Evaluation of Stand Biomass Estimation Methods for Major Forest Types in the Eastern Da Xing’an Mountains, Northeast China



Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Area and Data
2.2. Stand Biomass Estimation Models
2.2.1. Stand Biomass Models with Stand Variables (M-1)
2.2.2. Stand Biomass Models with Stand Volume (M-2)
2.2.3. Stand Biomass Models with Both Stand Volume and BCEFs (M-3)
2.3. Model Evaluation and Validation
2.4. Evaluation of Several Stand Biomass Estimation Methods
3. Results
3.1. Model Fitting for Stand Biomass Models
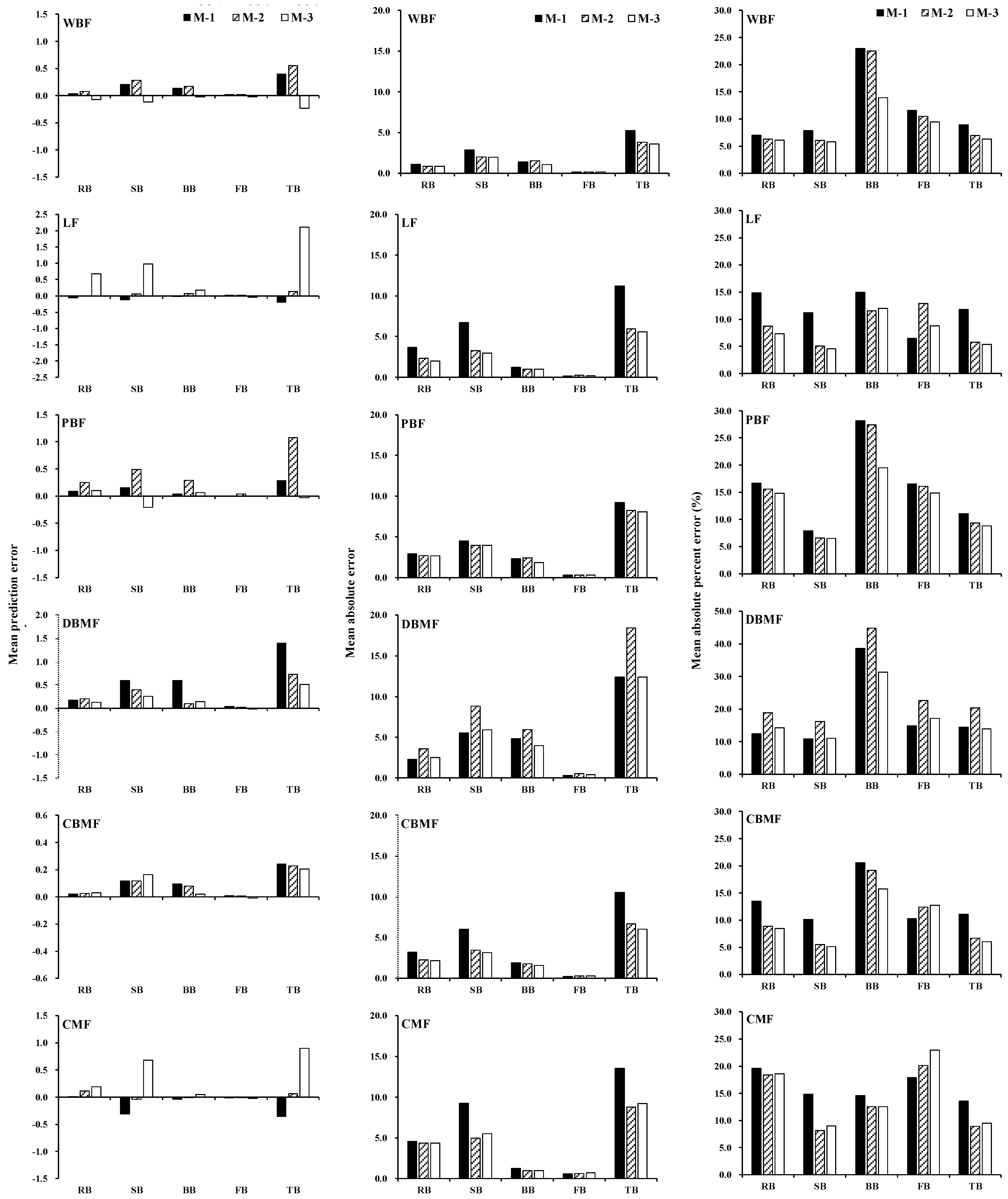
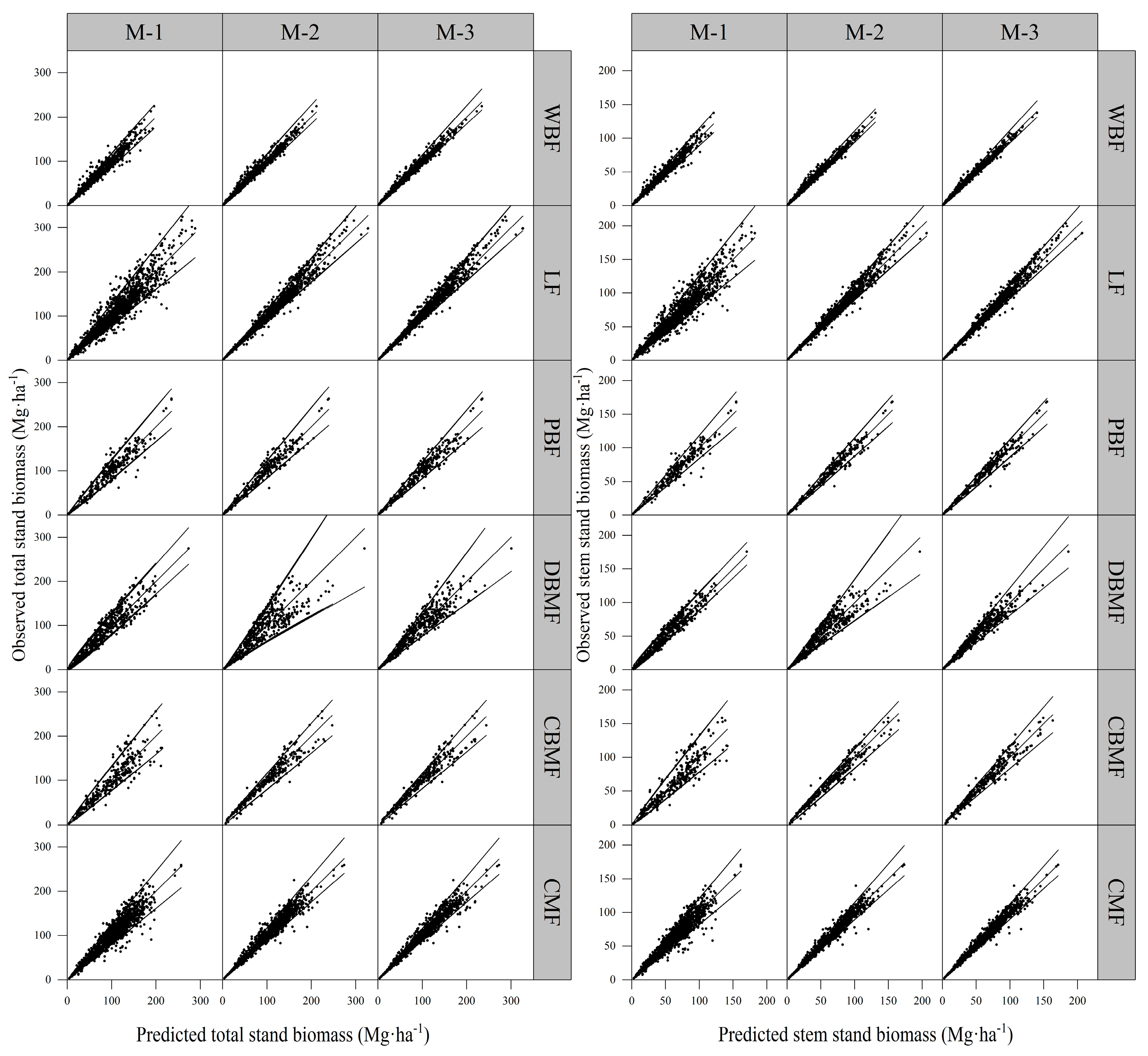
3.2. Model Validation for Stand Biomass Models
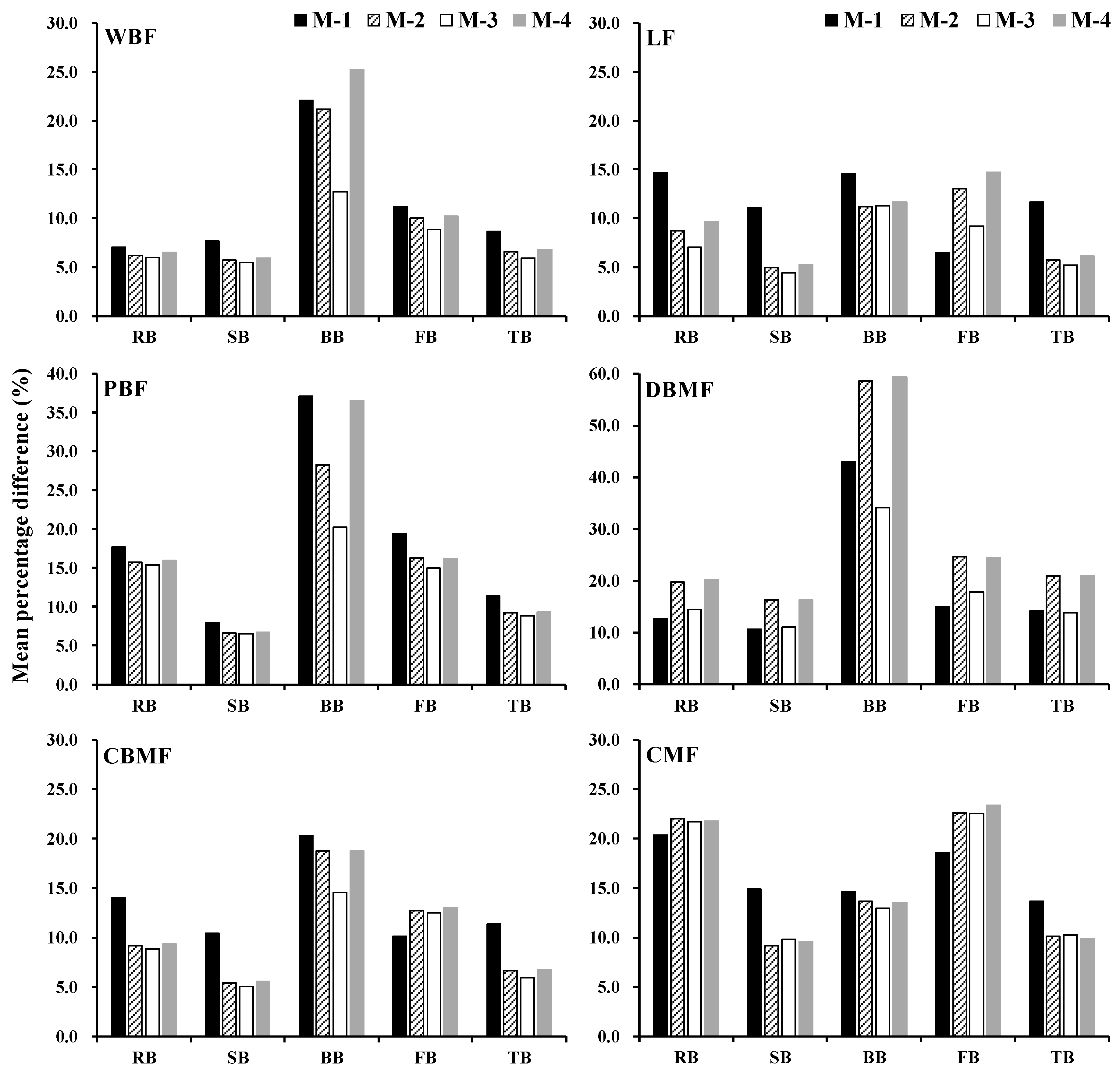
3.3. Comparison of Methods for Estimating Stand Biomass
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Canadell, J.G.; Raupach, M.R. Managing forests for climate change mitigation. Science 2008, 320, 1456–1457. [Google Scholar] [CrossRef] [PubMed]
- Pan, Y.; Birdsey, R.A.; Fang, J.; Houghton, R.; Kauppi, P.E.; Kurz, W.A.; Phillips, O.L.; Shvidenko, A.; Lewis, S.L.; Canadell, J.G. A large and persistent carbon sink in the world’s forests. Science 2011, 333, 988–993. [Google Scholar] [CrossRef] [PubMed]
- Foster, J.R.; Finley, A.O.; D’amato, A.W.; Bradford, J.B.; Banerjee, S. Predicting tree biomass growth in the temperate–boreal ecotone: Is tree size, age, competition, or climate response most important? Glob. Chang. Biol. 2016, 22, 2138–2151. [Google Scholar] [CrossRef] [PubMed]
- Kachamba, D.; Eid, T.; Gobakken, T. Above-and belowground biomass models for trees in the miombo woodlands of Malawi. Forests 2016, 7, 38. [Google Scholar] [CrossRef]
- Kapinga, K.; Syampungani, S.; Kasubika, R.; Yambayamba, A.M.; Shamaoma, H. Species-specific allometric models for estimation of the above-ground carbon stock in miombo woodlands of Copperbelt Province of Zambia. For. Ecol. Manag. 2018, 417, 184–196. [Google Scholar] [CrossRef]
- Bi, H.; Long, Y.; Turner, J.; Lei, Y.; Snowdon, P.; Li, Y.; Harper, R.; Zerihun, A.; Ximenes, F. Additive prediction of aboveground biomass for Pinus radiata (D. Don) plantations. For. Ecol. Manag. 2010, 259, 2301–2314. [Google Scholar] [CrossRef]
- Castedo-Dorado, F.; Gómez-García, E.; Diéguez-Aranda, U.; Barrio-Anta, M.; Crecente-Campo, F. Aboveground stand-level biomass estimation: A comparison of two methods for major forest species in northwest Spain. Ann. For. Sci. 2012, 69, 735–746. [Google Scholar] [CrossRef]
- Paré, D.; Bernier, P.; Lafleur, B.; Titus, B.D.; Thiffault, E.; Maynard, D.G.; Guo, X. Corrigendum: Estimating stand-scale biomass, nutrient contents, and associated uncertainties for tree species of Canadian forests. Can. J. For. Res. 2013, 43, 1084. [Google Scholar] [CrossRef]
- Di Cosmo, L.; Gasparini, P.; Tabacchi, G. A national-scale, stand-level model to predict total above-ground tree biomass from growing stock volume. For. Ecol. Manag. 2016, 361, 269–276. [Google Scholar] [CrossRef]
- Jagodziński, A.; Dyderski, M.; Gęsikiewicz, K.; Horodecki, P. Tree-and Stand-Level Biomass Estimation in a Larix decidua Mill. Chronosequence. Forests 2018, 9, 587. [Google Scholar] [CrossRef]
- Bi, H.; Turner, J.; Lambert, M.J. Additive biomass equations for native eucalypt forest trees of temperate Australia. Trees 2004, 18, 467–479. [Google Scholar] [CrossRef]
- Dong, L.; Zhang, L.; Li, F. Developing additive systems of biomass equations for nine hardwood species in Northeast China. Trees 2015, 29, 1149–1163. [Google Scholar] [CrossRef]
- Zhao, D.; Kane, M.; Markewitz, D.; Teskey, R.; Clutter, M. Additive tree biomass equations for midrotation loblolly pine plantations. For. Sci. 2015, 61, 613–623. [Google Scholar] [CrossRef]
- Dong, L.; Zhang, L.; Li, F. Additive biomass equations based on different dendrometric variables for two dominant species (Larix gmelini Rupr. and Betula platyphylla Suk.) in natural forests in the eastern Daxing’an Mountains, Northeast China. Forests 2018, 9, 261. [Google Scholar] [CrossRef]
- Teobaldelli, M.; Somogyi, Z.; Migliavacca, M.; Usoltsev, V.A. Generalized functions of biomass expansion factors for conifers and broadleaved by stand age, growing stock and site index. For. Ecol. Manag. 2009, 257, 1004–1013. [Google Scholar] [CrossRef]
- González-García, M.; Hevia, A.; Majada, J.; Barrio-Anta, M. Above-ground biomass estimation at tree and stand level for short rotation plantations of Eucalyptus nitens (Deane & Maiden) Maiden in Northwest Spain. Biomass Bioenergy 2013, 54, 147–157. [Google Scholar]
- Jagodziński, A.M.; Dyderski, M.K.; Gęsikiewicz, K.; Horodecki, P.; Cysewska, A.; Wierczyńska, S.; Maciejczyk, K. How do tree stand parameters affect young Scots pine biomass?—Allometric equations and biomass conversion and expansion factors. For. Ecol. Manag. 2018, 409, 74–83. [Google Scholar] [CrossRef]
- Liu, J.; Hyyppa, J.; Yu, X.; Jaakkola, A.; Kukko, A.; Kaartinen, H.; Zhu, L.; Liang, X.; Wang, Y.; Hyyppa, H. A novel GNSS technique for predicting boreal forest attributes at low cost. IEEE Trans. Geosci. Remote 2017, 55, 4855–4867. [Google Scholar] [CrossRef]
- Wang, X.; Ouyang, S.; Sun, O.J.; Fang, J. Forest biomass patterns across northeast China are strongly shaped by forest height. For. Ecol. Manag. 2013, 293, 149–160. [Google Scholar] [CrossRef]
- Fang, J.-Y.; Wang, G.G.; Liu, G.-H.; Xu, S.-L. Forest biomass of China: An estimate based on the biomass–volume relationship. Ecol. Appl. 1998, 8, 1084–1091. [Google Scholar]
- Luo, Y.; Wang, X.; Zhang, X.; Ren, Y.; Poorter, H. Variation in biomass expansion factors for China’s forests in relation to forest type, climate, and stand development. Ann. For. Sci. 2013, 70, 589–599. [Google Scholar] [CrossRef]
- Pan, Y.; Luo, T.; Birdsey, R.; Hom, J.; Melillo, J. New estimates of carbon storage and sequestration in China’s forests: Effects of age–class and method on inventory-based carbon estimation. Clim. Chang. 2004, 67, 211–236. [Google Scholar] [CrossRef]
- IPCC. 2006 IPCC Guidelines for National Greenhouse Gas Inventories; Institute for Global Environmental Strategies: Kanagawa, Japan, 2006. [Google Scholar]
- Zhou, G.; Wang, Y.; Jiang, Y.; Yang, Z. Estimating biomass and net primary production from forest inventory data: A case study of China’s Larix forests. For. Ecol. Manag. 2002, 169, 149–157. [Google Scholar] [CrossRef]
- Zhao, M.; Zhou, G.S. Estimation of biomass and net primary productivity of major planted forests in China based on forest inventory data. For. Ecol. Manag. 2005, 207, 295–313. [Google Scholar] [CrossRef]
- Soares, P.; Tomé, M. Analysis of the Effectiveness of Biomass Expansion Factors to Estimate Stand Biomass. Available online: https://www.researchgate.net/profile/Margarida_Tome3/publication/266016805_Analysis_of_the_effectiveness_of_biomass_expansion_factors_to_estimate_stand_biomass/links/54b5aac30cf28ebe92e799a8.pdf (accessed on 19 July 2019).
- Parresol, B.R. Assessing tree and stand biomass: A review with examples and critical comparisons. For. Sci. 1999, 45, 573–593. [Google Scholar]
- Parresol, B.R. Additivity of nonlinear biomass equations. Can. J. For. Res. 2001, 31, 865–878. [Google Scholar] [CrossRef]
- Tang, S.; Li, Y.; Wang, Y. Simultaneous equations, error-in-variable models, and model integration in systems ecology. Ecol. Model. 2001, 142, 285–294. [Google Scholar] [CrossRef]
- Zhao, D.; Westfall, J.; Coulston, J.W.; Lynch, T.B.; Bullock, B.P.; Montes, C.R. Additive biomass equations for slash pine trees: Comparing three modeling approaches. Can. J. For. Res. 2018, 49, 27–40. [Google Scholar] [CrossRef]
- Clifford, D.; Cressie, N.; England, J.R.; Roxburgh, S.H.; Paul, K.I. Correction factors for unbiased, efficient estimation and prediction of biomass from log–log allometric models. For. Ecol. Manag. 2013, 310, 375–381. [Google Scholar] [CrossRef]
- Dong, L.; Zhang, L.; Li, F. A three-step proportional weighting system of nonlinear biomass equations. For. Sci. 2014, 61, 35–45. [Google Scholar] [CrossRef]
- Dong, L.; Zhang, L.; Li, F. A compatible system of biomass equations for three conifer species in Northeast, China. For. Ecol. Manag. 2014, 329, 306–317. [Google Scholar] [CrossRef]
- Balboa-Murias, M.A.; Rodríguez-Soalleiro, R.; Merino, A.; Álvarez-González, J.G. Temporal variations and distribution of carbon stocks in aboveground biomass of radiata pine and maritime pine pure stands under different silvicultural alternatives. For. Ecol. Manag. 2006, 237, 29–38. [Google Scholar] [CrossRef]
- SAS Institute Inc. SAS/ETS 9.3 User’s Guide; SAS Institute Inc.: Cary, NC, USA, 2011. [Google Scholar]
- Bi, H.; Murphy, S.; Volkova, L.; Weston, C.; Fairman, T.; Li, Y.; Law, R.; Norris, J.; Lei, X.; Caccamo, G. Additive biomass equations based on complete weighing of sample trees for open eucalypt forest species in south-eastern Australia. For. Ecol. Manag. 2015, 349, 106–121. [Google Scholar] [CrossRef]
- António, N.; Tomé, M.; Tomé, J.; Soares, P.; Fontes, L. Effect of tree, stand, and site variables on the allometry of Eucalyptus globulus tree biomass. Can. J. For. Res. 2007, 37, 895–906. [Google Scholar] [CrossRef]
- Albaugh, T.J.; Bergh, J.; Lundmark, T.; Nilsson, U.; Stape, J.L.; Allen, H.L.; Linder, S. Do biological expansion factors adequately estimate stand-scale aboveground component biomass for Norway spruce? For. Ecol. Manag. 2009, 258, 2628–2637. [Google Scholar] [CrossRef]
- Jenkins, J.C.; Chojnacky, D.C.; Heath, L.S.; Birdsey, R.A. National-scale biomass estimators for United States tree species. For. Sci. 2003, 49, 12–35. [Google Scholar]
- Lehtonen, A.; Mäkipää, R.; Heikkinen, J.; Sievänen, R.; Liski, J. Biomass expansion factors (BEFs) for Scots pine, Norway spruce and birch according to stand age for boreal forests. For. Ecol. Manag. 2004, 188, 211–224. [Google Scholar] [CrossRef]
- Jagodziński, A.M.; Zasada, M.; Bronisz, K.; Bronisz, A.; Bijak, S. Biomass conversion and expansion factors for a chronosequence of young naturally regenerated silver birch (Betula pendula Roth) stands growing on post-agricultural sites. For. Ecol. Manag. 2017, 384, 208–220. [Google Scholar] [CrossRef]
- Goicoa, T.; Militino, A.; Ugarte, M. Modelling aboveground tree biomass while achieving the additivity property. Environ. Ecol. Stat. 2011, 18, 367–384. [Google Scholar] [CrossRef]
- Bi, H.; Birk, E.; Turner, J.; Lambert, M.; Jurskis, V. Converting stem volume to biomass with additivity, bias correction, and confidence bands for two Australian tree species. N. Z. J. For. Sci. 2001, 31, 298–319. [Google Scholar]
- Wang, X.; Feng, Z.; Ouyang, Z. The impact of human disturbance on vegetative carbon storage in forest ecosystems in China. For. Ecol. Manag. 2001, 148, 117–123. [Google Scholar] [CrossRef]
- Li, H.; Zhao, P.; Lei, Y.; Zeng, W. Comparison on estimation of wood biomass using forest inventory data. Sci. Silvae Sin. 2012, 48, 44–52. [Google Scholar]
- Fang, J.; Chen, A.; Peng, C.; Zhao, S.; Ci, L. Changes in forest biomass carbon storage in China between 1949 and 1998. Science 2001, 292, 2320–2322. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Forest Types | Measurements | Statistics | Dq | Ha | G | V | N | Wr | Ws | Wb | Wf |
|---|---|---|---|---|---|---|---|---|---|---|---|
| White birch forest | 963 | Min | 5.3 | 5.0 | 0.5 | 1.7 | 200.0 | 0.49 | 1.12 | 0.10 | 0.05 |
| Max | 23.2 | 24.0 | 30.8 | 226.0 | 3533.0 | 52.49 | 137.80 | 29.84 | 5.57 | ||
| Mean | 11.1 | 11.9 | 11.5 | 68.6 | 1226.7 | 15.18 | 40.51 | 7.58 | 1.76 | ||
| SD | 3.3 | 3.4 | 6.5 | 43.4 | 684.0 | 9.46 | 25.38 | 5.38 | 1.10 | ||
| Larch forest | 1749 | Min | 6.0 | 5.0 | 0.6 | 2.3 | 200.0 | 0.46 | 1.36 | 0.16 | 0.09 |
| Max | 36.7 | 32.0 | 39.6 | 340.0 | 3950.0 | 96.33 | 203.40 | 30.86 | 6.35 | ||
| Mean | 13.9 | 14.0 | 15.6 | 107.6 | 1130.9 | 25.91 | 62.86 | 7.74 | 2.10 | ||
| SD | 4.1 | 4.1 | 7.5 | 57.7 | 662.4 | 15.66 | 35.79 | 4.78 | 1.06 | ||
| Poplar-birch forest | 293 | Min | 5.3 | 5.1 | 0.7 | 2.6 | 200.0 | 0.47 | 1.66 | 0.12 | 0.05 |
| Max | 24.1 | 23.2 | 36.2 | 288.2 | 3433.3 | 57.59 | 168.53 | 31.49 | 5.48 | ||
| Mean | 12.1 | 13.1 | 16.9 | 111.9 | 1543.8 | 19.25 | 62.36 | 10.20 | 2.24 | ||
| SD | 3.8 | 4.1 | 7.5 | 58.8 | 712.4 | 10.54 | 32.25 | 6.55 | 1.16 | ||
| Deciduous broadleaf mixed forest | 501 | Min | 5.4 | 5.0 | 0.8 | 3.2 | 200.0 | 0.83 | 1.95 | 0.20 | 0.08 |
| Max | 27.0 | 23.1 | 37.3 | 298.8 | 3150.0 | 59.91 | 175.93 | 45.44 | 5.72 | ||
| Mean | 12.7 | 11.1 | 14.0 | 78.5 | 1207.7 | 18.65 | 54.41 | 13.18 | 2.31 | ||
| SD | 4.0 | 3.6 | 6.4 | 43.5 | 603.4 | 9.78 | 28.67 | 9.45 | 1.19 | ||
| Coniferous and broadleaf mixed forest | 1263 | Min | 6.9 | 5.0 | 1.0 | 4.5 | 217.0 | 0.88 | 2.40 | 0.29 | 0.13 |
| Max | 27.0 | 32.3 | 36.5 | 291.6 | 3350.0 | 60.32 | 170.78 | 27.78 | 6.70 | ||
| Mean | 12.8 | 12.8 | 16.1 | 106.0 | 1365.2 | 24.10 | 62.41 | 9.90 | 2.37 | ||
| SD | 3.0 | 3.5 | 6.6 | 47.8 | 683.5 | 11.36 | 28.65 | 5.13 | 1.04 | ||
| Coniferous mixed forest | 305 | Min | 6.3 | 5.4 | 1.2 | 10.3 | 200.0 | 0.55 | 1.90 | 0.30 | 0.18 |
| Max | 33.1 | 23.6 | 33.3 | 288.8 | 3933.0 | 69.77 | 158.62 | 22.14 | 8.50 | ||
| Mean | 14.1 | 13.7 | 17.2 | 123.2 | 1219.7 | 21.92 | 64.87 | 8.99 | 3.47 | ||
| SD | 4.4 | 3.9 | 6.8 | 56.8 | 601.3 | 11.62 | 32.40 | 4.29 | 1.57 |
| Forest Types | Statistics | BCEFr | BCEFs | BCEFb | BCEFf |
|---|---|---|---|---|---|
| White birch forest | Constant | 0.2255 | 0.5944 | 0.1056 | 0.0257 |
| SD | 0.0214 | 0.0552 | 0.0346 | 0.0039 | |
| Larch forest | Constant | 0.2338 | 0.5754 | 0.0699 | 0.0205 |
| SD | 0.0290 | 0.0409 | 0.0126 | 0.0041 | |
| Poplar-birch forest | Constant | 0.1725 | 0.5651 | 0.0856 | 0.0202 |
| SD | 0.0327 | 0.0529 | 0.0324 | 0.0040 | |
| Deciduous broadleaf mixed forest | Constant | 0.2438 | 0.6994 | 0.1639 | 0.0305 |
| SD | 0.0512 | 0.1269 | 0.0865 | 0.0076 | |
| Coniferous and broadleaf mixed forest | Constant | 0.2265 | 0.5872 | 0.0926 | 0.0229 |
| SD | 0.0269 | 0.0462 | 0.0260 | 0.0040 | |
| Coniferous mixed forest | Constant | 0.1775 | 0.5152 | 0.0731 | 0.0299 |
| SD | 0.0410 | 0.0621 | 0.0130 | 0.0097 |
| Forest Types | Components | Equations | βi0 | βi1 | βi2 | Ra2 | RMSE | Weight Function | |||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Estimate | SE | Estimate | SE | Estimate | SE | ||||||
| White birch forest | Root | −0.3681 | 0.0211 | 1.0134 | 0.0038 | 0.2417 | 0.0107 | 0.9670 | 1.7191 | G2.3111 | |
| Stem | 0.3658 | 0.0243 | 1.0138 | 0.0047 | 0.3378 | 0.0118 | 0.9720 | 4.2478 | G1.8435 | ||
| Branch | −2.5802 | 0.0755 | 0.9553 | 0.0143 | 0.8883 | 0.0333 | 0.8398 | 2.1523 | G1.3376 | ||
| Foliage | −3.0214 | 0.0379 | 0.9788 | 0.0075 | 0.4702 | 0.0173 | 0.9443 | 0.2592 | G1.2728 | ||
| Total | - | - | - | - | - | - | 0.9644 | 7.7291 | G1.7861 | ||
| Larch forest | Root | −0.9170 | 0.0387 | 1.0639 | 0.0075 | 0.4644 | 0.0166 | 0.8827 | 5.3645 | G2.4562 | |
| Stem | 0.2552 | 0.0290 | 1.0538 | 0.0057 | 0.3689 | 0.0124 | 0.9254 | 9.7728 | G2.3102 | ||
| Branch | −1.8547 | 0.0417 | 1.1227 | 0.0073 | 0.3007 | 0.0197 | 0.8412 | 1.9034 | G2.8988 | ||
| Foliage | −1.9338 | 0.0270 | 1.0276 | 0.0059 | −0.0552 | 0.0114 | 0.9498 | 0.2383 | G1.5773 | ||
| Total | - | - | - | - | - | - | 0.9175 | 16.3387 | G2.3770 | ||
| Poplar−birch forest | Root | −0.6818 | 0.0709 | 1.0891 | 0.0145 | 0.2072 | 0.0361 | 0.8644 | 3.8810 | G1.9913 | |
| Stem | 0.3915 | 0.0357 | 1.0531 | 0.0072 | 0.2872 | 0.0179 | 0.9645 | 6.0795 | G1.9630 | ||
| Branch | −2.2658 | 0.1651 | 1.0131 | 0.0442 | 0.6504 | 0.0669 | 0.7546 | 3.2449 | G1.2065 | ||
| Foliage | −2.6787 | 0.0948 | 0.9712 | 0.0274 | 0.2830 | 0.0385 | 0.8820 | 0.3969 | G0.7684 | ||
| Total | - | - | - | - | - | - | 0.9376 | 12.4215 | G1.5947 | ||
| Deciduous broadleaf mixed forest | Root | −0.0292 | 0.0457 | 1.1270 | 0.0111 | −0.0225 | 0.0211 | 0.9011 | 3.0743 | G2.0893 | |
| Stem | 0.7085 | 0.0336 | 1.1494 | 0.0084 | 0.0885 | 0.0151 | 0.9375 | 7.1641 | G1.9423 | ||
| Branch | −1.0325 | 0.1065 | 1.4481 | 0.0260 | −0.1398 | 0.0511 | 0.5196 | 6.5472 | G1.7915 | ||
| Foliage | −2.0889 | 0.0478 | 1.1408 | 0.0119 | −0.0519 | 0.0225 | 0.8434 | 0.4704 | G1.5845 | ||
| Total | - | - | - | - | - | - | 0.8838 | 16.2834 | G1.9621 | ||
| Coniferous and broadleaf mixed forest | Root | −0.2980 | 0.0460 | 1.0499 | 0.0097 | 0.2189 | 0.0179 | 0.8520 | 4.3714 | G1.9153 | |
| Stem | 0.6282 | 0.0341 | 1.0590 | 0.0071 | 0.2181 | 0.0132 | 0.9244 | 7.8758 | G1.9069 | ||
| Branch | −1.6087 | 0.0614 | 1.0813 | 0.0122 | 0.3442 | 0.0237 | 0.7140 | 2.7444 | G1.4223 | ||
| Foliage | −2.3012 | 0.0329 | 1.0264 | 0.0067 | 0.1207 | 0.0129 | 0.8902 | 0.3458 | G1.4523 | ||
| Total | - | - | - | - | - | - | 0.9097 | 13.6576 | G1.8568 | ||
| Coniferous mixed forest | Root | −0.2841 | 0.1084 | 1.1484 | 0.0233 | 0.0343 | 0.0520 | 0.6721 | 6.6523 | G2.8070 | |
| Stem | 0.3872 | 0.0814 | 1.1543 | 0.0196 | 0.1862 | 0.0363 | 0.8468 | 12.6796 | G2.1331 | ||
| Branch | −1.3594 | 0.0849 | 1.0907 | 0.0209 | 0.1701 | 0.0373 | 0.8421 | 1.7045 | G2.0005 | ||
| Foliage | −1.7837 | 0.1034 | 0.8950 | 0.0262 | 0.1876 | 0.0434 | 0.7893 | 0.7194 | G1.2489 | ||
| Total | - | - | - | - | - | - | 0.8420 | 19.2912 | G2.3796 | ||
| Forest Types | Components | Equations | βi0 | βi1 | Ra2 | RMSE | Weight Function | ||
|---|---|---|---|---|---|---|---|---|---|
| Estimate | SE | Estimate | SE | ||||||
| White birch forest | Root | −1.3278 | 0.0140 | 0.9580 | 0.0033 | 0.9799 | 1.3392 | V1.5306 | |
| Stem | −0.4863 | 0.0118 | 0.9893 | 0.0026 | 0.9849 | 3.1148 | V1.1589 | ||
| Branch | −2.7349 | 0.0371 | 1.1142 | 0.0083 | 0.8192 | 2.2864 | V1.2267 | ||
| Foliage | −3.6432 | 0.0193 | 0.9928 | 0.0044 | 0.9444 | 0.259 | V1.0907 | ||
| Total | - | - | - | - | 0.9783 | 6.0348 | V1.3182 | ||
| Larch forest | Root | −1.7833 | 0.0146 | 1.0742 | 0.0032 | 0.9486 | 3.5507 | V1.9175 | |
| Stem | −0.7210 | 0.0091 | 1.0381 | 0.0020 | 0.9797 | 5.0940 | V1.8483 | ||
| Branch | −3.0835 | 0.0216 | 1.0941 | 0.0048 | 0.8776 | 1.6705 | V2.3133 | ||
| Foliage | −3.3961 | 0.0277 | 0.8887 | 0.0060 | 0.8796 | 0.3691 | V1.4197 | ||
| Total | - | - | - | - | 0.9741 | 9.1558 | V1.9543 | ||
| Poplar-birch forest | Root | −1.7307 | 0.0645 | 0.9913 | 0.0135 | 0.8870 | 3.5422 | V1.5588 | |
| Stem | −0.4645 | 0.0216 | 0.9738 | 0.0046 | 0.9647 | 6.0568 | V1.5025 | ||
| Branch | −3.4476 | 0.1073 | 1.2090 | 0.0221 | 0.7181 | 3.4773 | V1.5094 | ||
| Foliage | −3.7540 | 0.0539 | 0.9639 | 0.0111 | 0.8568 | 0.4373 | V0.9094 | ||
| Total | - | - | - | - | 0.9414 | 12.0418 | V1.5480 | ||
| Deciduous broadleaf mixed forest | Root | −1.2042 | 0.0318 | 0.9457 | 0.0077 | 0.7794 | 4.5912 | V1.4114 | |
| Stem | −0.2496 | 0.0423 | 0.9723 | 0.0096 | 0.8465 | 11.2301 | V1.1079 | ||
| Branch | −1.9774 | 0.1601 | 1.0408 | 0.0354 | 0.3156 | 7.8146 | V1.0047 | ||
| Foliage | −2.9984 | 0.0658 | 0.8809 | 0.0149 | 0.6615 | 0.6916 | V0.9736 | ||
| Total | - | - | - | - | 0.752 | 23.7878 | V1.0922 | ||
| Coniferous and broadleaf mixed forest | Root | −1.5946 | 0.0124 | 1.0234 | 0.0029 | 0.9072 | 3.4624 | V1.9507 | |
| Stem | −0.5931 | 0.0107 | 1.0129 | 0.0024 | 0.9668 | 5.2164 | V1.7036 | ||
| Branch | −2.4238 | 0.0725 | 1.0102 | 0.0152 | 0.7265 | 2.6839 | V1.2166 | ||
| Foliage | −3.2728 | 0.0504 | 0.8894 | 0.0105 | 0.8447 | 0.4113 | V0.8493 | ||
| Total | - | - | - | - | 0.9512 | 10.0404 | V1.3309 | ||
| Coniferous mixed forest | Root | −1.9686 | 0.0854 | 1.0505 | 0.0184 | 0.7036 | 6.324 | V2.0523 | |
| Stem | −1.1586 | 0.0463 | 1.1051 | 0.0097 | 0.9535 | 6.9835 | V1.9406 | ||
| Branch | −2.5850 | 0.0885 | 0.9942 | 0.0178 | 0.8994 | 1.3603 | V1.0203 | ||
| Foliage | −2.3607 | 0.0899 | 0.7545 | 0.0187 | 0.7225 | 0.8256 | V0.8568 | ||
| Total | - | - | - | - | 0.9294 | 12.8935 | V1.8315 | ||
| Forest Types | Components | Equations | βi0 | βi1 | βi2 | Ra2 | RMSE | Weight Function | |||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Estimate | SE | Estimate | SE | Estimate | SE | ||||||
| White birch forest | Root | −3.8705 | 0.3870 | 4.8137 | 0.0377 | 0.9806 | 1.3183 | V1.7159 | |||
| Stem | 0.5195 | 0.0098 | 0.1354 | 0.0079 | −0.0803 | 0.0078 | 0.9866 | 2.9346 | V1.3715 | ||
| Branch | 0.0179 | 0.0008 | 0.9309 | 0.0239 | −0.1979 | 0.0219 | 0.8945 | 1.7465 | V2.1459 | ||
| Foliage | 0.0160 | 0.0005 | 0.1952 | 0.0133 | - | - | 0.9476 | 0.2515 | V1.7707 | ||
| Total | - | - | - | - | - | - | 0.9825 | 5.4113 | V1.5780 | ||
| Larch forest | Root | 13.8235 | 0.4135 | 3.2953 | 0.0314 | - | - | 0.9573 | 3.2350 | V2.2507 | |
| Stem | 0.4419 | 0.0052 | 0.1069 | 0.0049 | −0.0086 | 0.0025 | 0.9816 | 4.8573 | V2.2398 | ||
| Branch | 22.8657 | 2.2582 | 12.5955 | 0.1868 | - | - | 0.8729 | 1.7027 | V2.2522 | ||
| Foliage | -289.2900 | 4.4326 | 71.4847 | 0.4036 | - | - | 0.9232 | 0.2948 | V1.2022 | ||
| Total | - | - | - | - | - | - | 0.9743 | 9.1126 | V2.2993 | ||
| Poplar-birch forest | Root | 0.2137 | 0.0161 | 0.2494 | 0.0509 | −0.3270 | 0.0509 | 0.8884 | 3.5205 | V1.7272 | |
| Stem | 0.6663 | 0.0208 | 0.0725 | 0.0239 | −0.1369 | 0.0237 | 0.9618 | 6.2994 | V1.4822 | ||
| Branch | 0.0173 | 0.0021 | 1.1033 | 0.0680 | −0.4538 | 0.0693 | 0.8114 | 2.8447 | V2.1804 | ||
| Foliage | 0.0196 | 0.0017 | 0.3182 | 0.0539 | −0.3008 | 0.0533 | 0.8575 | 0.4361 | V1.5919 | ||
| Total | - | - | - | - | - | - | 0.9451 | 11.6543 | V1.8216 | ||
| Deciduous broadleaf mixed forest | Root | 0.2863 | 0.0116 | 0.3425 | 0.0183 | −0.4423 | 0.0194 | 0.8800 | 3.3866 | V1.7508 | |
| Stem | 0.5869 | 0.0167 | 0.3837 | 0.0134 | −0.3406 | 0.0146 | 0.9247 | 7.8648 | V2.0869 | ||
| Branch | 0.0296 | 0.0028 | 1.2145 | 0.0328 | −0.5961 | 0.0410 | 0.6560 | 5.5406 | V1.9637 | ||
| Foliage | 0.0328 | 0.0017 | 0.4190 | 0.0228 | −0.4854 | 0.0256 | 0.7798 | 0.5578 | V2.0743 | ||
| Total | - | - | - | - | - | - | 0.8783 | 16.6652 | V2.2717 | ||
| Coniferous and broadleaf mixed forest | Root | 0.1808 | 0.0058 | 0.1817 | 0.0176 | −0.0930 | 0.0153 | 0.9119 | 3.3740 | V2.3133 | |
| Stem | 0.4878 | 0.0085 | 0.1637 | 0.0097 | −0.0915 | 0.0084 | 0.9711 | 4.8728 | V1.9186 | ||
| Branch | 0.0280 | 0.0014 | 0.7682 | 0.0258 | −0.3026 | 0.0243 | 0.7655 | 2.4851 | V2.1090 | ||
| Foliage | −66.2815 | 7.3367 | 49.8705 | 0.6624 | - | - | 0.8360 | 0.4227 | V1.6276 | ||
| Total | - | - | - | - | - | - | 0.9575 | 9.3737 | V2.1261 | ||
| Coniferous mixed forest | Root | −0.9311 | 2.9416 | 5.7384 | 0.2412 | - | - | 0.7110 | 6.2451 | V2.2076 | |
| Stem | 4.3149 | 0.4804 | 1.6180 | 0.0360 | - | - | 0.9492 | 7.3040 | V1.9316 | ||
| Branch | 0.0589 | 0.0042 | 0.1876 | 0.0316 | −0.1121 | 0.0321 | 0.9015 | 1.3461 | V1.2137 | ||
| Foliage | 0.0455 | 0.0053 | −0.1797 | 0.0443 | - | - | 0.6828 | 0.8826 | V1.1395 | ||
| Total | - | - | - | - | - | - | 0.9282 | 13.0000 | V2.2442 | ||
| Forest Types | Source of Variation | Root Biomass | Stem Biomass | Branch Biomass | Foliage Biomass | Total Biomass | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| F-Value | p-Value | F-Value | p-Value | F-Value | p-Value | F-Value | p-Value | F-Value | p-Value | ||
| White birch forest | Block (Plot) | 641.65 | < 0.0001 | 593.86 | < 0.0001 | 84.73 | < 0.0001 | 406.9 | < 0.0001 | 503.58 | < 0.0001 |
| Treatment (4 Methods) | 48.64 | < 0.0001 | 15.15 | < 0.0001 | 16.81 | < 0.0001 | 25.62 | < 0.0001 | 12.33 | < 0.0001 | |
| Larch forest | Block (Plot) | 245.83 | < 0.0001 | 326.91 | < 0.0001 | 268.58 | < 0.0001 | 142.58 | < 0.0001 | 312.42 | < 0.0001 |
| Treatment (4 Methods) | 99.07 | < 0.0001 | 44.82 | < 0.0001 | 110.01 | < 0.0001 | 123.24 | < 0.0001 | 70.36 | < 0.0001 | |
| Poplar-birch forest | Block (Plot) | 245.88 | < 0.0001 | 306.33 | < 0.0001 | 66.16 | < 0.0001 | 221.05 | < 0.0001 | 273.76 | < 0.0001 |
| Treatment (4 Methods) | 2.84 | 0.0369 | 7.34 | 0.0001 | 10.87 | < 0.0001 | 8.83 | < 0.0001 | 3.04 | 0.0284 | |
| Deciduous broadleaf mixed forest | Block (Plot) | 92.43 | < 0.0001 | 124.58 | < 0.0001 | 32.7 | < 0.0001 | 77.67 | < 0.0001 | 94.89 | < 0.0001 |
| Treatment (4 Methods) | 16.26 | < 0.0001 | 6.36 | < 0.0001 | 6.76 | 0.0003 | 22.48 | < 0.0001 | 6.94 | < 0.0001 | |
| Coniferous and broadleaf mixed forest | Block (Plot) | 269.22 | < 0.0001 | 277.81 | < 0.0001 | 99.47 | < 0.0001 | 239.67 | < 0.0001 | 255.41 | < 0.0001 |
| Treatment (4 Methods) | 269.22 | 0.4381 | 0.13 | 0.9425 | 1.87 | 0.1329 | 59.34 | < 0.0001 | 0.1 | 0.9572 | |
| Coniferous mixed forest | Block (Plot) | 139.22 | < 0.0001 | 132.51 | < 0.0001 | 134.67 | < 0.0001 | 83.76 | < 0.0001 | 140.9 | < 0.0001 |
| Treatment (4 Methods) | 2.21 | 0.0859 | 6.64 | 0.0002 | 1.26 | 0.2864 | 30.48 | < 0.0001 | 3.4 | 0.0173 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, L.; Zhang, L.; Li, F. Evaluation of Stand Biomass Estimation Methods for Major Forest Types in the Eastern Da Xing’an Mountains, Northeast China. Forests 2019, 10, 715. https://doi.org/10.3390/f10090715
Dong L, Zhang L, Li F. Evaluation of Stand Biomass Estimation Methods for Major Forest Types in the Eastern Da Xing’an Mountains, Northeast China. Forests. 2019; 10(9):715. https://doi.org/10.3390/f10090715
Chicago/Turabian StyleDong, Lihu, Lianjun Zhang, and Fengri Li. 2019. "Evaluation of Stand Biomass Estimation Methods for Major Forest Types in the Eastern Da Xing’an Mountains, Northeast China" Forests 10, no. 9: 715. https://doi.org/10.3390/f10090715
APA StyleDong, L., Zhang, L., & Li, F. (2019). Evaluation of Stand Biomass Estimation Methods for Major Forest Types in the Eastern Da Xing’an Mountains, Northeast China. Forests, 10(9), 715. https://doi.org/10.3390/f10090715