
Site Quality Classification Models of Cunninghamia Lanceolata Plantations Using Rough Set and Random Forest West of Zhejiang Province, China


Abstract
1. Introduction
- (1)
- Site factors
- (2)
- Site quality evaluation method
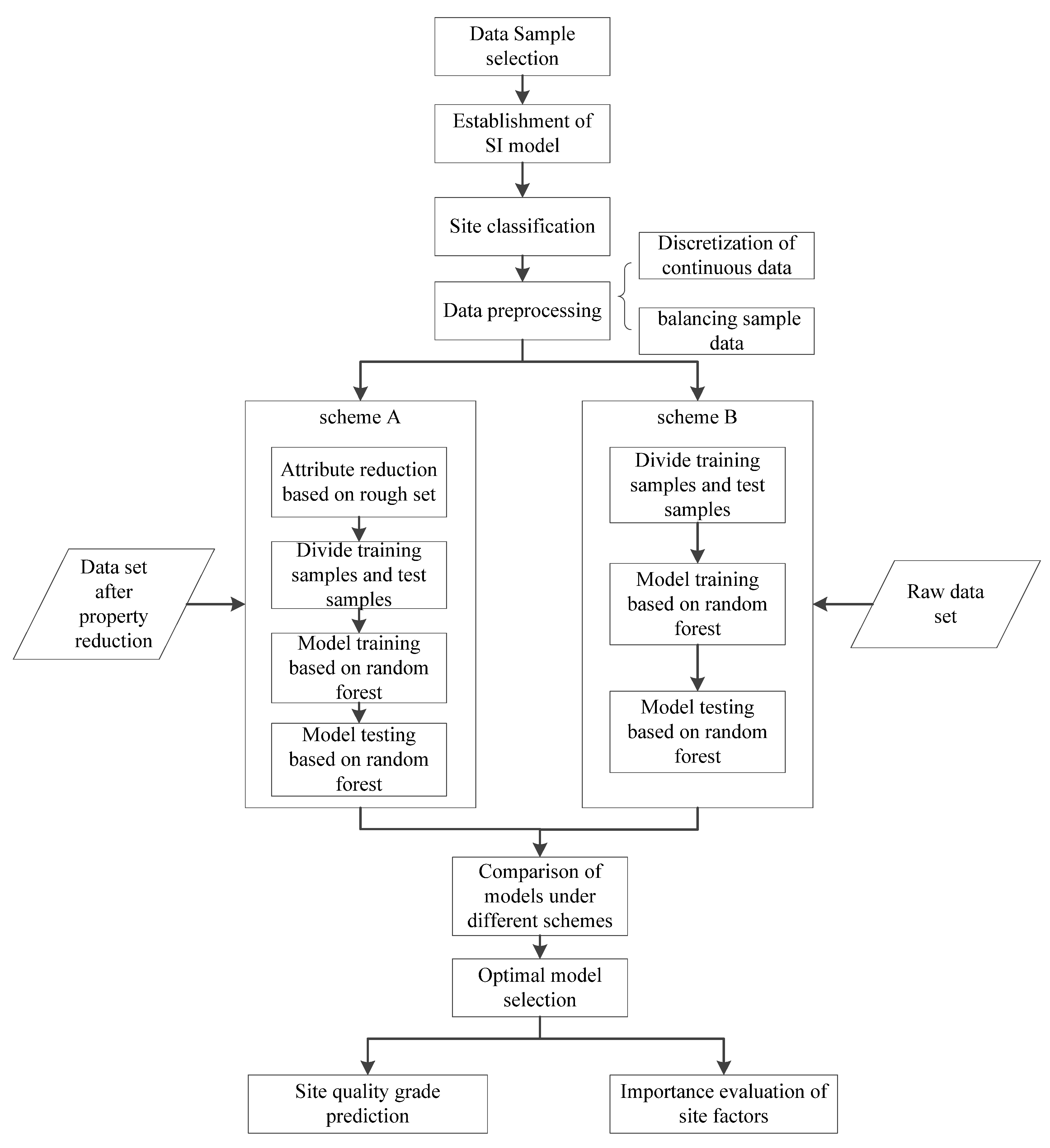
2. Materials and Methods
2.1. Data
2.2. Methods
2.2.1. Site Quality Grade Classification
- (1)
- Establishment of the SI model
- (2)
- Site grade division
2.2.2. Data Preprocessing
- (1)
- Discretization of continuous data
- (2)
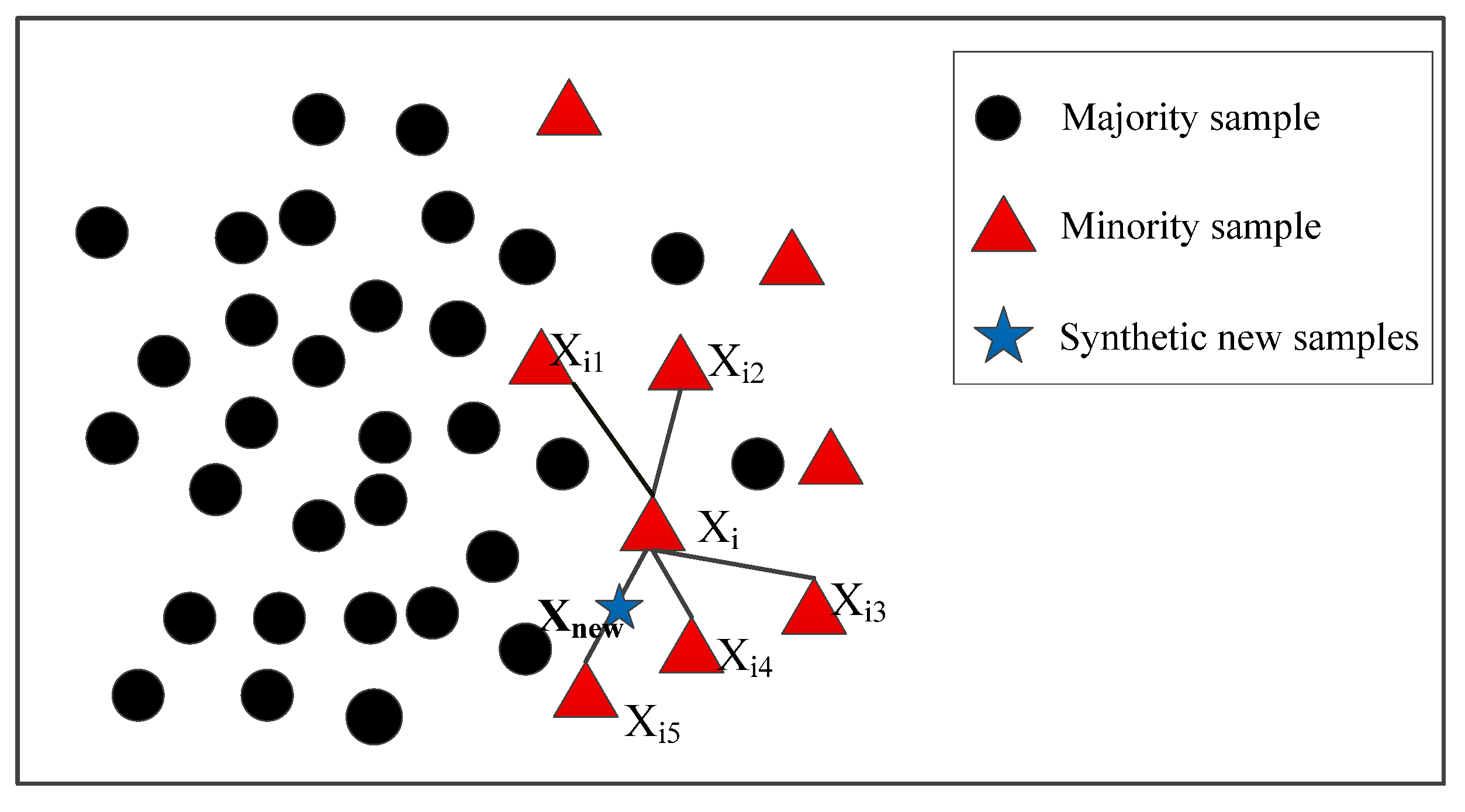
- Balanced sampling plans
2.2.3. Site Factor Reduction Based on Rough Set
2.2.4. Site Classification Modeling of Random Forest
- (1)
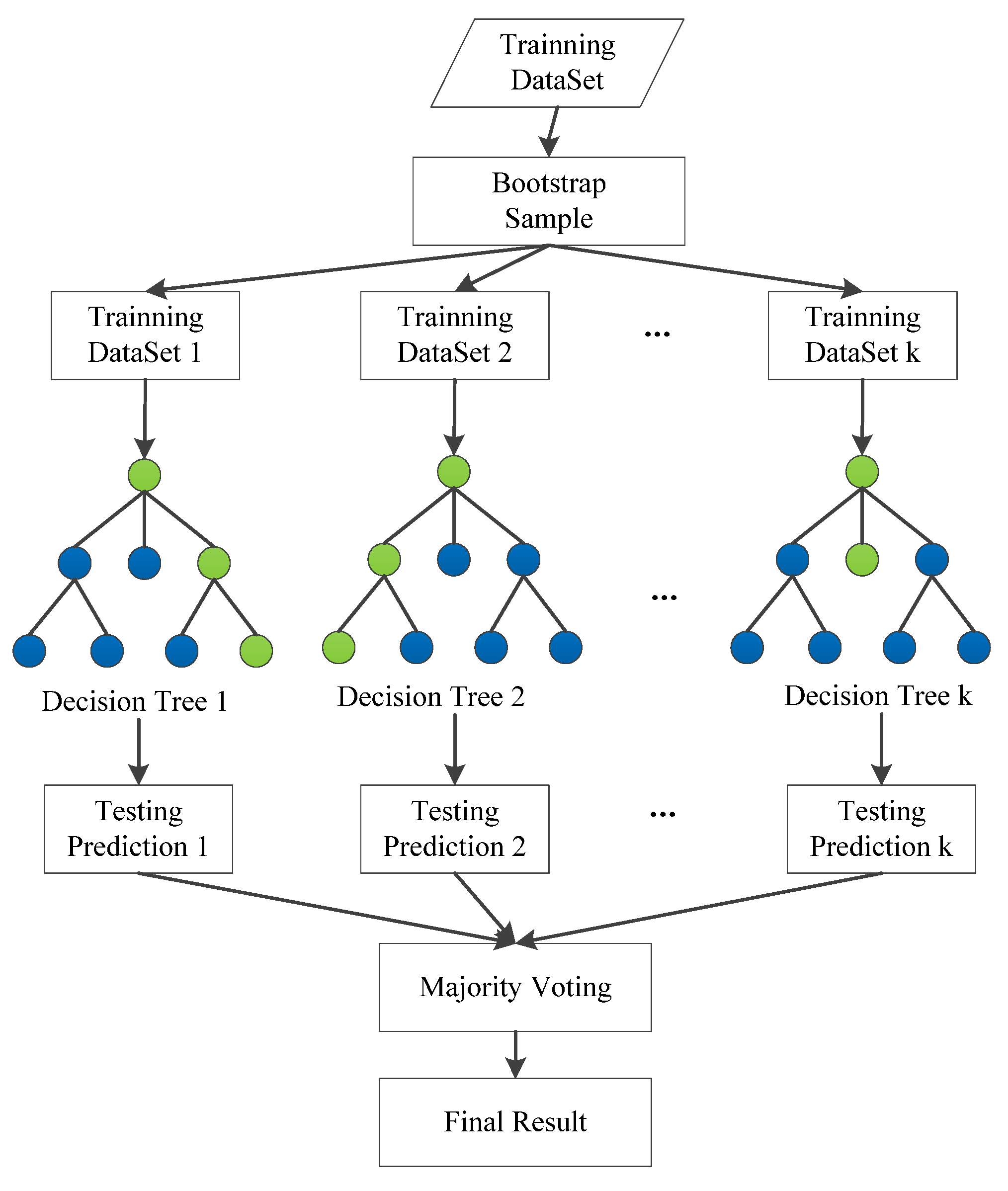
- Random forest principle
- (2)
- Implementation of the random forest model
- (3)
- Model evaluation method
- (4)
- Importance evaluation of variables
3. Results
3.1. Attribute Reduction Results Based on Rough Sets
3.2. Results of Classification Model Based on Random Forest
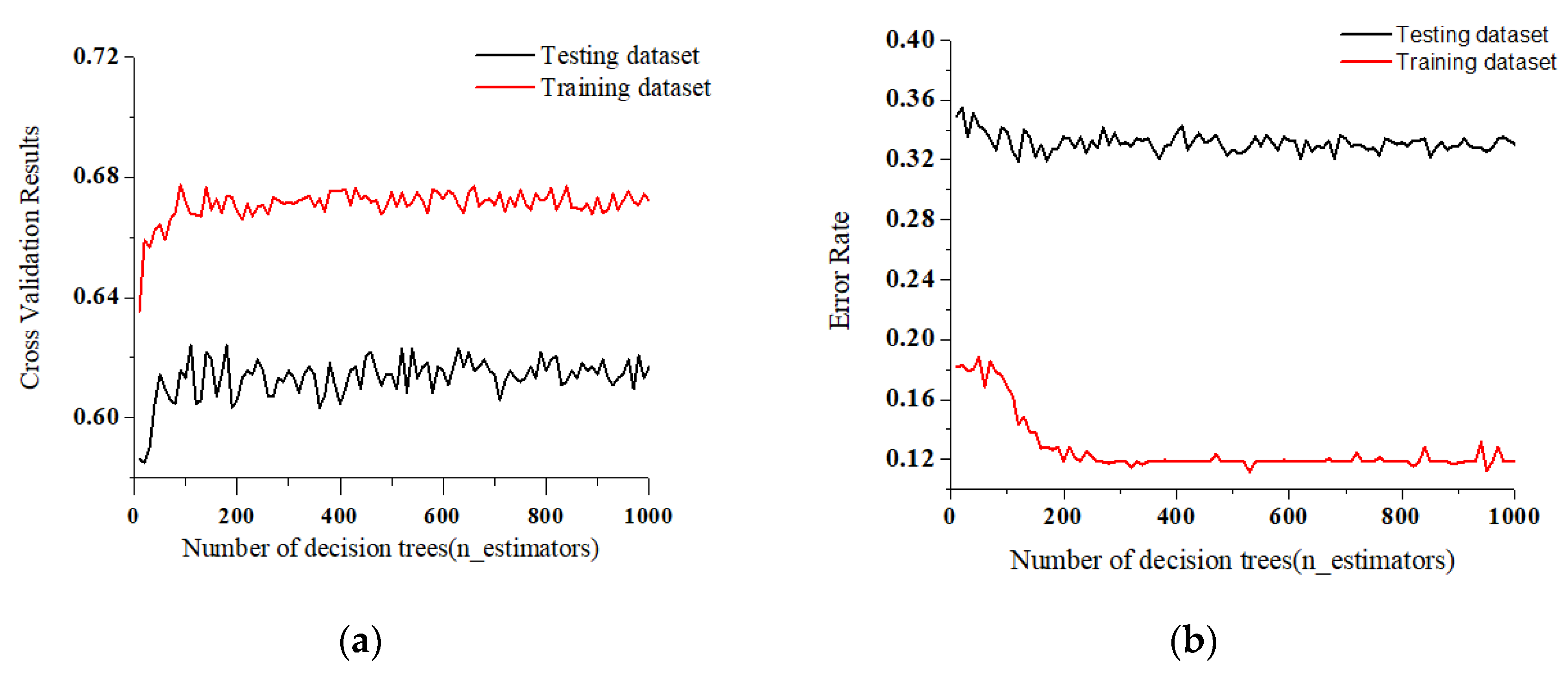
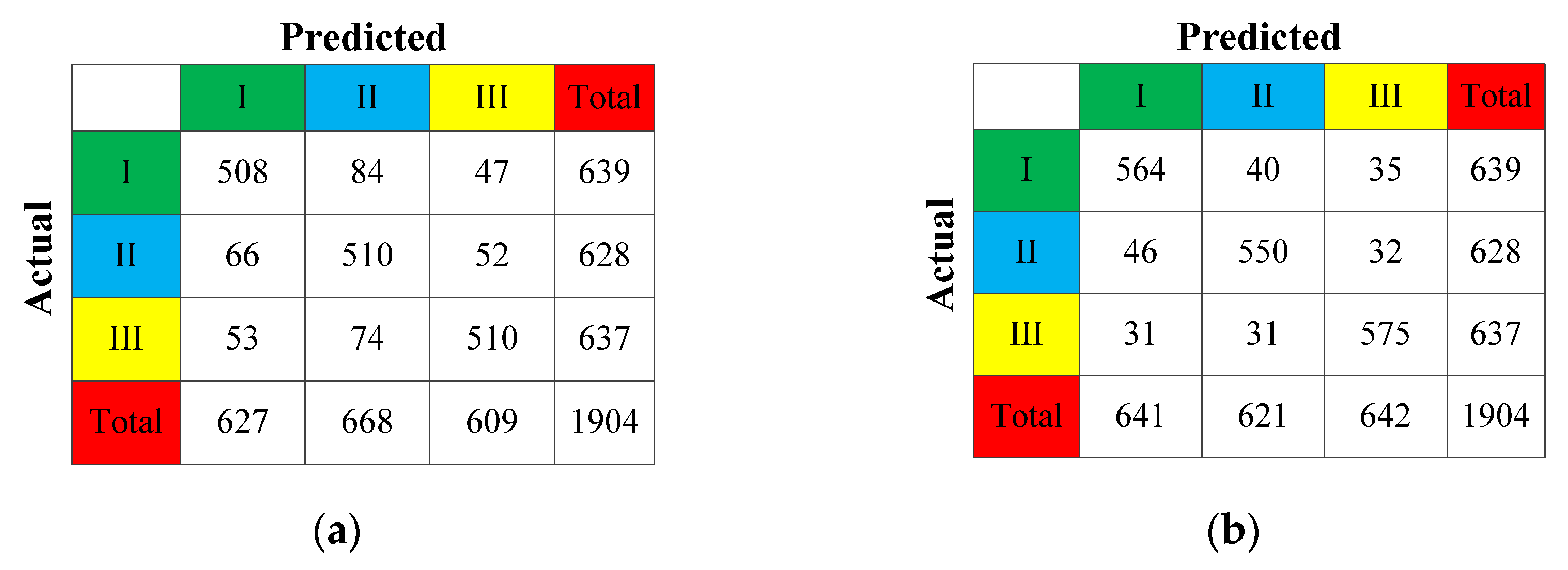
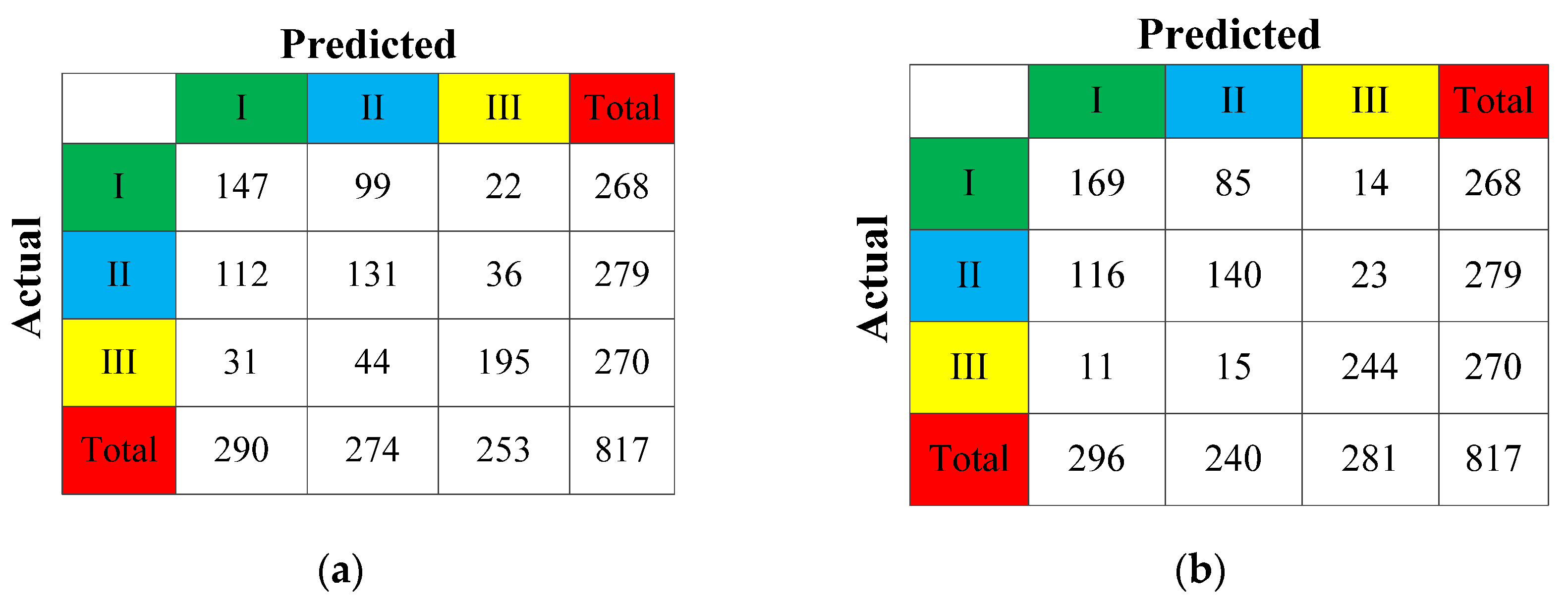
3.2.1. Comparison of Model Accuracy
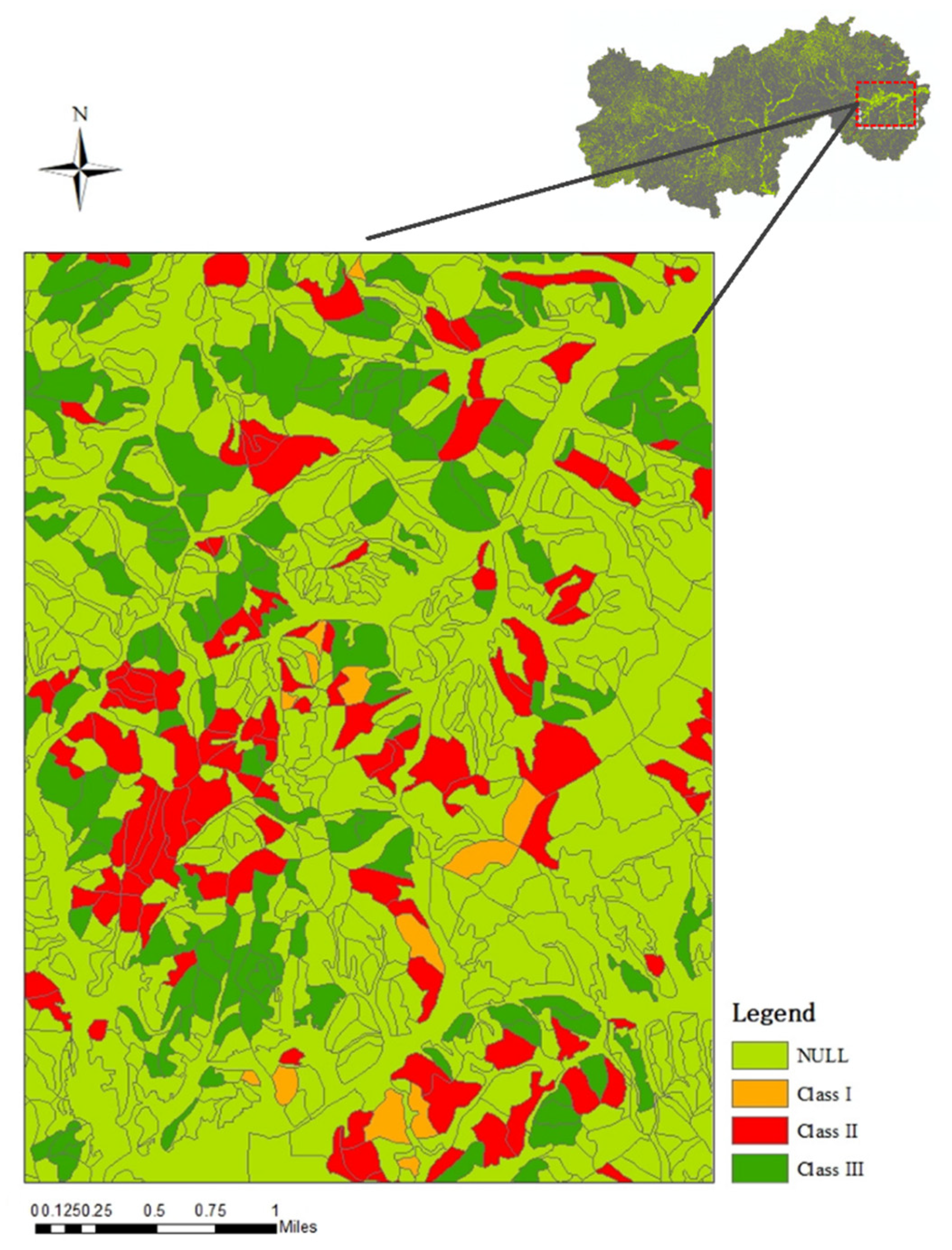
3.2.2. Application of the Model
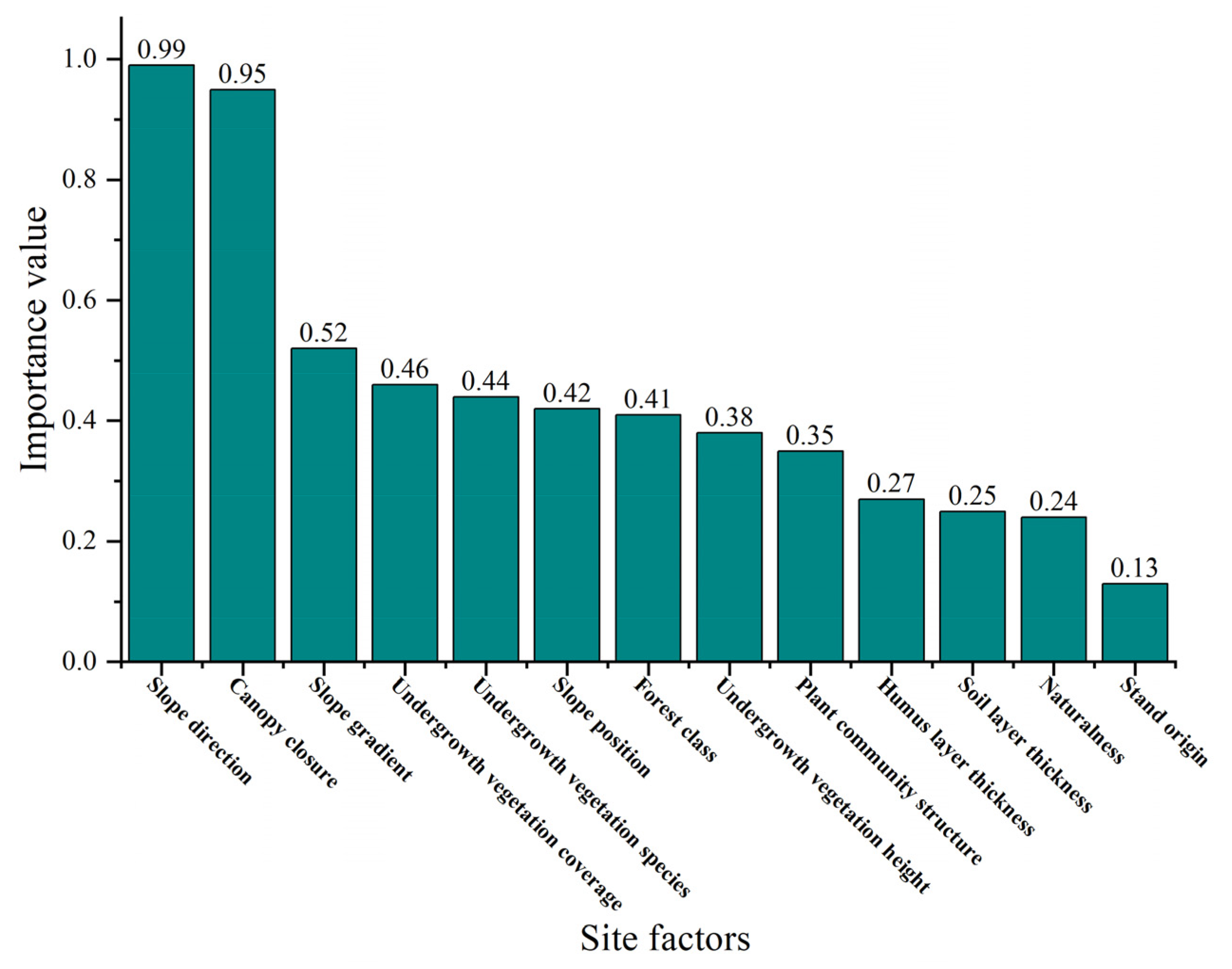
3.3. Importance Assessment of Site Factors
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yang, H. A Study of Site Quality Evaluation of Chinese Fir Plantation Based on NFI Data of Zhejiang Province. Master’s Thesis, Zhejiang A & F University, Hangzhou, China, 2019. [Google Scholar]
- Carmean, W.H. Forest Site-Quality Estimation Using Forest Ecosystem Classification in Northwestern Ontario. Environ. Monit. Assess. 1996, 39, 493–508. [Google Scholar] [CrossRef]
- Skovsgaard, J.P.; Vanclay, J.K. Forest site productivity: A review of evolution of dendrometric concepts for even-aged stands. Forestry 2008, 81, 13–31. [Google Scholar] [CrossRef]
- Quichimbo, P.; Jiménez, L.; Veintimilla, D.; Tischer, A.; Günter, S.; Mosandl, R.; Hamer, U. Forest Site Classification in the Southern Andean Region of Ecuador: A Case Study of Pine Plantations to Collect a Base of Soil Attributes. Forests 2017, 8, 473. [Google Scholar] [CrossRef]
- Dong, C.; Fang, L. Association analysis between the site index Model and the Site Factors of Cunninghamia Lanceolata Timber Forest in Western Zhejiang Province. Nat. Environ. Pollut. Technol. 2019, 18, 359–368. [Google Scholar]
- Qiu, H.; Liu, S.; Zhang, Y.; Li, J. Variation in height-diameter allometry of ponderosa pine along competition, climate, and species diversity gradients in the western United States. For. Ecol. Manag. 2021, 497, 119477. [Google Scholar] [CrossRef]
- Andrés, B.O.; Clemente, G.A.; Miren-del, R.; Montero, G. Regional changes of Pinus pinaster site index in Spain using a climate-based dominant height model. Can. J. For. Res. 2010, 40, 2036–2048. [Google Scholar]
- Hlásny, T.; Trombik, J.; Bošeľa, M.; Merganič, J.; Marušák, R.; Šebeň, V.; Štěpánek, P.; Kubišta, J.; Trnka, M. Climatic drivers of forest productivity in Central Europe. Agric. For. Meteorol. 2017, 234–235, 258–273. [Google Scholar] [CrossRef]
- Gao, R.; Xie, Y.; Lei, X.; Lu, Y.; Su, X. Study on prediction of natural forest productivity based on random forest model. J. Cent. South Univ. For. Technol. 2019, 39, 39–46. [Google Scholar]
- Site Productivity and Forest Growth Modelling Strategies: Monospecific Versus Mixed Species Forests. Available online: https://www.researchgate.net/publication/344201149 (accessed on 26 December 2019).
- Novor, S.; Abugre, S. Growth Performance, Undergrowth Diversity and Carbon Sequestration Potentials of Tree Species Stand Combinations, Ghana. Open J. For. 2020, 10, 135–154. [Google Scholar] [CrossRef][Green Version]
- Eslamdoust, J.; Sohrabi, H. Carbon storage in biomass, litter, and soil of different native and introduced fast-growing tree plantations in the South Caspian Sea. J. For. Res. 2018, 29, 449–457. [Google Scholar] [CrossRef]
- Huang, S.; Ramirez, C.; Conway, S.; Kennedy, K.; Kohler, T.; Liu, J. Mapping site index and volume increment from forest inventory, Landsat, and ecological variables in Tahoe National Forest, California, USA. Can. J. For. Res. 2017, 47, 147–156. [Google Scholar] [CrossRef]
- Kang, S.-p.; Kim, J.-y.; Ahn, K.-w. Site Index Estimation and Suitable-Land Evaluation of Cryptomeria japonica and Chamaecyparis Obtusa—Focused on Jeju Special Self-Governing Province and Southern Regions. TJOKI 2015, 27, 125–144. [Google Scholar]
- Chen, Y.; Wu, B.; Qi, Y. Using Machine Learning to Assess Site Suitability for Afforestation with Particular Species. Forests 2019, 10, 739. [Google Scholar] [CrossRef]
- Guo, Y.; Liu, Y.; Wu, B. Evaluating Dividing Rank and Quantification of Site Quality of Suitable Land for Forest in Fujian Province, China. J. Northeast For. Univ. 2014, 42, 54–59. [Google Scholar]
- Lv, F.Z.; Luo, H.J.; Lv, Y. Study on forestland quality indexes and their application. J. For. Environ. 2015, 1, 87–91. [Google Scholar]
- Pawlak, Z. Rough set theory and its applications to data analysis. Cybern. Syst. 1998, 29, 611–688. [Google Scholar] [CrossRef]
- Vanclay, J.K.; Henry, N.B. Assessing Site Productivity of Indigenous Cypress Pine Forest in Southern Queensland. Emp. For. Rev. 1988, 67, 53–64. [Google Scholar]
- Vanclay, J.K. Assessing site productivity in tropical moist forests: A review. For. Ecol. Manag. 1992, 54, 257–287. [Google Scholar] [CrossRef]
- Zhu, G.Y.; Hu, S.; Chhin, S.; Zhang, X.Q.; He, P. Modelling site site index of Chinese fir plantations using a random effects model across regional site types in Hunan province, China. For. Ecol. Manag. 2019, 446, 143–150. [Google Scholar] [CrossRef]
- Duan, G.; Wang, Q.; Fu, L. Comparison of Different Height–Diameter Modelling Techniques for Prediction of Site Productivity in Natural Uneven-Aged Pure Stands. Forests 2018, 9, 63. [Google Scholar] [CrossRef]
- Stankova, T.; Diéguez-Aranda, U. A tentative dynamic site index model for Scots pine (Pinus sylvestris) plantations in Bulgaria. Silva Balc. 2012, 13, 5–17. [Google Scholar]
- Trim, K.R.; Coble, D.W.; Weng, Y.H.; Stovall, J.P.; Hung, I.K. A New Site Index Model for Intensively Managed Loblolly Pine (Pinus taeda) Plantations in the West Gulf Coastal Plain. For. Sci. 2019, 66, 2–13. [Google Scholar] [CrossRef]
- Socha, J.; Tyminska-Czabanska, L.; Grabska, E.; Orzel, S. Site Index Models for Main Forest-Forming Tree Species in Poland. Forests 2020, 11, 301. [Google Scholar] [CrossRef]
- Batho, A.; García, O. A Site Index Model for Lodgepole Pine in British Columbia. For. Sci. 2014, 60, 982–987. [Google Scholar] [CrossRef]
- Daniel, M.; Juan, G.; Roque, R. National-scale assessment of forest site productivity in Spain. For. Ecol. Manag. 2018, 417, 197–207. [Google Scholar]
- Kahriman, A.; Yavuz, H.; Ercanli, I. Site index conversion equations for mixed stands of Scots pine(Pinus sylvestris L.) and Oriental beech (Fagus orientalis Lipsky) in the Black Sea Region, Turkey. Turk. J. Agric. For. 2013, 37, 488–494. [Google Scholar] [CrossRef]
- Bayat, M.; Bettinger, P.; Hassani, M.; Heidari, S. Ten-year estimation of Oriental beech (Fagus orientalis Lipsky) volume increment in natural forests: A comparison of an artificial neural networks model, multiple linear regression and actual increment. Forestry 2021, 94, 598–609. [Google Scholar] [CrossRef]
- Shen, J. Study on Site Quality Evaluation Methods of Uneven-Aged Coniferous and Broad-Leaved Mixed Stands in Guangdong Province. Ph.D. Thesis, Chinese Academy of Forestry, Beijing, China, 2018. [Google Scholar]
- Liu, Z.L.; Peng, C.H.; Work, T.; Candau, J.N.; DesRochers, A.; Kneeshaw, D. Application of machine-learning methods in forest ecology: Recent progress and future challenges. Environ. Rev. 2018, 26, 339–350. [Google Scholar] [CrossRef]
- Weng, Y.; Grogan, J.; Cheema, B.; Tao, J.; Lou, X.; Burkhart, H. Model-Based Growth Comparisons between Loblolly and Slash Pine and between Silvicultural Intensities in East Texas. Forests 2021, 12, 1611. [Google Scholar] [CrossRef]
- Lou, X.; Weng, Y.; Fang, L.; Gao, H.; Grogan, J.; Hung, I.K.; Oswald, B.P. Predicting stand attributes of loblolly pine in West Gulf Coastal Plain using gradient boosting and random forests. Can. J. For. Res. 2020, 51, 807–816. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, X.; Chhin, S.; Zhang, J.; Duan, A. Disentangling the effects of stand and climatic variables on forest productivity of Chinese fir plantations in subtropical China using a random forest algorithm. Agric. For. Meteorol. 2021, 304, 108412. [Google Scholar] [CrossRef]
- Zhao, M.; Xiang, W.; Peng, C.; Tian, D. Simulating age-related changes in carbon storage and allocation in a Chinese fir plantation growing in southern China using the 3-PG model. For. Ecol. Manag. 2009, 257, 1520–1531. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, B.; Qin, S. Review of research and application of forest canopy closure and its measuring methods. World For. Res. 2008, 21, 40–46. [Google Scholar]
- Guo, Y.; Wu, B.; Liu, Y. Research progress of site quality evaluation. World For. Res. 2012, 25, 47–52. [Google Scholar]
- Chen, Y. Research on Matching Tree Species with Site and Growth Yield Benefit Assessment of Plantation-in the Case of Cunninghamia lanceolata and Pinus massoniana in Guizhou Province. Ph.D. Thesis, Beijing Forestry University, Beijing, China, 2020. [Google Scholar]
- Zobel, J.M.; Schubert, M.R.; Granger, J.J. Shortleaf Pine (Pinus echinata) Site Index Equation for the Cumberland Plateau, USA. For. Sci. 2022, 68, 259–269. [Google Scholar] [CrossRef]
- Guo, Y.; Han, Y.; Wu, B. Study on modelling of site quality evaluation and its dynamic update technology for plantation forests. Nat. Environ. Pollut. Technol. 2013, 12, 591–597. [Google Scholar]
- Feng, L. Principle of Regression Analysis Method and Practical Operation of SPSS; China Finance Publishing House: Beijing, China, 2004; pp. 32–46. [Google Scholar]
- Ye, Y.; Wu, Q.; Huang, J.Z.; Ng, M.K.; Li, X. Stratified sampling for feature subspace selection in random forests for high dimensional data. Pattern Recognit. 2013, 46, 769–787. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Visual Studio Code Builds the Python Development Environment. Available online: https://www.cnblogs.com/liangqihui/articles/9241597.html (accessed on 29 June 2018).
- Ziegler, A.; Konig, I.R. Mining data with random forests: Current options for real-world applications. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2014, 4, 55–63. [Google Scholar] [CrossRef]
- Yoo, J.E. Random forests, an alternative data mining technique to decision tree. J. Educ. Eval. 2015, 28, 427–448. [Google Scholar]
- Jensen, R.; Shen, Q. Semantics-Preserving Dimensionality Reduction: Rough and Fuzzy-Rough-Based Approaches. IEEE Trans. Knowl. Data Eng. 2004, 16, 1457–1471. [Google Scholar] [CrossRef]
- Wang, Y.; Feng, Z.; Ma, W. Analysis of Tree Species Suitability for Plantation Forests in Beijing (China) Using an Optimal Random Forest Algorithm. Forests 2022, 13, 820. [Google Scholar] [CrossRef]
- Song, J. Discussion of the relationship between Chinese fir growth and environmental conditions. West. China Technol. 2008, 7, 54–55. [Google Scholar]
- Watt, M.S.; Kimberley, M.O.; Dash, J.P.; Harrison, D. Spatial prediction of optimal final stand density for even-aged plantation forests using productivity indices. Can. J. For. Res. 2017, 47, 527–535. [Google Scholar] [CrossRef]
- Sewerniak, P. Site index of Scots pine stands in south-western Poland in relation to forest site types and soil units. SYLWAN 2013, 157, 516–525. [Google Scholar]
- Sacewicz, W.A.; Bijak, S. Effect of selected soil properties on site index of oak stands in the Miezyrzec Forest District. SYLWAN 2018, 162, 3–11. [Google Scholar]
- Guner, S.T. Relationships between Site Index and Ecological Variables of Oriental Beech Forest in the Marmara Region of Turkey. Fresenius Environ. Bull. 2021, 30, 6920–6927. [Google Scholar]
- Fang, J.; Shen, Z.; Cui, H. Ecological characteristics of mountains and research issues of mountain ecology. Biodivers. Sci. 2004, 12, 10–19. [Google Scholar]
- Krner, C. The use of altitude in ecological research. Trends Ecol. Evol. 2007, 22, 569–574. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Factor Nos. | Site Factors | Related Values |
|---|---|---|
| 1 | Landform | Medium hills, lowland, irregular hillslopes |
| 2 | Altitude (m) | 10–1104 m |
| 3 | Slope direction | East, south, west, north, northeast, southeast, northwest, southwest |
| 4 | Slope position | Ridge, upper, middle, lower, valley, whole |
| 5 | Slope gradient | Flat, gentle, inclined, steep, abrupt, dangerous |
| 6 | Soil types | Red soil, yellow soil, limestone soil, purplish soil |
| 7 | Soil texture | Sandy soil, loamy soil, clay |
| 8 | Soil layer thickness | Thick, medium, thin |
| 9 | Humus layer thickness | Thick, medium, thin |
| 10 | Undergrowth vegetation species | Grass cluster, shrub, bush wood, miscan stem, bamboo fungus |
| 11 | Undergrowth vegetation height (cm) | 0–85 cm |
| 12 | Undergrowth vegetation coverage | 0%–90% |
| 13 | Plant community structure | Complete structure, relatively complete structure, simple structure |
| 14 | Naturalness | Classes I, II, III |
| 15 | Forest class | Public welfare forests, commercial forests |
| 16 | Forest protection grade | Grades I, II |
| 17 | Land type | Highwood land, open forest land |
| 18 | Age group | Young forest, middle-aged forest, near mature forest, mature forest |
| 19 | Stand origin | Natural forest, plantation |
| 20 | Canopy closure | 0–0.85 |
| SI | Sub-Compartment Frequency | SI Grade | SI Frequency |
|---|---|---|---|
| 6 | 86 | Grade III | 907 |
| 8 | 187 | ||
| 10 | 634 | ||
| 12 | 530 | Grade II | 874 |
| 14 | 344 | ||
| 16 | 106 | Grade I | 122 |
| 18 | 11 | ||
| 20 | 5 |
| Site Factors | Discrete Classification Standard |
|---|---|
| Altitude | High: ≥1000 m; medium: 500–1000 m; low: <500 m |
| Undergrowth vegetation height | High: ≥60 cm; medium: 30–60 cm; low: <30 m |
| Undergrowth vegetation coverage | High: ≥60%; medium: 30%–60%; low: <30% |
| Canopy closure | High: ≥70%; medium: 40%–70%; low: <40% |
| Sample Types | SI Grades | ||
|---|---|---|---|
| Grade I | Grade II | Grade III | |
| Original sample | 122 | 874 | 907 |
| Balanced sample | 907 | 907 | 907 |
| Categories | Specific Site Factors | Factor Numbers | Dependence Degree e |
|---|---|---|---|
| Reduced attributes | Forest protection grade, soil texture, altitude, land type, soil types, landform, age group | 7 | 0.94 |
| Reserved attributes | Naturalness, stand origin, plant community structure, forest class, soil layer thickness, humus layer thickness, undergrowth vegetation coverage, undergrowth vegetation height, undergrowth vegetation species, slope position, slope gradient, slope direction, canopy closure | 13 | |
| Core attributes | Canopy closure, slope direction, slope gradient, slope position, undergrowth vegetation species, undergrowth vegetation height, undergrowth vegetation coverage | 7 |
| Schemes | Number of Factors | Training Time | Training Dataset | Testing Dataset | ||||
|---|---|---|---|---|---|---|---|---|
| Precision | Recall | Accuracy | Precision | Recall | Accuracy | |||
| Scheme A | 20 | 5.40 s | 0.8037 | 0.8026 | 0.8683 | 0.5852 | 0.5800 | 0.7193 |
| Scheme B | 13 | 2.69 s | 0.8870 | 0.8870 | 0.9247 | 0.6742 | 0.6787 | 0.7846 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, C.; Chen, Y.; Lou, X.; Min, Z.; Bao, J. Site Quality Classification Models of Cunninghamia Lanceolata Plantations Using Rough Set and Random Forest West of Zhejiang Province, China. Forests 2022, 13, 1312. https://doi.org/10.3390/f13081312
Dong C, Chen Y, Lou X, Min Z, Bao J. Site Quality Classification Models of Cunninghamia Lanceolata Plantations Using Rough Set and Random Forest West of Zhejiang Province, China. Forests. 2022; 13(8):1312. https://doi.org/10.3390/f13081312
Chicago/Turabian StyleDong, Chen, Yuling Chen, Xiongwei Lou, Zhiqiang Min, and Jieyong Bao. 2022. "Site Quality Classification Models of Cunninghamia Lanceolata Plantations Using Rough Set and Random Forest West of Zhejiang Province, China" Forests 13, no. 8: 1312. https://doi.org/10.3390/f13081312
APA StyleDong, C., Chen, Y., Lou, X., Min, Z., & Bao, J. (2022). Site Quality Classification Models of Cunninghamia Lanceolata Plantations Using Rough Set and Random Forest West of Zhejiang Province, China. Forests, 13(8), 1312. https://doi.org/10.3390/f13081312