Botnet Detection Based On Machine Learning Techniques Using DNS Query Data


Abstract
:1. Introduction
2. Related Works
3. Machine Learning Based Botnet Detection
3.1. Introduction to Machine Learning and Its Techniques
3.1.1. Introduction to Machine Learning
3.1.2. Common Supervised Machine Learning Techniques
1. kNN
- -
- Step 1: Determine the parameter value k.
- -
- Step 2: Calculate the distance between the new object that needs to be classified with all objects in the training dataset.
- -
- Step 3: Arrange computed distances in the ascending order and identify k nearest neighbors with the new object.
- -
- Step 4: Take all the labels of the k neighbors selected above.
- -
- Step 5: Based on the k labels that have been taken, the label that holds the majority will be assigned to the new object.
2. Decision tree
3. Random forest
3.2. Proposed Botnet Detection Model Based on Machine Learning
4. Experiment and Evaluation
4.1. Experimental Dataset
4.2. Data Pre-Processing
4.2.1. Features of Bi-gram and Tri-gram Clusters
- -
- count(d) is the number of n-grams of the domain name d that are also found in DS(n-gram).
- -
- m(d) is the general frequency distribution of the n-grams of the domain name d, which is calculated by the following formula:where f(i) is the total number of occurrences of n-gram i in DS(n-gram) and index(i) is the rank of n-gram i in TS(n-gram).
- -
- s(d) is the weight of n-grams of the domain name d, calculated by the following formula:where vt(i) is the rank of n-gram i in DS(n-gram).
- -
- ma(d) is the average of the general frequency distribution of the n-grams of the domain name d, which is calculated by the following formula:where len(d) is total number of n-grams in the domain name d.ma(d) = m(d)/len(d)
- -
- sa(d) is the average of the weight of n-grams of the domain name d, calculated by the following formula:sa(d) = s(d)/len(d)
- -
- tan(d) is the average number of popular n-grams of the domain name d, calculated by the following formula:tan(d) = count(d)/len(d)
- -
- taf(d) is the average frequency of popular n-grams of the domain name d, calculated by the following formula:
- -
- entropy(d) is the entropy of the domain name d, calculated by the following formula:where L is the number of popular n-grams in the set of benign domain names, L = N for bi-grams and L = M for tri-grams.
4.2.2. Vowel Distribution Features
- -
- countnv(d) is the number of vowels of the domain name d.
- -
- tanv(d) is the average number of vowels of the domain name d, calculated by the following formula:tanv(d) = countnv(d)/len(d)
4.3. Experimental Scenarios and Classification Measures
4.3.1. Experimental Scenarios
4.3.2. Classification Measures
4.4. Experimental Results and Comments
4.4.1. Experimental Results
4.4.2. Comments
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Authority of Information Security. The 2016 Vietnam Information Security Report; Authority of Information Security, MIC: New York, NY, USA, 2016. [Google Scholar]
- Ferguson, R. The History of the Botnet. Available online: http://countermeasures.trendmicro.eu/the-history-of-the-botnet-part-i/ (accessed on 1 February 2018).
- Alieyan, K.; Almomani, A.; Manasrah, A.; Kadhum, M.M. A survey of botnet detection based on DNS. Nat. Comput. Appl. Forum 2017, 28, 1541–1558. [Google Scholar] [CrossRef]
- Li, X.; Wang, J.; Zhang, X. Botnet Detection Technology Based on DNS. J. Future Internet 2017, 9, 55. [Google Scholar] [CrossRef]
- Ramachandran, A.; Feamster, N.; Dagon, D. Revealing botnet membership using DNSBL counter-intelligence. In Proceedings of the 2nd USENIX: Steps to Reducing Unwanted Traffic on the Internet, San Jose, CA, USA, 7 July 2006; pp. 49–54. [Google Scholar]
- Villamari-Salomo, R.; Brustoloni, J.C. Identifying botnets using anomaly detection techniques applied to DNS traffic. In Proceedings of the 5th IEEE consumer communications and networking conference (CCNC 2008), Las Vegas, NV, USA, 10–12 January 2008; pp. 476–481. [Google Scholar]
- Perdisci, R.; Corona, I.; Dagon, D.; Lee, W. Detecting malicious flux service networks through passive analysis of recursive DNS traces. In Proceedings of the Annual Computer Security Applications Conference, Honolulu, HI, USA, 7–11 December 2009; pp. 311–320. [Google Scholar]
- Yadav, S.; Reddy, A.K.K.; Reddy, A.; Ranjan, S. Detecting algorithmically generated malicious domain names. In Proceedings of the 10th ACM sigcomm Conference on Internet Measurement, Melbourne, Australia, 1–30 November 2010; pp. 48–61. [Google Scholar]
- Stalmans, E.; Irwin, B. A framework for DNS based detection and mitigation of malware infections on a network. In Proceedings of the 2011 Information Security for South Africa (ISSA), Johannesburg, South Africa, 15–17 August 2011; pp. 1–8. [Google Scholar]
- Antonakakis, M.; Perdisci, R.; Lee, W.; Vasiloglou, N., II; Dagon, D. Detecting malware domains at the upper DNS hierarchy. In Proceedings of the USENIX security symposium, San Francisco, CA, USA, 8 August 2011; p. 16. [Google Scholar]
- Bilge, L.; Kirda, E.; Kruegel, C.; Balduzzi, M. Exposure: Finding Malicious Domains Using Passive DNS Analysis; NDSS: New York, NY, USA, 2011. [Google Scholar]
- Jiang, N.; Cao, J.; Jin, Y.; Li, L.; Zhang, Z.L. Identifying suspicious activities through DNS failure graph analysis. In Proceedings of the18th IEEE International Conference on Network Protocols (ICNP), Kyoto, Japan, 5–8 October 2010; pp. 144–153. [Google Scholar]
- Kheir, N.; Tran, F.; Caron, P.; Deschamps, N. Mentor: positive DNS reputation to skim-off benign domains in botnet C&C blacklists. In ICT Systems Security and Privacy Protection; Springer: Berlin/Heidelberg, Germany, 2014; pp. 1–14. [Google Scholar]
- Da Luz, P.M. Botnet Detection Using Passive DNS; Radboud University: Nijmegen, The Netherlands, 2014. [Google Scholar]
- Sangani, N.K.; Zarger, H. Machine Learning in Application Security. Advances in Security in Computing and Communications; IntechOpen: Karnataka, India, 2017. [Google Scholar]
- Smola, A.; Vishwanathan, S.V.N. Introduction to Machine Learning; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]
- Conficker. Available online: http://www.cert.at/static/conficker/all_domains.txt (accessed on 10 November 2017).
- DGA Dataset. Available online: https://github.com/nickwallen/botnet-dga-classifier/tree/master/data (accessed on 10 November 2017).
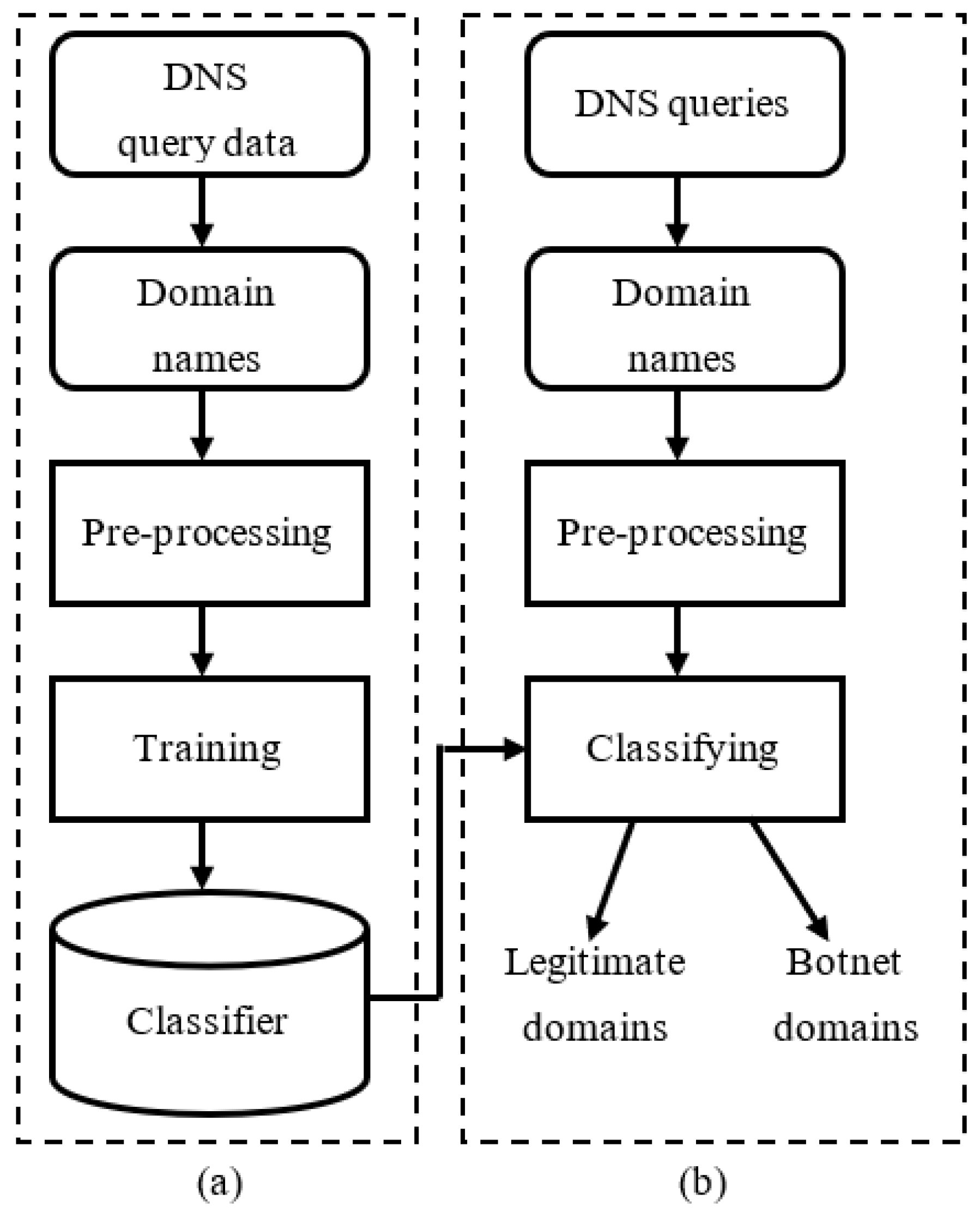

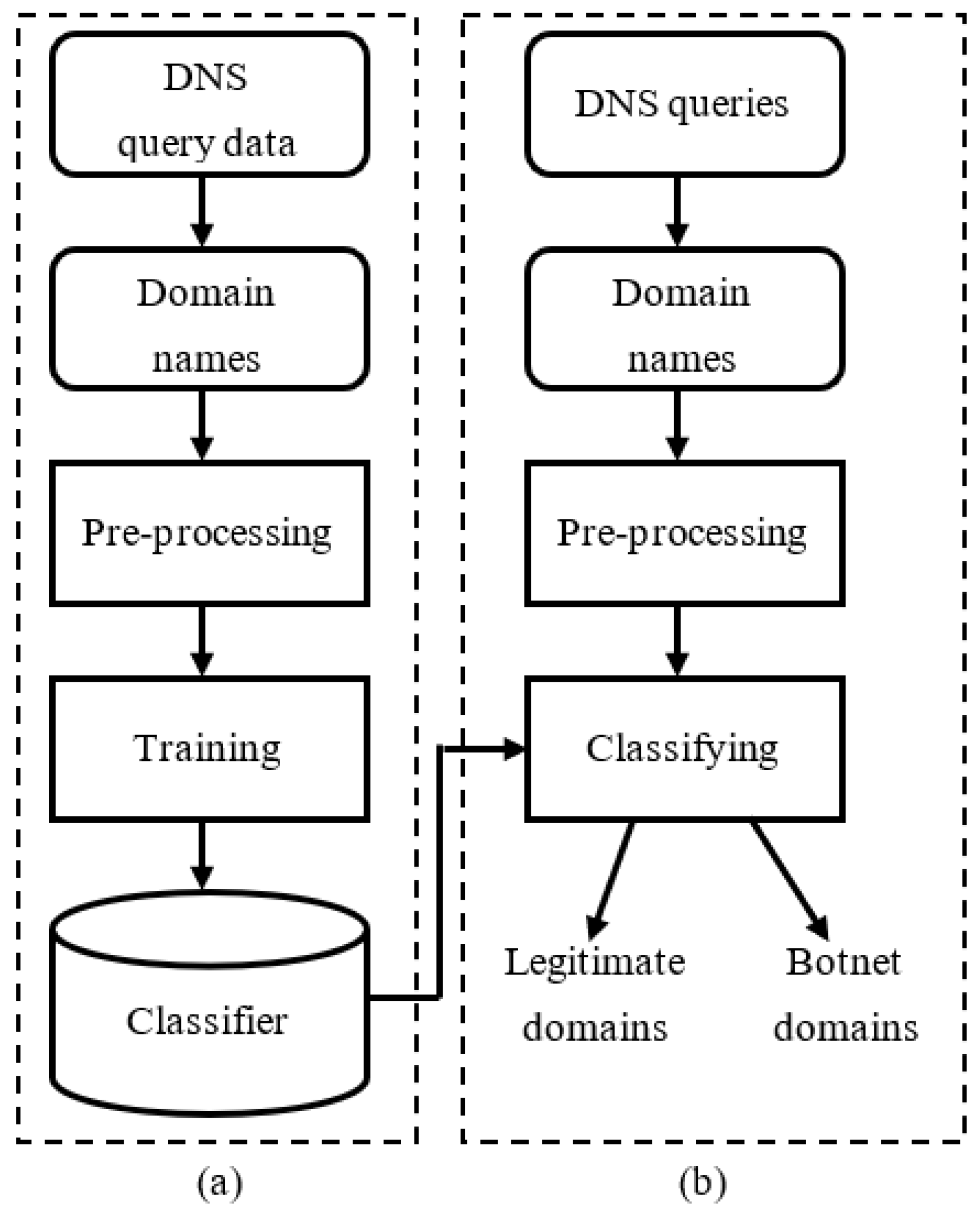{kind=link}
| Datasets for Training and Testing | The Number of Records From | |
|---|---|---|
| Dataset Labeled “Good” | Dataset Labeled “Bad” | |
| T1 training dataset | 10,000 | 10,000 |
| T2 training dataset | 5000 | 15,000 |
| T3 training dataset | 15,000 | 5000 |
| TEST testing dataset | 10,000 | 10,000 |
| Actual Class | |||
|---|---|---|---|
| Bad | Good | ||
| Predicted class | Bad | TP (True Positives) | FP (False Positives) |
| Good | FN (False Negatives) | TN (True Negatives) | |
| Machine Learning Algorithms | Measures (%) | ||||
|---|---|---|---|---|---|
| PPV | FPR | TPR | ACC | F1 | |
| kNN (k = 13) | 89.50 | 10.70 | 91.00 | 90.20 | 90.30 |
| C4.5 | 89.10 | 11.10 | 91.20 | 90.10 | 90.10 |
| RF (30 trees) | 90.70 | 9.30 | 91.00 | 90.80 | 90.80 |
| Naïve Bayes | 83.10 | 18.30 | 90.20 | 85.90 | 86.50 |
| Machine Learning Algorithms | Measures (%) | ||||
|---|---|---|---|---|---|
| PPV | FPR | TPR | ACC | F1 | |
| kNN (k = 9) | 82.70 | 20.10 | 96.40 | 88.10 | 89.00 |
| C4.5 | 81.50 | 22.10 | 97.30 | 87.60 | 88.70 |
| RF (38 trees) | 84.20 | 18.10 | 96.60 | 89.20 | 89.96 |
| Naïve Bayes | 82.80 | 18.80 | 90.50 | 85.80 | 86.50 |
| Machine Learning Algorithms | Measures (%) | ||||
|---|---|---|---|---|---|
| PPV | FPR | TPR | ACC | F1 | |
| kNN (k = 15) | 94.10 | 5.00 | 80.40 | 87.70 | 86.70 |
| C4.5 | 93.40 | 5.70 | 80.90 | 87.60 | 86.70 |
| RF (27 trees) | 94.40 | 4.80 | 80.90 | 88.10 | 87.20 |
| Naïve Bayes | 83.90 | 17.10 | 89.10 | 86.00 | 86.40 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hoang, X.D.; Nguyen, Q.C. Botnet Detection Based On Machine Learning Techniques Using DNS Query Data. Future Internet 2018, 10, 43. https://doi.org/10.3390/fi10050043
Hoang XD, Nguyen QC. Botnet Detection Based On Machine Learning Techniques Using DNS Query Data. Future Internet. 2018; 10(5):43. https://doi.org/10.3390/fi10050043
Chicago/Turabian StyleHoang, Xuan Dau, and Quynh Chi Nguyen. 2018. "Botnet Detection Based On Machine Learning Techniques Using DNS Query Data" Future Internet 10, no. 5: 43. https://doi.org/10.3390/fi10050043
APA StyleHoang, X. D., & Nguyen, Q. C. (2018). Botnet Detection Based On Machine Learning Techniques Using DNS Query Data. Future Internet, 10(5), 43. https://doi.org/10.3390/fi10050043