
Improvement and Assessment of Convolutional Neural Network for Tree Species Identification Based on Bark Characteristics


Abstract
1. Introduction
2. Materials and Methods
2.1. Datasets
2.2. Methodology
2.2.1. Selection of the Networks
2.2.2. Setting of the Network Parameters
2.2.3. Visualization of the Network Workflow
3. Results and Analysis
3.1. Comparison of Identification Results
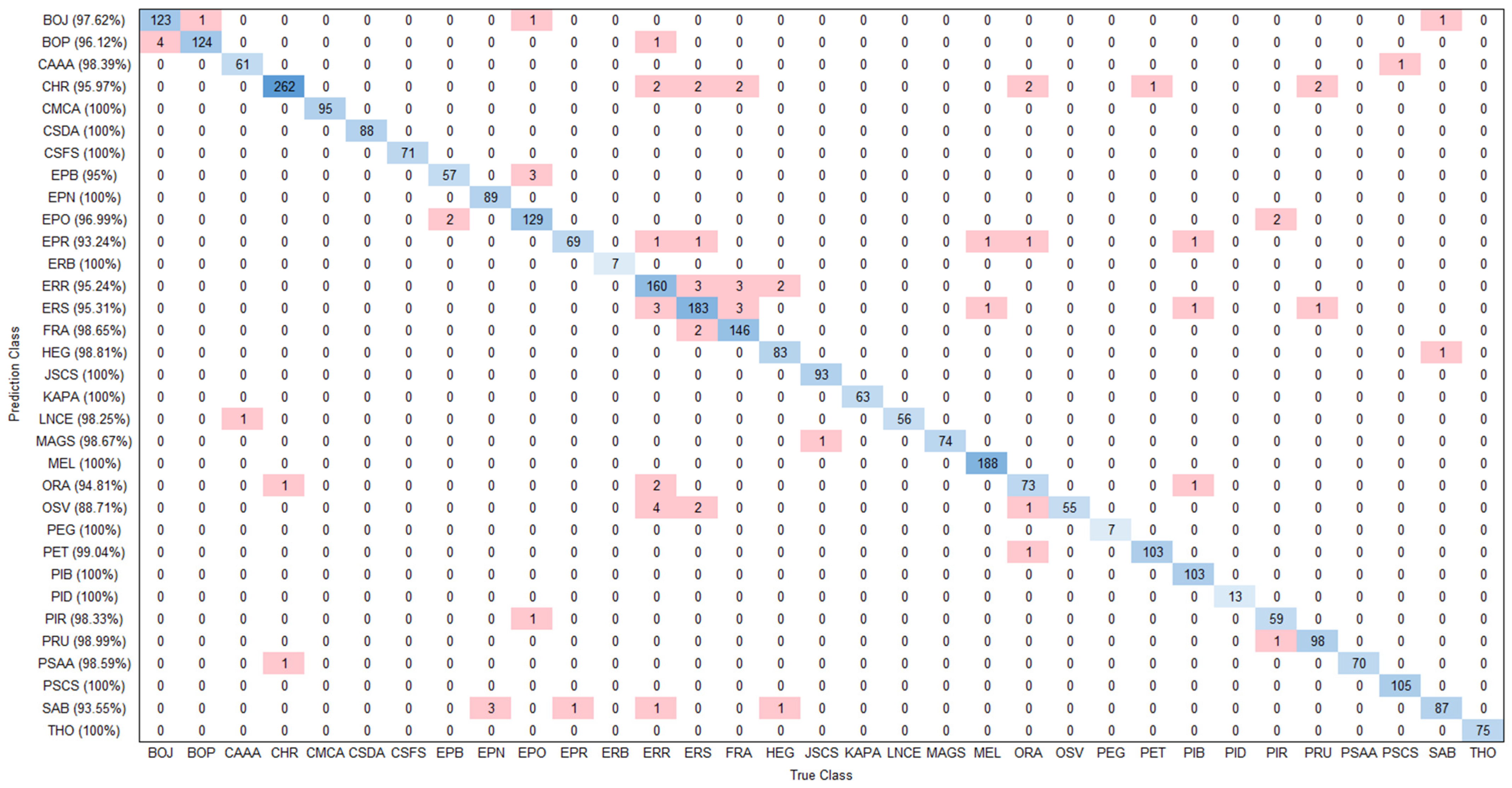
3.2. Identification Precision by Species
3.3. Visualization of Network Identification Process
3.3.1. Selection of Sample Images
3.3.2. Integrated Gradient Visualization
3.3.3. Class Activation Mapping Hot Spots
3.3.4. Image Depth Feature Decomposition
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Puri, M.; Pathak, Y.; Sutariya, V.K.; Tipparaju, S.; Moreno, W. Artificial Neural Network for Drug Design, Delivery and Disposition; Academic Press: Cambridge, UK, 2015. [Google Scholar]
- Brahme, A. Comprehensive Biomedical Physics; Brahme, A., Ed.; Elsevier: Amsterdam, The Netherlands, 2014; Volume 10. [Google Scholar]
- Xu, Z.Q.J.; Zhang, Y.Y.; Xiao, Y.Y. Training behavior of deep neural network in frequency domain. In Proceedings of the 26th International Conference on Neural Information Processing (ICONIP), Sydney, NSW, Australia, 12–15 December 2019; pp. 264–274. [Google Scholar] [CrossRef]
- Fiel, S.; Sablatnig, R. Automated identification of tree species from images of the bark, leaves or needles. In Proceedings of the 16th Computer Vision Winter Workshop, Graz, Austria, 3 February 2010; pp. 67–74. [Google Scholar]
- Wang, Y.; Zhang, W.; Gao, R.; Jin, Z.; Wang, X. Recent advances in the application of deep learning methods to forestry. Wood Sci. Technol. 2021, 55, 1171–1202. [Google Scholar] [CrossRef]
- Chi, Z.R.; Li, H.Q.; Wang, C. Plant species recognition based on bark patterns using novel Gabor filter banks. In Proceedings of the International Conference on Neural Networks and Signal Processing, Nanjing, China, 14–17 December 2003; Volume 2, pp. 1035–1038. [Google Scholar] [CrossRef]
- Kim, S.J.; Kim, B.W.; Kim, D.P. Tree recognition for land scape using by combination of features of its leaf, flower and bark. In Proceedings of the SICE Annual Conference, Tokyo, Japan, 13–18 September 2011; pp. 1147–1151. [Google Scholar]
- Blaanco, L.J.; Travieso, C.M.; Quinteiro, J.M.; Hernandez, P.V.; Dutta, M.K.; Singh, A. A bark recognition algorithm for plant classification using a least square support vector machine. In Proceedings of the Ninth International Conference on Contemporary Comput ing (IC3), Noida, India, 11–13 August 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Boudra, S.; Yahiaoui, I.; Behloul, A. Bark identification using improved statistical radial binary patterns. In Proceedings of the International Conference on Content-Based Multimedia Indexing (CBMI), La Rochelle, France, 4–6 September 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Reměs, V.; Haindl, M. Bark recognition using novel rotation ally invariant multispectral textural features. Pattern Recognit. Lett. 2019, 125, 612–617. [Google Scholar] [CrossRef]
- Bertrand, S.; Ameur, R.B.; Cerutti, G.; Coquin, D.; Valet, L.; Tougne, L. Bark and leaf fusion systems to improve auto matic tree species recognition. Ecol. Inform. 2018, 46, 27–73. [Google Scholar] [CrossRef]
- Ratajczak, R. Efficient bark recognition in the wild. In Proceedings of the International Conference on Computer Vision Theory and Applications—Volume 4 (VISAPP), Prague, Czech Republic, 25–27 February 2019; pp. 240–248. [Google Scholar] [CrossRef]
- Fekri-Ershad, S. Bark texture classification using improved local ternary patterns and multilayer neural network. Expert Syst. Appl. 2020, 158, 113509. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef] [PubMed]
- Chui, K.T.; Gupta, B.B.; Chi, H.R.; Zhao, M. Convolutional Neural Network and Deep One-Class Support Vector Machine with Imbalanced Dataset for Anomaly Network Traffic Detection. In Proceedings of the International Conference on Cyber Security, Privacy and Networking (ICSPN 2022), Fairfield, OH, USA, 3–11 July 2022; Volume 599, pp. 248–256. [Google Scholar] [CrossRef]
- Xin, M.Y.; Wang, Y. Research on image classification model based on deep convolution neural network. J. Image Video Process. 2019, 40, 1–11. [Google Scholar] [CrossRef]
- Choi, S. Plant Identification with Deep Convolutional Neural Network: SNUMedinfo at LifeCLEF Plant Identification Task 2015. In Proceedings of the Conference and Labs of the Evaluation Forum, Toulouse, France, 8–11 September 2015. [Google Scholar]
- Lee, S.H.; Chan, C.; Wilkin, P.; Remagnino, P. Deep-plant: Plant identification with convolutional neural networks. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 452–456. [Google Scholar] [CrossRef]
- Grinblat, G.L.; Uzal, L.C.; Larese, M.G.; Granitto, P.M. Deep learning for plant identification using vein morphological patterns. Comput. Electron. Agric. 2016, 127, 418–424. [Google Scholar] [CrossRef]
- Sun, Y.; Liu, Y.; Wang, G.; Zhang, H. Deep Learning for Plant Identification in Natural Environment. Comput. Intell. Neurosci. 2017, 6, 1–6. [Google Scholar] [CrossRef] [PubMed]
- Rawat, W.; Wang, Z.H. Deep Convolutional Neural Networks for Image Classification: A Comprehensive Review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef] [PubMed]
- He, K.M.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Carpentier, M.; Giguère, P.; Gaudreault, J. Tree Species Identification from Bark Images Using Convolutional Neural Networks. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1075–1081. [Google Scholar] [CrossRef]
- Misra, D.; Crispim, C.F.; Tougne, L. Patch-Based CNN Evaluation for Bark Classification. Eur. Conf. Comput. Vis. 2020, 12540, 197–212. [Google Scholar] [CrossRef]
- Robert, M.; Dallaire, P.; Giguère, P. Tree bark reidentification using a deep-learning feature descriptor. In Proceedings of the 17th Conference on Computer and Robot Vision (CRV), Ottawa, ON, Canada, 13–15 May 2020; pp. 25–32. [Google Scholar] [CrossRef]
- Faizal, S. Automated Identification of Tree Species by Bark Texture Classification Using Convolutional Neural Networks. Int. J. Res. Appl. Sci. Eng. Technol. 2022, 10, 1384–1392. [Google Scholar] [CrossRef]
- Kim, T.K.; Hong, J.; Ryu, D.; Kim, S.; Byeon, S.; Huh, W.; Kim, K.; Baek, G.H.; Kim, H.S. Identifying and extracting bark key features of 42 tree species using convolutional neural networks and class activation mapping. Sci. Rep. 2022, 12, 4772. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Mao, H.; Wu, C.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 11966–11976. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 9992–10002. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. Neural Inf. Process. Syst. 2019. submitted. [Google Scholar] [CrossRef]
- Sebastian, R. Machine Learning with PyTorch and Scikit-Learn: Develop Machine Learning and Deep Learning Models with Python; Liu, Y.X., Vahid, M., Dmytro, D., Eds.; Packt Publishing: Birmingham, UK, 2022. [Google Scholar]
- Sundararajan, M.; Taly, A.; Yan, Q. Axiomatic Attribution for Deep Networks. In Proceedings of the 34th International Conference on Machine Learning (ICML 17), Sydney, NSW, Australia, 6–11 August 2017; Volume 70. [Google Scholar] [CrossRef]
- Omeiza, D.; Speakman, S.; Cintas, C.; Weldemariam, K. Smooth Grad-CAM++: An Enhanced Inference Level Visualization Technique for Deep Convolutional Neural Network Models. Intell. Syst. Conf. 2019. submitted. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Das, A.; Vedantam, R.; Cogswell, M.; Parikh, D.; Batra, D. Grad-CAM: Why did you say that? Visual Explana tions from Deep Networks via Gradient-based Localization. arXiv 2019, arXiv:1610.02391. [Google Scholar] [CrossRef]
- Smilkov, D.; Thorat, N.; Kim, B.; Viégas, F.B.; Wattenberg, M. SmoothGrad: Removing noise by adding noise. arXiv 2017, arXiv:1706.03825. [Google Scholar] [CrossRef]
- Collins, E.; Achanta, R.; Süsstrunk, S. Deep Feature Factorization for Concept Discovery. arXiv 2018, arXiv:1806.10206. [Google Scholar] [CrossRef]
- Kapishnikov, A.; Venugopalan, S.; Avci, B.; Wedin, B.; Terry, M.; Bolukbasi, T. Guided Integrated Gradients: An Adaptive Path Method for Removing Noise. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 5050–5058. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar] [CrossRef]
- Ruan, D.; Yan, Y.; Lai, S.Q.; Chai, Z.H.; Shen, C.H.; Wang, H.Z. Feature Decomposition and Reconstruction Learning for Effective Facial Expression Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13967–13976. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Collaborators | Dataset Name | Species | Number of Images | Dataset Size | Creation Year |
|---|---|---|---|---|---|
| Truong Hoang | BarkVN 50 | 50 | 5578 | 185 MB | 2020 |
| Rémi Ratajczak | Bark 101 | 101 | 2592 | 317 MB | 2019 |
| Matic Švab | TRUNK 12 | 12 | 360 | 1.1 GB | 2014 |
| Tae Kyung | BARK-KR | 54 | 6918 | 9.77 GB | 2021 |
| Carpentier | BarkNet 1.0 | 23 | 23616 | 30.1 GB | 2017 |
| Cui | BarkNJ | 10 | 7671 | 21.4 GB | 2023 |
| ID | Species | Common Name | Species Index | Number of Trees | Number of Images |
|---|---|---|---|---|---|
| 1 | Abies balsamea | Balsam fir | SAB | 41 | 922 |
| 2 | Acer platanoides | Norway maple | ERB | 1 | 70 |
| 3 | Acer rubrum | Red maple | ERR | 64 | 1676 |
| 4 | Acer saccharum | Sugar maple | ERS | 81 | 1911 |
| 5 | Betula alleghaniensis | Yellow birch | BOJ | 43 | 1255 |
| 6 | Betula papyrifera | White birch | BOP | 32 | 1285 |
| 7 | Camptotheca acuminata | Campo tree | CAAA | 28 | 620 |
| 8 | Cedrus deodara | Deodar cedar | CSDA | 43 | 874 |
| 9 | Cinnamomum camphora | Camphor wood | CMCA | 49 | 947 |
| 10 | Cupressus funebris | Cypress wood | CSFS | 38 | 710 |
| 11 | Fagus grandifolia | American beech | HEG | 41 | 840 |
| 12 | Fraxinus americana | White ash | FRA | 61 | 1472 |
| 13 | Juniperus chinensis | Round cypress | JSCS | 52 | 927 |
| 14 | Koelreuteria paniculata | Golden rain tree | KAPA | 35 | 627 |
| 15 | Larix laricina | Tamarack | MEL | 77 | 1874 |
| 16 | Liriodendron chinense | Liriodendron | LNCE | 33 | 562 |
| 17 | Metasequoia glyptostroboides | Redwood | MAGS | 50 | 743 |
| 18 | Ostrya virginiana | American hophornbeam | OSV | 29 | 612 |
| 19 | Picea abies | Norway spruce | EPO | 72 | 1324 |
| 20 | Picea glauca | White spruce | PIR | 44 | 596 |
| 21 | Picea mariana | Black spruce | EPN | 44 | 885 |
| 22 | Picea rubens | Red spruce | EPR | 27 | 740 |
| 23 | Pinus rigida | Pitch pine | PID | 4 | 123 |
| 24 | Pinus resinosa | Red pine | EPB | 29 | 596 |
| 25 | Pinus strobus | Eastern white pine | PIB | 39 | 1023 |
| 26 | Platanus acerifolia | Plane tree | PSAA | 47 | 705 |
| 27 | Populus canadensis | Canadian poplar | PSCS | 69 | 1044 |
| 28 | Populus grandidentata | Big-tooth aspen | PEG | 3 | 64 |
| 29 | Populus tremuloides | Quaking aspen | PET | 58 | 1037 |
| 30 | Quercus rubra | Northern red oak | CHR | 109 | 2724 |
| 31 | Thuja occidentalis | Northern white cedar | THO | 38 | 746 |
| 32 | Tsuga canadensis | Eastern hemlock | PRU | 45 | 986 |
| 33 | Ulmus americana | American elm | ORA | 24 | 767 |
| Total | NA | NA | NA | 1398 | 31,287 |
| Network | Parameters (M) | Channels | Stage | Flops (G) | Accuracy (ImageNet-1k) |
|---|---|---|---|---|---|
| ConvNeXt-T(tiny) | 28.59 | (96, 192, 384, 768) | (3, 3, 9, 3) | 4.46 | 82.1% |
| ConvNeXt-S(small) | 50.22 | (96, 192, 384, 768) | (3, 3, 27, 3) | 8.69 | 83.1% |
| ConvNeXt-B(base) | 88.59 | (128, 256, 512, 1024) | (3, 3, 27, 3) | 15.36 | 85.1% |
| ConvNeXt-L(large) | 197.77 | (192, 384, 768, 1536) | (3, 3, 27, 3) | 34.37 | 85.5% |
| Network | Batch Size | Image Size | Learning Rate | Learning Rate Schedule | Training Epochs | Warm-Up Epochs |
|---|---|---|---|---|---|---|
| ConvNeXt-T | 32 | 224 × 224 | 1 × 10−3 | Cosine decay | 50 | 10 |
| ConvNeXt-S | 32 | 224 × 224 | 1 × 10−3 | Cosine decay | 50 | 10 |
| ConvNeXt-B | 32 | 224 × 224 | 1 × 10−3 | Cosine decay | 50 | 10 |
| Species Index | Scientific Name | Test Image | Mean | Std | Accuracy |
|---|---|---|---|---|---|
| BOJ | Betula alleghaniensis | 126 | 0.7952 | 0.1451 | 97.62% |
| BOP | Betula papyrifera | 129 | 0.7899 | 0.1701 | 96.12% |
| CAAA | Camptotheca acuminata | 62 | 0.8049 | 0.1104 | 98.39% |
| CHR | Quercus rubra | 273 | 0.7528 | 0.1713 | 95.97% |
| CMCA | Cinnamomum camphora | 95 | 0.8344 | 0.0354 | 100.00% |
| CSDA | Cedrus deodara | 88 | 0.8262 | 0.0328 | 100.00% |
| CSFS | Cupressus funebris | 71 | 0.7988 | 0.0697 | 100.00% |
| EPB | Pinus resinosa | 60 | 0.7465 | 0.2051 | 95.00% |
| EPN | Picea mariana | 89 | 0.8049 | 0.0794 | 100.00% |
| EPO | Picea abies | 133 | 0.7760 | 0.1517 | 96.99% |
| EPR | Picea rubens | 74 | 0.7925 | 0.1594 | 93.24% |
| ERB | Acer platanoides | 7 | 0.7662 | 0.1027 | 100.00% |
| ERR | Acer rubrum | 168 | 0.7654 | 0.1646 | 95.24% |
| ERS | Acer saccharum | 192 | 0.7215 | 0.2241 | 95.31% |
| FRA | Fraxinus americana | 148 | 0.8041 | 0.0846 | 98.65% |
| HEG | Fagus grandifolia | 84 | 0.7993 | 0.1348 | 98.81% |
| JSCS | Juniperus chinensis | 93 | 0.8190 | 0.0936 | 100.00% |
| KAPA | Koelreuteria paniculata | 63 | 0.8299 | 0.0307 | 100.00% |
| LNCE | Liriodendron chinense | 57 | 0.7917 | 0.0907 | 98.25% |
| MAGS | Metasequoia glyptostroboides | 75 | 0.7926 | 0.1030 | 98.67% |
| MEL | Larix laricina | 188 | 0.8451 | 0.0323 | 100.00% |
| ORA | Ulmus americana | 77 | 0.7246 | 0.1991 | 94.81% |
| OSV | Ostrya virginiana | 62 | 0.7519 | 0.1867 | 88.71% |
| PEG | Populus grandidentata | 7 | 0.9040 | 0.0805 | 100.00% |
| PET | Populus tremuloides | 104 | 0.8061 | 0.0889 | 99.04% |
| PIB | Pinus strobus | 103 | 0.7855 | 0.1454 | 100.00% |
| PID | Pinus rigida | 13 | 0.7917 | 0.1131 | 100.00% |
| PIR | Picea glauca | 60 | 0.7904 | 0.1546 | 98.33% |
| PRU | Tsuga canadensis | 99 | 0.8027 | 0.1131 | 98.99% |
| PSAA | Platanus acerifolia | 71 | 0.8106 | 0.0573 | 98.59% |
| PSCS | Populus canadensis | 105 | 0.8280 | 0.0295 | 100.00% |
| SAB | Abies balsamea | 93 | 0.7572 | 0.1913 | 93.55% |
| THO | Thuja occidentalis | 75 | 0.8108 | 0.0501 | 100.00% |
| True Class | Prediction Top-K Accuracy | ||||
|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | Sum of Top-n | |
| MEL (Larix laricina) | 0.865 (MEL) | 0.007 (ERR) | 0.007 (ERS) | 0.007 (ERR) | 0.133 |
| EPO (Picea abies) | 0.830 (EPO) | 0.014 (MEL) | 0.012 (EPR) | 0.009 (ERR) | 0.117 |
| LNCE (Liriodendron chinense) | 0.834 (LNCE) | 0.012 (ERR) | 0.011 (CHR) | 0.008 (PET) | 0.136 |
| MAGS (Metasequoia glyptostroboides) | 0.856 (MAGS) | 0.007 (MEL) | 0.007 (FRA) | 0.006 (SAB) | 0.123 |
| SAB (Abies balsamea) | 0.569 (EPN) | 0.272 (SAB) | 0.020 (EPO) | 0.011 (PIR) | 0.128 |
| ERS (Acer saccharum) | 0.644 (FRA) | 0.131 (CHR) | 0.080 (ERS) | 0.018 (ERR) | 0.127 |
| OSV (Ostrya virginiana) | 0.853 (ERR) | 0.012 (PIB) | 0.011 (FRA) | 0.010 (LNCE) | 0.114 |
| CAAA (Camptotheca acuminata) | 0.770 (PSCS) | 0.028 (FRA) | 0.020 (ERR) | 0.013 (THO) | 0.169 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, Z.; Li, X.; Li, T.; Li, M. Improvement and Assessment of Convolutional Neural Network for Tree Species Identification Based on Bark Characteristics. Forests 2023, 14, 1292. https://doi.org/10.3390/f14071292
Cui Z, Li X, Li T, Li M. Improvement and Assessment of Convolutional Neural Network for Tree Species Identification Based on Bark Characteristics. Forests. 2023; 14(7):1292. https://doi.org/10.3390/f14071292
Chicago/Turabian StyleCui, Zhelin, Xinran Li, Tao Li, and Mingyang Li. 2023. "Improvement and Assessment of Convolutional Neural Network for Tree Species Identification Based on Bark Characteristics" Forests 14, no. 7: 1292. https://doi.org/10.3390/f14071292
APA StyleCui, Z., Li, X., Li, T., & Li, M. (2023). Improvement and Assessment of Convolutional Neural Network for Tree Species Identification Based on Bark Characteristics. Forests, 14(7), 1292. https://doi.org/10.3390/f14071292