Mapping of Shorea robusta Forest Using Time Series MODIS Data

 , , and
, , and 
Abstract
1. Introduction
2. Materials and Methods
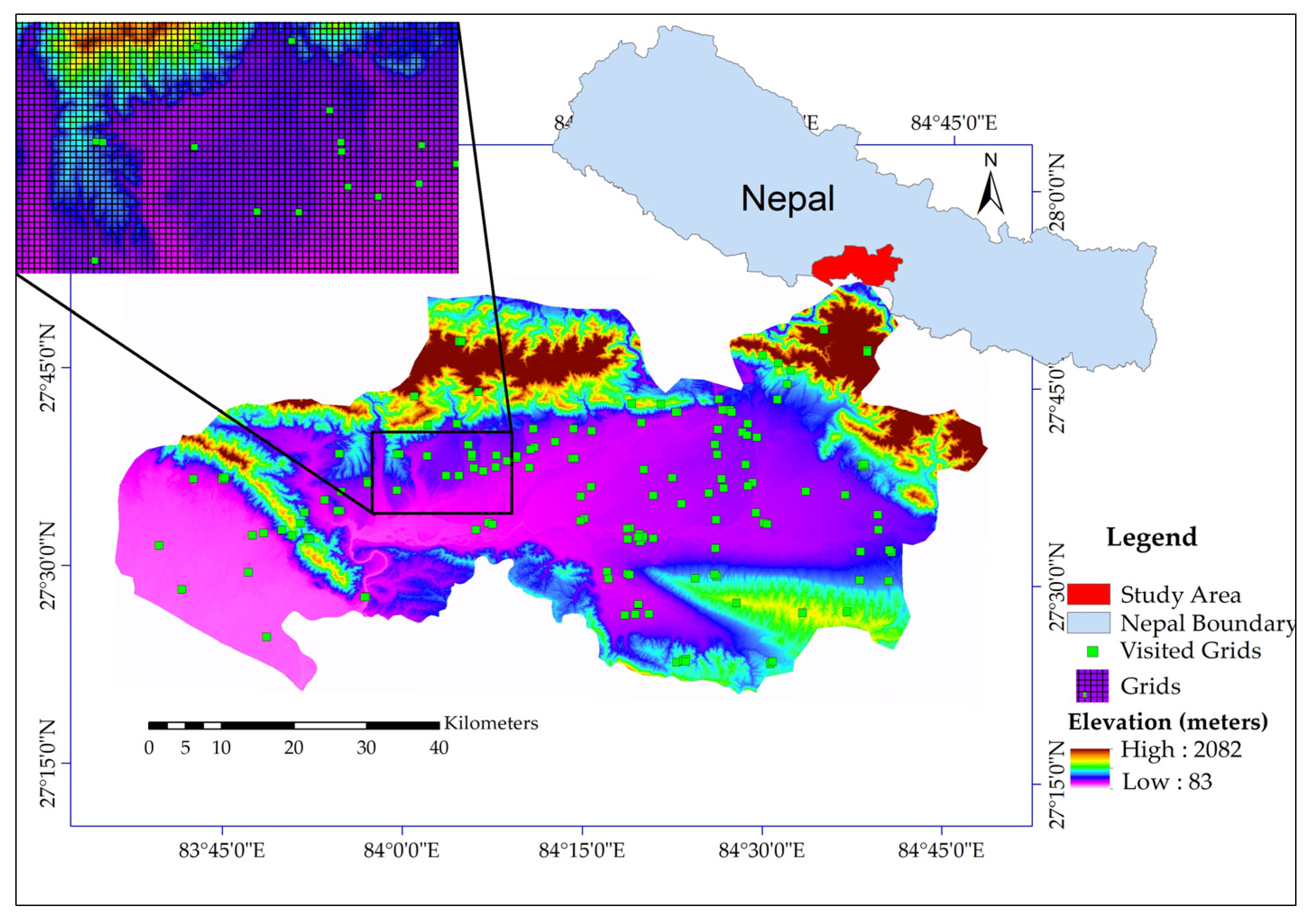
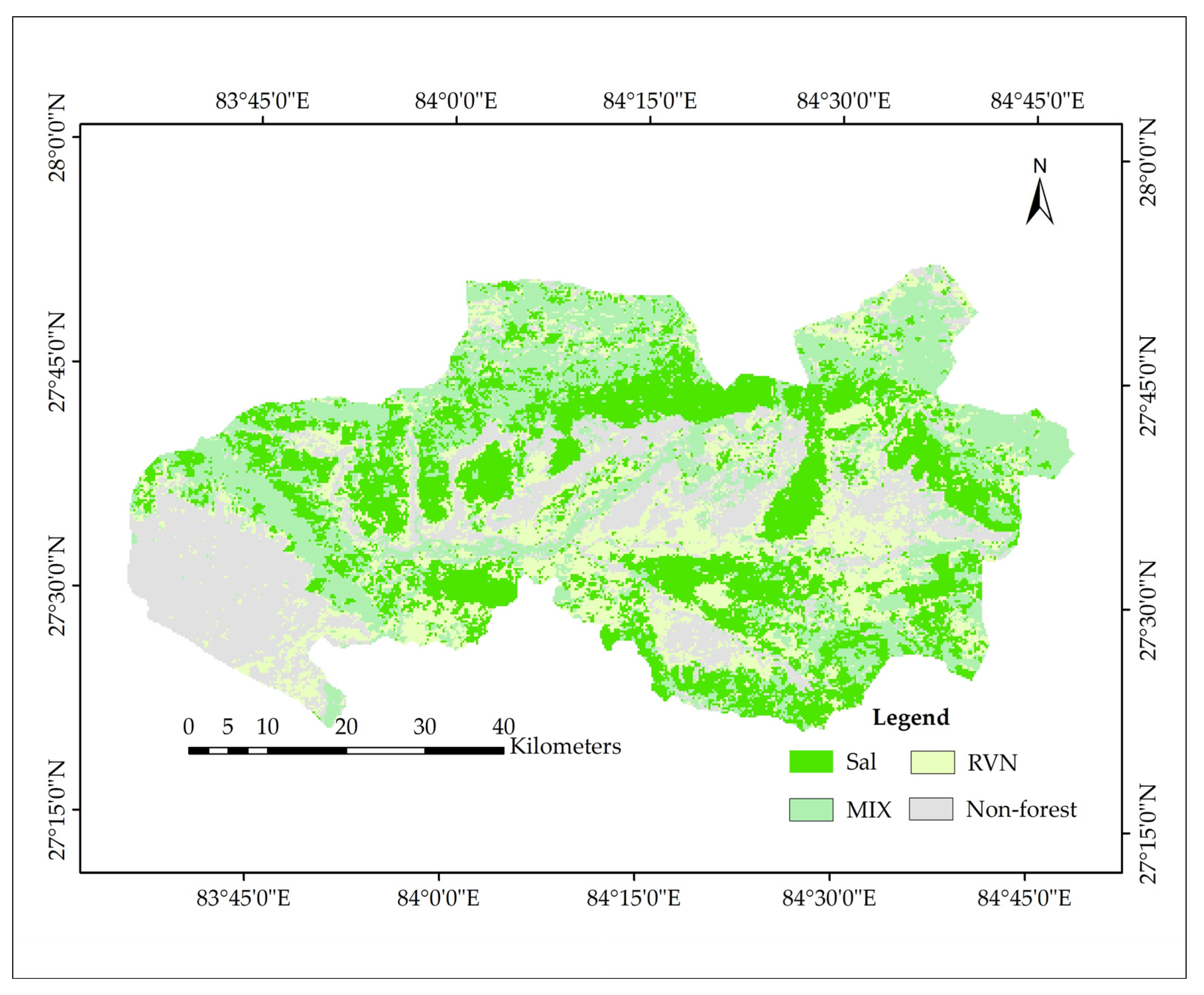
2.1. Study Area
2.2. Data
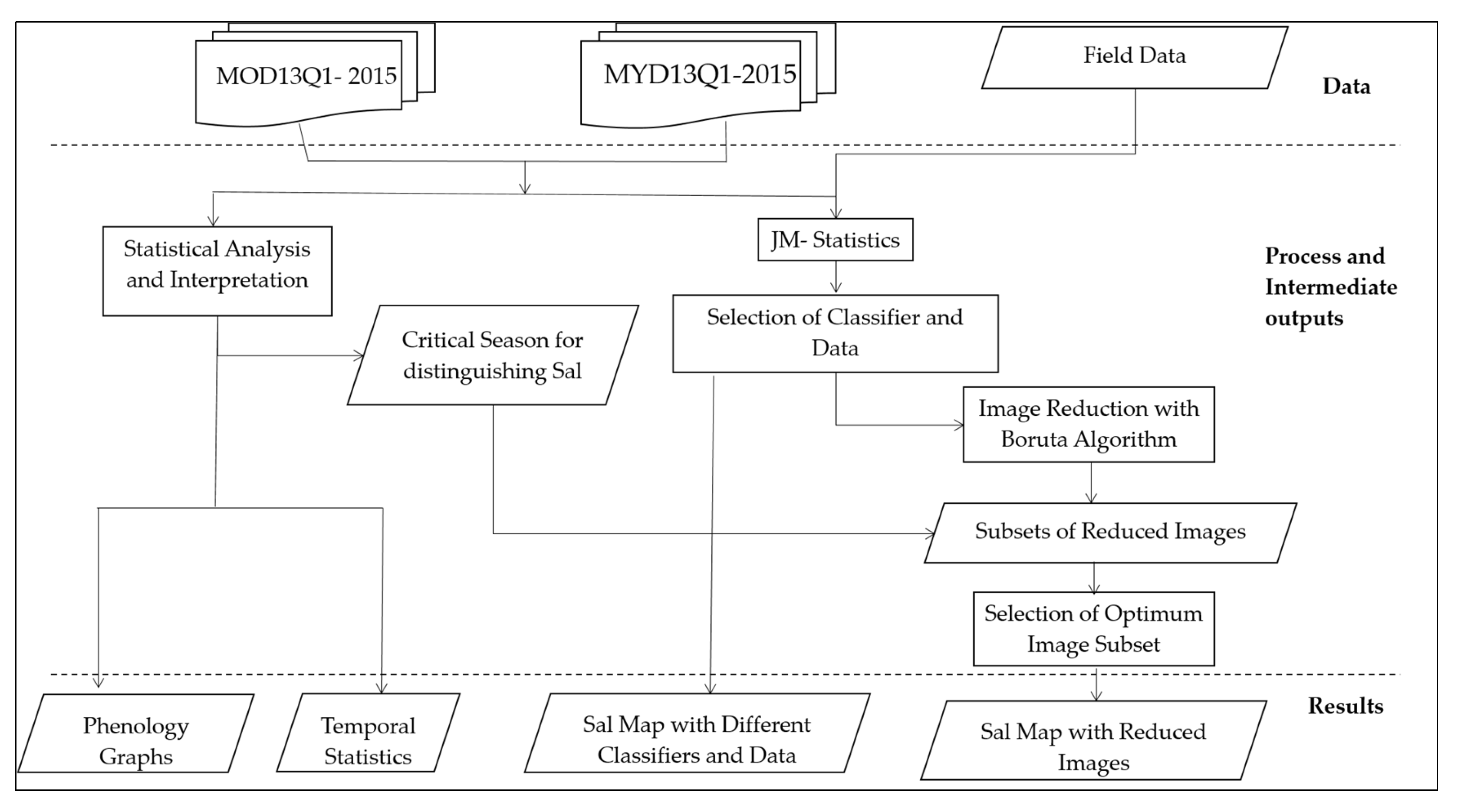
2.3. Overall Methodology
2.3.1. Graphical and Statistical Time Series Analysis
2.3.2. Region Of Interest (ROI) Separability
2.3.3. Classification Algorithms
2.3.4. Accuracy Assessment
2.3.5. Image Reduction
3. Results
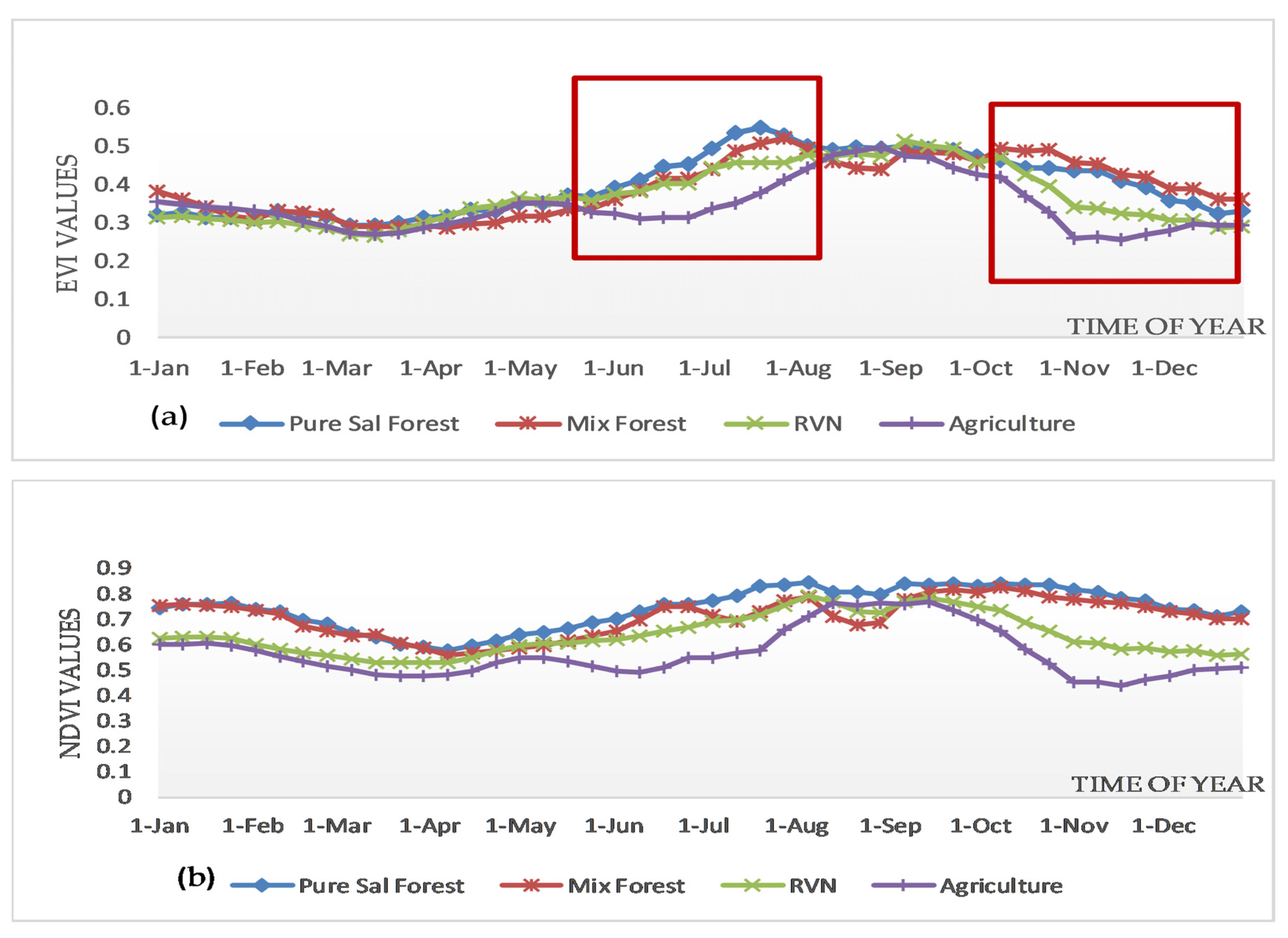
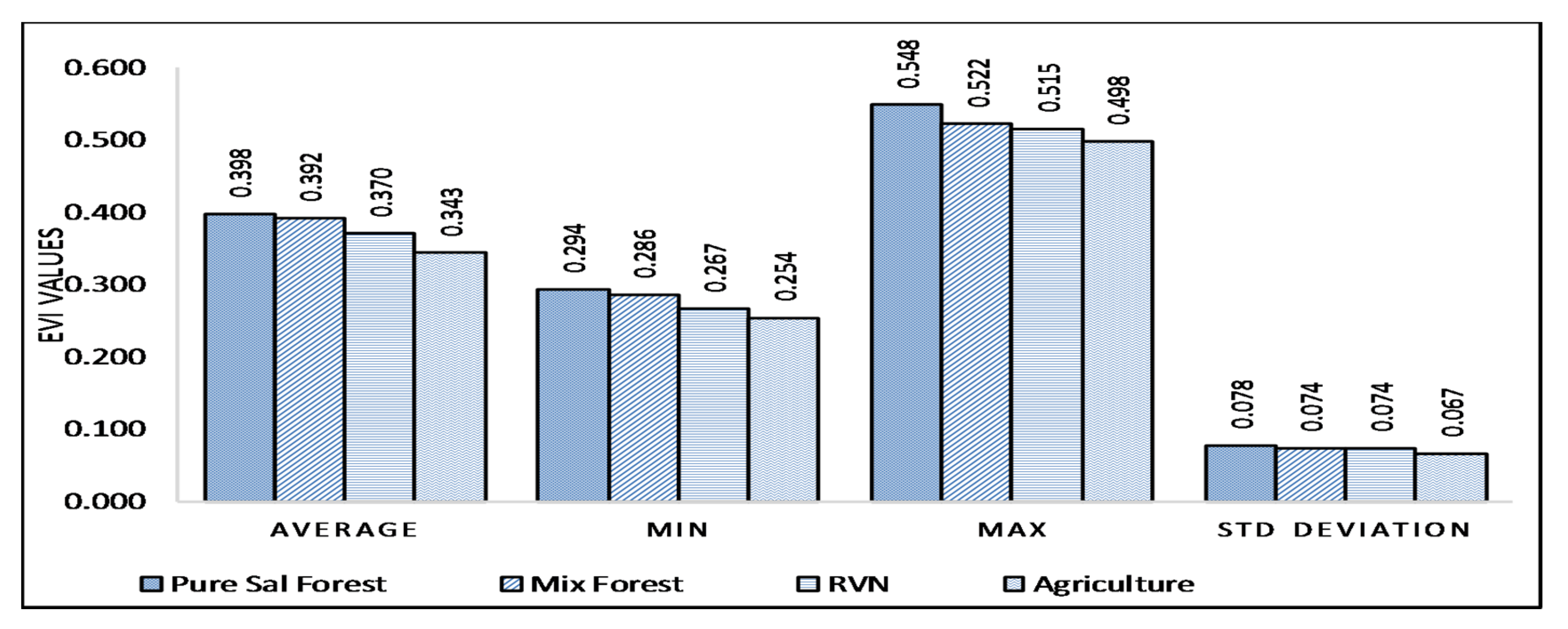
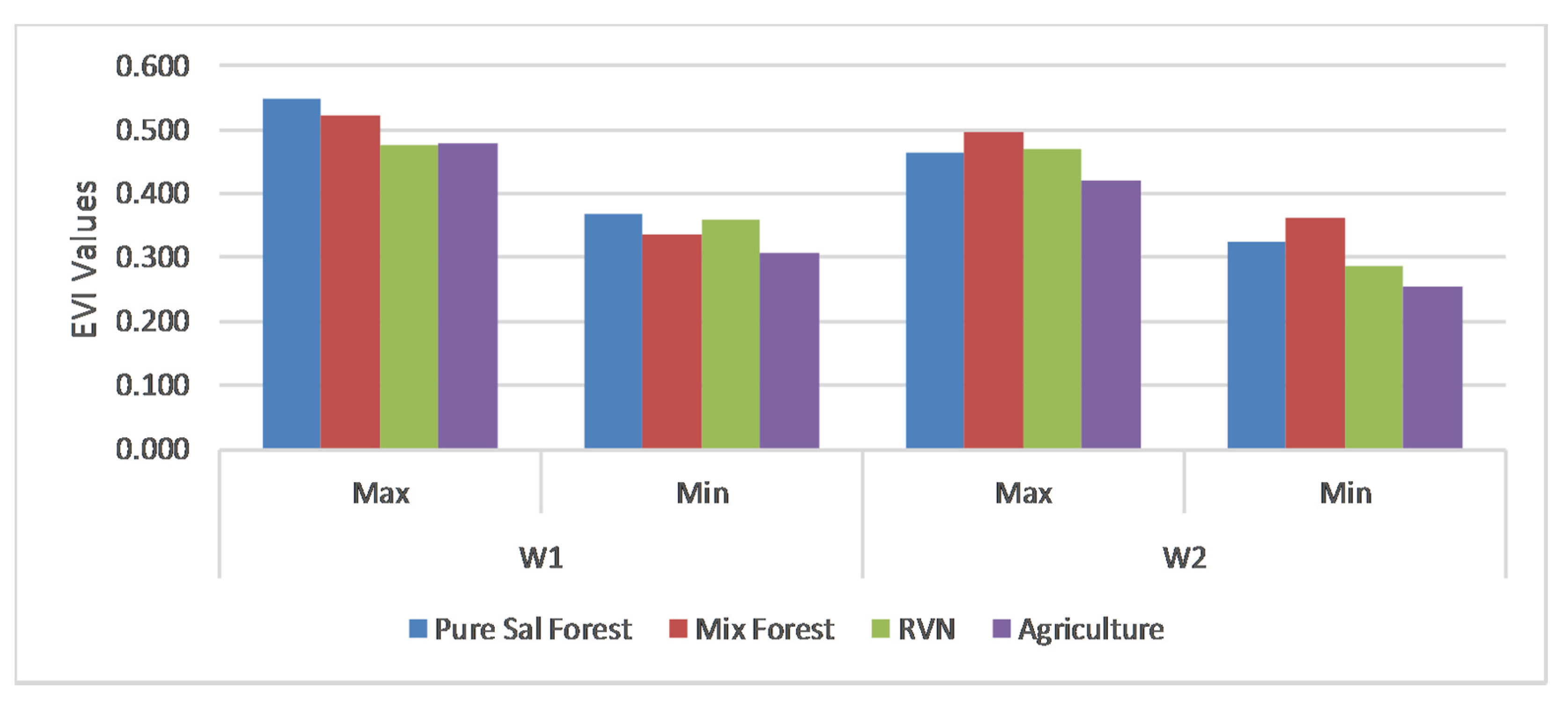
3.1. Time Series Statistics of VIs
3.2. Separability Indices
3.3. Selection of Data and Classifier
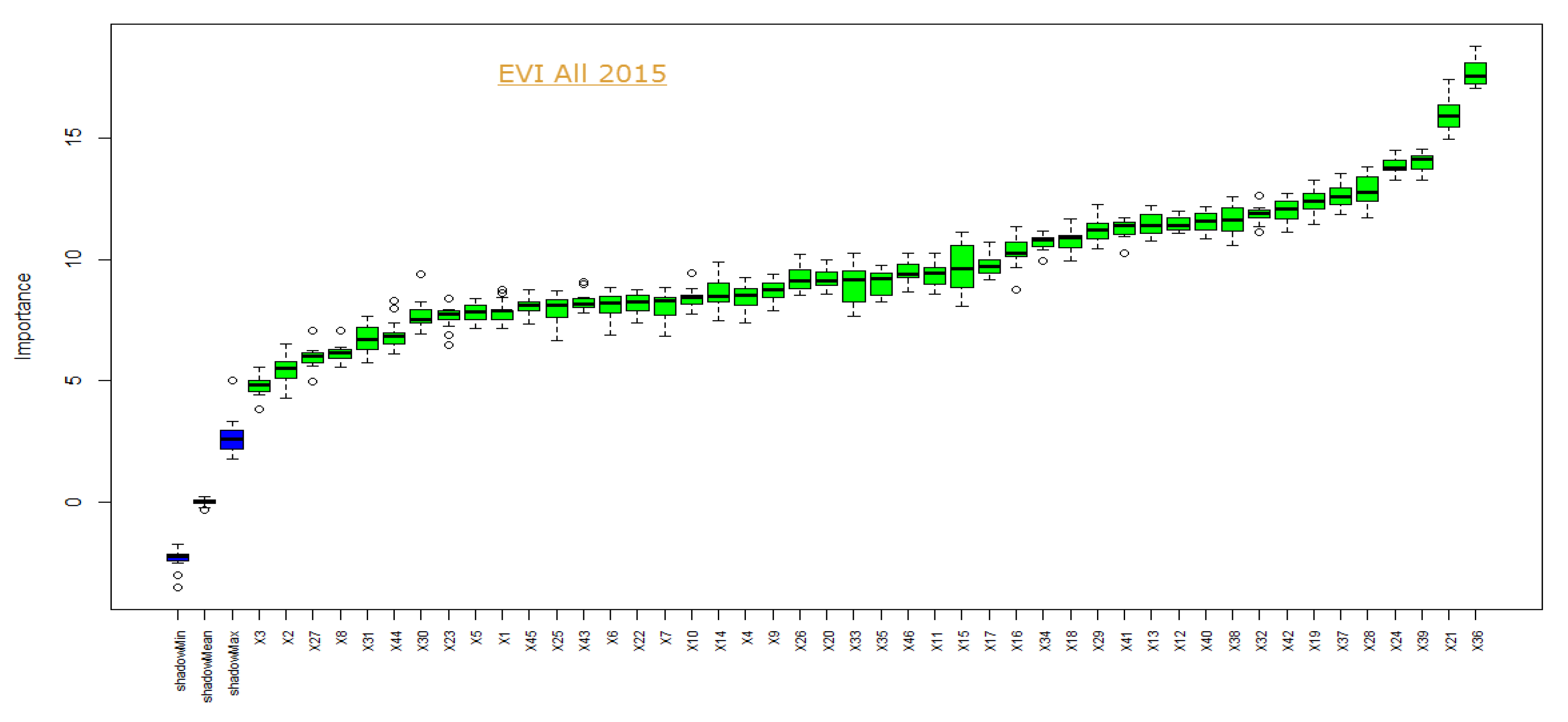
3.4. Reduced Feature Sets
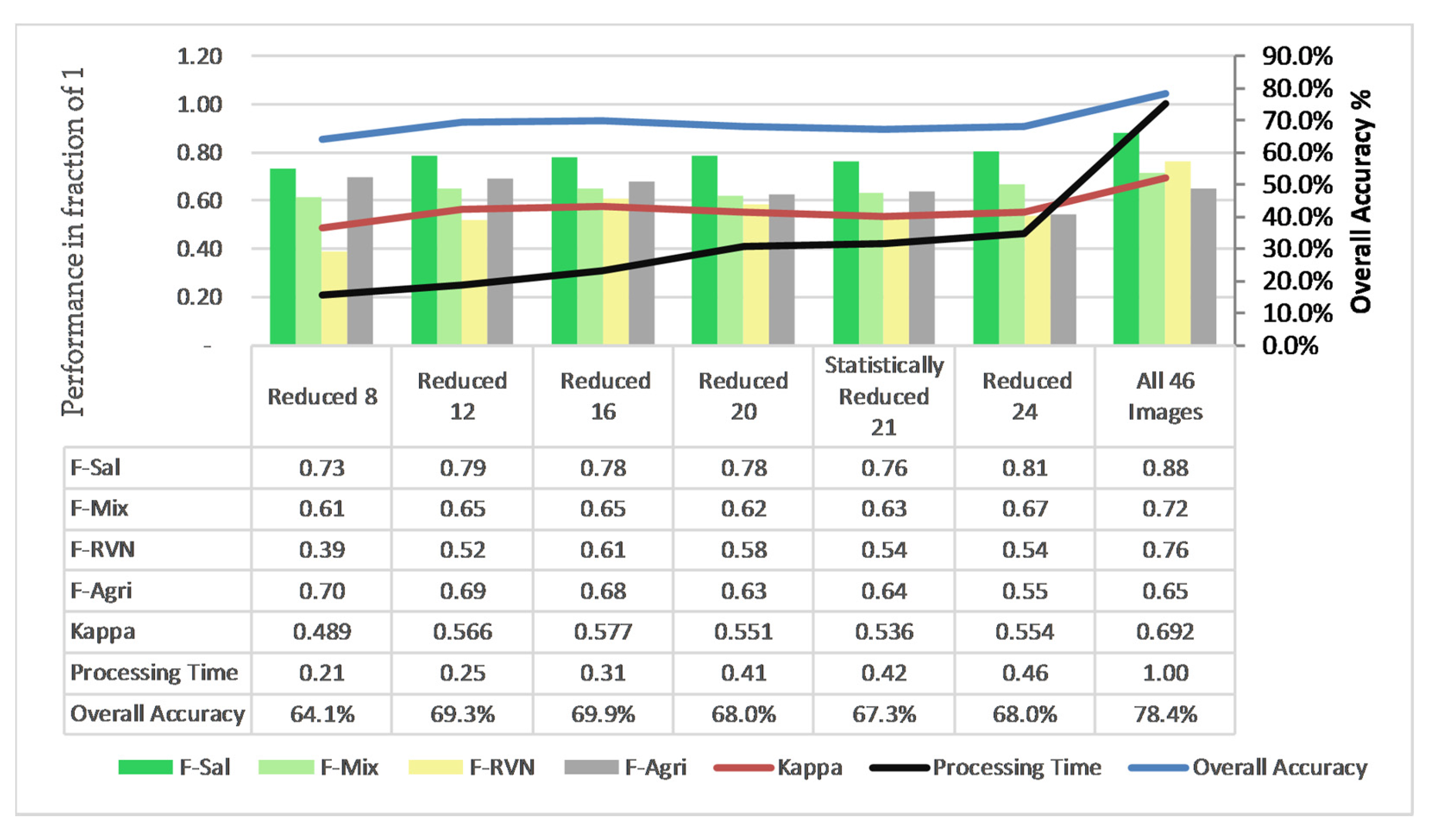
3.5. Comparison for Reduced Images
4. Discussion
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Ministry of Forests and Soil Conservation. State of Nepal’S Forests; Nepal Government: Kathmandu, Nepal, 2015.
- Ministry of Forests and Soil Conservation (MOFSC). Nepal Forestry Outlook Study; Ministry of Forests and Soil Conservation: Kathmandu, Nepal, 2009; p. 83.
- Ulvdal, P. Stand Dynamics and Carbon Stock in a Sal Dominated Forest in Southern Nepal. Master's Thesis, Swedish University of Agricultural Sciences, Alnarp, Switzerland, 2016. [Google Scholar]
- Mbaabu, P.R.; Hussin, Y.A.; Weir, M.; Gilani, H. Quantification of carbon stock to understand two different forest management regimes in Kayar Khola watershed, Chitwan, Nepal. J. Indian Soc. Remote Sens. 2014, 42, 745–754. [Google Scholar] [CrossRef]
- Gilani, H.; Krishna, S.; Murthy, M.S.R.; Koju, U.A.; Uddin, K.; Karky, B. Monitoring the performance of community forestry to achieve redd + goals through geospatial methods. Int. Arch. Photogr. Remote Sens. Spat. Inf. Sci. 2014, 40, 9–12. [Google Scholar] [CrossRef]
- Vedaraman, N.; Puhan, S.; Nagarajan, G.; Ramabrahmam, B.V.; Velappan, K.C. Methyl ester of Sal oil (Shorea robusta) as a substitute to diesel fuel-A study on its preparation, performance and emissions in direct injection diesel engine. Ind. Crops Prod. 2012, 36, 282–288. [Google Scholar] [CrossRef]
- Khan, M.Y.; Ali, S.A.; Pundarikakshudu, K. Wound healing activity of extracts derived from Shorea robusta resin. Pharm. Biol. 2016, 54, 542–548. [Google Scholar] [CrossRef] [PubMed]
- Islam, M.A.; Quli, S.M.S.; Rai, R.; Singh, P.K. Livelihood promotion through value addition to household traditional sal (Shorea robusta Gaertn.) leaf plate making in Jharkhand, India. Indian J. Nat. Prod. Resour. 2015, 6, 320–325. [Google Scholar]
- Koirala, R.K.; Raubenheimer, D.; Aryal, A.; Pathak, M.L.; Ji, W. Feeding preferences of the Asian elephant (Elephas maximus) in Nepal. BMC Ecol. 2016, 16, 54. [Google Scholar] [CrossRef] [PubMed]
- Singh, G.; Velmurugan, A.; Dakhate, M.P. Geospatial approach for tiger habitat evaluation and distribution in Corbett Tiger reserve, India. J. Indian Soc. Remote Sens. 2009, 37, 573–585. [Google Scholar] [CrossRef]
- Sasaki, N.; Asner, G.P.; Pan, Y.; Knorr, W.; Durst, P.B.; Ma, H.O.; Abe, I.; Lowe, A.J.; Koh, L.P.; Putz, F.E. Sustainable Management of Tropical Forests Can Reduce Carbon Emissions and Stabilize Timber Production. Front. Environ. Sci. 2016, 4. [Google Scholar] [CrossRef]
- Dian, Y.; Pang, Y.; Dong, Y.; Li, Z. Urban Tree Species Mapping Using Airborne LiDAR and Hyperspectral Data. J. Indian Soc. Remote Sens. 2016, 44, 595–603. [Google Scholar] [CrossRef]
- Alonzo, M.; Bookhagen, B.; Roberts, D.A. Urban tree species mapping using hyperspectral and lidar data fusion. Remote Sens. Environ. 2014, 148, 70–83. [Google Scholar] [CrossRef]
- Zhang, C.; Qiu, F. Mapping individual tree species in an urban forest using airborne lidar data and hyperspectral imagery. Photogramm. Eng. Remote Sens. 2012, 78, 1079–1087. [Google Scholar] [CrossRef]
- Lin, Y.; Herold, M. Tree species classification based on explicit tree structure feature parameters derived from static terrestrial laser scanning data. Agric. For. Meteorol. 2016, 216, 105–114. [Google Scholar] [CrossRef]
- Engler, R.; Waser, L.T.; Zimmermann, N.E.; Schaub, M.; Berdos, S.; Ginzler, C.; Psomas, A. Combining ensemble modeling and remote sensing for mapping individual tree species at high spatial resolution. For. Ecol. Manag. 2013, 310, 64–73. [Google Scholar] [CrossRef]
- Leckie, D.G.; Gougeon, F.; McQueen, R.; Oddleifson, K.; Hughes, N.; Walsworth, N.; Gray, S. Production of a Large-Area Individual Tree Species Map for Forest Inventory in a Complex Forest Setting and Lessons Learned. Can. J. Remote Sens. 2017, 43, 140–167. [Google Scholar] [CrossRef]
- Thompson, S.D.; Nelson, T.A.; White, J.C.; Wulder, M.A. Mapping Dominant Tree Species over Large Forested Areas Using Landsat Best-Available-Pixel Image Composites. Can. J. Remote Sens. 2015, 41, 203–218. [Google Scholar] [CrossRef]
- Fan, H.; Fu, X.; Zhang, Z.; Wu, Q. Phenology-based vegetation index differencing for mapping of rubber plantations using landsat OLI data. Remote Sens. 2015, 7, 6041–6058. [Google Scholar] [CrossRef]
- Bajpai, O.; Kumar, A.; Mishra, A.K.; Sahu, N.; Behera, S.K.; Chaudhary, B.L. Phenological Study of Two Dominant Tree Species in Troppical Moist Deciduous Forest from the Northern India. Int. J. Bot. 2012, 8, 66–72. [Google Scholar]
- Yan, E.; Wang, G.; Lin, H.; Xia, C.; Sun, H. Phenology-based classification of vegetation cover types in Northeast China using MODIS NDVI and EVI time series. Int. J. Remote Sens. 2015, 36, 489–512. [Google Scholar] [CrossRef]
- Zeng, L.; Wardlow, B.D.; Wang, R.; Shan, J.; Tadesse, T.; Hayes, M.J.; Li, D. A hybrid approach for detecting corn and soybean phenology with time-series MODIS data. Remote Sens. Environ. 2016, 181, 237–250. [Google Scholar] [CrossRef]
- Grzegozewski, D.M.; Johann, J.A.; Uribe-opazo, M.A.; Mercante, E.; Coutinho, A.C. Mapping soya bean and corn crops in the State of Paraná, Brazil, using EVI images from the MODIS sensor. Int. J. Remote Sens. 2016, 37, 1257–1275. [Google Scholar] [CrossRef]
- Sun, H.; Xu, A.; Lin, H.; Zhang, L.; Mei, Y. Winter wheat mapping using temporal signatures of MODIS vegetation index data. Int. J. Remote Sens. 2012, 33, 5026–5042. [Google Scholar] [CrossRef]
- Wardlow, B.D.; Egbert, S.L.; Kastens, J.H. Analysis of time-series MODIS 250 m vegetation index data for crop classification in the U.S. Central Great Plains. Remote Sens. Environ. 2007, 108, 290–310. [Google Scholar] [CrossRef]
- Xue, Z.; Du, P.; Member, S.; Feng, L. Phenology-Driven Land Cover Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 1142–1156. [Google Scholar] [CrossRef]
- Pandey, S.S.; Maraseni, T.N.; Cockfield, G. Carbon stock dynamics in different vegetation dominated community forests under REDD+: A case from Nepal. For. Ecol. Manag. 2014, 327, 40–47. [Google Scholar] [CrossRef]
- Patel, N.; Majumdar, A. Biomass estimation of Shorea robusta with principal component analysis of satellite data. J. For. Res. 2010, 21, 469–474. [Google Scholar] [CrossRef]
- Chitale, V.S.; Behera, M.D.; Matin, S.; Roy, P.S.; Sinha, V.K. Characterizing Shorea robusta communities in the part of Indian Terai landscape. J. For. Res. 2014, 25, 121–128. [Google Scholar] [CrossRef]
- Fassnacht, F.E.; Latifi, H.; Stereńczak, K.; Modzelewska, A.; Lefsky, M.; Waser, L.T.; Straub, C.; Ghosh, A. Review of studies on tree species classification from remotely sensed data. Remote Sens. Environ. 2016, 186, 64–87. [Google Scholar] [CrossRef]
- Adelabu, S.; Mutanga, O.; Adam, E.; Cho, M.A. Exploiting machine learning algorithms for tree species classification in a semiarid woodland using RapidEye image. J. Appl. Remote Sens. 2013, 7, 073480. [Google Scholar] [CrossRef]
- Shang, X.; Chisholm, L.A. Classification of Australian native forest species using hyperspectral remote sensing and machine-learning classification algorithms. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2481–2489. [Google Scholar] [CrossRef]
- Li, X.; Chen, W.; Cheng, X.; Liao, Y.; Chen, G. Comparison and integration of feature reduction methods for land cover classification with RapidEye imagery. Multimed. Tools Appl. 2017, 1–17. [Google Scholar] [CrossRef]
- Panta, M.; Kim, K.; Joshi, C. Temporal mapping of deforestation and forest degradation in Nepal: Applications to forest conservation. For. Ecol. Manag. 2009, 256, 1587–1595. [Google Scholar] [CrossRef]
- Liu, Y.; Wu, C.; Peng, D.; Xu, S.; Gonsamo, A.; Jassal, R.S.; Arain, M.A.; Lu, L.; Fang, B.; Chen, J.M. Improved modeling of land surface phenology using MODIS land surface reflectance and temperature at evergreen needleleaf forests of central North America. Remote Sens. Environ. 2016, 176, 152–162. [Google Scholar] [CrossRef]
- Simin, C.; Rongqun, Z.; Wenling, C.; Hui, Y. Band selection of hyperspectral images based on Bhattacharyya distance. WSEAS Trans. Inf. Sci. Appl. 2009, 6, 1165–1175. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Multi-label, G.; Karalas, K.; Tsagkatakis, G.; Zervakis, M.; Tsakalides, P. Land Classification Using Remotely Sensed Data: Going Multilabel. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3548–3563. [Google Scholar]
- Kursa, M.B.; Rudnicki, W.R. Feature Selection with the Boruta Package. J. Stat. Softw. 2010, 36, 1–13. [Google Scholar] [CrossRef]
- Räsänen, A.; Kuitunen, M.; Tomppo, E.; Lensu, A. Coupling high-resolution satellite imagery with ALS-based canopy height model and digital elevation model in object-based boreal forest habitat type classification. ISPRS J. Photogramm. Remote Sens. 2014, 94, 169–182. [Google Scholar] [CrossRef]
- Burai, P.; Deák, B.; Valkó, O.; Tomor, T. Classification of herbaceous vegetation using airborne hyperspectral imagery. Remote Sens. 2015, 7, 2046–2066. [Google Scholar] [CrossRef]
- Ferreira, M.P.; Zortea, M.; Zanotta, D.C.; Shimabukuro, Y.E.; de Souza Filho, C.R. Mapping tree species in tropical seasonal semi-deciduous forests with hyperspectral and multispectral data. Remote Sens. Environ. 2016, 179, 66–78. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Statistical Features | Sum | Mean | Variance | Slope | ||||
|---|---|---|---|---|---|---|---|---|
| Type | W1 | W2 | W1 | W2 | W1 | W2 | W1 | W2 |
| Pure Sal Forest | 5.167 | 4.046 | 0.470 | 0.405 | 0.004 | 0.002 | 0.015 | −0.015 |
| Mix Forest | 4.821 | 4.359 | 0.438 | 0.436 | 0.004 | 0.002 | 0.017 | −0.015 |
| RVN | 4.674 | 3.513 | 0.425 | 0.351 | 0.002 | 0.003 | 0.012 | −0.018 |
| Agriculture | 3.984 | 3.023 | 0.362 | 0.302 | 0.003 | 0.003 | 0.016 | −0.011 |
| Pair Wise ROI Separability | Jeffries-Matusita Value | |
|---|---|---|
| EVI | NDVI | |
| Mix Forest with Sal Forest | 1.95 | 1.82 |
| RVN with Agriculture | 1.95 | 1.96 |
| Mix Forest with RVN | 1.96 | 1.89 |
| Sal Forest with RVN | 1.99 | 1.8 |
| Mix Forest with Agriculture | 2 | 1.99 |
| Sal Forest with Agriculture | 2 | 2 |
| (a) RF NDVI | ||||||||
| Classes | Observed | UA (%) | ||||||
| Sal | MIX | RVN | Agri | Total | ||||
| Classified | Sal | 41 | 7 | 1 | 0 | 49 | 83.7 | |
| MIX | 10 | 29 | 0 | 4 | 43 | 67.4 | ||
| RVN | 11 | 7 | 18 | 10 | 46 | 39.1 | ||
| Agri | 0 | 0 | 3 | 12 | 15 | 80 | ||
| Total | 62 | 43 | 22 | 26 | 153 | |||
| PA (%) | 66.1 | 67.4 | 81.8 | 46.2 | OA | 65.4 | ||
| F Score | 0.74 | 0.67 | 0.53 | 0.59 | K | 0.53 | ||
| (b) SVM NDVI | ||||||||
| Classes | Observed | UA (%) | ||||||
| Sal | MIX | RVN | Agri | Total | ||||
| Classified | Sal | 45 | 9 | 1 | 0 | 55 | 81.8 | |
| MIX | 8 | 29 | 0 | 4 | 40 | 72.5 | ||
| RVN | 9 | 3 | 18 | 10 | 40 | 45 | ||
| Agri | 0 | 2 | 3 | 13 | 18 | 72.2 | ||
| Total | 62 | 43 | 22 | 26 | 153 | |||
| PA (%) | 72.6 | 67.4 | 81.8 | 50 | OA | 68.6 | ||
| F Score | 0.77 | 0.7 | 0.58 | 0.59 | K | 0.57 | ||
| (c) RF EVI | ||||||||
| Classes | Observed | UA (%) | ||||||
| Sal | MIX | RVN | Agri | Total | ||||
| Classified | Sal | 51 | 10 | 1 | 0 | 62 | 82.3 | |
| MIX | 5 | 25 | 0 | 5 | 35 | 71.4 | ||
| RVN | 6 | 5 | 18 | 7 | 36 | 50 | ||
| Agri | 0 | 3 | 3 | 14 | 20 | 70 | ||
| Total | 62 | 43 | 22 | 26 | 153 | |||
| PA (%) | 82.3 | 58.1 | 81.8 | 53.8 | OA | 70.6 | ||
| F Score | 0.82 | 0.64 | 0.62 | 0.61 | K | 0.59 | ||
| (d) SVM EVI | ||||||||
| Classes | Observed | UA (%) | ||||||
| Sal | MIX | RVN | Agri | Total | ||||
| Classified | Sal | 58 | 10 | 2 | 0 | 70 | 82.9 | |
| MIX | 3 | 29 | 0 | 6 | 38 | 76.3 | ||
| RVN | 1 | 2 | 19 | 6 | 28 | 67.9 | ||
| Agri | 0 | 2 | 1 | 14 | 17 | 82.4 | ||
| Total | 62 | 43 | 22 | 26 | 153 | |||
| PA (%) | 93.5 | 67.4 | 86.4 | 53.8 | OA | 78.4 | ||
| F Score | 0.88 | 0.72 | 0.76 | 0.65 | K | 0.69 | ||
| (e) Comparison of forest types coverage area under different algorithm and datasets | ||||||||
| Area | Area in % | Area in Sq Km | ||||||
| Method and Data | Sal | MIX | RVN | Non-Forest | Sal | MIX | RVN | Non-Forest |
| RF NDVI | 23% | 29% | 27% | 21% | 1006 | 1239 | 1157 | 888 |
| SVM NDVI | 24% | 31% | 27% | 19% | 1010 | 1320 | 1152 | 808 |
| RF EVI | 30% | 24% | 25% | 21% | 1277 | 1050 | 1070 | 892 |
| SVM EVI | 36% | 29% | 17% | 18% | 1526 | 1246 | 729 | 789 |
| Subset of 24 images—EVI (Boruta) | X36 | X21 | X39 | X24 | X28 | X37 | X19 | X42 | X32 | X38 | X40 | X12 |
| X13 | X41 | X29 | X18 | X34 | X16 | X17 | X15 | X11 | X46 | X35 | X33 | |
| Subset of 21 images—EVI (Statistical) | X19 | X20 | X21 | X22 | X23 | X24 | X25 | X26 | X27 | X28 | X29 | X36 |
| X37 | X38 | X39 | X40 | X41 | X42 | X43 | X44 | X45 | ||||
| Subset of 24 images—NDVI (Boruta) | X24 | X29 | X19 | X36 | X37 | X42 | X1 | X41 | X39 | X28 | X38 | X30 |
| X35 | X16 | X15 | X22 | X44 | X25 | X7 | X21 | X9 | X34 | X13 | X18 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ghimire, B.R.; Nagai, M.; Tripathi, N.K.; Witayangkurn, A.; Mishara, B.; Sasaki, N. Mapping of Shorea robusta Forest Using Time Series MODIS Data. Forests 2017, 8, 384. https://doi.org/10.3390/f8100384
Ghimire BR, Nagai M, Tripathi NK, Witayangkurn A, Mishara B, Sasaki N. Mapping of Shorea robusta Forest Using Time Series MODIS Data. Forests. 2017; 8(10):384. https://doi.org/10.3390/f8100384
Chicago/Turabian StyleGhimire, Bhoj Raj, Masahiko Nagai, Nitin Kumar Tripathi, Apichon Witayangkurn, Bhogendra Mishara, and Nophea Sasaki. 2017. "Mapping of Shorea robusta Forest Using Time Series MODIS Data" Forests 8, no. 10: 384. https://doi.org/10.3390/f8100384
APA StyleGhimire, B. R., Nagai, M., Tripathi, N. K., Witayangkurn, A., Mishara, B., & Sasaki, N. (2017). Mapping of Shorea robusta Forest Using Time Series MODIS Data. Forests, 8(10), 384. https://doi.org/10.3390/f8100384