The performance of the recognition system based on the proposed technique is evaluated in this section. The evaluation is performed using the McGill dataset formed in [
54].
Figure 5 shows samples of the object in the dataset. The dataset (McGill) serves as a benchmark dataset and includes nineteen classes expressed as 3D objects. These classes are categorized as planes, chairs, dinosaurs, fishes, cups, birds, spiders, spectacles, snakes, octopus, teddies, pliers, dolphins, fours, ants, humans, tables, and craps. For the SVM, we utilized the LIB-SVM version 3.24 [
55]. It is noteworthy that the experiment is performed using Matlab 2019 on an 8-core core i7-4700MQ CPU with a frequency of 2.4 HGz and 16 GB RAM.
In this paper, we focused on 19 different objects and applied a range of translation effects to enrich the original dataset. The augmentation process starts by shifting each object within a range from −10 to 10 along the x, y, and z axes, using a step size of 5. This systematic shifting creates a diverse array of translations, which helps the recognition system generalize better across various object positions. This augmentation approach guarantee that the dataset captures a wide range of spatial arrangements. A total of 5902 samples are generated as a result of the utilized augmentation techniques. To evaluate the performance of the proposed technique, we implemented different evaluation metric, which are discussed in the following sections.
4.1. Analysis of Optimal Parameter for Orthogonal Polynomial
In this section, first, we performed an experimental analysis to evaluate the performance of the proposed system for different values of the orthogonal polynomial parameter (
p). The goal of this analysis is to identify the optimal value that enhances the performance of the proposed system. Support vector machine (SVM) is utilized as a classifier for this analysis. SVM is a powerful tool in the field of machine learning which is widely employed for classification and regression tasks. Compared to other classifiers, SVM’s robustness against signal fluctuations makes it particularly effective for recognition applications [
53].
In this paper, SKTP is applied to 3D objects that are chosen from the McGill dataset. Various values of the polynomial parameter (p) are tested for the nth order of the polynomial (), where (p) affects the polynomial’s shift. The maximum order of the polynomial, denoted as (), is set to 8, 10, and 12, while the values of the polynomial parameter (p) include 0.2, 0.3, 0.4, 0.5, and 0.6.
The SVM model was trained using 4134 3D objects from the McGill dataset, and the testing phase involved 1768 3D objects. The details of the dataset are given in
Table 1 We examined three different cases of the orthogonal parameter to determine which configuration yields the best fitting effect of SKTP, ultimately aiming to achieve the most accurate signal representation based on the information provided by the 3D objects.
First, the SVM model is trained and tested in clean environment with the results reported in
Table 2.
The results shows that the highest performance score is 86.765, which is achieved with ( 0.4) and ( 10). This combination indicates that a moderate value of (p) paired with a polynomial order () of 10 yields optimal results. Furthermore, the results demonstrate that the accuracy increases as the polynomial parameter p increases from 0.2 to 0.4, and the recognition accuracy declines after the polynomial parameter p becomes greater than 0.4 (0.5 and 0.6).
Moreover, the analysis of the average recognition accuracy across different polynomial orders () is important to providing the effect of the polynomial order. For ( 8), the average recognition accuracy is 79.593, indicating a good ability to capture a relevant representation of the data. This recognition accuracy increases to 83.971 for ( 10), which shows that the model benefits from increasing the number of features by a higher polynomial order, which enhances the fitting capabilities of data distribution. However, as the polynomial order increases to ( 12), the average performance score decreases to 81.912. The decrease in average performance shows that as the order of the polynomial increases, the complexity is also increases, potentially resulting in overfitting. These findings show the importance of selecting an appropriate polynomial order, as the results indicate that while higher orders can improve performance, there exists an optimal threshold.
To investigate the performance of the proposed approach, an experiment is performed in different noisy environments, namely Gaussian, salt-and-pepper, and speckle noise. This experiment aims to examine the effects of these various noise types on the ability of the presented technique to generalize across different configurations of the orthogonal polynomial parameter (
p) and polynomial orders (
). The obtained results are reported in
Table 3,
Table 4 and
Table 5.
In
Table 3, a comprehensive evaluation of 3D object recognition based on the proposed technique for polynomial order (
8) is presented across various environments with different noise parameters. The Gaussian noisy environment reveals a decline in recognition accuracy as the noise level increases. At a Gaussian noise level of 1%, the recognition accuracy is 84.842 at
0.4, indicating that the performance can be considered good under low noise conditions. However, as the noise level increases to 5%, the recognition accuracy drops to 78.676. The recognition accuracy in the salt and pepper noisy environment follows a comparable trend when compared to the Gaussian noisy environment, with a maximum recognition accuracy of 84.785 at
0.4 and a noise density of 1%. As the noise level increases, the recognition accuracy declines, reaching a score of 80.147 at
0.4 and a noise density of 5%. The analysis of speckle noise further emphasizes the challenges posed by noise in maintaining recognition accuracy. The results show that the recognition accuracy is 84.615 at
0.4 and a noise variance of 0.2, but recognition accuracy decreases as the noise level increases, with a score of 80.882 at
0.4 and a noise variance of 1.
In
Table 4, we present a detailed assessment of 3D object recognition performance using the proposed technique for polynomial order (
10) across various environments with differing noise parameters. In the clean environment, the system exhibits a high recognition accuracy, achieving a peak score of 86.765 at
0.4. This high accuracy indicates that the system effectively captures the underlying features of the data without the interference of noise. The performance remains commendable across other parameter settings, with scores of 85.294 at
0.5 and 83.824 at
0.3. However, the lowest score of 81.618 is observed at
0.2. When Gaussian noise is applied to the objects, the recognition accuracy shows a gradual decline as the noise level increases. At a noise level of 1%, the system maintains a recognition accuracy of 85.464 at
0.4, indicating that it performs well under low noise conditions. However, as the noise level rises to 5%, the accuracy decreases to 82.127. The recognition accuracy for Gaussian noise at different levels demonstrate a consistent downward trend, with accuracy values of 84.615 at
0.4 for a noise level of 2% and 83.993 at the same parameter for a noise level of 3%. The performance in the salt and pepper noisy environment reveals the same trends observed in the Gaussian noise scenario. The system achieves a maximum recognition accuracy of 85.351 at
0.4 and a noise density of 0.01. As the noise density increases, the recognition accuracy declines, reaching 80.882 at
0.4 and a noise density of 0.05. This decline highlights that the system is sensitive to high levels of salt and pepper noise. The recognition accuracy for salt and pepper noise also reflect a gradual decrease, with values of 84.333 at
0.4 for a noise density of 0.02 and 83.258 at the same parameter for a noise density of 0.03. The analysis of speckle noise further illustrates the challenges associated with maintaining recognition accuracy in the presence of noise. The system achieves a recognition accuracy of 85.238 at
0.4 and a noise variance of 0.2. However, as the noise variance increases, the recognition accuracy declines, with a score of 83.088 at
0.4 and a noise variance of 1.
In
Table 5, we present a thorough evaluation of 3D object recognition performance using the proposed technique for polynomial order (
12) across various environments with differing noise parameters. In the clean environment, the system demonstrates comparable performance, achieving a peak recognition accuracy of 86.029 at
0.4. When Gaussian noise is applied to 3D objects, the recognition accuracy exhibits a decline as the noise level increases. At a noise level of 1%, the system maintains a recognition accuracy of 84.898 at
0.4, indicating that it performs well under low noise conditions. However, as the noise level rises to 5%, the accuracy decreases to 80.769. The accuracy for Gaussian noise at different levels shows a consistent downward trend, with accuracy values of 83.880 at
0.4 for a noise level of 2% and 83.258 at the same parameter for a noise level of 3%. The performance in the salt and pepper noisy environment follows a similar performance to that observed with Gaussian noise. The model achieves a maximum recognition accuracy of 84.842 at
0.4 and a noise density of 0.01. As the noise density increases, the recognition accuracy decreases, reaching 81.957 at
0.4 and a noise density of 0.05. The scores for salt and pepper noise also reflect a gradual decrease, with values of 84.219 at
0.4 for a noise density of 0.02 and 83.032 at the same parameter for a noise density of 0.03. The results of speckle noise illustrate the challenges associated with maintaining recognition accuracy in the presence of noise. The model achieves a recognition accuracy of 84.729 at
0.4 and a noise variance of 0.2. However, as the noise variance increases, the recognition accuracy declines, with a score of 81.618 at
0.4 and a noise variance of 1.
To this end, the results indicate that while the proposed technique performs well in clean environments, its slightly affected in the presence of noise, especially for OP parameter 0.4. The findings highlight that the recognition system based on the proposed technique is able to tackle the problem of noisy environments.
4.2. Comparison Between the Proposed System and Existing Works
To assess the effectiveness of the presented recognition system based on the proposed technique, we conducted a comparative analysis of its recognition accuracy against several existing methods. The algorithms included in this comparison are direct Krawtchouk moment invariants (DKMI), Tchebichef moment invariants (TMI), Krawtchouk moment invariants (KMI), Hahn moment invariants (HMI), Tchebichef–Tchebichef–Tchebichef moment invariants (TTTMI), Krawtchouk–Krawtchouk–Krawtchouk moment invariants (KKKMI), Tchebichef–Krawtchouk–Krawtchouk moment invariants (TKKMI), Tchebichef–Tchebichef–Krawtchouk moment invariants (TTKMI), geometric moment invariants (GMI), and overlapped block processing (OBP). The average recognition accuracy for both the presented recognition system and the existing methods are shown in
Table 6.
The comparison presented in
Table 6 highlights the performance of the proposed recognition system against several existing methods using the McGill database. The average recognition accuracy of each method is reported, providing a clear perspective on the effectiveness of the proposed approach.
The existing methods, including DKMI, HMI, KMI, and TMI, exhibit relatively low recognition accuracy, ranging from 60.32% to 62.01%. These results indicate that they are not too robust for the complexities presented in the McGill database. Moreover, the Tchebichef-based methods, which are TTTMI, KKKMI, TKKMI, and TTKMI, show improved performance, with an accuracy between 71.11% and 72.87%. This indicates that the incorporation of Tchebichef moments enhances the recognition capabilities compared to the earlier methods. However, even the best-performing Tchebichef-based method, TTKMI, achieves only 72.87%, which still falls short of optimal performance. In contrast, the proposed system demonstrates significantly higher recognition accuracy across all tested configurations. The system achieves an accuracy of 82.73% at polynomial order 8, which surpasses the best existing methods by a notable margin. When the polynomial order is increased to 10, the accuracy improves further to 83.85%, indicating that the proposed system benefits from higher polynomial orders, likely due to its enhanced ability to capture complex features in the data. In addition, for polynomial order of 12, the proposed system shows robust performance with an accuracy of 83.33% This stability of performance across different polynomials orders demonstrates that the proposed approach is robust and adaptable. thus, the variations in the dataset are effectively handled by the proposed approach.
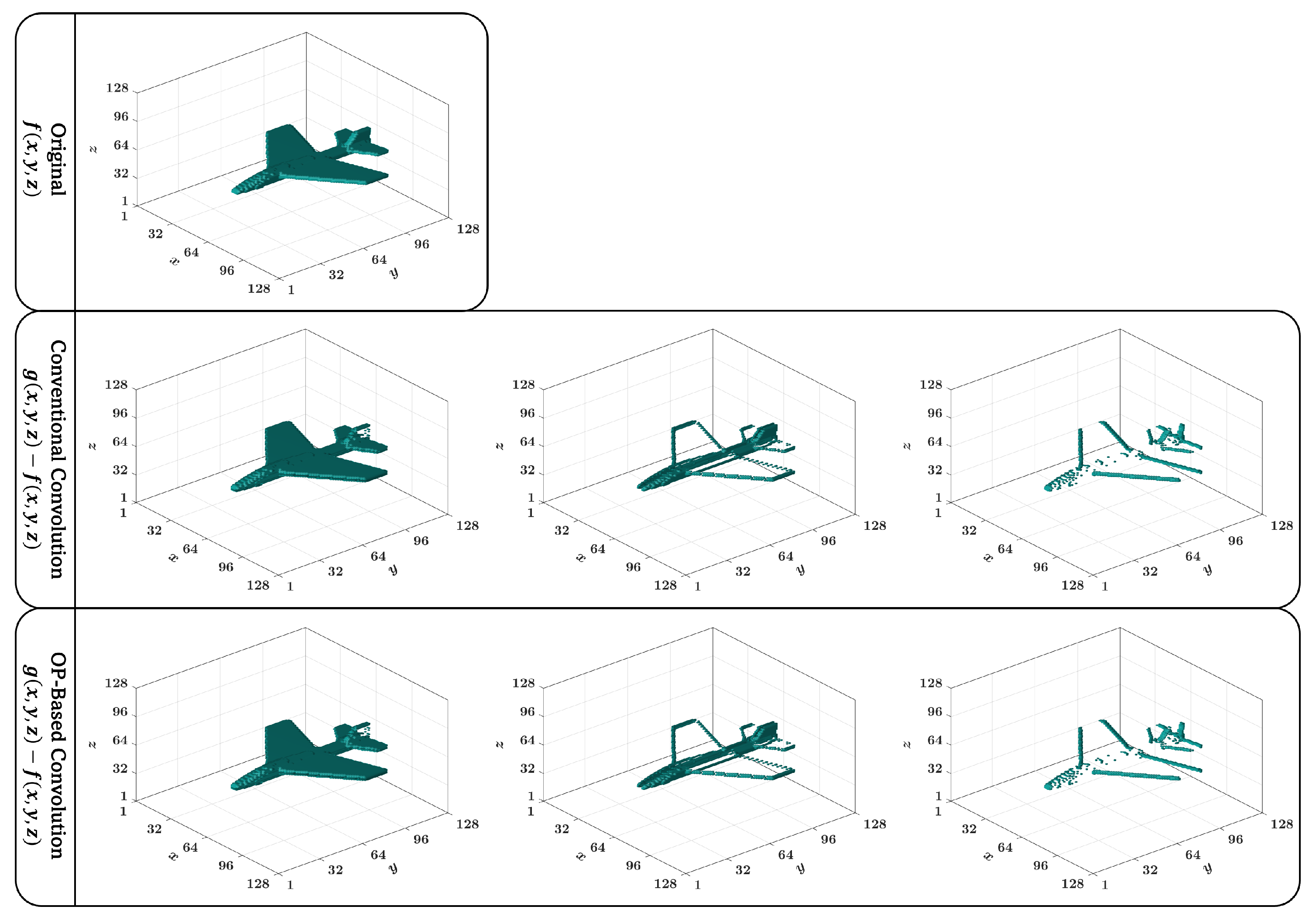
The performance of the proposed approach is further evaluated by benchmarking the proposed approach with the traditional method in terms of computational cost. In the traditional method, the 3D object is convolved by the kernel and then the moments are computed. It is noteworthy that the kernel utilized in the experiment is the averaging kernel with a length of 7.
For this purpose, the computation cost is evaluated by performing five runs for all 3D objects across different classes. Then, the average computation time is recorded for each 3D object. The comparison is conducted for three different polynomial orders (
8, 10, and 12), and the results are summarized in
Table 7. The table includes the computation time for both the proposed approach (Time (ours)) and the traditional method (Time (Trad)), as well as the percentage improvement (Imp) achieved by the proposed method over the traditional method. The percentage improvement is calculated using the following formula:
The minimum percentage improvement is observed for Class 16, with improvements of 47.0% at , 47.7% at 10, and 46.1% at 12. In contrast, the highest percentage improvement is achieved for Class 19, where the proposed method attains improvements of 64.2% at , 64.1% at 10, and 64.0% at 12.
The results demonstrate that the proposed algorithm significantly outperforms the traditional algorithm across all polynomial orders and classes. For instance, at , the average percentage improvement across all classes is 54.7%, while at and , the average improvements are 54.8% and 53.4%, respectively. This indicates that the proposed method consistently reduces computation time by more than half compared to the traditional approach. This clearly signifies the robustness and efficiency of the proposed algorithm, particularly when dealing with higher polynomial orders and complex 3D objects. The last row of the table provides the average computation time and improvement per 3D object, further confirming the superiority of the proposed method in terms of computational efficiency.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}