An Ontology-Based Recommender System with an Application to the Star Trek Television Franchise


Abstract
1. Introduction
2. Materials and Methods
2.1. Neighborhood-Based Collaborative Filtering
2.2. Item Similarity
2.2.1. Textual Representation
2.2.2. Content Representation Based on Controlled Vocabularies
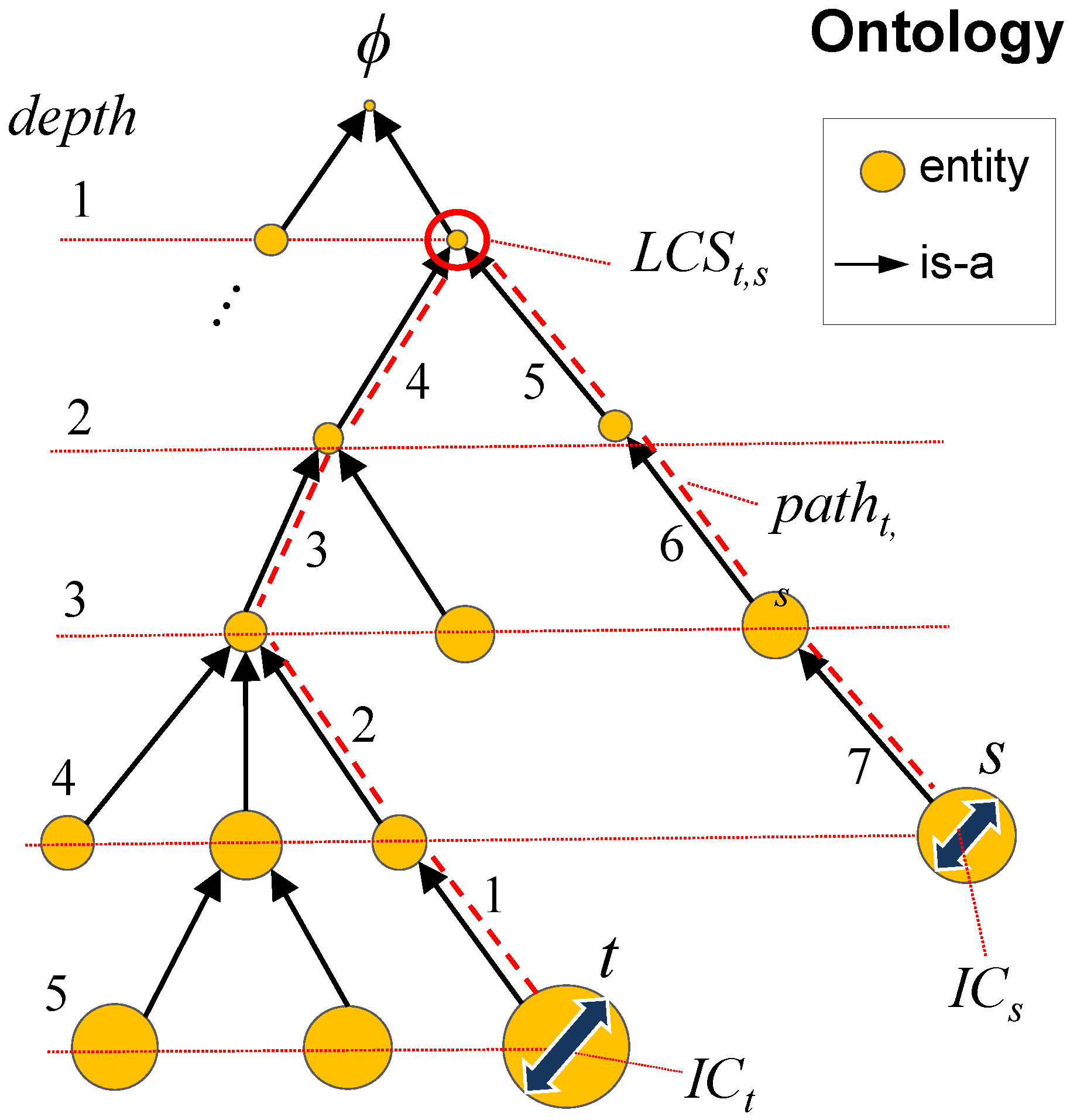
2.2.3. Ontology-Based Similarity Functions
- d: The maximum number of steps from any entity to .
- m: The maximum number of steps between any pair of entities.
- : The number of steps from entity t to .
- : The number of steps from entity t to entity u.
- : The least common subsumer of t and u (i.e., their deepest common ancestor).
- : The information content (IC) of entity t as proposed by Resnik et al. [46]. is a measure of the informativeness of an entity in a hierarchy obtained from statistics gathered from a corpus. In our scenario, the corpus is a collection of items, each of which is represented by a set of features associated with entities in an ontology. Thus, the of an entity t is defined as , where is the probability of t in the corpus. For instance, assume the corpus of items to be a set of TV episodes whose features are themes from a theme ontology. In addition, assume the following path of theme entities in an is-a chain: “wedding ceremony” → “ceremony” → “event” → . The probability of an entity t is the ratio between its number of occurrences and the total number of entity occurrences in the corpus M. Each occurrence of the theme “wedding ceremony” increases the counting up the hierarchy until is reached. Therefore, and . The IC scores agree with the information theoretical principle that events having low probability are highly informative and vice versa.
2.3. A Literary Theme Ontology with Application to Star Trek Television Series Episodes
2.3.1. The Star Trek Television Series
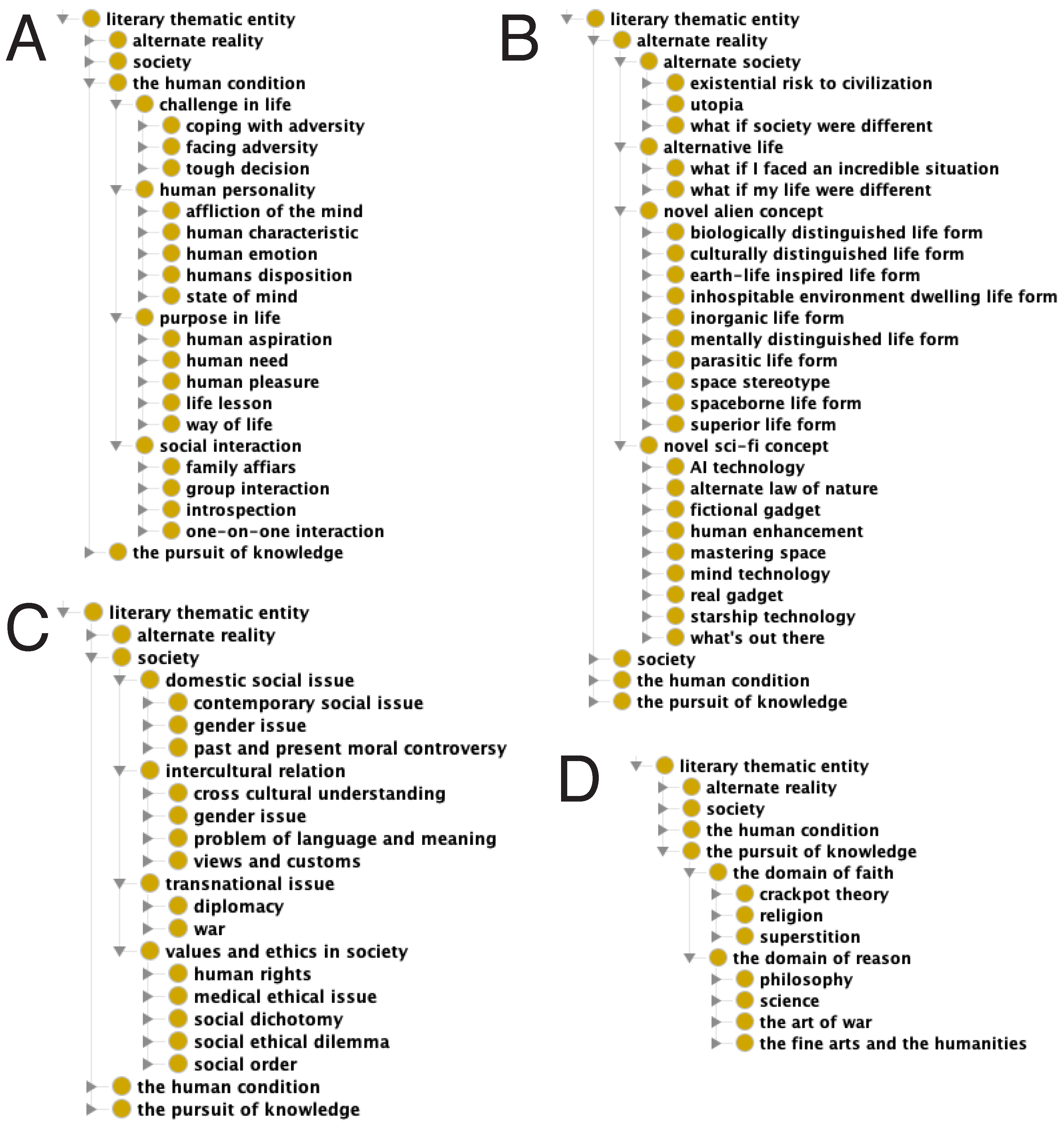
2.3.2. The Literary Theme Ontology
- The Human Condition:
- Themes pertaining to the inner and outer experiences of individuals be they about private life or pair and group interactions with others around them.
- Society:
- Themes pertaining to individuals involved in persistent social interaction, or a large social group sharing the same geographical or social territory, typically subject to the same political authority and dominant cultural expectations. These are themes about the interactions and patterns of relationships within or between different societies.
- The Pursuit of Knowledge:
- Themes pertaining to the expression of a view about how the world of nature operates, and how humans fit in relation to it. Put another way, these are themes about scientific, religious, philosophical, artistic, and humanist views on the nature of reality.
- Alternate Reality:
- Themes related to subject matter falling outside of reality as it is presently understood. This includes, but is not limited to, science fiction, fantasy, superhero fiction, science fantasy, horror, utopian and dystopian fiction, supernatural fiction as well as combinations thereof.
2.3.3. A Thematically Annotated Star Trek Episode Dataset
2.4. Episode Transcripts
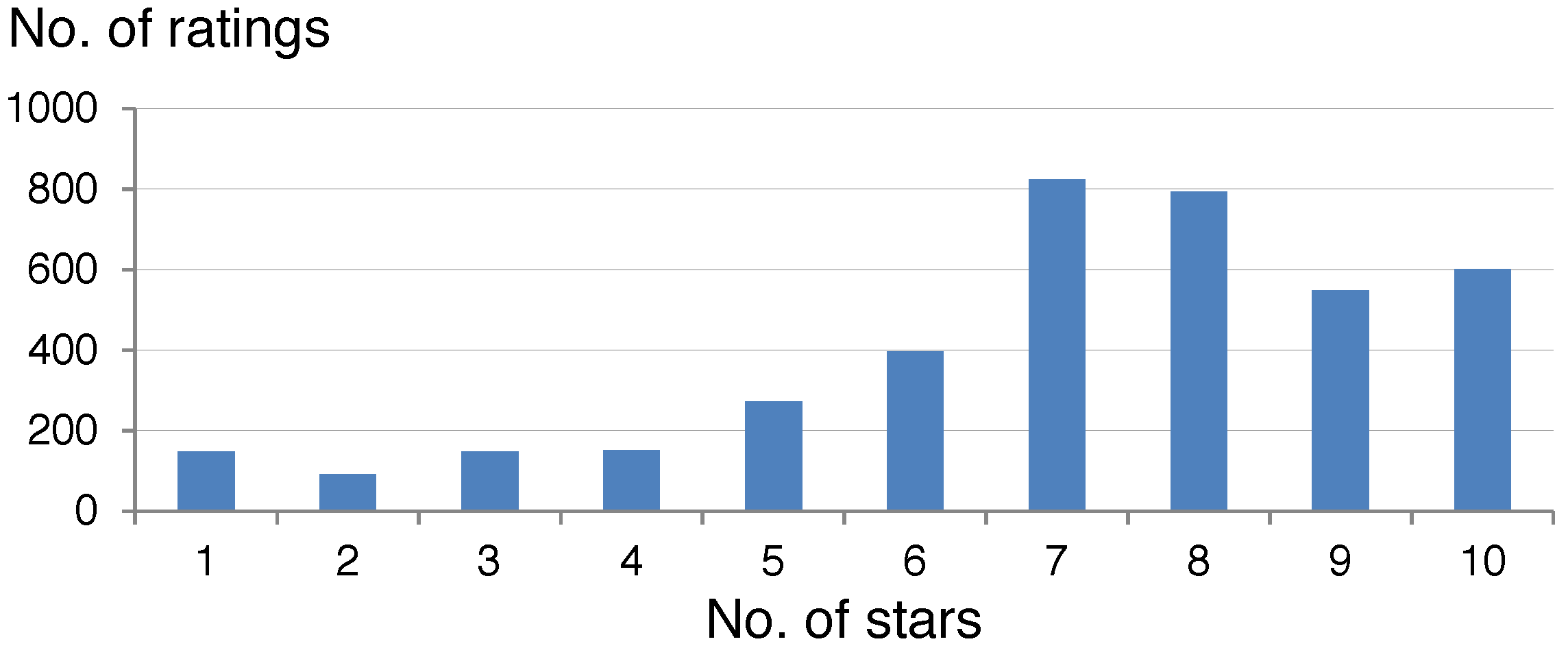
2.5. User Preferences
3. Experimental Validation
3.1. Experimental Setup
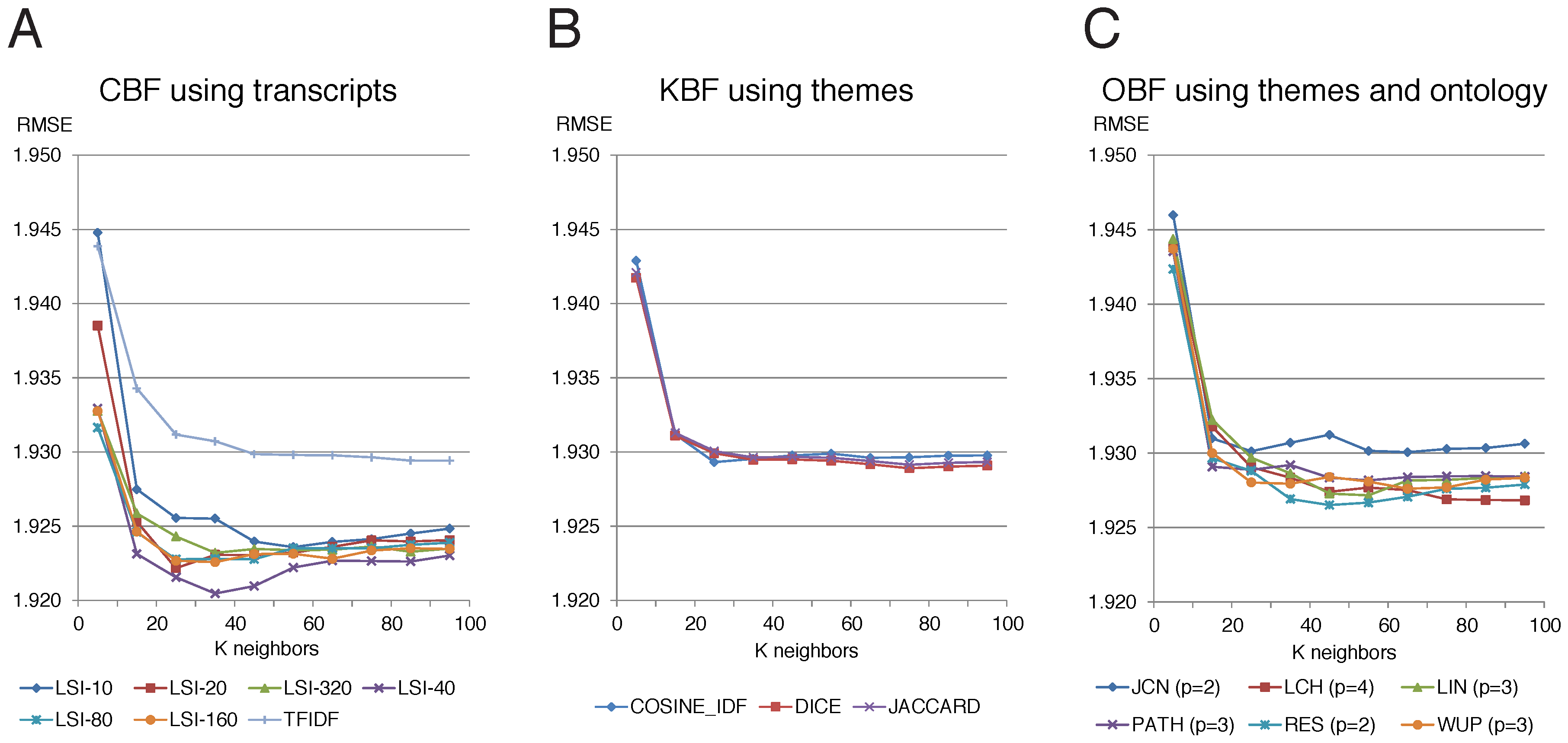
- CBF recommenders using transcripts:
- These methods use the data and preprocessing procedure described in Section 2.3. TFIDF is implemented using Equations (3) and (4), and LSI is implemented by performing SVD, as described in Section 2.2.1, on the document-term matrix obtained from the data. The number of latent factors was varied from 10 to 100 in increments of 10. Both approaches are implemented using the Gensim (Gensim: Topic modelling for humans (2019). URL: https://radimrehurek.com/gensim/. (Online; accessed 30 June 2019)) text processing library [71].
- KBF recommenders using themes:
- The three methods described in Section 2.2.2 applied to the thematically annotated representation of the episodes described in Section 2.3.3. JACCARD and DICE were implemented using the Equation (5) formulae as item similarity functions, while COSINE_IDF was implemented using Equation (6).
- OBF recommenders using themes and the ontology:
- This category comprises the methods introduced in this work, which are described in detail in Section 2.2.3. These methods make use of the thematically annotated Star Trek episodes described in Section 2.3.3, and of the LTO themes as presented in Section 2.3.2. Each of the six variants is named after the abbreviation for their assocaited item similarity function: , , , , , and .
- CF recommenders and baselines:
- In this group, we tested a set of classical RSs based purely on user ratings. These methods can be grouped into KNN [14] and matrix factorization approaches [15,66,67,68,69,70]. In addition, we included five popular baseline methods: (1) User Item Baseline, which produces rating predictions using the baselines described in Section 2.1; (2) Item Average Baseline, which uses as predictions the mean rating of each item; (3) User Average Baseline same as before, but averaging by user; (4) Global Average Baseline which always predicts the average rating of the dataset; and (5) Random Baseline, which produces random ratings distributed uniformly.
3.2. Results
3.3. Results Discussion
4. Discussion
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| BFO | Basic Formal Ontology |
| CF | collaborative filtering (general approach for recommender systems) |
| CBF | content-based filtering (general approach for recommender systems) |
| DF | document frequency |
| FM | factor model (general approach for CF recommender systems) |
| IC | information content |
| IDF | inverse document frequency |
| IKNN | item K-nearest neighbors (method for recommender systems) |
| IMDb | The Internet Movie Database |
| JCH | Jiang and Conrath measure [73] (entity similarity function in an ontology hierarchy) |
| KBF | knowledge-based filtering (general approach for recommender systems) |
| LCH | Leacock and Chodorow measure [47] (entity similarity function in an ontology hierarchy) |
| LCS | least common subsumer between two entities in an ontology |
| LIN | Lin’s measure [49] |
| LSI | latent semantic indexing (method for text representation) |
| LTO | Literary Theme Ontology |
| MF | matrix factorization |
| NLTK | Natural Language Toolkit |
| OBF | ontology-based filtering (general approach for recommender systems) |
| RES | Resnik’s measure [46] (entity similarity function in an ontology hierarchy) |
| RMSE | root-mean square error |
| RS | recommender system |
| SVD | singular value decomposition |
| s.d. | standard deviation |
| TAS | Star Trek: The Animated Series (series of Star Trek TV episodes) |
| TF | term frequency |
| TFIDF | term frequency–inverse document frequency (method for text representation) |
| TNG | Star Trek: The Next, Generation (series of Star Trek TV episodes) |
| TOS | Star Trek: The Original Series (series of Star Trek TV episodes) |
| WUP | Wu and Palmer’s measure [48] (entity similarity function in an ontology hierarchy) |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Literary Theme | Domain | Level | Comment |
|---|---|---|---|
| avarice |  | central | Arridor and Kol exploit a Bronze Age people for economic gain. |
| exploitation of sentient beings |  | central | Arridor and Kol exploit a Bronze Age people for economic gain. |
| fraud |  | central | Arridor and Kol fraudulently claim to be the Holy Sages prophesied in Takarian sacred scripture. |
| primitive point of view |  | central | The viewer is made to see the world through the eyes of a Bronze Age people. |
| religion as a control mechanism |  | central | Arridor and Kol use religion as a means of exploiting a technologically lesser advanced people. |
| science as magic to the primitive |  | central | Arridor and Kol use advanced technology to trick a Bronze Age people into thinking them gods. |
| the ethics of interfering in less advanced societies |  | central | Captain Janeway argued she had the authority to depose Arridor and Kol from their seat of power on the Takarian homeworld because the Federation was responsible for the cultural contamination caused by their arrival. |
| the fulfillment of prophesy |  | central | Arridor and Kol fraudulent claim to be the Holy Sages prophesied in Takarian sacred scripture. |
| the lust for gold |  | central | Arridor and Kol exploit a Bronze Age people for economic gain. |
| casuistry in interpretation of scripture |  | peripheral | Arridor and Kol advocated a nonliteral interpretation of the passage in Takarian sacred scripture condemning them to being burned at the stake. |
| wormhole |  | peripheral | Arridor and Kol travel through a wormhole to reach the Takarian homeworld. |
| matter replicator |  | peripheral | Arridor and Kol proliferated matter replicator technology on the Takarian homeworld. |
Appendix B

References
- Burke, R. Hybrid recommender systems: Survey and experiments. User Model. User-Adapt. Interact. 2002, 12, 331–370. [Google Scholar] [CrossRef]
- Cambria, E. Affective computing and sentiment analysis. IEEE Intell. Syst. 2016, 31, 102–107. [Google Scholar] [CrossRef]
- Véras, D.; Prota, T.; Bispo, A.; Prudêncio, R.; Ferraz, C. A literature review of recommender systems in the television domain. Expert Syst. Appl. 2015, 42, 9046–9076. [Google Scholar] [CrossRef]
- FX Chief John Landgraf Says ‘peak TV’ is Still Ascending. Available online: https://www.latimes.com/business/hollywood/la-fi-ct-fx-tca-20180803-story.html (accessed on 30 June 2019).
- Aharon, M.; Hillel, E.; Kagian, A.; Lempel, R.; Makabee, H.; Nissim, R. Watch-it-next: A contextual TV recommendation system. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Cham, Switzerland, 2015; pp. 180–195. [Google Scholar]
- Schafer, J.B.; Frankowski, D.; Herlocker, J.; Sen, S. Collaborative filtering recommender systems. In The Adaptive Web; Springer: Berlin/Heidelberg, Germany, 2007; pp. 291–324. [Google Scholar]
- Golbandi, N.; Koren, Y.; Lempel, R. Adaptive bootstrapping of recommender systems using decision trees. In Proceedings of the Fourth ACM International Conference on Web Search and Data Mining, Hong Kong, China, 9–12 February 2011; pp. 595–604. [Google Scholar]
- Becerra, C.J.; Jimenez, S.; Gelbukh, A.F. Towards User Profile-based Interfaces for Exploration of Large Collections of Items. Decisions@RecSys’13 2013, 9–16. [Google Scholar]
- Lika, B.; Kolomvatsos, K.; Hadjiefthymiades, S. Facing the cold start problem in recommender systems. Expert Syst. Appl. 2014, 41, 2065–2073. [Google Scholar] [CrossRef]
- Huddleston, T., Jr. ‘Star Trek’ Fans Beam into NYC for 50th Anniversary Celebration. 2016. Available online: https://fortune.com/2016/09/03/star-trek-new-york-50th/ (accessed on 30 June 2019).
- STARFLEET, The International Star Trek Fan Association, Inc. Available online: http://sfi.org/ (accessed on 30 June 2019).
- Sheridan, P.; Onsjö, M. stoRy: Functions for the Analysis of Star Trek Thematic Data. R package version 0.1.3. Available online: https://cran.r-project.org/web/packages/stoRy/index.html (accessed on 15 August 2019).
- Sheridan, P.; Onsjö, M.; Hastings, J. The Literary Theme Ontology for Media Annotation and Information Retrieval. arXiv 2019, arXiv:1905.00522. [Google Scholar]
- Koren, Y. Factor in the neighbors: Scalable and accurate collaborative filtering. ACM Trans. Knowl. Discov. Data (TKDD) 2010, 4, 1. [Google Scholar] [CrossRef]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix Factorization Techniques for Recommender Systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Li, Y.; Wang, S.; Pan, Q.; Peng, H.; Yang, T.; Cambria, E. Learning binary codes with neural collaborative filtering for efficient recommendation systems. Knowl. Based Syst. 2019, 172, 64–75. [Google Scholar] [CrossRef]
- De Gemmis, M.; Lops, P.; Musto, C.; Narducci, F.; Semeraro, G. Semantics-aware content-based recommender systems. In Recommender Systems Handbook; Springer: Boston, MA, USA, 2015; pp. 119–159. [Google Scholar]
- Bellekens, P.; van der Sluijs, K.; van Woensel, W.; Casteleyn, S.; Houben, G.J. Achieving efficient access to large integrated sets of semantic data in web applications. In Proceedings of the 2008 Eighth International Conference on Web Engineering, Yorktown Heights, NJ, USA, 14–18 July 2008; pp. 52–64. [Google Scholar]
- Blanco-Fernández, Y.; Pazos-Arias, J.J.; Gil-Solla, A.; Ramos-Cabrer, M.; López-Nores, M.; García-Duque, J.; Fernández-Vilas, A.; Díaz-Redondo, R.P.; Bermejo-Muñoz, J. An MHP framework to provide intelligent personalized recommendations about digital TV contents. Softw. Pract. Exp. 2008, 38, 925–960. [Google Scholar] [CrossRef]
- IJntema, W.; Goossen, F.; Frasincar, F.; Hogenboom, F. Ontology-based news recommendation. In Proceedings of the 2010 EDBT/ICDT Workshops, Lausanne, Switzerland, 22–26 March 2010; pp. 1–6. [Google Scholar]
- López-Nores, M.; Blanco-Fernändez, Y.; Pazos-Arias, J.J.; García-Duque, J. Exploring synergies between digital tv recommender systems and electronic health records. In Proceedings of the 8th European Conference on Interactive TV and Video, Tampere, Finland, 9–11 June 2010; pp. 127–136. [Google Scholar]
- Martinez-Cruz, C.; Porcel, C.; Bernabé-Moreno, J.; Herrera-Viedma, E. A model to represent users trust in recommender systems using ontologies and fuzzy linguistic modeling. Inf. Sci. 2015, 311, 102–118. [Google Scholar] [CrossRef]
- Porcel, C.; Martinez-Cruz, C.; Bernabé-Moreno, J.; Tejeda-Lorente, Á.; Herrera-Viedma, E. Integrating ontologies and fuzzy logic to represent user-trustworthiness in recommender systems. Procedia Comput. Sci. 2015, 55, 603–612. [Google Scholar] [CrossRef]
- Naudet, Y.; Mignon, S.; Lecaque, L.; Hazotte, C.; Groues, V. Ontology-based matchmaking approach for context-aware recommendations. In Proceedings of the 2008 International Conference on Automated Solutions for Cross Media Content and Multi-Channel Distribution, Florence, Italy, 17–19 November 2008; pp. 218–223. [Google Scholar]
- Yong, S.J.; Do Lee, H.; Yoo, H.K.; Youn, H.Y.; Song, O. Personalized recommendation system reflecting user preference with context-awareness for mobile TV. In Proceedings of the 2011 IEEE Ninth International Symposium on Parallel and Distributed Processing with Applications Workshops, Busan, Korea, 26–28 May 2011; pp. 232–237. [Google Scholar]
- Nilashi, M.; Ibrahim, O.; Bagherifard, K. A recommender system based on collaborative filtering using ontology and dimensionality reduction techniques. Expert Syst. Appl. 2018, 92, 507–520. [Google Scholar] [CrossRef]
- Martín-Vicente, M.I.; Gil-Solla, A.; Ramos-Cabrer, M.; Pazos-Arias, J.J.; Blanco-Fernández, Y.; López-Nores, M. A semantic approach to improve neighborhood formation in collaborative recommender systems. Expert Syst. Appl. 2014, 41, 7776–7788. [Google Scholar] [CrossRef]
- Ricci, F.; Rokach, L.; Shapira, B.; Kantor, P.B. Recommender Systems Handbook, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Falk, K. Practical Recommender Systems; Manning Publications Company: Shelter Island, NY, USA, 2019. [Google Scholar]
- Golub, G.H.; Reinsch, C. Singular Value Decomposition and Least Squares Solutions. Numer. Math. 1970, 14, 403–420. [Google Scholar] [CrossRef]
- Shani, G.; Heckerman, D.; Brafman, R.I. An MDP-based recommender system. J. Mach. Learn. Res. 2005, 6, 1265–1295. [Google Scholar]
- Su, X.; Khoshgoftaar, T.M. Collaborative filtering for multi-class data using belief nets algorithms. In Proceedings of the 2006 18th IEEE International Conference on Tools with Artificial Intelligence (ICTAI’06), Arlington, VA, USA, 13–15 November 2006; pp. 497–504. [Google Scholar]
- Hofmann, T. Probabilistic Latent Semantic Indexing. SIGIR Forum 2017, 51, 211–218. [Google Scholar] [CrossRef]
- Dubin, D. The Most Influential Paper Gerard Salton Never Wrote. Libr. Trends 2004, 52, 748–764. [Google Scholar]
- Deerwester, S.; Dumais, S.T.; Furnas, G.W.; Landauer, T.K.; Harshman, R. Indexing by latent semantic analysis. J. Am. Soc. Inf. Sci. 1990, 41, 391–407. [Google Scholar] [CrossRef]
- Nelson, S.J.; Johnston, W.D.; Humphreys, B.L. Relationships in Medical Subject Headings (MeSH). In Relationships in the Organization of Knowledge; Bean, C.A., Green, R., Eds.; Springer: Dordrecht, The Netherlands, 2001; Volume 2, pp. 171–184. [Google Scholar]
- Donnelly, K. SNOMED-CT: The advanced terminology and coding system for eHealth. Stud. Health Technol. Inform. 2006, 121, 279–290. [Google Scholar]
- Chan, L.; Intner, S.; Weihs, J. Guide to the Library of Congress Classification, 6th ed.; ABC-CLIO: Santa Barbara, CA, USA, 2016. [Google Scholar]
- Kahan, J.; Koivunen, M.R.; Prud’Hommeaux, E.; Swick, R. Annotea: An open RDF infrastructure for shared Web annotations. Comput. Netw. 2002, 39, 589–608. [Google Scholar] [CrossRef]
- Hotho, A.; Jäschke, R.; Schmitz, C.; Stumme, G. BibSonomy: A Social Bookmark and Publication Sharing System. In Proceedings of the First Conceptual Structures Tool Interoperability Workshop at the 14th International Conference on Conceptual Structures, Aalborg, Denmark, 16 July 2006; pp. 87–102. [Google Scholar]
- Estellés, E.; Del Moral, E.; González, F. Social Bookmarking Tools as Facilitators of Learning and Research Collaborative Processes: The Diigo Case. Interdiscip. J. E-Learn. Learn. Objects 2010, 6, 175–191. [Google Scholar] [CrossRef][Green Version]
- Jaccard, P. Étude comparative de la distribution florale dans une portion des Alpes et des Jura. Bull. Del La Société Vaudoise Des Sci. Nat. 1901, 37, 547–579. [Google Scholar]
- Dice, L.R. Measures of the Amount of Ecologic Association Between Species. Ecology 1945, 26, 297–302. [Google Scholar] [CrossRef]
- Gruber, T. Ontology. In Encyclopedia of Database Systems; Liu, L., Özsu, M.T., Eds.; Springer: Boston, MA, USA, 2009; pp. 1963–1965. [Google Scholar] [CrossRef]
- Matar, Y.; Egyed-Zsigmond, E.; Sonia, L. KWSim: Concepts Similarity Measure. Proceedings of The Fifth Francophone Conference on Information Retrieval and Applications (CORIA08), Trégastel, France, 12–14 March 2008; pp. 475–482. [Google Scholar]
- Resnik, P. Semantic similarity in a taxonomy: An information-based measure and its application to problems of ambiguity in natural language. J. Artif. Intell. Res. 1999, 11, 95–130. [Google Scholar] [CrossRef]
- Leacock, C.; Chodorow, M. Combining Local Context and WordNet Similarity for Word Sense Identification. In WordNet: An Electronic Lexical Database; Fellbaum, C., Ed.; MIT Press: Cambridge, MA, USA, 1998; pp. 265–283. [Google Scholar]
- Wu, Z.; Palmer, M. Verbs semantics and lexical selection. In Proceedings of the 32nd Annual Meeting on Association for Computational Linguistics. Association for Computational Linguistics, Las Cruces, New Mexico, 27–30 June 1994; pp. 133–138. [Google Scholar] [CrossRef]
- Lin, D. An Information-Theoretic Definition of Similarity. In Proceedings of the Fifteenth International Conference on Machine Learning, San Francisco, CA, USA, 24–27 July 1998; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1998; pp. 296–304. [Google Scholar]
- Jimenez, S.; Gonzalez, F.A.; Gelbukh, A. Mathematical properties of soft cardinality: Enhancing Jaccard, Dice and cosine similarity measures with element-wise distance. Inf. Sci. 2016, 367, 373–389. [Google Scholar] [CrossRef]
- Çano, E.; Morisio, M. Hybrid Recommender Systems: A Systematic Literature Review. Intell. Data Anal. 2017, 21, 1487–1524. [Google Scholar] [CrossRef]
- Hudson, W.H. In Introduction to the Study of Literature; George G. Harrap & Company: London, UK, 1913. [Google Scholar]
- Arp, R.; Smith, B.; Spear, A.D. Building Ontologies with Basic Formal Ontology; The MIT Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Jewell, M.O.; Lawrence, K.F.; Tuffield, M.M.; Prügel-Bennett, A.; Millard, D.E.; Nixon, M.S.; Schraefel, M.; Shadbolt, N. OntoMedia: An Ontology for the Representation of Heterogeneous Media. In Proceedings of the MultiMedia Information Retrieval (MMIR) Workshop at SIGIR, Singapore, 10–11 November 2005; pp. 3–8. [Google Scholar]
- Bartalesi, V.; Meghini, C. Using an ontology for representing the knowledge on literary texts: The Dante Alighieri case study. Semant. Web 2017, 8, 385–394. [Google Scholar] [CrossRef]
- Zöllner-Weber, A. Ontologies and Logic Reasoning as Tools in Humanities? Digit. Humanit. Q. 2009, 3, 1–15. [Google Scholar]
- Ciotti, F. Toward a formal ontology for narrative. Matlit Rev. Do Programa De Doutor. Em Mater. Da Lit. 2016, 4, 29–44. [Google Scholar] [CrossRef]
- Damiano, R.; Lombardo, V.; Pizzo, A. The Ontology of Drama. Appl. Ontol. 2019, 14, 79–118. [Google Scholar] [CrossRef]
- Onsjö, M.; Sheridan, P. Theme Enrichment Analysis: A Statistical Test for Identifying Significantly Enriched Themes in a List of Stories with an Application to the Star Trek Television Franchise. Digital Studies/Le Champ Numérique 2019, in press. [Google Scholar]
- Hitzler, P.; Krötzsch, M.; Parsia, B.; Patel-Schneider, P.F.; Rudolph, S. (Eds.) OWL 2 Web Ontology Language: Primer 2009. Available online: http://www.w3.org/TR/owl2-primer/ (accessed on 30 June 2019).
- Episode Transcripts for the Series Listed. Available online: http://www.chakoteya.net/StarTrek/ (accessed on 30 June 2019).
- Porter, M.F. An algorithm for suffix stripping. Program 1980, 14, 130–137. [Google Scholar] [CrossRef]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit; O’Reilly Media, Inc.: Newton, MA, USA, 2009. [Google Scholar]
- User Reviews. Available online: https://www.imdb.com/title/tt0708895/reviews?ref_ = tt_urv (accessed on 30 June 2019).
- Gantner, Z.; Rendle, S.; Freudenthaler, C.; Schmidt-Thieme, L. MyMediaLite: A Free Recommender System Library. In Proceedings of the 5th ACM Conference on Recommender Systems (RecSys 2011), Chicago, IL, USA, 23–27 October 2011. [Google Scholar]
- Bell, R.M.; Koren, Y.; Volinsky, C. The Bellkor Solution to the Netflix Prize. Available online: https://www.netflixprize.com/assets/GrandPrize2009_BPC_BellKor.pdf (accessed on 30 June 2019).
- Bell, R.; Koren, Y.; Volinsky, C. Modeling relationships at multiple scales to improve accuracy of large recommender systems. In Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Jose, CA, USA, 12–15 August 2007; pp. 95–104. [Google Scholar]
- Paterek, A. Improving regularized singular value decomposition for collaborative filtering. In Proceedings of the KDD Cup and Workshop, Warsaw, Poland, 12 August 2007; Volume 2007, pp. 5–8. [Google Scholar]
- Gower, S. Netflix Prize and SVD. Available online: http://buzzard.ups.edu/courses/2014spring/420projects/math420-UPS-spring-2014-gower-netflix-SVD.pdf (accessed on 30 June 2019).
- Lemire, D.; Maclachlan, A. Slope one predictors for online rating-based collaborative filtering. In Proceedings of the 2005 SIAM International Conference on Data Mining, Newport Beach, CA, USA, 21–23 April 2005; pp. 471–475. [Google Scholar]
- Řehůřek, R.; Sojka, P. Software Framework for Topic Modelling with Large Corpora. In Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks, Valletta, Malta, 22 May 2010; pp. 45–50. [Google Scholar] [CrossRef]
- Ma, Y.; Peng, H.; Cambria, E. Targeted aspect-based sentiment analysis via embedding commonsense knowledge into an attentive LSTM. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Jiang, J.J.; Conrath, D.W. Semantic similarity based on corpus statistics and lexical taxonomy. arXiv 1997, arXiv:cmp-lg/9709008. [Google Scholar]




| Series Title | Short Name | Original Release | No. of Seasons | No. of Episodes |
|---|---|---|---|---|
| Star Trek: The Original Series | TOS | 1966–1969 | 3 | 79 |
| Star Trek: The Animated Series | TAS | 1973–1974 | 2 | 22 |
| Star Trek: The Next, Generation | TNG | 1987–1994 | 7 | 178 |
| Star Trek: Deep Space Nine | DS9 | 1993–1999 | 7 | 177 |
| Star Trek: Voyager | Voyager | 1995–2001 | 7 | 172 |
| Star Trek: Enterprise | Enterprise | 2001–2005 | 4 | 99 |
| Star Trek: Discovery | Discovery | 2017–present | 2 | 29 |
| Star Trek: Shorts | Shorts | 2018–present | 1 | 4 |
| Domain Root Theme | Domain Color-Code | Theme Count | Leaf Theme Count | Tree Height |
|---|---|---|---|---|
| the human condition |  | 892 | 835 | 6 |
| society |  | 387 | 362 | 4 |
| the pursuit of knowledge |  | 329 | 308 | 4 |
| alternate reality |  | 521 | 484 | 4 |
| Series Short Name | No. of Episodes | Mean Number of Central Themes per Episode ± S.D. | Mean Number of Peripheral Themes per Episode ± S.D. |
|---|---|---|---|
| TOS | 80 | 12.42 ± 4.31 | 20.05 ± 6.23 |
| TAS | 22 | 6.77 ± 2.58 | 3.41 ± 2.28 |
| TNG | 178 | 11.64 ± 4.38 | 14.88 ± 5.60 |
| Voyager | 172 | 9.20 ± 2.99 | 7.63 ± 3.38 |
| # | Type | Method Description | Warm System Scenario | Cold Start Scenario | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE ± s.d. | 1 | 2 | 3 | 4 | 5 | 6 | RMSE ± s.d. | 1 | 2 | 3 | 4 | 5 | 6 | |||
| 1 | CBF | IKNN-LSI-40, k = 40 [this paper] | = | * | * | * | * | = | * | * | * | |||||
| 2 | OBF | IKNN-RES, p = 2, k = 50 [this paper] | * | = | * | * | * | = | * | |||||||
| 3 | OBF | IKNN-LCH, p = 4, k = 80 [this paper] | * | = | * | * | * | = | * | |||||||
| 4 | KBF | IKNN-DICE, k = 70 [this paper] | = | * | = | * | ||||||||||
| 5 | CF | IKNN, k = 40 [14] | * | * | * | = | * | = | * | |||||||
| 6 | CF | Sig. Item Asymm. FM, f = 10 [66] | * | * | * | * | * | = | * | * | * | * | * | = | ||
| CF | Sig. Comb. Asymm. FM, f = 10 [66] | * | * | * | * | * | * | * | * | * | * | |||||
| CF | Sig. User Asymm. FM, f = 10 [66] | * | * | * | * | * | * | * | * | * | * | |||||
| CF | User Item Baseline [14] | * | * | * | * | * | * | * | * | * | * | * | ||||
| CF | User KNN, k = 80 [14] | * | * | * | * | * | * | * | * | * | * | * | ||||
| CF | Biased MF, f = 10 [68] | * | * | * | * | * | * | * | * | * | * | * | ||||
| CF | SVD Plus Plus, f = 10 [69] | * | * | * | * | * | * | * | * | * | * | * | ||||
| CF | Slope One [70] | * | * | * | * | * | * | * | * | * | * | * | ||||
| CF | Item Average Baseline | * | * | * | * | * | * | * | * | * | * | * | ||||
| CF | User Average Baseline | * | * | * | * | * | * | * | * | * | * | * | ||||
| CF | MF, f = 10 [15] | * | * | * | * | * | * | * | * | * | * | * | ||||
| CF | Global Average Baseline | * | * | * | * | * | * | * | * | * | * | * | ||||
| CF | Factor Wise MF, f = 10 [67] | * | * | * | * | * | * | * | * | * | * | * | ||||
| Random Baseline | * | * | * | * | * | * | * | * | * | * | * | * | ||||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sheridan, P.; Onsjö, M.; Becerra, C.; Jimenez, S.; Dueñas, G. An Ontology-Based Recommender System with an Application to the Star Trek Television Franchise. Future Internet 2019, 11, 182. https://doi.org/10.3390/fi11090182
Sheridan P, Onsjö M, Becerra C, Jimenez S, Dueñas G. An Ontology-Based Recommender System with an Application to the Star Trek Television Franchise. Future Internet. 2019; 11(9):182. https://doi.org/10.3390/fi11090182
Chicago/Turabian StyleSheridan, Paul, Mikael Onsjö, Claudia Becerra, Sergio Jimenez, and George Dueñas. 2019. "An Ontology-Based Recommender System with an Application to the Star Trek Television Franchise" Future Internet 11, no. 9: 182. https://doi.org/10.3390/fi11090182
APA StyleSheridan, P., Onsjö, M., Becerra, C., Jimenez, S., & Dueñas, G. (2019). An Ontology-Based Recommender System with an Application to the Star Trek Television Franchise. Future Internet, 11(9), 182. https://doi.org/10.3390/fi11090182