
Enforcing Traffic Safety: A Deep Learning Approach for Detecting Motorcyclists’ Helmet Violations Using YOLOv8 and Deep Convolutional Generative Adversarial Network-Generated Images



Abstract
1. Introduction
2. Materials and Methods
2.1. Helmet Use and Motorcyclist Safety
2.2. Detection Algorithms
3. Dataset
4. Methodology
4.1. Pre-Processing Module
- Addressing missing and mislabeled ground truth data.
- Ensuring that there is a sufficient variety in environmental conditions to allow for adequate detections.
- Addressing issues surrounding class imbalance.
4.2. Data Augmentation Module
4.3. Data Generation Module
- The objective of training G is to increase D’s classification error to the maximum extent possible. This will ensure that the generated images appear authentic and realistic.
- The objective of training D is to reduce the final classification error as much as possible. This will enable D to correctly differentiate between real and fake data.
- D is structured to perform a supervised image classification task (for example, identifying if an image contains a driver helmet or not).
- The filters learned by the GAN can be utilized to generate specific objects in the resulting image.
- G has vectorized properties that can learn highly intricate semantic representations of objects.
4.4. Detector Training Module
4.5. Test Time Augmentation
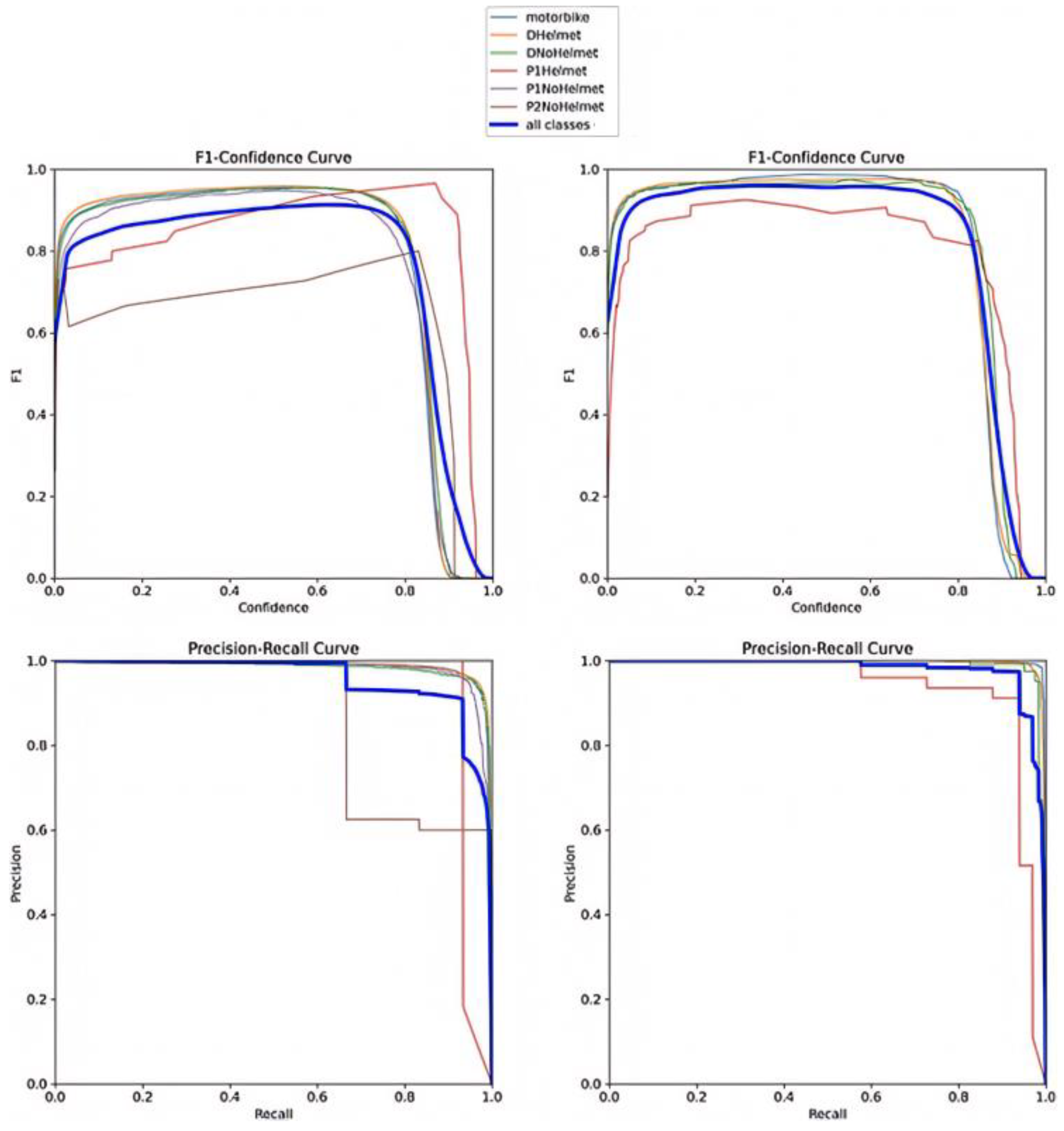
5. Results
5.1. Performance Metrics
5.2. Detector Model Results
5.3. Synthetic Augmentation Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lanzaro, G.; Sayed, T.; Alsaleh, R. Modeling Motorcyclist–Pedestrian Near Misses: A Multiagent Adversarial Inverse Reinforcement Learning Approach. J. Comput. Civ. Eng. 2022, 36, 04022038. [Google Scholar] [CrossRef]
- Haworth, N. Powered two wheelers in a changing world—Challenges and opportunities. Accid. Anal. Prev. 2012, 44, 12–18. [Google Scholar] [CrossRef]
- Dua, A.; Wei, S.; Safarik, J.; Furlough, C.; Desai, S.S. National mandatory motorcycle helmet laws may save $2.2 billion annually: An inpatient and value of statistical life analysis. J. Trauma Acute Care Surg. 2015, 78, 1182–1186. [Google Scholar] [CrossRef]
- World Health Organization. Global Status Report on Road Safety 2018; World Health Organization: Geneva, Switzerland, 2018; Available online: https://apps.who.int/iris/handle/10665/276462 (accessed on 3 January 2023).
- Rutter, D.R.; Quine, L. Age and experience in motorcycling safety. Accid. Anal. Prev. 1996, 28, 15–21. [Google Scholar] [CrossRef]
- Clabaux, N.; Fournier, J.-Y.; Michel, J.-E. Powered two-wheeler riders’ risk of crashes associated with filtering on urban roads. Traffic Inj. Prev. 2017, 18, 182–187. [Google Scholar] [CrossRef] [PubMed]
- Mullin, B.; Jackson, R.; Langley, J.; Norton, R. Increasing age and experience: Are both protective against motorcycle injury? A case-control study. Inj. Prev. 2000, 6, 32–35. [Google Scholar] [CrossRef]
- Vlahogianni, E.I. Powered-Two-Wheelers kinematic characteristics and interactions during filtering and overtaking in urban arterials. Transp. Res. Part F Traffic Psychol. Behav. 2014, 24, 133–145. [Google Scholar] [CrossRef]
- Gabella, B.; Reiner, K.L.; Hoffman, R.E.; Cook, M.; Stallones, L. Relationship of helmet use and head injuries among motorcycle crash victims in El Paso County, Colorado, 1989–1990. Accid. Anal. Prev. 1995, 27, 363–369. [Google Scholar] [CrossRef]
- Ichikawa, M.; Chadbunchachai, W.; Marui, E. Effect of the helmet act for motorcyclists in Thailand. Accid. Anal. Prev. 2003, 35, 183–189. [Google Scholar] [CrossRef]
- Vanlaar, W.; Hing, M.M.; Brown, S.; McAteer, H.; Crain, J.; Faull, S.M. Fatal and serious injuries related to vulnerable road users in Canada. J. Safety Res. 2016, 58, 67–77. [Google Scholar] [CrossRef]
- Chang, H.-L.; Yeh, T.-H. Risk Factors to Driver Fatalities in Single-Vehicle Crashes: Comparisons between Non-Motorcycle Drivers and Motorcyclists. J. Transp. Eng. 2006, 132, 227–236. [Google Scholar] [CrossRef]
- Yousif, M.T.; Sadullah, A.F.M.; Kassim, K.A.A. A review of behavioural issues contribution to motorcycle safety. IATSS Res. 2020, 44, 142–154. [Google Scholar] [CrossRef]
- RogÅLe, J.; El Zufari, V.; Vienne, F.; Ndiaye, D. Safety messages and visibility of vulnerable road users for drivers. Saf. Sci. 2015, 79, 29–38. [Google Scholar] [CrossRef]
- Truong, L.T.; Nguyen, H.T.T.; De Gruyter, C. Correlations between mobile phone use and other risky behaviours while riding a motorcycle. Accid. Anal. Prev. 2018, 118, 125–130. [Google Scholar] [CrossRef] [PubMed]
- Rowden, P.; Watson, B.; Haworth, N.; Lennon, A.; Shaw, L.; Blackman, R. Motorcycle riders’ self-reported aggression when riding compared with car driving. Transp. Res. Part F Traffic Psychol. Behav. 2016, 36, 92–103. [Google Scholar] [CrossRef]
- Manan, M.M.A.; Ho, J.S.; Arif, S.T.M.S.T.; Ghani, M.R.A.; VÅLarhelyi, A. Factors associated with motorcyclists’ speed behaviour on Malaysian roads. Transp. Res. Part F Traffic Psychol. Behav. 2017, 50, 109–127. [Google Scholar] [CrossRef]
- Drysdale, W.F.; Kraus, J.F.; Franti, C.E.; Riggins, R.S. Injury patterns in motorcycle collisions. J. Trauma Inj. Infect. Crit. Care 1975, 15, 99–115. [Google Scholar] [CrossRef] [PubMed]
- MacLeod, J.B.A.; DiGiacomo, J.C.; Tinkoff, G. An Evidence-Based Review: Helmet Efficacy to Reduce Head Injury and Mortality in Motorcycle Crashes: EAST Practice Management Guidelines. J. Trauma Inj. Infect. Crit. Care 2010, 69, 1101–1111. [Google Scholar] [CrossRef] [PubMed]
- Keng, S.-H. Helmet use and motorcycle fatalities in Taiwan. Accid. Anal. Prev. 2005, 37, 349–355. [Google Scholar] [CrossRef]
- Cunto, F.J.C.; Ferreira, S. An analysis of the injury severity of motorcycle crashes in Brazil using mixed ordered response models. J. Transp. Saf. Secur. 2017, 9 (Suppl. 1), 33–46. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001; pp. I-511–I-518. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; pp. 886–893. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Shoman, M.; Aboah, A.; Adu-Gyamfi, Y. Deep learning framework for predicting bus delays on multiple routes using heterogenous datasets. J. Big Data Anal. Transp. 2020, 2, 275–290. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; DollÅLar, P.; Girshick, R. Mask R-CNN. arXiv 2018. Available online: http://arxiv.org/abs/1703.06870 (accessed on 29 April 2023).
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2015. [Google Scholar] [CrossRef]
- Aboah, A.; Shoman, M.; Mandal, V.; Davami, S.; Adu-Gyamfi, Y.; Sharma, A. A vision-based system for traffic anomaly detection using deep learning and decision trees. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Nashville, TN, USA, 19–25 June 2021; pp. 4202–4207. [Google Scholar]
- Shoman, M.; Aboah, A.; Morehead, A.; Duan, Y.; Daud, A.; Adu-Gyamfi, Y. A region based deep learning approach to automated retail checkout. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, New Orleans, LA, USA, 18–24 June 2022; pp. 3209–3214. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Dahiya, K.; Singh, D.; Mohan, C.K. Automatic detection of bike-riders without helmet using surveillance videos in real-time. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 3046–3051. [Google Scholar] [CrossRef]
- Desai, M.; Khandelwal, S.; Singh, L.; Gite, S. Automatic helmet detection on public roads. Int. J. Eng. Trends Technol. 2016, 35, 185–188. [Google Scholar] [CrossRef]
- Medimi, V.S.; Mavilla Vari Palli, A.J. A Comparative Study of YOLO and Haar Cascade Algorithm for Helmet and License Plate Detection of Motorcycles; Blekinge Institute of Technology: Belkinge, Sweden, 2022. [Google Scholar]
- Liu, Y.; Alsaleh, R.; Sayed, T. Modeling Pedestrian Temporal Violations at Signalized Crosswalks: A Random Intercept Parametric Survival Model. Transp. Res. Rec. J. Transp. Res. Board 2022, 2676, 707–720. [Google Scholar] [CrossRef]
- Liu, Y.; Alsaleh, R.; Sayed, T. Modeling lateral interactions between motorized vehicles and non-motorized vehicles in mixed traffic using accelerated failure duration model. Transp. A Transp. Sci. 2022, 18, 910–933. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. 2020. Available online: http://arxiv.org/abs/2004.10934 (accessed on 29 April 2023).
- Jocher, G. ultralytics/yolov5: v6.0—YOLOv5n ‘Nano’ models, Roboflow integration, TensorFlow export, OpenCV DNN support. Zenodo 2021. [Google Scholar] [CrossRef]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo Algorithm Developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Jia, W.; Xu, S.; Liang, Z.; Zhao, Y.; Min, H.; Li, S.; Yu, Y. Real-time automatic helmet detection of motorcyclists in urban traffic using improved YOLOv5 detector. IET Image Process. 2021, 15, 3623–3637. [Google Scholar] [CrossRef]
- Siebert, F.W.; Lin, H. Detecting motorcycle helmet use with deep learning. Accid. Anal. Prev. 2020, 134, 105319. [Google Scholar] [CrossRef]
- Silva, R.R.V.E.; Aires, K.R.T.; De Melo Souza Veras, R. Helmet Detection on Motorcyclists Using Image Descriptors and Classifiers. In Proceedings of the 2014 27th SIBGRAPI Conference on Graphics, Patterns and Images, Rio de Janeiro, Brazil, 26–30 August 2014; pp. 141–148. [Google Scholar] [CrossRef]
- Doungmala, P.; Klubsuwan, K. Helmet Wearing Detection in Thailand Using Haar Like Feature and Circle Hough Transform on Image Processing. In Proceedings of the 2016 IEEE International Conference on Computer and Information Technology (CIT), Nadi, Fiji, 8–10 December 2016; pp. 611–614. [Google Scholar] [CrossRef]
- Jie, L.; Huanming, L.; Tianzheng, W.; Min, J.; Shuai, W.; Kang, L.; Xiaoguang, Z. “Safety helmet wearing detection based on image processing and machine learning. In Proceedings of the 2017 Ninth International Conference on Advanced Computational Intelligence (ICACI), Doha, Qatar, 4–6 February 2017; pp. 201–205. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2015. [Google Scholar] [CrossRef]
- Shoman, M.; Amo-Boateng, M.; Adu-Gyamfi, Y. Multi-purpose, multi-step deep learning framework for network-level traffic flow prediction. Adv. Data Sci. Adapt. Anal. 2022, 14, 2250010. [Google Scholar] [CrossRef]
- Shoman, M.; Aboah, A.; Daud, A.; Adu-Gyamfi, Y. Graph Convolutional Gated Recurrent Unit Network for Traffic Prediction using Loop Detector. Data Adv. Data Sci. Adapt. Anal. 2024. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Description | Instances |
|---|---|---|
| Motorcycle | A motorcycle being driven | 31,135 |
| D1Helmet | A motorcycle driver wearing a helmet | 23,260 |
| D1NoHelmet | A motorcycle driver not wearing a helmet | 6856 |
| P1Helmet | The first passenger wearing a helmet | 94 |
| P1NoHelmet | The first passenger not wearing a helmet | 4280 |
| P2Helmet | The second passenger wearing a helmet | 0 |
| P2NoHelmet | The second passenger not wearing a helmet | 40 |
| Hyperparameter | Value |
|---|---|
| batch_size | 128 |
| weight_init_std | 0.02 |
| weight_init_mean | 0.0 |
| leaky_relu_slope | 0.2 |
| downsize_factor | 2 |
| dropout_rate | 0.5 |
| scale_factor | 4 (downsize_factor) |
| optimizer | Adam |
| lr_initial_d | tfe.Variable (0.0002) |
| lr_initial_g | tfe.Variable (0.0002) |
| lr_decay_steps | 1000 |
| noise_dim | 128 |
| Hyperparameter | Value |
|---|---|
| batch_size | 8 |
| imgsz | 1088 |
| optimizer | Adam |
| learning_rate | 0.001 |
| dropout | 0.1 |
| iou | 0.7 |
| momentum | 0.937 |
| weight_decay | 0.0005 |
| warmup_bias_lr | 0.1 |
| fl_gamma | 2.0 |
| label_smoothing | 0.1 |
| mosaic | 0.1 |
| close_mosaic | 10 |
| Model | mAP50 | mAP50-95 | Precision | Recall | mAP | F1 | fps |
|---|---|---|---|---|---|---|---|
| YOLOv5 | 0.842 | 0.459 | 0.890 | 0.804 | 0.621 | 0.80 | 150 |
| DCGANs + YOLOv5 | 0.823 | 0.465 | 0.754 | 0.799 | 0.601 | 0.78 | 150 |
| YOLOv7 | 0.851 | 0.521 | 0.911 | 0.830 | 0.643 | 0.82 | 155 |
| DCGANs + YOLOv7 | 0.862 | 0.526 | 0.915 | 0.836 | 0.654 | 0.82 | 155 |
| YOLOv8 | 0.866 | 0.603 | 0.928 | 0.891 | 0.680 | 0.91 | 155 |
| DCGANs + YOLOv8 | 0.913 | 0.721 | 0.945 | 0.893 | 0.782 | 0.93 | 143 |
| DCGANs + YOLOv8 + TTA | 0.949 | 0.749 | 0.972 | 0.919 | 0.810 | 0.96 | 92 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shoman, M.; Ghoul, T.; Lanzaro, G.; Alsharif, T.; Gargoum, S.; Sayed, T. Enforcing Traffic Safety: A Deep Learning Approach for Detecting Motorcyclists’ Helmet Violations Using YOLOv8 and Deep Convolutional Generative Adversarial Network-Generated Images. Algorithms 2024, 17, 202. https://doi.org/10.3390/a17050202
Shoman M, Ghoul T, Lanzaro G, Alsharif T, Gargoum S, Sayed T. Enforcing Traffic Safety: A Deep Learning Approach for Detecting Motorcyclists’ Helmet Violations Using YOLOv8 and Deep Convolutional Generative Adversarial Network-Generated Images. Algorithms. 2024; 17(5):202. https://doi.org/10.3390/a17050202
Chicago/Turabian StyleShoman, Maged, Tarek Ghoul, Gabriel Lanzaro, Tala Alsharif, Suliman Gargoum, and Tarek Sayed. 2024. "Enforcing Traffic Safety: A Deep Learning Approach for Detecting Motorcyclists’ Helmet Violations Using YOLOv8 and Deep Convolutional Generative Adversarial Network-Generated Images" Algorithms 17, no. 5: 202. https://doi.org/10.3390/a17050202
APA StyleShoman, M., Ghoul, T., Lanzaro, G., Alsharif, T., Gargoum, S., & Sayed, T. (2024). Enforcing Traffic Safety: A Deep Learning Approach for Detecting Motorcyclists’ Helmet Violations Using YOLOv8 and Deep Convolutional Generative Adversarial Network-Generated Images. Algorithms, 17(5), 202. https://doi.org/10.3390/a17050202