A Method for Filtering Pages by Similarity Degree based on Dynamic Programming


Abstract
:1. Introduction
2. Related Works
2.1. Filtering Methods Based on URI
2.2. Filtering Methods Based on Contents
2.3. Filtering Methods Based on Structure
2.4. Filtering Methods Based on Autonomous Learning
3. Algorithm of MFPSDDP
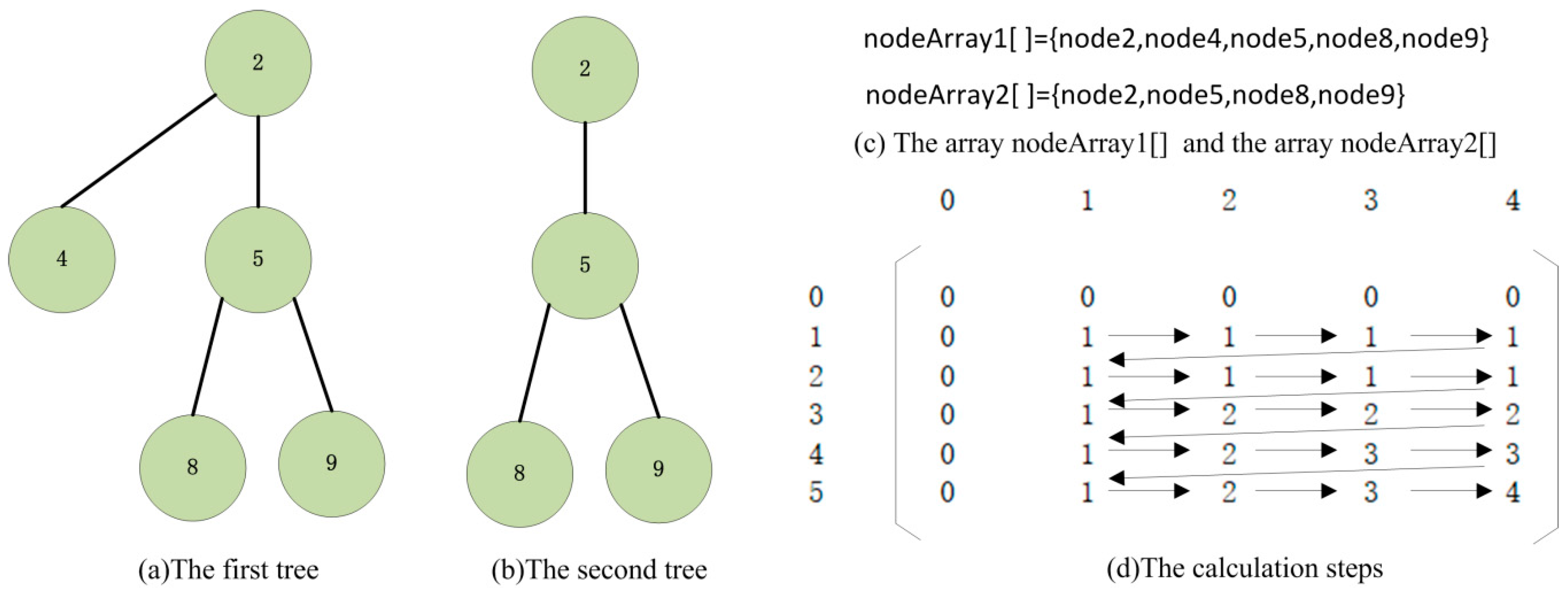
3.1. Same Relationship between Two Nodes
3.2. Algorithm of MFPSDDP
| Algorithm 1: caculateMaxSubSequenceLength (nodeArray1[ ],nodeArray2[ ]) Function: This algorithm calculates the length of the longest common subsequence between nodeArray1[ ] and nodeArray2[ ]. Parameter descriptions: The parameter nodeArray1 is the first node array. The parameter nodeArray2 is the second node array. Return value: This algorithm returns the length of the longest common subsequence between nodeArray1[ ] and nodeArray2[ ]. |
| /*Declare a two-dimensional array for recording the length of the longest common subsequence. The initial value of each element in the array is 0.*/ int lengthArray[ ][ ] = new int[nodeArray1.length + 1][nodeArray2.length + 1] For i = 1 to nodeArray1.length step For j = 1 to nodeArray2.length step 1 //Use CSR to judge the relationship between two nodes If nodeArray1[i] = nodeArray2[j] Then lengthArray[i][j] = lengthArray[i − 1][j − 1] + 1 Else lengthArray[i][j] = max(lengthArray[i][j − 1],lengthArray[i − 1][j]) End If End For End For return lengthArray[nodeArray1.length][nodeArray2.length] |
3.3. Selection of Same Relationship between Two Nodes
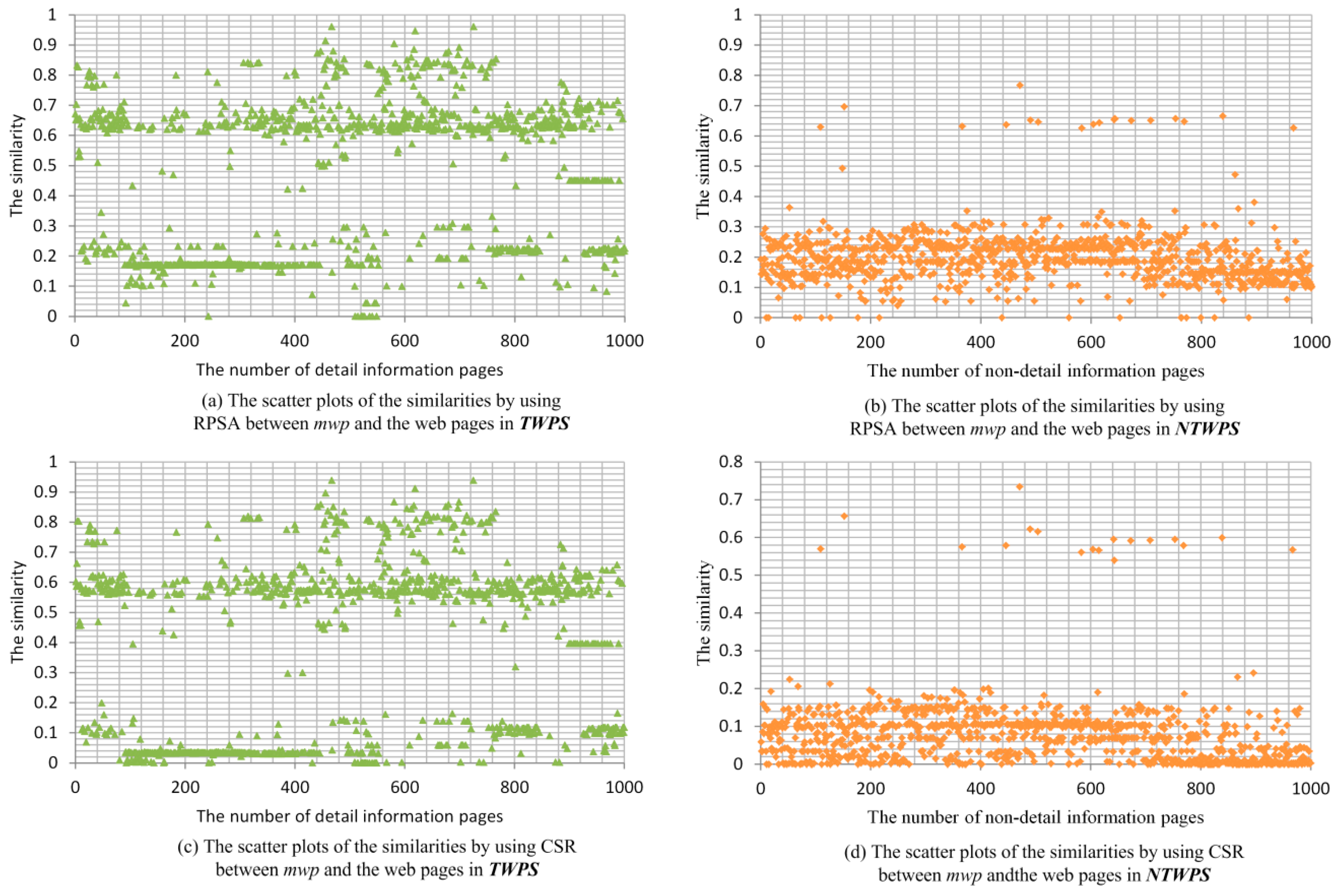
- It is easy to find a similarity threshold (e.g., 0.4), which can be used to distinguish the classification of webpages. If the similarity between the webpage and mwp is above the similarity threshold, the webpage is considered to belong to the type of target webpages.
- Compared with the filtering method using another relationship, the filtering method using this relationship has higher Precision Ratio (PR) value. The calculation method of PR is shown in Formula (2):where TAF is the number of target webpages obtained after filtering and AF is the number of webpages obtained after being filtered.
- Compared with the filtering method using another relationship, the filtering method using this relationship has higher Recall Ratio (RR) value. The calculation method of RR is showed in Formula (3).where RUF is the number of target webpages in the pages to be filtered. We use RR and PR as the accuracy indicators of filtering methods.
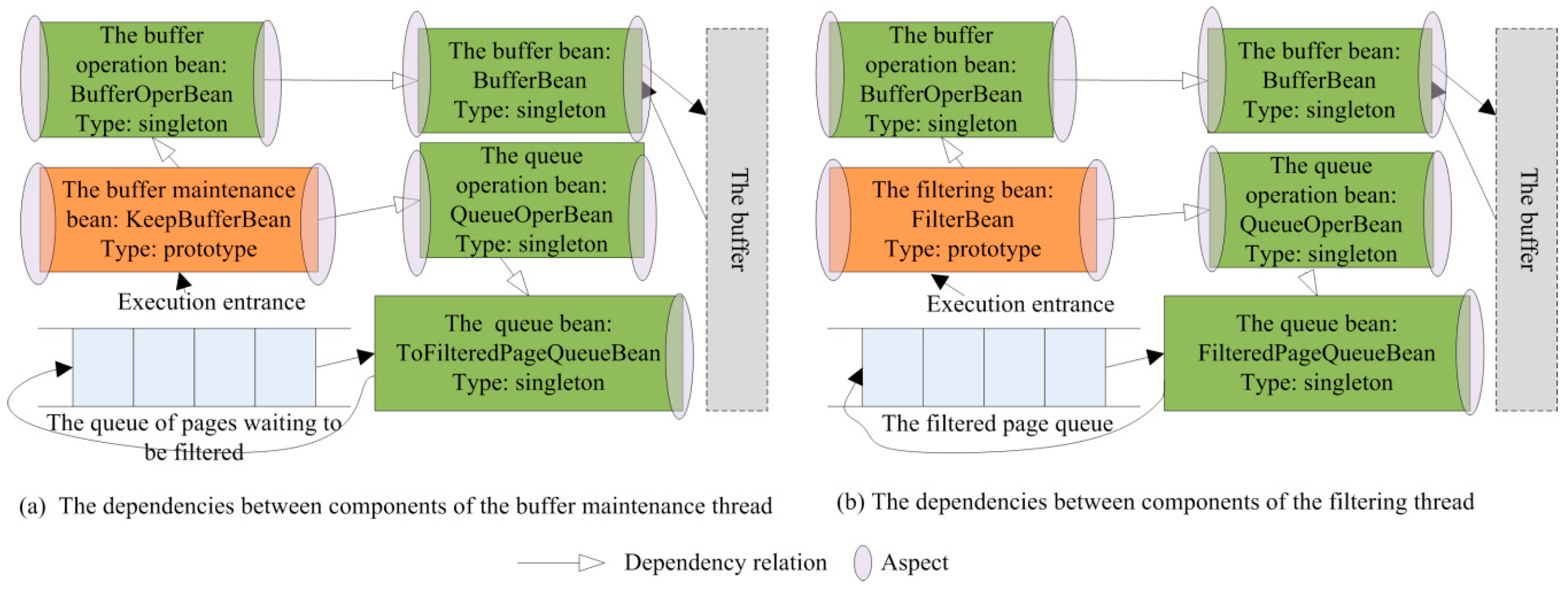
3.4. Software Design of MFPSDDP
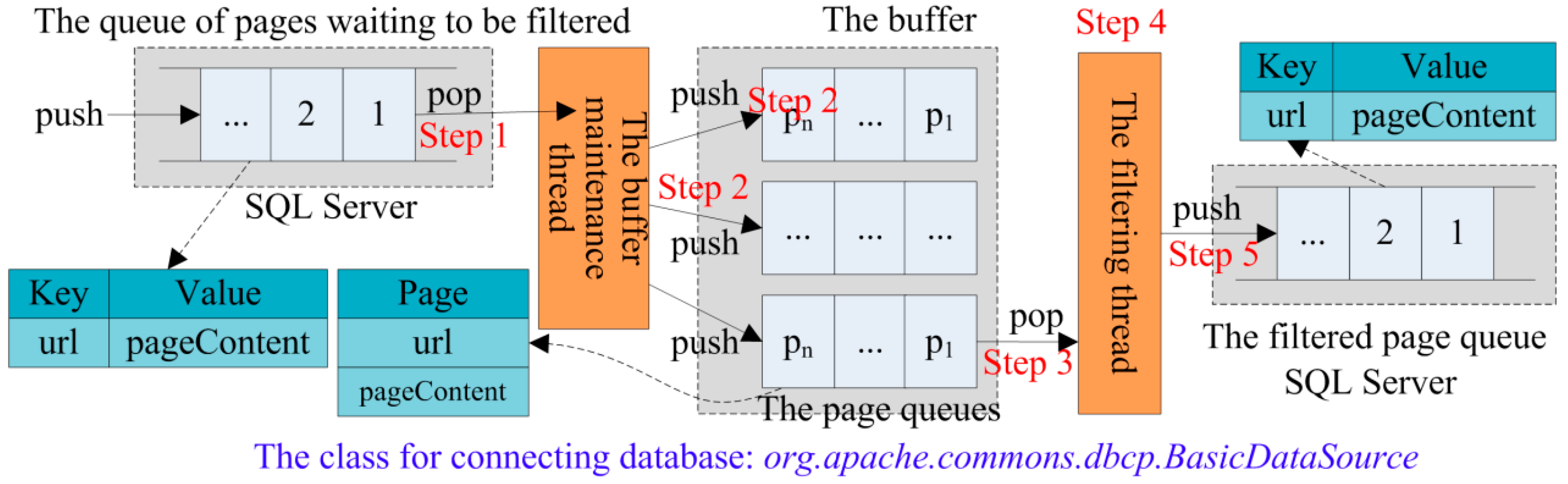
3.4.1. Queue Storage and Buffer
3.4.2. Double Thread Design
4. Experimental Analysis
4.1. Selection of Relationships and Determination of Similarity Threshold
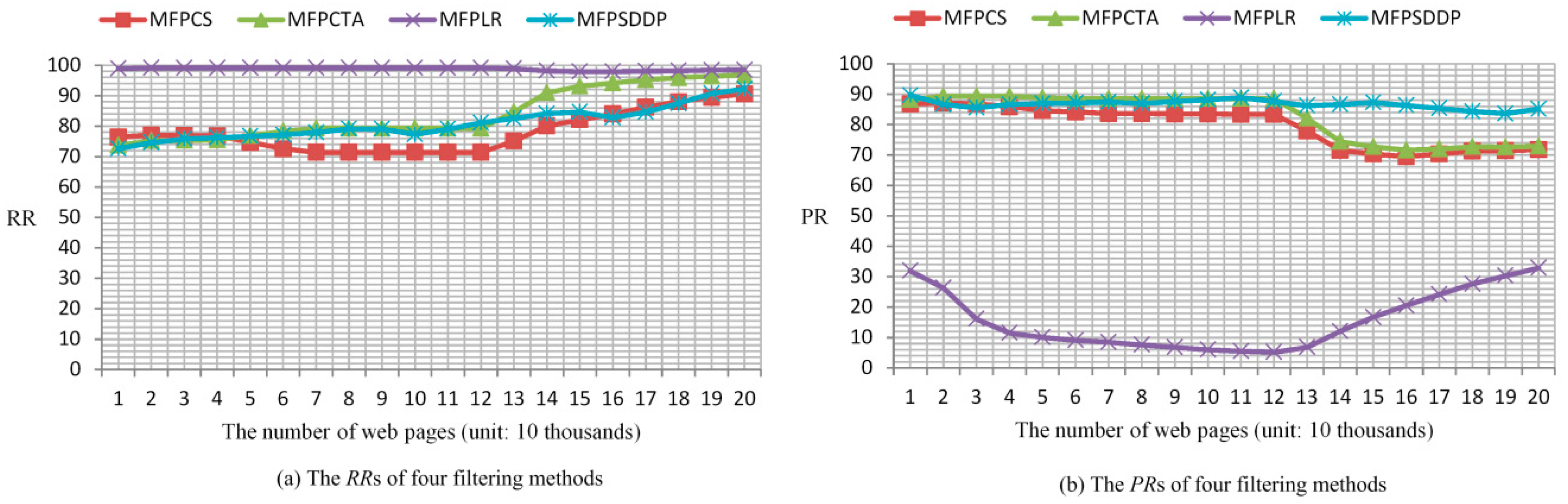
4.2. Comparison with Other Methods
5. Conclusions
- We will continue to find out some filtering methods with the highly RR and the highly PR by using Artificial Intelligence (AI) algorithms, such as deep neural networks. We can use thousands of known pages as a training set, get the feature of the training set, and then filter the webpages automatically.
- We continue to improve MFPSDDP. The improved method is to increase the number of template pages, and take the average similarity of multiple template webpages and filtered webpages as the similarity of filtered webpages, so we can get higher RR and PR.
Author Contributions
Funding
Conflicts of Interest
References
- Díaz-Manríquez, A.; Rios, A.B.; Barron-Zambrano, J.H.; Guerrero, T.Y.; Elizondo, J.C. An Automatic Document Classifier System Based on Genetic Algorithm and Taxonomy. IEEE Access 2018, 6, 21552–21559. [Google Scholar] [CrossRef]
- Bhalla, V.K.; Kumar, N. An efficient scheme for automatic web pages categorization using the support vector machine. New Rev. Hypermedia Multimedia 2016, 22, 223–242. [Google Scholar] [CrossRef]
- Zhang, R.; He, Z.; Wang, H.; You, F.; Li, K. Study on Self-Tuning Tyre Friction Control for Developing Main-Servo Loop Integrated Chassis Control System. IEEE Access 2017, 5, 6649–6660. [Google Scholar] [CrossRef]
- Ahmadi, A.; Fotouhi, M.; Khaleghi, M. Intelligent classification of web pages using contextual and visual features. Appl. Soft Comput. 2011, 11, 1638–1647. [Google Scholar] [CrossRef]
- Saleh, A.I.; Rahmawy, M.F.; Abulwafa, A.E. A semantic based Web page classification strategy using multi-layered domain ontology. World Wide Web 2017, 20, 939–993. [Google Scholar] [CrossRef]
- Baranauskas, J.; Netto, O.P.; Nozawa, S.R.; Macedo, A.A. A tree-based algorithm for attribute selection. Appl. Intell. 2018, 48, 821–833. [Google Scholar] [CrossRef]
- Yu, X.; Li, M.; Kim, K.A.; Chung, J.; Ryu, K.H. Emerging Pattern-Based Clustering of Web Users Utilizing a Simple Page-Linked Graph. Sustainability 2016, 8, 239. [Google Scholar] [CrossRef]
- Ilbahar, E.; Cebi, S. Classification of design parameters for e-commerce websites: A novel fuzzy Kano approach. Telematics Inform. 2017, 38, 1814–1825. [Google Scholar] [CrossRef]
- Popescu, D.A.; Radulescu, D. Approximately similarity measurement of web sites. In Proceedings of the 2015 International Conference on Telecommunications & Signal Processing, Istanbul, Turkey, 12 October 2015. [Google Scholar]
- Reddy, G.S.; Krishnaiah, R.V. Clustering algorithm with a novel similarity measure. IOSR J. Comput. Eng. 2012, 4, 37–42. [Google Scholar] [CrossRef]
- Crovella, M.E.; Bestavros, A. Self-Similarity in World Wide Web traffic: Evidence and possible causes. IEEE/ACM Trans. Network. 1997, 5, 835–846. [Google Scholar] [CrossRef]
- Deng, Z.; Zhang, J.; He, T. Automatic combination technology of fuzzy CPN for OWL-S web services in supercomputing cloud platform. Int. J. Pattern Recogit. Artif. Intell. 2017, 31, 1–27. [Google Scholar] [CrossRef]
- Du, Y.; Hai, Y. Semantic ranking of web pages based on formal concept analysis. J. Syst. Softw. 2013, 86, 187–197. [Google Scholar] [CrossRef]
- Xie, X.; Wang, B. Web page recommendation via twofold clustering: Considering user behavior and topic relation. Neural Comput. Appl. 2018, 29, 235–243. [Google Scholar] [CrossRef]
- Kou, G.; Lou, C. Multiple factor hierarchical clustering algorithm for large scale web page and search engine clickstream data. Ann. Oper. Res. 2012, 197, 123–134. [Google Scholar] [CrossRef]
- Nguyen, T.T.S.; Lu, H.Y.; Lu, J. Web-page recommendation based on web usage and domain knowledge. IEEE Trans. Knowl. Data Eng. 2014, 26, 2574–2587. [Google Scholar] [CrossRef]
- Du, Y.; Pen, Q.; Gao, Z. A topic-specific crawling strategy based on semantics similarity. Data Knowled. Eng. 2013, 88, 75–93. [Google Scholar] [CrossRef]
- Hussien, A. Comparison of machine learning algorithms to classify web pages. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 205–209. [Google Scholar]
- Ruchika, M.; Anjali, S. Quantitative evaluation of web metrics for automatic genre classification of web pages. Int. J. Syst. Assurance Eng. Manag. 2017, 8 (Suppl. 2), 1567–1579. [Google Scholar]
- Kavitha, C.; Sudha, G.; Kiruthika, S. Semantic similarity based web document classification using support vector machine. Int. Arab J. Inf. Technol. 2017, 14, 285–292. [Google Scholar]
- Wahab, S.A.R. An Automated web page classifier and an algorithm for the extraction of navigational pattern from the web data. J. Web Eng. 2017, 16, 126–144. [Google Scholar]
- Farman, A.; Pervez, K.; Kashif, R. A fuzzy ontology and SVM-based web content classification system. IEEE Access 2017, 5, 25781–25797. [Google Scholar]
- Lee, J.-H.; Yeh, W.-C.; Chuang, M.-C. Web page classification based on a simplified swarm optimization. Appl. Math. Comput. 2015, 270, 13–24. [Google Scholar] [CrossRef]
- Li, H.; Xu, Z.; Li, T. An optimized approach for massive web page classification using entity similarity based on semantic network. Future Gener. Comput. Syst. 2017, 76, 510–518. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Same Relationship | TUF | AF | TAF | RR | PR | Similarity Threshold |
|---|---|---|---|---|---|---|
| RPSA | 1000 | 823 | 703 | 70.3% | 85.4% | 0.4 |
| CSR | 1000 | 819 | 731 | 73.1% | 89.3% | 0.2 |
| Filtering Method | Main Configuration |
|---|---|
| MFPCS | The following conditions must be satisfied at the same time. Condition 1. Each webpage obtained after filtering must include one of the following strings: “price”, “flash purchase price”, “Jingdong price”, “exclusive price”, or “price spike”. This condition is expressed as follows: page.containsString (“price”) or page.containsString (“flash purchase price”) or page.containsString (“Jingdong price”) or page.containsString (“exclusive price”) or page.containsString (“price spike”) Condition 2. Each webpage obtained after filtering must include the string “distribution”. This condition is expressed as follows: page.containsString (“distribution”) Condition 3. Each webpage obtained after filtering must include one of the following strings: “commodity details” or “commodity introduction”. This condition is expressed as follows: page.containsString (“commodity details”) or page.containsString (“commodity introduction”) |
| MFPCTA | The following condition must be satisfied. Condition 1. Each webpage obtained after filtering must include the tag <div>, and the value of the “class” attribute of the tag <div> must be “crumb-wrap”. This condition is expressed as follows: page.containsTag (divTag) and page.divTags.containsAttribute (classAttribute) |
| MFPLR | The following condition must be satisfied. Condition 1. The link ratio threshold is set to 0.25. This condition is expressed as follows: page.linkRatioOut (0.25) |
| MFPSDDP | The following conditions must be satisfied at the same time. Condition 1. The tags in each webpage tree must include only the tags <div> and <span>. This condition is expressed as follows: page.onlyContainTags (divTagAndspanTag) Condition 2. The similarity between each webpage and a template webpage is calculated by CSR and Formula (1). The similarity threshold is set to 0.2. This condition is expressed as follows: page.similarityOut (0.2) |
| Filtering Method | TUF | AF | TAF | RR | PR |
|---|---|---|---|---|---|
| MFPCS | 57,570 | 72,643 | 52,175 | 90.6% | 71.8% |
| MFPCTA | 57,570 | 76,441 | 55,725 | 96.8% | 72.9% |
| MFPLR | 57,570 | 172,694 | 56,734 | 98.5% | 32.9% |
| MFPSDDP | 57,570 | 62,372 | 53,079 | 92.2% | 85.1% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, Z.; He, T. A Method for Filtering Pages by Similarity Degree based on Dynamic Programming. Future Internet 2018, 10, 124. https://doi.org/10.3390/fi10120124
Deng Z, He T. A Method for Filtering Pages by Similarity Degree based on Dynamic Programming. Future Internet. 2018; 10(12):124. https://doi.org/10.3390/fi10120124
Chicago/Turabian StyleDeng, Ziyun, and Tingqin He. 2018. "A Method for Filtering Pages by Similarity Degree based on Dynamic Programming" Future Internet 10, no. 12: 124. https://doi.org/10.3390/fi10120124
APA StyleDeng, Z., & He, T. (2018). A Method for Filtering Pages by Similarity Degree based on Dynamic Programming. Future Internet, 10(12), 124. https://doi.org/10.3390/fi10120124