1. Introduction
The growth of computing power and data availability has led to the development of more efficient pattern recognition techniques, such as neural networks and deep learning. When a sample accurately represents a population of data and is of sufficient size, deep learning methods can produce impressive results, even on unseen data, making them suitable for tasks such as classification and prediction tasks. Although these methods offer significant advantages, they also come with limitations, such as the sensitivity of deep neural networks (DNNs) to data quality and sources, as well as overfitting when trained on insufficient amounts of data. However, variations in input samples from different domains or insufficient training data can still significantly affect the performance of DNNs. As DNNs are increasingly being employed in critical applications such as medicine and transportation, enhancing their robustness is essential due to the potentially severe consequences of their unpredictability.
Using adversarial attacks is one approach to examining DNNs’ robustness to diverse inputs. Adversarial attacks aim to generate the smallest adversarial perturbation, i.e., a change in input, that results in a misclassification by the model.
This study investigated the abilities and drawbacks of modern defense techniques against adversarial attacks, such as adversarial and robust training. The latter refers to the hypothesis proposed by Ilyas et al. [
1]. It states that adversarial attacks exploit non-robust features inherent to the data set rather than the objects in the images. According to this hypothesis, removing these features from the data set and training a model on the modified data should render adversarial attacks ineffective.
We expanded the experiments from the original paper, trained a model on robust features, and tested it on unseen attacks. Our tests revealed that models trained on robust features are generally not resistant to -norm perturbations. According to our hypothesis, even if perturbations of the - and -norms are both imperceptible to humans, -norm attacks have a greater impact on the representations of the models.
We conducted a series of experiments and found strong evidence for our hypothesis. First, we compared the perturbations produced by different attacks utilising the theorem of vector norm equivalence in a finite-dimensional space. This comparison showed that the choice of perturbation constraints is too loose, despite being widely used in the literature. Second, by applying canonical correlation analysis, we discovered that -norm attacks cause the most dispersion in the latent representation. Finally, we analysed the impact of robust and adversarial training methods on the decision boundary of a model. The experiment showed that an -norm attack actually reduces the distance between the representations of a model and its decision boundary, which has a negative influence on the model generalisation.
Researchers might use our findings to develop more reliable adversarial training methods: while - and -norm perturbations look similar, the -norm ones are much harder to resist. To our knowledge, no one has paid so close attention to the differences between the attack norms before.
The structure of this paper is as follows: In
Section 2, we present a brief overview of various attacks on image classifiers, discuss the potential defense strategies that we used in our experiments, and review the theory of robust features.
To present our massive experiments in the most convenient way, we do not separate them into methodology and results Sections. Instead of that, we group the experiments into three logical blocks. Despite being separated into different Sections, all of them serve to answer to what extent adversarial and robust training are transferable. The corresponding results follow right after the experiment descriptions. In
Section 3, we challenge the generalisation of robust and adversarial training using various approaches. In
Section 4, we analyse how the robustly trained models represent the adversarial and benign data samples. In
Section 5, we investigate the impact of adversarial training on the decision boundaries of neural networks.
In
Section 6, we discuss the possible explanation of our observations. The conclusion of our study is presented in
Section 7.
2. Related Works
We focus on attacks on image classifiers, as they are the most widespread and mature; however, adversarial attacks are not limited by the type of input or task. The reader may find examples of attacks in other domains, such as malicious URL classification [
2], communication systems [
3], time series classification [
4], malware detection in PDF files [
5], etc. We suppose that an adversary has complete information about the neural network, including weights, gradients, and other internal details (white-box scenario). We also assume that in most cases, the adversary’s goal is to simply cause the classifier to produce an incorrect output without specifying a particular target class (untargeted attack scenario). Other possible scenarios of adversarial attacks can be found, for example, in [
6].
2.1. Adversarial Attacks
In this Subsection, we briefly describe the adversarial attacks that we used in the experiments.
2.1.1. Fast Gradient Sign Method (FGSM)
The FGSM was proposed by Goodfellow et al. in [
7]. Adversarial example
for image
x is calculated as
where
is the perturbation;
J is the cost function for a neural network with weight
, calculated for the input image
x with true classification label
y.
2.1.2. Projected Gradient Descent (PGD)
A PGD attack, introduced by Madry et al. in [
8], is an iterative variant of the FGSM, carrying out a similar operation to (
1) with projection on the
-ball:
where
is the projection of an adversarial example on the set of possible perturbations
S, and
t is the number of steps in iteration.
2.1.3. DeepFool
Moosavi-Dezfooli et al. [
9] provided a simple iterative algorithm to perturb images to the closest wrong class. In other words, DeepFool is equal to the orthogonal projection onto the classifier’s decision boundary. This property allows one to use the attack to test the robustness of a model:
where
is the average robustness,
f is the classifier,
is the successful perturbation from DeepFool, and
D is the data set. DeepFool can be used to calculate the distance from a data point to the closest point on the decision boundary [
10].
2.2. Adversarial Training as a Defense Method
One of the most popular approaches to defending neural networks against attacks is called adversarial training. It proposes “including” possible adversarial examples in the training data sets to prepare a model for attacks. To obtain an adversarially trained model, one should solve the following min–max optimisation problem [
8]:
where,
is the weight of the neural network,
D is the training data set,
S is the space for possible perturbations, and
for a given radius
.
Adversarial training was introduced by Goodfellow et al. in [
7]. Madry et al. [
8] proposed using a PGD attack during the training procedure and presented better robustness against adversarial attacks. However, Wong et al. [
11] achieved about the same accuracy against adversarial attacks using a simple one-step FGSM. Here and further, we refer to training based on empirical risk minimisation as “regular” since it does not involve any adversarial attack and is traditionally used to train neural networks.
It is important to note that the provable defense (i.e., “certified robust”) against any small-
attack has already been studied, for example, by Wong and Kolter [
12] and Wong et al. [
13]. However, the experiments in these works were conducted with relatively small perturbations. For example, in [
13] the maximum radius of the
perturbation is
, while the same norm in the adversarial training package in [
14] is
. Thus, we do not include certified methods in our research.
2.3. Hypothesis about the Cause of Adversarial Attacks
The exact reason why neural networks are susceptible to small changes in input data remains unclear. Goodfellow et al. [
7] argued that adversarial examples result from models being overly linear rather than nonlinear. However, another perspective considers poor generalisation as the source of attacks. Ilyas et al. [
1] hypothesised that neural networks’ vulnerability to adversarial attacks arises from their data representation. Classifiers aim to extract useful features from data to minimise a cost function. Ideally, these features should be related to the classification objects (robust features), but neural networks may utilise unexpected properties specific to a particular data set (non-robust features). As a consequence, an adversary can utilise non-robust features that actually make no sense for human perception. If a classifier can be trained on a data set containing only robust features, it should be resistant to adversarial attacks. We refer to this process as robust training.
This hypothesis serves as an entry point for our broad research on the role of adversarial attack norms in network prediction. We challenge the robust features hypothesis for several reasons. First, it is not fully proven, except for the toy example in [
1] and experiments on robust and non-robust data set creation. Second, subsequent works like [
15,
16] consider this hypothesis, though it might not be entirely accurate. For example, Zhang et al. [
16] proposed a similar experiment, referring to [
1], and developed it for universal perturbation. Although the results of [
1] were discussed in [
17], the accuracy of a robustly trained model was tested nowhere but in the original work, and we would like to fill this gap.
3. Generalisation of Robustly and Adversarially Trained Models
One of the goals of this work is to check the generalisation of robustly and adversarially trained models to various unseen attacks. The lack of generalisation can be critical for the users of such models who want to be sure that they respond adequately to any noisy data. In this Section, we show that, indeed, the robustly and adversarially trained models do not generalise well and highlight the cases when their performance can be compromised significantly. In the further experiments, we explain the difference between - and -norm perturbations, which might be the cause of the lack of generalisation.
3.1. The Broad Testing of Robust and Adversarial Training
We replicated robust training from [
1], employing a broader testing setup. It included various attack norms, data sets, and model architectures. The motivation for this experiment stems from the work of Tramer et al. [
18], which demonstrates that even adversarially trained models could be compromised by unseen attacks; thus, they do not generalise well. We wanted to test this statement and go further by checking the generalisation of robustly trained models.
Robust training involves several steps:
Select an adversarially pre-trained model and the data set for image classification.
For each image (named “target“) from the data set, randomly generate a noisy image.
Compute the representations using an adversarially trained model for both the random and target images. At each iteration, slightly adjust the random image to minimise the distance between the vectors of the two images. After a set number of steps, this method produces a modified image with robust features only. So, image by image, compute a new, robust data set from the original.
Train the model regularly with the same architecture on this modified data set, ultimately resulting in a robustly trained model.
Test the generalisation capacity of both the adversarial and robust models: compute the accuracy under attacks that were not considered during the adversarial training phase and hence not used in the formation of the robust model.
Following this approach, we performed several experiments. Firstly, we took two adversarially trained ResNet50-s [
19]. The training data set for the models was CIFAR-10 [
20]; the training attack was PGD with
- and
-norms. We tested their performance against FGSM (
-,
-,
-norms), PGD (
-,
-,
-norms), C-W (
-norm), and DeepFool (
-norm) attacks. A C-W attack refers to the Carlini and Wagner adversarial attack; a detailed description of it can be found in the original paper [
21]. The performance results of the
-trained model are outlined in
Table 1, and those of the
-trained model are presented in
Table 2.
Second, we performed the same experiment on the Inception V3 [
22] model. For computational reasons, we only took one model, trained with a PGD attack with an
-norm. The results are displayed in
Table A1. Note that
for the attacks differs from the similar ones for ResNet50-s because the model has a bigger input shape (224 × 224 vs. 32 × 32, respectively).
Thirdly, we tried to manage the entire adversarial training pipeline ourselves from scratch. Owing to computational constraints, we selected the relatively more manageable ResNet18 architecture. The models were trained on a PGD attack with five iterations and
- and
-norms. For data sets, we utilised CIFAR-10 and CINIC-10 [
23] as the data sets, and PGD and FGSM as the test attacks. The results for CIFAR-10 and CINIC-10 are displayed in
Table 3 and
Table A2, respectively.
To save space in this subsection, we put some of the tables in
Appendix A and do not specifically comment on them. However, these results make the experiment more solid, confirm the overall conclusion (written in the following), and present the same patterns of adversarial and robust training as the models in
Table 1 and
Table 2.
On examination, it is apparent that adversarial and robustly trained models demonstrate reasonable stability against some variations of PGD and FGSM attacks, for example, with an -norm. However, all attacks with an -norm significantly undermined the accuracy of the models. Hence, the model does not ensure generalisation against all attack types, primarily because a simple increase in norm or perturbation shows a drastic impact.
3.2. Equivalence of and Perturbation Norms
To explain the lack of generalisation in the previous experiment, we used the theorem of the equivalence of vector norms on finite-dimensional spaces. The theorem states that for a given two norms
and
on the finite-dimensional vector space
V over
C, there exists a pair of real numbers
such that, for all
, the following inequality holds:
In other words, all norms are equal to each other with respect to some coefficients. Images and adversarial perturbations are finite-dimensional vectors over
R; thus, the same inequality holds for the
- and
-norms. The
-s that we used in the previous experiments, such as
for the
-norm and
for the
-norm on the CIFAR-10 data set, are widely used [
7,
8]. In practice, such a choice seems reasonable because the corresponding perturbations are indistinguishable by the human eye. However, such
-s might be too loose, which can explain the superiority of
-norm attacks.
Take the CIFAR-10 test data set and two attacks: PGD with an -norm of attack and ; and PGD with an -norm and .
Generate adversarial perturbations by these attacks. Save only the perturbation that misclassifies a network: the prediction of such an adversarial sample must not be equal to the true label and prediction of the original image.
Flatten the perturbation matrices into vectors and calculate the norms.
Iterating over the perturbations, take
and
as
and
. Therefore, in Equation (
5) we picked
,
, but this was an arbitrary choice.
Repeat for three models: regular ResNet-50 and adversarially trained ResNets-50 with - and -norms of attacks. In addition, for all cases, calculate the percentage of adversarial misclassified samples by the model.
The results are presented in
Table 4.
For generalisation purposes, we also tested the same models on an FGSM attack with
(attack norm was
) and we present the results in
Table 5. We also conducted the same experiment on the CINIC data set (
Table 6).
The coefficients in attacks are significantly higher than those for -norm attacks. Since the coefficients are the fractions between the norms, and , the -norm of such perturbations is much higher than 0.25. In fact, when is approximately 55, each pixel of the perturbed image is equal to .
For attacks, on the other hand, the overall perturbation is restricted by 0.25, but some particular pixels can be changed more than 0.03. The small values of and for the -norm adversarially trained model indicate high magnitude in some image regions.
In this experiment, we called into question the traditional choice of -s in the literature on adversarial attacks. We leave the more detailed analysis of the coefficient range for a truly robust model for further research.
3.3. Loss Distributions of the Adversarially Trained Models
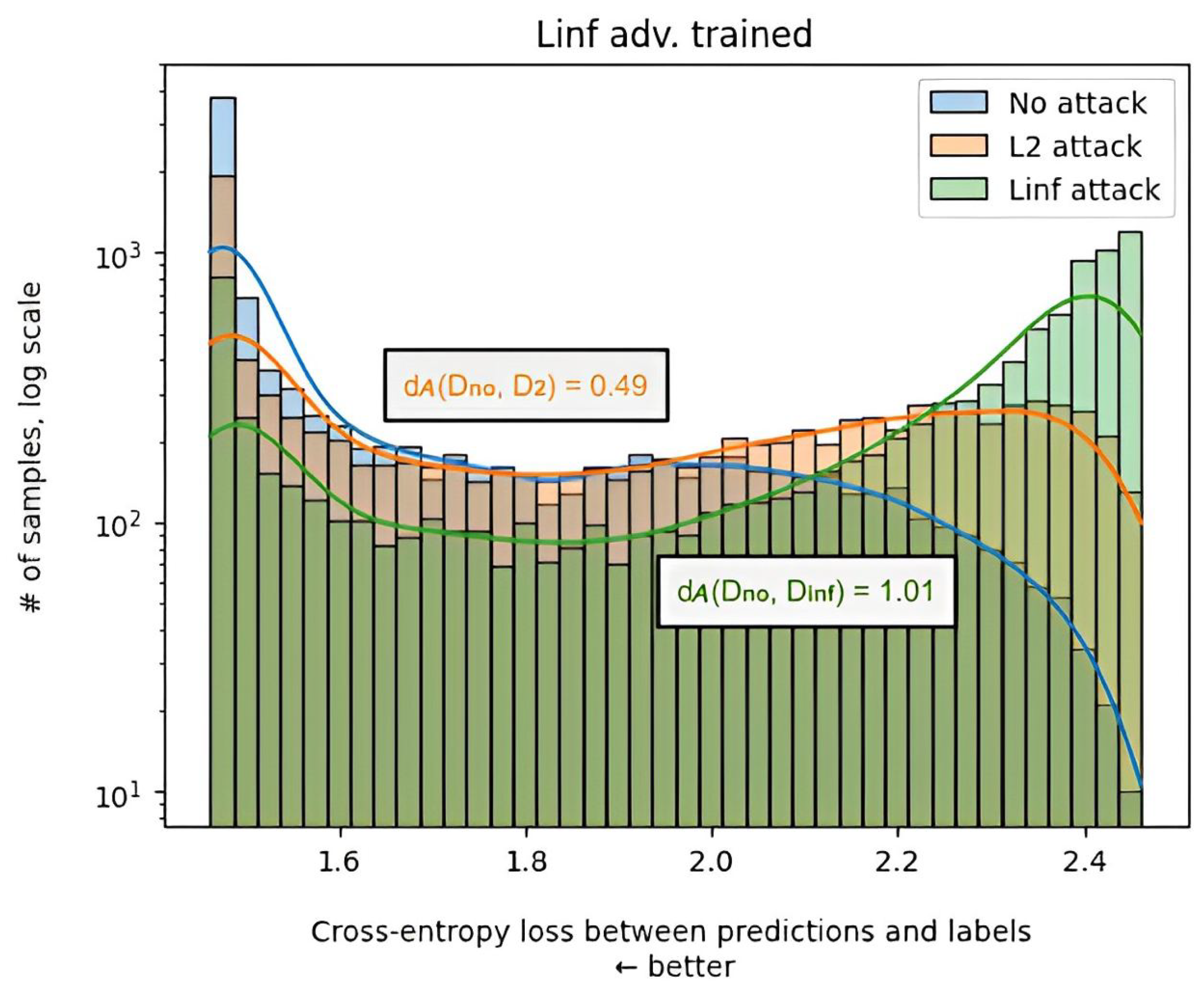
To illustrate the disparity between adversarial attack norms, we took three ResNet50 models from the first experiments: one model was regularly trained on CIFAR-10, while the other two were adversarially trained by PGD attacks with - and -norms, respectively. The performance of each model was evaluated using histogram plots, where the X-axis represents the cross-entropy loss between predictions and one-hot-encoded labels and the height of bars displays the number of samples in a given region. We used a CIFAR-10 test data set with 10,000 samples in total.
To challenge these models, we used two types of PGD attacks: the -norm of perturbation with and the -norm with . The number of steps for the -norm attack was set to five, while that for the attack on was 10. Additionally, the loss of each model on clean data was assessed.
Each plot represents one model and includes three distributions: losses in clean and adversarially perturbed CIFAR-10 test data (10,000 samples), with
- or
-norm attacks. The performance of each model is presented by histogram plots. The X-axis stands for the cross-entropy loss between predictions and one-hot encoded labels (lower is better). The height of bins displays the number of samples that fell in a given region. The A-distance, which is used in domain adaptation [
24], additionally illustrates the difference between the distributions of clean and adversarial samples. A higher A-distance value indicates greater dissimilarity between distributions. The plots are presented in
Figure 1,
Figure 2 and
Figure 3. For the better visualization, we plot kernel density estimation alongside with histogram for each attack, with the corresponding color.
In all figures, the distributions of attack with an
perturbation norm (
Figure 1) have a peak near the maximum loss. Although, for the regularly trained model (
Figure 3), approximately all samples are located near this peak, for adversarially trained models, there are also smaller peaks on the left side of the distributions. The distributions of clean data have about the same shape on every plot: a high peak on the very left bar (mean with the least error) and a smooth decrease to the right side. The distributions of adversarial samples with the
-norm (
Figure 2) have a similar peak for adversarially trained models; however, they have a more flattened tail. For the regularly trained model, most of the examples fall into the right region, as for the attack with the
-norm (note the scale).
The results indicate that adversarial attacks alter the shape of the sample distribution, with the norms of attack playing a significant role in determining the curves’ appearance. The A-distance confirms this finding. Adversarial training brings the adversarial and benign distributions closer together but does not achieve complete convergence, particularly for attacks with an -norm.
4. Analysis of the Representations
We extend the research on adversarial and robust training. While in the previous Section we focused mostly on attack parameters and perturbations, we are also interested in how a model represents benign and adversarial samples. We aim to determine the proximity of such representations for a robustly trained model. The degree of similarity between representations of samples with small
- or
-norms indicates the stability of a model. We analysed the representations of neural networks from the robust training experiment (
Section 3.1) using singular value canonical correlation analysis and performed a principal component analysis for their visualisation.
4.1. Comparison of Representations under Adversarial Attacks
Canonical correlation analysis (CCA) is a method used to compare the representations of neural networks. Its objective is to identify linear combinations of two sets of random variables that maximise their correlation. CCA has been employed to compare activations from different layers of neural networks, for example, by Morcos et al. [
25] and An et al. [
26]. Raghu et al. [
27] proposed an extension of CCA, singular value canonical correlation analysis (SVCCA), for neural network analysis.
We employed SVCCA to compare the representations of the original and corresponding adversarial images. For each experiment, we took a batch of 128 images, computed the related adversarial examples under some attack, calculated the SVCCA for the representations, and took the mean. In each experiment, we tested the same models as in the previous experiments: a regularly and two adversarially trained ResNet50-s. In this experiment, a high mean correlation coefficient indicated that the representations were similar to each other and that small perturbations did not impact the model.
Although attack norms were the primary variables in these experiments, we also tested two different attacks (FGSM and PGD) to eliminate the threat of validity. The means of SVCCA are presented in
Table 7. The results of the same for the best and worst cases from
Table 1 and
Table 2 in
Table A3 can be found in
Appendix B.
The results in
Table 7 and
Table A3 demonstrate that adversarial attacks with
-norm perturbation have the most significant impact on the representations. This effect is evident even in models that were trained specifically to handle
-norm attacks. These findings emphasise the importance of considering adversarial attack norms when evaluating model robustness because testing in the
-norm may provide a false sense of security.
4.2. Visualisation of Representations
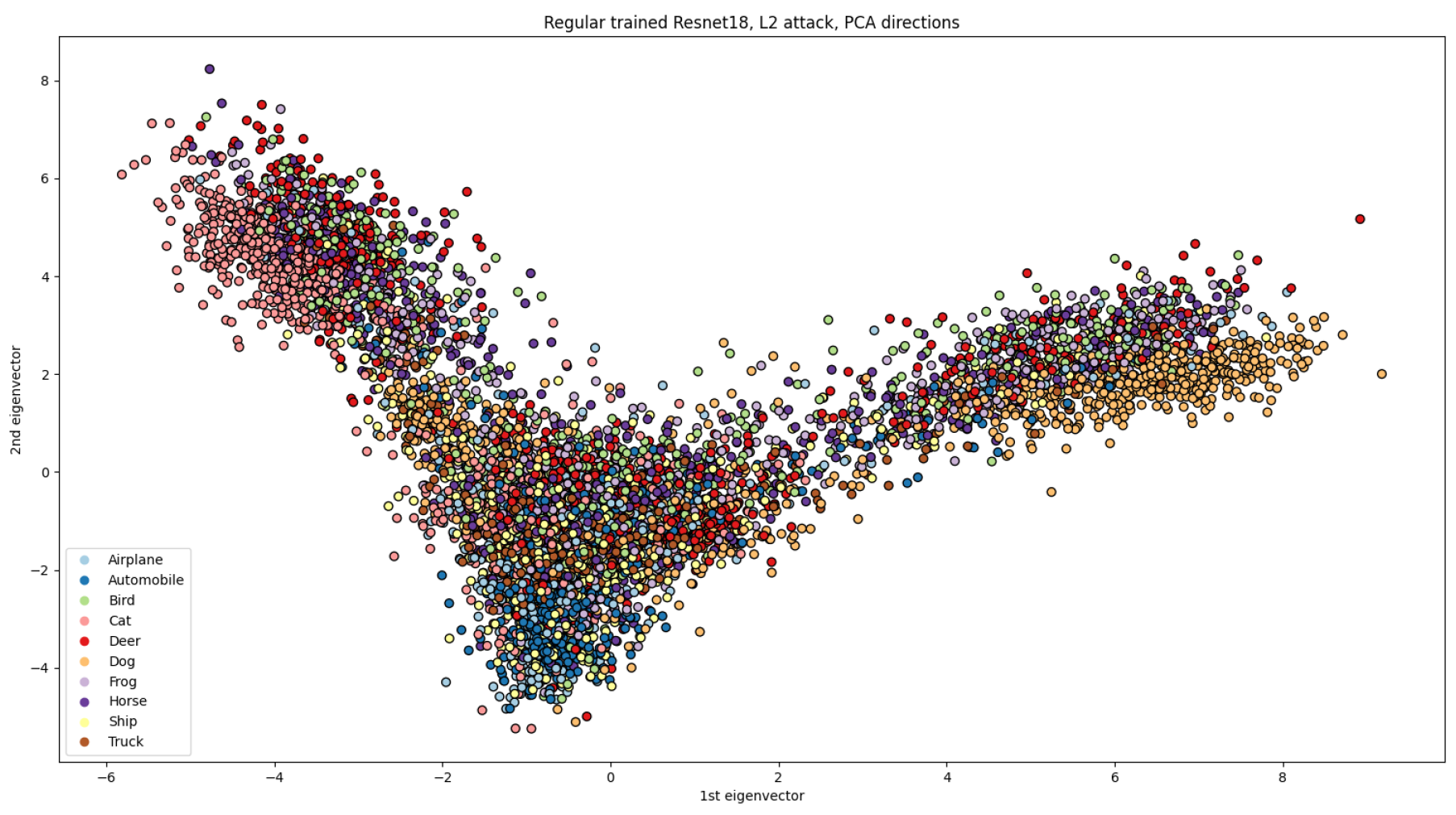
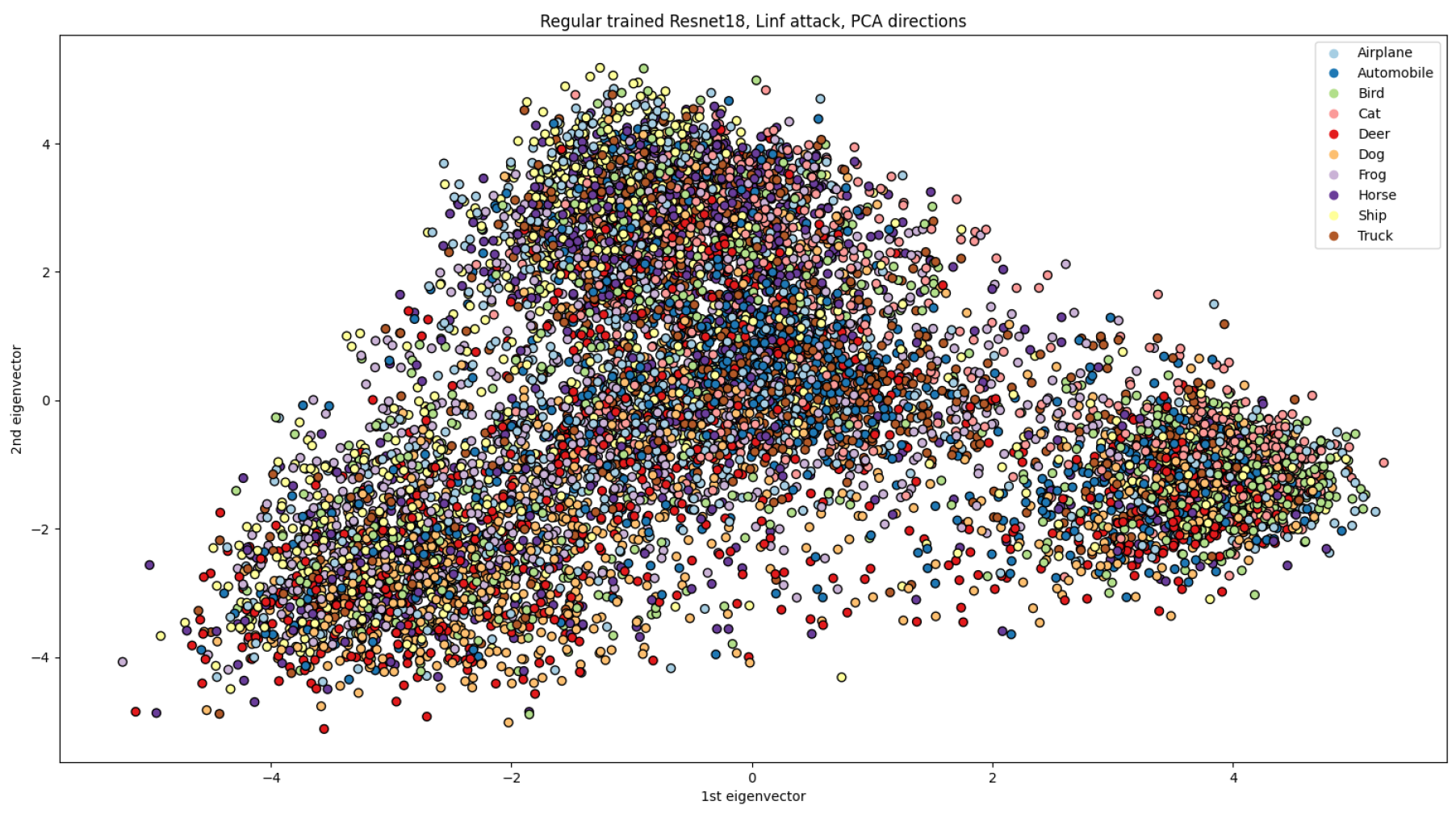
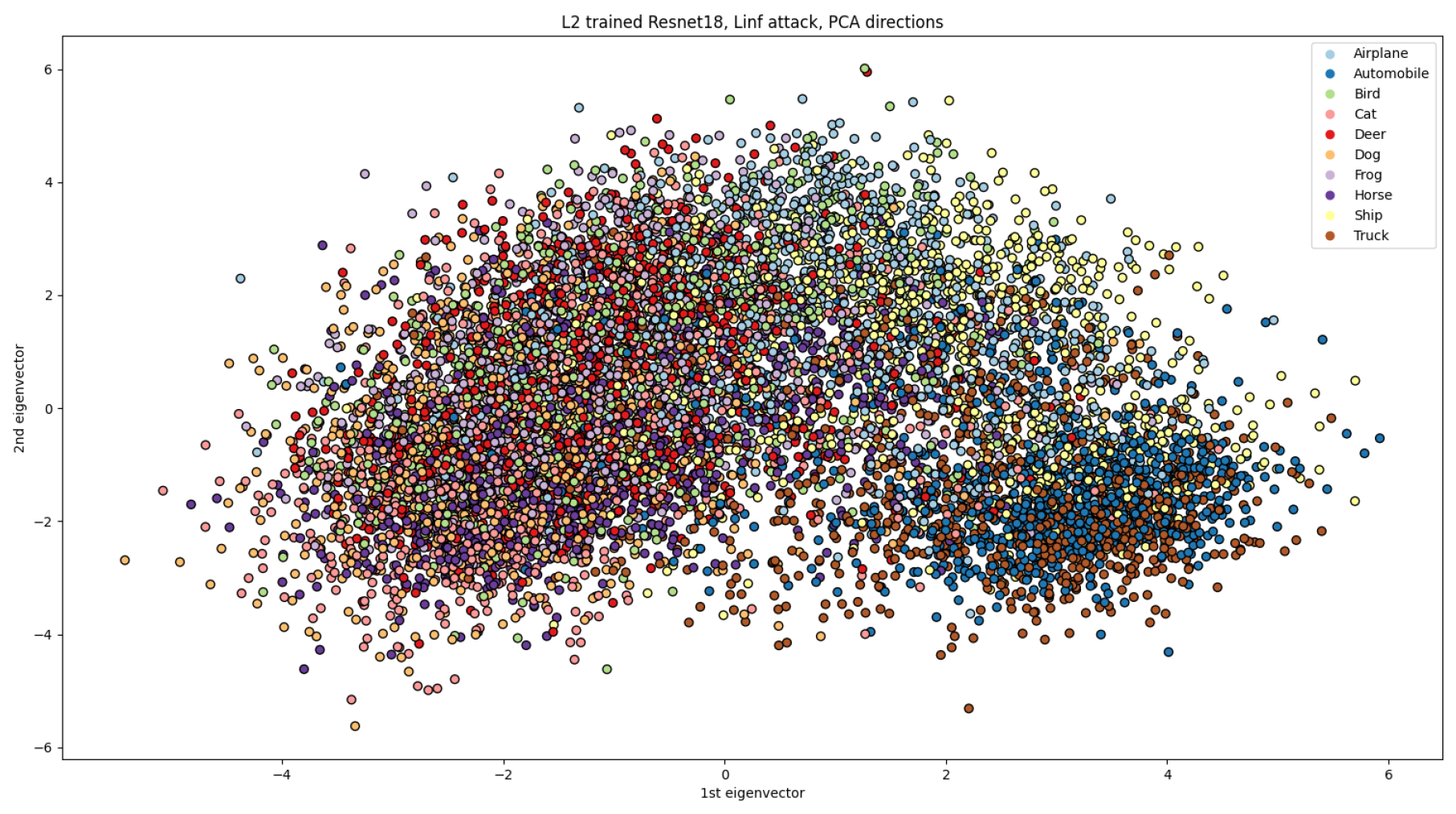
The visualisation of representations presents a challenge due to the high dimensionality of representation vectors. Nonetheless, such visualisation can be useful for analysis purposes. To address this issue, we employed principal component analysis (PCA) to reduce the dimensionality of representations from 512 to 2. We limited our experimentation to ResNet18 due to computational constraints.
We present the visualisation of representations for different combinations of models and norms of PGD attacks in
Figure 4,
Figure 5,
Figure 6,
Figure 7 and
Figure 8.
Figure 4 depicts the representations of samples from CIFAR-10 for a regularly trained ResNet18, which serves as a baseline case. In
Figure 5 and
Figure 6, we visualise the data as adversarial samples with
- and
-norms of attack, respectively. Furthermore, we examine the representations of adversarial samples for adversarially trained models in
Figure 7 and
Figure 8. To challenge the models, we use alter norms of attacks from training ones: the model trained on PGD with an
-norm is tested on an
-norm PGD (
Figure 8), and vice versa (
Figure 7). We group the representations of different classes by colours in all figures to comprehend how the representations of different classes intermingle under adversarial attacks.
The representations of the regularly trained networks are clustered according to the classes in the data set, as shown in
Figure 4. However, when subjected to adversarial attacks, all representations become heavily mixed, resulting in a more challenging classification task due to overlapping representations of different classes. The most mixed representations were observed on the regularly trained network through the
-norm PGD attack (
Figure 6). On the contrary, adversarial training, as shown in
Figure 7 and
Figure 8, resulted in some class representations (e.g., “Automobile” or “Truck”) remaining clustered while becoming closer to each other than those without attacks. The same pattern was observed for the
-norm attack (
Figure 6).
5. Impact of Adversarial Training on the Network’s Decision Boundary
As a continuation of generalisation testing, we aim to investigate the impact of robust and adversarial training methods on the decision boundary of a model. Particularly, we show how the mean distance between samples and decision boundaries varies for different models when exposed to adversarial attacks.
We use the idea of Mickisch et al. [
10], who utilised the DeepFool attack in
Section 2.1.3 to measure this distance. The decision boundary is defined as the set of input images where two or more classes share the same maximum probability, indicating that the classifier is uncertain about the class of the image:
where
c is the number of classes. Under this definition, the usage of the DeepFool attack looks natural because it aims to find a perturbation to the closest wrong class. The distance of the sample
x to the decision boundary
D can be measured as
The pre-trained ResNet50 model is used with 20 steps of PGD attack during training, while ResNet18 models are trained under PGD with only 5 steps. The test data set is CIFAR-10. The outputs of the ResNet18 and ResNet50 models with different training configurations are presented in
Table 8. The table displays the mean difference between the decision boundaries of models and images from CIFAR-10, calculated using the
distance. The “steps” column represents the mean iteration of DeepFool spent during the attack generation. A comparison is made between the models in
Table 1,
Table 2 and
Table 3.
The results indicate that the mean distance for ResNet18-s (for all types of training) from the decision boundary is relatively small, especially for the
-norm. A small distance from a sample to the decision boundary implies that it is easier to misclassify this sample because it does not require a significant perturbation. Interestingly, the distance for the
-norm adversarially trained model is actually less than training
. However, the testing of this model under PGD attack (
Table 3) suggests that it has some robustness. Therefore, the reliability of the popular method of model testing used in this study is called into question.
7. Conclusions
While strong adversarial attacks on neural networks have already been developed, most of the defense mechanisms still do not guarantee full resistance to them in general. In this study, we consider the impact of adversarial and robust training on a model’s ability to adequately represent adversarial samples. The experiments demonstrate that the model, trained on a “robust” data set, is still vulnerable to some attacks; thus, adversarial attacks do not compromise only non-robust features. Thus, the robust features are not well generalised, especially on the -norm of attack. We assume that the small difference between clean and adversary inputs for the attack leads to a huge gap in the latent space between them; SVCCA of different attack representations confirms this assumption. Our visualisation of neural network representation also shows the difference between - and -norms of attack. Moreover, we discover that -norm adversarial training decreases the distance between the representations and the decision boundary.
In light of these results, we recommend that researchers in the field of adversarial attacks and defense mechanisms pay closer attention to
-norm attacks to avoid a false sense of security. It is crucial to consider this norm in their tests to ensure the robustness of models against potential attacks. As the next step in this research, we would like to determine the perturbation coefficient range (experiment in
Section 3.2) that should be reasonable for a robust model.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}