Testing the Capability of Low-Cost Tools and Artificial Intelligence Techniques to Automatically Detect Operations Done by a Small-Sized Manually Driven Bandsaw




Abstract
1. Introduction
2. Materials and Methods
2.1. Facility Description and Machine’s Functions
2.2. Data Collection and Processing
2.3. Setup of the Artificial Neural Network
3. Results
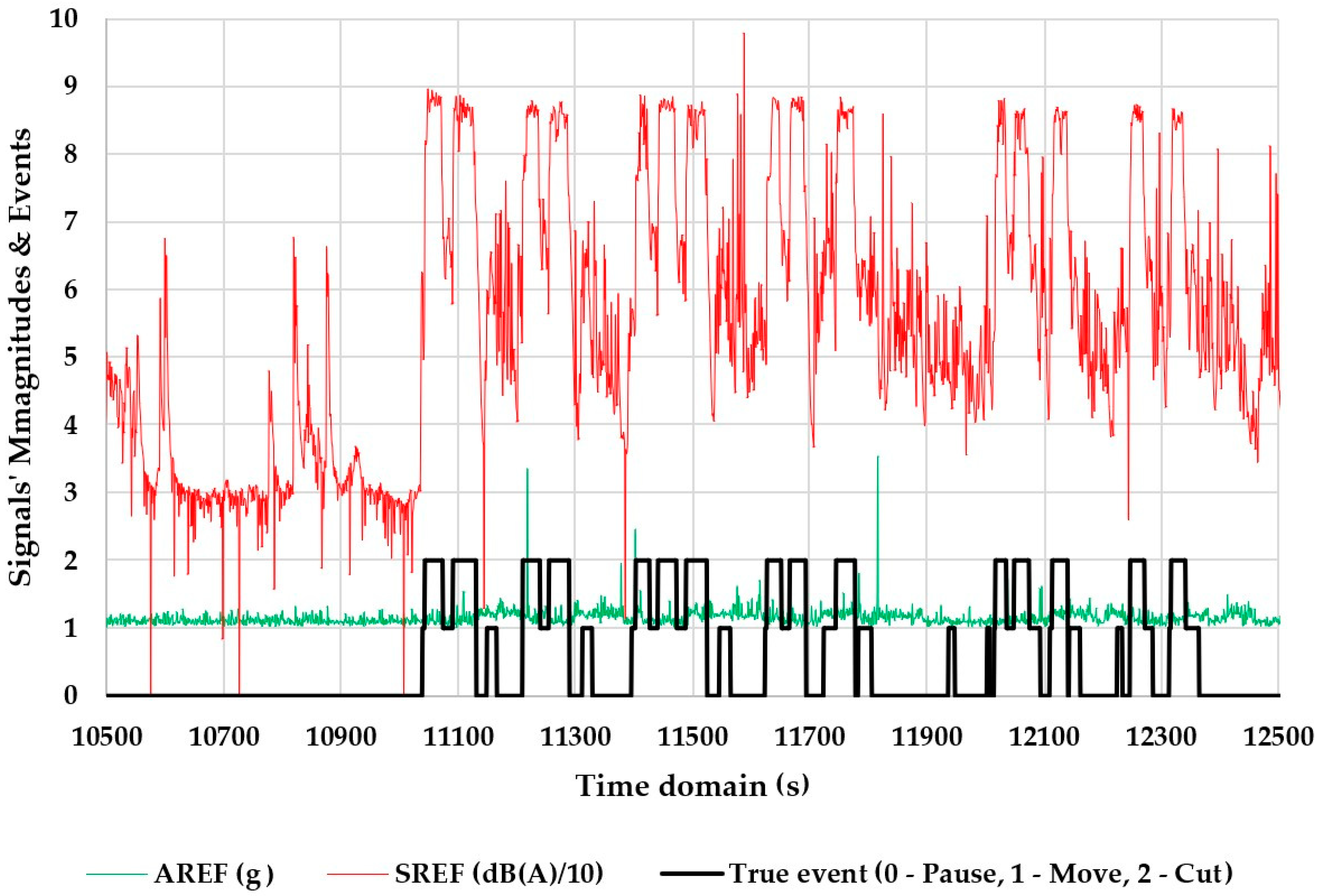
3.1. Descriptive Statistics of the Refined Signal Datasets
3.2. Training Results and Selection of the Model
3.3. Statistics and Classification Performance on the Test Signal Dataset
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Oprea, I. Tehnologia Exploatării Lemnului; Transilvania Publishing House: Brasov, Romania, 2008; 273p. [Google Scholar]
- Rauch, P.; Wolfsmayr, U.J.; Borz, S.A.; Triplat, M.; Krajnc, N.; Klock, M.; Oberwimmer, R.; Ketikidis, C.; Vasiljevic, A.; Stauder, M.; et al. SWOT analysis and strategy development for forest fuel supply chains in South East Europe. Forest Policy Econ. 2015, 61, 87–94. [Google Scholar] [CrossRef]
- Rauch, P.; Borz, S.A. Reengineering the Romanian Timber Supply Chain from a Process Management Perspective. Croat. J. For. Eng. 2020, 4, 85–94. [Google Scholar] [CrossRef]
- Fornea, M.; Bîrda, M.; Borz, S.A.; Popa, B.; Tomašić, Ž. Harvesting conditions, market particularities or just economic competition: A Romanian case study regarding the evolution of standing timber. Sumar. List 2018, 9–10, 499–508. [Google Scholar]
- Lundahl, C.G. Optimized Processes in Sawmills. Licentiate Thesis, Luleå University of Technology, Skellefteå, Sweden, 2007. [Google Scholar]
- Grönlund, A. Sågverksteknik del 2—Processen. Sveriges Skogsindustriförbund; Arbio: Markaryd, Sweden, 1992; p. 270. ISBN 91-7322-150-3. [Google Scholar]
- Hyytiäinen, A.; Viitanen, J.; Mutanen, A. Production efficiency of independent Finnish sawmills in the 2000′s. Baltic For. 2011, 17, 280–287. [Google Scholar]
- Sbera, I. Wood resources and the market potential in Romania. (Resursele de lemn şi potenţialul pieţei din România). Meridiane For. 2007, 2, 3–7. (In Romanian) [Google Scholar]
- Gigoraş, D.; Borz, S.A. Factors affecting the effective time consumption, wood recovery rate and feeding speed when manufacturing lumber using a FBO-02 CUT mobile bandsaw. Wood Res. 2015, 60, 329–338. [Google Scholar]
- Cedamon, E.D.; Harrison, S.; Herbohn, J. Comparative analysis of on-site free-hand chainsaw milling and fixed site mini-bandsaw milling of smallholder timber. Small-Scale For. 2013, 12, 389–401. [Google Scholar] [CrossRef]
- De Lasaux, M.J.; Spinelli, R.; Hartsough, B.R.; Magagnotti, N. Using a small-log mobile sawmill system to contain fuel reduction treatment cost on small parcels. Small-Scale For. 2009, 8, 367–379. [Google Scholar] [CrossRef]
- Ištvanić, J.; Lučić, R.B.; Jug, M.; Karan, R. Analysis of factors affecting log band saw capacity. Croat. J. For. Eng. 2009, 30, 27–35. [Google Scholar]
- Venn, T.J.; McGavin, R.L.; Leggate, W.W. Costs of portable sawmilling timbers from the acacia woodlands of Western Queensland, Australia. Small-Scale For. Econ. Manag. Policy 2004, 3, 161–175. [Google Scholar] [CrossRef]
- Acuna, M.; Bigot, M.; Guerra, S.; Hartsough, B.; Kanzian, C.; Kärhä, K.; Lindroos, O.; Magagnotti, N.; Roux, S.; Spinelli, R.; et al. Good Practice Guidelines for Biomass Production Studies; CNR IVALSA Sesto Fiorentino (National Research Council of Italy—Trees and Timber Institute): Sesto Fiorentino, Italy, 2012; pp. 1–51. ISBN 978-88-901660-4-4. [Google Scholar]
- Muşat, E.C.; Apăfăian, A.I.; Ignea, G.; Ciobanu, V.D.; Iordache, E.; Derczeni, R.A.; Spârchez, G.; Vasilescu, M.M.; Borz, S.A. Time expenditure in computer aided time studies implemented for highly mechanized forest equipment. Ann. For. Res. 2016, 59, 129–144. [Google Scholar] [CrossRef]
- Borz, S.A.; Adam, M. Analysis of video files in time studies by using free or low-cost software: Factors that quantitatively influence the time consumption data processing and its prediction. Revista Pădurilor 2015, 130, 60–71. [Google Scholar]
- Contreras, M.; Freitas, R.; Ribeiro, L.; Stringer, J.; Clark, C. Multi-camera surveillance system for time and motion studies of timber harvesting equipment. Comput. Electron. Agr. 2017, 135, 208–215. [Google Scholar] [CrossRef]
- Borz, S.A. Turning a winch skidder into a self-data collection machine using external sensors: A methodological concept. Bull. Transilv. Univ. Braşov 2016, 9, 1–6. [Google Scholar]
- Cheța, M.; Borz, S.A. Automating data extraction from GPS files and sound pressure level sensors with application in cable yarding time and motion studies. Bull. Transilv. Univ. Braşov 2017, 10, 1–10. [Google Scholar]
- Cheța, M.; Şerban, D.; Ignea, G.; Derczeni, R.A.; Sfeclă, V.; Borz, S.A. Using sound pressure sensors to monitor the performance of manually operated circular saws: What parameters and to what extent can they be inferred? Revista Pădurilor 2017, 132, 15–22. [Google Scholar]
- Borz, S.A.; Talagai, N.; Cheţa, M.; Gavilanes Montoya, A.V.; Castillo Vizuete, D.D. Automating data collection in motor-manual time and motion studies implemented in a willow short rotation coppice. Bioresources 2018, 13, 3236–3249. [Google Scholar] [CrossRef]
- Borz, S.A.; Talagai, N.; Cheţa, M.; Chiriloiu, D.; Gavilanes Montoya, A.V.; Castillo Vizuete, D.D.; Marcu, M.V. Physical strain, exposure to noise and postural assessment in motor-manual felling of willow short rotation coppice: Results of a preliminary study. Croat. J. For. Eng. 2019, 40, 377–388. [Google Scholar] [CrossRef]
- Marogel-Popa, T.; Cheța, M.; Marcu, M.V.; Duță, C.I.; Ioraș, F.; Borz, S.A. Manual cultivation operations in poplar stands: A characterization of job difficulty and risks of health impairment. Int. J. Environ. Res. Public Health 2019, 16, 1911. [Google Scholar] [CrossRef]
- Keefe, R.F.; Zimbelman, E.G.; Wempe, A.M. Use of smartphone sensors to quantify the productive cycle elements of hand fallers on industrial cable logging operations. Int. J. For. Eng. 2019, 30, 132–143. [Google Scholar] [CrossRef]
- Proto, A.R.; Sperandio, G.; Costa, C.; Maesano, M.; Antonucci, F.; Macri, G.; Scarascia Mugnozza, G.; Zimbalatti, G. A three-step neural network artificial intelligence modeling approach for time, productivity and costs prediction: A case study in Italian forestry. Croat. J. For. Eng. 2020, 41, 35–47. [Google Scholar] [CrossRef]
- Haykin, S.S. Neural Networks and Learning Machines; Pearson: Upper Saddle River, NJ, USA, 2009; Volume 3, 26p. [Google Scholar]
- Cheţa, M.; Marcu, M.; Borz, S. Workload, exposure to noise, and risk of musculoskeletal disorders: A case study of motor-manual tree feeling and processing in poplar clear cuts. Forests 2018, 9, 300. [Google Scholar] [CrossRef]
- Neal, C.G., Jr.; Gary, L.W. A theoretical analysis of the properties of median filters. IEEE Trans. Acoust. Signal Process. 1981, 29, 1136–1141. [Google Scholar]
- Leeb, S.B.; Shaw, S.R. Applications of real-time median filtering with fast digital and analog sorters. IEEE/ASME Trans. Mechatron. 1997, 2, 136–143. [Google Scholar] [CrossRef]
- Demsar, J.; Curk, T.; Erjavec, A.; Gorup, C.; Hocevar, T.; Milutinovic, M.; Mozina, M.; Polajnar, M.; Toplak, M.; Staric, A.; et al. Orange: Data Mining Toolbox in Python. J. Mach. Learn. Res. 2013, 14, 2349–2353. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the 30th International Conference on Machine Learning, ICML 2013, Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted Boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML 2010), Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Kingma, D.P.; Ba, J.L. ADAM: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Kamilaris, A.; Prenafeta-Boldu, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef]
- Fawcett, T. An introduction to ROC analysis. Pattern Recogn. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Karsoliya, S. Approximating number of hidden layer neurons in multiple hidden layer BPNN architecture. Int. J. Eng. Technol. 2012, 3, 714–717. [Google Scholar]
- Panchal, F.S.; Panchal, M. Review on methods of selecting number of hidden nodes in Artificial Neural Network. Int. J. Comput. Sci. Mob. Comput. 2014, 3, 455–464. [Google Scholar]
- Nasir, V.; Nourian, S.; Avramidis, S.; Cool, J. Classification of thermally treated wood using machine learning techniques. Wood Sci. Technol. 2019, 53, 275–288. [Google Scholar] [CrossRef]
- Borz, S.A.; Ignea, G. Aplicaţii V.B.A. şi M.S. Excel în Ingineria Forestieră; Lux Libris Publishing House: Braşov, Romania, 2013; 398p, ISBN 978-973-131-235-4. [Google Scholar]



{kind=link}
{kind=link}
| Definitions of Signals | Abbreviation | Number of Observations | Purpose/Use |
|---|---|---|---|
| Initial acceleration signal dataset | AINI | 90,405 | Reference of the study |
| Initial sound pressure level signal dataset | SINI | 90,405 | Reference of the study |
| Initial acceleration and sound pressure level signals dataset | ASINI | 90,405 | Reference of the study |
| Refined acceleration signal dataset | AREF | 78,189 | Machine-related events |
| Refined sound pressure level signal dataset | SREF | 78,189 | Machine-related events |
| Refined acceleration and sound pressure level signals dataset | ASREF | 78,189 | Machine-related events |
| Median filtered acceleration signal dataset for training | AMTRAIN | 20,050 | Removing impulses and train |
| Median filtered sound pressure level signal dataset for training | SMTRAIN | 20,050 | Removing impulses and train |
| Median filtered acceleration and sound pressure level signals dataset for training | ASMTRAIN | 20,050 | Removing impulses and train |
| Median filtered acceleration signal dataset for testing | AMTEST | 58,139 | Removing impulses and test |
| Median filtered sound pressure level signal for testing | SMTEST | 58,139 | Removing impulses and test |
| Median filtered acceleration and sound pressure level signals dataset for testing | ASMTEST | 58,139 | Removing impulses and test |
| Signal Abbreviation | Number of Observations | Share of Events (%) in the Number of Observations | ||
|---|---|---|---|---|
| Cut | Move | Pause | ||
| Refined (A, S, A and S) | 78,189 | 20.29 | 13.40 | 66.31 |
| Median filtered for training (A, S, A and S) | 20,050 | 18.47 | 13.00 | 68.53 |
| Median filtered for testing (A, S, A and S) | 58,139 | 20.20 | 13.11 | 66.68 |
| Input Signal | Training Time (s) | Event | Performance Metrics | ||||
|---|---|---|---|---|---|---|---|
| AUC | CA | F1 | PREC | REC | |||
| ASMTRAIN | 350 | Pause | 0.938 | 0.871 | 0.910 | 0.873 | 0.951 |
| Move | 0.888 | 0.884 | 0.400 | 0.608 | 0.299 | ||
| Cut | 0.997 | 0.977 | 0.939 | 0.927 | 0.951 | ||
| Overall | 0.944 | 0.866 | 0.849 | 0.848 | 0.866 | ||
| AMTRAIN | 125 | Pause | 0.635 | 0.685 | 0.813 | 0.685 | 1.000 |
| Move | 0.588 | 0.870 | 0.000 | 0.000 | 0.000 | ||
| Cut | 0.629 | 0.815 | 0.001 | 1.000 | 0.000 | ||
| Overall | 0.617 | 0.685 | 0.558 | 0.654 | 0.685 | ||
| SMTRAIN | 175 | Pause | 0.932 | 0.860 | 0.903 | 0.862 | 0.947 |
| Move | 0.880 | 0.878 | 0.362 | 0.570 | 0.265 | ||
| Cut | 0.996 | 0.975 | 0.934 | 0.929 | 0.939 | ||
| Overall | 0.939 | 0.857 | 0.838 | 0.837 | 0.857 | ||
| Features | Number of Observations | Share in Correctly Classified | AUC | CA | F1 | PREC | REC |
|---|---|---|---|---|---|---|---|
| Total correctly classified | 49,366 | 100 | |||||
| Cut | 11,330 | 22.95 | |||||
| Move | 2577 | 5.22 | |||||
| Pause | 35,459 | 71.83 | |||||
| Overall performance | 0.939 | 0.849 | 0.838 | 0.832 | 0.849 |
| Features | Number of Observations | Share in Misclassified |
|---|---|---|
| Total misclassified observations | 8773 | 100 |
| Cut misclassified as Pause | 341 | 3.89 |
| Cut misclassified as Move | 75 | 0.85 |
| Move misclassified as Cut | 303 | 3.45 |
| Move misclassified as Pause | 4745 | 54.09 |
| Pause misclassified as Cut | 1016 | 11.58 |
| Pause misclassified as Move | 2293 | 26.14 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheţa, M.; Marcu, M.V.; Iordache, E.; Borz, S.A. Testing the Capability of Low-Cost Tools and Artificial Intelligence Techniques to Automatically Detect Operations Done by a Small-Sized Manually Driven Bandsaw. Forests 2020, 11, 739. https://doi.org/10.3390/f11070739
Cheţa M, Marcu MV, Iordache E, Borz SA. Testing the Capability of Low-Cost Tools and Artificial Intelligence Techniques to Automatically Detect Operations Done by a Small-Sized Manually Driven Bandsaw. Forests. 2020; 11(7):739. https://doi.org/10.3390/f11070739
Chicago/Turabian StyleCheţa, Marius, Marina Viorela Marcu, Eugen Iordache, and Stelian Alexandru Borz. 2020. "Testing the Capability of Low-Cost Tools and Artificial Intelligence Techniques to Automatically Detect Operations Done by a Small-Sized Manually Driven Bandsaw" Forests 11, no. 7: 739. https://doi.org/10.3390/f11070739
APA StyleCheţa, M., Marcu, M. V., Iordache, E., & Borz, S. A. (2020). Testing the Capability of Low-Cost Tools and Artificial Intelligence Techniques to Automatically Detect Operations Done by a Small-Sized Manually Driven Bandsaw. Forests, 11(7), 739. https://doi.org/10.3390/f11070739