
Logical Execution Time and Time-Division Multiple Access in Multicore Embedded Systems: A Case Study

 ,
,  ,
,  ,
,  ,
,  and
and 
Abstract
1. Introduction
- We propose a solution that merges the predictability of Logical Execution Time (LET) applied to inter-task communication with the composability of time-controlled buffers.
- We utilize a TDMA scheme for inter-core communication to ensure consistent latency and temporal determinism in core-to-core communication.
- Our proposal reduces the need to bind applications to specific cores, facilitating the creation of less dependent event chains.
2. Related Works
3. Communication Strategies in Multicore Systems
- Sampling jitter;
- Sample loss;
- Lack of determinism in event chains;
- Variable data exchange latency.
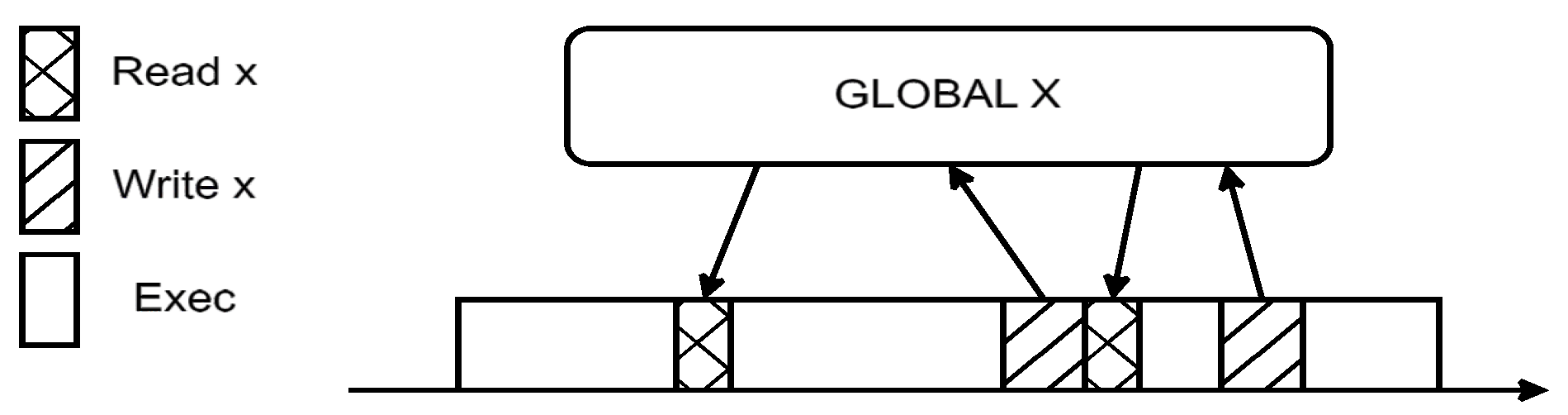
3.1. LET in Multicore Systems
- Assignment of a LET to a Task: A task requiring a Logical Execution Time (LET) needs data consistency and coherency during its execution. This is crucial when the task is part of an event chain where data must remain consistent and predictable throughout the chain. These tasks should have periodic executions, independent of their preemption characteristics. The LET assigned to such tasks defines the period during which they must perform their operations on shared memory. The LET is a fixed and predictable period that should match the rate of the task activation.
- Start of the LET Period: At the beginning of the LET period, read operations to shared memory are performed before the task starts its execution. This start is typically triggered by a system clock or an external event. Data read from shared memory are stored in the local context of the task, enabling it to perform operations locally.
- Execution of the Task’s Logic: During the LET, the task executes its logic, which may include data processing, decision-making, or interaction with other system components. During this time, output data that need to be written to shared memory are stored in local buffers to avoid contention.
- Completion of Execution: The task must complete its execution within the assigned LET period. If the task finishes before the LET period expires, it remains suspended until its next activation period. At the end of the LET, the output data are written to shared memory, ensuring data consistency and predictability throughout the system. Once the current LET ends, the next LET period begins, either for the same task or for a group of tasks in the system.
TDMA in Multicore Systems
4. Methodology
Predictability is the ability to provide an upper bound on the timing properties of a system. Composability is the ability to integrate components while preserving their temporal properties. Although composability implies predictability, the opposite is not true. A round-robin arbiter, for instance, is predictable, but not composable. A TDM (Time Division Multiplexing) arbiter, on the other hand, is predictable and composable [31].
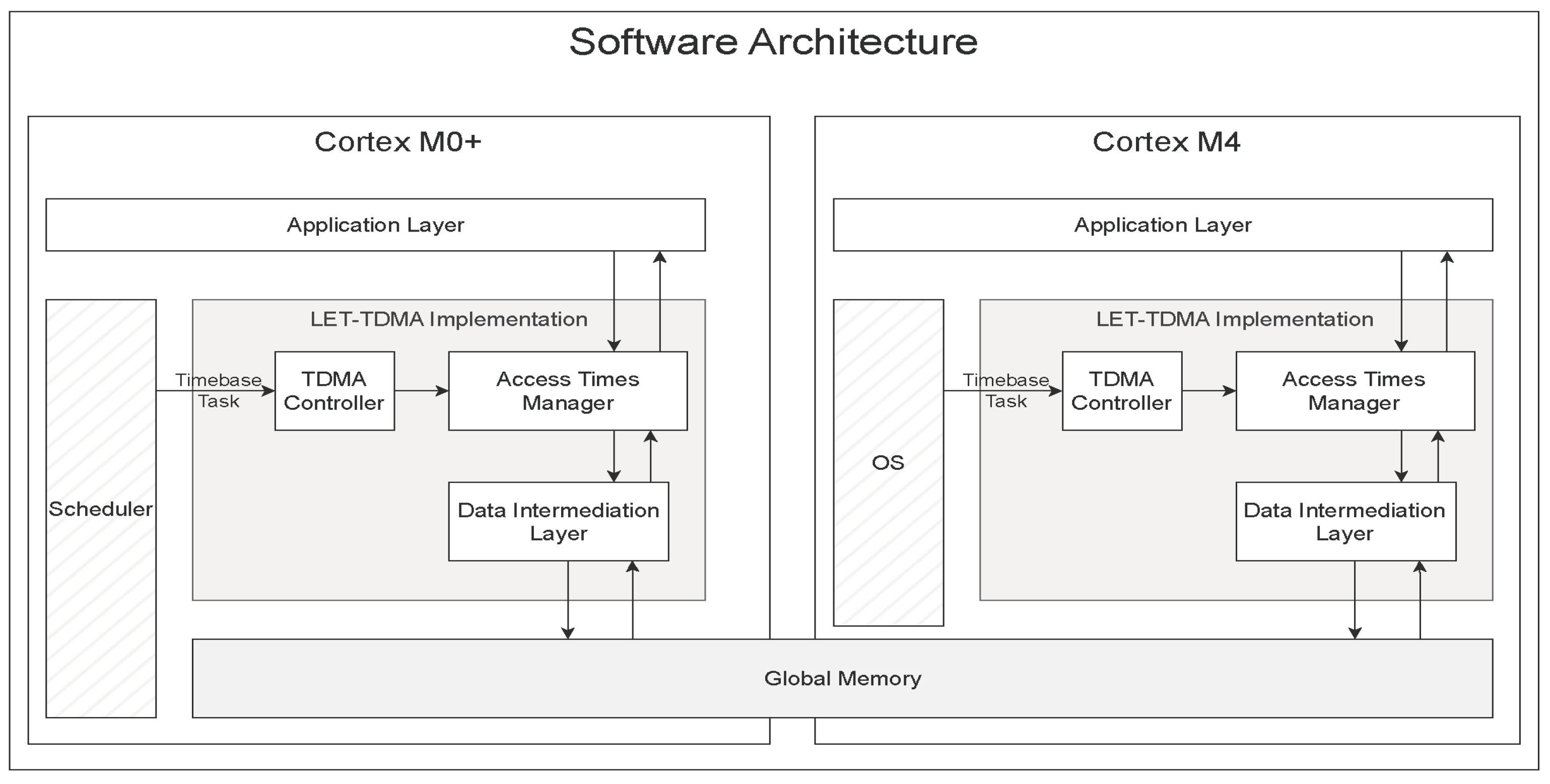
4.1. Implementation of LET Plus TDMA in Multicore Systems
- Determine the TDMA time intervals for communication between tasks on different cores that require sharing information. Assign specific time windows during which a task can transmit data through the communication channel.
- Assign an execution period to each task (LET), defining when the task should start its execution and when its results must be available. Additionally, set and fix the reading and writing times statically, allowing the system to behave predictably, as each task’s operations on shared memory have a defined execution period.
- Coordinate and plan the TDMA intervals with the LET execution times of the tasks to ensure that communication occurs without conflicts, thereby enabling communication within the TDMA intervals without interference.
- Implement mechanisms to synchronize the LET task groups with the same LET periods with their corresponding TDMA slots, maintaining the execution of tasks within the TDMA and LET processes.
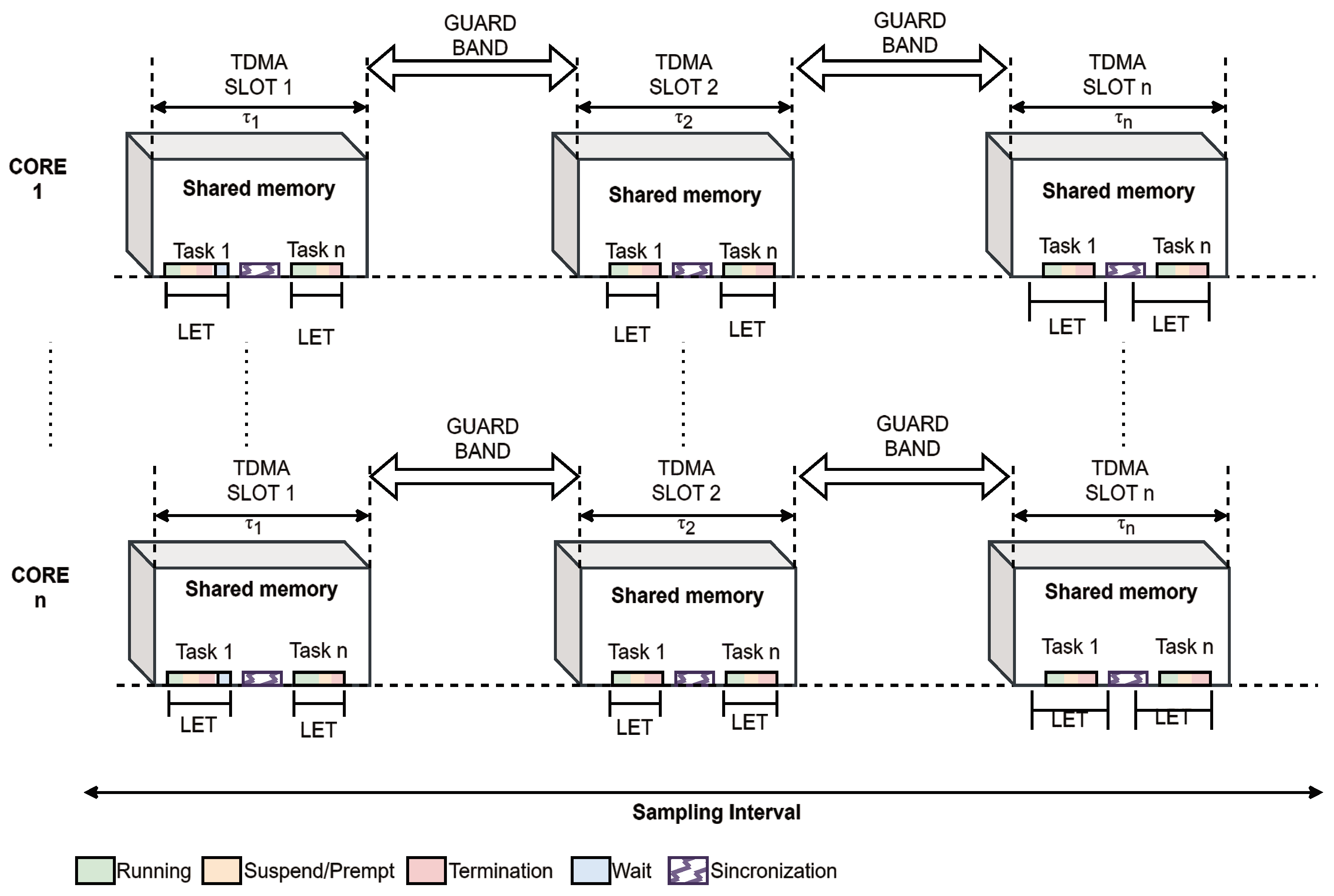
4.2. Implementation Details
- Enqueue: Organizes writing tasks from local memory to shared memory, acquiring local memory addresses from the local buffers for the writing process, and executes them throughout the task execution.
- Trigger: Checks and transfers pending data to the designated areas of the shared memory, ensuring its availability for other processes.
- Read: Facilitates access to the shared memory using specific identifiers to locate the necessary sections.
| Algorithm 1: Main system operation |
 |
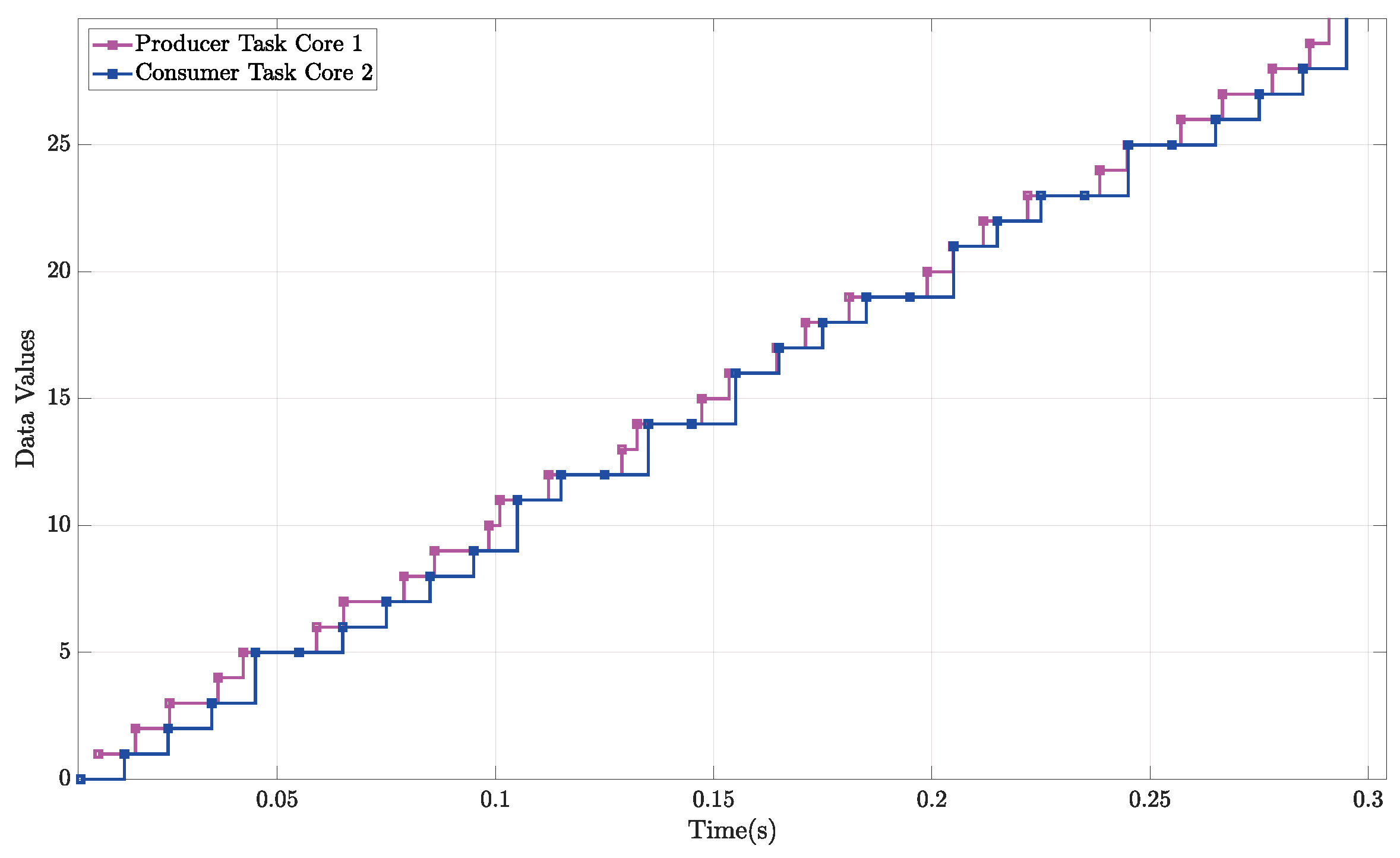
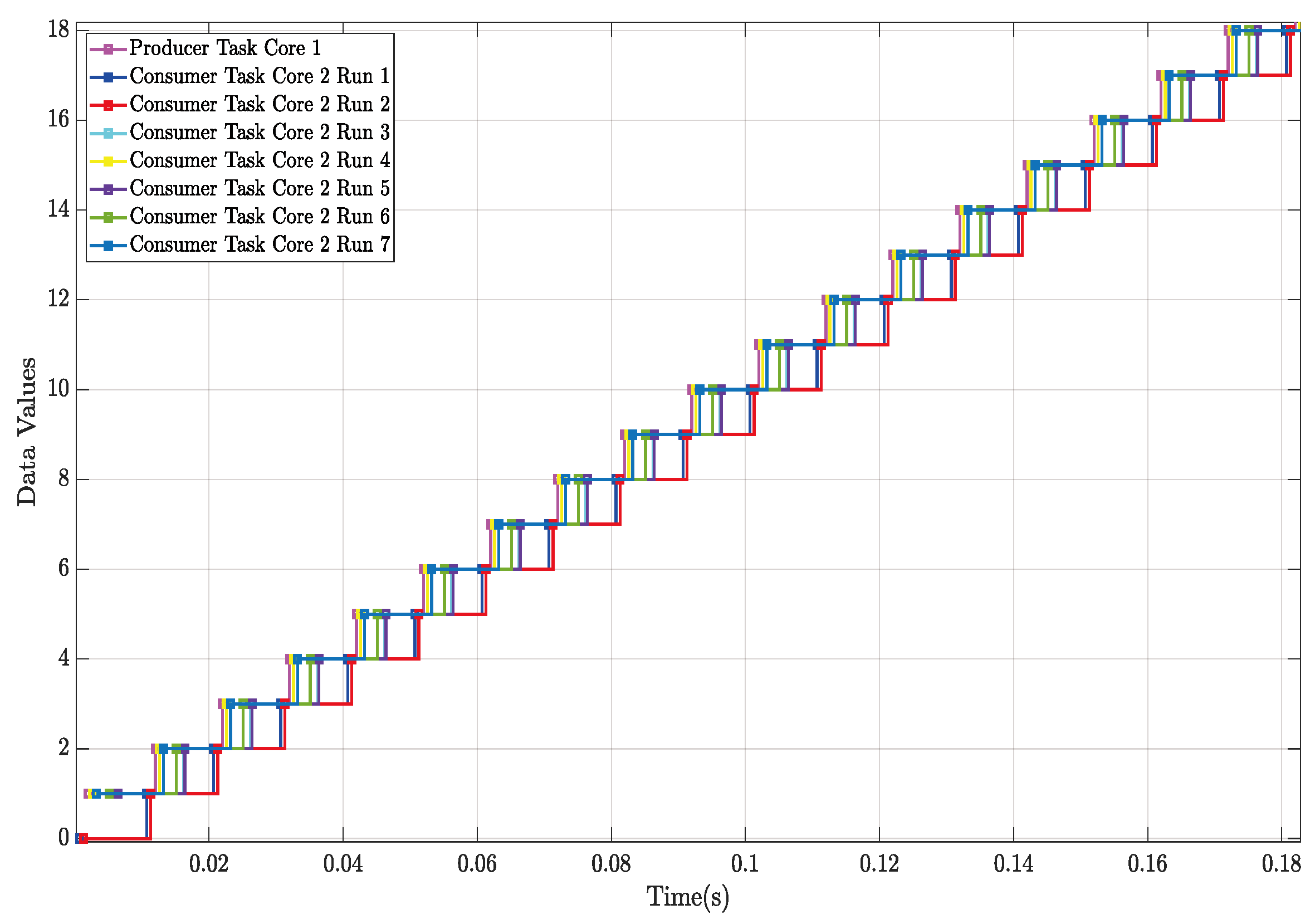
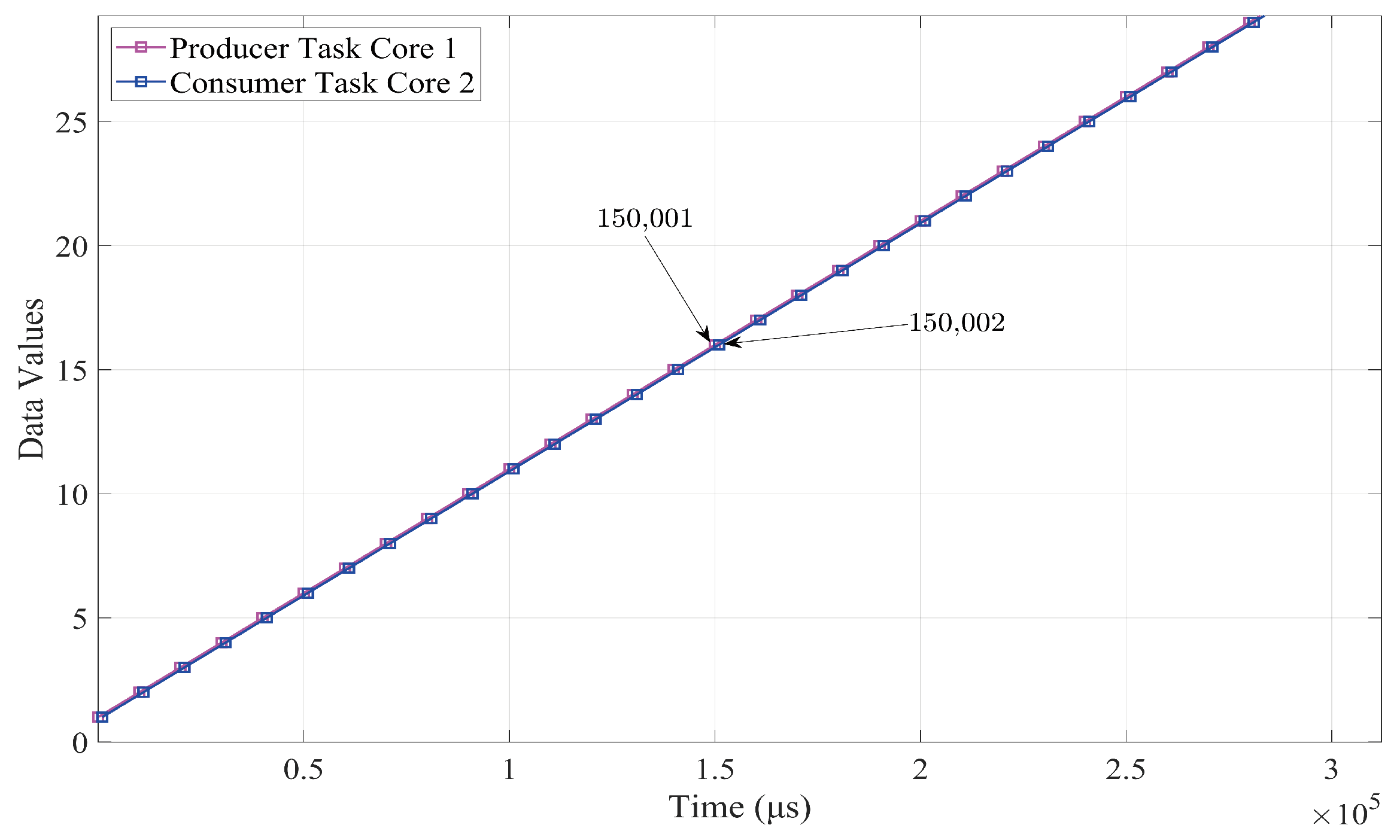
4.3. Characterization of Producer and Consumer Tasks
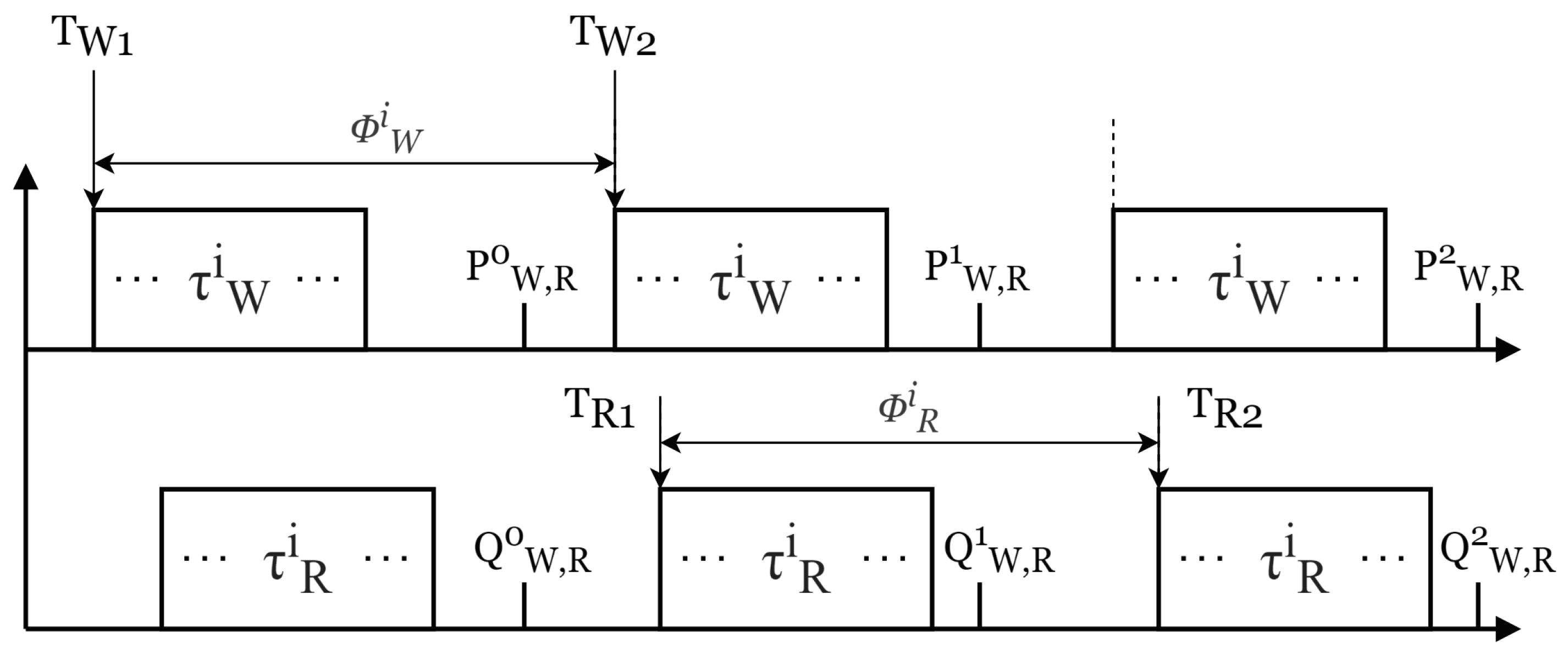
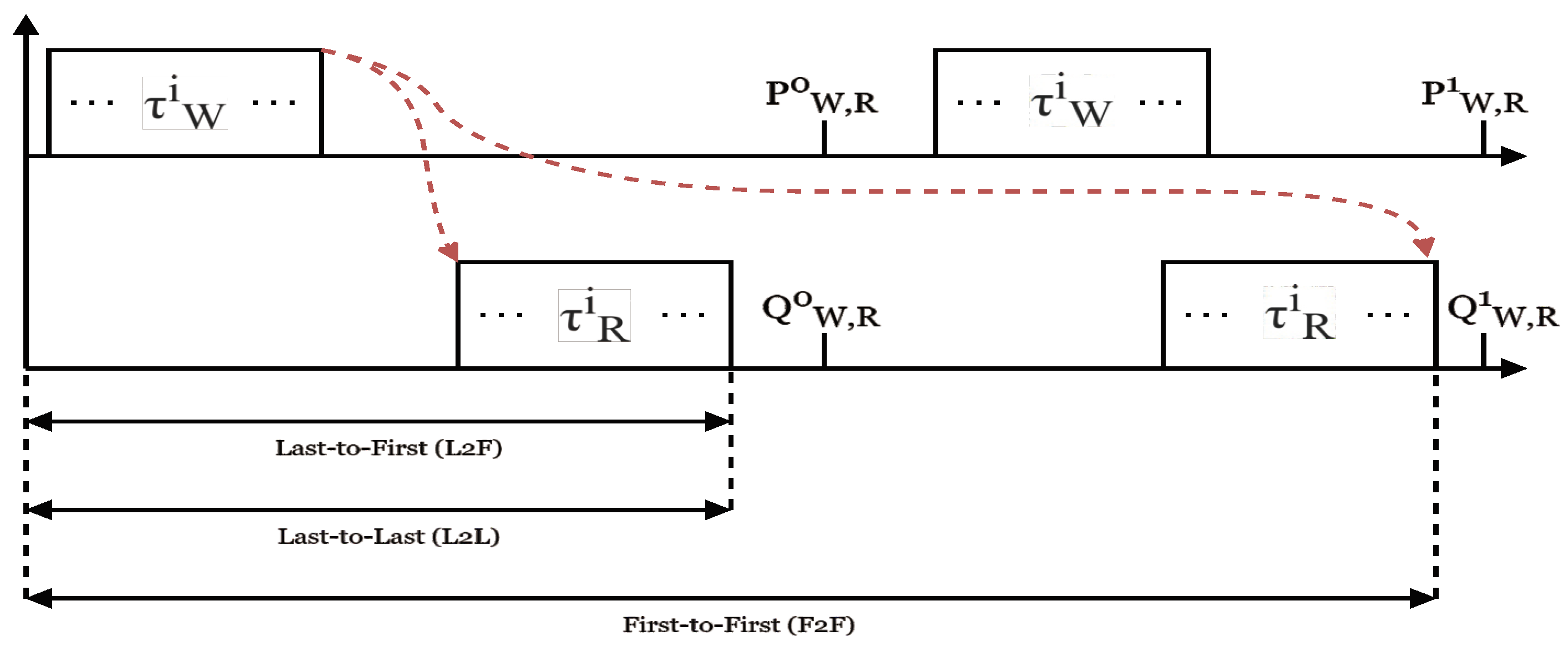
4.4. Characterization of End-to-End Latencies
4.5. Validation Methods
5. Results
6. Discussion
7. Conclusions and Future Directions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AUTOSAR | AUTOmotive Open System ARchitecture |
| CAB | Cyclic Asynchronous Buffer |
| DMA | Direct Memory Access |
| F2F | First-to-First |
| GASA | Genetic Simulated Annealing Optimization |
| ISR | Interrupt Service Routines |
| L2F | Last-to-First |
| L2L | Last-to-Last |
| LET | Logical Execution Time |
| MoDGWA | Multi-objective cost-aware Discrete Gray-Wolf optimization-based Algorithm |
| MPU | Memory Protection Unit |
| NoC | Network-on-a-Chip |
| NVM | Non-Volatile Memory |
| OS | Operative System |
| POSIX | Portable Operating System Interface |
| RAM | Random Access Memory |
| RMSE | Root Mean Squared Error |
| RTE | Runtime Environment |
| SFF | Scheduling Failure Factor |
| SL | System level |
| SMPU | Shared Memory Protection Unit |
| SPM | ScratchPad Memories |
| SRAM | Static Random Access Memory |
| TDM | Time-Division Multiplexing |
| TDMA | Time-Division Multiple Access |
| TIMEA | Time-Triggered Message-Based Architecture |
References
- Nidamanuri, J.; Nibhanupudi, C.; Assfalg, R.; Venkataraman, H. A progressive review: Emerging technologies for ADAS driven solutions. IEEE Trans. Intell. Veh. 2021, 7, 326–341. [Google Scholar] [CrossRef]
- Antinyan, V. Revealing the Complexity of Automotive Software. In Proceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE 2020), Sacramento, CA, USA, 6–16 November 2020; pp. 1525–1528. [Google Scholar] [CrossRef]
- Monot, A.; Navet, N.; Bavoux, B.; Simonot-Lion, F. Multicore scheduling in automotive ECUs. Embedded Real Time Software and Systems; ERTSS: Toulouse, France, 2010. [Google Scholar]
- Bucaioni, A.; Mubeen, S.; Ciccozzi, F.; Cicchetti, A.; Sjödin, M. Modelling multi-criticality vehicular software systems: Evolution of an industrial component model. Softw. Syst. Model. 2020, 19, 1283–1302. [Google Scholar] [CrossRef]
- Schoeberl, M.; Sørensen, R.B.; Sparsø, J. Models of communication for multicore processors. In Proceedings of the 2015 IEEE International Symposium on Object/Component/Service-Oriented Real-Time Distributed Computing Workshops, Auckland, New Zealand, 13–17 April 2015; IEEE: Piscataway, NJ, USA, 2015. [Google Scholar]
- Hamann, A.; Dasari, D.; Kramer, S.; Pressler, M.; Wurst, F. Communication centric design in complex automotive embedded systems. Leibniz Int. Proc. Inform. LIPIcs 2017, 76, 101–1020. [Google Scholar] [CrossRef]
- Martinez, J.; Sañudo, I.; Bertogna, M. End-to-End Latency Characterization of Task Communication Models for Automotive Systems; Springer Nature: Heidelberg, Germany, 2020; Volume 56, pp. 315–347. [Google Scholar] [CrossRef]
- Pazzaglia, P.; Biondi, A.; Di Natale, M. Optimizing the functional deployment on multicore platforms with logical execution time. Proc. Real-Time Syst. Symp. 2019, 2019, 207–219. [Google Scholar] [CrossRef]
- Toscanelli, M. Multicore Software Development for Engine Control Units. Master’s Thesis, Università di Bologna, Bolonia, Italia, 2019. [Google Scholar]
- Cerrolaza, J.P.; Obermaisser, R.; Abella, J.; Cazorla, F.J.; Grüttner, K.; Agirre, I.; Ahmadian, H.; Allende, I. Multi-core devices for safety-critical systems: A survey. ACM Comput. Surv. (CSUR) 2020, 53, 1–38. [Google Scholar] [CrossRef]
- Igarashi, S.; Azumi, T. Work in progress: Considering heuristic scheduling for NoC-Based clustered many-core processor using LET model. In Proceedings of the Real-Time Systems Symposium, Hong Kong, China, 3–6 December 2019; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2019; pp. 516–519. [Google Scholar] [CrossRef]
- Hung, S.H.; Chiu, P.H.; Shih, C.S. Building and optimizing a scalable and portable message-passing library for embedded multicore systems. Information 2012, 15, 3039–3057. [Google Scholar]
- Hung, S.H.; Tu, C.H.; Yang, W.L. A portable, efficient inter-core communication scheme for embedded multicore platforms. J. Syst. Archit. 2011, 57, 193–205. [Google Scholar] [CrossRef]
- Sørensen, R.B.; Puffitsch, W.; Schoeberl, M.; Sparsø, J. Message passing on a time-predictable multicore processor. In Proceedings of the 2015 IEEE 18th International Symposium on Real-Time Distributed Computing, ISORC 2015, Auckland, New Zealand, 13–17 April 2015; pp. 51–59. [Google Scholar] [CrossRef]
- Urbina, M. TIMEA: Time-Triggered Message-Based Multicore Architecture for AUTOSAR. Ph.D. Thesis, University of Siegen, Siegen, Germany, 2020. [Google Scholar]
- Beckert, M. Scheduling Mechanisms for Efficient and Safe Automotive Systems Integration. Ph.D. Thesis, Technischen Universität Braunschweig, Braunschweig, Germany, 2019. [Google Scholar] [CrossRef]
- Shirvani, M.H.; Talouki, R.N. A novel hybrid heuristic-based list scheduling algorithm in heterogeneous cloud computing environment for makespan optimization. Parallel Comput. 2021, 108, 102828. [Google Scholar] [CrossRef]
- Seifhosseini, S.; Shirvani, M.H.; Ramzanpoor, Y. Multi-objective cost-aware bag-of-tasks scheduling optimization model for IoT applications running on heterogeneous fog environment. Comput. Netw. 2024, 240, 110161. [Google Scholar] [CrossRef]
- Soliman, M.R.; Gracioli, G.; Tabish, R.; Pellizzoni, R.; Caccamo, M. Segment streaming for the three-phase execution model: Design and implementation. In Proceedings of the 2019 IEEE Real-Time Systems Symposium (RTSS), Hong Kong, China, 3–6 December 2019; pp. 260–273. [Google Scholar] [CrossRef]
- Tabish, R.; Mancuso, R.; Wasly, S.; Pellizzoni, R.; Caccamo, M. A real-time scratchpad-centric OS with predictable inter/intra-core communication for multi-core embedded systems. Real-Time Syst. 2019, 55, 850–888. [Google Scholar] [CrossRef]
- Bellassai, D.; Biondi, A.; Biasci, A.; Morelli, B. Supporting logical execution time in multi-core POSIX systems. J. Syst. Archit. 2023, 144, 102987. [Google Scholar] [CrossRef]
- Gemlau, K.B.; KÖHLER, L.; Ernst, R.; Quinton, S. System-Level Logical Execution Time: Augmenting the Logical Execution Time Paradigm for Distributed Real-Time Automotive Software. ACM Trans. Cyber-Phys. Syst. 2021, 5, 1–27. [Google Scholar] [CrossRef]
- Gemlau, K.B.; Kohler, L.; Ernst, R. A Platform Programming Paradigm for Heterogeneous Systems Integration. Proc. IEEE 2021, 109, 582–603. [Google Scholar] [CrossRef]
- Kang, D.; Oh, J.; Choi, J.; Yi, Y.; Ha, S. Scheduling of Deep Learning Applications Onto Heterogeneous Processors in an Embedded Device. IEEE Access 2020, 8, 43980–43991. [Google Scholar] [CrossRef]
- Hosseini Shirvani, M. A hybrid meta-heuristic algorithm for scientific workflow scheduling in heterogeneous distributed computing systems. Eng. Appl. Artif. Intell. 2020, 90, 103501. [Google Scholar] [CrossRef]
- Verucchi, M.; Theile, M.; Caccamo, M.; Bertogna, M. Latency-Aware Generation of Single-Rate DAGs from Multi-Rate Task Sets. In Proceedings of the 2020 IEEE Real-Time and Embedded Technology and Applications Symposium (RTAS), Sydney, Australia, 21–24 April 2020; pp. 226–238. [Google Scholar] [CrossRef]
- Noorian Talouki, R.; Hosseini Shirvani, M.; Motameni, H. A hybrid meta-heuristic scheduler algorithm for optimization of workflow scheduling in cloud heterogeneous computing environment. J. Eng. Des. Technol. 2022, 20, 1581–1605. [Google Scholar] [CrossRef]
- Becker, M.; Dasari, D.; Mubeen, S.; Behnam, M.; Nolte, T. End-to-end timing analysis of cause-effect chains in automotive embedded systems. J. Syst. Archit. 2017, 80, 104–113. [Google Scholar] [CrossRef]
- Igarashi, S.; Ishigooka, T.; Horiguchi, T.; Koike, R.; Azumi, T. Heuristic Contention-Free Scheduling Algorithm for Multi-core Processor using LET Model. In Proceedings of the 2020 IEEE/ACM 24th International Symposium on Distributed Simulation and Real Time Applications, DS-RT 2020, Prague, Czech Republic, 14–16 September 2020. [Google Scholar] [CrossRef]
- Kopetz, H. Real-Time Systems: Design Principles for Distributed Embedded Applications, 2nd ed.; Springer: New York, NY, USA, 2011. [Google Scholar] [CrossRef]
- Ecco, L.; Tobuschat, S.; Saidi, S.; Ernst, R. A mixed critical memory controller using bank privatization and fixed priority scheduling. In Proceedings of the RTCSA 2014—20th IEEE International Conference on Embedded and Real-Time Computing Systems and Applications, Chongqing, China, 20–22 August 2014. [Google Scholar] [CrossRef]
- Martinez, J.; Sañudo, I.; Bertogna, M. Analytical Characterization of End-to-End Communication Delays With Logical Execution Time. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2018, 37, 2244–2254. [Google Scholar] [CrossRef]
- Biondi, A.; Pazzaglia, P.; Balsini, A.; Natale, M.D. Logical Execution Time Implementation and Memory Optimization Issues in AUTOSAR Applications for Multicores. In Proceedings of the 8th International Workshop on Analysis Tools and Methodologies for Embedded and Real-Time Systems (WATERS), Dubrovnik, Croatia, 27 June 2017. [Google Scholar]
- Maia, L.; Fohler, G. Reducing End-to-End Latencies of Multi-Rate Cause-Effect Chains for the LET Model. arXiv 2023, arXiv:2305.02121. [Google Scholar]
- Wang, S.; Li, D.; Sifat, A.H.; Huang, S.Y.; Deng, X.; Jung, C.; Williams, R.; Zeng, H. Optimizing Logical Execution Time Model for Both Determinism and Low Latency. arXiv 2024, arXiv:2310.19699. [Google Scholar]
- Günzel, M.; Chen, K.H.; Ueter, N.; von der Brüggen, G.; Dürr, M.; Chen, J.J. Compositional Timing Analysis of Asynchronized Distributed Cause-effect Chains. ACM Trans. Embed. Comput. Syst. 2023, 22, 1–34. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Core | Clock Frequency | Prescaled Frequency | Scheduler Handler | Base Tick | Tasks | Buffer Memory | Shared Buffers | Buffer Sizes (Bits) |
|---|---|---|---|---|---|---|---|---|
| Cortex M0+ | 80 MHz | 1 MHz | ISR | 10 ms | 1 | SRAM | 3 | 8, 16, 32 |
| Cortex M4 | 160 MHz | 1 KHz | AUTOSAR OS | 1 ms | 2 | SRAM | 3 | 8, 16, 32 |
| 8 Bits | 8 Bits | 16 Bits | 16 Bits | 32 Bits | 32 Bits |
|---|---|---|---|---|---|
| 18,385,737 | 18,386,738 | 27,223,037 | 27,224,038 | 21,877,902 | 21,878,904 |
| 18,395,737 | 18,396,738 | 27,233,037 | 27,234,038 | 21,887,903 | 21,888,904 |
| 18,405,737 | 18,406,738 | 27,243,037 | 27,244,038 | 21,897,903 | 21,898,904 |
| 18,415,737 | 18,416,738 | 27,253,037 | 27,254,038 | 21,907,903 | 21,908,904 |
| 18,425,737 | 18,426,738 | 27,263,037 | 27,264,038 | 21,917,903 | 21,918,904 |
| 18,435,737 | 18,436,738 | 27,273,037 | 27,274,038 | 21,927,903 | 21,928,904 |
| 18,445,737 | 18,446,738 | 27,283,037 | 27,284,038 | 21,937,903 | 21,938,904 |
| 18,455,737 | 18,456,739 | 27,293,037 | 27,294,039 | 21,947,903 | 21,948,904 |
| 18,465,737 | 18,466,739 | 27,303,037 | 27,304,039 | 21,957,903 | 21,958,904 |
| 18,475,737 | 18,476,739 | 27,313,037 | 27,314,039 | 21,967,903 | 21,968,905 |
| 18,485,737 | 18,486,739 | 27,323,037 | 27,324,039 | 21,977,903 | 21,978,905 |
| 18,495,738 | 18,496,739 | 27,333,037 | 27,334,039 | 21,987,903 | 21,988,905 |
| 18,505,738 | 18,506,739 | 27,343,037 | 27,344,039 | 21,997,903 | 21,998,905 |
| 18,515,738 | 18,516,739 | 27,353,037 | 27,354,039 | 22,007,903 | 22,008,905 |
| 18,525,738 | 18,526,739 | 27,363,038 | 27,364,039 | 22,017,903 | 22,018,905 |
| 18,535,738 | 18,536,739 | 27,373,038 | 27,374,039 | 22,027,903 | 22,028,905 |
| 18,545,738 | 18,546,739 | 27,383,038 | 27,384,039 | 22,037,904 | 22,038,905 |
| 18,555,738 | 18,556,739 | 27,393,038 | 27,394,039 | 22,047,904 | 22,048,905 |
| 18,565,738 | 18,566,739 | 27,403,038 | 27,404,039 | 22,057,904 | 22,058,905 |
| 18,575,738 | 18,576,739 | 27,413,038 | 27,414,039 | 22,067,904 | 22,068,905 |
| 18,585,738 | 18,586,740 | 27,423,038 | 27,424,039 | 22,077,904 | 22,078,905 |
| 18,595,738 | 18,596,740 | 27,433,038 | 27,434,039 | 22,087,904 | 22,088,905 |
| 18,605,738 | 18,606,740 | 27,443,038 | 27,444,039 | 22,097,904 | 22,098,905 |
| 18,615,739 | 18,616,740 | 27,453,038 | 27,454,040 | 22,107,904 | 22,108,905 |
| 18,625,739 | 18,626,740 | 27,463,038 | 27,464,040 | 22,117,904 | 22,118,905 |
| 18,635,739 | 18,636,740 | 27,473,038 | 27,474,040 | 22,127,904 | 22,128,906 |
| 18,645,739 | 18,646,740 | 27,483,038 | 27,484,040 | 22,137,904 | 22,138,906 |
| 18,655,739 | 18,656,740 | 27,493,039 | 27,494,040 | 22,147,904 | 22,148,906 |
| 18,665,739 | 18,666,740 | 27,503,039 | 27,504,040 | 22,157,904 | 22,158,906 |
| 18,675,739 | 18,676,740 | 27,513,038 | 27,514,040 | 22,167,904 | 22,168,906 |
| 18,685,739 | 18,686,740 | 27,523,039 | 27,524,040 | 22,177,904 | 22,178,906 |
| 18,695,739 | 18,696,740 | 27,533,039 | 27,534,040 | 22,187,904 | 22,188,906 |
| 18,705,739 | 18,706,740 | 27,543,039 | 27,544,040 | 22,197,905 | 22,198,906 |
| 18,715,739 | 18,716,740 | 27,553,039 | 27,554,040 | 22,207,905 | 22,208,906 |
| 18,725,739 | 18,726,740 | 27,563,039 | 27,564,040 | 22,217,905 | 22,218,906 |
| 18,735,739 | 18,736,740 | 27,573,039 | 27,574,040 | 22,227,905 | 22,228,906 |
| 18,745,739 | 18,746,740 | 27,583,039 | 27,584,040 | 22,237,905 | 22,238,906 |
| 18,755,739 | 18,756,740 | 27,593,039 | 27,594,040 | 22,247,905 | 22,248,906 |
| 18,765,739 | 18,766,740 | 27,603,039 | 27,604,040 | 22,257,905 | 22,258,907 |
| 18,775,739 | 18,776,741 | 27,613,039 | 27,614,041 | 22,267,905 | 22,268,907 |
| 18,985,741 | 18,986,742 | 27,823,041 | 27,824,042 | 22,477,906 | 22,478,908 |
| 18,995,741 | 18,996,742 | 27,833,040 | 27,834,042 | 22,487,906 | 22,488,908 |
| 19,005,741 | 19,006,742 | 27,843,041 | 27,844,042 | 22,497,906 | 22,498,908 |
| 19,015,741 | 19,016,742 | 27,853,041 | 27,854,042 | 22,507,906 | 22,508,908 |
| 19,025,741 | 19,026,742 | 27,863,041 | 27,864,042 | 22,517,907 | 22,518,908 |
| 19,035,741 | 19,036,742 | 27,873,041 | 27,874,042 | 22,527,907 | 22,528,908 |
| 19,045,741 | 19,046,742 | 27,883,041 | 27,884,042 | 22,537,907 | 22,538,908 |
| 19,055,741 | 19,056,742 | 27,893,041 | 27,894,042 | 22,547,907 | 22,548,908 |
| 19,065,741 | 19,066,742 | 27,903,041 | 27,904,042 | 22,557,907 | 22,558,908 |
| 18,395,737 | 18,396,738 | 10,000 | 10,000 | 18,395,737 | 10,000 | 18,405,737 | 18,405,737 |
| 18,405,737 | 18,406,738 | 10,000 | 10,000 | 18,405,737 | 10,000 | 18,415,737 | 18,415,737 |
| 18,415,737 | 18,416,738 | 10,000 | 10,000 | 18,415,737 | 10,000 | 18,425,737 | 18,425,737 |
| 18,425,737 | 18,426,738 | 10,000 | 10,000 | 18,425,737 | 10,000 | 18,435,737 | 18,435,737 |
| 18,435,737 | 18,436,738 | 10,000 | 10,000 | 18,435,737 | 10,000 | 18,445,737 | 18,445,737 |
| 18,445,737 | 18,446,738 | 10,000 | 10,000 | 18,445,737 | 10,000 | 18,455,737 | 18,455,737 |
| 18,455,737 | 18,456,739 | 10,000 | 10,001 | 18,455,737 | 10,001 | 18,465,738 | 18,465,738 |
| 18,465,737 | 18,466,739 | 10,000 | 10,000 | 18,465,737 | 10,000 | 18,475,737 | 18,475,737 |
| 18,475,737 | 18,476,739 | 10,000 | 10,000 | 18,475,737 | 10,000 | 18,485,737 | 18,485,737 |
| 18,485,737 | 18,486,739 | 10,000 | 10,000 | 18,485,737 | 10,000 | 18,495,737 | 18,495,737 |
| 18,495,738 | 18,496,739 | 10,001 | 10,000 | 18,495,738 | 10,001 | 18,505,739 | 18,505,739 |
| 18,505,738 | 18,506,739 | 10,000 | 10,000 | 18,505,738 | 10,000 | 18,515,738 | 18,515,738 |
| 18,515,738 | 18,516,739 | 10,000 | 10,000 | 18,515,738 | 10,000 | 18,525,738 | 18,525,738 |
| 18,525,738 | 18,526,739 | 10,000 | 10,000 | 18,525,738 | 10,000 | 18,535,738 | 18,535,738 |
| 18,535,738 | 18,536,739 | 10,000 | 10,000 | 18,535,738 | 10,000 | 18,545,738 | 18,545,738 |
| 18,545,738 | 18,546,739 | 10,000 | 10,000 | 18,545,738 | 10,000 | 18,555,738 | 18,555,738 |
| 18,555,738 | 18,556,739 | 10,000 | 10,000 | 18,555,738 | 10,000 | 18,565,738 | 18,565,738 |
| 18,565,738 | 18,566,739 | 10,000 | 10,000 | 18,565,738 | 10,000 | 18,575,738 | 18,575,738 |
| 18,575,738 | 18,576,739 | 10,000 | 10,000 | 18,575,738 | 10,000 | 18,585,738 | 18,585,738 |
| 18,585,738 | 18,586,740 | 10,000 | 10,001 | 18,585,738 | 10,001 | 18,595,739 | 18,595,739 |
| 27,233,037 | 27,234,038 | 10,000 | 10,000 | 27,234,038 | 10,000 | 27,244,038 | 27,244,038 |
| 27,243,037 | 27,244,038 | 10,000 | 10,000 | 27,244,038 | 10,000 | 27,254,038 | 27,254,038 |
| 27,253,037 | 27,254,038 | 10,000 | 10,000 | 27,254,038 | 10,000 | 27,264,038 | 27,264,038 |
| 27,263,037 | 27,264,038 | 10,000 | 10,000 | 27,264,038 | 10,000 | 27,274,038 | 27,274,038 |
| 27,273,037 | 27,274,038 | 10,000 | 10,000 | 27,274,038 | 10,000 | 27,284,038 | 27,284,038 |
| 27,283,037 | 27,284,038 | 10,000 | 10,000 | 27,284,038 | 10,000 | 27,294,038 | 27,294,038 |
| 27,293,037 | 27,294,039 | 10,000 | 10,001 | 27,294,039 | 10,001 | 27,304,040 | 27,304,040 |
| 27,303,037 | 27,304,039 | 10,000 | 10,000 | 27,304,039 | 10,000 | 27,314,039 | 27,314,039 |
| 27,313,037 | 27,314,039 | 10,000 | 10,000 | 27,314,039 | 10,000 | 27,324,039 | 27,324,039 |
| 27,323,037 | 27,324,039 | 10,000 | 10,000 | 27,324,039 | 10,000 | 27,334,039 | 27,334,039 |
| 27,333,037 | 27,334,039 | 10,000 | 10,000 | 27,334,039 | 10,000 | 27,344,039 | 27,344,039 |
| 27,343,037 | 27,344,039 | 10,000 | 10,000 | 27,344,039 | 10,000 | 27,354,039 | 27,354,039 |
| 27,353,037 | 27,354,039 | 10,000 | 10,000 | 27,354,039 | 10,000 | 27,364,039 | 27,364,039 |
| 27,363,038 | 27,364,039 | 10,001 | 10,000 | 27,364,039 | 10,001 | 27,374,040 | 27,374,040 |
| 27,373,038 | 27,374,039 | 10,000 | 10,000 | 27,374,039 | 10,000 | 27,384,039 | 27,384,039 |
| 27,383,038 | 27,384,039 | 10,000 | 10,000 | 27,384,039 | 10,000 | 27,394,039 | 27,394,039 |
| 27,393,038 | 27,394,039 | 10,000 | 10,000 | 27,394,039 | 10,000 | 27,404,039 | 27,404,039 |
| 27,403,038 | 27,404,039 | 10,000 | 10,000 | 27,404,039 | 10,000 | 27,414,039 | 27,414,039 |
| 27,413,038 | 27,414,039 | 10,000 | 10,000 | 27,414,039 | 10,000 | 27,424,039 | 27,424,039 |
| 27,423,038 | 27,424,039 | 10,000 | 10,000 | 27,424,039 | 10,000 | 27,434,039 | 27,434,039 |
| 21,887,903 | 21,888,904 | 10,001 | 10,000 | 21,888,904 | 10,001 | 21,898,905 | 21,898,905 |
| 21,897,903 | 21,898,904 | 10,000 | 10,000 | 21,898,904 | 10,000 | 21,908,904 | 21,908,904 |
| 21,907,903 | 21,908,904 | 10,000 | 10,000 | 21,908,904 | 10,000 | 21,918,904 | 21,918,904 |
| 21,917,903 | 21,918,904 | 10,000 | 10,000 | 21,918,904 | 10,000 | 21,928,904 | 21,928,904 |
| 21,927,903 | 21,928,904 | 10,000 | 10,000 | 21,928,904 | 10,000 | 21,938,904 | 21,938,904 |
| 21,937,903 | 21,938,904 | 10,000 | 10,000 | 21,938,904 | 10,000 | 21,948,904 | 21,948,904 |
| 21,947,903 | 21,948,904 | 10,000 | 10,000 | 21,948,904 | 10,000 | 21,958,904 | 21,958,904 |
| 21,957,903 | 21,958,904 | 10,000 | 10,000 | 21,958,904 | 10,000 | 21,968,904 | 21,968,904 |
| 21,967,903 | 21,968,905 | 10,000 | 10,001 | 21,968,905 | 10,001 | 21,978,906 | 21,978,906 |
| 21,977,903 | 21,978,905 | 10,000 | 10,000 | 21,978,905 | 10,000 | 21,988,905 | 21,988,905 |
| 21,987,903 | 21,988,905 | 10,000 | 10,000 | 21,988,905 | 10,000 | 21,998,905 | 21,998,905 |
| 21,997,903 | 21,998,905 | 10,000 | 10,000 | 21,998,905 | 10,000 | 22,008,905 | 22,008,905 |
| 22,007,903 | 22,008,905 | 10,000 | 10,000 | 22,008,905 | 10,000 | 22,018,905 | 22,018,905 |
| 22,017,903 | 22,018,905 | 10,000 | 10,000 | 22,018,905 | 10,000 | 22,028,905 | 22,028,905 |
| 22,027,903 | 22,028,905 | 10,000 | 10,000 | 22,028,905 | 10,000 | 22,038,905 | 22,038,905 |
| 22,037,904 | 22,038,905 | 10,001 | 10,000 | 22,038,905 | 10,001 | 22,048,906 | 22,048,906 |
| 22,047,904 | 22,048,905 | 10,000 | 10,000 | 22,048,905 | 10,000 | 22,058,905 | 22,058,905 |
| 22,057,904 | 22,058,905 | 10,000 | 10,000 | 22,058,905 | 10,000 | 22,068,905 | 22,068,905 |
| 22,067,904 | 22,068,905 | 10,000 | 10,000 | 22,068,905 | 10,000 | 22,078,905 | 22,078,905 |
| 22,077,904 | 22,078,905 | 10,000 | 10,000 | 22,078,905 | 10,000 | 22,088,905 | 22,088,905 |
| Author | Method | Cores | Tasks | L2L (ms) | L2F (ms) | F2F (ms) | Chain Size |
|---|---|---|---|---|---|---|---|
| Tabish et al. [20] | TDMA-DMA with SPM | 3 | 5–20 | - | 400 | - | - |
| Biondi et al. [33] | Explicit Communication | 2 | 4 | - | 12.746 | 22.746 | 4, 3 labels |
| Implicit Communication | 2 | 3 | - | - | - | 3, 2 labels | |
| LET Communication | 2 | 5 | 154.234 | - | - | 14 labels | |
| Hamman et al. [6] | Explicit Communication | 4 | 3 | - | - | 8.6 | 10,000 labels |
| Implicit Communication | 4 | 3 | - | - | 36.9 | 10,000 labels | |
| LET | 4 | 3 | - | - | 111.97 | 10,000 labels | |
| Martinez et al. [7] | Explicit Communication (C1) | 4 | 3 | 123.718 | - | 125.710 | 3, 2 labels |
| Implicit Communication (C1) | 4 | 3 | 154.988 | - | 151.855 | 3, 2 labels | |
| LET (C1) | 4 | 3 | 210 | - | 212 | 3, 2 labels | |
| Explicit Communication (C2) | 4 | 3 | 2.844 | - | 64.894 | 3, 2 labels | |
| Implicit Communication (C2) | 4 | 3 | 6.54 | - | 66.33 | 3, 2 labels | |
| LET (C2) | 4 | 3 | 53.597 | - | 103.597 | 3, 2 labels | |
| Maia and Fohler [34] | LET | 4 | 2–5 | 4040 | 5000 | 420.43 | 38 labels |
| WCR-LET | 4 | 2–5 | - | 4000 | - | ||
| Maia–Fohler | 4 | 2–5 | 3237 | 4197 | - | ||
| Wang et al. [35] | fLETEnum | 4 | 21 | 2725 | 3685 | - | 31 to 63 labels |
| fLETSBacktracking | 4 | 1 | 2725 | 3685 | - | ||
| fLETSymbOpt | 4 | 1 | 2725 | 3685 | - | ||
| Günzel et al. [36] | D19 | 2–5 | 21 | 3250 | 4750 | - | 30 to 60 labels |
| K18 | 2–5 | 21 | 2650 | 2700 | - | ||
| B17 | 2–5 | 21 | 2650 | - | - | ||
| Günzel | 2–5 | 21 | 1750 | 3250 | - | ||
| Ours | LET | 2 | 2 | [20∼40] | [10∼40] | [10∼50] | 2, 1 labels |
| LET and TDMA (8, 16 and 32 bits) | 2 | 2 | 10 | 10 | 20 | 2, 1 labels |
| RMSE | Core M0 | Core M4 | 8-bit | 16-bit | 32-bit |
|---|---|---|---|---|---|
| LET | ISR | AUTOSAR | 3.2846 ms | 8.9257 ms | 0.2338 ms |
| ISR | ISR | 9.1680 ms | 7.9906 ms | 1.4070 ms | |
| LET-TDMA | ISR | AUTOSAR | ≈1 ms | ≈1 ms | ≈1 ms |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mosqueda-Arvizu, C.-A.; Romero-González, J.-A.; Córdova-Esparza, D.-M.; Terven, J.; Chaparro-Sánchez, R.; Rodríguez-Reséndiz, J. Logical Execution Time and Time-Division Multiple Access in Multicore Embedded Systems: A Case Study. Algorithms 2024, 17, 294. https://doi.org/10.3390/a17070294
Mosqueda-Arvizu C-A, Romero-González J-A, Córdova-Esparza D-M, Terven J, Chaparro-Sánchez R, Rodríguez-Reséndiz J. Logical Execution Time and Time-Division Multiple Access in Multicore Embedded Systems: A Case Study. Algorithms. 2024; 17(7):294. https://doi.org/10.3390/a17070294
Chicago/Turabian StyleMosqueda-Arvizu, Carlos-Antonio, Julio-Alejandro Romero-González, Diana-Margarita Córdova-Esparza, Juan Terven, Ricardo Chaparro-Sánchez, and Juvenal Rodríguez-Reséndiz. 2024. "Logical Execution Time and Time-Division Multiple Access in Multicore Embedded Systems: A Case Study" Algorithms 17, no. 7: 294. https://doi.org/10.3390/a17070294
APA StyleMosqueda-Arvizu, C.-A., Romero-González, J.-A., Córdova-Esparza, D.-M., Terven, J., Chaparro-Sánchez, R., & Rodríguez-Reséndiz, J. (2024). Logical Execution Time and Time-Division Multiple Access in Multicore Embedded Systems: A Case Study. Algorithms, 17(7), 294. https://doi.org/10.3390/a17070294