
Conditional Random Fields for Pattern Recognition Applied to Structured Data


Abstract
:1. Introduction

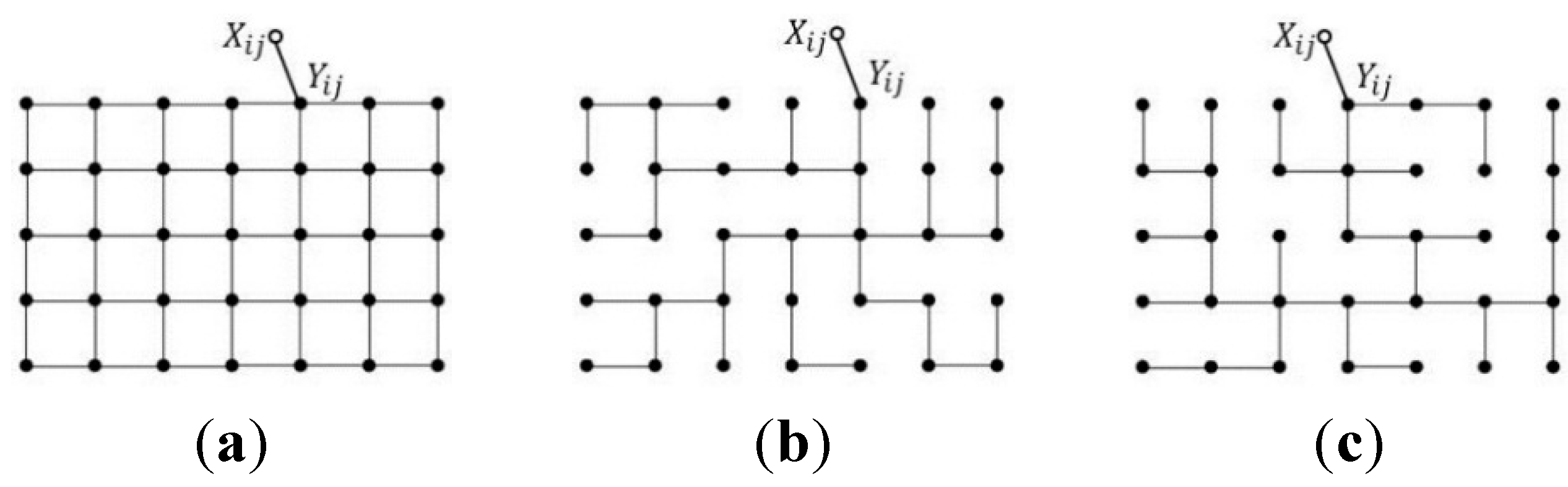
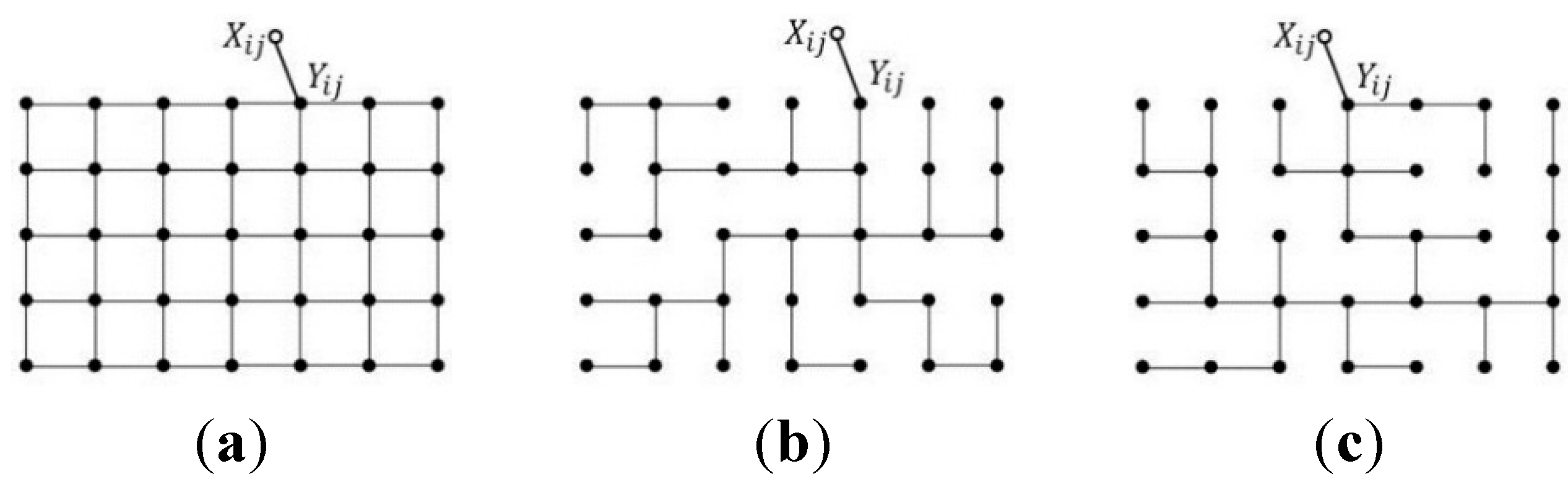
2. Conditional Random Fields
2.1. CRF Learning
2.1.1. Estimation of Model Parameters θ Using Markov Chain Monte Carlo
2.1.2. Estimation of Model Parameters θ Using Pseudo-Likelihood or Composite-Likelihood Methods
2.1.3. Estimation of Model Parameters θ Using Likelihood-Free Methods
3. CRF Applications and Challenges
4. Examples
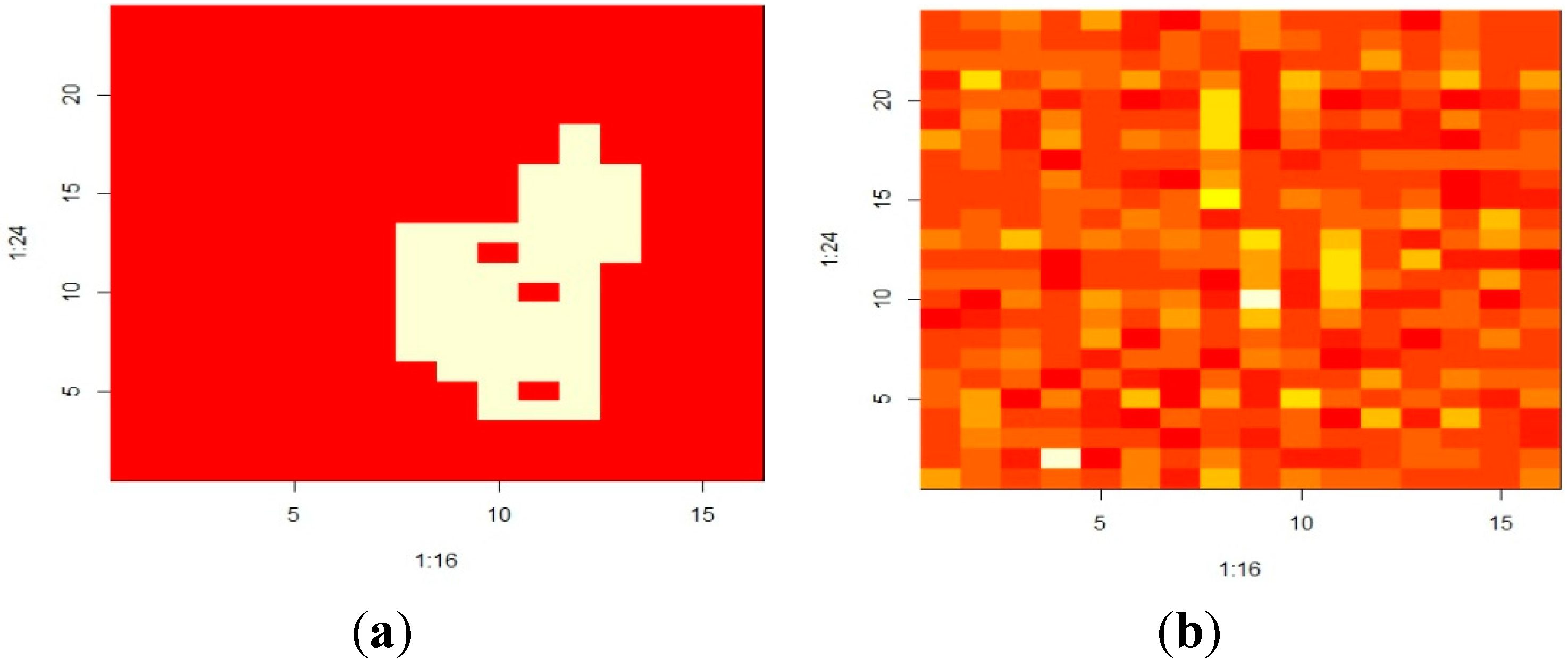
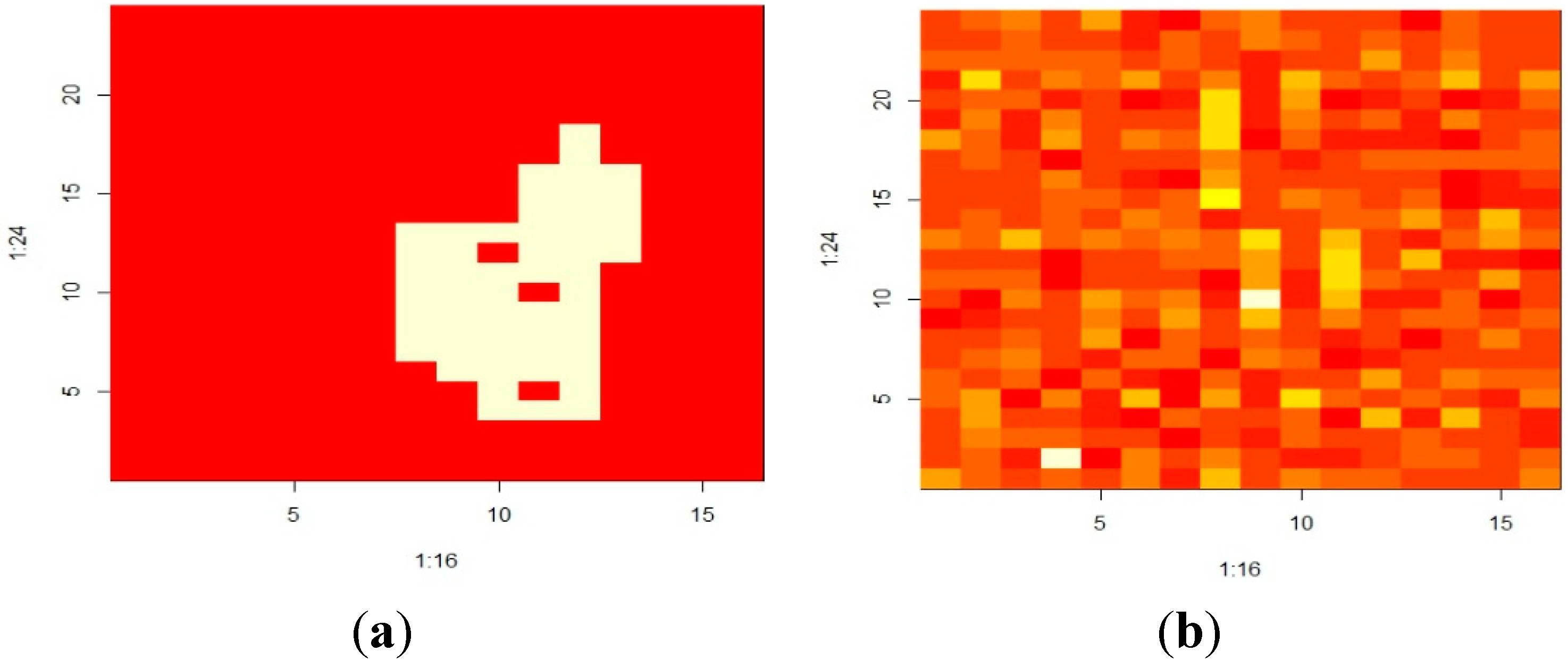
4.1. Example 1: Pattern Recognition to Distinguish Natural from Manmade Objects


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DR (%) | FP (Per Image) | |
|---|---|---|
| Markov Random Field [9] | 58.35 | 2.44 |
| Discriminative Random Fields [9] | 72.54 | 1.76 |
| LBP (MPM estimates) | 85.30 | 14.32 |
| Ensemble of spanning tree structured CRFs [66] | 90.52 | 9 |
| Hierarchical cascade of spanning tree structured CRFs (MPM estimates) [67] | 91.75 | 11.85 |
4.2. Example 2. Image Denoising

| Unimodal | Bimodal | |
|---|---|---|
| Logistic regression based classifier | 14.72 ± 0.02 | 23.10 ± 0.04 |
| KH’06 (DRF, penalized pseudo-likelihood parameter learning, MAP labelings estimated using graph cuts) | 2.30 | 6.21 |
| LBP (MPM estimates) | 2.65 ± 0.11 | 6.04 ± 0.09 |
| Ensemble of spanning tree structured CRFs [66] | 3.38 ± 0.04 | 5.80 ± 0.02 |
| Hierarchical cascade of spanning tree structured CRFs [67] | 3.06 ± 0.11 | 6.00 ± 0.12 |
5. Research Issues for CRFs
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Bolton, R.; Hand, D. Statistical fraud detection: A review. Stat. Sci. 2002, 17, 235–255. [Google Scholar]
- Fisher, R. The use of multiple measurements in taxonomic problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Koller, D.; Friedman, N. Probabilistic Graphical Models: Principles and Techniques; MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Lafferty, J.; McCallum, A.; Pereira, F. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of the 18th International Conference on Machine Learning, Williamstown, MA, USA, 28 June–1 July 2001.
- Sato, K.; Sakakibara, Y. RNA secondary structural alignment with conditional random fields. Bioinformatics 2005, 21, ii237–ii242. [Google Scholar] [CrossRef] [PubMed]
- Hayashida, M.; Kamada, M.; Song, J.; Akutsu, T. Prediction of protein-RNA residue-base contacts using two-dimensional conditional random field with the lasso. BMC Syst. Biol. 2013. [Google Scholar] [CrossRef] [PubMed]
- Sankararaman, S.; Mallick, S.; Dannemann, M.; Prufer, K.; Kelso, J.; Paabo, S.; Patterson, N.; Reich, D. The genomic landscape of Neanderthal ancestry in present-day humans. Nature 2014, 507, 354–357. [Google Scholar] [CrossRef] [PubMed]
- Kumar, S.; Hebert, M. Discriminative fields for modeling spatial dependencies in natural images. In Advances in Neural Information Processing Systems 16; Proceedings of the Neural Information Processing Systems, Vancouver, British Columbia, Canada, 8–13 December 2003.
- Kumar, S.; Hebert, M. Discriminative random fields. Int. J. Comp. Vis. 2006, 68, 179–201. [Google Scholar] [CrossRef]
- He, X.; Zemel, R.; Carreira-Perpinan, M. Multiscale conditional random fields for image labeling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004; Volume 2.
- Reiter, S.; Schuller, B.; Rigoll, G. Hidden conditional random fields for meeting segmentation. In Proceedings of the International Conference on Multimedia and Exposition, Beijing, China, 2–5 July 2007; pp. 639–642.
- Ladicky, L.; Sturgess, P.; Alahari, K.; Russell, C.; Torr, P. What, where and how many? Combining object detectors and CRFs. In Proceedings of the European Conference on Computer Vision, Hersonissos, Greece, 5–11 September 2010.
- Delong, A.; Gorelick, L.; Veksler, O.; Boykov, Y. Minimizing energies with hierarchical costs. Int. J. Comp. Vis. 2012, 100, 38–58. [Google Scholar] [CrossRef]
- Pellegrini, S.; Gool, L. Tracking with a mixed continuous-discrete conditional random field. Comp. Vis. Image Underst. 2013, 117, 1215–1228. [Google Scholar] [CrossRef]
- Bousmalis, K.; Zafeiriou, S.; Morency, L.; Pantic, M. Infinite hidden conditional random fields for human behavior analysis. IEEE Trans. Neural Netw. Learn. Syst. 2013, 24, 170–177. [Google Scholar] [CrossRef] [PubMed]
- He, X.; Gould, S. An exemplar based CRF for multi-instance object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014.
- Raje, D.; Mujumdar, P. A conditional random field based downscaling method for assessment of climate change impact on multisite daily precipitation in the Mahanadi basin. Water Resour. Res. 2009, 45, 20. [Google Scholar] [CrossRef]
- Martinez, O.; Tsechpenakis, G. Integration of active learning in a collaborative CRF. In Proceedings of the IEEE Computer Vision and Pattern Recognition Workshops, Anchorage, AK, USA, 23–28 June 2008.
- Zhang, K.; Xie, Y.; Yang, Y.; Sun, A.; Liu, H.; Choudhary, A. Incorporating conditional random fields and active learning to improve sentiment identification. Neural Netw. 2014, 58, 60–67. [Google Scholar] [CrossRef] [PubMed]
- Sha, F.; Pereira, S. Shallow parsing with conditional random fields. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology, Edmonton, Canada, 31 May–June 1 2003; pp. 134–141.
- Sutton, C.; McCallum, A. Piecewise training for undirected models. In Proceedings of the Conference on Uncertainty in Artificial Intelligence, Edinburgh, UK, 26–29 July 2005.
- Ammar, W.; Dyer, C.; Smith, N.A. Conditional random field autoencoders for unsupervised structured prediction. In Advances in Neural Information Processing Systems 27 (NIPS 2014), Proceedings of the Neural Information Processing Systems, Montreal, Canada, 8–13 December 2014.
- Sutton, C.; McCallum, A. An introduction to conditional random fields. Mach. Learn. 2011, 4, 267–373. [Google Scholar] [CrossRef]
- Besag, J. Statistical analysis of non-lattice data. J. R. Stat. Soc. Ser. D (Stat.) 1975, 24, 179–195. [Google Scholar] [CrossRef]
- Boykov, Y.; Veksler, O.; Zabih, R. Fast approximate energy minimization via graph cuts. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 1222–1239. [Google Scholar] [CrossRef]
- Shimony, S. Finding MAPs for belief networks is NP-hard. Artif. Intell. 1994, 68, 399–410. [Google Scholar] [CrossRef]
- Celeux, G.; Forbes, F.; Peyrard, N. EM procedures using mean field-like approximations for Markov model-based image segmentation. Pattern Recognit. 2003, 36, 131–144. [Google Scholar] [CrossRef]
- Pearl, J. Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference; Morgan Kaufmann: San Francisco, CA, USA, 1988. [Google Scholar]
- Frey, B.; MacKay, D. A revolution: Belief propagation in graphs with cycles. In Advances in Neural Information Processing Systems 10 (NIPS 1997), Proceedings of the Conference on Neural Information Processing Systems, Denver, CO, USA, 1–6 December 1997.
- Murphy, K.; Weiss, Y.; Jordan, M. Loopy belief propagation for approximate inference: An empirical study. In Proceedings of the Fifteenth Conference on Uncertainty in Artificial Intelligence, Stockholm, Sweden, 30 July 1–August 1999; pp. 467–475.
- Yedidia, J.; Freeman, W.; Weiss, Y. Constructing free energy approximations and generalized belief propagation algorithms. IEEE Trans. Inf. Theory 2005, 51, 2282–2312. [Google Scholar] [CrossRef]
- Yedidia, J.; Freeman, W.; Weiss, Y. Bethe free energy, Kukuchi approximations and belief propagation algorithms. In Advances in Neural Information Processing Systems 13 (NIPS 2000), Proceedings of the Conference on Neural Information Processing Systems, Denver, CO, USA, 28–30 November 2000.
- Yedidia, J.; Freeman, W.; Weiss, Y. Understanding belief propagation and its generalizations. In Proceedings of the International Joint Conference on Artificial Intelligence, Seattle, WA, USA, 4–10 August 2001.
- Wainwright, M.; Jaakkola, T.; Willsky, A. Tree-based reparametrization framework for analysis of sum-product and related algorithms. IEEE Trans. Inf. Theory 2005, 49, 1120–1146. [Google Scholar] [CrossRef]
- Wainwright, M.; Jaakkola, T.; Willsky, A. MAP estimation via agreement on (hyper) trees: Message-passing and linear programming approaches. IEEE Trans. Inf. Theory 2005, 51, 3697–3717. [Google Scholar] [CrossRef]
- Kolmogorov, V. Convergent tree-reweighted message passing for energy minimization. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1568–1583. [Google Scholar] [CrossRef] [PubMed]
- Ravikumar, P.; Lafferty, J. Quadratic programming relaxations for metric labeling and Markov random field MAP estimation. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006.
- Kumar, M.; Kolmogorov, V.; Torr, P. An analysis of convex relaxations for MAP estimation of discrete MRFs. J. Mach. Learn. Res. 2008, 10, 71–106. [Google Scholar]
- Peng, J.; Hazan, T.; McAllester, D.; Urtasum, R. Convex max-product algorithms for continuous MRFs with applications to protein folding. In Proceedings of the 28th International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2011.
- Schwing, A.; Pollefeys, M.; Hazan, T.; Urtasum, R. Globally convergent dual MAP LP relaxation solvers using Fenchel-Young margins. In Advances in Neural Information Processing Systems 25 (NIPS 2012), Proceedings of the Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–8 December 2012.
- Bach, S.; Huang, B.; Getoor, L. Unifying local consistency and MAX SAT relaxations for scalable inference with rounding guarantees. In Proceedings of the 18th International Conference on Artificial Intelligence and Statistics, San Diego, CA, USA, 9–12 May 2015.
- Boykov, Y.; Kolmogorov, V. An experimental comparison of min-cut/max-flow algorithms for energy minimization in vision. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 1124–1137. [Google Scholar] [CrossRef] [PubMed]
- Kolmogorov, V.; Zabih, R. What energy functions can be minimized via graph cuts? IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 147–159. [Google Scholar] [CrossRef] [PubMed]
- Tarlow, D.; Adams, R. Revisiting uncertainty in graph cut solutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012.
- Ramalingam, S.; Kohli, P.; Alahari, K.; Torr, P. Exact inference in multi-label CRFs with higher order cliques. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008.
- Kohli, P.; Ladický, L.; Torr, P. Robust higher order potentials for enforcing label consistency. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008.
- Schmidt, F.; Toppe, E.; Cremers, D. Efficient planar graph cuts with applications in computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–26 June 2009.
- Ladický, L.; Russell, C.; Kohli, P.; Torr, P. Graph cut based inference with co-occurrence statistics. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010.
- Liu, D.; Nocedal, J. On the limited memory BFGS method for large scale optimization methods. Math. Program. 1989, 45, 503–528. [Google Scholar] [CrossRef]
- Asuncion, A.; Liu, Q.; Ihler, A.; Smyler, P. Particle filtered MCMC-MLE with connections to contrastive divergence. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010.
- Asuncion, A.; Liu, Q.; Ihler, A.; Smyler, P. Learning with blocks: Composite likelihood and contrastive divergence. In Proceedings of the 13th International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010.
- Hinton, G. Training products of experts by minimizing contrastive divergence. Neural Comput. 2002, 14, 1771–1800. [Google Scholar]
- Carreira-Perpiñán, M.; Hinton, G. On contrastive divergence learning. In Proceedings of the Tenth International Workshop on Artificial Intelligence and Statistics, Barbados, 6–8 January 2005.
- Geyer, C.J. MCMC Package Example (Version 0.7-3). 2009. Available online: http://www.stat.umn.edu/geyer/mcmc/library/mcmc/doc/demo.pdf (accessed on 16 December 2014).
- Burr, T.; Skurikhin, A. Conditional random fields for modeling structured data, Encyclopedia of Information Science and Technology, 3rd ed.; Khosrow-Pour, M., Ed.; Information Resources Management Association: Hershey, PA, USA, 2015; Chapter 608; pp. 6167–6176. [Google Scholar]
- Besag, J. Efficiency of pseudo-likelihood estimation for simple Gaussian fields. Biometrika 1977, 64, 616–618. [Google Scholar] [CrossRef]
- Lindsay, B. Composite likelihood methods. Contemp. Math. 1988, 80, 221–239. [Google Scholar]
- Burr, T.; Skurikhin, A. Pseudo-likelihood inference for Gaussian Markov random fields. Stat. Res. Lett. 2013, 2, 63–68. [Google Scholar]
- Sutton, C.; McCallum, A. Piecewise pseudolikelihood for efficient training of conditional random fields. In Proceedings of the 24th International Conference on Machine Learning, Corvallis, OR, USA, 20–24 June 2007.
- Friel, N. Bayesian inference for Gibbs random fields using composite likelihoods. In Proceedings of the 2012 Winter Simulation Conference, Berlin, Germany, 9–12 December 2012.
- Pereyra, M.; Dobigeon, N.; Batatia, H.; Tourneret, J. Estimating the granularity coefficient of a Potts-Markov random field within a Markov chain Monte Carlo algorithm. IEEE Trans. Image Process. 2012, 22, 2385–2397. [Google Scholar] [CrossRef] [PubMed]
- Barahona, F. On the computational complexity of Ising spin glass models. J. Phys. A 1982, 15, 3241–3253. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer: New York, NY, USA, 2001. [Google Scholar]
- Stoehr, J.; Pudlo, P.; Cucala, L. Adaptive ABC model choice and geometric summary statistics for hidden Gibbs random fields. Stat. Comput. 2015, 25, 129–141. [Google Scholar] [CrossRef]
- Quattoni, A.; Wang, S.; Morency, L.; Collins, M.; Darrell, T. Hidden conditional random fields. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1848–1853. [Google Scholar] [CrossRef] [PubMed]
- Skurikhin, A. Learning tree-structured approximations for conditional random fields. In Proceedings of the IEEE Applied Imagery Pattern Recognition Workshop, Washington, DC, USA, 14–16 October 2014.
- Skurikhin, A.N. Hierarchical spanning tree-structured approximation for conditional random fields: An empirical study. Adv. Vis. Comput. Lect. Notes Comput. Sci. 2014, 8888, 85–94. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2012. [Google Scholar]
- Geman, S.; Geman, D. Stochastic relaxation, Gibbs distributions, and the Bayesian restoration of images. IEEE Trans. Pattern Anal. Mach. Intell. 1984, 6, 721–741. [Google Scholar] [CrossRef] [PubMed]
- Kaiser, M.; Lahiri, S.; Nordman, D. Goodness of fit tests for a class of Markov random field models. Ann. Stat. 2012, 40, 104–130. [Google Scholar] [CrossRef]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Burr, T.; Skurikhin, A. Conditional Random Fields for Pattern Recognition Applied to Structured Data. Algorithms 2015, 8, 466-483. https://doi.org/10.3390/a8030466
Burr T, Skurikhin A. Conditional Random Fields for Pattern Recognition Applied to Structured Data. Algorithms. 2015; 8(3):466-483. https://doi.org/10.3390/a8030466
Chicago/Turabian StyleBurr, Tom, and Alexei Skurikhin. 2015. "Conditional Random Fields for Pattern Recognition Applied to Structured Data" Algorithms 8, no. 3: 466-483. https://doi.org/10.3390/a8030466
APA StyleBurr, T., & Skurikhin, A. (2015). Conditional Random Fields for Pattern Recognition Applied to Structured Data. Algorithms, 8(3), 466-483. https://doi.org/10.3390/a8030466