
Forest Fire Prediction Based on Long- and Short-Term Time-Series Network




Abstract
1. Introduction
2. Materials and Methods
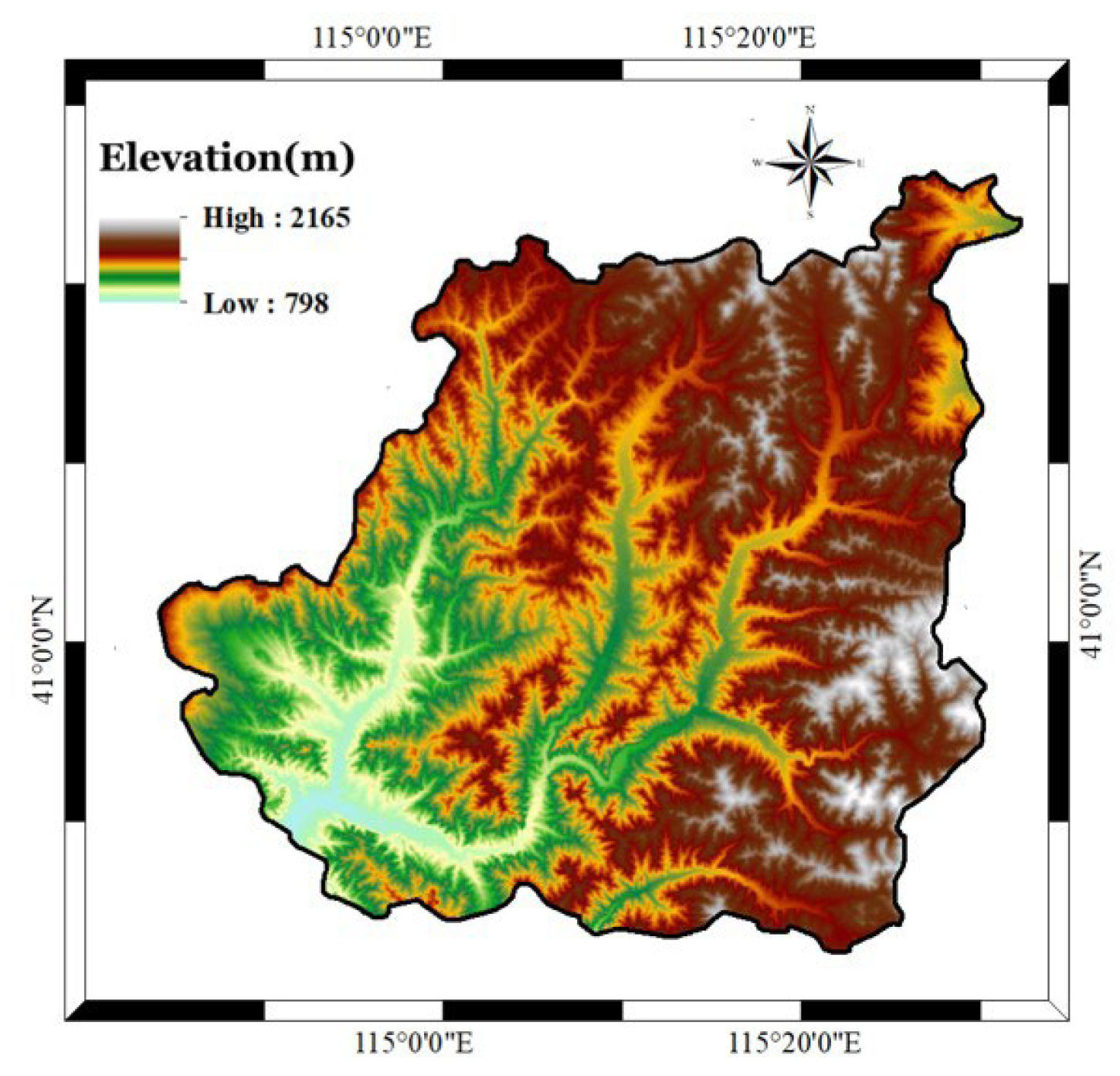
2.1. Overview of the Study Area
2.2. Generations of Data Sets
2.2.1. Data Source
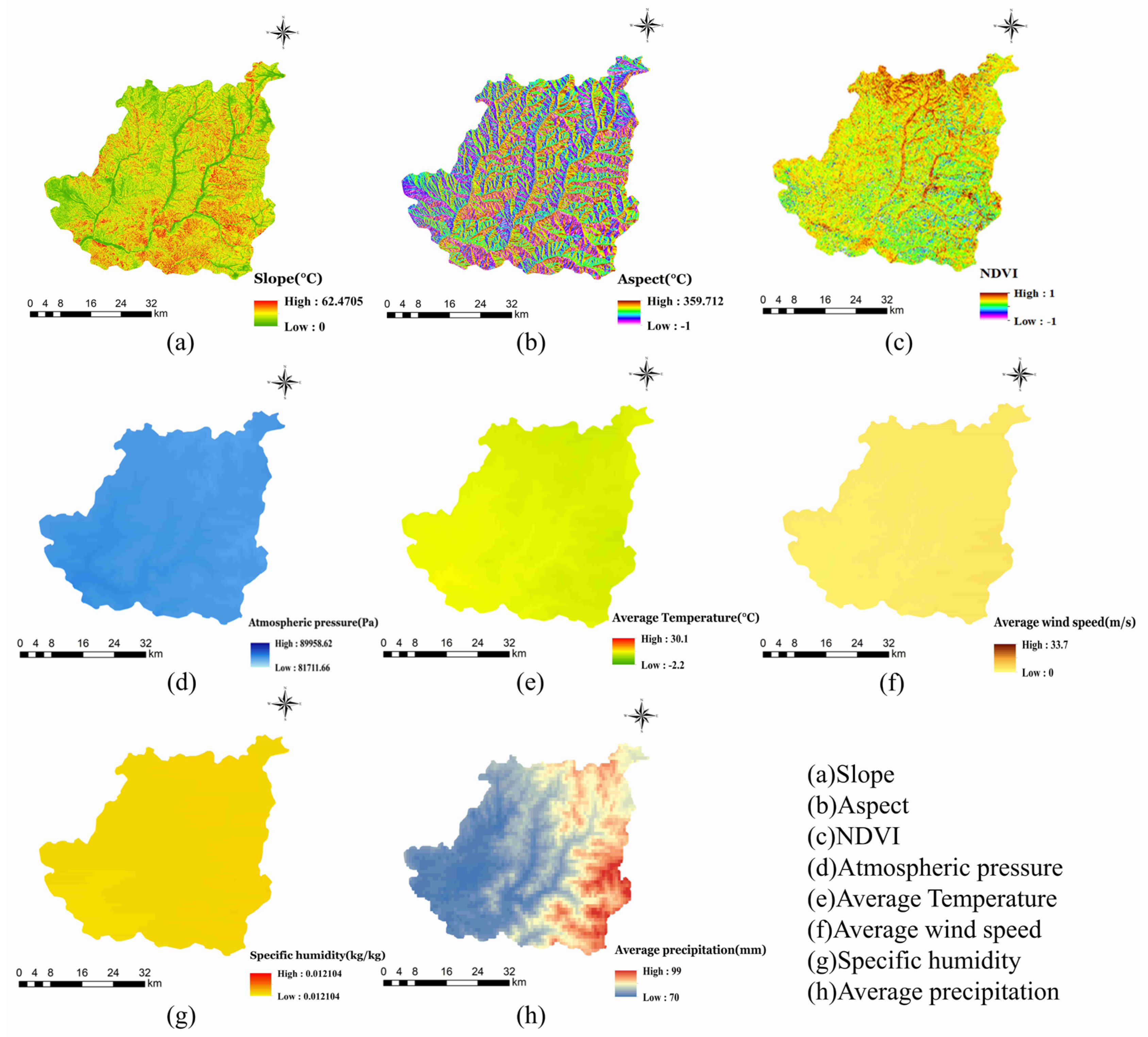
2.2.2. Factors Influencing Forest Fires
2.3. Impact Factor Assessment
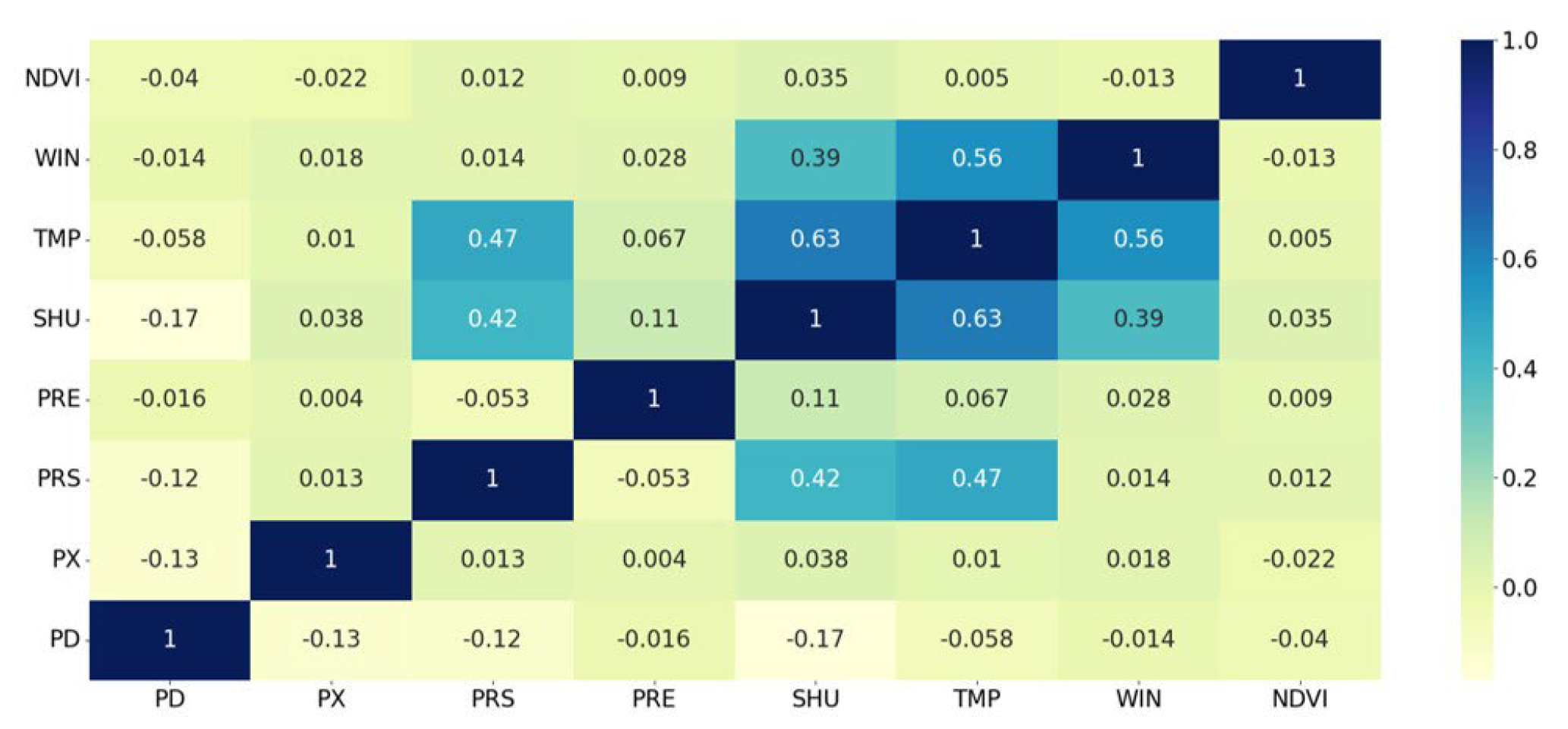
2.3.1. Pearson Analysis
2.3.2. Multicollinearity Test
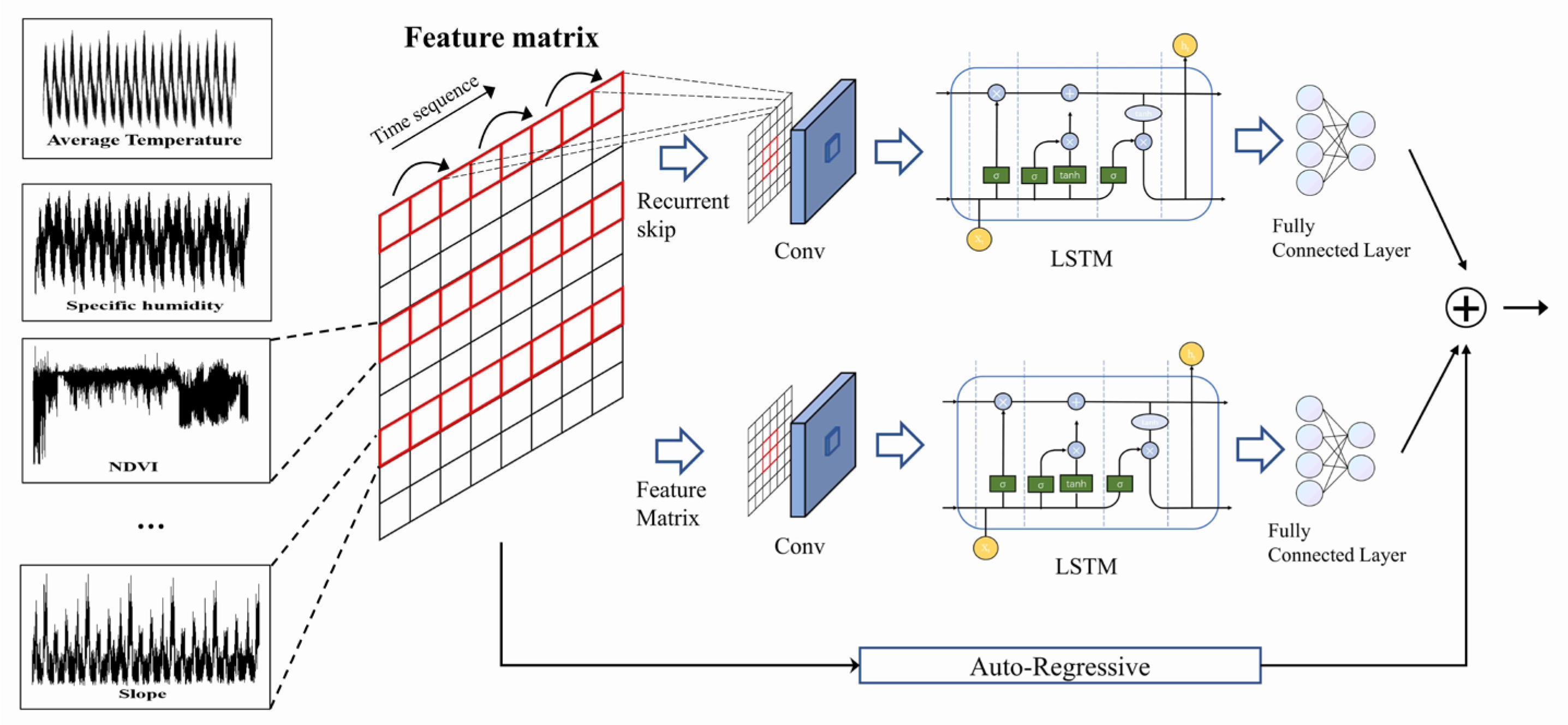
2.4. Algorithm Model
2.4.1. Convolutional Component
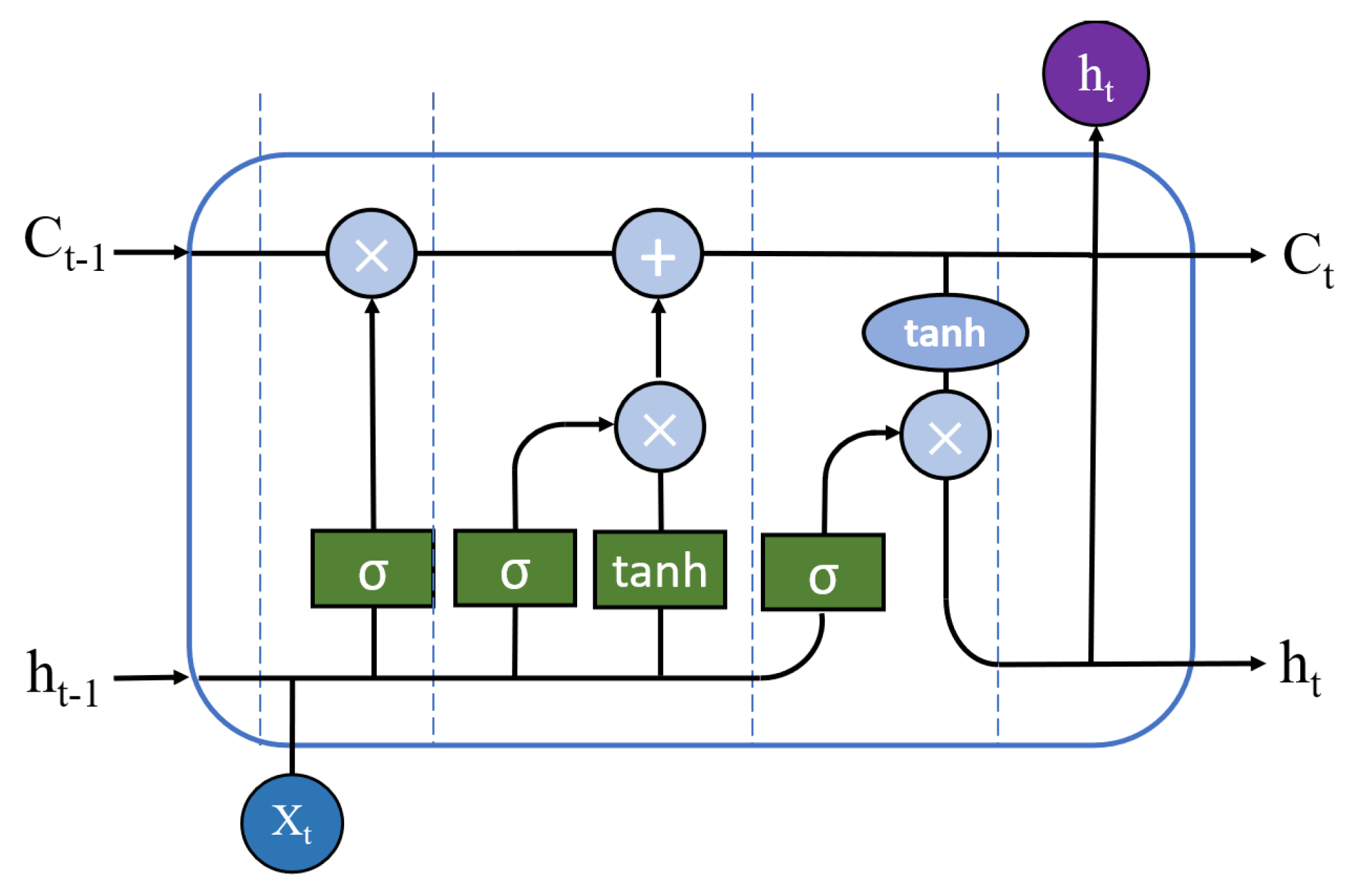
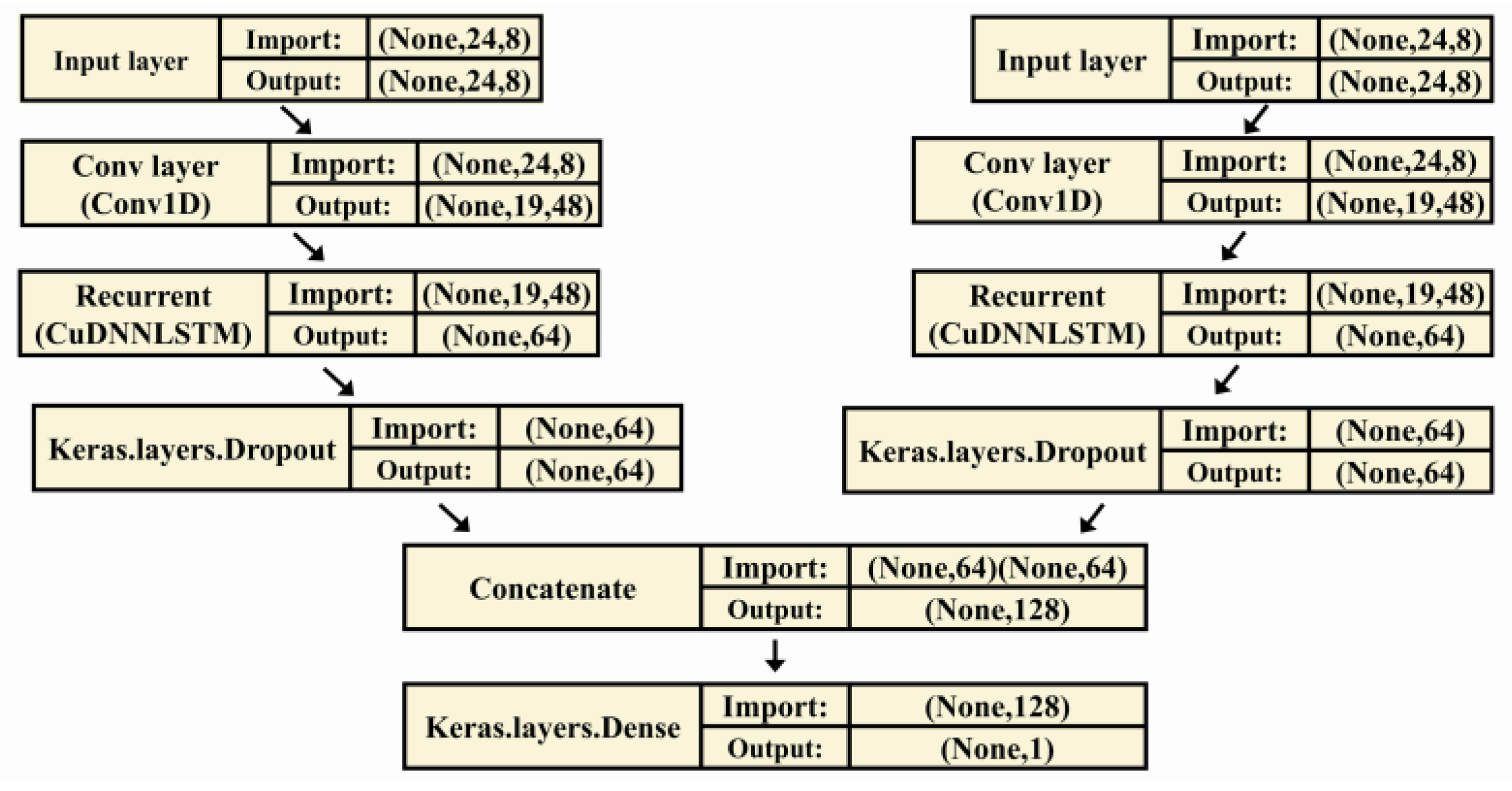
2.4.2. Recurrent Component
2.4.3. Recurrent-Skip Component
2.4.4. Autoregressive Component
3. Results
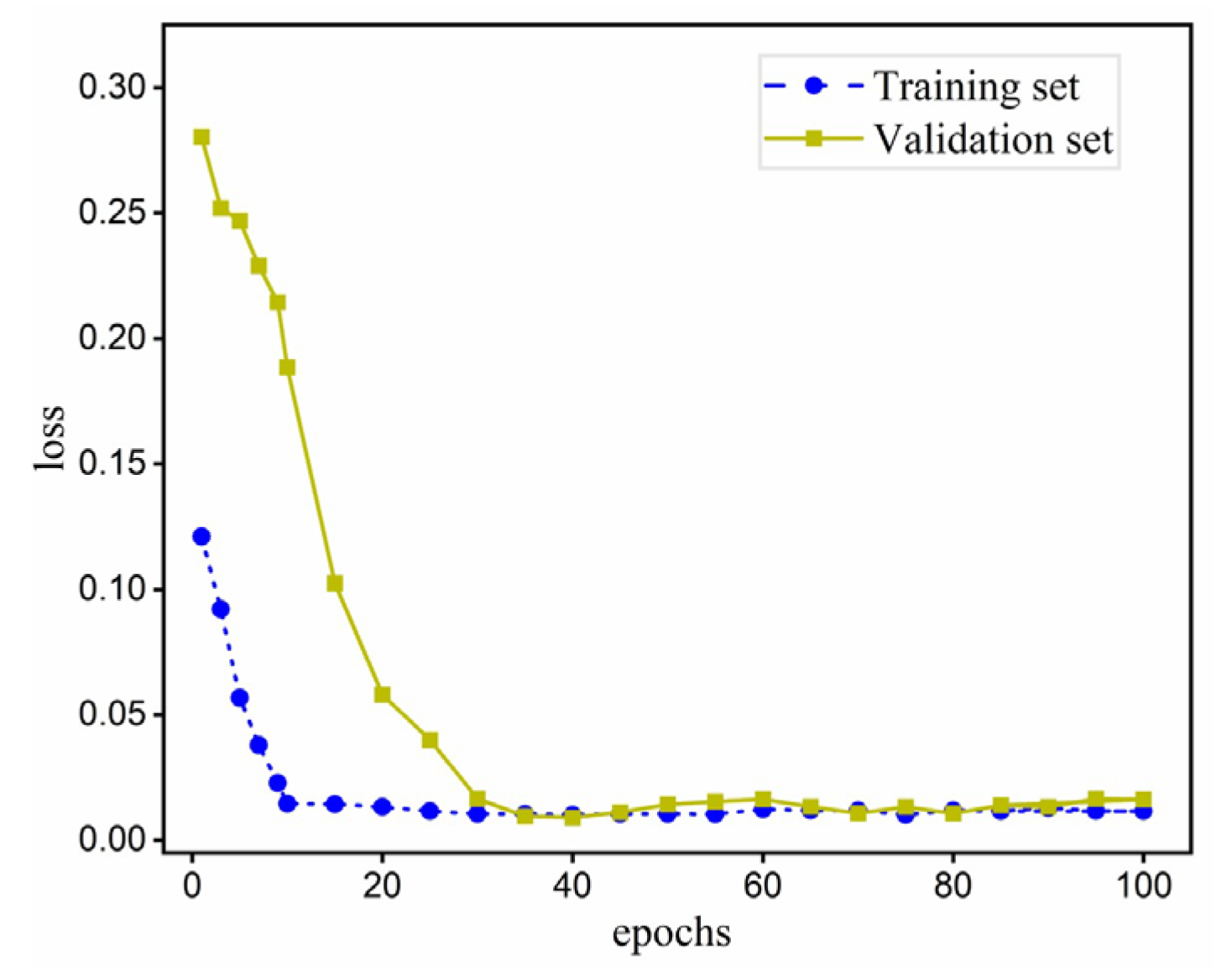
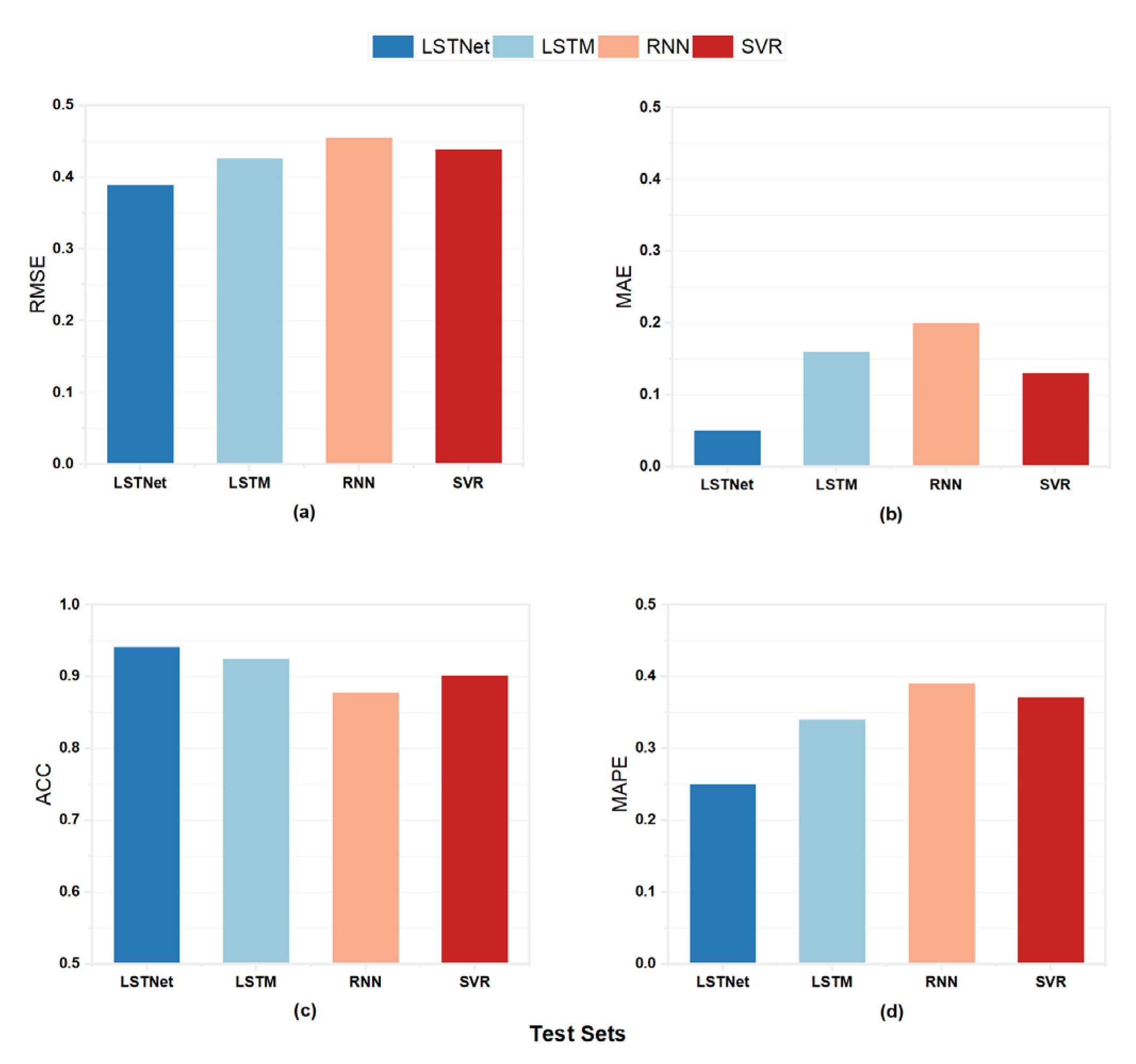
3.1. Model Parameters and Accuracy
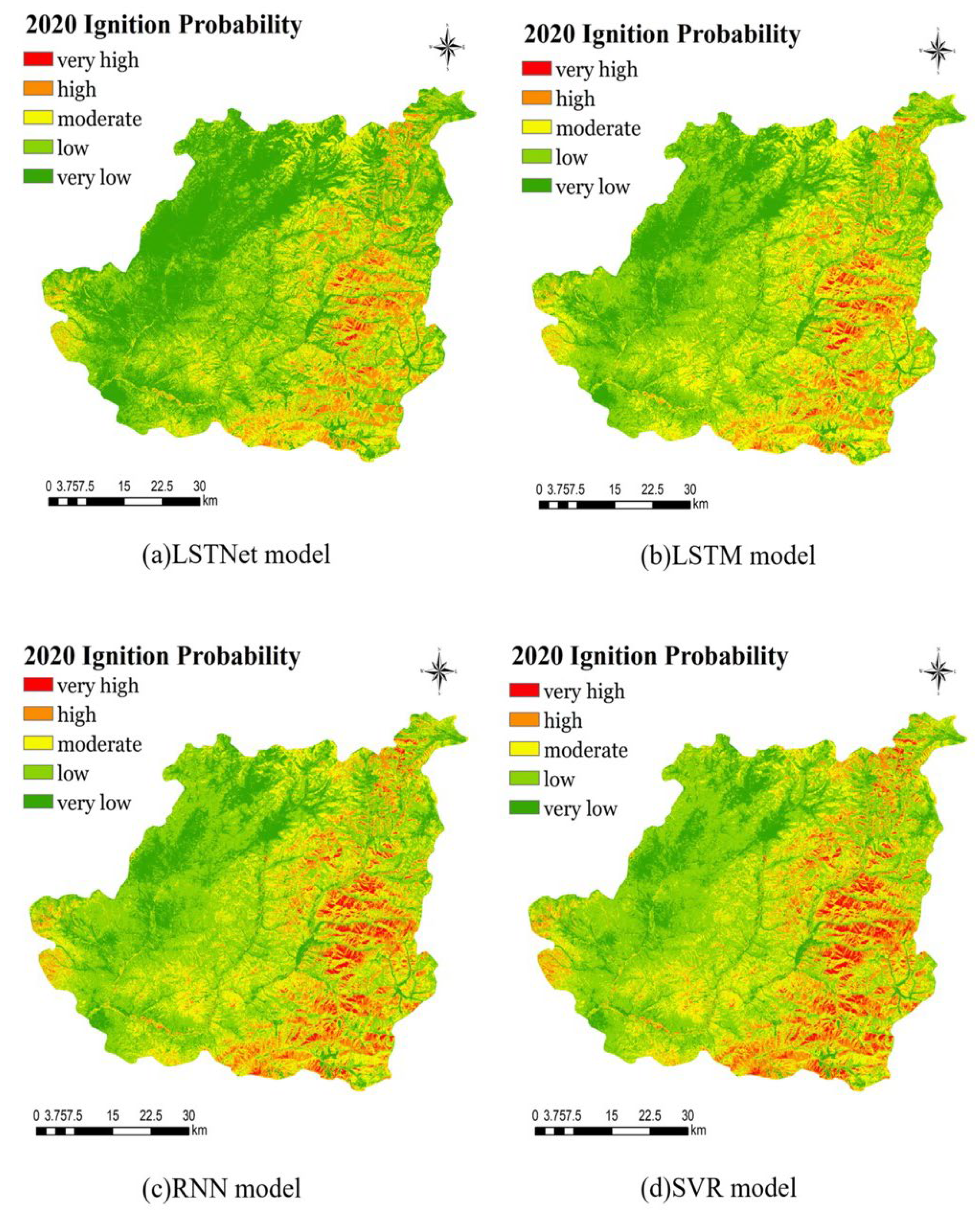
3.2. Forest Fire Susceptibility Mapping
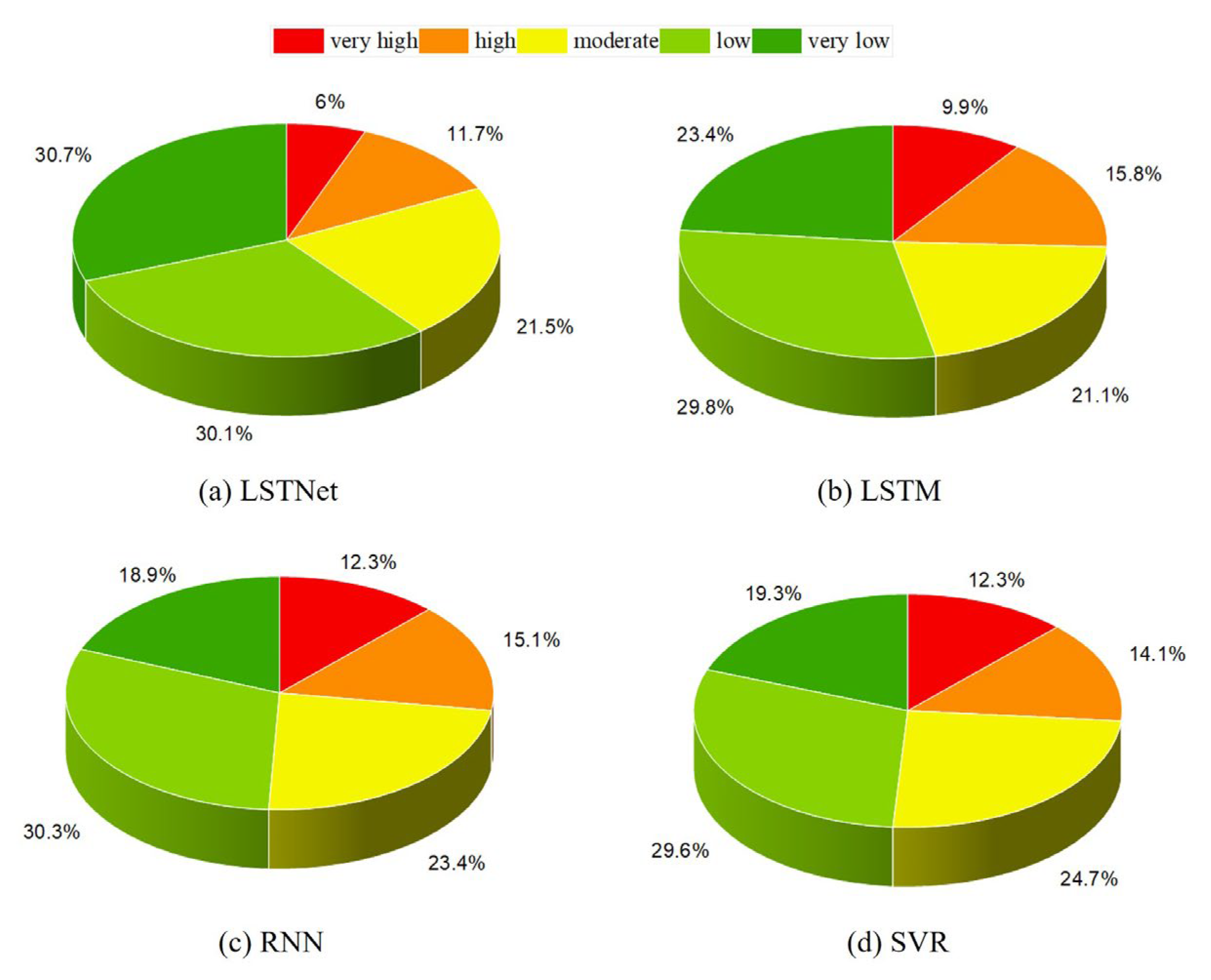
3.3. Predicted Forest Fire Class Distribution of Various Models
4. Discussion
4.1. Model Evaluation Metrics
4.2. Model Comparison
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hao-ruo, Y. Studies on Controlling Strategy for Forest Fire under the Global Warm Climate. 2009. Available online: https://typeset.io/papers/studies-on-controlling-strategy-for-forest-fire-under-the-pf9obfpr6x (accessed on 6 March 2023).
- Pechony, O.; Shindell, D.T. Driving forces of global wildfires over the past millennium and the forthcoming century. Proc. Natl. Acad. Sci. USA 2010, 107, 19167–19170. [Google Scholar] [CrossRef]
- Cisneros, R.; Schweizer, D.W.; Tarnay, L.; Navarro, K.M.; Veloz, D.; Procter, C.T. Climate Change, Forest Fires, and Health in California. In Climate Change and Air Pollution; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Zhang, Y.; Qin, D.; Yuan, W.; Jia, B. Historical trends of forest fires and carbon emissions in China from 1988 to 2012. J. Geophys. Res. Biogeosci. 2016, 121, 2506–2517. [Google Scholar] [CrossRef]
- Mahalingam, S.; Deep, M.S.; Krishna, K.S. Wireless Sensor Based Forest Fire Early Detection with Online Remote Monitoring. Int. J. Eng. Adv. Technol. 2021, 10, 143–145. [Google Scholar] [CrossRef]
- Fried, J.S.; Gilless, J.K.; Riley, W.J.; Moody, T.J.; Simón de Blas, C.; Hayhoe, K.; Moritz, M.A.; Stephens, S.L.; Torn, M.S. Predicting the effect of climate change on wildfire behavior and initial attack success. Clim. Change 2008, 87, 251–264. [Google Scholar] [CrossRef]
- Fried, J.S.; Torn, M.S.; Mills, E. The Impact of Climate Change on Wildfire Severity: A Regional Forecast for Northern California. Clim. Change 2004, 64, 169–191. [Google Scholar] [CrossRef]
- Baranovskiy, N.V.; Podorovskiy, A.; Malinin, A. Parallel Implementation of the Algorithm to Compute Forest Fire Impact on Infrastructure Facilities of JSC Russian Railways. Algorithms 2021, 14, 333. [Google Scholar] [CrossRef]
- Barmpoutis, P.; Papaioannou, P.; Dimitropoulos, K.; Grammalidis, N. A Review on Early Forest Fire Detection Systems Using Optical Remote Sensing. Sensors 2020, 20, 6442. [Google Scholar] [CrossRef] [PubMed]
- Sakr, G.E.; Elhajj, I.H.; Mitri, G.H. Efficient forest fire occurrence prediction for developing countries using two weather parameters. Eng. Appl. Artif. Intell. 2011, 24, 888–894. [Google Scholar] [CrossRef]
- Pradeep, G.S.; Prasad, M.K.; Kuriakose, S.L.; Ajin, R.S.; Oniga, V.E.; Rajaneesh, A.; Mammen, P.C.; Patel, N.; Nikhil, S.; Danumah, J.H. Forest Fire Risk Zone Mapping of Eravikulam National Park in India. Croat. J. For. Eng. 2021, 43, 199–217. [Google Scholar] [CrossRef]
- Bowman, D.; Williamson, G.J. River Flows Are a Reliable Index of Forest Fire Risk in the Temperate Tasmanian Wilderness World Heritage Area, Australia. Fire 2021, 4, 22. [Google Scholar] [CrossRef]
- Gülçin, D.; Deniz, B. Remote sensing and GIS-based forest fire risk zone mapping: The case of Manisa, Turkey. Turk. J. For./Türkiye Orman. Derg. 2020, 21, 15–24. [Google Scholar] [CrossRef]
- Maffei, C.; Lindenbergh, R.C.; Menenti, M. Combining multi-spectral and thermal remote sensing to predict forest fire characteristics. ISPRS J. Photogramm. Remote Sens. 2021, 181, 400–412. [Google Scholar] [CrossRef]
- Jin, R.-X.; Lee, K.S. Investigation of Forest Fire Characteristics in North Korea Using Remote Sensing Data and GIS. Remote Sens. 2022, 14, 5836. [Google Scholar] [CrossRef]
- Tian, Y.; Wu, Z.; Li, M.; Wang, B.; Zhang, X. Forest Fire Spread Monitoring and Vegetation Dynamics Detection Based on Multi-Source Remote Sensing Images. Remote Sens. 2022, 14, 4431. [Google Scholar] [CrossRef]
- Cunningham, A.A.; Martell, D.L. A Stochastic Model for the Occurrence of Man-caused Forest Fires. Can. J. For. Res. 1973, 3, 282–287. [Google Scholar] [CrossRef]
- Shi, S.; Yao, C.; Wang, S.; Han, W. A Model Design for Risk Assessment of Line Tripping Caused by Wildfires. Sensors 2018, 18, 1941. [Google Scholar] [CrossRef]
- Kalantar, B.; Ueda, N.; Idrees, M.O.; Janizadeh, S.; Ahmadi, K.; Shabani, F. Forest Fire Susceptibility Prediction Based on Machine Learning Models with Resampling Algorithms on Remote Sensing Data. Remote Sens. 2020, 12, 3682. [Google Scholar] [CrossRef]
- Ye, Q.; Huang, P.; Zhang, Z.; Zheng, Y.; Fu, L.; Yang, W. Multiview Learning With Robust Double-Sided Twin SVM. IEEE Trans. Cybern. 2021, 52, 12745–12758. [Google Scholar] [CrossRef]
- Dampage, U.; Bandaranayake, L.; Wanasinghe, R.; Kottahachchi, K.; Jayasanka, B. Forest fire detection system using wireless sensor networks and machine learning. Sci. Rep. 2021, 12, 46. [Google Scholar] [CrossRef]
- Qiu, J.; Wang, H.; Shen, W.; Zhang, Y.; Su, H.; Li, M. Quantifying Forest Fire and Post-Fire Vegetation Recovery in the Daxin’anling Area of Northeastern China Using Landsat Time-Series Data and Machine Learning. Remote Sens. 2021, 13, 792. [Google Scholar] [CrossRef]
- Xu, R.; Lin, H.X.; Lu, K.; Cao, L.; Liu, Y. A Forest Fire Detection System Based on Ensemble Learning. Forests 2021, 12, 217. [Google Scholar] [CrossRef]
- Bui, D.T.; Le, K.; Nguyen, V.C.; Le, H.D.; Revhaug, I. Tropical Forest Fire Susceptibility Mapping at the Cat Ba National Park Area, Hai Phong City, Vietnam, Using GIS-Based Kernel Logistic Regression. Remote Sens. 2016, 8, 347. [Google Scholar]
- Chang, Y.; Zhu, Z.; Bu, R.; Chen, H.; Feng, Y.-t.; Li, Y.; Hu, Y.; Wang, Z. Predicting fire occurrence patterns with logistic regression in Heilongjiang Province, China. Landsc. Ecol. 2013, 28, 1989–2004. [Google Scholar] [CrossRef]
- Bisquert, M.; Caselles, E.; Sánchez, J.M.; Caselles, V. Application of artificial neural networks and logistic regression to the prediction of forest fire danger in Galicia using MODIS data. Int. J. Wildland Fire 2012, 21, 1025–1029. [Google Scholar] [CrossRef]
- Oliveira, S.; Oehler, F.; San-Miguel-Ayanz, J.; Camia, A. Modeling spatial patterns of fire occurrence in Mediterranean Europe using Multiple Regression and Random Forest. For. Ecol. Manag. 2012, 275, 117–129. [Google Scholar] [CrossRef]
- Satir, O.; Berberoglu, S.; Donmez, C. Mapping regional forest fire probability using artificial neural network model in a Mediterranean forest ecosystem. Geomat. Nat. Hazards Risk 2016, 7, 1645–1658. [Google Scholar] [CrossRef]
- Fan, R.; Pei, M. Lightweight Forest Fire Detection Based on Deep Learning. In Proceedings of the 2021 IEEE 31st International Workshop on Machine Learning for Signal Processing (MLSP), Gold Coast, QLD, Australia, 25–28 October 2021; pp. 1–6. [Google Scholar]
- Sathishkumar, V.E.; Cho, J.; Subramanian, M.; Naren, O.S. Forest fire and smoke detection using deep learning-based learning without forgetting. Fire Ecol. 2023, 19, 9. [Google Scholar] [CrossRef]
- Bui, D.T.; Bui, Q.-T.; Nguyen, Q.-P.; Pradhan, B.; Nampak, H.; Trinh, P.T. A hybrid artificial intelligence approach using GIS-based neural-fuzzy inference system and particle swarm optimization for forest fire susceptibility modeling at a tropical area. Agric. For. Meteorol. 2017, 233, 32–44. [Google Scholar]
- Kang, Y.; Jang, E.; Im, J.; Kwon, C.G. A deep learning model using geostationary satellite data for forest fire detection with reduced detection latency. GISci. Remote Sens. 2022, 59, 2019–2035. [Google Scholar] [CrossRef]
- Guo, F.t.; Hu, H.q.; Ma, Z.H.; Zhang, Y. Applicability of different models in simulating the relationships between forest fire occurrence and weather factors in Daxing’an Mountains. J. Appl. Ecol. 2010, 21, 159–164. [Google Scholar]
- Fu, L.; Zhang, D.; Ye, Q. Recurrent Thrifty Attention Network for Remote Sensing Scene Recognition. IEEE Trans. Geosci. Remote Sens. 2020, 59, 8257–8268. [Google Scholar] [CrossRef]
- Mohajane, M.; Costache, R.; Karimi, F.; Pham, Q.B.; Essahlaoui, A.; Nguyen, H.; Laneve, G.; Oudija, F. Application of remote sensing and machine learning algorithms for forest fire mapping in a Mediterranean area. Ecol. Indic. 2021, 129, 107869. [Google Scholar] [CrossRef]
- Guo, F.; Zhang, L.; Jin, S.; Tigabu, M.; Su, Z.; Wang, W. Modeling Anthropogenic Fire Occurrence in the Boreal Forest of China Using Logistic Regression and Random Forests. Forests 2016, 7, 250. [Google Scholar] [CrossRef]
- Natekar, S.; Patil, S.; Nair, A.; Roychowdhury, S. Forest Fire Prediction using LSTM. In Proceedings of the 2021 2nd International Conference for Emerging Technology (INCET), Belgaum, India, 21–23 May 2021; pp. 1–5. [Google Scholar]
- Murali Mohan, K.V.; Satish, A.R.; Mallikharjuna Rao, K.; Yarava, R.K.; Babu, G.C. Leveraging Machine Learning to Predict Wild Fires. In Proceedings of the 2021 2nd International Conference on Smart Electronics and Communication (ICOSEC), Trichy, India, 7–9 October 2021; pp. 1393–1400. [Google Scholar]
- Jiang, K.; Chen, L.; Wang, X.; An, F.; Zhang, H.; Yun, T. Simulation on Different Patterns of Mobile Laser Scanning with Extended Application on Solar Beam Illumination for Forest Plot. Forests 2022, 13, 2139. [Google Scholar] [CrossRef]
- Fu, J.J.; Wu, Z.W.; Yan, S.J.; Zhang, Y.; Gu, X.; Du, L. Effects of climate, vegetation, and topography on spatial patterns of burn severity in the Great Xing’an Mountains. Acta Ecol. Sin. 2020, 40, 1672–1682. [Google Scholar]
- Li, W.; Xu, Q.; Yi, J.-h.; Liu, J. Predictive model of spatial scale of forest fire driving factors: A case study of Yunnan Province, China. Sci. Rep. 2022, 12, 19029. [Google Scholar] [CrossRef] [PubMed]
- Guo, F.; Wang, G.; Su, Z.; Liang, H.; Wenhui, W.; Lin, F.; Liu, A. What drives forest fire in Fujian, China? Evidence from logistic regression and Random Forests. Int. J. Wildland Fire 2016, 25, 505–519. [Google Scholar] [CrossRef]
- Ma, W.; Feng, Z.; Cheng, Z.; Chen, S.; Wang, F. Identifying Forest Fire Driving Factors and Related Impacts in China Using Random Forest Algorithm. Forests 2020, 11, 507. [Google Scholar] [CrossRef]
- Sharma, K.M.; Thapa, G.B. Analysis and interpretation of forest fire data of Sikkim. For. Soc. 2021, 5, 261–276. [Google Scholar] [CrossRef]
- Zhu, Y.; Li, D.; Fan, J.; Zhang, H.; Eichhorn, M.P.; Wang, X.; Yun, T. A reinterpretation of the gap fraction of tree crowns from the perspectives of computer graphics and porous media theory. Front. Plant Sci. 2023, 14, 115. [Google Scholar] [CrossRef]
- Bajocco, S.; Dragoz, E.; Gitas, I.Z.; Smiraglia, D.; Salvati, L.; Ricotta, C. Mapping Forest Fuels through Vegetation Phenology: The Role of Coarse-Resolution Satellite Time-Series. PLoS ONE 2015, 10, e0119811. [Google Scholar] [CrossRef] [PubMed]
- Schulte, L.A.; Mladenoff, D.J. Severe Wind and Fire Regimes in Northern Forests: Historical Variability at the Regional Scale. Ecology 2005, 86, 431–445. [Google Scholar] [CrossRef]
- Tobler, W. A Computer Movie Simulating Urban Growth in the Detroit Region. Econ. Geogr. 1970, 46, 234–240. [Google Scholar] [CrossRef]
- Liang, H.; Zhang, M.; Wang, H. A Neural Network Model for Wildfire Scale Prediction Using Meteorological Factors. IEEE Access 2019, 7, 176746–176755. [Google Scholar] [CrossRef]
- Lai, G.; Chang, W.-C.; Yang, Y.; Liu, H. Modeling Long- and Short-Term Temporal Patterns with Deep Neural Networks. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2017. [Google Scholar]
- Kong, W.; Dong, Z.Y.; Jia, Y.; Hill, D.J.; Xu, Y.; Zhang, Y. Short-Term Residential Load Forecasting Based on LSTM Recurrent Neural Network. IEEE Trans. Smart Grid 2019, 10, 841–851. [Google Scholar] [CrossRef]
- Zhang, Z.; Yang, Y.; Zhao, H.; Xiao, R. Prediction method of line loss rate in low-voltage distribution network based on multi-dimensional information matrix and dimensional attention mechanism-long-and short-term time-series network. IET Gener. Transm. Distrib. 2022, 16, 4187–4203. [Google Scholar] [CrossRef]
- Zaremba, W.; Sutskever, I.; Vinyals, O. Recurrent Neural Network Regularization. arXiv 2014, arXiv:1409.2329. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Data | Scale/Resolution Original | Unit | Original Data Format | Source |
|---|---|---|---|---|---|
| 1 | Slope | 30 m | m | Raster | ASTER GDEM |
| 2 | Aspect | 30 m | degree | Raster | |
| 3 | NDVI | 500 m | Raster | Sentinel-2 | |
| 4 | Average temperature | - | °C | NetCDF | CIMISS |
| 5 | Average precipitation | - | kg/m2 | NetCDF | |
| 6 | Average wind speed | - | m/s | NetCDF | |
| 7 | Specific humidity | - | kg/kg | NetCDF | |
| 8 | Atmospheric pressure | - | Pa | NetCDF |
| No. | Forest Fire Influencing Factor | TOL | VIF |
|---|---|---|---|
| 1 | Slope | 0.945 | 1.058 |
| 2 | Aspect | 0.982 | 1.018 |
| 3 | NDVI | 0.996 | 1.004 |
| 4 | Average temperature | 0.394 | 2.536 |
| 5 | Average precipitation | 0.971 | 1.030 |
| 6 | Average wind speed | 0.592 | 1.690 |
| 7 | Specific humidity | 0.554 | 1.804 |
| 8 | Atmospheric pressure | 0.644 | 1.554 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, X.; Li, Z.; Chen, W.; Sun, X.; Gao, D. Forest Fire Prediction Based on Long- and Short-Term Time-Series Network. Forests 2023, 14, 778. https://doi.org/10.3390/f14040778
Lin X, Li Z, Chen W, Sun X, Gao D. Forest Fire Prediction Based on Long- and Short-Term Time-Series Network. Forests. 2023; 14(4):778. https://doi.org/10.3390/f14040778
Chicago/Turabian StyleLin, Xufeng, Zhongyuan Li, Wenjing Chen, Xueying Sun, and Demin Gao. 2023. "Forest Fire Prediction Based on Long- and Short-Term Time-Series Network" Forests 14, no. 4: 778. https://doi.org/10.3390/f14040778
APA StyleLin, X., Li, Z., Chen, W., Sun, X., & Gao, D. (2023). Forest Fire Prediction Based on Long- and Short-Term Time-Series Network. Forests, 14(4), 778. https://doi.org/10.3390/f14040778