1. Introduction
Nowadays, partly driven by many Web 2.0 applications, more and more social network data are publicly available and analyzed in one way or another, as the social network data has significant application value for commercial and research purposes [
1]. However, the social network data often have privacy information of individuals. It has become a major concern to prevent individual privacy disclosure when publishing the social network data. Additionally, the
k-anonymity
l-diversity models aim to sanitize the published graph, eventually leading to data usability reduction for published social network data. Therefore, the tradeoff between the individual’s privacy security and data utility while publishing the social network data has become a major concern [
2,
3,
4].
Generally, the social networks are modelled as graphs in which nodes and edges correspond to social entities and social links between them, respectively, while users’ attributes and graph structures are composed of the corresponding social network data [
5].
Although researchers have proposed various anonymous models based on
k-anonymity [
6] to achieve privacy protection in existing research [
7,
8,
9], the balance between privacy safety and data utility is still new in the field of social network publishing [
4]. The existing approaches may prevent leakage of some privacy information when publishing social network data, but may result in nontrivial utility loss without exploring the attribute of sparse distribution and without recognizing the fact that different nodes have different impacts on the network structure. Statistics from security research institutions show that many existing methods have the problem of excessive anonymity for preserving sensitive attributes [
10]. According to a report from Google data, nearly 30% of the users marked attributes, and the users with >4 attributes do not exceed 5%. This may hedge that user attribute distribution is relatively sparse in social networks. Additionally, in realistic social networks, almost every attribute has a rich diversity of values, only some of which are sensitive. It is claimed that existing privacy-preserving algorithms do not distinguish between the sensitivity of privacy attribute values, therefore, non-sensitive information is altered and this leads to a lower usability of the published data [
6,
11]. For example, as depicted in
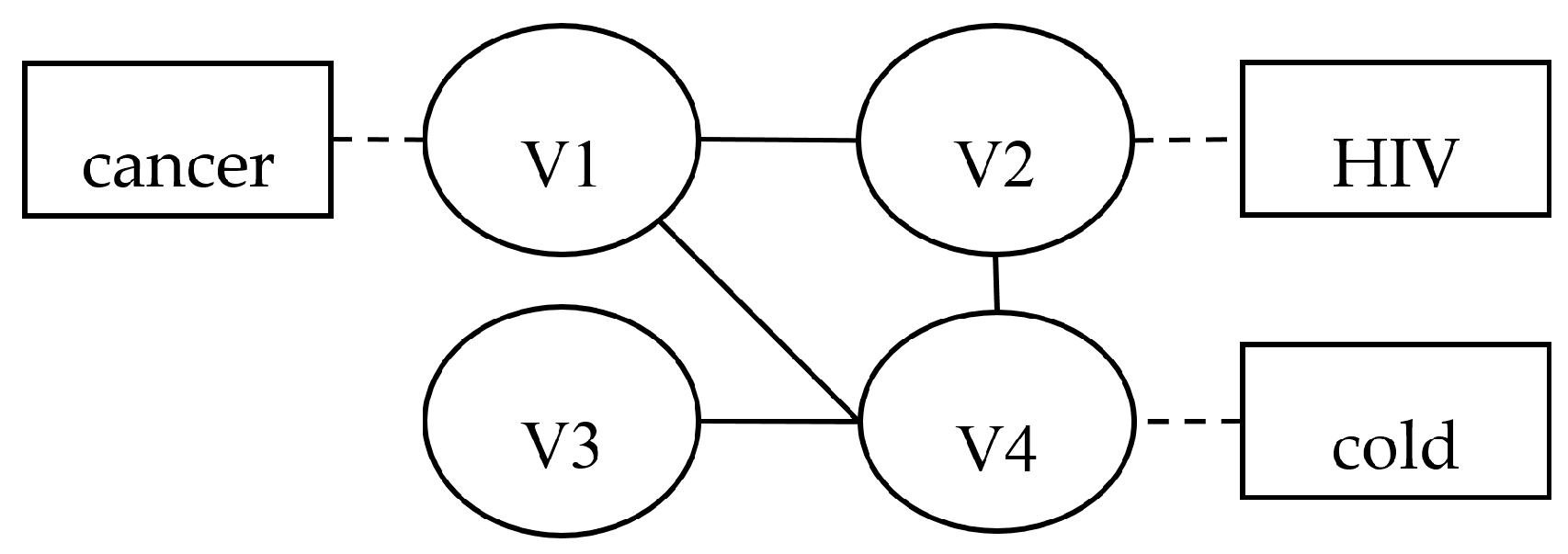
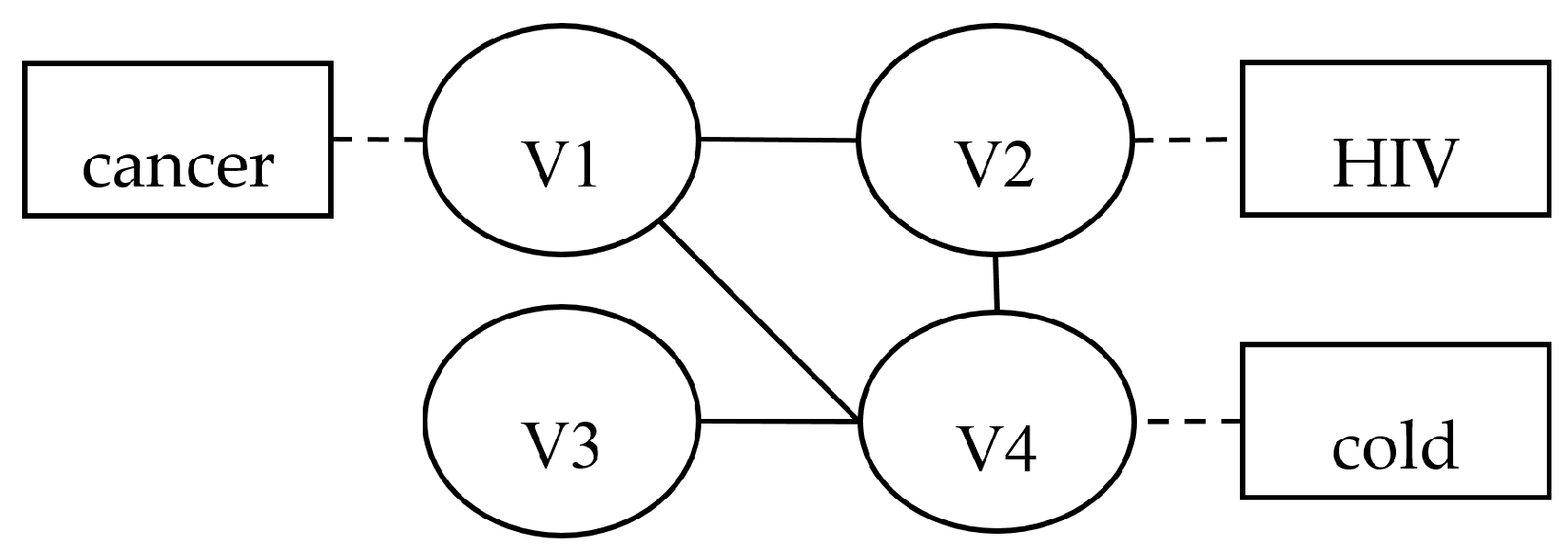
Figure 1, the human disease network has various values. Most people generally consider the disease HIV as private, while considering the disease cold as non-sensitive information. Meanwhile, node V3 does not mark health status. Thus, the human disease network in
Figure 1 is sparse and the existing methods may lead to excessive data utility loss for published data. To tackle this issue, we explored the attributes’ sparse distribution and studied differentiated sensitivity of varied attribute values, proposing a finer granular anonymization algorithm that shifts anonymous objects from the attribute to some sensitive attribute values.
In addition, most previous works take the total number of modified edges or modified nodes as the only metric to measure the social network utility loss without considering the graph structure interference. The lack of exploring utility is partially responsible for the high rate of structure interference in publishing data and contributes to the decrease of data availability. To approach this dearth of research on anonymized data utility for anonymity algorithms, we have undertaken to develop a proper utility function targeted at measuring both information loss and network structure interference that have been shown to be essential for data integrity and authenticity.
To date, many researchers have put forward a variety of personalized privacy protection models and algorithms to improve the published data utility. These personalized anonymous models almost insist that individuals in social networks have different privacy protection requirements and put users who have different privacy protection needs into different anonymous equivalence group. For example, Jiao et al. [
12] divided user privacy protection needs into S (ultra), H (high), M (middle), and L (low) levels, then put forward a personalized
k-degree-
l-diversity anonymity model. Wang [
13] proposed a personal privacy protection scheme based on a social network subset. The scheme divided social networks into three levels according to the attacker’s background knowledge: levels a, b, and c. For level a, the scheme removes all node labels; for level b, it releases the sub-structure of the social network graph that could satisfy the requirement of
k-anonymity; and, for level c, it releases the sub-structure that could satisfy the requirement of
l-diversity anonymity. However, when the social network scale is very large, setting different privacy requirements for each user will significantly increase the time complexity of the algorithm. More importantly, these personalized privacy protection strategies ignore the fact that the influence of each individual is different in a social network.
Above all, in this paper, we treat node attributes as sensitive information (such as salary) that has to be protected and the node degree as background knowledge. Then we propose a differentiated graph anonymity algorithm based on the k-degree-l-diversity model targeted at reducing the utility loss for anonymity. The key idea of our model is that we consider the differences of node importance and attribute value sensitivity. The major contributions of this paper are as follows:
First, a novel utility metric for measuring the published utility loss, named UL(G,G’), is proposed based on the attribute distribution and network structure. Our metric focuses on the different influences of node (edge) modification to both the network data information and the network structure instead of purely the number of node (edge) modifications. We believe that our metric is a better measurement of the utility loss when compared with other existing utility metrics. As this metric assumes each node modification has an equal impact on the original social network properties, the existing k-anonymization algorithms based on this metric has natural flaws in providing high-utility anonymized social network data. Therefore, we designed an algorithm that caters to our metric to improve published anonymized data utility. Although our metric has slightly higher computing complexity, the measurement is more comprehensive and conducive to selecting anonymity operations that can result in less utility loss.
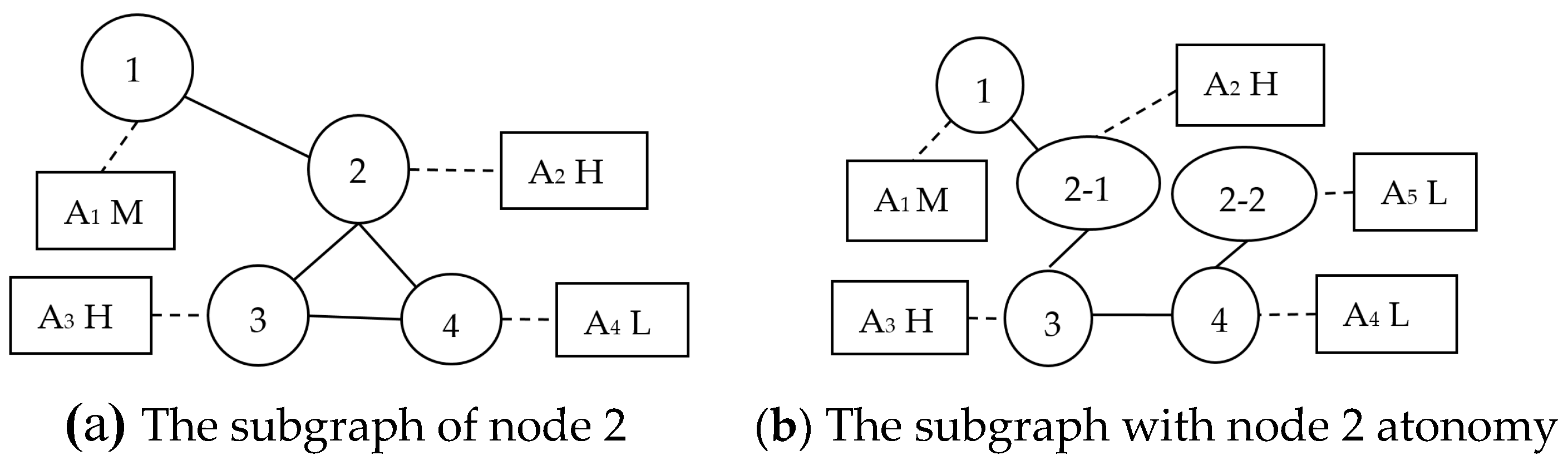
Second, a heuristic anonymizing algorithm, called DKDLD-UL, namely due to the differentiated k-degree-l-diversity anonymity based on data utility, is designed to modify a given social network G to G’ aiming at preserving attribute privacy with relatively low utility loss. On one hand, we make differential protection for diverse sensitive attribute values by the fuzzy function and establish a sensitivity matrix according all possible attribute values for each sensitive attribute having different sensitivity. On the other hand, we implement differential anonymizing operations for different important nodes based on the key node analysis in social network analysis. Above all, we propose the differentiated protection algorithm to prevent privacy information leakage while reducing data utility loss as much as possible.
The rest of the paper is organized as follows.
Section 2 briefly provides some background knowledge and reviews related works about social network data anonymity.
Section 3 details the novel utility measure model based on the structure of topological similarity of the social network, then presents the differentiated protection algorithm based on the proposed utility metric.
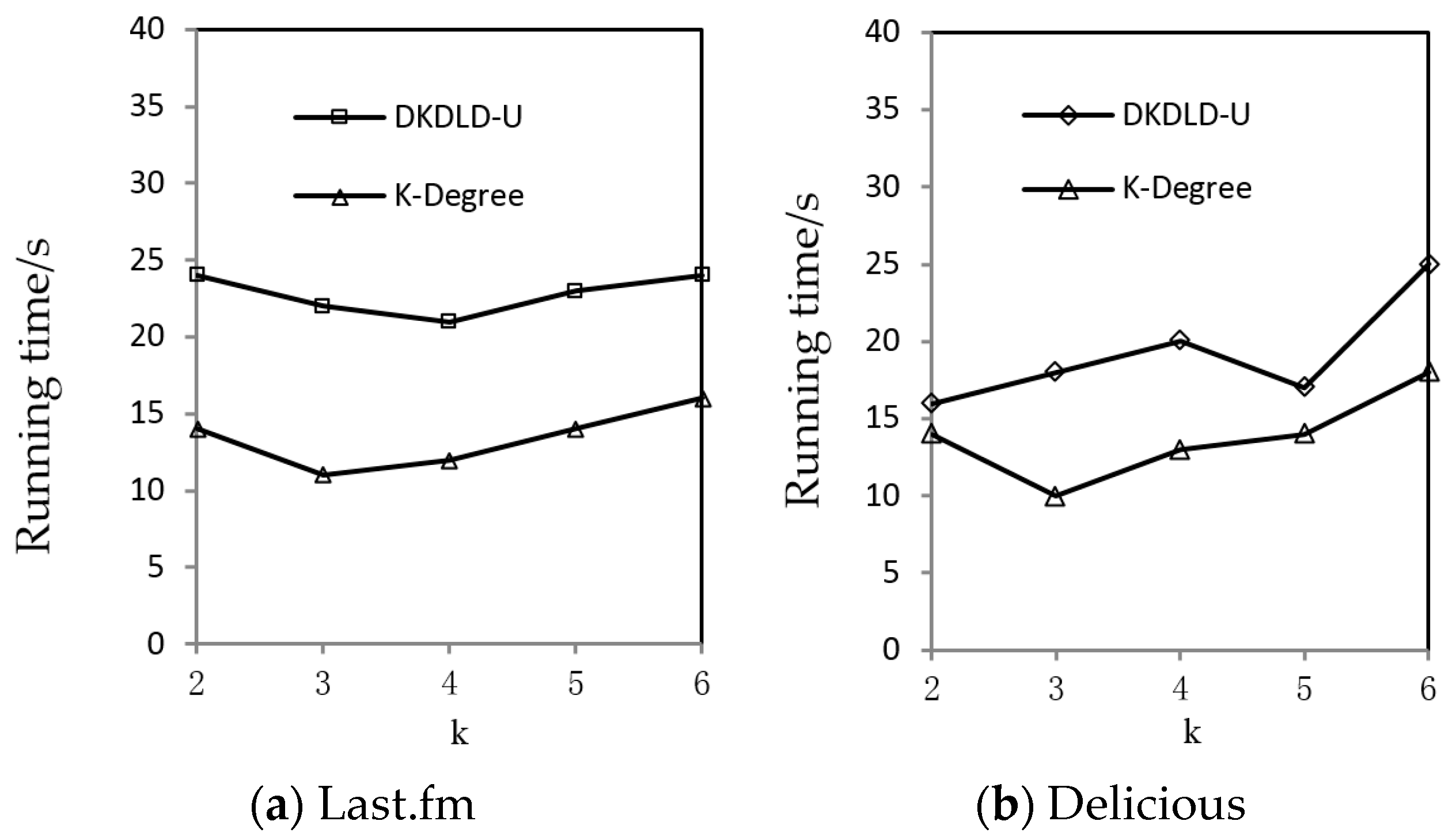
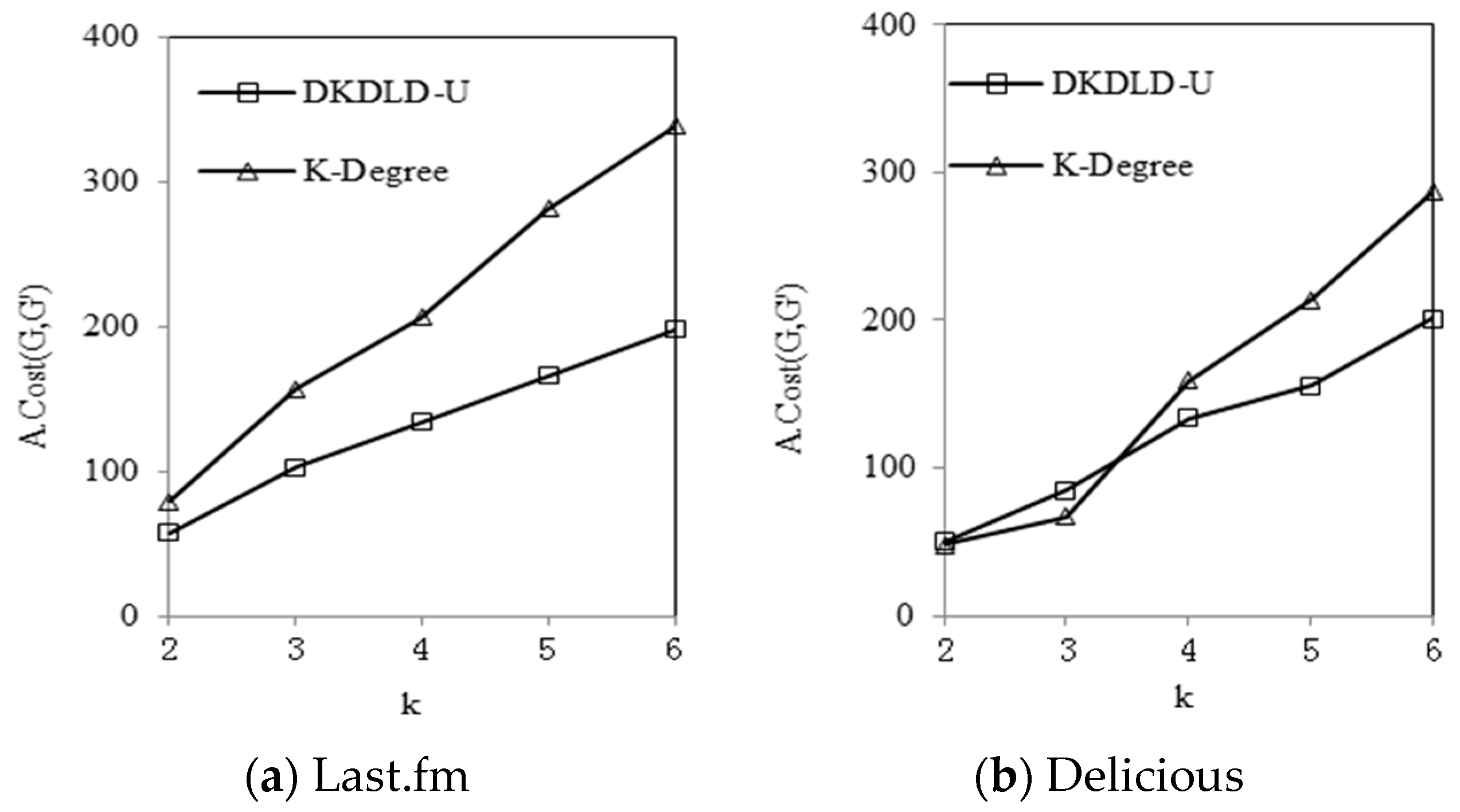
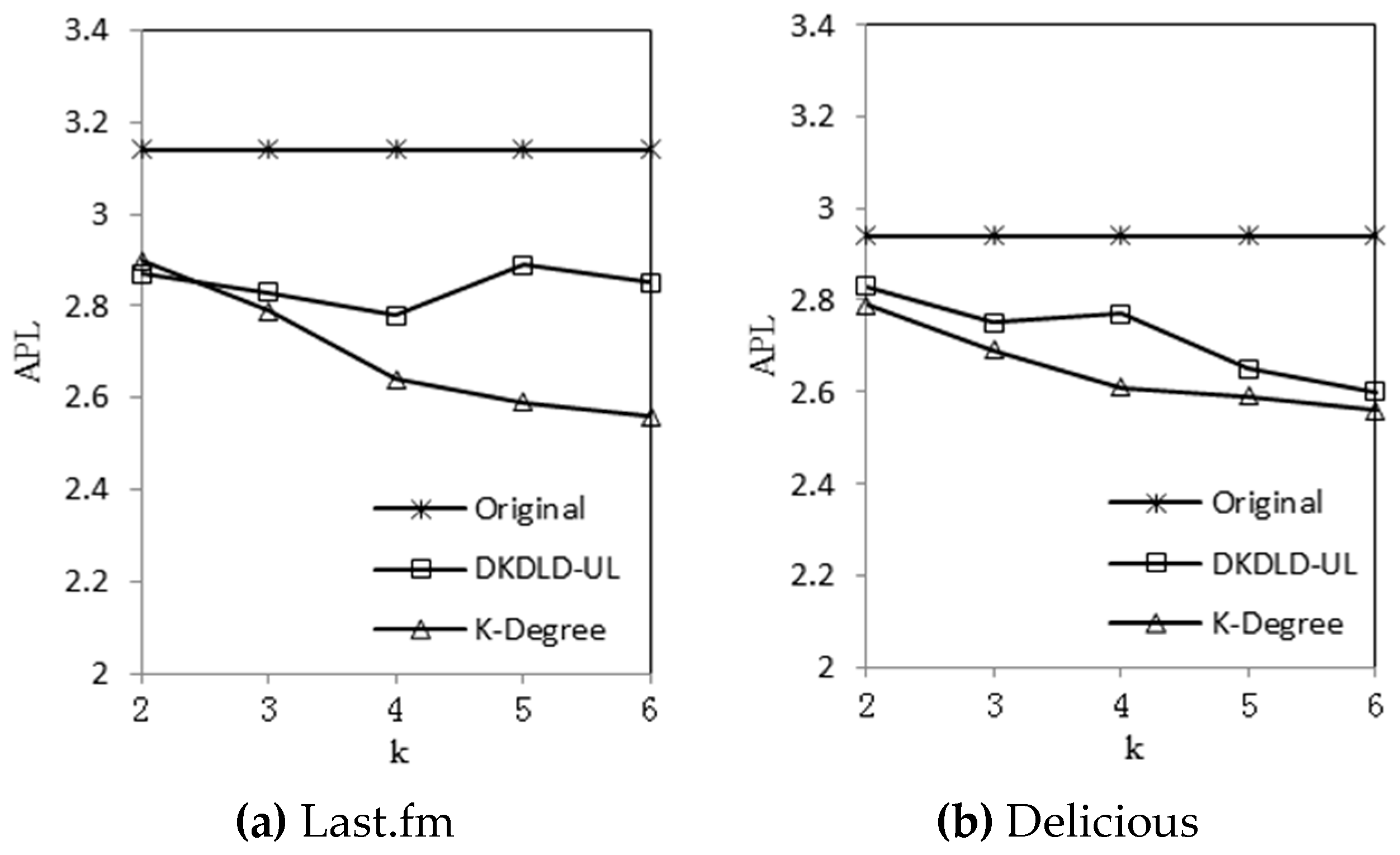
Section 4 reports the experimental results. Finally,
Section 5 concludes the paper.
2. Problem Description
We first present the terminology that will be used in this paper. We focus on the attribute privacy-preserving problem for an un-weighted, undirected, simple graph with a privacy attribute.
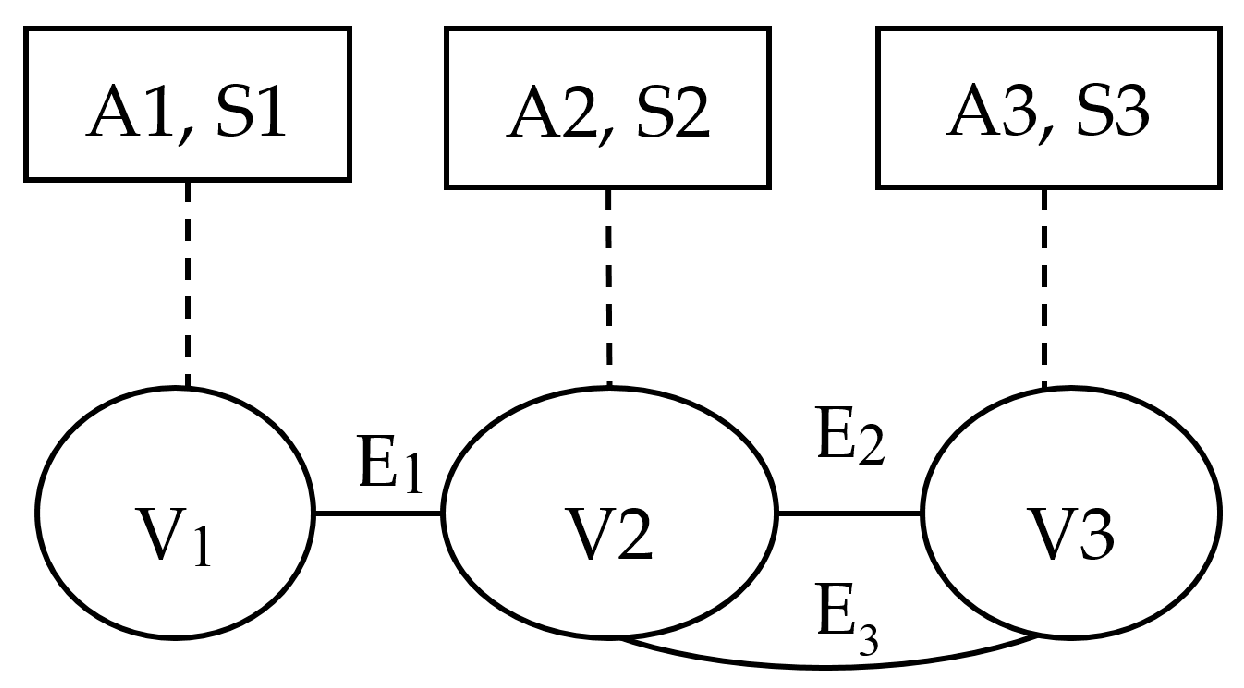
Figure 2 shows an example of such a graph. A social network graph is defined as follows:
Definition 1. Social Network Graph [14]. The social network data is modeled by a graph with a four tuple G = (V, E, A, S). V is a set of nodes representing users; E ⊆ V × V is a set of edges representing social relations between users; A= {A1, A2,…, An} is a set of attribute nodes representing all users’ possible values of the privacy attribute, and Ai corresponds to any privacy attribute values in a social network. For example, for the attribute called health-state, pneumonia and influenza, as two different property values form two different attribute nodes showed by A1 = pneumonia, A2 = influenza. S = {H, M, L}, is the set of the sensitivity of privacy attribute values; S(Ai) represents the sensitivity of attribute value Ai, and Si is the short name of S(Ai), as shown in Figure 2.
Definition 2. Structural Re-identification Attack (SRA) [15]. Given a social network G(V, E), its published graph G’(V’, E’), a target entity t∈V, and the attacker background knowledge F(t), the attacker performs the structural re-identification attack by searching for all of the vertices in G’ that could be mapped to t, i.e., VF (t) = {v∈V’|F(v) = F(t)}. If |VF (t)| << |V’|, then t has a high probability to be re-identified.
Definition 3. K-degree Anonymity [15]. Given a graph G = (V, E) with V = {v1, v2, …,vn} and d(vi) =|{u∈V : (u, vi)∈E}|, and the type of attacker’s background knowledge F, the degree sequence of G is defined to be the sequence P = (d(v1), d(v2), …, d(vn)). P can be divided into a group of subsequences [[d(1), …, d(i1)], [d(i1 + 1), …, d(i2)], …, [d(im + 1), …, P(j)]] such that G satisfies k-degree anonymity if, for every vertex vi∈V, there exist at least k–1 other vertices in G with the same degree as vi. In other words, for any subsequences Py = [d(iy + 1), …, d(iy+1)], Py satisfies two constraints: (1) All of the elements in Py share the same degree (d(iy + 1) = d(iy + 2) = … = d(iy+1)); and (2) Py has size of at least k, namely (|iy+1 − iy| ≥ k).
Definition 4. L-diversity Anonymity [16]. Given an anonymized graph G’ = (V’, E’, A’, S), G’ satisfies l-diversity anonymity if, for any privacy attribute values Ai’, there exists at least l–1 different attribute values in an equivalence group.
Definition 5. Attribute Value Sensitivity Function. The sensitivity of privacy attribute values are usually established by a membership function. We use a trapezoidal distribution membership function sensitivity(x) which ranges from [0, 1] to determine the attribute value sensitivity S as shown in Equation (1). The independent variable x is any privacy attribute value from the set A, the sensitivity of x is written S(x), and we classify the privacy sensitivity into three categories which are denoted by H (high), M (middle), and L (low). The following three parts show the details of three categories.
(1) When x ≤ a, S(x) = L, L is the shorthand of low. We think the attribute value x may have little chance to be privacy information, so it can be published without anonymity, such as the attribute value “cold”, as almost no person will think of “cold” as private information. Many existing privacy-preserving algorithms do not distinguish between the sensitivity of attribute values, so that even non-sensitive information is anonymized, which leads to a lower usability of the published data.
(2) When a < x ≤ b, S(x) = M, M is middle, which means attribute value x has the potential to be private information. Thus, we take one time division for nodes whose attribute value sensitivity is M before publishing data.
(3) When x > b, S(x) = H, attribute value x is usually considered as private information, so we take two, or more, time node divisions.
Above all, when S(Ai) = M or S(Ai) = H, we consider the attribute value Ai as private, and add user node Vi to the sensitive vertex set SV. The critical points a, b are two threshold values, for the convenience of the experiment, we set the threshold based on experience: a = 0.6, b = 0.8. However, for the practical application, it should be established by statistics and analysis.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}