
Learning State-Specific Action Masks for Reinforcement Learning

Abstract
1. Introduction
- Bisimulation Metrics on Actions by States (BMAS): The paper introduces a novel metric, BMAS, based on the concept of bisimulation, which quantifies the behavioral differences between actions by states.
- Automatic Action Masking: The paper introduces a method for automated acquisition of state-specific action masks in RL for environments with discrete action spaces, alleviating the need for expert knowledge or manual design. This contributes to making RL more applicable in real-world scenarios by accelerating exploration efficiency while preserving strong interpretability.
- Experimental Validation: The paper demonstrates the effectiveness of the proposed approach through comprehensive experiments conducted in environments with discrete spaces, including Maze, Atari, and RTS2. The results showcase compelling performance, complemented by visualizations that underscore the interpretability of the proposed method.
2. Related Work
2.1. Action Space Factorization
2.2. Action Space Reduction
2.3. Action Mask
3. Background
3.1. MDP Problem
3.2. Bisimulation
4. Approach
4.1. Bisimulation Metric on Actions
4.2. A Perfect Mask Model
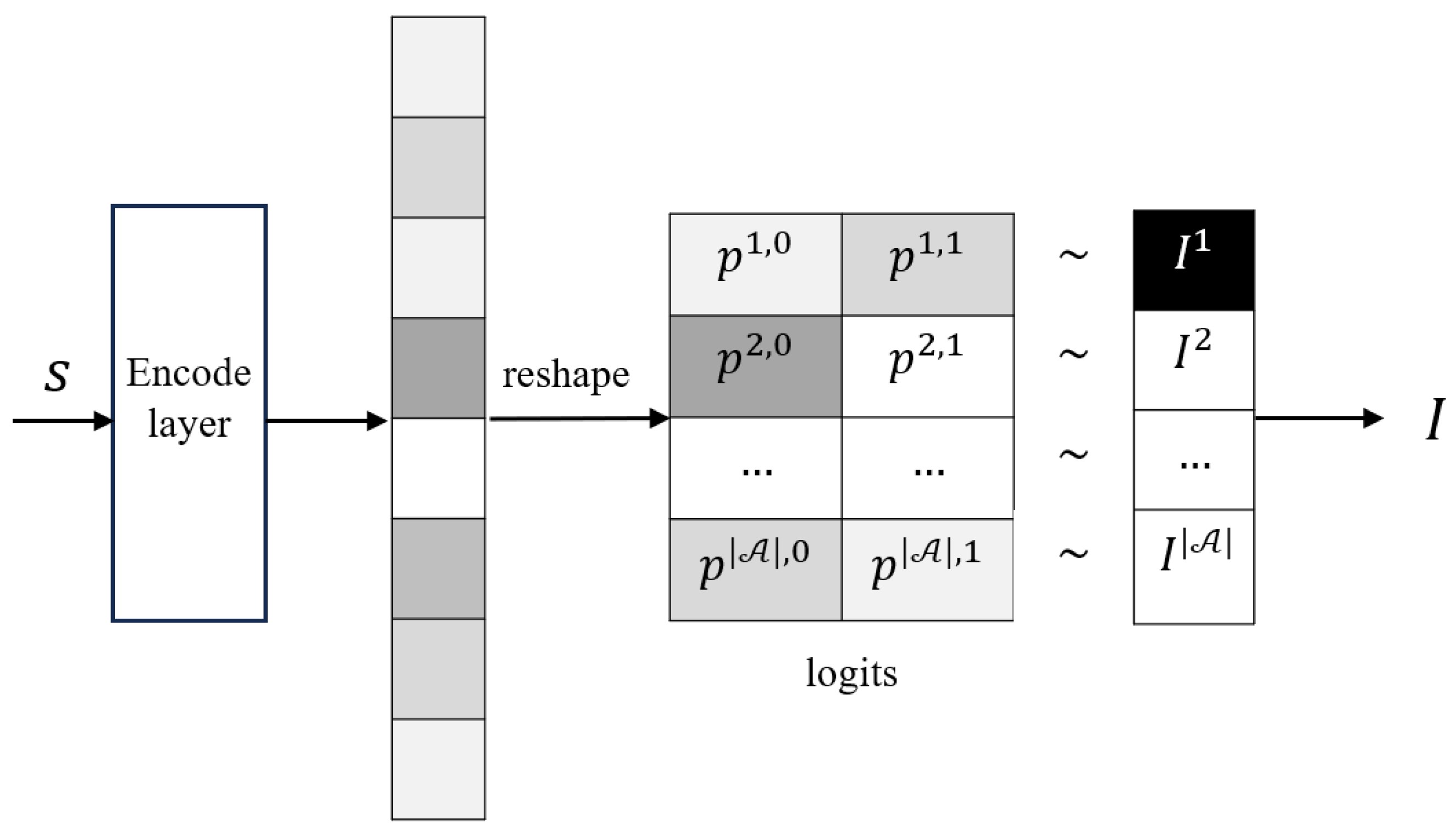
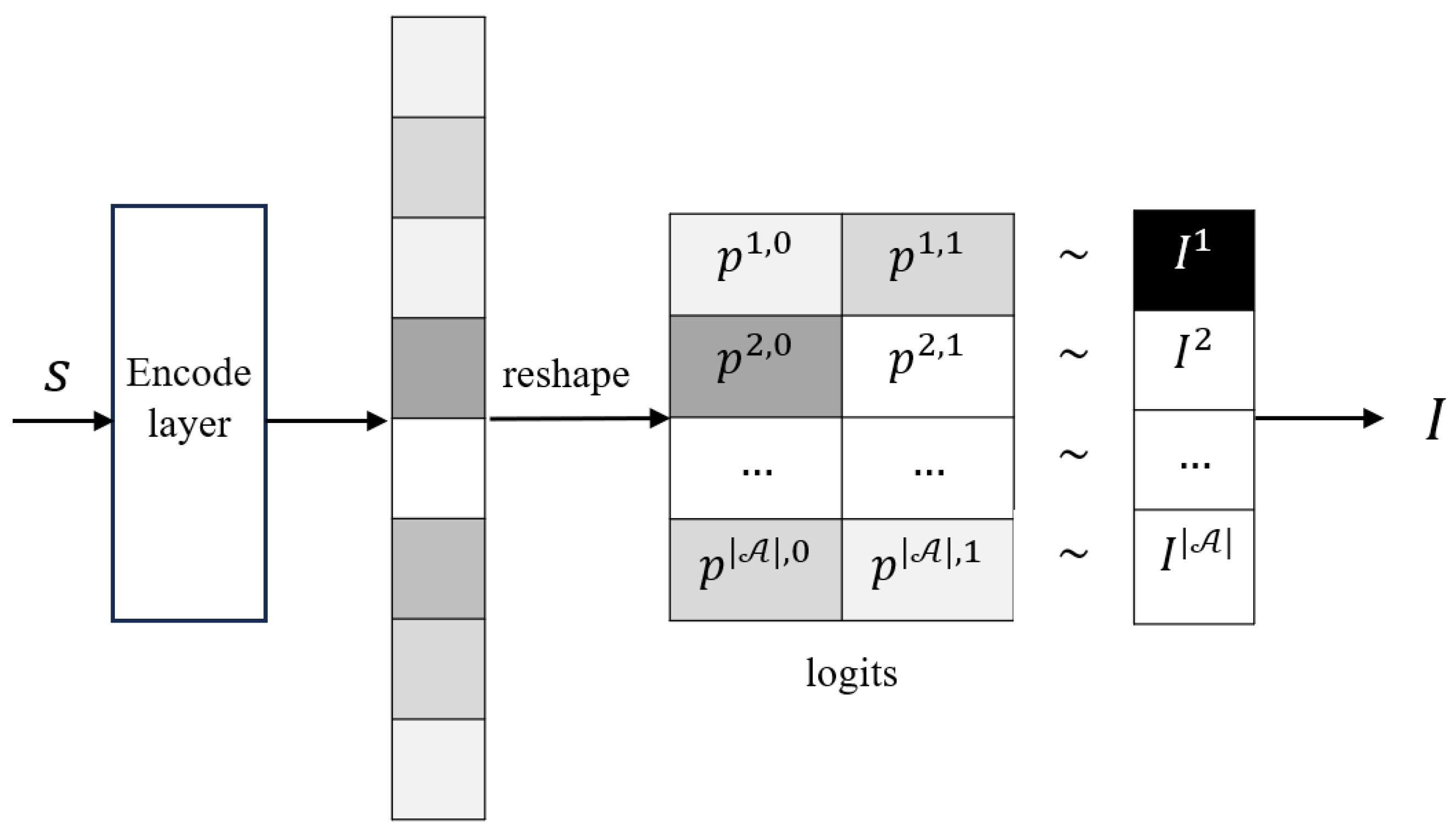
4.3. Learning the Action Mask Supervised
| Algorithm 1 Training an action mask model |
|
| Algorithm 2 RL with action mask |
|
5. Experiments
5.1. Implementation Details
5.2. Domains
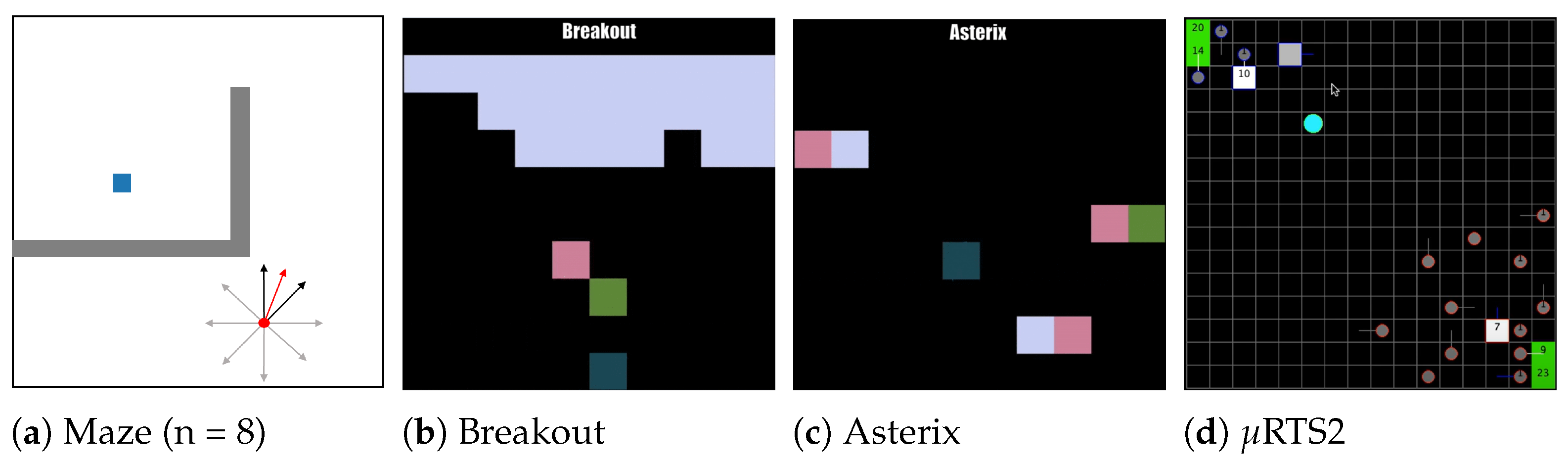
5.2.1. Maze
5.2.2. MinAtar
5.2.3. RTS2
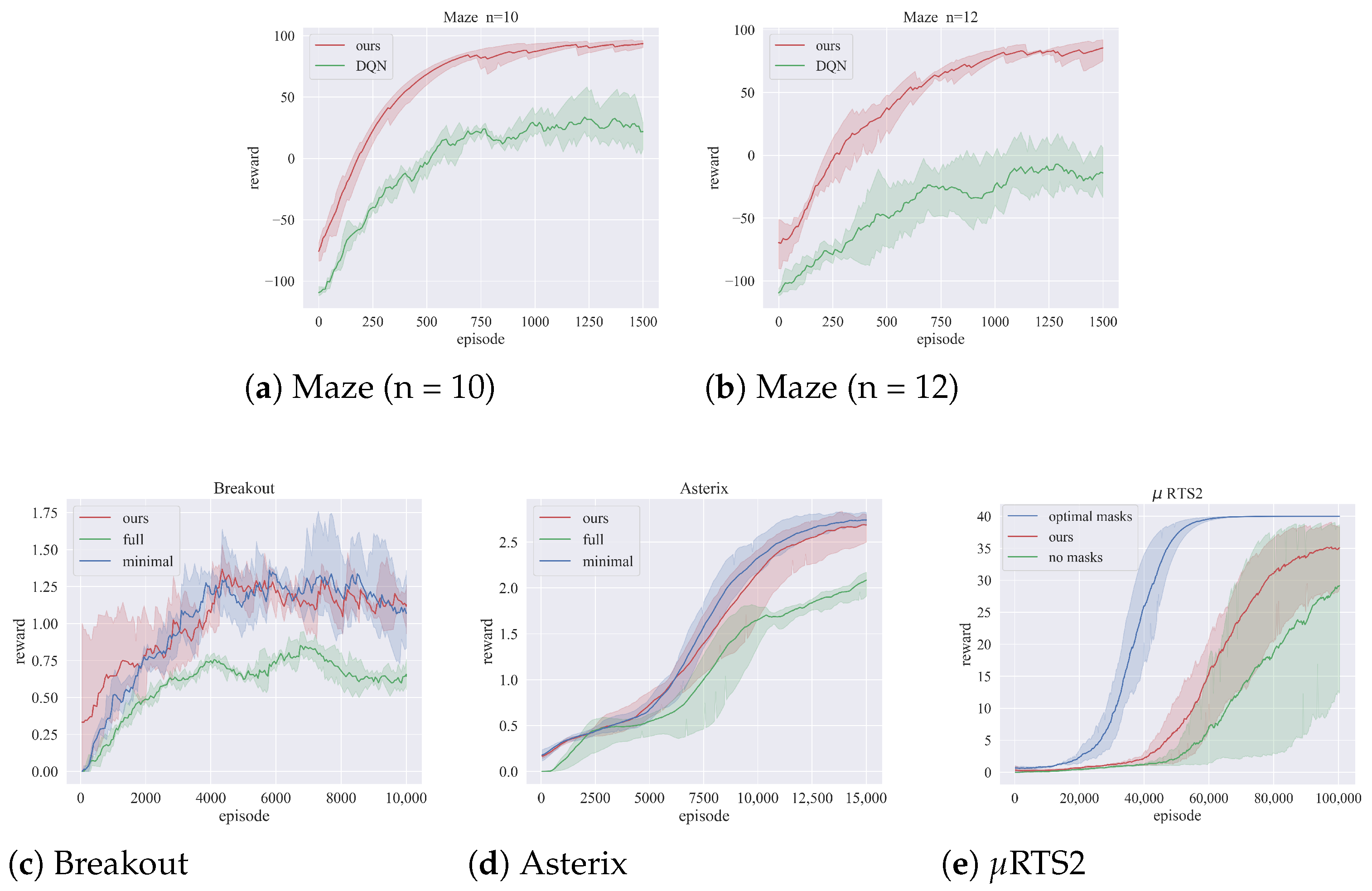
5.3. Results
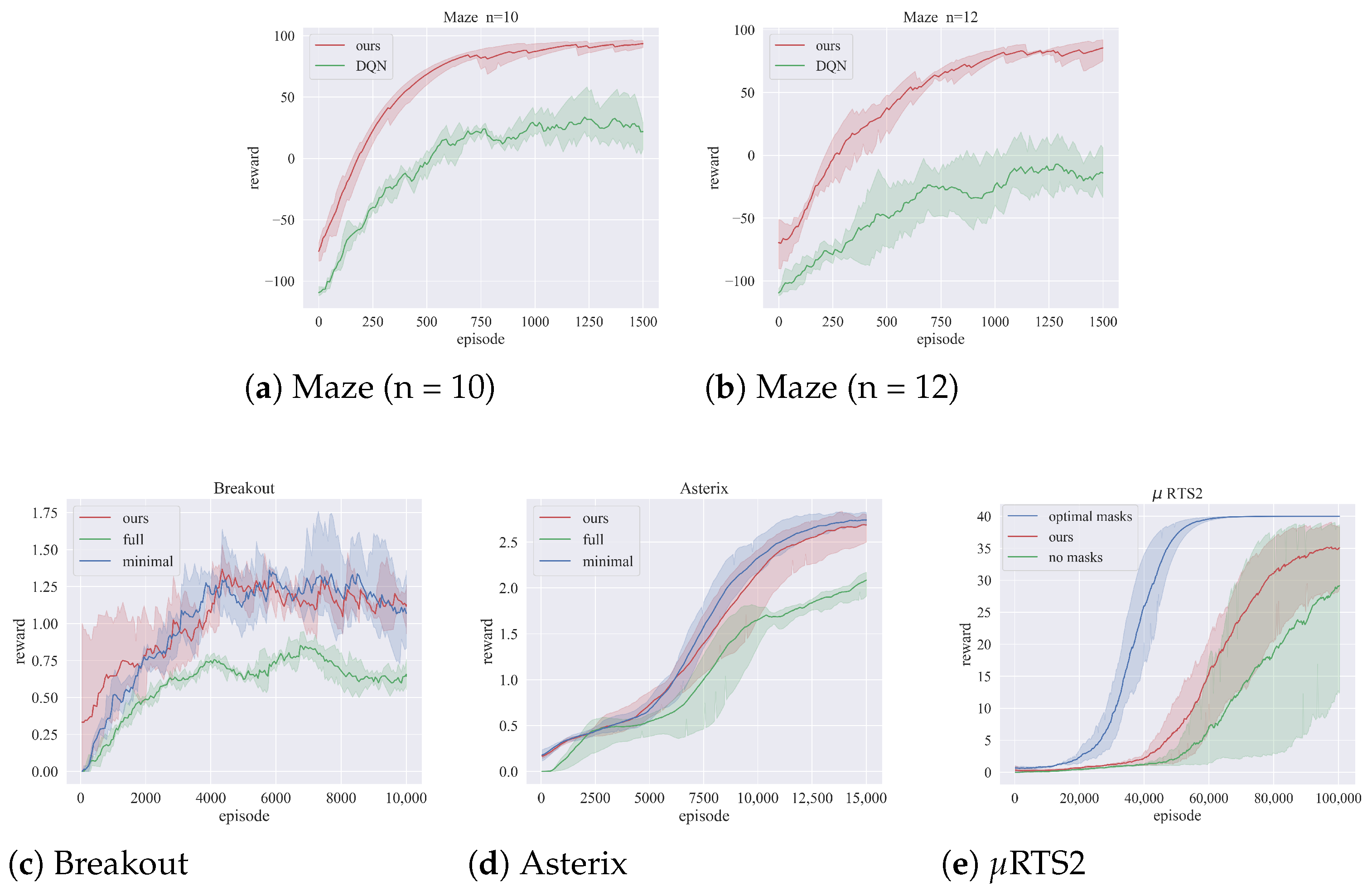
5.3.1. Main Results
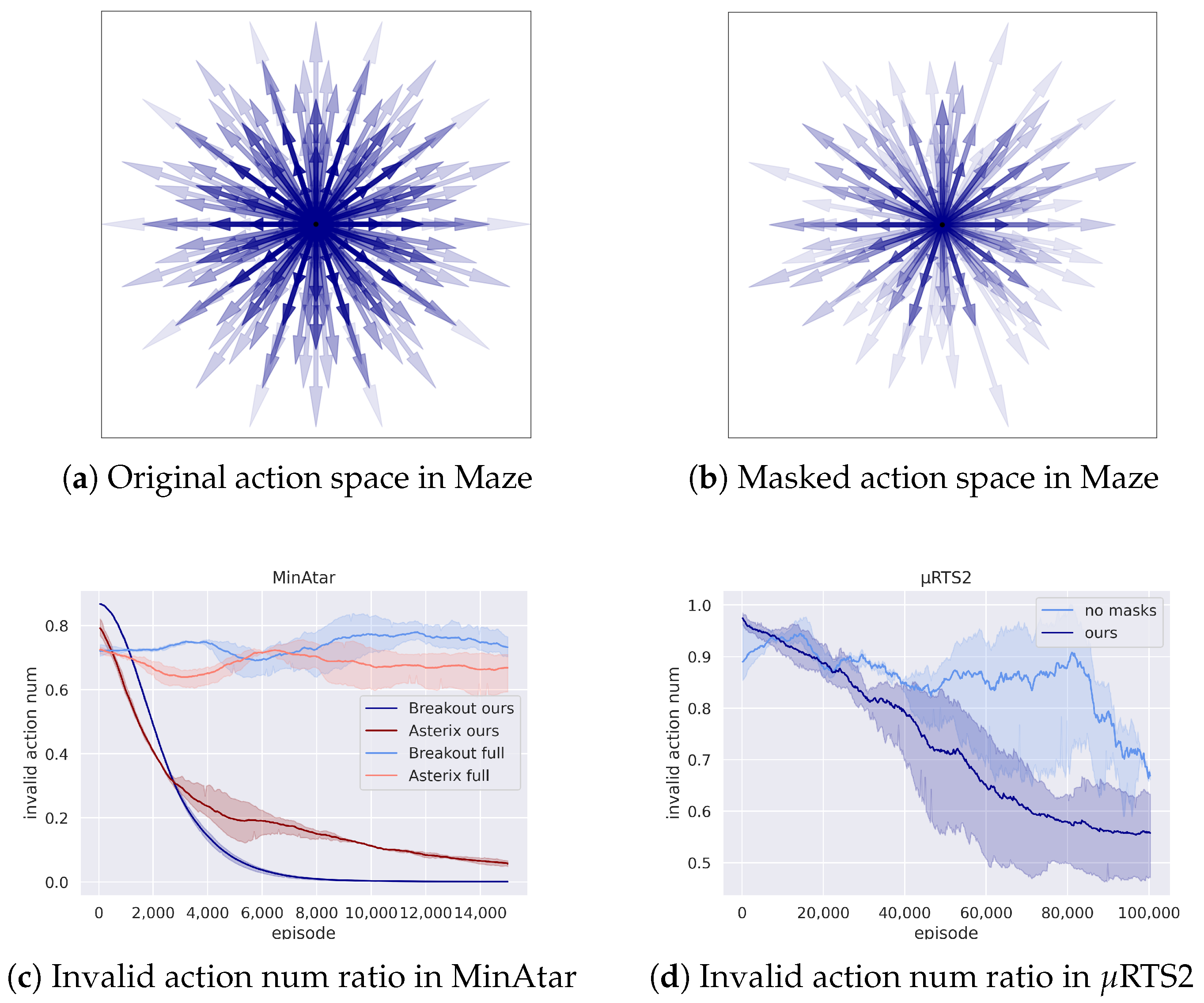
5.3.2. Visualization
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Proof of Proposition 1
Appendix B. Implementation Details of Masked DQN and PPO
Appendix B.1. DQN with Action Mask
| Algorithm A1 Getting actions in DQN with masks |
|
Appendix B.2. PPO with Action Mask
| Algorithm A2 Train PPO with action masks |
|
References
- Ye, D.; Chen, G.; Zhang, W.; Chen, S.; Yuan, B.; Liu, B.; Chen, J.; Liu, Z.; Qiu, F.; Yu, H.; et al. Towards playing full moba games with deep reinforcement learning. Adv. Neural Inf. Process. Syst. 2020, 33, 621–632. [Google Scholar]
- Zhang, Y.; Chen, L.; Liang, X.; Yang, J.; Ding, Y.; Feng, Y. AlphaStar: An integrated application of reinforcement learning algorithms. In Proceedings of the International Conference on Computer, Artificial Intelligence, and Control Engineering (CAICE 2022), SPIE, Zhuhai, China, 25–27 February 2022; Volume 12288, pp. 271–278. [Google Scholar]
- Shyalika, C.; Silva, T.; Karunananda, A. Reinforcement learning in dynamic task scheduling: A review. SN Comput. Sci. 2020, 1, 1–17. [Google Scholar] [CrossRef]
- Damjanović, I.; Pavić, I.; Puljiz, M.; Brcic, M. Deep reinforcement learning-based approach for autonomous power flow control using only topology changes. Energies 2022, 15, 6920. [Google Scholar] [CrossRef]
- Afsar, M.M.; Crump, T.; Far, B. Reinforcement learning based recommender systems: A survey. ACM Comput. Surv. 2022, 55, 1–38. [Google Scholar] [CrossRef]
- Ma, N.; Wang, Z.; Ba, Z.; Li, X.; Yang, N.; Yang, X.; Zhang, H. Hierarchical Reinforcement Learning for Crude Oil Supply Chain Scheduling. Algorithms 2023, 16, 354. [Google Scholar] [CrossRef]
- Lesort, T.; Díaz-Rodríguez, N.; Goudou, J.F.; Filliat, D. State representation learning for control: An overview. Neural Netw. 2018, 108, 379–392. [Google Scholar] [CrossRef] [PubMed]
- Laskin, M.; Srinivas, A.; Abbeel, P. Curl: Contrastive unsupervised representations for reinforcement learning. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 5639–5650. [Google Scholar]
- Zhang, A.; McAllister, R.; Calandra, R.; Gal, Y.; Levine, S. Learning invariant representations for reinforcement learning without reconstruction. arXiv 2020, arXiv:2006.10742. [Google Scholar]
- Zhu, J.; Xia, Y.; Wu, L.; Deng, J.; Zhou, W.; Qin, T.; Liu, T.Y.; Li, H. Masked contrastive representation learning for reinforcement learning. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3421–3433. [Google Scholar] [CrossRef] [PubMed]
- Chandak, Y.; Theocharous, G.; Kostas, J.; Jordan, S.; Thomas, P. Learning action representations for reinforcement learning. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 941–950. [Google Scholar]
- Martin-Martin, R.; Allshire, A.; Lin, C.; Mendes, S.; Savarese, S.; Garg, A. LASER: Learning a Latent Action Space for Efficient Reinforcement Learning. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021. [Google Scholar]
- Zhou, W.; Bajracharya, S.; Held, D. Plas: Latent action space for offline reinforcement learning. In Proceedings of the Conference on Robot Learning, PMLR, London, UK, 8 November 2021; pp. 1719–1735. [Google Scholar]
- Pritz, P.J.; Ma, L.; Leung, K.K. Jointly-learned state-action embedding for efficient reinforcement learning. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Gold Coast, QLD, Australia, 1–5 November 2021; pp. 1447–1456. [Google Scholar]
- Åström, K.J.; Hägglund, T. The future of PID control. Control Eng. Pract. 2001, 9, 1163–1175. [Google Scholar] [CrossRef]
- Schrijver, A. Theory of Linear and Integer Programming; John Wiley & Sons: Hoboken, NJ, USA, 1998. [Google Scholar]
- Huang, S.; Ontañón, S. A closer look at invalid action masking in policy gradient algorithms. arXiv 2020, arXiv:2006.14171. [Google Scholar] [CrossRef]
- Kanervisto, A.; Scheller, C.; Hautamäki, V. Action space shaping in deep reinforcement learning. In Proceedings of the 2020 IEEE Conference on Games (CoG), IEEE, Osaka, Japan, 24–27 August 2020; pp. 479–486. [Google Scholar]
- Johnson, M.; Hofmann, K.; Hutton, T.; Bignell, D. The Malmo Platform for Artificial Intelligence Experimentation. In Proceedings of the IJCAI, New York, NY, USA, 9–15 July 2016; pp. 4246–4247. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Nag, S.; Zhu, X.; Song, Y.Z.; Xiang, T. Proposal-free temporal action detection via global segmentation mask learning. In Proceedings of the European Conference on Computer Vision, Springer, Glasgow, UK, 23–28 August 2022; pp. 645–662. [Google Scholar]
- Li, L.; Walsh, T.J.; Littman, M.L. Towards a unified theory of state abstraction for MDPs. In Proceedings of the AI&M, Fort Lauderdale, FL, USA, 4–6 January 2006; pp. 531–539. [Google Scholar]
- Sharma, S.; Suresh, A.; Ramesh, R.; Ravindran, B. Learning to factor policies and action-value functions: Factored action space representations for deep reinforcement learning. arXiv 2017, arXiv:1705.07269. [Google Scholar]
- Berner, C.; Brockman, G.; Chan, B.; Cheung, V.; Dębiak, P.; Dennison, C.; Farhi, D.; Fischer, Q.; Hashme, S.; Hesse, C.; et al. Dota 2 with large scale deep reinforcement learning. arXiv 2019, arXiv:1912.06680. [Google Scholar]
- Vinyals, O.; Babuschkin, I.; Czarnecki, W.M.; Mathieu, M.; Dudzik, A.; Chung, J.; Choi, D.H.; Powell, R.; Ewalds, T.; Georgiev, P.; et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature 2019, 575, 350–354. [Google Scholar] [CrossRef] [PubMed]
- Wang, T.; Gupta, T.; Mahajan, A.; Peng, B.; Whiteson, S.; Zhang, C. Rode: Learning roles to decompose multi-agent tasks. arXiv 2020, arXiv:2010.01523. [Google Scholar]
- Wang, T.; Dong, H.; Lesser, V.; Zhang, C. Roma: Multi-agent reinforcement learning with emergent roles. arXiv 2020, arXiv:2003.08039. [Google Scholar]
- Zeng, X.; Peng, H.; Li, A. Effective and Stable Role-based Multi-Agent Collaboration by Structural Information Principles. arXiv 2023, arXiv:2304.00755. [Google Scholar] [CrossRef]
- Mahajan, A.; Samvelyan, M.; Mao, L.; Makoviychuk, V.; Garg, A.; Kossaifi, J.; Whiteson, S.; Zhu, Y.; Anandkumar, A. Tesseract: Tensorised actors for multi-agent reinforcement learning. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 7301–7312. [Google Scholar]
- Mahajan, A.; Samvelyan, M.; Mao, L.; Makoviychuk, V.; Garg, A.; Kossaifi, J.; Whiteson, S.; Zhu, Y.; Anandkumar, A. Reinforcement Learning in Factored Action Spaces using Tensor Decompositions. arXiv 2021, arXiv:2110.14538. [Google Scholar]
- Dulac-Arnold, G.; Evans, R.; van Hasselt, H.; Sunehag, P.; Lillicrap, T.; Hunt, J.; Mann, T.; Weber, T.; Degris, T.; Coppin, B. Deep reinforcement learning in large discrete action spaces. arXiv 2015, arXiv:1512.07679. [Google Scholar]
- Tang, Y.; Agrawal, S. Discretizing continuous action space for on-policy optimization. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 5981–5988. [Google Scholar]
- Wang, S.; Papallas, R.; Leouctti, M.; Dogar, M. Goal-Conditioned Action Space Reduction for Deformable Object Manipulation. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), IEEE, London, UK, 29 May–2 June 2023; pp. 3623–3630. [Google Scholar]
- Givan, R.; Dean, T.; Greig, M. Equivalence notions and model minimization in Markov decision processes. Artif. Intell. 2003, 147, 163–223. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the KDD, Portland, OR, USA, 2–4 August 1996; Volume 96, pp. 226–231. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Env | Baseline Training Time | Time to Threshold |
|---|---|---|
| Maze (n = 10) | 10.3 m ± 183 s | 7.8 m ± 192 s |
| Maze (n = 12) | 24.4 m ± 237 s | 17.8 m ± 239 s |
| Breakout | 27 m ± 130 s | 22.5 m ± 121 s |
| Asterix | 45.3 m ± 162 s | 14.3 m ± 153 s |
| RTS2 | 10.8 m ± 80 s | 3.1 m ± 82 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Li, X.; Sun, L.; Zhang, H.; Liu, H.; Wang, J. Learning State-Specific Action Masks for Reinforcement Learning. Algorithms 2024, 17, 60. https://doi.org/10.3390/a17020060
Wang Z, Li X, Sun L, Zhang H, Liu H, Wang J. Learning State-Specific Action Masks for Reinforcement Learning. Algorithms. 2024; 17(2):60. https://doi.org/10.3390/a17020060
Chicago/Turabian StyleWang, Ziyi, Xinran Li, Luoyang Sun, Haifeng Zhang, Hualin Liu, and Jun Wang. 2024. "Learning State-Specific Action Masks for Reinforcement Learning" Algorithms 17, no. 2: 60. https://doi.org/10.3390/a17020060
APA StyleWang, Z., Li, X., Sun, L., Zhang, H., Liu, H., & Wang, J. (2024). Learning State-Specific Action Masks for Reinforcement Learning. Algorithms, 17(2), 60. https://doi.org/10.3390/a17020060