
Mapping China’s Forest Fire Risks with Machine Learning

 ,
,  ,
, 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Data Sources and Description
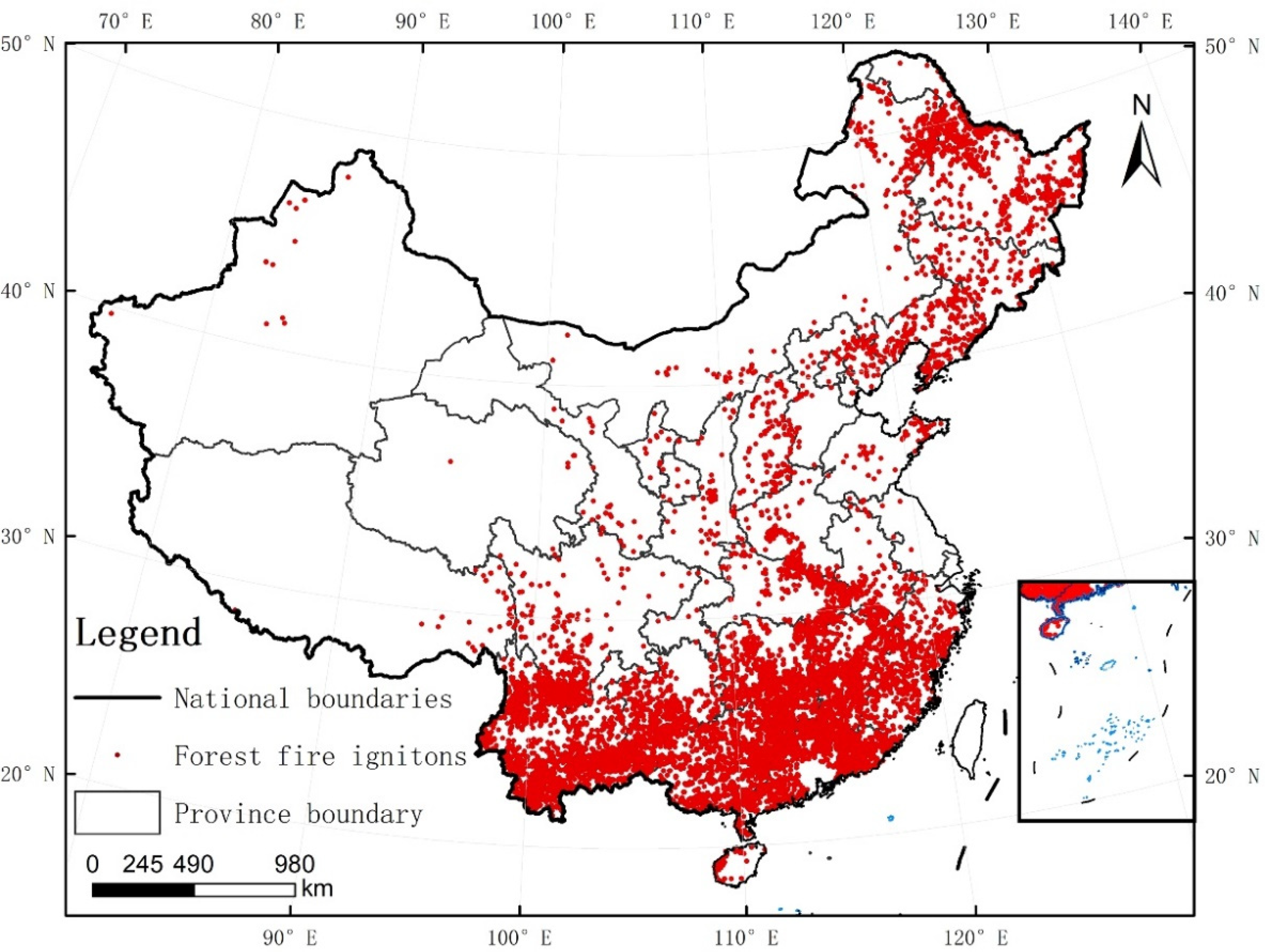
2.2.1. Forest-Fire Data Sources and Processing
2.2.2. Other Data
- Topographic
- 2.
- Climatic
- 3.
- Vegetation
- 4.
- Socioeconomic
2.3. Methods
2.3.1. Random Forest
2.3.2. Support Vector Machine
2.3.3. Multi-Layer Perceptron
2.3.4. Gradient Boosting Decision Tree
2.3.5. Evaluation of the Performance of the Models
3. Results
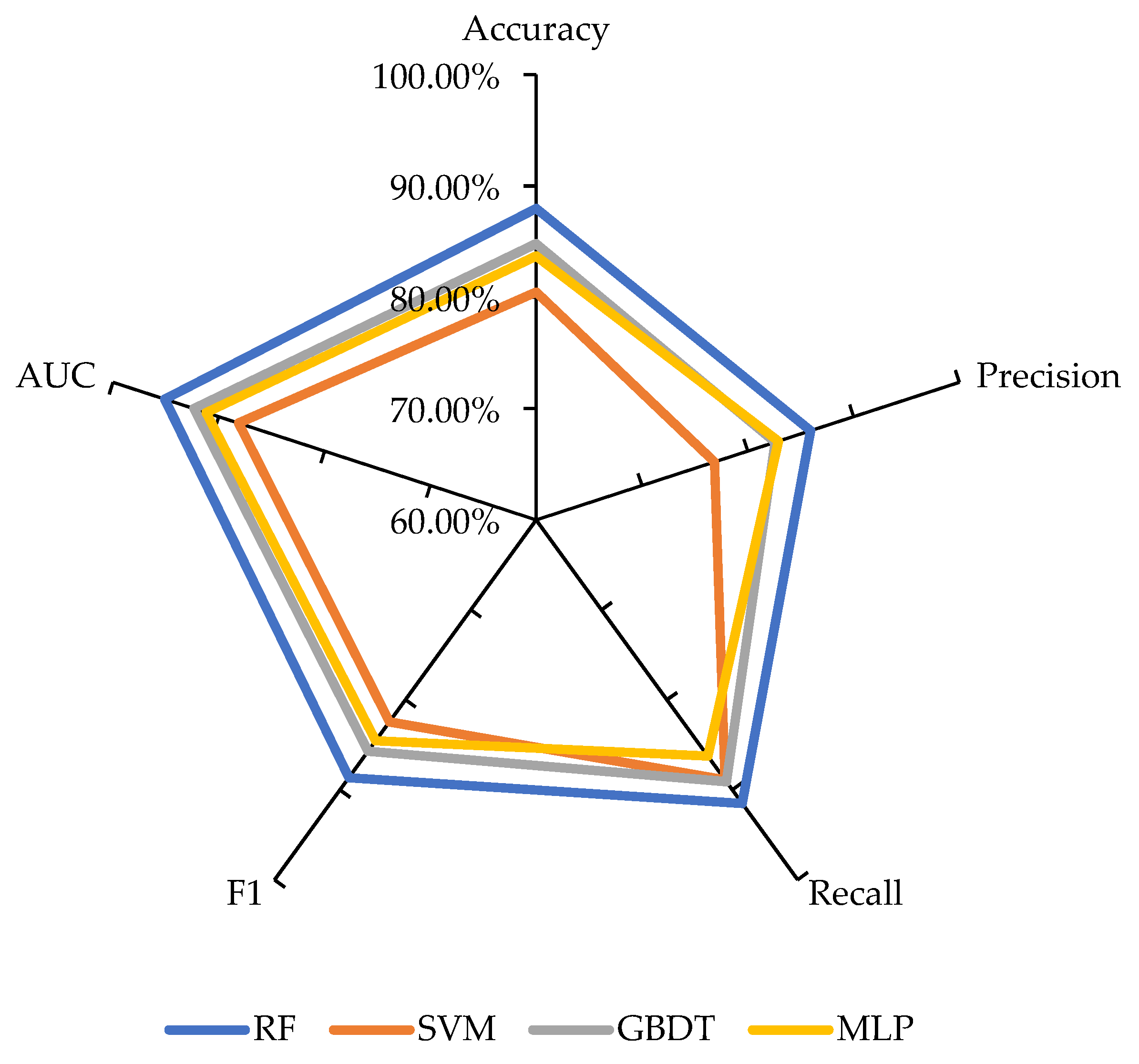
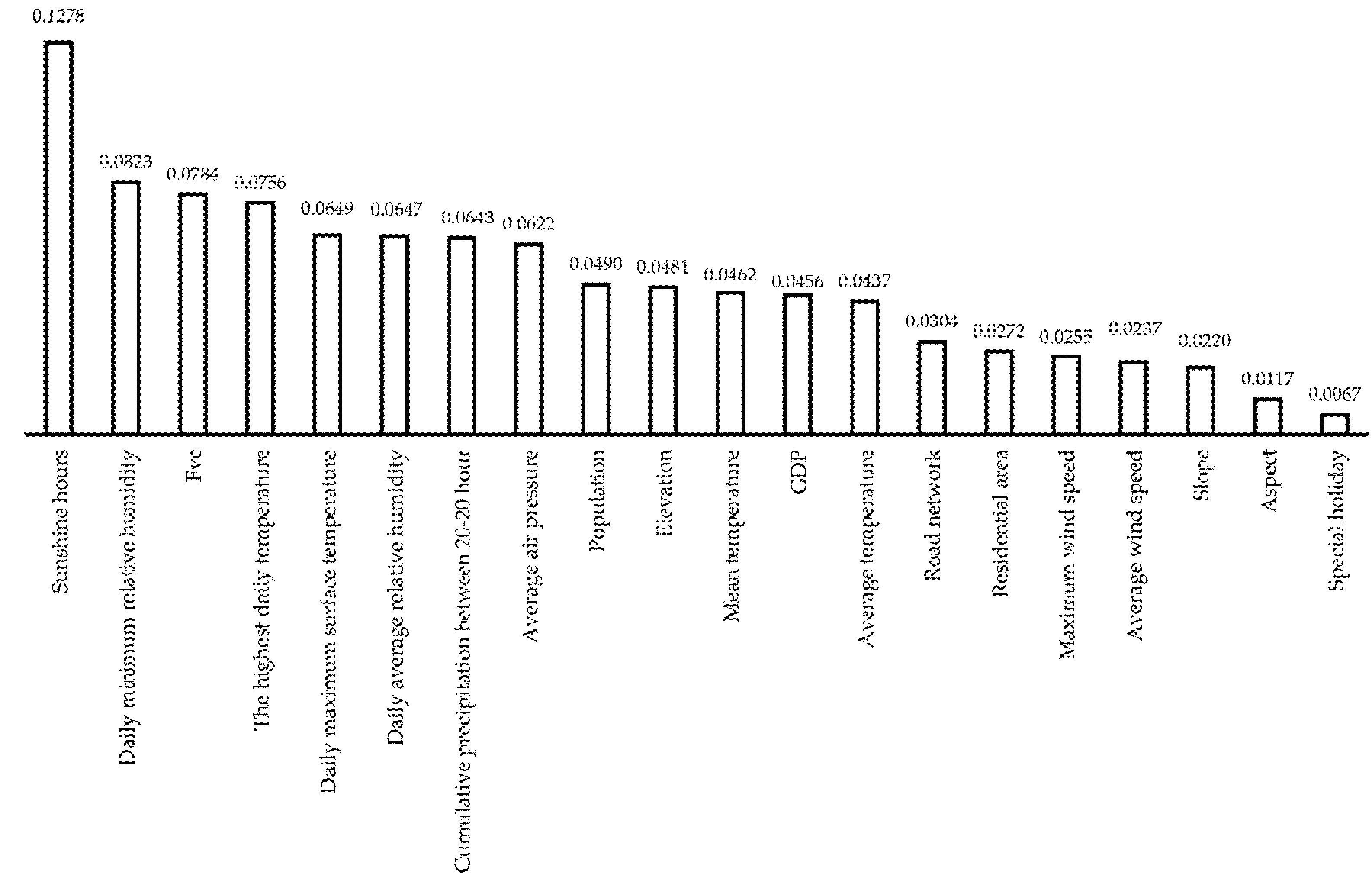
3.1. Model Comparison and Validation
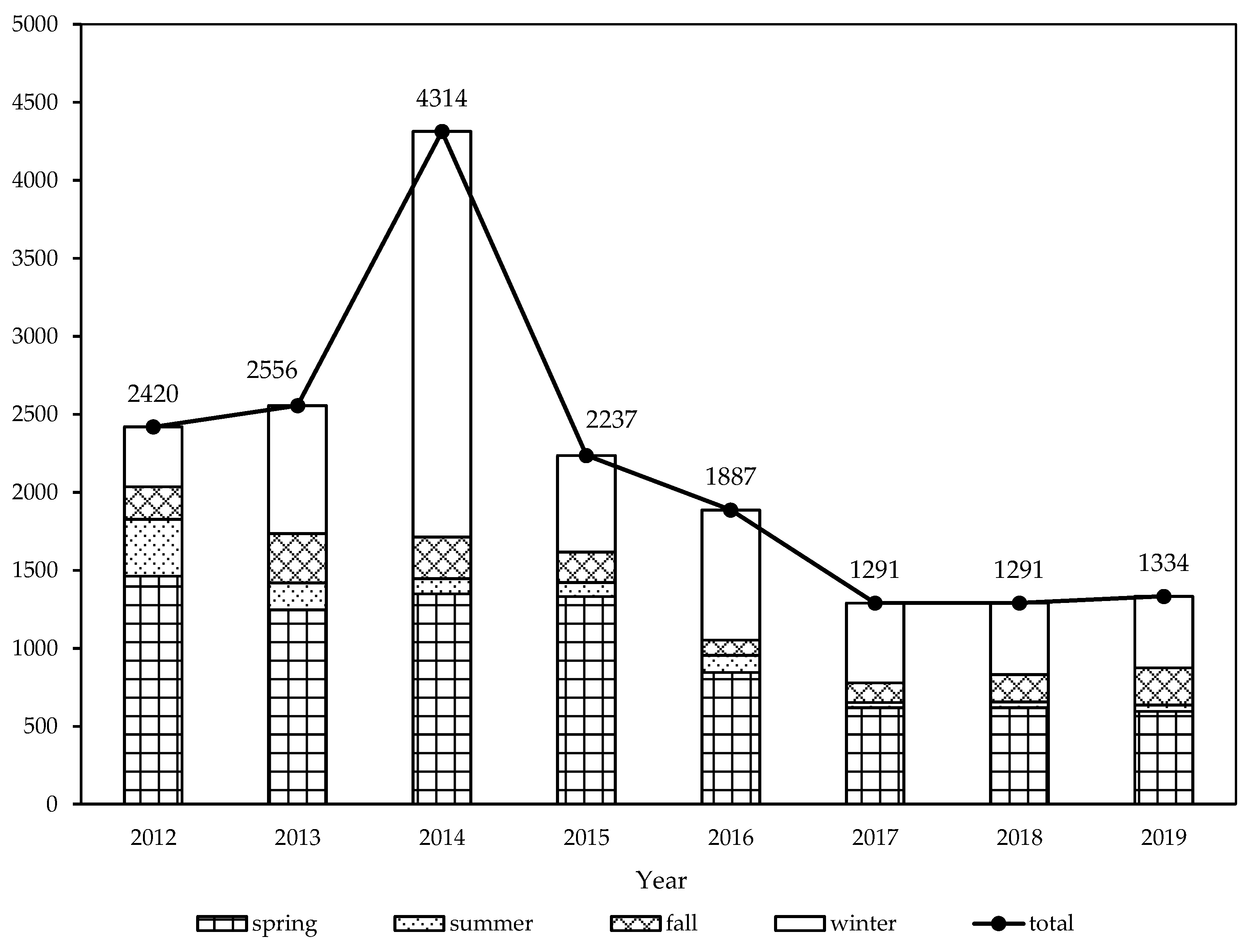
3.2. Forest Fire Statistics in China
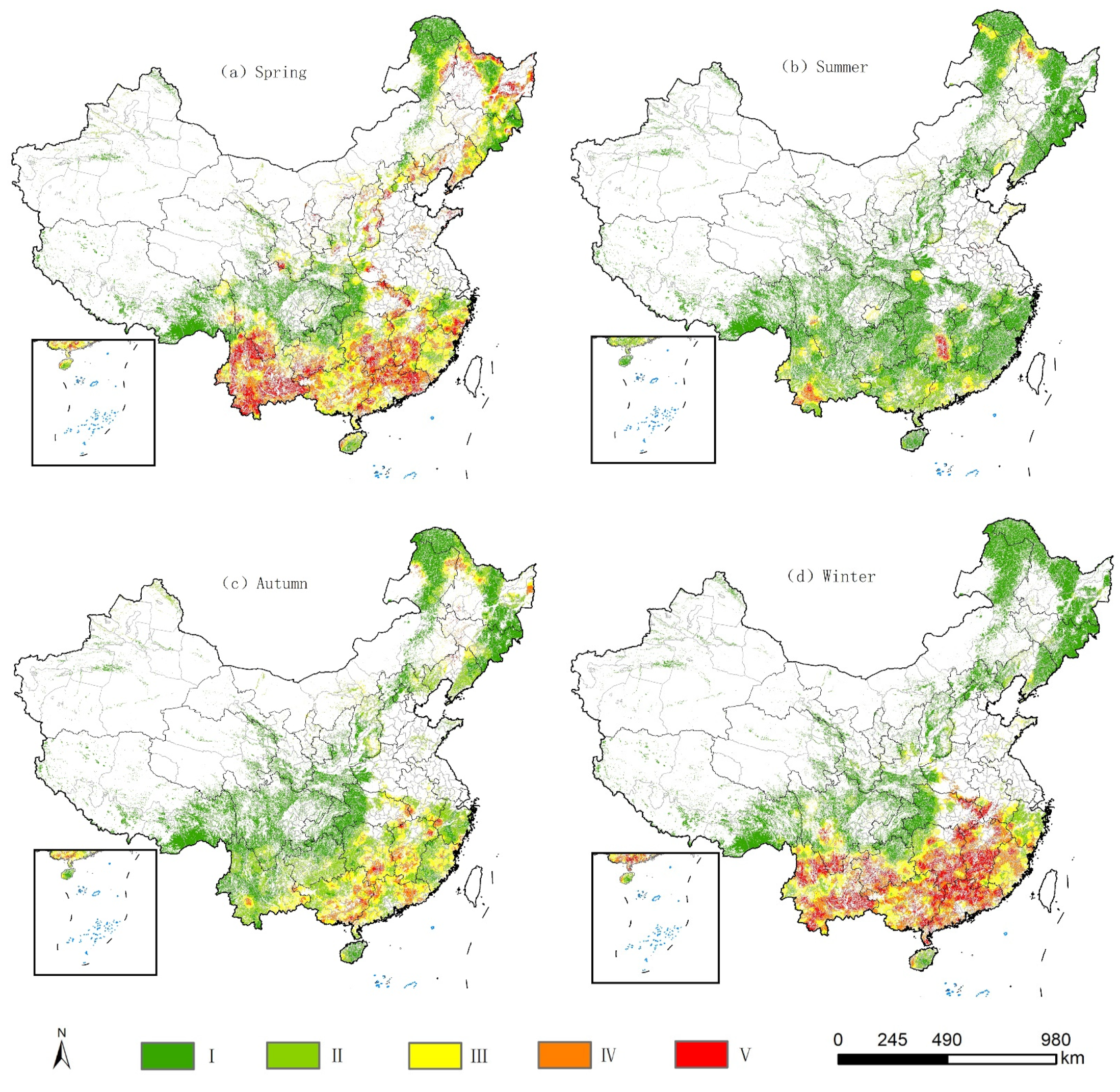
3.3. Seasonal Fire Zoning Map
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Morales-Hidalgo, D.; Oswalt, S.N.; Somanathan, E. Status and trends in global primary forest, protected areas, and areas designated for conservation of biodiversity from the Global Forest Resources Assessment 2015. For. Ecol. Manag. 2015, 352, 68–77. [Google Scholar] [CrossRef] [Green Version]
- Qiu, Z.; Feng, Z.; Song, Y.; Li, M.; Zhang, P. Carbon sequestration potential of forest vegetation in China from 2003 to 2050: Predicting Forest vegetation growth based on climate and the environment. J. Clean. Prod. 2019, 252, 119715. [Google Scholar] [CrossRef]
- Motazeh, A.G.; Ashtiani, E.F.; Baniasadi, R.; Choobar, F.M. Rating and mapping fire hazard in the hardwood Hyrcanian forests using GIS and expert choice software. For. Ideas. 2013, 19, 141–150. [Google Scholar]
- Ke, Z.; Gebdang, B.; Xin, L.B.; Zhijia, B.; Zhongbo, Y.; Jun, X.; Zengchuan, D. A comprehensive assessment framework for quantifying climatic and anthropogenic contributions to streamflow changes: A case study in a typical semi-arid North China basin. Environ. Model. Softw. 2020, 128, 104704. [Google Scholar]
- Feng, W.; Lu, H.; Yao, T.; Yu, Q. Drought characteristics and its elevation dependence in the Qinghai–Tibet plateau during the last half-century. Sci. Rep. 2020, 10, 14323. [Google Scholar] [CrossRef]
- Zheng, Z. Study on the risk, spread and assessment of forest fire based on the model and remote sensing. Acta Geod. Cartogr. Sin. 2019, 48, 133. [Google Scholar]
- Sachdeva, S.; Bhatia, T.; Verma, A.K. GIS-based evolutionary optimized gradient boosted decision trees for forest fire susceptibility mapping. Nat. Hazards 2018, 92, 1399–1418. [Google Scholar] [CrossRef]
- Boer, M.M.; Dios, V.; Bradstock, R.A. Unprecedented burn area of Australian mega forest fires. Nat. Clim. Chang. 2020, 10, 171–172. [Google Scholar] [CrossRef]
- Venkatesh, K.; Preethi, K.; Ramesh, H. Evaluating the effects of forest fire on water balance using fire susceptibility maps. Ecol. Indic. 2019, 110, 105856. [Google Scholar] [CrossRef]
- Ghorbanzadeh, O.; Blaschke, T.; Gholamnia, K.; Aryal, J. Forest fire susceptibility and risk mapping using social/infrastructural vulnerability and environmental variables. Fire 2019, 2, 50. [Google Scholar] [CrossRef] [Green Version]
- Ma, W.; Feng, Z.; Cheng, Z.; Chen, S.; Wang, F. Identifying forest fire driving factors and related impacts in China using random forest algorithm. Forests 2020, 5, 507. [Google Scholar] [CrossRef]
- Kuuluvainen, T.; Grenfell, R. Natural disturbance emulation in boreal forest ecosystem management—theories, strategies, and a comparison with conventional even-aged management. Can. J. For. Res. 2012, 42, 1185–1203. [Google Scholar] [CrossRef]
- Moreno, M.V.; Chuvieco, E. Characterising fire regimes in Spain from fire statistics. Int. J. Wildland Fire 2013, 22, 296–305. [Google Scholar] [CrossRef]
- González, J.R.; Kolehmainen, O.; Pukkala, T. Using expert knowledge to model forest stand vulnerability to fire. Comput. Electron. Agric. 2007, 55, 107–114. [Google Scholar] [CrossRef]
- Stock, M.; Williams, J.; Cleaves, D.A. Estimating the risk of escape of prescribed fires: An expert system approach. AI Appl. Nat. Resour. Agric. Environ. Sci. 1996, 10, 63. [Google Scholar]
- Jaafari, A.; Mafi-Gholami, D.; Thai Pham, B.; Tien Bui, D. Wildfire Probability Mapping: Bivariate vs. Multivariate Statistics. Remote Sens. 2019, 11, 618. [Google Scholar] [CrossRef] [Green Version]
- Su, Z.; Zeng, A.; Cai, Q.; Hu, H. Study on prediction model and driving factors of forest fire in Da Hinggan Mountains using Gompit regression method. J. For. Eng. 2019, 4, 135–142. [Google Scholar]
- Rodrigues, M.; Riva, J.D.L.; Fotheringham, S. Modeling the spatial variation of the explanatory factors of human-caused wildfires in Spain using geographically weighted logistic regression. Appl. Geogr. 2014, 48, 52–63. [Google Scholar] [CrossRef]
- Pourghasemi, H.R. GIS-based forest fire susceptibility mapping in Iran: A comparison between evidential belief function and binary logistic regression models. Scand. J. For. Res. 2015, 31, 80–98. [Google Scholar] [CrossRef]
- Qin, K.; Guo, F.; Di, X.; Sun, L.; Pan, J. Selection of advantage prediction model for forest fire occurrence in Tahe, Daxing’an Mountain. Chin. J. Appl. Ecol. 2014, 25, 731–737. [Google Scholar]
- Boubeta, M.; Lombardia, M.J.; Marey-Perez, M.F.; Morales, D. Prediction of forest fires occurrences with area-level Poisson mixed models. J. Environ. Manag. 2015, 154, 151–158. [Google Scholar] [CrossRef] [PubMed]
- Jaafari, A.; Gholami, D.M. Wildfire hazard mapping using an ensemble method of frequency ratio with Shannon’s entropy. Iran. J. For. Poplar Res. 2017, 25, 232–242. [Google Scholar]
- Gholamnia, K.; Gudiyangada Nachappa, T.; Ghorbanzadeh, O.; Blaschke, T. Comparisons of diverse machine learning approaches for wildfire susceptibility mapping. Symmetry 2020, 12, 604. [Google Scholar] [CrossRef] [Green Version]
- Sayad, Y.O.; Mousannif, H.; Al Moatassime, H. Predictive modeling of wildfires: A new dataset and machine learning approach. Fire Saf. J. 2019, 104, 130–146. [Google Scholar] [CrossRef]
- Song, Y.; Liu, B.; Miao, W.; Chang, D.; Zhang, Y. Spatiotemporal variation in nonagricultural open fire emissions in China from 2000 to 2007. Global Biogeochem. Cycles 2009, 23. [Google Scholar] [CrossRef]
- Adab, H.; Kanniah, K.D.; Solaimani, K. Modeling forest fire risk in the northeast of Iran using remote sensing and GIS techniques. Nat. Hazards 2013, 65, 1723–1743. [Google Scholar] [CrossRef]
- Yu, C.; Zhu, Z.; Bu, R.; Chen, H.; Wang, Z. Predicting fire occurrence patterns with logistic regression in Heilongjiang Province, China. Landsc. Ecol. 2013, 28, 1989–2004. [Google Scholar]
- Ying, L.; Han, J.; Du, Y.; Shen, Z. Forest fire characteristics in China: Spatial patterns and determinants with thresholds. For. Ecol. Manag. 2018, 424, 345–354. [Google Scholar] [CrossRef]
- Morgan, P.; Hardy, C.C.; Swetnam, T.W.; Rollins, M.G.; Long, D.G. Mapping fire regimes across time and space: Understanding coarse and fine-scale fire patterns. Int. J. Wildland Fire 2001, 10, 329–342. [Google Scholar] [CrossRef] [Green Version]
- Sun, J.; Zhong, C.; He, H.; Hugeman, G.; Li, H. Continuous remote sensing monitoring and changes of land desertification in China from 2000 to 2015. J. Northeast. For. Univ. 2021, 49, 87–92. [Google Scholar]
- Unnikrishnan, A.; Reddy, C.S. Characterizing distribution of forest fires in Myanmar using earth observations and spatial statistics tool. J. Indian Soc. Remote Sens. 2020, 48, 227–234. [Google Scholar] [CrossRef]
- Ning, J.; Liu, J.; Kuang, W.; Xu, X.; Zhang, S.; Yan, C.; Li, R.; Wu, S.; Hu, Y.; Du, G.; et al. Spatiotemporal patterns and characteristics of land-use change in China during 2010–2015. J. Geogr. Sci. 2018, 28, 547–562. [Google Scholar] [CrossRef] [Green Version]
- Guo, F.; Su, Z.; Wang, G.; Sun, L.; Tigabu, M.; Yang, X.; Hu, H. Understanding fire drivers and relative impacts in different Chinese forest ecosystems. Sci. Total Environ. 2017, 605–606, 411–425. [Google Scholar] [CrossRef] [PubMed]
- Holden, Z.A.; Jolly, W.M. Modeling topographic influences on fuel moisture and fire danger in complex terrain to improve wildland fire management decision support. For. Ecol. Manag. 2011, 262, 2133–2141. [Google Scholar] [CrossRef]
- Wu, Z.; He, H.S.; Yang, J.; Liu, Z.; Liang, Y. Relative effects of climatic and local factors on fire occurrence in boreal forest landscapes of northeastern China. Sci. Total Environ. 2014, 493, 472–480. [Google Scholar] [CrossRef]
- Sun, Y.L.; Shan, M.; Pei, X.R.; Zhang, X.K.; Yang, Y.L. Assessment of the impacts of climate change and human activities on vegetation cover change in the Haihe River basin, China. Phys. Chem. Earth 2020, 115, 102834. [Google Scholar] [CrossRef]
- Gutman, G.; Ignatov, A. The derivation of the green vegetation fraction from NOAA/AVHRR data for use in numerical weather prediction models. Int. J. Remote Sens. 1998, 19, 1533–1543. [Google Scholar] [CrossRef]
- Guo, F.; Wang, G.; Su, Z.; Liang, H.; Wang, W.; Lin, F. What drives forest fire in Fujian, China? Evidence from logistic regression and random forests. Int. J. Wildland Fire 2016, 25, 505. [Google Scholar] [CrossRef]
- Gigović, L.; Pourghasemi, H.R.; Drobnjak, S.; Bai, S. Testing a new ensemble model based on SVM and random forest in forest fire susceptibility assessment and its mapping in Serbia’s Tara National Park. Forests 2019, 10, 408. [Google Scholar] [CrossRef] [Green Version]
- Ma, Z.C.; Yu, H.B.; Cao, C.M.; Zhang, Q.F.; Hou, L.L.; Liu, Y.X. Spatio temporal Characteristics of Fractional Vegetation Coverage and Its Influencing Factors in China. Resour. Environ. Yangtze Val. 2020, 29, 12. [Google Scholar]
- Ma, W.; Feng, Z.; Cheng, Z.; Chen, S.; Wang, F. Study on driving factors and distribution pattern of forest fires in Shanxi province. J. Cent. South Univ. For. Technol. 2020, 40, 57–69. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Diao, C.; Wang, L. Incorporating plant phenological trajectory in exotic saltcedar detection with monthly time series of Landsat imagery. Remote Sens. Environ. 2016, 182, 60–71. [Google Scholar] [CrossRef]
- Shi, H. Best-First Decision Tree Learning. Master’s Thesis, University of Waikato, Hamilton, New Zealand, 2007. Available online: https://hdl.handle.net/10289/2317 (accessed on 24 February 2007).
- Vapnik, V. The support vector method of function estimation. In Nonlinear Modeling: Advanced Black-Box Techniques; Suykens, J.A.K., Vandewalle, J., Eds.; Springer: Boston, MA, USA, 1998; pp. 55–85. [Google Scholar]
- Negri, R.G.; Dutra, L.V.; Sant’Anna, S.J.S. An innovative support vector machine based method for contextual image classification. ISPRS J. Photogramm. Remote Sens. 2014, 87, 241–248. [Google Scholar] [CrossRef]
- Belousov, A.I.; Verzakov, S.A.; von Frese, J. Applicational aspects of support vector machines. J. Chemom. 2010, 16, 482–489. [Google Scholar] [CrossRef]
- Vapnik, V.N. An overview of statistical learning theory. IEEE Trans. Neural Netw. 1999, 10, 988–999. [Google Scholar] [CrossRef] [Green Version]
- Maser, B.; Söllinger, D.; Uhl, A. PRNU-based finger vein sensor identification in the presence of presentation attack data. In Proceedings of the Joint ARW/OAGM Workshop 2019 (ARW/OAGM’19), Steyr, Austria, 9–10 May 2019. [Google Scholar]
- Araujo, L.N.; Belotti, J.T.; Alves, T.A.; Tadano, Y.D.S.; Siqueira, H. Ensemble method based on artificial neural networks to estimate air pollution health risks. Environ. Model. Softw. 2020, 123, 104567. [Google Scholar] [CrossRef]
- Feng, R.; Gao, H.; Luo, K.; Fan, J.R. Analysis and accurate prediction of ambient PM2.5 in China using multi-layer perceptron. Atmos. Environ. 2020, 232, 117534. [Google Scholar] [CrossRef]
- Zhang, T.; He, W.; Zheng, H.; Cui, Y.; Song, H.; Fu, S. Satellite-based ground PM2.5 estimation using a gradient boosting decision tree. Chemosphere 2021, 268, 128801. [Google Scholar] [CrossRef]
- Friedman, J. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Rong, G.; Alu, S.; Li, K.; Su, Y.; Li, T. Rainfall induced landslide susceptibility mapping based on Bayesian optimized random forest and gradient boosting decision tree models—A case study of Shuicheng County, China. Water 2020, 12, 3066. [Google Scholar] [CrossRef]
- Yang, S.; Wu, J.; Du, Y.; He, Y.; Chen, X. Ensemble learning for short-term traffic prediction based on gradient boosting machine. J. Sens. 2017, 2017, 7074143. [Google Scholar] [CrossRef]
- Takran, T.; Chartrungruang, B.; Tantranont, N.; Somhom, S. Constructing a Thai homestay standard assessment model by implementing a decision tree technique. Int. J. Comput. Internet Manag. 2017, 25, 106–112. [Google Scholar]
- Swets, J. Measuring the accuracy of diagnostic systems. Science 1988, 240, 1285–1293. [Google Scholar] [CrossRef] [Green Version]
- Gigliarano, C.; Figini, S.; Muliere, P. Making classifier performance comparisons when ROC curves intersect. Comput. Stat. Data Anal. 2014, 77, 300–312. [Google Scholar] [CrossRef]
- Bui, D.T.; Shirzadi, A.; Shahabi, H.; Geertsema, M.; Lee, S. New ensemble models for shallow landslide susceptibility modeling in a semi-arid watershed. Forests 2019, 10, 743. [Google Scholar]
- Genuer, R.; Poggi, J.M.; Tuleau-Malot, C. Variable selection using random forests. Pattern Recognit. Lett. 2010, 31, 2225–2236. [Google Scholar] [CrossRef] [Green Version]
- Chuvieco, E.; Cocero, D.; Riaño, D.; Martin, P.; Martínez-Vega, J.; de la Riva, J.; Pérez, F. Combining NDVI and surface temperature for the estimation of live fuel moisture content in forest fire danger rating. Remote Sens. Environ. 2004, 92, 322–331. [Google Scholar] [CrossRef]
- Vasilakos, C.; Kalabokidis, K.; Hatzopoulos, J.; Matsinos, I. Identifying wildland fire ignition factors through sensitivity analysis of a neural network. Nat. Hazards 2009, 50, 125–143. [Google Scholar] [CrossRef]
- Holsten, A.; Dominic, A.R.; Costa, L.; Kropp, J.P. Evaluation of the performance of meteorological forest fire indices for German federal states. For. Ecol. Manag. 2013, 287, 123–131. [Google Scholar] [CrossRef]
- Vilar, L.; Woolford, D.G.; Martell, D.L.; MP Martín. A model for predicting human-caused wildfire occurrence in the region of Madrid, Spain. Int. J. Wildland Fire 2010, 19, 325–337. [Google Scholar] [CrossRef]
- Eugenio, F.C.; Santos, A.D.; Fiedler, N.C.; Ribeiro, G.A.; Silva, A.; Dos Santos, Á.B.; Paneto, G.G.; Schettino, V.R. Applying GIS to develop a model for forest fire risk: A case study in Espírito Santo, Brazil. J. Environ. Manag. 2016, 173, 65–71. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; He, H.S.; Wu, Z.; Liang, Y.; Schneiderman, J.E. Comparing effects of climate warming, fire, and timber harvesting on a boreal forest landscape in northeastern China. PLoS ONE 2013, 8, e59747. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhong, M.; Fan, W.; Liu, T.; Li, P. Statistical analysis on current status of China forest fire safety. Fire Saf. J. 2003, 38, 257–269. [Google Scholar] [CrossRef]
- Yi, K.; Bao, Y.; Zhang, J. Spatial distribution and temporal variability of open fire in China. Int. J. Wildland Fire. 2016, 26, 122–135. [Google Scholar] [CrossRef] [Green Version]
- Fang, K.; Yao, Q.; Guo, Z.; Zheng, B.; Trouet, V. ENSO modulates wildfire activity in China. Nat. Commun. 2021, 12, 1764. [Google Scholar] [CrossRef]
- Massada, A.B.; Syphard, A.D.; Stewart, S.I.; Radeloff, V.C. Wildfire ignition-distribution modelling: A comparative study in the Huron–Manistee National Forest, Michigan, USA. Int. J. Wildland Fire 2013, 22, 174–183. [Google Scholar] [CrossRef]
- Xie, Y.; Peng, M. Forest fire forecasting using ensemble learning approaches. Neural Comput. Appl. 2019, 31, 4541–4550. [Google Scholar] [CrossRef]
- Vasconcelos, M.J.P.D.; Silva, S.; Tome, M.; Alvim, M.; Pereira, J.M.C. Spatial prediction of fire ignition probabilities: Comparing logistic regression and neural networks. Photogramm. Eng. Remote Sens. 2001, 67, 73–81. [Google Scholar]
- Rodrigues, M.; de la Riva, J. An insight into machine-learning algorithms to model human-caused wildfire occurrence. Environ. Model. Softw. 2014, 57, 192–201. [Google Scholar] [CrossRef]
- Oliveira, S.; Oehler, F.; San-Miguel-Ayanz, J.; Camia, A.; Pereira, J.M. Modeling spatial patterns of fire occurrence in Mediterranean Europe using multiple regression and random forest. For. Ecol. Manag. 2012, 275, 117–129. [Google Scholar] [CrossRef]
- Al Janabi, S.; Al Shourbaji, I.; Salman, M.A. Assessing the suitability of soft computing approaches for forest fires prediction. Appl. Comput. Inform. 2018, 14, 214–224. [Google Scholar]
- Pham, B.T.; Jaafari, A.; Avand, M.; Al-Ansari, N.; Dinh Du, T.; Yen, H.P.H.; Phong, T.V.; Nguyen, D.H.; Le, H.V.; Mafi-Gholami, D.; et al. Performance evaluation of machine learning methods for forest fire modeling and prediction. Symmetry 2020, 12, 1022. [Google Scholar] [CrossRef]
- Mohajane, M.; Costache, R.D.; Karimi, F.; Pham, Q.B.; Essahlaoui, A.; Nguyen, H.; Laneve, G.; Oudija, F. Application of remote sensing and machine learning algorithms for forest fire mapping in a Mediterranean area. Ecol. Indic. 2021, 129, 1–17. [Google Scholar] [CrossRef]
- Ghorbanzadeh, O.; Valizadeh Kamran, K.; Blaschke, T.; Aryal, J.; Naboureh, A.; Einali, J.; Bian, J. Spatial prediction of wildfire susceptibility using field survey GPS data and machine learning approaches. Fire 2019, 2, 43. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Feng, Z.; Chen, S.; Zhao, Z.; Wang, F. Application of the artificial neural network and support vector machines in forest fire prediction in the Guangxi Autonomous Region, China. Discrete Dyn. Nat. Soc. 2020, 2020, 5612650. [Google Scholar] [CrossRef] [Green Version]
- Gao, J. Middle and long term plan discussion of key problems to forest fire prevention in China. For. Inventory Plan. 2015, 40, 4. [Google Scholar]
- Jaafari, A.; Razavi Termeh, S.V.; Bui, D.T. Genetic and firefly metaheuristic algorithms for an optimized neuro-fuzzy prediction modeling of wildfire probability. J. Environ. Manag. 2019, 243, 358–369. [Google Scholar] [CrossRef]
- Tien Bui, D.; Hoang, N.-D.; Samui, P. Spatial pattern analysis and prediction of forest fire using new machine learning approach of multivariate adaptive regression splines and differential flower pollination optimization: A case study at Lao Cai province (Viet Nam). J. Environ. Manag. 2019, 237, 476–487. [Google Scholar] [CrossRef]
- Field, R.D. Evaluation of Global Fire Weather Database reanalysis and short-term forecast products. Nat. Hazard Earth Syst. 2020, 20, 1123–1147. [Google Scholar] [CrossRef]
- Pettinari, M.L.; Chuvieco, E. Generation of a global fuel data set using the Fuel Characteristic Classification System. Biogeosciences 2016, 13, 2061–2076. [Google Scholar] [CrossRef] [Green Version]
- Fan, L.; Wigneron, J.P.; Xiao, Q.; Al-Yaari, A.; Wen, J.; Martin-StPaul, N.; Dupuy, J.L.; Pimont, F.; Al Bitar, A.; Fernandez-Moran, R.; et al. Evaluation of microwave remote sensing for monitoring live fuel moisture content in the Mediterranean region. Remote Sens. Environ. 2018, 205, 210–223. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sub-Classification | Data | Source | Resolution, Units | References |
|---|---|---|---|---|
| Topographic | Aspect | https://www.resdc.cn | 1 km | [34] |
| Slope | https://www.resdc.cn | 1 km | ||
| Elevation | https://www.resdc.cn | 1 km | ||
| Climatic | Daily average ground surface temperature | China Ground Climate Data (V3.0) Daily Dataset, | 0.1 °C | [11,35] |
| Daily maximum surface temperature | National Meteorological Information Centre | 0.1 °C | ||
| Cumulative precipitation from 20–20 h | (https://data.cma.cn, accessed on 1 January 2022) | 0.1 mm | ||
| Average air pressure | 0.1 hPa | |||
| Daily average relative humidity | 1% | |||
| Daily minimum relative humidity | 1% | |||
| Sunshine hours | 0.1 h | |||
| Mean temperature | 0.1 °C | |||
| Daily maximum temperature | 0.1 °C | |||
| Average wind speed | 0.1 m/s | |||
| Maximum wind speed | 0.1 m/s | |||
| Vegetation | FVC | https://www.resdc.cn | 1 km | [36,37] |
| Socioeconomic | Road network | https://www.webmap.cn (accessed on 1 January 2022) | 1:1,000,000 | [38] |
| Residential area | https://www.webmap.cn | 1:1,000,000 | ||
| GDP | https://www.resdc.cn | 1 km | ||
| Population | https://www.resdc.cn | 1 km | ||
| Special holiday | - | - | - |
| No | Methods Used | Best Method | Study Area | Ref. |
|---|---|---|---|---|
| 1 | Generalized linear models, RF, maximum entropy | Maximum entropy | Huron–Manistee National Forest, MI, USA | [70] |
| 2 | RF, extreme gradient boosting | RF | Montesinho Natural Park, Portugal | [71] |
| 3 | Logistic regression, NN | NN | Central Portugal | [72] |
| 4 | RF, boosting regression trees, SVMs, logistic regression | RF | Lào Cai province, Vietnam | [73] |
| 5 | Multiple linear regression and RF | RF | Mediterranean Europe | [74] |
| 6 | Cascade correlation network, MLP NN, polynomial NN, RBF, SVM | SVM | Montesinho Natural Park, Portugal | [75] |
| 7 | Bayes network, naïve Bayes, decision tree, multivariate logistic regression | Multivariate logistic regression | Pu Mat National Park, Vietnam | [76] |
| 8 | Frequency ratio–multilayer perceptron, frequency ratio–classification and regression tree, frequency ratio–support vector machine, frequency ratio–RF | Frequency ratio–RF | Tanger-Tétouan-Al Hoceima region, northern Morocco | [77] |
| 9 | Artificial NN, SVM, RF | RF | Amol County, Iran | [78] |
| 10 | Artificial NN, SVM | Artificial NN | Guangxi, China | [79] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shao, Y.; Feng, Z.; Sun, L.; Yang, X.; Li, Y.; Xu, B.; Chen, Y. Mapping China’s Forest Fire Risks with Machine Learning. Forests 2022, 13, 856. https://doi.org/10.3390/f13060856
Shao Y, Feng Z, Sun L, Yang X, Li Y, Xu B, Chen Y. Mapping China’s Forest Fire Risks with Machine Learning. Forests. 2022; 13(6):856. https://doi.org/10.3390/f13060856
Chicago/Turabian StyleShao, Yakui, Zhongke Feng, Linhao Sun, Xuanhan Yang, Yudong Li, Bo Xu, and Yuan Chen. 2022. "Mapping China’s Forest Fire Risks with Machine Learning" Forests 13, no. 6: 856. https://doi.org/10.3390/f13060856
APA StyleShao, Y., Feng, Z., Sun, L., Yang, X., Li, Y., Xu, B., & Chen, Y. (2022). Mapping China’s Forest Fire Risks with Machine Learning. Forests, 13(6), 856. https://doi.org/10.3390/f13060856