Pedestrian Attribute Recognition with Graph Convolutional Network in Surveillance Scenarios

Abstract
:1. Introduction
- This paper creatively applies the novel end-to-end trainable multi-label image recognition framework to pedestrian attribute recognition, which to our knowledge, is the first one tackling pedestrian attribute recognition by graph convolutional network.
- Graph convolutional network normally propagates information between nodes based on correlation matrix. So, we design the correlation matrix for GCN in-depth and propose some improvement methods. Finally, we evaluate our method on pedestrian attribute recognition dataset, and our proposed method consistently achieves superior performance over previous competing approaches.
2. Related Work
3. Approach
3.1. Preliminary
3.1.1. Multi-Label Learning
- First-order strategy, which directly transform the multi-class into multiple binary-classification problem. This strategy obviously does not take the correlations into consideration and will cause exponential-sized output size;
- Second-order strategy, which only considers the correlations between each label pair; however, label correlations are more complicated than the second-order strategy in real-world applications;
- High-order strategy, which considers all the label relationships by modeling the correlations among labels. Normally, this strategy can achieve better performance but with higher computational complexity.
3.1.2. Graph Convolutional Network
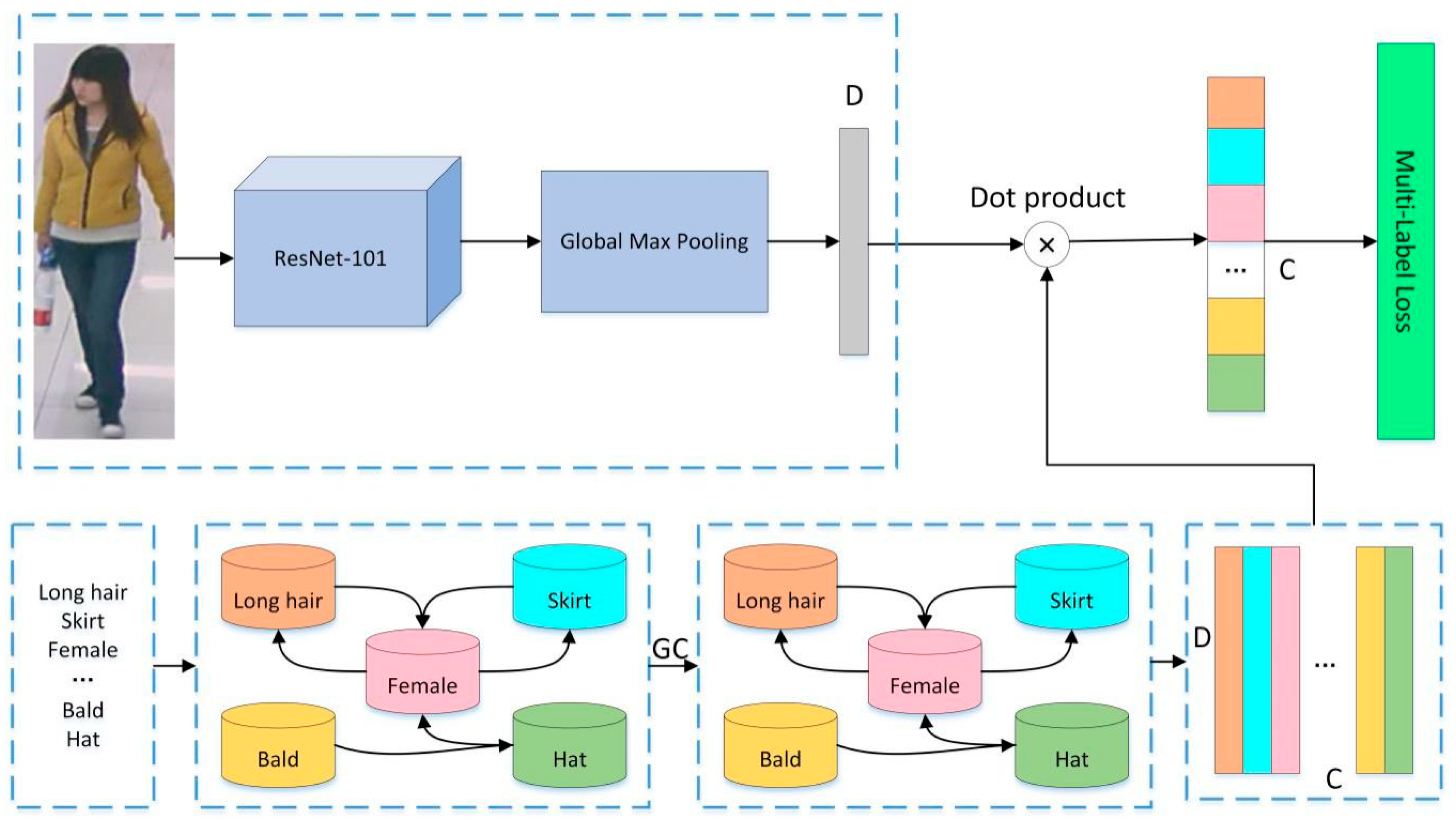
3.2. Architecture of Our Model
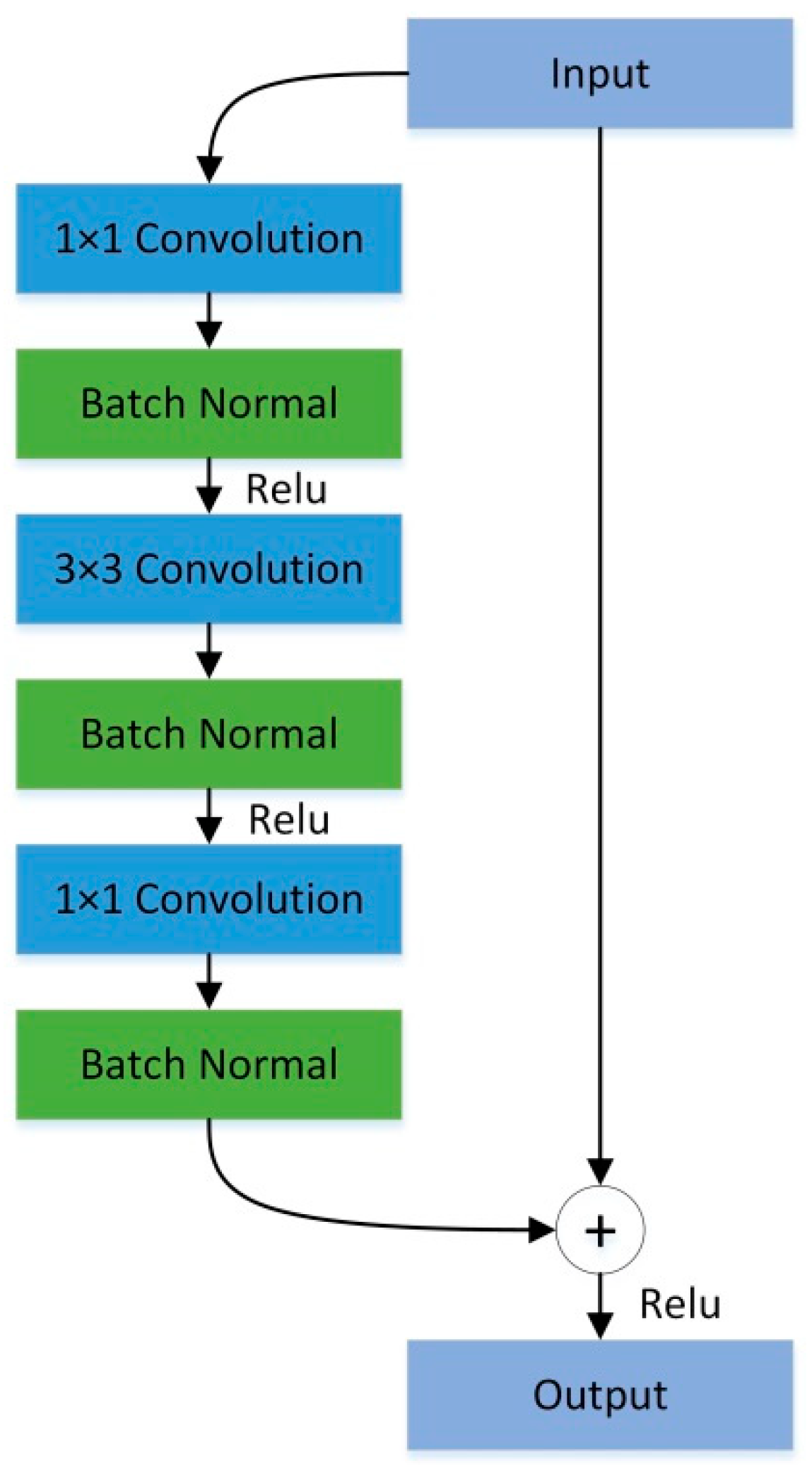
3.2.1. Image Feature Extraction
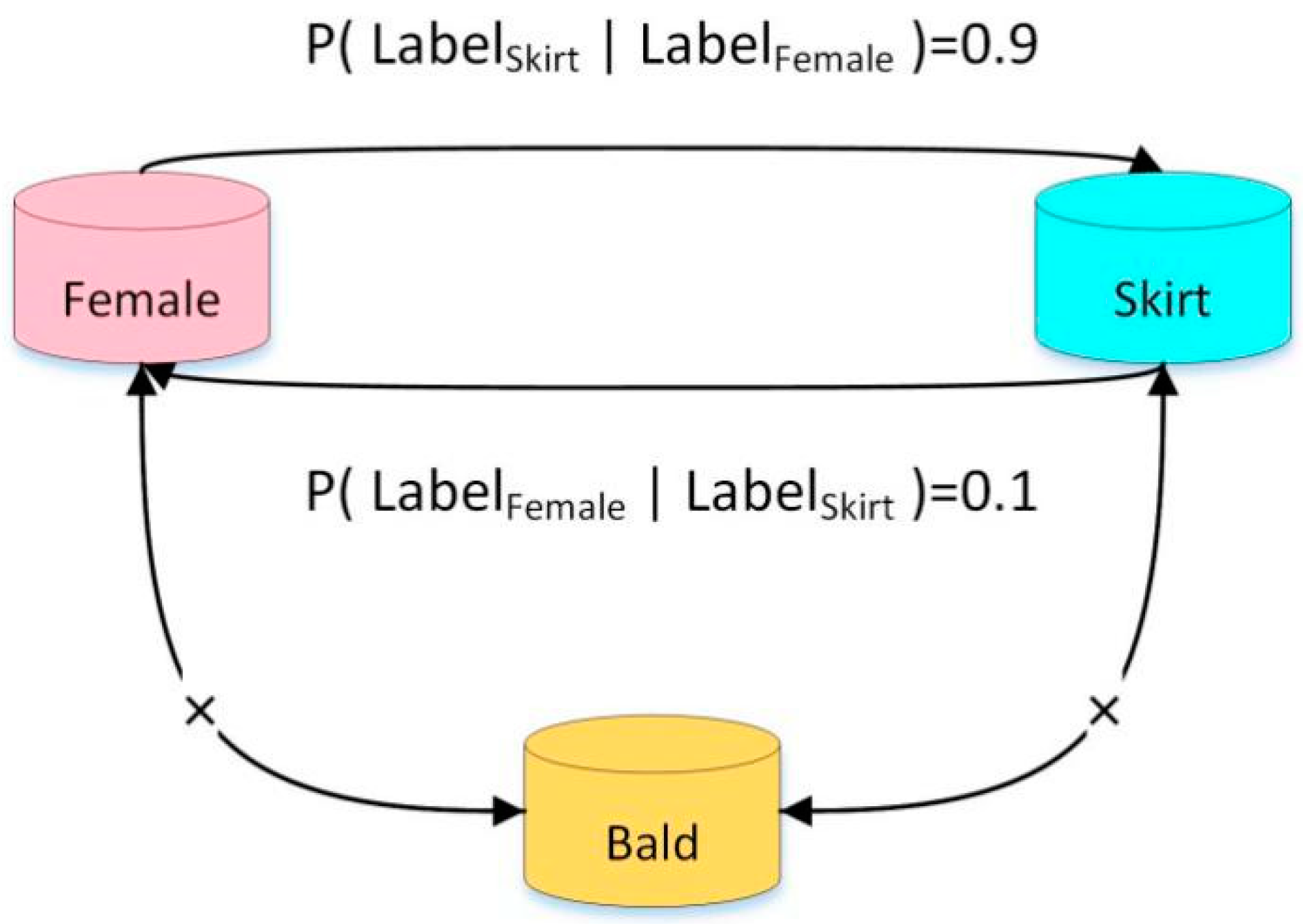
3.2.2. Correlation Matrix
4. Experiments
4.1. Evaluation Metrics
4.2. Dataset
4.3. Implement Details
4.4. Experiment Results
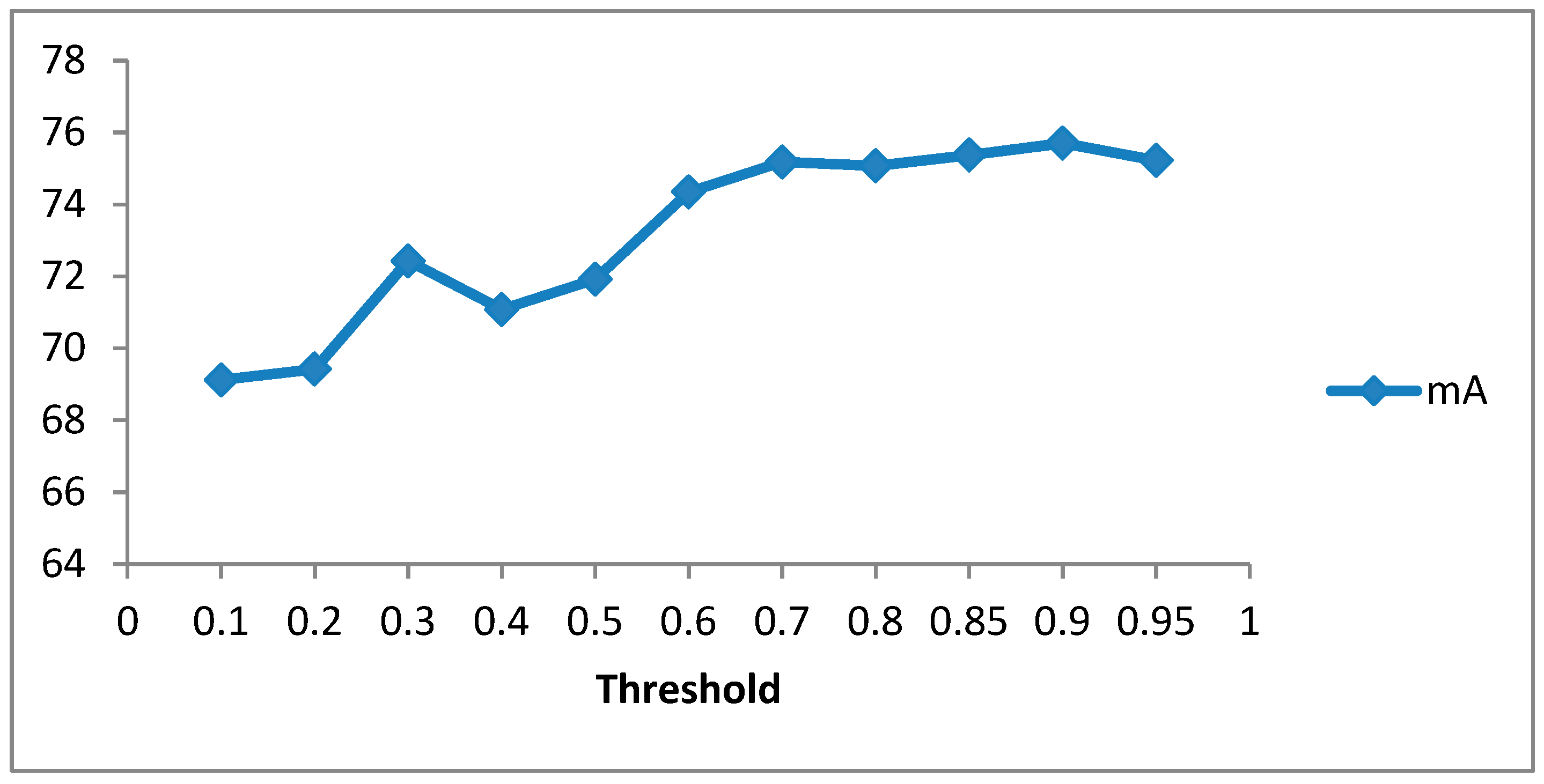
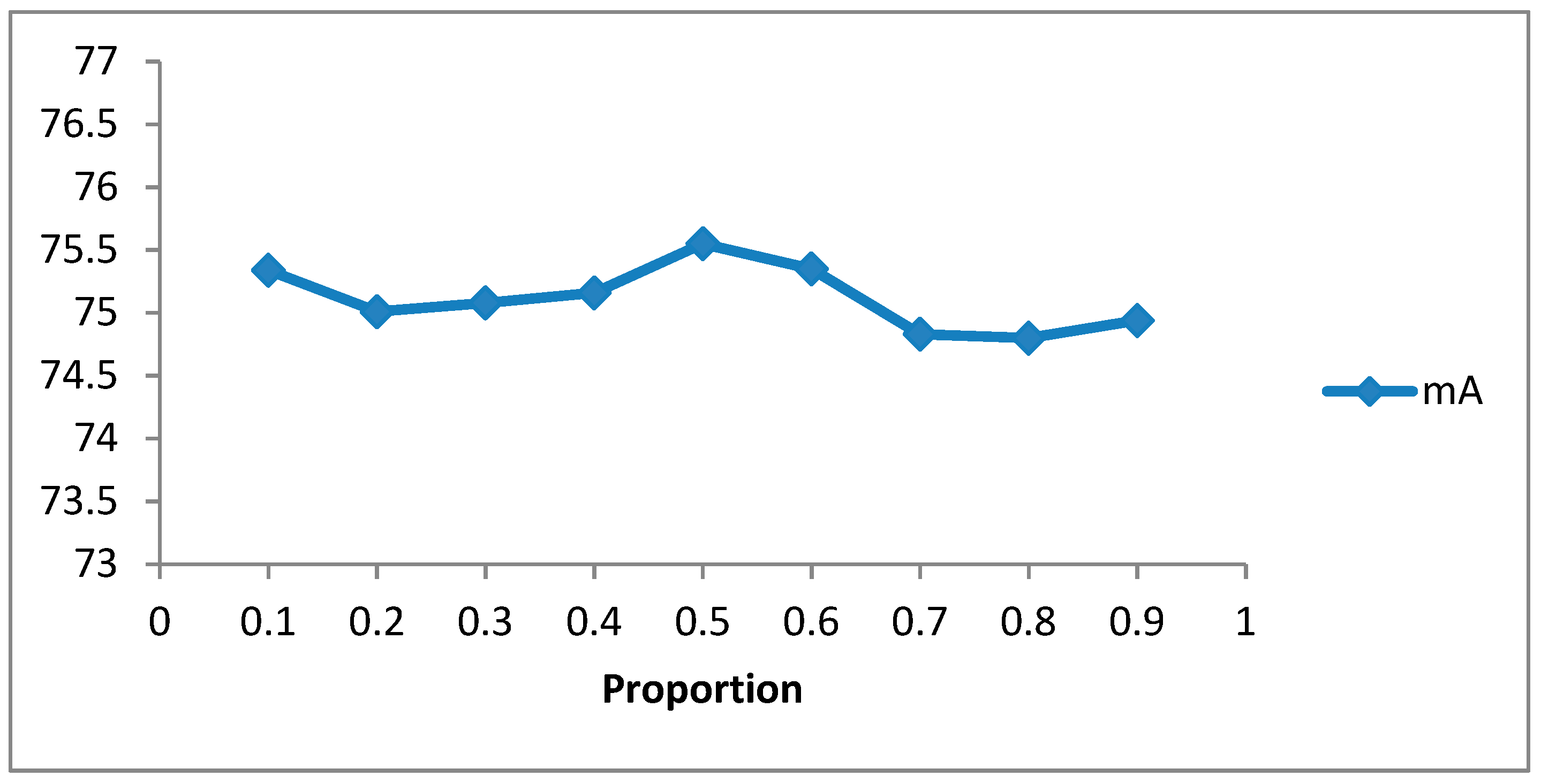
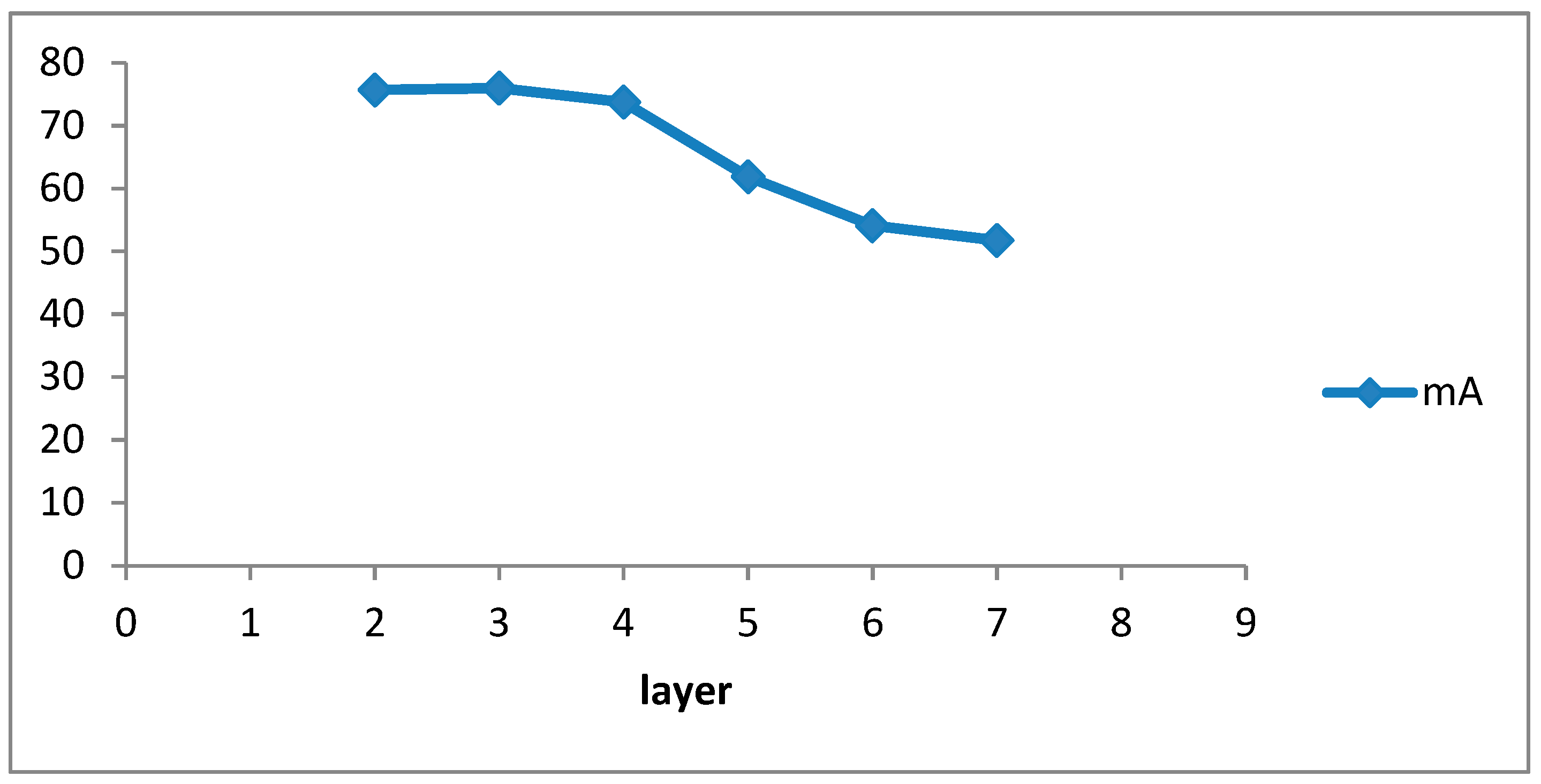
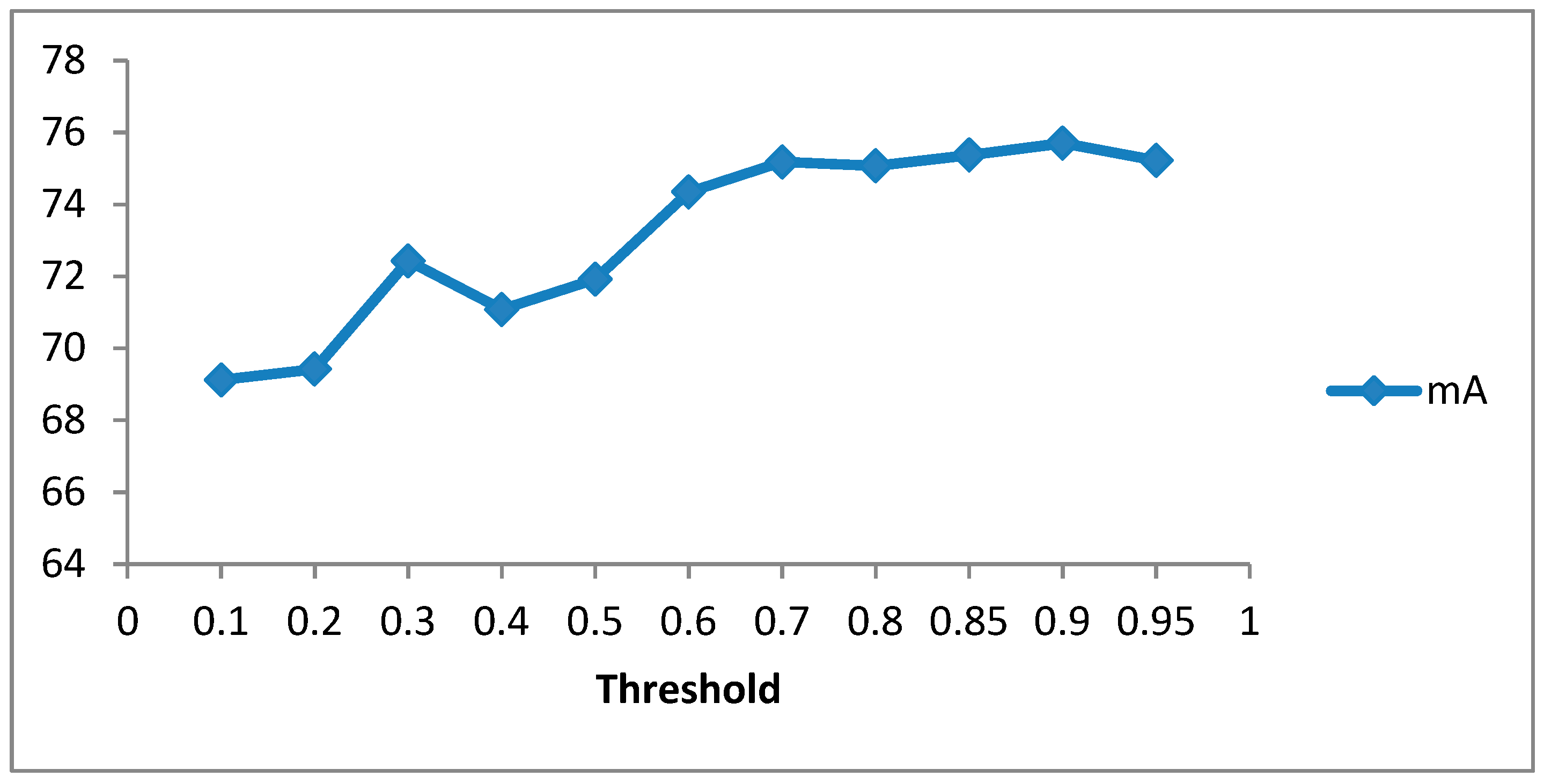
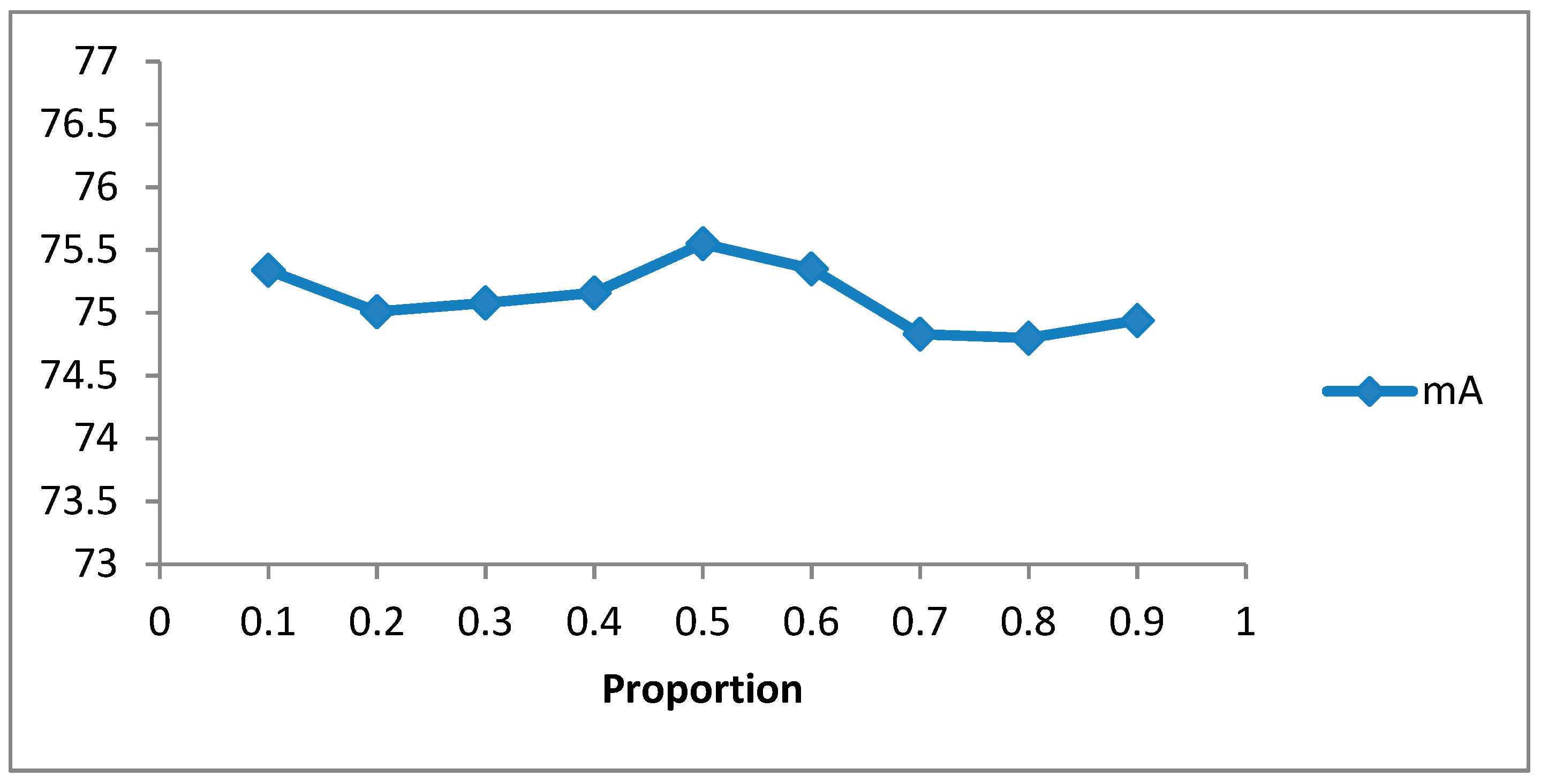
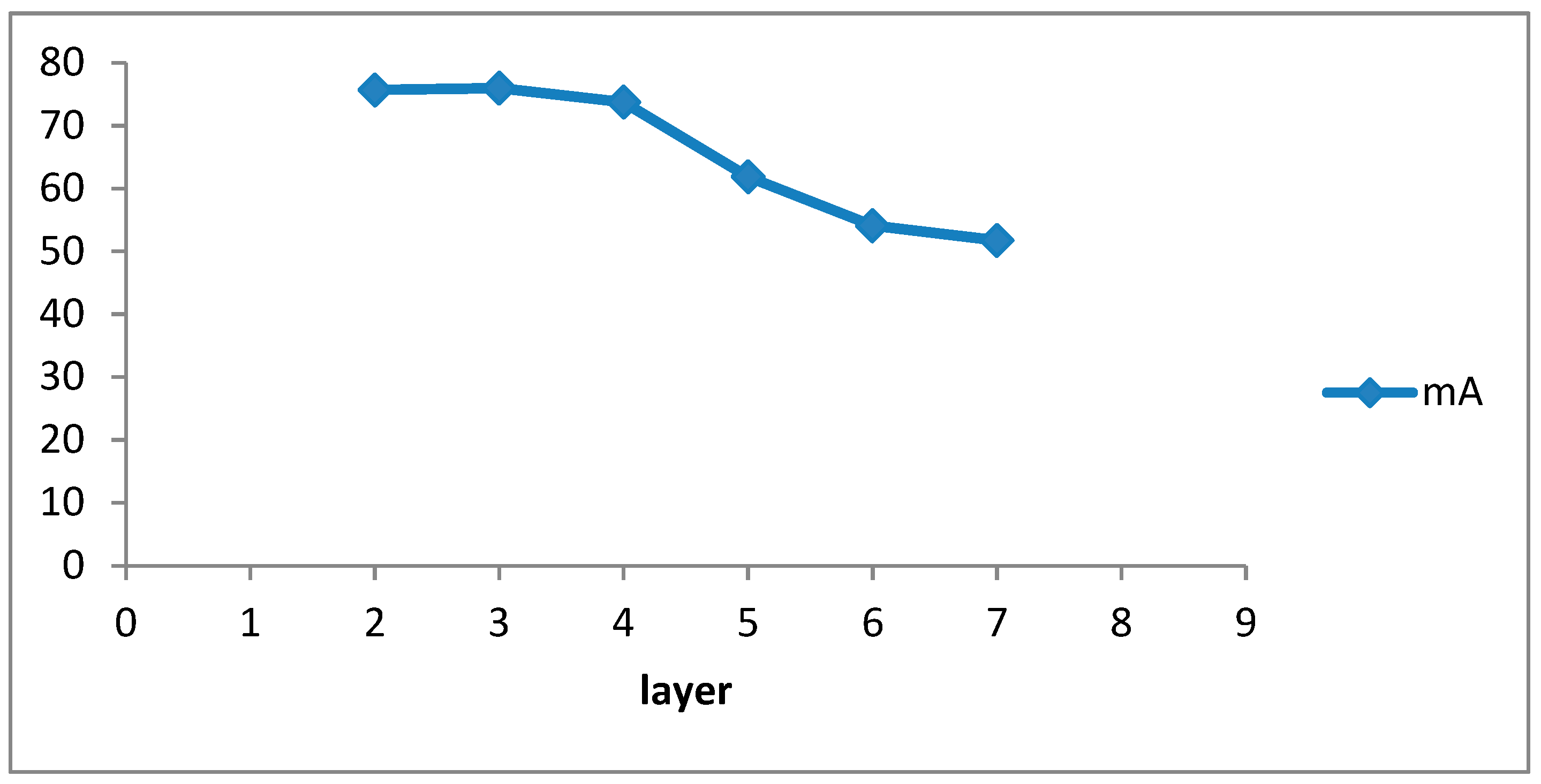
4.5. Ablation Study
4.6. Image Retrieval
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Porikli, F.; Bremond, F.; Dockstader, S.L.; Ferryman, J.; Hoogs, A.; Lovell, B.C.; Pankanti, S.; Rinner, B.; Tu, P.; Venetianer, P.L. Video surveillance: Past, present, and now the future. IEEE Signal Process. Mag. 2013, 30, 190–198. [Google Scholar] [CrossRef]
- Li, Q.; Zhao, X.; He, R.; Huang, K. Visual-semantic graph reasoning for pedestrian attribute recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Wang, Y.; Gan, W.; Wu, W.; Yan, J. Dynamic Curriculum Learning for Imbalanced Data Classification. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Wang, X. Pedestrian Attribute Recognition: A Survey. arXiv 2019, arXiv:1901.07474. [Google Scholar]
- Huang, G.; Huang, G.-B.; Song, S.; You, K. Trends in extreme learning machines: A review. Neural Netw. 2015, 61, 32–48. [Google Scholar] [CrossRef] [PubMed]
- Salerno, V.M.; Rabbeni, G. An Extreme Learning Machine Approach to Effective Energy Disaggregation. Electronics 2018, 7, 235. [Google Scholar] [CrossRef]
- Hussain, T.; Siniscalchi, S.M.; Lee, C.-C.; Wang, S.-S.; Tsao, Y.; Liao, W.-H. Experimental study on extreme learning machine applications for speech enhancement. IEEE Access 2017, 5, 25542–25554. [Google Scholar] [CrossRef]
- Yang, K.; Du, E.Y.; Delp, E.J.; Jiang, P.; Jiang, F.; Chen, Y.; Sherony, R.; Takahashi, H. An Extreme Learning Machine-based pedestrian detection method. In Proceedings of the 2013 IEEE Intelligent Vehicles Symposium (IV), Gold Coast, Australia, 23–26 June 2013. [Google Scholar]
- Chen, Z.; Wei, X. Multi-Label Image Recognition with Graph Convolutional Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition CVPR, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Li, D.; Chen, X.; Huang, K. Multi-attribute learning for pedestrian attribute recognition in surveillance scenarios. In Proceedings of the 2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR), Kuala Lumpur, Malaysia, 3–6 November 2015; pp. 111–115. [Google Scholar]
- Li, D.; Chen, X.; Zhang, Z.; Huang, K. Pose guided deep model for pedestrian attribute recognition in surveillance scenarios. In Proceedings of the 2018 IEEE International Conference on Multimedia and Expo (ICME), San Diego, CA, USA, 23–27 July 2018; pp. 1–6. [Google Scholar]
- Liu, X.; Zhao, H.; Tian, M.; Sheng, L.; Shao, J.; Yi, S.; Yan, J.; Wang, X. Hydraplus-net: Attentive deep features for pedestrian analysis. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 350–359. [Google Scholar]
- Wang, J.; Zhu, X.; Gong, S.; Li, W. Attribute recognition by joint recurrent learning of context and correlation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 531–540. [Google Scholar]
- Zhao, X.; Sang, L.; Ding, G.; Han, J.; Di, N.; Yan, C. Recurrent attention model for pedestrian attribute recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Dong, Q.; Gong, S.; Zhu, X. Multi-task curriculum transfer deep learning of clothing attributes. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017. [Google Scholar]
- Fabbri, M.; Calderara, S.; Cucchiara, R. Generative adversarial models for people attribute recognition in surveillance. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017. [Google Scholar]
- Zhong, J.; He, E.; Wang, H.; Yang, A. Image-attribute reciprocally guided attention network for pedestrian attribute recognition. Pattern Recognit. Lett. 2019, 120, 89–95. [Google Scholar]
- Tan, Z.; Yang, Y.; Wan, J.; Chen, Y.; Guo, G.; Li, S. Attention based Pedestrian Attribute Analysis. IEEE Trans. Image Process. 2019, 28, 6126–6140. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.; Zhao, X.; He, R.; Huang, K. Pedestrian Attribute Recognition by Joint Visual-semantic Reasoning and Knowledge Distillation. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019. [Google Scholar]
- Han, K.; Wang, Y.; Shu, H.; Liu, C.; Xu, C.J.; Xu, C. Attribute Aware Pooling for Pedestrian Attribute Recognition. arXiv 2019, arXiv:1907.11837. [Google Scholar]
- Xiang, L.; Jin, X.; Ding, G.; Han, J.; Li, L. Incremental Few-Shot Learning for Pedestrian Attribute Recognition. arXiv 2019, arXiv:1906.00330. [Google Scholar]
- Bekele, E.; Lawso, W. The Deeper, the Better: Analysis of Person Attributes Recognition. arXiv 2019, arXiv:1901.03756. [Google Scholar]
- Chen, Z.; Li, A.; Wang, Y. Video-Based Pedestrian Attribute Recognition. arXiv 2019, arXiv:1901.05742. [Google Scholar]
- Zhang, M.-L.; Zhou, Z.-H. A review on multi-label learning algorithms. IEEE Trans. Knowl. Data Eng. 2014, 26, 1819–1837. [Google Scholar] [CrossRef]
- Zhou, J.; Cui, G.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph Neural Networks: A Review of Methods and Applications. arXiv 2018, arXiv:1812.08434. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef] [PubMed]
- Bruna, J.; Zaremba, W.; Szlam, A.; Lecun, Y. Spectral networks and locally connected networks on graphs. arXiv 2013, arXiv:1312.6203. [Google Scholar]
- Hammond, D.K.; Vandergheynst, P.; Gribonval, R. Wavelets on graphs via spectral graph theory. Appl. Comput. Harmon. Anal. 2011, 30, 129–150. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2016. [Google Scholar]
- Li, D.; Zhang, Z.; Chen, X.; Huang, K. A richly annotated pedestrian dataset for person retrieval in real surveillance scenarios. IEEE Trans. Image Process. 2019, 28, 1575–1590. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Attribute |
|---|---|
| Whole body | gender, age, shape, role |
| Head | hair style, hair color, hat, glasses |
| Upper body | clothes style, clothes color |
| Lower body | clothes style, clothes color, shoes style, shoes color |
| Other | bounding box, accessories, actions, occlusion |
| Method | RAP | |||||
|---|---|---|---|---|---|---|
| Metric | mA | Accuracy | Precision | Recall | F1 | |
| ACN | 69.66 | 62.61 | 80.12 | 72.26 | 75.98 | |
| DeepMar | 73.79 | 62.02 | 74.92 | 76.21 | 75.56 | |
| HydraPlus-Net | 76.12 | 65.39 | 77.33 | 78.79 | 78.05 | |
| JRL | 77.81 | - | 78.11 | 78.98 | 78.58 | |
| VeSPA | 77.70 | 67.35 | 79.51 | 79.67 | 79.59 | |
| Ours | 74.04 | 65.78 | 80.12 | 76.88 | 78.47 | |
| Ours-improved | 75.97 | 68.99 | 81.48 | 79.97 | 80.72 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, X.; Yang, H.; Zhou, C. Pedestrian Attribute Recognition with Graph Convolutional Network in Surveillance Scenarios. Future Internet 2019, 11, 245. https://doi.org/10.3390/fi11110245
Song X, Yang H, Zhou C. Pedestrian Attribute Recognition with Graph Convolutional Network in Surveillance Scenarios. Future Internet. 2019; 11(11):245. https://doi.org/10.3390/fi11110245
Chicago/Turabian StyleSong, Xiangpeng, Hongbin Yang, and Congcong Zhou. 2019. "Pedestrian Attribute Recognition with Graph Convolutional Network in Surveillance Scenarios" Future Internet 11, no. 11: 245. https://doi.org/10.3390/fi11110245
APA StyleSong, X., Yang, H., & Zhou, C. (2019). Pedestrian Attribute Recognition with Graph Convolutional Network in Surveillance Scenarios. Future Internet, 11(11), 245. https://doi.org/10.3390/fi11110245