
Stem Volume Prediction of Chamaecyparis obtusa in South Korea Using Machine Learning and Field-Measured Tree Variables


Abstract
1. Introduction
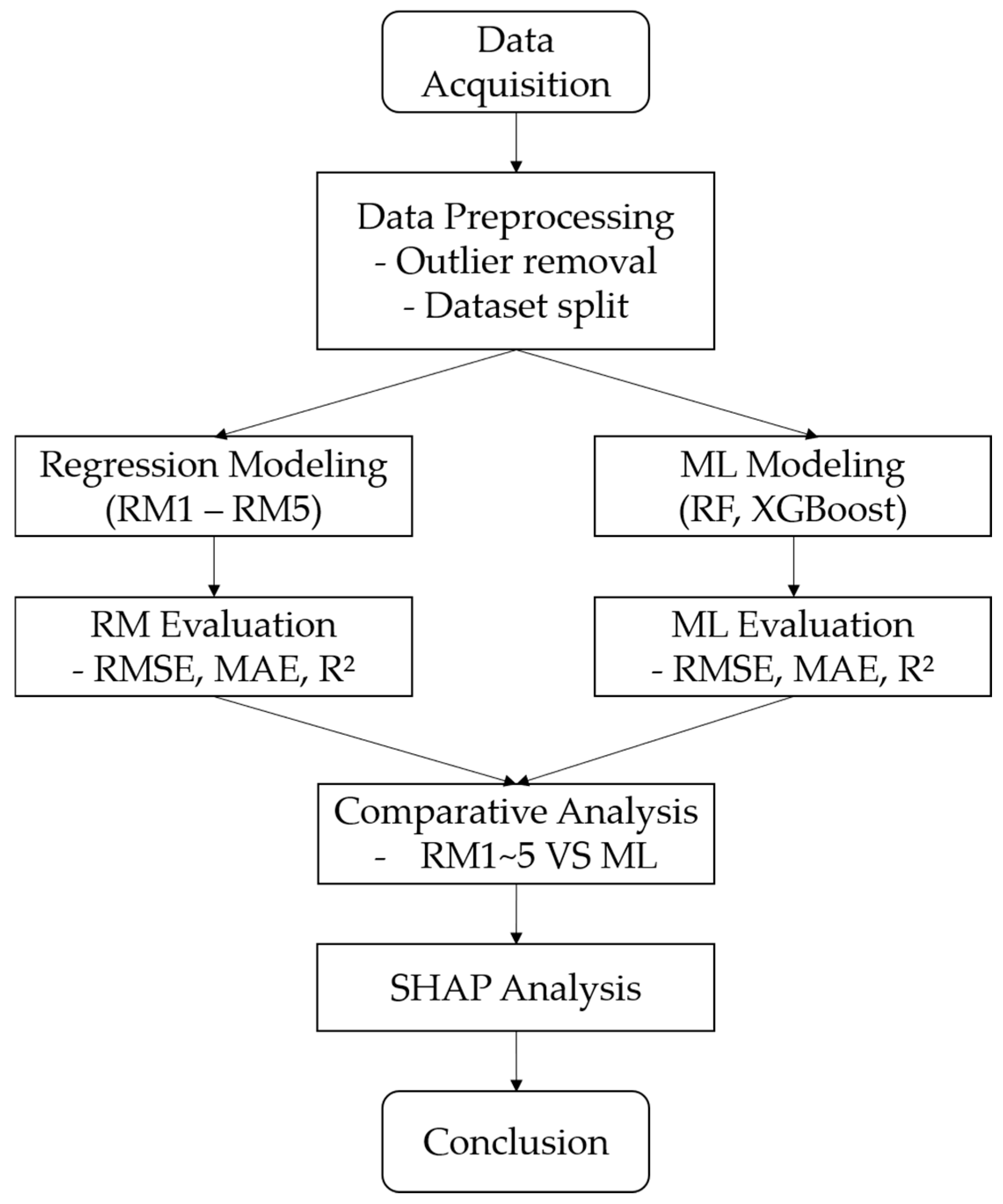
2. Materials and Methods
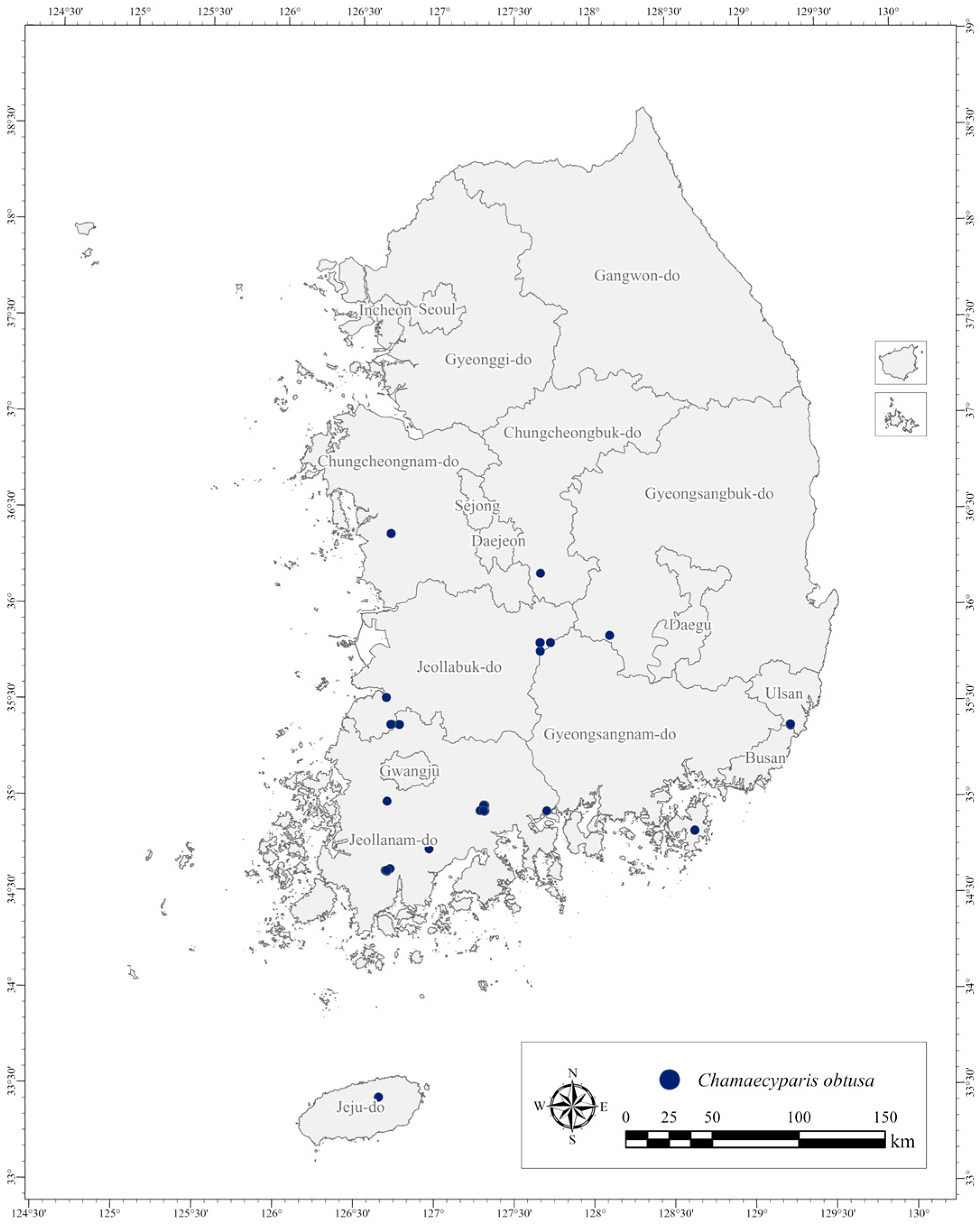
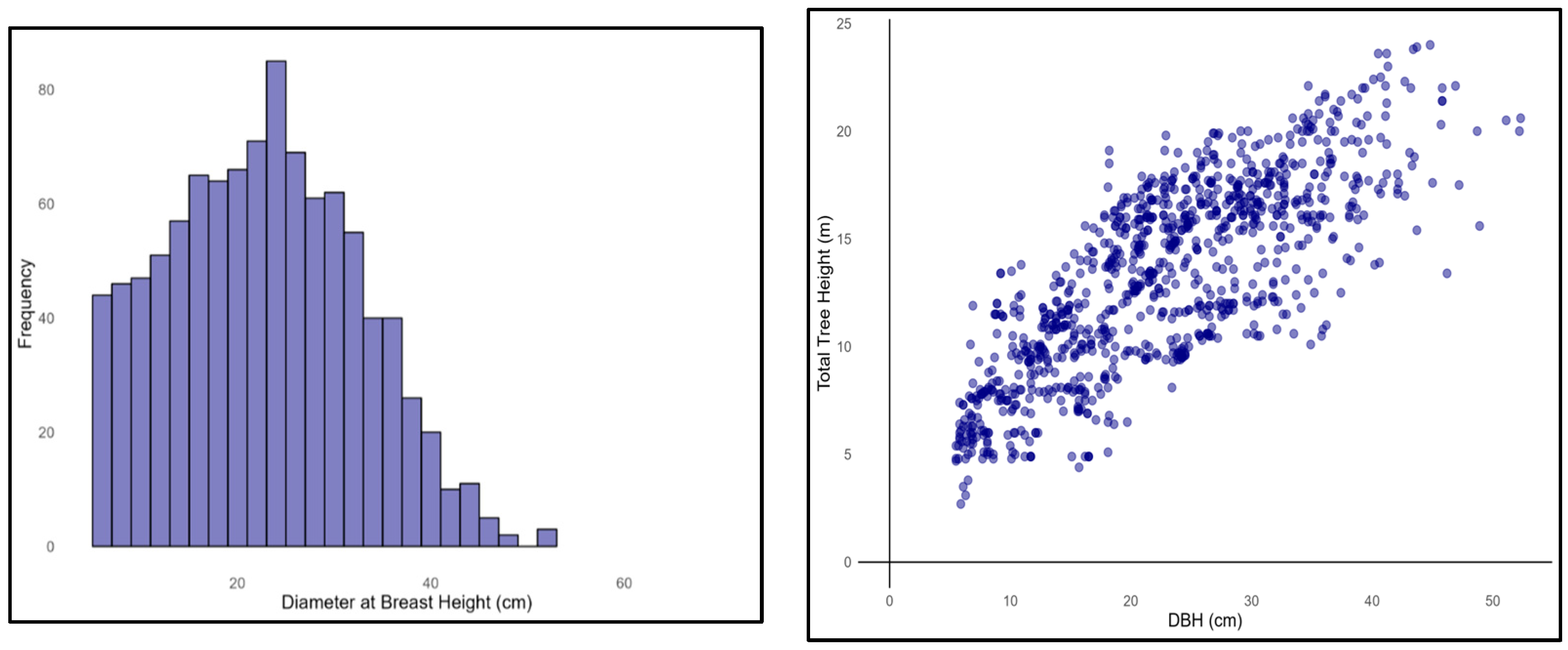
2.1. Study Materials
2.2. Analytical Methods
2.2.1. Traditional Regression Models (RM1–RM4)
2.2.2. Custom Polynomial Regression Model (RM5)
2.3. Machine Learning-Based Predictive Models
2.4. Model Training and Evaluation
2.5. Statistical Comparison of Model Performance
3. Results
3.1. Predictive Performance of Traditional Regression Models
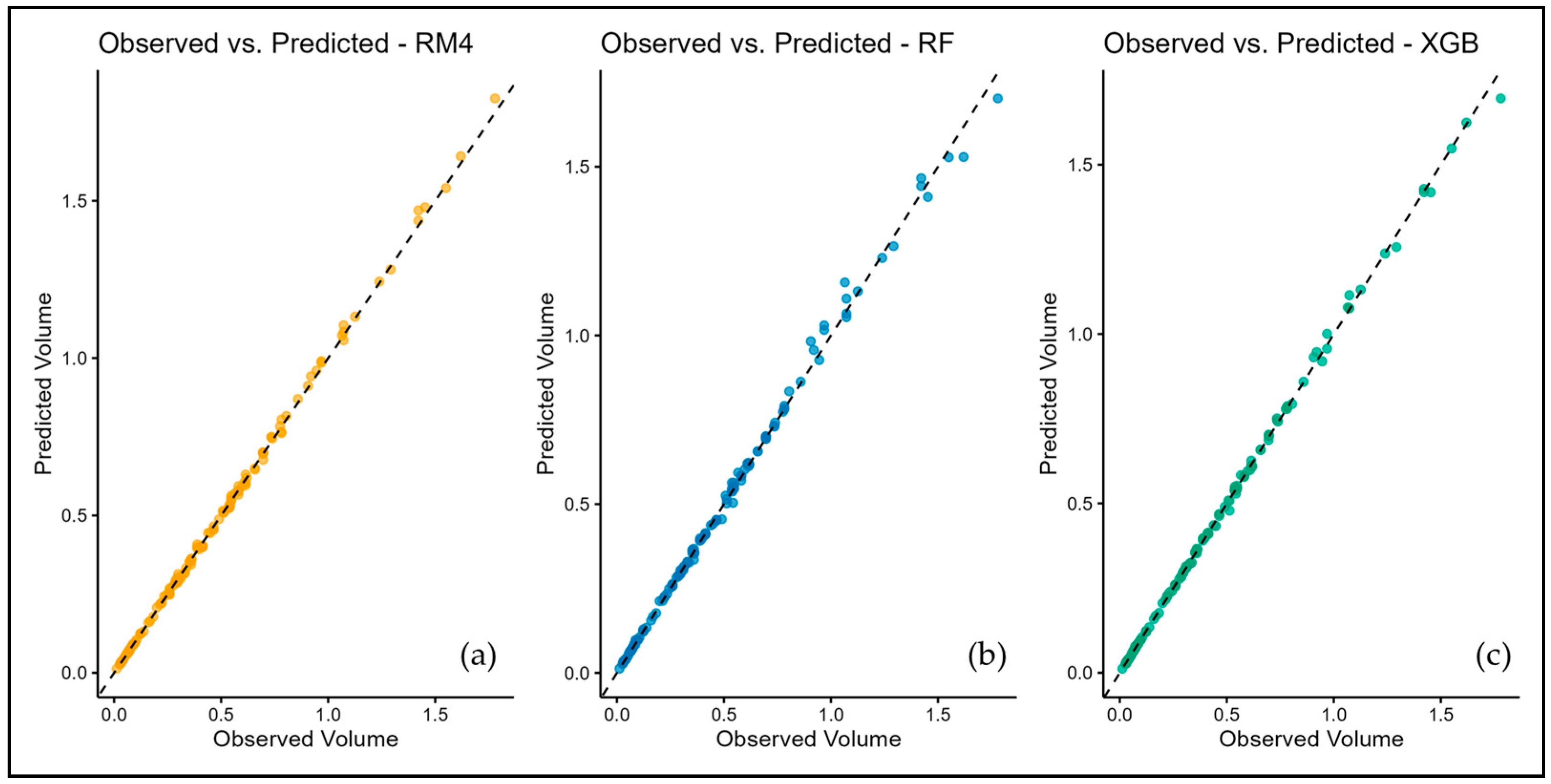
3.2. Predictive Performance and Interpretation of Machine Learning Models
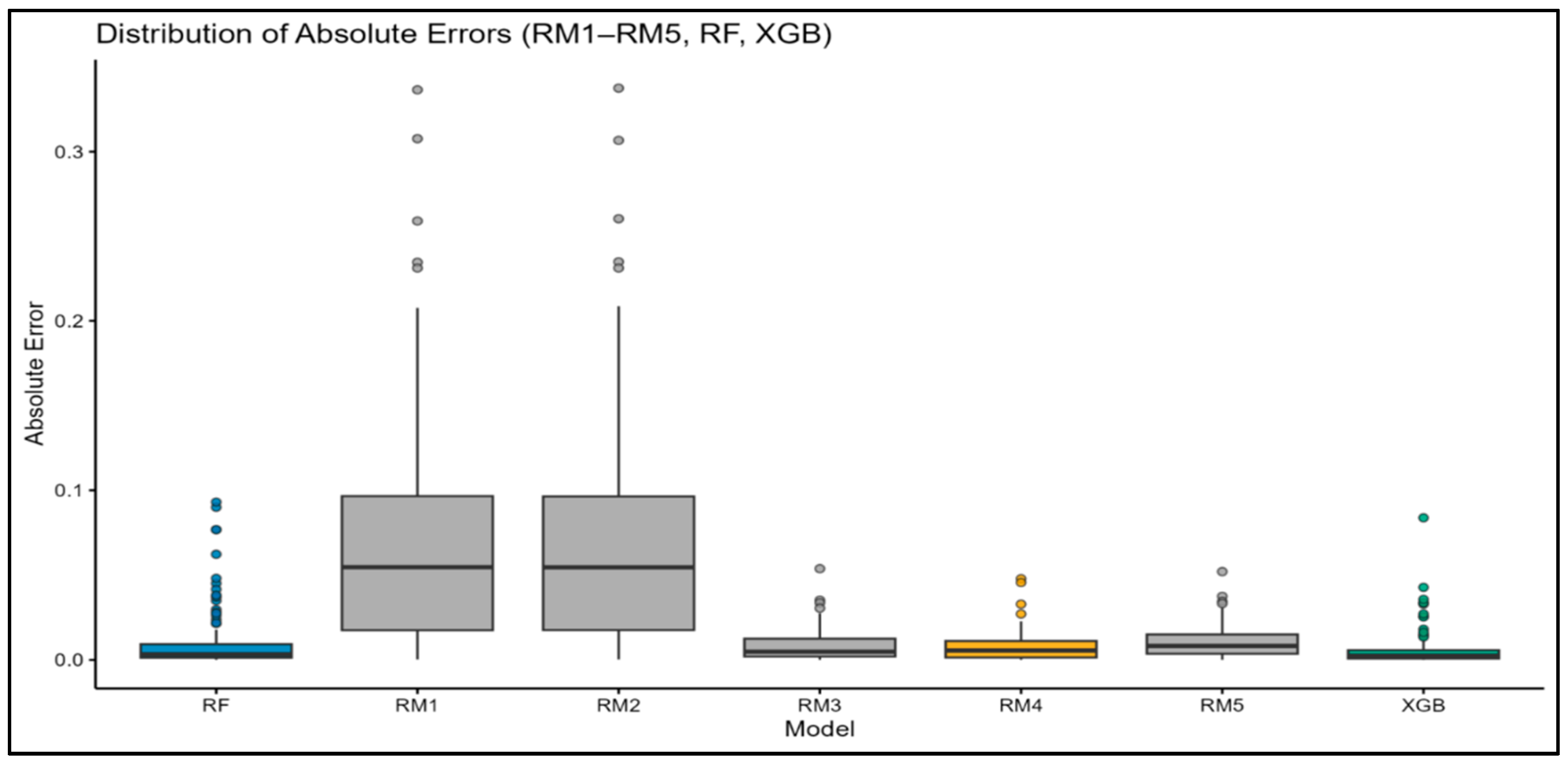
3.3. Statistical Testing and Visual Interpretation of Model Performance Differences
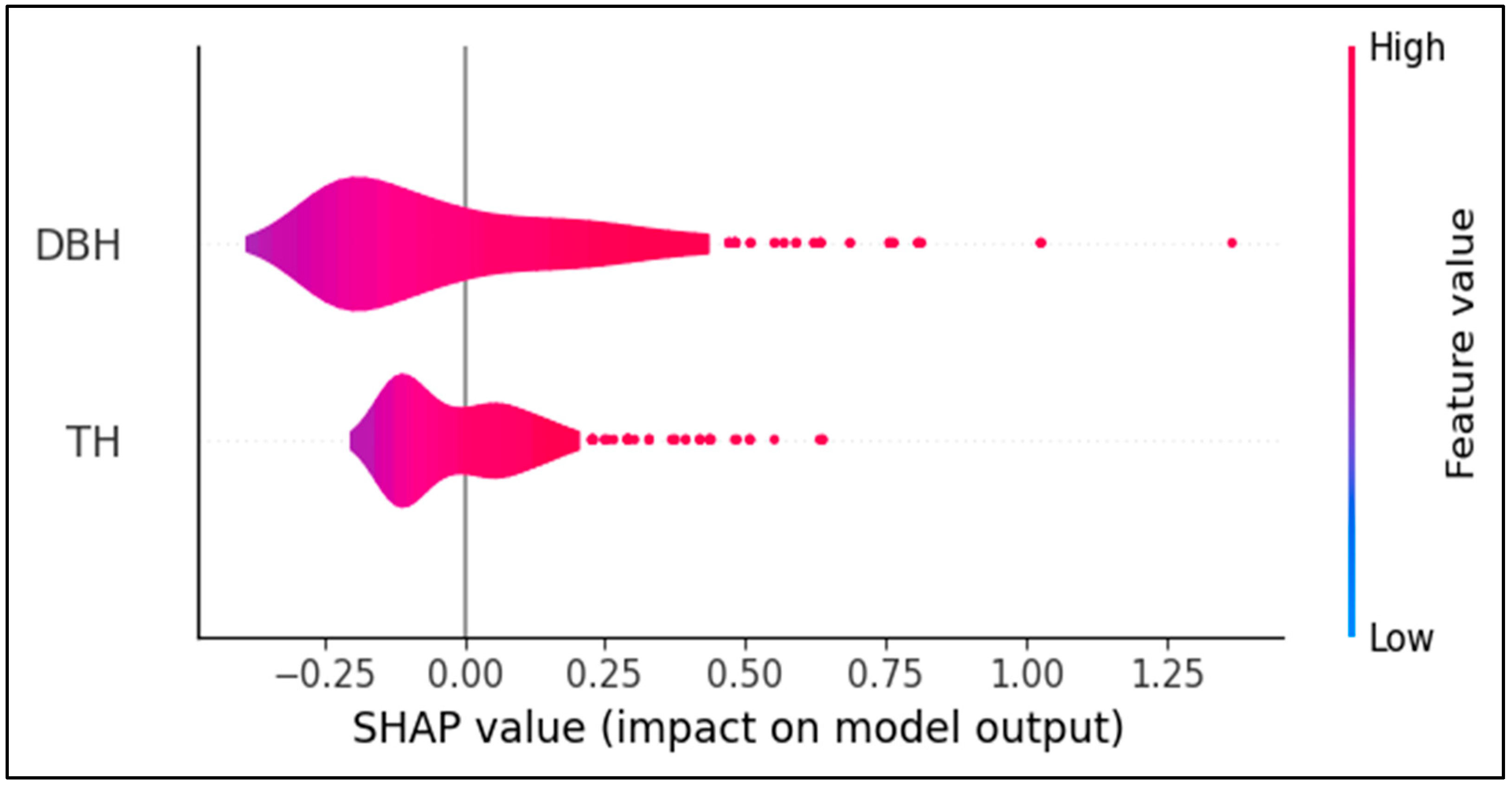
3.4. Variable Contribution Analysis Based on SHAP
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kim, H.; Jung, S.; Lee, G. Development of stem volume tables for Pinus thunbergii in Southern Korea based on comparison of major stem-taper equations. J. Environ. Sci. Int. 2024, 33, 453–462. [Google Scholar] [CrossRef]
- Jung, S.; Lee, K.S.; Kim, H.S.; Park, J.H.; Kim, J.; Park, C.; Son, Y. Derivation of stem taper equations and a stem volume table for Quercus acuta in a warm temperate region. J. Korean Soc. For. Sci. 2023, 112, 417–425. [Google Scholar] [CrossRef]
- Bae, E.J.; Son, Y.; Kang, J.-T. Estimation of stem taper equations and stem volume tables for Phyllostachys pubescens Mazel in South Korea. J. Korean Soc. For. Sci. 2022, 111, 622–629. [Google Scholar] [CrossRef]
- Kim, H.-S.; Jung, S.-Y.; Lee, K.-S. Evaluation of major taper equation models for developing a stem volume table for Cryptomeria japonica on Jeju Island. J. Environ. Sci. Int. 2022, 31, 941–950. [Google Scholar] [CrossRef]
- Shin, J.-H.; Han, H.; Kim, Y.-H.; Yim, J.-S.; Chang, Y.-S. Uncertainty in stand volume estimation based on taper-derived stand volume tables and its implications on carbon stock bias: A case study in Hongcheon-gun, Gangwon-do, Korea. J. Clim. Change Res. 2022, 13, 355–364. [Google Scholar] [CrossRef]
- Son, Y.-M.; Kim, H.; Lee, H.Y.; Kim, C.-M.; Kim, C.-S.; Kim, J.-W.; Ju, R.-W.; Lee, K.-H. Taper equations and stem volume tables for Eucalyptus pellita and A. mangium plantations in Indonesia. J. Korean Soc. For. Sci. 2009, 98, 633–638. [Google Scholar]
- Lee, S.J.; Ko, C.U.; Yim, J.S.; Kang, J.T. A study on the application of a new stem volume table to estimate forest carbon stocks in South Korea. J. Clim. Change Res. 2019, 10, 463–471. [Google Scholar] [CrossRef]
- Son, Y.-M.; Jeon, J.-H.; Pyo, J.-K.; Kim, K.-N.; Kim, S.-W.; Lee, K.-H. Development of a stem volume table for Robinia pseudoacacia using Kozak’s stem profile model. J. Agric. Life Sci. 2012, 46, 43–49. [Google Scholar]
- National Institute of Forest Science. Stem Volume and Biomass, Yield Table; NIFoS: Seoul, Republic of Korea, 2023. [Google Scholar]
- Moon, G.H.; Yim, J.S. Changes in the carbon stocks of coarse woody debris in national forest inventories: Focusing on Gangwon province. J. Korean Soc. For. Sci. 2021, 110, 233–243. [Google Scholar] [CrossRef]
- Kim, E.; Kim, K.-M.; Kim, C.-C.; Lee, S.-H.; Kim, S.-H. The spatial distribution of forest stand volume in Gyeonggi Province was estimated using national forest inventory data and forest-type maps. J. Korean Soc. For. Sci. 2010, 99, 827–835. [Google Scholar]
- Seo, Y.O.; Lee, Y.J.; Noh, D.K.; Kim, S.H.; Choi, J.K.; Lee, W.K.; Height, D.B.H. Growth models of major tree species in Chungcheong Province. J. Korean Soc. For. Sci. 2011, 100, 62–69. [Google Scholar]
- Yim, J.-S.; Shin, M.-Y.; Jeong, I.-B.; Kim, C.-C.; Kim, S.-H.; Ryu, J.-H. Estimation of forest growing stock by combining annual forest inventory data. J. Korean Soc. For. Sci. 2012, 101, 213–219. [Google Scholar]
- Ko, C.; Kim, D.-G.; Kang, J.-T. Estimation of the stem volume table of Quercus acutissima in South Korea Using Variable Exponent Equation. J. Korean Soc. For. Sci. 2019, 108, 357–363. [Google Scholar] [CrossRef]
- Gonzalez-Benecke, C.A.; Gezan, S.A.; Samuelson, L.J.; Cropper, W.P., Jr.; Leduc, D.J.; Martin, T.A. Estimating Pinus palustris Tree diameter and stem volume from tree height, crown area and stand-level parameters. J. For. Res. 2014, 25, 43–52. [Google Scholar] [CrossRef]
- Buba, T. Relationship between stem diameter at breast height (DBH), tree height, crown length, and crown ratio of Vitellaria paradoxa C.F. Gaertn in the Nigerian Guinea Savanna. Afr. J. Biotechnol. 2013, 12, 22. [Google Scholar]
- Bae, S.; Lee, C.; Kim, K.; Park, B.; Kwon, K.; Kang, G.; Lee, W.; Hong, S.; Lee, K.; Song, T.; et al. Economically Important Tree Species V: Chamaecyparis obtusa (Hinoki Cypress); Korea Forest Research Institute: Seoul, Republic of Korea, 2012; pp. 1–155. [Google Scholar]
- Kang, J.T.; Seo, Y.O.; Park, J.; Ko, C.; Kwon, S. Development of weight estimation equation and weight table for Chamaecyparis obtusa and Cryptomeria japonica. J. Korean Soc. For. Sci. 2025, 114, 94–109. [Google Scholar]
- Baek, G.W.; Hwang, D.K.; Kim, C.S. Effects of thinning on nutrient concentrations and stocks in Cryptomeria japonica and Chamaecyparis obtusa plantations. J. Agirc Life Sci. 2025, 59, 97–104. [Google Scholar] [CrossRef]
- Jung, S.; Lee, K.S.; Kim, H.S.; Park, J. Improvement of the thinning system by exploring stand density management criteria for Chamaecyparis obtusa in South Korea. J. Korean Soc. For. Sci. 2024, 113, 131–142. [Google Scholar]
- Kim, S.-J. Preparation and characterization of wood-plastic composite panels fabricated with Chamaecyparis obtusa Wood Flour. J. Converg. Inform. Technol. 2022, 12, 126–132. [Google Scholar] [CrossRef]
- Hwang, D.; Baek, G.; Bae, E.J.; Kim, C. Short-term effect of thinning on carbon stocks in Cryptomeria japonica and Chamaecyparis obtusa plantations. Korean J. Agric. For. Meteorol. 2024, 26, 295–302. [Google Scholar]
- Sumida, A.; Miyaura, T.; Torii, H. Relationships of tree height and diameter at breast height revisited: Analyses of stem growth using 20-year data from an even-aged Chamaecyparis obtusa stand. Tree Physiol. 2013, 33, 106–118. [Google Scholar] [CrossRef] [PubMed]
- Kumagai, T.; Nagasawa, H.; Mabuchi, T.; Ohsaki, S.; Kubota, K.; Kogi, K.; Utsumi, Y.; Koga, S.; Otsuki, K. Sources of error in estimating stand transpiration using allometric relationships between stem diameter and sapwood area for Cryptomeria japonica and Chamaecyparis obtusa. For. Ecol. Manag. 2005, 206, 191–195. [Google Scholar] [CrossRef]
- Hemery, G.E.; Savill, P.S.; Pryor, S.N. Applications of the crown diameter–stem diameter relationship for different species of broadleaved trees. For. Ecol. Manag. 2005, 215, 285–294. [Google Scholar] [CrossRef]
- Ko, C.; Kang, J.; Won, H.; Seo, Y.; Lee, M. Stem profile estimation of Pinus densiflora in Korea using machine learning models: Towards precision forestry. Forests 2025, 16, 840. [Google Scholar] [CrossRef]
- Özçelik, R.; Diamantopoulou, M.J.; Trincado, G. Evaluation of potential modeling approaches for Scots pine stem diameter prediction in north-eastern Turkey. Comput. Electron. Agric. 2019, 162, 773–782. [Google Scholar] [CrossRef]
- Bayat, M.; Bettinger, P.; Heidari, S.; Henareh Khalyani, A.; Jourgholami, M.; Hamidi, S.K. Estimation of Tree Heights in an Uneven-Aged, Mixed Forest in Northern Iran Using Artificial Intelligence and Empirical Models. Forests 2020, 11, 324. [Google Scholar] [CrossRef]
- Özçelik, R.; Diamantopoulou, M.J.; Brooks, J.R.; Wiant, H.V., Jr. Estimating tree bole volume using artificial neural network models for four species in Turkey. J. Environ. Manag. 2009, 90, 3687–3695. [Google Scholar] [CrossRef] [PubMed]
- Antúnez, P.; Wehenkel, C.; Basave-Villalobos, E.; Calixto-Valencia, C.G.; Valenzuela-Encinas, C.; Ruiz-Aquino, F.; Sarmiento-Bustos, D. Predictive modeling of volume and biomass in Pinus pseudostrobus using machine learning and allometric approaches. For. Sci. Technol. 2025, 21, 110–122. [Google Scholar] [CrossRef]
- Diamantopoulou, M.J.; Georgakis, A. Improving European Black Pine Stem Volume Prediction Using Machine Learning Models with Easily Accessible Field Measurements. Forests 2024, 15, 2251. [Google Scholar] [CrossRef]
- Breiman, L.; Forests, R. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Lee, S.H.; Ko, C.U.; Shin, J.H.; Kang, J.T. Estimation of Stem Taper for Quercus acutissima Using Machine Learning Techniques. J. Agirc Life Sci. 2020, 54, 29–37. [Google Scholar] [CrossRef]
- Nunes, M.H.; Görgens, E.B. Artificial intelligence procedures for tree taper estimation within a complex vegetation mosaic in Brazil. PLoS ONE 2016, 11, e0154738. [Google Scholar] [CrossRef] [PubMed]
- Mauro, F.; Frank, B.; Monleon, V.J.; Temesgen, H.; Ford, K.R. Prediction of diameter distributions and tree-lists in Southwestern Oregon using LiDAR and stand-level auxiliary information. Can. J. For. Res. 2019, 49, 775–787. [Google Scholar] [CrossRef]
- Yang, S.I.; Burkhart, H.E.; Seki, M. Evaluating semi- and nonparametric regression algorithms in quantifying stem taper and volume with alternative test data selection strategies. Forestry 2023, 96, 465–480. [Google Scholar] [CrossRef]
- Pokhrel, N.R.; Subedi, M.R.; Malego, B. Fitting and evaluating taper functions to predict upper stem diameter of planted teak (Tectona grandis L.f.) in eastern and central regions of Nepal. Forests 2025, 16, 77. [Google Scholar] [CrossRef]
- Yang, S.I.; Burkhart, H.E. Robustness of parametric and nonparametric fitting procedures of tree-stem taper with alternative definitions for validation data. J. For. 2020, 118, 576–583. [Google Scholar] [CrossRef]
- Chen, Q.; Gong, P.; Baldocchi, D.; Tian, Y.Q. Estimating basal area and stem volume for individual trees from lidar data. Photogramm. Eng. Remote Sens. 2007, 73, 1355–1365. [Google Scholar] [CrossRef]
- An, Z.; Froese, R.E. Tree stem volume estimation from terrestrial LiDAR point cloud by unwrapping. Can. J. For. Res. 2023, 53, 2. [Google Scholar] [CrossRef]
- Lee, Y.; Lee, J. Advancing stem volume estimation using multi-platform LiDAR and taper model integration for precision forestry. Remote Sens. 2025, 17, 785. [Google Scholar] [CrossRef]
- Hyyppä, J.; Yu, X.; Hakala, T.; Kaartinen, H.; Kukko, A.; Hyyti, H.; Muhojoki, J.; Hyyppä, E. Under-canopy UAV laser scanning providing canopy height and stem volume accurately. Forests 2021, 12, 856. [Google Scholar] [CrossRef]
- Balestra, M.; Marselis, S.; Sankey, T.T.; Cabo, C.; Liang, X.; Mokroš, M.; Peng, X.; Singh, A.; Stereńczak, K.; Vega, C.; et al. LiDAR data fusion to improve forest attribute estimates: A review. Curr. For. Rep. 2024, 10, 281–297. [Google Scholar] [CrossRef]
- Ko, C.; Lee, S.; Yim, J.; Kim, D.; Kang, J. Comparison of forest inventory methods at plot-level between a backpack personal laser scanning (BPLS) and conventional equipment in Jeju island, South Korea. Forests 2021, 12, 308. [Google Scholar] [CrossRef]
- Kozak, A. A variable-exponent taper equation. Can. J. For. Res. 1988, 18, 1363–1368. [Google Scholar] [CrossRef]
- Cysneiros, V.C.; Gaui, T.D.; Silveira Filho, T.B.; Pelissari, A.L.; Machado, S.d.A.; De Carvalho, D.C.; Moura, T.A.; Amorim, H.B. Tree volume modeling for forest types in the Atlantic Forest: Generic and specific models. iForest 2020, 13, 417–425. [Google Scholar] [CrossRef]
- Oliveira, L.Z.; Klitzke, A.R.; Fantini, A.C.; Uller, H.F.; Correia, J.; Vibrans, A.C. Robust volumetric models for supporting the management of secondary forest stands in the Southern Brazilian Atlantic Forest. An. Acad. Bras. Ciênc 2018, 90, 3729–3744. [Google Scholar] [CrossRef] [PubMed]
- Shapley, L.S. A value for n-person games. In Contributions to the Theory of Games II; Kuhn, H.W., Tucker, A.W., Eds.; Princeton University Press: Princeton, NJ, USA, 1953; Volume 2, pp. 307–317. [Google Scholar]
- Lundberg, S.M.; Lee, S.-I. A unified approach to interpreting model predictions. arXiv 2017. [Google Scholar] [CrossRef]
- Kim, Y.; Kim, Y. Explainable heat-related mortality with random forest and SHapley Additive exPlanations (SHAP) models. Sustain. Cities Soc. 2022, 79, 103677. [Google Scholar] [CrossRef]
- Socha, J.; Netzel, P.; Cywicka, D. Stem taper approximation by artificial neural network and a regression set models. Forests 2020, 11, 79. [Google Scholar] [CrossRef]
- Özçelik, R.; Diamantopoulou, M.J.; Brooks, J.R. The use of tree crown variables in over-bark diameter and volume prediction models. iForest 2014, 7, 132–139. [Google Scholar] [CrossRef]
- Sanquetta, C.R.; Wojciechowski, J.; Dalla Corte, A.P.D.; Rodrigues, A.L.; Maas, G.C.B. On the use of data mining for estimating carbon storage in the trees. Carbon Balance Manag. 2013, 8, 6. [Google Scholar] [CrossRef] [PubMed]
- Yazdi, H.; Moser-Reischl, A.; Rötzer, T.; Ludwig, F.; Tost, J. Machine learning-based prediction of tree crown development in competitive urban environments. Urban For. Urban Green 2024, 101, 128527. [Google Scholar] [CrossRef]
- Du, Q.; Zhu, C.; Ji, B.; Xu, S.; Xie, B.; Wang, J.; Wang, Z. Quantification of the influencing factors of stand productivity of subtropical natural broadleaved forests in Eastern China using an explainable machine learning framework. Forests 2025, 16, 95. [Google Scholar] [CrossRef]
- Al Saim, A.A.; Aly, M. Enhancing tree species mapping in Arkansas’ forests through machine learning and satellite data fusion: A google earth engine–based approach. J. Geovisualization Spat. Anal. 2025, 9, 20. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Mean | Standard Deviation | Minimum | Maximum |
|---|---|---|---|---|
| DBH (cm) | 18.35 | 7.62 | 6 | 46 |
| TH (m) | 12.56 | 3.25 | 4 | 21 |
| Stand Age (yr) | 35.91 | 8.97 | 13 | 62 |
| Height to Crown Base (m) | 5.1 | 1.83 | 0.8 | 13.2 |
| Statistics | Calculation Forms |
|---|---|
| Root mean square error (RMSE) | |
| Mean absolute error (MAE) | |
| Coefficient of determination (R2) | |
| Furnival Index (FI) |
| Model | RMSE | MAE | R2 | FI |
|---|---|---|---|---|
| RM1 | 0.0994 | 0.0745 | 0.9348 | 0.0995 |
| RM2 | 0.0995 | 0.0745 | 0.9347 | 0.0996 |
| RM3 | 0.0128 | 0.0091 | 0.9989 | 0.0129 |
| RM4 | 0.0123 | 0.0087 | 0.9990 | 0.0124 |
| RM5 | 0.0146 | 0.0112 | 0.9986 | 0.0147 |
| Model | RMSE | MAE | R2 |
|---|---|---|---|
| Random Forest | 0.0187 | 0.0086 | 0.9977 |
| XGBoost | 0.0164 | 0.0068 | 0.9982 |
| Model vs. XGB | Shapiro–Wilk p | Method | Wilcoxon p |
|---|---|---|---|
| RM1 vs. XGB | <0.00001 | Wilcoxon Signed-rank | 2.57 × 10−23 |
| RM2 vs. XGB | <0.00001 | 2.52 × 10−23 | |
| RM3 vs. XGB | <0.00001 | 9.09 × 10−5 | |
| RM4 vs. XGB | <0.00001 | 1.13 × 10−4 | |
| RM5 vs. XGB | <0.00001 | 9.27 × 10−11 | |
| RF vs. XGB | <0.00001 | 3.65 × 10−4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ko, C.; Kang, J.; Kim, D. Stem Volume Prediction of Chamaecyparis obtusa in South Korea Using Machine Learning and Field-Measured Tree Variables. Forests 2025, 16, 1228. https://doi.org/10.3390/f16081228
Ko C, Kang J, Kim D. Stem Volume Prediction of Chamaecyparis obtusa in South Korea Using Machine Learning and Field-Measured Tree Variables. Forests. 2025; 16(8):1228. https://doi.org/10.3390/f16081228
Chicago/Turabian StyleKo, Chiung, Jintaek Kang, and Donggeun Kim. 2025. "Stem Volume Prediction of Chamaecyparis obtusa in South Korea Using Machine Learning and Field-Measured Tree Variables" Forests 16, no. 8: 1228. https://doi.org/10.3390/f16081228
APA StyleKo, C., Kang, J., & Kim, D. (2025). Stem Volume Prediction of Chamaecyparis obtusa in South Korea Using Machine Learning and Field-Measured Tree Variables. Forests, 16(8), 1228. https://doi.org/10.3390/f16081228