
3D Reconstruction Based on Iterative Optimization of Moving Least-Squares Function


Abstract
1. Introduction
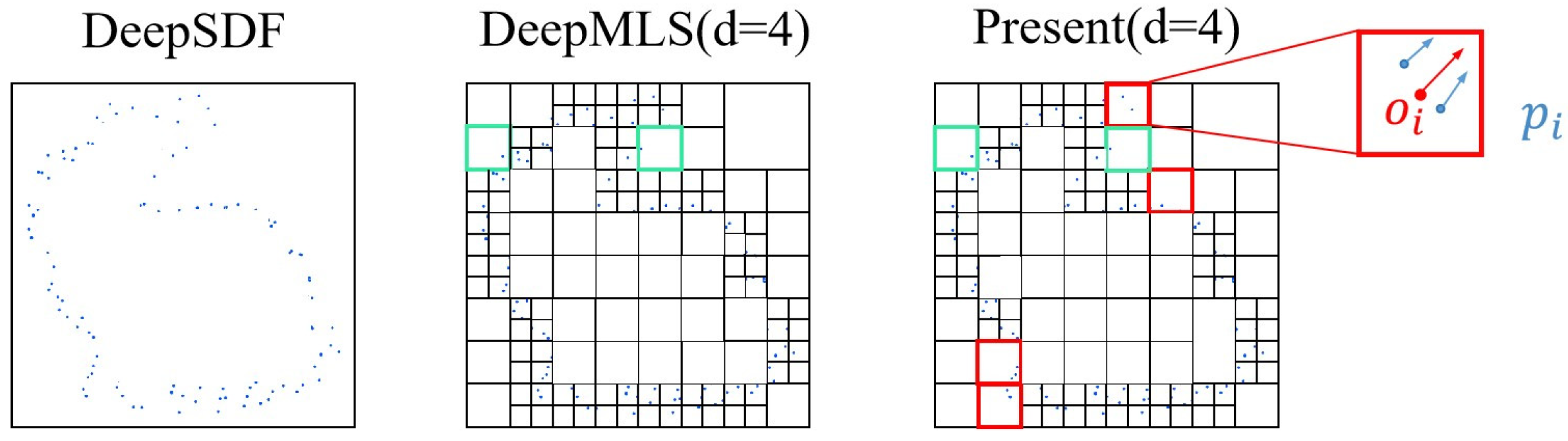
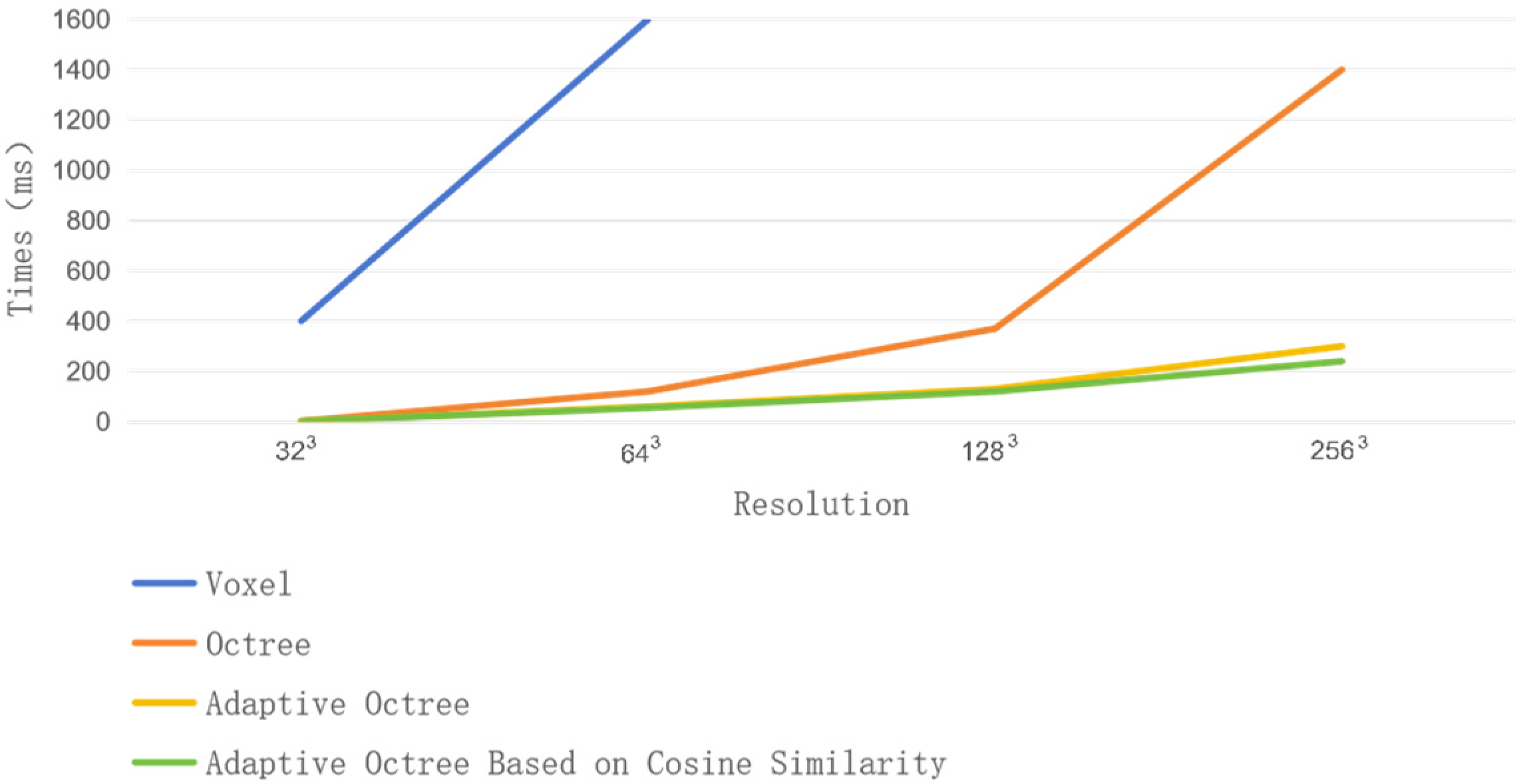
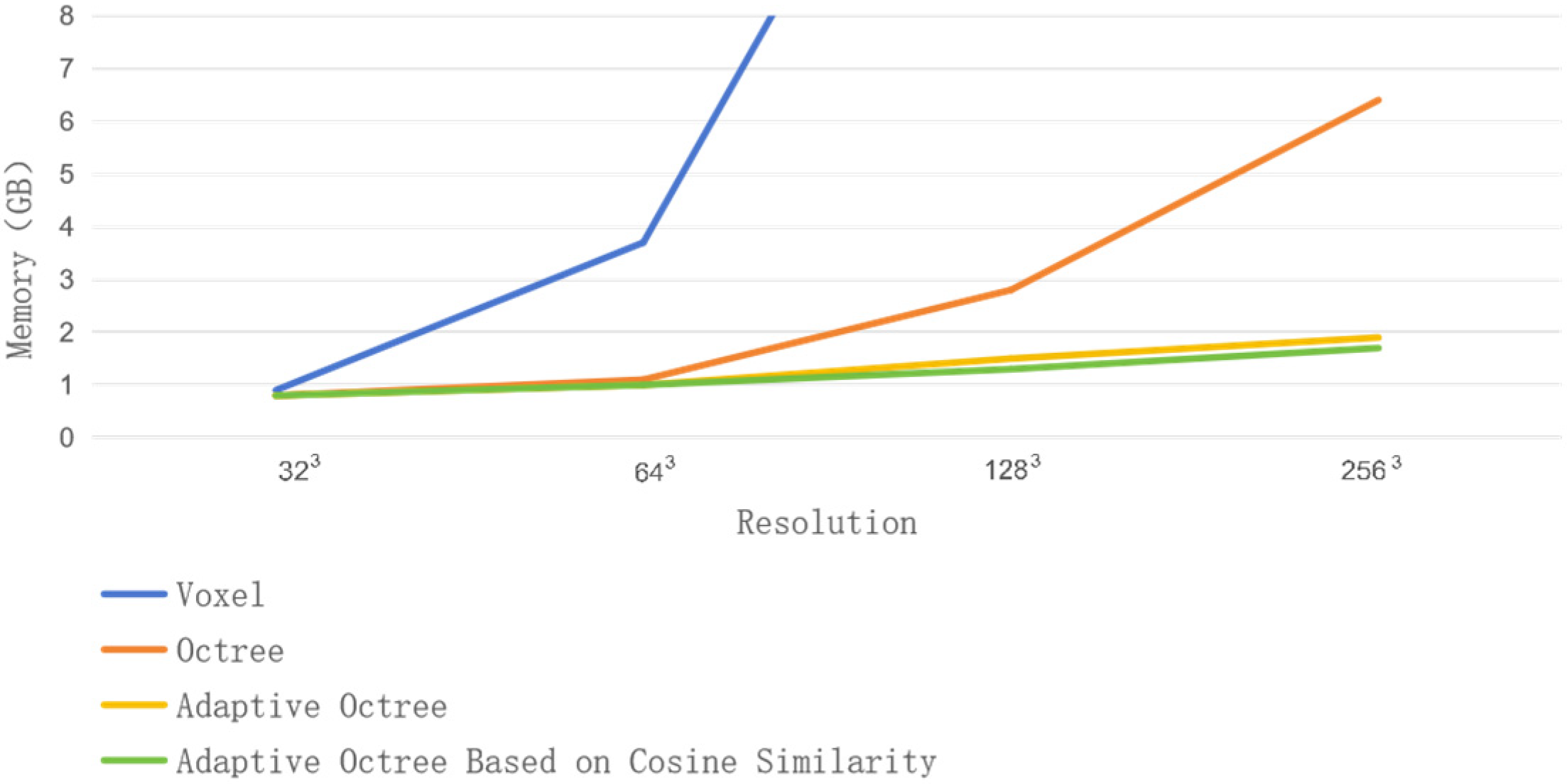
- Adaptive octree partitioning: This scheme speeds up iteration and saves memory space by dynamically adjusting the partitioning based on local shape characteristics;
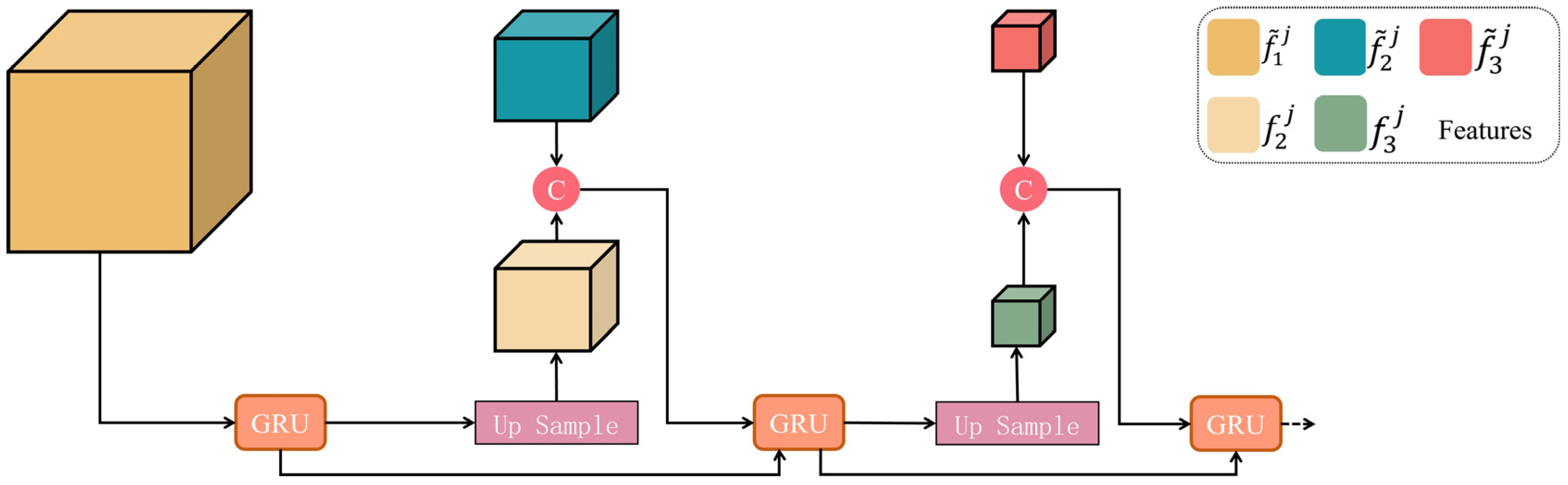
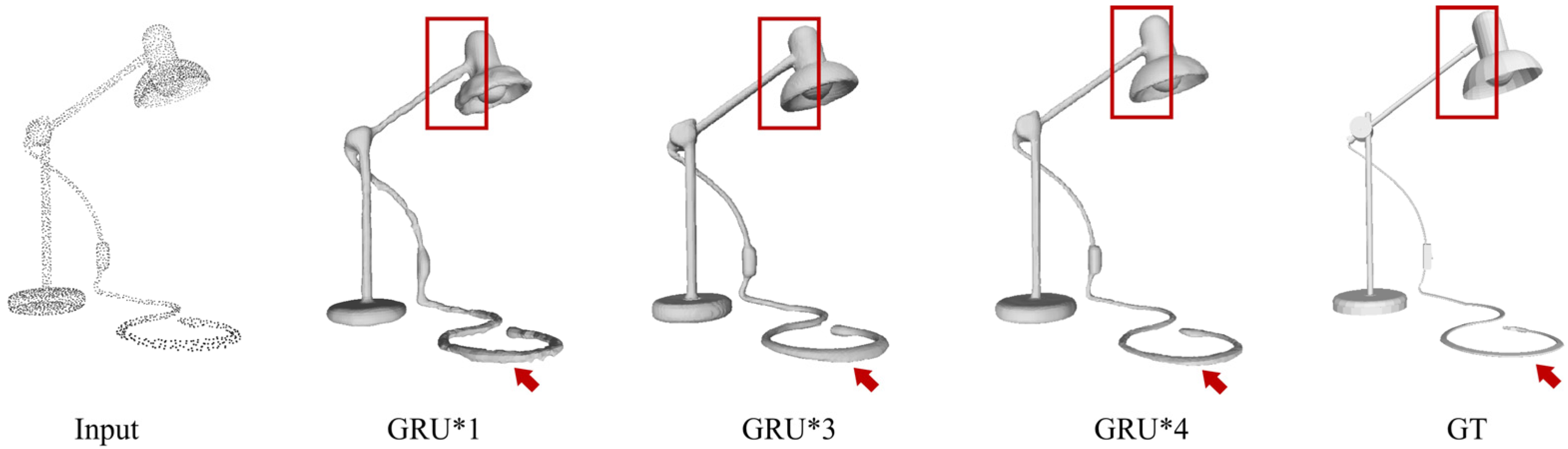
- GRU-based feature optimization: The GRU module iteratively optimizes local features, capturing the correlation and contextual information between shape features and achieving dynamic learning of feature changes;
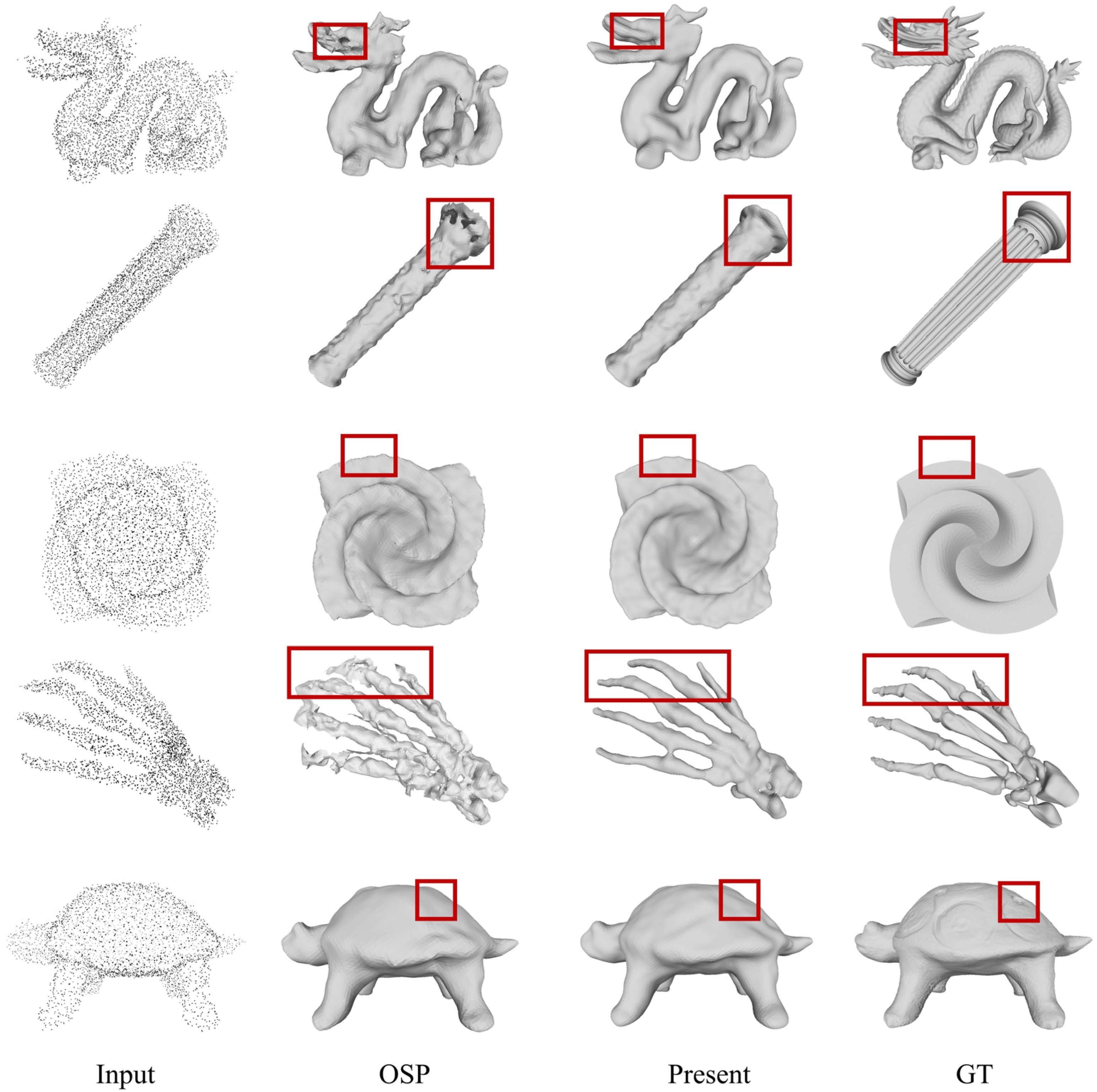
- Excellent visualization results: Our method achieves state-of-the-art results on ShapeNet, ABC, and Famous datasets, demonstrating its effectiveness in generating high-quality 3D surfaces.
2. Related Work
3. Methods
- Adaptive Octree Voxel Partitioning: The input point cloud undergoes adaptive octree voxel partitioning based on cosine similarity, as detailed in Section 3.1;
- Contextual Information Encoding: A convolutional neural network (CNN) is employed to extract local features within the smallest octant voxel. Subsequently, a GRU transmits contextual information across different scales, as described in Section 3.2;
- Moving Least Squares Surface Generation: Following MLP processing, the accumulated contextual information from voxels of various scales is utilized to generate a moving least squares point set. This enables the approximation of locally smooth and coherent surface geometry on a large scale, as elaborated in Section 3.3;
- Model Optimization: The network parameters are optimized by minimizing the loss function defined in Section 3.4.

3.1. Adaptive Octree Voxel Partitioning
3.2. Contextual Information Encoding
3.3. Moving Least-Squares Surface Generation
3.4. Model Optimization
4. Experiments
4.1. Dataset
4.2. Evaluation Metrics
4.3. Implementation Details
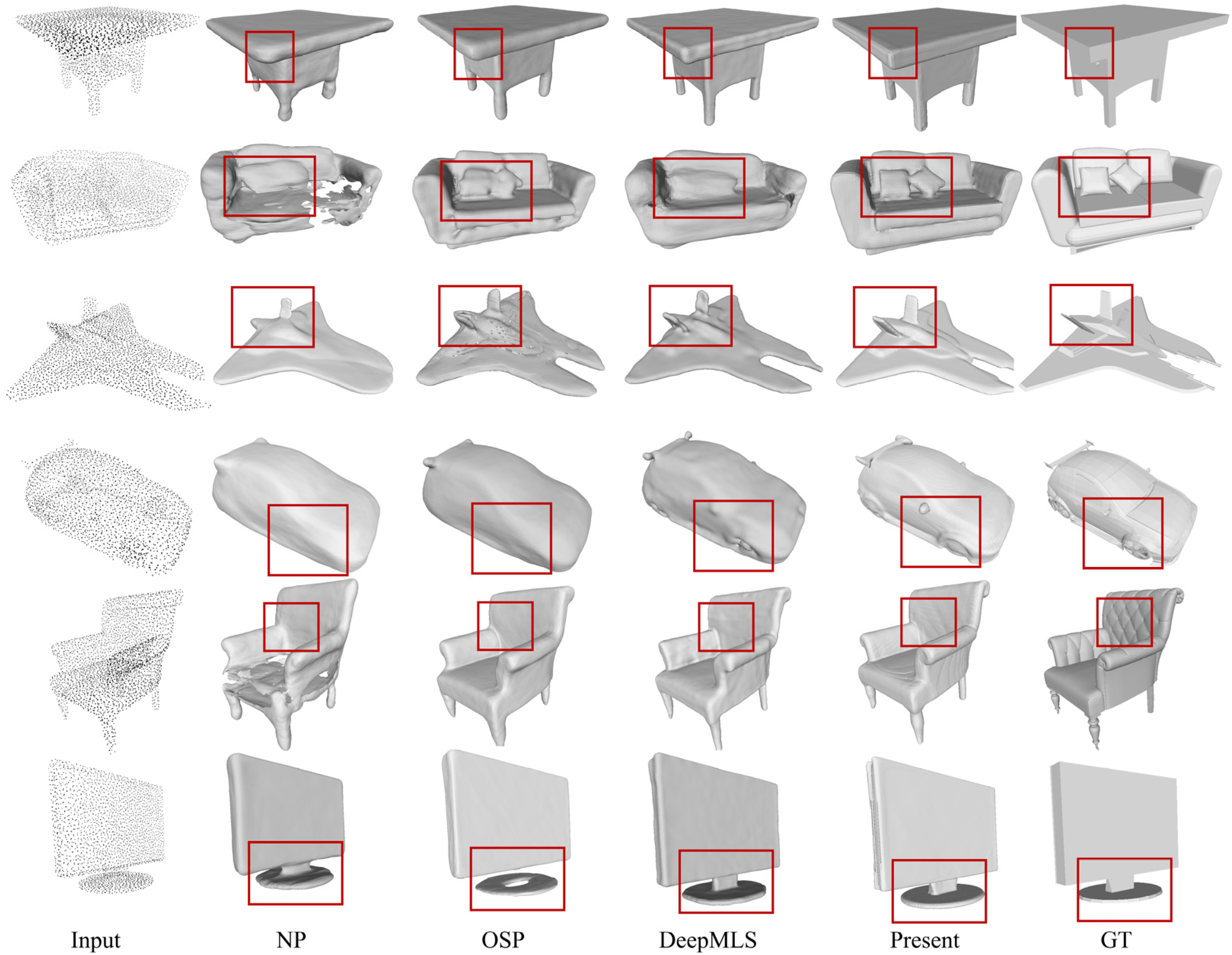
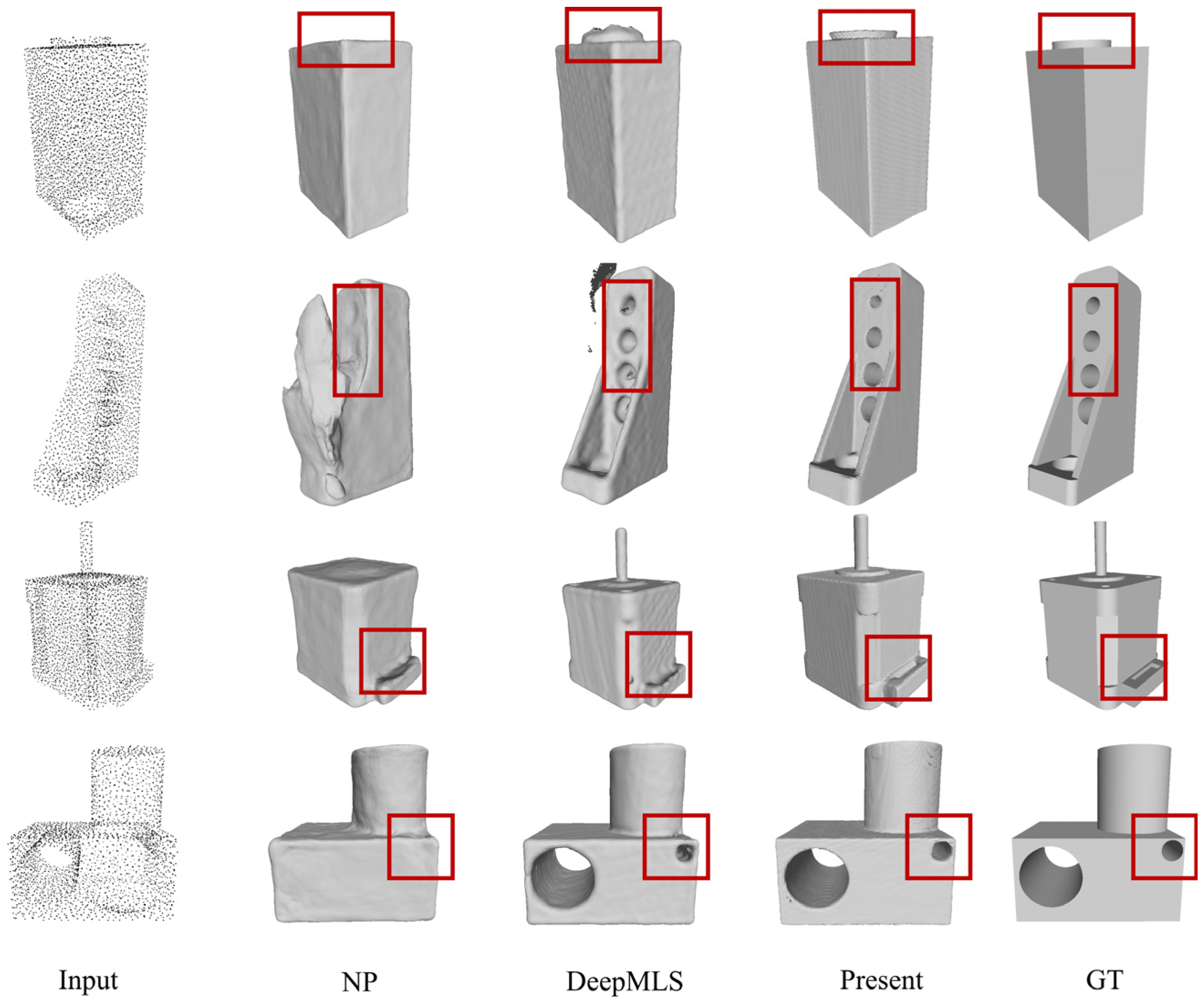
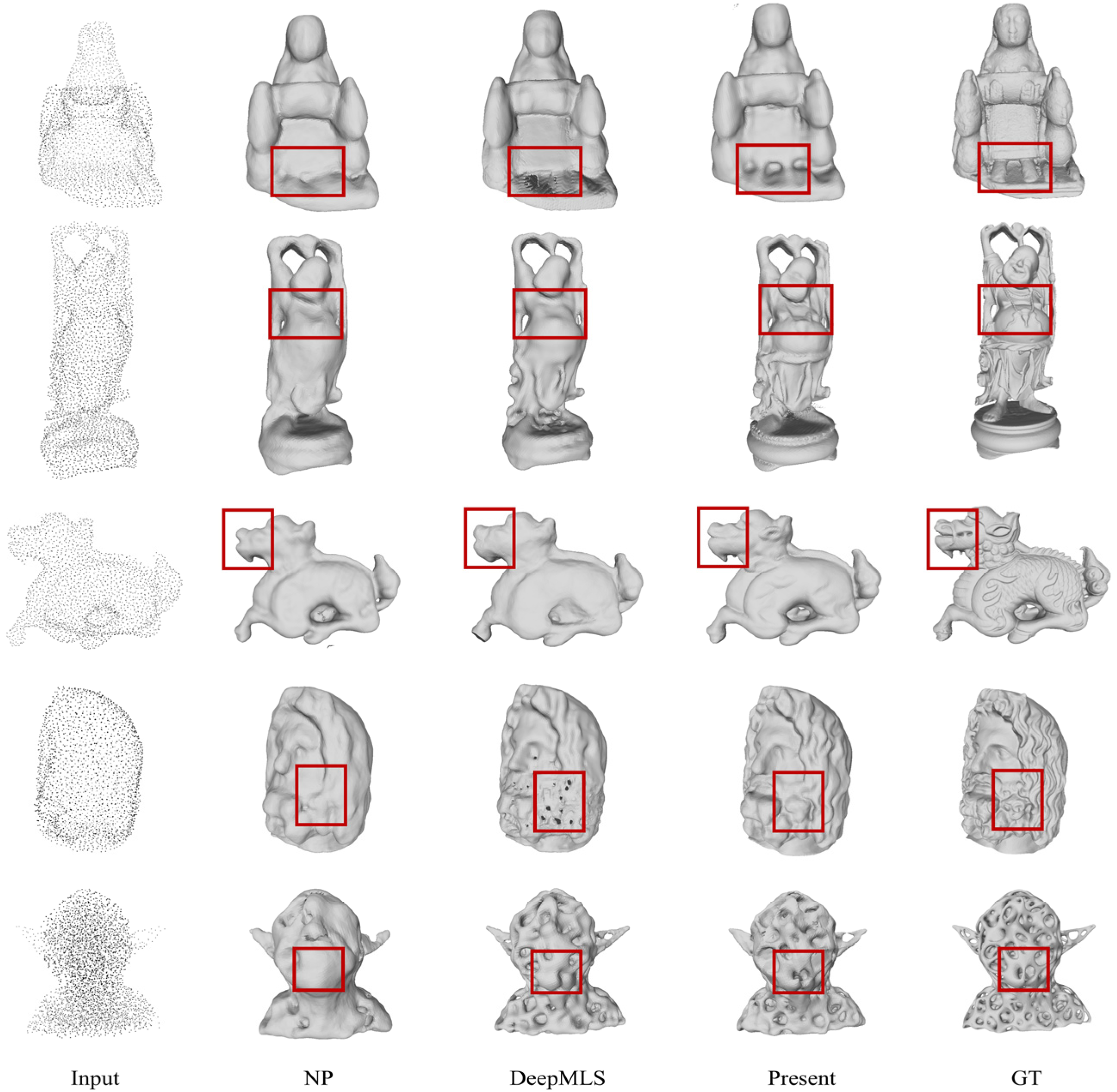
4.4. Result
4.5. Ablation Studies
4.5.1. Adaptive Partitioning
4.5.2. GRU
4.5.3. Robustness Test on Noise
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Park, J.J.; Florence, P.; Straub, J.; Newcombe, R.; Lovegrove, S. DeepSDF: Learning continuous signed distance functions for shape representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 165–174. [Google Scholar]
- Lorensen, W.E.; Cline, H.E. Marching cubes: A high resolution 3D surface construction algorithm. In Seminal Graphics: Pioneering Efforts That Shaped the Field; ACM SIGGRAPH: Chicago, IL, USA, 1998; pp. 347–353. [Google Scholar]
- Chabra, R.; Lenssen, J.E.; Ilg, E.; Schmidt, T.; Straub, J.; Lovegrove, S.; Newcombe, R. Deep local shapes: Learning local SDF priors for detailed 3D reconstruction. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Proceedings, Part XXIX 16, Glasgow, UK, 23–28 August 2020; pp. 608–625. [Google Scholar]
- Liu, S.-L.; Guo, H.-X.; Wang, P.-S.; Tong, X.; Liu, Y. Deep implicit moving least-squares functions for 3D reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1788–1797. [Google Scholar]
- Kolluri, R. Provably good moving least squares. ACM Trans. Algorithms (TALG) 2008, 4, 18. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Coudron, I.; Puttemans, S.; Goedemé, T.; Vandewalle, P. Semantic extraction of permanent structures for the reconstruction of building interiors from point clouds. Sensors 2020, 20, 6916. [Google Scholar] [CrossRef] [PubMed]
- Lim, G.; Doh, N. Automatic reconstruction of multi-level indoor spaces from point cloud and trajectory. Sensors 2021, 21, 3493. [Google Scholar] [CrossRef] [PubMed]
- Mescheder, L.; Oechsle, M.; Niemeyer, M.; Nowozin, S.; Geiger, A. Occupancy networks: Learning 3D reconstruction in function space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4460–4470. [Google Scholar]
- Saito, S.; Huang, Z.; Natsume, R.; Morishima, S.; Kanazawa, A.; Li, H. PIFu: Pixel-aligned implicit function for high-resolution clothed human digitization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2304–2314. [Google Scholar]
- Chibane, J.; Pons-Moll, G. Neural unsigned distance fields for implicit function learning. Adv. Neural Inf. Process. Syst. 2020, 33, 21638–21652. [Google Scholar]
- Bernardini, F.; Mittleman, J.; Rushmeier, H.; Silva, C.; Taubin, G. The ball-pivoting algorithm for surface reconstruction. IEEE Trans. Vis. Comput. Graph. 1999, 5, 349–359. [Google Scholar] [CrossRef]
- Wang, P.-S.; Liu, Y.; Guo, Y.-X.; Sun, C.-Y.; Tong, X. O-CNN: Octree-based convolutional neural networks for 3D shape analysis. ACM Trans. Graph. (TOG) 2017, 36, 72. [Google Scholar] [CrossRef]
- Wang, P.-S.; Sun, C.-Y.; Liu, Y.; Tong, X. Adaptive O-CNN: A patch-based deep representation of 3D shapes. ACM Trans. Graph. (TOG) 2018, 37, 217. [Google Scholar] [CrossRef]
- Wang, P.-S.; Liu, Y.; Tong, X. Dual octree graph networks for learning adaptive volumetric shape representations. ACM Trans. Graph. (TOG) 2022, 41, 103. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, P.; Dong, Q.; Gao, J.; Chen, S.; Xin, S.; Tu, C. Neural-IMLS: Learning implicit moving least-squares for surface reconstruction from unoriented point clouds. arXiv 2021, arXiv:2109.04398. [Google Scholar]
- Liu, Z.; Wang, Y.; Qi, X.; Fu, C.-W. Towards implicit text-guided 3D shape generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17896–17906. [Google Scholar]
- Li, T.; Wen, X.; Liu, Y.-S.; Su, H.; Han, Z. Learning deep implicit functions for 3D shapes with dynamic code clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12840–12850. [Google Scholar]
- Erler, P.; Guerrero, P.; Ohrhallinger, S.; Mitra, N.J.; Wimmer, M. Points2Surf learning implicit surfaces from point clouds. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 108–124. [Google Scholar]
- Chen, C.; Liu, Y.-S.; Han, Z. Latent partition implicit with surface codes for 3D representation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 322–343. [Google Scholar]
- Chibane, J.; Alldieck, T.; Pons-Moll, G. Implicit functions in feature space for 3D shape reconstruction and completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6970–6981. [Google Scholar]
- Tang, J.-H.; Chen, W.; Yang, J.; Wang, B.; Liu, S.; Yang, B.; Gao, L. Octfield: Hierarchical implicit functions for 3D modeling. arXiv 2021, arXiv:2111.01067. [Google Scholar]
- Zhou, J.; Ma, B.; Liu, Y.-S.; Fang, Y.; Han, Z. Learning consistency-aware unsigned distance functions progressively from raw point clouds. Adv. Neural Inf. Process. Syst. 2022, 35, 16481–16494. [Google Scholar]
- Wang, M.; Liu, Y.-S.; Gao, Y.; Shi, K.; Fang, Y.; Han, Z. LP-DIF: Learning local pattern-specific deep implicit function for 3D objects and scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 21856–21865. [Google Scholar]
- Huang, J.; Chen, H.-X.; Hu, S.-M. A neural galerkin solver for accurate surface reconstruction. ACM Trans. Graph. (TOG) 2022, 41, 1–16. [Google Scholar] [CrossRef]
- Xiao, D.; Shi, Z.; Wang, B. Alternately denoising and reconstructing unoriented point sets. Comput. Graph. 2023, 116, 139–149. [Google Scholar] [CrossRef]
- Hou, F.; Wang, C.; Wang, W.; Qin, H.; Qian, C.; He, Y. Iterative poisson surface reconstruction (iPSR) for unoriented points. arXiv 2022, arXiv:2209.09510. [Google Scholar] [CrossRef]
- Feng, Y.-F.; Shen, L.-Y.; Yuan, C.-M.; Li, X. Deep shape representation with sharp feature preservation. Comput.-Aided Des. 2023, 157, 103468. [Google Scholar] [CrossRef]
- Xu, X.; Guerrero, P.; Fisher, M.; Chaudhuri, S.; Ritchie, D. Unsupervised 3D shape reconstruction by part retrieval and assembly. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 8559–8567. [Google Scholar]
- Koneputugodage, C.H.; Ben-Shabat, Y.; Gould, S. Octree guided unoriented surface reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 16717–16726. [Google Scholar]
- Chen, C.; Liu, Y.-S.; Han, Z. Unsupervised inference of signed distance functions from single sparse point clouds without learning priors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 17712–17723. [Google Scholar]
- Sun, J.; Xie, Y.; Chen, L.; Zhou, X.; Bao, H. NeuralRecon: Real-time coherent 3D reconstruction from monocular video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15598–15607. [Google Scholar]
- Ma, B.; Zhou, J.; Liu, Y.-S.; Han, Z. Towards better gradient consistency for neural signed distance functions via level set alignment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 17724–17734. [Google Scholar]
- Kazhdan, M.; Bolitho, M.; Hoppe, H. Poisson surface reconstruction. In Proceedings of the Fourth Eurographics Symposium on Geometry Processing, Cagliari, Italy, 26–28 June 2006. [Google Scholar]
- Angel, X.; Thomas, F.; Leonidas, G.; Pat, H.; Huang, Q.; Li, Z.; Silvio, S.; Manolis, S.; Song, S.; Su, H.; et al. ShapeNet: An information-rich 3D model repository. arXiv 2015, arXiv:1512.03012. [Google Scholar]
- Koch, S.; Matveev, A.; Jiang, Z.; Williams, F.; Artemov, A.; Burnaev, E.; Alexa, M.; Zorin, D.; Panozzo, D. ABC: A big cad model dataset for geometric deep learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9601–9611. [Google Scholar]
- Ma, B.; Han, Z.; Liu, Y.-S.; Zwicker, M. Neural-pull: Learning signed distance functions from point clouds by learning to pull space onto surfaces. arXiv 2020, arXiv:2011.13495. [Google Scholar]
- Ma, B.; Liu, Y.-S.; Han, Z. Reconstructing surfaces for sparse point clouds with on-surface priors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 6315–6325. [Google Scholar]
- Liu, M.; Zhang, X.; Su, H. Meshing point clouds with predicted intrinsic-extrinsic ratio guidance. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Proceedings, Part VIII 16, Glasgow, UK, 23–28 August 2020; pp. 68–84. [Google Scholar]
- Jiang, C.; Sud, A.; Makadia, A.; Huang, J.; Nießner, M.; Funkhouser, T. Local implicit grid representations for 3D scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6001–6010. [Google Scholar]
- Chen, Z.; Zhang, H. Learning implicit fields for generative shape modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5939–5948. [Google Scholar]
- Huang, J.; Gojcic, Z.; Atzmon, M.; Litany, O.; Fidler, S.; Williams, F. Neural kernel surface reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 4369–4379. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class Name | DeepSDF | MeshP | LIG | IMNET | NP | DeepMLS | Present |
|---|---|---|---|---|---|---|---|
| Display | 0.932 | 0.974 | 0.926 | 0.574 | 0.964 | 0.973 | 0.988 |
| Lamp | 0.864 | 0.963 | 0.882 | 0.592 | 0.930 | 0.922 | 0.963 |
| Airplane | 0.872 | 0.955 | 0.817 | 0.550 | 0.947 | 0.937 | 0.964 |
| Cabinet | 0.872 | 0.957 | 0.948 | 0.700 | 0.930 | 0.955 | 0.986 |
| Vessel | 0.841 | 0.953 | 0.847 | 0.574 | 0.941 | 0.932 | 0.964 |
| Table | 0.901 | 0.962 | 0.936 | 0.702 | 0.908 | 0.962 | 0.977 |
| Chair | 0.886 | 0.962 | 0.920 | 0.820 | 0.937 | 0.950 | 0.955 |
| Sofa | 0.906 | 0.971 | 0.944 | 0.818 | 0.951 | 0.963 | 0.982 |
| Mean | 0.884 | 0.962 | 0.903 | 0.666 | 0.939 | 0.949 | 0.972 |
| Class Name | DeepSDF | MeshP | LIG | IMNET | NP | DeepMLS | Present |
|---|---|---|---|---|---|---|---|
| Display | 0.632 | 0. 903 | 0.551 | 0.601 | 0.989 | 0.994 | 0.998 |
| Lamp | 0.268 | 0.855 | 0.624 | 0.836 | 0.891 | 0.979 | 0.990 |
| Airplane | 0.350 | 0.844 | 0.564 | 0.698 | 0.996 | 0.992 | 0.998 |
| Cabinet | 0.573 | 0.860 | 0.733 | 0.343 | 0.980 | 0.981 | 0.987 |
| Vessel | 0.323 | 0.862 | 0.467 | 0.147 | 0.985 | 0.987 | 0.996 |
| Table | 0.577 | 0.880 | 0.844 | 0.425 | 0.922 | 0.987 | 0.975 |
| Chair | 0.447 | 0.875 | 0.710 | 0.181 | 0.954 | 0.982 | 0.985 |
| Sofa | 0.577 | 0.895 | 0.822 | 0.199 | 0.968 | 0.987 | 0.994 |
| Mean | 0.468 | 0.872 | 0.664 | 0.429 | 0.961 | 0.986 | 0.990 |
| Class | DeepSDF | MeshP | NUD | SALD | NP | DeepMLS | Present |
|---|---|---|---|---|---|---|---|
| Display | 0.317 | 0.069 | 0.077 | - | 0.039 | 0.012 | 0.007 |
| Lamp | 0.955 | 0.053 | 0.075 | 0.071 | 0.080 | 0.015 | 0.012 |
| Airplane | 1.043 | 0.049 | 0.076 | 0.054 | 0.008 | 0.008 | 0.006 |
| Cabinet | 0.921 | 0.112 | 0.041 | - | 0.026 | 0.024 | 0.015 |
| Vessel | 1.254 | 0.061 | 0.079 | - | 0.022 | 0.011 | 0.014 |
| Table | 0.660 | 0.076 | 0.067 | 0.066 | 0.060 | 0.014 | 0.012 |
| Chair | 0.483 | 0.071 | 0.063 | 0.061 | 0.054 | 0.027 | 0.010 |
| Sofa | 0.496 | 0.080 | 0.071 | 0.058 | 0.012 | 0.014 | 0.017 |
| Mean | 0.766 | 0.071 | 0.069 | 0.062 | 0.038 | 0.016 | 0.014 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, S.; Su, J.; Jiang, G.; Huang, Z.; Zhang, X. 3D Reconstruction Based on Iterative Optimization of Moving Least-Squares Function. Algorithms 2024, 17, 263. https://doi.org/10.3390/a17060263
Li S, Su J, Jiang G, Huang Z, Zhang X. 3D Reconstruction Based on Iterative Optimization of Moving Least-Squares Function. Algorithms. 2024; 17(6):263. https://doi.org/10.3390/a17060263
Chicago/Turabian StyleLi, Saiya, Jinhe Su, Guoqing Jiang, Ziyu Huang, and Xiaorong Zhang. 2024. "3D Reconstruction Based on Iterative Optimization of Moving Least-Squares Function" Algorithms 17, no. 6: 263. https://doi.org/10.3390/a17060263
APA StyleLi, S., Su, J., Jiang, G., Huang, Z., & Zhang, X. (2024). 3D Reconstruction Based on Iterative Optimization of Moving Least-Squares Function. Algorithms, 17(6), 263. https://doi.org/10.3390/a17060263