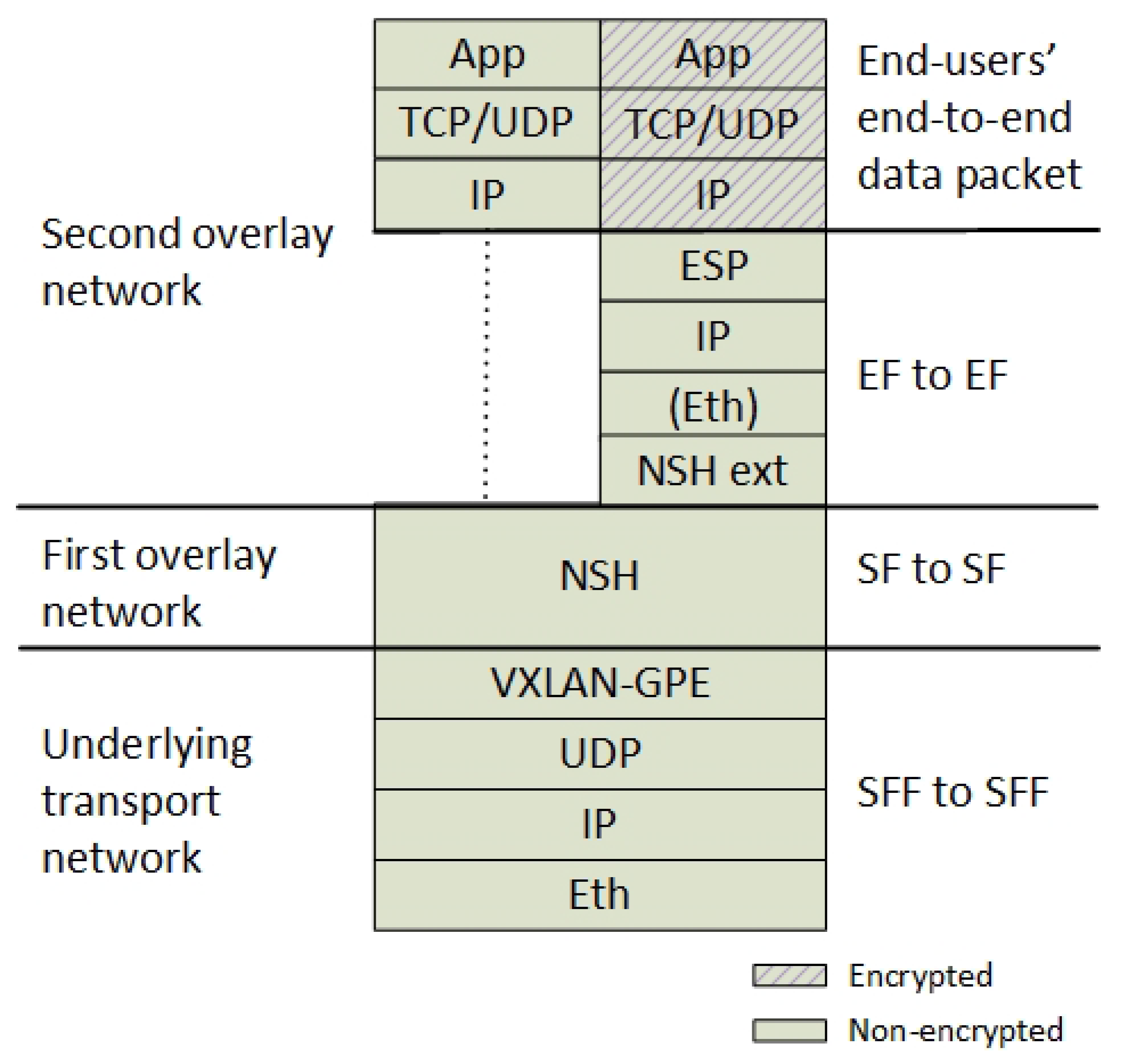
30], which implies that the sender of an IP packet specifies the packet path. Specifically, SR implies that the packet header contains SFC state information of how to route a specific packet for a selection of intermediate routers. We use NSH as a data plane enabler for SR in order to steer the traffic in such SR paths between the SFs and the EFs (
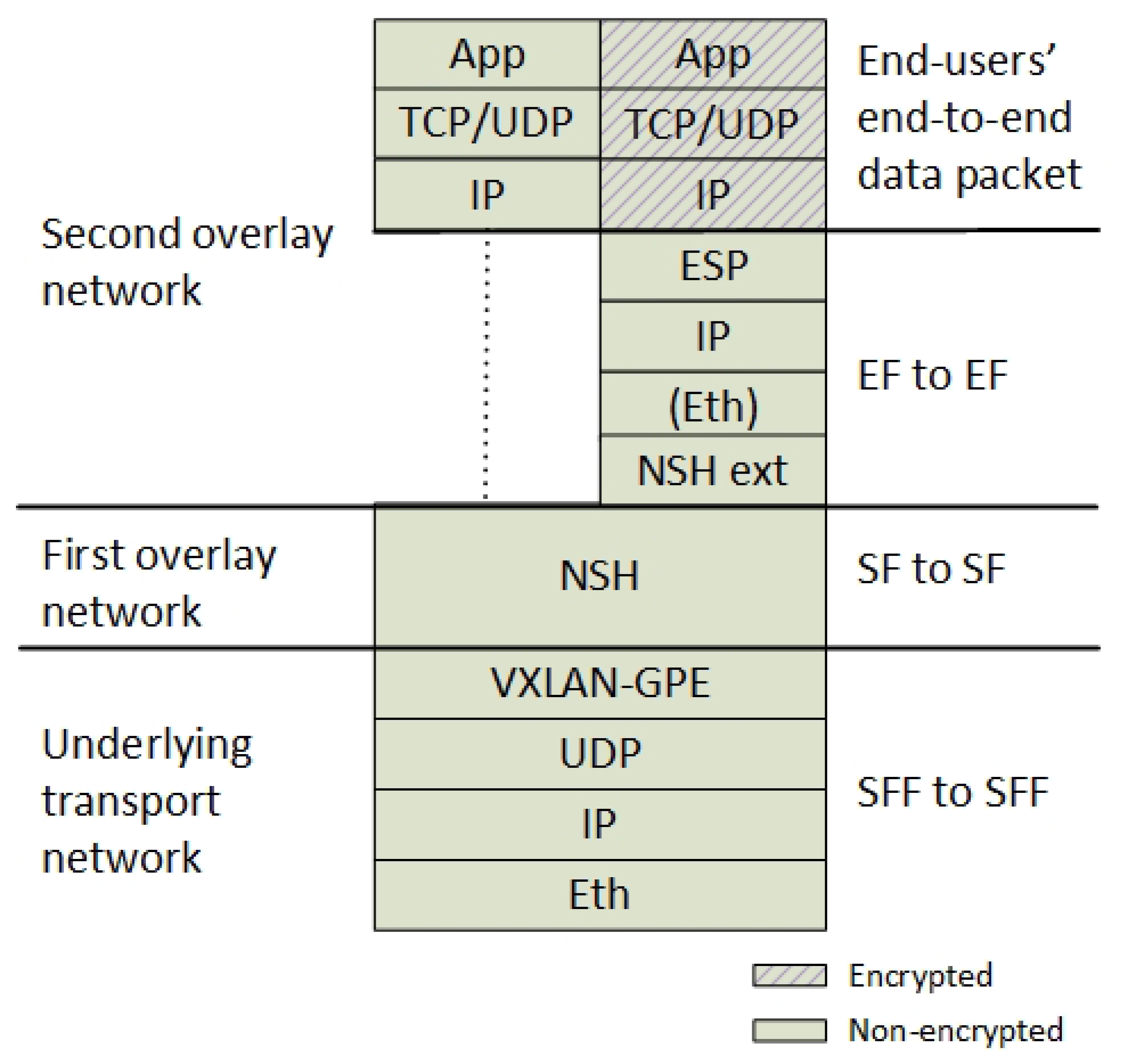
Section 4.1.1). Two layers of NSH headers constitute two overlay networks. One layer addressing the communication between the SFs and one additional layer addressing the point to point communication between the EFs (
Figure 4).
Currently, SR by NSH is not widely supported by routers and neither is the new NSH encryption header extension that we have suggested. Therefore, in order to ensure packet forwarding through legacy network devices, we define that the NSH packet must be encapsulated by an outer transport network between the NSH-aware routers.
Figure 4 shows that we use VXLAN-GPE for this underlying network. Each of these network layers accommodates the different communication layers in the architecture. For example, an NSH header is only valid between two SFs, while the new additional NSH header is only valid between two EFs. Hence, the structured packet header (
Figure 4) is also reflected in a structured design of the networking components (
Figure 3), where each data plane component is responsible for each layer.
4.1.1. Overlay Network Topologies
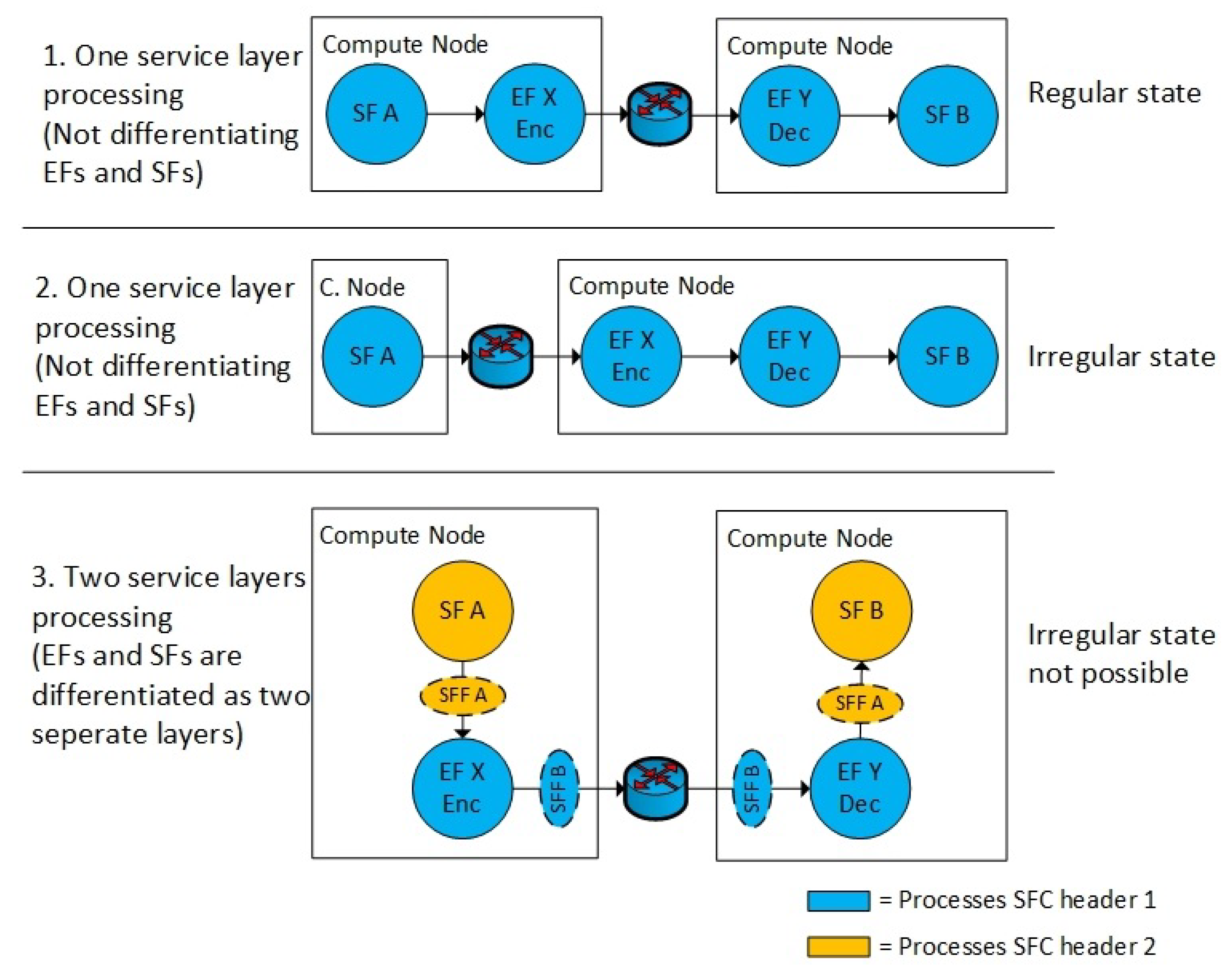
This structured setup of the networking components ensures that the routing of the data packets is not only controlled by flow-rules, but it is also controlled by how the network topology is designed. This is the main objective behind the design of the structured hierarchy of the NSH headers. The structured network topology disallows unencrypted data traffic between an SF and an EF to be routed out of the Compute Node and out on the network.
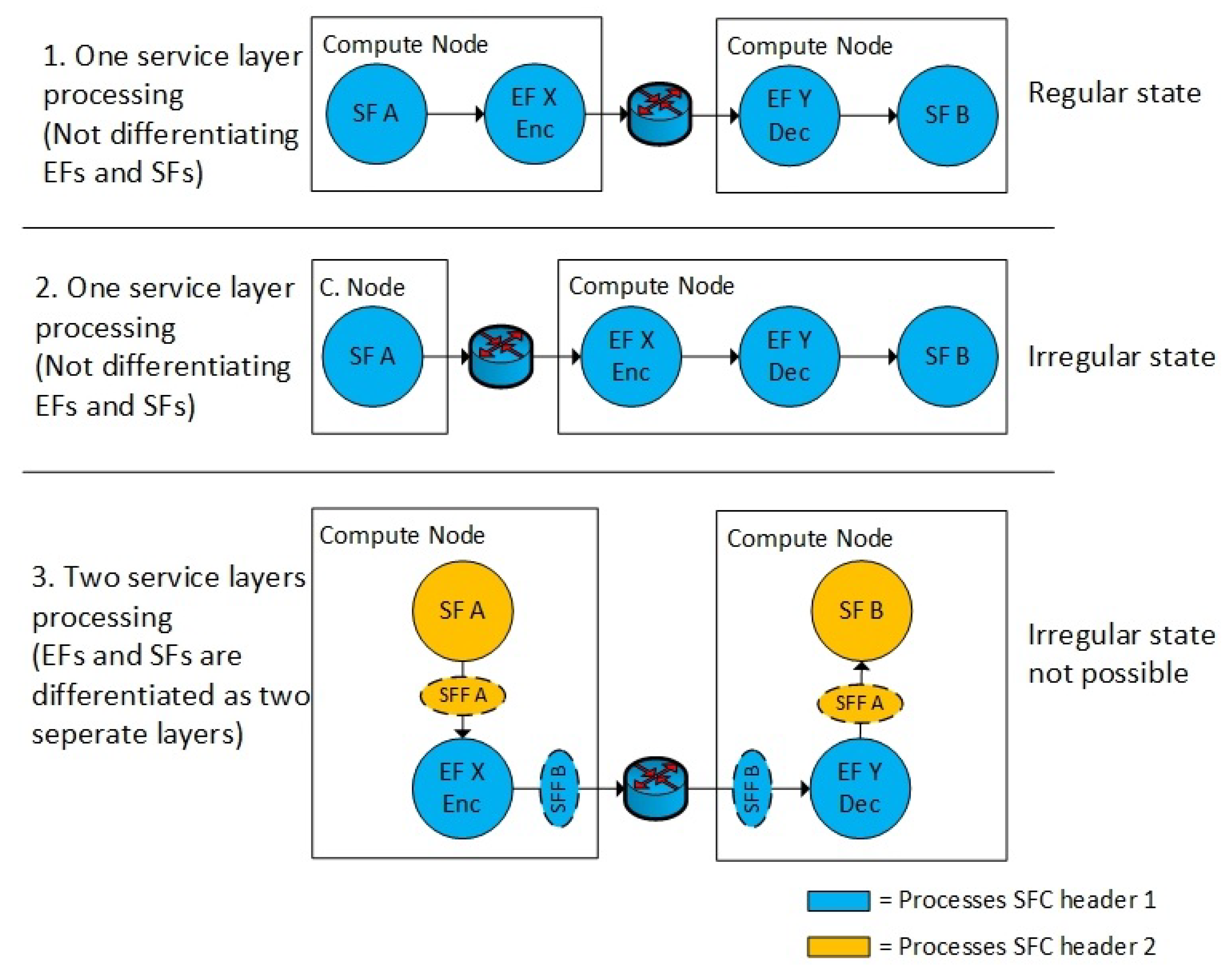
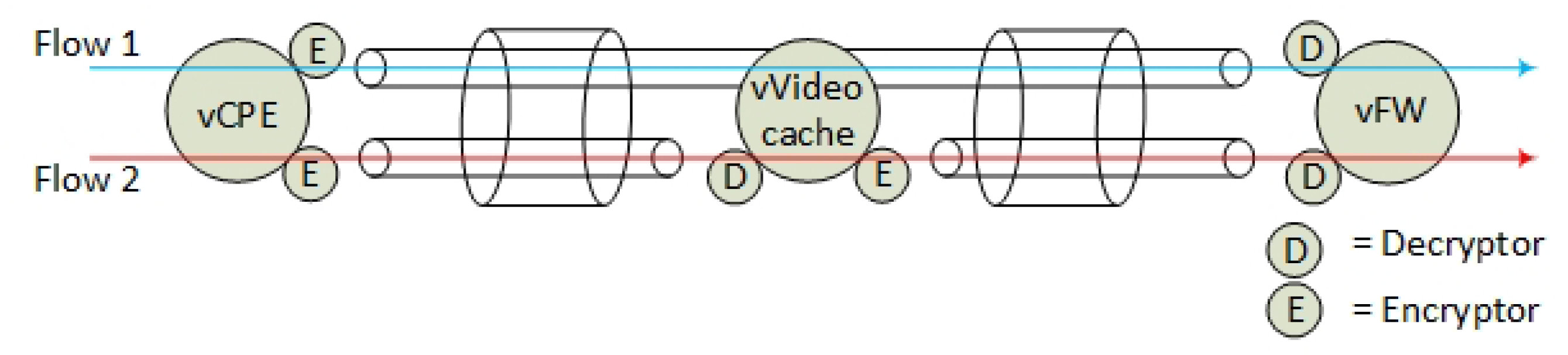
Figure 5 shows the main difference between using and not using an additional NSH header. Within the current NSH RFC [
17] (no additional NSH header), the EF must be treated as a regular SF on one NSH layer (
Figure 5 (1, 2)). The VL is perceived as encrypted and protected if both the EF and SF is located on the same Compute Node. However, if the EF is migrated to another host (
Figure 5 (2)), the non-encrypted traffic (between SF-A and EF-X) is in fact allowed to flow both between different Compute Nodes or between different infrastructure domains. Hence, enabling the EF in a separate network layer (
Figure 5 (3)) makes the network topology more secure. Using two NSH layers ensures that the SF never can be distributed in a way where non-encrypted traffic can leave the Compute Node. The VM, such as the EF-X (
Figure 5 (3)), is in this case also open for VM migration, but, if the VM EF-X is migrated to another Compute Node, the next-hop network destination is unavailable due to a header mismatch between the two types of NSH headers. Hence, the VM’s EF-X and SF-A must be migrated in pairs for allowing the communication between them.
Dedicated networking components per Compute Node that are responsible for the inner and the outer NSH headers logically separate the EFs and the SFs. Therefore, we implemented two separate virtual switches on each compute node that is responsible for the routing of the two NSH layers. This structured setup of Compute Node components (
Figure 3) ensures that the EFs must be co-located with the SF.
4.1.2. Underlay Network
A threat to this structured networking model is an underlying VXLAN-GPE network. In traditional data centres with no NSH overlay, VXLAN is not defined as an underlay network, but it constitutes an overlay network by abstracting the physical network into one big distributed virtualised switch. This implies that, if all the components in our architecture are running as VMs on one underlying distributed virtual switch, the overlaying NSH switches are unaware of the underlying Compute Node location. This compromises the structured setup of networking components on the Compute Node. We solved this problem by combining VXLAN and NSH networks into one customised virtual switch. In addition, we adopted the architectural networking principles from VMware NSX [
23] and pinned the virtual switch to the Compute Node and perceived it as a hypervisor component. We simulated this structure by locking the virtual switch VM to the Compute Node and pretending that the virtual switch was not available in the hypervisor user space. According to the SFC RFC [
2], introducing NSH/SFC-awareness to a virtual switch makes it a Service Function Forwarder (SFF). Hence, we defined two underlying SFFs to be responsible for each NSH layer respectively and let them also to be responsible for handling the VXLAN-GPE tunnels.
4.2. The Service Function Forwarders
In order to support the new NSH packet header formats [
3], we created a new customised virtual switch, based on P4. The programming language P4 enables programmers to customise packet forwarding rules in switches. We made a very simple switch that constitutes an SFF, with VXLAN-GPE and NSH forwarding support. The SFF has the following functionality:
It can parse the new encryption attributes in the NSH header (MD-type = 3, E-SPI, E-SI [
3]).
It classifies IPv4 traffic in order to apply NSH headers.
The SFF can act as a forwarder for NSH packet destined to other SFFs.
It can act as an NSH packet forwarder inside an SF in order to make the SF NSH-aware.
It can provide Layer 2 mac-address resolution based NSH packets instead of using IP and ARP (see
Section 4.4).
It can provide VXLAN-GPE support.
4.3. The Service Function Forwarder Controller
In our previous work [
3], we have suggested using BGP as a control plane mechanism in order to have a standardised method of exchanging NSH routes. However, we identified concerns related to scalability and security of using BGP. Applying route security in BGP includes that each route has to be authorised on a per-peer basis and all viable routes need to be pre-enumerated. In addition, with no route aggregation, route propagation and exponential growth of BGP routes for EFs, we question the scalability of BGP as an NSH control plane protocol. Hence, we changed the control plane component from our previous work [
3] from BGP to distributed RESTconf. This opened up for more efficiently giving the exact routing instructions to the specific Compute Nodes only. RESTconf also enabled a more flexible authorisation of the NSH routes, by authenticating the RESTconf connection by the Secure Socket Layer (SSL).
However, we also selected RESTconf as the control plane protocol due to interoperability reasons. In federated multi-tenant NFV environments, an overlay network is created with virtual forwarding devices such as an SFF. This opens up for customising the virtual network devices and the network controller. This enables network operators to deploy customised networking software in an agile and fast manner. By utilising P4, it is also possible to specify customised flow rules when configuring these network devices. Hence, we utilised the feature of SDN-based network programmability, by specifying customised network configuration by the use of P4 flow rules over RESTconf. The need for customised flow rules is reasoned by the new NSH header extension.
For Proof-of-Concept purposes, we created a very simple RESTconf based network controller with a set of predefined P4 flow-entries. It consists of a simple HTTP client that distributes flow rules over RESTconf by using Linux shell scripts.
4.4. Service Functions
The Service Functions (SFs), applied as VMs, are intended to manipulate the end-user data packets. We simulated that we used SFs acting as a vCPE, video caching service and a virtual firewall by using dummy services. Therefore, all SFs are configured to simply forward all data traffic according to the flow-specification rules we apply. The SFC RFC 7665 [
2] defines that an SF has primarily two data plane interfaces: one for incoming and one for outgoing traffic. Inside the SF, the packet forwarding is explicitly set to follow the SFC directions and not the standard routing table. Specifically, data traffic coming in on one interface must go out on the other interface and vice versa. We solved this SF routing problem by making the SF NSH-aware. This implies that the NSH header is not removed when a packet enters an SF. Due to the lack of NSH state capabilities in operating systems such as native Linux systems, we introduce a new virtual NSH network stack inside the SF. This new network stack is an NSH-aware P4 switch which acts as a front-end network stack inside the SF. This principle of NSH-awareness in the SF is extracted from the VXLAN-tool [
31] implementation and adopted to a P4 environment in order to support the new NSH header. We defined the following features in the SF:
One SF can appear multiple times in one single SFC. Hence, the SF is NSH-aware by using an underlying P4 switch in the SF. The P4 switch is connected to two virtual veth interfaces facing the SF application and two native interfaces facing network interfaces of the VM.
According to the SFC specification, the SF should be independent of the IP subnet topology between the SFs. This means that the IP subnets connected to VM interfaces do not follow standard IP subnetting topologies. For example, when an SFC changes, the mac-address of the next-hop SF are also changing. From an SF perspective, this mac-address has to correspond to the next NSH hop. Hence, the virtual P4 switch in the SF must be able to map interface mac-addresses to SFs. For outgoing traffic from an SF, we use dummy static destination mac-addresses. For incoming traffic to an SF, it is the responsibility of the P4 switch to set the correct destination mac-address to the IP interface of the SF. This mac-address is based on next hop in the SFC. Hence, instead of using standard ARP as a binding between layer 2 and layer 3, we introduce a new mac-address mapping scheme between mac-addresses and NSH Service Function Identifiers. This is implemented as P4 flow-rule actions. A dynamic side effect of this is that the IPv4 addresses of the SF application theoretically can be reused for each hop in an SFC.
4.5. Service Function Provisioner
The Service Function Provisioner component corresponds to the Virtual Infrastructure Manager (VIM) in the NFV reference model [
32]. It is responsible for maintaining the lifecycle management of all virtual network functions. We simplified this function and used Vagrant [
33] and Vagrant scripts as a provisioning tool for all VMs per Compute Node. As an overlay to multiple Vagrant nodes, we used RESTconf to instantiate the Vagrant scrips.
4.6. The Encryption Service Function
This component is responsible for both encrypting and decrypting the data traffic in front of the SF. This functionality is realised with a data encryption application in a customised SF that we named the Encryption Service Function (EF). From a network infrastructure perspective, the EF is a copy of the SF, except for being responsible for a different network layer (the additional NSH layer). In addition to the P4 networking functionalities, the EF adopts the Software-Defined IPsec application (SD-SA) functionality that we have presented in our previous work [
7]. In summary, this application has the following features:
We use the Linux based IP XFRM application to encrypt and decrypt IP packets and encapsulates them with an IPsec Encapsulating Security Payload (ESP) header.
The encryption application runs inside a Linux network namespace (netns) that separates the encryption application from the P4 switch.
IPsec Internet Key Exchange (IKE) is replaced with a new web service application that exchanges the encryption keys and the integrity keys in a separate control plane channel.
The EF is instantiated with a set of preshared keys. These keys are used to establish a secure connection to a centralised Authentication Center (AuC) that manages the key distribution.
4.7. The Authentication Centre (AuC)
The EFs are controlled by an Authentication centre that distributes the encryption keys and the integrity keys. Due to the non-bidirectional NSH communication channel between EFs [
2], an IPsec IKE channel is not possible to establish on the data plane. Hence, we adopt the aforementioned SD-SA application from our previous work [
7] in order to replace IKE in IPsec. In summary, this application includes the following functionality. The initial step is to pre-configure an authentication key for every EF during EF instantiation. Second, all EFs establish a secure channel to the AuC. Third, the AuC sends the integrity and confidentiality key to the encryption function over the authenticated and secured RESTconf channel. This last step is a periodic event that is repeated for every key change. An important requirement for this concept to work is that all EFs are connected to one common AuC. This also requires a shared control plane VPN between all data centre tenants. This control plane VPN is established by using site-to-site IPsec VPN tunnels between the data centres.
5. Implementation
Based on the aforementioned scenarios (
Section 3), we constructed a network topology consisting of three simple SFs and two underlying pairs of encrypted channels.
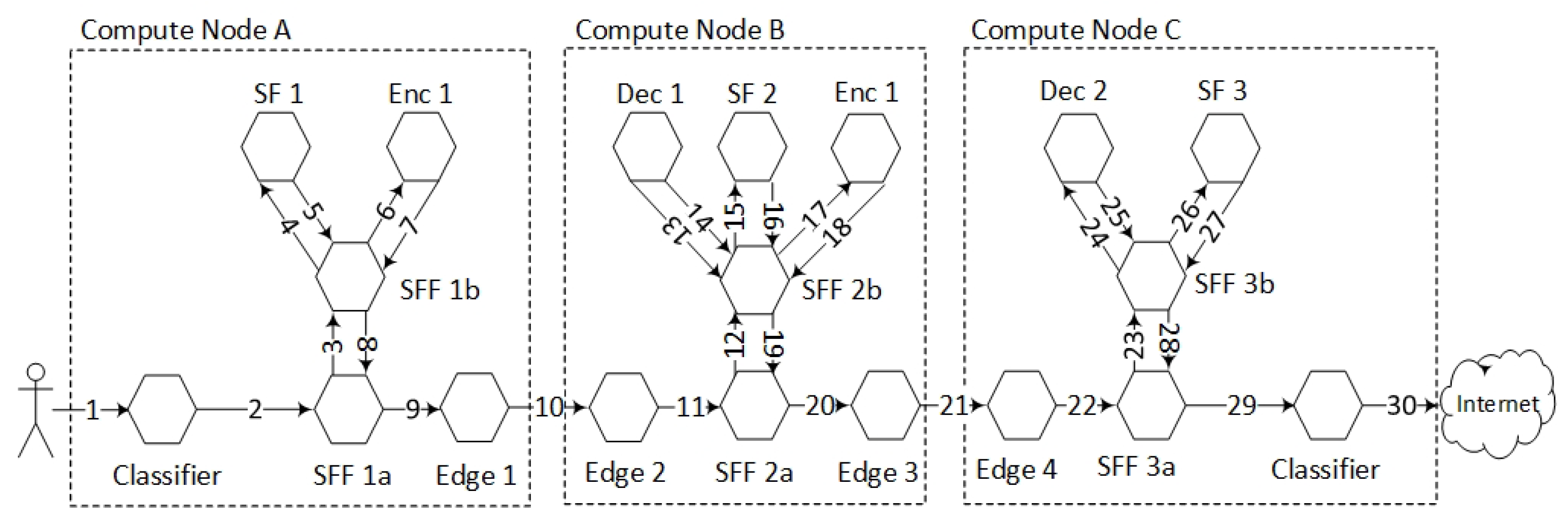
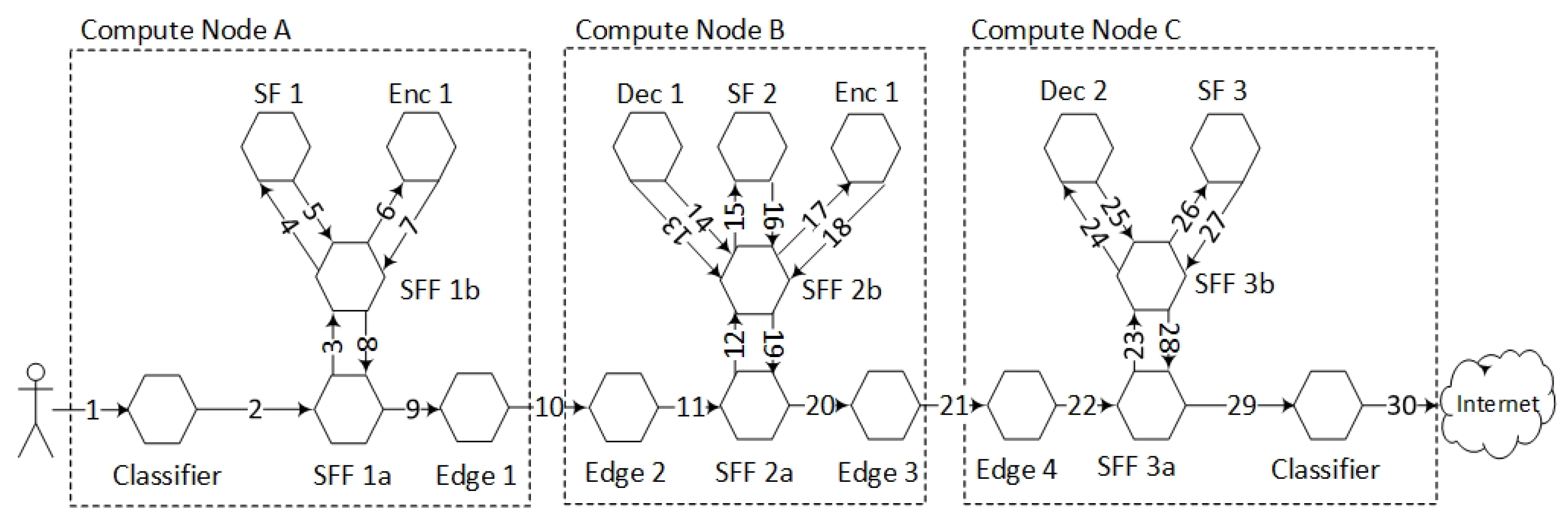
Figure 6 shows the components that are involved in the data plane forwarding of the NSH packets.
This network topology setup implements the use case scenario (
Figure 2) and also reflects the tiered network topology (
Figure 3). We implemented this topology by running one Compute Node per ISP where each Compute Node had one inner and one outer SFF. We also configured an Edge gateway per network domain that was responsible for interconnecting the data centre domains. We used one Compute Node per NFV domain. Correspondingly, there is one Edge gateway per Compute Node.
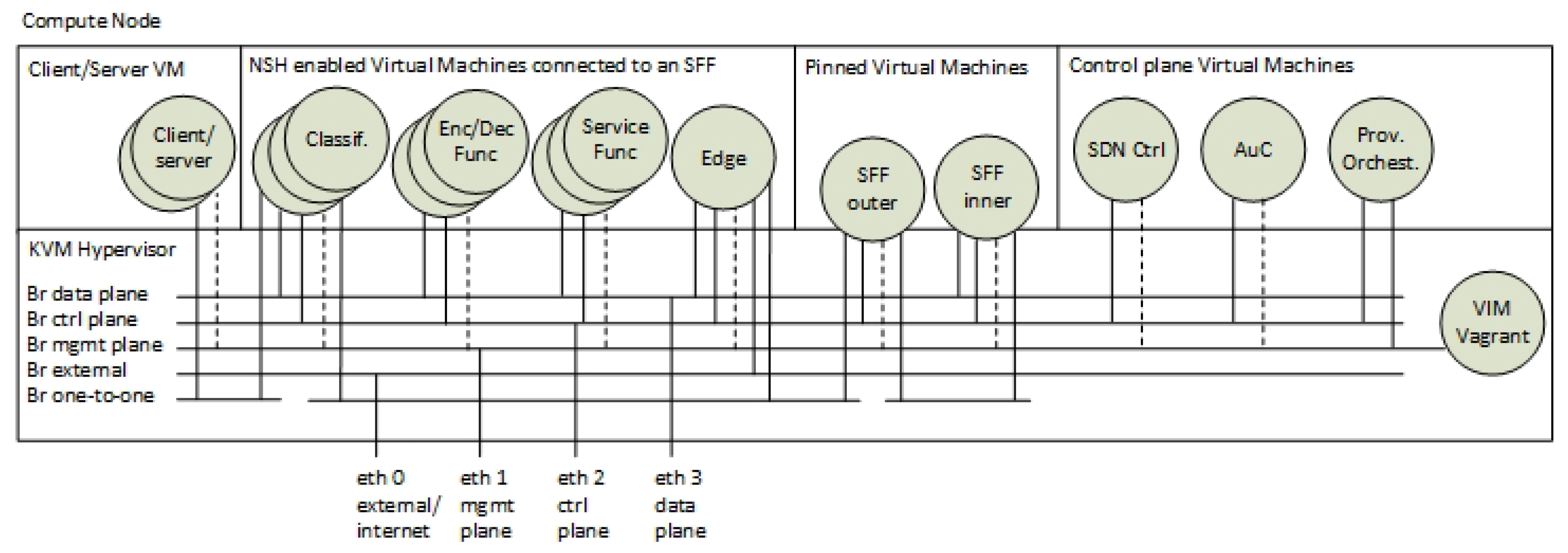
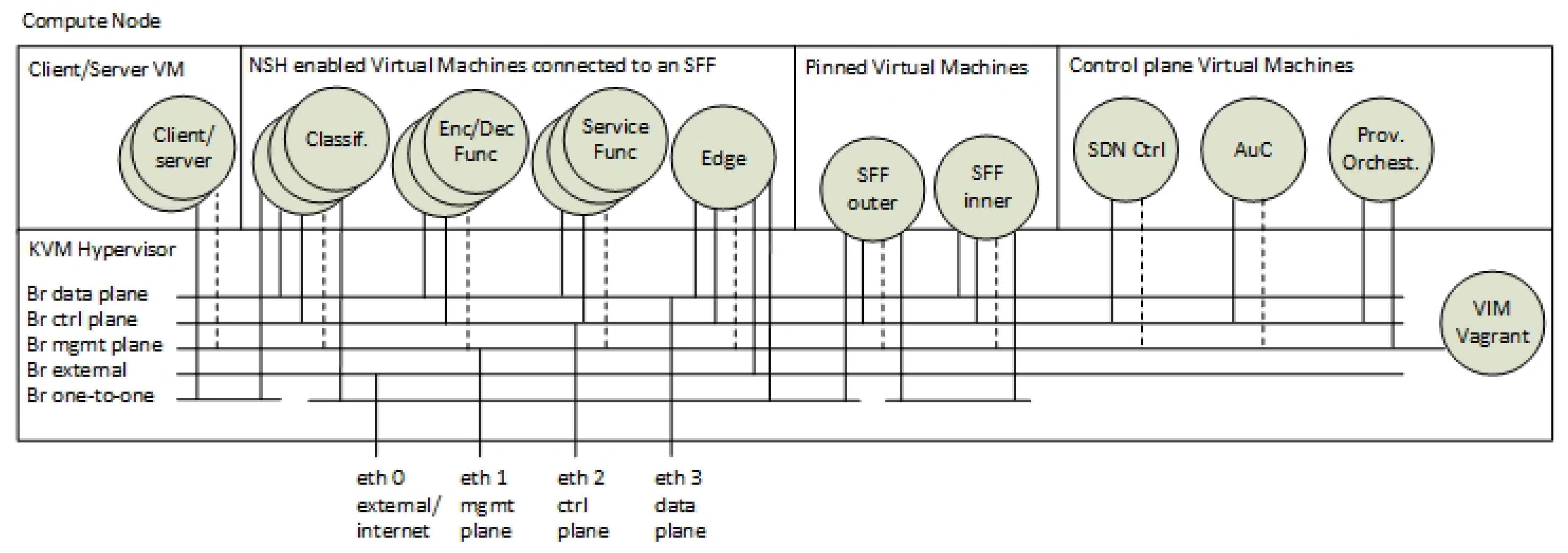
Figure 7 shows the categorisation, the enumerations and the virtual bridge connections of the VMs running on each Compute Node. The SFs, the EFs and the classifiers are instantiated as multiple instances of VMs. These VMs are instantiated per SFC during service provisioning. The SFFs are statically deployed VMs that are pinned to the hypervisor. The control plane components are also categorised as a special group of VMs. This is because they are only instantiated at one of the Compute Nodes and because they are not connected to the data plane.
From a networking perspective,
Figure 7 also shows that each VM is connected to different Linux-bridge domains. We used virtual Linux interfaces (veth) to interconnect VMs to virtual bridges. Furthermore, these virtual bridges are also connected to the physical network interfaces. This network construction follows the principle of virtual network infrastructures in Linux that is also used in, for example, OPNFV [
34] and OpenStack [
35].
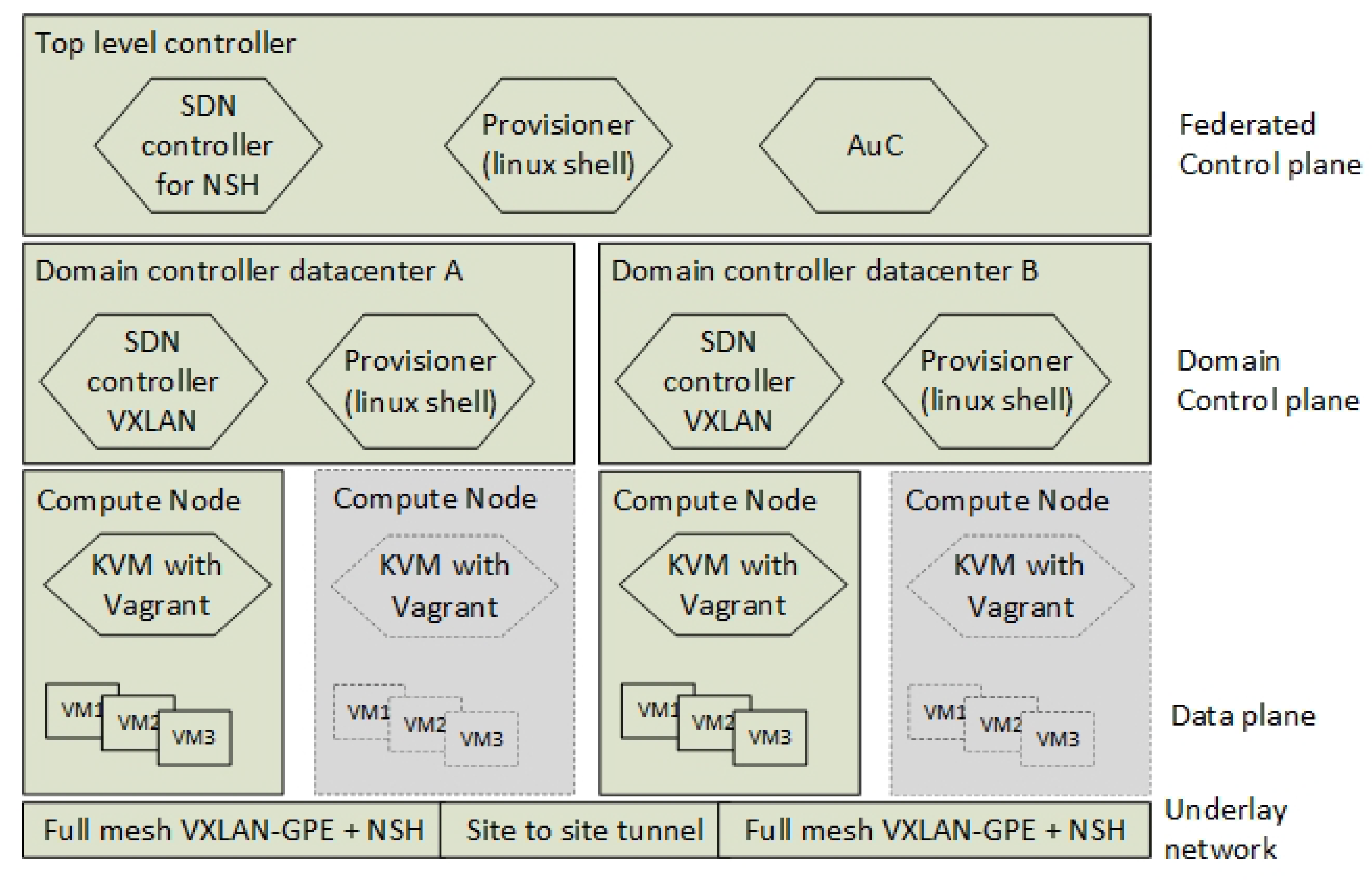
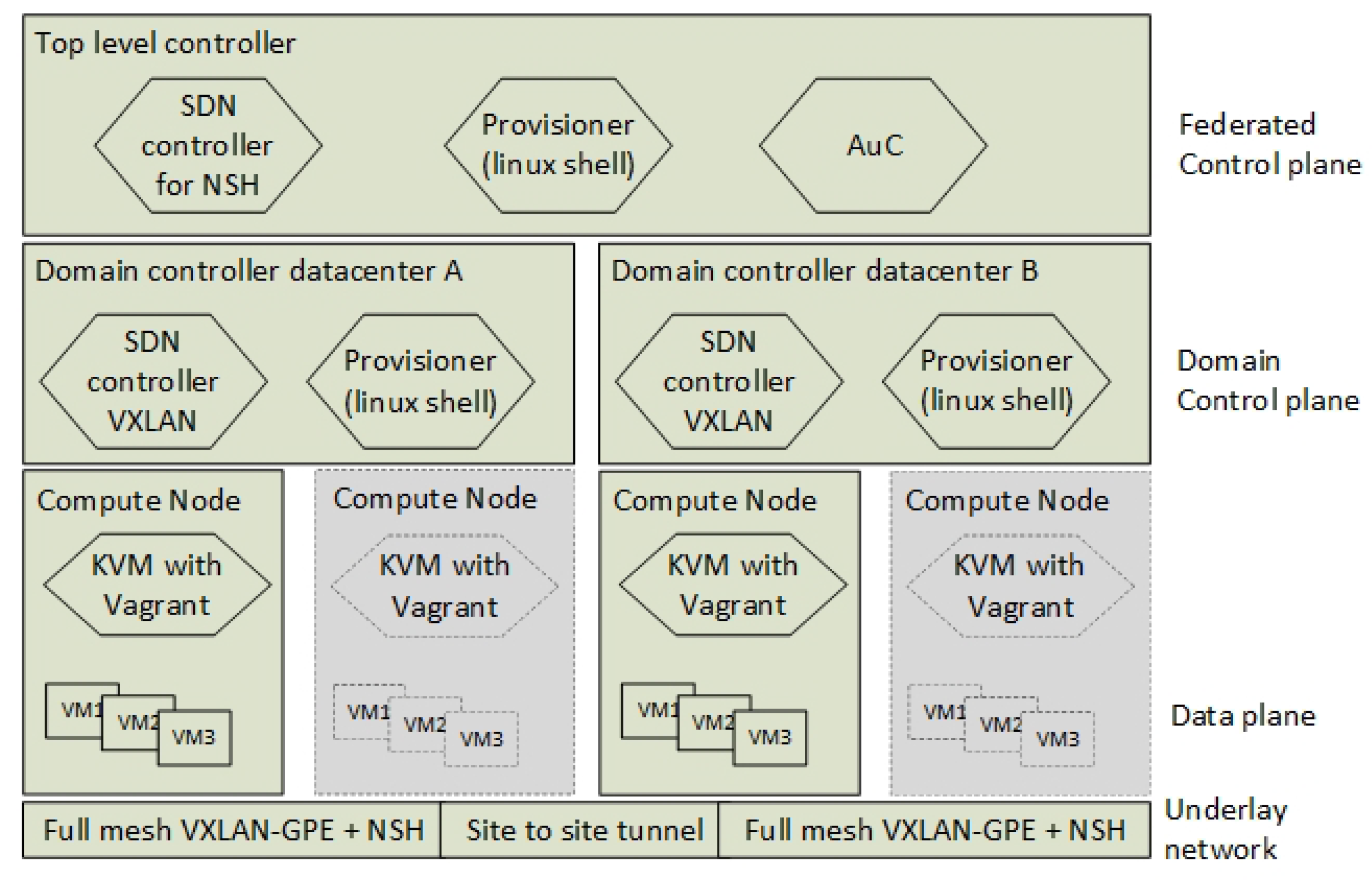
For local Virtual Infrastructure Management (VIM), we ran the VM provisioning tools and the local network/bridge management as non-virtual function alongside the Kernel-based Virtual Machine (KVM) environment. We used Linux scripts and Vagrant to control the instantiation of VMs and to control the mapping the virtual network interfaces to the underlying VXLAN-GPE infrastructure. The local VIM is orchestrated by a simple top-level RESTconf based orchestrator.
Figure 8 shows the hierarchy of both this orchestrator and the other control plane components. For proof-of-concept purposes, we only used one Compute Node per domain controller.
The NFV implementation is developed by the use of Vagrant, Linux bash scripting and the switch programming language P4. The source code, the demonstrations and the test results are available at
https://github.com/gunleifsen/encNSHinP4.
7. Conclusions
This paper proposes an architecture for on-demand provisioning of encrypted and isolated SFC using P4, NFV and SDN architectural principles.
A comprehensive view of the developed security framework for SFC has been presented, according to the scenarios executed during the concluding system validation demonstrations. A subset of the security-related functionalities supported by the developed architecture has also been shown in order to highlight critical architectural details towards its implementation.
Furthermore, this article unifies the publicly available results of our security-related studies, by highlighting how the distinct components presented earlier interoperate towards providing secure SFCs. The presented results highlight the capacity of micro-segmented SFC in NFV, given that the corresponding security requirements are satisfied.
The presented architecture is based on virtualised overlay networks and the upcoming technology P4. These technologies aim to overcome network protocol standardisation and interoperability issues. Hence, the architecture is applicable in any IP network and any Infrastructure as a Service (IaaS) platform. However, this abstraction of physical resources raises new standardisation issues within the virtualised environment, such as the encryption application in the service function. This puts a burden on the SF developers and calls for a standardisation of the encryption application interfaces in the SF and the AuC. Hence, this proof of concept experiment aims to contribute to the standardisation of NFV application interfaces for enabling encrypted Virtual Links.
Through the executed studies of encrypted SFCs, a variety of future work paths have been identified. These include the investigation of hardware accelerators, integrated QoS, availability and security policies, particularly for protected and encrypted SFC. Furthermore, another potentially critical path of future work refers to the investigation of packed injection between SFCs where encryption enabled SF is a possible solution.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}