


Lightweight Model Design and Compression of CRN for Trunk Borers’ Vibration Signals Enhancement

Abstract
1. Introduction
2. Materials and Methods
2.1. Struct of Lightweight Vibration Signal Enhancement Model
2.2. Loss Function
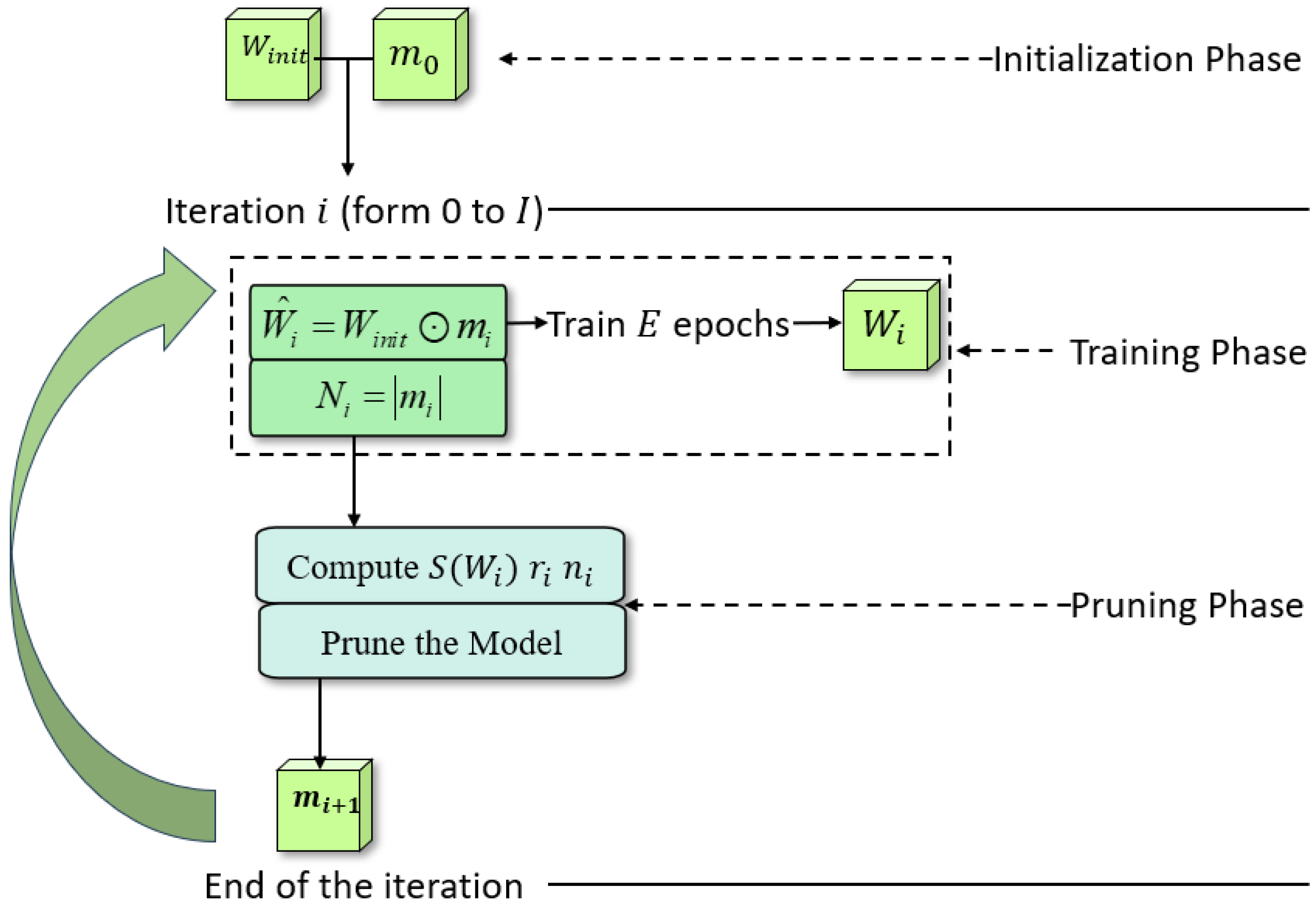
2.3. Pruning Algorithm
2.3.1. Sparsity Measure
2.3.2. Dynamic Pruning Algorithm Based on Sparsity
3. Collection and Preprocessing of Dataset
- We carefully calibrated and tested our vibration signal collector to ensure its reliability and accuracy in capturing the signals. We also followed strict protocols during the data collection, ensuring consistent placement of the probes and maintaining stable recording conditions.
- We cross-validated the collected data by conducting multiple rounds of data collection for each tree segment. This helped to minimize any potential variability or outliers in the dataset.
- The visual inspection of the larvae inside the tree trunks served as an additional validation step, which means after data collection, we peeled off the bark under the guidance of the forestry personnel and directly observed EAB larvae and SCM larvae inside the trunk.
4. Experiment
4.1. Experimental Setup
4.2. Evaluation Metrics
4.3. Details of Experiments
4.3.1. Experiment I
4.3.2. Experiment II
4.3.3. Experiment III
4.3.4. Experiment IV
5. Results
5.1. Results and Analysis of Experiment I
5.2. Results and Analysis of Experiment II
5.3. Results and Analysis of Experiment III
5.4. Results and Analysis of Experiment IV
6. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jha, K.; Doshi, A.; Patel, P.; Shah, M. A comprehensive review on automation in agriculture using artificial intelligence. Intell. Agric. 2019, 2, 1–12. [Google Scholar] [CrossRef]
- Pearce, D.W.; Pearce, C.G. The Value of Forest Ecosystems; Centre for Social and Economic Research on the Global Environment (CSERGE): Norfolk, UK, 2001. [Google Scholar]
- Fiala, P.; Friedl, M.; Cap, M.; Konas, P.; Smira, P.; Naswettrova, A. Non destructive method for detection wood-destroying insects. In Proceedings of the PIERS Proceedings, Guangzhou, China, 25–28 August 2014; pp. 1642–1646. [Google Scholar]
- Sutin, A.; Yakubovskiy, A.; Salloum, H.R.; Flynn, T.J.; Sedunov, N.; Nadel, H. Towards an automated acoustic detection algorithm for wood-boring beetle larvae (Coleoptera: Cerambycidae and Buprestidae). J. Econ. Entomol. 2019, 112, 1327–1336. [Google Scholar] [CrossRef] [PubMed]
- Farr, I.; Chesmore, D. Automated Bioacoustic Detection and Identification of Wood-Boring Insects for Quarantine Screening and Insect Ecology; University of York: York, UK, 2007; pp. 201–208. [Google Scholar]
- Mankin, R.W.; Mizrach, A.; Hetzroni, A.; Levsky, S.; Nakache, Y.; Soroker, V. Temporal and spectral features of sounds of wood-boring beetle larvae: Identifiable patterns of activity enable improved discrimination from background noise. Fla. Entomol. 2008, 91, 241–248. [Google Scholar] [CrossRef]
- Bilski, P.; Bobiński, P.; Krajewski, A.; Witomski, P. Detection of wood boring insects’ larvae based on the acoustic signal analysis and the artificial intelligence algorithm. Arch. Acoust. 2016, 42, 61–70. [Google Scholar] [CrossRef][Green Version]
- Korinšek, G.; Tuma, T.; Virant-Doberlet, M. Automated vibrational signal recognition and playback. In Biotremology: Studying Vibrational Behavior; Springer: Berlin/Heidelberg, Germany, 2019; pp. 149–173. [Google Scholar]
- Sun, Y.; Tuo, X.; Jiang, Q.; Zhang, H.; Chen, Z.; Zong, S.; Luo, Y. Drilling vibration identification technique of two pest based on lightweight neural networks. Sci. Silvae Sin. 2020, 56, 100–108. [Google Scholar]
- Wang, D.L. On ideal binary mask as the computational goal of auditory scene analysis. In Speech Separation by Humans and Machines; Springer: Berlin/Heidelberg, Germany, 2005; pp. 181–197. [Google Scholar]
- Wang, D.; Brown, G.J. Computational Auditory Scene Analysis: Principles, Algorithms, and Applications; Wiley: Hoboken, NJ, USA; IEEE: Piscataway, NJ, USA, 2006. [Google Scholar]
- Wang, D.; Chen, J. Supervised speech separation based on deep learning: An overview. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 1702–1726. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Wang, D. Towards scaling up classification-based speech separation. IEEE Trans. Audio Speech Lang. Process. 2013, 21, 1381–1390. [Google Scholar] [CrossRef]
- Healy, E.W.; Yoho, S.E.; Wang, Y.; Wang, D. An algorithm to improve speech recognition in noise for hearing-impaired listeners. J. Acoust. Soc. Am. 2013, 134, 3029–3038. [Google Scholar] [CrossRef]
- Weninger, F.; Hershey, J.R.; Le Roux, J.; Schuller, B. Discriminatively trained recurrent neural networks for single-channel speech separation. In Proceedings of the 2014 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Atlanta, GA, USA, 3–5 December 2014; pp. 577–581. [Google Scholar]
- Weninger, F.; Erdogan, H.; Watanabe, S.; Vincent, E.; Le Roux, J.; Hershey, J.R.; Schuller, B. Speech enhancement with LSTM recurrent neural networks and its application to noise-robust ASR. In Proceedings of the Latent Variable Analysis and Signal Separation: 12th International Conference, LVA/ICA 2015, Liberec, Czech Republic, 25–28 August 2015; pp. 91–99. [Google Scholar]
- Park, S.R.; Lee, J. A fully convolutional neural network for speech enhancement. arXiv 2016, arXiv:1609.07132. [Google Scholar]
- Rethage, D.; Pons, J.; Serra, X. A wavenet for speech denoising. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5069–5073. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.; Le, Q.V.; Salakhutdinov, R. Transformer-xl: Attentive language models beyond a fixed-length context. arXiv 2019, arXiv:1901.02860. [Google Scholar]
- Zhou, S.; Dong, L.; Xu, S.; Xu, B. A comparison of modeling units in sequence-to-sequence speech recognition with the transformer on Mandarin Chinese. In Proceedings of the 25th International Conference, ICONIP 2018, Siem Reap, Cambodia, 13–16 December 2018; pp. 210–220. [Google Scholar]
- Lin, T.; Wang, Y.; Liu, X.; Qiu, X. T-gsa: Transformer with gaussian-weighted self-attention for speech enhancement. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 9 April 2020; pp. 6649–6653. [Google Scholar]
- Yu, W.; Zhou, J.; Wang, H.; Tao, L. SETransformer: Speech enhancement transformer. In Cognitive Computation; Springer: Berlin/Heidelberg, Germany, 2022; pp. 1–7. [Google Scholar]
- Wang, K.; He, B.; Zhu, W.P. TSTNN: Two-stage transformer based neural network for speech enhancement in the time domain. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 13 May 2021; pp. 6649–6653. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Qiu, Z.; Yao, T.; Mei, T. Deep quantization: Encoding convolutional activations with deep generative model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6759–6768. [Google Scholar]
- Gong, Y.; Liu, L.; Yang, M.; Bourdev, L. Compressing deep convolutional networks using vector quantization. arXiv 2014, arXiv:1412.6115. [Google Scholar]
- Young, S.I.; Zhe, W.; Taubman, D.; Girod, B. Transform quantization for CNN compression. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 5700–5714. [Google Scholar] [CrossRef] [PubMed]
- Haeffele, B.; Young, E.; Vidal, R. Structured low-rank matrix factorization: Optimality, algorithm, and applications to image processing. In Proceedings of the International Conference on Machine Learning, Beijing, China, 22–24 June 2014; pp. 2007–2015. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- He, Y.; Zhang, X.; Sun, J. Channel pruning for accelerating very deep neural networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1389–1397. [Google Scholar]
- Pasandi, M.M.; Hajabdollahi, M.; Karimi, N.; Samavi, S. Modeling of pruning techniques for deep neural networks simplification. arXiv 2020, arXiv:2001.04062. [Google Scholar]
- Wei, X.; Wu, Y.; Reardon, R.; Sun, T.-H.; Lu, M.; Sun, J.-H. Biology and damage traits of emerald ash borer (Agrilus planipennis Fairmaire) in China. Insect Sci. 2007, 14, 367–373. [Google Scholar] [CrossRef]
- Zhang, L.; Feng, Y.-Q.; Ren, L.-L.; Luo, Y.-Q.; Wang, F.; Zong, S.-X. Sensilla on antenna, ovipositor and leg of E riborus applicitus (Hymenoptera: Ichneumonidae), a parasitoid wasp of H olcocerus insularis staudinger (Lepidoptera: Cossidae). Acta Zool. 2015, 96, 253–263. [Google Scholar] [CrossRef]
- Krawczyk, M.; Gerkmann, T. STFT phase reconstruction in voiced speech for an improved single-channel speech enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1931–1940. [Google Scholar] [CrossRef]
- Luo, Y.; Chen, Z.; Yoshioka, T. Dual-path rnn: Efficient long sequence modeling for time-domain single-channel speech separation. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 46–50. [Google Scholar]
- Gehring, J.; Auli, M.; Grangier, D.; Yarats, D.; Dauphin, Y.N. Convolutional sequence to sequence learning. In Proceedings of the 34th International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; pp. 1243–1252. [Google Scholar]
- Liu, X.; Yu, H.-F.; Dhillon, I.; Hsieh, C.-J. Learning to encode position for transformer with continuous dynamical model. In Proceedings of the 37th International Conference on Machine Learning, Virtual Event, 13–18 July 2020; pp. 6327–6335. [Google Scholar]
- Wang, B.; Zhao, D.; Lioma, C.; Li, Q.; Zhang, P.; Simonsen, J.G. Encoding word order in complex embeddings. arXiv 2019, arXiv:1912.12333. [Google Scholar]
- Luo, Y.; Mesgarani, N. Conv-tasnet: Surpassing ideal time–frequency magnitude masking for speech separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1256–1266. [Google Scholar] [CrossRef] [PubMed]
- Ding, J.; Tarokh, V.; Yang, Y. Model selection techniques: An overview. IEEE Signal Process. Mag. 2018, 35, 16–34. [Google Scholar] [CrossRef]
- Zhou, Z.; Yu, J. A new nonconvex sparse recovery method for compressive sensing. Front. Appl. Math. Stat. 2019, 5, 14. [Google Scholar] [CrossRef]
- Wang, W.; Lu, Y. Analysis of the mean absolute error (MAE) and the root mean square error (RMSE) in assessing rounding model. In Proceedings of the IOP Conference Series: Materials Science and Engineering, Kuala Lumpur, Malaysia, 15–16 December 2017; p. 012049. [Google Scholar]
- Frankle, J.; Carbin, M. The lottery ticket hypothesis: Finding sparse, trainable neural networks. arXiv 2018, arXiv:1803.03635. [Google Scholar]
- Shi, H.; Chen, Z.; Zhang, H.; Li, J.; Liu, X.; Ren, L.; Luo, Y. Enhancement of Boring Vibrations Based on Cascaded Dual-Domain Features Extraction for Insect Pest Agrilus planipennis Monitoring. Forests 2023, 14, 902. [Google Scholar] [CrossRef]
- Shi, H.; Chen, Z.; Zhang, H.; Li, J.; Liu, X.; Ren, L.; Luo, Y. A Waveform Mapping-Based Approach for Enhancement of Trunk Borers’ Vibration Signals Using Deep Learning Model. Insects 2022, 13, 596. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Li, J.; Cai, G.; Chen, Z.; Zhang, H. A CNN-Based Method for Enhancing Boring Vibration with Time-Domain Convolution-Augmented Transformer. Insects 2023, 14, 631. [Google Scholar] [CrossRef]
- Desplanques, B.; Thienpondt, J.; Demuynck, K. Ecapa-tdnn: Emphasized channel attention, propagation and aggregation in tdnn based speaker verification. arXiv 2020, arXiv:2005.07143. [Google Scholar]
- Potamitis, I.; Rigakis, I.; Tatlas, N.-A.; Potirakis, S. In-vivo vibroacoustic surveillance of trees in the context of the IoT. Sensors 2019, 10, 1366. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, H.; Jiang, Q.; Ren, L.; Chen, Z.; Luo, Y.; Li, J. Acoustic Denoising Using Artificial Intelligence for Wood-Boring Pests Semanotus bifasciatus Larvae Early Monitoring. Sensors 2022, 22, 3861. [Google Scholar] [CrossRef]
- Lacey, G.; Taylor, G.W.; Areibi, S. Deep learning on fpgas: Past, present, and future. arXiv 2016, arXiv:1602.04283. [Google Scholar]
- Querner, P. Insect pests and integrated pest management in museums, libraries and historic buildings. Insects 2015, 6, 595–607. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | 0 dB | −2.5 dB | −5 dB | −7.5 dB | −10 dB | Average |
|---|---|---|---|---|---|---|
| SNR | 16.8637 | 15.1525 | 13.5645 | 11.7643 | 10.3246 | 13.5339 |
| LLR | 0.0658 | 0.0762 | 0.1467 | 0.2485 | 0.3478 | 0.1769 |
| InferTime (s) 1 | 144.89 | 148.05 | 144.26 | 144.26 | 146.58 | 145.61 |
| Metrics | 0 dB | −2.5 dB | −5 dB | −7.5 dB | −10 dB | Average |
|---|---|---|---|---|---|---|
| SNR | 17.0834 | 15.4113 | 13.5786 | 12.1928 | 10.3559 | 13.7244 |
| LLR | 0.0681 | 0.0787 | 0.1476 | 0.2550 | 0.3446 | 0.1788 |
| InferTime (s) | 141.39 | 149.28 | 148.44 | 139.60 | 147.57 | 145.25 |
| Parameters | InferTime (s) | Average SNR (dB) | Average LLR | |
|---|---|---|---|---|
| Original | 884,928 | 145.61 | 13.5339 | 0.1769 |
| DPAS | 337,038 | 113.35 | 13.1144 | 0.2899 |
| percentage change 1 | −62% | −22% | −3% | +63% |
| LTP | 423,257 | 119.77 | 12.1589 | 0.2978 |
| percentage change | −52% | −17% | −10% | +68% |
| Model | Param. (M) | % | InferTime (s) | % | SNR (dB) | % |
|---|---|---|---|---|---|---|
| DVEN | 1.32 | −74.2% | 165.6 | −31.5% | 18.73 | −12.3% |
| VibDenoiser | 10.75 | −96.8% | 273.6 | −58.5% | 18.57 | −11.6% |
| T-CENV | 4.23 | −91.9% | 195.8 | −42.1% | 17.84 | −7.96% |
| VibEnh-DPAS | 0.34 | - | 113.4 | - | 16.42 | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, X.; Li, J.; Zhang, H. Lightweight Model Design and Compression of CRN for Trunk Borers’ Vibration Signals Enhancement. Forests 2023, 14, 2001. https://doi.org/10.3390/f14102001
Zhao X, Li J, Zhang H. Lightweight Model Design and Compression of CRN for Trunk Borers’ Vibration Signals Enhancement. Forests. 2023; 14(10):2001. https://doi.org/10.3390/f14102001
Chicago/Turabian StyleZhao, Xiaorong, Juhu Li, and Huarong Zhang. 2023. "Lightweight Model Design and Compression of CRN for Trunk Borers’ Vibration Signals Enhancement" Forests 14, no. 10: 2001. https://doi.org/10.3390/f14102001
APA StyleZhao, X., Li, J., & Zhang, H. (2023). Lightweight Model Design and Compression of CRN for Trunk Borers’ Vibration Signals Enhancement. Forests, 14(10), 2001. https://doi.org/10.3390/f14102001