1. Introduction
In forestry practice, timber is harvested as the trees stand in the forest, i.e., with bark, but value calculation utilises under-bark volume when it comes to the sale. That is why precisely determining the bark thickness (BT) is crucial for forest operations. Nowadays, when multi-operational machines are increasingly used, specific models can be used to estimate BT based on other parameters, usually stem diameter (D) in any location within the stem or just diameter at breast height (DBH).
Two approaches to bark thickness modelling can be observed in forest research. The first one applies relatively simple models for specific purposes. Studies from the other approach focus on searching for complex models that will fit well for the data, both at the individual tree (ITL) and/or all trees together (ATL) levels. The previous approach includes analysis of the bark thickness as a function of stem diameter and distance from the stem base (tree length) [
1,
2]. Linear or nonlinear (but linearizable) regression models were used for modelling. The elaborated models should be simple enough to be easily applied in practice. Such an approach was also used to estimate other tree parameters. Amidon [
3] used stem diameter and height measurements as two variables to accurately and precisely predict stem volume for five conifer species. Logistic regression was used to evaluate fire-induced tree mortality [
4]. The proposed models were applicable for assessing fire-caused mortality in individual trees and mixed conifer stands. Hengst and Dowson [
5] addressed a similar topic, determining selected physical, thermal, and chemical properties of the bark of 16 deciduous tree species to assess their potential to protect the vascular cambium from fire damage. For this purpose, the relationship between D and BT was modelled for each tree species separately. A linear mixed effects model was also used to determine the relationship between BT and DBH for Scots pine [
6]. Simple nonlinear regression models were used to model the diameter over and under bark and the thickness of the bark along the black locust stem [
7].
With access to more developed statistical software, more explanatory variables and more complex functions began to be used for modelling, which decreased the unexplained variation in the dependent variable. Since the 1990s, there has been a shift from mechanistic models, in which oversimplification resulted in a high proportion of unexplained variability [
8]. Poor matches and uncertain estimation errors were treated as occupational risks [
9]. Attention shifted to unstructured random components, such as spatial dependence and autocorrelation, or temporal dependence and autocorrelation [
10]. Multiple nonlinear mixed-effects models have begun to be used to simultaneously describe several characteristics of wood quantity at the plot level [
11]. Previously used models were tested in studies of bark resources on a regional scale, and new models were proposed for optimizing bark estimation in the forest-wood sector [
12]. A single model has been proposed to predict the bark volume of different species using two approaches [
13,
14]. In the first one, it was verified that if a model existed but was not adapted to the species under study then it should be readapted. In the other case, if a suitable model had not existed, a new one had to be developed regardless of its complexity. Modifications of the models were also dealt with in a study on the variability of bark thickness of silver fir [
15]. The predictive performance of models known from the literature was compared to estimate the effect of size on the precision of predictions. A similar study was performed for Norway spruce, where random effects in generalised additive mixed models were used to compare regression models [
14]. A study [
16] of sap flow in the stem of Scots pine trees as a function of temperature under the canopy of the stand used nonlinear mixed-effects regression models for repeated data.
The studies above prove that linear or nonlinear (linearizable) regression models often estimate various tree parameters. The methodology of their application is well described [
17,
18]. Both publications provide practical examples of using different regression models as well. Conducting regression diagnostics concerning model residuals is essential when fitting a regression model. Special attention should be paid to the outliers [
19]. Statistical software made it possible to use nonlinear models with mixed effects. These complex models were explained in detail, and calculations were performed on procedures of the SAS system [
20]. The most complex model we propose in this work deals with correlated data, as explained by Vonesh [
21].
We aimed to model stem diameter-dependent stem bark thickness using regression models with random effects for repeated data. So far, such models have not been used to model bark thickness. We hypothesise that their use will make it possible to obtain good estimates of bark thickness in the analysis of each tree separately and in the combined analysis of all trees. We will present the methodology for selecting regression models to estimate bark thickness based on the stem diameter measured at different heights. Regression models with random effects for repeated data will be compared with classical regression models.
3. Results
In the first stage of the research, among 25 regression models (
Table 1) the regression model that most frequently topped the fitting rankings for individual trees was selected. This was the double reciprocal model 1/(y = 1/(a + b/x) (
Table 2). At this stage of the research, all regression functions were functions subject to linearisation transformation. All fitted regression functions had high and similar R-squared values.
Table 1 presents the transformations of the explanatory (stem diameter D) and response variables (bark thickness BT) and the R-squared values at the weakest fit. In addition, the model fit ranking, obtained from the sum of the ranks, is shown in
Table A1.
In the second stage of the research, the values of studentised residuals were checked to improve the regression function fit quality and eliminate outliers. Linear regression, like nonlinear regression, assumes that the spread of the data around an ideal curve has a Gaussian or normal distribution. This assumption leads to the known goal of regression: to minimise the sum of squares of the vertical distances or Y-values between points and the curve. In our measurements, an outlier is a data point whose BT value does not follow the general trend of the rest of the data. Such a data point can affect any part of the regression analysis. It can affect the predicted values of the regression coefficients, the R-square value, i.e., the fit of the regression function to the data, or the results of a hypothesis test on the significance of the regression model. At this stage of statistical analyses, we have simple methods to pick out outliers. However, we are unaware of any practical and straightforward method to routinely identify outliers during curve fitting using nonlinear regression [
32]. The results shown in
Table 1 and
Table 2 are the final values after the second stage of the research.
For location SITE1, outlier observations have been removed for the following trees: for tree 1 (height 18 m), the measurement at 0 m has been removed; for tree 5 (height 32 m), measurements at 28 m and 30 m have been removed; for tree 6 (height 16 m), the measurement at 8 m has been removed; and for tree 7 (height 28 m), the measurement at 28 m has been removed. For the second location SITE2, outlier observations have been removed for tree 1 (height 30 m) at the 30 m level; for tree 4 (height 26 m), the measurements at 0 m, 20 m, and 26 m have been removed; for tree 8 (height 26 m), the measurement at 24 m has been removed; and for tree 9 (height 26 m), the measurement at 24 m has been removed. The prepared data was used in subsequent stages. The removal of the observations above was performed for a linearised regression model, which in practice makes it easy from the computational side to check if a given observation is an outlier and effectively influential and if it changes the model fit by at least 1% (R-squared).
At this analysis stage, the two following nonlinear regression functions were obtained: the first, MM, calculated at the ITL level and with the values of the regression function parameters averaged, and the second, M1, calculated at the ATL level. Each approach depends on the goal the researcher has set for themself. Suppose the researcher is interested in individual trees and estimates of different tree parameters. In that case, they will choose the MM, but if the researcher is interested in a large forest area and overall estimates of the whole stand then they will select the M1 model.
In the third stage, the classic model of the nonlinear regression function was initially fitted to each tree separately (ITL). Based on the regression coefficients for individual trees, an overall regression model for all trees was calculated (
Table A2), resulting in the marginal model MM (also known as the population-averaged model). The MM was then compared to the nonlinear regression function determined from the values for all trees combined (model M1). Both functions for both locations are shown in
Figure 2, and the estimated regression coefficients are given in
Table A4.
To compare the fitting of nonlinear regression models, the error ratio to the mean forecast size was expressed in percentage terms as RMSE% (Equation (5)). For SITE1, the fit of the MM was 18.52%, while for the M1 model it was 14.84%. Meanwhile, for SITE2 these values were 24.8% and 24.2%, respectively. The fit of the MM is poorer than that of M1, particularly for SITE1 (
Figure 2).
Because the research aimed to find a model that best fits all the trees collectively and each tree individually, the fit of the MM and M1 functions was compared for individual trees (
Table 3).
The fit of MM to individual trees compared to model M1 was better (the exception being tree 6 in SITE2). However, the fit of MM for all trees combined was worse than that of model M1.
Subsequently, an M2 regression model was specified to account for the possible correlation of residuals within a single tree. The MM and M1 models do not consider the correlation between measurements, i.e., by taking measurements at, e.g., 1.3 m and 2 m or higher, we do not think each second measurement depends on the previous one.
The overall fit of the regression function according to model M2 for all trees was for SITE1, 14.88%, and SITE2, 24.12%, which is comparable to model M1 for both locations. However, the fit of model M2 for individual trees (
Table 3) was most often between the fitting results for models MM and M1.
We have three regression functions at this research stage: MM, M1, and M2. We know that the MM function best fits at the ITL level and M1 at the ATL level. However, neither has a good fit at the ITL and ATL levels. Considering the correlations between measurements at successive heights, we found a function M2, whose values at the ITL level are better than M1 but worse than MM, and whose values at the ATL level are close to M1. Considering both ITL and ATL levels, the M2 function is the most universal.
The fourth and most complicated and complex regression function is the M3 model, which considers random effects specific to the given tree in addition to the correlation of residuals (as in the M2 model). In practice, the regression function for the M3 model will have fixed and random coefficients. It should combine the advantages of the MM and M1 functions and consider the correlations between the results of the M2 function. The random components in the regression model should consider the tree’s nature. By taking measurements, the researcher does not see differences between trees of the same age growing in a similar forest environment. One may only notice that one tree is slightly thinner or thicker. It is only possible to talk about BT when all the measurements are taken together. To account for these slight differences in tree characteristics, we introduce random effects into the regression model, which should show us the individual characteristics of each tree in a single universal regression function.
The first problem with such a complex function is determining good starting values, as the methods for determining the parameters of the nonlinear regression function are iterative. When determining the model’s parameters, known boundary values or asymptotes of the regression function can be used [
24,
25,
28]. In practice, we most often do not see the boundary values of the dependent variable (the asymptote of the model). Due to the model’s complex form, we cannot provide starting values. In such a situation, fitting models with different random effects,
bi (Equation (3)), remains. Although this is a monotonous method, with computers and good statistical software at one’s disposal it is possible to check all combinations of random effects and select the best-fitting model based on, for example, the Schwarz BIC. Schwarz’s BIC was used to compare the fit quality of regression functions with different random effects (
Table 4). Schwarz proposed a Bayesian information criterion (BIC) that provides a criterion for model selection: models with lower BICs are preferred. The Bayesian information criterion (BIC) measures model performance by considering model complexity. The large availability of procedures for calculating BIC values provides a quick and easy way to compare models.
To fit the M3 model, the following were considered: 1. various combinations of the three random components
bi (Equation (3)); 2. convergence of the iterative method; 3. the value of the BIC (
Table 4). For the location SITE1 the best combination of random components was the combination with only
b3 (Equation (6)), while for SITE2 it was the combination of the two components
b1 and
b3 (Equation (7)). These are represented as follows:
where
when
I = 1,2,3 are fixed effects and
bj when
j = 1, 3 are random effects. The estimated fixed and random regression effects are given in
Table A3 and
Table A4.
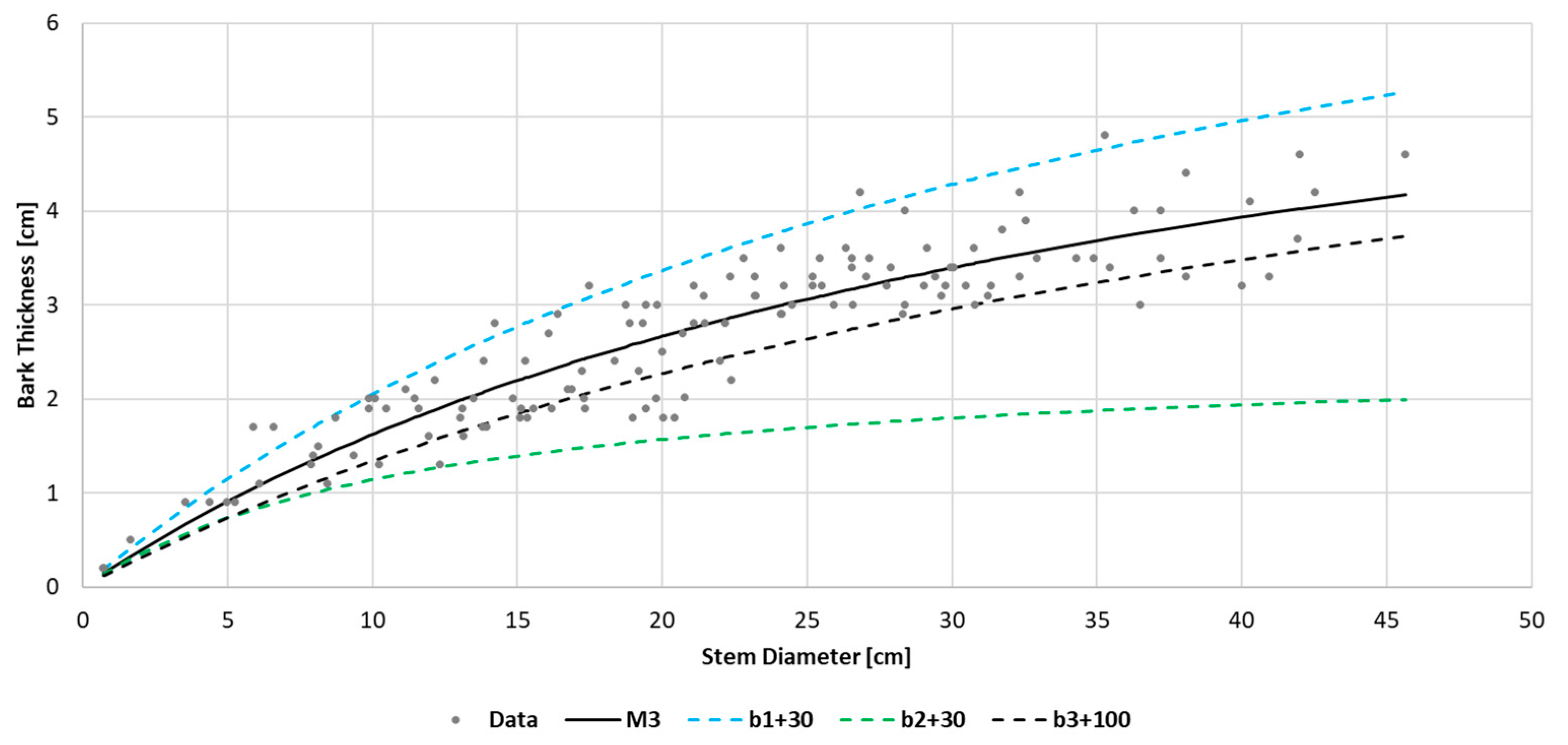
One can also use graphs when selecting random effect components for the M3 model. It is necessary to compare the trajectory of the averaged regression function M3 with the simulation graphs (
Figure 3). The simulation graphs show how the trajectory of the averaged M3 model changes depending on variations in the values of the random effect coefficients
b1,
b2, and
b3. In our case, a shift in
b1 increases the estimates of BT at high D values, while a change in
b2 decreases the BT estimates at high D values. Meanwhile, a change in
b3 causes a parallel shift in the graph across nearly the entire trajectory of the regression function.
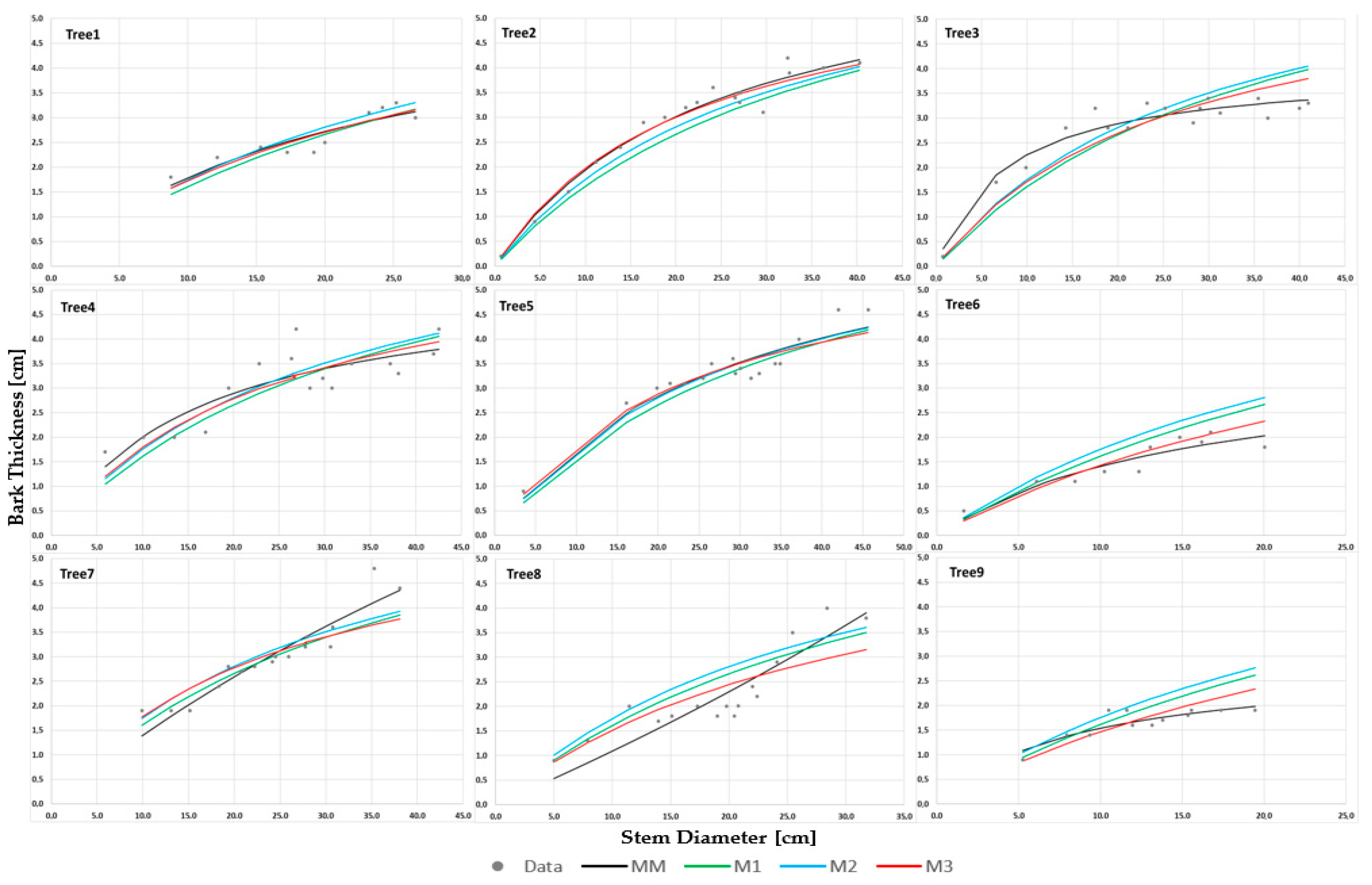
To determine which random effects are significant for individual trees (ITL), it is necessary to compare the shift in the estimated function M3 against the position of the regression function without random effects, namely model M2 (
Figure 4 and
Figure 5, model M3—red, M2—blue). In SITE1 (
Figure 4) for trees 1, 3, 6, 8, and 9, the position of function M2 is above that of function M3, indicating an overestimation of BT values. Conversely, for tree 2 the position of M2 is below that of model M3, indicating an underestimation of BT. In SITE2 (
Figure 5) the position of function M2 for trees 1, 2, and 4 is above that of function M3, whilst for trees 3, 6, 7, and 9 it is below the function for model M3. The shift in the graph close to parallel corresponds to the random effect
b3. However, it is harder to notice the influence of the impact of
b1 on the graphs, which is observable if the parallel shift in graph M2 compared to M3 is disturbed upwards or downwards. The graphs for trees 2, 3, 4, 6, 7, and 9 in SITE2 exhibit such a disturbance, which is confirmed by the low BIC value for model M3 with random effect
b1. In SITE1 such a disturbance can only be observed for two trees (3 and 6), which confirms that the selection of model M3, with only the random component
b3 obtained through BIC, was appropriate.
The fit of model M3 to all trees (ATL) for the location SITE1 was 12.49%, and for SITE2 it was 19.05%. Compared to previous models, these were the best fits. However, the fit of model M3 for individual trees (ITL), compared to MM, was slightly worse, but in most cases it was better than models M1 and M2 (
Table 3). Considering the differences between the average RMSE% (
Table 3) in the individual fit to trees at location SITE1, it is evident that model M1 had a worse fit than MM by an average of 5.33%, model M2 by 5.6%, and model M3 by 2.41%. Meanwhile, at SITE2, compared to MM, worse fits were obtained for M1 by 4.8%, M2 by 4.88%, and for M3 a better fit was obtained by 0.29%. At location SITE2 the exception was tree 6, for which the fits, compared to MM, were better: M1 by 6.15%, M2 by 4.84%, and M3 by 17.98%.
In
Figure 4 and
Figure 5 the fit for individual trees can be traced. For models M1 and M2 about MM there is often an overestimation, meaning that the graphs for M1 and M2 lie above MM (for SITE1: tree 6 and tree 9, for SITE2: tree 1, tree 2, tree 4, and tree 6) or an underestimation, meaning that the graphs for M1 and M2 lie below MM (for SITE1: tree 2 and tree 5, for SITE2: tree 3 and tree 7). For the remaining trees the regression function graphs for M1 and M2 intersect with MM. However, the regression function graph for M3 runs between MM and M1 or M2 and is always close to the points representing the data.
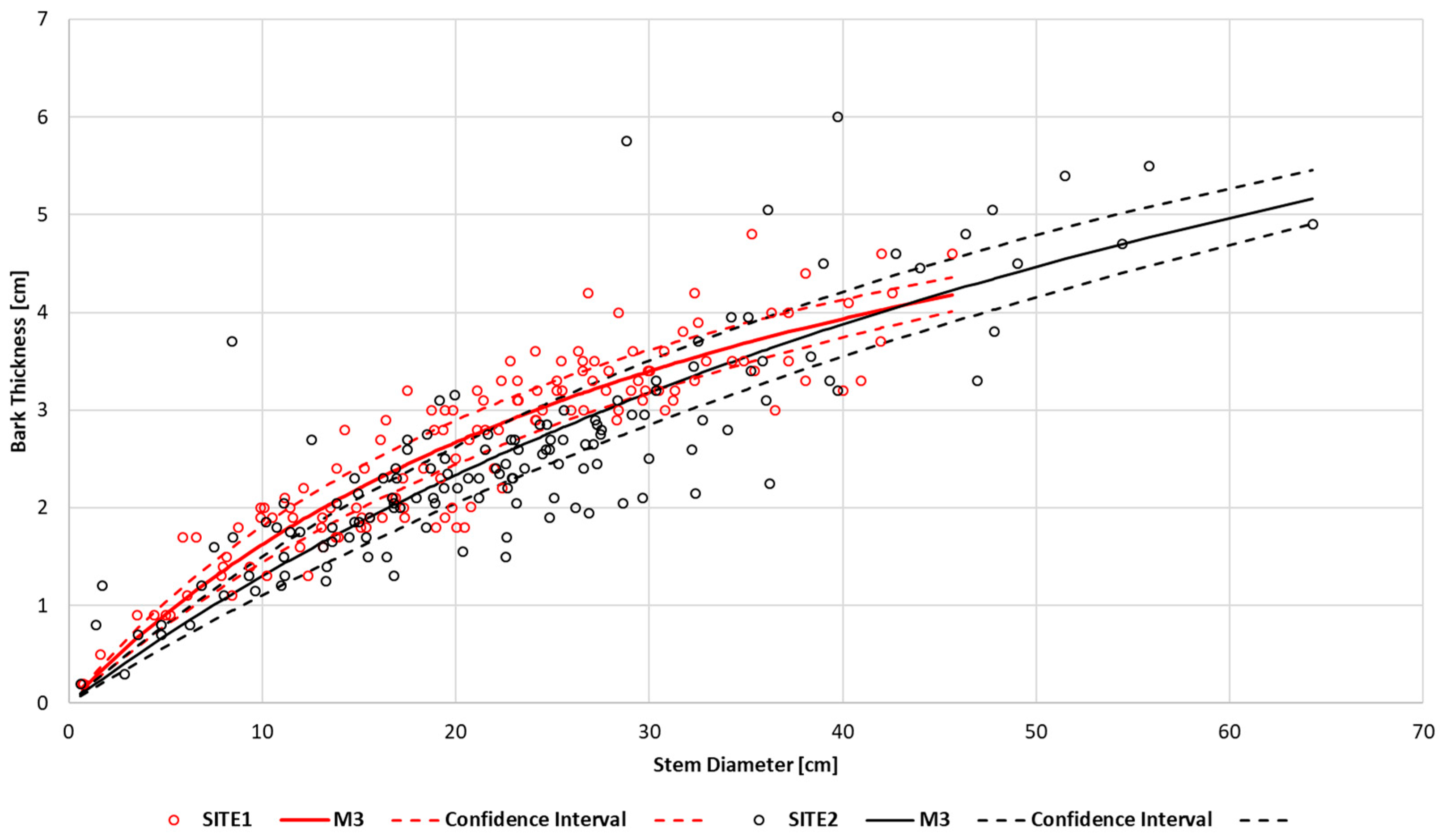
To demonstrate the regression functions of M3 for each location, it is necessary to average them as the values of the random effects differ for each tree.
Figure 6 presents the regression functions of M3 along with confidence intervals for locations SITE1 and SITE2. By comparing the course of the confidence interval graphs, it can be concluded that there are no significant differences between the average bark thicknesses at both locations. For this reason, we calculated the averaged regression function for both locations (
Figure 6,
Table 3). The overall fit of the resulting regression function is at a level of 19.67% (ATL). Regarding the analysis for individual trees, considering the differences between the average RMSE%, the average regression function’s fit compared to the MM for SITE1 was worse by 3.56% and for SITE2 by 2.51% (
Table 3). However, the individual fit of this function is worse than that of the M3 model but better than the fit of models M1 and M2.
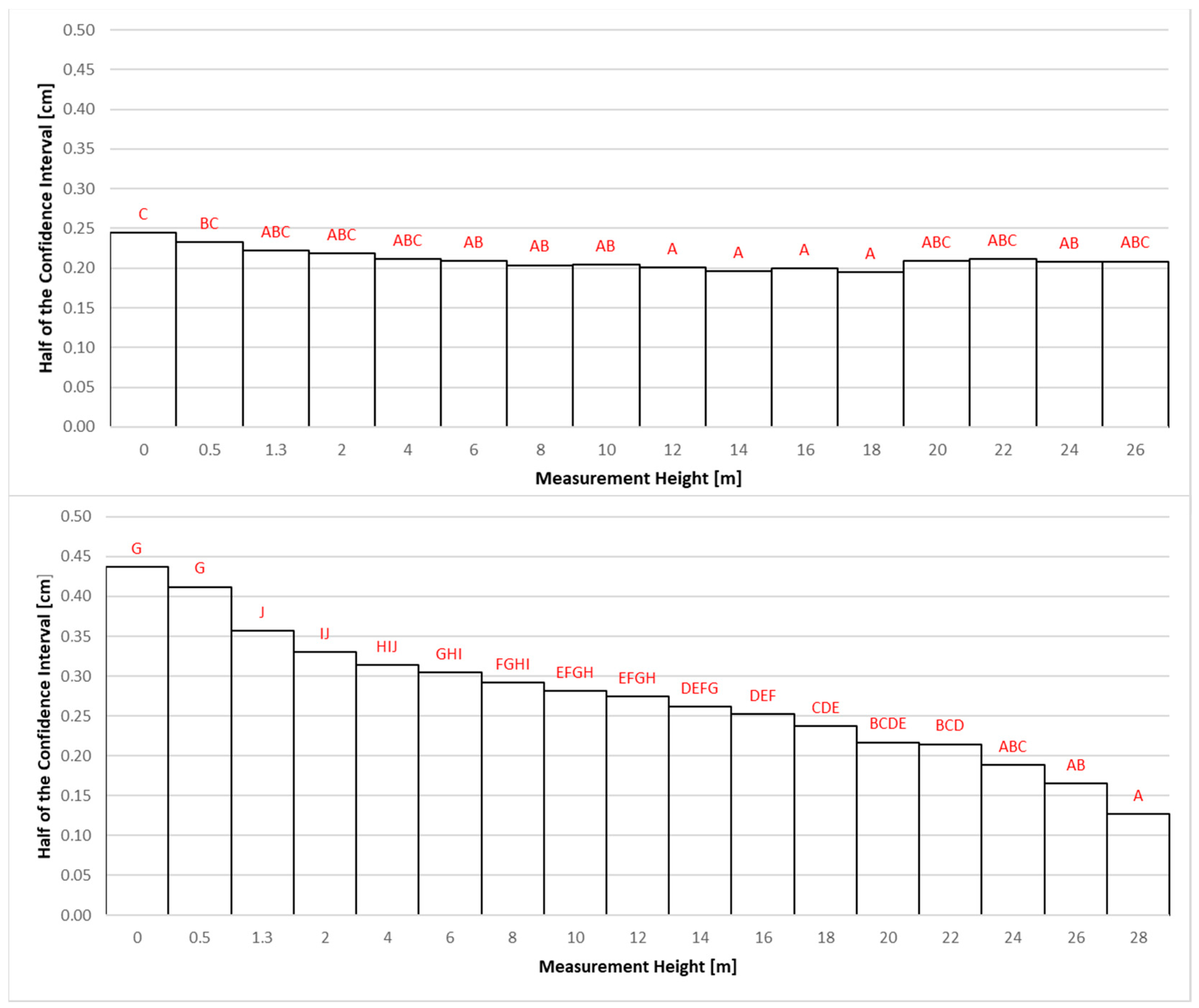
The final stage of the research was to check the accuracy of estimating the average thickness of bark at different measurement heights. For this purpose, at each height where the bark thickness was measured (0, 0.5, 1.3, 2 m, and then every 2 m up to the top), confidence interval halves were determined for the M3 regression function for both locations. Treating each tree as a replicate, a one-way analysis of variance was conducted. Homogeneous groups were established using Tukey’s test (
Figure 7).
In location SITE1, the largest deviations (the greatest prediction error of the average) from the estimated mean bark thickness were recorded at the base of the tree (0 m) and a height of 0.5 m (
Figure 7). The smallest deviations (the least prediction error of the average) were obtained at heights between 12 and 18 m. For location SITE2, a decrease in deviations from the estimated mean bark thickness (continuous improvement in average predictions) with an increase in measurement height can be observed. The largest deviations occurred at the tree’s base and heights of 0.5 m and 1.3 m, while the smallest were at 26 and 28 m heights. The observed differences in the precision of BT estimation between analysed sites may result from the difference in the age of the investigated trees (50 vs. 63 years). However, a clear pattern in which the lowest parts of the tree exhibit the highest inaccuracy is shared between the studied plots.
4. Discussion
In research on the variability of bark thickness (BT), the most commonly used explanatory variable is stem diameter (D), typically measured at a height of 1.3 m (DBH). Rosell [
33], using a linear regression function, demonstrated that stem diameter can explain 72% (calculated using R-squared) of the overall variability in BT. In our studies, due to the comparison of simple nonlinear models and nonlinearizable models (MM and M1) with complex nonlinear models (M2, M3), we could not apply the R-squared coefficient of determination. Instead, we used the RMSE% measure for model comparison. However, for model M3 we calculated the adjusted R-squared to compare our results with those obtained in other studies. The fit of our proposed regression function M3 for SITE1 was 87.44%, and for SITE2 it was 80.6%, indicating a significantly better explanation of BT variability by D compared to earlier works. Another advantage of the M3 regression model is that it estimates BT at any measurement height, not just at a height of 1.3 m (DBH).
Considering the complexity of the bark thickness models, modelling has two directions. In the first, simple linear regression models are used. In a study [
1], an analysis of bark thickness was conducted depending on stem diameter and the distance from the base of the stem. Simple models, referred to in our work as MM and M1, were utilised, and they are easy to apply in practice. At this study stage, we must know we will not obtain a universal regression function at ITL and ATL levels. Choosing the MM will result in significant errors in feature estimates for whole stands, and choosing M1 will not be a good choice for characterisation and comparisons at the ITL level.
Forecasting uses measurements at a single height to eliminate issues with repeated data (M2), i.e., DBH [
2,
5,
6]. This direction includes studies on tree mortality assessment (depending on BT) caused by fire [
4]. The applied simple logistic regression models were substitutes for more complex nonlinear models, M1, and did not require estimating starting values for iterative calculations. In modelling bark thickness, with the help of simple models MM or M1, an attempt was made to achieve more than 70% variability in BT as explained by R-squared. The downside of this approach was modelling BT based on a single D measurement at 1.3 m (DBH). Our proposed M3 regression model allows BT to be predicted from a D measurement at any tree height. The percentage of explained variation based on the M3 model can be more than 80% (the adjusted R-squared).
Models with more variables were selected, or artificial/transformed variables were introduced to explain as much variability as possible. In another study [
34], the thickness of the bark of
Pinus radiata D. Don was predicted based on the diameter above the bark, position up the stem, tree height, and diameter above the bark at breast height, as well as an artificial variable of the type (h/H)—level of measurement above ground [m]/total tree height [m]. Similarly, in another study [
35], the thickness of the bark at any point along the stem of
Eucalyptus pilularis,
E. obliqua,
E. andrewsii,
E. saligna, and
Corymbia maculata was estimated depending on the diameter above the bark at that point, the height above the ground at the measurement point along the stem, total tree height, and breast height above the bark. Similarly, some studies [
36,
37] present several variables related to differences in the structure of the bark and the proportions of the inner and outer bark. The strength of the MM function was its good individual fit for trees (ITL) and the use of only one D variable. Using a single explanatory variable makes it very easy to describe the characteristics of the tree, and good model fitting guarantees minor errors. The determined models MM, M1, M2, and M3 share the common feature of having only one explanatory variable.
Since our four presented models differ in calculating and considering correlations between measurements and random changes between trees, we show the advantages and disadvantages. The MM became a benchmark when comparing results for the more complex models M2 and M3 concerning individual fitting for each tree. In contrast, the advantage of the M1 model was its good overall fitting to all trees (ATL). As a result, the M1 model became the benchmark for the more complex models M2 and M3 regarding overall fitting to all trees. In contrast, the M3 model proved to be the most universal.
In the second direction of the research, complex regression models are used. The study in [
10] examined spatial dependencies or spatial autocorrelations. Relatively simple functions from the M2 model group were applied. Among the complex models, nonlinear regression functions with mixed effects were used [
11,
14]. However, these models did not consider the influence of correlations resulting from repeated measurements, meaning they were simple models serving as the basis for deriving the formula for the M3 model. A similar situation occurred in the studies [
38], where nonlinear regression functions used in harvesters to estimate the diameter under the bark were examined and modified based on bark measurements. The modifications to these functions [
39] were so complicated that SAS system 8.02 procedures [
40] NLIN, MIXED, and REG were used for the calculations. Considering the SAS system 8.02 procedures set, models such as M2 and M3 were complicated. A good example of the application of the complex M3 model is found in the study in [
16], which demonstrates how straightforward the results obtained from the complex M3 regression functions can be in practice. The application we present in this paper may suggest another direction of M3-like model usage, i.e., determination of the various parameters along the stem, which might be performed, e.g., by harvesters.
This research follows a similar trajectory to historical growth curve modelling studies (e.g., orange trees), where models evolved from simple functions to complex mixed-effects approaches [
18]. The results were re-evaluated in works [
41,
42], where a more complex logistic model of the growth curve was proposed. The last proposal for analysing this data was a model with repeated measures and random effects calculated using the NLINMIXED procedure in the SAS system in the study from [
21]. The NLINMIXED procedure was initially written to implement the algorithm of Lindstrom and Bates [
43]. Our research may reflect the described historical process of improving the regression model of the growth curve of orange trees.
We started with simple nonlinear MM and M1 models, whose advantages were a good fit at the ITL level for the MM and a good fit at the ATL level for the M1 model. Unfortunately, none of these models were nulliparous, meaning they fit well at both levels.
The second step was to use repeated measurements in the M2 model, i.e., we considered the correlations between measurements at different tree heights. The results obtained for model M2 indicated that considering the correlation between observations was a valid assumption. The M2 model at the ITL level was worse than the MM but better than the M1, and at the ATL level it was comparable to the M1 model.
In the third step of the model M2 we added random effects, resulting in the model M3. Model M3 accounted for random variations between the trees. For model M3 (ITL) at SITE1 the RMSE% coefficient obtained was on average 2.41% worse than MM, while at SITE2 it was 0.29% better (
Table 3). For all trees (ATL) the RMSE% for model M3 was 12.49% at SITE1 and 19.05% at SITE2, and it was better than the RMSE% of model M2 (SITE1 14.84% and SITE2 24.2%). Considering the above results, it can be said that the regression functions determined for model M3 (Equations (6) and (7)) meet both conditions set out for the work as they are well fitted both individually and overall for all trees, indicating that the objective of the work has been achieved.
In the final stage of the research, the regression functions designated according to the M3 model were used to check how the estimation error of bark thickness (the midpoint of the 95% confidence interval for the regression function) varies at different measurement heights (
Figure 7). The obtained results may indicate at which heights to measure the diameter to achieve the most accurate estimates of bark thickness. Due to our observation of a decrease in deviations from the forecasted average bark thickness with an increase in height, it is worthwhile to consider additional measurements at greater heights than DBH in practice. An elaborate model construction methodology may be used for programming algorithms in harvesters so that the under-bark volume of a stem or log could be calculated directly during its manipulation by the machine. It might also provide valuable solutions, e.g., biomass estimation modelling, so that the biomass of the bark component can be more easily calculated. However, those prospective applications require further studies on accuracy and workload.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}