Virtually Possible: Enhancing Quality Control of 3D-Printed Medicines with Machine Vision Trained on Photorealistic Images


 , ,
, , 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Experimental Procedure
2.1. Virtual Image Generation
2.2. SLA Image Generation
2.2.1. Computer-Aided Design (CAD) of Formulations
2.2.2. SLA Printing Process
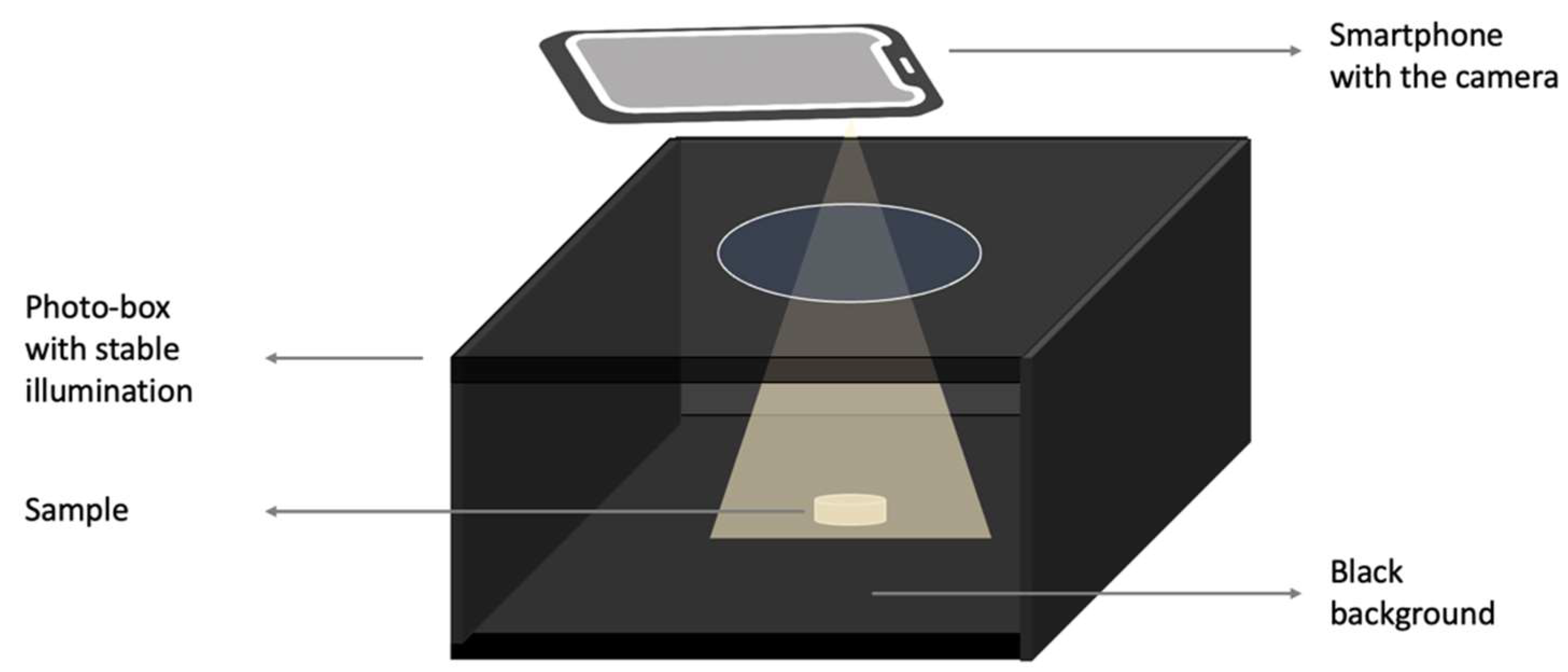
2.2.3. Photogrammetry Setup
2.3. AI Pipeline Development
3. Results
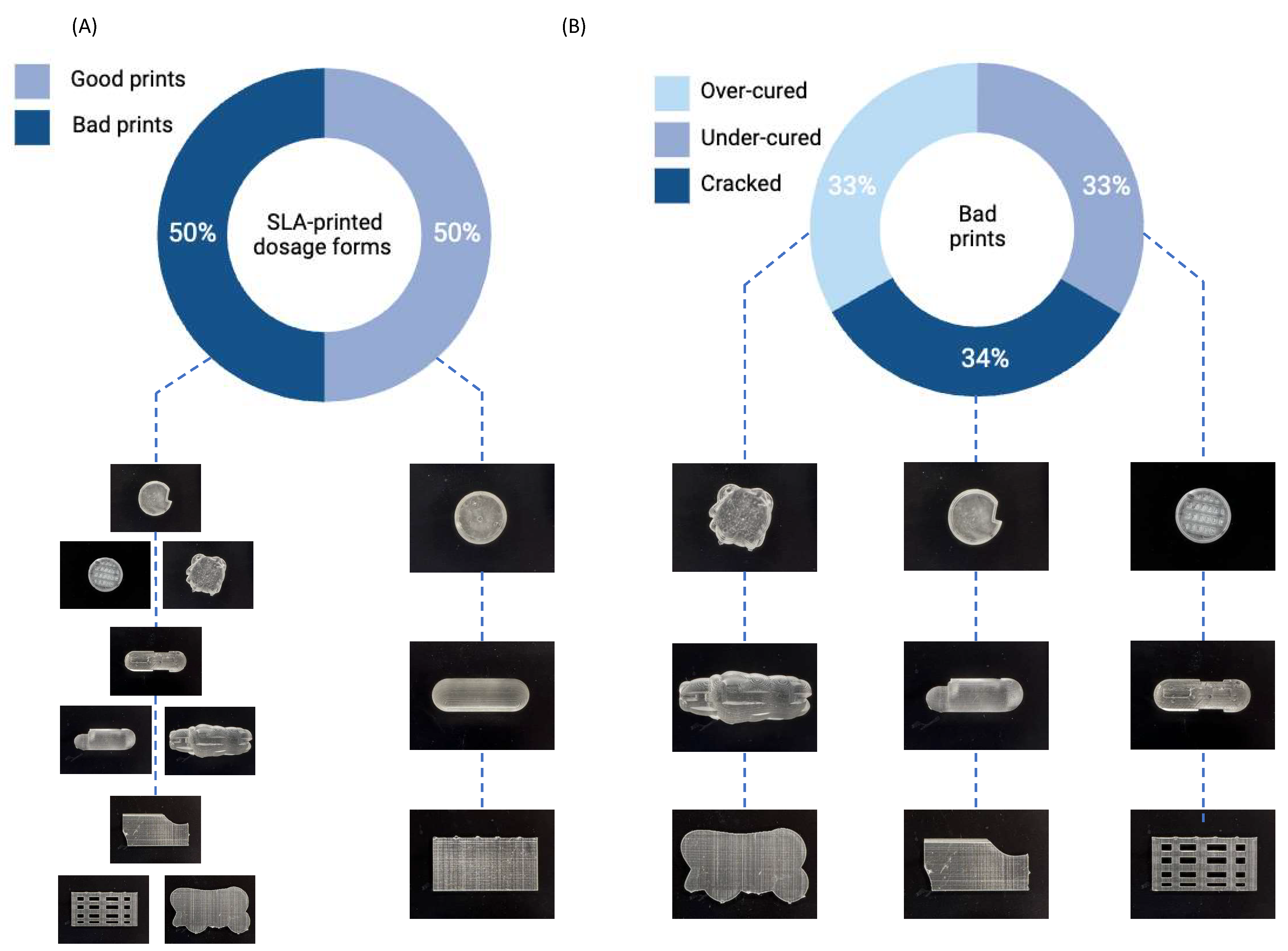
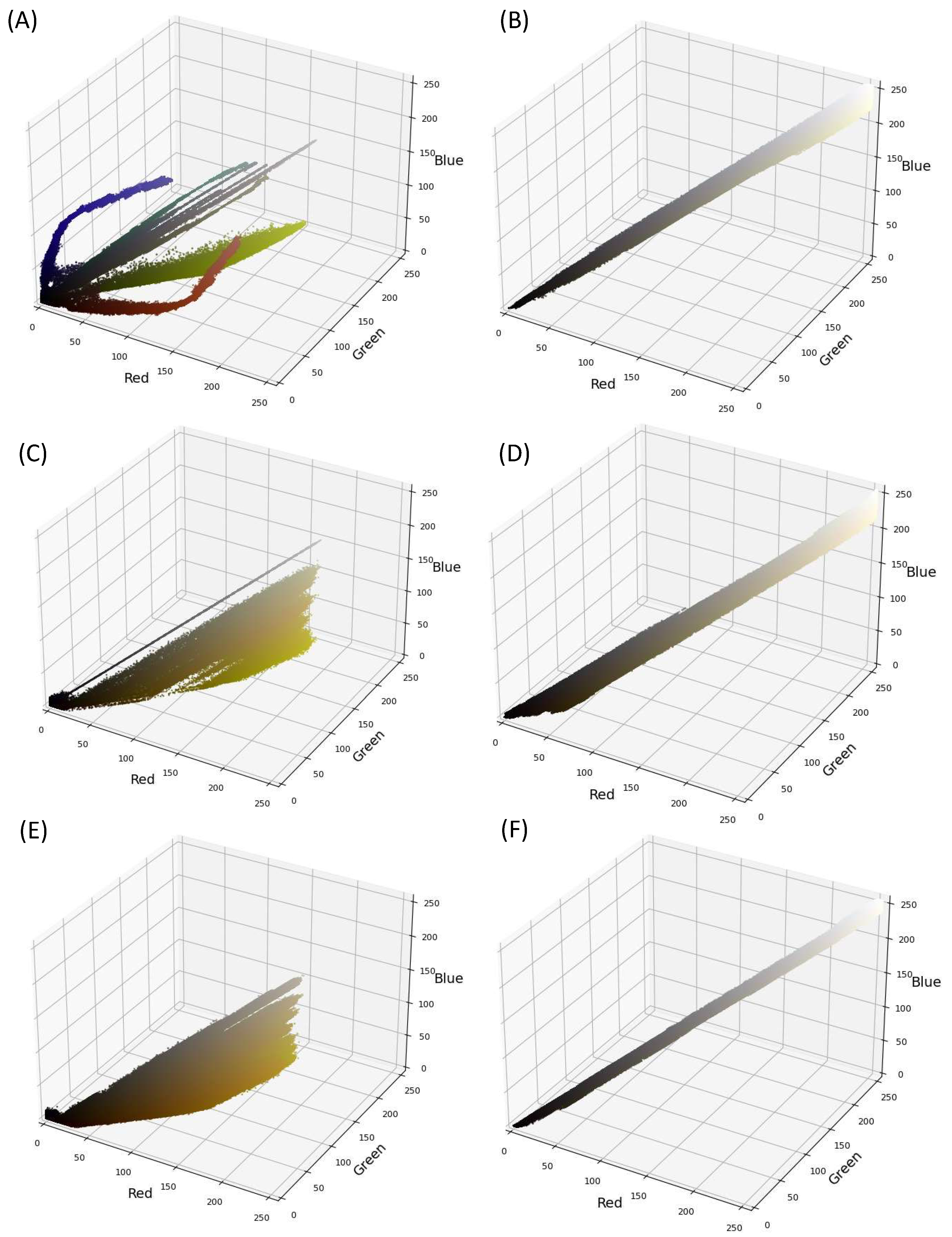
3.1. Exploratory Data Analysis (EDA)
3.2. ML Results
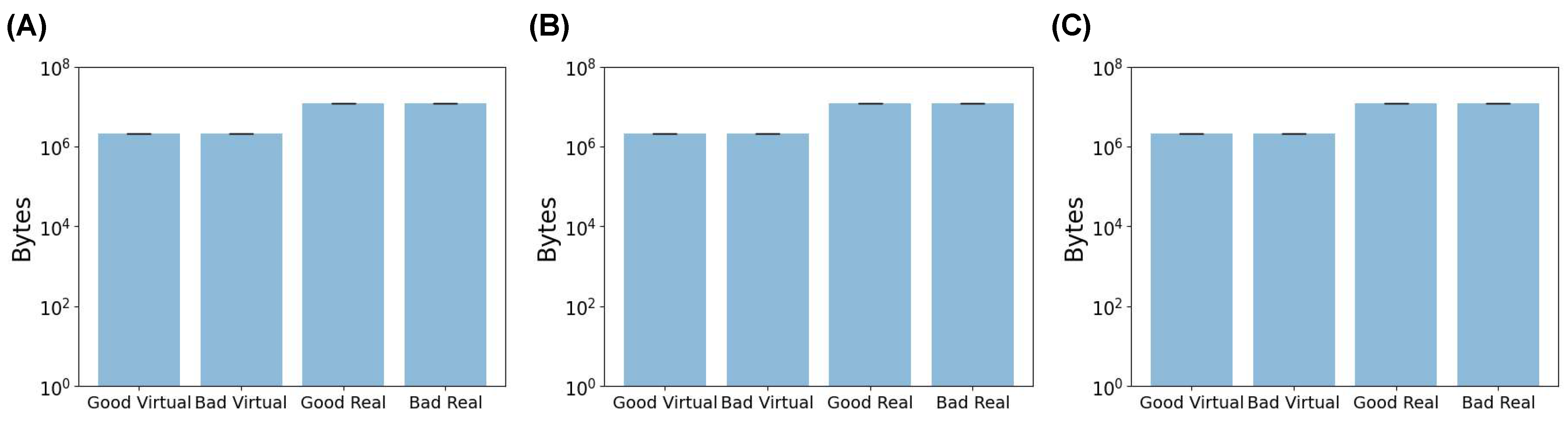
3.2.1. The Effect of Image Size
3.2.2. The Effect of Grayscale Transformation
3.3. Model Robustness: Stress Testing to Ensure High Performance
3.3.1. Scalability
3.3.2. Model Confidence
3.3.3. Out-of-Data (OOD) Distribution
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Trenfield, S.J.; Awad, A.; Goyanes, A.; Gaisford, S.; Basit, A.W. 3D printing pharmaceuticals: Drug development to frontline care. Trends Pharmacol. Sci. 2018, 39, 440–451. [Google Scholar] [CrossRef] [PubMed]
- Awad, A.; Fina, F.; Goyanes, A.; Gaisford, S.; Basit, A.W. 3D printing: Principles and pharmaceutical applications of selective laser sintering. Int. J. Pharm. 2020, 586, 119594. [Google Scholar] [CrossRef]
- Sen, K.; Mehta, T.; Sansare, S.; Sharifi, L.; Ma, A.W.; Chaudhuri, B. Pharmaceutical applications of powder-based binder jet 3D printing process–a review. Adv. Drug Deliv. Rev. 2021, 177, 113943. [Google Scholar] [CrossRef] [PubMed]
- Awad, A.; Fina, F.; Trenfield, S.J.; Patel, P.; Goyanes, A.; Gaisford, S.; Basit, A.W. 3D printed pellets (miniprintlets): A novel, multi-drug, controlled release platform technology. Pharmaceutics 2019, 11, 148. [Google Scholar] [CrossRef] [PubMed]
- Awad, A.; Yao, A.; Trenfield, S.J.; Goyanes, A.; Gaisford, S.; Basit, A.W. 3D printed tablets (printlets) with braille and moon patterns for visually impaired patients. Pharmaceutics 2020, 12, 172. [Google Scholar] [CrossRef]
- Fina, F.; Madla, C.M.; Goyanes, A.; Zhang, J.; Gaisford, S.; Basit, A.W. Fabricating 3D printed orally disintegrating printlets using selective laser sintering. Int. J. Pharm. 2018, 541, 101–107. [Google Scholar] [CrossRef] [PubMed]
- Seoane-Viaño, I.; Trenfield, S.J.; Basit, A.W.; Goyanes, A. Translating 3D printed pharmaceuticals: From hype to real-world clinical applications. Adv. Drug Deliv. Rev. 2021, 174, 553–575. [Google Scholar] [CrossRef]
- Varghese, R.; Sood, P.; Salvi, S.; Karsiya, J.; Kumar, D. 3D printing in the pharmaceutical sector: Advances and evidences. Sens. Int. 2022, 3, 100177. [Google Scholar] [CrossRef]
- Goyanes, A.; Madla, C.M.; Umerji, A.; Piñeiro, G.D.; Montero, J.M.G.; Diaz, M.J.L.; Barcia, M.G.; Taherali, F.; Sánchez-Pintos, P.; Couce, M.-L. Automated therapy preparation of isoleucine formulations using 3D printing for the treatment of MSUD: First single-centre, prospective, crossover study in patients. Int. J. Pharm. 2019, 567, 118497. [Google Scholar] [CrossRef]
- Awad, A.; Goyanes, A.; Basit, A.W.; Zidan, A.S.; Xu, C.; Li, W.; Narayan, R.J.; Chen, R.K. A review of state-of-the-art on enabling additive manufacturing processes for precision medicine. J. Manuf. Sci. Eng. 2023, 145, 010802. [Google Scholar] [CrossRef]
- Jørgensen, A.K.; Ong, J.J.; Parhizkar, M.; Goyanes, A.; Basit, A.W. Advancing non-destructive analysis of 3D printed medicines. Trends Pharmacol. Sci. 2023, 44, 379–393. [Google Scholar] [CrossRef]
- Geigert, J. Quality Assurance and Quality Control for Biopharmaceutical Products. In Development and Manufacture of Protein Pharmaceuticals; Nail, S.L., Akers, M.J., Eds.; Springer: Boston, MA, USA, 2002; pp. 361–404. [Google Scholar]
- Trenfield, S.J.; Tan, H.X.; Goyanes, A.; Wilsdon, D.; Rowland, M.; Gaisford, S.; Basit, A.W. Non-destructive dose verification of two drugs within 3D printed polyprintlets. Int. J. Pharm. 2020, 577, 119066. [Google Scholar] [CrossRef]
- Fonteyne, M.; Vercruysse, J.; De Leersnyder, F.; Van Snick, B.; Vervaet, C.; Remon, J.P.; De Beer, T. Process analytical technology for continuous manufacturing of solid-dosage forms. TrAC Trends Anal. Chem. 2015, 67, 159–166. [Google Scholar] [CrossRef]
- Pauli, V.; Roggo, Y.; Pellegatti, L.; Trung, N.Q.N.; Elbaz, F.; Ensslin, S.; Kleinebudde, P.; Krumme, M. Process analytical technology for continuous manufacturing tableting processing: A case study. J. Pharm. Biomed. Anal. 2019, 162, 101–111. [Google Scholar] [CrossRef] [PubMed]
- Corredor, C.C.; Bu, D.; McGeorge, G. Applications of MVDA and PAT for Drug Product Development and Manufacturing. In Multivariate Analysis in the Pharmaceutical Industry; Elsevier: Amsterdam, The Netherlands, 2018; pp. 211–234. [Google Scholar]
- Food and Drug Administration. Guidance for Industry, PAT-A Framework for Innovative Pharmaceutical Development, Manufacturing and Quality Assurance. 2004. Available online: http://www.fda.gov/cder/guidance/published.html (accessed on 9 August 2023).
- Trenfield, S.J.; Januskaite, P.; Goyanes, A.; Wilsdon, D.; Rowland, M.; Gaisford, S.; Basit, A.W. Prediction of Solid-State Form of SLS 3D Printed Medicines Using NIR and Raman Spectroscopy. Pharmaceutics 2022, 14, 589. [Google Scholar] [CrossRef] [PubMed]
- Trenfield, S.J.; Xu, X.; Goyanes, A.; Rowland, M.; Wilsdon, D.; Gaisford, S.; Basit, A.W. Releasing fast and slow: Non-destructive prediction of density and drug release from SLS 3D printed tablets using NIR spectroscopy. Int. J. Pharm. X 2023, 5, 100148. [Google Scholar] [CrossRef] [PubMed]
- Abdalla, Y.; Elbadawi, M.; Ji, M.; Alkahtani, M.; Awad, A.; Orlu, M.; Gaisford, S.; Basit, A.W. Machine learning using Multi-Modal Data Predicts the Production of Selective Laser Sintered 3D Printed Drug Products. Int. J. Pharm. 2023, 633, 122628. [Google Scholar] [CrossRef] [PubMed]
- Castro, B.M.; Elbadawi, M.; Ong, J.J.; Pollard, T.; Song, Z.; Gaisford, S.; Pérez, G.; Basit, A.W.; Cabalar, P.; Goyanes, A. Machine learning predicts 3D printing performance of over 900 drug delivery systems. J. Control. Release 2021, 337, 530–545. [Google Scholar] [CrossRef]
- Ryu, J.Y.; Kim, H.U.; Lee, S.Y. Deep learning improves prediction of drug–drug and drug–food interactions. Proc. Natl. Acad. Sci. USA 2018, 115, E4304–E4311. [Google Scholar] [CrossRef]
- Zheng, Y.; Wang, X.; Wu, Z. Machine learning modeling and predictive control of the batch crystallization process. Ind. Eng. Chem. Res. 2022, 61, 5578–5592. [Google Scholar] [CrossRef]
- Tao, H.; Wu, T.; Aldeghi, M.; Wu, T.C.; Aspuru-Guzik, A.; Kumacheva, E. Nanoparticle synthesis assisted by machine learning. Nat. Rev. Mater. 2021, 6, 701–716. [Google Scholar] [CrossRef]
- Sheila Anand, L.P. A Guide for Machine Vision in Quality Control; CRC Press: Boca Raton, FL, USA, 2020. [Google Scholar]
- O’Reilly, C.S.; Elbadawi, M.; Desai, N.; Gaisford, S.; Basit, A.W.; Orlu, M. Machine learning and machine vision accelerate 3D printed orodispersible film development. Pharmaceutics 2021, 13, 2187. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Li, X.; Zhong, H.; Yang, Y.; Wu, Q.J.; Ge, J.; Wang, Y. Automated machine vision system for liquid particle inspection of pharmaceutical injection. IEEE Trans. Instrum. Meas. 2018, 67, 1278–1297. [Google Scholar] [CrossRef]
- Ficzere, M.; Mészáros, L.A.; Kállai-Szabó, N.; Kovács, A.; Antal, I.; Nagy, Z.K.; Galata, D.L. Real-time coating thickness measurement and defect recognition of film coated tablets with machine vision and deep learning. Int. J. Pharm. 2022, 623, 121957. [Google Scholar] [CrossRef] [PubMed]
- Tikhomirov, E.; Åhlén, M.; Strømme, M.; Lindh, J. In situ thermal image analysis of selective laser sintering for oral dosage form manufacturing. J. Pharm. Biomed. Anal. 2023, 231, 115396. [Google Scholar] [CrossRef]
- Floryanzia, S.; Ramesh, P.; Mills, M.; Kulkarni, S.; Chen, G.; Shah, P.; Lavrich, D. Disintegration testing augmented by computer Vision technology. Int. J. Pharm. 2022, 619, 121668. [Google Scholar] [CrossRef]
- Das, H.P.; Tran, R.; Singh, J.; Yue, X.; Tison, G.; Sangiovanni-Vincentelli, A.; Spanos, C.J. Conditional synthetic data generation for robust machine learning applications with limited pandemic data. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; pp. 11792–11800. [Google Scholar]
- de Melo, C.M.; Torralba, A.; Guibas, L.; DiCarlo, J.; Chellappa, R.; Hodgins, J. Next-generation deep learning based on simulators and synthetic data. Trends Cogn. Sci. 2021, 26, 174–187. [Google Scholar] [CrossRef]
- Wang, Q.; Gao, J.; Lin, W.; Yuan, Y. Learning from synthetic data for crowd counting in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8198–8207. [Google Scholar]
- Tang, J.; Zhou, H.; Wang, T.; Jin, Z.; Wang, Y.; Wang, X. Cascaded foreign object detection in manufacturing processes using convolutional neural networks and synthetic data generation methodology. J. Intell. Manuf. 2023, 34, 2925–2941. [Google Scholar] [CrossRef]
- Condrea, F.; Ivan, V.-A.; Leordeanu, M. In search of life: Learning from synthetic data to detect vital signs in videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 298–299. [Google Scholar]
- Medicines and Healthcare products Regulatory Agency. New Synthetic Datasets to Assist COVID-19 and Cardiovascular Research. Available online: https://www.gov.uk/government/news/new-synthetic-datasets-to-assist-covid-19-and-cardiovascular-research (accessed on 17 September 2023).
- Gaul, N.J.; Leishman, R.C. Artificial Dataset Generation for Automated Aircraft Visual Inspection. In Proceedings of the NAECON 2021-IEEE National Aerospace and Electronics Conference, Dayton, OH, USA, 16–19 August 2021; pp. 302–306. [Google Scholar]
- Xu, X.; Goyanes, A.; Trenfield, S.J.; Diaz-Gomez, L.; Alvarez-Lorenzo, C.; Gaisford, S.; Basit, A.W. Stereolithography (SLA) 3D printing of a bladder device for intravesical drug delivery. Mater. Sci. Eng. C 2021, 120, 111773. [Google Scholar] [CrossRef]
- Mahajan, S.; Das, A.; Sardana, H.K. Image acquisition techniques for assessment of legume quality. Trends Food Sci. Technol. 2015, 42, 116–133. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Bradski, G.; Kaehler, A. Learning OpenCV: Computer Vision with the OpenCV Library; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2008. [Google Scholar]
- Vocaturo, E.; Zumpano, E.; Veltri, P. Image pre-processing in computer vision systems for melanoma detection. In Proceedings of the 2018 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Madrid, Spain, 3–6 December 2018; pp. 2117–2124. [Google Scholar]
- Alibrahim, H.; Ludwig, S.A. Hyperparameter optimization: Comparing genetic algorithm against grid search and bayesian optimization. In Proceedings of the 2021 IEEE Congress on Evolutionary Computation (CEC), Kraków, Poland, 28 June–1 July 2021; pp. 1551–1559. [Google Scholar]
- Wang, F.; Elbadawi, M.; Tsilova, S.L.; Gaisford, S.; Basit, A.W.; Parhizkar, M. Machine learning to empower electrohydrodynamic processing. Mater. Sci. Eng. C 2022, 132, 112553. [Google Scholar] [CrossRef]
- Bradley, A.P. The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recognit. 1997, 30, 1145–1159. [Google Scholar] [CrossRef]
- Chen, Q.; Zou, B.; Lai, Q.; Zhu, K. SLA-3d printing and compressive strength of PEGDA/nHAP biomaterials. Ceram. Int. 2022, 48, 30917–30926. [Google Scholar] [CrossRef]
- Al Hassanieh, S.; Alhantoobi, A.; Khan, K.A.; Khan, M.A. Mechanical properties and energy absorption characteristics of additively manufactured lightweight novel re-entrant plate-based lattice structures. Polymers 2021, 13, 3882. [Google Scholar] [CrossRef]
- Kennedy, B.M.; De Barra, E.; Hampshire, S.; Kelleher, M.C. Investigation of oleic acid as a dispersant for hydroxyapatite powders for use in ceramic filled photo-curable resins for stereolithography. J. Eur. Ceram. Soc. 2023, 43, 7146–7166. [Google Scholar] [CrossRef]
- Voet, V.S.; Strating, T.; Schnelting, G.H.; Dijkstra, P.; Tietema, M.; Xu, J.; Woortman, A.J.; Loos, K.; Jager, J.; Folkersma, R. Biobased acrylate photocurable resin formulation for stereolithography 3D printing. ACS Omega 2018, 3, 1403–1408. [Google Scholar] [CrossRef]
- Chouhan, G.; Bidare, P.; Doodi, R.; Murali, G.B. Identification of Surface Defects on an SLA-Printed Gyroid Lattice Structure. In Proceedings of the International Conference on Research into Design, Bangalore, India, 9–11 January 2023; pp. 697–707. [Google Scholar]
- Mennel, L.; Symonowicz, J.; Wachter, S.; Polyushkin, D.K.; Molina-Mendoza, A.J.; Mueller, T. Ultrafast machine vision with 2D material neural network image sensors. Nature 2020, 579, 62–66. [Google Scholar] [CrossRef]
- Galata, D.L.; Meszaros, L.A.; Kallai-Szabo, N.; Szabó, E.; Pataki, H.; Marosi, G.; Nagy, Z.K. Applications of machine vision in pharmaceutical technology: A review. Eur. J. Pharm. Sci. 2021, 159, 105717. [Google Scholar] [CrossRef]
- Mistry, P.; Neagu, D.; Trundle, P.R.; Vessey, J.D. Using random forest and decision tree models for a new vehicle prediction approach in computational toxicology. Soft Comput. 2016, 20, 2967–2979. [Google Scholar] [CrossRef]
- Talevi, A.; Morales, J.F.; Hather, G.; Podichetty, J.T.; Kim, S.; Bloomingdale, P.C.; Kim, S.; Burton, J.; Brown, J.D.; Winterstein, A.G.; et al. Machine Learning in Drug Discovery and Development Part 1: A Primer. CPT Pharmacomet. Syst. Pharmacol. 2020, 9, 129–142. [Google Scholar] [CrossRef]
- Boldini, D.; Grisoni, F.; Kuhn, D.; Friedrich, L.; Sieber, S.A. Practical guidelines for the use of gradient boosting for molecular property prediction. J. Cheminform. 2023, 15, 73. [Google Scholar] [CrossRef]
- Afifi, K.; Al-Sadek, A.F. Improving classical scoring functions using random forest: The non-additivity of free energy terms’ contributions in binding. Chem. Biol. Drug Des. 2018, 92, 1429–1434. [Google Scholar] [CrossRef]
- Mikołajczyk, A.; Grochowski, M. Data augmentation for improving deep learning in image classification problem. In Proceedings of the 2018 international interdisciplinary PhD workshop (IIPhDW), Świnouście, Poland, 9–12 May 2018; pp. 117–122. [Google Scholar]
- Banerjee, S.; Mohammed, A.; Wong, H.R.; Palaniyar, N.; Kamaleswaran, R. Machine learning identifies complicated sepsis course and subsequent mortality based on 20 genes in peripheral blood immune cells at 24 H post-ICU admission. Front. Immunol. 2021, 12, 592303. [Google Scholar] [CrossRef]
- Dinga, R.; Penninx, B.W.; Veltman, D.J.; Schmaal, L.; Marquand, A.F. Beyond accuracy: Measures for assessing machine learning models, pitfalls and guidelines. BioRxiv 2019, 743138. [Google Scholar] [CrossRef]
- Li, J.; Gu, J.; Huang, Z.; Wen, J. Application research of improved YOLO V3 algorithm in PCB electronic component detection. Appl. Sci. 2019, 9, 3750. [Google Scholar] [CrossRef]
- Židek, K.; Lazorík, P.; Piteľ, J.; Hošovský, A. An automated training of deep learning networks by 3D virtual models for object recognition. Symmetry 2019, 11, 496. [Google Scholar] [CrossRef]
- DeCost, B.L.; Holm, E.A. Characterizing powder materials using keypoint-based computer vision methods. Comput. Mater. Sci. 2017, 126, 438–445. [Google Scholar] [CrossRef]
- Li, L.; McGuan, R.; Isaac, R.; Kavehpour, P.; Candler, R. Improving precision of material extrusion 3D printing by in-situ monitoring & predicting 3D geometric deviation using conditional adversarial networks. Addit. Manuf. 2021, 38, 101695. [Google Scholar]
- Wang, K.; Gou, C.; Zheng, N.; Rehg, J.M.; Wang, F.-Y. Parallel vision for perception and understanding of complex scenes: Methods, framework, and perspectives. Artif. Intell. Rev. 2017, 48, 299–329. [Google Scholar] [CrossRef]
- İncetan, K.; Celik, I.O.; Obeid, A.; Gokceler, G.I.; Ozyoruk, K.B.; Almalioglu, Y.; Chen, R.J.; Mahmood, F.; Gilbert, H.; Durr, N.J. VR-Caps: A virtual environment for capsule endoscopy. Med. Image Anal. 2021, 70, 101990. [Google Scholar] [CrossRef] [PubMed]
- Abdullah, N.B.; Taylor, M.; Al-Dargazelli, A.; Montaner, M.B.; Kareem, F.; Locks, A.; Cao, Z.; Bowles, B.; Schafhauser, S.; Sarraf, J.-C. Breaking the Access to Education Barrier: Enhancing HPLC Learning with Virtual Reality Digital Twins. ChemRxiv 2023, preprint. [Google Scholar] [CrossRef]
- Bae, S.-Y.; Lee, J.; Jeong, J.; Lim, C.; Choi, J. Effective data-balancing methods for class-imbalanced genotoxicity datasets using machine learning algorithms and molecular fingerprints. Comput. Toxicol. 2021, 20, 100178. [Google Scholar] [CrossRef]
- Su, J.; Vargas, D.V.; Sakurai, K. One pixel attack for fooling deep neural networks. IEEE Trans. Evol. Comput. 2019, 23, 828–841. [Google Scholar] [CrossRef]
- Bommert, A.; Sun, X.; Bischl, B.; Rahnenführer, J.; Lang, M. Benchmark for filter methods for feature selection in high-dimensional classification data. Comput. Stat. Data Anal. 2020, 143, 106839. [Google Scholar] [CrossRef]
- Borboudakis, G.; Stergiannakos, T.; Frysali, M.; Klontzas, E.; Tsamardinos, I.; Froudakis, G.E. Chemically intuited, large-scale screening of MOFs by machine learning techniques. NPJ Comput. Mater. 2017, 3, 40. [Google Scholar] [CrossRef]
- Cutler, D.R.; Edwards Jr, T.C.; Beard, K.H.; Cutler, A.; Hess, K.T.; Gibson, J.; Lawler, J.J. Random forests for classification in ecology. Ecology 2007, 88, 2783–2792. [Google Scholar] [CrossRef]
- Elbadawi, M.; Castro, B.M.; Gavins, F.K.; Ong, J.J.; Gaisford, S.; Pérez, G.; Basit, A.W.; Cabalar, P.; Goyanes, A. M3DISEEN: A novel machine learning approach for predicting the 3D printability of medicines. Int. J. Pharm. 2020, 590, 119837. [Google Scholar] [CrossRef]
- Jakubowska, E.; Ciepluch, N. Blend segregation in tablets manufacturing and its effect on drug content uniformity—A review. Pharmaceutics 2021, 13, 1909. [Google Scholar] [CrossRef]







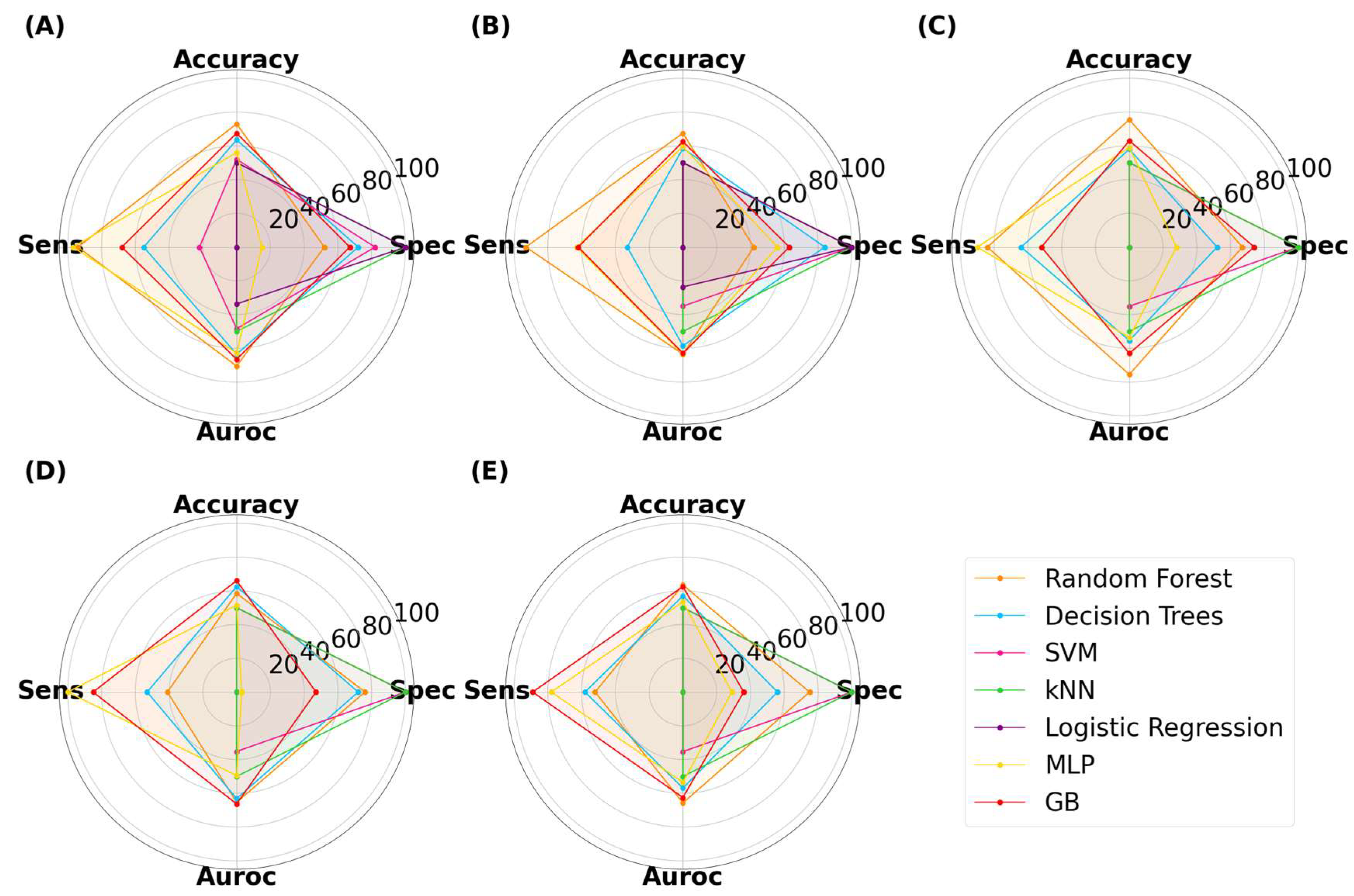




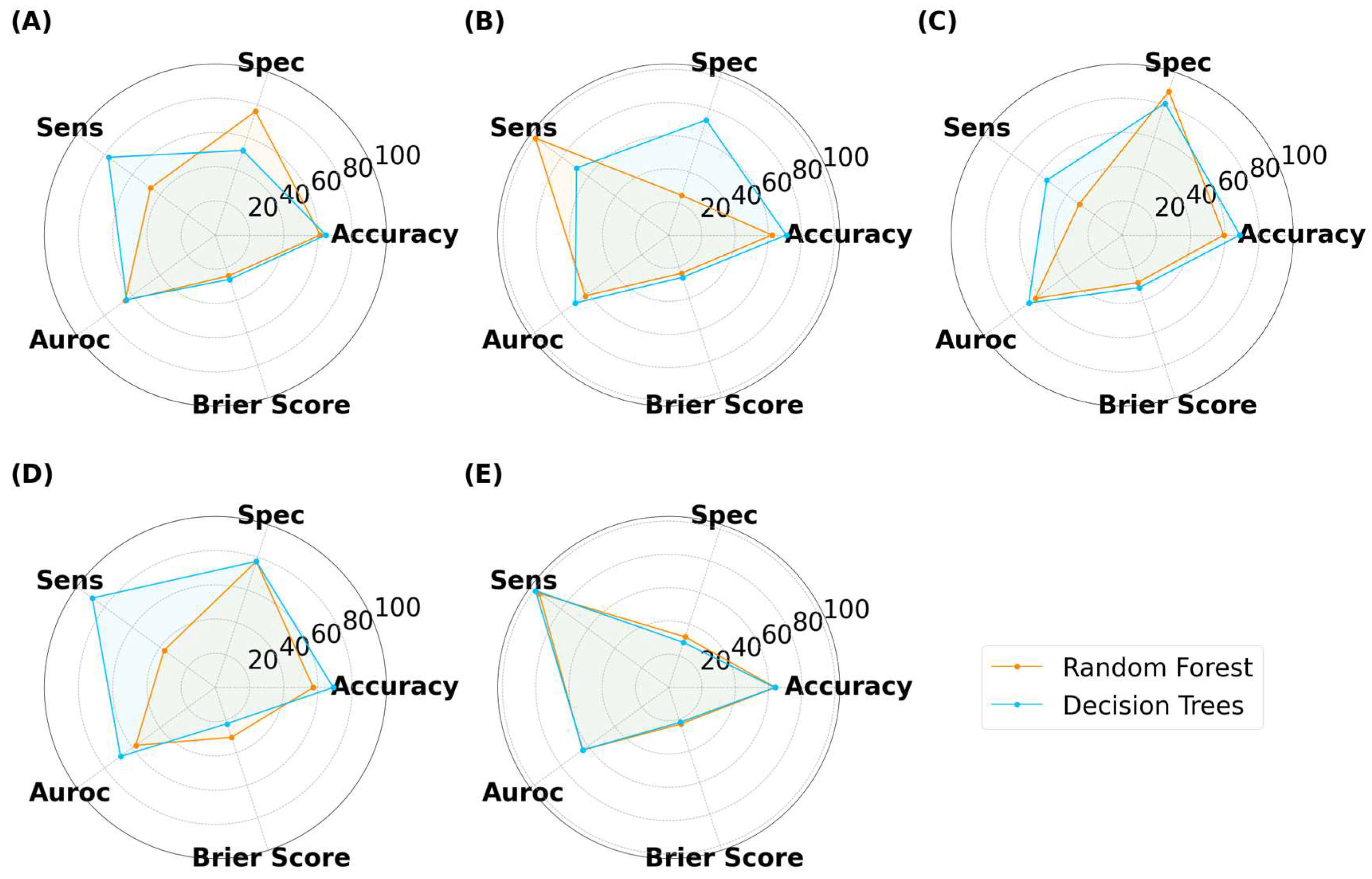
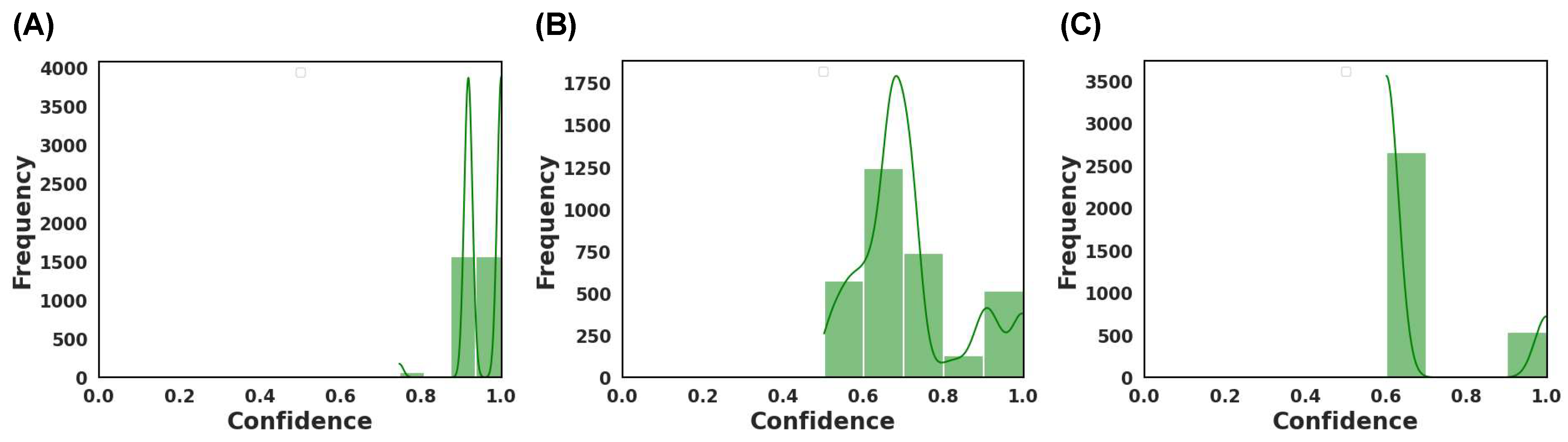


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, S.; Alkahtani, M.E.; Gaisford, S.; Basit, A.W.; Elbadawi, M.; Orlu, M. Virtually Possible: Enhancing Quality Control of 3D-Printed Medicines with Machine Vision Trained on Photorealistic Images. Pharmaceutics 2023, 15, 2630. https://doi.org/10.3390/pharmaceutics15112630
Sun S, Alkahtani ME, Gaisford S, Basit AW, Elbadawi M, Orlu M. Virtually Possible: Enhancing Quality Control of 3D-Printed Medicines with Machine Vision Trained on Photorealistic Images. Pharmaceutics. 2023; 15(11):2630. https://doi.org/10.3390/pharmaceutics15112630
Chicago/Turabian StyleSun, Siyuan, Manal E. Alkahtani, Simon Gaisford, Abdul W. Basit, Moe Elbadawi, and Mine Orlu. 2023. "Virtually Possible: Enhancing Quality Control of 3D-Printed Medicines with Machine Vision Trained on Photorealistic Images" Pharmaceutics 15, no. 11: 2630. https://doi.org/10.3390/pharmaceutics15112630
APA StyleSun, S., Alkahtani, M. E., Gaisford, S., Basit, A. W., Elbadawi, M., & Orlu, M. (2023). Virtually Possible: Enhancing Quality Control of 3D-Printed Medicines with Machine Vision Trained on Photorealistic Images. Pharmaceutics, 15(11), 2630. https://doi.org/10.3390/pharmaceutics15112630