
AI Under Attack: Metric-Driven Analysis of Cybersecurity Threats in Deep Learning Models for Healthcare Applications



Abstract
1. Introduction
- Comprehensive analysis of FGSM, data poisoning and evasion attacks to offer a holistic view of the cybersecurity threats faced by DL models in healthcare.
- Introduction of the PAVI as a core feature of the HAVA to standardize quantification and comparison of DL model vulnerabilities across different attack scenarios.
- Empirical evaluation of the impact of these attacks on a DL model trained with the Wisconsin Diagnostic Breast Cancer (WDBC) dataset to provide actionable insights into the model vulnerabilities.
- Provision of actionable recommendations and customized defense strategies based on visualizations and comparative analyses generated by the HAVA, focusing on improving the reliability of AI applications in healthcare.
2. Related Works
3. Materials and Methods
3.1. The Classification Model
3.2. Simulated Attacks
3.2.1. Adversarial Fast Gradient Sign Method (FGSM) Attack
3.2.2. Data Poisoning Attack
3.2.3. Adversarial Evasion Attack
4. Healthcare AI Vulnerability Assessment Algorithm (HAVA)
| Algorithm 1: Healthcare AI Vulnerability Assessment Algorithm (HAVA) |
Process:
return , and for all scenarios. |
5. Results and Discussion
5.1. Quantifying Post-Attack Impact for Iterative Improvement
5.2. Mitigation Workflow
5.2.1. Attack Simulation and Evaluation
5.2.2. Prioritization of Defenses
5.2.3. Testing and Validation
5.2.4. Iterative Improvement
5.3. Contextualizing Vulnerability and Guiding Actionable Insights
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Heng, W.W.; Abdul-Kadir, N.A. Deep Learning and Explainable Machine Learning on Hair Disease Detection. In Proceedings of the 2023 IEEE 5th Eurasia Conference on Biomedical Engineering, Healthcare and Sustainability (ECBIOS), Tainan, Taiwan, 2–4 June 2023; pp. 150–153. [Google Scholar] [CrossRef]
- Niteesh, K.R.; Pooja, T.S. Application of Deep Learning in Detection of various Hepatic Disease Classification Using H & E Stained Liver Tissue Biopsy. In Proceedings of the 2024 2nd International Conference on Artificial Intelligence and Machine Learning Applications Theme: Healthcare and Internet of Things (AIMLA), Namakkal, India, 15–16 March 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Bouali, L.Y.; Boucetta, I.; Bekkouch, I.E.I.; Bouache, M.; Mazouzi, S. An Image Dataset for Lung Disease Detection and Classification. In Proceedings of the 2021 International Conference on Theoretical and Applicative Aspects of Computer Science (ICTAACS), Skikda, Algeria, 15–16 December 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Mastoi, Q.; Latif, S.; Brohi, S.; Ahmad, J.; Alqhatani, A.; Alshehri, M.S.; Al Mazroa, A.; Ullah, R. Explainable AI in medical imaging: An interpretable and collaborative federated learning model for brain tumor classification. Front. Oncol. 2025, 15, 1535478. [Google Scholar] [CrossRef]
- Murty, P.S.R.C.; Anuradha, C.; Naidu, P.A.; Mandru, D.; Ashok, M.; Atheeswaran, A.; Rajeswaran, N.; Saravanan, V. Integrative hybrid deep learning for enhanced breast cancer diagnosis: Leveraging the Wisconsin Breast Cancer Database and the CBIS-DDSM dataset. Sci. Rep. 2024, 14, 26287. [Google Scholar] [CrossRef] [PubMed]
- Alshayeji, H.; Ellethy, H.; Abed, S.; Gupta, R. Computer-aided detection of breast cancer on the Wisconsin dataset: An artificial neural networks approach. Biomed. Signal Process. Control 2022, 71, 103141. [Google Scholar] [CrossRef]
- Jain, A.; Sangeeta, K.; Sadim, S.B.M.; Dwivedi, S.P.; Albawi, A. The Impact of Adversarial Attacks on Medical Imaging AI Systems. In Proceedings of the IEEE 13th International Conference on Communication Systems and Network Technologies (CSNT), Jabalpur, India, 6–7 April 2024; pp. 362–367. [Google Scholar] [CrossRef]
- Akhtar, N.; Mian, A. Threat of adversarial attacks on deep learning in computer vision: A survey. IEEE Access 2018, 6, 14410–14430. [Google Scholar] [CrossRef]
- Biggio, B.; Roli, F. Wild patterns: Ten years after the rise of adversarial machine learning. Pattern Recognit. 2018, 84, 317–331. [Google Scholar] [CrossRef]
- Muthalagu, R.; Malik, J.A.; Pawar, P.M. Detection and prevention of evasion attacks on machine learning models. Expert Syst. Appl. 2025, 266, 126044. [Google Scholar] [CrossRef]
- Tsai, M.J.; Lin, P.Y.; Lee, M.E. Adversarial Attacks on Medical Image Classification. Cancers 2023, 15, 4228. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Muoka, G.W.; Yi, D.; Ukwuoma, C.C.; Mutale, A.; Ejiyi, C.J.; Mzee, A.K.; Gyarteng, E.S.A.; Alqahtani, A.; Al-antari, M.A. A Comprehensive Review and Analysis of Deep Learning-Based Medical Image Adversarial Attack and Defense. Mathematics 2023, 11, 4272. [Google Scholar] [CrossRef]
- Finlayson, S.G.; Bowers, J.D.; Ito, J.; Zittrain, J.L.; Beam, A.L.; Kohane, I.S. Adversarial attacks on medical machine learning. Science 2019, 363, 1287–1289. [Google Scholar] [CrossRef]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated Machine Learning: Concept and Applications. ACM Trans. Intell. Syst. Technol. 2019, 10, 2. [Google Scholar] [CrossRef]
- Javed, H.; El-Sappagh, S.; Abuhmed, T. Robustness in deep learning models for medical diagnostics: Security and adversarial challenges towards robust AI applications. Artif. Intell. Rev. 2025, 58, 12. [Google Scholar] [CrossRef]
- Mutalib, N.; Sabri, A.; Wahab, A.; Abdullah, E.; AlDahoul, N. Explainable deep learning approach for advanced persistent threats (APTs) detection in cybersecurity: A review. Artif. Intell. Rev. 2024, 57, 297. [Google Scholar] [CrossRef]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2014, arXiv:1312.6199. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2015, arXiv:1412.6572. [Google Scholar] [CrossRef]
- Sorin, V.; Soffer, S.; Glicksberg, B.S.; Barash, Y.; Konen, E.; Klang, E. Adversarial attacks in radiology—A systematic review. Eur. J. Radiol. 2023, 167, 111085. [Google Scholar] [CrossRef]
- Albattah, A.; Rassam, M.A. Detection of Adversarial Attacks against the Hybrid Convolutional Long Short-Term Memory Deep Learning Technique for Healthcare Monitoring Applications. Appl. Sci. 2023, 13, 6807. [Google Scholar] [CrossRef]
- Yang, Y.; Jin, Q.; Huang, F.; Lu, Z. Adversarial Attacks on Large Language Models in Medicine. arXiv 2024, arXiv:2406.12259. [Google Scholar] [CrossRef]
- Newaz, A.I.; Haque, N.I.; Sikder, A.K.; Rahman, M.A.; Uluagac, A.S. Adversarial Attacks to Machine Learning-Based Smart Healthcare Systems. In Proceedings of the GLOBECOM 2020–2020 IEEE Global Communications Conference, Taipei, Taiwan, 7 – 11 December 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Aljanabi, M.; Omran, A.H.; Mijwil, M.M.; Abotaleb, M.; El-kenawy, E.-S.M.; Mohammed, S.Y. Data poisoning: Issues, challenges, and needs. In Proceedings of the 7th IET Smart Cities Symposium (SCS 2023), Manama, Bahrain, 3–5 December 2023. [Google Scholar] [CrossRef]
- Verde, L.; Marulli, F.; Marrone, S. Exploring the Impact of Data Poisoning Attacks on Machine Learning Model Reliability. Procedia Comput. Sci. 2021, 192, 1184–1193. [Google Scholar] [CrossRef]
- Xu, W.; Evans, D.; Qi, Y. Feature squeezing: Detecting adversarial examples in deep neural networks. In Proceedings of the 2018 Network and Distributed Systems Security Symposium (NDSS), San Diego, CA, USA, 18 – 21 February 2018; pp. 1–15. [Google Scholar]
- Hong, S.; Chandrasekaran, V.; Kaya, Y.; Dumitraş, T.; Papernot, N. On the Effectiveness of Mitigating Data Poisoning Attacks with Gradient Shaping. arXiv 2020, arXiv:2002.11497. [Google Scholar] [CrossRef]
- Atmane, B.; Ahmad, W. On the Validity of Traditional Vulnerability Scoring Systems for Adversarial Attacks against LLMs. arXiv 2024, arXiv:2309.12345. [Google Scholar] [CrossRef]
- Zou, A.; Wang, Z.; Carlini, N.; Nasr, M.; Kolter, J.Z.; Fredrikson, M. Universal and Transferable Adversarial Attacks on Aligned Language Models. arXiv 2023, arXiv:2307.15043. [Google Scholar] [CrossRef]
- Wolberg, W.; Mangasarian, O.; Street, N.; Street, W. Breast Cancer Wisconsin (Diagnostic). 1995. Available online: https://archive.ics.uci.edu/dataset/17/breast+cancer+wisconsin+diagnostic (accessed on 9 January 2025).
- Street, W.N.; Wolberg, W.H.; Mangasarian, O.L. Nuclear feature extraction for breast tumor diagnosis. Biomed. Image Process. Biomed. Vis. 1993, 1905, 861–870. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted Boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Biggio, B.; Nelson, B.; Laskov, P. Poisoning attacks against support vector machines. In Proceedings of the 29th International Conference on Machine Learning (ICML-12), Edinburgh, Scotland, 26 June–1 July 2012; pp. 1467–1474. [Google Scholar]
- Hamid, R.; Brohi, S. A Review of Large Language Models in Healthcare: Taxonomy, Threats, Vulnerabilities, and Framework. Big Data Cogn. Comput. 2024, 8, 161. [Google Scholar] [CrossRef]
- Liu, X.; Cheng, H.; He, P.; Chen, W.; Wang, Y.; Poon, H.; Gao, J. Adversarial Training for Large Neural Language Models. arXiv 2020, arXiv:2004.08994. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Univariate Selection | Multi-Method Selection |
|---|---|---|
| 1 | radius mean | concave points worst |
| 2 | compactness worst | texture mean |
| 3 | radius worst | perimeter mean |
| 4 | texture mean | concavity worst |
| 5 | perimeter mean | concavity mean |
| 6 | area se | perimeter worst |
| 7 | area worst | area se |
| 8 | perimeter se | texture worst |
| 9 | texture worst | radius worst |
| 10 | perimeter worst | concave points mean |
| 11 | concavity worst | area worst |
| 12 | concave points worst | smoothness worst |
| 13 | concavity mean | area mean |
| 14 | area mean | radius mean |
| 15 | radius se |
| Symbol | Meaning |
|---|---|
| Weighted input to the l-th layer of the neural network. | |
| Activation output of the l-th layer of the neural network. | |
| Weight matrix for the l-th layer of the neural network. | |
| Bias vector for the l-th layer of the neural network. | |
| f | Activation function (e.g., ReLU, Logistic, Tanh) applied to compute the layer output. |
| y | True label of the input sample. |
| Predicted probability of the input sample. | |
| Cross-entropy loss function for optimizing the model parameters. | |
| Adversarial example generated using the FGSM method. | |
| x | Original input data. |
| Magnitude of the perturbation applied in FGSM attack. | |
| Gradient of the loss function with respect to the input x. | |
| Gaussian noise with mean 0 and variance , used in evasion attacks. | |
| Post-Attack Vulnerability Index; quantifies the relative degradation in model performance. |
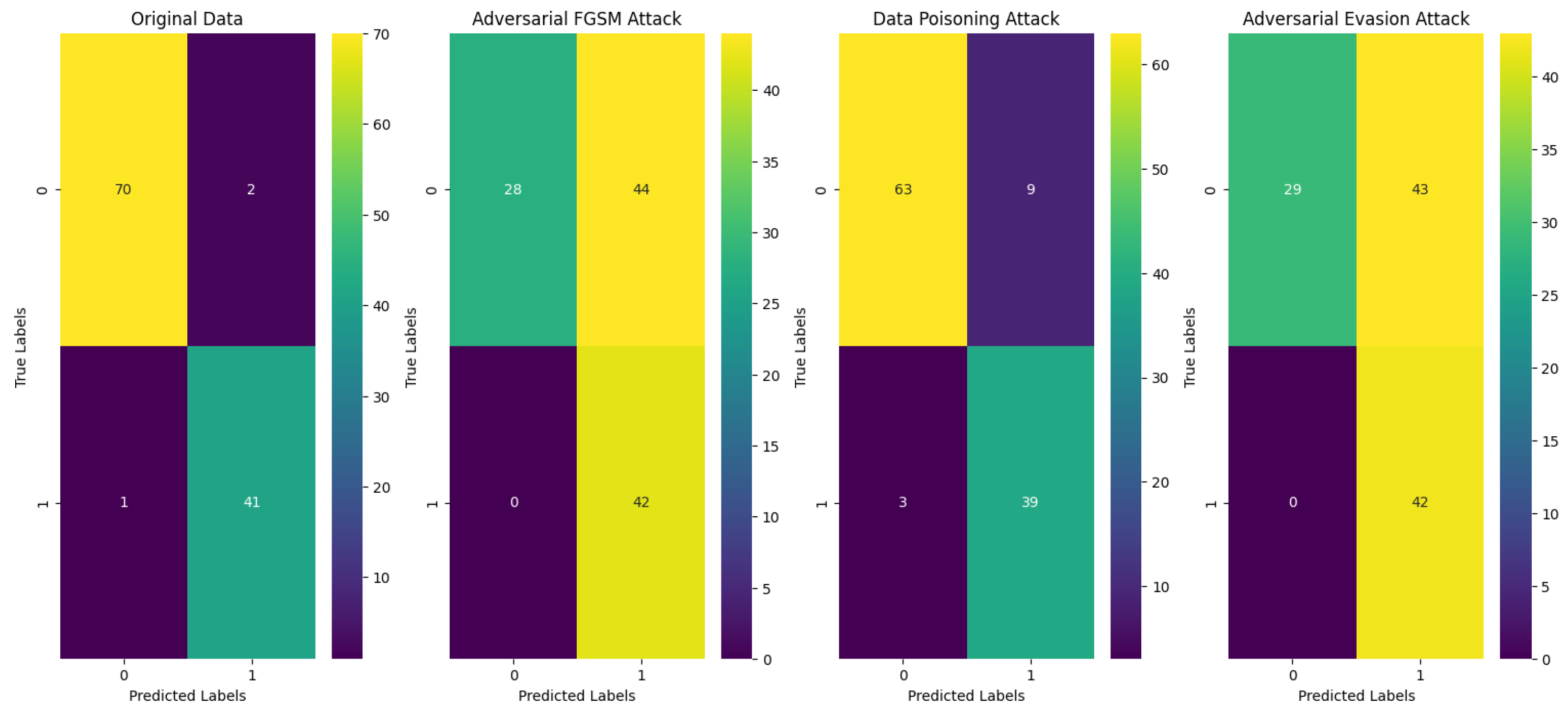
| Attack Type | Accuracy | PAVI | Confusion Matrix |
|---|---|---|---|
| Original data | 0.973684 | N/A | TN = 70, FP = 2, FN = 1, TP = 41 |
| Adversarial FGSM attack | 0.614035 | 0.385965 | TN = 28, FP = 44, FN = 0, TP = 42 |
| Data-poisoning attack | 0.894737 | 0.105263 | TN = 63, FP = 9, FN = 3, TP = 39 |
| Adversarial evasion attack | 0.622807 | 0.377193 | TN = 29, FP = 43, FN = 0, TP = 42 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Brohi, S.; Mastoi, Q.-u.-a. AI Under Attack: Metric-Driven Analysis of Cybersecurity Threats in Deep Learning Models for Healthcare Applications. Algorithms 2025, 18, 157. https://doi.org/10.3390/a18030157
Brohi S, Mastoi Q-u-a. AI Under Attack: Metric-Driven Analysis of Cybersecurity Threats in Deep Learning Models for Healthcare Applications. Algorithms. 2025; 18(3):157. https://doi.org/10.3390/a18030157
Chicago/Turabian StyleBrohi, Sarfraz, and Qurat-ul-ain Mastoi. 2025. "AI Under Attack: Metric-Driven Analysis of Cybersecurity Threats in Deep Learning Models for Healthcare Applications" Algorithms 18, no. 3: 157. https://doi.org/10.3390/a18030157
APA StyleBrohi, S., & Mastoi, Q.-u.-a. (2025). AI Under Attack: Metric-Driven Analysis of Cybersecurity Threats in Deep Learning Models for Healthcare Applications. Algorithms, 18(3), 157. https://doi.org/10.3390/a18030157