1. Introduction
Artificial intelligence (AI) and machine learning (ML) have transformed numerous fields by emulating human cognitive abilities and enhancing performance through algorithms driven by data. Within the healthcare domain, AI and ML have demonstrated great potential in disease detection, diagnosis, and treatment. In dermatology, these technologies have been particularly valuable in analyzing visually complex and diverse skin diseases. However, despite these advancements, the detection and classification of skin cancer remain significant research challenges in the fields of medical image analysis and computer-aided diagnosis. Early detection of skin cancer is vital for improving patient outcomes, underscoring the critical need for automated methods for detection and classification [
1].
Skin cancer, specifically melanoma, is a prevalent and dangerous form of cancer that exhibits an increasing incidence compared to other types [
2]. Melanoma originates in melanocytes, leading to skin darkening, and can manifest in various colors and shades [
3]. Its aggressive spread makes it highly hazardous and potentially fatal. These factors emphasize the urgent requirement for effective methods of detection and classification.
Accurate identification of skin diseases, including melanoma, is crucial for successful treatment, and machine learning methods have emerged as valuable tools for prognosis. However, the diverse characteristics of melanoma pose challenges to its precise extraction. Manual detection of skin cancer necessitates a comprehensive understanding of various types and features, while early detection using discriminatory features remains complex. Advanced techniques are therefore necessary to automate the extraction of relevant features.
This study aims to leverage the Principal Component Analysis (PCA) algorithm for extracting relevant features in skin cancer detection. Additionally, accurately classifying skin images into malignant and benign categories presents an additional challenge, which is addressed through the utilization of the AdaBoost algorithm as an ensemble classifier technique. AdaBoost enhances classification accuracy by iteratively training classifiers with low individual performance and combining their predictions through weighted voting.
Our approach addresses the challenges associated with skin cancer detection and classification by incorporating advanced techniques and algorithms. Consequently, this paper has the following contributions:
The primary contributions of this work involve the development of an efficient and accurate model for classifying and detecting skin cancer based on the CNN model. This model offers several key features and benefits:
To evaluate machine learning algorithms and select one model based on its best performance in predicting skin cancer.
To design a model that can automatically extract discriminative features without human expert intervention.
To build an ensemble classifier with an AdaBoost algorithm to improve performance.
The rest of the paper is structured as follows:
Section 2 presents a concise summary of the related work conducted in the field of skin cancer diagnosis. In
Section 3, the proposed methodology for detecting and classifying skin cancer is presented. In
Section 4, the experimental results are illustrated. Finally,
Section 5 encompasses the conclusions and future work.
2. Related Work
Cancer is one of the leading causes of deaths in the last two decades. It is either diagnosed malignant or benign [
1]. Skin cancer is the most frequent cancer in humans, and its rate is increasing intensely worldwide [
2]. Every year, more than 46,000 new cases are recorded in the United Kingdom [
4]. Early identification is critical for boosting survival chances, with one study reporting a 90% reduced mortality rate for early-stage skin cancer. However, the present biopsy procedure for diagnosis is laborious and time-consuming. Fortunately, computer technologies provide a viable answer by making it faster, simpler, and more economical to detect skin cancer indications. These systems use clinical pictures and machine learning algorithms to conduct early assessments of suspected skin disorders.
Melanoma skin cancer is the most serious and fatal disease in the family of skin cancer diseases [
3]. According to studies, the incidence of skin cancer is growing year after year in comparison to various types of cancer [
5]. Melanoma, an among the most prevalent kinds of skin cancer, involves melanocytes, cells on the skin’s surface that produce pigmentation [
6]. It can appear in a variety of dark tints and colors, including rose pink, royal purple, blue, and even colorless [
7]. Melanoma’s aggressive nature and tendency to spread quickly make it highly dangerous and potentially lethal. Melanoma can appear anywhere on the body; however, it most commonly occurs on the rear of the lower limbs [
8]. Skin cancer death rates can be considerably reduced with timely identification and early diagnosis [
7,
8]. As a result, the early detection and classification of skin cancer are crucial. Dermatologists noted that melanoma may spread to several sites and organs of the human body [
9]. As a result, melanoma is the most serious type of skin cancer. As a result, despite its rarity, it is far and away the leading cause of death [
10]. The rising frequency of skin cancer can be due to prolonged and direct sun exposure, which can cause the development of both benign and malignant tumors.
Melanoma and nevi are both melanocytic tumors, which can lead physicians to misclassify patients based only on visual inspection [
11]. Early diagnosis is critical since there is a greater likelihood of successful therapy in the early stages of the disease. However, visual variables such as eye tiredness might impede effective diagnosis, frequently resulting in inaccurate lesion detection [
12]. Identifying skin cancer early improves the odds of effective therapy. However, distinguishing between malignant and benign skin lesions and precisely diagnosing skin cancer at these early stages can be difficult. This is because skin lesions commonly resemble one another. Melanoma’s early development features are similar to those of other benign moles, making it difficult for even experienced dermatologists to distinguish between what is malignant and what is benign [
13].
Researchers are currently examining and evaluating different deep learning algorithms to detect skin diseases. In a study, five machine learning algorithms, namely Random Forest, Kernel SVM, Naive Bayes, Logistic Regression, and Convolutional Neural Networks, were utilized to diagnose skin disorders [
14]. According to the results, the Convolutional Neural Network model displayed the best performance in identifying diseases based on the confusion matrix. Another group of researchers proposed an AI system based on neural networks, which involved extracting features during image collection and utilizing a feed-forward neural network for classification. In a separate study, six alternative data mining methods were recommended to classify different types of skin diseases. Additionally, an ensemble approach combining Bagging, AdaBoost, and Gradient Boosting classifiers was developed, demonstrating higher accuracy and effectiveness in detecting skin diseases [
14]. Furthermore, the authors introduced an artificial intelligence technique for skin cancer detection that employed image processing and a deep neural network [
15]. The approach included segmenting the affected region, extracting its features using image processing, and utilizing a Convolutional Neural Network for prediction. The training and testing accuracy achieved were 93.77% and 89.5%, respectively. Finally, researchers presented an adaptable federated machine learning model for diagnosing various skin disorders. This model incorporated Dermoscopy and global intelligence (server) and exhibited improved accuracy in diagnosing skin conditions [
16].
Mustafa and Kimura [
17] proposed an automated method for detecting skin cancer, specifically melanoma, from photographs of affected skin regions. Their aim was to achieve higher precision by utilizing a small set of features. The images were initially divided into the relevant lesions, and then 15 features were extracted using techniques from image processing and computer vision. To implement the system, they employed a nonlinear Support Vector Machine (SVM) with a Gaussian radial basis function (RBF) kernel. The study involved a dataset of 200 photos, and the results showed that only six criteria were necessary for accurately identifying melanoma. The system achieved an accuracy of 86.67% using the optimal parameters.
Daghrir et al. [
18] introduced a hybrid approach that combined a Convolutional Neural Network (CNN) with two classical machine learning techniques, specifically K-nearest neighbors (KNN) and Support Vector Machines (SVM). They collected a dataset of 640 lesion images from the International Skin Imaging Collaboration (ISIC) archive, using 512 images for training and the remaining 128 images for testing. The CNN architecture comprised 9 layers, including 3 convolutional layers, 3 max pooling layers, 2 dropout layers, and a fully connected layer for prediction. Various preprocessing techniques, such as the Otsu method, filters, and the morphological snake’s method, were employed. The final classification involved all three algorithms, with a majority vote. This hybrid approach achieved an accuracy of 88.4%. Specifically, the CNN achieved the highest accuracy of 85.5% individually, followed by the SVM with a second-best accuracy of 71.8%.
Esteva et al. [
19] devised a method to classify universal skin diseases by fine-tuning the VGG16 and VGG19 architectures for training their networks. Their network attained a Top-1 classification accuracy of 60.0% and a Top-3 classification accuracy of 80.3%. These outcomes demonstrated a substantial improvement compared to existing methods in their experiments. The researchers further advocated for the adoption of a similar approach to enhance classification outcomes in skin disease detection.
Nasr-Esfahani et al. [
20] developed their own CNN that encompassed preprocessing, feature extraction, and classification functions. They employed a dataset of 170 nondermoscopic images obtained from the digital image archive of the Department of Dermatology at the University Medical Center Groningen (UMCG). To enhance the training process, the dataset was augmented, resulting in a total of 6120 original and synthesized images. Various preprocessing techniques, including illumination correction, mask generation, and Gaussian filtering, were applied. The CNN architecture consisted of an input layer, followed by alternating layers of convolution and max-pooling, culminating in a fully connected layer. The objective was to classify between two classes, melanoma and nevus. The proposed model achieved an accuracy of 81% with a specificity rate of 80%.
Jenitha et al. [
21] conducted a study where pre-processed images from a medical database were employed as input for three different machine learning algorithms: K-nearest neighbors (KNN), Support Vector Machines (SVM), and Convolutional Neural Networks (CNN). The objective of the classification task was to assign images to either the cancerous or noncancerous class. The dataset consisted of 1000 lesion images obtained from a medical institute. The data were divided into three subsets: training data, testing data, and validation data. In this study, the KNN algorithm achieved an accuracy of 80%.
Shah et al. [
22] presented an innovative method for classifying skin cancer based on texture and color features. Their system was designed to aid pathologists in determining the specific type of skin cancer. To evaluate the effectiveness of their approach, they utilized a benchmark image database containing 225 skin cancer images. The accuracy obtained using the K-nearest neighbors (KNN) classifier was 85%, which was slightly lower compared to the accuracy achieved with the Support Vector Machine (SVM) and Convolutional Neural Network (CNN) classifiers.
Yuan et al. [
23] developed a decision-based support system aimed at assisting in the early diagnosis of skin cancer. The main focus of the system was to utilize texture information exclusively to predict whether skin lesions were benign or malignant. To enhance generalization error rates and computational efficiency, a three-layer system based on SVM was employed. To validate their approach, a binary class benchmark classifier was used. They trained an SVM with a polynomial kernel of various degrees on a dataset of 2000 samples. By identifying the malignancy in skin lesion images, they found that a degree 4 polynomial yielded optimal results, achieving a standard accuracy rate of 70%.
Ashafuddula and Islam [
24] developed an automated deep learning system for classifying melanoma and nevus moles using high-intensity pixel values from lesion images. The model achieved notable performance metrics, including an accuracy of 92.58%, sensitivity of 93.76%, specificity of 91.56%, and precision of 90.68%. However, the study has several limitations, such as reliance on a specific dataset, which may limit the model’s generalizability to other datasets or diverse populations. Additionally, the model’s focus on high-intensity pixel values may overlook other important features like texture and shape. The study also lacks extensive real-world validation and faces challenges in model interpretability, which are crucial for clinical adoption. Addressing these limitations through broader validation, incorporating diverse features, and enhancing interpretability could improve the model’s robustness and facilitate its use in clinical settings.
Yang et al. [
25] developed a hybrid system combining machine learning and computerized adaptive testing (CAT) based on the Rasch model to classify skin cancer using data from the HAM10000 and ISIC 2019 datasets. Despite its promising results, the study has several limitations. These include its reliance on specific datasets, which may limit the model’s generalizability to other populations. The incremental learning approach requires careful data integration management to avoid model degradation. Additionally, challenges in model interpretability and the need for extensive real-world validation are significant hurdles for clinical adoption. Addressing these issues through broader validation, incorporating diverse data, and enhancing interpretability is crucial for ensuring the model’s robustness and practical applicability in clinical settings.
Dondapati et al. [
26] developed a system to classify skin cancer using CNNs, evaluated on datasets like HAM10000 and ISIC 2019. Despite achieving high classification accuracy, the study faces several limitations. These include reliance on specific datasets that may limit generalizability to other populations, substantial computational resource requirements, and the need for high-quality annotated data. The performance inconsistency across different skin lesion types highlights challenges with class imbalance and dataset diversity. Additionally, the interpretability of CNN models remains a significant hurdle for clinical adoption, as clinicians need to understand and trust the model’s decisions.
Zareen et al. [
27] developed a system that utilizes hybrid texture features for skin cancer classification. The study demonstrated the effectiveness of combining texture features with machine learning techniques to improve classification accuracy. However, the study has several limitations. The reliance on specific datasets may affect the generalizability of the model to other populations or real-world clinical settings. Additionally, while the hybrid texture features improve classification accuracy, the computational complexity and resource requirements may be high. The need for high-quality, annotated datasets is also a significant challenge, as these may not always be readily available. Furthermore, the interpretability of the machine learning models remains a critical issue, which is essential for clinical adoption. Addressing these limitations through the use of more diverse datasets, optimizing computational efficiency, and enhancing model interpretability is crucial for improving the robustness and practical applicability of the proposed system.
3. Materials and Methods
Self-learning algorithms are enabled by models inspired by the human brain. These models let machines to learn from data and gradually enhance their performance over time. Machine learning algorithms have grown in relevance across a wide range of industries, including healthcare. They are very useful for identifying disorders by utilizing medical databases. Many firms use these tools to forecast diseases early on and improve medical diagnostics. This study seeks to overcome the issues involved with skin cancer diagnosis and categorization by establishing a complete strategy.
This research focuses on addressing the challenges associated with skin cancer detection and classification by developing a comprehensive approach. The motivation behind the research is to improve the accuracy, efficiency, and accessibility of skin cancer diagnosis by incorporating advanced techniques and algorithms. The research builds on the Efficient Net B0 model, which is noted for its lightweight construction and strong picture categorization performance. To assess the effectiveness of our approach, we compare the performance of the Efficient Net B0 model with other widely used models, including EfficientNet B7, VGG-16, and AlexNet. These models represent state-of-the-art architectures in the field of image classification. The comparison encompasses evaluation metrics such as accuracy, precision, recall, and F1-score. Transfer learning is used to utilize pre-trained weights and improve skin cancer-classification accuracy. The Principal Component Analysis (PCA) technique is used for feature extraction, which reduces dataset dimensionality while keeping key properties. This helps to capture underlying information, simplify calculations, and decrease overfitting. The Adaboost technique improves classification accuracy by iteratively training weak classifiers and applying greater weights to misclassified examples. The combined strength of numerous weak classifiers improves overall performance and overcomes difficulties in correctly categorizing skin lesions. For classification and prediction, the model utilizes SVM, a supervised learning algorithm that creates a hyperplane to separate different classes in the dataset. By mapping the input data into a higher-dimensional space and finding the optimal hyperplane, SVM maximally separates the classes. As shown in
Figure 1, the model architecture consists of multiple algorithms working in tandem to achieve robust and accurate skin cancer diagnosis.
Through our research, we aim to develop a robust and accurate skin cancer diagnosis and categorization system by combining the power of the Efficient Net B0 model, PCA algorithm, Adaboost algorithm, and SVM algorithm. The use of these new approaches has the ability to enhance early detection, increase diagnosis accuracy, and eventually contribute to better treatment results for people with skin cancer.
3.1. Convolutional Neural Networks (CNNs)
CNNs are deep learning models developed to analyze visual data such as photos and movies. They are made up of many layers that extract hierarchical features using convolution, pooling, and nonlinear activation. CNNs are modeled after the visual processing systems seen in the human brain. The convolutional layer is the central component, capturing local patterns with learnable filters. Pooling levels down the sample while maintaining key information adds complexity, as do non-linear activation functions. Fully connected layers complete the final classification or regression operation, which is frequently followed by a SoftMax activation function for multi-class classification. CNNs learn optimum parameters via backpropagation and gradient descent to optimize a loss function. Large annotated datasets are essential for successful training. CNNs learn optimum parameters via backpropagation and gradient descent to optimize a loss function. Large annotated datasets are essential for successful training. CNNs excel at autonomously learning hierarchical representations and abstract features, making them extremely useful in computer vision applications. CNNs have revolutionized medical image analysis by extracting relevant characteristics that enable effective classification, segmentation, and detection. They have transformed medical image analysis and contributed to substantial progress.
3.2. EfficientNet B0 Model
The EfficientNet B0 model is a lightweight CNN design that performs well in image categorization. It is part of the EfficientNet family, which includes increasingly complicated models. EfficientNet B0 balances accuracy and computing economy by consistently scaling its breadth, depth, and resolution. Its design incorporates convolutional, pooling, and fully connected layers, which allow it to learn hierarchical representations from input pictures. During training, methods like backpropagation and gradient descent are used to improve the model parameters. It is often trained on large-scale picture datasets, such as ImageNet, to obtain generalizable features. Once trained, the EfficientNet B0 model may be used to perform various image-classification tasks, such as identifying skin cancer, by determining the probability distribution across classes. Its usefulness stems from its ability to retain accuracy while remaining computationally efficient.
3.3. Principal Component Analysis (PCA)
The curse of dimensionality refers to the difficulties that come when working with datasets that have a large number of dimensions. It makes it difficult to generate statistically significant findings, increases overfitting, takes longer to compute, and reduces accuracy in machine learning models. This issue is addressed using feature engineering approaches such as feature selection and extraction. PCA is a widely used dimensionality-reduction approach that uses an orthogonal transformation to convert correlated variables into uncorrelated ones. It detects primary components, captures the highest variation in the data, and decreases dimensionality while keeping key patterns, as shown in Algorithm 1. Using PCA in skin cancer-classification procedures improves efficiency and efficacy by lowering computing complexity and the risk of overfitting. PCA works by preprocessing the data, calculating the covariance matrix, conducting eigen decomposition, selecting principal components based on eigenvalues, and projection the data onto the chosen components. It enhances data visualization, computational efficiency, and the effectiveness of machine learning algorithms by collecting useful aspects. PCA is a strong feature extraction approach that minimizes dimensionality while maintaining crucial properties.
Here is how PCA works to extract features:
Data preprocessing: Initially, the input data are preprocessed by shifting them to a mean of zero. This step ensures that the data are centered on the mean. The preprocessed data are then grouped into matrix X, which has n samples and m variables. This matrix is typically referred to as X and has dimensions (n × m).
Mean calculation: We determine the mean for each variable across all samples. The mean vector has dimensions of 1 × m
Calculate the covariance matrix: It quantifies the associations between various characteristics in the dataset, revealing how they co-vary with one another. The covariance matrix is generated from preprocessed data and represents the connections between variables. The following formula is used to determine each element in the matrix.
- 4.
Eigen decomposition: The covariance matrix is decomposed to obtain its eigenvectors and eigenvalues. The resulting eigenvectors reflect the primary components, which encapsulate the data’s key patterns. The associated eigenvalues indicate the amount of variation explained by each major component. During the eigen decomposition procedure, the covariance matrix is divided into eigenvectors and eigenvalues. Eigenvalue decomposition and Singular Value Decomposition (SVD) are typical techniques for obtaining these eigenvectors and eigenvalues.
- 5.
Selecting principal components: The corresponding eigenvalues are used to calculate the principal components. The eigenvalues are arranged in descending sequence, with the top k eigenvalues chosen as principal components. PCA reduces the dimensionality of the data by identifying the top k main components. These main components are orthogonal to one another, implying they are uncorrelated. This quality enables PCA to reduce duplicate and less useful elements while focusing on the most important ones.
- 6.
Feature projection: The original data are projected onto the chosen primary components to produce a lower-dimensional representation. This projection effectively converts the data to a new feature space, with each dimension representing a primary component. This is accomplished by multiplying the transposed eigenvector matrix by the preprocessed data matrix (X).
Overall, PCA is an effective feature extraction approach that reduces the dimensionality of data while retaining its key properties. By identifying the most important features, PCA improves data visualization and computational efficiency, in addition to the effectiveness of subsequent machine learning techniques. The Pseudo Code of PCA is presented in Algorithm 1.
| Algorithm 1. The Pseudo Code of Principal Component Analysis (PCA) Algorithm |
Input: Data matrix X of size
where n is the number of samples and p is the number of features
Number of components k (k <= p)
Steps:
1. Standardize the data:
Compute the mean of each feature
Subtract the mean from each feature value to center the data
2. Compute the covariance matrix of the centered data:
Covariance matrix
3. Compute the eigenvalues and eigenvectors of the covariance matrix:
Eigenvalues λ and eigenvectors V of C such that
4. Sort the eigenvalues and their corresponding eigenvectors in descending order:
Sort eigenvalues λ in descending order
Reorder the eigenvectors V accordingly
5. Select the top k eigenvectors to form a new matrix W:
W = (v1, v2,..., vk) where vi is the i-th eigenvector
6. Transform the original data to the new subspace:
Principal components Z = X_centered × W
7. Compute the explained variance:
Total variance = sum(λ)
Explained variance for each principal component = (λ / total_variance)
8. Extract the most informative features:
Calculate the contribution of each original feature to the principal components:
feature_contributions = |W|
9. Output the principal components return Z, explained variance, and feature contributions. |
3.4. Adaptive Boosting (AdaBoost) Algorithm
AdaBoost, which stands for “adaptive boosting”, AdaBoost, or “adaptive boosting” is a well-known machine learning algorithm used for binary classification. It combines many weak classifiers to form a stronger classifier. Its core principle is to award larger weights to misclassified samples. This technique seeks to correct misclassifications in succeeding rounds, eventually resulting in the right classifications. The Pseudo Code of AdaBoost Algorithm is presented in Algorithm 2.
The working principles of Adaboost are stated below:
Weights for each sample:
Number of training instances:
- 2.
Training weak classifiers: Training samples are trained on classifiers, and the overall error of the model is determined as
- 3.
Calculating classifier weight: The weight of each weak classifier is determined by its performance. A classifier that performs better receives more weight.
The basic classifier’s performance is computed using the formula:
- 4.
Weight updating: This provides for a reduction in the weight of correctly identified samples while raising the weight of wrongly categorized ones.
New weights for misclassified samples:
To calculate new weights for successfully identified samples, multiply the old weight by
- 5.
Combining weak classifiers: The weak classifiers are combined by assigning weights to them based on their performance. These weights determine the contribution of each classifier to the final prediction.
- 6.
Making predictions: The final strong classifier is constructed by integrating the predictions of all weak classifiers. The forecast is produced based on the weighted majority vote of the weak classifiers.
| Algorithm 2. The Pseudo Code of AdaBoost Algorithm |
1. is the number of trainings
2. for
3. = ,) base classifier
4. ) weighted error of the base classifier
5. coefficient of the base classifier
6. for re-weighting the training points
7. then error
8. weight increase
9. else correct classification
10. weight decrease
11. return weighted “vote” of base classifier produces (strong classifier) |
3.5. Support Vector Machines (SVM)
SVM is a widely and commonly used machine learning technique for classification. As shown in Algorithm 3, it works by determining the best margin for separating distinct types of data. SVM uses kernel functions to handle both linearly and non-linearly separable data. Its goal is to optimize the margin between classes while accurately categorizing data points. SVM is a strong supervised learning classifier that can be applied to both binary and multi-class classification applications.
SVM have a hierarchical foundation made up of several layers. SVM is fundamentally made up of a training dataset, a training method, and a model structure. The training data consist of input characteristics and their related classifications, and the method uses support vectors to establish the ideal margin. The model structure includes information about the margin, support vectors, and feature weights. SVM sublayers contain the kernel function, which converts input to a higher-dimensional space for linear separation. Support vectors, which are critical for decision boundaries, are the data points that come closest to the margin. The decision margin defines the distance between the support vectors and the decision boundaries, with the goal of maximizing it. During classification, the trained SVM model is used to classify fresh data by translating it into a high-dimensional space and analyzing its location relative to the model’s margins and bounds.
In addition to its layered architecture, the SVM algorithm is enhanced with the inclusion of a pseudo code snippet, as detailed in Algorithm 3. This pseudo code provides a structured representation of the algorithmic steps involved in SVM classification. Additional layers of SVM, such as the direct inference extension and the multi-class SVM layer, further contribute to its classification efficiency and handling of multi-class classification issues.
| Algorithm 3. The Pseudo Code of SVM Algorithm |
Inputs:
: Training matrix (each row represents a training sample)
: Corresponding classifications (values can be +1 or −1)
: Penalty parameter (measures the allowance for errors)
epsilon: A small value for stopping criterion (convergence threshold)
max_iterations: The maximum number of iterations
Steps:
1. Initialize parameters:
Set weights w to zeros
Set bias b to zero
Set iteration counter t to 0
2. Repeat until convergence or reaching the maximum number of iterations:
Increment t by 1
For:
If margin < 1:
Compute the gradient of the loss function with respect to
Compute the gradient of the loss function with respect to
b: gradient_b = −C ∗ y_i − Update weights:
Return w, b |
3.6. Dataset
The International Skin Imaging Collaboration (ISIC (and DermIS datasets were chosen for their comprehensive and diverse collection of skin cancer images, which are essential for developing a generalized model. By incorporating these datasets, we ensured that our model could effectively classify a wide range of skin lesion types and conditions. These datasets serve as crucial resources for training and testing machine learning models, especially those based on CNNs. By leveraging these datasets, researchers and practitioners can successfully extract unique features and improve the accuracy of skin cancer-classification algorithms. They are indispensable tools for enhancing the performance of machine learning algorithms used in diagnosing skin cancer.
We divided the dataset into 10 equal parts (folds). For each fold, 9 parts were used for training the model, and the remaining part was used for testing. This process was repeated 10 times, each time using a different fold for testing and the remaining folds for training. By averaging the results across all folds, we obtained a comprehensive and unbiased evaluation of the model’s performance. As shown in
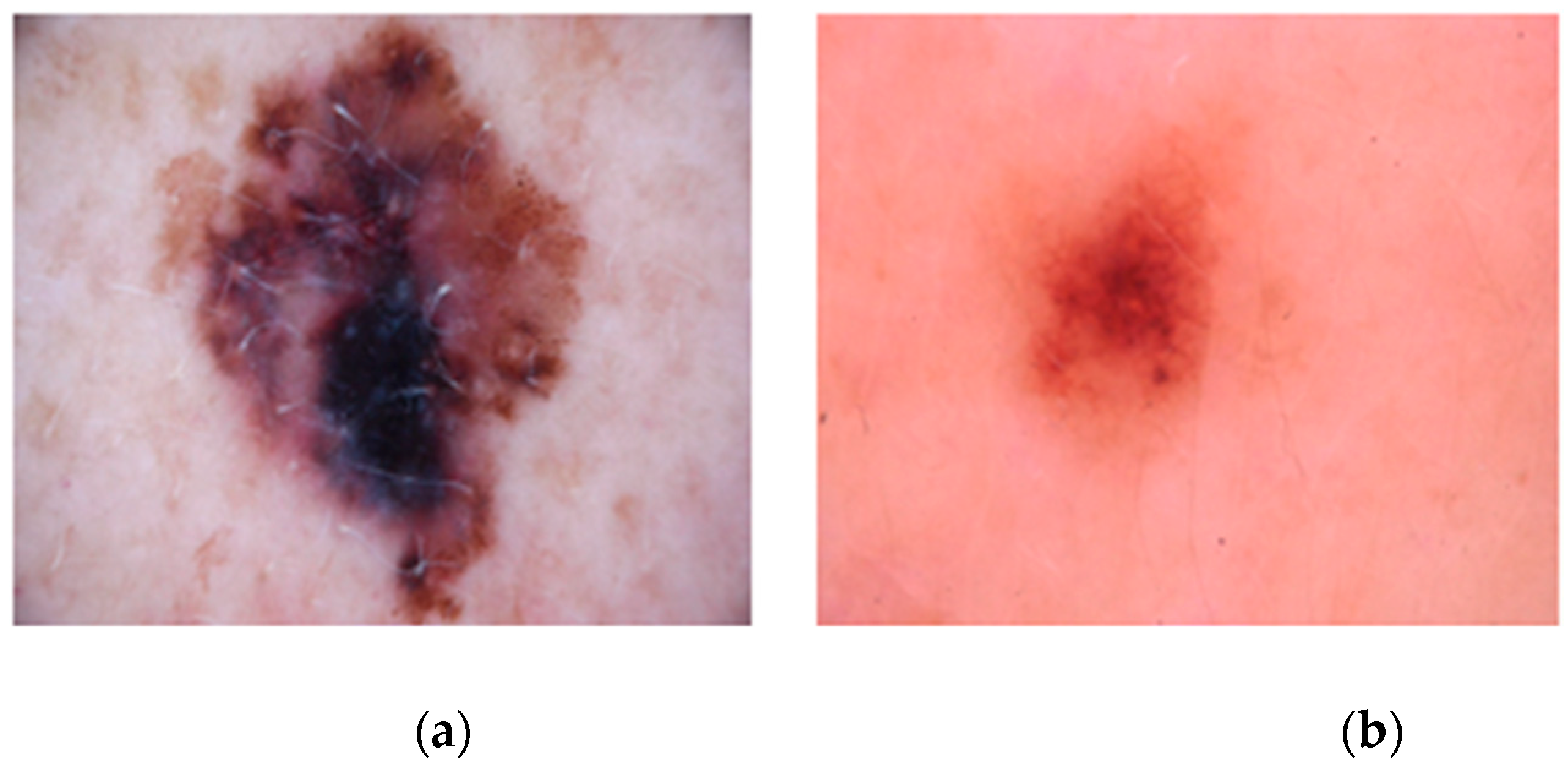
Figure 2, the images used in this study include both melanoma and benign skin lesions, which are critical for training the model to distinguish between different types of skin conditions.
Figure 2a illustrates a melanoma image, while
Figure 2b shows a benign image.
4. Experimental Results
When evaluating the efficiency of a classification model, relying solely on accuracy can be inadequate. Therefore, we assessed the efficiency of our skin cancer classifier using various metrics, including accuracy, precision, recall, F1 score, and support. Additionally, we utilized a Confusion Matrix to account for the number of correct and incorrect predictions, providing a comprehensive evaluation of the model’s performance. To measure the performance in a multi-class classification task, we calculated the average accuracy, recall, and F1 score.
These metrics were calculated using the mean and standard deviation across multiple cross-validation folds to ensure robustness and reliability. We employed 10-fold cross-validation to classify skin cancer using the ISIC and DERMIS datasets. Cross-validation is a robust statistical method that enhances the reliability and generalizability of machine learning models by preventing overfitting and ensuring performance consistency. This technique involves dividing the dataset into multiple folds (in our case, 10-fold cross-validation), training the model on 80% of the data, and validating it on the remaining 20%. By averaging the results across all folds, we obtained a comprehensive and unbiased evaluation of the model’s performance. Using both the ISIC and DERMIS datasets further validated the robustness and effectiveness of our model across different data sources, ensuring a reliable classification of skin cancer.
4.1. Evaluation Metrics for Performance
Several performance indicators, including accuracy, sensitivity, specificity, precision, and the F1-score, are used to evaluate the efficacy of various approaches for identifying skin cancer. These measurements are computed using the true positive (TP), false positive (FP), false negative (FN), and true negative (TN) values. Performance metrics are critical for assessing the success of a model. After the model has been trained on the existing data, performance measurements are used to assess its ability to properly categorize fresh, unseen data that were not included in the training process. To evaluate a model’s performance, numerous formulae are employed to determine key metrics including as sensitivity, accuracy, precision, recall, and F1 score.
These formulae are as follows:
- 2.
(Specificity) true negative rate: The true negative rate is determined by dividing the number of true negative (TN) predictions by the sum of TN and FP.
The formula for specificity is given below:
- 3.
Accuracy: is calculated by dividing the sum of true positives and true negatives by the total number of samples.
The accuracy formula is as follows:
- 4.
Precision: The amount of genuine positive predictions is divided by the sum of true positives and false positives.
Precision is calculated using the formula below:
- 5.
Recall (Sensitivity): To calculate recall, divide the number of true positive predictions by the sum of true positives and false negatives to compute recall.
The recall formula is as follows:
- 6.
F1 Score: This metric combines precision and recall. It is calculated using the harmonic mean of accuracy and recall, assigning equal weight to both measures.
The F1 score is calculated using the formula below:
These formulas provide a quantitative assessment of the model’s performance by comparing its capacity to accurately classify data and discriminate between true positives, true negatives, false positives, and false negatives.
4.2. Evaluation Metrics of the Algorithms and Classifiers That Were Applied in the Proposed Model
In our study, we conducted a comparative analysis of four classification algorithms (SVM, Random Forest, Neural Network, and Decision Tree) for skin cancer classification. We evaluated their performance using metrics such as accuracy, precision, recall, and F1-score. These metrics were calculated using the mean and standard deviation across multiple cross-validation folds to ensure robustness and reliability of the results.
4.2.1. Performance Evaluation of Classification Algorithms
Table 1 displays the mean and standard deviation of accuracy, precision, recall, and F1-score for each classification algorithm on the ISIC dataset and DermIS.
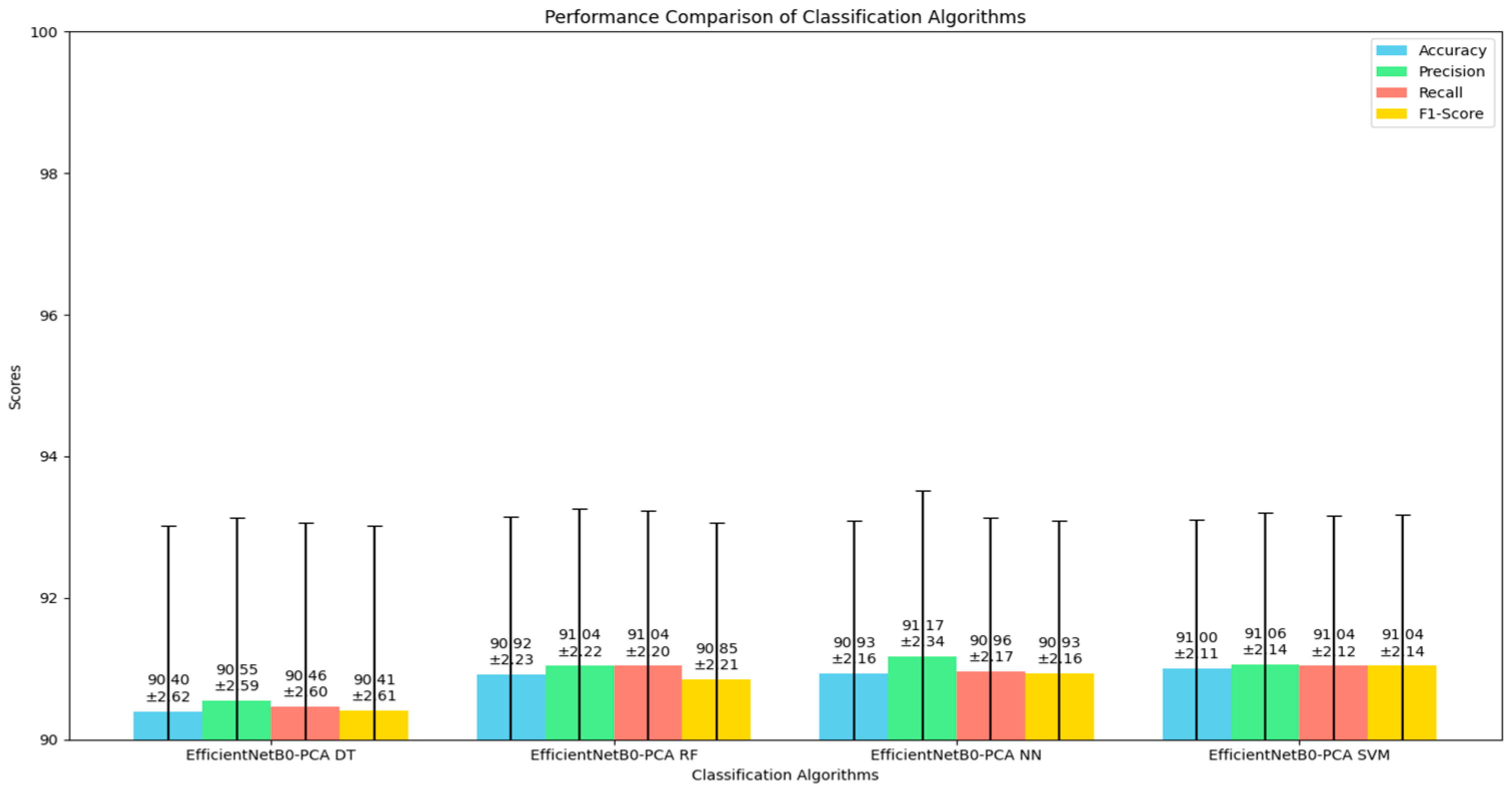
Table 1 presents the performance metrics for four classification algorithms evaluated for skin cancer classification using the ISIC dataset. The models compared include EfficientNetB0 with PCA followed by Decision Tree (DT), Random Forest (RF), Neural Network (NN), and SVM. The EfficientNetB0-PCA DT model achieved an accuracy of 90.40% with a standard deviation of 2.62%, while the EfficientNetB0-PCA RF model showed a slightly better performance with an accuracy of 90.92% and a standard deviation of 2.23%. The EfficientNetB0-PCA NN model achieved a mean accuracy of 90.93% with a standard deviation of 2.16%, demonstrating high precision and stability. The EfficientNetB0-PCA SVM model achieved the highest accuracy of 91.00% with the lowest standard deviation of 2.11%, indicating the best overall performance and stability among the models compared. The metrics are reported as “mean ± standard deviation” to provide insight into the average performance and variability across different cross-validation folds, ensuring a robust comparison and highlighting the reliability of the model in classifying skin cancer. This approach emphasizes the effectiveness of using EfficientNetB0 for feature extraction combined with PCA for dimensionality reduction and demonstrates that the SVM classifier outperforms other classifiers in this setup.
These results clearly show that EfficientNetB0-PCA SVM outperforms the other classification algorithms in terms of accuracy, precision, recall, and F1-score for skin cancer classification using the ISIC dataset. As shown in
Figure 3, The graphical plot highlights the comparative performance of each model, where EfficientNetB0-PCA SVM consistently achieves the highest metrics across all evaluation criteria. The bar representing the SVM model is noticeably higher, indicating superior accuracy (91.00 ± 2.11%) and demonstrating the least variability, which underscores its reliability and robustness in classification tasks. In contrast, the Decision Tree model, despite its simplicity, shows the lowest performance with an accuracy of 90.40 ± 2.62%, indicating higher variability and less stability. The Random Forest and Neural Network models perform better than the Decision Tree but still fall short compared to the SVM model. The precision, recall, and F1-score metrics follow a similar trend, reinforcing the conclusion that the SVM model provides a more balanced and consistent performance. This visualization effectively communicates the advantage of using EfficientNetB0-PCA SVM, making it a promising candidate for accurate and reliable skin cancer classification.
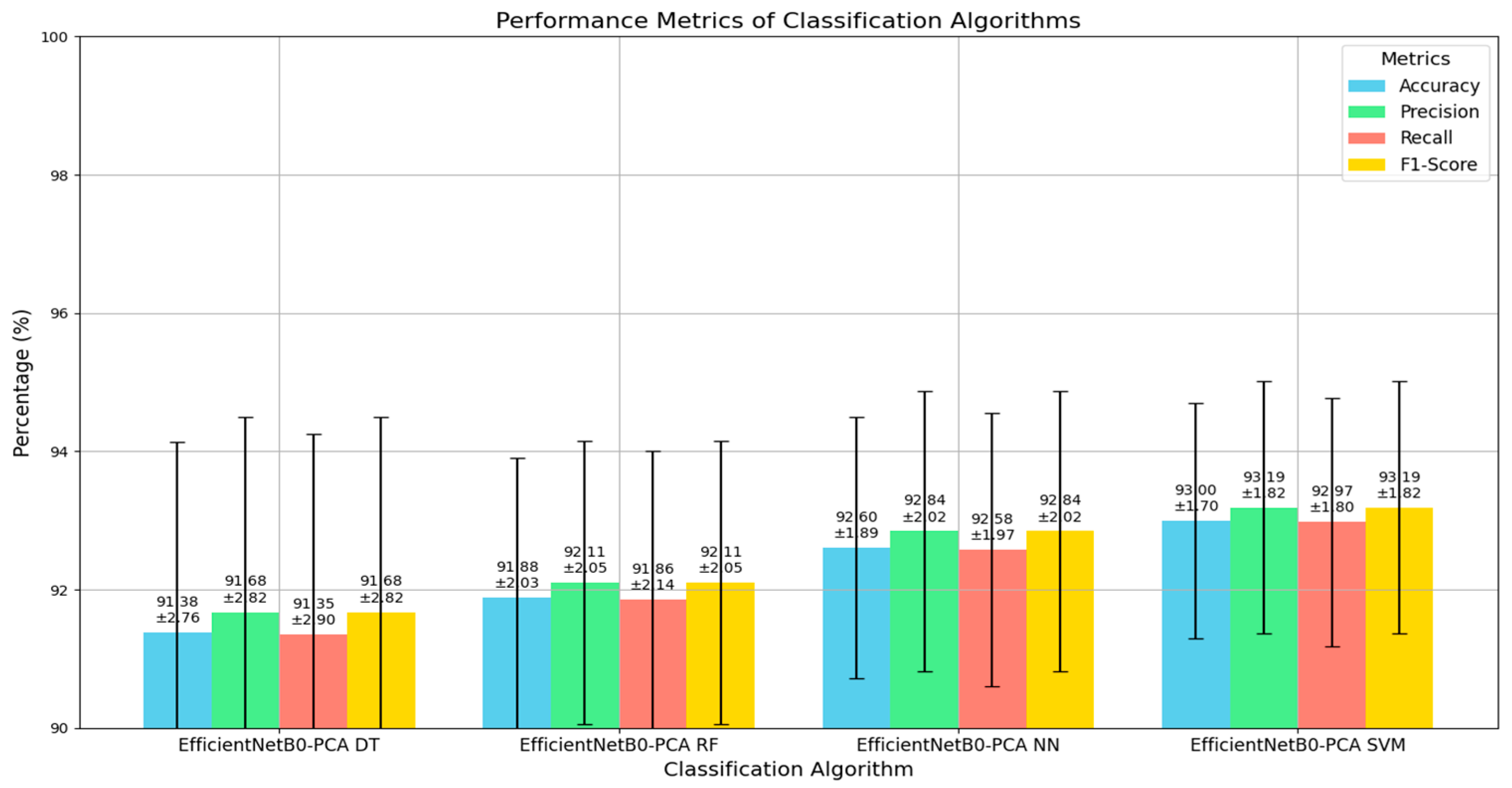
Table 2 provides a comparison of the performance of various classification algorithms in our model by showing their mean accuracy, standard deviation, precision, recall, and F1-score, all expressed as percentages. The EfficientNetB0-PCA NN classifier achieved a mean accuracy of 92.60% with a standard deviation of 1.89%, indicating strong and consistent performance. Its precision, recall, and F1-score were also high, with mean values of 92.845%, 92.579%, and 92.845%, respectively, and low standard deviations. The EfficientNetB0-PCA RF classifier had a slightly lower mean accuracy of 91.88% and a standard deviation of 2.03%. Its precision and F1-score were 92.106%, and recall was 91.855%, showing reliable but slightly less consistent performance compared to the NN model. The EfficientNetB0-PCA DT classifier had the lowest performance, with a mean accuracy of 91.38% and a higher standard deviation of 2.76%. Its precision, recall, and F1-score followed the same trend, with values of 91.676%, 91.348%, and 91.676%, respectively, indicating more variability in performance. EfficientNetB0-PCA SVM stood out with the highest mean accuracy of 93.00% and the lowest standard deviation of 1.70%, reflecting excellent and consistent performance. Its precision, recall, and F1-score were also the highest among all algorithms, with values of 93.185%, 92.975%, and 93.185%, respectively, and the lowest standard deviations, highlighting the robustness and reliability of this classifier. In summary, EfficientNetB0-PCA SVM surpasses other classifiers in terms of accuracy, precision, recall, and F1-score, with the additional advantage of lower performance variability, making it an exceptionally reliable choice for classification tasks in our model.
Based on our results, the performance metrics provide an overview of how each algorithm classifier performed in our model, as depicted in
Figure 4. The EfficientNetB0-PCA SVM classifier had the best overall performance, followed by EfficientNetB0-PCA RF and EfficientNetB0-PCA NN, while the EfficientNetB0-PCA DT classifier performed somewhat worse. The experimental findings clearly show that the EfficientNetB0-PCA SVM classifier beat the other methods in terms of accuracy, precision, recall, and the F1-score. As a result, we elected to use EfficientNetB0-PCA SVM algorithms in our model to identify and classify skin cancers. The excellent accuracy, as well as the balanced precision and recall values, demonstrate EfficientNetB0-PCA SVM’s ability to effectively detect cases of skin cancer.
The comparison study provided us with useful insights into the performance of several algorithms, which influenced our decision to choose the EfficientNetB0-PCA SVM classifier for skin cancer diagnosis and categorization. The experimental results showed how each model and algorithm combination performed in terms of accuracy, precision, recall, F1 score, and support. Our goal in comparing these results was to discover the most powerful algorithm that delivers high accuracy in skin cancer categorization.
4.2.2. Statistical Analysis: T-Test Results
To assess the statistical significance of the differences between the performance of various classification algorithms, we conducted pairwise T-tests on the accuracy results obtained from 10-fold cross-validation.
The results presented in
Table 3, showing no statistically significant differences between the classification algorithms (DT, NN, RF, SVM) using EfficientNetB0-PCA on the ISIC dataset, can be interpreted as positive. This indicates that multiple algorithms are effective for this task, providing flexibility and robustness in model selection. Researchers and practitioners can choose any of these models based on other factors such as computational efficiency, ease of implementation, or specific application requirements, without worrying about significant performance discrepancies.
The statistical analysis of classification algorithms for the DermIS dataset using EfficientNetB0-PCA, as shown in
Table 4, reveals no statistically significant differences between the compared pairs of algorithms. The T-statistic and P-value for each comparison (DT vs. NN, DT vs. RF, DT vs. SVM, NN vs. RF, NN vs. SVM, and RF vs. SVM) indicate that Decision Tree (DT), Neural Network (NN), Random Forest (RF), and SVM perform similarly on the DermIS dataset. This lack of significant differences suggests that these algorithms are equally effective for this task, allowing flexibility in choosing any of them based on other considerations such as computational efficiency or ease of implementation, without concern for substantial performance variations.
4.2.3. Mean Accuracy and Confidence Intervals of Classification Algorithms
This section presents the mean accuracy and the associated 95% confidence intervals for various classification models. Mean accuracy indicates the overall effectiveness of each model in correctly classifying the data. The 95% confidence intervals show the range within which the true accuracy. This takes into account the variability in the model’s performance across different data subsets, providing a clearer understanding of the model’s reliability and stability.
Table 5 presents the analysis of classification algorithms for the DermIS dataset using EfficientNetB0-PCA, as shown by the mean accuracy and 95% confidence intervals, demonstrates that all four models—Decision Tree (DT), Random Forest (RF), Neural Network (NN), and SVM—perform at a high level with comparable accuracy. The mean accuracies are 90.40% for DT, 90.92% for RF, 90.93% for NN, and 91.00% for SVM. The overlapping confidence intervals indicate no significant differences between their performances, suggesting that any of these algorithms can be effectively used for this classification task, providing flexibility in model selection based on other considerations such as computational resources or ease of implementation.
Table 6 shows the analysis of classification algorithms for the DermIS dataset using EfficientNetB0-PCA, demonstrating high performance across all models: DT (91.38%), RF (91.88%), NN (92.60%), and SVM (93.00%). The overlapping 95% confidence intervals indicate no significant performance differences, suggesting that any of these models can be effectively used for this task.
4.3. Evaluation Metrics of the Proposed Model with State-of-the-Art Pre-Trained Techniques
In
Table 7, we compare our suggest model’s performance with other state-of-the-art approaches. The table showcases the results of different classifiers applied to the DermIS dataset, using the SVM technique, and reports their corresponding accuracy scores.
In the study conducted by Amelard et al. [
28], a classifier was developed for the DermIS dataset, achieving an accuracy of 86%. Similarly, Almansour et al. [
29] introduced another classifier on the same dataset, obtaining an accuracy of 90%. Additionally, Farooq et al. [
30] presented their classifier for the DermIS dataset, obtaining an accuracy of 80%. Priya Natha [
31] worked on the ISIC dataset using an SVM classifier and achieved an accuracy of 86.9%, while A Abdelhafeez [
32] reached 85.74% accuracy on the ISIC dataset using the same technique.
In contrast, our proposed model achieved an impressive accuracy of 93% on the DermIS dataset and 91.00% on the ISIC dataset. These results clearly indicate that our proposed model exceeds the state-of-the-art models presented by Amelard et al. [
28], Almansour et al. [
29], Farooq et al. [
30], Priya Natha [
31], and A Abdelhafeez [
32] in terms of accuracy for both the DermIS and ISIC dataset.






{kind=link}
{kind=link}
{kind=link}
{kind=link}