Can Field Crews Telecommute? Varied Data Quality from Citizen Science Tree Inventories Conducted Using Street-Level Imagery


Abstract
1. Introduction
1.1. Citizen Science Tree Inventories
1.2. Virtual Surveys Using Street-Level Imagery
1.3. Aims and Research Questions
- To what degree do virtual survey analysts in the same self-rated expertise category agree with one another? Does this level of agreement vary among expertise categories? For example, do experts agree with one another more often than novices agree with one another?
- What is the level of agreement between virtual survey data and field data? How does this vary according to analyst expertise?
2. Materials and Methods
2.1. Study Area
2.2. Field Data Collection
2.3. Google Street View Virtual Surveys
2.3.1. Recruitment and Training of Analysts
2.3.2. Data Collection Procedure
2.4. Data Analysis
2.4.1. Time Comparison between Field and Virtual Surveys
2.4.2. Agreement within and among Analyst Expertise Groups
2.4.3. Agreement with Field Data
3. Results
3.1. Overview of Virtual Survey Analysts and Tree Data
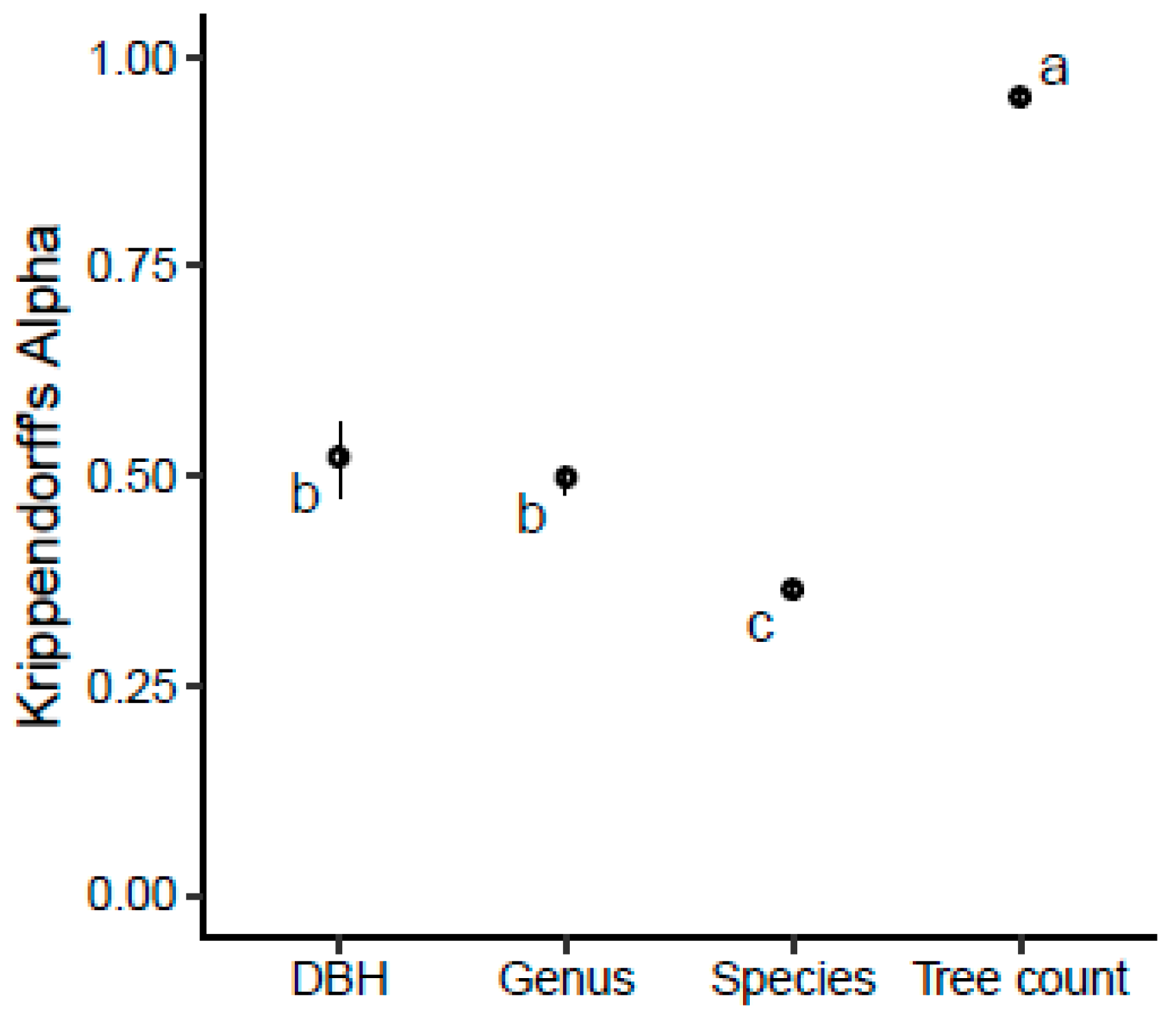
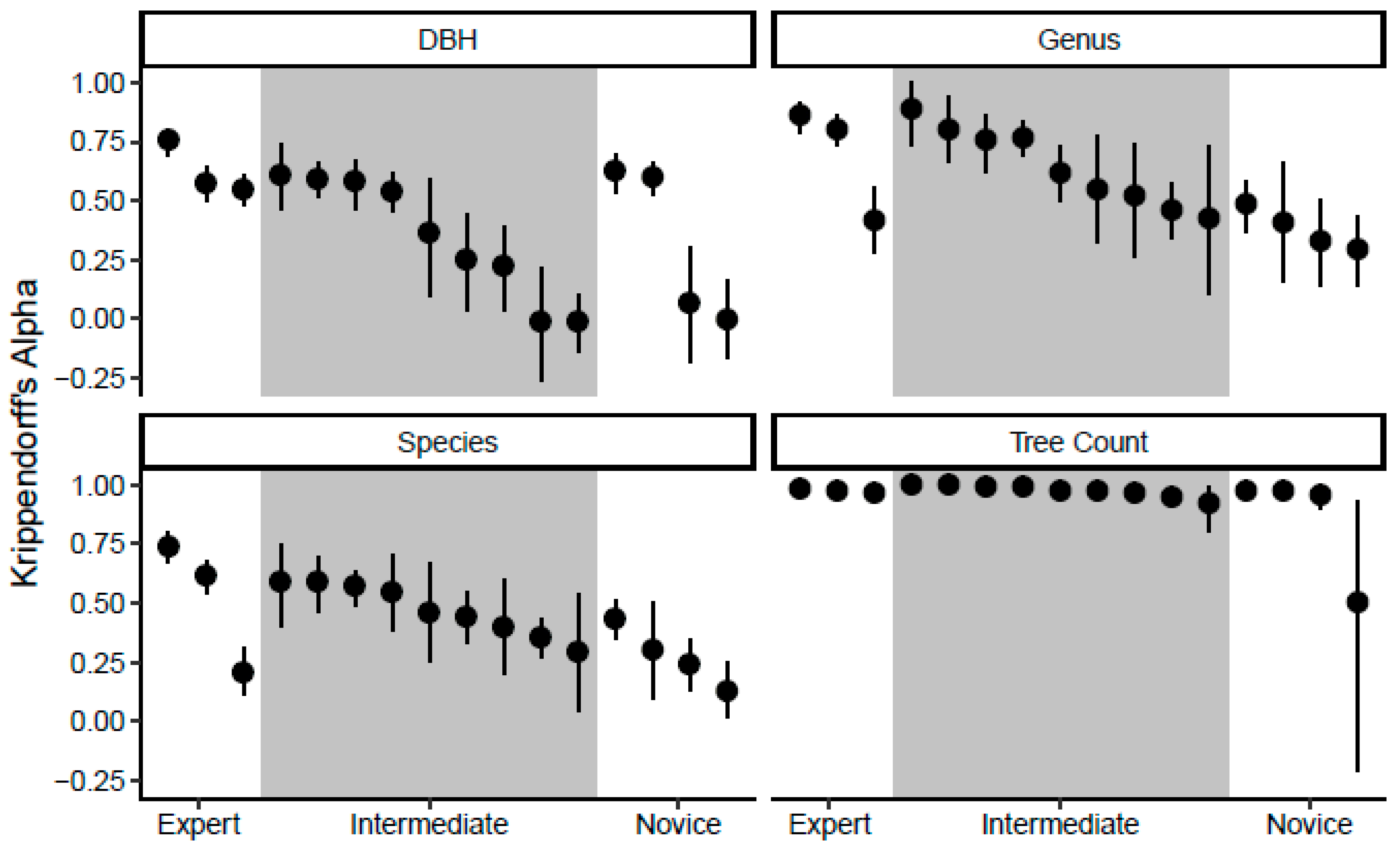
3.2. Agreement among Analysts
3.3. Agreement between Field Data and Virtual Survey Data
4. Discussion
4.1. Data Quality from GSV Virtual Surveys
4.2. Limitations
4.3. Recommendations
- Street tree inventories are used for a wide variety of purposes requiring varying levels of data accuracy and precision [32]. In deciding whether a citizen science virtual survey is appropriate for your purposes, consider how the data will be used and then evaluate whether virtual survey data can reasonably be expected to meet those needs. Our study indicates that virtual surveys may provide useful information for management purposes, but perhaps not for research applications requiring more accurate and detailed data, similar to the findings from field-based street tree volunteer inventories in Roman, et al. [32]. Kosmala, et al. [63] recommend that citizen science data should be of sufficient quality to address management applications or research questions, implying that some volunteer data may be “good enough” for specific uses [52].
- Task complexity should be tailored to the expertise of the analyst. Novices may only be able to provide high quality data for basic variables like tree counts, street address, and broad size classes (e.g., small, medium, and large), while experts can produce more reliable data for more detailed tree attributes like genus [49]. When designing a study, familiarity with the potential pool of participants can help guide the level of task complexity to assign. An iterative process of study design and refinement should consider the data quality needed for the project objectives as well as the observed capabilities of volunteers [63].
- For species identification, volunteers’ self-reported confidence level can be reported with each tree, or their overall identification skills can be evaluated with pre-tests. We observed substantially higher data quality when analysts were confident. Similarly, Roman, et al. [52] reported that crews had less confidence in the variables which showed the lowest consistency with experts. For virtual street tree surveys, it may be reasonable to accept the analyst’s tree identification when they are confident (particularly for experts and intermediate analysts). However, data quality results regarding the importance of prior knowledge and self-reported confidence levels have been mixed in other citizen science contexts [30].
- Virtual surveys should not replace field inspections by qualified professionals for the purposes of identifying pest/pathogen problems (but see [64]). Similarly, virtual surveys are not appropriate for detailed assessments of tree risk because the analyst cannot examine the tree up close or from all angles, and because municipalities may want only certified arborists evaluating risk and pruning needs. However, for a very basic inventory that identifies standing dead trees in need of removal (as opposed to living trees that may be deemed structurally unstable or declining), virtual surveys may be appropriate [32,52,54].
- Virtual surveys may not be suitable where in-person public engagement is a primary goal. While virtual survey analysts would engage with the city’s urban forestry program in the process of contributing data, virtual survey participants in general miss out on chances to engage with members of the public in the field [65], which occurs frequently as field crews inventory trees. For example, volunteers with a citizen science street tree inventory in New York City, NY were motivated by a desire to explore neighborhoods and meet new people [4]. However, virtual surveys may appeal to individuals who are physically disabled [66], and approaches such as gamification can deepen engagement and increase participation [67]. Future research about crowdsourcing in urban forestry could explore motivations for participation and the impacts of varied engagement approaches.
- Consider how recent the imagery must be to meet management needs. Street-level imagery products such as GSV offer nearly complete coverage of cities in the USA and many other countries, but imagery updates are not guaranteed on a timeline that is compatible with your needs. If the management goal is to produce a baseline inventory of street trees, then outdated imagery may be acceptable. But if the goal is to update an existing inventory, newer imagery would likely be necessary to characterize changes since the previous inventory. For example, a virtual survey could potentially be used to monitor trees from a planting program to assess whether the trees are alive, standing dead, or removed, as long as the GSV images are recent. Urban forestry nonprofits sometimes use volunteers to do such monitoring in the field [13,52], but the potential for online data collection could generate more data about planting program performance across towns that do not have the institutional capacity for field work.
- Implement a strategy to provide midstream feedback to analysts, as this can improve tree identification and estimation of DBH [49]. We provided analysts with illustrated examples of common tree species and GSV photos of trees in each DBH class, but analysts were not given feedback during the study to learn from their mistakes. Comparing their virtual survey data to field data for a subset of trees should help analysts refine the self-rated confidence and ultimately improve data quality. This strategy improved data quality in a previous study of virtual street tree surveys [49] and it aligns with feedback mechanisms designed to promote data quality and volunteer retention in other citizen science projects [63].
- Rare taxa slow analysts down, so we recommend using virtual surveys to efficiently inventory common species and note the locations of unidentifiable trees, which could be identified later in the field. Alternatively, the analyst could save screen captures of trees that are difficult to identify, and then an expert could attempt to identify the trees based on the photos. Such expert validation is a well-established strategy employed in citizen science projects from other fields [63,68]. Rare species have been shown to have particularly low species identification quality for other projects and taxa [69,70].
- Use this technique to update existing street tree inventories. In this study, analysts across all expertise groups excelled at documenting the locations of trees, but they struggled to identify trees to the species level and estimate DBH (Figure 2 and Figure 3). Existing inventories will already contain information on tree species and sizes, so the analysts can focus on documenting tree plantings and removals. We expect this simple assessment of tree presence/absence would offer significant time savings over both field surveys and the more detailed virtual surveys used in this study.
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Nowak, D.J.; Noble, M.H.; Sisinni, S.M.; Dwyer, J.F. People and trees: Assessing the US urban forest resource. J. For. 2001, 99, 37–42. [Google Scholar] [CrossRef]
- Galenieks, A. Importance of urban street tree policies: A comparison of neighbouring Southern California cities. Urban For. Urban Green. 2017, 22, 105–110. [Google Scholar] [CrossRef]
- Roy, S. Anomalies in Australian municipal tree managers’ street-tree planting and species selection principles. Urban For. Urban Green. 2017, 24, 125–133. [Google Scholar] [CrossRef]
- Johnson, M.L.; Campbell, L.K.; Svendsen, E.S.; Silva, P. Why count trees? Volunteer motivations and experiences with tree monitoring in New York City. Arboric. Urban For. 2018, 44, 59–72. [Google Scholar]
- McPherson, G.; Simpson, J.R.; Peper, P.J.; Maco, S.E.; Xiao, Q. Municipal forest benefits and costs in five US cities. J. For. 2005, 103, 411–416. [Google Scholar]
- Mullaney, J.; Lucke, T.; Trueman, S.J. A review of benefits and challenges in growing street trees in paved urban environments. Landsc. Urban Plan. 2015, 134, 157–166. [Google Scholar] [CrossRef]
- Soares, A.L.; Rego, F.C.; McPherson, E.G.; Simpson, J.R.; Peper, P.J.; Xiao, Q. Benefits and costs of street trees in Lisbon, Portugal. Urban For. Urban Green. 2011, 10, 69–78. [Google Scholar] [CrossRef]
- Fischer, B.C.; Steed, B.C. Street trees—A misunderstood common-pool resource. In Proceedings of the 84th International Society of Arboriculture Annual Conference, St. Louis, MO, USA, 8 October 2008; p. 19. [Google Scholar]
- Ricard, R.M. Shade trees and tree wardens: Revising the history of urban forestry. J. For. 2005, 103, 230–233. [Google Scholar] [CrossRef]
- Mincey, S.K.; Hutten, M.; Fischer, B.C.; Evans, T.P.; Stewart, S.I.; Vogt, J.M. Structuring institutional analysis for urban ecosystems: A key to sustainable urban forest management. Urban Ecosyst. 2013, 16, 553–571. [Google Scholar] [CrossRef]
- Vogt, J.; Hauer, R.J.; Fischer, B.C. The costs of maintaining and not maintaining the urban forest: A review of the urban forestry and arboriculture literature. Arboric. Urban For. 2015, 41, 293–323. [Google Scholar]
- Östberg, J.; Delshammar, T.; Wiström, B.; Nielsen, A.B. Grading of parameters for urban tree inventories by city officials, arborists, and academics using the delphi method. Environ. Manag. 2013, 51, 694–708. [Google Scholar] [CrossRef] [PubMed]
- Roman, L.A.; McPherson, E.G.; Scharenbroch, B.C.; Bartens, J. Identifying common practices and challenges for local urban tree monitoring programs across the United States. Arboric. Urban For. 2013, 39, 292–299. [Google Scholar]
- Koeser, A.K.; Hauer, R.J.; Miesbauer, J.W.; Peterson, W. Municipal tree risk assessment in the United States: Findings from a comprehensive survey of urban forest management. Arboric. J. 2016, 38, 218–229. [Google Scholar] [CrossRef]
- Bond, J. Best Management Practices—Tree inventories; International Society of Arboriculture: Champaign, IL, USA, 2013; p. 35. [Google Scholar]
- Harris, R.; Clark, J.; Matheny, N. Arboriculture: Integrated Management of Landscape Trees, Shrubs, and Vines, 4th ed.; Prentice Hall: Upper Saddle River, NJ, USA, 2004; p. 592. [Google Scholar]
- McPherson, E.G.; Kotow, L. A municipal forest report card: Results for California, USA. Urban For. Urban Green. 2013, 12, 134–143. [Google Scholar] [CrossRef]
- Sjöman, H.; Östberg, J.; Bühler, O. Diversity and distribution of the urban tree population in ten major Nordic cities. Urban For. Urban Green. 2012, 11, 31–39. [Google Scholar] [CrossRef]
- Cowett, F.D.; Bassuk, N.L. Statewide assessment of street trees in New York State, USA. Urban For. Urban Green. 2014, 13, 213–220. [Google Scholar] [CrossRef]
- Maco, S.E.; McPherson, E.G. A practical approach to assessing structure, function, and value of street tree populations in small communities. J. Arboric. 2003, 29, 84–97. [Google Scholar]
- Ordóñez, C.; Duinker, P.N. An analysis of urban forest management plans in Canada: Implications for urban forest management. Landsc. Urban Plan. 2013, 116, 36–47. [Google Scholar] [CrossRef]
- Stobbart, M.; Johnston, M. A Survey of Urban Tree Management in New Zealand. Arboric. Urban For. 2012, 38, 247–254. [Google Scholar]
- Kenney, W.A.; van Wassenaer, P.J.E.; Satel, A.L. Criteria and indicators for strategic urban forest planning and management. Arboric. Urban For. 2011, 37, 108–117. [Google Scholar]
- Dickinson, J.L.; Shirk, J.; Bonter, D.; Bonney, R.; Crain, R.L.; Martin, J.; Phillips, T.; Purcell, K. The current state of citizen science as a tool for ecological research and public engagement. Front. Ecol. Environ. 2012, 10, 291–297. [Google Scholar] [CrossRef]
- Conrad, C.C.; Hilchey, K.G. A review of citizen science and community-based environmental monitoring: Issues and opportunities. Environ. Monit. Assess. 2011, 176, 273–291. [Google Scholar] [CrossRef] [PubMed]
- Bancks, N.; North, E.A.; Johnson, G.R. An analysis of agreement between volunteer- and researcher-collected urban tree inventory data. Arboric. Urban For. 2018, 44, 73–86. [Google Scholar]
- Bloniarz, D.V.; Ryan, H. The use of volunteer initiatives in conducting urban forest resource inventories. J. Arboric. 1996, 22, 75–82. [Google Scholar]
- Estellés-Arolas, E.; Navarro-Giner, R.; González-Ladrón-de-Guevara, F. Crowdsourcing fundamentals: Definition and typology. In Advances in Crowdsourcing; Garrigos-Simon, F., Gil-Pechuán, I., Estelles-Miguel, S., Eds.; Springer: Cham, Switzerland, 2015; pp. 33–48. [Google Scholar]
- Newman, G.; Wiggins, A.; Crall, A.; Graham, E.; Newman, S.; Crowston, K. The future of citizen science: Emerging technologies and shifting paradigms. Front. Ecol. Environ. 2012, 10, 298–304. [Google Scholar] [CrossRef]
- Lewandowski, E.; Specht, H. Influence of volunteer and project characteristics on data quality of biological surveys. Conserv. Biol. 2015, 29, 713–723. [Google Scholar] [CrossRef]
- Gillett, D.J.; Pondella, D.J.; Freiwald, J.; Schiff, K.C.; Caselle, J.E.; Shuman, C.; Weisberg, S.B. Comparing volunteer and professionally collected monitoring data from the rocky subtidal reefs of Southern California, USA. Environ. Monit. Assess. 2012, 184, 3239–3257. [Google Scholar] [CrossRef] [PubMed]
- Roman, L.A.; Scharenbroch, B.C.; Östberg, J.P.A.; Mueller, L.S.; Henning, J.G.; Koeser, A.K.; Sanders, J.R.; Betz, D.R.; Jordan, R.C. Data quality in citizen science urban tree inventories. Urban For. Urban Green. 2017, 22, 124–135. [Google Scholar] [CrossRef]
- Brandon, A.; Spyreas, G.; Molano-Flores, B.; Carroll, C.; Ellis, J. Can volunteers provide reliable data for forest vegetation surveys? Nat. Areas J. 2003, 23, 254–262. [Google Scholar]
- Crown, C.A.; Greer, B.Z.; Gift, D.M.; Watt, F.S. Every Tree Counts: Reflections on NYC’s Third Volunteer Street Tree Inventory. Arboric. Urban For. 2018, 44, 49–58. [Google Scholar]
- Hauer, R.; Peterson, W. Municipal Tree Care and Management in the United States: A 2014 Urban & Community Forestry Census of Tree Activities; College of Natural Resources, University of Wisconsin-Stevens Point: Stevens Point, WI, USA, 2016; p. 71. [Google Scholar]
- Cozad, S.; McPherson, E.G.; Harding, J.A. STRATUM Case Study Evaluation in Minneapolis, Minnesota; Center for Urban Forest Research, USDA Forest Service, Pacific Southwest Research Station: Davis, CA, USA, 2005.
- Nowak, D.J.; Rowntree, R.A.; McPherson, E.G.; Sisinni, S.M.; Kerkmann, E.R.; Stevens, J.C. Measuring and analyzing urban tree cover. Landsc. Urban Plan. 1996, 36, 49–57. [Google Scholar] [CrossRef]
- Rowntree, R.A. Forest canopy cover and land use in four Eastern United States cities. Urban Ecol. 1984, 8, 55–67. [Google Scholar] [CrossRef]
- Zhang, Y. Texture-integrated classification of urban treed areas in high-resolution color-infrared imagery. Photogramm. Eng. Remote Sens. 2001, 67, 1359–1365. [Google Scholar]
- Ossola, A.; Hopton, M.E. Measuring urban tree loss dynamics across residential landscapes. Sci. Total Environ. 2018, 612, 940–949. [Google Scholar] [CrossRef] [PubMed]
- Alonzo, M.; Bookhagen, B.; Roberts, D.A. Urban tree species mapping using hyperspectral and lidar data fusion. Remote Sens. Environ. 2014, 148, 70–83. [Google Scholar] [CrossRef]
- Li, X.; Zhang, C.; Li, W.; Ricard, R.; Meng, Q.; Zhang, W. Assessing street-level urban greenery using Google Street View and a modified green view index. Urban For. Urban Green. 2015, 14, 675–685. [Google Scholar] [CrossRef]
- Li, X.; Zhang, C.; Li, W.; Kuzovkina, Y.A.; Weiner, D. Who lives in greener neighborhoods? The distribution of street greenery and its association with residents’ socioeconomic conditions in Hartford, Connecticut, USA. Urban For. Urban Green. 2015, 14, 751–759. [Google Scholar] [CrossRef]
- Long, Y.; Liu, L. How green are the streets? An analysis for central areas of Chinese cities using Tencent Street View. PLoS ONE 2017, 12, e0171110. [Google Scholar] [CrossRef] [PubMed]
- Richards, D.R.; Edwards, P.J. Quantifying street tree regulating ecosystem services using Google Street View. Ecol. Indic. 2017, 77, 31–40. [Google Scholar] [CrossRef]
- Li, X.; Ratti, C.; Seiferling, I. Quantifying the shade provision of street trees in urban landscape: A case study in Boston, USA, using Google Street View. Landsc. Urban Plan. 2018, 169, 81–91. [Google Scholar] [CrossRef]
- Seiferling, I.; Naik, N.; Ratti, C.; Proulx, R. Green streets—Quantifying and mapping urban trees with street-level imagery and computer vision. Landsc. Urban Plan. 2017, 165, 93–101. [Google Scholar] [CrossRef]
- Branson, S.; Wegner, J.D.; Hall, D.; Lang, N.; Schindler, K.; Perona, P. From Google Maps to a fine-grained catalog of street trees. ISPRS J. Photogramm. Remote Sens. 2018, 135, 13–30. [Google Scholar] [CrossRef]
- Berland, A.; Lange, D.A. Google Street View shows promise for virtual street tree surveys. Urban For. Urban Green. 2017, 21, 11–15. [Google Scholar] [CrossRef]
- Bassuk, N.L. Street tree diversity—Making better choices for the urban landscape. In Proceedings of the 7th Conference of the Metropolitan Tree Improvement Alliance, Lisle, IL, USA, 11–12 June 1990; pp. 71–78. [Google Scholar]
- Rooney, C.J.; Ryan, H.D.P.; Bloniarz, D.V.; Kane, B.C.P. The reliability of a windshield survey to locate hazards in roadside trees. J. Arboric. 2005, 31, 89–94. [Google Scholar]
- Roman, L.A.; Smith, B.C.; Dentice, D.; Maslin, M.; Abrams, G. Monitoring young tree survival with citizen scientists: The evolving Tree Checkers Program in Philadelphia, PA. Arboric. Urban For. 2018, 44, 255–265. [Google Scholar]
- Roman, L.A.; Campbell, L.K.; Jordan, R.C. Civic science in urban forestry: An introduction. Arboric. Urban For. 2018, 44, 41–48. [Google Scholar]
- Maldonado, S. Philly mapped street trees for smarter maintenance. PlanPhilly, 29 July 2016. [Google Scholar]
- Butt, N.; Slade, E.; Thompson, J.; Malhi, Y.; Riutta, T. Quantifying the sampling error in tree census measurements by volunteers and its effect on carbon stock estimates. Ecol. Appl. 2013, 23, 936–943. [Google Scholar] [CrossRef] [PubMed]
- Harrison, B.; Martin, T.E.; Mustari, A.H. The accuracy of volunteer surveyors for obtaining tree measurements in tropical forests. Ambio 2019, 1–9. [Google Scholar] [CrossRef]
- US Census Bureau. American FactFinder. Available online: http://factfinder.census.gov/ (accessed on 13 March 2019).
- Village of Dolton. Public Works. Available online: https://vodolton.org/departments/public-works/ (accessed on 13 March 2019).
- Nowak, D.J.; Hoehn, R.; Bodine, A.R.; Crane, D.E.; Dwyer, J.F.; Bonnewell, V.; Watson, G. Urban Trees and Forests of the Chicago Region; Resource Bulletin NRS-84; USDA Forest Service Northern Research Station: Newtown Square, PA, USA, 2013.
- Krippendorff, K. Reliability in content analysis. Hum. Commun. Res. 2004, 30, 411–433. [Google Scholar] [CrossRef]
- Hayes, A.F.; Krippendorff, K. Answering the call for a standard reliability measure for coding data. Commun. Methods Meas. 2007, 1, 77–89. [Google Scholar] [CrossRef]
- Proutskova, P.; Gruszczynski, M. kripp.boot: Bootstrap Krippendorff’s alpha Intercoder Relability Statistic, R package, version 1.0.0; 2017; Available online: https://github.com/MikeGruz/kripp.boot (accessed on 19 April 2019).
- Kosmala, M.; Wiggins, A.; Swanson, A.; Simmons, B. Assessing data quality in citizen science. Front. Ecol. Environ. 2016, 14, 551–560. [Google Scholar] [CrossRef]
- Rousselet, J.; Imbert, C.-E.; Dekri, A.; Garcia, J.; Goussard, F.; Vincent, B.; Denux, O.; Robinet, C.; Dorkeld, F.; Roques, A.; et al. Assessing species distribution using Google Street View: A pilot study with the pine processionary moth. PLoS ONE 2013, 8, e74918. [Google Scholar] [CrossRef]
- Mooney, S.J.; Bader, M.D.M.; Lovasi, G.S.; Teitler, J.O.; Koenen, K.C.; Aiello, A.E.; Galea, S.; Goldmann, E.; Sheehan, D.M.; Rundle, A.G. Street audits to measure neighborhood disorder: Virtual or in-person? Am. J. Epidemiol. 2017, 186, 265–273. [Google Scholar] [CrossRef]
- Baruch, A.; May, A.; Yu, D. The motivations, enablers and barriers for voluntary participation in an online crowdsourcing platform. Comput. Hum. Behav. 2016, 64, 923–931. [Google Scholar] [CrossRef]
- Morschheuser, B.; Hamari, J.; Koivisto, J.; Maedche, A. Gamified crowdsourcing: Conceptualization, literature review, and future agenda. Int. J. Hum. Comput. Stud. 2017, 106, 26–43. [Google Scholar] [CrossRef]
- Wiggins, A.; Newman, G.; Stevenson, R.; Crowston, K. Mechanisms for data quality and validation in citizen science. In Proceedings of the 2011 IEEE Seventh International Conference on e-Science Workshops, Stockholm, Sweden, 5–8 December 2011; 2011; pp. 14–19. [Google Scholar]
- Gardiner, M.M.; Allee, L.L.; Brown, P.M.; Losey, J.E.; Roy, H.E.; Smyth, R.R. Lessons from lady beetles: Accuracy of monitoring data from US and UK citizen-science programs. Front. Ecol. Environ. 2012, 10, 471–476. [Google Scholar] [CrossRef]
- Swanson, A.; Kosmala, M.; Lintott, C.; Packer, C. A generalized approach for producing, quantifying, and validating citizen science data from wildlife images. Conserv. Biol. 2016, 30, 520–531. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Year | % of Total | Month | % of Total |
|---|---|---|---|
| 2009 | 3 | June | < 1 |
| 2011 | 33 | July | 38 |
| 2012 | 51 | August | 55 |
| 2014 | 1 | September | 2 |
| 2015 | 7 | November | 5 |
| 2016 | 1 | ||
| 2017 | 5 |
| Analyst Group | Minutes Per Tree |
|---|---|
| All virtual survey analysts | 3.01 (1.07–8.75) |
| Expert | 1.45 (1.07–1.90) |
| Intermediate | 3.41 (1.45–8.75) |
| Novice | 4.23 (2.99–7.16) |
| Field crew 1 | 3.14 |
| All | Expert | Intermediate | Novice | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DBH class | Under | Agree | Over | Under | Agree | Over | Under | Agree | Over | Under | Agree | Over |
| 0–7.6 cm (n = 1) | -- | 0 | 100 | -- | 0 | 100 | -- | 0 | 100 | -- | 0 | 100 |
| 7.6–15.2 cm (n = 4) | 33 | 55 | 12 | 20 | 70 | 10 | 48 | 48 | 5 | 18 | 55 | 27 |
| 15.2–30.5 cm (n = 14) | 41 | 46 | 14 | 40 | 47 | 13 | 48 | 39 | 13 | 28 | 56 | 16 |
| 30.5–45.7 cm (n = 64) | 34 | 49 | 17 | 40 | 48 | 12 | 33 | 42 | 25 | 27 | 65 | 9 |
| 45.7–61.0 cm (n = 103) | 56 | 35 | 9 | 54 | 37 | 9 | 54 | 34 | 13 | 66 | 33 | 2 |
| 61.0–76.2 cm (n = 84) | 73 | 23 | 4 | 61 | 33 | 7 | 75 | 22 | 3 | 85 | 14 | 1 |
| 76.2 + cm (n = 61) | 80 | 20 | -- | 74 | 26 | -- | 84 | 16 | -- | 80 | 20 | -- |
| All trees (n = 331) | 60 | 32 | 8 | 56 | 37 | 8 | 61 | 29 | 10 | 64 | 32 | 4 |
| Genus | Field Relative Frequency (%) | Percent Agreement with Field Identification | |||
|---|---|---|---|---|---|
| All | Expert | Intermediate | Novice | ||
| Apple (Malus Mill.) | 0.6 | 75 | 75 | 100 | 25 |
| Ash (Fraxinus L.) | 5.5 | 55 | 78 | 58 | 10 |
| Cedar (Thuja L.) | 0.3 | 60 | 100 | 50 | 0 |
| Cherry (Prunus L.) | 0.6 | 60 | 50 | 50 | 100 |
| Dogwood (Cornus L.) | 0.3 | 13 | 50 | 0 | 0 |
| Elm (Ulmus L.) | 9.2 | 45 | 68 | 40 | 20 |
| Ginkgo (Ginkgo L.) | 0.6 | 43 | 67 | 0 | 100 |
| Hackberry (Celtis L.) | 0.3 | 33 | 67 | 25 | 0 |
| Honeylocust (Gleditsia L.) | 2.8 | 68 | 77 | 90 | 21 |
| Linden (Tilia L.) | 2.2 | 53 | 57 | 60 | 32 |
| Magnolia (Magnolia L.) | 0.6 | 50 | 100 | 0 | NA |
| Maple (Acer L.) | 72.6 | 94 | 95 | 96 | 88 |
| Mulberry (Morus L.) | 0.3 | 0 | 0 | 0 | NA |
| Oak (Quercus L.) | 0.9 | 93 | 100 | 83 | 100 |
| Redbud (Cercis L.) | 0.3 | 100 | 100 | 100 | NA |
| Spruce (Picea A. Dietr.) | 0.3 | 88 | 100 | 89 | 75 |
| Sweetgum (Liquidambar L.) | 0.6 | 100 | 100 | 100 | NA |
| Sycamore (Platanus L.) | 0.9 | 56 | 71 | 69 | 0 |
| Tuliptree (Liriodendron L.) | 0.9 | 72 | 100 | 50 | 83 |
| All trees | 100.0 | 84 | 89 | 87 | 74 |
| Confident | Somewhat Confident | Not Confident | ||||
|---|---|---|---|---|---|---|
| Expertise | % of Ratings | % Agreement | % of Ratings | % Agreement | % of Ratings | % Agreement |
| Genus | ||||||
| All analysts | 75.9 | 94.5 | 13.4 | 66.3 | 10.7 | 36.4 |
| Expert | 77.0 | 98.7 | 10.8 | 77.0 | 12.2 | 38.8 |
| Intermediate | 80.8 | 94.1 | 10.4 | 66.1 | 8.8 | 46.3 |
| Novice | 64.8 | 88.9 | 22.8 | 59.9 | 12.4 | 19.5 |
| Species | ||||||
| All analysts | 50.2 | 89.6 | 39.6 | 50.0 | 10.2 | 23.3 |
| Expert | 47.5 | 96.0 | 40.9 | 59.6 | 11.6 | 26.1 |
| Intermediate | 57.7 | 89.8 | 33.8 | 46.5 | 8.4 | 28.4 |
| Novice | 38.9 | 78.7 | 49.4 | 44.7 | 11.7 | 12.5 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Berland, A.; Roman, L.A.; Vogt, J. Can Field Crews Telecommute? Varied Data Quality from Citizen Science Tree Inventories Conducted Using Street-Level Imagery. Forests 2019, 10, 349. https://doi.org/10.3390/f10040349
Berland A, Roman LA, Vogt J. Can Field Crews Telecommute? Varied Data Quality from Citizen Science Tree Inventories Conducted Using Street-Level Imagery. Forests. 2019; 10(4):349. https://doi.org/10.3390/f10040349
Chicago/Turabian StyleBerland, Adam, Lara A. Roman, and Jess Vogt. 2019. "Can Field Crews Telecommute? Varied Data Quality from Citizen Science Tree Inventories Conducted Using Street-Level Imagery" Forests 10, no. 4: 349. https://doi.org/10.3390/f10040349
APA StyleBerland, A., Roman, L. A., & Vogt, J. (2019). Can Field Crews Telecommute? Varied Data Quality from Citizen Science Tree Inventories Conducted Using Street-Level Imagery. Forests, 10(4), 349. https://doi.org/10.3390/f10040349