2.1. Study Area
The study area is the state of Oregon, located in the northwestern United States. Oregon contains a multitude of land cover types, including densely populated urban areas, agricultural land, forest land, deserts, and alpine areas. A recent study indicated that 48.4% of the Oregon land base is forested, of which 79.8% is timberland, i.e., capable of producing at least 1.4 m
3 per hectare per year of industrial wood, and not withdrawn from utilization for timber production by regulation [
14]. The remaining share are reserved forests, such as wilderness areas, or land incapable of producing least 1.4 m
3 per hectare per year. Oregon has a diverse set of tree species, with the areas west of the Cascade mountain range dominated by Douglas-fir (
Pseudotsuga menziesii (Mirb.) Franco), western hemlock (
Tsuga heterophylla (Raf.) Sarg), and Sitka spruce (
Picea stichensis (Bong.) Carrière). Areas east of the Cascade Range dominated by ponderosa pine (
Pinus ponderosa Lawson & C. Lawson), lodgepole pine (
Pinus contorta Douglas ex Loudon), and western juniper (
Juniperus occidentalis Hook. var.
occidentalis). While coniferous species such as those stated are the most common, a number of deciduous species are present as well, including red alder (
Alnus rubra (Bong.)), bigleaf maple (
Acer macrophyllum Pursh), and quaking aspen (
Populus tremuloides Michx.), among many others.
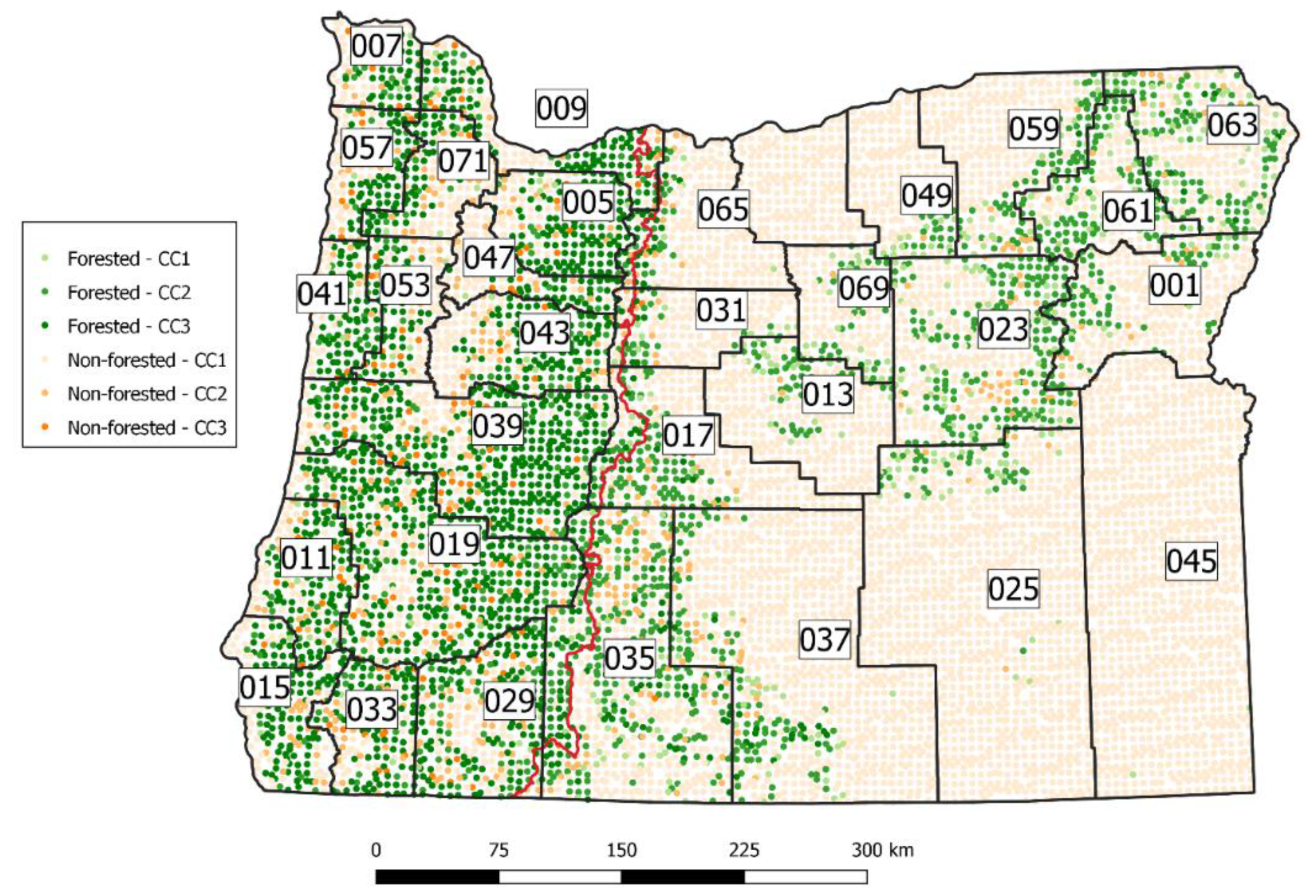
We used a set of 10,537 inventory plots collected by the FIA program between 2009 and 2018. The FIA in Oregon uses a 10-year panel rotation, and this set represents all ten panels, depicted in
Figure 1. Each plot is a cluster of four fixed-radius, nested subplots. At each subplot, trees between 12.70 cm and a “breakpoint” diameter are measured on a circular plot of radius 7.32 m and trees larger than the breakpoint diameter are measured on a circular plot of radius 17.95 m. The breakpoint diameter is either 60.96 cm or 76.20 cm depending on whether the plot is east or west of the Cascade Range crest, respectively. For each tree, diameter at breast height (DBH), total height, and species are recorded, among other attributes. Cubic volumes for each tree, including top and stump, are predicted using the National Volume Estimator Library (NVEL) [
15].
2.2. Sampling Design, Forest Attributes and Domains
The network of field plot locations for the FIA in Oregon used in this study arise from a random tessellated sampling design [
1]. Plot centers were located using a compact hexagonal tessellation with hexagons that are approximately 2184 hectares in size, such that one field plot exists in each hexagon. The plot centers were located using a random azimuth and distance from the hexagon center. In some cases, plots from previous inventory systems were already present, and the locations of those plots were assigned to the hexagon rather than allocating a new field plot. For each field plot we calculated the stem volume (
), basal area (
), and stem density (
) for all species combined and for the species that were in the 40th percentile of the total volume in Oregon or greater.
Given this set of 10,537 field plots and their corresponding attributes, we created a population upon which variance estimators could be assessed by assigning each field plot to a position in a discrete two-dimensional space. This discrete space consists of a set of
positions upon which systematic sampling can be conducted. Population means of each species-specific attribute considered are given in
Table 1, along with a proportion representing the number of times the species appeared in a plot divided by
.
To subsample this set of
positions, we leveraged the hexagonal tessellation by assigning each field plot to its coincident hexagon in the original sample. The centroids of this set of
hexagons, with forest attributes calculated from the field plots, represents the population upon which systematic sampling is conducted. To retain a hexagonal structure of any systematic sample produced from this population, every
th population unit along the horizontal, diagonal, and vertical axes of the hexagonal grid were included in the sample. Let
represent the row vector of discrete spatial coordinates of the
th plot in the
th post-stratum.
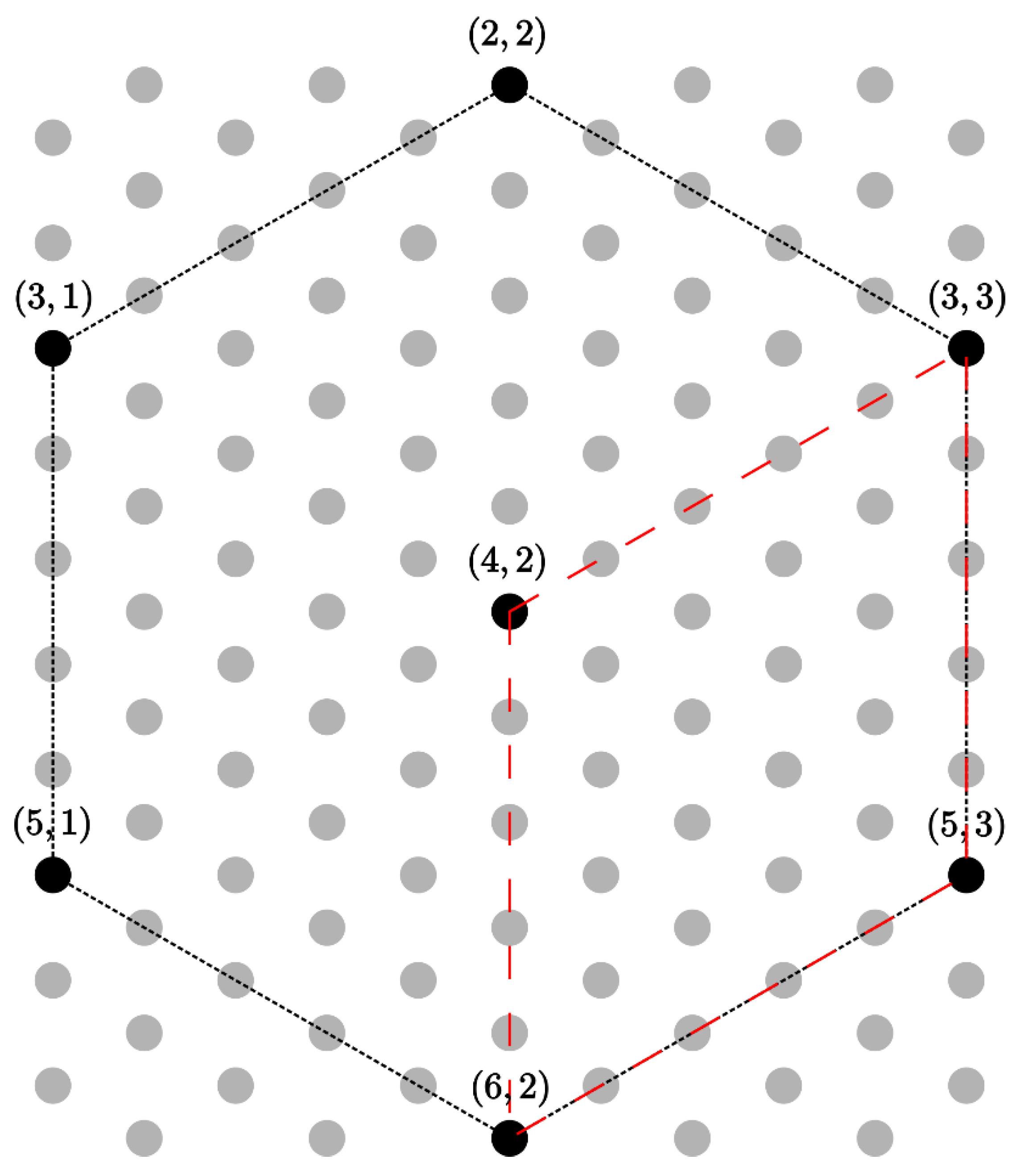
Figure 2 displays one possible systematic sample from a hypothetical population in the discrete space with the discrete vectors
displayed for one systematic sample. Repeating this procedure for every possible systematic sample provides
samples. We used a sampling interval of
for the following assessments. For the remainder of the analysis, the discrete positions
were treated as the true positions of the field plots.
The performance of the standard estimator of the variance is affected by the degree of spatial correlation between the observations in the sample as well as large-scale trend in a given attribute. By spreading the sample by a distance corresponding to the interval , the spatial correlation will likely decrease, and the observations may become independent. Therefore, the advantage of alternative estimators may not be apparent. However, the density of the sample does not affect trends in the population, and even a less dense sample would allow evaluation of the effect of trends and post-stratification on the performance of the estimators.
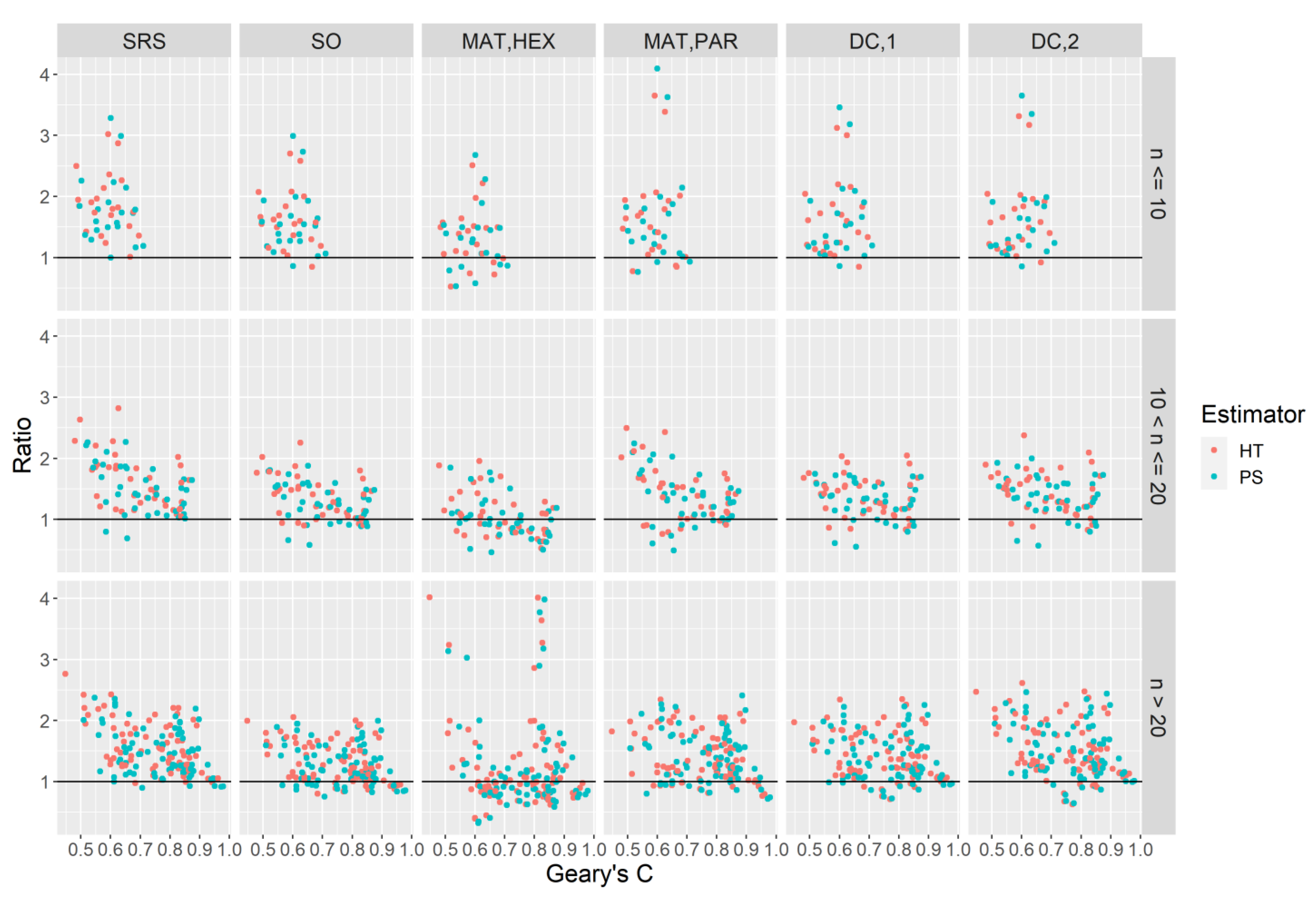
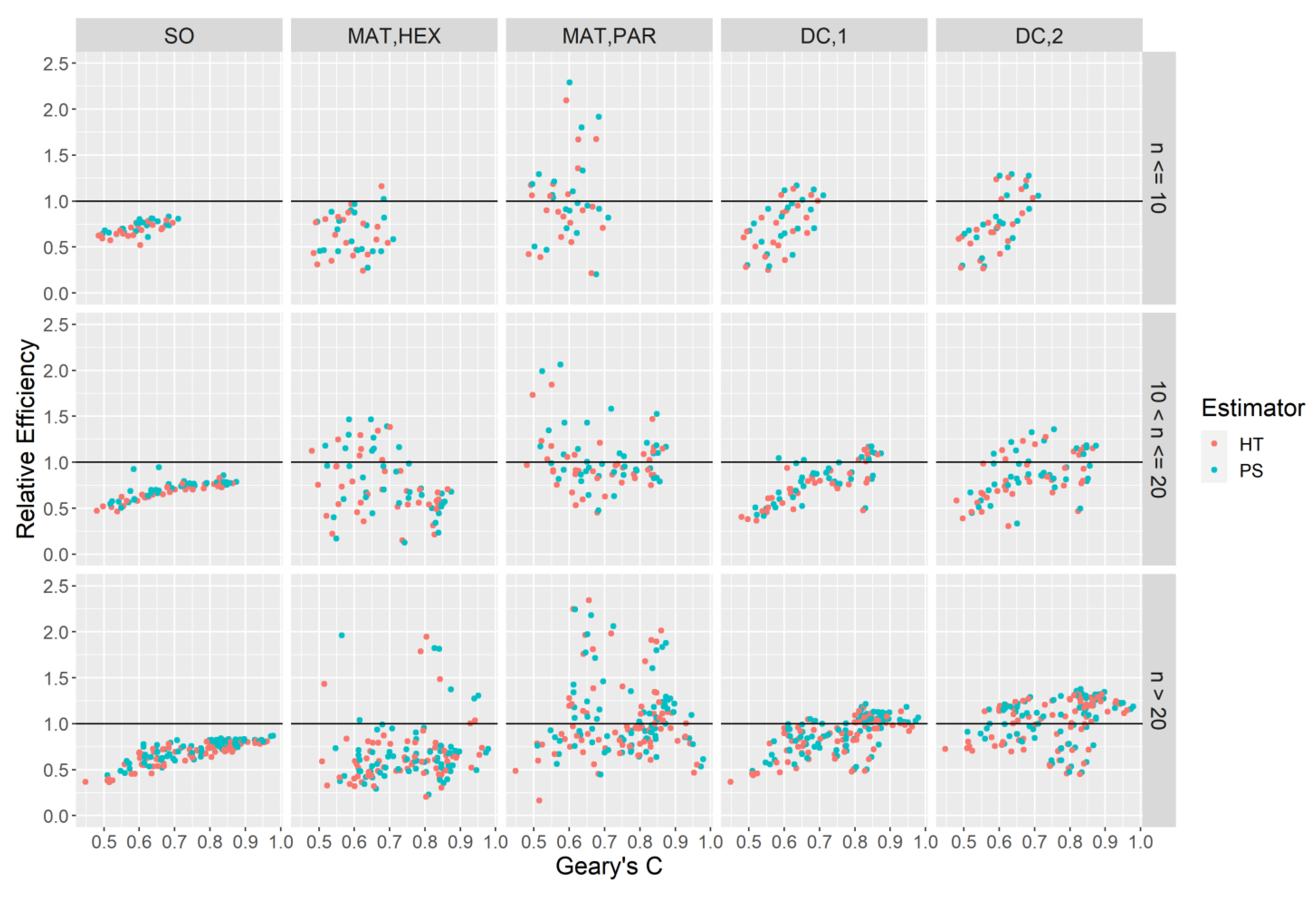
The FIA program provides standard reports on many forest attributes for a wide range of domains. Domains are defined as subpopulations of trees that meet certain criteria that serve to define parameters of interest. Examples of domains include spatial domains such as counties, and species domains, such as the set of trees of a particular species. To assess the performance of the estimators when subpopulations are of interest, we defined several domains over which we conducted the analysis: a set of two spatial domains and a set of eighteen species domains. The first spatial domain is the area within the Oregon state boundary, which we will refer to as the “large domain”. In addition to this we create domains from the set of Oregon counties which we refer to as “small domains”. Two adjacent counties (Sherman and Gilliam, east of small domain 65,
Figure 1) were removed from consideration as a small domain because no trees were present on any plot. Note that the plots in these counties were still included in the large domain.
The FIA program uses post-strata to enhance the precision of point estimates. FIA uses a large number of post-strata that contain information about forest structure, property ownership, land use and other variables. We used a coarser set of post-strata that mimic the forest structure covariates used operationally by the FIA in Oregon for the purposes of this study. First, we used a forest-non-forest mask produced for 2016 provided by the United States Forest Service Geospatial Technology and Applications Center using the methodology described in [
16]. Second, we used three canopy cover classes, corresponding to 0–33%, 33–66% and 66–100% canopy cover derived from a canopy cover map published by the Multi-Resolution Land Characteristics Consortium (
http://www.mrlc.gov/ (accessed on 17 August 2020)). Finally, we used an east-west delineation of Oregon derived from the level three ecoregions used by the Environmental Protection Agency (EPA) [
17]. The combinations of the forest-non-forest classes, canopy cover classes, and east-west classes produce the twelve post-strata used in this study and are depicted in
Figure 1.
2.3. Point Estimators
Observations of plot-level species-specific attributes were calculated by computing a weighted sum of trees that meet the criteria for a given domain. These weights arise from the different sizes used in the nested plot design ([
4], p. 53). Let
represent the observation of the
th plot-level forest attribute in the
th post-strata at the two-dimensional position vector
. Let
refer to the set of index pairs
and
that correspond to the
th stratum and
th field plot included in the
th sample, i.e., each element of
is an index pair. We obtain an unbiased estimate of the population mean via the post-stratification estimator under an equal inclusion probability design:
where
is the sample mean of the observations in the
th post-stratum,
is the weight of the
th post-stratum where
is the number of population elements in the
th post-stratum and
is the number of elements in the
th sample. This differs from actual practices in the FIA, where
is determined from wall-to-wall covariate rasters of fine resolution, rather than field plots [
4]. The second summation is over all stratum and plot index pairs in the sample. The error term
explains the deviation of
from the estimate of the corresponding post-stratum-level mean. Using the above estimator, we can obtain the Horvitz-Thompson estimator for equal inclusion probability designs by setting
as a special case. We obtain:
where
is the sample mean of the
in the sample. Note that the second term is equal to zero and we obtain the sample mean as the HT estimator under equal inclusion probabilities. For brevity, we reserve the notation
to refer to either the HT or PS estimator.
2.4. Variance Estimators
The sampling variance of the PS point estimator under simple random sampling designs is typically approximated using a first order Taylor expansion ([
2], p. 235). We obtain:
where
is the error between
and its corresponding stratum mean
and
is the finite population correction factor for the
th sample. Note that, for the HT estimator we obtain
. Many variance estimators for PS or, more generally, model-assisted estimators consider only this residual term (e.g., [
18]). The standard estimator of the systematic variance that assumes the sample was collected with simple random sampling is one such estimator. We obtain the estimator:
In the case of systematic sampling designs, pairwise inclusion probabilities for many population units will be zero, precluding the possibility of unbiased estimation of
. Under HT estimation, many alternatives have been proposed which typically involve squared differences between a local mean of neighboring points and the observation. To make these estimators consistent with PS estimation, we plug in the residual
to alternative estimators presented for HT variance estimation, which is an approach taken in several other studies [
19,
20].
Stevens and Olsen [
3] proposed a neighborhood-based estimator for the use in the generalized random tessellated stratified (GRTS) sampling design that can be used in systematic designs. The estimator computes a weighted sum of squared errors over the neighborhood
. The neighborhood is developed iteratively, first by including
itself plus the
nearest neighbors according to Euclidean distance from the element at
. Then any other points,
, that have
as a neighbor themselves are added to the neighborhood. Noting that the first-order inclusion probabilities for all units are
, where
is the systematic sampling interval, we obtain the estimator:
where
is a plot-specific weight that decreases as the distance between
and
increases and
. This distance weighting effect is similar to kriging, where residual pairs that are close together will be weighted more than pairs of residuals further away when computing the neighborhood-level variance. These weights are optimized by ensuring the sum of
over all plots adds up to the total error (refer to [
3] for further information on this optimization procedure). We consider the special case where
. Implementations for
were provided by the R package
spsurvey [
21].
Matérn ([
11], pp. 120–122) describes an estimator for two-dimensional systematic sampling designs that relies on computing contrasts of units within non-overlapping neighborhoods as local variance estimates and aggregating these variance estimates over all neighborhoods to produce a final estimate. We considered two neighborhood configurations. First, we consider:
which represents the nearest neighbors with respect to
and:
which represents a parallelogram constructed from the neighbors of
and itself. This second configuration closely mimics the original Matérn estimator, which was developed for the case of rectangular grids. Both neighborhood specifications are displayed in
Figure 2.
For each neighborhood, a contrast of the mean-centered residuals of the elements in the neighborhood is computed. Let
represent the vector of mean-centered residuals for the
th neighborhood using configuration
of the Matérn estimator (
Table 2). Points in the neighborhood that fall outside of the study space are given a value of zero. For each neighborhood calculate the value:
where
indicates the number of sampled population units in the neighborhood and
is a vector containing elements that are either −1 or 1. We use the vectors
and
for the hexagonal and parallelogram neighborhood structures, respectively. The positive and negative elements of
create two groups which each make a prediction for the mean residual in the neighborhood, and Equation (8) calculates a squared difference between these two predictions. This squared difference creates the basis for a neighborhood-level variance estimate. Using these values, we obtain the Matérn variance estimator:
where
and
for the parallelogram and hexagonal neighborhood structures, respectively.
Adjustment-based estimators rely on applying an adjustment factor to
that approximates the inter-cluster correlation coefficient. This approach is motivated by the fact that variance estimates using
in the case of systematic sampling will tend to have a larger positive bias in situations where the inter-cluster correlation, i.e., the correlation between pairs of possible systematic samples, is strongly positive or negative. One such estimator was proposed by D’Orazio [
12] which relies on the Geary’s C index. We consider two neighborhood structures. The first structure considers the six closest points to an element at
to be neighbors. This is equivalent to the
neighborhood. We also consider second order neighbors, i.e., those elements that are first order neighbors, as well as their first order neighbors. Noting this we obtain the expression for Geary’s C:
where
is an indicator variable that takes the value one if the element at
is considered a neighbor of the element at
. We obtain the D’Orazio’s Geary’s C estimator:
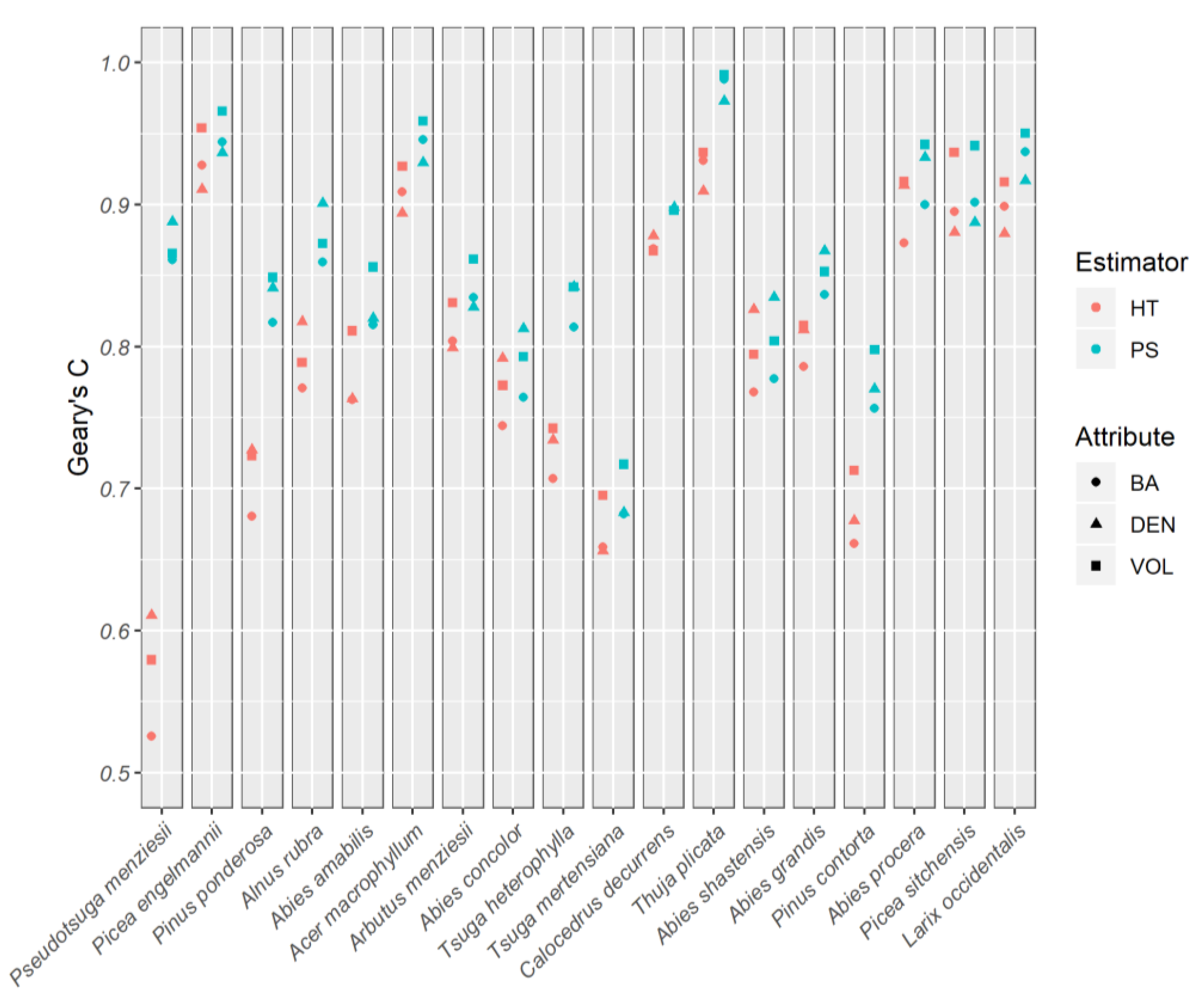
The first condition of (11) ensures that Geary’s C can be calculated. If not,
is used without adjustment. For the purposes of reporting results, we calculate Geary’s C using Equation (10) with all
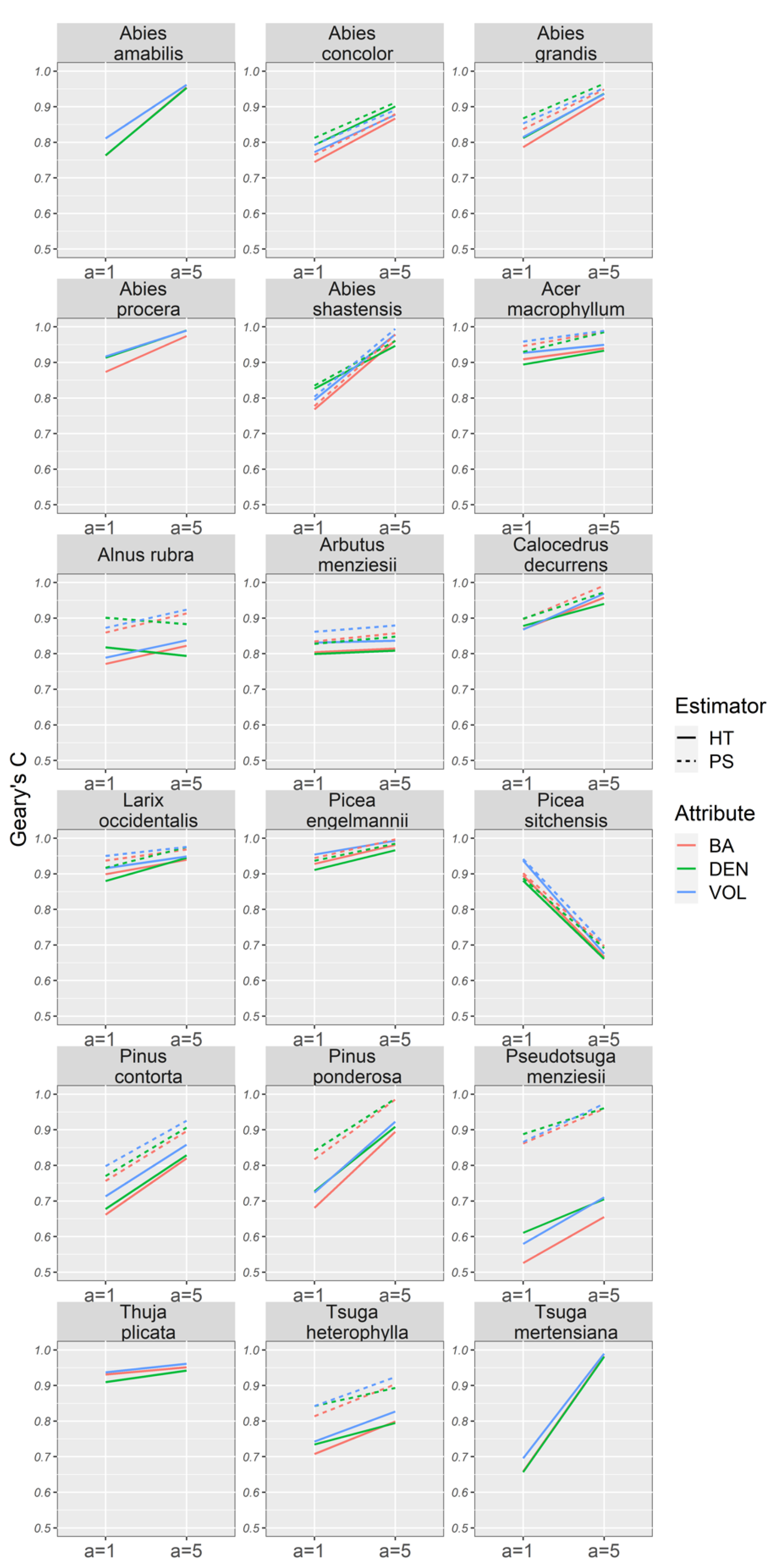
field plots using the residuals obtained from the HT estimator. We refer to this quantity as
for the remainder of the text.
2.5. Performance Measures
Define a systematic sampling interval
such that every
th element along each axis is sampled. Sampling in this fashion for a hexagonal tessellation implies that there are
possible subsamples. Furthermore, all samples produced will retain a hexagonal structure (
Figure 2). Using all subsamples, we obtain the actual variance of the estimator, which we will refer to as the “true variance” for brevity:
where the superscript
is used to refer to a domain-attribute combination indexed by
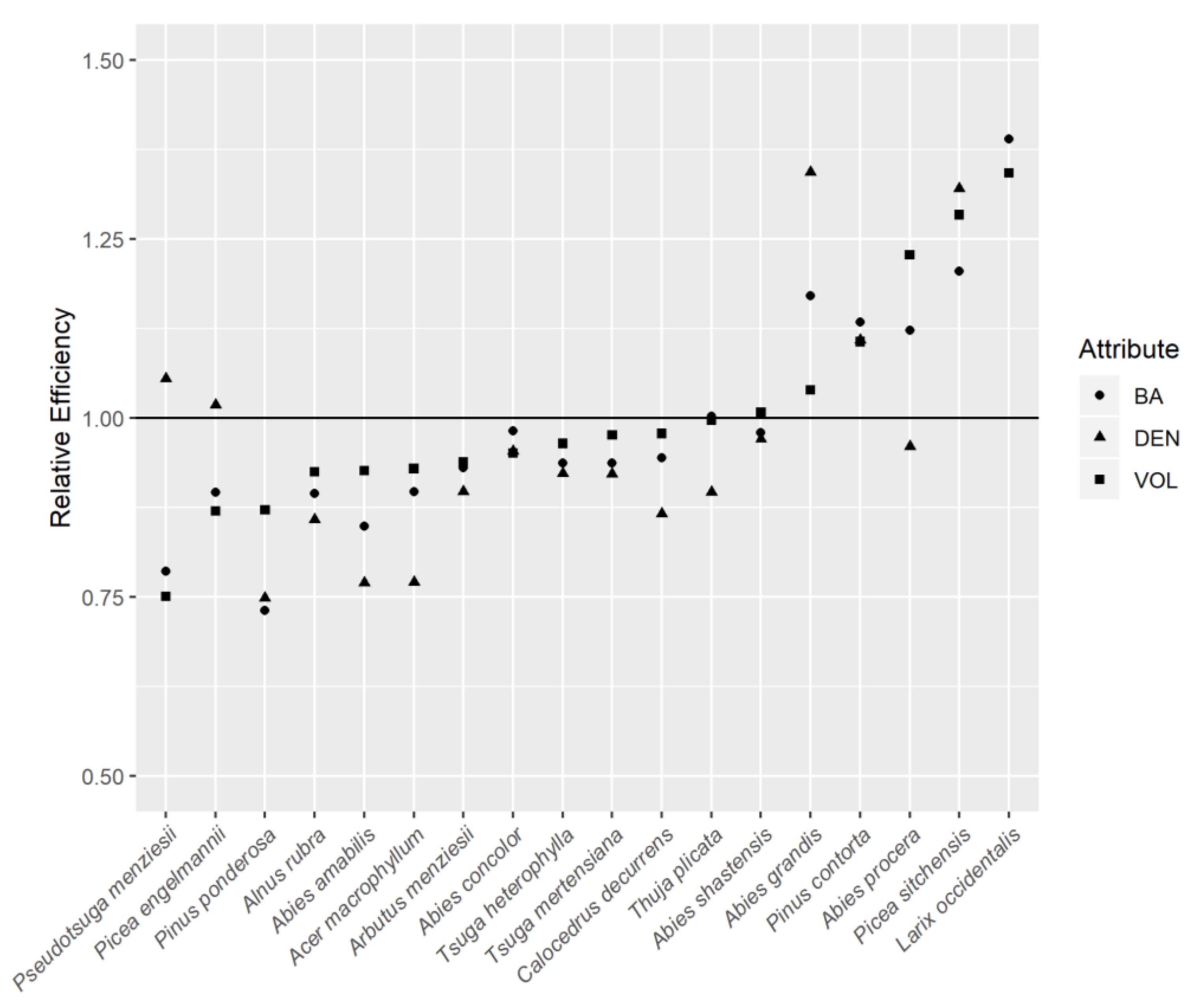
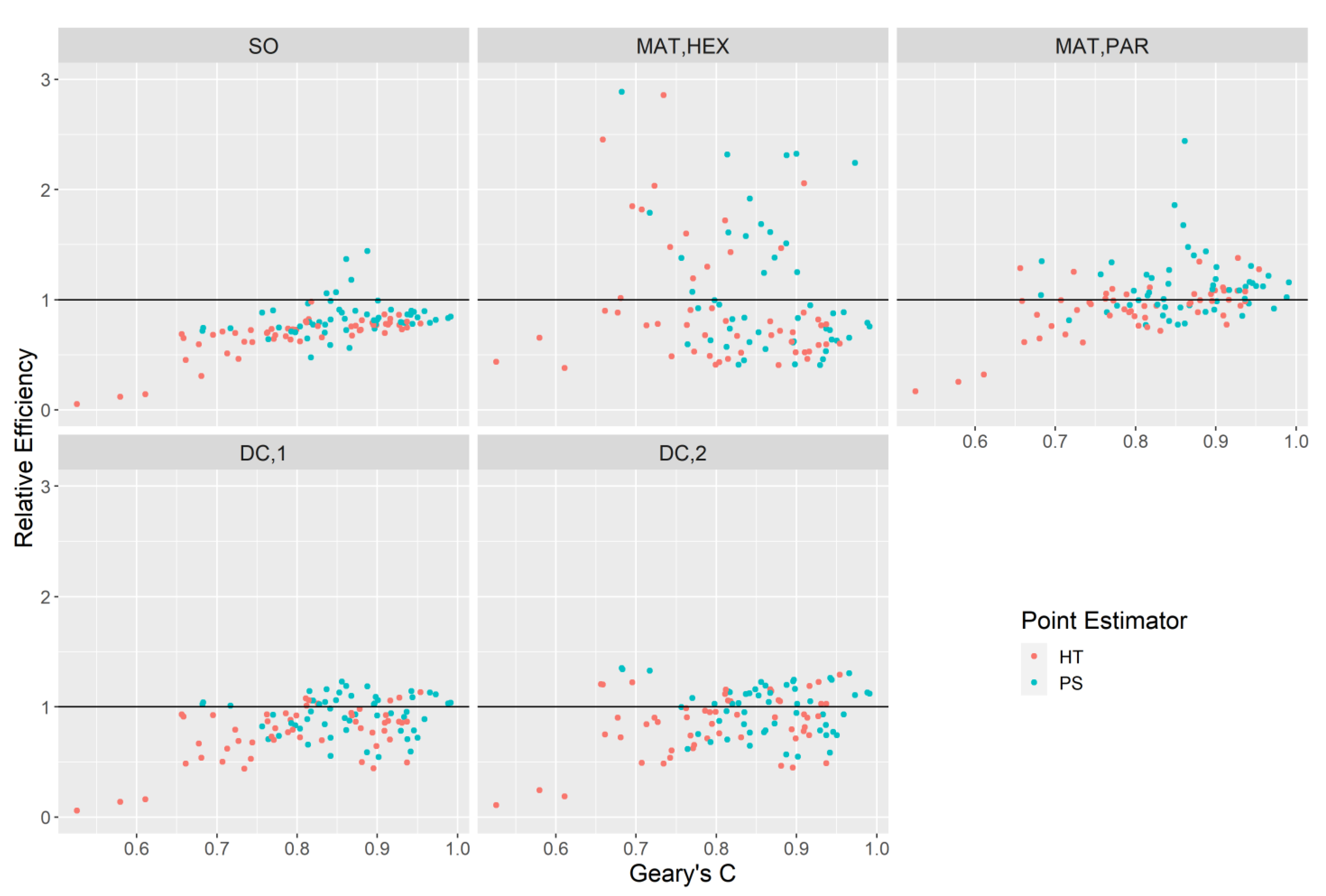
. Although secondary to the objective of this study, comparing the performances of the point estimators HT and PS can be done using the relative efficiency of the true variances:
We relied on two general categories of performance measures to assess the behavior of the proposed variance estimators. The first category assesses the performance of an estimator for a particular attribute in a particular domain. Let
refer to the
th variance estimate for the
th domain-attribute combination for estimator
. For brevity, let
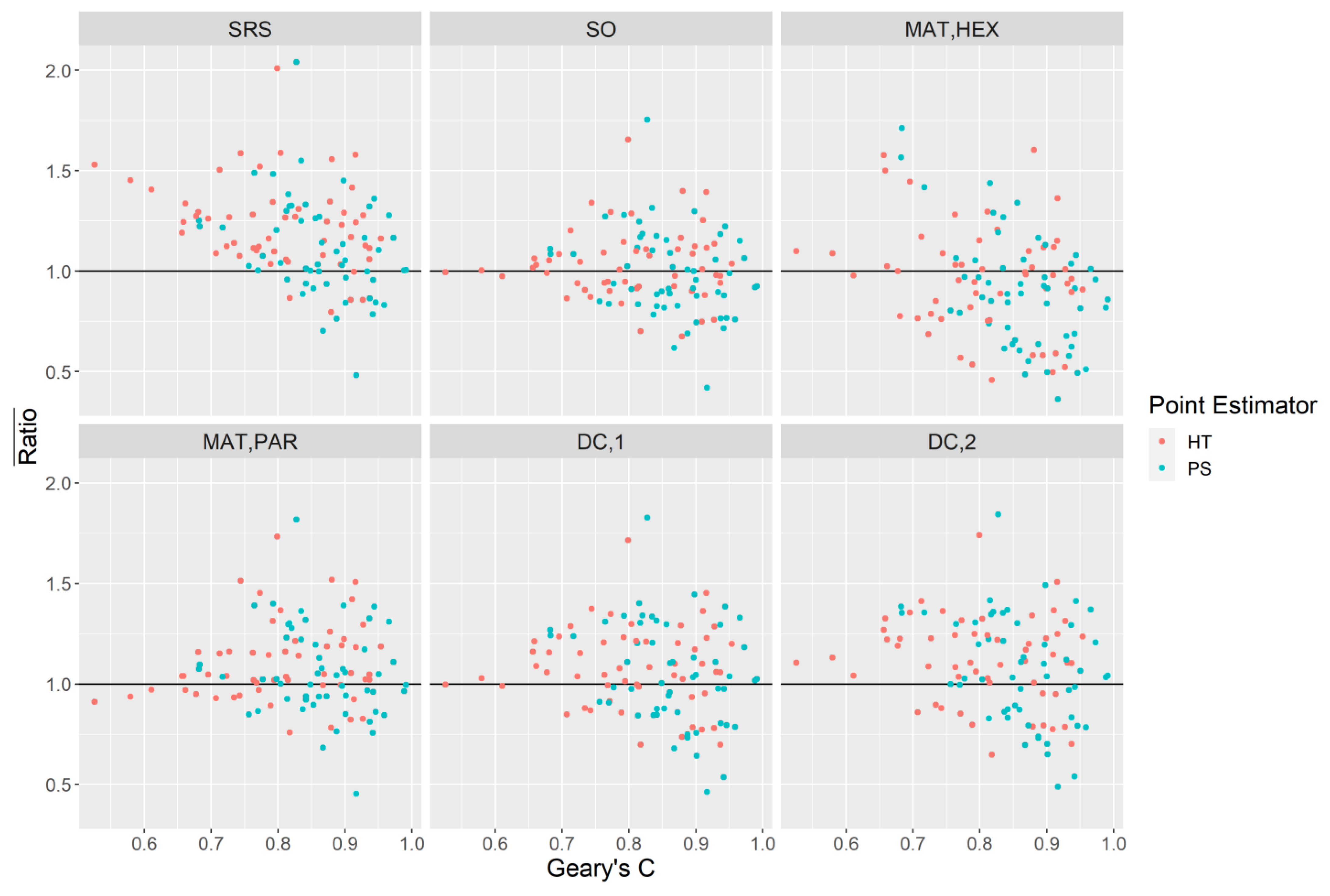
. We obtain the mean error of the ratio of the variance estimate to the systematic variance:
which quantifies the mean deviation of the ratio of the variance estimate from one.
is equivalent to the design expectation of the quantity
. Equation (14) can be considered a relative measure of bias for a variance estimate for a particular domain-attribute combination. In addition to (14) we also produce the relative efficiencies of the variance estimators themselves with respect to the simple random sampling estimator,
. In many environmental sampling surveys
is considered the standard choice for a variance estimator under this design and thus assessing the alternatives with respect to
can provide valuable information on potential efficiency gains. We obtain:
where
represents any estimator that is not the simple random sampling estimator and
is the sum of squared errors for a given estimator over all
subsamples.
The second category of performance measures consider the performance of an estimator across several domain-attribute combinations. We consider the mean of the mean ratio across all
domain-attribute combinations:
while
is a measure of relative bias,
is simply an aggregation of these measures across several attributes and is not strictly a measure of bias itself. Instead,
can be interpreted as a performance index over many estimates of the true variance for a particular estimator.
values close to one indicate a tendency for an estimator to over-estimate the true variance across many domain-attribute combinations, and vice versa. In a similar manner, we consider the mean of the relative efficiencies across all
domain-attribute combinations and obtain:
which is the mean relative efficiency for a given estimator over all
domain-attribute combinations.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}