A Scheme to Design Community Detection Algorithms in Various Networks



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Related Work
- There is material transmission between them, and/or
- they share some identical or similar properties.
3. Concrete Problem Reduction
3.1. Transmission Network
- The shorter STT is, the stronger the corresponding relation is.
- The shorter CM is, the stronger the corresponding relation is.
- The shorter the time to transfer a certain number of points is, the stronger the corresponding relation is.
- 1.
- , and
- 2.
- if and only if .
- 1.
- . (non-negativity)
- 2.
- if and only if u and v coincide. (coincidence axiom)
- 3.
- if and only if there is no path between u and v.
- 4.
- , and the equality holds if the components containing u and v are connected by the cutting node w.
- 5.
- Suppose is a graph that is the same as G except that for and its counterpart , . Then, for and their counterparts , .
- 6.
- . (symmetry)
3.2. Similarity Network
- 1.
- , (non-negativity)
- 2.
- if and only if , and (coincidence axiom)
- 3.
- . (symmetry)
- .
- if and only if for all properties in P, u and v have the same cases.
- .
- .
3.3. Relations between Similarity Networks and Transmission Networks
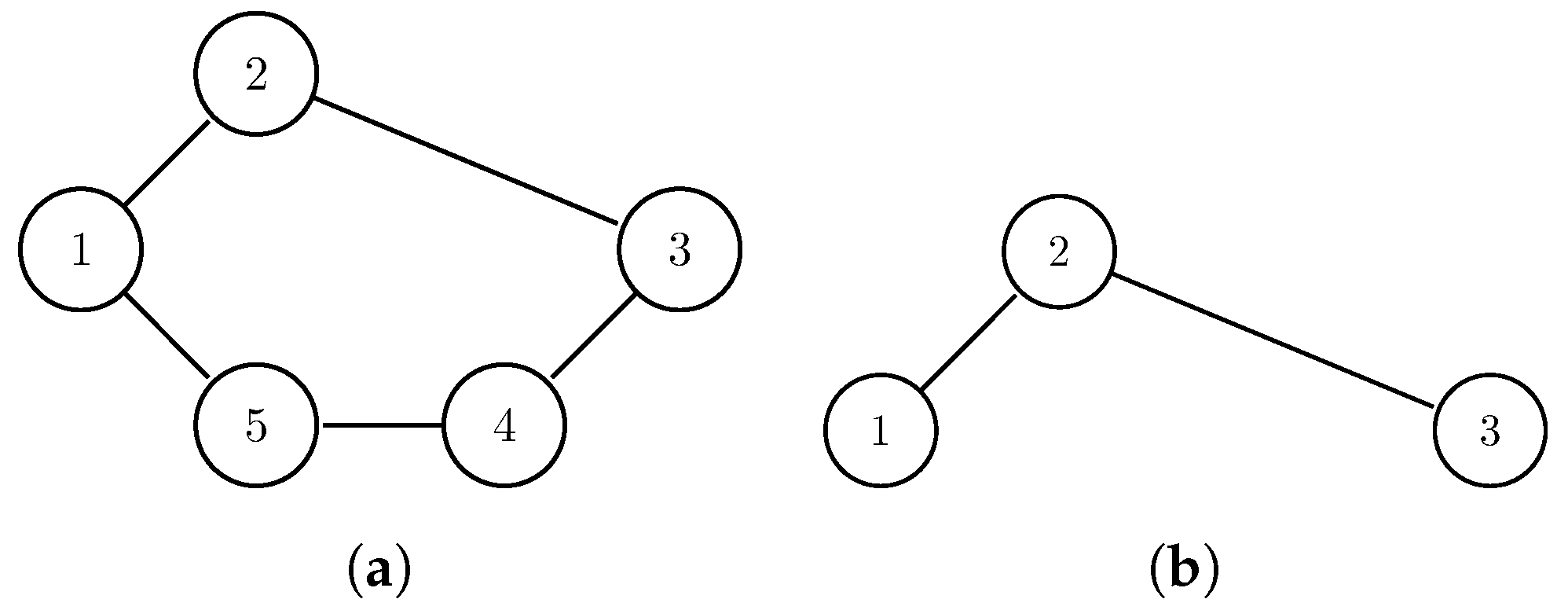
4. Communities and Detection Algorithms
- 1.
- is a community, and
- 2.
- There is no such that is a community and .
| Algorithm 1 Find Maxiaml Communities |
| for where do if & then else end if end for |
5. Demonstration
5.1. The Current Model and Klein and Randic’s Effective Resistance
- 1.
- 2.
- 3.
- 4.
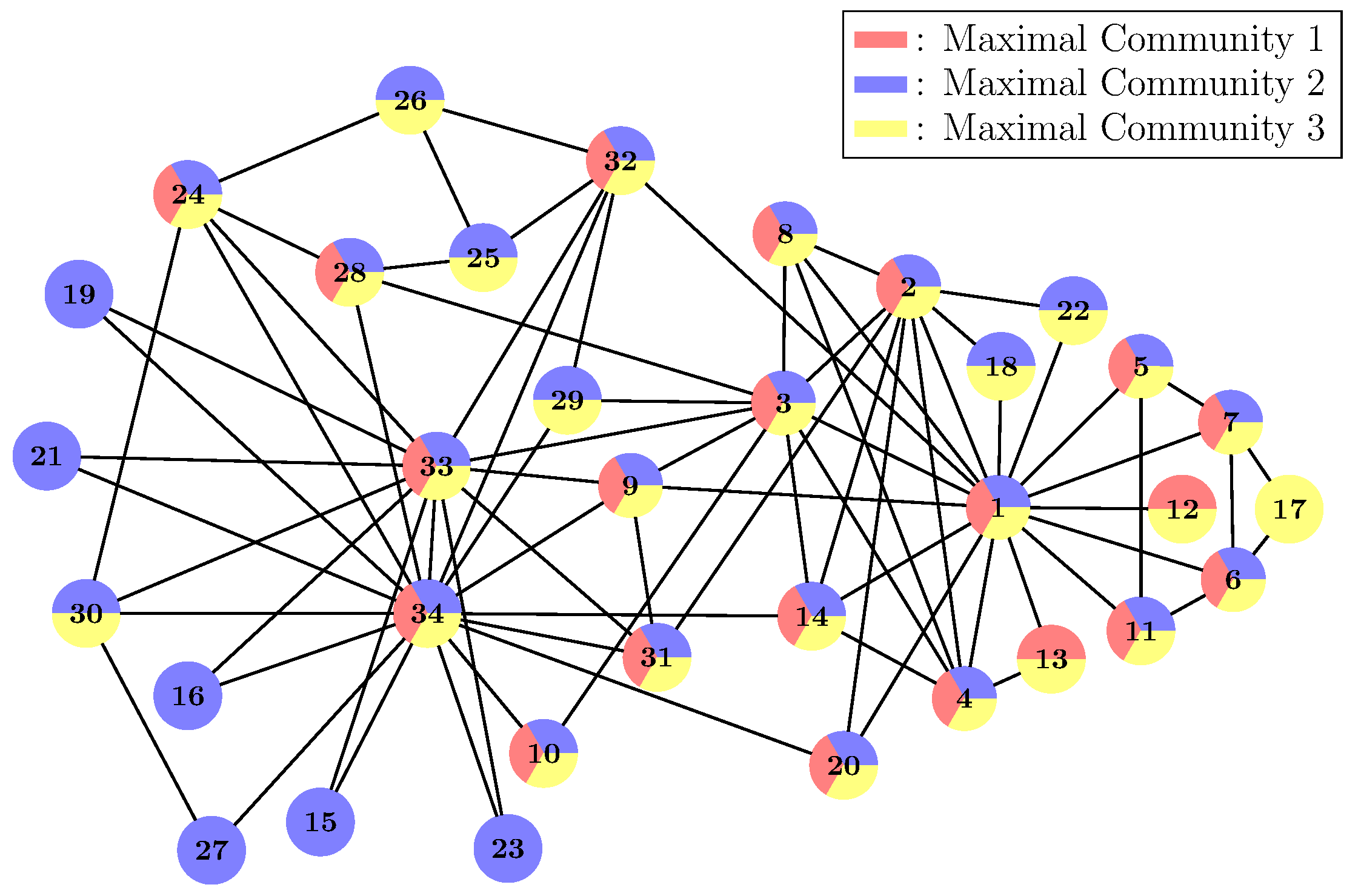
5.2. Community Detection in Zachary’s Karate Club
5.3. Comparison Results
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Fortunato, S. Community detection in graphs. Phys. Rep. 2010, 486, 75–174. [Google Scholar] [CrossRef]
- Porter, M.; Onnela, J.; Mucha, P. Communities in networks. Not. Am. Math. Soc. 2009, 56, 1082–1097. [Google Scholar]
- Newman, M.E.J. Communities, modules and large-scale structure in networks. Nat. Phys. 2012, 8, 25–31. [Google Scholar]
- Kernighan, B.W.; Lin, S. An Efficient Heuristic Procedure for Partitioning Graphs. Bell Syst. Tech. J. 1970, 49, 291–307. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning, 2nd ed.; Springer: New York, NY, USA, 2009; pp. 520–523. [Google Scholar]
- Hlaoui, A.; Wang, S. A direct approach to graph clustering. Neural Netw. Comput. Intell. 2004, 4, 158–163. [Google Scholar]
- Rattigan, M.J.; Maier, M.; Jensen, D. Graph Clustering with Network Structure Indices. In Proceedings of the 24th International Conference on Machine Learning, Corvallis, OR, USA, 20–24 June 2007; pp. 783–790. [Google Scholar]
- Barnes, E.R. An Algorithm for Partitioning the Nodes of a Graph. In Proceedings of the 20th IEEE Conference on Decision and Control including the Symposium on Adaptive Processes, San Diego, CA, USA, 16–18 December 1982; pp. 541–550. [Google Scholar]
- Luxburg, U. A Tutorial on Spectral Clustering. Stat. Comput. 2007, 17, 395–416. [Google Scholar] [CrossRef]
- Li, Y.; He, K.; Kloster, K.; Bindel, D.; Hopcroft, J. Local Spectral Clustering for Overlapping Community Detection. ACM Trans. Knowl. Discov. Data 2018, 12, 1–27. [Google Scholar] [CrossRef]
- Lu, Z.; Wahlström, J.; Nehorai, A. Community Detection in Complex Networks via Clique Conductance. Sci. Rep. 2018, 8, 5982. [Google Scholar] [CrossRef]
- Newman, M.E. Fast algorithm for detecting community structure in networks. Phys. Rev. E 2004, 69, 066133. [Google Scholar] [CrossRef]
- Chen, M.; Kuzmin, K.; Szymanski, B.K. Community Detection via Maximization of Modularity and Its Variants. IEEE Trans. Comput. Soc. Syst. 2014, 1, 46–65. [Google Scholar] [CrossRef]
- Kaur, M.; Mahajan, A. Community Detection in Complex Networks: A Novel Approach Based on Ant Lion Optimizer. In Proceedings of the International Conference on Soft Computing for Problem Solving; Springer: Singapore, 2016; pp. 22–34. [Google Scholar]
- Reichardt, J.; Bornholdt, S. Detecting Fuzzy Community Structures in Complex Networks with a Potts Model. Phys. Rev. Lett. 2004, 93, 218701. [Google Scholar] [CrossRef] [PubMed]
- Wan, C.; Peng, S.; Wang, C.; Yuan, Y. Communities Detection Algorithm Based on General Stochastic Block Model in Mobile Social Networks. In Proceedings of the 2016 International Conference on Advanced Cloud and Big Data (CBD), Chengdu, China, 13–16 August 2016. [Google Scholar]
- Bickel, P.J.; Chen, A. A nonparametric view of network models and Newman-Girvan and other modularities. Proc. Natl. Acad. Sci. USA 2009, 106, 21068–21073. [Google Scholar] [CrossRef] [PubMed]
- Airoldi, E.M.; Blei, D.M.; Fienberg, S.E.; Xing, E.P. Mixed Membership Stochastic Blockmodels. In Proceedings of the International Conference on Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 8–10 December 2008. [Google Scholar]
- Wahlstrom, J.; Skog, I.; Rosa, P.S.L.; Handel, P.; Nehorai, A. The β-Model–Maximum Likelihood, Cramer–Rao Bounds, and Hypothesis Testing. IEEE Trans. Signal Process. 2017, 65, 3234–3246. [Google Scholar] [CrossRef]
- Milo, R.; Shen-Orr, S.; Itzkovitz, S.; Kashtan, N.; Chklovskii, D.; Alon, U. Network Motifs: Simple Building Blocks of Complex Networks. Science 2002, 298, 824–827. [Google Scholar] [CrossRef] [PubMed]
- Yaveroğlu, Ö.N.; Malod-Dognin, N.; Davis, D.; Levnajic, Z.; Janjic, V.; Karapandza, R.; Stojmirovic, A.; Pržulj, N. Revealing the Hidden Language of Complex Networks. Sci. Rep. 2014, 4, 4547. [Google Scholar] [CrossRef] [PubMed]
- Benson, A.R.; Gleich, D.F.; Leskovec, J. Higher-order organization of complex networks. Science 2016, 353, 163–166. [Google Scholar] [CrossRef] [PubMed]
- Bu, Z.; Li, H.; Cao, J.; Wang, Z.; Gao, G. Dynamic Cluster Formation Game for Attributed Graph Clustering. IEEE Trans. Cybern. 2019, 49, 328–341. [Google Scholar] [CrossRef]
- Newman, M.E.J. Equivalence between modularity optimization and maximum likelihood methods for community detection. Phys. Rev. E 2016, 94, 052315. [Google Scholar] [CrossRef]
- Li, H.; Bu, Z.; Li, A.; Liu, Z.; Shi, Y. Fast and Accurate Mining the Community Structure: Integrating Center Locating and Membership Optimization. IEEE Trans. Knowl. Data Eng. 2016, 28, 2349–2362. [Google Scholar] [CrossRef]
- Li, H.J.; Bu, Z.; Li, Y.; Zhang, Z.; Chu, Y.; Li, G.; Cao, J. Evolving the attribute flow for dynamical clustering in signed networks. Chaos Solitons Fractals 2018, 110, 20–27. [Google Scholar] [CrossRef]
- Li, H.; Bu, Z.; Wang, Z.; Cao, J.; Shi, Y. Enhance the Performance of Network Computation by a Tunable Weighting Strategy. IEEE Trans. Emerg. Top. Comput. Intell. 2018, 2, 214–223. [Google Scholar] [CrossRef]
- Peel, L.; Larremore, D.B.; Clauset, A. The ground truth about metadata and community detection in networks. Sci. Adv. 2017, 3, e1602548. [Google Scholar] [CrossRef] [PubMed]
- Guimera, R.; Mossa, S.; Turtschi, A.; Amaral, L.A.N. The worldwide air transportation network: Anomalous centrality, community structure, and cities’ global roles. PNAS 2005, 102, 7794–7799. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Yuan, B. Detecting Functional Modules in the Yeast Protein–protein Interaction Network. Bioinformatics 2006, 22, 2283–2290. [Google Scholar] [CrossRef]
- Scholkopf, B.; Platt, J.; Hofmann, T. Fundamental Limitations of Spectral Clustering. In Proceedings of the International Conference on Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 3–6 December 2007. [Google Scholar]
- Li, H.J.; Daniels, J.J. Social significance of community structure: Statistical view. Phys. Rev. E 2015, 91, 012801. [Google Scholar] [CrossRef] [PubMed]
- Bron, C.; Kerboscht, J. Finding All Cliques of an Undirected Graph. Commun. ACM 1973, 16, 575–577. [Google Scholar] [CrossRef]
- Eppstein, D.; Löffler, M.; Strash, D. Listing All Maximal Cliques in Sparse Graphs in Near-Optimal Time. In Algorithms and Computation; Springer: Berlin/Heidelberg, Germany, 2010; pp. 403–414. [Google Scholar]
- Zachary, W. An information flow model for conflict and fission in small groups. J. Anthropol. Res. 1977, 33, 452–473. [Google Scholar] [CrossRef]
- Klein, D.J.; Randic, M. Resistance distance. J. Math. Chem. 1993, 12, 81–95. [Google Scholar] [CrossRef]
- Lancichinetti, A.; Fortunato, S.; Radicchi, F. Benchmark graphs for testing community detection algorithms. Phys. Rev. E 2008, 78, 046110. [Google Scholar] [CrossRef]
- Wong, E.T. Generalised Inverses as Linear Transformations. Math. Gaz. 1979, 63, 176–181. [Google Scholar] [CrossRef]
- Yang, T.; Jin, R.; Chi, Y.; Zhu, S. Combining link and content for community detection: A discriminative approach. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; pp. 927–936. [Google Scholar]
- Gregory, S. Finding overlapping communities in networks by label propagation. New J. Phys. 2010, 12, 103018. [Google Scholar] [CrossRef]
- Baumes, J.; Goldberg, M.K.; Krishnamoorthy, M.; Magdon-Ismail, M.; Preston, N. Finding communities by clustering a graph into overlapping subgraphs. In Proceedings of the IADIS International Conference on Applied Computing, Algarve, Portugal, 22–25 February 2005. [Google Scholar]
- Adamcsek, B.; Palla, G.; Farkas, I.J.; Derényi, I.; Vicsek, T. CFinder: Locating Cliques and Overlapping Modules in Biological Networks. Bioinformatics 2006, 22, 1021–1023. [Google Scholar] [CrossRef] [PubMed]
- Ahn, Y.Y.; Bagrow, J.P.; Lehmann, S. Link communities reveal multiscale complexity in networks. Nature 2010, 466, 761–764. [Google Scholar] [CrossRef] [PubMed]
- Lee, C.; Reid, F.; McDaid, A.F.; Hurley, N.J. Detecting highly overlapping community structure by greedy clique expansion. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 25–28 July 2010. [Google Scholar]
- Xie, J.; Szymanski, B. Towards Linear Time Overlapping Community Detection in Social Networks. Adv. Knowl. Discov. Data Min. 2012, 7302, 25–36. [Google Scholar]






© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, H.; Nayak, A. A Scheme to Design Community Detection Algorithms in Various Networks. Future Internet 2019, 11, 41. https://doi.org/10.3390/fi11020041
Lu H, Nayak A. A Scheme to Design Community Detection Algorithms in Various Networks. Future Internet. 2019; 11(2):41. https://doi.org/10.3390/fi11020041
Chicago/Turabian StyleLu, Haoye, and Amiya Nayak. 2019. "A Scheme to Design Community Detection Algorithms in Various Networks" Future Internet 11, no. 2: 41. https://doi.org/10.3390/fi11020041
APA StyleLu, H., & Nayak, A. (2019). A Scheme to Design Community Detection Algorithms in Various Networks. Future Internet, 11(2), 41. https://doi.org/10.3390/fi11020041