ESCAPE: Evacuation Strategy through Clustering and Autonomous Operation in Public Safety Systems



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
Contributions and Outline
- (a)
- A novel paradigm for distributed and autonomous evacuation planning is introduced, allowing the evacuees to make the most beneficial actions for themselves by using the proposed ESCAPE service, which can run on their mobile devices. The ESCAPE service was developed based on the principles of the reinforcement learning and game theory, and consists of two decision-making layers.
- (b)
- At the first layer, the evacuees acting as stochastic learning automata [6,7,8] decide which evacuation route they want to join based on their past decisions while performing the current evacuation, and taking the (limited) available information from the disaster area through the ESCAPE service, e.g., evacuation rate per route, evacuees already on the route, and capacity of the route. The latter information can easily be available in a real implementation scenario through sensors deployed at the evacuation routes. Based on evacuees’ decisions, a cluster of them is created at each evacuation route. It is highlighted that this human decision expresses the evacuation route where the evacuee desires to go, and if they finally evacuate through the specific evacuation route is determined by the second layer of their decision.
- (c)
- At the second layer, the evacuees of each cluster have to determine if they will finally go or not toward the initially selected evacuation route. Given that the evacuees usually exhibit aggressive and non-co-operative behavior under the risk of their lives, the decision-making process at each cluster of each evacuation route is formulated as a non-co-operative game among the evacuees. It is also highlighted that evacuees’ decisions are interdependent. The theory of minority games [9,10] was adopted, allowing evacuees to dynamically and in a distributed fashion choose if they will finally go through the evacuation route, while considering the route’s available free space (Distributed Exponential learning algorithm for Minority Games (DEMG)). The formulated minority game is solved using an exponential learning algorithm.
- (d)
- A distributed and low-complexity evacuation planning algorithm, named ESCAPE, is introduced to implement both decision-making layers of the evacuees. ESCAPE complexity is provided that demonstrates the low time overhead of the proposed evacuation planning, and therefore could be adopted and considered for realistic implementation.
- (e)
- Detailed numerical and comparative results demonstrate that the proposed holistic framework concludes to a promising solution for realizing a distributed and autonomous evacuation planning that confronts with the needs and requirements of both the evacuees and the Emergency Control Center.
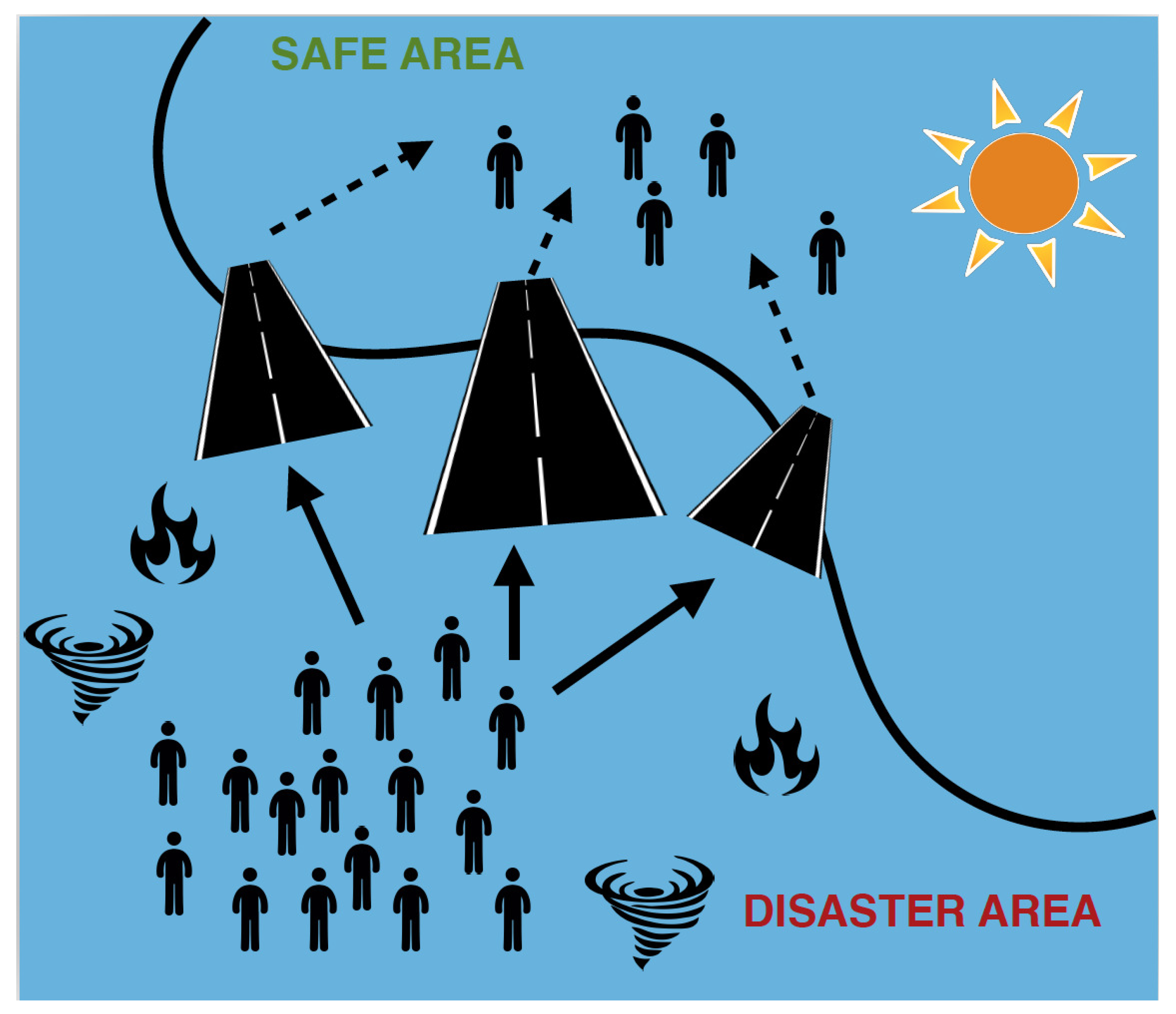
2. System Model and Overview
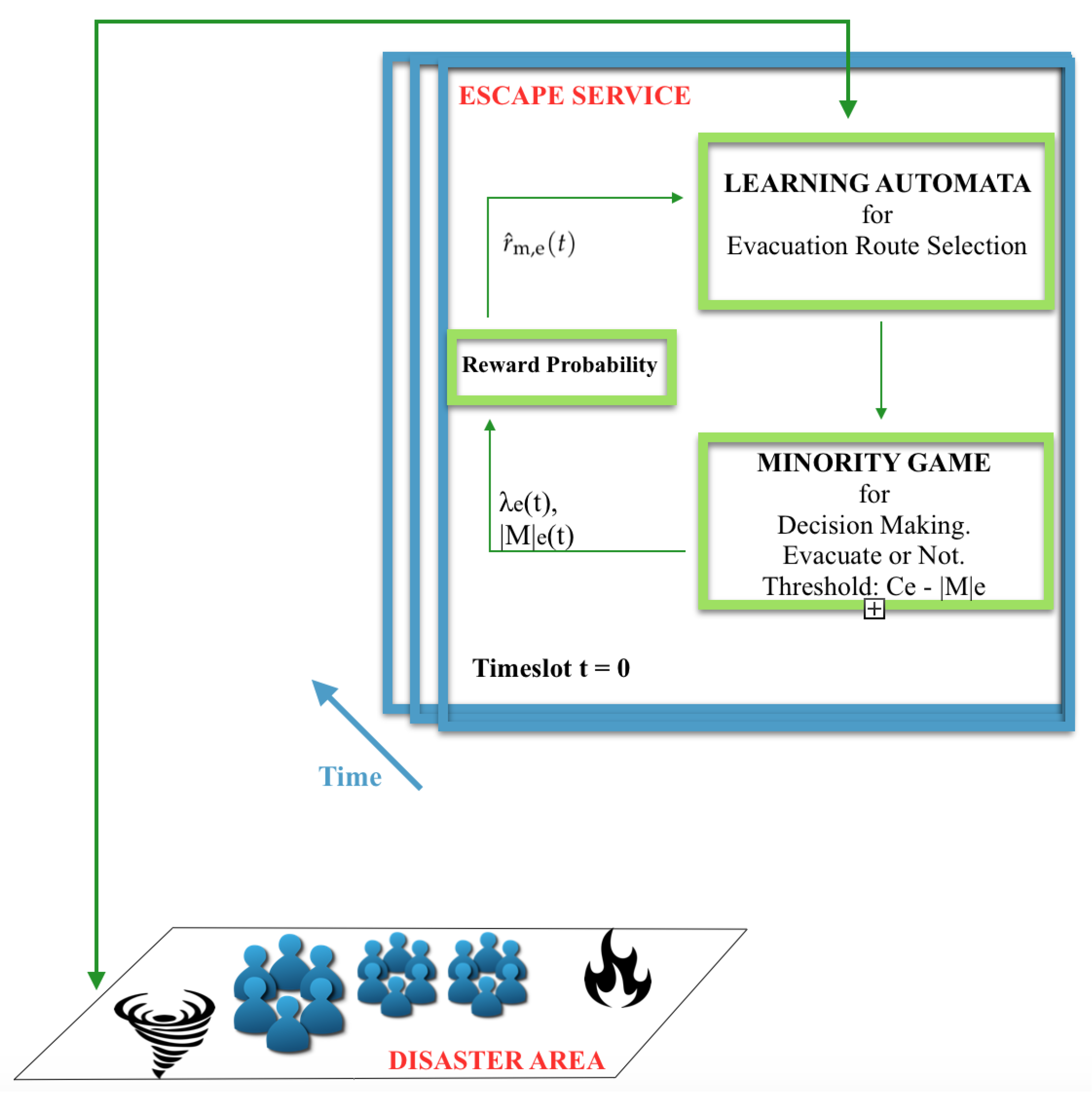
2.1. ESCAPE Methodology
- (a)
- evacuation-route selection, during which evacuees decide where they want to go, which is based on reinforcement learning, and
- (b)
- the decision-making process of whether evacuees will finally go or not go to the initially selected evacuation route, which is formulated via the concept of minority games.
2.2. Related Work
2.3. Discussion, Threats, and Solutions
3. Evacuation Planning through Reinforcement Learning
4. Evacuate or Not? A Minority Game Approach
5. ESCAPE Algorithm
| Algorithm 1 ESCAPE Algorithm |
|
| Algorithm 2 Distributed Exponential Learning Algorithm for Minority Games (DEMG) |
|
6. Numerical Results
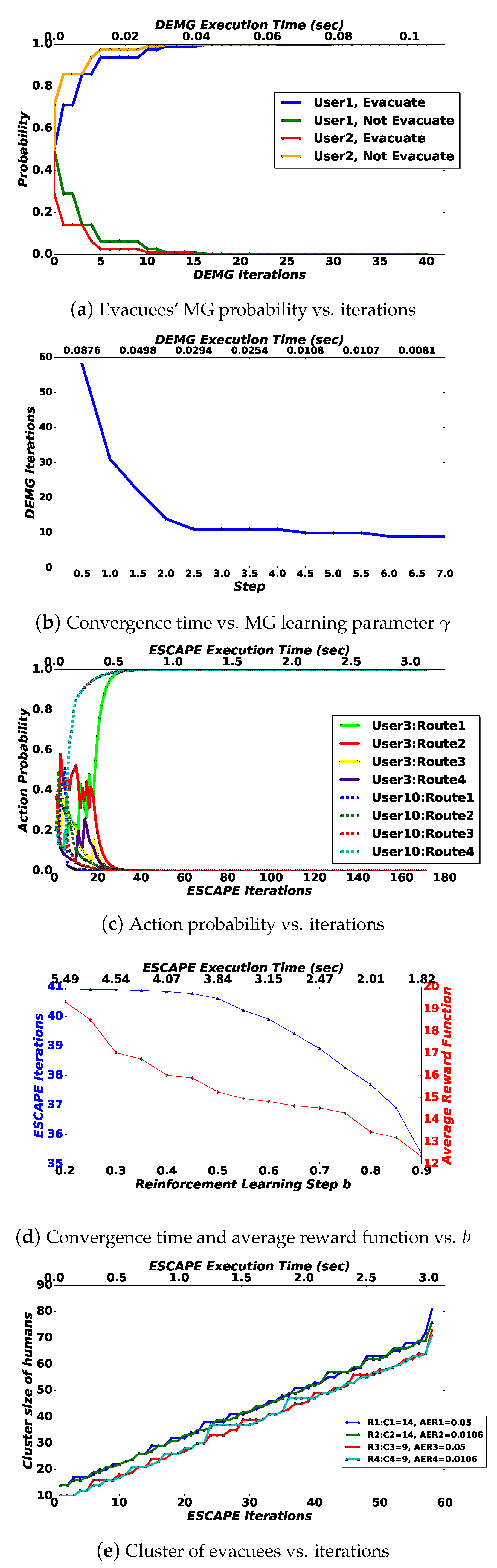
6.1. Pure Operation of the Framework
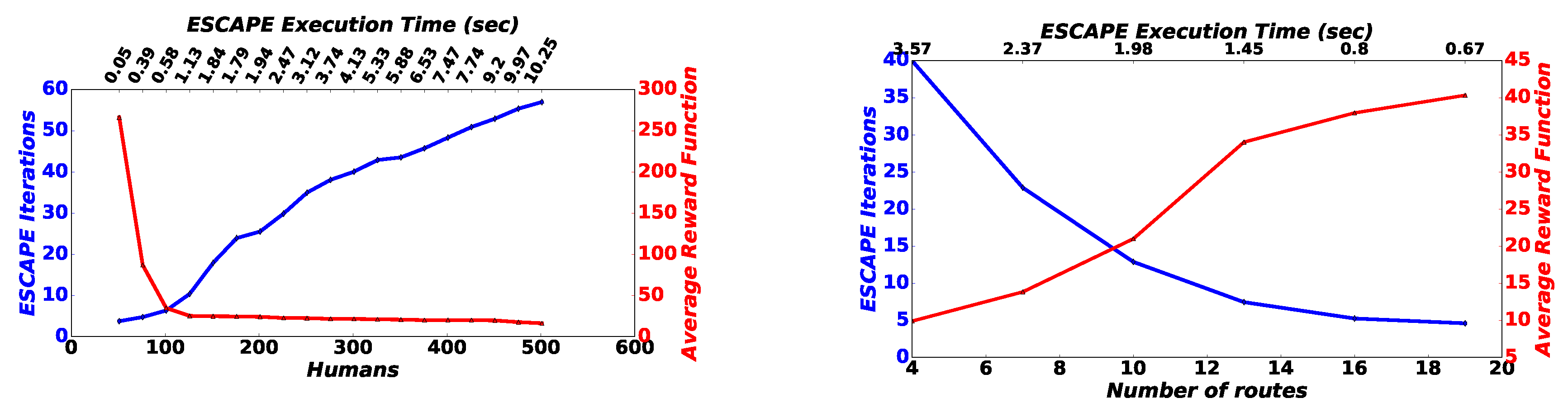
6.2. Scalability and Complexity Evaluation
6.3. Comparative Evaluation
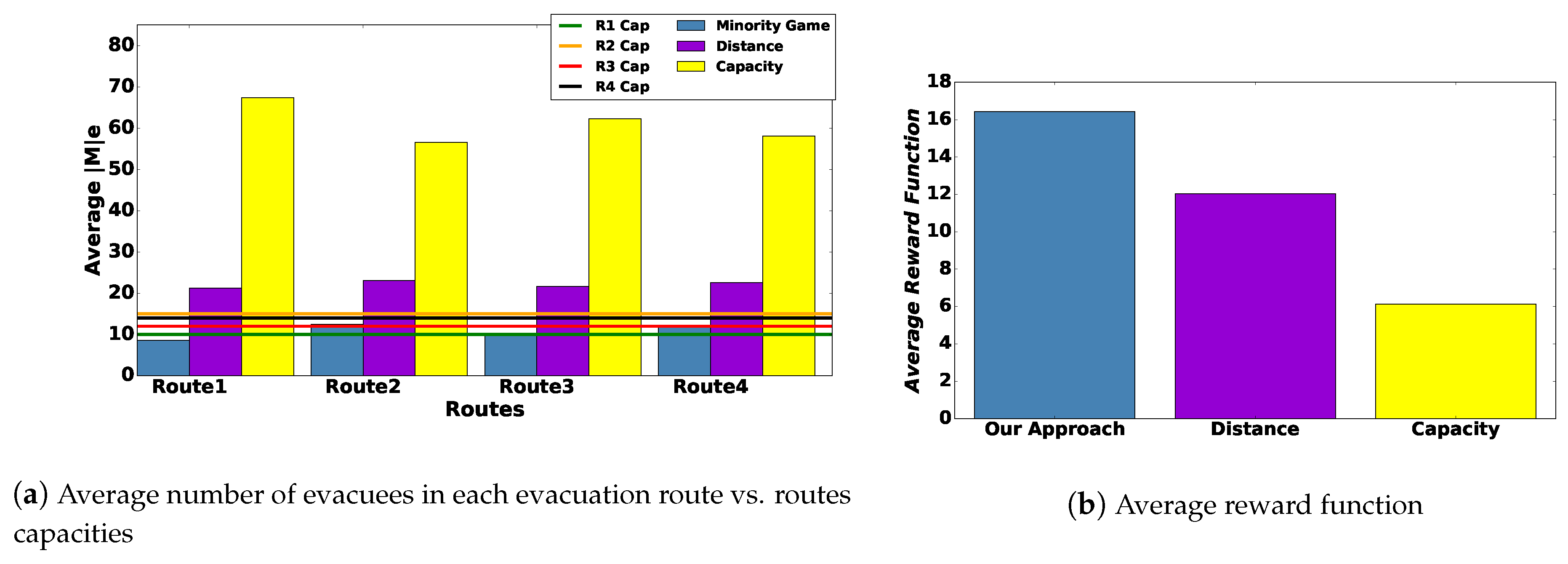
6.3.1. First Scenario: Why Minority Games?
- (a)
- The first alternative method is the following: evacuee m chooses whether they will evacuate or not through desired evacuation route e by taking into consideration how far they are from e, i.e., based on distance . The greater is, the lower the probability for the evacuee to evacuate is; conversely, the lower is, the greater their probability to evacuate is. That is: and . In the following, we refer to this strategy as “Distance”.
- (b)
- The second alternative method is the following: evacuee m chooses whether they will evacuate or not through desired evacuation route e by taking into consideration the threshold number of evacuees that can physically go through evacuation route e at time slot t, i.e., , as discussed in Section 4. In particular, if then and , meaning that the more evacuees are already in the evacuation route, the greater the probability of not to evacuate is, as the evacuation route is congested. Now, if then we consider that and . In the following we refer to this strategy as “Capacity”.
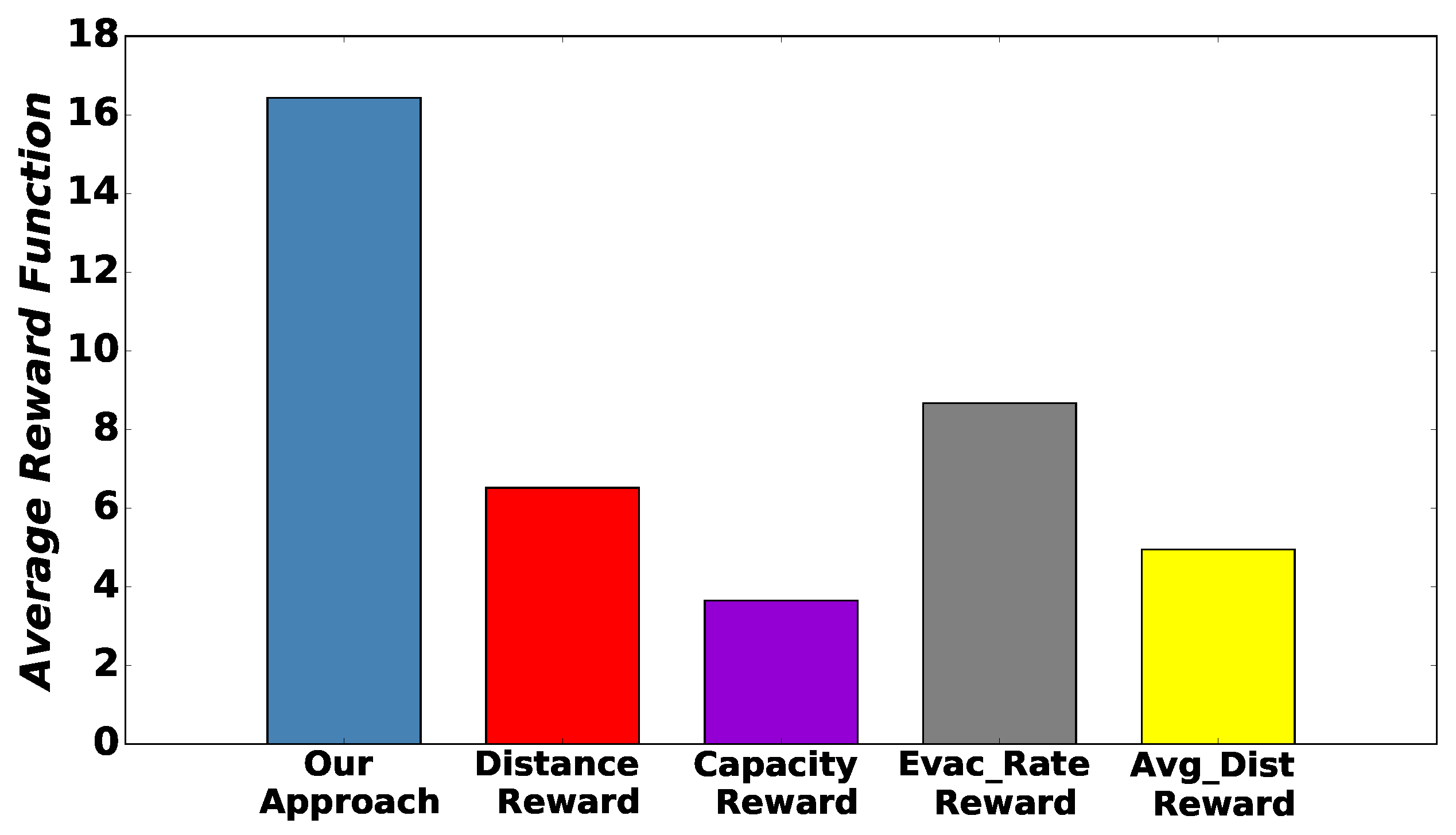
6.3.2. Second Scenario: Why Reinforcement Learning?
- (a)
- The first alternative approach is defined by reward function as . The greater distance of evacuee m from evacuation route e is, the lower the corresponding reward function is (we refer to this strategy as “Distance Reward”).
- (b)
- The second alternative defines the reward function as: . The greater the (i.e., Capacity) of selected evacuation route e is, the greater the reward function is as the aforementioned evacuation route fits more evacuees (we refer to this strategy as “Capacity Reward”).
- (c)
- The third alternative approach is defined by reward function . The greater evacuation rate is, the greater the reward function is (we refer to this strategy as: “Evac_Rate Reward”).
- (d)
- The last approach is defined by reward function , where is the average distance of all other evacuees from respective evacuation route e that evacuee m selected (we refer to this strategy as “Avg_Dist Reward”).
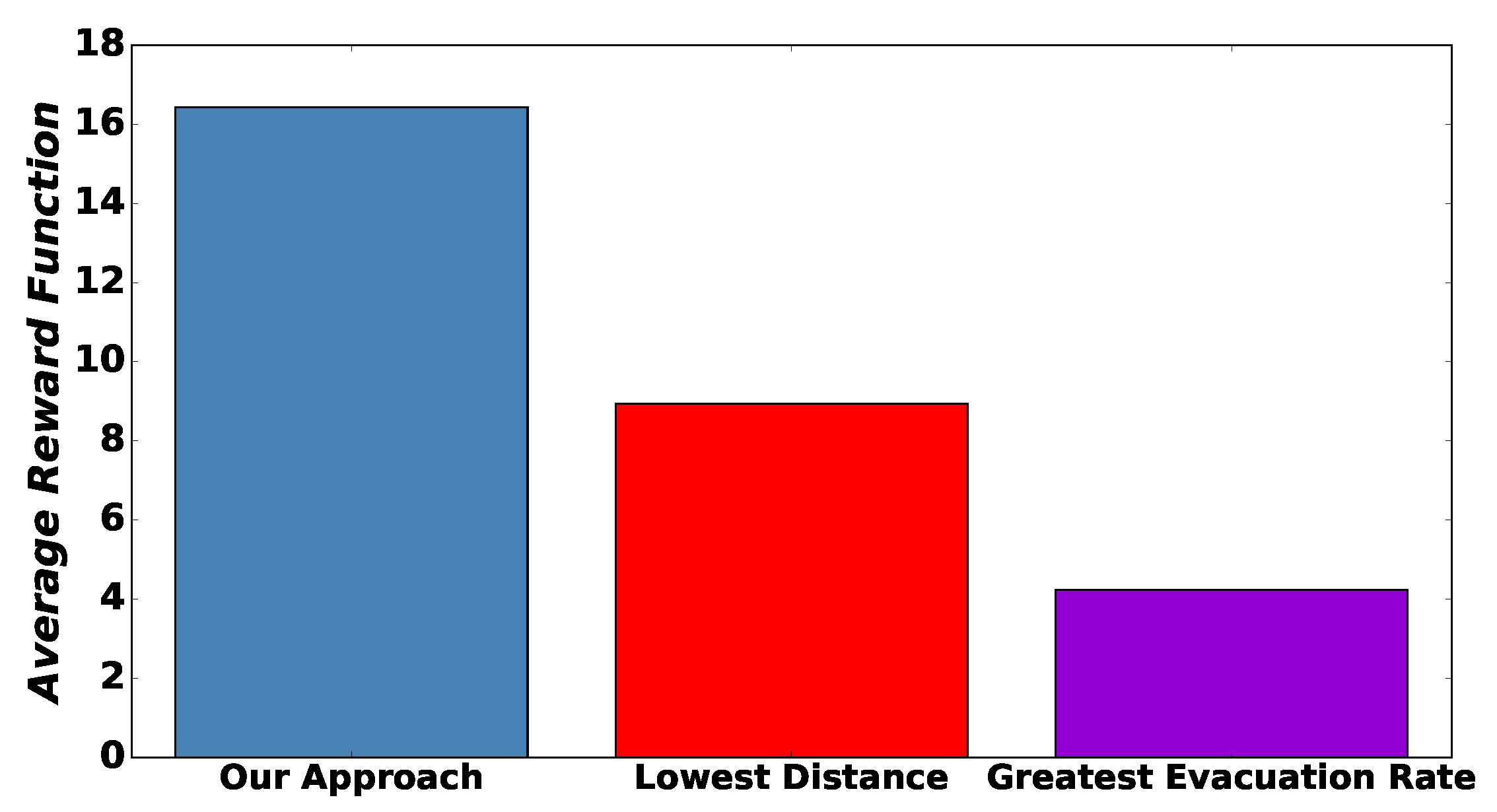
6.3.3. Third Scenario: Benefits of Learning
- (a)
- The first alternative approach is that evacuee m chooses evacuation route e with lowest respective distance .
- (b)
- The second approach is that evacuee m chooses evacuation route e with greatest evacuation route .
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Moulik, S.; Misra, S.; Obaidat, M.S. Smart-evac: Big data-based decision making for emergency evacuation. IEEE Cloud Comput. 2015, 2, 58–65. [Google Scholar] [CrossRef]
- Shahabi, K.; Wilson, J.P. Scalable evacuation routing in a dynamic environment. Comput. Environ. Urban Syst. 2018, 67, 29–40. [Google Scholar] [CrossRef]
- Lu, Q.; George, B.; Shekhar, S. Capacity constrained routing algorithms for evacuation planning: A summary of results. In International Symposium on Spatial and Temporal Databases; Springer: Berlin/Heidelberg, Germany, 2005; pp. 291–307. [Google Scholar]
- Han, Q. Managing emergencies optimally using a random neural network-based algorithm. Future Internet 2013, 5, 515–534. [Google Scholar] [CrossRef]
- Bi, H. Routing diverse evacuees with the cognitive packet network algorithm. Future Internet 2014, 6, 203–222. [Google Scholar] [CrossRef]
- Apostolopoulos, P.A.; Tsiropoulou, E.E.; Papavassiliou, S. Demand response management in smart grid networks: A two-stage game-theoretic learning-based approach. Mob. Netw. Appl. 2018, 1–14. [Google Scholar] [CrossRef]
- Sikeridis, D.; Tsiropoulou, E.E.; Devetsikiotis, M.; Papavassiliou, S. Socio-physical energy-efficient operation in the internet of multipurpose things. In Proceedings of the 2018 IEEE International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018; pp. 1–7. [Google Scholar]
- Tsiropoulou, E.E.; Kousis, G.; Thanou, A.; Lykourentzou, I.; Papavassiliou, S. Quality of Experience in Cyber-Physical Social Systems Based on Reinforcement Learning and Game Theory. Future Internet 2018, 10, 108. [Google Scholar] [CrossRef]
- Apostolopoulos, P.A.; Tsiropoulou, E.E.; Papavassiliou, S. Game-Theoretic Learning-Based QoS Satisfaction in Autonomous Mobile Edge Computing. In Proceedings of the IEEE Global Information Infrastructure and Networking Symposium (GIIS 2018), Guadalajara, Mexico, 28–30 October 2018. [Google Scholar]
- Sikeridis, D.; Tsiropoulou, E.E.; Devetsikiotis, M.; Papavassiliou, S. Self-Adaptive Energy Efficient Operation in UAV-Assisted Public Safety Networks. In Proceedings of the 2018 IEEE 19th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Kalamata, Greece, 25–28 June 2018; pp. 1–5. [Google Scholar]
- Tsiropoulou, E.E.; Koukas, K.; Papavassiliou, S. A Socio-Physical and Mobility-Aware Coalition Formation Mechanism in Public Safety Networks. EAI Endorsed Trans. Future Internet 2018, 4, 154176. [Google Scholar] [CrossRef]
- Pollino, M.; Fattoruso, G.; La Porta, L.; Della Rocca, A.B.; James, V. Collaborative open source geospatial tools and maps supporting the response planning to disastrous earthquake events. Future Internet 2012, 4, 451–468. [Google Scholar] [CrossRef]
- Khan, M.U.S.; Khalid, O.; Huang, Y.; Ranjan, R.; Zhang, F.; Cao, J.; Veeravalli, B.; Khan, S.U.; Li, K.; Zomaya, A.Y. MacroServ: A Route Recommendation Service for Large-Scale Evacuations. IEEE Trans. Serv. Comput. 2017, 10, 589–602. [Google Scholar] [CrossRef]
- Kim, S.; Shekhar, S.; Min, M. Contraflow Transportation Network Reconfiguration for Evacuation Route Planning. IEEE Trans. Knowl. Data Eng. 2008, 20, 1115–1129. [Google Scholar] [CrossRef]
- Wang, J.W.; Wang, H.F.; Zhang, W.J.; Ip, W.H.; Furuta, K. Evacuation Planning Based on the Contraflow Technique with Consideration of Evacuation Priorities and Traffic Setup Time. IEEE Trans. Intell. Transp. Syst. 2013, 14, 480–485. [Google Scholar] [CrossRef]
- Wang, P.; Luh, P.B.; Chang, S.-C.; Sun, J. Modeling and optimization of crowd guidance for building emergency evacuation. In Proceedings of the 2008 IEEE International Conference on Automation Science and Engineering, Arlington, VA, USA, 23–26 August 2008; pp. 328–334. [Google Scholar]
- Yazici, A.; Ozbay, K. Evacuation Network Modeling via Dynamic Traffic Assignment with Probabilistic Demand and Capacity Constraints. Transp. Res. Rec. J. Transp. Res. Board 2010, 2196, 11–20. [Google Scholar] [CrossRef]
- Kinoshita, K.; Iizuka, K.; Iizuka, Y. Effective Disaster Evacuation by Solving the Distributed Constraint Optimization Problem. In Proceedings of the 2013 Second IIAI International Conference on Advanced Applied Informatics, Los Alamitos, CA, USA, 31 August–4 September 2013; pp. 399–400. [Google Scholar]
- Li, X.; Li, Q.; Claramunt, C. A time-extended network model for staged evacuation planning. Saf. Sci. 2018, 108, 225–236. [Google Scholar] [CrossRef]
- Fu, H.; Pel, A.J.; Hoogendoorn, S.P. Optimization of Evacuation Traffic Management With Intersection Control Constraints. IEEE Trans. Intell. Transp. Syst. 2015, 16, 376–386. [Google Scholar] [CrossRef]
- Guo, D.; Gao, C.; Ni, W.; Hu, X. Max-Flow Rate Priority Algorithm for Evacuation Route Planning. In Proceedings of the 2016 IEEE First International Conference on Data Science in Cyberspace (DSC), Changsha, China, 13–16 June 2016; pp. 275–283. [Google Scholar]
- Akinwande, O.J.; Bi, H.; Gelenbe, E. Managing Crowds in Hazards With Dynamic Grouping. IEEE Access 2015, 3, 1060–1070. [Google Scholar] [CrossRef]
- Gelenbe, E.; Han, Q. Near-optimal emergency evacuation with rescuer allocation. In Proceedings of the 2014 IEEE International Conference on Pervasive Computing and Communication Workshops (PERCOM WORKSHOPS), Budapest, Hungary, 24–28 March 2014; pp. 314–319. [Google Scholar]
- Ranadheera, S.; Maghsudi, S.; Hossain, E. Minority games with applications to distributed decision making and control in wireless networks. IEEE Wirel. Commun. 2017, 24, 184–192. [Google Scholar] [CrossRef]







© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fragkos, G.; Apostolopoulos, P.A.; Tsiropoulou, E.E. ESCAPE: Evacuation Strategy through Clustering and Autonomous Operation in Public Safety Systems. Future Internet 2019, 11, 20. https://doi.org/10.3390/fi11010020
Fragkos G, Apostolopoulos PA, Tsiropoulou EE. ESCAPE: Evacuation Strategy through Clustering and Autonomous Operation in Public Safety Systems. Future Internet. 2019; 11(1):20. https://doi.org/10.3390/fi11010020
Chicago/Turabian StyleFragkos, Georgios, Pavlos Athanasios Apostolopoulos, and Eirini Eleni Tsiropoulou. 2019. "ESCAPE: Evacuation Strategy through Clustering and Autonomous Operation in Public Safety Systems" Future Internet 11, no. 1: 20. https://doi.org/10.3390/fi11010020
APA StyleFragkos, G., Apostolopoulos, P. A., & Tsiropoulou, E. E. (2019). ESCAPE: Evacuation Strategy through Clustering and Autonomous Operation in Public Safety Systems. Future Internet, 11(1), 20. https://doi.org/10.3390/fi11010020