Analysis of Error Structure for Additive Biomass Equations on the Use of Multivariate Likelihood Function

Abstract
1. Introduction
2. Material and Methods
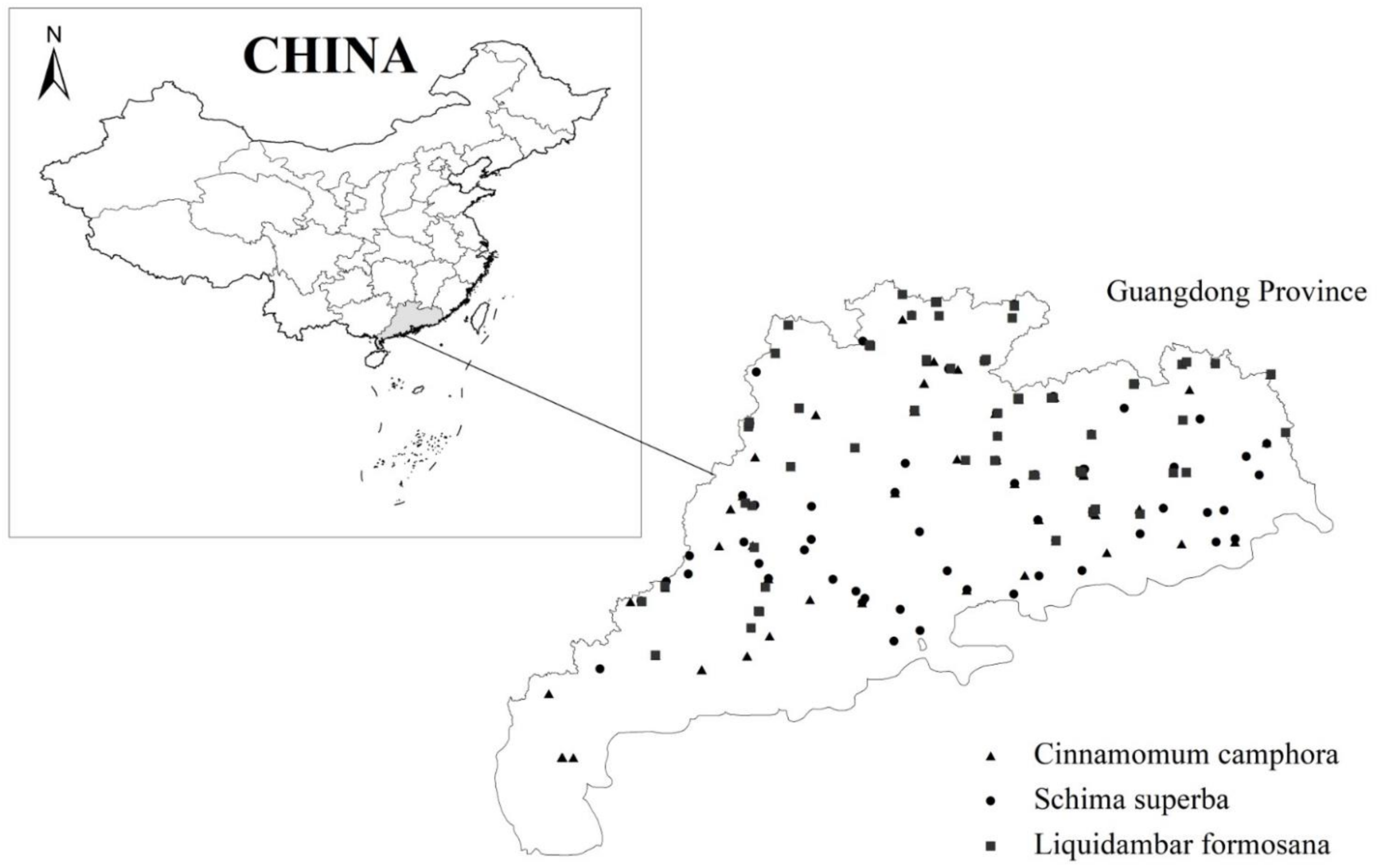
2.1. Data Collection
2.2. Model Specification and Estimation
2.3. Multivariate Likelihood Function to Analyze Error Structure
2.4. Back-Transformed Correction Factor for Additive Equations
2.5. Model Assessment
3. Result
3.1. Error Structure for Each Component Equation and Additive System
3.2. Assessment of Anti-Log Correction Factor for Additive System
3.3. Comparison of Model Fitting and Error Structure
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1. Multivariate Normal Distribution
Appendix A.2. Multivariate Log-Normal Distribution and Correction Factor
Appendix A.3. Multivariate Conditional Distribution
Appendix A.4. Toward Akaike Weights and Evidence Ratios
References
- Bolte, A.; Rahmann, T.; Kuhr, M.; Pogoda, P.; Murach, D.; Gadow, K.V. Relationships between tree dimension and coarse root biomass in mixed stands of European beech (Fagus sylvatica L.) and Norway spruce (Picea abies [L.] Karst.). Plant Soil 2004, 264, 1–11. [Google Scholar] [CrossRef]
- West, G.B.; Brown, J.H.; Enquist, B.J. A general model for the origin of allometric scaling laws in biology. Science 1997, 276, 122–126. [Google Scholar] [CrossRef] [PubMed]
- Huxley, J.S. Problems of Relative Growth; Dial Press: New York, NY, USA, 1931; pp. 1–31. [Google Scholar]
- Kittredge, J. Estimation of the amount of foliage of trees and stands. J. For. 1944, 42, 905–912. [Google Scholar]
- Jenkins, J.C.; Chojnacky, D.C.; Heath, L.S.; Birdsey, R.A. National-scale biomass estimators for United States tree species. For. Sci. 2003, 49, 12–35. [Google Scholar]
- Ter-Mikaelian, M.T.; Korzukhin, M.D. Biomass equations for sixty-five north American tree species. For. Ecol. Manag. 1997, 97, 1–24. [Google Scholar] [CrossRef]
- Zianis, D.; Xanthopoulos, G.; Kalabokidis, K.; Kazakis, G.; Ghosn, D.; Roussou, O. Allometric equations for aboveground biomass estimation by size class for pinus brutia ten. trees growing in north and south Aegean islands, Greece. Eur. J. For. Res. 2011, 130, 145–160. [Google Scholar] [CrossRef]
- Baskerville, G.L. Use of Logarithmic Regression in the Estimation of Plant Biomass. Can. J. For. Res. 1972, 2, 49–53. [Google Scholar] [CrossRef]
- Brown, J.H.; Gillooly, J.F.; Allen, A.P.; Savage, V.M.; West, G.B. Toward a metabolic theory of ecology. Ecology 2004, 85, 1771–1789. [Google Scholar] [CrossRef]
- Smith, R.J. Allometric scaling in comparative biology: Problems of concept and method. Am. J. Physiol. 1984, 246, 152–160. [Google Scholar] [CrossRef] [PubMed]
- Smith, R.J. Logarithmic transformation bias in allometry. Am. J. Phys. Anthropol. 1993, 90, 215–228. [Google Scholar] [CrossRef]
- Beauchamp, J.J.; Olson, J.S. Corrections for bias in regression estimates after logarithmic transformation. Ecology 1973, 54, 1403–1407. [Google Scholar] [CrossRef]
- Gingerich, P.D. Arithmetic or geometric normality of biological variation: An empirical test of theory. J. Theor. Biol. 2000, 204, 201–221. [Google Scholar] [CrossRef] [PubMed]
- Zar, J.H. Calculation and miscalculation of the allometric equation as a model in biological data. Bioscience 1968, 18, 1118–1120. [Google Scholar] [CrossRef]
- Snowdon, P. A ratio estimator for bias correction in logarithmic regressions. Can. J. For. Res. 1991, 21, 720–724. [Google Scholar] [CrossRef]
- Madgwick, H.A.I.; Satoo, T. On estimating the aboveground weights of tree stands. Ecology 1975, 56, 1446–1450. [Google Scholar] [CrossRef]
- Zianis, D.; Mencuccini, M. Aboveground biomass relationships for beech (fagus moesiaca cz.) trees in vermio mountain, northern Greece, and generalized equations for fagus sp. Ann. For. Sci. 2003, 60, 439–448. [Google Scholar] [CrossRef]
- Glass, N.R. Discussion of calculation of power function with special reference to respiratory metabolism in fish. J. Fish. Res. Board Can. 1969, 26, 2643–2650. [Google Scholar] [CrossRef]
- Packard, G.C.; Boardman, T.J. Model selection and logarithmic transformation in allometric analysis. Physiol. Biochem. Zool. 2008, 81, 496–507. [Google Scholar] [CrossRef]
- Jansson, M. A comparison of detransformed logarithmic regressions and power function regressions. Geogr. Ann. Ser. A Phys. Geogr. 1985, 67, 61–70. [Google Scholar] [CrossRef]
- Packard, G.C. On the use of logarithmic transformations in allometric analyses. J. Theor. Biol. 2009, 257, 515–518. [Google Scholar] [CrossRef]
- Packard, G.C.; Birchard, G.F.; Boardman, T.J. Fitting statistical models in bivariate allometry. Biol. Rev. 2011, 86, 549–563. [Google Scholar] [CrossRef]
- Packard, G.C. Multiplicative by nature: logarithmic transformation in allometry. J. Exp. Zool. 2014, 322, 202–207. [Google Scholar] [CrossRef]
- Kerkhoff, A.J.; Enquist, B.J. Multiplicative by nature: Why logarithmic transformation is necessary in allometry. J. Theor. Biol. 2009, 257, 519–521. [Google Scholar] [CrossRef]
- Li, H.; Zhao, P. Improving the accuracy of tree-level aboveground biomass equations with height classification at a large regional scale. For. Ecol. Manag. 2013, 289, 153–163. [Google Scholar] [CrossRef]
- Parresol, B.R. Additivity of nonlinear biomass equations. Can. J. For. Res. 2001, 31, 865–878. [Google Scholar] [CrossRef]
- Wang, C. Biomass allometric equations for 10 co-occurring tree species in Chinese temperate forests. For. Ecol. Manag. 2006, 222, 9–16. [Google Scholar] [CrossRef]
- Finney, D.J. Was this in your statistics textbook? v. transformation of data. Exp. Agric. 1989, 25, 165–175. [Google Scholar] [CrossRef]
- Asselman, N.E.M. Fitting and interpretation of sediment rating curves. J. Hydrol. 2000, 234, 228–248. [Google Scholar] [CrossRef]
- Xiao, X.; White, E.P.; Hooten, M.B.; Durham, S.L. On the use of log-transformation vs. nonlinear regression for analyzing biological power laws. Ecology 2011, 92, 1887–1894. [Google Scholar] [CrossRef]
- Ballantyne, F.T. Evaluating model fit to determine if logarithmic transformations are necessary in allometry: A comment on the exchange between packard (2009) and kerkhoff and enquist (2009). J. Theor. Biol. 2013, 317, 418–421. [Google Scholar] [CrossRef]
- Lai, J.; Yang, B.; Lin, D.; Kerkhoff, A.J.; Ma, K. The allometry of coarse root biomass: Log-transformed linear regression or nonlinear regression? PLoS ONE 2013, 8, e77007. [Google Scholar] [CrossRef]
- Ma, Y.; Jiang, L. Error structure and variance function of allometric model. Sci. Silva Sin. 2018, 54, 90–97. [Google Scholar]
- Dong, L.; Zhang, L.; Li, F. A compatible system of biomass equations for three conifer species in northeast, china. For. Ecol. Manag. 2014, 329, 306–317. [Google Scholar] [CrossRef]
- Cunia, T.; Briggs, R.D. Forcing additivity of biomass tables: Some empirical results. Can. J. For. Res. 1984, 14, 376–384. [Google Scholar] [CrossRef]
- Kozak, A. Methods for ensuring additivity of biomass components by regression analysis. For. Chron. 1970, 46, 402–405. [Google Scholar] [CrossRef]
- Parresol, B.R. Assessing tree and stand biomass: A review with examples and critical comparisons. For. Sci. 1999, 45, 573–593. [Google Scholar]
- Bi, H.; Turner, J.; Lambert, M.J. Additive biomass equations for native eucalypt forest trees of temperate Australia. Trees 2004, 18, 467–479. [Google Scholar] [CrossRef]
- Zou, W.; Zeng, W.; Zhang, L.; Zeng, M. Modeling crown biomass for four pine species in China. Forests 2015, 6, 433–449. [Google Scholar] [CrossRef]
- State Forestry Administration of PR China. Technical Regulation on Sample Collections for Tree Biomass Modeling. In LY/T 2259-2014; Chinese Standard Press: Beijing, China, 2014. [Google Scholar]
- Zeng, W. Comparison of different weight function in weighted regression. For. Res. Manag. 2013, 5, 55–61. [Google Scholar]
- Zeng, W. Research on weighting regression and modeling. Sci. Silva Sin. 1999, 35, 5–11. [Google Scholar]
- Richard, A.J.; Dean, W.W. Applied Multivariate Statistical Analysis, 6th ed.; Prentice Hall: Upper Saddle River, NJ, USA, 2007; pp. 149–173. [Google Scholar]
- Burnham, K.P.; Anderson, D.R. Model Selection and Multimodel Inference, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2002; pp. 70–79. [Google Scholar]
- Kozak, A.; Kozak, R. Does cross validation provide additional information in the evaluation of regression models. Can. J. For. Res. 2003, 33, 976–987. [Google Scholar] [CrossRef]
- Packard, G.C. Is logarithmic transformation necessary in allometry? Biol. J. Linn. Soc. 2013, 109, 476–486. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Cinnamomum camphora (L.) Presl | Schima superba Gardn. et Champ. | Liquidambar formosana Hance. | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Range | Mean | SD | Range | Mean | SD | Range | Mean | SD | |
| Diameter/cm | 1.9–41.0 | 14.5 | 10.5 | 1.7–51.5 | 14.4 | 10.9 | 1.8–43.5 | 14.4 | 10.6 |
| Branch/kg | 0.1–547.0 | 44.8 | 105.1 | 0.1–371.0 | 36.3 | 65.9 | 0.1–468.7 | 30.0 | 62.4 |
| Foliage/kg | 0.1–89.8 | 5.8 | 12.5 | 0.1–45.7 | 5.7 | 8.7 | 0.1–46.4 | 4.6 | 9.6 |
| Stem wood/kg | 0.2–519.7 | 62.1 | 100.1 | 0.3–570.7 | 69.2 | 110.5 | 0.2–569.9 | 81.5 | 127.8 |
| Stem bark/kg | 0.1–75.5 | 10.5 | 16.1 | 0.1–89.0 | 12.6 | 19.5 | 0.1–121.6 | 13.1 | 20.5 |
| Aboveground/kg | 0.4–1016.9 | 123.1 | 221.7 | 0.6–897.4 | 123.8 | 192.2 | 0.3–955.5 | 129.2 | 206.1 |
| Species | Component | ER | LR | NLR | |||||
|---|---|---|---|---|---|---|---|---|---|
| a | b | a | b | ||||||
| Cinnamomum camphora | Branch | 38.3 | <<10−2 | 0.01231 (0.00218) | 2.74507 (0.06317) | 357.8 | 0.01213 (0.00197) | 2.75077 (0.05655) | 396.1 |
| Foliage | 263.2 | <<10−2 | 0.01429 (0.00356) | 2.04953 (0.09561) | 228.3 | 0.01360 (0.00246) | 2.09921 (0.07636) | 491.5 | |
| Stem wood | −55.5 | >>102 | 0.07100 (0.00741) | 2.26782 (0.03982) | 350.8 | 0.08086 (0.02089) | 2.26358 (0.07766) | 295.3 | |
| Stem bark | −15.9 | >>102 | 0.02016 (0.00307) | 2.0898 (0.05842) | 216.5 | 0.03274 (0.01061) | 1.99888 (0.09682) | 200.6 | |
| Aboveground | −105.6 | >>102 | — | — | 396.1 | — | — | 290.5 | |
| Schima superba | Branch | −495.5 | >>102 | 0.03682 (0.00596) | 2.37522 (0.06300) | 340.0 | 0.05756 (0.01954) | 2.18189 (0.10335) | −155.5 |
| Foliage | −263.2 | >>102 | 0.07793 (0.01242) | 1.44971 (0.07602) | 276.3 | 0.04990 (0.01759) | 1.66296 (0.11131) | 13.1 | |
| Stem wood | −530.9 | >>102 | 0.08755 (0.00892) | 2.24571 (0.04176) | 317.8 | 0.14024 (0.02612) | 2.13536 (0.05512) | −213.1 | |
| Stem bark | −311.7 | >>102 | 0.02301 (0.00295) | 2.13066 (0.05245) | 253.0 | 0.04092 (0.01291) | 1.9895 (0.09415) | −58.7 | |
| Aboveground | −617.1 | >>102 | — | — | 364.8 | — | — | −252.3 | |
| Liquidambar formosana | Branch | −595.5 | >>102 | 0.01603 (0.00312) | 2.51909 (0.07487) | 357.3 | 0.01702 (0.00551) | 2.51466 (0.10100) | −238.2 |
| Foliage | −221.5 | >>102 | 0.00385 (0.00117) | 2.26453 (0.12098) | 167.8 | 0.00475 (0.00219) | 2.33859 (0.13845) | −53.7 | |
| Stem wood | −670.7 | >>102 | 0.08077 (0.00991) | 2.33577 (0.04822) | 347.8 | 0.09299 (0.01878) | 2.30736 (0.06021) | −322.9 | |
| Stem bark | −401.6 | >>102 | 0.02048 (0.00310) | 2.19051 (0.05960) | 238.5 | 0.02329 (0.00480) | 2.17340 (0.06284) | −163.1 | |
| Aboveground | −731.2 | >>102 | — | — | 379.6 | — | — | −351.6 | |
| Species | ER | LR | NLR | |||
|---|---|---|---|---|---|---|
| Cinnamomum camphora | −7.0 | 33 | −961.8 | 1941.3 | −958.3 | 1934.3 |
| Schima superba | −810.2 | >>102 | −1018.0 | 2053.8 | −612.9 | 1243.6 |
| Liquidambar formosana | −846.7 | >>102 | −952.4 | 1922.6 | −529.1 | 1075.9 |
| Species | Model | Basic CF | Additive Model CF | CF Value | R2 | SEE | TRE | ASE | RMA | MPE |
|---|---|---|---|---|---|---|---|---|---|---|
| Cinnamomum camphora | NLR | - | - | - | 0.897 | 73.14 | 1.36 | −5.52 | 17.92 | 10.22 |
| LR | CF0 | - | 1.00000 | 0.880 | 78.91 | 9.62 | 4.38 | 19.35 | 11.02 | |
| CF1 | 1.13975 | 0.905 | 70.25 | −3.82 | −8.42 | 18.17 | 9.81 | |||
| 1.07544 | 0.898 | 72.84 | 1.93 | −2.94 | 17.83 | 10.18 | ||||
| CF2 | 1.11111 | 0.903 | 71.08 | −1.35 | −6.06 | 17.82 | 9.93 | |||
| 1.09824 | 0.901 | 71.63 | −0.19 | −4.96 | 17.76 | 10.01 | ||||
| Schima superba | NLR | - | - | - | 0.903 | 60.32 | 0.92 | −6.65 | 21.71 | 8.54 |
| LR | CF0 | - | 1.00000 | 0.890 | 64.15 | 2.61 | 5.72 | 21.61 | 9.08 | |
| CF1 | 1.12639 | 0.849 | 75.06 | −8.90 | −6.15 | 19.86 | 10.63 | |||
| 1.06502 | 0.875 | 68.42 | −3.65 | −0.74 | 20.05 | 9.69 | ||||
| CF2 | 1.08285 | 0.868 | 70.11 | −5.24 | −2.37 | 19.88 | 9.93 | |||
| 1.03248 | 0.884 | 65.88 | −0.62 | 2.39 | 20.68 | 9.33 | ||||
| Liquidambar formosana | NLR | - | - | - | 0.933 | 53.85 | 0.23 | −2.77 | 19.79 | 7.31 |
| LR | CF0 | - | 1.00000 | 0.929 | 55.42 | 6.54 | 5.30 | 21.05 | 7.52 | |
| CF1 | 1.17647 | 0.915 | 60.36 | −9.44 | −10.5 | 20.32 | 8.19 | |||
| 1.08010 | 0.932 | 54.18 | −1.36 | −2.51 | 19.67 | 7.36 | ||||
| CF2 | 1.16312 | 0.919 | 59.06 | −8.40 | −9.47 | 20.12 | 8.02 | |||
| 1.06842 | 0.932 | 53.99 | −0.28 | −1.45 | 19.71 | 7.33 |
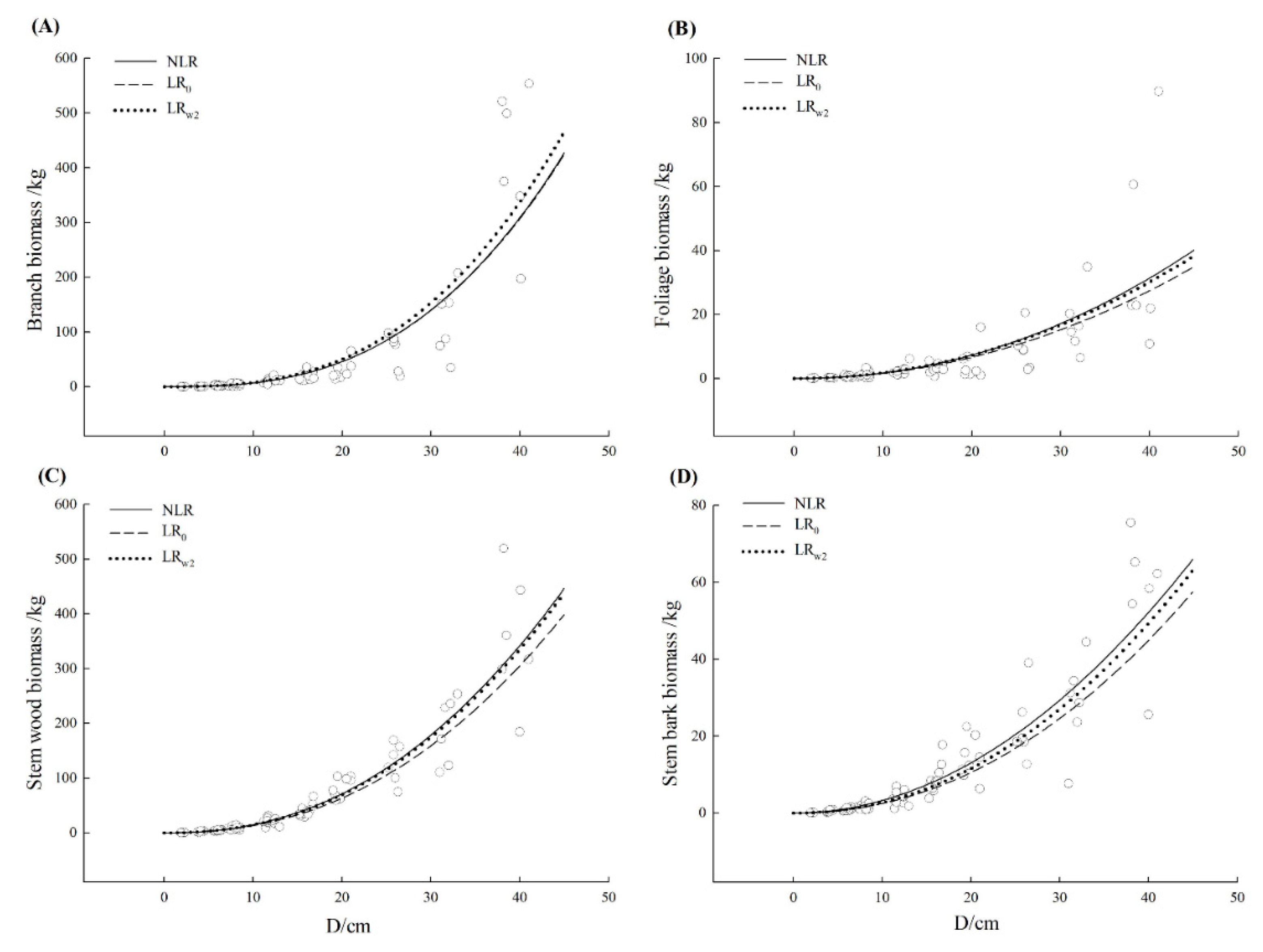
| Tree Species | Component | Model | R2 | SEE | TRE | ASE | RMA | MPE |
|---|---|---|---|---|---|---|---|---|
| Cinnamomum camphora | Branch | NLR | 0.782 | 51.65 | 1.63 | −2.39 | 41.70 | 19.18 |
| LR0 | 0.780 | 51.87 | 2.09 | −2.56 | 41.58 | 19.26 | ||
| LRw2 | 0.799 | 49.59 | −7.05 | −11.27 | 40.65 | 18.42 | ||
| Foliage | NLR | 0.580 | 8.17 | −3.93 | −5.78 | 46.85 | 24.91 | |
| LR0 | 0.554 | 8.42 | 7.43 | 0.81 | 47.73 | 25.68 | ||
| LRw2 | 0.572 | 8.25 | −2.18 | −8.21 | 46.31 | 25.16 | ||
| Stem wood | NLR | 0.875 | 35.62 | 1.74 | −3.10 | 22.47 | 10.07 | |
| LR0 | 0.854 | 38.49 | 14.26 | 9.22 | 24.65 | 10.88 | ||
| LRw2 | 0.873 | 35.88 | 4.04 | −0.55 | 22.57 | 10.14 | ||
| Stem bark | NLR | 0.848 | 6.31 | 1.01 | −10.54 | 30.03 | 10.52 | |
| LR0 | 0.806 | 7.12 | 22.16 | 16.03 | 35.55 | 11.88 | ||
| LRw2 | 0.836 | 6.54 | 11.23 | 5.65 | 30.32 | 10.91 | ||
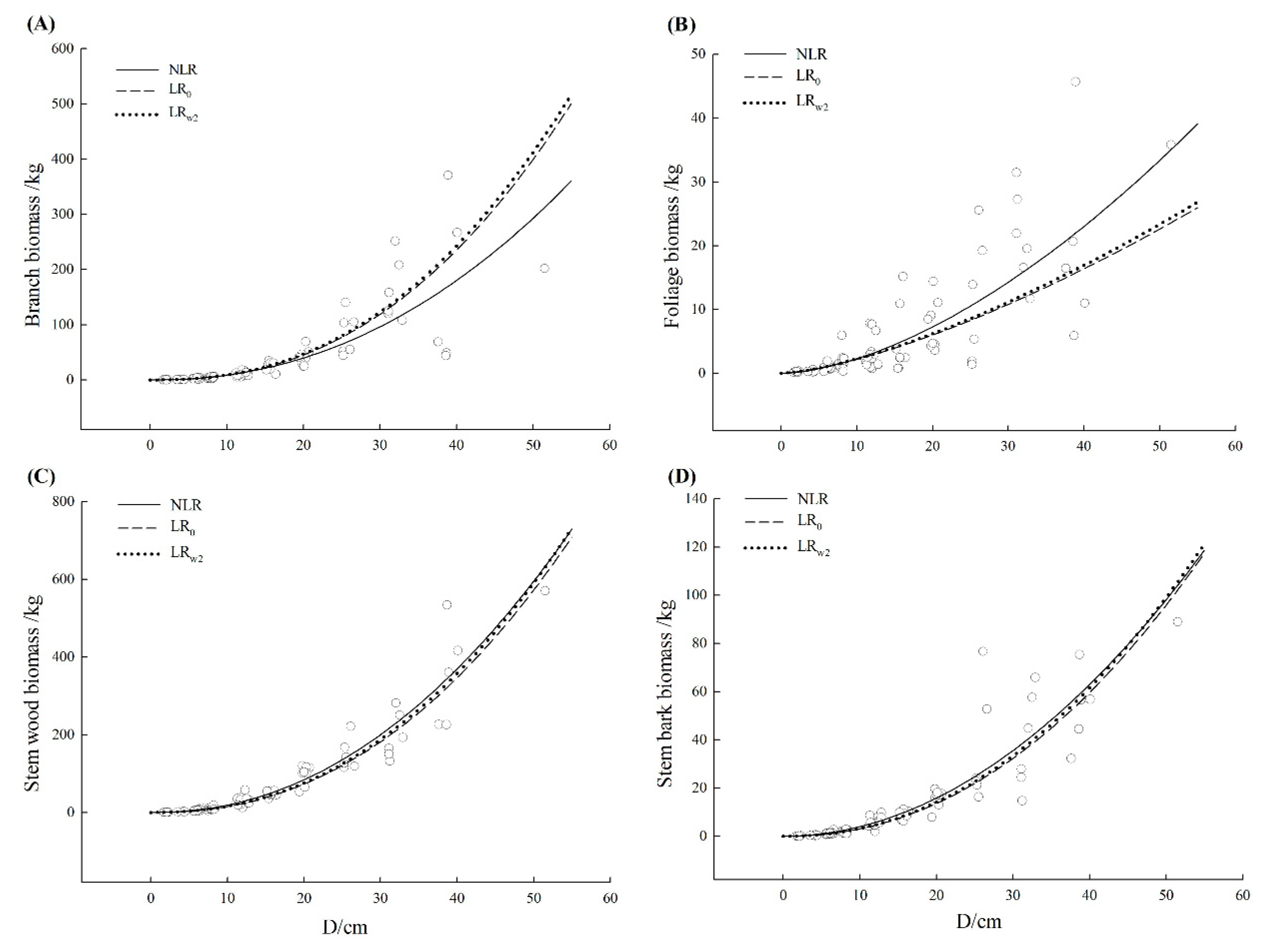
| Schima superba | Branch | NLR | 0.636 | 39.95 | 7.21 | −5.25 | 36.42 | 19.31 |
| LR0 | 0.533 | 45.25 | −12.14 | −6.66 | 34.24 | 21.87 | ||
| LRw2 | 0.508 | 46.44 | −14.9 | −9.60 | 33.93 | 22.45 | ||
| Foliage | NLR | 0.655 | 5.16 | 5.16 | 0.50 | 51.07 | 15.84 | |
| LR0 | 0.560 | 5.82 | 31.52 | 8.77 | 56.98 | 17.86 | ||
| LRw2 | 0.574 | 5.73 | 27.38 | 5.35 | 55.95 | 17.59 | ||
| Stem wood | NLR | 0.908 | 33.73 | −2.07 | −7.79 | 25.34 | 8.55 | |
| LR0 | 0.905 | 34.27 | 8.76 | 13.03 | 27.09 | 8.68 | ||
| LRw2 | 0.906 | 34.00 | 5.34 | 9.47 | 25.69 | 8.61 | ||
| Stem bark | NLR | 0.813 | 8.49 | −1.04 | −10.28 | 28.60 | 11.79 | |
| LR0 | 0.804 | 8.68 | 10.67 | 13.08 | 30.54 | 12.05 | ||
| LRw2 | 0.805 | 8.67 | 7.19 | 9.52 | 29.12 | 12.04 | ||
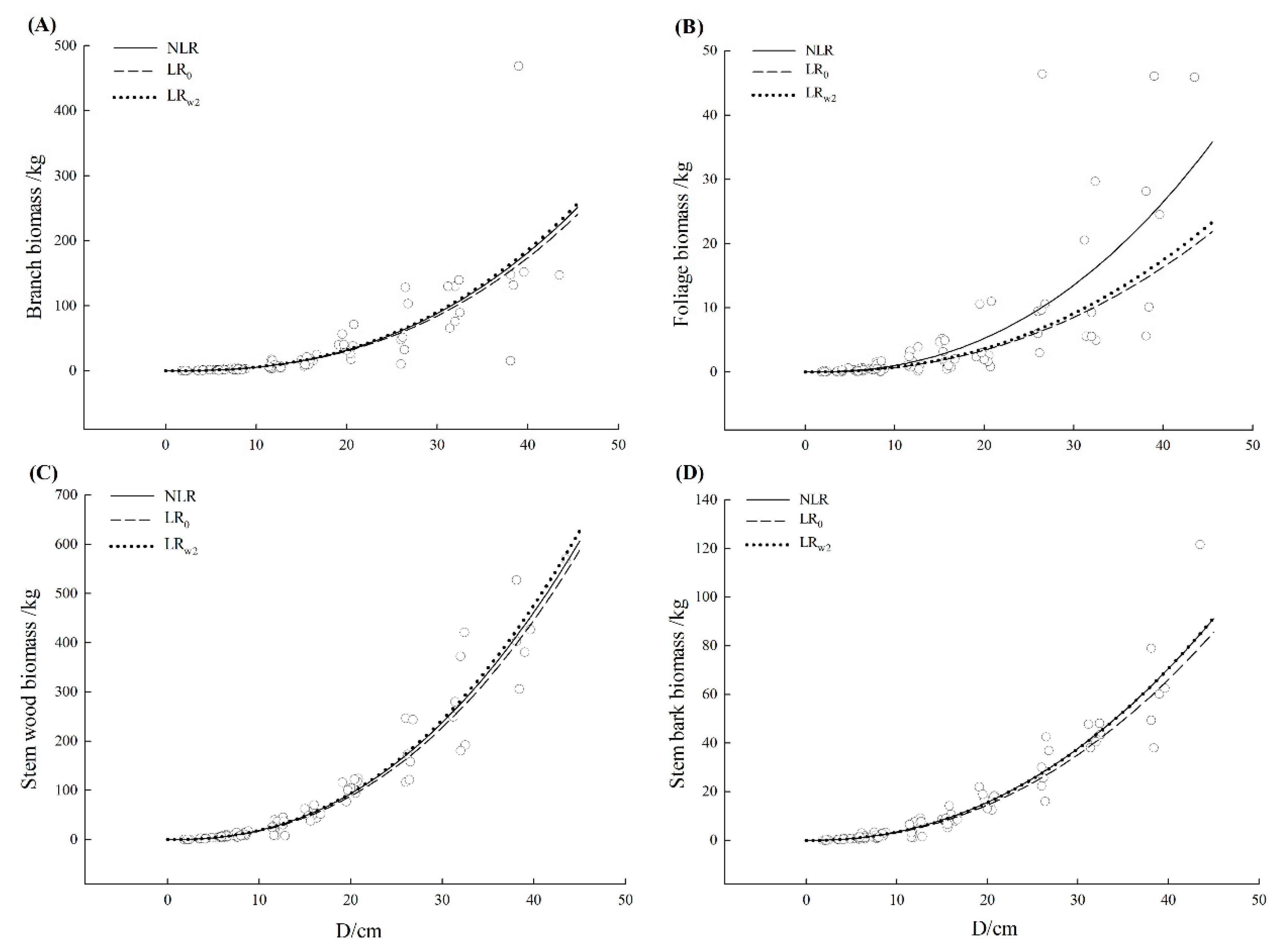
| Liquidambar formosana | Branch | NLR | 0.609 | 39.22 | 0.87 | −2.37 | 37.89 | 22.94 |
| LR0 | 0.607 | 39.31 | 5.52 | 2.58 | 38.84 | 22.99 | ||
| LRw2 | 0.608 | 39.24 | −1.23 | −3.99 | 37.68 | 22.95 | ||
| Foliage | NLR | 0.597 | 6.14 | −0.39 | 7.03 | 68.27 | 23.45 | |
| LR0 | 0.468 | 7.05 | 56.97 | 56.25 | 94.13 | 26.93 | ||
| LRw2 | 0.494 | 6.88 | 46.92 | 46.25 | 88.25 | 26.28 | ||
| Stem wood | NLR | 0.932 | 33.4 | 0.05 | −3.41 | 21.59 | 7.19 | |
| LR0 | 0.931 | 33.81 | 4.84 | 3.83 | 23.20 | 7.28 | ||
| LRw2 | 0.931 | 33.86 | −1.87 | −2.82 | 21.64 | 7.29 | ||
| Stem bark | NLR | 0.909 | 6.20 | 0.17 | −1.53 | 27.97 | 8.28 | |
| LR0 | 0.902 | 6.46 | 7.69 | 7.46 | 30.34 | 8.63 | ||
| LRw2 | 0.910 | 6.19 | 0.79 | 0.57 | 28.46 | 8.27 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, L.; Li, H. Analysis of Error Structure for Additive Biomass Equations on the Use of Multivariate Likelihood Function. Forests 2019, 10, 298. https://doi.org/10.3390/f10040298
Cao L, Li H. Analysis of Error Structure for Additive Biomass Equations on the Use of Multivariate Likelihood Function. Forests. 2019; 10(4):298. https://doi.org/10.3390/f10040298
Chicago/Turabian StyleCao, Lei, and Haikui Li. 2019. "Analysis of Error Structure for Additive Biomass Equations on the Use of Multivariate Likelihood Function" Forests 10, no. 4: 298. https://doi.org/10.3390/f10040298
APA StyleCao, L., & Li, H. (2019). Analysis of Error Structure for Additive Biomass Equations on the Use of Multivariate Likelihood Function. Forests, 10(4), 298. https://doi.org/10.3390/f10040298