
Using Advanced Machine-Learning Algorithms to Estimate the Site Index of Masson Pine Plantations

Abstract
1. Introduction
2. Materials and Methods
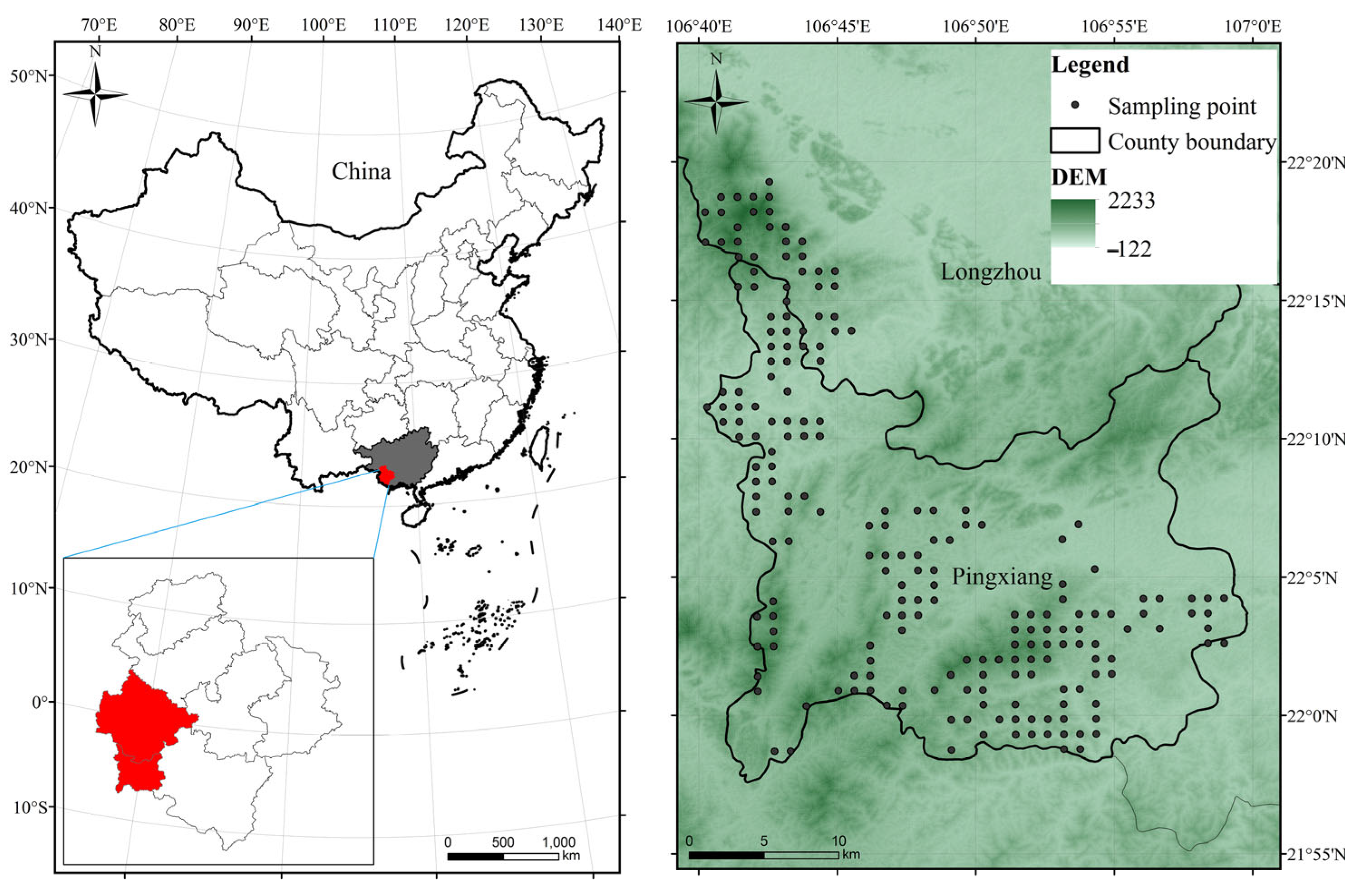
2.1. Study Area
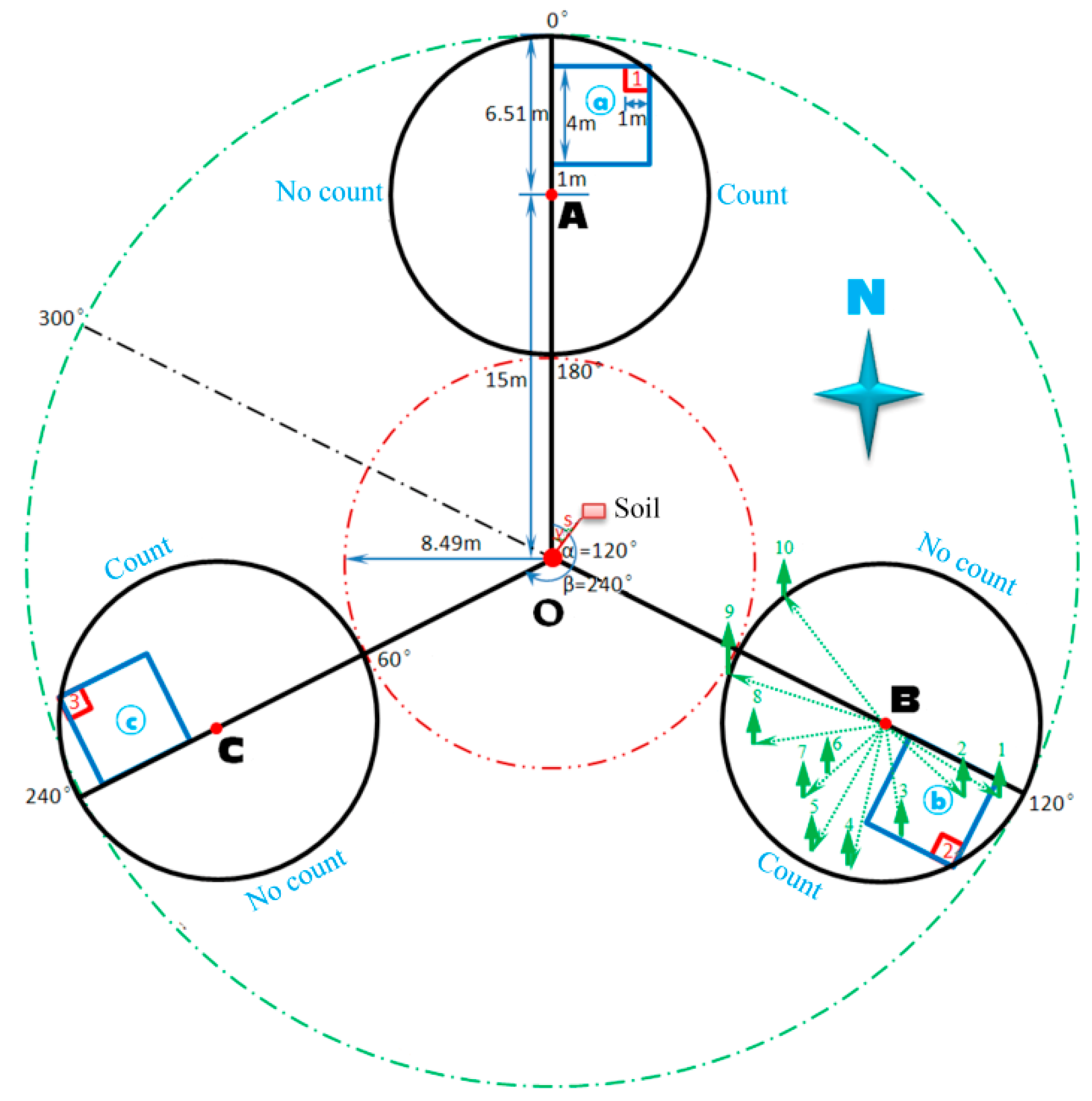
2.2. Plot Layout and Data Collection
2.3. Data and Preliminary Analysis
2.3.1. Dominant Height of the Stand
2.3.2. Soil Data
2.3.3. Climate Data
2.4. Quantification of Category Characteristics
2.5. Modelling Methods
2.5.1. Multiple Linear Regression
2.5.2. Random Forest
2.5.3. Extreme Gradient Boosting
2.5.4. Light Gradient Boosting Machine
2.6. Variable Importance
2.7. Model Evaluation
2.8. SI Prediction
3. Results
3.1. Modeling Results
3.1.1. Machine-Learning Model Hyperparameters
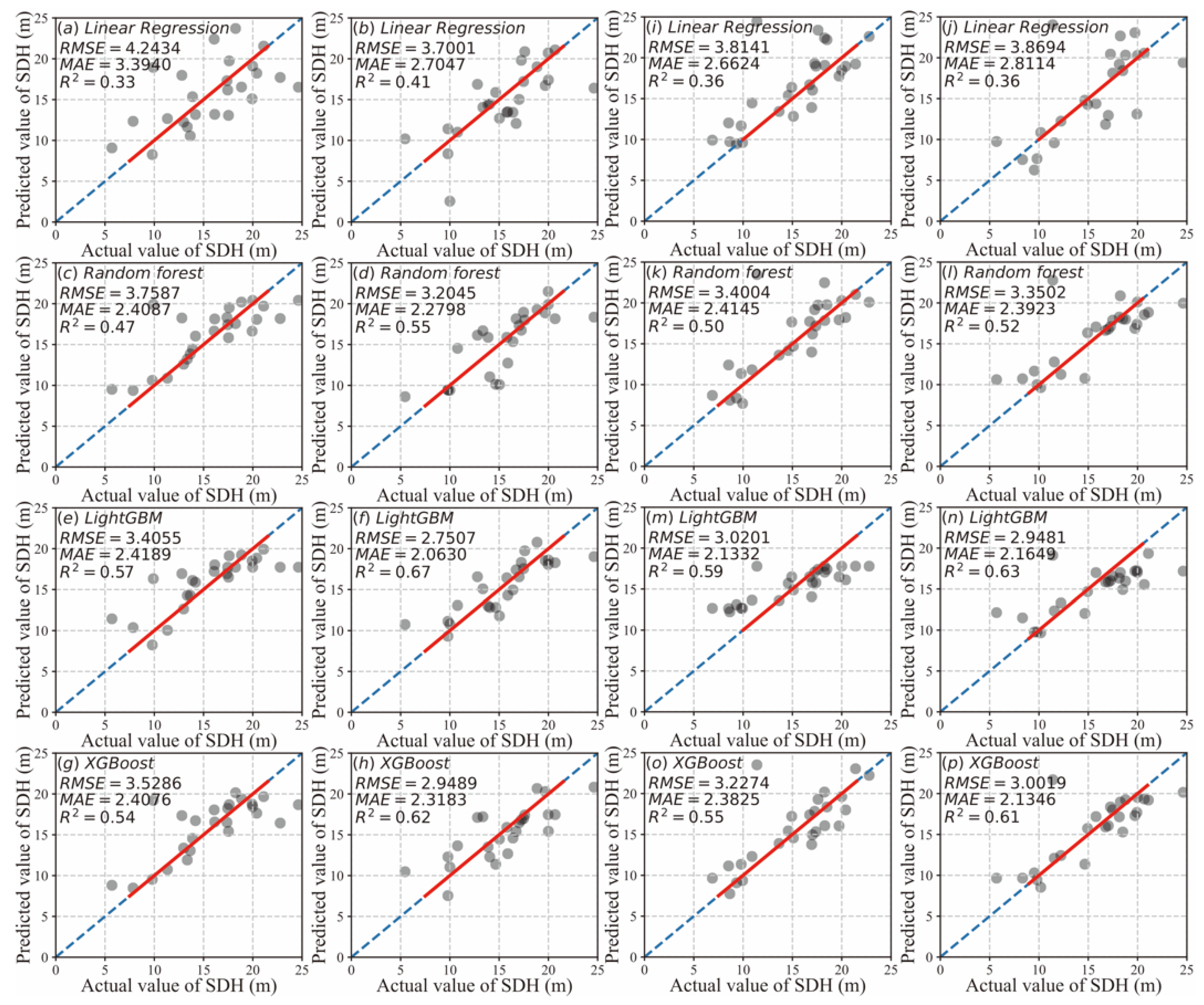
3.1.2. Model Comparison
3.1.3. Model Bias
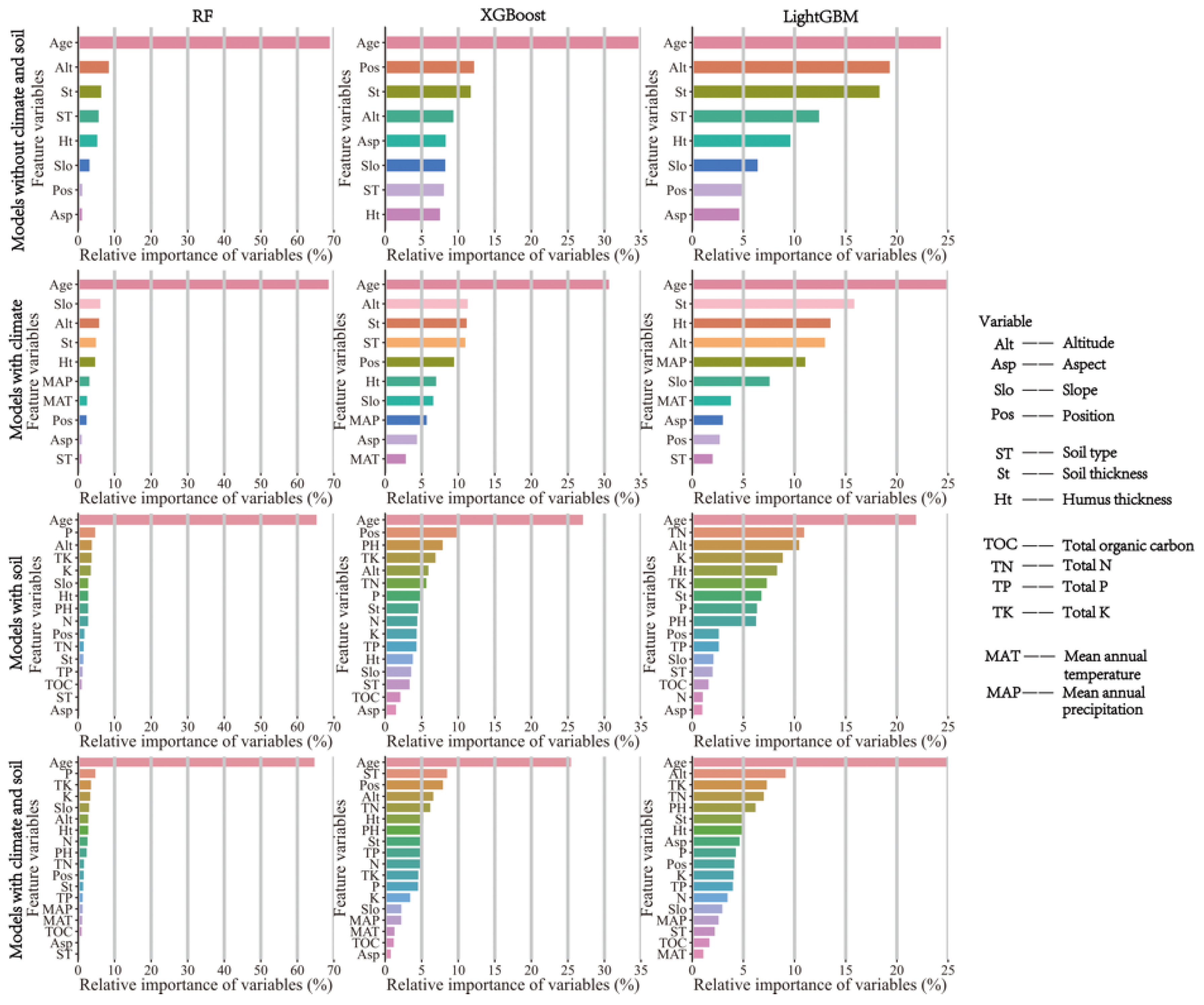
3.2. Variable Importance
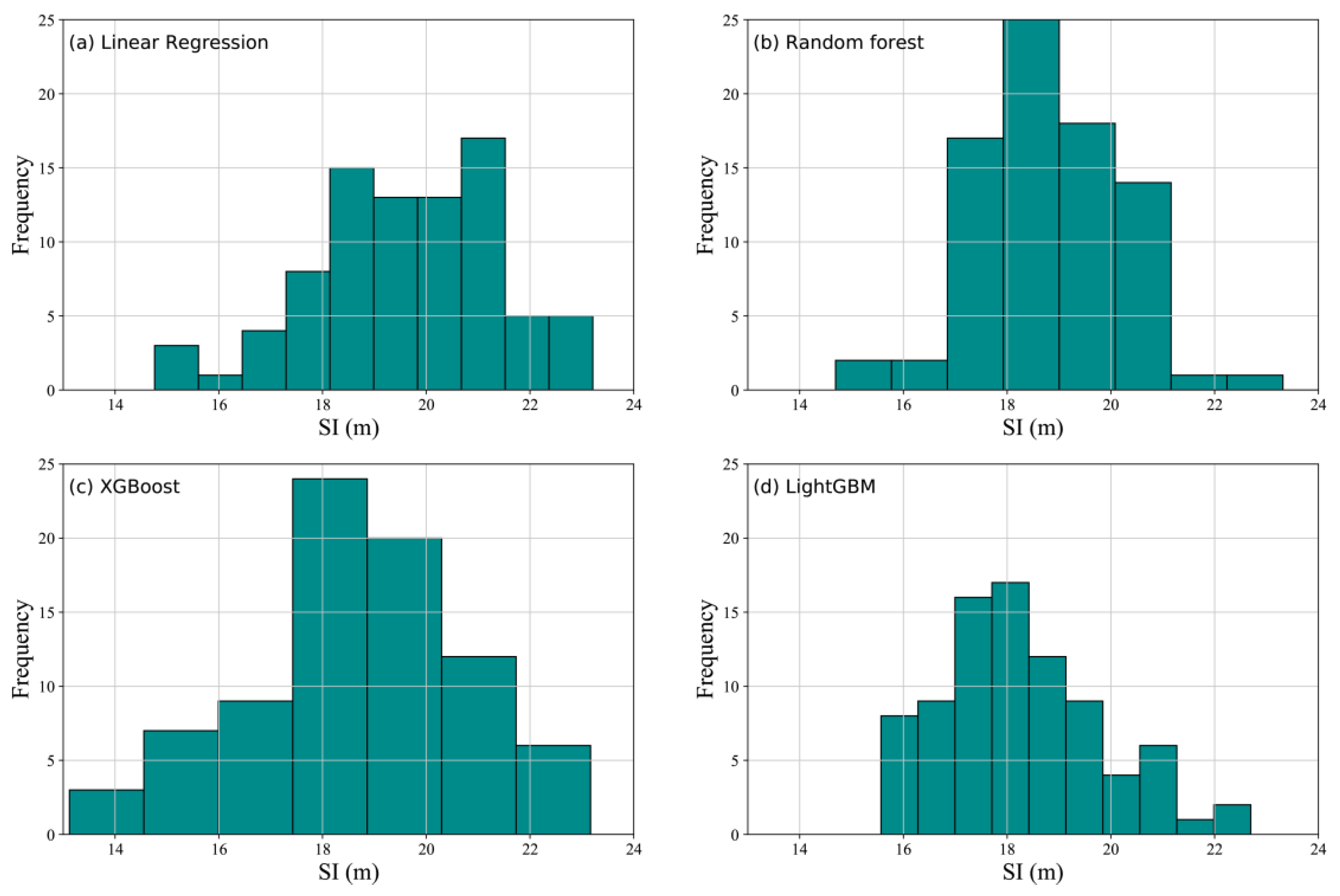
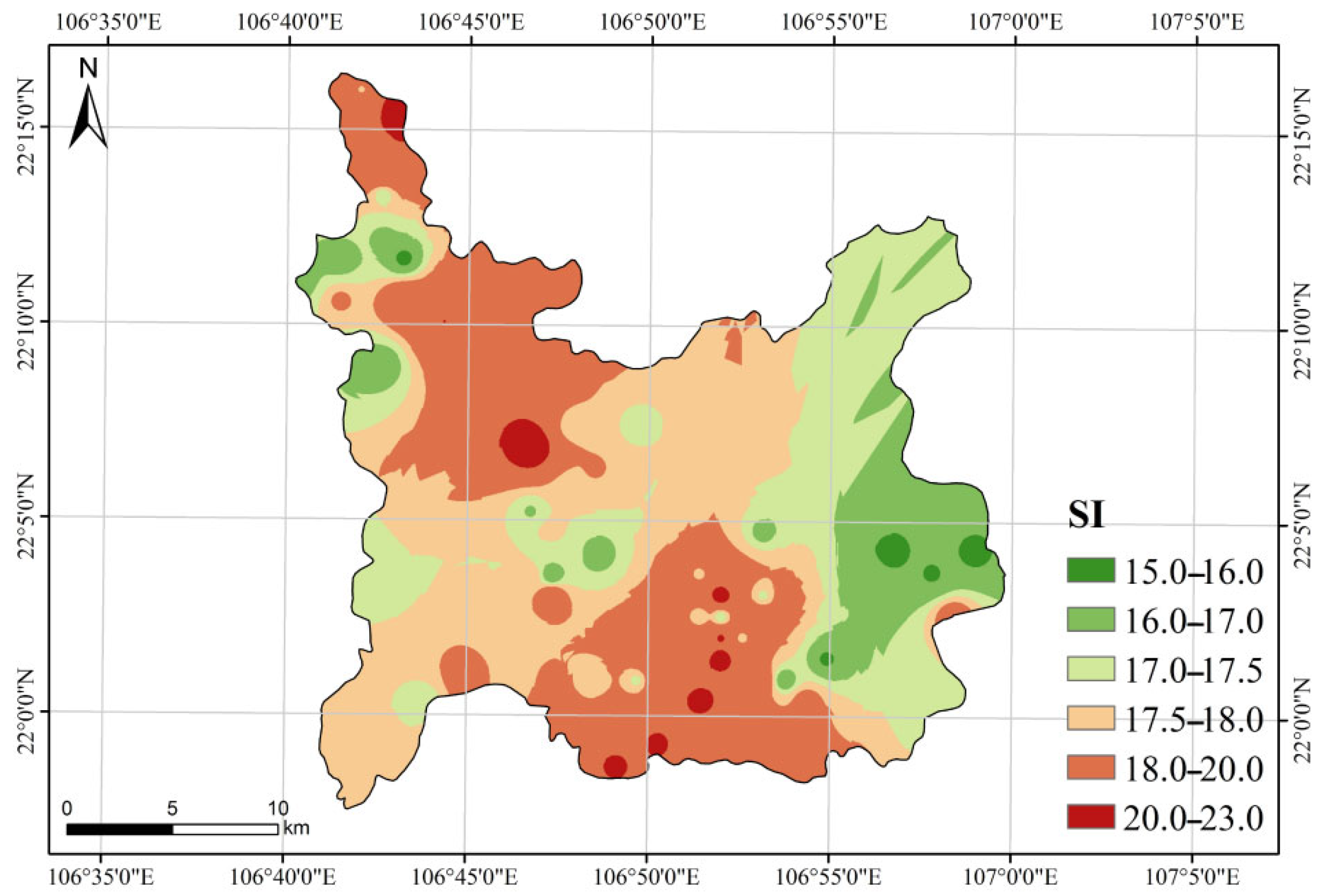
3.3. SI Prediction
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable Type | Number | Variable | Variable Definition |
|---|---|---|---|
| Geographical variables | 4 | Altitude | Vertical distance above sea level |
| Aspect | Orientation of the slope | ||
| Slope | Slope value | ||
| Position | Slope position | ||
| Soil physical variables | 3 | ST | Soil type |
| St | Soil thickness | ||
| Ht | Soil humus layer thickness | ||
| Soil chemical variables | 8 | PH | Soil pH value |
| TOC | Total soil organic carbon content | ||
| TN | Total soil nitrogen content | ||
| TP | Total soil phosphorus content | ||
| TK | Total soil potassium content | ||
| N | Soil available nitrogen content | ||
| P | Soil available phosphorus content | ||
| K | Soil available potassium content | ||
| Climate variables | 2 | MAT | Mean annual temperature |
| MAP | Mean annual precipitation | ||
| Forest variables | 1 | Age | Average stand age |
| Variable Name | Variable Definition | Method | ||
|---|---|---|---|---|
| RF | XGBoost | LightGBM | ||
| N_estimators | Number of trees | 500–1500 | 500–1500 | 500–1500 |
| Max_depth | Maximum depth of the tree | 3–15 | 3–15 | −1–15 |
| Min_samples_split | Minimum sample size required to split nodes | 1–4 | — | — |
| Min_samples_leaf | Minimum value of samples on leaf node | 1,2 | — | — |
| Min_child_weight | Minimum sample weight sum of leaf nodes | — | 1–6 | 1–6 |
| Gamma (min_gain_to_split) | Decreasing value of minimum loss function required for node splitting | — | 0–1 | 0–1 |
| Num_leaves | Number of leaf nodes of the tree | — | 5–100 | 5–100 |
| Subsample | Proportion of tree random sampling | — | 0.6–1 | 0.6–1 |
| Colsample_bytree | Feature sampling scale | — | 0.1–1 | 0.1–1 |
| Learning_rate | Tree model learning rate | — | 0.01–0.2 | 0.01–0.2 |
| Lambda_l1 | L1 regularization term | — | 10−5–1 | 10−5–1 |
| Lambda_l2 | L2 regularization term | — | 10−5–1 | 10−5–1 |
| Variable | Model without Climate and Soil Chemical Variables | Model with Climatic Variables | Model with Soil Chemical Variables | Model with Climatic and Soil Chemical Variables |
|---|---|---|---|---|
| Age | 3.6755 | 3.6700 | 3.5780 | 3.5415 |
| Altitude | −0.6261 | −1.0191 | 0.1406 | −1.6870 |
| Aspect | 0.1985 | 0.4049 | 0.1837 | 0.2820 |
| Slope | 0.3899 | 0.1693 | 0.4051 | 0.1082 |
| Position | 0.4629 | 0.3591 | 0.3077 | 0.2520 |
| ST | −0.5486 | −0.5974 | −0.0729 | −0.1289 |
| St | 0.3970 | 0.3234 | 0.7566 | 0.8219 |
| Ht | −0.3202 | −0.4112 | −0.4362 | −0.5494 |
| PH | — | — | −1.1538 | −1.1094 |
| TOC | — | — | −1.1817 | 1.1586 |
| TN | — | — | 1.6408 | 1.8775 |
| TP | — | — | 0.0050 | 0.0737 |
| TK | — | — | −0.8459 | −0.9823 |
| N | — | — | −1.3421 | 1.4449 |
| P | — | — | 0.5487 | 0.4990 |
| K | — | — | −0.4861 | −0.4168 |
| MAT | — | −0.7778 | — | −1.4857 |
| MAP | — | 1.2172 | — | 0.5283 |
References
- Ge, X.G.; Xiao, W.F.; Zeng, L.X.; Huang, Z.L.; Lei, J.P.; Li, M.H. The Link Between Litterfall, Substrate Quality, Decomposition Rate, and Soil Nutrient Supply in 30-Year-Old Pinus massoniana Forests in the Three Gorges Reservoir Area, China. Soil Sci. 2013, 178, 442–451. [Google Scholar] [CrossRef]
- Chen, F.; Yu, J.Y.; Shu, L.Y.; Tong, W.Z. Influence of climate warming and resin collection on the growth of Masson pine (Pinus massoniana) in a subtropical forest, southern China. Trees 2016, 30, 1017. [Google Scholar] [CrossRef]
- Hu, W.; Yang, X.; Mi, B.; Fang, L.; Tao, Z.; Fei, B.; Jiang, Z.; Liu, Z. Investigating chemical properties and combustion characteristics of torrefied masson pine. Wood Fiber Sci. J. Soc. Wood Sci. Technol. 2017, 49, 33–42. [Google Scholar]
- Shen, C.; Duan, W.; Cen, B.; Tan, J. Comparison of chemical components of essential oils in needles of Pinus massoniana Lamb and Pinus elliottottii Engelm from Guangxi. Se Pu = Chin. J. Chromatogr. 2006, 24, 619–624. [Google Scholar]
- Tesch, S.D. The evolution of forest yield determination and site classification. For. Ecol. Manag. 1980, 3, 169–182. [Google Scholar] [CrossRef]
- Burkhart, H.E.; Tomé, M. Modeling Forest Trees and Stands; Springer: Berlin, Germany, 2012. [Google Scholar]
- Mcleod, S.D.; Running, S.W. Comparing site quality indices and productivity in ponderosa pine stands of western Montana. Can. J. For. Res. 1988, 18, 346–352. [Google Scholar] [CrossRef]
- Curt, T.; Bouchaud, M.; Agrech, G. Predicting site index of Douglas-Fir plantations from ecological variables in the Massif Central area of France. For. Ecol. Manag. 2001, 149, 61–74. [Google Scholar] [CrossRef]
- Louw, J.H.; Scholes, M. Forest site classification and evaluation: A South African perspective. For. Ecol. Manag. 2002, 171, 153–168. [Google Scholar] [CrossRef]
- Fonweban, J.N.; Tchanou, Z.; Defo, M. Site index equations for Pinus kesiya in Cameroon. J. Trop. For. Sci. 1995, 8, 24–32. [Google Scholar]
- Skovsgaard, J.P.; Vanclay, J.K. Forest site productivity: A review of the evolution of dendrometric concepts for even-aged stands. Forestry 2008, 81, 13–31. [Google Scholar] [CrossRef]
- Eichhorn, F. Beziehungen zwischen bestandshöhe und bestandsmasse. Allg. Forst-Und Jagdztg. 1904, 80, 45–49. [Google Scholar]
- Bontemps, J.D.; Bouriaud, O. Predictive approaches to forest site productivity: Recent trends, challenges and future perspectives. Forestry 2014, 87, 109–128. [Google Scholar] [CrossRef]
- Pienaar, L.V.; Shiver, B.D. The effect of planting density on dominant height in unthinned slash pine plantations. For. Sci. 1984, 30, 1059–1066. [Google Scholar]
- Lanner, R.M. On the insensitivity of height growth to spacing. For. Ecol. Manag. 1985, 13, 143–148. [Google Scholar] [CrossRef]
- Maclaren, J.P.; Grace, J.C.; Kimberley, M.O.; Knowles, R.L.; West, G.G. Height growth of Pinus radiata as affected by stocking. New Zealand. New Zealand. J. Forest. Sci. 1995, 25, 73–90. [Google Scholar]
- Perron, J. Inventaire forestier. In Manuel de Foresterie; Les Presses de l’Université Laval: Ste-Foy, QC, Canada, 1996; pp. 390–473. [Google Scholar]
- Lockhart, B.R. Site Index Determination Techniques for Southern Bottomland Hardwoods. South. J. Appl. For. 2013, 37, 5–12. [Google Scholar] [CrossRef]
- Shen, J.; Wang, Y.; Lei, X.; Lei, Y.; Wang, Q. Site quality evaluation of uneven-aged mixed coniferous and broadleaved stands in Guangdong Province of southern China based on BP neural network. J. Beijing For. Univ. 2019, 4, 38–47, (In Chinese with English abstract). [Google Scholar]
- Wang, Y.; Lemay, V.M.; Baker, T.G. Modelling and prediction of dominant height and site index of Eucalyptus globulus plantations using a nonlinear mixed-effects model approach. Can. J. For. Res. 2007, 37, 1390–1403. [Google Scholar] [CrossRef]
- Martin-Benito, D.; Gea-Izquierdo, G.; del Rio, M.; Canellas, I. Long-term trends in dominant-height growth of black pine using dynamic models. For. Ecol. Manag. 2008, 256, 1230–1238. [Google Scholar] [CrossRef]
- Guo, Y.; Han, Y.; Wu, B.; Yang, L. Study on Modelling of Site Quality Evaluation and its Dynamic Update Technology for Plantation Forests. Nat. Environ. Pollut. Technol. 2013, 12, 591–597. [Google Scholar]
- Wang, G.G. White spruce site index in relation to soil, understory vegetation, and foliar nutrients. Can. J. For. Res. 1995, 25, 29–38. [Google Scholar] [CrossRef]
- Chen, H.Y.H.; Krestov, P.V.; Klinka, K. Trembling aspen site index in relation to environmental measures of site quality at two spatial scales. Can. J. For. Res. 2002, 32, 112–119. [Google Scholar] [CrossRef]
- Sánchez-Rodrıguez, F.; Rodrıguez-Soalleiro, R.; Español, E.; López, C.A.; Merino, A. Influence of edaphic factors and tree nutritive status on the productivity of Pinus radiata D. Don plantations in northwestern Spain. For. Ecol. Manag. 2002, 171, 181–189. [Google Scholar] [CrossRef]
- Hamel, B.; Bélanger, N.; Paré, D. Productivity of black spruce and Jack pine stands in Quebec as related to climate, site biological features and soil properties. For. Ecol. Manag. 2004, 191, 239–251. [Google Scholar] [CrossRef]
- Nigh, G.D.; Ying, C.C.; Qian, H. Climate and productivity of major conifer species in the interior of British Columbia, Canada. For. Sci. 2004, 50, 659–671. [Google Scholar]
- Wang, G.G.; Huang, S.; Monserud, R.A.; Klos, R.J. Lodgepole pine site index in relation to synoptic measures of climate, soil moisture and soil nutrients. For. Chron. 2004, 80, 678–686. [Google Scholar] [CrossRef]
- Seynave, I.; Gégout, J.-C.; Hervé, J.-C.; Dhôte, J.-F.; Drapier, J.; Bruno, É.; Dumé, G. Picea abies site index prediction by environmental factors and understorey vegetation: A two-scale approach based on survey databases. Can. J. For. Res. 2005, 35, 1669–1678. [Google Scholar] [CrossRef]
- Monserud, R.A.; Huang, S.; Yang, Y. Predicting lodgepole pine site index from climatic parameters in Alberta. For. Chron. 2006, 82, 562–571. [Google Scholar] [CrossRef]
- Seynave, I.; Gégout, J.C.; Hervé, J.C.; Dhôte, J.F. Is the spatial distribution of European beech (Fagus sylvatica L.) limited by its potential height growth? J. Biogeogr. 2008, 35, 1851–1862. [Google Scholar] [CrossRef]
- Socha, J. Effect of topography and geology on the site index of Picea abies in the West Carpathian, Poland. Scand. J. For. Res. 2008, 23, 203–213. [Google Scholar] [CrossRef]
- Pinno, B.D.; Paré, D.; Guindon, L.; Bélanger, N. Predicting productivity of trem- bling aspen in the Boreal Shield ecozone of Quebec using different sources of soil and site information. For. Ecol. Manag. 2009, 257, 782–789. [Google Scholar] [CrossRef]
- Watt, M.S.; Palmer, D.J.; Dungey, H.; Kimberley, M.O. Predicting the spatial distribution of Cupressus lusitanica productivity in New Zealand. For. Ecol. Manag. 2009, 258, 217–223. [Google Scholar] [CrossRef]
- Watt, M.S.; Palmer, D.J.; Kimberley, M.O.; Hock, B.; Payn, T.; Lowe, D. Development of models to predict Pinus radiata productivity throughout New Zealand. Can. J. For. Res. 2010, 40, 488–499. [Google Scholar] [CrossRef]
- Codilan, A.L.; Nakajima, T.; Tatsuhara, S.; Shiraishi, N. Estimating site index from ecological factors for industrial tree plantation species in Mindanao, Philippines. Bull. Univ. Tokyo For. 2015, 133, 19–41. [Google Scholar]
- González-Rodríguez, M.A.; Diéguez-Aranda, U. Exploring the use of learning techniques for relating the site index of radiata pine stands with climate, soil and physiography. For. Ecol. Manag. 2020, 458, 117–803. [Google Scholar] [CrossRef]
- Weiskittel, A.R.; Crookston, N.L.; Radtke, P.J. Linking climate, gross primary productivity, and site index across forests of the western United States. Can. J. For. Res. 2011, 41, 1710–1721. [Google Scholar] [CrossRef]
- Sabatia, C.O.; Burkhart, H.E. Predicting site index of plantation loblolly pine from biophysical variables. For. Ecol. Manag. 2014, 326, 142–156. [Google Scholar] [CrossRef]
- Aertsen, W.; Kint, V.; Van Orshoven, J.; Özkan, K.; Muys, B. Comparison and ranking of different modelling techniques for prediction of site index in Mediterranean mountain forests. Ecol. Model. 2010, 221, 1119–1130. [Google Scholar] [CrossRef]
- Aertsen, W.; Kint, V.; Van Orshoven, J.; Muys, B. Evaluation of modelling techniques for forest site productivity prediction in contrasting ecoregions using stochastic multicriteria acceptability analysis (SMAA). Environ. Modell. Softw. 2011, 26, 929–937. [Google Scholar] [CrossRef]
- Yu, L.; Lei, X.; Wang, Y.; Yang, Y.; Wang, Q. Impact of climate on individual tree radial growth based on generalized additive model. J. Beijing For. Univ. 2014, 36, 22–32, (In Chinese with English abstract). [Google Scholar]
- Shen, C.; Lei, X.; Liu, H.; Wang, L.; Liang, W. Potential impacts of regional climate change on site productivity of Larix olgensis plantations in northeast China. iForest Biogeosci. For. 2015, 8, 642. [Google Scholar] [CrossRef]
- Ou, Q.X.; Lei, X.D.; Shen, C.C. Individual Tree Diameter Growth Models of Larch-Spruce-Fir Mixed Forests Based on Machine Learning Algorithms. Forests 2019, 10, 187. [Google Scholar] [CrossRef]
- De’Ath, G. Boosted trees for ecological modeling and prediction. Ecology 2007, 88, 243–251. [Google Scholar] [CrossRef]
- Wu, D.; Jennings, C.; Terpenny, J. A Comparative Study on Machine Learning Algorithms for Smart Manufacturing: Tool Wear Prediction Using Random Forests. J. Manuf. Sci. Eng. Trans. Asme 2017, 139, 7. [Google Scholar] [CrossRef]
- Wang, H.; Li, Y. Analyzing Variation of Soil Salinity Content in the Agricultural Areas: A Factorial Analysis Based Random Forest Estimation Method. IOP Conf. Ser. Earth Environ. Sci. 2021, 793, 012032. [Google Scholar] [CrossRef]
- Qiu, Y.G.; Zhou, J.; Khandelwal, M.; Yang, H.T.; Yang, P.X.; Li, C.Q. Performance evaluation of hybrid WOA-XGBoost, GWO-XGBoost and BO-XGBoost models to predict blast-induced ground vibration. Eng. Comput. 2021, 1–18. [Google Scholar] [CrossRef]
- Sun, B.; Sun, T.; Jiao, P.P. Spatio-Temporal Segmented Traffic Flow Prediction with ANPRS Data Based on Improved XGBoost. J. Adv. Transp. 2021, 1, 1–24. [Google Scholar] [CrossRef]
- Zhan, Z.H.; You, Z.H.; Li, L.P.; Zhou, Y.; Yi, H.C. Accurate Prediction of ncRNA-Protein Interactions From the Integration of Sequence and Evolutionary Information. Front. Genet. 2018, 9, 458. [Google Scholar] [CrossRef]
- Deng, X.S.; Li, M.; Deng, S.B.; Wang, L. Hybrid gene selection approach using XGBoost and multi-objective genetic algorithm for cancer classification. Med. Biol. Eng. Comput. 2021, 60, 663–681. [Google Scholar] [CrossRef]
- Ahirwal, J.; Nath, A.; Brahma, B.; Deb, S.; Sahoo, U.K.; Nath, A.J. Patterns and driving factors of biomass carbon and soil organic carbon stock in the Indian Himalayan region. Sci. Total Environ. 2021, 770, 145292. [Google Scholar] [CrossRef]
- Wang, Z.G.; Wang, G.C.; Zhang, G.H.; Wang, H.B.; Ren, T.Y. Effects of land use types and environmental factors on spatial distribution of soil total nitrogen in a coalfield on the Loess Plateau, China. Soil Tillage Res. 2021, 211, 105027. [Google Scholar] [CrossRef]
- Luo, M.; Wang, Y.F.; Xie, Y.H.; Zhou, L.; Qiao, J.J.; Qiu, S.Y.; Sun, Y.J. Combination of Feature Selection and CatBoost for Prediction: The First Application to the Estimation of Aboveground Biomass. Forests 2021, 12, 216. [Google Scholar] [CrossRef]
- Effrosynidis, D.; Tsikliras, A.; Arampatzis, A.; Sylaios, G. Species Distribution Modelling via Feature Engineering and Machine Learning for Pelagic Fishes in the Mediterranean Sea. Appl. Sci. 2020, 10, 8900. [Google Scholar] [CrossRef]
- Effrosynidis, D.; Arampatzis, A. An evaluation of feature selection methods for environmental data. Ecol. Inform. 2021, 61, 101224. [Google Scholar] [CrossRef]
- Watt, M.S.; Palmer, D.J.; Leonardo, E.; Bombrun, M. Use of advanced modelling methods to estimate radiata pine productivity indices. For. Ecol. Manag. 2021, 479, 118–557. [Google Scholar] [CrossRef]
- Gavilán-Acuña, G.; Olmedo, G.F.; Mena-Quijada, P.; Guevara, M.; Barría-Knopf, B.; Watt, M.S. Reducing the Uncertainty of Radiata Pine Site Index Maps Using an Spatial Ensemble of Machine Learning Model. Forests 2021, 12, 77. [Google Scholar] [CrossRef]
- Watt, M.S.; Dash, J.P.; Bhandari, S.; Watt, P. Comparing parametric and non-parametric methods of predicting Site Index for radiata pine using combinations of data derived from environmental surfaces, satellite imagery and airborne laser scanning. For. Ecol. Manag. 2015, 357, 1–9. [Google Scholar] [CrossRef]
- Bravo-Oviedo, A.; Roig, S.; Bravo, F.; Montero, G.; Del-Rio, M. Environmental variability and its relationship to site index in Mediterranean maritine pine. For. Syst. 2011, 20, 50–64. [Google Scholar] [CrossRef]
- Sharma, R.P.; Brunner, A.; Eid, T. Site index prediction from site and climate variables for Norway spruce and Scots pine in Norway. Scand. J. For. Res. 2012, 27, 619–636. [Google Scholar] [CrossRef]
- Carmean, W.H. Forest site quality evaluation in the United States. Adv. Agron. 1975, 27, 209–269. [Google Scholar]
- Turner, J.; Thompson, C.H.; Turvey, N.D.; Hopmans, P.; Ryan, P.J. A soil technical classification for Pinus radiata (D. Don) plantations. I. Development. Aust. J. Soil Res. 1990, 28, 797–811. [Google Scholar] [CrossRef]
- Ritchie, M.W.; Hamann, J.D. Individual-tree height-, diameter- and crown-width increment equations for young Douglas-fir plantations. New For. 2008, 35, 173–186. [Google Scholar] [CrossRef]
- Grigal, D.F. A soil-based aspen productivity index for Minnesota. For. Ecol. Manag. 2009, 257, 1465–1473. [Google Scholar] [CrossRef]
- Wang, T.L.; Hamann, A.; Spittlehouse, D.L.; Murdock, T.Q. ClimateWNA—High-Resolution Spatial Climate Data for Western North America. J. Appl. Meteorol. Climatol. 2012, 51, 16–29. [Google Scholar] [CrossRef]
- Hamann, A.; Wang, T.L.; Spittlehouse, D.L.; Murdock, T.Q. A comprehensive, high-resolution database of historical and projected climate surfaces for western north america. Bull. Am. Meteorol. Soc. 2013, 94, 1307–1309. [Google Scholar] [CrossRef]
- Wang, T.L.; Innes, G.Y.; Seely, J.L.; Chen, B.Z. ClimateAP: An application for dynamic local downscaling of historical and future climate data in Asia Pacific. Front. Agr. Sci. Eng. 2017, 4, 448–458. [Google Scholar] [CrossRef]
- Grant, J.C.; Nichols, J.D.; Smith, R.G.B.; Brennan, P.; Vanclay, J.K. Site index prediction of Eucalyptus dunnii Maiden plantations with soil and site parameters in sub-tropical eastern Australia. Aust. For. 2010, 73, 234–245. [Google Scholar] [CrossRef]
- Merian, P.; Lebourgeois, F. Size-mediated climate-growth relationships in temperate forests: A multi-species analysis. For. Ecol. Manag. 2013, 261, 1382–1391. [Google Scholar] [CrossRef]
- Lei, X.D.; Yu, L.; Hong, L.X. Climate-sensitive integrated stand growth model (CS-ISGM) of Changbai larch (Larix olgensis) plantations. For. Ecol. Manag. 2016, 376, 265–275. [Google Scholar] [CrossRef]
- Xiang, W.; Lei, X.D.; Zhang, X.Q. Modelling tree recruitment in relation to climate and competition in semi-natural Larix-Picea-Abies forests in northeast China. For. Ecol. Manag. 2016, 382, 100–109. [Google Scholar] [CrossRef]
- Danescu, A.; Albrecht, A.T.; Bauhus, J.; Kohnle, U. Geocentric alternatives to site index for modeling tree increment in uneven-aged mixed stands. For. Ecol. Manag. 2017, 392, 1–12. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; Volume 785, p. 794. [Google Scholar]
- Jin, Q.; Fan, X.; Liu, J.; Xue, Z.; Jian, H. Estimating Tropical Cyclone Intensity in the South China Sea Using the XGBoost Model and FengYun Satellite Images. Atmosphere 2020, 11, 423. [Google Scholar] [CrossRef]
- Samat, A.; Li, E.; Wang, W.; Liu, S.; Lin, C.; Abuduwaili, J. Meta-XGBoost for Hyperspectral Image Classification Using Extended MSER-Guided Morphological Profiles. Remote Sens. 2020, 12, 1973. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. Lightgbm: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Proces. Syst. 2017, 39, 3146–3154. [Google Scholar]
- Strobl, C.; Malley, J.; Tutz, G. An introduction to recursive partitioning: Rationale, application, and characteristics of classification and regression trees, bagging, and random forests. Psychol. Meth. 2009, 14, 323. [Google Scholar] [CrossRef]
- Shehadeh, A.; Alshboul, O.; Al Mamlook, E.; Hamedat, O. Machine learning models for predicting the residual value of heavy construction equipment: An evaluation of modified decision tree, LightGBM, and XGBoost regression. Autom. Constr. 2021, 129, 103827. [Google Scholar] [CrossRef]
- Yan, F.; Song, K.; Liu, Y.; Chen, S.; Chen, J. Predictions and mechanism analyses of the fatigue strength of steel based on machine learning. J. Mater. Sci. 2020, 55, 15334–15349. [Google Scholar] [CrossRef]
- Li, M.; Zhang, Y.; Wallace, J.; Campbell, E. Estimating annual runoff in response to forest change: A statistical method based on random forest. J. Hydrol. 2020, 589, 125168. [Google Scholar] [CrossRef]
- Montorio, R.; Perez-Cabello, F.; Alves, D.B.; Garcia-Martin, A. Unitemporal approach to fire severity mapping using multispectral synthetic databases and Random Forests. Remote Sens. Environ. 2020, 249, 112025. [Google Scholar] [CrossRef]
- Dong, H.; Xu, X.; Wang, L.; Pu, F. Gaofen-3 PolSAR Image Classification via XGBoost and Polarimetric Spatial Information. Sensors 2018, 18, 611. [Google Scholar] [CrossRef]
- Bentejac, C.; Csorgo, A.; Martinez-Munoz, G. A comparative analysis of gradient boosting algorithms. Artif. Intell. Rev. 2021, 54, 1937–1967. [Google Scholar] [CrossRef]
- Koerselman, W.; Meuleman, A.F.M. The vegetation N:P ratio: A new tool to detect the nature of nutrient limitation. J. Appl. Ecol. 1996, 33, 1441–1450. [Google Scholar] [CrossRef]
- Wright, I.J.; Reich, P.B.; Westoby, M.; Ackerly, D.; Baruch, Z.; Bongers, F.; Cavender-Bares, J.; Chapin, T.; Cornelissen, J.; Diemer, M. 2004. The worldwide leaf economics spectrum. The worldwide leaf economics spectrum. Nature 2004, 428, 821–827. [Google Scholar]
- Yu, H.; Chen, Z.; Shang, H.; Cao, J. Effects of ectomycorrhizal fungi on seedlings of Pinus massoniana under simulated acid rain. Acta Ecol. Sin. 2017, 37, 5418–5427, (In Chinese with English abstract). [Google Scholar]
- Tyminska-Czabanska, L.; Socha, J.; Maj, M.; Cywicka, D.; Duong, X.V.H. Environmental Drivers and Age Trends in Site Productivity for Oak in Southern Poland. Forests 2021, 12, 209. [Google Scholar] [CrossRef]
- Zhang, L.; Liu, X.; Su, Y.; Xia, W.; Liang, J. Research progress on the biomass and productivity of Pinus Massoniana plantation. Ecol. Sci. 2018, 37, 213–221, (In Chinese with English abstract). [Google Scholar]
- Qin, J.; Li, Y.; Ma, J.; Lan, C.; Li, H. Biomass model construction and distribution pattern of Pinus Massoniana plantations under different climatic conditions in Guangxi. Guangxi Sci. 2020, 27, 165–174, (In Chinese with English abstract). [Google Scholar]
- Mahlstein, I.; Knutti, R. Regional climate change patterns identified by cluster analysis. Clim. Dyn. 2010, 35, 587–600. [Google Scholar] [CrossRef]
- Dunckel, K.; Weiskittel, A.; Fiske, G. Projected Future Distribution of Tsuga canadensis across Alternative Climate Scenarios in Maine, U.S. Forests 2017, 8, 285. [Google Scholar] [CrossRef]
- Ahmadi, K.; Alavi, S.J.; Kouchaksaraei, M.T. Constructing site quality curves and productivity assessment for uneven-aged and mixed stands of oriental beech (Fagus oriental Lipsky) in Hyrcanian forest, Iran. For. Sci. Technol. 2017, 13, 41–46. [Google Scholar]






| Variable | Description | Minimum | Maximum | Mean | Sd |
|---|---|---|---|---|---|
| Age (a) | Average stand age | 3.0 | 38.0 | 19.4 | 8.6 |
| N (trees∙hm−2) | Number of trees per hectare | 250 | 1750 | 827 | 340 |
| H (m) | Average stand height | 4.1 | 22.2 | 10.8 | 3.2 |
| Hd (m) | Dominant height of stand | 5.5 | 29.1 | 15.2 | 4.7 |
| Feature | Ⅰ | Ⅱ | Ⅲ | Ⅳ | Ⅴ |
|---|---|---|---|---|---|
| Soil type | reddish yellow | brick red | red | crimson | purple |
| Aspect | no slope | shady slope | semi-shady slope | semi-sunny slope | sunny slope |
| Slope position | flat slope | gentle slope | ramp | steep slope | dangerous slope |
| Model | Optimal Hyperparameter Value |
|---|---|
| Models without climate and soil chemical variables | |
| RF | N_estimators = 1000, Max_depth = 8, Min_samples_split = 2, Min_samples_leaf = 2 |
| XGBoost | N_estimators = 950, Max_depth = 5, Min_child_weight = 3, Gamma = 0.1, Num_leaves = 10, Subsample = 0.4, Colsample_bytree = 0.4, Learning rate = 0.01, Lambda_l1 = 0.01, Lambda_l2 = 0.2 |
| LightGBM | N_estimators = 1000, Max_depth= −1, Min_child_weight = 3, Gamma = 0.2, Num_leaves = 10, Subsample = 0.5, Colsample_bytree = 0.6, Learning_rate = 0.01, Lambda_l1 = 0.05, Lambda_l2 = 0.5 |
| Models with climate variables | |
| RF | N_estimators = 950, Max_depth = 10, Min_samples_split = 2, Min_samples_leaf = 2 |
| XGBoost | N_estimators = 850, Max_depth = 5, Min_child_weight = 3, Gamma = 0.1, Num_leaves = 12, Subsample = 0.6, Colsample_bytree = 0.6, Learning_rate = 0.01, Lambda_l1 = 0.011, Lambda_l2 = 0.1 |
| LightGBM | N_estimators = 1050, Max_depth = 1, Min_child_weight = 5, Gamma = 0.5, Num_leaves = 9, Subsample = 0.5, Colsample_bytree = 0.8, Learning_rate = 0.01, Lambda_l1 = 0.1, Lambda_l2 = 1.0 |
| Models with soil chemical variables | |
| RF | N_estimators = 1000, Max_depth = 10, Min_samples_split = 4, Min_samples_leaf = 2 |
| XGBoost | N_estimators = 950, Max_depth = 5, Min_child_weight = 5, Gamma = 0.01, Num_leaves = 12, Subsample = 0.6, Colsample_bytree = 1.0, Learning_rate = 0.01, Lambda_l1 = 0.01, Lambda_l2 = 0.01 |
| LightGBM | N_estimators = 1050, Max_depth = 3, Min_child_weight = 8, Gamma = 0.8, Num_leaves = 5, Subsample = 0.6, Colsample_bytree = 0.8, Learning_rate = 0.01, Lambda_l1 = 0.01, Lambda_l2 = 0.8 |
| Models with climate and soil chemical variables | |
| RF | N_estimators = 750, Max_depth = 15, Min_samples_split = 4, Min_samples_leaf = 2 |
| XGBoost | N_estimators = 1050, Max_depth = 5, Min_child_weight = 5, Gamma = 0.0, Num_leaves = 15, Subsample = 0.6, Colsample_bytree = 1.0, Learning_rate = 0.02, Lambda_l1 = 0.001, Lambda_l2 = 0.01 |
| LightGBM | N_estimators = 1200, Max_depth = 3, Min_child_weight = 11, Gamma = 0.9, Num_leaves = 5, Subsample = 0.6, Colsample_bytree = 0.9, Learning_rate = 0.01, Lambda_l1 = 0.001, Lambda_l2 = 0.9 |
| Variables | Model | RMSE | RMSE% | MAE | R2 |
|---|---|---|---|---|---|
| m | % | m | |||
| Without climate and soil chemical variables | Linear regression | 4.2434 | 26.11 | 3.3940 | 0.3301 |
| RF | 3.7587 | 23.12 | 2.4087 | 0.4744 | |
| XGBoost | 3.5286 | 21.71 | 2.4076 | 0.5368 | |
| LightGBM | 3.4055 | 20.95 | 2.4189 | 0.5685 | |
| With climate variables | Linear regression | 3.8141 | 25.56 | 2.6624 | 0.3696 |
| RF | 3.4004 | 22.79 | 2.4145 | 0.4989 | |
| XGBoost | 3.2274 | 21.63 | 2.3825 | 0.5486 | |
| LightGBM | 3.0201 | 19.66 | 2.1332 | 0.5951 | |
| With soil chemical variables | Linear regression | 3.8694 | 26.61 | 2.8114 | 0.3564 |
| RF | 3.3502 | 22.64 | 2.3923 | 0.5199 | |
| XGBoost | 3.0019 | 18.98 | 2.1346 | 0.6132 | |
| LightGBM | 2.9481 | 18.32 | 2.1649 | 0.6255 | |
| With climate and soil chemical variables | Linear regression | 3.7001 | 23.10 | 2.7047 | 0.4065 |
| RF | 3.2045 | 20.01 | 2.2798 | 0.5549 | |
| XGBoost | 2.9489 | 18.41 | 2.3183 | 0.6230 | |
| LightGBM | 2.7507 | 17.18 | 2.0630 | 0.6720 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, R.; Meng, J. Using Advanced Machine-Learning Algorithms to Estimate the Site Index of Masson Pine Plantations. Forests 2022, 13, 1976. https://doi.org/10.3390/f13121976
Yang R, Meng J. Using Advanced Machine-Learning Algorithms to Estimate the Site Index of Masson Pine Plantations. Forests. 2022; 13(12):1976. https://doi.org/10.3390/f13121976
Chicago/Turabian StyleYang, Rui, and Jinghui Meng. 2022. "Using Advanced Machine-Learning Algorithms to Estimate the Site Index of Masson Pine Plantations" Forests 13, no. 12: 1976. https://doi.org/10.3390/f13121976
APA StyleYang, R., & Meng, J. (2022). Using Advanced Machine-Learning Algorithms to Estimate the Site Index of Masson Pine Plantations. Forests, 13(12), 1976. https://doi.org/10.3390/f13121976