Edge Computing: A Survey On the Hardware Requirements in the Internet of Things World



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
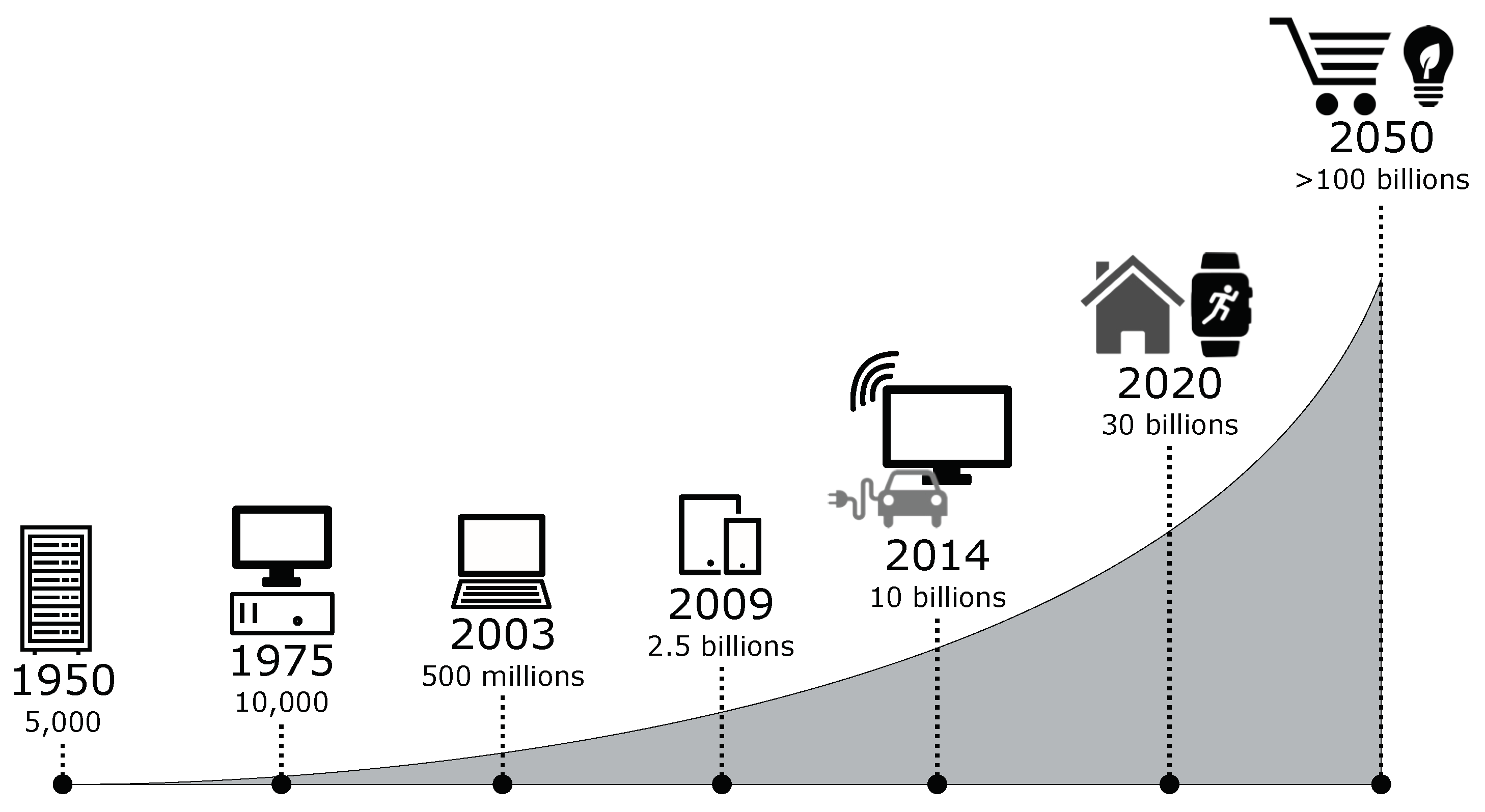
:1. Introduction
Methodology and Organization
- topic and objectives definition;
- primary search;
- information refinement and secondary search;
- data retrieving;
- analyzed data presentation.
- literature collection and screening;
- data extrapolation and examination;
- composition of the review script.
2. Definitions and Motivations
3. Ultra-Low Power MCU Architectures
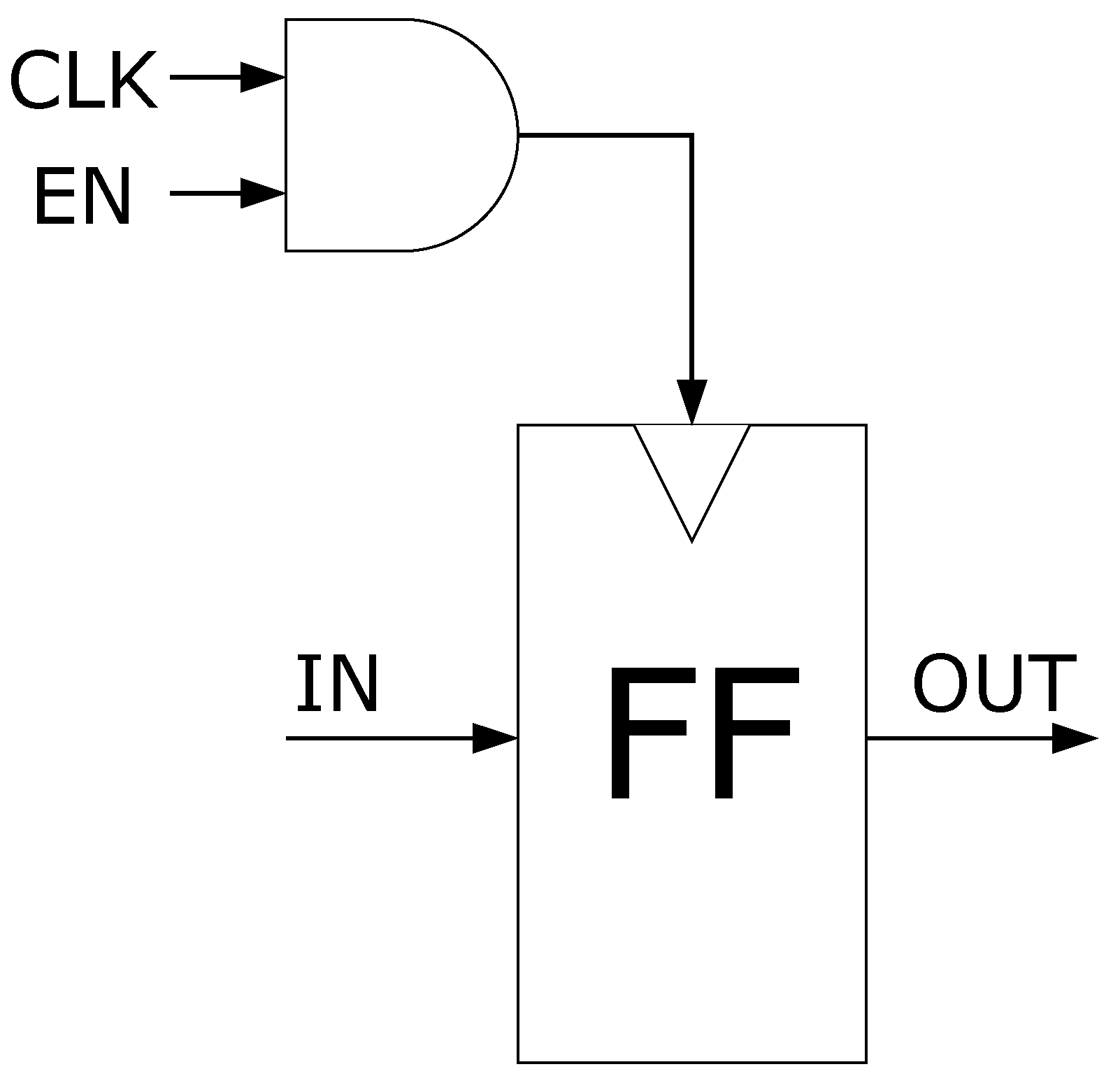
3.1. IO Architecture
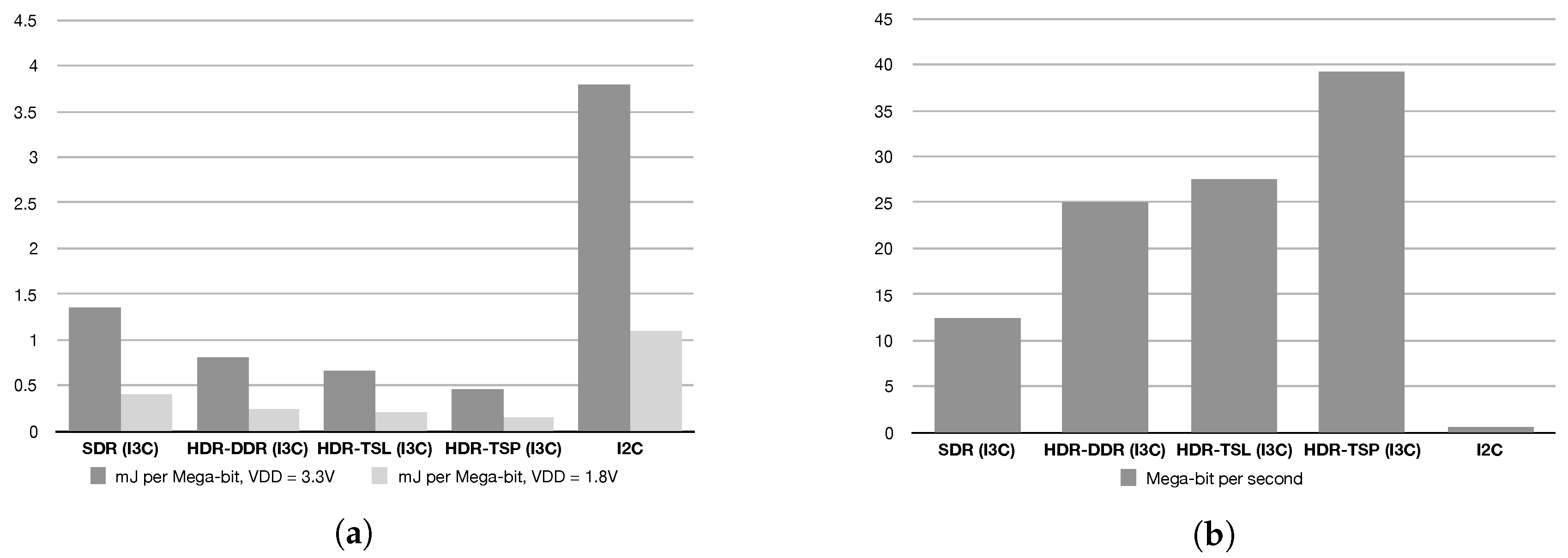
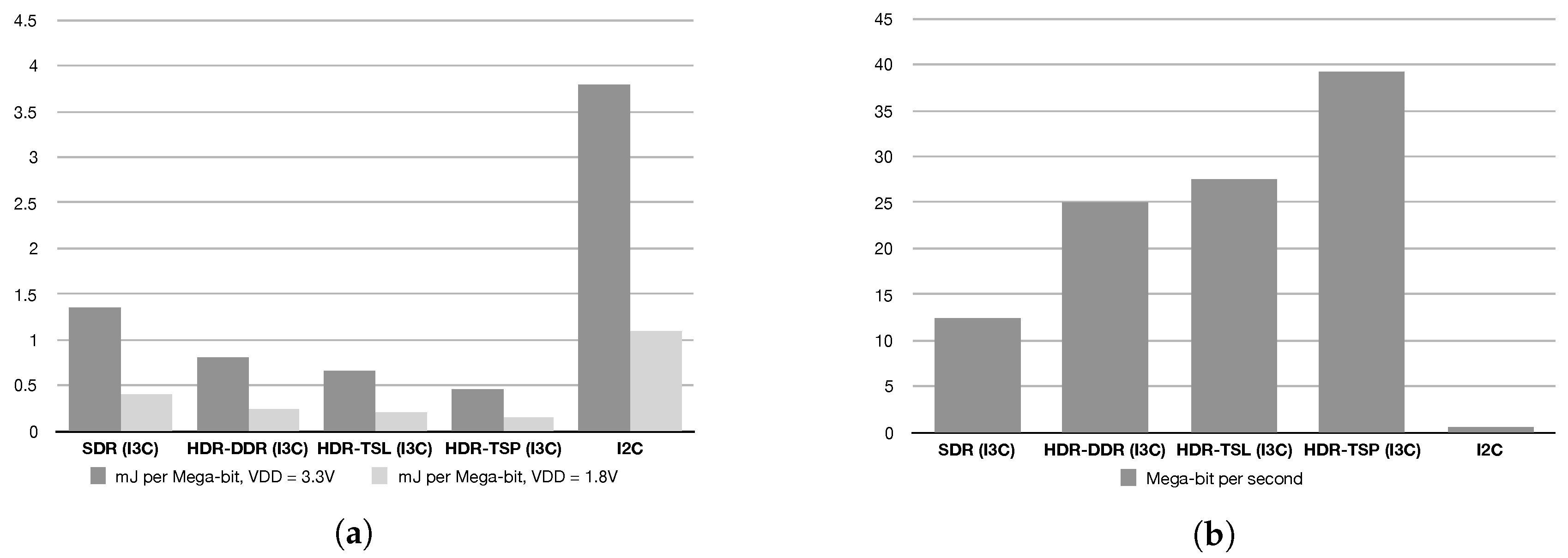
3.2. Communication and Security
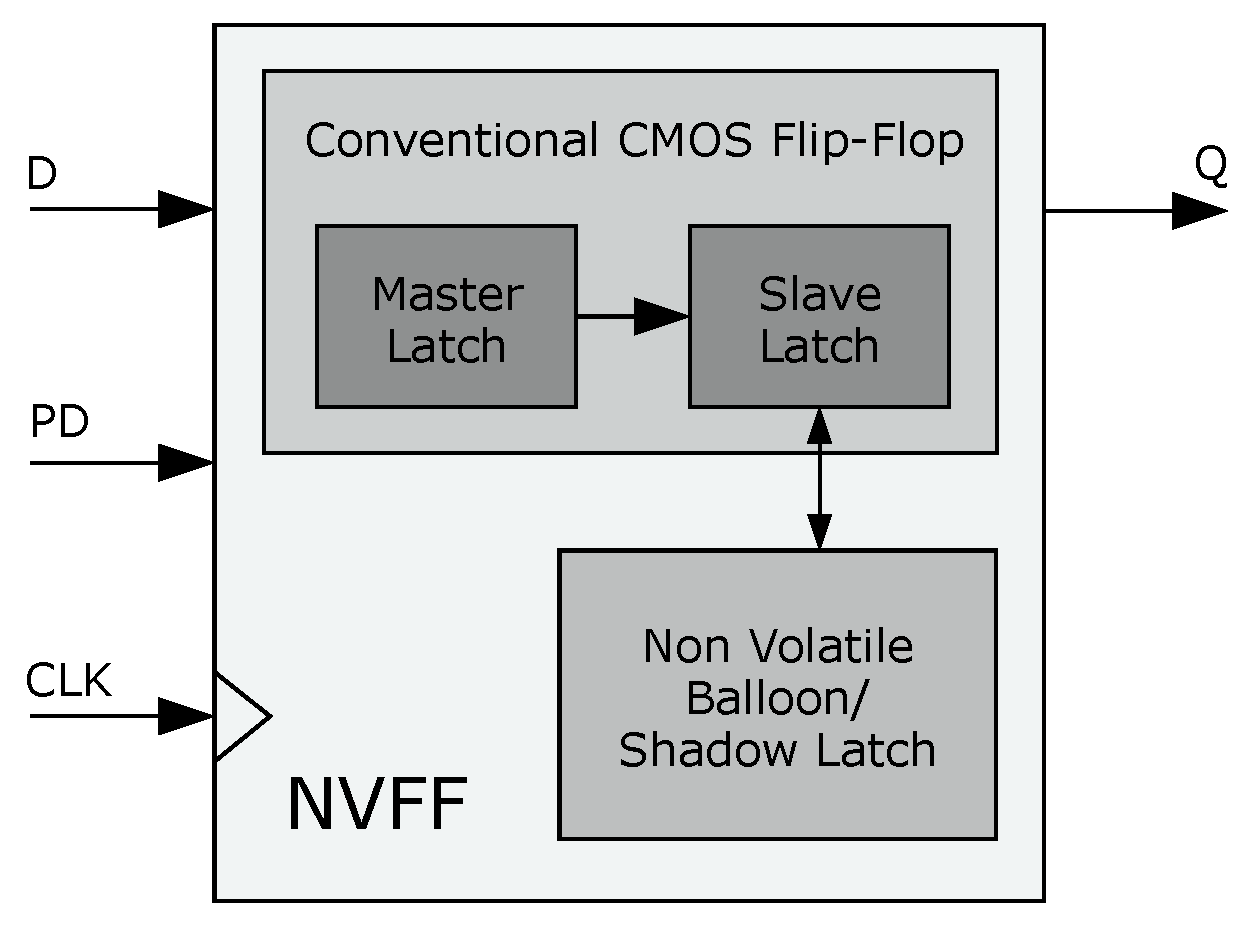
3.3. Non-Volatile Memories
- Resistive RAMs (ReRAMs) [57,58,59,60,61,62,63], which store the information as the variation of resistivity of a thin oxide film. A current is injected in the oxide to change its structure and to modify its resistance value. It is possible to program one cell to high or low resistance and so to assign a logic value to each of these two states. This technology is compatible with the current (CMOS) process. Moreover, it can achieve switching speeds of up to 10 ns and it features multilevel capability. However, the current required to reset the oxide state is high, usually being difficult to integrate in the circuit.
- Ferroelectric RAMs (FeRAMs) [64,65,66], which work like Dynamic RAMs but store the information in a ferroelectric layer instead of a dielectric one. The technology can be compatible with DRAM process, but it is usually built on old processes (350 to 130 nm). In addition, this type of memory consumes power only to read or write the memory cell, which drastically lowers the consumption with respect to DRAMs. The technology is intrinsically fast, it takes about 1 ns to modify the state of the layer, indeed. Usually, the bottleneck is the electronic control, which is rather complex, like in DRAMs.
- Phase-Changing RAMs (PCRAMs) [67,68,69,70,71,72], in which a chalcogenide glass can change phase from amorphous to crystalline. Moreover, chalcogenide glass can also hold an intermediate state, allowing for multilevel storage. However, the cells are difficult to program, so their use is still limited. These devices are faster than Flash-based memories, in particular for writing operations as PCRAMs that feature the possibility to modify each cell individually. The drawbacks are that the cells are prone to aging (even if they are better than Flash memories) and they are susceptible to temperature variations.
- Magnetic RAMs (MRAMs) [73,74,75,76,77,78,79,80,81], which use electron spin to store information. Currently, MRAMs look a very promising solution and several researchers envision that they might replace both the main memory and the storage memory in future architectures. When reading an MRAM, a current is forced to flow near the magnetic material, and the reading operation is accomplished by sensing the polarization of the magnetic field. When writing, an external current needs to overcome the stored field to impose a new value. As a consequence, writing requires more power consumption than reading. This technology can compete with Static RAM cells speed, while presenting a much lower area utilization.
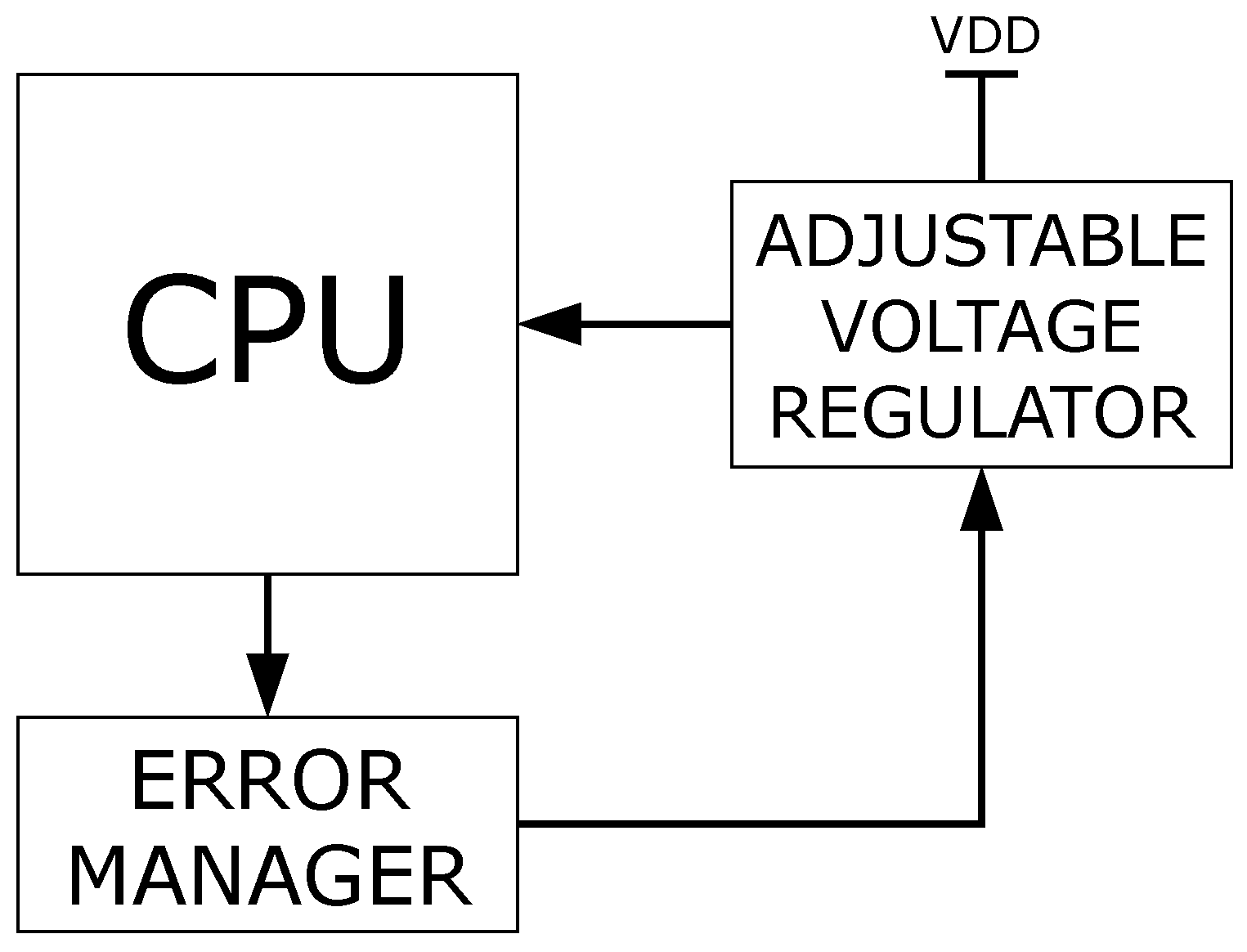
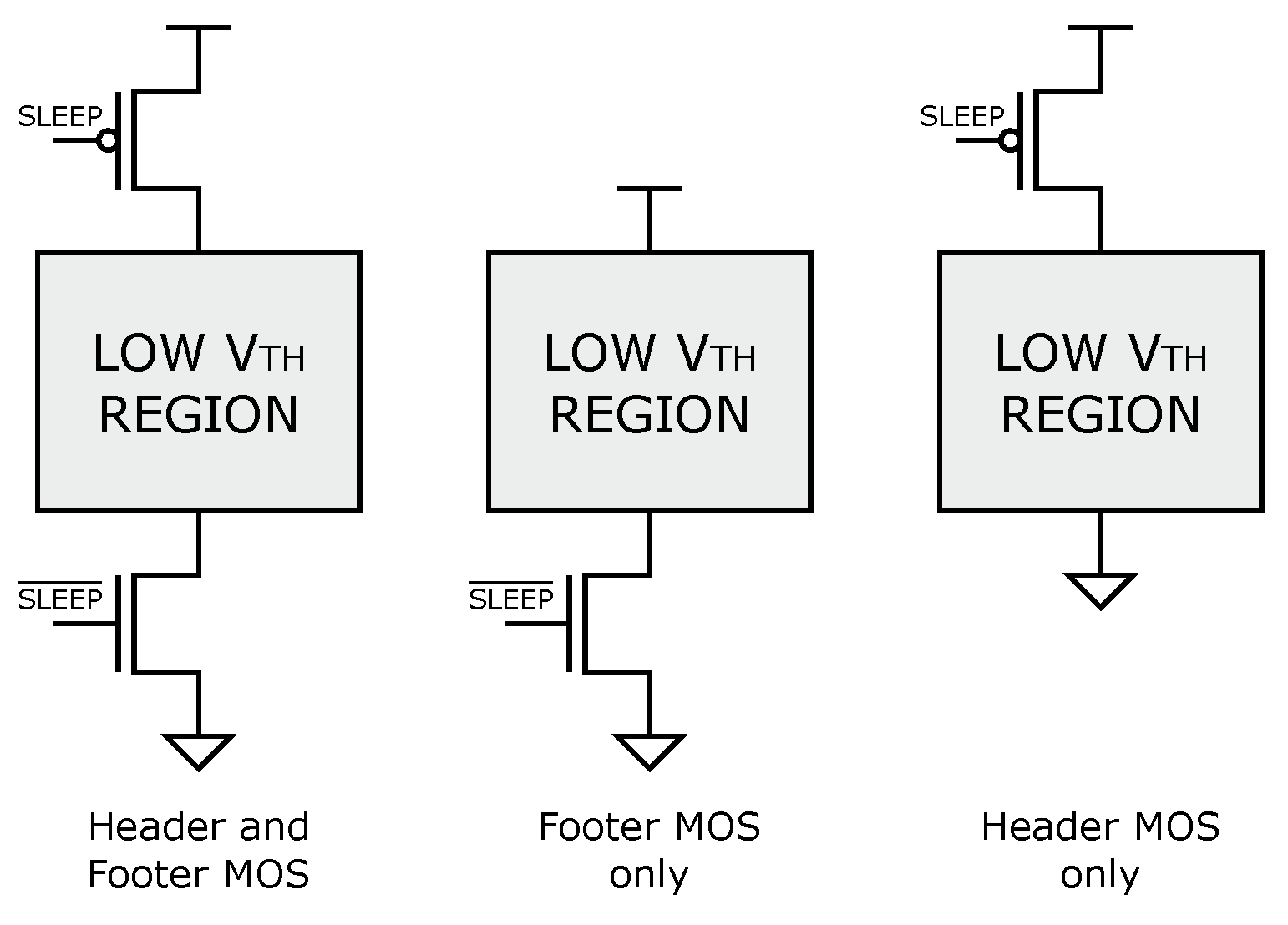
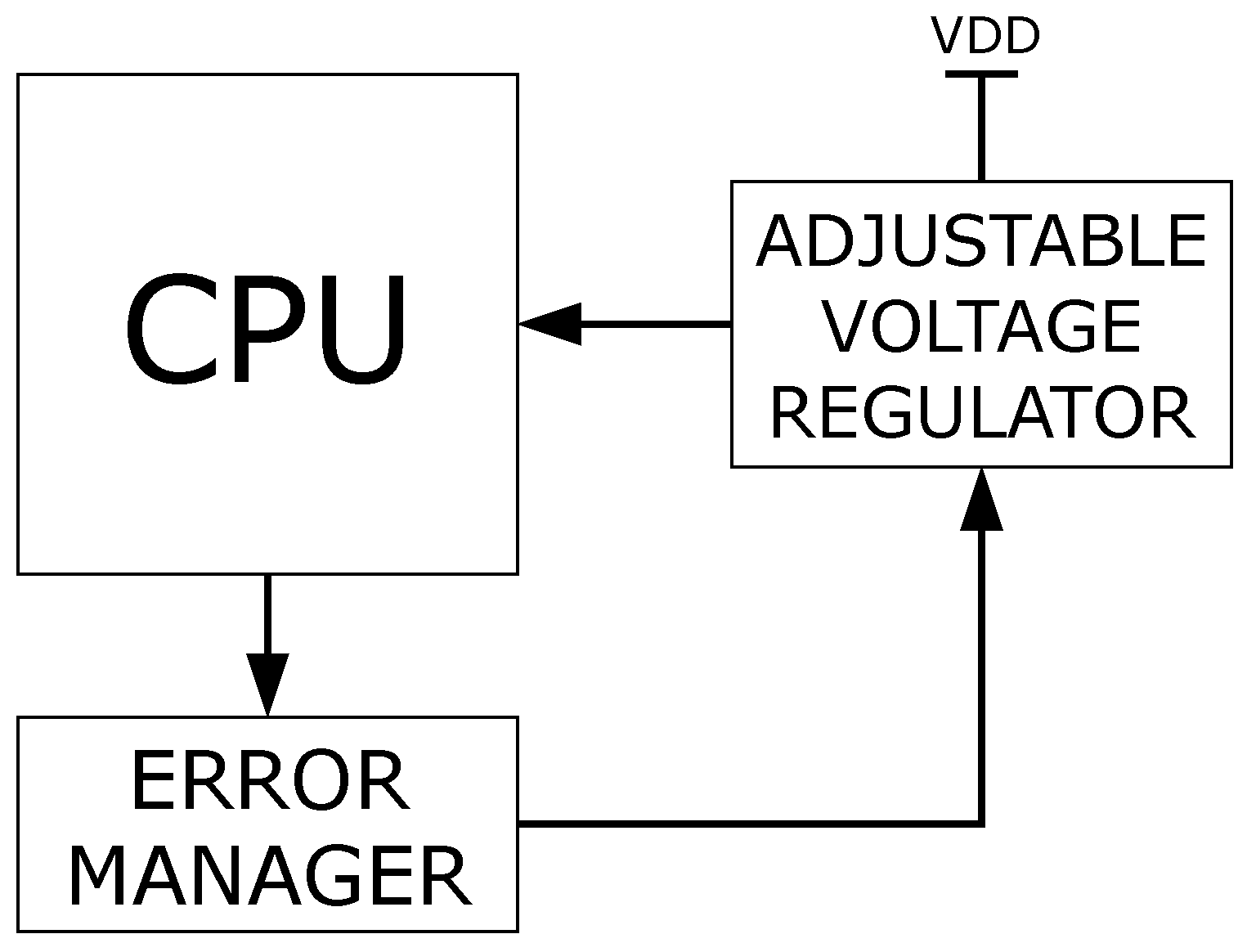
3.4. Power Management
- to reduce the power consumption by excluding elements that are not involved in the current task;
- to enhance the lifetime of the battery and consequently of the embedded system;
- to tone down the noise produced by all the components forming the system;
- to reduce the effort and requirements of the cooling apparatus.
3.5. Near-Threshold MCU Architectures
3.6. Data Processing
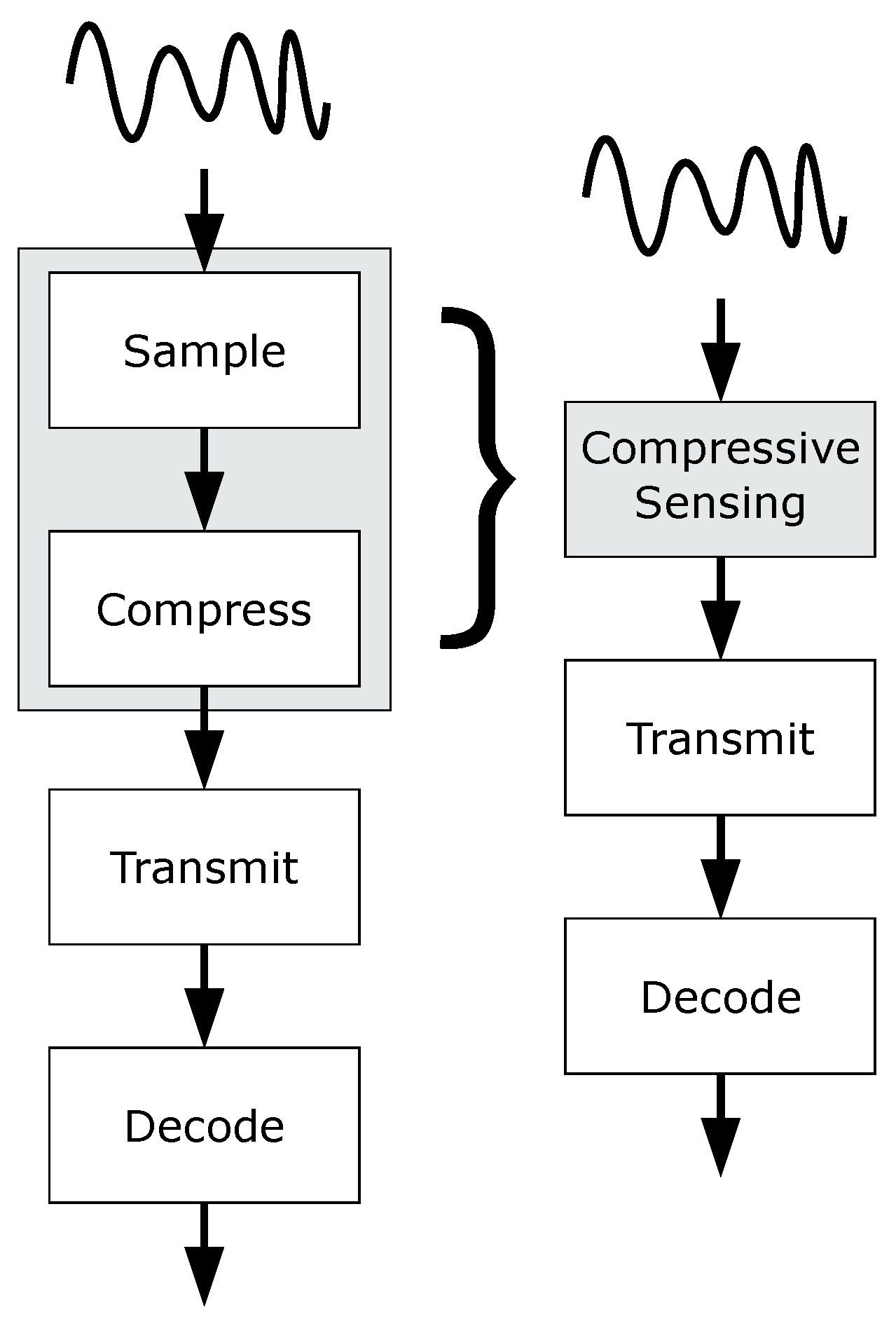
3.7. Compressive Sensing
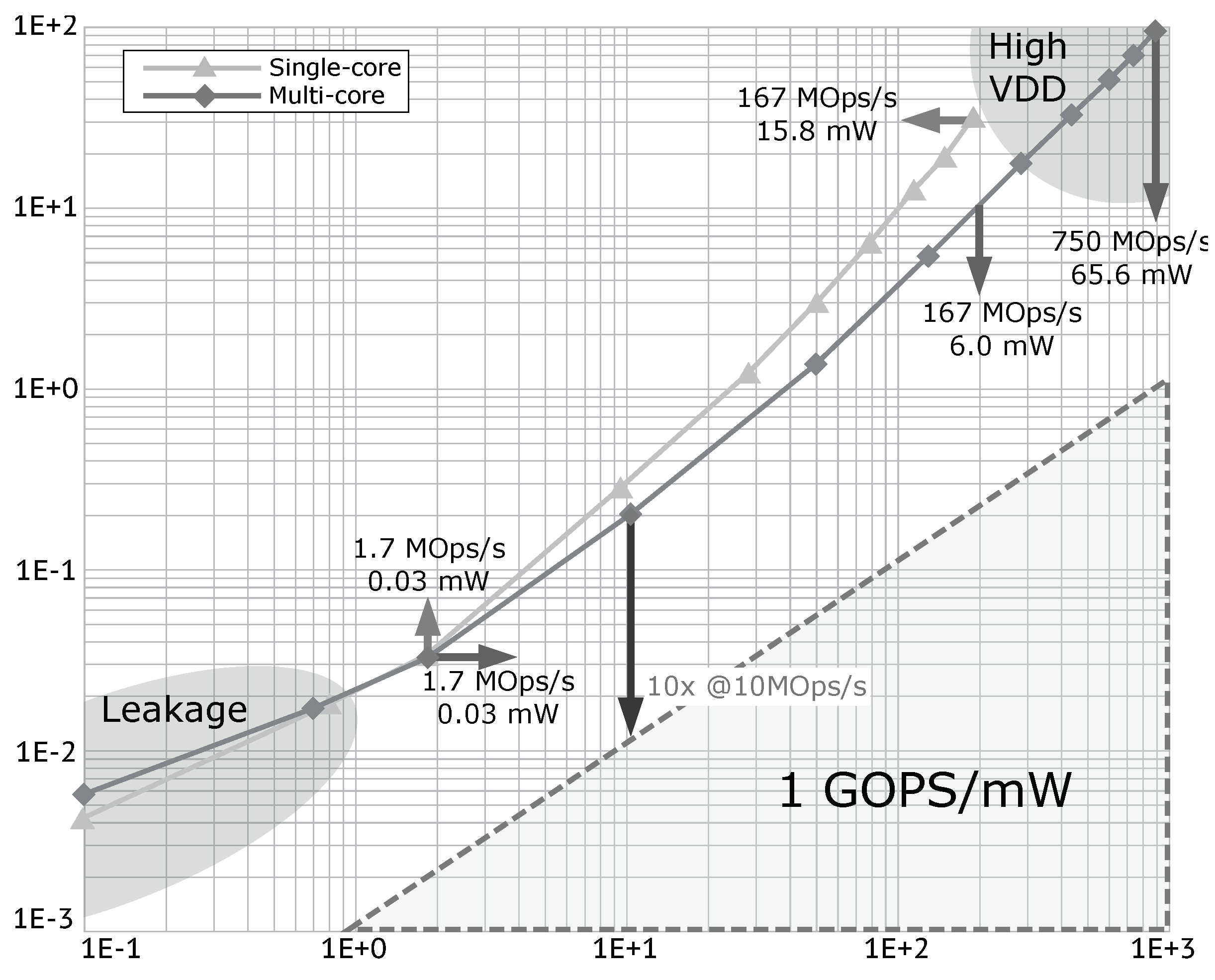
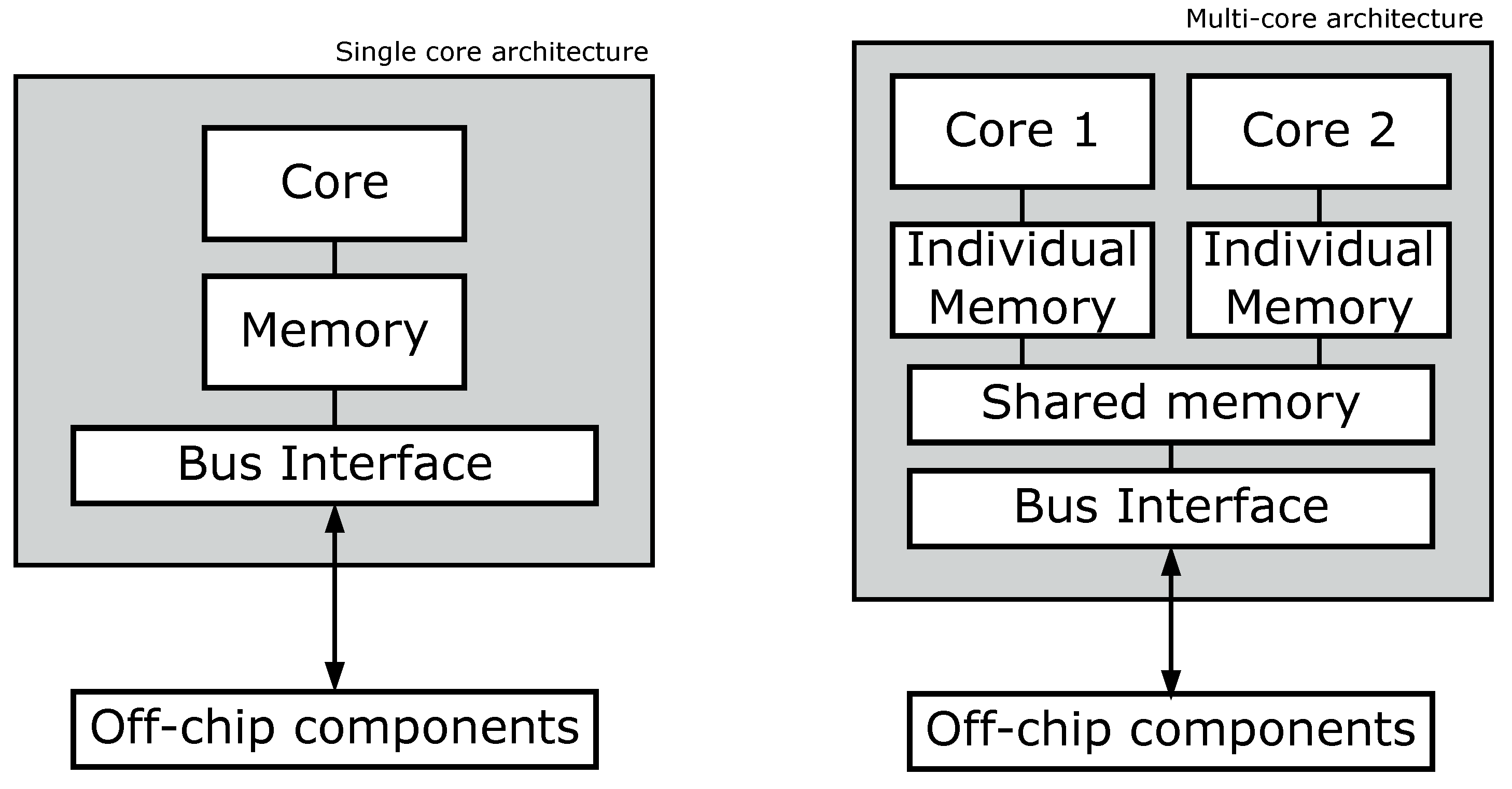
3.8. From Single Core to Multi Core
3.9. Memory Hierarchy for Multi-Core Domain
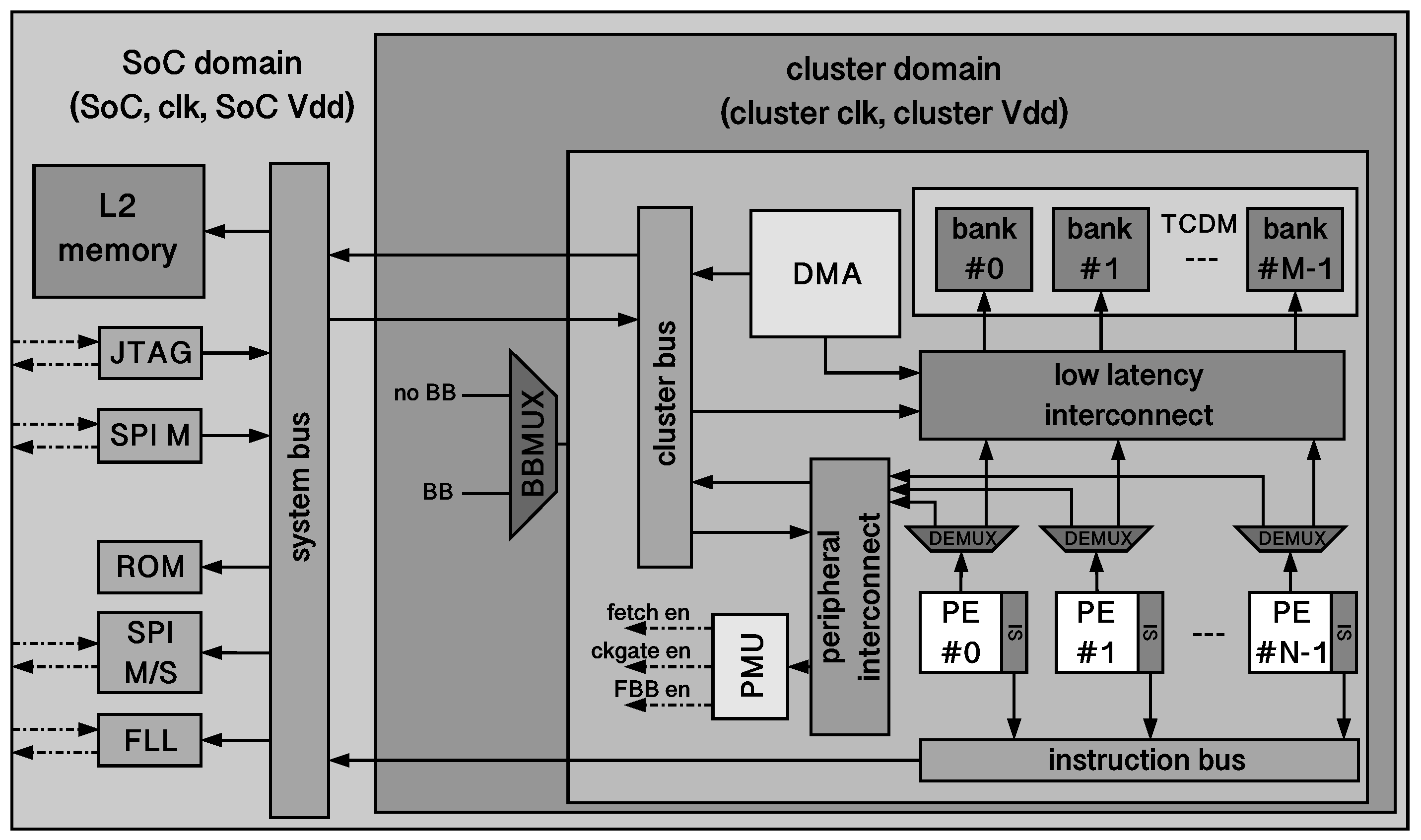
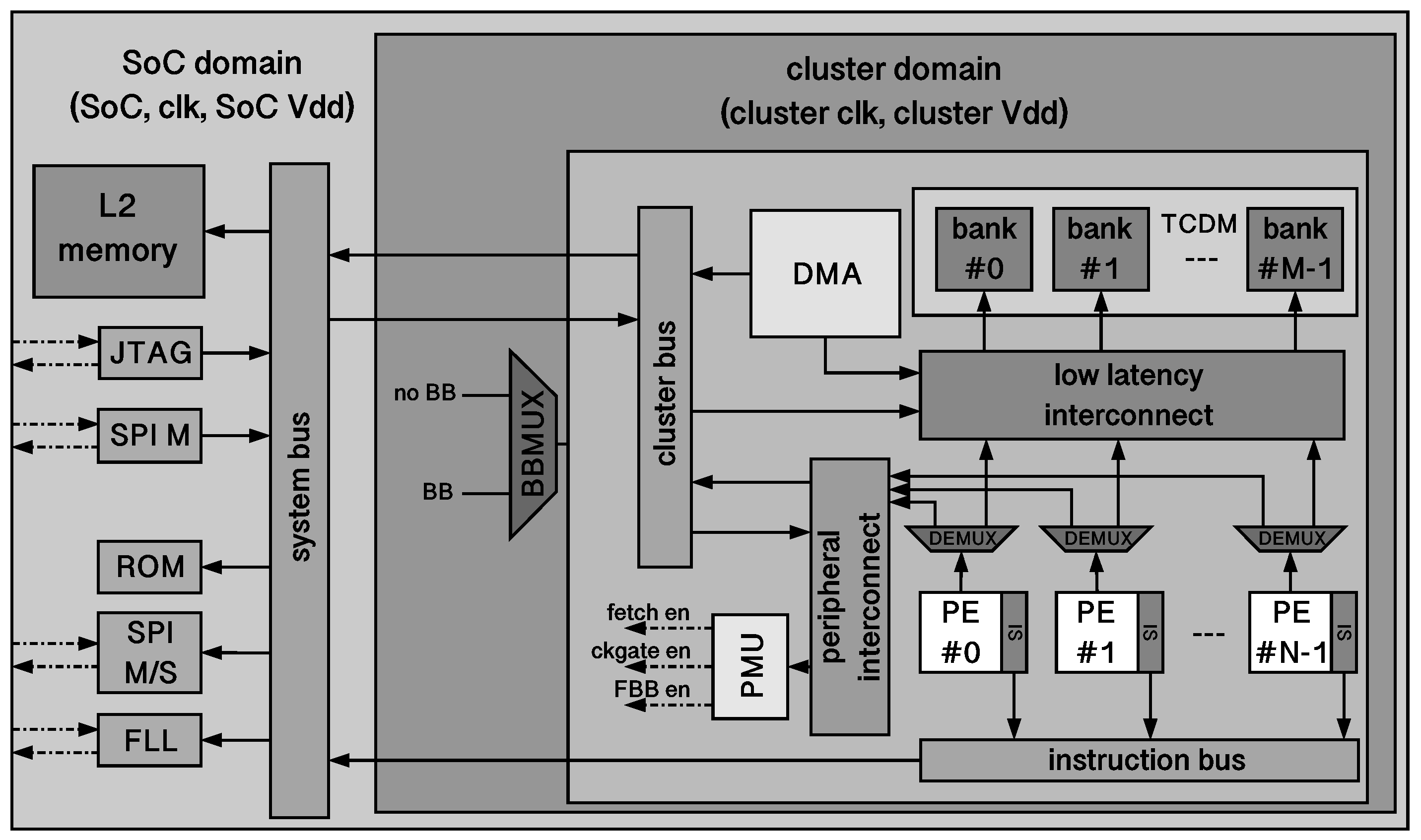
4. Example of a Many-Core Low-Power Processor: PULP
5. Conclusions and Future Perspectives
Author Contributions
Funding
Conflicts of Interest
References
- Gartner Website. Available online: http://www.gartner.com (accessed on 20 April 2019).
- Routh, K.; Pal, T. A survey on technological, business and societal aspects of Internet of Things by Q3, 2017. In Proceedings of the 2018 3rd International Conference on Internet of Things: Smart Innovation and Usages (IoT-SIU), Bhimtal, India, 23–24 February 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Ture, K.; Devos, A.; Maloberti, F.; Dehollain, C. Area and Power Efficient Ultra-Wideband Transmitter Based on Active Inductor. IEEE Trans. Circuits Syst. II Express Briefs 2018, 65, 1325–1329. [Google Scholar] [CrossRef]
- Saputra, N.; Long, J.R. A Fully-Integrated, Short-Range, Low Data Rate FM-UWB Transmitter in 90 nm CMOS. IEEE J. Solid-State Circuits 2011, 46, 1627–1635. [Google Scholar] [CrossRef]
- Mercier, P.P.; Daly, D.C.; Chandrakasan, A.P. An Energy-Efficient All-Digital UWB Transmitter Employing Dual Capacitively-Coupled Pulse-Shaping Drivers. IEEE J. Solid-State Circuits 2009, 44, 1679–1688. [Google Scholar] [CrossRef]
- Zhang, Z.; Li, Y.; Wang, G.; Lian, Y. The Design of an Energy-Efficient IR-UWB Transmitter With Wide-Output Swing and Sub-Microwatt Leakage Current. IEEE Trans. Circuits Syst. II Express Briefs 2018, 65, 1485–1489. [Google Scholar] [CrossRef]
- Zhao, M.J.; Li, B.; Wu, Z.H. 20-pJ/Pulse 250 Mbps Low-Complexity CMOS UWB Transmitter for 3–5 GHz Applications. IEEE Microw. Wirel. Compon. Lett. 2013, 23, 158–160. [Google Scholar] [CrossRef]
- Xu, R.; Jin, Y.; Nguyen, C. Power-efficient switching-based CMOS UWB transmitters for UWB communications and Radar systems. IEEE Trans. Microw. Theory Tech. 2006, 54, 3271–3277. [Google Scholar] [CrossRef]
- Chen, L.; Thombre, S.; Järvinen, K.; Lohan, E.S.; Alén-Savikko, A.; Leppäkoski, H.; Bhuiyan, M.Z.H.; Bu-Pasha, S.; Ferrara, G.N.; Honkala, S.; et al. Robustness, Security and Privacy in Location-Based Services for Future IoT: A Survey. IEEE Access 2017, 5, 8956–8977. [Google Scholar] [CrossRef]
- Wang, S.; Zhao, Y.; Xu, J.; Yuan, J.; Hsu, C.H. Edge server placement in mobile edge computing. J. Parallel Distrib. Comput. 2019, 127, 160–168. [Google Scholar] [CrossRef]
- Anawar, M.R.; Wang, S.; Zia, M.A.; Jadoon, A.K.; Akram, U.; Raza, S. Fog Computing: An Overview of Big IoT Data Analytics. Wirel. Commun. Mob. Comput. 2018, 2018, 1–22. [Google Scholar] [CrossRef]
- Liu, J.; Wang, S.; Zhou, A.; Yang, F.; Buyya, R. Availability-aware Virtual Cluster Allocation in Bandwidth-Constrained Datacenters. IEEE Trans. Serv. Comput. 2018, 1. [Google Scholar] [CrossRef]
- Lau, F.; Kuziemsky, C. Handbook of eHealth Evaluation: An Evidence-Based Approach; University of Victoria: Victoria, BC, Canada, 2017; Chapter 9. [Google Scholar]
- Finfgeld-Connett, D.; Johnson, E.D. Literature search strategies for conducting knowledge-building and theory-generating qualitative systematic reviews. J. Adv. Nurs. 2013, 69, 194–204. [Google Scholar] [CrossRef]
- Levy, Y.; Ellis, T.J. A Systems Approach to Conduct an Effective Literature Review in Support of Information Systems Research. Inform. Sci. Int. J. Emerg. Transdiscipl. 2006, 9, 181–212. [Google Scholar] [CrossRef]
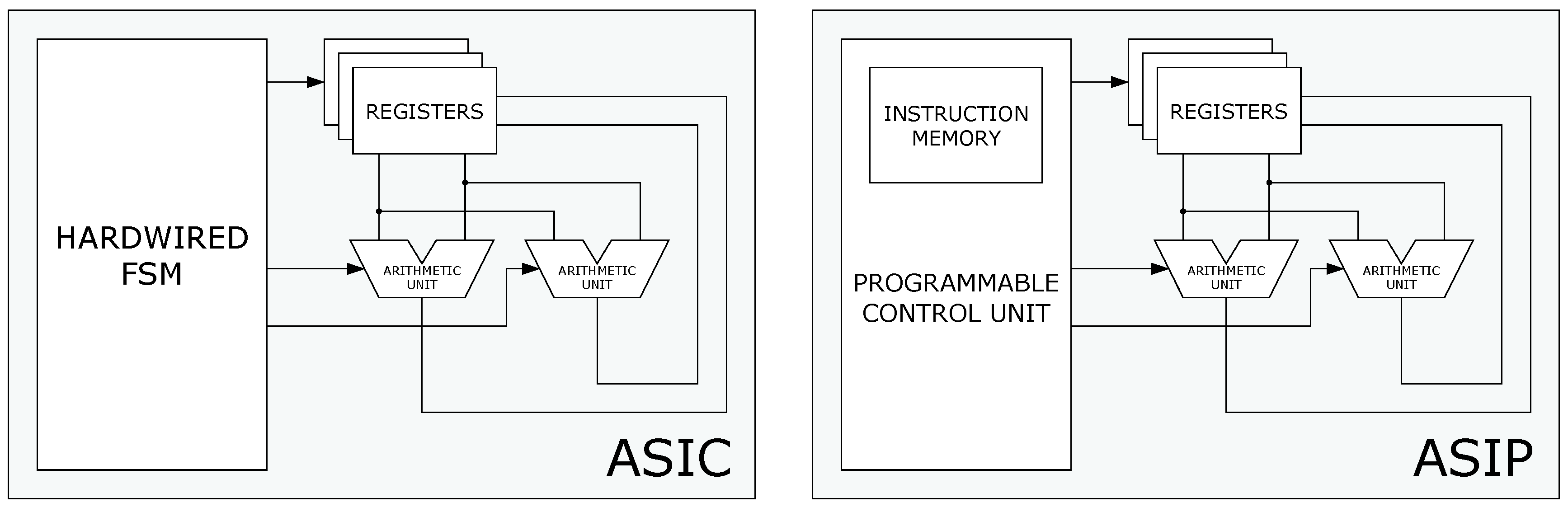
- Keutzer, K.; Malik, S.; Newton, A.R. From ASIC to ASIP: The next design discontinuity. In Proceedings of the IEEE International Conference on Computer Design: VLSI in Computers and Processors, Freiberg, Germany, 18 September 2002; pp. 84–90. [Google Scholar] [CrossRef]
- Bluetooth Communication System. Available online: https://www.bluetooth.com (accessed on 20 April 2019).
- Wi-Fi Alliance. Available online: https://www.wi-fi.org (accessed on 20 April 2019).
- Zigbee Alliance. Available online: https://www.zigbee.org (accessed on 20 April 2019).
- Z-Wave Communication System. Available online: https://www.z-wave.com (accessed on 20 April 2019).
- LoRa Alliance. Available online: https://lora-alliance.org (accessed on 20 April 2019).
- Fernandes, J.R.; Wentzloff, D. Recent advances in IR-UWB transceivers: An overview. In Proceedings of the 2010 IEEE International Symposium on Circuits and Systems, Paris, France, 30 May–2 June 2010; pp. 3284–3287. [Google Scholar] [CrossRef]
- Roch, M.R.; Martina, M. Integrated Light Sensing and Communication for LED Lighting. Designs 2018, 2, 49. [Google Scholar] [CrossRef]
- Haas, H. LiFi is a paradigm-shifting 5G technology. Rev. Phys. 2018, 3, 26–31. [Google Scholar] [CrossRef]
- Nanda, U.; Pattnaik, S.K. Universal Asynchronous Receiver and Transmitter (UART). In Proceedings of the 2016 3rd International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 22–23 January 2016; Volume 1, pp. 1–5. [Google Scholar] [CrossRef]
- Serial Peripheral Interface Specificantions. Available online: https://www.nxp.com/files-static/microcontrollers/doc/ref_manual/S12SPIV3.pdf (accessed on 20 April 2019).
- Inter-Integrated Circuit Bus Specifications. Available online: https://www.nxp.com/docs/en/user-guide/UM10204.pdf (accessed on 20 April 2019).
- MIPI Alliance Specifications Overview. Available online: https://www.mipi.org/specifications (accessed on 20 April 2019).
- Hsieh, S.; Hsieh, C. A 0.44fJ/conversion-step 11b 600KS/s SAR ADC with semi-resting DAC. In Proceedings of the 2016 IEEE Symposium on VLSI Circuits (VLSI-Circuits), Honolulu, HI, USA, 15–17 June 2016; pp. 1–2. [Google Scholar] [CrossRef]
- Wang, A.; Wang, Y.; Dhawan, V.; Shi, R. Design of a 10 bit 50MS/s SAR ADC in 14nm SOI FinFET CMOS. In Proceedings of the 2015 International SoC Design Conference (ISOCC), Gyungju, Korea, 2–5 November 2015; pp. 85–86. [Google Scholar] [CrossRef]
- Hsieh, S.; Hsieh, C. A 0.3V 0.705fJ/conversion-step 10-bit SAR ADC with shifted monotonie switching scheme in 90 nm CMOS. In Proceedings of the 2016 IEEE International Symposium on Circuits and Systems (ISCAS), Montreal, QC, Canada, 22–25 May 2016; p. 2899. [Google Scholar] [CrossRef]
- Kung, C.; Huang, C.; Li, C.; Chang, S. A Low Energy Consumption 10-Bit 100kS/s SAR ADC with Timing Control Adaptive Window. In Proceedings of the 2018 IEEE International Symposium on Circuits and Systems (ISCAS), Florence, Italy, 27–30 May 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Lin, J.; Hsieh, C. A 0.3 V 10-bit SAR ADC With First 2-bit Guess in 90-nm CMOS. IEEE Trans. Circuits Syst. I Regul. Pap. 2017, 64, 562–572. [Google Scholar] [CrossRef]
- Hsieh, S.; Hsieh, C. A 0.44-fJ/Conversion-Step 11-Bit 600-kS/s SAR ADC With Semi-Resting DAC. IEEE J. Solid-State Circuits 2018, 53, 2595–2603. [Google Scholar] [CrossRef]
- Alioto, M. IoT: Bird’s Eye View, Megatrends and Perspectives. In Enabling the Internet of Things: From Integrated Circuits to Integrated Systems; Alioto, M., Ed.; Springer International Publishing: Cham, Switzerland, 2017; pp. 1–45. [Google Scholar] [CrossRef]
- Xu, J.; Ma, J.; Zhang, D.; Zhang, Y.; Lin, S. Compressive video sensing based on user attention model. In Proceedings of the 28th Picture Coding Symposium, Nagoya, Japan, 8–10 December 2010; pp. 90–93. [Google Scholar] [CrossRef]
- Wang, Z.; Zhu, J. Single-pixel compressive imaging based on motion compensation. IET Image Process. 2018, 12, 2283–2291. [Google Scholar] [CrossRef]
- Dias, U.V.; Patil, S.A. Compressive sensing based microarray image acquisition. In Proceedings of the International Conference for Convergence for Technology-2014, Pune, India, 6–8 April 2014; pp. 1–5. [Google Scholar] [CrossRef]
- Zhang, M.; Bermak, A. Compressive Acquisition CMOS Image Sensor: From the Algorithm to Hardware Implementation. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2010, 18, 490–500. [Google Scholar] [CrossRef]
- Lima, J.A.; Miosso, C.J.; Farias, M.C.Q. Per-Pixel Mirror-Based Acquisition Method for video compressive sensing. In Proceedings of the 2014 22nd European Signal Processing Conference (EUSIPCO), Lisbon, Portugal, 1–5 September 2014; pp. 1058–1062. [Google Scholar]
- Zhu, H.; Zhang, M.; Suo, Y.; Tran, T.D.; der Spiegel, J.V. Design of a Digital Address-Event Triggered Compressive Acquisition Image Sensor. IEEE Trans. Circuits and Syst. I Regul. Pap. 2016, 63, 191–199. [Google Scholar] [CrossRef]
- Ejaz, W.; Anpalagan, A.; Imran, M.; Jo, M.; Muhammad, N.; Qaisar, S.; Wang, W. Internet of Things (IoT) in 5G Wireless Communications. IEEE Access 2016, 4, 10310–10314. [Google Scholar] [CrossRef]
- Al Ridhawi, I.; Aloqaily, M.; Kotb, Y.; Al Ridhawi, Y.; Jararweh, Y. A collaborative mobile edge computing and user solution for service composition in 5G systems. Trans. Emerg. Telecommun. Technol. 2018, 29, e3446. [Google Scholar] [CrossRef]
- Hezam, A.; Konstantas, D.; Mahyoub, M. A Comprehensive IoT Attacks Survey based on a Building-blocked Reference Mode. Int. J. Adv. Comput. Sci. Appl. 2018, 9. [Google Scholar] [CrossRef]
- Yaseen, Q.; AlBalas, F.; Jararweh, Y.; Al-Ayyoub, M. A Fog Computing Based System for Selective Forwarding Detection in Mobile Wireless Sensor Networks. In Proceedings of the 2016 IEEE 1st International Workshops on Foundations and Applications of Self* Systems (FAS*W), Augsburg, Germany, 12–16 September 2016; pp. 256–262. [Google Scholar] [CrossRef]
- Otoum, S.; Kantarci, B.; Mouftah, H. Adaptively Supervised and Intrusion-Aware Data Aggregation for Wireless Sensor Clusters in Critical Infrastructures. In Proceedings of the 2018 IEEE International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Otoum, S.; Kantarci, B.; Mouftah, H.T. Detection of Known and Unknown Intrusive Sensor Behavior in Critical Applications. IEEE Sens. Lett. 2017, 1, 1–4. [Google Scholar] [CrossRef]
- Ghafir, I.; Saleem, J.; Hammoudeh, M.; Faour, H.; Prenosil, V.; Jaf, S.; Jabbar, S.; Baker, T. Security threats to critical infrastructure: the human factor. J. Supercomput. 2018, 74, 4986–5002. [Google Scholar] [CrossRef]
- Otoum, S.; Kantarci, B.; Mouftah, H.T. Mitigating False Negative intruder decisions in WSN-based Smart Grid monitoring. In Proceedings of the 2017 13th International Wireless Communications and Mobile Computing Conference (IWCMC), Valencia, Spain, 26–30 June 2017; pp. 153–158. [Google Scholar] [CrossRef]
- Yaseen, Q.; Jararweh, Y.; Al-Ayyoub, M.; AlDwairi, M. Collusion attacks in Internet of Things: Detection and mitigation using a fog based model. In Proceedings of the 2017 IEEE Sensors Applications Symposium (SAS), Glassboro, NJ, USA, 13–15 March 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Aloqaily, M.; Kantarci, B.; Mouftah, H.T. Trusted Third Party for service management in vehicular clouds. In Proceedings of the 2017 13th International Wireless Communications and Mobile Computing Conference (IWCMC), Valencia, Spain, 26–30 June 2017; pp. 928–933. [Google Scholar] [CrossRef]
- Aloqaily, M.; Kantarci, B.; Mouftah, H.T. Fairness-Aware Game Theoretic Approach for Service Management in Vehicular Clouds. In Proceedings of the 2017 IEEE 86th Vehicular Technology Conference (VTC-Fall), Toronto, ON, Canada, 24–27 September 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Alkheir, A.A.; Aloqaily, M.; Mouftah, H.T. Connected and Autonomous Electric Vehicles (CAEVs). IT Prof. 2018, 20, 54–61. [Google Scholar] [CrossRef]
- Ridhawi, I.A.; Aloqaily, M.; Kantarci, B.; Jararweh, Y.; Mouftah, H.T. A continuous diversified vehicular cloud service availability framework for smart cities. Comput. Netw. 2018, 145, 207–218. [Google Scholar] [CrossRef]
- Otoum, S.; Kantarci, B.; Mouftah, H.T. Hierarchical trust-based black-hole detection in WSN-based smart grid monitoring. In Proceedings of the 2017 IEEE International Conference on Communications (ICC), Paris, France, 21–25 May 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Khan, S.; Paul, D.; Momtahan, P.; Aloqaily, M. Artificial intelligence framework for smart city microgrids: State of the art, challenges, and opportunities. In Proceedings of the 2018 Third International Conference on Fog and Mobile Edge Computing (FMEC), Barcelona, Spain, 23–26 April 2018; pp. 283–288. [Google Scholar] [CrossRef]
- Vianello, E.; Thomas, O.; Molas, G.; Turkyilmaz, O.; Jovanović, N.; Garbin, D.; Palma, G.; Alayan, M.; Nguyen, C.; Coignus, J.; et al. Resistive Memories for Ultra-Low-Power embedded computing design. In Proceedings of the 2014 IEEE International Electron Devices Meeting, San Francisco, CA, USA, 15–17 December 2014; pp. 6.3.1–6.3.4. [Google Scholar] [CrossRef]
- DeSalvo, B.; Vianello, E.; Thomas, O.; Clermidy, F.; Bichler, O.; Gamrat, C.; Perniola, L. Emerging resistive memories for low power embedded applications and neuromorphic systems. In Proceedings of the 2015 IEEE International Symposium on Circuits and Systems (ISCAS), Lisbon, Portugal, 24–27 May 2015; pp. 3088–3091. [Google Scholar] [CrossRef]
- Hemavathy, B.; Meenakshi, V. A novel design for low power Re-RAM based non-volatile flip flop using content addressable memory. In Proceedings of the 2017 Third International Conference on Science Technology Engineering Management (ICONSTEM), Chennai, India, 23–24 March 2017; pp. 879–883. [Google Scholar] [CrossRef]
- Kazi, I.; Meinerzhagen, P.; Gaillardon, P.; Sacchetto, D.; Leblebici, Y.; Burg, A.; Micheli, G.D. Energy/Reliability Trade-Offs in Low-Voltage ReRAM-Based Non-Volatile Flip-Flop Design. IEEE Trans. Circuits Syst. I Regul. Pap. 2014, 61, 3155–3164. [Google Scholar] [CrossRef]
- Biglari, M.; Lieske, T.; Fey, D. High-Endurance Bipolar ReRAM-Based Non-Volatile Flip-Flops with Run-Time Tunable Resistive States. In Proceedings of the 2018 IEEE/ACM International Symposium on Nanoscale Architectures (NANOARCH), Athens, Greece, 17–19 July 2018; pp. 1–6. [Google Scholar]
- Lee, A.; Lo, C.; Lin, C.; Chen, W.; Hsu, K.; Wang, Z.; Su, F.; Yuan, Z.; Wei, Q.; King, Y.; et al. A ReRAM-Based Nonvolatile Flip-Flop With Self-Write-Termination Scheme for Frequent-OFF Fast-Wake-Up Nonvolatile Processors. IEEE J. Solid-State Circuits 2017, 52, 2194–2207. [Google Scholar] [CrossRef]
- Chien, T.; Chiou, L.; Chuang, Y.; Sheu, S.; Li, H.; Wang, P.; Ku, T.; Tsai, M.; Wu, C. A low store energy and robust ReRAM-based flip-flop for normally off microprocessors. In Proceedings of the 2016 IEEE International Symposium on Circuits and Systems (ISCAS), Montreal, QC, Canada, 22–25 May 2016; pp. 2803–2806. [Google Scholar] [CrossRef]
- Koga, M.; Iida, M.; Amagasaki, M.; Ichida, Y.; Saji, M.; Iida, J.; Sueyoshi, T. A power-gatable reconfigurable logic chip with FeRAM cells. In Proceedings of the TENCON 2010—2010 IEEE Region 10 Conference, Fukuoka, Japan, 21–24 November 2010; pp. 317–322. [Google Scholar] [CrossRef]
- Qazi, M.; Amerasekera, A.; Chandrakasan, A.P. A 3.4-pJ FeRAM-Enabled D Flip-Flop in 0.13-μm CMOS for Nonvolatile Processing in Digital Systems. IEEE J. Solid-State Circuits 2014, 49, 202–211. [Google Scholar] [CrossRef]
- Masui, S.; Yokozeki, W.; Oura, M.; Ninomiya, T.; Mukaida, K.; Takayama, Y.; Teramoto, T. Design and applications of ferroelectric nonvolatile SRAM and flip-flop with unlimited read/program cycles and stable recall. In Proceedings of the IEEE 2003 Custom Integrated Circuits Conference, San Jose, CA, USA, 24 September 2003; pp. 403–406. [Google Scholar] [CrossRef]
- Lee, H.; Jung, S.; Song, Y.H. PCRAM-assisted ECC management for enhanced data reliability in flash storage systems. IEEE Trans. Consum. Electron. 2012, 58, 849–856. [Google Scholar] [CrossRef]
- Raoux, S.; Burr, G.W.; Breitwisch, M.J.; Rettner, C.T.; Chen, Y.; Shelby, R.M.; Salinga, M.; Krebs, D.; Chen, S.; Lung, H.; Lam, C.H. Phase-change random access memory: A scalable technology. IBM J. Res. Dev. 2008, 52, 465–479. [Google Scholar] [CrossRef]
- Lung, H.L.; Ho, Y.H.; Zhu, Y.; Chien, W.C.; Kim, S.; Kim, W.; Cheng, H.Y.; Ray, A.; Brightsky, M.; Bruce, R.; et al. A novel low power phase change memory using inter-granular switching. In Proceedings of the 2016 IEEE Symposium on VLSI Technology, Honolulu, HI, USA, 14–16 June 2016; pp. 1–2. [Google Scholar] [CrossRef]
- Cheng, H.Y.; Chien, W.C.; BrightSky, M.; Ho, Y.H.; Zhu, Y.; Ray, A.; Bruce, R.; Kim, W.; Yeh, C.W.; Lung, H.L.; et al. Novel fast-switching and high-data retention phase-change memory based on new Ga-Sb-Ge material. In Proceedings of the 2015 IEEE International Electron Devices Meeting (IEDM), Washington, DC, USA, 7–9 December 2015; pp. 3.5.1–3.5.4. [Google Scholar] [CrossRef]
- Cheon, J.; Lee, I.; Ahn, C.; Stanisavljevic, M.; Athmanathan, A.; Papandreou, N.; Pozidis, H.; Eleftheriou, E.; Shin, M.; Kim, T.; et al. Non-resistance metric based read scheme for multi-level PCRAM in 25 nm technology. In Proceedings of the 2015 IEEE Custom Integrated Circuits Conference (CICC), San Jose, CA, USA, 28–30 September 2015; pp. 1–4. [Google Scholar] [CrossRef]
- Nirschl, T.; Philipp, J.B.; Happ, T.D.; Burr, G.W.; Rajendran, B.; Lee, M.; Schrott, A.; Yang, M.; Breitwisch, M.; Chen, C.; et al. Write Strategies for 2 and 4-bit Multi-Level Phase-Change Memory. In Proceedings of the 2007 IEEE International Electron Devices Meeting, Washington, DC, USA, 10–12 December 2007; pp. 461–464. [Google Scholar] [CrossRef]
- Lakys, Y.; Zhao, W.S.; Klein, J.; Chappert, C. Hardening techniques for MRAM-based non-volatile storage cells and logic. In Proceedings of the 2011 12th European Conference on Radiation and Its Effects on Components and Systems, Sevilla, Spain, 19–23 September 2011; pp. 669–674. [Google Scholar] [CrossRef]
- Münch, C.; Bishnoi, R.; Tahoori, M.B. Multi-bit non-volatile spintronic flip-flop. In Proceedings of the 2018 Design, Automation Test in Europe Conference Exhibition (DATE), Dresden, Germany, 19–23 March 2018; pp. 1229–1234. [Google Scholar] [CrossRef]
- Huang, K.; Lian, Y. A Low-Power Low-VDD Nonvolatile Latch Using Spin Transfer Torque MRAM. IEEE Trans. Nanotechnol. 2013, 12, 1094–1103. [Google Scholar] [CrossRef]
- Sakimura, N.; Sugibayashi, T.; Nebashi, R.; Kasai, N. Nonvolatile Magnetic Flip-Flop for Standby-Power-Free SoCs. IEEE J. Solid-State Circuits 2009, 44, 2244–2250. [Google Scholar] [CrossRef]
- Pyle, S.D.; Li, H.; DeMara, R.F. Compact low-power instant store and restore D flip-flop using a self-complementing spintronic device. Electron. Lett. 2016, 52, 1238–1240. [Google Scholar] [CrossRef]
- Chabi, D.; Zhao, W.; Zhang, Y.; Klein, J.; Chappert, C. Low power magnetic flip-flop based on checkpointing and self-enable mechanism. In Proceedings of the 2013 IEEE 11th International New Circuits and Systems Conference (NEWCAS), Paris, France, 16–19 June 2013; pp. 1–4. [Google Scholar] [CrossRef]
- Sakimura, N.; Sugibayashi, T.; Nebashi, R.; Kasai, N. Nonvolatile Magnetic Flip-Flop for standby-power-free SoCs. In Proceedings of the 2008 IEEE Custom Integrated Circuits Conference, San Jose, CA, USA, 21–24 September 2008; pp. 355–358. [Google Scholar] [CrossRef]
- Gangalakshmi, S.; Banu, A.K.; Kumar, R.H. Implementing the design of magnetic flip-flop based on swapped MOS design. In Proceedings of the 2015 2nd International Conference on Electronics and Communication Systems (ICECS), Coimbatore, India, 26–27 February 2015; pp. 987–989. [Google Scholar] [CrossRef]
- Zhao, W.; Belhaire, E.; Chappert, C. Spin-MTJ based Non-volatile Flip-Flop. In Proceedings of the 2007 7th IEEE Conference on Nanotechnology (IEEE NANO), Hong Kong, China, 2–5 August 2007; pp. 399–402. [Google Scholar] [CrossRef]
- Kimura, H.; Zhong, Z.; Mizuochi, Y.; Kinouchi, N.; Ichida, Y.; Fujimori, Y. Highly Reliable Non-Volatile Logic Circuit Technology and Its Application. In Proceedings of the 2013 IEEE 43rd International Symposium on Multiple-Valued Logic, Toyama, Japan, 22–24 May 2013; pp. 212–218. [Google Scholar] [CrossRef]
- Cai, H.; Wang, Y.; Naviner, L.; Zhao, W. Novel Pulsed-Latch Replacement in Non-Volatile Flip-Flop Core. In Proceedings of the 2017 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), Bochum, Germany, 3–5 July 2017; pp. 57–61. [Google Scholar] [CrossRef]
- Jovanović, N.; Thomas, O.; Vianello, E.; Portal, J.; Nikolić, B.; Naviner, L. OxRAM-based non volatile flip-flop in 28nm FDSOI. In Proceedings of the 2014 IEEE 12th International New Circuits and Systems Conference (NEWCAS), Trois-Rivieres, QC, Canada, 22–25 June 2014; pp. 141–144. [Google Scholar] [CrossRef]
- Li, M.; Huang, P.; Shen, L.; Zhou, Z.; Kang, J.; Liu, X. Simulation of the RRAM-based flip-flops with data retention. In Proceedings of the 2016 IEEE International Nanoelectronics Conference (INEC), Chengdu, China, 9–11 May 2016; pp. 1–2. [Google Scholar] [CrossRef]
- Kazi, I.; Meinerzhagen, P.; Gaillardon, P.; Sacchetto, D.; Burg, A.; Micheli, G.D. A ReRAM-based non-volatile flip-flop with sub-VT read and CMOS voltage-compatible write. In Proceedings of the 2013 IEEE 11th International New Circuits and Systems Conference (NEWCAS), Paris, France, 16–19 June 2013; pp. 1–4. [Google Scholar] [CrossRef]
- Ali, K.; Li, F.; Lua, S.Y.H.; Heng, C. Compact spin transfer torque non-volatile flip flop design for power-gating architecture. In Proceedings of the 2016 IEEE Asia Pacific Conference on Circuits and Systems (APCCAS), Jeju, Korea, 25–28 October 2016; pp. 119–122. [Google Scholar] [CrossRef]
- Kang, W.; Ran, Y.; Lv, W.; Zhang, Y.; Zhao, W. High-Speed, Low-Power, Magnetic Non-Volatile Flip-Flop With Voltage-Controlled, Magnetic Anisotropy Assistance. IEEE Magn. Lett. 2016, 7, 1–5. [Google Scholar] [CrossRef]
- Ueda, M.; Otsuka, T.; Toyoda, K.; Morimoto, K.; Morita, K. A novel non-volatile flip-flop using a ferroelectric capacitor. In Proceedings of the 13th IEEE International Symposium on Applications of Ferroelectrics, 2002 (ISAF 2002), Nara, Japan, 1 June 2002; pp. 155–158. [Google Scholar] [CrossRef]
- Park, J. Area-efficient STT/CMOS non-volatile flip-flop. In Proceedings of the 2017 IEEE International Symposium on Circuits and Systems (ISCAS), Baltimore, MD, USA, 28–31 May 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Zhao, W.; Belhaire, E.; Javerliac, V.; Chappert, C.; Dieny, B. A non-volatile flip-flop in magnetic FPGA chip. In Proceedings of the International Conference on Design and Test of Integrated Systems in Nanoscale Technology, 2006 (DTIS 2006), Tunis, Tunisia, 5–7 September 2006; pp. 323–326. [Google Scholar] [CrossRef]
- Na, T.; Ryu, K.; Kim, J.; Jung, S.; Kim, J.P.; Kang, S.H. High-performance low-power magnetic tunnel junction based non-volatile flip-flop. In Proceedings of the 2014 IEEE International Symposium on Circuits and Systems (ISCAS), Melbourne, Australia, 1–5 June 2014; pp. 1953–1956. [Google Scholar] [CrossRef]
- Izumi, S.; Kawaguchi, H.; Yoshimoto, M.; Kimura, H.; Fuchikami, T.; Marumoto, K.; Fujimori, Y. A ferroelectric-based non-volatile flip-flop for wearable healthcare systems. In Proceedings of the 2015 15th Non-Volatile Memory Technology Symposium (NVMTS), Beijing, China, 12–14 October 2015; pp. 1–4. [Google Scholar] [CrossRef]
- Jung, Y.; Kim, J.; Ryu, K.; Jung, S.; Kim, J.P.; Kang, S.H. MTJ based non-volatile flip-flop in deep submicron technology. In Proceedings of the 2011 International SoC Design Conference, Jeju, Korea, 17–18 November 2011; pp. 424–427. [Google Scholar] [CrossRef]
- Kimura, H.; Fuchikami, T.; Maramoto, K.; Fujimori, Y.; Izumi, S.; Kawaguchi, H.; Yoshimoto, M. A 2.4 pJ ferroelectric-based non-volatile flip-flop with 10-year data retention capability. In Proceedings of the 2014 IEEE Asian Solid-State Circuits Conference (A-SSCC), KaoHsiung, Taiwan, 10–12 November 2014; pp. 21–24. [Google Scholar] [CrossRef]
- Portal, J.M.; Bocquet, M.; Moreau, M.; Aziza, H.; Deleruyelle, D.; Zhang, Y.; Kang, W.; Klein, J.O.; Zhang, Y.; Chappert, C.; et al. An Overview of Non-Volatile Flip-Flops Based on Emerging Memory Technologies. J. Electron. Sci. Technol. 2014, 12, 173–181. [Google Scholar] [CrossRef]
- Aiassa, S.; Ros, P.M.; Masera, G.; Martina, M. A low power architecture for AER event-processing microcontroller. In Proceedings of the 2017 IEEE Biomedical Circuits and Systems Conference (BioCAS), Torino, Italy, 19–21 October 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Georgiou, J.; Andreou, A.G. Address-data event representation for communication in multichip neuromorphic system architectures. Electron. Lett. 2007, 43. [Google Scholar] [CrossRef]
- Georgiou, J.; Andreou, A.G. Address Data Event Representation (ADER) for Efficient Neuromorphic Communication. In Proceedings of the 2007 41st Annual Conference on Information Sciences and Systems, Baltimore, MD, USA, 14–16 March 2007; pp. 755–758. [Google Scholar] [CrossRef]
- Kapoor, C.; Singh, H.; Laxmi, V. A Survey on Energy Efficient Routing for Delay Minimization in IoT Networks. In Proceedings of the 2018 International Conference on Intelligent Circuits and Systems (ICICS), Phagwara, India, 20–21 April 2018; pp. 320–323. [Google Scholar] [CrossRef]
- Rzepecki, W.; Iwanecki, L.; Ryba, P. IEEE 802.15.4 Thread Mesh Network—Data Transmission in Harsh Environment. In Proceedings of the 2018 6th International Conference on Future Internet of Things and Cloud Workshops (FiCloudW), Barcelona, Spain, 6–8 August 2018; pp. 42–47. [Google Scholar] [CrossRef]
- Joo, S.; Kim, H. Low power wireless mesh network over the TDMA link for connecting things. In Proceedings of the 2015 17th International Conference on Advanced Communication Technology (ICACT), Seoul, Korea, 1–3 July 2015; pp. 143–146. [Google Scholar] [CrossRef]
- Kim, J.; Lee, J. Cluster-Based Mobility Supporting WMN for IoT Networks. In Proceedings of the 2012 IEEE International Conference on Green Computing and Communications, Besancon, France, 20–23 November 2012; pp. 700–703. [Google Scholar] [CrossRef]
- Matthys, N.; Yang, F.; Daniels, W.; Michiels, S.; Joosen, W.; Hughes, D.; Watteyne, T. uPnP-Mesh: The plug-and-play mesh network for the Internet of Things. In Proceedings of the 2015 IEEE 2nd World Forum on Internet of Things (WF-IoT), Milan, Italy, 14–16 December 2015; pp. 311–315. [Google Scholar] [CrossRef]
- Vittecoq, S. A Radio Mesh Platform for the IOT. In Proceedings of the 2013 Seventh International Conference on Innovative Mobile and Internet Services in Ubiquitous Computing, Taichung, Taiwan, 3–5 July 2013; pp. 530–534. [Google Scholar] [CrossRef]
- Liu, Y.; Tong, K.F.; Qiu, X.; Liu, Y.; Ding, X. Wireless Mesh Networks in IoT networks. In Proceedings of the 2017 International Workshop on Electromagnetics: Applications and Student Innovation Competition, London, UK, 30 May–1 June 2017; pp. 183–185. [Google Scholar] [CrossRef]
- Paek, J. Fast and Adaptive Mesh Access Control in Low-Power and Lossy Networks. IEEE Intern. Things J. 2015, 2, 435–444. [Google Scholar] [CrossRef]
- Darroudi, S.M.; Gomez, C. Modeling the Connectivity of Data-Channel-Based Bluetooth Low Energy Mesh Networks. IEEE Commun. Lett. 2018, 22, 2124–2127. [Google Scholar] [CrossRef]
- Daly, E.L.; Bernhard, J.T. The rapidly tuned analog-to-information converter. In Proceedings of the 2013 Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 3–6 November 2013; pp. 495–499. [Google Scholar] [CrossRef]
- Cambareri, V.; Mangia, M.; Pareschi, F.; Rovatti, R.; Setti, G. A rakeness-based design flow for Analog-to-Information conversion by Compressive Sensing. In Proceedings of the 2013 IEEE International Symposium on Circuits and Systems (ISCAS2013), Beijing, China, 19–23 May 2013; pp. 1360–1363. [Google Scholar] [CrossRef]
- Pareschi, F.; Albertini, P.; Frattini, G.; Mangia, M.; Rovatti, R.; Setti, G. Hardware-Algorithms Co-Design and Implementation of an Analog-to-Information Converter for Biosignals Based on Compressed Sensing. IEEE Trans. Biomed. Circuits Syst. 2016, 10, 149–162. [Google Scholar] [CrossRef]
- Liu, S.; Zhang, M.; Jiang, W.; Wang, J.; Qi, P. Theory and hardware implementation of an analog-to-Information Converter based on Compressive Sensing. In Proceedings of the 2013 IEEE 10th International Conference on ASIC, Shenzhen, China, 28–31 October 2013; pp. 1–4. [Google Scholar] [CrossRef]
- Cambareri, V.; Mangia, M.; Rovatti, R.; Setti, G. Joint analog-to-information conversion of heterogeneous biosignals. In Proceedings of the 2013 IEEE Biomedical Circuits and Systems Conference (BioCAS), Rotterdam, The Netherlands, 31 October–2 November 2013; pp. 158–161. [Google Scholar] [CrossRef]
- Mangia, M.; Rovatti, R.; Setti, G. Analog-to-information conversion of sparse and non-white signals: Statistical design of sensing waveforms. In Proceedings of the 2011 IEEE International Symposium of Circuits and Systems (ISCAS), Rio de Janeiro, Brazil, 15–18 May 2011; pp. 2129–2132. [Google Scholar] [CrossRef]
- Singh, W.; Deb, S. Energy Efficient Analog-to-Information Converter for Biopotential Acquisition Systems. In Proceedings of the 2015 IEEE International Symposium on Nanoelectronic and Information Systems, Indore, India, 21–23 December 2015; pp. 141–145. [Google Scholar] [CrossRef]
- Abari, O.; Chen, F.; Lim, F.; Stojanovic, V. Performance trade-offs and design limitations of analog-to-information converter front-ends. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 5309–5312. [Google Scholar] [CrossRef]
- Bellasi, D.E.; Bettini, L.; Benkeser, C.; Burger, T.; Huang, Q.; Studer, C. VLSI Design of a Monolithic Compressive-Sensing Wideband Analog-to-Information Converter. IEEE J. Emerg. Sel. Top. Circuits Syst. 2013, 3, 552–565. [Google Scholar] [CrossRef]
- Amarlingam, M.; Mishra, P.K.; Rajalakshmi, P.; Giluka, M.K.; Tamma, B.R. Energy efficient wireless sensor networks utilizing adaptive dictionary in compressed sensing. In Proceedings of the 2018 IEEE 4th World Forum on Internet of Things (WF-IoT), Singapore, 5–8 February 2018; pp. 383–388. [Google Scholar] [CrossRef]
- Ros, P.M.; Crepaldi, M.; Damilano, A.; Demarchi, D. Integrated bio-inspired systems: An event-driven design framework. In Proceedings of the 2014 10th International Conference on Innovations in Information Technology (IIT), Al Ain, UAE, 9–11 November 2014; pp. 48–53. [Google Scholar] [CrossRef]
- Crepaldi, M.; Dapra, D.; Bonanno, A.; Aulika, I.; Demarchi, D.; Civera, P. A Very Low-Complexity 0.3–4.4 GHz 0.004 mm2 All-Digital Ultra-Wide-Band Pulsed Transmitter for Energy Detection Receivers. IEEE Trans. Circuits Syst. I Regul. Pap. 2012, 59, 2443–2455. [Google Scholar] [CrossRef]
- Crepaldi, M.; Sanginario, A.; Ros, P.M.; Demarchi, D. Low-latency asynchronous networking for the IoT: Routing analog pulse delays using IR-UWB. In Proceedings of the 2016 14th IEEE International New Circuits and Systems Conference (NEWCAS), Vancouver, BC, Canada, 26–29 June 2016; pp. 1–4. [Google Scholar] [CrossRef]
- Crepaldi, M.; Angotzi, G.N.; Maviglia, A.; Berdondini, L. A 1 Gpps asynchronous logic OOK IR-UWB transmitter based on master-slave PLL synthesis. In Proceedings of the 2017 IEEE International Symposium on Circuits and Systems (ISCAS), Baltimore, MD, USA, 28–31 May 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Crepaldi, M.; Angotzi, G.N.; Maviglia, A.; Diotalevi, F.; Berdondini, L. A 5 pJ/pulse at 1-Gpps Pulsed Transmitter Based on Asynchronous Logic Master–Slave PLL Synthesis. IEEE Trans. Circuits Syst. I Regul. Pap. 2018, 65, 1096–1109. [Google Scholar] [CrossRef]
- Rani, M.; Dhok, S.B.; Deshmukh, R.B. A Systematic Review of Compressive Sensing: Concepts, Implementations and Applications. IEEE Access 2018, 6, 4875–4894. [Google Scholar] [CrossRef]
- Loi, I.; Benini, L. A multi banked—Multi ported—Non blocking shared L2 cache for MPSoC platforms. In Proceedings of the 2014 Design, Automation Test in Europe Conference Exhibition (DATE), Dresden, Germany, 24–28 March 2014; pp. 1–6. [Google Scholar] [CrossRef]
- Poursafaei, F.R.; Bazzaz, M.; Ejlali, A. NPAM: NVM-Aware Page Allocation for Multi-Core Embedded Systems. IEEE Trans. Comput. 2017, 66, 1703–1716. [Google Scholar] [CrossRef]
- Ax, J.; Sievers, G.; Daberkow, J.; Flasskamp, M.; Vohrmann, M.; Jungeblut, T.; Kelly, W.; Porrmann, M.; Rückert, U. CoreVA-MPSoC: A Many-Core Architecture with Tightly Coupled Shared and Local Data Memories. IEEE Trans. Parallel Distrib. Syst. 2018, 29, 1030–1043. [Google Scholar] [CrossRef]
- Conti, F.; Rossi, D.; Pullini, A.; Loi, I.; Benini, L. PULP: A Ultra-Low Power Parallel Accelerator for Energy-Efficient and Flexible Embedded Vision. J. Signal Process. Syst. 2016, 84, 339–354. [Google Scholar] [CrossRef]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Capra, M.; Peloso, R.; Masera, G.; Ruo Roch, M.; Martina, M. Edge Computing: A Survey On the Hardware Requirements in the Internet of Things World. Future Internet 2019, 11, 100. https://doi.org/10.3390/fi11040100
Capra M, Peloso R, Masera G, Ruo Roch M, Martina M. Edge Computing: A Survey On the Hardware Requirements in the Internet of Things World. Future Internet. 2019; 11(4):100. https://doi.org/10.3390/fi11040100
Chicago/Turabian StyleCapra, Maurizio, Riccardo Peloso, Guido Masera, Massimo Ruo Roch, and Maurizio Martina. 2019. "Edge Computing: A Survey On the Hardware Requirements in the Internet of Things World" Future Internet 11, no. 4: 100. https://doi.org/10.3390/fi11040100
APA StyleCapra, M., Peloso, R., Masera, G., Ruo Roch, M., & Martina, M. (2019). Edge Computing: A Survey On the Hardware Requirements in the Internet of Things World. Future Internet, 11(4), 100. https://doi.org/10.3390/fi11040100