1. Introduction
Gesture communication is a widely used method in people’s daily lives. Gesture interaction can be used in many kinds of scenes and has rich expressive power. For instance, sign language recognition is an important application of gestures, especially in the communication between deaf and dumb people [
1]. People presently pay more and more attention to the efficiency of gesture recognition. The difficulty of gesture recognition mainly lies in the difference in body shape, video background and video noise, etc. [
2]. The research of gesture recognition mainly includes static aspects and dynamic aspects. Accuracy is an important criterion to measure gesture recognition algorithms. Effective gesture recognition is still a very challenging problem [
3], partly due to the cultural differences, various observation conditions, noises, relative small size of fingers in images, out-of-vocabulary motions, etc.
In traditional machine learning algorithms, HMM (Hidden Markov Model) and SVM (Support Vector Machine) are often used for the recognition of gesture [
4]. SVM is often paired with HOG (Histogram of Oriented Gradient) to realize the static gesture recognition of images, which is not a suitable method for dynamic gesture recognition. In the study of dynamic gesture recognition, the HMM model is applicable to the prediction of time series, and has a good recognition rate for gestures with high complexity. However, since the HMM requires more samples to complete the graph optimization, the process of training is relatively complicated. CRF (Conditional Random Field) can be trained to recognize non-classified gesture trajectories and achieve good results [
5]. However, CRF training is costly and complex, and it is not suitable for large data sets.
With the rapid development of the neural network, the recognition method has gradually transferred from traditional machine learning to deep learning. In the deep learning gesture recognition algorithm, 2D CNN and denoising self-encoder (SDAE) are often applied to feature extraction of images [
6]. The 2D CNN can achieve the effect of predicting video by extracting spatial feature information of successive sets of frames in the video. 3D CNN extracts the spatio-temporal features of the entire video to get more comprehensive information [
7]. Because some gesture videos may take longer time, many researchers use long short-term memory (LSTM) network to predict the gesture video [
8]. LSTM can extract the timing features between frames more effectively [
9]. ConvLSTM is a network structure proposed according to convolution operation and LSTM. It does not just extract spatial features like CNN, but also model according to time series like LSTM [
10].
Neural networks are often used in combination when recognizing the video data set of gestures. In the combination of CNN and LSTM, videos are firstly divided into a set of frames with fixed length. Then several convolution operations and pooling operations should be carried out for each frame, and finally several feature graphs obtained after processing are predicted as input of LSTM [
11]. When 3D CNN is combined with LSTM to classify video, videos should be divided into several picture sets of frames firstly, and then these frames were operated by 3D CNN in time and space according to the convolution kernel of a certain size. Finally, the processed feature set was combined to predict the input of LSTM, and we can get the accuracy [
12]. However, in the combination of conventional CNN network and RNN network, single RNN operation may not obtain more accurate prediction information. Therefore, in this paper, we proposed a multi-prediction neural network with multiple mixing of 3D CNN operation and convLSTM operation. We call it the MEMP network. The MEMP network can improve the accuracy of gesture recognition. Experiments show that this network is suitable for medium and large data sets.
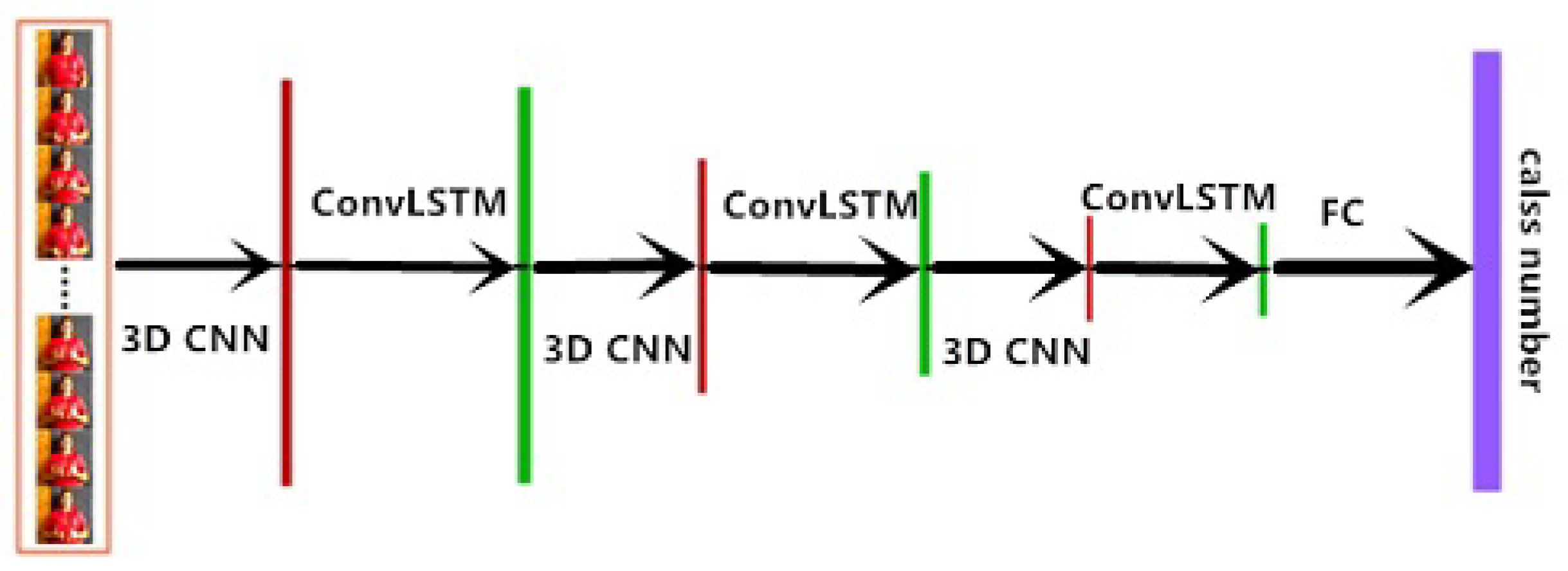
In the MEMP network, each gesture video needs to be split into 16 consecutive frames. These frames are subject to three consecutive 3D CNN operations and ConvLSTM. 3D CNN is used to extract spatial-temporal features of the frame set. ConvLSTM does not just predict the frame set, but also extract more spatial feature information during the prediction process. Therefore, compared with the traditional combined neural network, MEMP network retains more spatial-temporal feature information through multiple information extraction and prediction of feature maps. In dynamic gesture video, information is contained in the spatial-temporal sequence of the video. Thus, more gesture recognition accurate prediction results can be obtained.
Figure 1 shows the overall structure of the network.
In the related work section, we will introduce the development of gesture recognition from traditional machine learning to deep learning. In the proposed method section, we will analyze the internal structure of the MEMP network in detail. In the experimental part, we will use three data sets to verify the characteristics of the MEMP network.
2. Related Work
In the study of computer vision, getting the spatial-temporal information in videos is paramount. In traditional machine learning, Ahmed and Aly used LBP and PCA for feature extraction, HMM was also used for classification [
13], they have got outstanding results. However, LBP cannot distinguish between neighborhood pixels and central pixels, or neighborhood pixels are larger than central pixels. The situation may result in the loss of information extraction. Under the work of Chen and Luo, a realtime Kinect-based dynamic hand gesture recognition system which contains hand tracking, data processing, model training and gesture classification is proposed [
14]. Support Vector Machine is used as the recognition algorithm in the proposed system. Methods based on the state-of-the-art handcrafted features are difficult to handle large data sets [
15]. At the same time, deep neural networks have achieved remarkable results in processing large-scale data sets [
15].
Neural network structure plays an important role in the study of static gesture recognition. Xing and Li proposed a CNN structure for vision-based static hand gesture recognition with competitive performance [
16]. In the dynamic gesture recognition based on deep learning, the first thing to do is preprocess the gesture video. Each video is divided into a set of frames of fixed width, length and height (the frame set in this paper is 64 × 64 × 16, where the frame has a length and a height of 64 and a width of 16). RNN is often used to process those frames. Chai and Liu presented an effective spotting-recognition framework based on RNN for large-scale continuous gesture recognition [
17]. Naguri and Bunescu presented a gesture recognition system based on LSTM networks, the architecture was trained on raw input sequences of 3D hand positions [
18]. In many new studies of gesture recognition, people tend to use 3D CNN to extract the temporal and spatial features of video [
19,
20]. Zhu and Zhang used the combined network of 3dcnn and convLSTM to extract the features of video, and finally conducted classification operations through SPP (Spatial Pyramid Pooling) and FC (Fully Connected Layer) [
3]. However, in traditional combined neural networks, a single RNN operation may not fully grasp the spatial-temporal information. Therefore, the MEMP network obtains more decisive information by cross-using CNN and RNN.
Although 2D CNN extracts spatial features well, 3D CNN can extract more information (spatial-temporal feature information) [
7]. LSTM inherits the characteristics of most RNN models and solves the problem of gradient disappearance caused by gradual reduction of gradient backpropagation process, which is often used to predict the time characteristics of sequences [
9]. However, LSTM often neglects the extraction of spatial features of feature maps in the prediction of sequences, which may affect the final spatial and temporal feature information. ConvLSTM not only has the capability of LSTM time series modeling, but also can describe local features like CNN. During the work of MEMP Neural Networks, 3D CNN is used to extract the spatial and temporal feature information of each frame, and then ConvLSTM was used to predict the set of features. Repeated 3D CNN operation and ConvLSTM operation will get more distinct information. The output size is determined by the number of gestures in the data set. ReLU is the activation function of the hidden layer, and it can improve the learning speed of neural networks at different depths. This means that using ReLU activation function can avoid the vanishing gradient problem [
21].
3. Proposed Method
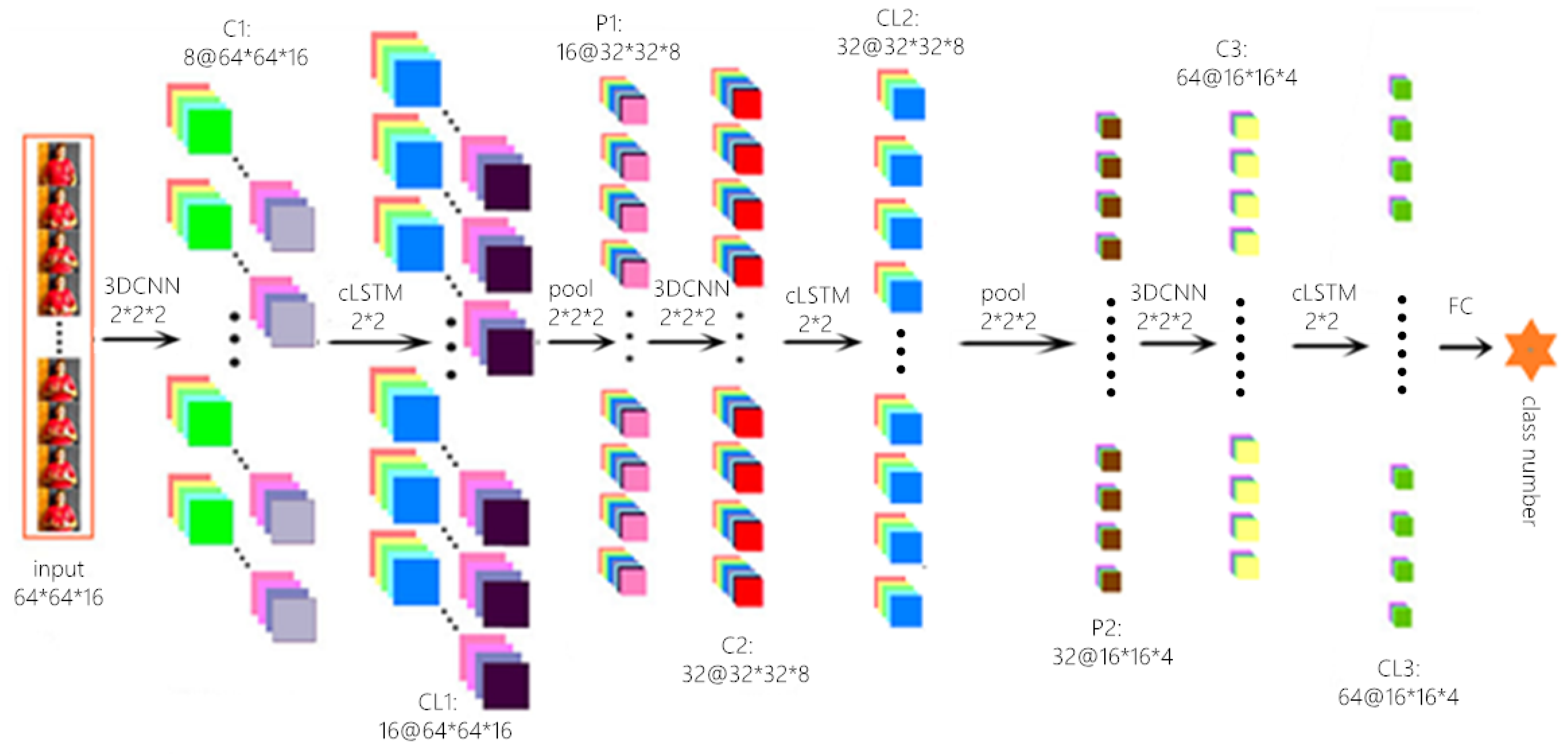
In this section, we will describe the internal structure of the MEMP Neural Networks in detail. Predicted results were obtained after the video frame sets operated by three consecutive 3DCNN operations and ConvLSTM operations.
CNN plays a significant role in image feature extraction [
22]. Here F =
represents the frame set of video. The size of
is 64 × 64. After a 3D CNN operation, the size of each feature map was not changed, and the number of channels increased to 8. This operation can extract spatial-temporal information of feature maps. Then, after a convLSTM operation, the set became F’ =
. The number of channels increased to 16, the number of each channel was 16 and the size of feature map is 64 × 64. Then, through a 3D POOL operation, the number of feature maps in each channel and the length and width of each feature map were reduced by half. After similar operations of 3DCNN, convLSTM and POOL, the size of feature set became F” =
, with 64 channels. The number of each channel was 4, and the size of feature map was 16 × 16. After above operations, the spatial-temporal feature information of the frame set will be retained. At the end of the full connection layer, the results will be classified to obtain different types of gestures. The specific operation is as follows.
3D CNN is good at extracting features of video [
23]. So in MEMP Neural Networks, 3D CNN is used to process spatial and temporal features of feature graph sets. As shown in
Figure 2, there are three 3D convolution operations (C1, C2, C3), three convLSTM operations (CL1, CL2, CL3) and two pooling operations (P1, P2) in the network. The size of the three 3D convolution kernels is 2 × 2 × 2, and the step length is 1 × 1 × 1. Since the convolution mode of ‘SAME’ is adopted, the size of each feature map in the convolution operation will not change. The filter sizes corresponding to the three convolution operations are 8, 32 and 64 respectively. The pooled method is ‘max pooling’ and the pooled size is 2 × 2 × 2. After each cisterization operation, a ‘droupout’ layer will be followed. ‘droupout’ will effectively reduce the occurrence of over-fitting, which can reach the effect of regularization to a certain extent [
24]. The formula of 3D CNN is as follows:
‘
ReLU’ is the activation function of the hidden layer.
represents the current value of the coordinates (x, y, z) in the
i-th and
j-th feature graph sets.
represents the bias of the
i-th layer and the
j-th feature graph set,
represents the weight of the
m-th filter connected by the position (p, q, r) in the
i-th layer and
j-th feature graph set.
,
and
represent the height, width and depth of the convolution kernel respectively [
23].
Compared with traditional LSTM, convLSTM can better extract spatial and temporal features of feature graph sets [
10]. The reason is that ConvLSTM can consider the spatial information of a single feature map when it processes and predicts time series events. So ConvLSTM can solve timing problems in dynamic gesture recognition more effectively. In this experiment, the processed feature graph set need to be further extracted by convLSTM after 3D CNN operation. The convolution kernel is 2 × 2, and the step lengths is 1 × 1. The convolution way is ‘SAME’, so the size of the feature graph is not changed. The final output filter size is 64. The main formula of convLSTM is as follows:
where
...
are input,
...
are unit output, and
...
are hidden layer.
,
and
are three dimensional tensor of convLSTM respectively. The last two dimensions are spatial dimension (row and column). ‘∘’ is the convolution operation, and ‘*’ is ‘Hadamard product’ [
10]. The feature set passes through a full connection layer after a ConvLSTM operation, and the output size of the full connection layer is based on the number of gestures. The final optimization function adopts the ‘Adam’ algorithm. ‘Adam’ has high computational efficiency and low memory demand and has no impact on the gradual diagonal scaling. So it is very suitable for the problem of large data processing [
24].
4. Experiment
4.1. Datasets
This experiment used three dynamic gesture data sets: LSA (Argentinian Sign Language), chalearn 2016 (IsoGD) and SKIG.
LSA: This data set represents the Argentine sign language. The LSA data set include 3200 RGB videos and 10 non-expert subjects repeated 64 different LSA signs five times. Each video has a resolution of
, 60 frames per second [
25].
Table 1 shows the statistical information of training part and test part in LSA dataset.
IsoGD: This is a large-scale gesture data set, which is derived from chalearn gesture data set [
26]. The data set contains 47,933 rgb-depth video gestures made by a total of 249 gestures made by 21 different individuals.
Table 2 shows the statistical information of training part and test part in IsoGD dataset.
SKIG: This data set contains 1080 rgb-depth gesture sequences collected from six individuals. All of these sequences were shot synchronously through the Kinect sensor, which includes an RGB camera and a depth camera. A total of 10 gestures were collected in this data set [
27].
Table 3 shows the statistical information of training part and test part in SKIG dataset.
4.2. Video Processing
The dynamic gesture data set is generally composed of a large number of video. Video’s resolution and time length will be different, so each video needs to be preprocessed. Videos will be split into a set of 16 consecutive frames with uniform time first, and then all frames need to be resized (64 × 64).
4.3. Implementation
In terms of hardware environment, the graphics card used in our experiment is Quadro P5000 (NVIDIA, USA), CPU is E5 2650 v4 (Intel, USA), and the memory size is 128 G. Our development system is Windows 10 and the development tool used is PyCharm 2018.1 (JetBrains, Czech Republic). We use keras along with tensorflow. All data sets video are split into 16 consecutive frames of 64 × 64. Then 64 batches were processed when processing data, and all data were trained 100 times in total. The initial learning rate of the training process is 0.001. The exponential decay rate of the first order moment estimate is 0.9, and the exponential decay rate of the second moment estimate is 0.999. At last, the softmax function is used for the full connection classification, and the activation function is ‘Adam’.
4.4. Experimental Results
LSA: 2D CNN, 3D CNN, 3D CNN + LSTM and the MEMP network structure were respectively used to train LSA data set. The network structure proposed in the paper [
11] is 2D CNN + LSTM. Therefore, there are four groups of experiments in this data set, and the experimental results are shown in
Table 4.
As can be seen from
Table 4, the MEMP neural network structure proposed in this paper has improved the recognition rate of LSA data sets by 3.846% compared with the structure proposed in this paper [
11], and the MEMP network is 1.171% higher than the 3D CNN network frequently used in video processing. It can be seen that this network structure has high accuracy in processing LSA data sets.
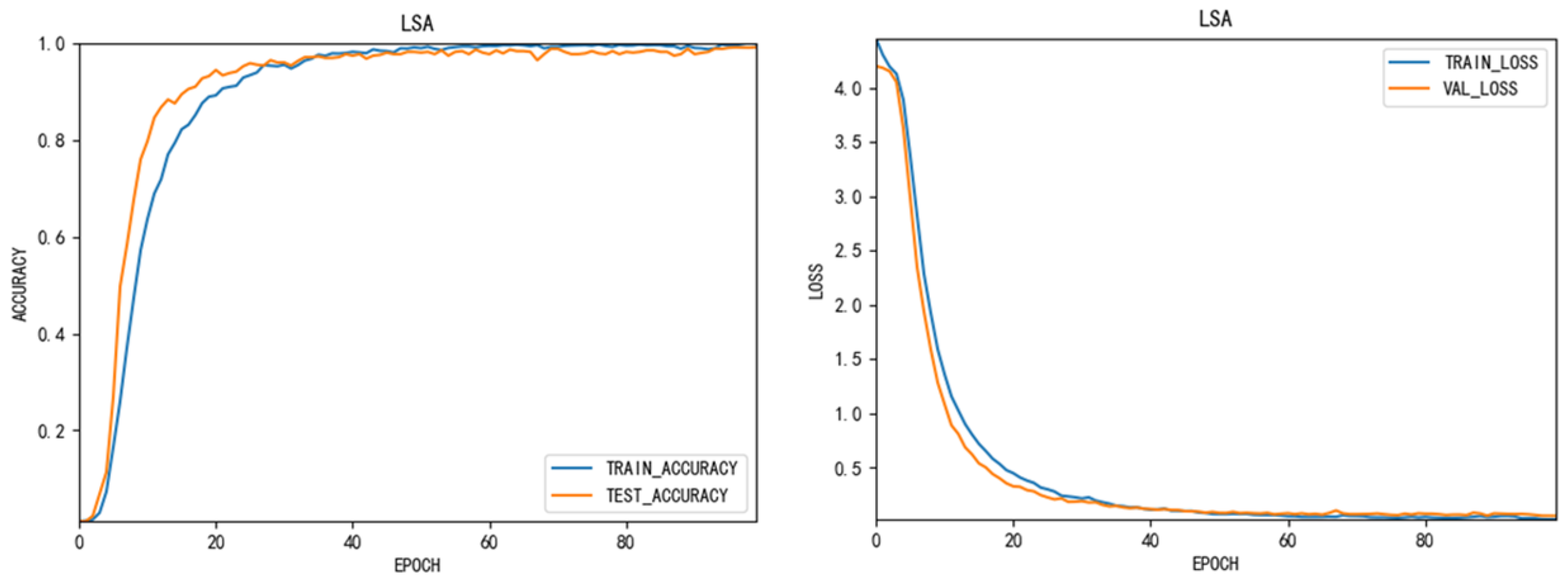
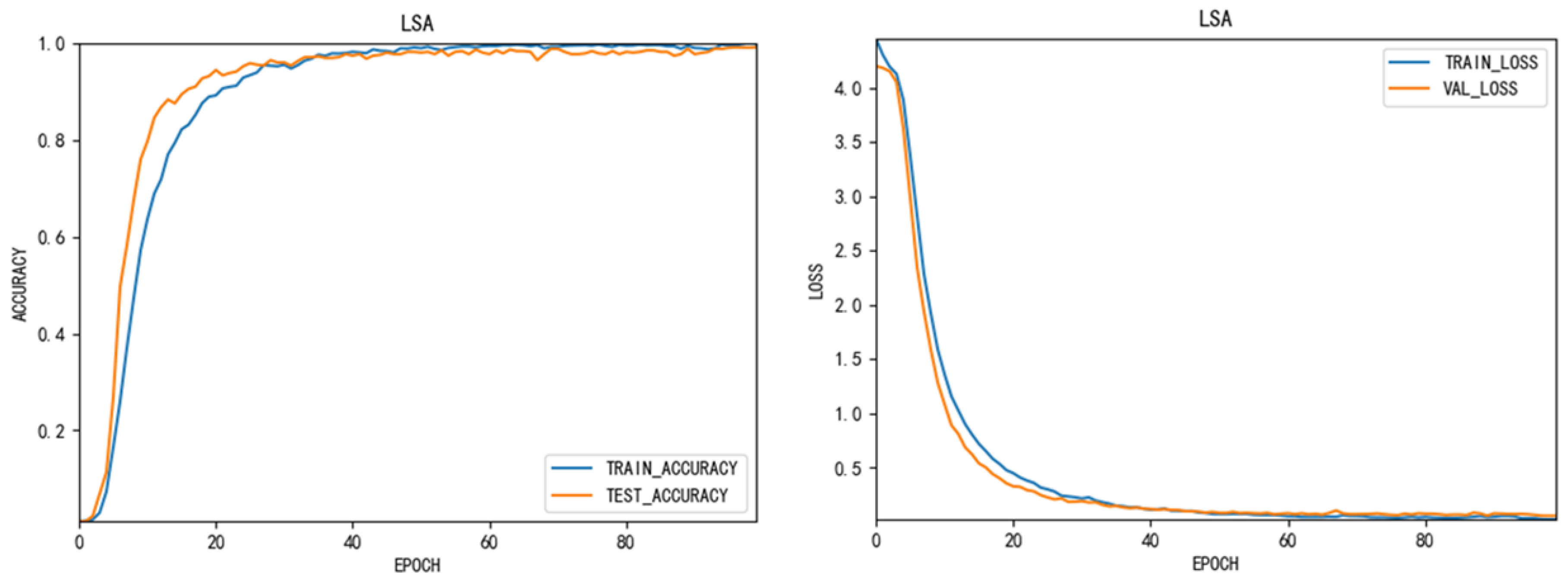
Figure 3 show the accuracy and loss function change of LSA data set during the training of this network. The epoch of the entire network is 100. The loss function used is ‘categorical-crossentropy’. The yellow line represents the verification set and the blue line represents the training set. From this we can see that when the epoch reaches 40, the accuracy and loss function of the network tends to be stable. This shows the stability of the network.
IsoGD: in this data set, the MEMP network and the 3D CNN network are used to train RGB and rgb-depth data sets respectively. In the paper [
20], the author used C3D and LSTM networks to train IsoGD data. The experimental results are shown in
Table 5.
It can be seen from the results that, in the IsoGD data set, the accuracy of MEMP network is 10.43% higher than that of the paper [
20], which is a big breakthrough. In the same data set, MEMP network was 24.89% higher in RGB and 23.73% higher in rgb-depth data sets than the commonly used 3D CNN network. In comparison with the paper [
3], we have improved 30.69% and 27.83% in RGB and RGB-Depth part respectively. These improvements illustrate the importance of multi-fetch multi-prediction for frame sets. In the experiment, the size of frame is
, which is smaller than the size of paper [
3] and paper [
20]. This shows that MEMP network can save a lot of time. Compared with the current popular ResNet and 3D ResNet, the MEMP network also has a significant improvement in accuracy.
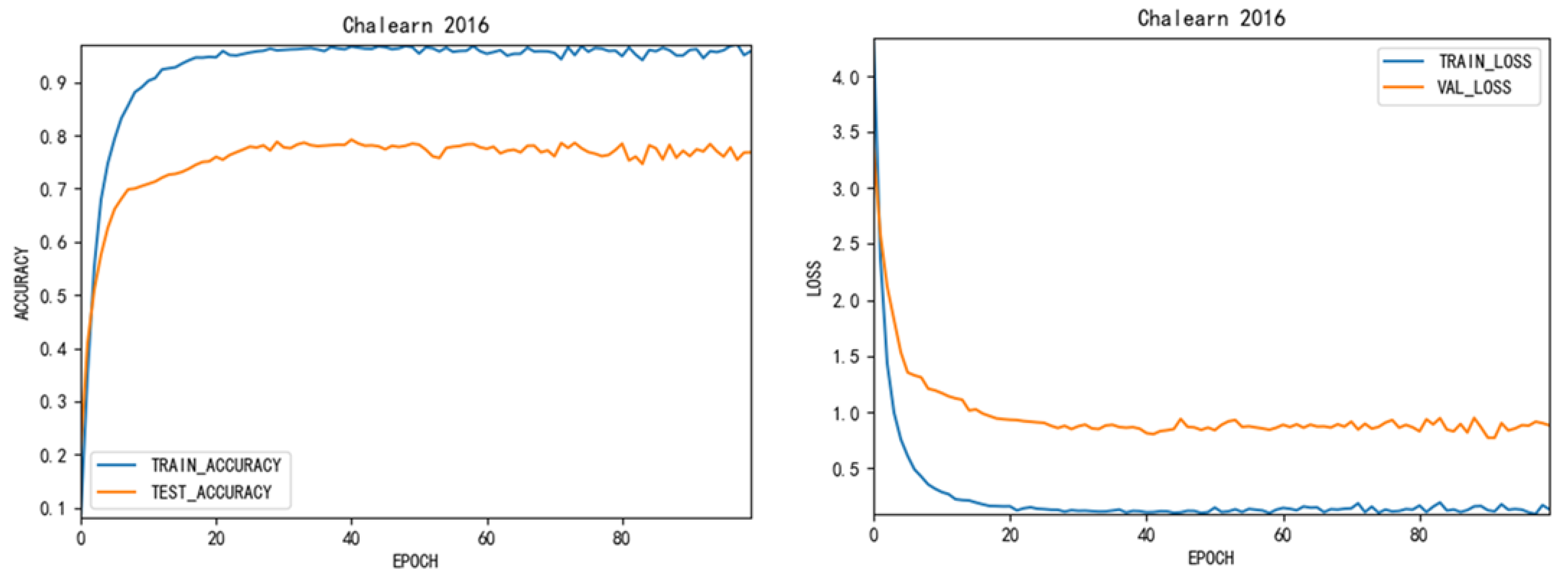
Figure 4 shows the variation of accuracy and loss function in training IsoGD data set.
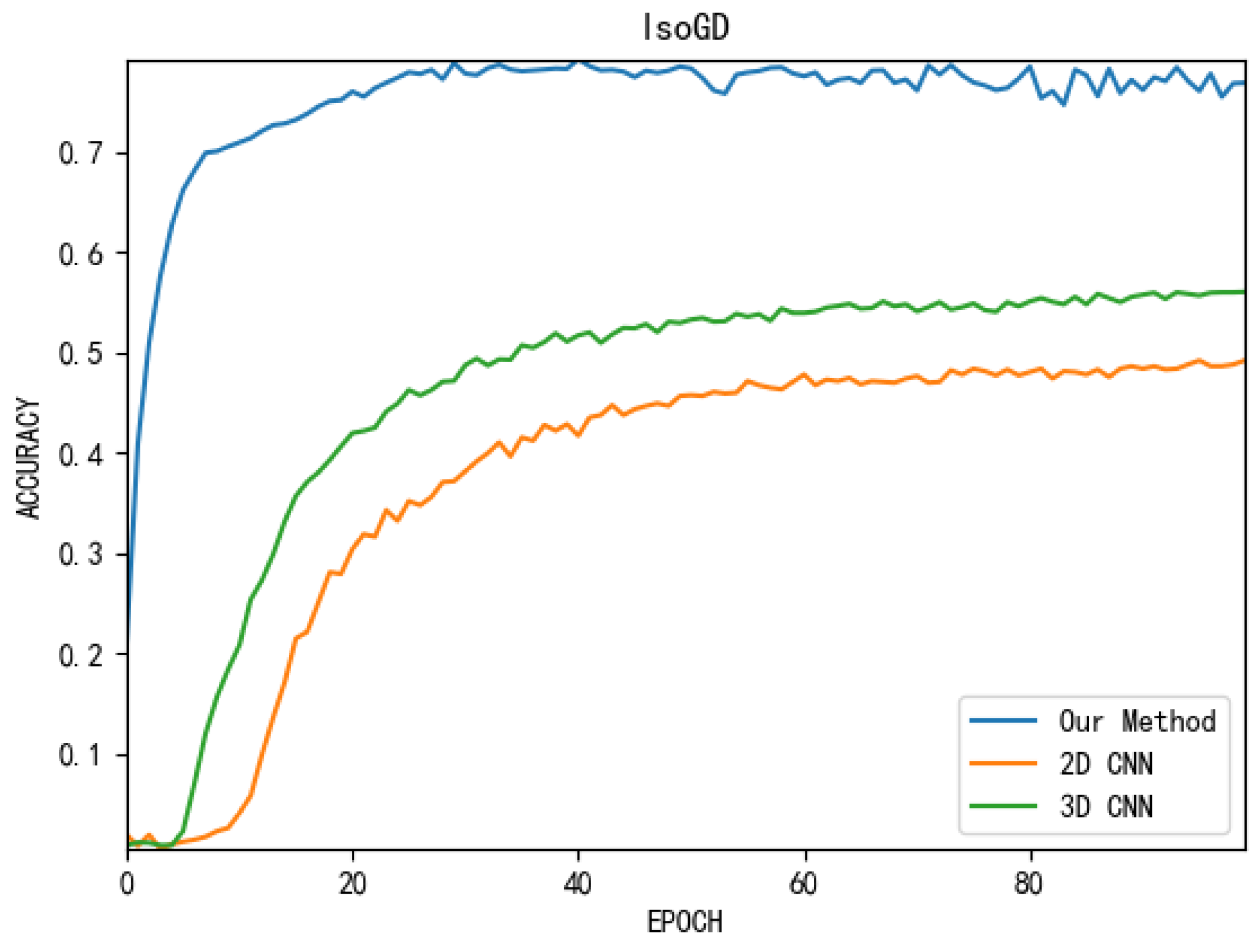
Figure 5 shows the accuracy comparison between 2D CNN, 3D CNN and our method (MEMP network) in the IsoGD (RGB-Depth) data set. From this we can see that our method in large data sets are superior to the mainstream deep learning networks in both accuracy and speed of convergence.
SKIG: in the paper [
28], the author proposed a network structure of LPSNet to train SKIG data sets. In this experiment, the RGB data set and rgb-depth data set in SKIG were trained respectively, and the results are shown in
Table 6.
As can be seen from the results in
Table 6, accuracies of MEMP network in the RGB part and the rgb-depth part are higher than the LPSNet proposed in the paper [
28]. Compared with the paper [
3], our results are also superior to theirs.
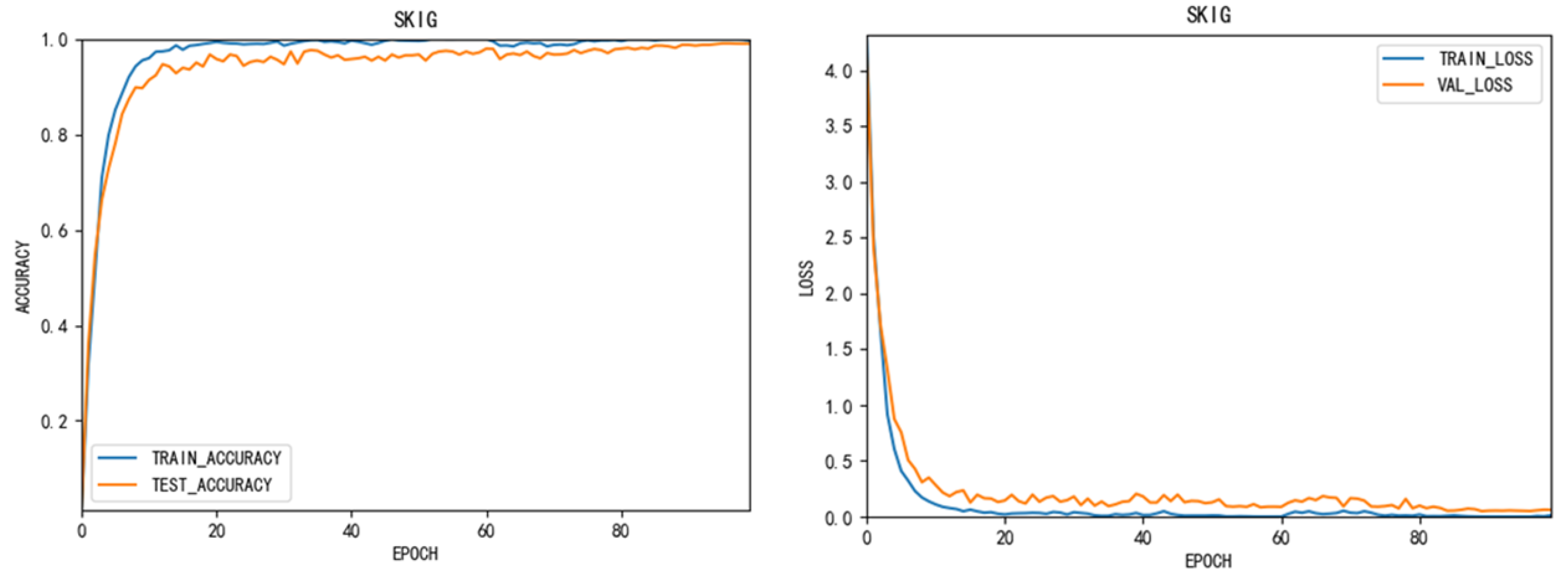
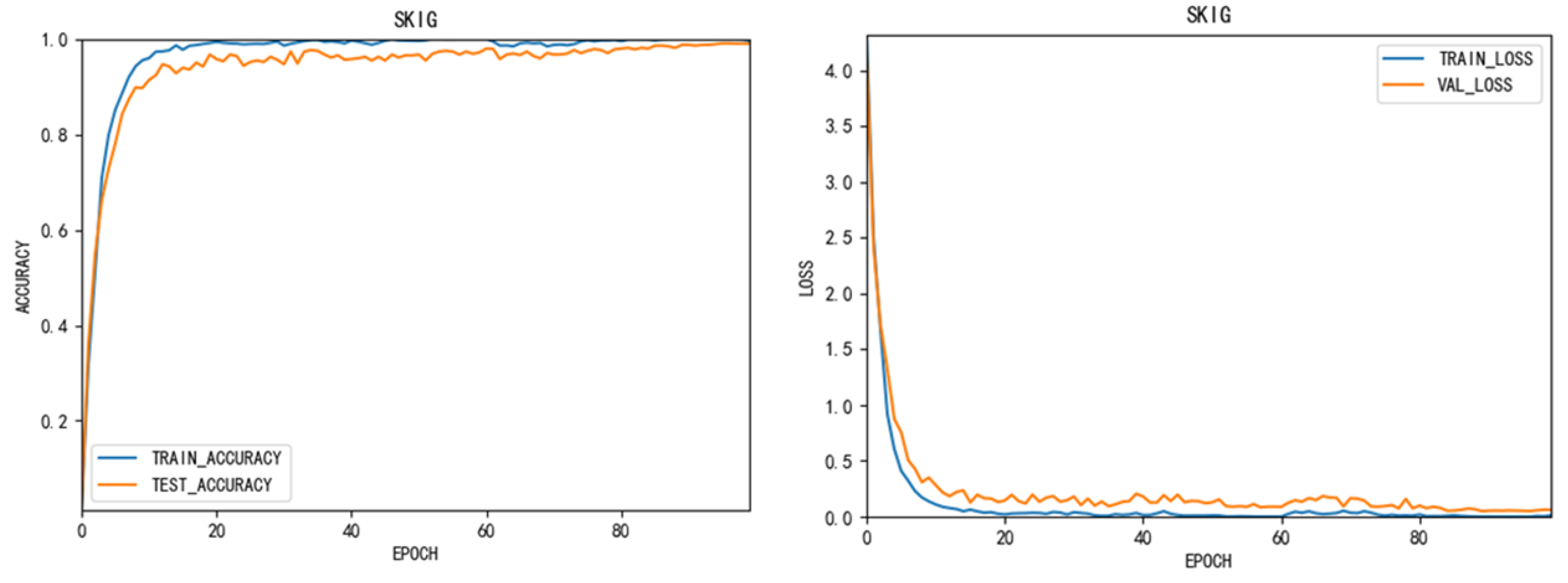
Figure 6 shows the variation of accuracy and loss function in the training SKIG data set. As can be seen from the graph above, MEMP network has achieved outstanding results in different data sets. This indicate that our method can be applied to many medium and large data sets.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}